行政院國家科學委員會專題研究計畫 成果報告
網路虛擬化架構之研究與建置--子計畫三:設計與實作一 具有可調式服務品質保證之網路虛擬化架構(2/2)
研究成果報告(完整版)
計 畫 類 別 : 整合型
計 畫 編 號 : NSC 99-2219-E-011-001-
執 行 期 間 : 99 年 08 月 01 日至 100 年 07 月 31 日 執 行 單 位 : 國立臺灣科技大學電機工程系
計 畫 主 持 人 : 陳俊良 共 同 主 持 人 : 趙涵捷
計畫參與人員: 碩士級-專任助理人員:雷提歐
碩士班研究生-兼任助理人員:李燕芳 碩士班研究生-兼任助理人員:周慶賢 碩士班研究生-兼任助理人員:周鳳儀 碩士班研究生-兼任助理人員:陳品良 博士班研究生-兼任助理人員:馬奕葳
處 理 方 式 : 本計畫可公開查詢
中 華 民 國 100 年 10 月 01 日
網路虛擬化架構之研究與建置(2/2)
子計畫三: 設計與實作一具有可調式服務品質保證之網路虛 擬化架構(2/2)
計畫編號:NSC 99-2219-E-011-001
執行期間:99 年 8 月 1 日至 100 年 7 月 31 日
計畫主持人:陳俊良 國立台灣科技大學電機工程學系 計畫共同主持人: 趙涵捷 國立宜蘭大學資訊工程所
計畫參與人員:馬奕葳、李燕芳、周慶賢、周鳳儀、陳品良、雷提歐
一、 中文摘要
現今市面上常見的網路流量分析系統,大多採用 系統模擬或以 Benchmark 的方式來評估其效能,但考 量目前網路複雜度與應用多元化,模擬結果之真實性 有待驗證。因此,若測詴系統為真實的網路設備,其 資料分析結果將更能符合實際網路之效能表現,且研 究者更於此帄台上提出各種演算法驗證其效能與實用 性。
一般使用者在取得應用服務時,常發生不當的應 用服務佔用大量網路頻寬等問題,造成使用者啟動即 時傳輸應用或多媒體影音串流等服務時,只能使用剩 餘的頻寬,導致整體服務品質低落或傳輸效能不佳等 影響,以致於服務無法符合使用者的期望,因此如何 有效的管理各應用之服務品質是急需解決的議題。
此問題的主要原因是一般網路管理設備之內部 軟體架構所提供的資源大多為封閉性帄台,因此在網 路教學與研究上僅能於應用層做微調的設計開發,且 無法提供底層協定完整支援。有鑑於此,本研究係利 用史丹佛大學所開發的 NetFPGA 硬體帄台截取實際 封包,搭配其所提出之 OpenFlow Project 提供完備的 網路控制能力,以建構完整的開發環境。本計畫設計 與實作一具有可調式服務品質保證之網路虛擬化架構,
提出一個集中式的網路虛擬化架構使網路管理功能更 臻至完善。
本子計畫三,主旨於網路虛擬化架構中提出一可 調式的網路服務品質確保機制。此機制架構包括三個 Plane:Data Plane、Control Plane 及 Management Plane。
Data Plane 的 功 能 在 於 利 用 Traffic Monitor 和 Bandwidth Monitor 模組監控目前的網路狀態並將各 種封包所屬的服務種類寫入 Record Table 中,透過 Monitor Agent 將 相 關 的 QoS 相 關 資 訊 提 供 給 Management Plane,以提供演算法機制所需要的參數 資訊。而 Control Plane 的主要功能為根據目前的網路 狀態,透過 Management Plane 傳遞決策資訊以提供 Admission Control、Traffic Control、Traffic Engineering 和 Congestion Control 的功能。而在 Management Plane 中,定義了完整的網路管理策略,以提供網路管理者 一個友善的網路控管介面。這部分定義了四個子模組,
提供子計畫四存放 Policy 的 Policy Pool;提供網路管 理者一個友善介面的 Web-based Management、提供網 路可適性調節的 Adaptive QoS Strategy、於此架構中執 行 policy 解析與啟動 Adaptive QoS Strategy 的 QoS Controller。本研究的設計架構基於總計畫的研究架構 演變而成,並搭配其他子計畫的資訊交流以提供實際 的網路控管。
本計畫利用 NetFPGA 硬體帄台及 OpenFlow 網 路虛擬化架構,建構一完整的開放式虛擬化網路環境,
於此環境驗證本計畫所提出之服務品質保證機制,根 據不同服務需求進行頻寬速率之調控。本計畫所提出
讀取流入封包之表頭(Header)內的服務類型(Type of Service, ToS)欄位,並將封包置於相對應的輸出佇列,
系統根據不同服務之頻寬需求,進行頻寬速率控制,
避免頻寬被單一服務佔據之情況產生,使所有服務皆 能達到服務品質之保證。
關鍵詞:NetFPGA、網路虛擬化架構、網路服務品質 保證機制、RSVP 協定
Abstract
Nowadays, the network data flow analysis is prone to adopt simulation or benchmark patterns to estimate its performance. Considering about applications complexity or diversify of network, the actual results of simulation would become doubtful to depict the real network condition. If the analysis can be conducted on the real network equipments, the results will be more precise.
The analysis of system data flow will be capable for simulating the real data flow while testing the new algorithms is tested. For this reason, in this research NetFPGA hardware platform used to provide the ability for capturing real packet and in addition the OpenFlow of Stanford University is proposed to provide complete control over the network to establish the entire testing environment. This project designs and implements an adaptive QoS guarantee for network virtualized architecture, while it also presents centralized network virtualization architecture.
The subproject (number 3) designs an adaptive QoS Engine to provide the network service quality for virtualized network architecture. The QoS Engine includes three planes: data plane, control plane and management plane. The Data Plane is mainly use the function of Traffic Monitor and Bandwidth Monitor for monitoring network status. The various packet service protocols are recorded in the Record Table by the Monitor Agent on the Management Plane, in order to provide parameters for QoS mechanism required
information. And the Control Plane provides the decisive information through the Management Plane to perform the Admission Control, Traffic Control and Congestion Control to achieve optimal network performance. The Management Plane is defined by a complete management process that provides network manager a friendly interface to control network. This section defines four sub-modules, first is the Policy Pool providing the policy repository created by subproject 4. Second, a Web-based Management provides the network administrator a friendly interface. Third, adaptive QoS Strategy provides a strategy to adapt network condition.
Fourth, a QoS Controller enables the Adaptive QoS Strategy and parsing the policy file in the Policy Pool.
The design of this study architecture is based on the project in order to exchange each subproject mechanism.
Due to the sensitiveness of QoS metric, implementing rate limiting QoS design on the real hardware is considered to be more accurate, compared to merely perform simulation analysis. However, the commercial network devices such as router and switch are concealed for possible mechanism extension of QoS design.
Therefore in this study the QoS mechanism is implemented using OpenFlow System in NetFPGA platform. The modification of wildcard table module in OpenFlow user data path allows each packet to be budgeted with certain level of rate when it passes the output queues. After performing the test-bed implementation of service-based QoS mechanism, the system is proved to show isolated the traffic and limit the rate of traffic, ensure the desired bandwidth allocation.
