國立高雄大學統計學研究所
碩士論文
Applications of HAR-GARCH Models
滯後自迴歸條件異質變異模型之應用
研究生:張益誠 撰
指導教授:黃士峰
致謝辭
時光荏苒、白駒過隙,眨眼間兩年的研究所生涯即將邁入尾聲,在行囊滿載 而歸以及祝福之際,即將畢業了。回首一看,內心總有幾分悸動,此時此刻的心 情是充滿著無限的感恩。 本論文能夠順利的完成,首先感謝我的指導教授黃士峰老師,於論文撰寫期 間給予悉心的教導與督促,當我一而再,再而三的犯錯時,總給我無限的包容和 原諒,每次的當頭棒喝,更讓我發現自己多麼像是井底之蛙,每次的耳提面命都 告訴我社會上是多麼的現實,要我不准再次犯錯,謝謝老師您的啟發,讓我在這 段期間內受益良多,在此向老師您至上我最崇高的敬意與最誠摯的感激。 再者,感謝口試委員郭錕霖老師和張志浩老師,細心的指正,提供諸多寶貴 的意見,使本論文更臻完備,在此致上深深的謝意。感謝在所上所有老師的教導 與照顧,謝謝您們燃燒您們的教學熱情,讓我們的專業更加穩健、敏銳。還有一 位為我們默默付出的系助,每次完美的準備活動、溫柔的叮嚀與打氣,謝謝您。 碩士班修業期間,謝謝所有的同儕們,提點我許多我未知的事物,還有那一 同熬夜奮鬥的夜晚,因為有了你們,讓我在研究生涯中豐富我的回憶。 此外,謝謝我的大學好兄弟們–祥恩、俊逸、昭霖、彥鈞(雅婷和易塏)、廷 勳、秉承、承杰、冠穎、星達,不管過了幾年,你們還是一樣有趣、瘋狂,也謝 謝你們在我低潮的時候給我見解與陪伴,幸好大學認識了你們。還有一直記在心 裡的三位恩師,謝良瑜老師、吳土城老師和陳清怡姐,謝謝你們那時候的諄諄教 誨,也謝謝你們在我想放棄時,拉了我一把,滿心的感謝您們。 最後,要感謝我最重要的家人,謝謝爸爸、媽媽和姊姊讓我在充滿幸福與愛 的環境中成長,尊重我的決定,包容我的任性,把你們最好的都給了我,因為有 你們一路上的支持與鼓勵,才能讓我無後顧之憂地接受各種困難與挑戰,未來, 換我成為你們的後盾,也希望我能永遠成為你們心目中的驕傲,謝謝你們,我愛 你們。 要謝謝的太多,千言萬語也說不完、道不盡,謹以此向所有關心我的人致上 最深的謝意,並將這份成果呈現給你們,感謝所有。 張益誠 謹誌于國立高雄大學 理學院統計學研究所 中華民國一○八年八月Applications of HAR-GARCH Models
by
Yi-Cheng Chang
Advisor
Shih-Feng Huang
Institute of Statistics
National University of Kaohsiung
Kaohsiung, Taiwan 811, R.O.C.
目錄
摘要(中文)... viii 摘要(英文) ... ix 第一章 緒論... 1 第一節 研究動機與目的... 1 第二節 研究架構... 2 第二章 文獻回顧... 3 第一節 滯後自迴歸模型 (Li et al., 2015) ... 3 第二節 滯後自迴歸條件異質變異模型 (Chen et al., 2016) ... 3 第三節 關聯規則... 4 第三章 參數估計方法... 6 第一節 參數估計... 6 第四章 數值結果... 12 第一節 模擬研究... 12 第二節 實證研究... 14 第五章 結論... 17 參考文獻... 18 附錄... 20表目錄
表格 1:模擬研究中,模擬陳等人(Chen et al., 2016)參數設定的後驗平均值和 標準差... 20 表格 2:模擬研究中,模擬加權指數的後驗平均值和標準差... 21 表格 3:實證研究中,德國加權指數的各參數區間... 22 表格 4:2009 年各國均方預測誤差列表,𝐴1~𝐴13依序為澳洲、日本、韓國、馬 來西亞、新加玻、香港、印度、法國、德國、英國、巴西、加拿大及美國,而𝐵1~𝐵13國 家排序順序與𝐴1~𝐴13相同,藍色區塊為原本閾值參數報酬的均方預測誤差 (MSPE1),橘色為更改狀態後閾值參數報酬的均方預測誤差(MSPE2) ... 23 表格 5:2010 年各國均方預測誤差列表,𝐴1~𝐴13依序為澳洲、日本、韓國、馬 來西亞、新加玻、香港、印度、法國、德國、英國、巴西、加拿大及美國,而𝐵1~𝐵13國 家排序順序與𝐴1~𝐴13相同,藍色區塊為原本閾值參數報酬的均方預測誤差 (MSPE1),橘色為更改狀態後閾值參數報酬的均方預測誤差(MSPE2) ... 24 表格 6:2011 年各國均方預測誤差列表,𝐴1~𝐴13依序為澳洲、日本、韓國、馬 來西亞、新加玻、香港、印度、法國、德國、英國、巴西、加拿大及美國,而𝐵1~𝐵13國 家排序順序與𝐴1~𝐴13相同,藍色區塊為原本閾值參數報酬的均方預測誤差 (MSPE1),橘色為更改狀態後閾值參數報酬的均方預測誤差(MSPE2) ... 25 表格 7:2012 年各國均方預測誤差列表,𝐴1~𝐴13依序為澳洲、日本、韓國、馬 來西亞、新加玻、香港、印度、法國、德國、英國、巴西、加拿大及美國,而𝐵1~𝐵13國 家排序順序與𝐴1~𝐴13相同,藍色區塊為原本閾值參數報酬的均方預測誤差 (MSPE1),橘色為更改狀態後閾值參數報酬的均方預測誤差(MSPE2) ... 26 表格 8:2013 年各國均方預測誤差列表,𝐴1~𝐴13依序為澳洲、日本、韓國、馬 來西亞、新加玻、香港、印度、法國、德國、英國、巴西、加拿大及美國,而𝐵1~𝐵13國 家排序順序與𝐴1~𝐴13相同,藍色區塊為原本閾值參數報酬的均方預測誤差 (MSPE1),橘色為更改狀態後閾值參數報酬的均方預測誤差(MSPE2) ... 27 表格 9:2014 年各國均方預測誤差列表,𝐴1~𝐴13依序為澳洲、日本、韓國、馬 來西亞、新加玻、香港、印度、法國、德國、英國、巴西、加拿大及美國,而𝐵1~𝐵13國 家排序順序與𝐴1~𝐴13相同,藍色區塊為原本閾值參數報酬的均方預測誤差 (MSPE1),橘色為更改狀態後閾值參數報酬的均方預測誤差(MSPE2) ... 28 表格 10:2015 年各國均方預測誤差列表,𝐴1~𝐴13依序為澳洲、日本、韓國、 馬來西亞、新加玻、香港、印度、法國、德國、英國、巴西、加拿大及美國,而 𝐵1~𝐵13國家排序順序與𝐴1~𝐴13相同,藍色區塊為原本閾值參數報酬的均方預 測誤差(MSPE1),橘色為更改狀態後閾值參數報酬的均方預測誤差(MSPE2) . 29 表格 11:2016 年各國均方預測誤差列表,𝐴1~𝐴13依序為澳洲、日本、韓國、 馬來西亞、新加玻、香港、印度、法國、德國、英國、巴西、加拿大及美國,而 𝐵1~𝐵13國家排序順序與𝐴1~𝐴13相同,藍色區塊為原本閾值參數報酬的均方預 測誤差(MSPE1),橘色為更改狀態後閾值參數報酬的均方預測誤差(MSPE2) . 30表格 12:2017 年各國均方預測誤差列表,𝐴1~𝐴13依序為澳洲、日本、韓國、 馬來西亞、新加玻、香港、印度、法國、德國、英國、巴西、加拿大及美國,而 𝐵1~𝐵13國家排序順序與𝐴1~𝐴13相同,藍色區塊為原本閾值參數報酬的均方預 測誤差(MSPE1),橘色為更改狀態後閾值參數報酬的均方預測誤差(MSPE2) . 31 表格 13:2018 年各國均方預測誤差列表,𝐴1~𝐴13依序為澳洲、日本、韓國、 馬來西亞、新加玻、香港、印度、法國、德國、英國、巴西、加拿大及美國,而 𝐵1~𝐵13國家排序順序與𝐴1~𝐴13相同,藍色區塊為原本閾值參數報酬的均方預 測誤差(MSPE1),橘色為更改狀態後閾值參數報酬的均方預測誤差(MSPE2) . 32 表格 14:2009~2013 年(由上至下),將德國加權指數利用閾值參數將報酬分成 兩 群 和 將 閾 值 參 數 之 間 將 報 酬 分 成 兩 群 , 並 分 別 於 使 用 關 聯 規 則 前 後 做 Wilcoxon–Mann–Whitney 和 Kolmogorov-Smirnov 檢定 ... 33 表格 15:2014~2018 年(由上至下),將德國加權指數利用閾值參數將報酬分成 兩 群 和 將 閾 值 參 數 之 間 將 報 酬 分 成 兩 群 , 並 分 別 於 使 用 關 聯 規 則 前 後 做 Wilcoxon–Mann–Whitney 和 Kolmogorov-Smirnov 檢定 ... 34 表格 16:各年網絡中心... 35 表格 17:各年網絡密度... 35
圖目錄
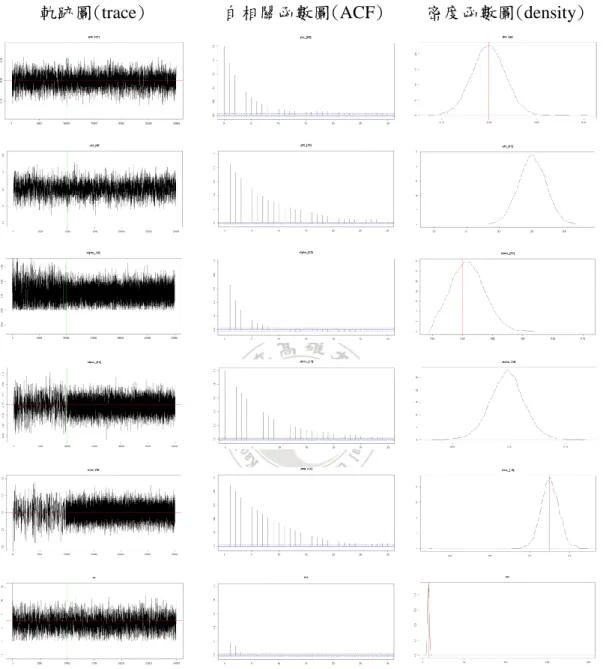
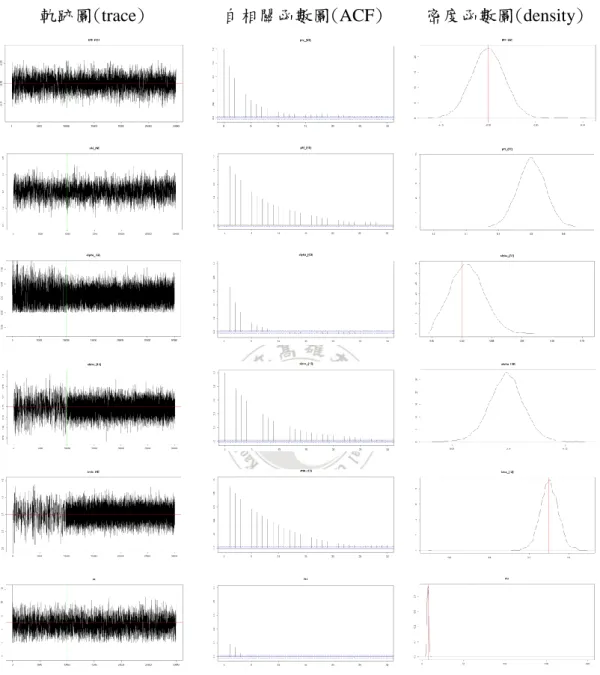
圖 1 : 分 別 為 模 擬 研 究 中 模 擬 陳 等 人 (Chen et al., 2016) 𝑟𝑈, 𝑟𝐿 , ∅01, ∅11, 𝛼01, 𝛼11, 𝛽11的前 10000 個樣本的馬可夫鏈蒙地卡羅軌跡圖、自我相關 函數圖和密度函數圖... 36 圖 2:分別為模擬研究中模擬陳等人(Chen et al., 2016)∅02, ∅12, 𝛼02, 𝛼12, 𝛽12, 𝜈 的前 10000 個樣本的馬可夫鏈蒙地卡羅軌跡圖、自我相關函數圖和密度函數圖 ... 37 圖 3:分別為模擬研究中模擬加權指數𝑟𝑈, 𝑟𝐿, ∅01, ∅11, 𝛼01, 𝛼11, 𝛽11的前 10000 個樣本的馬可夫鏈蒙地卡羅軌跡圖、自我相關函數圖和密度函數圖... 38 圖 4:分別為實證研究中模擬加權指數∅02, ∅12, 𝛼02, 𝛼12, 𝛽12, 𝜈的前 10000 個樣 本的馬可夫鏈蒙地卡羅軌跡圖、自我相關函數圖和密度函數圖... 39 圖 5:2009~2018 年的德國指數關聯分析之報酬圖,藍線為大於閾值參數𝑟𝑈的 報酬、黑線為界於閾值參數之間的報酬、紅線為小於閾值參數𝑟𝐿的報酬,而垂直 橘色線為利用第(7)~(16)式的關聯規則,將美國影響德國的市場景氣狀態置換 ... 40 圖 6:(a) 2009 年,德國指數之報酬盒鬚圖,U𝐺𝑒𝑟𝑚𝑎𝑛𝑦、L𝐺𝑒𝑟𝑚𝑎𝑛𝑦為大於閾 值 參 數 𝑟𝑈 、 小 於 閾 值 參 數 𝑟𝐿 所 對 應 之 報 酬 盒 鬚 圖 ; 𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝑈𝑆𝐴 、 𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝑈𝑆𝐴為利用加入美國狀態的關聯分析後,大於閾值參數𝑟𝑈、小於閾值 參數𝑟𝐿所對應之報酬盒鬚圖 ... 41 圖 7:(b) 2009 年,德國指數之報酬盒鬚圖,DU𝐺𝑒𝑟𝑚𝑎𝑛𝑦、DL𝐺𝑒𝑟𝑚𝑎𝑛𝑦為介於 閾值參數之間而被分為大於閾值參數𝑟𝑈、小於閾值參數𝑟𝐿所對應之報酬盒鬚圖; 𝐷𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝑈𝑆𝐴、𝐷𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝑈𝑆𝐴為利用加入美國狀態的關聯分析後,介於閾 值參數之間而被分為大於閾值參數𝑟𝑈、小於閾值參數𝑟𝐿所對應之報酬盒鬚圖 . 