國立交通大學
資訊管理研究所
碩士論文
以
ROUGE 和 WordNet 為基礎的 N-gram 共現於
剽竊偵測
Plagiarism Detection using N-gram Co-occurrence
Statistics Based on ROUGE and WordNet
研究生 : 陳建穎
指導教授 : 柯皓仁 博士
Plagiarism Detection using N-gram Co-occurrence
Statistics Based on ROUGE and WordNet
Student: Chien-ying, Chen Advisor: Professor Hao-ren, Ke
Institute of Information Management National Chiao Tung University
Abstract
With the arrival of Digital Era and the Internet, control of information flow is nearly impossible; the lack of control provides an incentive for Internet users and computer owners to freely copy and paste any content available to them. Plagiarism often occurs when users fail to credit the original owner for the content borrowed, and such behavior leads to violation of intellectual property.
Two main approaches to plagiarism detection are fingerprinting and term occurrence. Although these two approaches have yielded considerable results, they are not without faults. One common weakness suffered by both approaches, especially fingerprinting, is the incapability to detect modified text plagiarism. This research proposed adoption of ROUGE and WordNet. The former includes n-gram co-occurrence statistics, skip-bigram, and longest common subsequence (LCS), while the latter acts as a thesaurus dictionary, which also provides semantic information. N-gram co-occurrence statistics can detect verbatim copy and certain sentence structural changes, skip-bigram and LCS is immune from text modification such as simple addition or deletion of words, and WordNet may handle the problem of word
substitution.
The proposed methods have been tested on two manually created corpora, abstract set and paraphrased set. Empirically derived threshold and preprocessing setting for each method are recommended based on the evaluation of the performance. Different types of plagiarism examples are shown to support the statements made about the strengths and weaknesses of the proposed methods.
以 ROUGE 和 WordNet 為基礎的 N-gram 共現於剽竊
偵測
研究生: 陳建穎 指導教授: 柯皓仁國立交通大學資訊管理研究所 碩士班
摘要
隨著數位時代的到來和網際網路的蓬勃發展,對於資訊流的控制幾乎是不可 能的。而在資訊缺乏管制的情況下,網路和電腦使用者可以隨意地複製並使用任 何他們能取得的資訊內容。但是如果在使用時,沒有列出資料的出處和其智慧財 產的擁有者,那麼此舉就會形成剽竊而侵犯了智慧財產權。目前大多數的剽竊偵測方法分成fingerprinting 和 term occurrence。雖然兩種
方法在剽竊偵測的領域裡已有一定的成果,它們還是有不足之處。刻意針對原文
做修改就會影響上述方法對於剽竊偵測的表現,尤其是fingerprinting 受其影響甚
鉅。因此,本論文提出了套用了ROUGE 和 WordNet 來偵測剽竊的演算法,因為
前 者 包 括 了 n-gram co-occurrence statistics、 skip-bigram 和 longest common subsequence (LCS),而後者有著同義詞典的功能也提供詞意上的資訊。N-gram co-occurrence statistics 可以有效地偵測照抄和更動句子結構的剽竊,skip-bigram
和 LCS 則不會受到純粹地新增詞彙於原文中或部分原文被刪除的影響,而運用
WordNet 則得以偵測用同義詞替換原文的情形。
本論文用兩組以人力做成的資料集(稱之為 abstract 和 paraphrased),來評 估方法的效果。每個方法都依實驗結果的觀察來推薦適合的標準值和前置處理的
設定。最後,由幾個不同類型的剽竊例子來支持先前對於每個方法的強項和弱點
的假設。
Acknowledgements
First of all, I would like to thank my instructor, Professor Hao-Ren Ke, for his guidance for the past two years. His unique sense of humor had made the entire learning process easier and more enjoyable. Despite his friendliness, he managed to provide valuable advices from time to time. It has been a pleasure to be his student. Second, I would like to thank my senior, Jen-Yuan Yeh, who had been guiding me for the last eight months of my Master’s program. He showed me the right way of doing research and educated me along the way. Third, I would like to thank my fellow classmates who had helped me during the past two years, especially Jian-Quan, Huang Qiang, Zhen-Dong, and my lab mates Yi-Xiang and You-Ying. They offered their help when I encountered problems. I learned and gained knowledge each time they solved the problems and explained to me the causes patiently. I am really happy and grateful to be able to know the members of IIM. I also want to thank them for the valuable memories I share with them. Besides the students of IIM, I also would like to thank Shu-Hui and Xin-Xin who were of great help when I first started my Master’s program and for the following two years as well. Finally, I would like to thank my family for their supports, especially my parents. If not for them, I will never have the chance of experiencing all these.
Contents
Abstract... I
摘要...III
Acknowledgements ... V Contents ...VI List of Figures... VIII List of Tables... X List of Tables... X
1. Introduction...1
1.1 Background ...1
1.2 Motivation and Objective...3
2. Related Work...6 2.1 Existing Methods...6 2.1.1 Fingerprinting ...6 2.1.2 Term Occurrence ...10 2.1.3 Style Analysis ...12 2.2 ROUGE...14 2.3 WordNet...15 3. Methodology ...19
3.1 System Architecture for Plagiarism Detection ...19
3.2 Preprocessing...20
3.2.1 Tokenization and Sentences ...20
3.2.2 Part-of-Speech (POS) Tagger...22
3.2.3 Punctuation Removal and Lowercasing ...23
3.2.4 Stopwords Removal ...23
3.2.5 Stemming ...24
3.3 Plagiarism Detection Methods ...25
3.3.1 ROUGE-N...26
3.3.1.1 Unigram ...26
3.3.1.2 N-grams...28
3.3.2 Longest Common Subsequence (LCS)...28
3.3.3 Skip-Bigram...30
3.3.4 WordNet...31
3.3.4.1 Synonyms-based...32
3.3.4.2 Relationship-based...35
3.3.5 Google Mutual Information (MI) ...37
4. Experiments and Evaluation...40
4.1 Data Sets ...40
4.2 Experiments...45
4.3 Evaluation...48
4.3.1 Recommended Settings – ROUGE-based Methods ...48
4.3.2 Recommended Settings - WordNet...52
4.3.3 Evaluation of WordNet-based Methods for Abstract Set...58
4.3.4 Evaluation of WordNet-based Methods for Paraphrased Set ...61
4.3.5 Evaluation of Google MI Method for Abstract and Paraphrased Sets...62
4.3.6 Strengths and Weaknesses of Each Method ...65
5. Conclusion ...71
Bibliography:...74
Appendix 1 Line Graphs of Bigram to LCS:...78
Appendix 2 Partial Line Graphs of Bigram to LCS:...81
List of Figures