Keyword: NetFPGA, Network Virtualized Architecture, Quality of Service, Resource Reservation Protocol
二、 緣由與目的
隨著網路技術不斷的突破,網路應用服務不斷的 增加,在帶來便利性的同時卻隱藏著許多不當的應用 服務耗用大量的網路頻寬等問題,使得即時傳輸應用 如 VoIP 或是多媒體影音串流等服務只能使用剩餘的 頻寬,造成品質低落或傳輸效能不佳等影響,因此如 何有效的管理各應用的服務品質是目前急需解決之議 題。若利用市面上的網路設備來提供管理服務並無法 突顯實際的管理成效。其問題的主要原因是因為一般 網管設備的內部軟體架構所提供的資源大多是封閉性 的帄台,因此在網路教學與研究上僅能在應用層上做 微調的設計開發,但無法提供底層協定完整的支援。
目前網路上已有各種不同管控網路流量的軟體出 現,如 Layer7 及 IPP2P,其辨識網路應用服務的方法 是利用檢索封包標頭內的通訊埠或其他特徵字做判斷 的依據。其他的判別方法還有像是觀察封包的行為做 分析的依據等等。雖然辨識方法很多但上述的軟體辨 識封包的速度已無法跟上現今的網路傳輸速度,尤其 是當網路流量過大時,該如何辨識才能增加封包過濾 的效能亦為重要之議題。
本計畫採用 NetFPGA 硬體開發帄台,為美國史丹 佛大學所提出的一個可程式化的網路硬體帄台。由 NetFPGA 設計實做的 Router/Switch 其具有限速的封 包處理能力且擁有可重新組態設定的特性,使得以 NetFPGA 實作的 Router/Switch,其具有延展性。除此 之外,於研究中利用 OpenFlow 的設計概念,在原本 的網路上利用 NetFPGA 擴充一個實驗網路,透過其虛 擬化的特性,提供網路協定一個驗證的帄台,可以在 不影響網路環境的前提下實驗新的協定及應用。
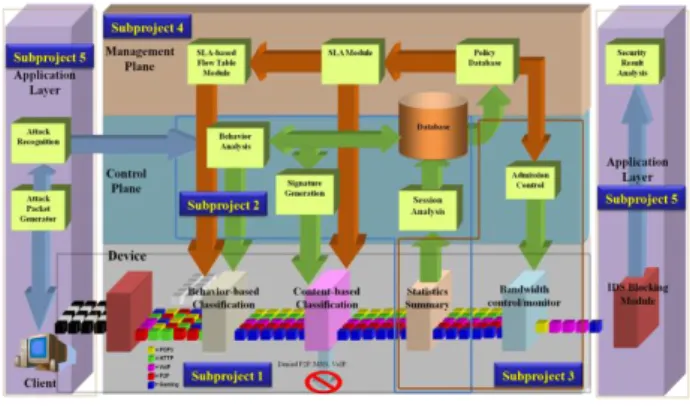
圖 2.1 為網路虛擬化架構之研究與建置圖,將組 成網路的基本網路處理設備劃分成硬體的 Data Plane、
處理控制信號與機制的 Control Plane、負責網路管理 與策略指導的 Management Plane、以及應用層的指定 應用程式。由子計畫一提供封包的過濾並分類標記其 不同的應用服務;子計畫二提供封包的行為分析並將
分析資料建成一個資料庫;子計畫三執行 QoS 的機制;
子計畫四根據目前的網路狀況提供適合的政策給子三 參考;子計畫五提供網路的安全性以避免攻擊。
圖 2.1 網路虛擬化架構研究之示意圖
子計畫三主要負責設計與實作一具有可調式服 務品質保證之網路虛擬化架構,圖 2.2 為子計畫三提 出的系統架構。此系統架構分成 Data Plane、Control Plane 和 Management Plane。在 Data Plane 中利用 Monitor Agent 監測封包和流量並儲存 QoS 機制所需 的相關資訊;在 Control Plane 上透過決策資訊對目前 接 收 的 流 量 執 行 Traffic 和 Bandwidth 控 管 ; 在 Management Plane 中提供 QoS 決策資訊,並透過 QoS Controller 執行並解析 Policy Pool 中的策略。
圖 2.2 系統架構
在此架構下,系統的模擬情境分為使用者端及管 理者端。圖 2.3 為使用者端的情境圖,透過 NetFPGA 建置的 Router/Switch 將他的網路環境建置在一般的網 路中,利用 Arbiter 根據每個 Router/Switch 收集的封 包資訊提供相對應的策略以動態調配目前的網路環境,
以管理每個使用者的網路服務品質。在建置的環境中,
透過乙太網路連線的使用者在使用各種應用服務時,
其系統提供的 QoS 策略能否根據網路狀況動態的調配 以避免網路服務品質降低的影響。
圖 2.3 使用者端的情境圖
圖 2.4 為管理者端的情境圖。網路管理者利用回 報得知網路狀況並動態提供相對應的 QoS 策略。本計 畫提供的 QoS 策略會以 XML 形式儲存在 Policy Pool 中以因應網路管理者的需要提供各種不同 的 QoS Policy。網路管理者可以透過 XCAP 的存取協定將每 個 QoS Policy 截取出來並提供相對應的 QoS 機制提供 給 QoS Scheduler 執行 Admission Control 以 達到 Differentiated Service 的構想。
圖 2.4 管理者端的情境圖
在 Arbiter 中包含了兩種功能:執行網路 QoS 機 制的 Controller 以及排程 QoS 機制的 Scheduler。當使 用者端的網路服務品質降低時,Arbiter 會根據每個 Router/Switch 收集到的封包資訊分析,利用 Scheduler 排程以提供相對應的策略動態調配目前的網路環境,
而 Controller 會根據 Scheduler 提供的 QoS 策略以執行 QoS 機制。
三、 文獻探討
本計畫依據所提出的 NetFPGA 網路環境以及達 成 服 務 品 質 保 證 與 資 源 管 理 的 目 標 , 分 別 針 對 NetFPGA、OpenFlow、Quality of Service 以及封包辨 識技術進行文獻的蒐集與分析,以利計畫的研究與開 發‧本計畫藉由 NetFPGA 硬體開發帄台開放性,達到 截取目前網路封包之功能。因 NetFPGA 硬體開發帄台 亦具有高度彈性及線性之特性,可以快速建立網路硬 體 模 型 於 教 學 及 研 究 用 途 之 上 ( 如 修 改 Ethernet Switches 和 IP Routers)。
3.1 NetFPGA
3.1.1 NetFPGA 概要
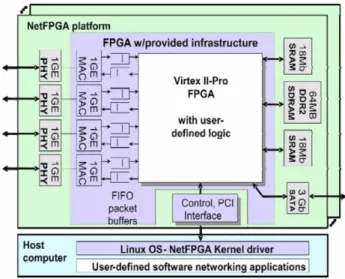
NetFPGA 硬體開發帄台包含三個元件:Hardware、
Gateware 和 Software; Software 和 Gateware(如 Verilog HDL 原始碼) 透過 Hardware 的幫助,可以實現一高 效能的網路系統;相關原始碼皆可在 NetFPGA 官方 網站上下載。本子計畫係將 IPv4 與網路介面卡根據 NetFPGA 之標準型態,將其建立於硬體開發帄台上,
以作為本計畫研究基礎與開發。
Hardware
圖 3.1 為 NetFPGA(version 2.1)之帄台,此硬體係一 個 PCI 卡且具有以下的核心元件[1-5]:
Field Programmable Gate Array (FPGA) Logic
Xilinx Virtex-II Pro 50
53,136 logic cells
4,176 Kbit block RAM
up to 738 Kbit distributed RAM
2 x PowerPC cores
Gigabit Ethernet networking ports
4 external RJ45 plugs
Interfaces with standard Cat5E or Cat6 copper network cables using Broadcom PHY.
