進階區域式對角型Tuple Space 搜尋之快速封包分類演算法
82
0
0
全文
(2) 進接區域式對角型 Tuple Space 搜尋之快速封包分類演算法 Fast Packet Classification Using Advanced Regional Diagonal Tuple Space Search 研 究 生:高鳴遠. Student:Ming-Chao Huang. 指導教授:陳. Advisor:Chien Chen. 健. 國 立 交 通 大 學 資 訊 科 學 系 碩 士 論 文. A Thesis Submitted to Department of Computer and Information Science College of Electrical Engineering and Computer Science National Chiao Tung University in partial Fulfillment of the Requirements for the Degree of Master In Computer and Information Science June 2005 Hsinchu, Taiwan, Republic of China. 中華民國九十四年十二月.
(3)
(4)
(5) 進階區域式對角型 Tuple Space 搜尋之 快速封包分類演算法. 研究生:高鳴遠. 指導教授:陳 健 國立交通大學電機資訊學院. 教授. 資訊科學所碩士班. 摘要. 為了提供安全防護,虛擬私有網路,品質保證等等網際網路的服務。網際網 路路由器需要將收到的封包進行快速的分類。封包分類是利用在封包標頭所包含 的資訊與路由器中事先定義的規則表進行比對,一般而言,多重欄位的封包分類 是一個相當困難的問題,已經有許多不同的演算法被提出來解決這個問題。在這 篇論文中,我們提出一個稱為Addvanced Regional Diagonal Tuple Space Search的封 包分類演算法,採用Diagonal Tuple Space Search之觀念,並利用分區搜尋,鏈結搜 尋,單向搜尋等三種搜尋加以改良演算法:分區搜尋將整個Tuple space切割成許多 區塊;鏈結搜尋使得搜尋進展能跳越至指定區域;單向搜尋則能將Diagonal seacr 的至多三次二元搜尋減少為二次二元搜尋。透過實驗的觀察,可以將搜尋次數提 升為只需 2logw,w為維度之長度;同時對儲存空間的複雜度由O(n2wlog w)改變為 2. O(nlogw + n w),n表示規則之總數。在封包分類的效能上。因為Addvanced Regional Diagonal Tuple Space Search只需要比Diagonal Tuple Space Search更少的記憶體存 取時間,而在封包分類的問題中,記憶體的存取往往決定了整體的查詢時間,所 以,即使Addvanced Regional Diagonal Tuple Space Search需要另外對區塊作搜尋的 步驟,仍會有比Diagonal Tuple Space Search更快的分類速度。. i.
(6) Fast Packet Classification Using Advanced Regional Diagonal Tuple Space Search. Student: Ming-Yung Kao. Advisor: Prof. Chia-Hoang Lee. Department of Computer and Information Science National Chiao Tung University. 英文摘要 Abstract. In order to support Internet security, virtual private networks, QoS and etc., Internet routers need to classify incoming packets quickly into flows. Packet classification uses information contained in the packet header to look up the predefined rule table in the routers. In general, packet classification on multiple fields is a difficult problem. A variety of algorithms had been proposed. This thesis presents a novel packet classification algorithm, called advanced regional diagonal tuple space search algorithm using the concept of diagonal tuple space search algorithmand three search types: block seach, link-list search and single-direction search. Block search can divide all tuple space into many small blocks; link-list search can jump to assigned blocks to start process; single-direction search oly need two binary search. Our experiment results show that the advanced regional diagonal tuple space search algorithm only need 2 log w, where w denotes the length of dimensions, and the storage complexity from. ii.
(7) 2. O(n2wlog w) of the diagonal tuple space search algorithm to O(nlogw + n w), where n represents the number of rules. On the classification performance, the advanced regional diagonal tuple space search algorithm requires much less memory access time than diagonal tuple space search algorithm. Since memory access dominates the lookup time. Even though extra processing time for searching areas is required for the advanced regional diagonal tuple space search algorithm, the advanced regional diagonal tuple space search algorithm still outperforms diagonal tuple space algorithm on the classification speed.. iii.