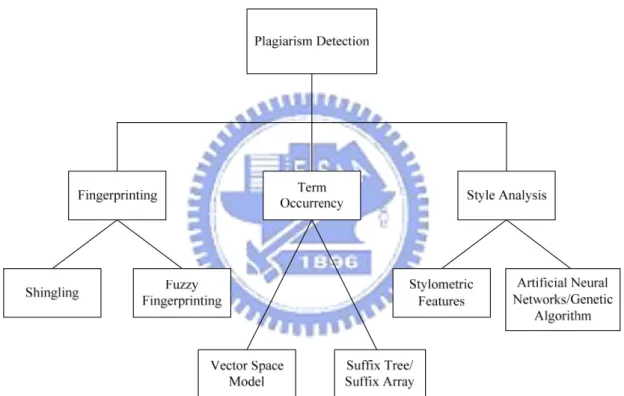
Figure 1 Classification of Detection Methods ...6
Figure 2 Fingerprint Formation [32]...7
Figure 3 Shingles of a String [2]...9
Figure 4 Document Tree [28]...11
Figure 5 Search Result of “fly” in WordNet ...15
Figure 6 Lexical and Semantic Functions Available for “fly”...17
Figure 7 Hypernym Hierarchy of “fly” in WordNet ...18
Figure 8 System Architecture ………..20
Figure 9 Unprocessed Text ...22
Figure 10 Text Divided into Sentences ...22
Figure 11 Words with Corresponding POS Tag...23
Figure 12 Text with Stopwords Removed...24
Figure 13 Stemmed Text ...25
Figure 14 Example of Clipped Precision...27
Figure 15 Examples of LCS...29
Figure 16 Example of Skip-bigrams Formation ...30
Figure 17 Example of Jaccard’s Coefficient between Two Synsets ...33
Figure 18 Example of Hypernym/Hyponym Relationship between Two Words ...36
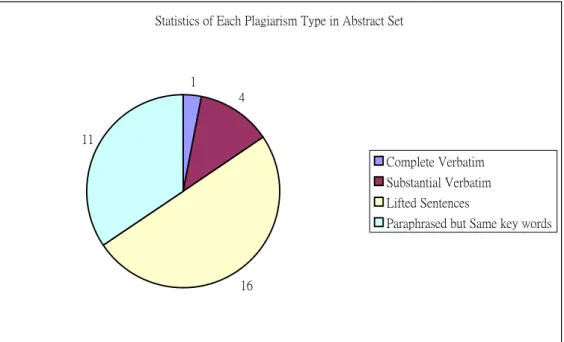
Figure 19 Statistics of Each Plagiarism Type in the Abstract Set ...43
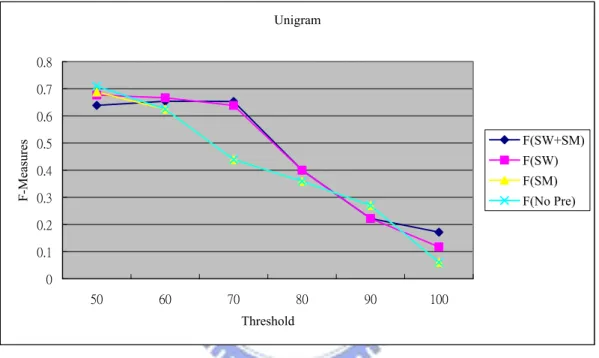
Figure 20 Ling Graph of Unigram under Different Preprocessing Settings 49 Figure 21 Partial Graph of Figure 19 ...50
Figure 22 Hypernym Relationship in WordNet for Play and Ownership ....54
Figure 23 Hypernym Relationship in WordNet for Support and Provide....54
Figure 24 F-Measures of Three Schemes with SW Removed ...56
Figure 25 F-Measures of Three Schemes with No Preprocessing...56
Figure 26 2nd Weighting Scheme under Different Settings...57
Figure 27 Synonyms-based Method under Different Settings...58
Figure 28 F-Measures Comparison with Stopwords Removed for WordNet-based Methods...59
Figure 29 F-Measures Comparison with No Preprocessing for WordNet-based Methods...59
Figure 30 Comparison Graph for Abstract Set with Stopwords Removed for WordNet-based Methods...60
Figure 31 Comparison Graph for Abstract Set with No Preprocessing for WordNet-based Methods...60
Figure 32TPs of Unigram and WordNet-based Methods with Stopwords Removed………...61 Figure 33 TPs of Unigram and WordNet-based Methods with No
Preprocessing ...62 Figure 34 Comparison Graph for Abstract Set with Stopwords Removed
Including Google Method ...63 Figure 35 Comparison Graph for Paraphrased Set with Stopwords
List of Tables
Table 1 Kappa Statistics [16] ...41
Table 2 Example of Verbatim Copy...43
Table 3 Example of Substantial Verbatim...43
Table 4 Example of Lifted Sentences ...44
Table 5 Example of Paraphrased but Same Key Words...44
Table 6 Examples of Sensitivity, Specificity, and F-measure ...47
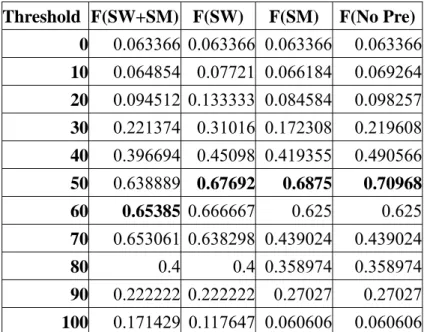
Table 7 F-measures of Unigram under Different Settings ...49
Table 8 Results of F(SW+SM)...51
Table 9 Results of F(SW)...51
Table 10 Summarization Table of Recommended Settings ...52
Table 11 Relationship-based method Stopwords Removed (Initial Weighting Scheme)...53
Table 12 Relationship-based method Stopwords Removed (2nd Weighting Scheme)...55
Table 13 Results at Threshold=60...63
Table 14 F-measures under Different Settings Recommended Threshold...65
Table 15 F-Measures of Example 1 ...66
Table 16 F-Measures of Example 2 ...67
Table 17 F-measures of Example 3...68
1. Introduction
1.1 Background
Looking up plagiarism in some of the dictionaries, one will find different definitions. Though slightly different from one another, these definitions convey an identical idea – plagiarism is the use of other people’s work/idea as one’s own without crediting the original owner. This kind of behavior is equivalent to stealing. Nevertheless, cases of plagiarism are still being reported in classes and even in academic research. Maurer et al. [22] described the policies against plagiarism in some of the most prestigious universities and how each of the schools handles such misconduct; some of these universities were seeing increasing number of reported plagiarism cases, including Web plagiarism, in recent years that ranged from 2003 to 2006.
Plagiarism can occur unintentionally or intentionally. Unintentional plagiarism is caused by the lack of understanding about plagiarism, as the offender does not know that what he/she has done constitutes plagiarism. As there is a saying – prevention is better than cure, introducing students to the concept of plagiarism and educating them to avoid plagiarism is crucial before they start their first research-oriented writing assignment. The importance of preaching the right idea about plagiarism is illustrated in [8], as one of the authors shared her own experience on students’ understanding about plagiarism. In her story, she introduced the concept of plagiarism to the students and taught them how to avoid it in the beginning of a course. Yet, three students plagiarized in an assignment; and when asked to see her anonymously, other than the three offenders another 11 students showed up as they were not sure if they were one of the students. Despite the initial effort, some students still chose to plagiarize while some were still not clear on the issue of plagiarism. Perhaps, even more time is
needed to be spent on defining plagiarism and teaching the students about citations and reference of borrowed work, so that students can develop the right research writing habit from the beginning. At the same time, complementary work can be done. For example, Maurer et al. mentioned how universities provide online resources such as tutorials, or brochures for educational purposes. There is nothing wrong to borrow and refer to existing work of other people because this is an essential step of learning; however, one just has to credit the rightful owners for their contribution in a right way.