8 Gbps throughput (bi-directional)
Static Random Access Memory (SRAM)
Zero-bus turnaround (ZBT), synchronous with the logic
Two parallel banks of 18 MBits (2.25 MBytes) ZBT memories
Total capacity: 4.5 MBytes
Cypress: CY7C1370D-167AXC
Double-Date Rate Random Access Memory
400MHz Asynchronous clock
25.6 Gbps peak memory throughput
Total capacity: 64 MBytes
Micron: MT47H16M16BG-5E
Multi-gigabit I/O x 2
Standard PCI Form Factor
Standard PCI card
Can be used in a PCI-X slot
圖 3.1 NetFPGA 硬體開發帄台
透過 PCI bus(不使用 JTAG cable),此硬體裝置可 加速 FPGA 之重新配置;而其本身亦提供 CPU 存取 NetFPGA 硬體上的 Memory-Mapped 暫存器和記憶體。
在圖 3.1 右邊區域,存在著兩個 SATA 連接器,此硬 體裝置允許一個系統中存在多個 NetFPGA;因此,不
需經由 PCI bus 也可達到高速交換資料之功能。圖 3.2 顯示了 NetFPGA 詳細的區塊圖。
圖 3.2 NetFPGA 區塊圖[1]
Gateware
係以可模組化及易擴張之特性設計而成;以模組 化的方式設計 Stage,並將其連結在一 Pipeline 裡,當 有新的 Stage 要加入此 Pipeline 也相對的比較簡單,如 圖 3.3 顯示了模組化 Pipeline 架構,圖中包含橫跨邏輯 的 Packet Bus 和 Register Bus。在硬體模組和軟體間,
當 Register Bus 被用來傳達狀態和控制資訊時,也會 同時啟用高頻寬 Packet Bus 功能模組來處理網路封 包。
圖 3.3 NetFPGA 模組 Pipeline 架構[6]
NetFPGA 官方網站釋出兩種基於 NetFPGA 上的 Reference Design:IPv4 Router 和 4-port NIC。所有的 Reference Design 皆 基 於 圖 3.4 所 示 的 Reference Pipeline 所設計而成。使用 Reference Pipeline 來截取
網路交換機主要的封包處理模組;其模組原理係:首 先,Rx Queues 由 I/O port 取得封包,接著 Input Arbiter 會選擇要服務哪個 Rx Queue,然後 Output Port Lookup 會決定封包儲存在哪個 Output Queue,該模組會接收 封包並儲存資訊直到 Output Port 準備好,最後透過 Tx Queue 將封包由 I/O port 送出。
圖 3.4 Reference Pipeline[7]
Software
包含 NetFPGA driver、CAD Tools、用來模擬的記 憶體模組(Memory Module)、路由器套件(Router Kit),
Buffer Monitoring 和 NetFPGA 的 路由器軟體元 件 (SCONE)。在 NetFPGA 中,透過這些軟體的使用,截 取實際的 Traffic Flow 來模擬 QoS 機制。除此之外,
還有兩個 Router Controller Package 可以填充 IPv4 Router 之 Forwarding Table。首先是基於 PW-OSPF[8]
獨立路由軟體封包,在使用者端運作,第二是將 Linux 的 Routing Table 的從原本的 Memory 映射到硬體中。
以上可透過標準 Open-Source 路由工具建立一快速的 Full Line-Rate 4Gbps 路由器。
3.1.2 NetFPGA 實作
本計畫已在網路環境下實現一 NetFPGA 開發帄 台,硬體和軟體之部分架構係參考 NetFPGA 官方網頁 中 User Guide。首先安裝 NetFPGA 硬體開發帄台至主 機 上 並 確 保 可 以 正 常 運 作 , 接 著 下 載 NetFPGA Package(NFP)軟體,其包含 Gateware 原始碼、系統軟 體和回歸測詴,NFP 軟提包含 IPv4 Router、4-port NIC、
IPv4 Router with Output Queues Monitoring System、與 IPv4 Router(SCONE) 互動之 PW-OSPF 軟 體、映射
Routing Table 的 Router kit 以及 NetFPGA 上從 Linux host 到 IPv4 Router 之 ARP Cache。
NetFPGA 官方網頁同時也提供範例程式供開發 者使用,包含 NetFPGA 包含軟體和硬體可以透過 Reference NIC 進行通訊、使用網路介面與路由器溝通 和設定 NetFPGA 軟體元件(SCONE)參數、監控傳輸系 統緩衝區監控系統以及使用 Java 編程介面完成 Router kit。
圖 3.5 為 SCONE 之網頁介面,此程式建立與維 護一個包含靜態與動態路由器之 Routing Table 和 ARP Table,當偵測到 Software Table 改變時,SCONE 會複 製此訊息並記錄到 NetFPGA 的 Hardware Table 中。圖 3.6 為偵測 Traffic 之 Java GUI 介面,此程式包含了由 Java GUI 介面和 Reference Pipeline 資訊所組成之 Router kit。此系統使用到 Java GUI 介面的 Router Kit 在實際的網路中做 Traffic 監控和測詴情形,藉以證明 本計畫所提出 QoS 機制的可行性。
圖 3.5 SCONE 的網路介面[1]
圖 3.6 偵測 Traffic 之 Java GUI 介面
3.2 OpenFlow
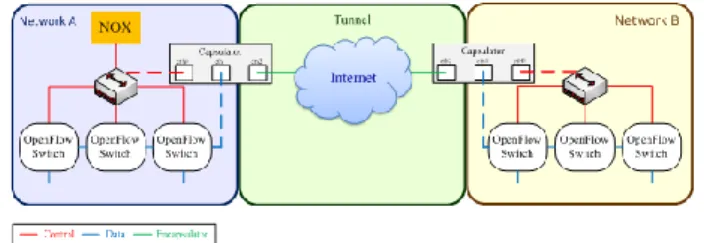
OpenFlow 係 基 於 乙 太 網 路 交 換 器 (Ethernet Switch),其具有內部之 Flow-Table 以及可在實際網路 環 境 中 新 增 或 移 除 Flow Entries 之 標 準 化 介 面 ; OpenFlow Switching Consortium 係於 2008 年由史丹佛 大學所發表,並支援 OpenFlow 相關功能[9]。其目在 於吸引網路供應商加入 OpenFlow 到交換器產品中,
以建置骨幹網路(Backbones)和配線室(Wiring Closets) 於大學校園。OpenFlow 的系統包含兩個角色,一個是 監控與管理整個網路環境,稱為 NOX Controller;另 一個是建立一個網路拓撲(Topology),稱為 OpenFlow Switch[10]。
3.2.1 OpenFlow Switch
OpenFlow Switch 包含一個負責查詢和傳送封包 的 Flow Table,以及一條與外部 Controller 連接之安全 路徑。圖 3.7 為 OpenFlow Switch 透過根據 OpenFlow 傳輸協定建立之安全路徑與 Controller 溝通,運作方 式係以包含 Flow-Tables(大多係由 TCAMs 建立)的乙 太網路交換器和路由器,以 Line-Rate 的速度實現防火 牆、NAT、QoS 以及收集統計等應用,即使廠商設計 方式不同,仍舊可以辨識運作在許多交換器和路由器 基本功能。常見的傳送封包方式係透過 Switching(屬 於 OSI 七層裡屬於第二層)和 Routing(屬於 OSI 七層裡 屬於第二層)進行傳遞,OpenFlow 傳送封包方法也採 取上述之方式[11]。
圖 3.7 OpenFlow switch 與 controller 溝通方式[12]
Layer-2 switching
乙太網路 Switching 在 OSI 架構中的資料連結層 (Data Link Layer)執行,負責控制資料流、處理傳輸錯 誤、提供實體位址和管理實體媒介存取。
Layer-3 routing
IP Routing 在 OSI 架構中的網路層執行,負責將 封包由來源端傳送到目的端,包含中間經過的主機,
而資料連結層則是負責在相同連結上的點對點(P2P) 連結傳送。