(8) 誌謝. 本論文得以順利完成,首先要感謝指導教授陳健老師與李嘉晃老師,其嚴謹 的研究態度及細心的指導,使我在這些日子裡受益良多。其次要感謝口試委員簡 榮宏教授、陳志成教授的指正與建議,使得本論文能更加完善。 此外,感謝陳健教授的Wireless/Wireline Convergence Networks實驗室的游宸 同學,以及我研究室的明超、駿豪、沛言、佑銘、建良、國懿、信宏、志鵬、開 國、仁信等同學與學弟們對我的關心與幫助,豐富了我的實驗室生活。 最後感謝我的家人,因為他們的支持是我努力的最大動力。謹以此篇論文給 我的摯愛們。. 高鳴遠 謹誌於交通大學 民國九十四年十二月. iv.
(9) 目錄 中文摘要............................................................. i 英文摘要............................................................ ii 誌謝................................................................ iv 目錄................................................................. v 表目錄............................................................. vii 圖目錄............................................................ viii 第一章 緒論......................................................... 1 1.1 背景 ........................................................ 1 1.2 Performance Metrics for Packet Classification Algorithm ..... 4 1.3貢獻 ......................................................... 4 1.4論文架構 ..................................................... 5 第二章 與封包分類有關之演算法....................................... 6 2.1前言 ......................................................... 6 2.2演算法之簡介 ................................................. 6 2.2.1 Linear search.......................................... 6 2.2.2 Hierarchical tries..................................... 7 2.2.3 Set-pruning tries...................................... 7 2.2.4 Grid of tries.......................................... 7 2.2.5 Cross-producting....................................... 8 2.2.6 Are-base quadtree...................................... 8 2.2.7 Hierarchical intelligent cuttings...................... 9 2.2.8 Hyper-Cuts............................................. 9 2.2.9 Recursive flow classification.......................... 9 2.2.10 Ternary content addressable memory................... 10 2.2.11 Bit-map intersection................................. 10 2.2.12 Aggregated Bit Vector................................ 11 2.3演算法之比較................................................. 11 第三章 相關研究.................................................... 13 3.1 Tuple Space ................................................ 13 3.1.1 Tuple Space之定義..................................... 13 3.1.2 Tuple Relationship.................................... 15 3.1.3 Marker 與 Precomputation.............................. 16 3.2 Rectangle Search ........................................... 18 3.3 Diagonal Tuple Space Search ................................ 20 第四章 Advanced Regional Diagonal Tuple Space Search............... 24 4.1動機 ........................................................ 24. v.
(10) 4.2資料結構的描述 .............................................. 4.3演算法的描述 ................................................ 4.3.1 分區.................................................. 4.3.2 Link-list與marker生成................................. 4.4衝突(Conflict)的處理 ........................................ 4.4.1單方向衝突的處理....................................... 4.4.2雙方向衝突的處理....................................... 4.5流程的說明 .................................................. 4.5.1 Marker生成的流程...................................... 4.5.2搜尋的流程............................................. 4.6演算法的証明 ................................................ 4.7搜尋範例 .................................................... 第五章 模擬與分析.................................................. 5.1 Advanced regional diagonal tuple space search之分析環境 ..... 26 27 27 30 41 41 43 49 49 50 52 54 56 56. 5.1.1分區之測試............................................. 5.1.2 Link-list之測試....................................... 5.1.3單方向之測試........................................... 5.2 總合模擬.................................................... 5.2.1總合模擬之環境......................................... 5.2.2模擬結果............................................... 5.3複雜度的計算 ................................................ 第六章 結論與未來工作.............................................. 參考資料............................................................. 56 59 60 62 62 63 65 67 68. vi.
(11) 表目錄 表1-1:封包分類之規則表範例.......................................... 3 表2-1:封包分類演算法之分類。........................................ 6 表2-2:封包分類演算法之複雜度比較。................................. 12 表3-1:規則對應至Tuple之範例。...................................... 14 表3-2:表 3-1 之Tuple space。 ....................................... 14 表5-1:當有 0%的規則位於Wildcard區域時,各個演算法分別生成的marker總數 量以及平均搜尋結果。.......................................... 63 表5-2:當有 20%的規則位於Wildcard區域時,各個演算法分別生成的marker總數 量以及平均搜尋結果。.......................................... 63 表5-3:當有 50%的規則位於Wildcard區域時,各個演算法分別生成的marker總數 量以及平均搜尋結果。.......................................... 63 表5-4:Rectangle search,Diagonal tuple space search及Advanced regional diagonal tuple space search之複雜度比較。..................... 66. vii.
