Top-Down Discovery of Cross-Level Web Browsing
Sequences on Taxonomy
Shyue-Liang Wang
Department of Information Management National University of Kaohsiung
Kaohsiung, Taiwan [email protected]
Wei-Shuo Lo
Department of Business Administration Mei-Ho Institute of Technology
Pingtun, Taiwan
Tzung-Pei Hong
Department of Computer Science and Information Engineering National University of Kaohsiung
Department of Computer Science and Engineering National Sun Yat-sen University
Kaohsiung, Taiwan [email protected]
ABSTRACT
others. In particular, many techniques for mining user browsing patterns have been
proposed in recent years. However, most of these works focus on mining browsing
patterns of web pages directly. In this work, we consider the problem of mining
generalized browsing patterns on both multiple-level and cross-level of taxonomy
comprised of web pages. We propose here an algorithm to discover these generalized
browsing patterns based on top-down level-wise searching approach. Example
demonstrating the proposed approach is given. Comparisons with the Generalized
Sequential Patterns (GSP) approach [16] and Apriori-Level approach [19] show that
the proposed top-down approach generates fewer candidate sequences. This
indicates that the proposed algorithm is more efficient in discovering cross-level web
browsing sequences.
Keywords: Web Mining, Browsing Patterns, Sequential Patterns, Cross-Level,
Taxonomy, Top-Down.
1. INTRODUCTION
Web mining can be viewed as the use of data mining techniques to automatically
documents and services [11]. It has been studied extensively in recent years due to
practical applications of extracting useful knowledge from inhomogeneous data
sources in the World Wide Web. Web mining can be divided into three classes: web
content mining, web structure mining and web usage mining [7]. Web content
mining focuses on the discovery of useful information from the web contents, data
and documents. Web structure mining deals with mining the structure of hyperlinks
within the web itself. Web usage mining emphasizes on the discovery of user access
patterns from secondary data generated by users’ interaction with the web.
In the past, several web mining approaches for finding user access patterns and user
interesting information from the World Wide Web were proposed [3-6, 15]. Chen
and Sycara proposed the WebMate system to keep track of user interests from the
contents of the web pages browsed [4]. It can thus help users to easily search data
from World Wide Web. Chen et. al. mined path-traversal patterns by first finding the
maximal forward references from log data and then obtaining the large reference
sequences according to the occurring numbers of the maximal forward references.
Cohen et. al. sampled only portions of the server logs to extract user access patterns,
which were then grouped as volumes [5]. Files in a volume could then be fetched
proposed the Web Utilization Miner to discover interesting navigation patterns. The
human expert dynamically specifies the interestingness criteria for navigation patterns,
which could be statistical, structural and textual. To discover the navigation patterns
satisfying the criteria, it exploits an innovative aggregated storage representation for
the information in the web server log. Web Site Information Filter System
(WebSIFT) [6] is a web usage mining framework that uses the content and structure
information from a Web site, and finally identifies interesting results from mining
usage data. WebSIFT divides the web usage mining process into three principal
parts that are corresponding to the three phases of usage mining: preprocessing,
pattern discovery, and pattern analysis. The input of the mining process includes
server logs (access, referrer, and agent), HTML files, and optional data. The
preprocessing process constructs a user session file with the input data to derive a site
topology and to classify the pages of a site. The user session file will be converted
to the transaction file and output to next phase. The pattern discovery process uses
the techniques such as statistics, association rules, clustering, sequential to generate
rules and patterns. In the pattern analysis process, the site topology and page
classification are fed into the information filter, the output of pattern discovery will be
Web browsing pattern is a kind of user access pattern that considers users’ browsing
sequences of web pages. In fact, it is similar to the discovery of sequential patterns
from transaction databases. The problem of mining sequential patterns was first
introduced in [1]. Let I={i1, i2, …, im} be a set of literals, called items. An itemset is a non-empty unordered set of items. A sequence is an ordered list of itemsets.