When all precautions have been carried out to prevent plagiarism, there is still no guarantee that plagiarism will stop because there are people who plagiarize intentionally. Students who choose to plagiarize probably do not take his/her work seriously, and they do not know much about the subject they are plagiarizing, that is why they use existing information directly. Violation of copyright does not really bother them, what is more important is to complete the assignment and hand it in on time. On the contrary, some students plagiarize because they are serious about their assignments in terms of the grades they receive. As a result, they look for existing works, which are probably better than what they can come up with by themselves and hand in as their works. A survey done on Year 11 high school students suggests that those who plagiarized the most cared more about grades than the learning process [23]. There are plagiarism cases in which students downloaded papers from the Internet and turned in the exact papers as their own work. Unfortunately, cases of plagiarism are being reported by research journals too. These researchers whether graduate students or professors, should know more about the seriousness of plagiarism than the undergraduate students, and should be more self disciplined. Nonetheless, some of them decided to include other researchers’ results in their works
One tempting factor may be the reason for plagiarism – convenience. Especially with the arrival of digital era, electronic storage hardware has replaced papers to become the media for data keeping and channeling, and plagiarism has never been easier. The situation worsens with the invention of the Internet, which becomes a huge resource center for searching information and retrieving the information at one’s fingertips. Another cause of plagiarism besides convenience may be the lack of control for online distribution of copyrighted contents. The number of Web pages available and the amount of data flow on the Internet make scrutinized data transfer infeasible. Almost nonexistent control encourages Internet users to freely copy the information they want and use it as if it is their property. Even if a person makes some alterations to the original text by substituting a few words with synonyms, making some grammatical changes, or breaking up the sentences and inserting into different parts of his/her work, case of plagiarism still stands. These are some common examples of plagiarism. The modification of original work together with naturally similar non-plagiarism works makes plagiarism detection even more difficult.
1.2 Motivation and Objective
Copyright protection has always been an issue, especially when digital technology shortens the time for both duplication and distribution. Copyright laws cover a wide range of categories such as music, video, software, books and many other fields. The topic of this research will focus on the field of text plagiarism.
Not only does plagiarism violate copyright regulation, but also influence the quality of education and research. Knowledge is accumulated through learning and thinking, and school assignments force students to learn and think during the process of completing the assignments. Whether the students choose to look up resources in
the Internet or printed articles, or come up with innovative ideas through brainstorming, either step benefits students who put in efforts and time as they gain something new with each assignment. However, plagiarism deprives students of undergoing such process as they spend less time to think. Even if students do read the content before they plagiarize, they are most likely to forget about the content faster than those who genuinely do their work. This reasoning is not without support as the observation from a case study is in accordance with the above opinion. The observer stated that “…when asked about his learning, Brett was unable to recall anything about his topic.” [23].
In the academic research domain, no new discoveries will be made if the researchers only reuse existing information. Collberg et al. [7] focused on self-plagiarism and argued that self-plagiarism causes new but similar papers to be published without contributing to the overall advancement of academic research.
With the problem of plagiarism being taken seriously, considerable amount of research has been done in detecting plagiarism. The approaches mainly focus on the calculation of document similarity through analyzing the content of the texts. Content may be referred to words, sentences or paragraphs in the texts, or even the intrinsic structure of the texts. Besides academic research on plagiarism, there are online detection services and tools available. Most of the better and more established services are for staff of educational institutions to examine suspicious works from the students. Individual service is also available. However, majority of the services are not free of charge while the remaining options may not be as effective. [22] acts as a gateway to learn more about the available tools as the authors provided a rather detail introduction to the three following tools, Turnitin, SafeAssignment, and Docol©c; the authors also briefly summarized several other tools, a couple of which are tools that
Although there are different plagiarism detection approaches, each method has its pros and cons. One common weakness is the vulnerability to text modification that can be achieved through addition, deletion and substitution of words, and also change of sentence structure or word order. In this research, we propose a prototype of a system that adopts ROUGE and utilizes WordNet (a thesaurus-like dictionary), in hope of combining the strengths of individual method and overcoming the disadvantages of each separate method. Generally, the proposed methods should be able to conquer most of the text alteration strategies mentioned earlier. We will discuss in more detail about related work in Chapter 2, methodology in Chapter 3, experiments and evaluation in Chapter 4, and conclusion in Chapter 5.
2. Related Work
Until now, quite a considerable amount of research has focused on plagiarism detection. Figure 1 provides an overview about the development of plagiarism detection. The classification is derived from the taxonomy in [29]. As Figure 1 indicates, the plagiarism detection methods can be categorized into three main categories: fingerprinting, term occurrence, and style analysis.
Figure 1 Classification of Detection Methods
2.1 Existing Methods
2.1.1 Fingerprinting
Fingerprinting can be considered as the most widely adopted approach in plagiarism detection. The origin of this method, as suggested by previous studies, is attributed to the work done by Udi Manber [21]. In that research, Manber aimed to find out similar documents in a database. The research was based on Rabin
Fingerprint scheme, which was applied to generate a unique identity (fingerprint) for each document. Rabin fingerprint scheme or hash function as often used interchangeably, can transform a sequence of substring into an integer. And a good scheme/function should generate the same integer for the same substring; on the other hand, it should generate different integer for each unique substring to ensure consistency and avoid undesirable collisions of fingerprints. Furthermore, there are other factors that need to be considered when generating fingerprints. They are fingerprint granularity, fingerprint selection, and fingerprint resolution. These issues are discussed in greater detail in [11]. Figure 2 below illustrates how a fingerprint is formed, followed by a summarization of the three factors.
Figure 2 Fingerprint Formation [32]
First, fingerprint granularity means the amount of data a fingerprint represents. Observing from Figure 2, a fingerprint/hash can be either generated from a word or a string of text, and a word-level fingerprint has higher granularity than a sentence-level fingerprint. From a different perspective, granularity also means how much information must be exactly the same between two documents for the respective fingerprints to match. In other words, granularity defines the “fineness” of detection
because high granularity fingerprints can match in smaller portions of overlapping text. However, as high granularity fingerprints have a greater chance of finding a match, it will lead to higher similarity or even false positive between two documents.
Second, fingerprint selection means how the substrings of a text are chosen before being transformed into fingerprints to represent the documents. The more accurately fingerprint(s) can represent a document the better; therefore, selection of the most representative substrings in the text is important as the effectiveness and reliability of detection will be affected. Some selection schemes are available and they include but not limited to full fingerprinting [1], random fingerprinting adopted by [21] and [5], and selective fingerprinting as in [10].
Third, fingerprint resolution means how many fingerprints are used to represent a document. When more fingerprints are included, especially those unique and important ones, matching of the fingerprints becomes more meaningful and the similarity between two documents is truly reflected.
The above three factors influence the efficiency and accuracy of the matching process directly. Each of the choices, higher granularity, full fingerprinting scheme, and higher resolution, leads to more memory consumption. Although better results may be obtained, processing time will be longer. Hence, each factor should be adjusted to best suit the need for different purposes.
Fingerprinting was first applied to the field of plagiarism detection in COPS [1] for copy detection in digital documents. In COPS, the smallest detection unit was a sentence, but multiple sentences could form a larger unit of detection called chunk. The research included a document database to save newly processed documents and compare a suspect document with registered documents. Later, SCAM (Stanford Copy Analysis Mechanism) [27] was developed based on the foundation of [1].
generated in unit of word instead of sentence. The change led to better performance in detecting partial copy but more false positives as a tradeoff. Majority of later approaches focus on various aspects of fingerprinting; usually, different strategies are deployed or other techniques are integrated with fingerprinting. Variations include shingling and fuzzy fingerprinting. The former is a combination of fingerprinting and unique n-gram substrings [2] while the latter adopts inverse document frequency (idfs) into substring selection [6] to pick out feature terms. In fact, the concept behind these two methods is the same.
The concept behind shingling can be understood through brief descriptions of both methods. First, Figure 3 is a simplified example of how shingles of a document are obtained. Let (a, rose is, a, rose, is, a, rose) be document D, and the size of each shingle/n-gram, w, be four. A total of five 4-grams can be obtained from D. Any repeated 4-gram is removed, leaving three unique 4-grams, which are the shingles of D. The shingles can be transformed into fingerprints or hash values, and altogether they form a representation of D.
All valid 4-grams: a rose is a, rose is a rose, is a rose is, a rose is a, rose is a rose Unique 4-gram (Shingles): a rose is a, rose is a rose, is a rose is
Document D: (a, rose, is, a, rose, is, a, rose)
Figure 3 Shingles of a String [2]
Fuzzy fingerprinting in [6] implements the same concept by taking a different approach. Instead of removing repeated terms, the method adopts (idfs) to determine which words are meaningful enough to represent the document. A single hash value will be generated using all the feature terms. Matching between two hash values
means that two documents are duplicates of each other.