41 圖 8:(a) 2010 年,德國指數之報酬盒鬚圖,U𝐺𝑒𝑟𝑚𝑎𝑛𝑦、L𝐺𝑒𝑟𝑚𝑎𝑛𝑦為大於閾 值 參 數 𝑟𝑈 、 小 於 閾 值 參 數 𝑟𝐿 所 對 應 之 報 酬 盒 鬚 圖 ; 𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐹𝑟𝑎𝑛𝑐𝑒 、 𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐹𝑟𝑎𝑛𝑐𝑒為利用加入法國狀態的關聯分析後,大於閾值參數𝑟𝑈、小於閾 值參數𝑟𝐿所對應之報酬盒鬚圖 ... 42 圖 9:(b) 2010 年,德國指數之報酬盒鬚圖,DU𝐺𝑒𝑟𝑚𝑎𝑛𝑦、DL𝐺𝑒𝑟𝑚𝑎𝑛𝑦為介於 閾值參數之間而被分為大於閾值參數𝑟𝑈、小於閾值參數𝑟𝐿所對應之報酬盒鬚圖; 𝐷𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐹𝑟𝑎𝑛𝑐𝑒、𝐷𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐹𝑟𝑎𝑛𝑐𝑒為利用加入法國狀態的關聯分析後, 介於閾值參數之間而被分為大於閾值參數𝑟𝑈、小於閾值參數𝑟𝐿所對應之報酬盒 鬚圖... 42 圖 10:(a) 2011 年,德國指數之報酬盒鬚圖,U𝐺𝑒𝑟𝑚𝑎𝑛𝑦、L𝐺𝑒𝑟𝑚𝑎𝑛𝑦為大於 閾 值 參 數 𝑟𝑈 、 小 於 閾 值 參 數 𝑟𝐿 所 對 應 之 報 酬 盒 鬚 圖 ; 𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝑈𝑆𝐴 、 𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝑈𝑆𝐴為利用加入美國狀態的關聯分析後,大於閾值參數𝑟𝑈、小於閾值 參數𝑟𝐿所對應之報酬盒鬚圖 ... 43 圖 11:(b) 2011 年,德國指數之報酬盒鬚圖,DU𝐺𝑒𝑟𝑚𝑎𝑛𝑦、DL𝐺𝑒𝑟𝑚𝑎𝑛𝑦為介於閾值參數之間而被分為大於閾值參數𝑟𝑈、小於閾值參數𝑟𝐿所對應之報酬盒鬚 圖;𝐷𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝑈𝑆𝐴、𝐷𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝑈𝑆𝐴為利用加入美國狀態的關聯分析後,介 於閾值參數之間而被分為大於閾值參數𝑟𝑈、小於閾值參數𝑟𝐿所對應之報酬盒鬚 圖... 43 圖 12:(a) 2012 年,德國指數之報酬盒鬚圖,U𝐺𝑒𝑟𝑚𝑎𝑛𝑦、L𝐺𝑒𝑟𝑚𝑎𝑛𝑦為大於閾 值 參 數 𝑟𝑈 、 小 於 閾 值 參 數 𝑟𝐿 所 對 應 之 報 酬 盒 鬚 圖 ; 𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐹𝑟𝑎𝑛𝑐𝑒 、 𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐹𝑟𝑎𝑛𝑐𝑒為利用加入法國狀態的關聯分析後,大於閾值參數𝑟𝑈、小於閾 值參數𝑟𝐿所對應之報酬盒鬚圖 ... 44 圖 13:(b) 2012 年,德國指數之報酬盒鬚圖,DU𝐺𝑒𝑟𝑚𝑎𝑛𝑦、DL𝐺𝑒𝑟𝑚𝑎𝑛𝑦為介 於閾值參數之間而被分為大於閾值參數𝑟𝑈、小於閾值參數𝑟𝐿所對應之報酬盒鬚 圖;𝐷𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐹𝑟𝑎𝑛𝑐𝑒、𝐷𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐹𝑟𝑎𝑛𝑐𝑒為利用加入法國狀態的關聯分析 後,介於閾值參數之間而被分為大於閾值參數𝑟𝑈、小於閾值參數𝑟𝐿所對應之報 酬盒鬚圖... 44 圖 14:(a) 2013 年,德國指數之報酬盒鬚圖,U𝐺𝑒𝑟𝑚𝑎𝑛𝑦、L𝐺𝑒𝑟𝑚𝑎𝑛𝑦為大於閾 值 參 數 𝑟𝑈 、 小 於 閾 值 參 數 𝑟𝐿 所 對 應 之 報 酬 盒 鬚 圖 ; 𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐹𝑟𝑎𝑛𝑐𝑒 、 𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐹𝑟𝑎𝑛𝑐𝑒為利用加入法國狀態的關聯分析後,大於閾值參數𝑟𝑈、小於閾 值參數𝑟𝐿所對應之報酬盒鬚圖 ... 45 圖 15:(b) 2013 年,德國指數之報酬盒鬚圖,DU𝐺𝑒𝑟𝑚𝑎𝑛𝑦、DL𝐺𝑒𝑟𝑚𝑎𝑛𝑦為介 於閾值參數之間而被分為大於閾值參數𝑟𝑈、小於閾值參數𝑟𝐿所對應之報酬盒鬚 圖;𝐷𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐹𝑟𝑎𝑛𝑐𝑒、𝐷𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐹𝑟𝑎𝑛𝑐𝑒為利用加入法國狀態的關聯分析 後,介於閾值參數之間而被分為大於閾值參數𝑟𝑈、小於閾值參數𝑟𝐿所對應之報 酬盒鬚圖... 45 圖 16:(a) 2014 年,德國指數之報酬盒鬚圖,U𝐺𝑒𝑟𝑚𝑎𝑛𝑦、L𝐺𝑒𝑟𝑚𝑎𝑛𝑦為大於 閾值參數𝑟𝑈、小於閾值參數𝑟𝐿 所對應之報酬盒鬚圖;𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐶𝑎𝑛𝑎𝑑𝑎 、 𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐶𝑎𝑛𝑎𝑑𝑎為利用加入加拿大狀態的關聯分析後,大於閾值參數𝑟𝑈、小 於閾值參數𝑟𝐿所對應之報酬盒鬚圖 ... 46 圖 17:(b) 2014 年,德國指數之報酬盒鬚圖,DU𝐺𝑒𝑟𝑚𝑎𝑛𝑦、DL𝐺𝑒𝑟𝑚𝑎𝑛𝑦為介 於閾值參數之間而被分為大於閾值參數𝑟𝑈、小於閾值參數𝑟𝐿所對應之報酬盒鬚 圖;𝐷𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐶𝑎𝑛𝑎𝑑𝑎、𝐷𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐶𝑎𝑛𝑎𝑑𝑎為利用加入加拿大狀態的關聯分 析後,介於閾值參數之間而被分為大於閾值參數𝑟𝑈、小於閾值參數𝑟𝐿所對應之 報酬盒鬚圖... 46 圖 18:(a) 2015 年,德國指數之報酬盒鬚圖,U𝐺𝑒𝑟𝑚𝑎𝑛𝑦、L𝐺𝑒𝑟𝑚𝑎𝑛𝑦為大於 閾 值 參 數 𝑟𝑈 、 小 於 閾 值 參 數 𝑟𝐿 所 對 應 之 報 酬 盒 鬚 圖 ; 𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐽𝑎𝑝𝑎𝑛 、 𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐽𝑎𝑝𝑎𝑛為利用加入日本狀態的關聯分析後,大於閾值參數𝑟𝑈、小於閾 值參數𝑟𝐿所對應之報酬盒鬚圖 ... 47 圖 19:(b) 2015 年,德國指數之報酬盒鬚圖,DU𝐺𝑒𝑟𝑚𝑎𝑛𝑦、DL𝐺𝑒𝑟𝑚𝑎𝑛𝑦為介 於閾值參數之間而被分為大於閾值參數𝑟𝑈、小於閾值參數𝑟𝐿所對應之報酬盒鬚 圖;𝐷𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐽𝑎𝑝𝑎𝑛、𝐷𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐽𝑎𝑝𝑎𝑛為利用加入日本狀態的關聯分析後,
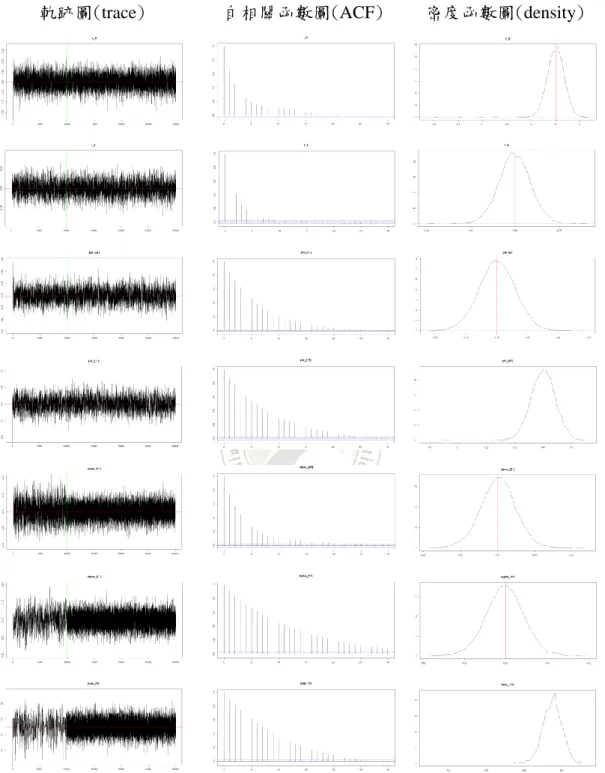
介於閾值參數之間而被分為大於閾值參數𝑟𝑈、小於閾值參數𝑟𝐿所對應之報酬盒 鬚圖... 47 圖 20:(a) 2016 年,德國指數之報酬盒鬚圖,U𝐺𝑒𝑟𝑚𝑎𝑛𝑦、L𝐺𝑒𝑟𝑚𝑎𝑛𝑦為大於閾 值 參 數 𝑟𝑈 、 小 於 閾 值 參 數 𝑟𝐿 所 對 應 之 報 酬 盒 鬚 圖 ; 𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐼𝑛𝑑𝑖𝑎 、 𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐼𝑛𝑑𝑖𝑎為利用加入印度狀態的關聯分析後,大於閾值參數𝑟𝑈、小於閾 值參數𝑟𝐿所對應之報酬盒鬚圖 ... 48 圖 21:(b) 2016 年,德國指數之報酬盒鬚圖,DU𝐺𝑒𝑟𝑚𝑎𝑛𝑦、DL𝐺𝑒𝑟𝑚𝑎𝑛𝑦為介 於閾值參數之間而被分為大於閾值參數𝑟𝑈、小於閾值參數𝑟𝐿所對應之報酬盒鬚 圖;𝐷𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐼𝑛𝑑𝑖𝑎、𝐷𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐼𝑛𝑑𝑖𝑎為利用加入印度狀態的關聯分析後, 介於閾值參數之間而被分為大於閾值參數𝑟𝑈、小於閾值參數𝑟𝐿所對應之報酬盒 鬚圖... 48 圖 22:(a) 2017 年,德國指數之報酬盒鬚圖,U𝐺𝑒𝑟𝑚𝑎𝑛𝑦、L𝐺𝑒𝑟𝑚𝑎𝑛𝑦為大於閾 值 參 數 𝑟𝑈 、 小 於 閾 值 參 數 𝑟𝐿 所 對 應 之 報 酬 盒 鬚 圖 ; 𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐾𝑜𝑟𝑒𝑎 、 𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐾𝑜𝑟𝑒𝑎為利用加入韓國狀態的關聯分析後,大於閾值參數𝑟𝑈、小於閾 值參數𝑟𝐿所對應之報酬盒鬚圖 ... 49 圖 23:(b) 2017 年,德國指數之報酬盒鬚圖,DU𝐺𝑒𝑟𝑚𝑎𝑛𝑦、DL𝐺𝑒𝑟𝑚𝑎𝑛𝑦為介 於閾值參數之間而被分為大於閾值參數𝑟𝑈、小於閾值參數𝑟𝐿所對應之報酬盒鬚 圖;𝐷𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐾𝑜𝑟𝑒𝑎、𝐷𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐾𝑜𝑟𝑒𝑎為利用加入韓國狀態的關聯分析後, 介於閾值參數之間而被分為大於閾值參數𝑟𝑈、小於閾值參數𝑟𝐿所對應之報酬盒 鬚圖... 49 圖 24:(a) 2018 年,德國指數之報酬盒鬚圖,U𝐺𝑒𝑟𝑚𝑎𝑛𝑦、L𝐺𝑒𝑟𝑚𝑎𝑛𝑦為大於閾 值 參 數 𝑟𝑈 、 小 於 閾 值 參 數 𝑟𝐿 所 對 應 之 報 酬 盒 鬚 圖 ; 𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝑈𝑆𝐴 、 𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝑈𝑆𝐴為利用加入美國狀態的關聯分析後,大於閾值參數𝑟𝑈、小於閾值 參數𝑟𝐿所對應之報酬盒鬚圖 ... 