An itemset i is denoted as (i1, i2, …, im), where ij is an item. A sequence s is denoted as (s1
→
s2→
…sq), where sj is an itemset. Given a database D of customer transactions, each transaction T consists of fields: customer-id, transaction-time, andthe items purchased in the transaction. All the transactions of a customer can
together be viewed as a sequence. This sequence is called a customer-sequence. A
customer supports a sequence s if s is contained in the customer-sequence for this
customer. The support for a sequence is the fraction of total customers who support
this sequence. A sequence with support greater than a user-specified minimum
support is called a large sequence. In a set of sequences, a sequence is maximal if it
is not contained in any other sequences. The problem of finding sequential patterns
is to find the maximal sequences among all sequences that have supports greater than
a certain user-specified minimum support.
proposed [1,2,12,14,16-22]. In application to web browsing patterns, techniques for
mining simple sequential browsing patterns and sequential patterns with browsing
times have been proposed [4,5,6,7,10,11,15]. However, most of these works focus
on mining browsing patterns of web pages directly. In this work, we consider the
problem of mining generalized browsing patterns on both multiple-level and
cross-level of taxonomy comprised of web pages. We propose here an algorithm to
discover these generalized browsing patterns based on top-down level-wise searching
approach. Comparisons with the Generalized Sequential Patterns (GSP) approach
[16] and Apriori-Level approach [19] are also discussed.
The rest of our paper is organized as follows. Section 2 reviews some related work
of mining sequential pattern. Section 3 presents the top-down mining algorithm of
generalized browsing patterns. Section 4 gives an example to illustrate the
feasibility of the proposed algorithm and shows the difference between the GSP
algorithm, the Apriori-Level algorithm, and the Top-Down algorithm. A conclusion
is given at the end of the paper.
Sequential pattern mining, similar to association rule mining, is the mining of
frequently occurring patterns that are related to time or other sequences. Many
algorithms for efficient mining of sequential patterns on single and multiple concept
levels have been proposed [1-5, 9-17,20-22]. This section reviews some of the basic
algorithms for discovering various types of sequential patterns.
For single concept level sequential pattern discovery, two main approaches have been
proposed. The first approach, called generate-and-test, uses a process of candidate
generation and testing to find frequent patterns. The second approach, called data
transformation, transforms the original data into a representation better suited for
frequent pattern mining.
For the generate-and-test approach, several different algorithms have been proposed
to find all frequent patterns in a dataset. The Apriori-All and GSP algorithms [1, 16]
accomplish this by employing a bottom-up search. The Apriori-All algorithm first
generates large itemsets from candidate itemsets that meet the minimum support
requirement on each pass. It then joins the large itemsets to form candidate
sequences. The large sequences are those candidate sequences with support greater
lead to poor performance due to large frequent pattern sizes. The SPADE algorithm
[21] is a generate-and-test approach with divide-and-conquer and efficient lattice
searching features. The candidate sequences are stored on a lattice and further
divided to equivalence classes. Depth-first and/or breadth-first searches are then
applied to each sub-lattice, which is induced by the equivalence relation, to search for
the large sequences with certain pruning strategies. It usually requires three database
scans, or only a single scan with some pre-processed information, thus minimizing the
I/O costs. Experimental results show that the SPADE performs better than the
previous Apriori-All algorithm.
For the data transformation approach, several different algorithms have been proposed.
The DSG (Direct Sequential pattern Generation) algorithm [20] is a graph-based
algorithm to find large sequences. It constructs an association graph to indicate the
associations between items and then traverse the graph to generate large sequences.
The algorithm needs to scan the database only once. However, the related
information may not fit in the main memory when the size of the database is very
large. The Free-Span and Prefix-Span algorithms [12, 14] are tree-based algorithm
to find large sequences. The general idea is to examine only the prefix subsequences
In each projected database, sequential patterns are grown by exploring only local
frequent patterns. To further improve mining efficiency, two kinds of database
projections are explored: level-by-level projection and bi-level projection, with an
optimization technique using pseudo-projection. Experimental results show that the
Prefix-Span performs better than the previous Apriori-All, GSP, and Free-Span
algorithms.