(12) 圖目錄 圖1-1:封包分類處理之流程圖.......................................... 2 圖3-1:Tuple space可視為一二維空間。................................ 15 圖3-2:Tuple(x,y)與其他tuple之關係之二維空間表示圖。............... 16 圖3-3:Precomputation所包含之範圍。................................. 18 圖3-4:Marker的生成。............................................... 18 圖3-5:Rectangle search之範例。..................................... 19 圖3-6:Rectangle search之最糟情形。................................. 20 圖3-7:Diagonal tuple space search之marker生成方向。................ 21 圖3-8:Diagonal tuple search之範例。................................ 22 圖4-1:真實網路環境的規則配置情形。................................. 24 圖4-2:Advanced Diagonal Tuple Space的區域配置圖示。................ 27 圖4-3:區域內的marker配置圖示。..................................... 28 圖4-4:Linklist區間配置方式與header tuple之設置。................... 圖4-5.a:簡單的非對角線tuple之marker生成流程範例,加入R1。.......... 圖4-5.b:簡單的非對角線tuple之marker生成流程範例,加入R2。.......... 圖4-5.c:簡單的非對角線tuple之marker生成流程範例,加入R3。.......... 圖4-6:每一列(行)可與Diagonal tuple組成Link-list樹狀圖。............ 圖4-7:圖 4-6 之搜尋路徑圖。......................................... 圖4-8:二元搜尋較線性搜尋佳之例子。................................. 圖4-9:線性搜尋較二元搜尋佳之例子。................................. 圖4-10:動態決定區域搜尋演算法之流程圖。............................ 圖4-11:最後對二元搜尋範圍內鏈結之規則或marker之處理。.............. 圖4-12:封包單方向搜尋之流程圖。.................................... 圖4-13:產生衝突的範例圖示。........................................ 圖4-14:解決衝突之範例。............................................ 圖4-15:解決雙方向衝突之範例。...................................... 圖4-16.a:最佳配對規則可能分布範圍(a)。............................. 圖4-16.b:最佳配對規則可能分布範圍(b)。............................. 圖4-16.c:最佳配對規則可能分布範圍(c)。............................. 圖4-17:雙方向衝突的例外情形。...................................... 圖4-18:最深tuple(d,d)之最佳符合規則範圍圖。....................... 圖4-19:LongTuple與IncomparableTuple之範圍圖。...................... 圖4-20:Tuple space之範例圖。....................................... 圖5-1:演算法之差異性:採用分區之影響。.............................. 30 32 33 33 34 35 36 36 36 38 40 41 43 45 46 46 47 49 52 53 54 57. 圖5-2:規則總數為 1000 時,tuple(0,0)至tuple(15,15)中各個diagonal tuple 中的marker總數之折線圖。...................................... 57. viii.
(13) 圖5-3:規則總數為 5000 時,tuple(0,0)至tuple(15,15)中各個diagonal tuple 中的marker總數之折線圖。...................................... 58 圖5-4:規則總數為 10000 時,tuple(0,0)至tuple(15,15)中各個diagonal tuple 中的marker總數之折線圖。...................................... 58 圖5-5:演算法之差異性:採用link-list機制之影響。.................... 59 圖5-6:在不同的規則總數以及conflicting狀態下對tuple搜尋之平均結果折線 圖。.......................................................... 60 圖5-7:演算法之差異性:採用單方向機制之影響。....................... 60 圖5-8:在不同的規則總數以及conflicting狀態下對tuple搜尋之平均結果折線 圖。.......................................................... 61 圖5-9:在不同的規則總數以及conflicting狀態下的marker總數量之折線圖。 61. ix.