50 圖 25:(b) 2018 年,德國指數之報酬盒鬚圖,DU𝐺𝑒𝑟𝑚𝑎𝑛𝑦、DL𝐺𝑒𝑟𝑚𝑎𝑛𝑦為介 於閾值參數之間而被分為大於閾值參數𝑟𝑈、小於閾值參數𝑟𝐿所對應之報酬盒鬚 圖;𝐷𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝑈𝑆𝐴、𝐷𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝑈𝑆𝐴為利用加入美國狀態的關聯分析後,介 於閾值參數之間而被分為大於閾值參數𝑟𝑈、小於閾值參數𝑟𝐿所對應之報酬盒鬚 圖... 50 圖 26:(a) ~(f) 2009~2011 年德國指數之經驗累積分布圖,(a)、(c)和(e)圖的 𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦(藍線)為大於閾值參數𝑟𝑈的報酬經驗累積分布圖及𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝑈𝑆𝐴、 𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐹𝑟𝑎𝑛𝑐𝑒和𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝑈𝑆𝐴(紅線)為利用加入美國、法國和美國狀態的 關聯分析後,大於閾值參數𝑟𝑈的報酬經驗累積分布圖;(b)、(d)和(f)圖的 𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦(藍線)為小於閾值參數𝑟𝐿的報酬經驗累積分布圖及𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝑈𝑆𝐴、 𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐹𝑟𝑎𝑛𝑐𝑒和𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝑈𝑆𝐴(紅線)為利用加入美國、法國和美國狀態的 關聯分析後,小於閾值參數𝑟𝐿的報酬經驗累積分布圖 ... 51 圖 27:(a) ~(f) 2012~2014 年德國指數之經驗累積分布圖,(a)、(c)和(e)圖的 𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦(藍線)為大於閾值參數𝑟𝑈的報酬經驗累積分布圖及𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐽𝑎𝑝𝑎𝑛、
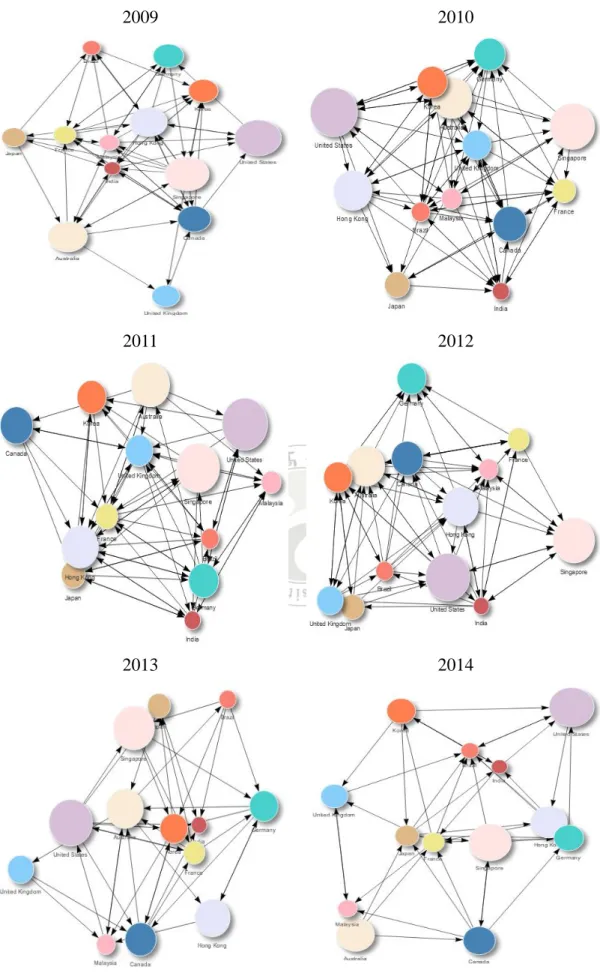
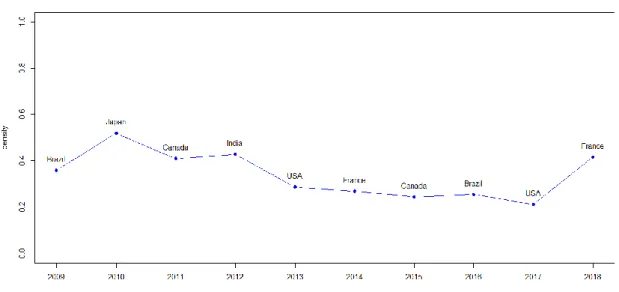
𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐹𝑟𝑎𝑛𝑐𝑒和𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐶𝑎𝑛𝑎𝑑𝑎(紅線)為利用加入日本、法國和加拿大 狀態的關聯分析後,大於閾值參數𝑟𝑈的報酬經驗累積分布圖;(b)、(d)和(f)圖 的 𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦 ( 藍 線 ) 為 小 於 閾 值 參 數 𝑟𝐿 的 報 酬 經 驗 累 積 分 布 圖 及 𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐽𝑎𝑝𝑎𝑛、𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐹𝑟𝑎𝑛𝑐𝑒和𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐶𝑎𝑛𝑎𝑑𝑎(紅線)為利用加入日 本、法國和加拿大狀態的關聯分析後,小於閾值參數𝑟𝐿的報酬經驗累積分布圖 ... 52 圖 28:(a)~(f) 2015~2017 年德國指數之經驗累積分布圖,(a)、(c)和(e)圖的 𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦(藍線)為大於閾值參數𝑟𝑈的報酬經驗累積分布圖及𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐽𝑎𝑝𝑎𝑛、 𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐼𝑛𝑑𝑖𝑎和𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐾𝑜𝑟𝑒𝑎(紅線)為利用加入日本、印度和韓國狀態的 關聯分析後,大於閾值參數𝑟𝑈的報酬經驗累積分布圖;(b)、(d)和(f)圖的 𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦(藍線)為小於閾值參數𝑟𝐿的報酬經驗累積分布圖及𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐽𝑎𝑝𝑎𝑛、 𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐼𝑛𝑑𝑖𝑎和𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝐾𝑜𝑟𝑒𝑎(紅線)為利用加入日本、印度和韓國狀態的 關聯分析後,小於閾值參數𝑟𝐿的報酬經驗累積分布圖 ... 53 圖 29:(a)和(b) 2018 年德國指數之經驗累積分布圖,(a)圖的𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦(藍線) 為大於閾值參數𝑟𝑈的報酬經驗累積分布圖及𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝑈𝑆𝐴(紅線)為利用加入 美國狀態的關聯分析後,大於閾值參數𝑟𝑈的報酬經驗累積分布圖;(b)圖的 𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦 ( 藍 線 ) 為 小 於 閾 值 參 數 𝑟𝐿 的 報 酬 經 驗 累 積 分 布 圖 及 𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦𝑈𝑆𝐴(紅線)為利用加入美國狀態的關聯分析後,小於閾值參數𝑟𝐿的報 酬經驗累積分布圖... 54 圖 30:2009~2014 年各國關係網絡圖,其中箭頭方向代表被影響國家 ... 55 圖 31:2015~2018 年各國關係網絡圖,其中箭頭方向代表被影響國家 ... 56 圖 32:對照表格 16 和表格 17 之各年網絡特徵折線圖,其中藍點線為各年之網 絡圖密度,代表該年國家間影響的密集程度,黑字為該年之網絡中心,代表該年 綜合影響他國最多的國家... 57
滯後自迴歸條件異質變異模型之應用
指導教授:黃士峰 博士 國立高雄大學應用數學系 學生:張益誠 國立高雄大學統計學研究所 摘要 本研究透過滯後自迴歸條件異質變異模型(簡記 HAR-GARCH)建立全球金 融市場景氣狀態的關聯規則,利用 HAR-GARCH 對金融時間序列資料進行建模, 並採用蒙地卡羅馬可夫鏈演算法估計模型參數,同時獲得市場景氣狀態的估計。 實證研究採用 13 個全球金融市場主要指數於 2008 年 8 月 1 日至 2018 年 8 月 30 日間的資料進行模型配適,以及為該 13 個金融市場建立與其他金融市場的市場 景氣狀態的關聯規則,並透過各種關聯規則指標,進一步了解各市場在調查時間 內相互影響關係。 關鍵字: 關聯規則;滯後自迴歸條件異質變異模型;蒙地卡羅馬可夫鏈法Applications of HAR-GARCH Models
Advisor: Shih-Feng Huang Department of Applied Mathematics
National University of Kaohsiung
Student: Yi-Cheng Chang Institute of Statistics National University of Kaohsiung
ABSTRACT
This study proposes to construct association rules for global economic conditions by fitting hysteretic autoregressive models with GARCH in mean effects, denoted by HAR-GARCH, to financial time series. A Markov Chain Monte Carlo algorithm is employed to estimate the model parameters and the economic conditions of a financial market are obtained accordingly. In the empirical study, we collect 13 global stock market indices from August 1, 2008, to August 30, 2018, and fit HAR-GARCH models for their daily returns. The association rules of the 13 stock markets are established based on the fitted models. In addition, the mutual interactions in the
financial markets during the investigation period are better understood through
various indicators of the association rules.