For multiple concept level sequential pattern discovery, a few algorithms have been
proposed. The GSP algorithm [16] is an extension of Apriori-All algorithm. The
algorithm consists of two phases: candidate generation and counting candidates.
However, each data sequence d is replaced with an “extended sequence” d’, where
each transaction d’i of d’ contains the items in the corresponding transaction di of d, as
well as all the ancestors of each item in di. For example, with the taxonomy shown
in Figure 1, a data sequence <(Legislative)> would be replaced with the extended
sequence <(Legislative, Central, Government)>. The algorithm will run on these
extended sequences and find all large sequences. The sequences thus discovered
contains itemsets that appeared on all levels of the taxonomy. The multiple-level
sequential pattern algorithm [2] is a top-down level-wise Apriori-All-based algorithm.
The database is transformed to a filtered database by pruning those itemsets with
supports lower than the user specified minimum support. It then finds the large
k-sequences on the top level. The large 1-sequences of the next level can be
calculated from the filtered database of previous level. The process repeats itself by
calculating the large k-sequences and then the next level. The sequences discovered
contains itemsets that appeared on the same level of the taxonomy.
3. MINING OF GENERALIZED WEB BROWSING PATTERNS
In this section, we describe the proposed top-down data-mining algorithm to discover
generalized web browsing patterns from log data.
3.1 NOTATION
The following notation is used in our proposed algorithm:
n: the total number of log data;
m: the total number of files in the log data;
ni: the number of log data from the i-th client, 1≤i≤c;
Di: the browsing sequence of the i-th client, 1≤i≤c;
Did: the d-th log data in Di, 1≤d≤ni;
Ig: the g-th file, 1≤g≤m;
α: the predefined minimum support value;
Cr: the set of candidate sequences with r files;
r
L : the set of large sequences with r files.
3.2 THE TOP-DOWN ALGORITHM
The proposed algorithm, Top-Down algorithm, first finds all large one itemsets on
every level of the concept hierarchy. These itemsets are actually the large sequences
of size one, which are also called large 1-sequences. Based on these large 1-sequences,
it generates large sequences by performing a top-down level-wise searching. This step
basically finds the large sequences consisting itemsets on the same concept level. To
obtain sequences containing itemsets from different concept levels, large sequences of
current level must be joined with large sequences of upper levels. However, the
computational effort of joining can be reduced by first checking the ancestor
given two large 2-sequences, <x, y> and <y, z>, if x and y are on the same path or y
and z are on the same path of the concept hierarchy, then <x, z> is a large 2-sequence.
Steps of the proposed mining algorithm are described below.
INPUT: A server log, a predefined taxonomy of web pages, a predefined
minimum support valueα.
OUTPUT: A set of maximal generalized browsing patterns
STEP 1: Select the web pages with file names including .asp, .htm, .html, .jva .cgi
and close the connection from the log data; keep only the fields date,
time, client-ip and file-name. Denote the resulting log data as D.
STEP 2:Encode each web page with a file name using a sequence of number and
the symbol “*”, with the t-th number representing the branch number of
a certain web page on level t.
STEP 3:Form a browsing sequence Dj for each client cj by sequentially listing
his/her nj tuples (web page), where nj is the number of web page
browsed by client cj. Denote the d-th tuple in Dj as Djd.
STEP 4:Find the set of large itemsets with respect to each level of concept
hierarchies, level by level and from top to bottom. In fact, the large
of all large 1-sequences from all level is denoted as LS1.
STEP 5:Find the k-sequences from the large itemsets in the same level and then
find the k-sequences from the large itemsets of different levels. It starts
searching for large sequences on the top level and proceeds a top-down
level-wise searching.
(5.1) For level m=1, find all large k-sequences based on all large itemsets
of this level.