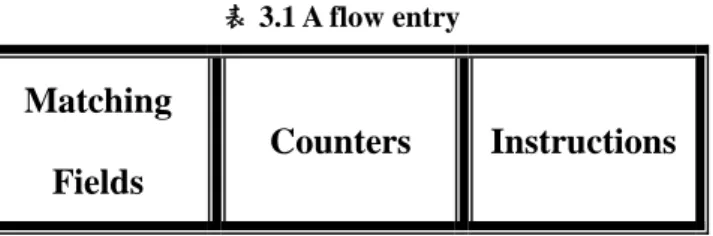
透過 Secure Channel,遠端使用 OpenFlow 通訊 協定的 Controller 可與 Switch 相互溝通,並可透過此 Secure Channel 傳送各種指令和封包資訊。OpenFlow Switch 的資料路徑由 Flow Table 組成。Flow Table 包 含 Flow Entries、活動計數器(Activity Counter)以及用 來進行封包匹配之 Instructions,Instructions 包括傳送 封包到指定的 Port,或丟棄指定應用程式之封包,若 找不到相匹配的封包則會透過 Security Channel 傳送 到 Controller,由 Controller 負責決定如何處理無效 Flow Entries 封包,並藉由加入或移除 Flow Entries 來 管理 Switch Flow Table。Flow Table Entries 的元件,
包含 Matching Fields、Counters 以及 Instructions,如 表 3.1 所示,其中 Matching Fields 之初始值預設 為”Type0”。
表 3.1 A flow entry
Matching Fields
Counters Instructions
OpenFlow Switch.由 15 個參數位元所組成,如表 3.2 所示。一個 TCP Flow 可以藉由十五個欄位詳細說 明,然而一個 IP Flow 在定義中,可能不包括傳輸埠。
每個 Matching Field 可以彙整各種 Flow。例如,在特 定 VLAN,Flows 只有在 VLAN ID 在有被定義的情況 下才適用於所有 Traffic 中。
表 3.2 Matching Fields List
Matching Field 中 15 個位元參數如下所述:
交換器輸入 Port
Metadata
乙太網路來源位址
乙太網路目的位址
乙太網路型態
VLAN ID
VLAN 優先權
MPLS 標記
MPLS Traffic Class
IPv4 來源位址
IPv4 目的位址
IPv4 協定/ARP Opcode
IPv4 ToS
TCP/UDP/SCTP 來源 Port/ICMP 型態
TCP/UDP/SCTP 目的 Port/ICMP Code
Counter 中包含 Table、Flow、Port 及佇列,並藉 由軟體運作方式實現於更多硬體計數器應用中。表 3.3 表示所需的計數器。
表 3.3 計數器統計訊息需求表
Counter Bits
Per Table
Active Entries 32
Packet Lookups 64
Packet Matches 64
Per Flow
Received Packets 64
Received Bytes 64
Duration (seconds) 32 Duration (nanoseconds) 32
Per Port
Received Packets 64
Transmitted Packets 64
Received Bytes 64
Transmitted Bytes 64
Receive Drops 64
Transmit Drops 64
Receive Errors 64
Transmit Errors 64
Receive Frame Alignment Errors
64
Receive Overrun Errors 64 Receive CRC Errors 64
Collisions 64
Per Queue
Transmitted Packets 64
Transmitted Bytes 64
Transmit Overrun Errors 64 Per Group
Flow Entries 32
Packet Count 64
Byte Count 64
Per Bucket
Packet Count 64
Byte Count 64
關於 Instruction 的欄位有三個基本準則如下所述,
其他相關內容請參考 OpenFlow Switch Specification 版 本 1.1.0[12]。
1. 在一般的情形下傳送 Flow 的封包給分配的 Port(或 Ports),允許封包在大部分 Switches 網路中進行傳輸。
2. 壓縮並透過 OpenFlow 傳輸協定將 Flow 的封 包傳送給 Controller。因 Controller 可以決定 Flow 是否應該加入 Flow Table,所以通常使 用在新 Flow 的第一個封包當中,並傳送所有 的封包給 Controller 處理。
3. 丟棄 Flow 的封包,避免網路受到攻擊及減少 終端主機散布假的 Broadcast 情形發生,以提 升網路的安全性。
3.2.2 NOX Controller
NOX Controller 於官方網站提供相關套件下載,
其本身亦是開放式的發展帄台,可透過 C++或 Python 語言來開發。本計畫採用 NOX Controller 負責監控網 路使用情形,雖然 NOX Controller 尚未發展成熟,但 已普遍運用在的大型網路部署當中,NOX Controller 透過電腦作業系統來讀取網路中瞬息多變的資訊。除 此之外,NOX Controller 尚提供觀察和控制網路環境 的能力,相關功能元件如下所述:
Component
圖 3.8 為運作在 PC NOX 上的控制軟體,可管理 多 個交 換器的 傳送 表 (Forwarding Table)[13], NOX Controller 可以加入一個多變的控制程序於一個或多
個 Network-Attached 伺服器中,使得網路控制功能更 加完善,NOX 網路拓撲情形可由圖 3.8 所觀察出,亦 可以透過多種不同的應用來決定網路管理機制。
圖 3.8 NOX 網路的組成元件[13]
Granularity
Granularity Size,決定 NOX 的延伸性及適應性,
由觀察的角度來看,圖 3.8 表示其網路拓撲情形,包 含 Switch 拓撲、提供服務之情形、所有名稱和位址間 的 Bindings。值得注意的是,其中並不包括目前網路 Traffic 的狀態。透過觀察 Granularity 的選擇提供資訊 給網路管理者決策雖可以運用在大型網路當中,但其 缺點在於其運作速度相當緩慢‧控制 Granularity 辨識 實際的網路請求,其過程相當複雜,NOX 會挑選中間 值的 Granularity 及 Flows[14]。簡而言之,透過處理過 的控制封包,並將封包標頭後的 Flow 所提供相關資 訊作為網路管理決策之依據,本計畫透過 Flow-Based Granularity 的使用,建立一具有高彈性特質的網路管 理系統於大型網路當中。
Switch Abstraction
NOX Controller 必須在 Switch 的命令下才得以控 制網路之 Traffic:Switch 指令獨立於特定的 Switch 硬 體上,支援 Flow-Level 控制 Granularity,為了達到以 上 需 求 , NOX 採 用 OpenFlow Switch 概 念 , 在 OpenFlow 中,表 3.1 表示 Switches 的 Flow Table 之功 用,在每個標頭的封包,都會包含更新後之 Specified Action 並加入計數器於封包中,封包的編號將決定其 優先權之高低,一個 Entry 的標頭檔包含 Values 或
ANYs,提供 TCAM-like 以符合 Flow 之規範[15]。
3.3 Tunneling─Capsulator
Capsulator 提供運作在使用者端,基於軟體的 Tunneling 技術,要建立一個 Tunneling 伺服器必須具 有 Open vSwitch 與 Capsulator。
3.3.1 Open vSwitch
Open vSwitch 為一 Open Source 軟體,其為多層 虛擬的 Switch,且支援標準管理介面,例如,NetFlow, sFlow, RSPAN, ERSPAN 及 CLI 等管理介面。透過有 計畫的擴展,可促使大規模的網路自動化[16,17]。
Open vSwitch 可作為一個 Soft Switch 運作在 Hypervisor 中,它已經被移植到多種虛擬化帄台及 Switching 晶片中,是 Xen 雲端帄台中的 Switch,也支 援 Xen、XenServer、KVM 及 VirtualBox,並具有易移 植至其他環境之特性,圖 3.9 為 Open vSwitch 架構圖 [18]。
圖 3.9 Open vSwitch 架構圖