Keywords: association rule, hysteretic autoregressive model, Markov Chain Monte
第一章 緒論
第一節 研究動機與目的
隨著經濟全球化的發展下,各金融市場之間的變動與相互關係引人注目,對 於理性的金融決策者來說,常常需要考量報酬的波動行為,投資者若能確認波動 形式,將有助於報酬的相關決策。在金融領域裡,許多實證文獻證實金融時間序
列具有許多典型的特徵,包括不對稱性、偏度(Li and Lam, 1995)、厚尾(Mittnik et
al., 2000)和波動的群聚現象(Tseng and Li, 2011),文獻上已有描述上述特徵的非
線 性 時間 序 列模 型 ,例 如 : 自 迴 歸條 件 異質 變 異 (autoregressive conditional
heteroskedasticity, ARCH)模型(Bollerslev et al., 1992; Engle, 1982)和門檻自迴歸
(threshold autoregressive, TAR)模型(Tong, 1983)。然而,上述的非線性時間序列
模型仍存在著殘差無法影響條件變異和無法延遲狀態切換的缺陷,近年來,李等
人(Li et al., 2015)提出了滯後自迴歸(hysteretic autoregressive, HAR)模型,當滯後
變量位於滯後區域時,可以延遲狀態切換,因此其具有比門檻自迴歸模型更靈活
的狀態切換機制,而陳等人(Chen et al., 2016)將滯後自迴歸模型擴展到滯後自迴
歸條件異質變異(HAR-GARCH)模型,用於描述財務數據中固有的廣義自迴歸條
件異質變異(Generalized autoregressive conditional heteroskedasticity, GARCH)效
應。在本研究中,我們延用陳等人(Chen et al., 2016)的馬可夫鏈蒙地卡羅(Markov
Chain Monte Carlo, MCMC)算法(Chen and Lee, 1995; Chen and So, 2006; Chen
and Wen, 2001; Li and Li, 1996)來估計滯後自迴歸條件異質變異模型中的參數,
利用滯後自迴歸條件異質變異模型的指標參數來表示市場趨勢且於滯後自迴歸
條件異質變異模型中的模擬結果顯示所使用的參數估計方法可以產生準確且可
靠的參數估計結果,於實證資料中亦可產生不錯的效果。
市場趨勢是金融市場隨著時間變動的趨勢。我們可以將市場趨勢分成三種型
Timmermann, 2004),它們分別描述了向下的市場趨勢、向上的市場趨勢和介於 熊市和牛市之間的市場趨勢。於不同時間下,各國的市場趨勢存在著相互影響的
關係,在本研究中,我們利用滯後自迴歸條件異質變異模型建構了全球經濟狀況
的市場趨勢,並將關聯規則(Agrawal et al., 1993; Verykios et al., 2004)引入世界
各國的市場趨勢,利用關聯規則中三種有趣的指標來衡量世界各國市場趨勢中具 有強規則的關聯,其分別為支持度(support)、信賴度(confidence)和增益(lift), 目的分別衡量關聯規則的顯著性、衡量關聯規則的正確信和衡量關聯規則的資訊 價值,使用上述指標有助於我們獲得全球市場趨勢的關聯性,將發現的關聯用於 更改容易被影響國家之市場景氣狀態,來表示各國在不同時間下的關係。 實證資料從 2008 年 8 月 1 日到 2018 年 8 月 30 日,於雅虎財經(Yahoo Finance) 網站上的美國(GSPC)、日本(N225)、韓國(KS11)、德國(GDAXI)、英國(FTSE)、 馬來西亞(KLSE)、加拿大(GSPTSE)、新加坡(STI)、香港(HSI)、澳洲(AORD)、 法國(FCHI)、印度(BSESN)、巴西(BVSP)的每日加權指數,我們將上述的 13 個國家的每日加權指數用於我們的實證研究中。
第二節 研究架構
本文的研究架構共分為五章,分別如下:第一章為緒論,敘述本研究的研究 動機與研究目的。第二章為文獻回顧,主要介紹滯後自迴歸模型、滯後自迴歸條 件異質變異模型和關聯規則。第三章為參數估計方法,主要介紹本研究如何延用 陳等人(Chen et al., 2016)的馬可夫鏈蒙地卡羅方法來估計滯後自迴歸條件異質 變異模型的參數。第四章為數值結果,包含參數估計的模擬結果、加權指數的實 證研究結果和利用關聯規則改變市場景氣狀態的結果。第五章為結論,對本研究 結果的討論與總結。附錄為的表格和圖,呈現本研究的結果。第二章 文獻回顧
第一節 滯後自迴歸模型 (A hysteretic autoregressive model
of Li et al., 2015)
李等人(Li et al., 2015)提出了滯後自迴歸模型,當滯後變量位於滯後區域時, 透過使用滯後狀態來模擬非線性動態轉換。具有滯後狀態𝑅𝑡的滯後自迴歸模型由 下式定義: 𝑦𝑡 = { ∅0(1)+ ∑ ∅𝑖(1)𝑦𝑡−𝑖 𝑝1 𝑖=1 + 𝜎1𝜀𝑡, 𝑖𝑓 𝑅𝑡= 1, ∅0(2)+ ∑ ∅𝑖(2)𝑦𝑡−𝑖 𝑝2 𝑖=1 + 𝜎2𝜀𝑡, 𝑖𝑓 𝑅𝑡= 0, (1) 其中 𝑅𝑡 = { 1, 𝑖𝑓 𝑦𝑡−𝑑 ≤ 𝑟𝐿, 0, 𝑖𝑓 𝑦𝑡−𝑑 > 𝑟𝑈, 𝑅𝑡−1, 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒, (2) 𝜀𝑡是獨立且相同分佈(i.i.d.)的隨機變量,其服從平均數為 0 和變異數為 1 的分佈, 𝜎1 > 0和𝜎2 > 0是純量,d 為正整數的滯後參數,𝑟𝐿 ≤ 𝑟𝑈是滯後區的閾值參數。 如果𝑟𝐿 = 𝑟𝑈,則模型(2)回到閾值自迴歸模型。第二節 滯後自迴歸條件異質變異模型 (A hysteretic
heteroskedastic model of Chen et al., 2016)
陳等人(Chen et al., 2016)將滯後自迴歸模型擴展到滯後自迴歸條件異質變 異模型,模型由下式定義: 𝑦𝑡 = { ∅0(1)+ ∑ ∅𝑖(1)𝑦𝑡−𝑖 𝑝1 𝑖=1 + 𝑎𝑡, 𝑖𝑓 𝑅𝑡 = 1, ∅0(2)+ ∑ ∅𝑖(2)𝑦𝑡−𝑖 𝑝2 𝑖=1 + 𝑎𝑡, 𝑖𝑓 𝑅𝑡 = 0, (3)
𝑎𝑡 = √ℎ𝑡𝜀𝑡, 𝜀𝑡 𝑖𝑖𝑑∼ 𝐷(0,1) (4) ℎ𝑡= { α0(1)+ ∑ α𝑖(1)𝑎𝑡−𝑖2 𝑞1 𝑖=1 ∑ 𝛽𝑖(1)ℎ𝑡−𝑖 𝑚1 𝑖=1 , 𝑖𝑓 𝑅𝑡 = 1, α0(2)+ ∑ α𝑖(2)𝑎𝑡−𝑖2 𝑞2 𝑖=1 ∑ 𝛽𝑖(2)ℎ𝑡−𝑖 𝑚2 𝑖=1 , 𝑖𝑓 𝑅𝑡 = 0, (5) 其中 𝑅𝑡 = { 1, 𝑖𝑓 𝑦𝑡−𝑑 ≤ 𝑟𝐿, 0, 𝑖𝑓 𝑦𝑡−𝑑 > 𝑟𝑈, 𝑅𝑡−1, 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒. (6) 𝑅𝑡是狀態指標,定義於模型(6),在模型(3)-(5),在ℱ = σ(𝑦𝑡−1, 𝑦𝑡−2, … )下, ℎ𝑡 = 𝑉𝑎𝑟(𝑦𝑡|ℱ𝑡−1)是條件波動,𝜀𝑡是獨立且相同分佈(i.i.d.)的隨機變量,其服從 平均數為 0 和變異數為 1 的分佈,記為D(0,1),𝑝1和𝑝2為正整數的自迴歸次序, 𝑞1, 𝑞2, 𝑚1和𝑚2波動方程的次序,(𝑟𝐿, 𝑟𝑈)是滯後區的閾值參數且滿足於𝑟𝐿 ≤ 𝑟𝑈。 除 此 之外 ,在 模型 (3)的{∅𝑖(𝑗), 𝑖 ≥ 0, 𝑗 = 1, 2} 在模型(5)的 {𝛼𝑖(𝑗), 𝛽𝑖(𝑗), 𝑖 ≥ 0, 𝑗 = 1, 2}必須分別滿足自迴歸模型和廣義自迴歸條件異質變異模型的平穩條件,換言 之,∑𝑝𝑖=1𝑗 |∅𝑖(𝑗)| < 1、𝛼0(𝑗) > 0, 𝛼𝑖(𝑗), 𝛽𝑖(𝑗) ≥ 0, ∑𝑞𝑖=1𝑗 𝛼𝑖(𝑗)+ ∑𝑚𝑖=1𝑗 𝛽𝑖(𝑗) < 1, j = 1, 2。此
外,陳等人(Chen et al., 2016)利用了馬可夫鏈蒙地卡羅中的 random walk
metropolis-hastings(RW–MH)和 independent kernel metropolis-hastings(IK-MH) 算法來估計滯後自迴歸條件異質變異模型中的參數。
第三節 關聯規則
Agrawal 等人(Agrawal et al., 1993)提出關聯規則的主要概念,目的在於用來 在大量資料中找出每個不同項目(item)之間的關聯性。其中,最重要的三個關聯 規則指標為支持度(support)、信賴度(confidence)和增益(lift)。支持度為衡量前 提項目𝐴與結果項目𝐵一起出現的機率,記為𝑠𝑢𝑝𝑝𝑜𝑟𝑡(A→B) = P(A∩B);信賴度 為衡量關聯規則是否具有可信度指標,亦即衡量前提項目𝐴發生的情況下,結果 項目𝐵發生的條件機率,記為𝑐𝑜𝑛𝑓𝑖𝑑𝑒𝑛𝑐𝑒(A→B) = P(B|A);增益為用於比較信 賴度與結果項目𝐵單獨發生時兩者間的大小,記為𝑙𝑖𝑓𝑡(A→B) =𝑃(𝐵|𝐴) 𝑃(𝐵) 。
我們利用上述三個關聯規則指標來發現國家與國家之間的強規則。首先,我 們將事件分為容易受某國指數上漲影響及容易受某國指數下跌影響,下列以美國 和德國作為例子,分別為𝐴𝑈事件,美國在𝑡時間的真實報酬大於閾值參數𝑟𝑈、𝐵𝑈事 件,德國在𝑡 − 1時間估計𝑡時間的狀態,其報酬落於閾值參數之間,且在𝑡時間的 真實報酬大於閾值參數𝑟𝑈、 𝐴𝐿事件,美國在𝑡時間的真實報酬小於閾值參數𝑟 𝐿、𝐵𝐿 事件,德國在𝑡 − 1時間估計𝑡時間的狀態,其報酬落於閾值參數之間,且在𝑡時間 的真實報酬小於閾值參數𝑟𝐿,我們將這些事件表示如下: 𝐴𝑈: {𝑟𝑡𝑈𝑆𝐴> 𝑟𝑈𝑈𝑆𝐴} (7) 𝐵𝑈: {𝑟𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦 < 𝑟̂𝑡|𝑡−1𝐺𝑒𝑟𝑚𝑎𝑛𝑦 < 𝑟𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦, 𝑟𝑡𝐺𝑒𝑟𝑚𝑎𝑛𝑦 > 𝑟𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦} (8) 𝐴𝐿: {𝑟𝑡𝑈𝑆𝐴< 𝑟𝐿𝑈𝑆𝐴} (9) 𝐵𝐿: {𝑟𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦 < 𝑟̂𝑡|𝑡−1𝐺𝑒𝑟𝑚𝑎𝑛𝑦 < 𝑟𝑈𝐺𝑒𝑟𝑚𝑎𝑛𝑦, 𝑟𝑡𝐺𝑒𝑟𝑚𝑎𝑛𝑦 < 𝑟𝐿𝐺𝑒𝑟𝑚𝑎𝑛𝑦} (10) 利用容易被美國指數上漲影響的三種關聯規則指標和容易被美國指數下跌影響 的三種關聯規則的指標,支持度、信賴度和增益來決定是否更換德國目前的市場 景氣狀態,六種關聯規則的指標分別定義如下: support(A𝑈→𝐵𝑈) = P(A𝑈∩𝐵𝑈) (11) confidence(A𝑈→𝐵𝑈) = P(B𝑈|A𝑈) (12) lift(A𝑈→𝐵𝑈) =𝑃(𝐵 𝑈|𝐴𝑈) 𝑃(𝐵𝑈) (13) support(A𝐿→𝐵𝐿) = P(A𝐿∩𝐵𝐿) (14) confidence(A𝐿→𝐵𝐿) = P(B𝐿|A𝐿) (15) lift(A𝐿→𝐵𝐿) = 𝑃(𝐵 𝐿|𝐴𝐿) 𝑃(𝐵𝐿) (16)