(5.2) For level m ≥ 2
(5.2.1) Find all large k-sequences on the current level.
(5.2.2) Find all large cross-level k-sequences between current level
and all upper levels in a level-by-level manner from current
level to top level. Perform ancestor transitivity checking for
cross-level candidate sequences with constituent itemsets
from levels that are at least two-level apart.
(5.2.3) Repeat tasks(5.2.1)and(5.2.2)until the lowest level is reached.
STEP 6:Find the maximal sequences by deleting those sequences that are
subsequences of others.
In this section, we describe an example to demonstrate the proposed mining
algorithm of generalized web browsing patterns. The example shows how the
proposed algorithm can be used to discover the generalized sequential patterns from
the web browsing log data shown in Table 1. In addition, the predefined taxonomy
for web pages is shown in Figure 1. The predefined minimum support α is set at
50 %.
Table 1 A part of log data used in the example
Date Time Client-IP Server-IP Server
-port File-name 2007-06-01 05:39:56 140.117.72.1 140.117.72.88 11 News.htm 2007-06-01 05:40:08 140.117.72.1 140.117.72.88 11 Exective.htm 2007-06-01 05:40:10 140.117.72.1 140.117.72.88 11 Stock.htm …….. …….. …….. …….. …….. …….. 2007-06-01 05:40:26 140.117.72.1 140.117.72.88 11 University.htm …….. …….. …….. …….. …….. …….. 2007-06-01 05:40:52 140.117.72.2 140.117.72.88 11 Golf.htm 2007-06-01 05:40:53 140.117.72.2 140.117.72.88 11 Stock.htm …….. …….. …….. …….. …….. …….. 2007-06-01 05:41:08 140.117.72.3 140.117.72.88 11 Golf.htm …….. …….. …….. …….. …….. …….. 2007-06-01 05:48:38 140.117.72.4 140.117.72.88 11 Closing connection …….. …….. …….. …….. …….. …….. 2007-06- 05:48:53 140.117.72.5 140.117.72.88 11 Golf.htm
01 …….. …….. …….. …….. …….. …….. 2007-06-01 05:50:13 140.117.72.6 140.117.72.88 11 Stock.htm …….. …….. …….. …….. …….. …….. 2007-06-01 05:53:33 140.117.72.6 140.117.72.88 11 Closing connection
Figure 1 The predefined taxonomy used in this example
The proposed data-mining algorithm proceeds as follows.
STEP 1: Select the web pages with file names including .asp, .htm, .html, .jva .cgi
and close the connection from Table 1. Keep only the fields date, time,
client-ip and file-name. Denote the resulting log data as Table 2.
Government Entertainment Business Sport Education
Central Local TV Music Investment Management Ball Stellar School Extension
L an g u ag e C o m p u te r H ig h sc h o o l U n iv er si ty T ig er W o o d s B ec k h am G o lf F o o tb al l M ar k et in g M IS F o u n d S to ck C la ss ic al F as h io n D is co v er y N ew s K ao h si u n g T ai p ei L eg is la tiv e
Table 2 The resulting log data for web mining
Client-IP Server-IP Server-port File-name
140.117.72.1 140.117.72.88 11 News.htm 140.117.72.1 140.117.72.88 11 Exective.htm 140.117.72.1 140.117.72.88 11 Stock.htm …….. …….. …….. …….. 140.117.72.1 140.117.72.88 11 University.htm …….. …….. …….. …….. 140.117.72.2 140.117.72.88 11 Golf.htm 140.117.72.2 140.117.72.88 11 Stock.htm …….. …….. …….. …….. 140.117.72.3 140.117.72.88 11 Golf.htm …….. …….. …….. …….. 140.117.72.4 140.117.72.88 11 Closing connection …….. …….. …….. …….. 140.117.72.5 140.117.72.88 11 Golf.htm …….. …….. …….. …….. 140.117.72.6 140.117.72.88 11 Stock.htm …….. …….. …….. …….. 140.117.72.6 140.117.72.88 11 Closing connection