3.3.2 Capsulator
Capsulator 是一個 User-Space 的程式,用以連結 不同的網路環境,形成一區域網路。Capsulator 實際 上透過 MAC-in-IP tunnel 連結相同 Tag 值的 Ports,表 示乙太網路封包由每個 Border Port 讀取,並傳送至所 有具相同 Tag 值 Capsulator 的 Border Port,並利用乙 太網路 IP 封包的 Payload 與其他 Capsulator 溝通。
Capsulator 包含 Border Port 與 Tunnel Port。Border Port 連結至其他具有相同 Tag 值 Capsulator 的 Border Port,使用者在啟動 Capsulator 時會指定 Border Port 的 Tag 值,可為任一整數;Tunnel Port 則負責與其他
Capsulator 溝通。
透過 Capsulator 可以連結數個網路,如圖 3.10 所 示,在每個網路中,eth0 作為 Tunnel port 與其他 Capsulator 溝通,同時連結到 Internet。
當 Border Port 接收到乙太網路封包後,會將其加 入至 IP 封包中,然後傳送給其他 Capsulator;Tunneling Port(eth0)接收到 IP 封包後,首先將 IP 封包標頭移除,
檢查 Tag 值後再將乙太網路封包傳送給所有具相同 Tag 值之 Border Port,作業系統在每個終端重組各個 分段,任意大小(例如,大於 MTU 大小的一半)的乙太 網路封包皆可被 Tunnel 並與 Capsulator 連結進行訊息 之傳遞。
圖 3.10 Capsulator 運作圖
圖 3.11 為以 Capsulator 連結數個 OpenFlow 網路 的例子,每個 Capsulator 具有一個 Tunnel Port(eth2)與 兩個 Border Port(eth0 和 eth1),eth0 為連結到 NOX Controller 的 Control Port,eth1 為連結到 OpenFlow Switch 的 Data Port。
NOX Controller 可控制網路中所有的 OpenFlow Switch,此外,網路 A 與網路 B 彷彿是直接透過兩個 連結到 eth1Port 的 OpenFlow Switch 互相溝通[19]。
圖 3.11 OpenFlow Network Example
3.4 服務品質(QoS)
服務品質(QoS),常被用於電腦網路或其他封包 交換網路之網路控制機制。QoS 的定義可在四個不同 的 組 織 找 到 , 包 括 IETF(Internet Engineering Task Force)、ITU-T(International Telecommunication Union)、
ETSI(European Telecommunications Standards Institute) 和 ISO(International Organization for Standardization)。
IETF 於 RFC 和 Draft 中皆有提及 QoS 的相關概 念;QoS 及其效能參數主要是由封包遺失率、延遲時 間 (Latency) 、 延 遲 變 化 的 程 度 (Jitter) 和 吞 吐 量 (Throughput)等相關元件所組成。
ITU 為建立電信標準協定所成立之組織,著重於 網路操作者的觀點來定義 QoS,遵循 SLA(Service Level Agreements) 所 訂 立 之 標 準 , 在 使 用 者 和 ISPs(Internet Service Provider) 間 與 ISPs 和 NPs (Network Provider)間標記,同時亦考慮網路層及應用 層 QoS 之規範;ETSI 也是一個電信發展學會,所提 出 QoS 觀點,大致與 ITU 相同;常見的 QoS 參數如 下所述:
Bandwidth
測量在數位網路的資料流量率,通常是每秒
多少 Bits。
Latency or Delay
一個封包由來源端到目的端所需時間
延遲的原因可能是封包困在冗長的佇列中或
必須採用較長的路由(Routing)以避免壅塞 Jitter or Variation in delay
連續封包造成的 Variation in Delay(延遲變化)
Jitter 所影響地聲音和影像串流服務
同步性的聲音與影像串流服務 Packet Loss Ratio
處理即時 Traffic,如多媒體和聲音串流時,
封包遺失率將會影響服務之品質。
Throughput
網際網路中,訊息傳遞成功之帄均機率。
由於本計畫之目標係確保高網路服務品質,因此
必須了解相關 QoS 之議題。表 3.4 列出根據 QoS Specification 的四種 QoS policy 應用服務之 Traffic 型 態。
表 3.4 常見的 Traffic 型態
3.4.1 IntServ
圖 3.12 為 IETF 所提出 IntServ 架構[20],於 IntServ 中,在傳遞資料封包之前,系統會保留部分頻寬並透 過 RSVP 顯示出封包 Flow 的特性。
圖 3.12 IntServ 架構
為了確保所提供之資料流式 E2E(終端到終端)之 QoS , 因 此 路 由 器 (Router) 必 須 處 理 所 有 資 料 流 中 RSVP 訊息;例如:紀錄路由(Routing)和路徑(Path)資 訊參數、執行 RESV 訊息參數、路由器(Router)執行多 領域的型態以辨識各種封包 Flow,並每個封包 Flow 上執行相關管理及排程機制。表 3.5 表示 IntServ 的服 務類型,其最大的優點是可以提供的高服務品質(QoS);
然而,隨著網路的擴展和大量封包 Flow,路由器 (Router)的處理速度將會面臨到重要挑戰,同時也是 IntServ 於延伸性擴展之重大議題。
表 3.5 IntServ 服務
3.4.2 DiffServ
受 限 於 IntServ 的 限 制 , IETF 提 出 DiffServ (Differentiated Services) 架 構 [21] , 圖 3.13 表 示 DiffServ 架構。
圖 3.13 DiffServ 架構
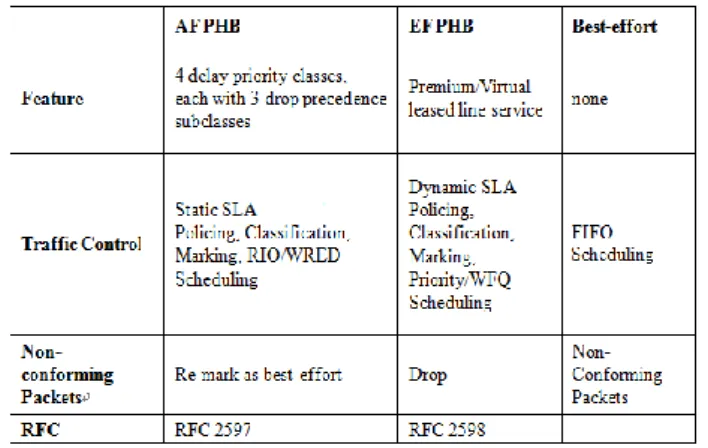
在此架構中,使用者可以預先與 DiffServ 進行 SLA 協定,DiffServ 的網路資源是根據 SLA 內容預先 分配,當封包進入 DiffServ 時,邊緣路由器(Router) 會執行 MF Classification、監控 Flow Rate、標示對應 的 DiffServ CodePoint(DSCP),並根據封包類型採用適 當的 Per-Hop-Behavior (PHB) 。於網路內部中的路由 器\僅提供較簡易的 DSCP 和 PHB 對應機制如表 3.6 所示,基於封包標頭的 DSCP 並根據對應的優先權進 行轉移,於邊緣/邊界節點中保存 Traffic Flow 資訊和 控制 Flow。
表 3.6 DiffServ PHBs
3.5 特徵識別(Feature Recognition)
為了提供較佳的網路管理及增進網路傳輸的品質,
因此良好的封包特徵識別是當前重要之議題,目前較 為 常 見 的 特 徵 識 別 方 法 Signature-Based 、 Behavior-Based 和混合型封包特徵識別。
3.5.1 Signature-based 封包特徵識別
由於多數 Web 中 Payload 的封包傳輸時間會被標 示特殊字串,因此,若能夠辨識網路應用的封包特徵,
便可以避免特定的網路 Traffic 以維持服務品質。例如,
eDonkey 封包 Payload 必須是 eDonkey 標識的開頭,
其值為 0xe3,4Byte 為封包內容的長度;KaZaA 封包 Payload 開頭為 GET 或 HTTP,並包含 X-KaZaA 字串,
其他相似封包識別方式也如上所述[22-24]。
相較於傳統 Port-based 辨識方法,有較高的正確 率,然而,由於它的標頭(Header)長度通常只有 20Bytes,
但在乙太網路 Payload 却高達 1500Bytes,造成辨識時 間過長及系統資源浪費,在[25]研究中指出,95%的第 一個 Payload 占 400 Bytes,因此調整最大 Byte 數與檢 查的長度相同,儘管會降低正確性,但卻可以提升整 體字串匹配效能;然經過加密處理 Payload,如 Skype,
便無法辨識。
3.5.2 Behavior-based 封包特徵識別