若滿足support > 0.1, confidence > 0.7, lift > 1,我們將決定更換目前的市場 景氣狀態。
第三章 參數估計方法
第一節 參數估計
在本節,我們將介紹馬可夫鏈蒙地卡羅來估計滯後自迴歸條件異質變異模型 中的參數。根據貝氏(Bayes)規則,在觀測值y = (𝑦1, 𝑦2, … , 𝑦𝑛)下,後驗密度π(θ|y) 由下式給出 π(θ|y) ∝ L(y|θ)π(θ), 其中θ表示參數的向量,L(y|θ)為概似函數,π(θ)是θ的先驗密度。為了簡化指令, 在模型(3)和模型(5),我們設置𝑝1, 𝑝2, 𝑞1, 𝑞2, 𝑚1 和 𝑚2 的值等於 1 且將θ分 成 七 個 部 分 , θ = (𝜃1, 𝜃2, 𝜃3, 𝜃4, 𝜃5, 𝜃6, 𝜃7) , 其 中 𝜃1 = (𝑟𝐿, 𝑟𝑈) 為 閾 值 參 數 、 𝜃2 = (∅0 (1) , ∅1(1)) 和 𝜃3 = (∅0 (2) , ∅1(2)) 為 均 值 方 程 參 數 、 𝜃4 = (𝛼0 (1) , 𝛼1(1), 𝛽1(1)) 和 𝜃5 = (𝛼0 (2) , 𝛼1(2), 𝛽1(2))為波動方程參數、𝜃6 = 𝜈為自由度參數和𝜃7 = 𝑑為滯後參數。 馬可夫鏈蒙地卡羅的算法將於下面介紹。 步驟 1: 讓 𝑗 = 0 且設置起始值為 𝜃0。 步驟 2: 更新閾值指標參數如下:(i) 利用 random walk Metropolis-Hasting 方法生成𝜃1∗,讓𝜃1∗ = 𝜃1(𝑗)+ 𝜀,其
中𝜃1(𝑗)為𝜃1的第 j 次迭代、𝜀~U(−0.1, 0.1)且將(𝑟𝐿, 𝑟𝑈)的先驗設置為 𝑟𝐿~𝑈𝑛𝑖𝑓(𝑎1, 𝑏1)且𝑟𝑈|𝑟𝐿~𝑈𝑛𝑖𝑓(𝑎2, 𝑏2),其中𝑎1和𝑏1分別是整數1, 2, … , 𝑛 的第100ℎ百分位數和第100(1 − 2ℎ)百分位數,除此之外,𝑏2是整數 1, 2, … , 𝑛的第100(1 − ℎ)百分位數且𝑎2 = 𝑟𝐿+ ℎ𝑛。這個設置為了確保 𝑟𝐿 < 𝑟𝑈且每區間內至少存在100ℎ%的觀測值。這裡設置ℎ = 0.15。 (ii) 計算接受𝜃1∗的機率 𝑝 = min {1, 𝜋(𝜃1 ∗, 𝜃 2 (𝑗) , 𝜃3(𝑗), 𝜃4(𝑗), 𝜃5(𝑗), 𝜃6(𝑗), 𝜃7(𝑗)|𝑦) 𝜋(𝜃1(𝑗), 𝜃2(𝑗), 𝜃3(𝑗), 𝜃4(𝑗), 𝜃5(𝑗), 𝜃6(𝑗), 𝜃7(𝑗)|𝑦)} 。
(iii) 從𝑈𝑛𝑖𝑓𝑜𝑟𝑚(0, 1)模擬一個𝑈且更新參數 𝜃1(𝑗+1)= {𝜃1
∗, 𝑖𝑓 𝑈 < 𝑝
𝜃1(𝑗), 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒。
步驟 3: 更新均值參數如下:
(i) 利用 random walk Metropolis-Hasting 方法生成𝜃2∗,讓𝜃2∗ = 𝜃
2 (𝑗) + 𝜀,其 中𝜃2(𝑗)為𝜃2的第 j 次迭代、𝜀~𝑁(0, 𝑎𝛺)、𝑎 = 0.47、𝛺 = (Z𝑇H−1Z + V𝑗−1)−1、Z = [ 1 𝑦𝜆1−1 ⋮ ⋮ 1 𝑦𝜆𝑎−1 ]、H = [ ℎ𝜆1 0 … 0 0 ℎ𝜆2 … 0 ⋮ ⋮ ⋱ 0 0 0 … ℎ𝜆𝑎] ,其中𝜆𝑡為對應於 𝑅𝑡= 1時間點集合的升序索引, 𝑡 = 1, … , 𝑎,a 為𝑅𝑡 = 1狀態下的觀察 值 個 數 , 且 將 ∅0(1), ∅1(1)的 先 驗 設 置 為 ∅(1)~𝑁(∅0(1), 𝑉1)I(𝑆11) , 其 中 𝑆11: ∑𝑝1 |∅𝑖(1)| < 1 𝑖=1 ,也就是平均數為 0 且變異數為𝑉1的截斷常態分布。 (ii) 計算接受𝜃2∗的機率 𝑝 = min {1, 𝜋(𝜃2 ∗, 𝜃 1 (𝑗+1) , 𝜃3(𝑗), 𝜃4(𝑗), 𝜃5(𝑗), 𝜃6(𝑗), 𝜃7(𝑗)|𝑦) 𝜋(𝜃2(𝑗), 𝜃1(𝑗+1), 𝜃3(𝑗), 𝜃4(𝑗), 𝜃5(𝑗), 𝜃6(𝑗), 𝜃7(𝑗)|𝑦)} 。 (iii) 從𝑈𝑛𝑖𝑓𝑜𝑟𝑚(0, 1)模擬一個𝑈且更新參數 𝜃2(𝑗+1)= {𝜃2 ∗, 𝑖𝑓 𝑈 < 𝑝 𝜃2(𝑗), 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒。
(iv) 利用 random walk Metropolis-Hasting 方法生成𝜃3∗,讓𝜃3∗ = 𝜃3(𝑗)+ 𝜀,其
中𝜃3(𝑗)為𝜃3的第 j 次迭代、𝜀~𝑁(0, 𝑎𝛺)、a = 0.47、𝛺 = (Z𝑇H−1Z + V𝑗−1)−1、Z = [ 1 𝑦𝜆1−1 ⋮ ⋮ 1 𝑦𝜆𝑏−1 ]、H = [ ℎ𝜆1 0 … 0 0 ℎ𝜆2 … 0 ⋮ ⋮ ⋱ 0 0 0 … ℎ𝜆𝑏] ,其中𝜆𝑡為對應於 𝑅𝑡= 0時間點集合的升序索引, 𝑡 = 1, … , 𝑏,b 為𝑅𝑡= 0狀態下的觀察 值 個 數 , 且 將 ∅0(2), ∅1(2)的 先 驗 設 置 為 ∅(2)~𝑁(∅ 0 (2) , 𝑉2)I(𝑆12) , 其 中
𝑆12: ∑𝑝2 |∅𝑖(2)| < 1 𝑖=1 ,也就是平均數為 0 且變異數為𝑉2的截斷常態分布。 (v) 計算接受𝜃3∗的機率 𝑝 = min {1, 𝜋(𝜃3 ∗, 𝜃 1 (𝑗+1) , 𝜃2(𝑗+1), 𝜃4(𝑗), 𝜃5(𝑗), 𝜃6(𝑗), 𝜃7(𝑗)|𝑦) 𝜋(𝜃3(𝑗), 𝜃1(𝑗+1), 𝜃2(𝑗+1), 𝜃4(𝑗), 𝜃5(𝑗), 𝜃6(𝑗), 𝜃7(𝑗)|𝑦)} 。 (vi) 從𝑈𝑛𝑖𝑓𝑜𝑟𝑚(0, 1)模擬一個𝑈且更新參數 𝜃3(𝑗+1)= {𝜃3 ∗, 𝑖𝑓 𝑈 < 𝑝 𝜃3(𝑗), 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒。 步驟 4: 更新波動參數如下: 當 𝑗 = 1, … , 𝑀
(i) 利用 random walk Metropolis-Hasting 方法生成𝜃4∗,讓𝜃4∗ = 𝜃4
(𝑗) + 𝜀,其 中𝜃4(𝑗)為𝜃4的第 j 次迭代、𝜀~𝑁(0, 0.001 × 𝐼3)、𝐼3為一對角矩陣,且將 𝛼0(1), 𝛼1(1), 𝛽1(1)的先驗設置為𝛼(1)~𝑁(𝛼 0 (1) , 𝑉1)I(𝑆21),且滿足𝑆21:𝛼0 (1) > 0, 𝛼𝑖(1), 𝛽𝑖(1) ≥ 0, ∑𝑞1 𝛼𝑖(1) 𝑖=1 + ∑ 𝛽𝑖 (1) < 1 𝑚1 𝑖=1 。 (ii) 計算接受𝜃4∗ 的機率 𝑝 = min {1, 𝜋 (𝜃4 ∗, 𝜃 1 (𝑗+1) , 𝜃2(𝑗+1), 𝜃3(𝑗+1), 𝜃5(𝑗), 𝜃6(𝑗), 𝜃7(𝑗)|𝑦) 𝜋 (𝜃4(𝑗), 𝜃1(𝑗+1), 𝜃2(𝑗+1), 𝜃3(𝑗+1), 𝜃5(𝑗), 𝜃6(𝑗), 𝜃7(𝑗)|𝑦)} 。 (iii) 從𝑈𝑛𝑖𝑓𝑜𝑟𝑚(0, 1)模擬一個𝑈且更新參數 𝜃4(𝑗+1)= {𝜃4 ∗, 𝑖𝑓 𝑈 < 𝑝 𝜃4(𝑗), 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒。 當 𝑗 = 𝑀 + 1, … , 𝑁
(iv) 利用 independent kernel Metropolis-Hasting 方法生成𝜃4∗,讓𝜃
4∗ = 𝜇𝛼+ 𝜀, 其中𝜇𝛼= 1 𝑀(𝜃4 1+ ⋯ + 𝜃 4𝑀)、𝜀~𝑁(0, 𝛺𝛼)、𝛺𝛼為前 M 步的共變異數, 且 將 𝛼0(1), 𝛼1(1), 𝛽1(1)的 先 驗 設 置 為 𝛼(1)~𝑁(𝛼 0 (1) , 𝑉1)I(𝑆21) , 且 滿 足 𝑆21:𝛼0 (1) > 0, 𝛼𝑖(1), 𝛽𝑖(1) ≥ 0, ∑𝑞1 𝛼𝑖(1) 𝑖=1 + ∑ 𝛽𝑖 (1) < 1 𝑚1 𝑖=1 。
(v) 計算接受𝜃4∗的機率 𝑝 = min {1, 𝜋 (𝜃4 ∗, 𝜃 1 (𝑗+1) , 𝜃2(𝑗+1), 𝜃3(𝑗+1), 𝜃5(𝑗), 𝜃6(𝑗), 𝜃7(𝑗)|𝑦) 𝜋 (𝜃4(𝑗), 𝜃1(𝑗+1), 𝜃2(𝑗+1), 𝜃3(𝑗+1), 𝜃5(𝑗), 𝜃6(𝑗), 𝜃7(𝑗)|𝑦)} 。 (vi) 從𝑈𝑛𝑖𝑓𝑜𝑟𝑚(0, 1)模擬一個𝑈且更新參數 𝜃4(𝑗+1)= {𝜃4 ∗, 𝑖𝑓 𝑈 < 𝑝 𝜃4(𝑗), 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒。 當 𝑗 = 1, … , 𝑀
(vii) 利用 random walk Metropolis-Hasting 方法生成𝜃5∗,讓𝜃5∗ = 𝜃5(𝑗)+ 𝜀,
其中𝜃5(𝑗)為𝜃5的第 j 次迭代、𝜀~𝑁(0, 0.001 × 𝐼3)、𝐼3為一對角矩陣, 且 將 𝛼0(2), 𝛼1(2), 𝛽1(2)的 先 驗 設 置 為 𝛼(2)~𝑁(𝛼0(2), 𝑉2)I(𝑆22) , 且 滿 足 𝑆22:𝛼0(2) > 0, 𝛼𝑖(2), 𝛽𝑖(2) ≥ 0, ∑𝑞2 𝛼𝑖(2) 𝑖=1 + ∑ 𝛽𝑖 (2) < 1 𝑚2 𝑖=1 。 (viii) 計算接受𝜃5∗的機率 𝑝 = min {1, 𝜋 (𝜃5 ∗, 𝜃 1 (𝑗+1) , 𝜃2(𝑗+1), 𝜃3(𝑗+1), 𝜃4(𝑗+1), 𝜃6(𝑗), 𝜃7(𝑗)|𝑦) 𝜋 (𝜃5(𝑗), 𝜃1(𝑗+1), 𝜃2(𝑗+1), 𝜃3(𝑗+1), 𝜃4(𝑗+1), 𝜃6(𝑗), 𝜃7(𝑗)|𝑦)} 。 (ix) 從𝑈𝑛𝑖𝑓𝑜𝑟𝑚(0, 1)模擬一個𝑈且更新參數 𝜃5(𝑗+1)= {𝜃5 ∗, 𝑖𝑓 𝑈 < 𝑝 𝜃5(𝑗), 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒。 當 𝑗 = 𝑀 + 1, … , 𝑁