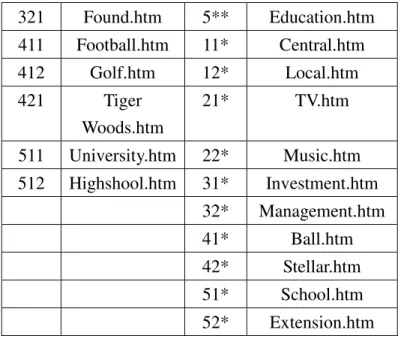
STEP 2: Each file name is encoded using the predefined taxonomy shown in Figure
1. Results are shown in Table 3.
Table 3 Codes of file names
Code File name Code File name
111 Executive.htm 1** Government.htm
211 News.htm 2** Entertainment.htm
212 Discovery.htm 3** Business.htm
321 Found.htm 5** Education.htm 411 Football.htm 11* Central.htm 412 Golf.htm 12* Local.htm 421 Tiger Woods.htm 21* TV.htm 511 University.htm 22* Music.htm 512 Highshool.htm 31* Investment.htm 32* Management.htm 41* Ball.htm 42* Stellar.htm 51* School.htm 52* Extension.htm
STEP 3: The web pages browsed by each client are listed as a browsing sequence.
Each tuple is represented as (web page), as shown in Table 4. The
resulting browsing sequences from Table 4 are shown in Table 5.
Table 4 The web pages browsed with their duration
Client-ID (Web page)
1 (111) 1 (211) 1 (231) 2 (112) 2 (111) 2 (231) 3 (111) 3 (211) 4 (211) 4 (313) 4 (323) 4 (421)
Table 5 The browsing sequences formed from Table4
Client ID Browsing sequences
1 (111), (211), (231), (222)
2 (112), (111), (231)
3 (111), (211)
4 (211), (313), (323), (421), (534)
STEP 4: Find the set of large itemsets with respect to each level of concept
hierarchies, level by level and from top to bottom. In fact, the large
itemsets in each level are the large 1-sequences for that level. The set of
all large 1-sequences from all level is denoted as LS1. The candidate and
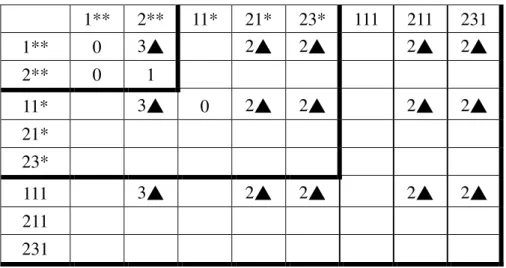
large 2-sequence at level-1 are shown in Table 6, where ▲ represents
large sequence.
Table 6 Candidate and Large 2-sequence at level-1
1** 2**
1** 0 3▲
2** 0 1
STEP 5: Find the k-sequences from the large itemsets in the same level and then
find the k-sequences from the large itemsets of different levels. It starts
level-wise searching. For cross-level sequences, pruning can be achieved
by checking the ancestor-descendant relation, e.g. if 2** → 1** is pruned,
then 21* → 1**, 211 → 11* are pruned too. Tables 7 and 8 show the
sequences at levels 1, 2 and levels 1, 3 respectively.