(14) 第一章 緒論. 1.1 背景 隨著網際網路迅速的發展,使用網路的人數逐年增加,同時對於網路頻寬與 品質的需求亦逐漸提高,進而邁向寬頻普及化的時代。人們逐漸能夠藉此從事各 種通訊行為及互動,諸如網路安全性,防火牆(firewall),Virtual private network(VPN) 以及 Quality of service(QoS)等等的網路應用服務技術也隨著網際網路的重要性的 提升而逐漸發展與成熟。為了達到這樣的應用,因此我們需要封包分類(Packet classification)技術的支援。封包分類技術是建立在路由器或網路閘道器上,其功 能是將封包分類到不同的資料串流(Flows),使得相對應資料串流的動作能夠快速 地被執行,能有更好的封包處理效能。 網際網路的路由器(router)可以利用所收到的封包的表頭(header)作為資訊, 並檢索預先定義的規則表(Predefined rule table)中所定義的規則,將封包分類至適 當的類別中,規則表負責記載並管理著每一條規則以供檢索,範圍從數十條甚至 是數千條規則不等,每一條規則的制定則是依據封包的表頭的欄位內容來設限, 其中包含著網路來源端位址(Network source address),網路目的端位址(Network destination address),來源端接口(Source port),目的端接口(Destination port),協定 型式(Protocol)等等可用資訊,而規則的定義可能是來源端位址或目的端位址的前 幾位元字首(稱為 prefix),可能是來源端接口或目的端接口中一段指定的範圍(稱 為 range),或是協定型式中用來表示某些協定的數字(如 TCP,UDP 或 ICMP)。 圖 1-1 為封包處理的流程 [1],當接收到一個封包時,首先會截取出封包的 表頭資訊並比對規則表中各個規則中的每一個欄位是否相符合,當一個規則能夠 符合所有的欄位條件時,便將該規則視為可配對的規則(matching rule),路由器會 將所擷取到的封包表頭資訊與規則表中的規則進行比對分類動作,並找出數個可. 1.
(15) 符合的規則,從中挑選出擁有最高優先權的可配對規則,即為最佳符合規則 (Best-matching rule),也是分類該封包最佳的類別,最後路由器會根據最佳符合規 則的內容而對該封包採取相對應的動作(接受或拒絕)。一般而言,處理封包分類 的應用環境可以分成靜態與動態二種:在靜態的環境下較不需要去處理規則的插 入及刪除等狀態,或是規則表的變動較不頻繁,相對的在動態環境中規則表可能 有較為頻繁的更新動作,因此一個好的封包分類演算法必須能夠適應到各種的環 境。. 圖 1-1:封包分類處理之流程圖。 表 1-1 為規則表的範例 [2]。我們假設來源端位置與目的端位址皆為三位元 字首長,位址欄裡頭的一個星星符號"*"視為一個遮罩位元,當一規則某一欄位 內容為 11*時,則封包表頭資訊中相對應該欄位內容為 110 或 111 皆是為羽根規 則相符合。當規則中某一欄位全是用星星符號表示時,則將規規則視為泛用規則 (Wildcard rule),亦即不論封包表頭資訊中該欄位內容為何,都能通過泛用規則在 該欄位的檢查;而在來源端接口或是目的端接口等欄位中則是用一段數字範圍或 是萬用字元來表示,最後的協定欄位則是指出明確的協定型式,如 TCP,UDP 或 ICMP,甚至是萬用字元等,規則都有指定各自對應的行為,分為接受與拒絕二種,. 2.
(16) 當一封包能通過規則表中的某一規則中的來源端位址,目的端位址,來源端接口, 目的端接口,通訊協定等五個欄位的檢查比對時,便會採取該規則所對應的動作 對封包做處理,每個規則都有各自的優先權設定,當封包與多各規則相符合時, 會選取最高優先權的規則的動作為優先。在表 1-1 中,優先權高低的設定以編號 1 的規則為最高優先權,編號 5 的規則為最低優先權。假設一封包 P 表頭資訊中 的來源端位址為 110,目的端位址為 011,來源端接口為 4,目的端接口為 6,通 訊協定為 TCP,根據表 1-1 我們可以得知封包 P 能夠與規則 1 與規則 4 相符合, 然而規則 1 有著較高的優先權,所以規則 1 便是封包 P 的最佳符合規則,接著根 據規則 1 所對應的動作.封包 P 便被"拒絕接受"。. Rule. Source address. Destination address. Source port. Destination Port. Protocol type. Action. 1. 1**. 010. 2-4. 6-9. TCP. Deny. 2. 101. ***. 1-7. 4-6. UDP. Pass. 3. 00*. 10*. *. *. ICMP. Deny. 4. 11*. 01*. 4-8. *. TCP. Pass. 5. ***. *** * 10-15 表 1-1:封包分類之規則表範例。. *. Deny. 我們可以定義出 d-維封包處理問題:假設一規則表有一集合的規則 R={R1, R2,…,Rn}表現在 d 維空間上,每一個規則都是由 d 個欄位組成,Ri={F1,i, F2,i,…,Fd,i},其中 Fj,i 即為規則 i 的第 j 個欄位中的內容,同時每一個規則 也需要一個定義優先權的數值,當收到一封包 P(p1,p2,…,pd),若表頭資訊的 所有欄位內容 p1,p2…,pd 皆能符合於某一規則 Ri 的所有欄位內容 F1,, i F2,, i …, Fd,i 的範圍之內,便能將封包 P 視為能與規則 Ri 配對。如果封包 P 能與多個規 則相符合,則路由器便會選擇擁有最高優先權的規則為所求,並對封包 P 採取相 對應的動作。. 3.