(x) 利用 independent kernel Metropolis-Hasting 方法生成𝜃5∗,讓𝜃5∗ = 𝜇
𝛼+ 𝜀, 其中𝜇𝛼 = 1 𝑀(𝜃5 1+ ⋯ + 𝜃 5𝑀)、𝜀~𝑁(0, 𝛺𝛼)、𝛺𝛼為前 M 步的共變異數, 且 將 𝛼0(2), 𝛼1(2), 𝛽1(2)的 先 驗 設 置 為 𝛼(2)~𝑁(𝛼0(2), 𝑉2)I(𝑆22) , 且 滿 足 𝑆22:𝛼0(2) > 0, 𝛼𝑖(2), 𝛽𝑖(2) ≥ 0, ∑𝑞2 𝛼𝑖(2) 𝑖=1 + ∑ 𝛽𝑖 (2) < 1 𝑚2 𝑖=1 。 (xi) 計算接受𝜃5∗ 的機率
𝑝 = min {1, 𝜋 (𝜃5 ∗, 𝜃 1 (𝑗+1) , 𝜃2(𝑗+1), 𝜃3(𝑗+1), 𝜃4(𝑗+1), 𝜃6(𝑗), 𝜃7(𝑗)|𝑦) 𝜋 (𝜃5(𝑗), 𝜃1(𝑗+1), 𝜃2(𝑗+1), 𝜃3(𝑗+1), 𝜃4(𝑗+1), 𝜃6(𝑗), 𝜃7(𝑗)|𝑦)} 。 (xii) 從𝑈𝑛𝑖𝑓𝑜𝑟𝑚(0, 1)模擬一個𝑈且更新參數 𝜃5(𝑗+1)= {𝜃5 ∗, 𝑖𝑓 𝑈 < 𝑝 𝜃5(𝑗), 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒。 步驟 5: 更新自由度參數如下:
(i) 利用 random walk Metropolis-Hasting 方法生成𝜃6∗,讓𝜃6∗ = 𝜃
6 (𝑗) + 𝜀,其 中𝜃6(𝑗)為𝜃6的第 j 次迭代、𝜀~U(−5, 5),且將參數𝜈的先驗設置為𝜌 = 𝜈−1, 其中𝜌~U(0, 0.25),且讓𝜈 > 4,確保𝜀的四階動差存在且有限。 (ii) 計算接受𝜃6∗的機率 𝑝 = min {1, 𝜋(𝜃6 ∗, 𝜃 1 (𝑗+1) , 𝜃2(𝑗+1), 𝜃3(𝑗+1), 𝜃4(𝑗+1), 𝜃5(𝑗+1), 𝜃6(𝑗+1), 𝜃7(𝑗)|𝑦) 𝜋(𝜃6(𝑗), 𝜃1(𝑗+1), 𝜃2(𝑗+1), 𝜃3(𝑗+1), 𝜃4(𝑗+1), 𝜃5(𝑗+1), 𝜃6(𝑗+1), 𝜃7(𝑗)|𝑦)} 。 (iii) 從𝑈𝑛𝑖𝑓𝑜𝑟𝑚(0, 1)模擬一個𝑈且更新參數 𝜃6(𝑗+1)= {𝜃6 ∗, 𝑖𝑓 𝑈 < 𝑝 𝜃6(𝑗), 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒。 步驟 6: 更新滯後參數如下: (i) 分 別 計 算𝑑 = 1, 𝑑 = 2, 𝑑 = 3 的 後 驗 機 率 p(𝑑 = 𝑗|𝑦𝑠+1,𝑛, 𝑅0, 𝜃−𝑑) = 𝑝(𝑦𝑠+1,𝑛|𝑑=𝑗,𝜃−𝑑)𝑝(𝑑=𝑗) ∑ 𝑝(𝑦𝑠+1,𝑛|𝑑=𝑖,𝜃 −𝑑) 𝑑0 𝑖=1 𝑝(𝑑=𝑖) , j = 1, … , 𝑑0,這裡的𝑑0 = 3。 (ii) 根據後驗機率p(𝑑 = 𝑗|𝑦𝑠+1,𝑛, 𝑅 0, 𝜃−𝑑) = 𝑝(𝑦𝑠+1,𝑛|𝑑=𝑗,𝜃−𝑑)𝑝(𝑑=𝑗) ∑ 𝑝(𝑦𝑠+1,𝑛|𝑑=𝑖,𝜃 −𝑑) 𝑑0 𝑖=1 𝑝(𝑑=𝑖) , 𝑗 = 1, … , 𝑑0,對 1、2 和 3 進行抽樣。
這裡延用陳等人(Chen et al., 2016) 的參數估計方法,與陳等人(Chen et al.,
2016)不同的地方為只有於𝜃4和𝜃5採用 random walk Metropolis-Hasting 方法和
independent kernel Metropolis-Hasting 方法,其餘的參數部分只採用 random walk Metropolis-Hasting 方法,且延用陳和蘇(Chen and So, 2006)的自適應採樣方法,
於生成樣本期間,我們丟棄𝜃𝑖𝑘的前𝑀個樣本且利用剩餘的𝑁 − 𝑀個樣本來進行估
θ̂ = 1 𝑁 − 𝑀 ∑ 𝜃𝑖 (𝑘) 𝑀 𝑘=𝑁+1 , 𝑖 = 1, … , |θ| (17) 其中𝜃̂ = (𝜃̂1, … , 𝜃̂|𝜃|),|θ|表示θ的長度。
第四章
數值結果
第一節 模擬研究
於陳等人(Chen et al., 2016)的文獻中,該研究為研究股票市場和指數期貨市 場之間的關係,其實證資料採用股票和指數期貨,於本研究為研究全球市場景氣 狀態,實證資料採用各國加權指數。為了說明滯後自迴歸條件異質變異模型用於 加權指數上亦可獲得不錯的成效,分別於表格 1 和表格 2 呈現兩種不同情形下的 模擬結果。 於表格 1,我們參考陳等人(Chen et al., 2016)的參數設定,使用大小為 𝑛 = 2000的樣本來調查滯後自迴歸條件異質變異模型研究方法的成效,參數設定 為 𝜃1 = (𝑟𝐿, 𝑟𝑈) = (−0.3, 0.2), 𝜃2 = (∅0 (1) , ∅1(1)) = (−0.1, 0.4), 𝜃3 = (∅0 (2) , ∅1(2)) = (−0.1, 0.3), 𝜃4 = (𝛼0 (1) , 𝛼1(1), 𝛽1(1)) = (0.1, 0.1, 0.75), 𝜃5 = (𝛼0 (2) , 𝛼1(2), 𝛽1(2)) = (0.02, 0.1, 0.7), 𝜃6 = 𝜈 = 7, 𝜃7 = 𝑑 = 1且我們模擬𝑁 = 30000次的馬可夫鏈蒙地 卡羅且丟棄前𝑀 = 10000次的馬可夫鏈蒙地卡羅來進行參數估計。研究的程序如 下: 1. 設置起始值𝑦0且讓𝑡 = 0。 2. 從三個區域生成樣本,分別為𝑅𝑡 = 0的區域、𝑅𝑡= 1的區域和𝑅𝑡 = 𝑅𝑡−1的滯 後區域。 3. 我們根據步驟 2 的𝑅𝑡來生成𝑦𝑡+1。 4. 讓𝑡 = 𝑡 + 1且重複步驟 2 和步驟 3 直到𝑡 = 𝑛。 5. 根 據𝑦𝑡和 𝑅𝑡生 成 的 樣 本 , 利 用馬 可 夫 鏈 蒙 地 卡 羅 來 估 計 參 數 ,其 中 𝑡 = 1, … , 𝑛。 於圖 1 和圖 2 中,我們繪畫模型(3)-(6)中所有參數𝜃𝑖𝑘的馬可夫鏈蒙地卡羅軌跡(trace)圖、自相關函數(ACF)圖和密度函數(density)圖,其中密度函數圖中
和自相關函數圖顯示出馬可夫鏈蒙地卡羅樣本是平穩的。密度函數圖顯示出馬可 夫鏈蒙地卡羅樣本能夠提供可靠的估計,因為每個參數估計的真值位於估計後驗 分佈的中心附近。 表格 1 總結估計結果,包含真值𝜃𝑖、樣本平均值𝜃̂𝑖、陳等人(Chen et al., 2016) 的樣本標準差𝜃̂𝑖、樣本標準差𝜃̂𝑖和配適 AR(1)模型的樣本標準差𝜃̂𝑖,其算法為 𝜎2 1−𝛽12,這裡將其記為𝑠𝑑(𝜃̂𝑖)。於表格 1 中,所有真值皆落在[𝜃̂𝑖 − 𝑠𝑑(𝜃̂𝑖), 𝜃̂𝑖 + 𝑠𝑑(𝜃̂𝑖)]裡,此結果表示所使用的馬可夫鏈蒙地卡羅算法能夠獲得可靠的參數估計。 於表 格 2,我們 將參數設定為𝜃1 = (𝑟𝐿, 𝑟𝑈) = (−2.00𝐸 − 03, 4.00𝐸 − 03), 𝜃2 = (∅0(1), ∅1(1)) = (3.00𝐸 − 05, −9.00𝐸 − 03), 𝜃3 = (∅0(2), ∅1(2)) = (−3.00𝐸 −
05, −8.90𝐸 − 03), 𝜃4 = (𝛼0(1), 𝛼1(1), 𝛽1(1)) = (4.00E − 05, 4.00E − 01, 5.00E − 01),
𝜃5 = (𝛼0(2), 𝛼1(2), 𝛽1(2)) = (3.00E − 05, 3.00E − 01, 4.00E − 01), 𝜃6 = 𝜈 = 7, 𝜃7 =
𝑑 = 1且我們模擬𝑁 = 30000次的馬可夫鏈蒙地卡羅且丟棄前𝑀 = 10000次的馬 可夫鏈蒙地卡羅來進行參數估計。研究的程序如下: 1. 設置起始值𝑦0且讓𝑡 = 0。 2. 從三個區域生成樣本,分別為𝑅𝑡 = 0的區域、𝑅𝑡= 1的區域和𝑅𝑡 = 𝑅𝑡−1的滯 後區域。 3. 我們根據步驟 2 的𝑅𝑡來生成𝑦𝑡+1。 4. 讓𝑡 = 𝑡 + 1且重複步驟 2 和步驟 3 直到𝑡 = 𝑛。 5. 根 據𝑦𝑡和 𝑅𝑡生 成 的 樣 本 , 利 用馬 可 夫 鏈 蒙 地 卡 羅 來 估 計 參 數 ,其 中 𝑡 = 1, … , 𝑛。 於圖 3 和圖 4 中,我們繪畫模型(3)-(6)中所有參數𝜃𝑖𝑘的馬可夫鏈蒙地卡羅 軌跡圖、自相關函數圖和密度函數圖,其中密度函數圖中的紅線為參數的真值、 綠線為丟棄參數的界線,𝑘 = 1, … , 𝑀, 𝑖 = 1, … , 5。軌跡圖和自相關函數圖顯示出 馬可夫鏈蒙地卡羅樣本是平穩的。密度函數圖顯示出馬可夫鏈蒙地卡羅樣本能夠
提供可靠的估計,因為每個參數估計的真值位於估計後驗分佈的中心附近。 表格 2 總結估計結果,包含真值𝜃𝑖、樣本標準差𝜃̂𝑖和配適 AR(1)模型的樣本 標準差𝜃̂𝑖,其算法為 𝜎2 1−𝛽12,這裡將其記為𝑠𝑑(𝜃̂𝑖)。於表格 2 中,所有真值皆落在 [𝜃̂𝑖 − 𝑠𝑑(𝜃̂𝑖), 𝜃̂𝑖 + 𝑠𝑑(𝜃̂𝑖)]裡,此結果表示所使用的馬可夫鏈蒙地卡羅能夠獲得可 靠的參數估計。
第二節 實證研究