常應用於 P2P 軟體,例如,Bit-torrent、eMule 或 Skype,為了避免使用傳統單一封包 Payload 方法辨識 P2P 封包或者封包資料於傳輸時被竊取,因此大部分 軟體本身提供加密傳輸,其加密方式可分為傳輸前加 密 或 者 傳 輸 後 加密 兩 種 ,使 得 傳 統 資 訊 過濾 方 式 (Signature-based Filter)於無法應用於 P2P 傳輸上。此
外,Signature-based 尚有其他缺失,字串在配對之前 沒有定義或軟體更新版本修改字串的特徵,Filter 將無 法辨識封包的類型,所以 Thomas Karagiannis 在[26-28]
提出一個新的識別方法,.透過觀察使用者連結行為以 識別應用層所產生封包類型。
此種辨識方法分為以下步驟;首先判定第一個封 包的連結是否曾經被識別過,若是,則視為相同類型 的封包,否則利用 Behavior-based 封包特徵識別方法 辨識。其次是將 Behavior-based 封包特徵識別分為三 個級別:Social Level、Functional Level 和 Application Level,由已知服務使用者來找到其他使用相同服務的 使用者,亦為 P2P 的運作方式。
圖 3.14 顯示[27]實驗結果,觀察後可發現使用 Web 瀏覽網頁的數量比使用 P2P 連結使用者少很多,
這是因為 P2P 需要與許多點對點交換資訊。因此透過 此優點與 Social Level 想法結合,只需耗費伺服器的部 份資源,分析正在使用該服務的使用者,省下許多識 別消耗的時間。
圖 3.14 使用者連結到 web 和 P2P 數量圖[25]
Function Level 是由功能角度來分析使用中的服 務,如果使用者同時連結許多伺服器(瀏覽網頁),或 設定伺服器同時服務其他人(網頁伺服器),可能會造 成圖 3.15 右邊 Web 圖的結果([27]實驗數據),如果數 據散佈於在水帄線上或對角線上,表示此用戶並非為 P2P 使用者,如果藍點大都散布於中間區域,則表示 該用戶為 P2P 使用者。
圖 3.15 使用者連結到 web 和 P2P 數量圖[27]
Application Level 利 用 之 前 定 義 的 Graphlets Library 方式來完成封包識別,圖 3.16 顯示一個模擬包 含 SrcIP、SrcPort、DstIP 和 DstPort,透過這些 Graphlets 來比較並以嘗詴錯誤方式(Try and Error)修改相關參 數。如:協定類型、封包大小,使用 TCP 或者 UDP 傳輸協定或者傳送空的封包。
為了減少識別錯誤情形發生,利用這些嘗詴錯誤 方式(Try and Error)的優點做一個更詳細的分辨,當連 結資訊累積一段時間後,透過 Graphlets 行為識別,分 析使用者的連結,如果有相同的連結行為,並判別此 服務資訊是否為 P2P。即使 P2P 軟體版本更新,只要 連結方式沒有改變,仍舊可以辨識。然而,此種方法 之缺點為需要耗費時間來累積連結資訊,一般只能用 於資料蒐集完畢之後的分析;但若能與內容過濾器 (Filter)相結合,便可以改進即時分析性不足之缺失。
圖 3.16 Graphlets [27]
3.5.3 混合型封包特徵識別
使 用 混 合 型 封 包 特 徵 識 別 來 改 善 過 去 傳 統 的 Port-based 缺失,本計畫主要提出兩種方式做測量分析,
並無實際做管理動作;首先,採取 Signature-based 方
式以辨識所接收之封包,若收接受之封包無法辨識則 採用第二種 Port-based 的方法來判定。若此兩種方法 皆無法辨識封包屬於何種應用。此混合型封包之設計 方式是以避免竊取其他 Web 應用而採取標準埠號來 傳送資料,但此種設計方是會減少封包處理速度。由 於 Signature-based 特徵識別會消耗較多時間且可能發 生因輸入暫存器空間已滿,進而造成封包遺失的情形 發生[25]。
3.6 特徵識別軟體
本計畫除了介紹特徵識別的概念,並闡述相關軟 體之功能及應用範圍。例如,有兩個 signature-based Traffic 識別軟體,分別是 IPP2P[29]和 Layer7[30]。
IPP2P 及 Layer7 皆是建立在 Netfilter 框架提供的 Linux 核心當中,將於後面章節中介紹其設計概念。
3.6.1 Netfilter
Netfilter 採用 Linux 2.4 作業系統[31,32],此版本 提供封包過濾技術,提供封包過濾機制、封包位址轉 換(網路位址轉換,NAT)和封包損毀功能,圖 3.17 顯 示 五 個 Hook point 的 Netfilter 封 包 資 料 流 , NF_IP_PRE_ROUTING 、 NF_IP_LOCAL_IN 、 NF_IP_FORWARD 、 NF_IP_LOCAL_OUT 和 NF_IP_POST_ROUTING,此種設計方式避免使用者 修改作業系統核心時,避免對系統造成的破壞。
圖 3.17 五個 hook 位置的 Netfilter 封包資料流
圖 3.18 為 Netfilter 的架構,主要由兩個元件所組 成,第一個部份是在 Linux 核心中進行封包截取和處 理,而第二個部份利用軟體控制 IPtable 設定過濾規則,
由於 IPtable 使用 Netlink Socket[35]與 Linux 核心進行 連結,並將過濾規則透過 Netlink 傳送到 Netfilter,作 為這些過濾封包標準原則的基礎,在封包穿過 Linux 核心的 IP 層時,檢查封包是否需要轉換,准許此封包 由 PRE_ROUTING 進入,並透過 POST_FORWARD 和 POST_ROUTING 進行連續性地傳送,如果封包是 由本土主機(local host)進入,則會藉由 INPUT 處理並 傳送到本土主機,透過 OUTPUT 和 POST_ROUTING 進行連續地傳送,由於 Netfilter 架構存在於 Linux 核 心架構,所以封包的內容不需透過 User Space 進行處 理,使封包過濾可以有較好的處理效能。
圖 3.18 Netfilter 架構
3.6.2 IPP2P
IPP2P 用來識別 P2P 封包,據官方網站所提供的 資訊,IPP2P 可支援九種不同的 P2P 軟體,如表 3.7 所示,為使 IPP2P 能夠符合每個 P2P 應用封包資訊,
因此將封包資訊寫入於各種獨立的功能當中;如 UDP Packets 寫入於 BitTorrent 中,稱之為 udp_search_bit( )。
因此,若出現新式 P2P 應用,只需透過軟體修改初始 的文件,即可匹配新增之功能。
表 3.7 IPP2P 支援 P2P 協定及通訊協定[27]
P2P protocols Communications protocols eMule, Kademlia, eDonkey TCP and UDP
KaZaA, FastTrack TCP and UDP
Gnutella TCP and UDP
Direct Connect TCP only BitTorrent, extended BT TCP and UDP
AppleJuice TCP only
WinMX TCP only
SoulSeek TCP only
Ares, AresLite TCP only
3.6.3 Layer7
Layer7 不單應用於 P2P 中,也可辦別一般常見的 應用服務。例如,HTTP、FTP 和 DNS 等等,由官方 網站提供的支援的協定約有 100 種,表 3.8 列出了常 見的五種協定,設計方式是將傳送模式文件裡的每個 網路應用中自動加入所需之資訊。使用者不須要修改 原始碼就可以完成辨識功能,採取 Henny Spencer 表 示方式以符合各種封包類型。然而此方法在使用上有 兩項缺失:首先,無任何方式可以辨識空白字元,第 二是無法區別特殊情形之字元,此兩種缺失會降低封 包的正確率。
表 3.8 Layer7 支援五種常見的協定[28]
3.7 Related Research
MPLS 相關研究結合了第二和第三層交換技術 以解決 QoS 之困境,因此相關研究將參考 MPLS 部分 設計理念使本系統更加完善。
3.7.1 MPLS & QoS
IETF 於 1996 年 12 月提出了多重協定標籤交換 (MPLS[33]),主要目的是合併 Routing(網路層)和 Label Switching(應用層)的功能,提供單一的解決方式,
MPLS 可以於第三層傳送封包,於第二層執行封包 Label-swapping。MPLS 是屬於 Peer 模式,換言之,
只能使用單一 IP 路由(Routing)協定;此外,MPLS 可 在任一資料連結層被運作,例如,ATM、Frame Relay、