(17) 1.2 Performance Metrics for Packet Classification Algorithm 而一個好的封包處理方法必須要滿足下列五點特性: z. z. z. z. z. 搜尋速度(Search speed):封包分類的目標即為能夠快速的分類,達到線 路的速度。目前網路環境能夠以極高速的方式運作,如一些路由器及侵 入阻止裝置甚至能夠達到每秒傳輸約 125000000 個封包(一個 IP 封包至 少約是 40bytes),因此封包分類裝置的處理效率也必須儘可能地達到此 一速度。 儲存空間(Storage space):用來儲存規則表的記憶體需求量必須要盡可能 的小以減少消耗,越小的記憶體需求便能允許演算法能夠更快速的被執 行,但同時也會要求更高超的記憶體使用技術以達成更好的效能,如 on-chip SRAM 提供高速記憶體存取能力,但儲存空間卻相對的減少, 更新效率(Update):每當規則表有所改變時,資料結構就必須要被更新, 而更新的頻率取決於不同的應用環境,如 QoS 需要動態地驗證每個類 別,因此規則需要快速的更新,相反的如防火牆因為其中定義的規則較 少被更動因而可以接受緩慢的更新速度,一般而言一個封包分類演算法 必須能夠高速地處理更新動作以應付各種處理環境 可規劃性(Scalability):不同的網路應用服務技術會強調封包表頭資訊中 的不同欄位,因此一個好的封包分類演算法必須能夠對多個欄位資訊加 以規劃處理,以利於目前不同的網路環境甚至是未來的網路發展所使 用,避免過時淘汰。 彈性(Flexibility):規則的規格應該要能夠廣泛且充分地陳述出封包表頭 資訊中的不同欄位。為了能夠適用於真實的網路環境,一個好的封包分 類演算法必須盡可能的接受各種欄位的規格,如精確的數值,字首與遮 罩位元,一段的範圍,以及泛用字元. 大部分的封包分類演算都致力於提升搜尋速度的效率,但卻犧牲了儲存空間 及更新時間,然而為了提供一更具備更新能力的演算法,則所需考慮的層面便不 能僅僅只是侷限在搜尋效益的提升,也須放眼於更新速度的表現以及儲存空間的 消耗等方面。. 1.3 貢獻 在這篇論文中,我們將提出一個能適用於靜態,動態等多種環境之封包分類. 4.
(18) 演算法,此方法不僅能滿足於 Section 1.2 的五點需求,並能夠在搜尋的表現中比 起其他演算法較佳的成果,同時也能減少空間的浪費。更甚者我們的方法採用動 態規劃的方式,更能避免一些極端的分類問題。. 1.4 論文架構 本篇論文全文共分為六章,除了本章為簡介外,第二章針對眾多的封包分類 演算法做個簡短的介紹,第三章介紹雜湊表的使用以及 Tuple space 的概念及相關 的演算法,第四章對 Advanced Regional Diagonal Tuple Space Search 做詳細的描 述,第五章為實驗實做及結果分析,比較各演算法的優劣,第六章為結論並說明 本研究接下來的一些可行方向。. 5.
(19) 第二章 與封包分類有關之演算法. 2.1 前言 在最近幾年,眾多的學者紛紛提出許多的演算法來解決多維度的封包分類問 題,使得處理的層次能勝於二維空間,我們可以藉由一些簡單的特徵來對這些演 算法做區分,歸類成如表 2-1 中的四種形式 [3],接著,我們會簡單的描述並比較 其中一些較具代表性的演算法的優劣及特徵。 Category Data. Algorithms Linear Search,Hierarchical tries,Set-pruning tries,. structure-based. Grid of tries,Cross-producting. Geometric based. Are-base quadtree Hierarchical intelligent cuttings,Hyper-Cuts, Recursive Flow Classification,Tuple space search. Heuristic. Hardware-based. Diagonal tuple space search Ternary Content Addressable Memory, Bit-map intersection,Aggregated Bit Vector 表 2-1:封包分類演算法之範疇。. 2.2 演算法之簡介. 2.2.1 Linear Search Linear search 是眾多演算法之中最為簡單的演算法,它擁有最簡單的資料結 構,使得更新最為快速容易,只需從規則索引表中依序比對每一條規則即可,此 演算法能夠有效地使用記憶體,但卻有可能因為數量龐大的規則而增加了搜尋的 時間與次數。. 6.