2.1.2 Term Occurrence
Term occurrence is probably the most intuitive approach because lexical words contain explicit information of the text and they can be analyzed to determine the similarity between two documents. One assumption is that the more terms both documents have in common, the more similar they are. Term occurrence has been applied to a range of studies such as automatic evaluation of summaries, automatic evaluation of machine translation, and common information retrieval problems like clustering and categorization. Due to a common purpose between the aforementioned studies and plagiarism detection, i.e. determining similarities between documents, application of term occurrence in plagiarism detection seems promising. Strictly speaking, fingerprinting in word granularity may be categorized under term occurrence; however, since fingerprinting has been discussed earlier under different category, we will only discuss other term occurrence methods.
CHECK [28], which incorporates a well-known IR model - vector space model (VSM), is a plagiarism detection method that first parses a document into a tree structure before comparing two documents. The root node contains the overall information of a document while the internal and leaf nodes contain information of subsections and paragraphs respectively. The authors called the tree structure the document tree (Figure 4) and the information within as structural characteristics (SC) of the document. CHECK operates on one assumption that if a pair of documents does not share similar topics, they are not suspects of plagiarism. Hence, before any comparison of specific information between two documents is carried out, CHECK will compare the root nodes of the two documents first. Each root node contains the
vector. Thus, the overall similarity between two documents is equivalent to the value of the cosine of the angle between the two vectors.
If the cosine measure exceeds a certain threshold, two documents are thought to be similar in content and child nodes will be compared. Like root nodes, child nodes are expressed in weighted vectors as well and they specifically represent subsections of the documents. The process stops when cosine measure falls below the threshold or when leaf nodes are reached.
Figure 4 Document Tree [28]
Next, Smart Version 13 is the information retrieval system in [4] and it adopts VSM to produce representatives of documents. Although [4] is not particularly
designed for plagiarism detection, one of its goals is near-duplicate detection, which can be applied to find instances of plagiarism.
Zaslavsky et al. [37] utilized suffix trees, each of which contains all the suffixes of a string and therefore all the substrings as well. By including all the substrings, a suffix tree is “a data structure … that allows for a particularly fast implementation of many important string operations” [34]. When applied at document level, the suffix tree method, together with the matching statistics algorithm, is able to find overlapping chunks between two documents [37]. One disadvantage is that such a data structure is more memory consuming than just saving the document. In [17], instead of using suffix trees, the idea of suffix arrays is adopted to reduce the memory problem found in suffix trees.
2.1.3 Style Analysis
Style analysis is the most special approach to plagiarism, because unlike other methods, it requires no reference corpus and it focuses more on implicit information than explicit information of the texts. The basic principle behind style analysis is that every author has his/her own writing style, may it be the difference in text length or choices of words. Other measures also include richness in vocabulary and the number of closed class words and open class words used. Analysis of those measures enables the researchers to turn the abstract idea of writing style into realistic numbers [24]. The principle is in accordance with stylometry. If the style in a document is not consistent throughout the entire document, plagiarism may have occurred. The hypothesis is based on two assumptions that each person’s writing style should remain consistent throughout the text, and that the characteristics of each style is hard to manipulate or imitate, making the plagiarized portion of work to stand out in the text
trained to learn about rules of writing. Hence, various artificial neural networks (ANNs) and genetic algorithms (GAs) have been applied to analyze style and authorship [9]. The trained ANNs or GAs will be able to recognize the style of a particular author and therefore articles written by the author.
2.1.4 Comparison and Contrast
The popularity of fingerprinting is probably due to its efficiency in speed and data storage, making it feasible to work on a large corpus. Although fingerprinting has been proved to perform well for verbatim copy of large scale and subset overlapping, it is also known for its vulnerability to modified text. With some minor changes, entirely different fingerprints are generated even if two sets of data remain highly similar. For example, the last two strings in Figure 2 are represented by two different fingerprints even though the only difference between them is just a verb. As a result, true positive may be judged as false negative. Even fuzzy fingerprinting and shingling, which do not require full matching between two sentence, are affected by substitution, addition, and deletion of words because idfs and shingles will change accordingly.
As VSM includes term frequency and inverse document frequency, it shares the same vulnerability mentioned above. Another weakness of VSM is inevitable due to the nature of this model, which works in a bag-of-words manner; as a result, the vector represents only the global information of a document. And it is only capable of global plagiarism detection and is not able to point out the exact location of an instance of plagiarism. Although the document tree in CHECK can focus the location of probable plagiarism, the smallest unit of detection is still in paragraphs.
With only the information of all substrings, the suffix tree approach is vulnerable to rewording, especially substitution of words when doing substring matching. Although a suffix tree is capable of fast string operations, [37] indicates that the tree
stores only the substrings and does not record the positions of substrings in the document. Such a data structure cannot locate exact substring match in the document. Style analysis does not require a reference corpus when detecting plagiarism and does not seem to be affected by text alteration based on its theory. However, writing style of a person can change with time and age; thus making the analysis of style too inconsistent and unreliable. Moreover, even if no reference corpus is needed, a training corpus is still required.
2.2 ROUGE
One straightforward way to determine if a sentence in a candidate document is plagiarized from a sentence in a reference document is to compare the candidate sentence with all the sentences in the reference document. Based on the intuition that a pair of plagiarized sentence and plagiarizing sentence is identical in content, we can find out sentence pairs that may be subject to plagiarism by calculating the similarity for each pair.
There are methods for calculating the similarity between two sentences; one method is n-gram co-occurrence statistics in BLEU [25] for machine translation evaluation. Followed by the success of BLEU, the same method was included as part of ROUGE [18], which is implemented in the proposed system with some minor modifications and extended applications. Implementation consists of major ROUGE components: ROUGE-N, longest common subsequence, and skip-bigram. Applications of each individual method in this research will be discussed more deeply in Chapter 3.
Lin [18] tested the performance of each method, including variations of LCS and skip-bigram, by comparing one or more reference summary(ies) with a candidate
summary, then came up with a score representing the quality of the candidate summary. Moreover, experiments were carried out under different settings such as stopword removal and stemming. During experimental evaluation, the scores given by the methods were compared with those of human judgment, which served as the answers. Various correlation measures were used to assess the performance of the methods. Higher correlation between a method and its corresponding human scores suggests that the method can evaluate summaries in a way close to human judgment, proving the effectiveness of the method.
2.3 WordNet
Figure 5 Search Result of “fly” in WordNet
WordNet [35] is a dictionary-like database developed by Cognitive Science Laboratory of Princeton University. Some of the previous plagiarism detection research, such as Iyer and Singh [12] and Kang et al. [14], had adopted WordNet, both used the database for finding synonyms of words to detect plagiarism through
substitution of words. However, Kang et al. did not illustrate how WordNet was used to find synonyms while Iyer and Singh compared synsets to determine if two words were synonyms of each other. Figure 5 shows the interface of local version of WordNet 2.1.