於實證研究中,我們將滯後自迴歸條件異質變異模型用於各國的加權指數上, 發現模擬研究中的每個參數的設定皆介於表格 3 中每個參數的區間內,因此,說 明我們的參數設定是合乎常理的。 我們配適滯後自迴歸條件異質變異模型來獲得每個國家的每日市場景氣狀 態且利用關聯規則來發現國家與國家之間的關聯性。於實證資料中,因時區關係 導致各金融市場收盤時間有所不同,因此我們將13個市場加權指數按時區建立兩 兩金融市場的關聯性,各國市場時區分別依序為澳洲、日本、韓國、馬來西亞、 新加玻、香港、印度、法國、德國、英國、巴西、加拿大及美國,於(7)-(10)式 中定義,利用(11)-(16)式中的六種關聯規則的指標和移動窗口方法決定是否更 換 目 前 的 市 場 景 氣 狀 態 , 此 移 動 窗 口 約 為 225 日 , 若 滿 足 support > 0.1 , confidence > 0.7, lift > 1,我們將決定更換已有的狀態,於圖5中,藍線為大於 閾值參數𝑟𝑈的報酬、黑線為介於閾值參數之間的報酬、紅線為小於閾值參數𝑟𝐿的 報酬,而橘色垂直線為滿足三種關聯規則指標,更改原始狀態的時間點。於表格 4到表格13中,我們計算原本(𝐵𝑛 → 𝐴𝑛, 𝑛 = 1, … , 13)閾值參數報酬的均方預測誤 差(MSPE1),即藍色區域和更改狀態後(𝐵𝑖 → 𝐴𝑗, 𝑖 ≠ 𝑗, 𝑖, 𝑗 = 1, … , 13)閾值參數報酬 的均方預測誤差(MSPE2) 即橘色區域,分別如下: MSPE1 = 1 𝑛 ∑ (𝑦𝑡1 − 𝑦̂𝑡1) 2 𝑛 𝑡1=1MSPE2 = 1 𝑛 ∑ (𝑦𝑡2 − 𝑦̂𝑡2) 2 𝑛 𝑡2=1 結果顯示大部分更改後的均方預測誤差比原本的均方預測誤差還要小,表示 藉由關聯規則更改狀態使其誤差表現變好。此外,我們利用閾值參數將報酬(這 裡將以德國報酬為例)分成兩種狀態,並將使用均方預測誤差(MSPE2)較小的國 家來置換德國狀態,於圖6、圖8、圖10、圖12、圖14、圖16、圖18、圖20、圖22 和圖24中,藍色的盒鬚圖為大於閾值參數𝑟𝑈的報酬,分別利用加入其它國家狀態 的關聯分析前後之報酬盒鬚圖,紅色的盒鬚圖為小於閾值參數𝑟𝐿的報酬,分別利 用加入其它國家狀態的關聯分析前後之報酬盒鬚圖;於圖7、圖9、圖11、圖13、 圖15、圖17、圖19、圖21、23和圖25中,藍色的盒鬚圖為介於閾值參數而被分為 大於閾值參數𝑟𝑈的報酬,分別利用加入其它國家狀態的關聯分析前後之報酬盒鬚 圖,紅色的盒鬚圖為介於閾值參數而被分為小於閾值參數𝑟𝐿的報酬,分別利用加 入其它國家狀態的關聯分析前後之報酬盒鬚圖,從圖6到圖25中,我們可以發現 加入其它國家狀態的關聯分析後,可以更明顯將報酬分成兩群,讓市場趨勢更加 清楚,於表格14和表格15中,我們亦發現加入關聯規則後,檢定的結果更加顯著, 此結果說明,加入關聯規則後,使我們更明確的知道該國的市場趨勢。 觀察2009~2018年間,使用關聯分析後所獲得的更新的狀態,因目前只研究 兩兩國家間的相關性,為更清楚觀察各國以及是否有多個國家影響單一國家或單 一國家影響多國等特性,本研究使用網絡密度及網絡中心作為觀察指標,其中, 網絡密度(degree centrality, 簡記 𝐶𝐷)用於觀察網絡中國家間互相連邊的密集程 度,換言之,表示該年金融市場互相牽引程度強弱,定義如下: 𝐶𝐷 = 2𝐼 𝑁(𝑁 − 1) 其中N為國家總數,本文的國家總數為13,I為國家與國家連線的總數目,網絡密 度可再細分為出度密度(out-degree, 簡記 𝐷𝑜𝑢𝑡)和入度密度(in-degree, 簡記 𝐷𝑖𝑛), 定義分別如下:
𝐷𝑜𝑢𝑡 = 𝐼𝑜𝑢𝑡 𝑁 − 1, 𝐷𝑖𝑛 = 𝐼𝑖𝑛 𝑁 − 1 其中出度密度在此代表對他國影響的程度強弱,入度密度表示被他國影響的程度 強弱,而網絡中間中心性(betweenness centrality, 簡記 𝐶𝐵)為以經過某個國家的最 短路徑數目來刻畫國家重要性的指標,定義如下: 𝐶𝐵 = 𝐼 𝑁 − 1 在此取該年平均影響最多的國家作為網絡中心,最後以指標帶來的資訊作為網絡 關係的觀察結果。
第五章 結論
本研究使用滯後自迴歸條件異質變異模型描述世界各國的市場景氣狀態,採 用蒙地卡羅馬可夫鏈演算法估計滯後自迴歸條件異質變異模型的參數,並引入關 聯規則以協助評估是否應修正對該國的市場景氣狀態預測。實證研究採用 13 個 全球金融市場主要加權指數於 2008 年 8 月 1 日至 2018 年 8 月 30 日間的資料, 研究結果顯示,加入關聯規則的三種指標後,可達到改善介於牛市和熊市的市場 景氣狀態預測的效果,使其均方預測誤差比原來的均方誤差更小,降低高估或低 估的問題。由此可知,加入關聯規則後,使原本利用滯後自迴歸條件異質變異模 型估計的世界各國景氣狀態更加接近於真實的世界各國景氣狀態。 於研究中只考慮針單一金融市場對單一金融市場同時上漲或同時下跌的市 場趨勢,然而,在經濟全球化下,我們想了解多個國家之間在不同市場趨勢下的 影響,因此此研究尚有問題可以加以探討,例如:上漲的市場趨勢影響下跌的市 場趨勢或下跌市場趨勢影響上漲的市場趨勢,多個國家的市場趨勢對單一國家的 市場趨勢或多個國家的市場趨勢對多個國家的市場趨勢進行研究,甚至利用網絡 圖觀察出上述情形或利用網絡模型及特徵預測下一步的全球金融市場網絡圖,以 便協助獲得更多全球金融市場之間的關係,這些技術的導入將能讓問題有更深入 的研究。參考文獻
[1] Agrawal, R., Imieliński, T. and Swami, A. (1993). Mining association rules between sets of items in large databases. Acm Sigmod Record , 22, 207-216. [2] Bollerslev, T., Chou, R. Y. and Kroner, K. F. (1992). ARCH modeling in finance:
A review of the theory and empirical evidence. Journal of Econometrics, 52, 5-59.
[3] Chen, C. W. and Lee, J. C. (1995). Bayesian inference of threshold autoregressive models. Journal of Time Series Analysis, 16, 483-492.
[4] Chen, W. S. and So, K. P. (2006). On a threshold heteroscedastic model. Journal
of Forecasting, 22, 73-89.
[5] Chen, C. W. and Truong, B. C. (2016). On double hysteretic heteroskedastic model. Journal of Statistical Computation and Simulation, 86, 2684-2705. [6] Chen, C. W. and Wen, Y. W. (2001). On goodness of fit for time series regression
models. Journal of Statistical Computation and Simulation, 69, 239-256.
[7] Engle, R. F. (1982). Autoregressive conditional heteroscedasticity with estimates of the variance of United Kingdom inflation. Journal of the Econometric Society, 50, 987-1007.
[8] Li, C. W. and Li, W. K. (1996). On a double‐threshold autoregressive heteroscedastic time series model. Journal of Applied Econometrics, 11, 253-274.
[9] Li, G., Guan, B., Li, W. K. and Yu, P. L. (2015). Hysteretic autoregressive time series models. Biometrika, 102, 717-723.
[10] Li, W. K. and Lam, K. (1995). Modelling asymmetry in stock returns by a threshold autoregressive conditional heteroscedastic model. The Statistician, 44, 333-341.
[11] Lunde, A. and Timmermann, A. (2004). Duration dependence in stock prices: An analysis of bull and bear markets. Journal of Business and Economic
Statistics, 22, 253-273.
[12] Mittnik, S., Paolella, M. S. and Rachev, S. T. (2000). Diagnosing and treating the fat tails in financial returns data. Journal of Empirical Finance, 7, 389-416. [13] Tong, H. (1983). Threshold models in non-linear time series analysis (vol. 21 of
Lecture Notes in Statistics). New York:Springer-Verlag.
[14] Tseng, J. J. and Li, S. P. (2011). Asset returns and volatility clustering in financial time series. Physica A: Statistical Mechanics and its Applications, 390, 1300-1314.
[15] Verykios, V. S., Elmagarmid, A. K., Bertino, E., Saygin, Y. and Dasseni, E. (2004). Association rule hiding. IEEE Transactions on Knowledge and Data
Engineering, 16, 434-447.
[16] Zhu, K., Yu, P. L. and Li, W. K. (2014). Testing for the buffered autoregressive processes. Statistica Sinica, 24, 971-984.