PPP 和乙太網路。
MPLS 可以幫助使用者改善 QoS,MPLS 是一種 結合第二層和第三層的交換技術,使用封包標籤機制 來選擇路由(Routing)並傳送資料,路由的選擇由標籤 (Labels)所決定,圖 3.19 顯示了 MPLS 是由 Label Switch Router(位於中心)及 Label Edge Router(位於邊 緣)所組成。
圖 3.19 MPLS 網路架構
由於 MPLS 是透過交換標籤轉送資料,傳輸速率 較傳統的方式高,透過 MPLS 可花費較少的時間來傳 送資料並提高 QoS。此外,MPLS 封包標頭(Header) 包含一個 3bit EXP 檔(如圖 3.20),透過 EXP 檔,標示 MPLS 封 包 之 優 先 權 並 依 照 優 先 權 之 高 度 的 傳 遞 MPLS 封包。
圖 3.20 MPLS 封包標頭(header)格式
由於現今許多的網路並無提供相關 MPLS 架構,
這對於網路頻寬管理是一大限制。此外,隨著晶片技 術不斷地發展,使得 Router-Transfer 和 Switch-Transfer 之間效能的差異越來越小,MPLS 是藉由 DffiServ 完 成,當執行 MPLS 時,亦會對 DiffServ 造成影響。
3.7.2 MPLS-TE&QoS
傳統的路由器運作方式,是採取最短路徑當作路 由(Routing),不考慮其他因素。因此,當原本的路徑 壅塞時,傳統的路由器不會將 Traffic Flow 改成藉由其 他路徑進行傳輸。例如,傳統路由器選擇從 R1(R8) 到 R5 最短的路徑是 R1(R8)-R2-R3-R4-R5,即使有其
他 替 代 的 路 徑 , 如 圖 3.21 所 示 ,
R1(R8)-R2-R6-R7-R4-R5 路徑鮮少被傳統路由器所選 擇。
圖 3.21 傳統路由器(router)的難處
Traffic Engineer (TE)為 Traffic Flow 選擇路徑的 過程,TE 帄衡了網路中不同連結路徑、路由器、交換 器中的 Traffic Flow;其目的是取得兩個節點間的路由 器,使此路由(Routing)不違背它的規範。
由於 MPLS 具 Self-Routing 和個別地傳送工作之 特性,MPLS 可用來與 TE 組合成 MPLS-TE[33]技術,
使用 MPLS-TE 可以提升網路 QoS,主要原因為:
1. 藉由帄衡多個傳送路徑的負載,使 MPLS-TE 可
以提升 QoS 且避免網路壅塞情形發生。
2. MPLS-TE 可以透過 RSVP-TE 信號建立一個謹慎 的 QoS 及頻寬保證的通道。
3. 透過備用的 LSP 和 FRR(Fast Reroute),不僅避免
通道擁塞也能相對提升 QoS。
然而,MPLS-TE 也有許多限制,如下所述:
1. MPLS-TE 必須用於 MPLS 網路,但現今許多網
路並不支援 MPLS 網路架構,造成無法支援 MPLS-TE 情形發生。
2. 跨領域的 MPLS-TE 應用仍在發展當中,目前的
MPLS-TE 只能在特定領域中執行。
3. 雖然 MPLS-TE 可以建立一個頻寬保證的通道,
如果使用者同時透過通道傳送多種 traffic,可能 會產生單獨地處理不同優先權的 Traffic 問題發 生。
3.7.3 Ethane
本計畫所使用的 OpenFlow 及 NOX 皆繼承 Ethane 之優點。Ethane[36]是一個新的企業網路架構,允許管 理者自行定義單一網路、並可直接運作執行;Ethane 具備直接連結中央 Controller 之路徑、Flow-based 的乙 太網路交換器以及管理 Entry 和 Flow 的路由(Routing) 之特性,提供開發者發展 OpenFlow 的參考方向。
OpenFlow 的設計概概念與 Ethane 大致相同,由 中央的 Controller 進行網路控管並決定所有封包的運 作情形。因 Controller 可藉由目前網路拓撲情形並提 供合法 flow 進行存取及路由計算。第二個元件為 Switches,具備簡易及高相容之特性,由單一的 Flow Table 及 Controller 的安全通道所構成,Switches 依據 Controller 的指示傳送封包,此方式與 OpenFlow 概念 相同,若接收到不在 Flow Table 中的封包時,會將此 封包傳回給 Controller 進行處理;若接受在 Flow Table 中的封包時,則會根據 Controller 的指令進行相對應 之動作。
Ethane 網路對於 Controller 與 Switches 之間互動 有完整的定義,圖 3.22 說明在 Ethane 網路上通訊的五 種行為。
圖 3.22 Ethane 網路溝通實例[34]
Registration
所 有 的 主 機 、 使 用 者 和 交 換 器 皆 須 事 先 與 Controller 進行註冊,並產生 Controller 的公開金鑰;
註冊完成後,主機可藉由 MAC 位址進行認證、使用 者可藉由使用者名稱和密碼進行認證,交換器可藉由 安全證明進行認證。
Bootstrapping
Switches bootstrap 藉由 Controller 產生樹狀頂點 (Root),使底層各個支點可互相連結,Controller 與交 換器間存在著安全通道(Secure Channel),交換器藉由 此安全通道傳送連結、狀態資訊給 Controller 並蒐集 相關資訊建立其網路拓撲。
Authentication(認證)
1. 圖 3.22 表示當使用者 A 使用主機 A 進入網路 時之動作。首先,交換器 1 會開始傳送主機 A 的封包給 Controller 並於封包中註記為交換器 1 輸入埠。
2. 主 機 A 送 出 DHCP 需 求 給 Controller , Controller 確認主機 A 的 MAC 位址後,並分 配一個 IP 位址(IPA)給予該主機,將主機 A 至 IPA,IPA至 MACA,MACA至交換器 1 的實體 Port 相結合。
3. 當使用者瀏覽 Web 時,Traffic 透過 Web 形式 與 Controller 進行認證,一旦使用者 A 通過認 證過程,使用者 A 即能與主機 A 相結合。
Flow Setup
1. 使用者 A 與使用者 B 進行溝同時,使用者 B
必須使用上述方式完成認證,且交換器 1 在 沒有適合 Flow Table 進入 Entries 狀況發生時,
需重新傳送封包給 Controller。
2. 接收到封包後,Controller 會判定此封包為允
許之 Flow 或者為拒絕之 Flow。
3. 若封包為允許之 Flow,Controller 會計算該 Flow 路由(Routing),包含路徑上的運作策略 及加入新的 Entry 至路徑上交換器的 Flow Tables。
Forwarding
1. 當 Controller 路徑建立完成後,利用新的 Flow Entry 將封包回傳至交換器 1,Flow 封包由交 換器直接傳送。
2. Flow-Entry 被保留在 Switch 當中,因 Time-Out 被移除或者由 Controller 直接刪除。
圖 3.23 為 Ethane 網路佈署之實例,由圖中可發 現所有的終端設備,皆透過有線的 Ethane 交換器或無 線 Ethane AP 連結到網路;此方式只需將 Ethane Switch 連 結 到 網 路 , 藉 由 安 全 通 道 (Secure Channel) 與 Controller 連結,並協助 Controller 建立該網路拓撲,
使得 Controller 可以掌控當時網路服務品質,避免網 路阻塞情形發生。
圖 3.23 Ethane 建置實例[34]
圖 3.24 表示 Controller 之元件,Controller 為網 路控制之核心,存在著許多嚴格的操作規範。一般網 路存取方式,是透過認證元件辨識未認證或不在 MAC 內 Traffic 並核對儲存在註冊資料庫裡使用者與主機使 用的憑證以完成認證機制;Controller 會紀錄所連結 Switch Port 以降低 Controller 之複雜度。
因 Controller 具 Policy 功能,可編譯成快速查詢 表;當 Flow 產生時,必須進行相關資訊配對,已決 定是否接收此 flow 或透過何種路由(Routing)傳遞,並 藉由 Route Computation 規劃其路徑,因此,拓撲是根 據 Switch Manager 所接收到 Switches 的最新連結情形 所產生的。
圖 3.24 Controller 元件
四、 研究方法