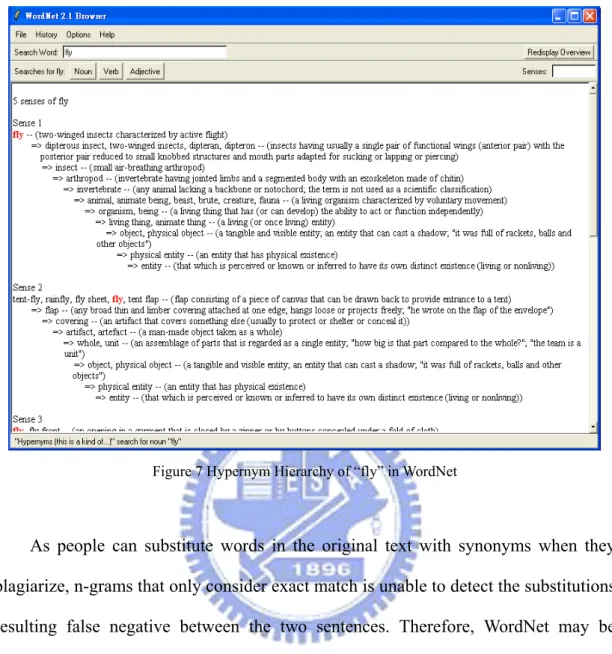
Basically, every word in WordNet can be assigned to one or more part-of-speech (POS) categories. There are four POS categories: noun, verb, adjective and adverb. For example, the word “fly” has three POS in WordNet as the blue box in Figure 5 indicates three options – Noun, Verb, and Adjective. Each word has different numbers of senses under each category. Senses can be understood as different valid meanings given to a word. The orange box in Figure 5 shows that “fly” has five senses under Noun. A synset, which is a group of synonyms, is associated with each sense. The red box in Figure 5 encloses the synset of sense 2 of “fly” under Noun. However, a synset may contain just the target word itself for any of its senses. Reasonably, a word can belong to multiple synsets because as mentioned just now, a word or polysemy can have multiple meanings.
Figure 6 Lexical and Semantic Functions Available for “fly”
Words in WordNet are linked by two major relations – lexical and conceptual semantics. Besides synonyms, other lexical relations including but not limited to holonyms and meronymy are also found in WordNet. As shown in Figure 6, by clicking any of the three POS icons, one will see a drop list which contains available options. WordNet can hierarchically show the hypernym relationship between words. Figure 7 shows the hierarchy of hypernyms of “fly” under Noun.
Figure 7 Hypernym Hierarchy of “fly” in WordNet
As people can substitute words in the original text with synonyms when they plagiarize, n-grams that only consider exact match is unable to detect the substitutions, resulting false negative between the two sentences. Therefore, WordNet may be helpful when analyzing a sentence pair for this type of plagiarism, because it can be applied to find implicit relationship between two words. Weighting or score can be given according to the closeness of two words either lexically or conceptually.
There are many WordNet-related projects available. A Java API – Java WordNet Library (JWNL) [36], which has a dictionary database that contains all the words and their relationships in WordNet, was integrated into the program. Through JWNL, users can retrieve the same information of a word as in the local version of WordNet via the right Java application.
3. Methodology
Having discussed about existing plagiarism detection methods, the methods proposed in this research will be discussed next. The purpose of this research is to provide a framework of a plagiarism detection tool.
The methods are based on the foundation of n-gram co-occurrence statistics at sentence level. N-gram co-occurrence statistics can detect verbatim copy as good as fingerprinting. However, by including longest common subsequence and skip-bigram, we hope to overcome problems caused by addition and deletion of original text. In situations where original words are substituted with synonyms, WordNet has been implemented to overcome this problem. Sentence level matching means that we can locate the position of plagiarism instance in the document by recording the sentence numbers for all the comparing pairs and their similarity scores. As mentioned earlier, fingerprinting can handle large amount of information, and several studies have applied their methods on relatively large corpora. However, this research focuses on the accuracy of plagiarism detection within a document, instead of trying to detect plagiarism in a corpus.
The documents are processed and saved in string tokens, which are compatible with WordNet. But by using string tokens, it means that the efficiency is most likely poorer than integer-based fingerprinting. Another issue is the comparing scheme, whose complexity is . If both documents’ contents are lengthy, memory consumption problem may rise.
2 ( ) O n
3.1 System Architecture for Plagiarism Detection
Two documents will be uploaded, and they will be preprocessed and then analyzed according to the options chosen by the user. At the end, the output will be
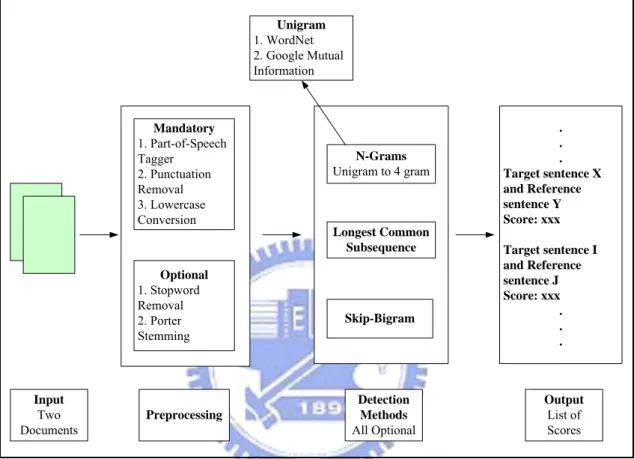
pair-wise scores that indicate the probability of plagiarism. Figure 8 shows the architecture and components of our system, and the following sections will explicate the components in detail.
Mandatory 1. Part-of-Speech Tagger 2. Punctuation Removal 3. Lowercase Conversion Optional 1. Stopword Removal 2. Porter Stemming N-Grams Unigram to 4 gram Longest Common Subsequence Skip-Bigram Unigram 1. WordNet 2. Google Mutual Information . . . Target sentence X and Reference sentence Y Score: xxx Target sentence I and Reference sentence J Score: xxx . . . Input Two Documents Preprocessing Output List of Scores Detection Methods All Optional
Figure 8 System Architecture
3.2 Preprocessing
3.2.1 Tokenization and Sentences
Since our basic unit of detection is in sentence, documents will be processed into tokens and sentences by using LingPipe’s [19] sentence detection API, which is just one of the many language processing Java APIs offered by LingPipe. The API will store the text with two arrays – tokens and whites. The tokens array stores the tokens and punctuations while the whites array stores white spaces. Using the MEDLINE sentence model, the API can recognize sentence boundary indicators and present the
original text in sentences by knowing which tokens are at the end of the sentences. With this information, the API can reassemble each sentence correctly. MEDLINE, according to LingPipe, “is a collection of 13 million plus citations into the bio-medical literature maintained by the United States National Library of Medicine (NLM), and is distributed in XML format.” [20]. In this research, only the tokens array was used. Figure 9 shows the layout of a text in the text editor while Figure 10 shows the display of the same text after it has been processed by the API. The same problem which had been brought up in other research was encountered when the API looks for sentence boundary indicators to determine the end of a sentence: periods that are not used as an end-of-sentence indicator will be mistaken. Acronyms cannot be processed properly because individual letters that are supposed to be joined by period(s) will be separated as independent characters. It is hard to distinguish acronyms because we only use the tokens array; there is no additional information that can be used to disambiguate a period. The layout of research papers also causes problems because the section title usually will be included in the first sentence of the paragraph that follows immediately after the title, which has no indicator to separate it from the sentence.
Figure 9 Unprocessed Text
ping-pong and to bowl. The key ingredients are: (1) inducing a response, (2) reinforcing subtle improvements or refinements i n the behavior, (3) providing for the transfer of stimulus control by gradually withdrawing the prompts or cues, and (4) scheduling reinforcements so that the ratio of reinforcements in responses gradually increases and natural reinforcers can maintain their behavior.