Table 7 Candidate and Large 2-sequence at levels 1 and 2
1** 2** 11* 21* 23* 1** 0 3▲ 2▲ 2▲ 2** 0 1 11* 3▲ 0 2▲ 2▲ 21* 23*
Table 8 Candidate and Large 2-sequence at levels 1 to 3
1** 2** 11* 21* 23* 111 211 231 1** 0 3▲ 2▲ 2▲ 2▲ 2▲ 2** 0 1 11* 3▲ 0 2▲ 2▲ 2▲ 2▲ 21* 23* 111 3▲ 2▲ 2▲ 2▲ 2▲ 211 231
STEP 6: Find the maximal sequences by deleting those sequences that are
Large-1-sequence:<(1**)>, < (2**)>, <(11*)>, < (21*)>, < (23*)> <(111)>, < (211)> < (231)> Large-2-sequence:< (1**), (2**)>, < (1**), (21*)>, < (1**), (23*)> , < (1**), (211)>, < (1**), (231)>, <(11*), (2**)> , < (11*), (21*)>, < (11*), (23*)>, < (11*), (211)> , < (11*), (231)>, <(111), (2**)>, < (111), (21*)> , < (111), (23*)> ,< (111), (211)>, < (111), (231)>
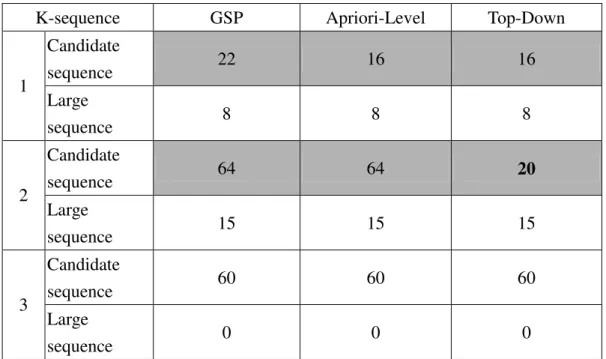
In the following, we compare our algorithm with the GSP and the Apriori-Level
approaches. Table 9 shows the candidate and large sequences generated by the three
approaches, using the example in this section. It can be seen that Top-Down approach
generates fewer candidate sequences at both 1-sequence and 2-sequence phases.
Table 9 Comparison of generated sequences
K-sequence GSP Apriori-Level Top-Down
Candidate sequence 22 16 16 1 Large sequence 8 8 8 Candidate sequence 64 64 20 2 Large sequence 15 15 15 Candidate sequence 60 60 60 3 Large sequence 0 0 0
The complexity of finding maximal browsing sequences on a given level depends
on the number of large itemsets and sequences on that level. The complexities of
finding multiple-level web browsing sequences therefore are independent from each
other. Meaning the complexity only depends on the large itemsets and sequences
from its own level. However, the complexity of finding cross-level web browsing
sequences depends on not only the large itemsets and sequences of current level but
also all higher levels. For simplicity, assuming running time complexity for each
level is constant, O(T), and there are M levels. The total running time complexity for
finding multiple-level web browsing sequences will be O(MT). However, the total
running time complexity for finding cross-level web browsing sequences will be (1 +
2 + ... + M)T, i.e., O(M2T).
5. CONCLUSION
In this work, we have proposed a top-down level-wise web-mining algorithm that can
process web server logs to discover generalized web browsing patterns. The
inclusion of concept hierarchy (taxonomy) of web pages produces browsing patterns
of different granularity. This allows the views of users’ browsing behavior from
various levels of perspectives. In addition, we show that the proposed Town-Down
Apriori-Level approaches.
Although the proposed method works well in generalized web browsing patterns
mining, it is just a beginning. The proposed algorithm is a generate-and-test
approach that requires several database scans, depending on the size of large itmesets.
To improve the efficiency, algorithms based on data transformation approach need to
be considered and compared. More numerical simulations need to be carried out in
order to justify the efficiency of the different approaches.
5. ACKNOWLEDGEMENT
This work was partially supported by National Science Council of the Republic of
China, under grant number NSC-96-2213-E-390-003.
6. REFERENCES
1. Agrawal, R. and Srikant, R.: Mining Sequential Patterns, Proc. of the 11th
International Conference on Data Engineering (1995), 3-14.
2. Chen, N., Chen, A.: Discovery of Multiple-Level Sequential Patterns from Large
Database, Proc. of the International Symposium on Future Software Technology,
3. Chen, M.S., Park J.S. and Yu, P.S.: Efficient Data Mining for Path Traversal
Patterns, IEEE Transactions on Knowledge and Data Engineering, Vol. 10 (1998),
209-221.