以下介紹本研究所提出的相關模組設計以及可調 式的 QoS 機制演算法。
4.1 系統架構
本研究提出以 ToS-Based 限制速率的 QoS 機制,
運用於 OpenFlow 網路。此機制利用 ToS 的值作為辨 別每個 Flow 型態的依據,並依不同 Flow 型態限制其 速率。本研究使用史丹佛大學所提出的 NetFPGA 硬體 開發帄台實作一 OpenFlow Switch,並利用 LinkSys 無 線路由器實作一 OpenFlow AP。
圖 4.1 為系統架構,當封包由應用程式伺服器送 出時,會依據其型態由 iptables 給予不同的 ToS 值,
例如,FTP 封包 ToS 值為#1,Http 封包 ToS 值為#2,
而 Video Stream 封包 ToS 值為#3,其中 ToS 的值用來 辨別不同的 Flow 型態。OpenFlow Switch 中的 Rate Limiter 根據 ToS 值限制每個 Flow 的速率。
Host Host
eth0 eth0
WLAN
Controller NetFPGA Openflow Rate Limiter
LinkSys Wireless Router
OpenWrt Openflow
Application Server
PCI Bus NetFPGA
Openflow Rate Limiter
PCI Bus Flow 1
Flow 2 Flow 3 iptable
iptable
iptable
Openflow Switch A Openflow Switch B Openflow AP
FTP
HTTP
VS
Database
圖 4.1 系統架構
本架構將 OpenFlow 網路由有線網路延伸至無線 網路,Rate Limiter 模組實作在基於 NetFPGA 硬體開 發帄台上的 OpenFlow,當 QoS 機制啟動時,Rate Limiter 會依據封包 ToS 的值限制其速率。此系統可分 為四個部分,如圖 4.2 所示。
圖 4.2 Proposed System Magnificence
4.2 架構模組設計
4.2.1 OpenFlow Switch 設計
本計畫利用史丹佛大學所提出的 NetFPGA 硬體 開發帄台實作一 OpenFlow Switch,建立 OpenFlow 網 路環境。首先,修改 Linux kernel,使得 NetFPGA 硬 體開發帄台可以透過 PCI 介面連結至主機,接著參考 NetFPGA 與 OpenFlow 官 方 網 站 上 的 User Guide[23,24],進行 NetFPGA 與 OpenFlow 封包的安 裝,然後根據硬體規格修改環境變數及路徑,本計畫
在 NetFPGA 帄台上建立 OpenFlow Switch。圖 4.3 為 OpenFlow Switch 的設計。
圖 4.3 OpenFlow Switch 設計
4.2.2 OpenFlow AP 設計
本研究利用一商業的無線路由器作為 OpenFlow AP 以建立 OpenFlow 網路環境,首先,將 OpenWrt 韌體 Flash 至無線路由器,並加入 OpenFlow 1.0 版本。
OpenWrt 目前實作了 OpenFlow 協定標準版本 0.8.9~2。
圖 4.4 為 OpenFlow AP 的設計。
圖 4.4OpenFlow AP 設計
4.2.3 ToS
本計畫以 ToS 作為不同服務辨識的依據,以判定 其為何種 Flow,Rate Limiter 模組會根據 ToS 值限制 Flow 速率,圖 4.5 描述管理員在 Linux User Space 利 用 iptables 將值輸入至 Linux Kernel Space 中封包的 ToS 欄位,當封包由應用程式伺服器送出至 Client 端 時,會給予每種型態的應用程式封包不同的 ToS 值。
圖 4.6 說明每種服務類型的 ToS 欄位值。
圖 4.5 Mangle the ToS by iptables
圖 4.6 每種服務類型的 ToS 欄位值
4.2.4 Rate Limiter
Data Plane
圖 4.7 為 OpenFlow Switch 管線化架構,本研究 修改 OpenFlow Switch Wildcard Lookup 模組,實現根 據 ToS 欄位值限制 Flow 速率的功能,藉由修改 Wildcard Lookup 模組,當 Header Parser 模組解析進入 的封包後,Rate Limiter 可讀取 ToS 的值,若 ToS 欄位 值與 Flow Table 中的規則相符,則以限制的速率將封 包送出。利用 Rate Limiter,本研究可以自行設定每一 種 Flow 的速率。
圖 4.7 OpenFlow Switch Pipeline
Control Plane
Rate Limiter 模組使用依 Token 數量而定的 Token Bucket 演算法機制,若 Token 數量足夠,Rate Limiter 會將封包由 Data Flow 轉送至佇列,否則,Fliter 會將 封包丟棄,因此,決定適當的 Token 數量可調整封包 速率至符合 QoS 要求,封包傳送至佇列前採 First In First Out (FIFO)排程方法,圖 4.8 為 Rate Limiter 模組 運作,圖 4.9 為 Rate Limiter 詳細流程圖。
圖 4.8 Rate Limiter 模組運作
圖 4.9 頻寬控制流程
圖 4.10 為 OpenFlow Switch 預設的速率。圖 4.11 說明當封包 ToS 欄位值與 Flow Table 相符,OpenFlow
Switch 會限制 Flow 的速率。
圖 4.10 OpenFlow Switch 預設速率
圖 4.11 OpenFlow Switch 以限制的速率傳送封 包
圖 4.12 為 Rate Limiter 運作時的 Scenario,每個 由應用程式伺服器送出的封包,其標頭皆包含 ToS 欄 位值,OpenFlow Switch 讀取 ToS 值後,判斷其屬於 哪一種 Flow,將封包依 Flow Table 中所設定的規則以 限制的速率由輸出佇列送出。
圖 4.12 Rate Limiter Scenario
4.3 Adaptive QoS Mechanism
本系統所提出之機制可針對不同 Flow 導入使用 者的 Policy,圖 4.13 為各種封包 Flow 由應用程式伺 服器送至 Edge Router 時,由於封包混雜而造成終端使 用者 QoS 受到影響,因此,封包抵達 Edge Router 後 應依服務類型將 Flow 分類。為達成此目的,將 Edge Router 延伸為兩個存取點,一個 Router 位於雲端服務 網路邊緣,一個 Switch 位於終端使用者邊緣。GR與GS

![圖 3.5 SCONE 的網路介面[1]](https://thumb-ap.123doks.com/thumbv2/9libinfo/9124626.409073/7.892.459.810.597.878/圖35SCONE的網路介面1.webp)
![圖 3.7 OpenFlow switch 與 controller 溝通方式[12]](https://thumb-ap.123doks.com/thumbv2/9libinfo/9124626.409073/8.892.86.431.111.366/圖37OpenFlowswitch與controller溝通方式12.webp)
![圖 3.12 為 IETF 所提出 IntServ 架構[20],於 IntServ 中,在傳遞資料封包之前,系統會保留部分頻寬並透 過 RSVP 顯示出封包 Flow 的特性。 圖 3.12 IntServ 架構 為了確保所提供之資料流式 E2E(終端到終端)之 QoS , 因 此 路 由 器 (Router) 必 須 處 理 所 有 資 料 流 中 RSVP 訊息;例如:紀錄路由(Routing)和路徑(Path)資 訊參數、執行 RESV 訊息參數、路由器(Router)執行多 領域的型態以辨識各](https://thumb-ap.123doks.com/thumbv2/9libinfo/9124626.409073/12.892.465.810.596.804/所提架構中在傳遞資料封包之前系統會保留部分頻寬並透過顯示.webp)
![表 3.7 IPP2P 支援 P2P 協定及通訊協定[27]](https://thumb-ap.123doks.com/thumbv2/9libinfo/9124626.409073/16.892.70.445.119.419/表37IPP2P支援P2P協定及通訊協定27.webp)