Sentence 1: developing complex skills in the classroom involves the key ingredients identified in teaching pigeons to play ping-pong and to bowl
Sentence 2: the key ingredients are 1 inducing a response 2 reinforcing subtle improvements or refinements i n the behavior 3 providing for the transfer of stimulus control by gradually withdrawing the prompts or cues and 4 scheduling reinforcements so that the ratio of reinforcements in responses gradually increases and natural reinforcers can maintain their behavior
Developing complex skills in the classroom involves the key ingredients identified in teaching pigeons to play
Figure 10 Text Divided into Sentences
3.2.2 Part-of-Speech (POS) Tagger
After the tokens array is obtained, the tokens are processed by LingPipe’s part-of-speech tagging API. Using the Hidden Markov Model trained with the Brown Corpus, each token in the tokens array will be tagged with a POS, which is saved in another array tags. Brown Corpus is a statistical analysis of American English consisting of 1,014,312 words. The corpus used text materials printed in 1961 and was done by W. N. Francis and H. Kucera at Brown University [3][31]. POS tagging is a crucial step which enables us to look up the appropriate synsets and meanings of a word in the WordNet more accurately. Figure 11 shows the tokens and their respective
POS tag separated by an underscore.
Sentence 1: developing_vbg complex_jj skills_nns in_in the_at classroom_nn involves_vbz the_at key_jjs ingredients_nns identified_vbn in_in teaching_vbg pigeons_nns to_to play_vb ping-pong_nn and_cc to_in bowl_nn
Sentence 2: the_at key_jjs ingredients_nns are_ber 1_cd inducing_vbg a_at response_nn 2_cd reinforcing_vbg subtle_jj improvements_nns or_cc refinements_nns i_nil n_nil the_at behavior_nn 3_cd providing_vbg for_in the_at transfer_nn of_in stimulus_nn control_nn by_in gradually_rb withdrawing_vbg the_at prompts_nns or_cc cues_nns and_cc 4_cd scheduling_nn reinforcements_nns so_rb that_cs the_at ratio_nn of_in reinforcements_nns in_in responses_nns gradually_rb increases_vbz and_cc natural_jj reinforcers_nns can_md maintain_vb their_pp$ behavior_nn
Figure 11 Words with Corresponding POS Tag
3.2.3 Punctuation Removal and Lowercasing
When a text is stored as tokens and each of the tokens has been POS tagged, common punctuations and their respective POS tag are removed from the tokens array. At the same time, each token is converted into lower case. Hereafter, the three terms token, word, and unigram are used interchangeably.
3.2.4 Stopwords Removal
Stopwords are words that are often not informative. They may cause false positives during matching because two unrelated sentences may get a higher score than what they really deserve due to matched stopwords such as this, if, in and many others. We use a Java stopword removal API from Terrier [30], plus a stopword list stored in plain text. Any word that finds a match in the list will be removed from the tokens array. At the same time, the stopword list can be adjusted anytime. According
to the official website, Terrier stands for Terabyte Retrieval and it is developed by the Computing Science Department of the University of Glasgow. Terrier is an open source information retrieval platform. Figure 12 shows the same text as in Figure 9 with stopwords removed.
Sentence 1: developing complex skills classroom involves key ingredients identified teaching pigeons play ping-pong bowl
Sentence 2: key ingredients 1 inducing response 2 reinforcing subtle improvements refinements behavior 3 providing transfer stimulus control gradually withdrawing prompts cues 4 scheduling reinforcements ratio reinforcements responses gradually increases natural reinforcers maintain behavior
Figure 12 Text with Stopwords Removed
3.2.5 Stemming
“Stemming is the process for reducing inflected (or sometimes derived) words to their stem, base or root form – generally a written word form.” [33]. For example, “computing”, “computer”, and “computation” have a common root – “comput”. And words that share the same root/stem are usually semantically close. By stemming the words, higher rate of meaningful matching can be achieved. Such a concept is the opposite of stopword removal, which aims to reduce useless matching. A Java version of Porter stemming is used and it is available in Terrier as well. Figure 13 shows a sample of stemmed text.
Sentence 1: develop complex skill in the classroom involv the kei ingredi identifi in teach pigeon to plai ping-pong and to bowl
Sentence 2: the kei ingredi ar 1 induc a respons 2 reinforc subtl improv or refin i n the behavior 3 provid for the transfer of stimulu control by gradual withdraw the prompt or cue and 4 schedul reinforc so that the ratio of reinforc in respons gradual increas and natur reinforc can maintain their behavior
Figure 13 Stemmed Text
3.3 Plagiarism Detection Methods
Figure 8 clearly shows that the proposed system includes n-gram analysis up to 4-gram, LCS, skip-bigram, WordNet, and Google mutual information (MI). Initially, all the above methods were based on recall, i.e. the number of matched tokens between two sentences was divided by the length of reference sentence. The perspective is that plagiarism occurs when original work is being copied or modified without proper citation; the amount of material being plagiarized is not really an issue, whether it is a paragraph or just a sentence being copied, instance of plagiarism still holds. Therefore, the higher the recall of tokens/n-grams of a reference sentence, the higher the probability of plagiarism However, later observation discovered that by just considering the length of reference sentence, problems occur when sentence lengths differ substantially. In case of a long candidate sentence and a short reference sentence, false positive may occur and vice versa. To minimize the problems, in the final version of all the measures, the score is represented by F-measure, a balanced average between the recall of a reference sentence and the precision of a candidate sentence.
3.3.1 ROUGE-N
3.3.1.1 UnigramEach token in a sentence is a unigram. Before comparing the sentences, every unique unigram and its number of occurrence(s) in the sentence will be recorded for every sentence. Beginning with the first sentence of the reference document, every unique unigram is compared with all unique unigrams in every sentence of the candidate document, followed by the second sentence of the reference document and so on and so forth. Overall, all reference sentences will be compared with all candidate sentences for a total of times, where M and N are the number of sentences in the reference and candidate documents respectively.
M x N
The number of overlapping unigram(s) between two sentences, one from the reference document and the other from the candidate document, will be counted. The overlapping total, numerator of Equations (1) and (2), is divided by the length of the reference sentence and length of the candidate sentence separately in order to calculate recall and precision. We take the smaller number of occurrence of the overlapping unigrams in the two sentences as the numerator. This is to avoid false positive in certain cases, in which a particular unigram are found in both the candidate and reference sentences but appears multiple times in the candidate sentence. Such modification is called clipping [25]. Figure 14 is an example from BLEU [25], in which the word, the, appears in both the reference and candidate sentences two times and seven times respectively, if according to Equation (1) without the clipping mechanism, the precision score contributed by this word will be 7/7, which is clearly exaggerated. However, if the score is clipped it becomes 2/2, which is more reasonable.
Candidate Sentence: the the the the the the the Reference Sentence: the cat is on the mat Standard Precision: 7/7 Clipped Precision: 2/7
Figure 14 Example of Clipped Precision
During sentence matching, we do not consider any reference sentence that has less than four tokens, because a short sentence often leads to high score and false positive. (1) n-gram S and SRu Cv ' 1 ( , ) = Count (n-gram ) R C u v u y R N S S ∈ ≤ ≤−
∑
' R u clip 1 n-gram S Count (n-gram) v z ≤ ≤ ∈∑
R uS and C represent the sentence pair, n-gram is the overlapping gram of length n
v S (2) R C u v cl P N ' C v ip n-gram S and S ' 1 1 n-gram S Count (n-gram) ( , ) = Count (n-gram ) R C u v u y v z S S ∈ ≤ ≤ ≤ ≤ ∈ −
∑
∑
N-gram (including unigram) score is expressed as Equation (3) below:
1 1 2* * ( R, C) = u v u y v z R N P N F N S S R N P N ≤ ≤ ≤ ≤ − − − − + − (3)
3.3.1.2 N-grams
The comparison procedure for n-grams (from two to four) is the same as unigram. The only two differences are the definition of a unique n-gram and an extra step when processing the documents.