(20) 2.2.2 Hierarchical tries Hierarchical tries (又稱 Multilevel trie 或 backtracking trie)主要是藉由遞迴規則 的維度領域建構而成的二元樹,首先選定所指定的第一個的維度領域的 bit(0,1) 建立第一層的二元樹,接著再由第一層二元樹中每個葉部節點建立起第二層的二 元樹,並以此方式依序處理剩餘的維度空間,因此 Hierarchical tries 中的每一條由 根部節點至最底層的葉部節點間的路徑都可以視為能與規則相符合的搜尋路徑, 當我們能夠依據一封包的表頭資訊從根部節點搜尋至尾端葉部節點時,我們便可 以判斷跟路徑的規則能夠與封包相符合,而不管規則是否符合,都有必要繼續搜 尋其他的路徑以找出更佳的規則,因此便有回朔的必要,造成搜尋次數過多的問 題。. 2.2.3 Set-pruning tries Set-pruning tries [4]與 Hierarchical tries 近似,但能夠藉由將同一規則配置至 不同分支以避免 Hierarchical tries 的遞迴與回碩的問題來減少搜尋時間,如規則 R(011,110)對 0*->110 的分支多配置ㄧ條新的支線,但也由於規則的重複配置, 使得記憶體空間的需求將隨著規則表規模的增加而變得更為龐大。. 2.2.4 Grid of tries Grid of triesy [5]在 Data structure-based 類別的方法之中對搜尋時間及儲存空 間的處理是最為有效率的演算法,藉由配置單一規則至 Hierarchical tries 的單一節 點的方式來減少對儲存空間的需求,以及利用 Set-pruning tries 的預先計算和轉換 指標來達到與 Set-pruning tries 般少量的搜尋次數,當封包分類的問題能夠壓縮至 二維空間來思量時,Grid of tries 會是最好的方法之一,然而 Grid of tries 卻無法. 7.
(21) 把演算法理念擴展至超過二維的多維空間上。. 2.2.5 Cross-producting Cross-producting [2]將整個維度以多維空間的方式表示出來,每個規則都擁 有屬於自己的位置及範圍大小,而 Cross-producting 再將整個多維空間做若干的切 割使得切割之後的每一個區塊僅能存在一個最佳的規則,接著建立一索引表紀錄 每一個區塊空間的組合位置以及在該區塊內的最佳符合規則,當搜尋進行時只需 分別找出在每一個維度空間切割之後的位置區塊再進行組合以便查詢索引表找出 屬於該封包的最佳符合規則,然而當維度增加或規則的數目增加時,可能會造成 整個維度空間的切割變得更加複雜、細微,間接造成索引表變的龐大化,以致於 需要更多的記憶體空間去儲存索引表。. 2.2.6 Are-base quadtree Are-base quadtree(AQT) [6]也是將整個維度空間以多維空間的方式表示出 來,與 Cross-producting 不同的是 Are-base quadtree 將整個維度空間以遞迴的方式 不斷的切割成編號為 00,01,10 及 11 的等份的四個子區塊,若以節點表示,第 一層節點變為整各維度空間,第二層節點為第一層節點之子樹,以第一層分割來 說,各自表示著(0*,0*),(0*,1*),(1*,0*)及(1*,1*)等字首組合,因此理論 上來說每各歸則都能被分配至四各子區塊之一,即儲存於四個子節點中,但若存 在能夠覆蓋該區塊某一維度的規則時,如(001,*),則將此規則配置於原本區塊 而非子區塊中。當收到封包進行搜尋,只需對四元樹進行檢索即可,並對所在節 點之規則進行比對,當搜尋至葉部節點時便能找出最佳符合規則並回傳。. 8.