4. Chen, L., Sycara, K.: WebMate: A Personal Agent for Browsing and Searching,
The Second International Conference on Autonomous Agents, ACM (1998).
5. Cohen, E., Krishnamurthy B. and Rexford, J.: Efficient Algorithms for Predicting
Requests to Web Servers, The Eighteenth IEEE Annual Joint Conference on
Computer and Communications Societies, Vol. 1 (1999), 284-293.
6. Cooley, R., Mobasher B. and Srivastava, J.: Grouping Web Page References into
Transactions for Mining World Wide Web Browsing Patterns, Knowledge and
Data Engineering Exchange Workshop (1997), 2-9.
7. Cosala, R., Blockleel, H.: Web Mining Research: A Survey, ACM SIGKDD, Vol.
2, Issue 1 (2000),1-15.
8. Mannila H. and Toivonen, H.: Discovering Generalized Episodes Using Minimal
Occurrences, Proc. of the 2nd International Conference on Knowledge Discovery
and Data Mining (1996), 146-151.
9. Oates, T. et al.: A Family of Algorithms for Finding Temporal Structure in Data,
Proc. of the 6th International Workshop on AI and Statistics (1997), 371-378.
of the 5th International Conference on Knowledge-based Intelligent Information
Engineering Systems, Osaka, Japan (2001), 495-499.
11. Pal, S.K., Talwar, V. and Mitra, P.: Web Mining in Soft Computing Framework:
Relevance, State of the Art and Future Directions, IEEE Transactions on Neural
Network, 13(5) (2002), 1163-1177.
12. Pei, J., Han, J.W., Mortazavi-Asl, B., Pinto, H., Chen, Q., Dayal U. and Hsu,
M.C.: Prefixspan: Mining Sequential Patterns by Prefix-Projected Growth, Proc.
of the 17th IEEE International Conference on Data Engineering, Heidelberg,
Germany, (2001).
13. Piategsky-Shapiro, G.: Discovery, Analysis and Presentation of Strong Rules,
Knowledge Discovery in Databases, AAAI/MIT press (1991), 229-248.
14. Pinto, H.: Multiple-Dimensional Sequential Patterns Mining, University of Lethe
bridge, Alberta, Canada, Master Thesis, (2001).
15. Spliliopoulou, M., Faulstich, L.C.: WUM: A Web Utilization miner, Workshop
on the Web and Data Base (WEBKDD) (1998 ),109-115.
16. Srikant, R. and Agrawal, R.: Mining Sequential Patterns: Generalizations and
Performance Improvements, Proc. of the 5th International Conference on
Extending Database Technology (1996), 3-17.
Transaction Databases, Proc. of the 9th National Conference on Fuzzy Theory
and Its Application, Taiwan (2001), 624-628.
18. Wang, S.L., Lo, W.S., Hong, T.P.: Discovery of Cross-Level Sequential Patterns
from Transaction Databases, Proceedings of the 6th International Conference on
Knowledge-based Intelligent Information Engineering Systems (2002), 683-687.
19. Wang, S.L., Lo, W.S., Hong, T.P.: Mining of Generalized Web Browsing Patterns,
Proceedings of the 7th World Multi Conference on Systemics, Cybernetics, and
Informatics, Orlando, Florida, USA (2003), 267-271.
20. Yen, S.J. and Chen, A.L.P.: An Efficient Approach to Discovering Knowledge
from Large Databases, Proceedings of the 4th International Conference on
Parallel and Distributed Information Systems (1996), 8-18.
21. Zaki, M.J.: Efficient Enumeration of Frequent Sequences, Proc. of the 7th
International Conference on Information and knowledge Management,
Washington DC (1998), 68-75.
22. Zhang, M,. Kao, B., Yip, C.L. and Cheung, D.: A GSP-Based Efficient Algorithm
for Mining Frequent Sequences, Proc. of the IC-AI’2001, Las Vegas, Nevada,