As mentioned in unigram, each token is a unique unigram; however, a unique n-gram is made up of more than one token, i.e. a unique bigram consists of two consecutive tokens in the sentence, three tokens for a trigram, and so on and so forth. Therefore, the number of n-grams per sentence has to be determined first. This is done by recording all the n-grams by scanning the sentence with a window size n, and advancing the window by one token along the sentence for a total of times. s is the number of tokens in the sentence. At the end of this step, we can go on to compare the documents as described in Unigram. If a sentence is shorter than the window size, no n-gram will be formed and hence no score for that particular sentence pair.
(s n− +1)
3.3.2 Longest Common Subsequence (LCS)
LCS is the longest in-sequence string of matched tokens between two sentences. In unigram matching, the position of matched token is not a constraint. As long as a unigram co-occurs in both sentences, it will contribute to the similarity between two sentences. Although LCS is also based on matching unigrams, it only considers matched tokens that form the longest in-sequence subsequence of the reference sentence. In other words, even if a unique unigram is in both the reference and candidate sentences, but if it is out of order with other matched tokens, it is not included in the LCS and will not contribute to the LCS score. And if there is more than one common subsequence, LCS will only reflect the longest subsequence among
allows skip of matched tokens, which need not be strictly consecutive. Figure 15, which is taken from ROUGE [18], illustrates how LCS is derived.
Candidate sentence 1: Police kill the gunman Candidate sentence 2: The gunman kill police Reference sentence: Police killed the gunman
The LCS between Reference sentence and Candidate sentence 1 is police the gunman while the LCS between Reference sentence and Candidate sentence 2 is the gunman, excluding police. The first pair of sentences shows the skipping nature of LCS and the second pair of sentences shows the in-sequence rule that bounds LCS.
Figure 15 Examples of LCS
If LCS is less than four unigrams long, we drop the sentence due to the same reason mentioned in Unigram.
LCS can be expressed as follows:
(4) (5) 2*( )*( ) ( , ) ( ) ( ) C R v u R LCS P LCS F LCS S S R LCS P LCS − − − = − + − (6) R u unigram S ( , ) ( , ) Count (unigram) C R C R v u v u LCS S S CS S S ∈ − =
∑
R L C v unigram S ( , ) ( , ) Count (unigram C R C R v u v u LCS S S P LCS S S ∈ − =∑
)3.3.3 Skip-Bigram
Skip-bigram is an evolved version of bigram. The difference is the formation of bigrams. For skip-bigram, bigrams are formed not only by consecutive tokens, but also by other in-sequence tokens within the window. Skip distance, d, has to be set before counting skip-bigrams in the sentence. Skip distance is the maximum number of tokens in between any two combining tokens. When skip distance is determined, we can start finding all the skip-bigrams within a sentence. Let be a sentence. Starting with , it will form skip-bigrams with of the following d+1 words, followed by , which forms skip-bigrams with another in-sequence d+1 words. The process stops when
1, 2,..., n w w w 1 w 2 w 1 n
w− forms the last skip-bigram with . Therefore, the total number of skip-bigrams for a sentence is the denominator of Equations (7) and (8) with the sentence being the only difference between them. Figure 16 shows how skip-bigrams of a four-word string are formed.
n
w
There are a total of six skip-bigrams by the sequence above when d=2. They are as shown:
For a given sequence: Andy eats an apple
When d=2, skip-bigrams generated will be as follows:
Start with the first word andy, it can form a bigram with the furthest token, apple, and followed by eats and an respectively. When andy has formed bigrams with all possible tokens, eats will form bigrams with an and apple. Finally, the last skip-bigram is an apple.
Figure 16 Example of Skip-bigrams Formation
After finding the skip-bigrams for the sentence pair, we can compare the skip-bigrams using the same steps for n-grams.
(7) ( , ) 1 clip u v R C u v d R Skip S S 0 2 ( , ) ( 1)( 1) R C r SKIP S S p d d d − = − = − − + +
∑
−r SentenceSRof length p (8) 1 u P S − 0 2 ( , ) ( , ) ( 1)( 1) R C clip v R C u v d r SKIP S S kip S S q d d d r = − = − − + +∑
− SentenceSCof length q 2*( )*( ) ( , ) ( ) ( ) R C u v R Skip P Skip F Skip S S R Skip P Skip − − − = − + − (9)In situations where people insert or delete words from an original sentence, or change tenses from past tense to past perfect tense and vice versa, pure bigram has minimal use; this is because the bigrams will not be the same between reference and candidate sentences. As skip-bigram allows gaps, it has higher chance of producing the correct bigrams to match with the ones in the reference sentence.
3.3.4 WordNet
WordNet is integrated into unigram to go beyond matching of exact tokens. In unigram, no score is given if two comparing unigrams are not exactly the same. However, extra steps are taken after integrating WordNet. Following the same procedures in Section 3.3.1.1, a unique unigram from the reference sentence will be
matched against all the unique unigrams in the candidate sentence. However, if there is not an exact match, the relationship between the two words in WordNet will be looked up.
First, connection to JWNL’s dictionary will be established in order to access the WordNet database. Second, the WordNet POS of each comparing word has to be determined. As mentioned in Section 2.3, WordNet uses four general POS tags but the Brown POS tagger has a much longer list of tags; therefore, POS tags have to be classified. For example, if a word has been tagged by the Brown POS tagger with any of the following tags: “nn”, “nns”, “np”, “nps”, or “nr”, it will be assigned with a WordNet POS tag - NOUN. Similar classification is applied to the remaining three WordNet POS tags. The classification tries to include tags for meaningful terms (open word class) while exclude tags that are for stopwords (closed word class) and punctuations. Third, if both words with their specific POS can be found in the WordNet, their lexical and semantic relationship can be determined. If not, no further action is taken and this pair of words is considered irrelevant.
Two different measures are taken to determine the relationship between two words. They will be discussed as follows.
3.3.4.1 Synonyms-based
Jaccard’s coefficient, Equation (10), is used to measure the similarity between two synsets. The numerator is the intersection of synonyms between synsets k and l while the denominator is the distinct union of synonyms of synsets k and l. After synsets for each word are obtained, synonyms in each synset have to be separated as an individual word. Next, the number of overlapping synonyms between two synsets of reference word and candidate word is counted, and divided by the sum of distinct
documents, each of the synsets of a word will be compared with all the synsets of the other word. The highest score – Equation (11) will be recorded and this is the similarity score between two unigrams. The same steps are repeated until a reference unigram has compared with all the unique unigrams in the candidate sentence. The highest similarity score among the calculated scores will be chosen - Equation (12). The maximum value adds to the total plagiarism score between the two sentences. Figure 17 is an example of how synsets of two words are matched:
1. shout, shout out, cry, call, yell, scream, holler, hollo, squall 2. yell, scream
As shown above, the verb, shouts, has four synsets and the verb, yells, has two synsets in WordNet. By looking at synsets 1 of both words, there is only one overlapping synonym while the distinct union of synonyms is 9. Therefore, the Jaccard’s coefficient for these two synsets will be 1/9.