附錄
表格 1:模擬研究中,模擬陳等人(Chen et al., 2016)參數設定的後驗平均值和標 準差 參數 真值 平均值 標準差 (Chen et al., 2016) 標準差 標準差(配 適 AR(1)模 型) rU 0.2 0.200*** 0.035 0.036 0.044 rL -0.3 -0.299*** 0.018 0.021 0.023 ∅0(1) -0.1 -0.099*** 0.029 0.031 0.056 ∅1(1) 0.4 0.400*** 0.042 0.043 0.082 α0(1) 0.1 0.100*** 0.029 0.027 0.021 α1(1) 0.1 0.097*** 0.027 0.026 0.019 β1(1) 0.75 0.749*** 0.061 0.058 0.044 ∅0(2) -0.1 -0.100*** 0.018 0.020 0.027 ∅1(2) 0.3 0.300*** 0.042 0.043 0.078 α0(2) 0.02 0.023*** 0.016 0.017 0.010 α1(2) 0.1 0.099*** 0.019 0.018 0.014 β1(2) 0.7 0.700*** 0.059 0.056 0.043 ν 7 6.680*** 1.036 1.235 1.370 d 1 1.000*** 0.010 0.010 0.010 ***平均值落在真值±1 個標準差(配適 AR(1)模型)之內表格 2:模擬研究中,模擬加權指數的後驗平均值和標準差
參數 真值 平均值 標準差(配適
AR(1)模型)
rU 4.00E-03 4.32E-03*** 1.01E-03
rL -2.00E-03 -2.77E-03*** 1.00E-03
∅0(1) 3.00E-05 3.01E-05*** 3.05E-05
∅1(1) -9.00E-03 -9.09E-03*** 1.05E-03
α0(1) 4.00E-05 4.04E-05*** 7.19E-05
α1(1) 4.00E-01 4.01E-01*** 7.20E-02
β1(1) 5.00E-01 5.02E-01*** 7.34E-02
∅0(2) -3.00E-05 -3.03E-05*** 4.99E-05
∅1(2) -8.90E-03 -8.93E-03*** 2.00E-03
α0(2) 3.00E-05 3.06E-05*** 1.40E-03
α1(2) 3.00E-01 3.03E-01*** 7.22E-02
β1(2) 4.00E-01 4.02E-01*** 7.66E-02
ν 7 7.659*** 1.473
d 1 1.000*** 0.010
表格 3:實證研究中,德國加權指數的各參數區間 參數 區間 rU [2.51E − 03, 6.02E − 03] rL [−4.63E − 03, −0.19E − 03] ∅0(1) [0.98E − 05, 6.16E − 05] ∅1(1) [−1.26E − 02, −6.67E − 03] α0(1) [1.46E − 05, 7.19E − 05] α1(1) [3.67E − 01, 4.73E − 01] β1(1) [4.56E − 01, 5.19E − 01] ∅0(2) [−0.98E − 05, −6.73E − 05] ∅1(2) [−1.91E − 02, −6.95E − 03] α0(2) [0.83E − 05, 7.46E − 05] α1(2) [2.89E − 01, 4.55E − 01] β1(2) [3.13E − 01, 5.21E − 01] ν [4.13, 10.51]
表格 4 : 2009 年 各國 均方預測 誤差列 表, 𝐴1 ~ 𝐴13 依序為 澳洲 、日本 、韓國 、馬來西 亞、新 加玻、 香港、印 度、法國、德國、英國 、巴西、加拿大及美國 ,而 𝐵1 ~ 𝐵13 國家排序順序與 𝐴1 ~ 𝐴13 相同,藍色區塊為原本 閾 值參數報酬的均方預測誤差 (M SPE 1 ) ,橘色為更改狀態後閾值參數報酬的均方預測誤差 (M SPE 2 ) 𝐴1 𝐴2 𝐴3 𝐴4 𝐴5 𝐴6 𝐴7 𝐴8 𝐴9 𝐴10 𝐴11 𝐴12 𝐴13 𝐵1 1 .7 3 E -04 7 .0 4 E -05 9 .9 9 E -05 5 .2 6 E -05 5 .1 4 E -05 1 .4 0 E -04 7 .3 3 E -05 1 .0 2 E -04 1 .1 7 E -04 1 .1 4 E -04 1 .1 5 E -04 6 .4 5 E -05 8 .1 2 E -05 𝐵2 7 .5 6 E -05 1 .8 0 E -04 7 .6 4 E -05 1 .1 3 E -04 8 .3 2 E -05 1 .3 6 E -04 8 .8 1 E -04 9 .0 9 E -05 1 .5 4 E -04 9 .8 6 E -06 1 .3 0 E -04 8 .4 8 E -05 1 .9 2 E -04 𝐵3 1 .7 1 E -04 1 .3 7 E -04 9 .3 0 E -04 2 .5 1 E -05 8 .8 1 E -05 1 .0 0 E -04 7 .1 8 E -05 9 .4 6 E -05 1 .2 7 E -04 7 .2 1 E -05 1 .0 3 E -04 9 .0 7 E -05 6 .2 2 E -05 𝐵4 7 .6 3 E -05 9 .9 5 E -05 8 .9 9 E -05 8 .6 7 E -05 9 .9 0 E -05 1 .5 2 E -04 1 .3 2 E -04 7 .1 0 E -05 1 .1 1 E -04 7 .1 5 E -05 9 .2 4 E -05 2 .0 7 E -04 7 .3 0 E -05 𝐵5 1 .1 2 E -04 1 .2 9 E -04 2 .5 2 E -04 9 .8 1 E -05 7 .0 8 E -05 1 .2 9 E -04 7 .6 2 E -05 1 .2 1 E -04 1 .5 7 E -04 8 .7 3 E -05 1 .2 2 E -04 7 .0 2 E -05 7 .3 5 E -05 𝐵6 1 .1 7 E -04 9 .8 4 E -05 1 .0 0 E -04 6 .7 4 E -05 8 .7 7 E -05 1 .0 0 E -04 2 .5 6 E -04 1 .1 2 E -04 1 .0 8 E -04 7 .6 6 E -05 1 .1 1 E -04 4 .3 9 E -05 6 .7 7 E -05 𝐵7 6 .6 7 E -05 9 .3 8 E -05 8 .5 9 E -05 5 .1 1 E -05 6 .0 5 E -05 1 .1 3 E -04 1 .0 1 E -04 1 .1 1 E -04 1 .1 3 E -04 1 .0 9 E -04 1 .3 9 E -04 7 .9 7 E -05 8 .2 1 E -05 𝐵8 1 .1 2 E -04 1 .2 9 E -04 2 .5 2 E -04 9 .8 1 E -05 1 .1 0 E -04 9 .1 6 E -05 1 .0 2 E -04 1 .0 1 E -04 1 .5 7 E -04 8 .7 3 E -05 1 .2 2 E -04 7 .0 2 E -05 7 .3 5 E -05 𝐵9 4 .5 4 E -04 9 .4 5 E -05 7 .5 1 E -05 7 .0 6 E -05 7 .1 6 E -05 1 .2 0 E -04 2 .5 6 E -04 1 .1 2 E -04 1 .0 2 E -04 9 .9 9 E -05 1 .0 6 E -04 6 .5 3 E -05 1 .0 5 E -04 𝐵10 9 .8 8 E -05 9 .1 8 E -05 1 .3 6 E -04 3 .2 6 E -05 8 .6 7 E -05 1 .0 1 E -04 7 .5 7 E -05 8 .0 6 E -05 1 .3 2 E -04 7 .7 3 E -05 1 .2 1 E -04 6 .6 2 E -05 7 .7 6 E -05 𝐵11 9 .1 0 E -05 1 .4 8 E -04 1 .2 9 E -04 5 .2 9 E -05 1 .0 9 E -04 1 .1 5 E -04 8 .0 2 E -05 7 .7 5 E -05 1 .4 9 E -04 1 .3 1 E -04 1 .0 7 E -04 7 .4 3 E -05 1 .0 3 E -04 𝐵12 7 .9 2 E -05 7 .6 6 E -05 1 .6 7 E -04 5 .4 9 E -05 7 .4 1 E -05 1 .0 5 E -04 8 .1 0 E -05 1 .1 6 E -04 1 .4 1 E -04 2 .5 5 E -04 1 .0 8 E -04 5 .6 8 E -05 1 .0 5 E -04 𝐵13 2 .3 7 E -04 8 .2 8 E -05 1 .4 5 E -04 6 .0 7 E -05 6 .1 8 E -05 1 .1 1 E -04 9 .1 6 E -05 8 .9 4 E -04 7 .8 5 E -05 9 .9 1 E -04 1 .1 6 E -04 8 .3 7 E -05 6 .5 3 E -05
表格 5 : 2010 年 各國 均方預測 誤差列 表, 𝐴1 ~ 𝐴13 依序為 澳洲 、日 本 、韓 國 、馬 來西 亞、 新 加玻 、 香港 、印 度、法國、德國、英國 、巴西、加拿大及美國 ,而 𝐵1 ~ 𝐵13 國家排序順序與 𝐴1 ~ 𝐴13 相同,藍色區塊為原本 閾 值參數報酬的均方預測誤差 (M SPE 1 ) ,橘色為更改狀態後閾值參數報酬的均方預測誤差 (M SPE 2 ) 𝐴1 𝐴2 𝐴3 𝐴4 𝐴5 𝐴6 𝐴7 𝐴8 𝐴9 𝐴10 𝐴11 𝐴12 𝐴13 𝐵1 2 .1 3 E -04 3 .2 2 E -04 2 .7 2 E -04 2 .1 8 E -04 2 .3 0 E -04 2 .2 6 E -04 2 .6 1 E -04 3 .1 7 E -04 3 .5 9 E -04 2 .6 8 E -04 3 .3 9 E -04 2 .4 0 E -04 3 .6 5 E -04 𝐵2 2 .8 2 E -04 3 .0 5 E -04 2 .3 7 E -04 1 .7 4 E -04 2 .1 1 E -04 2 .8 5 E -04 2 .8 4 E -04 3 .5 7 E -04 2 .8 7 E -04 3 .8 4 E -04 3 .1 4 E -04 1 .7 8 E -04 2 .9 0 E -04 𝐵3 2 .6 7 E -04 2 .8 4 E -04 2 .5 8 E -04 3 .3 0 E -04 2 .1 5 E -04 3 .8 0 E -04 1 .9 3 E -04 3 .7 5 E -04 4 .2 0 E -04 2 .3 4 E -04 3 .8 2 E -04 2 .1 7 E -04 2 .2 8 E -04 𝐵4 2 .3 5 E -04 2 .7 1 E -04 3 .1 6 E -04 1 .5 3 E -04 2 .2 8 E -04 2 .0 0 E -04 3 .4 2 E -04 4 .3 2 E -04 5 .2 9 E -04 2 .4 8 E -04 2 .7 7 E -04 1 .8 9 E -04 2 .5 7 E -04 𝐵5 5 .4 7 E -04 2 .9 4 E -04 2 .2 8 E -04 1 .6 3 E -04 2 .0 6 E -04 2 .5 6 E -04 3 .0 8 E -04 3 .8 8 E -04 2 .1 9 E -04 2 .9 8 E -04 2 .7 5 E -04 1 .9 4 E -04 2 .3 1 E -04 𝐵6 2 .2 4 E -04 2 .8 9 E -04 2 .0 1 E -04 2 .9 6 E -04 1 .6 8 E -04 2 .0 9 E -04 2 .9 6 E -04 3 .5 4 E -04 2 .5 3 E -04 3 .4 1 E -04 3 .3 3 E -04 2 .0 3 E -04 2 .5 3 E -04 𝐵7 2 .9 0 E -04 2 .9 5 E -04 1 .8 4 E -04 1 .5 7 E -04 2 .3 8 E -04 2 .8 1 E -04 2 .8 3 E -04 3 .2 4 E -04 2 .6 8 E -04 3 .1 6 E -04 3 .2 7 E -04 1 .9 4 E -04 2 .5 0 E -04 𝐵8 5 .4 7 E -04 2 .9 4 E -04 2 .2 8 E -04 1 .6 3 E -04 1 .9 8 E -04 3 .2 5 E -04 2 .3 1 E -04 3 .8 2 E -04 2 .1 9 E -04 2 .9 8 E -04 2 .7 5 E -04 1 .9 4 E -04 2 .3 1 E -04 𝐵9 2 .3 9 E -04 2 .8 5 E -04 2 .0 4 E -04 1 .6 7 E -04 3 .6 0 E -04 2 .4 2 E -04 2 .9 6 E -04 3 .5 4 E -04 2 .2 7 E -04 2 .2 2 E -04 3 .7 8 E -04 2 .0 4 E -04 2 .3 9 E -04 𝐵10 2 .2 1 E -04 3 .3 4 E -04 1 .6 6 E -04 1 .8 0 E -04 2 .1 9 E -04 2 .7 0 E -04 2 .2 2 E -04 3 .4 5 E -04 2 .4 2 E -04 2 .8 4 E -04 4 .0 4 E -04 2 .4 2 E -04 2 .5 5 E -04 𝐵11 1 .9 8 E -04 3 .1 5 E -04 2 .4 8 E -04 1 .8 6 E -04 1 .6 5 E -04 3 .9 4 E -04 2 .5 2 E -04 3 .5 9 E -04 2 .8 2 E -04 2 .7 5 E -04 2 .5 0 E -04 1 .7 1 E -04 2 .5 7 E -04 𝐵12 2 .2 7 E -04 2 .6 7 E -04 3 .6 3 E -04 2 .0 9 E -04 1 .8 8 E -04 2 .4 7 E -04 2 .3 2 E -04 3 .6 1 E -04 2 .2 2 E -04 2 .4 6 E -04 4 .2 8 E -04 2 .6 5 E -04 2 .3 7 E -04 𝐵13 3 .4 4 E -04 4 .1 2 E -04 2 .1 4 E -04 1 .6 0 E -04 1 .5 8 E -04 2 .8 9 E -04 2 .0 7 E -04 4 .1 7 E -04 2 .6 4 E -04 2 .2 9 E -04 2 .7 8 E -04 3 .3 2 E -04 2 .8 6 E -04