Synsets of shouts (verb): 1. shout
2. shout, shout out, cry, call, yell, scream, holler, hollo, squall 3. exclaim, cry, cry out, outcry, call out, shout
4. abuse, clapperclaw, blackguard, shout Synsets of yells (verb):
Figure 17 Example of Jaccard’s Coefficient between Two Synsets
Jaccard’s coefficient:
( , )
i j k lk
l
sim s s
k
l
∩
=
∪
(10) i ks is synset k of word i while j is synset l of word j
l
Similarity between two words: 1 1
(
,
)
max
( ,
i j)
R C k l k m l n i jsim w w
Arg
sim s s
≤ ≤ ≤ ≤
=
(11)i
w is word i with m synsets and wjis word j with n synsets
Similarity score between word i and a given sentence: 1 1 ( , ) max ( , i R C i p j q
sim w S Arg sim w w
≤ ≤ ≤ ≤
= )
i j
R C (12)
Word i∈sentenceSRof length p and word j∈sentenceSCof length q
Therefore, the plagiarism score for any pair of reference sentence and candidate sentence is as follows: R u 1 1 1 unigram S ( , ) ( , ) Count (unigram) i p R C clip v i R C u v u y v z sim w S R Synset S S = ≤ ≤ ≤ ≤ ∈ ⎛ ⎞ ⎜ ⎟ ⎝ ⎠ − =
∑
∑
(13) C v 1 1 1 unigram S ( , ) ( , ) Count (unigram) i p R C clip v i R C u v u y v z sim w S P Synset S S = ≤ ≤ ≤ ≤ ∈ ⎛ ⎞ ⎜ ⎟ ⎝ ⎠ − =∑
∑
(14)1 1 2*( )*( ) ( , ) ( ) ( R C u v u y v z ) R Synset P Synset F Synset S S R Synset P Synset ≤ ≤ ≤ ≤ − − − = − + − (15) i
w ∈SR∈Document R of length u andSC∈Document C of length v
3.3.4.2 Relationship-based
Relationship refers to hypernym and hyponym relationships in WordNet. The first few steps for finding hypernym and hyponym relationships are exactly the same as the first few steps for comparing synonyms up to the step where we obtain the senses for both words. After that, hypernym and hyponym relationships between two senses can be found. The term senses is used here instead of synsets because synonyms are not the focus but how each sense/meaning of a word is semantically related to other senses of the other word. Again, all senses of the reference unigram have to be compared with all the other senses of the candidate unigram. The relationship is expressed hierarchically in terms of depth. If two words are actually in the same synset, the depth is zero. This research only considers relationship depth within three levels in the hierarchy. Figure 18 is an example of how hypernym/hyponym relationships between two words are determined.
Both hypernym and hyponym relationships are obtained in identical manner. As there is not any reference about how to set the weight, in Equation (18), initial assignment of weight for each depth will be as follows: 1.0 if the returned depth is zero, 0.9 if the depth is one and so forth with the maximum depth being three. Then we choose the bigger value between the hypernym score and hyponym score and use it to represent the relationship between the word pair like Equation (16).
wt
Figure 18 Example of Hypernym/Hyponym Relationship between Two Words
Synsets of shouts (verb): 1. shout
2. shout, shout out, cry, call, yell, scream, holler, hollo, squall 3. exclaim, cry, cry out, outcry, call out, shout
4. abuse, clapperclaw, blackguard, shout Synsets of yells (verb):
1. shout, shout out, cry, call, yell, scream, holler, hollo, squall 2. yell, scream
Although there are a total of eight possible combinations of synsets between the two verbs, shouts and yells, these two words are linked by two pairs of synsets. Synset 1 of shouts and synset 2 of yells; synset 2 of shouts and synset 1 of yells. The first pair only has hypernym relationship of depth 1, while the second pair has both hypernym and hyponym relationships of depth 0. Since depth 0 is the closest relationship possible, the relationship between shouts and yells is represented by the second pair.
1 1
(
,
)
max(
max
( , )
max
( , ))
i j,
R C i k l k m l n i j k lRS w w
Arg
Arg
hypernym s s
Arg
hyponym s s
≤ ≤ ≤ ≤=
j i j R C (16) iw is word i with m synsets and wjis word j with n synsets
1 1 ( , ) max ( , ) i R C i p j q RS w S Arg RS w w ≤ ≤ ≤ ≤ = (17)
1 2 3 4 if depth=0, if depth=1, if depth=2, if depth=3, wt wt wt wt wt ⎧ ⎪ ⎪ = ⎨ ⎪ ⎪⎩ R u 1 1 1 unigram S ( , ) ( , ) = Count (unigram) i p R C clip v i R C u v u y v z sim w S wt R RS S S = ≤ ≤ ≤ ≤ ∈ ⎛ ⎞ ⎜ ⎟ ⎝ ⎠ −
∑
∑
(18) C v 1 1 1 unigram S ( , ) ( , ) = Count (unigram) i p R C clip v i R C u v u y v z sim w S wt P RS S S = ≤ ≤ ≤ ≤ ∈ ⎛ ⎞ ⎜ ⎟ ⎝ ⎠ −∑
∑
(19) 2*( )*( ) ( , ) ( ) ( ) R C u v R RS P RS F RS S S R RS P RS − − − = − + − (20)3.3.5 Google Mutual Information (MI)
The tremendous number of Web pages on the Internet constitutes a giant database of tokens. A method for calculating the mutual information (relatedness) between two words [13][26] is applied to plagiarism detection between two sentences. Google’s SOAP Search API is responsible for sending the queries to Google and retrieving information about the queries. For each pair of words, three queries are sent: one query per word plus an additional query with both words. We record the number of retrieved pages and use the numbers to calculate MI. The expressions are as follows:
log( ) log( ) 2*log( , ) ( , ) i j i i j w w w w MI w w Max MI + − = j j (21) (22) 1 1 ( , ) max ( , ) i i R C R C v i p j q sim w S Arg MI w w ≤ ≤ ≤ ≤ = (23) R u 1 i R M 1 1 unigram S ( , ) ( , ) = Count (unigram ) p R C clip v R C i u v u y v z sim w S I S S = ≤ ≤ ≤ ≤ ∈ −
∑
∑
(24) C v 1 ) i P M 1 1 unigram S ( , ) ( , ) = Count (unigram p R C clip v R C i u v u y v z sim w S I S S = ≤ ≤ ≤ ≤ ∈ −∑
∑
(25) ( , ) 2*( )*( ) ( ) ( ) R C u v R MI P MI F MI S S R MI P MI − − − = − + −Note: Google SOAP Search API only allows 1000 queries per key per day.
3.3.6 Caching
We realize that the processing speed is impractically slow even for short paragraphs after implementing WordNet. Therefore, we add a caching mechanism into WordNet and Google MI in hope of improving the speed. The entire process is described as follows:
1. If two unigrams do not match, go to the established MySQL database and search for the score of the specific word pair;
2. If no match of the word pair can be found in the database, calculate the score for the word pair and update the score into the database for future use;
4. Experiments and Evaluation
4.1 Data Sets
In the field of plagiarism detection, there is not a standard and valid plagiarism corpus that is publicly available yet. A number of works used news corpus such as the Reuters News corpus for their evaluation, while a small number of works used research articles corpora that are managed by the university and therefore only accessible by the university members. The remaining choice is to make one’s own plagiarism corpus, which usually is relatively small due to limited resources. This research adopted the last approach instead of using a news corpus because even though news content is often reused, modification of this nature may not be able to represent plagiarism.
There are two different manually generated data sets for evaluating the proposed methods. One of the sets contains 978 pairs of sentences while the other set contains 100 pairs of sentences. These two sets will be referred to as the abstract set and the paraphrased set respectively hereafter. The abstract set was used primarily to determine the ideal settings for the methods. It was based on the observation that abstracts of some papers are actually formed by sentences taken from the main text. Such characteristic may be utilized to simulate the plagiarism scenario by treating the abstract as the candidate of plagiarism and the main text as the source being plagiarized. First, a collection of research papers were retrieved from research databases like Elsevier and EBSCOhost using the query “plagiarism”. Second, the abstract and the main text of each paper were separated and saved in two different plain text files. Some manual efforts were required to remove undesirable texts that appeared in certain parts of the papers as they interfered with the main body of the text and might affect the outcome of the experiment. Third, each abstract sentence
![Figure 2 Fingerprint Formation [32]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8104790.165324/18.892.289.646.512.800/figure-fingerprint-formation.webp)


![Table 1 Kappa Statistics [16]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8104790.165324/52.892.139.749.463.1096/table-kappa-statistics.webp)