(22) 2.2.7 Hierarchical intelligent cuttings Hierarchical intelligent cuttings(HiCuts) [7]藉由規則表的資料結構所衍生的啟 發法(heuristics)以對每一個維度空間做切割並建立起一決策樹(decision tree),決策 樹的資料結構則是以規則表為基礎預先處理而成的,在建立決策樹的過程中,每 一步僅對單一的維度空間做切割,最後,每個葉部節點都表示著一小群的資料集 合,在這裡則是一小群性質類似的規則集合,每當接收到封包時,便會不段地追 蹤整個決策樹結構直到找到最理想的葉部節點,再針對該葉部節點所對應的規則 及合作線性搜尋,以便找出能與該封包符合的最佳符合規則,這一演算法強調規 則表中的每個規則各有個自的特性,也會有相近似的特性,並以此為基礎發展而 成,然而如何在龐大的規則表中建立起最理想的決策樹以使得搜尋能更加有效率 仍是需要再深入研究的問題之一。. 2.2.8 Hyper-Cuts Hyper-Cuts [8]類似 HiCuts,但不像 HiCuts 在建立決策樹的過程中每一次只 對單一維度切割,Hyper-Cuts 會在每一次遞迴的建樹過程中對多個維度空間進行 更深的切割動作,因此決策樹中的每一個節點都可以表示成跨越了多維空間的多 維體,而非 HiCuts 般僅只是代表著某一平面帶,因此 Hyper-Cuts 對檢索效能有著 優越的表現,也能在許多的狀況下對儲存空間做更有效率的運用,但不幸地,在 泛用規則的處理上卻無法達成理想的結果。. 2.2.9 Recursive Flow Classification Recursive Flow Classification(RFC) [9]也是最早期的啟發式分類法之一,首先 先設置 T 個識別用位元,其中 T=log N (N 是規則的總數),接著將 S 個封包表頭. 9.
(23) 資訊位元映射至識別位元,並且 S 必須遠大於 T,而映射的過程可能是以遞迴的 方式分成數個階段,每個階段都不斷地消減位元的數量直到 T 個位元為止,而映 射的方式可以採用 Cross-producting 逐漸分群,因此 RFC 演算法能夠對封包做極 高速的分類,然而卻有著即為可觀的記憶體使用量,也無法有效率的對更做處理。. 2.2.10 Ternary Content Addressable Memory Ternary Content Addressable Memory(TCAM) [10]的每個單位組織有三種 值:0,1,X,而 X 如同遮罩位元般可以接受 0 或 1 的值,所以 TCAM 可以支援 較精確的數值或字首配對,每一段範圍也能轉換成字首或數值,如範圍大小為 1023 可以表示成六種字首表示法:000001*,00001**,0001***,001****,01*****, 1******,因此 TCAM 在接收到封包之後能夠同步的比較每一條規則,此一演算 法適用於較小型的規則表,然而對於龐大的規則表,TCAM 就需要大量的空間, 造成極大的效能被消耗掉。. 2.2.11 Bit-map intersection Bit-map intersection [11]亦是如同 Cross-producting 般地使用維度空間分割的 概念來處理封包分類的問題,然而不同的是它將分割成數個子問題再組合出結 果,首先,針對每一層維度空間,以幾何空間的型式針對每一個規則在該層維度 空間所映射的位置做切割,因此若有 N 條規則,每一層維度最多將會產生 2N+1 個區間,而規則與區間的關係就僅只有覆蓋與未覆蓋二種,接著再針對每一塊區 間,給予相對應且大小為 N 位元的位元向量,其中每一個位元 i 表示相對應於規 則表中的第 i 條規則,當某一區間的某一位元 j 設為 1 即表示規則 j 所涵蓋的範圍 能夠包含覆蓋該區間,反之當位元 j 設為 0 即表示規則 j 並無覆蓋該區間,當接 收到一封包時,便針對每一維度的區間做檢查,找出該封包座落於何區間,並取 10.
(24) 得相對應的位元向量表,因此便能得知在不同維度下有哪些規則能與風包廂配 合,最後針對由每一層維度取得的位元向量做聯集的運算,並找出擁有最高優先 權的規則,便為該封包的最佳符合規則,然而也如同 Cross-producting 般當規則表 極為龐大時,會造成整個維度空間與幾何空間複雜化,需要配置更多位元的位元 向量給更多的區間,然而沒有規則覆蓋的區間也會大量增加,便會形成即為可觀 的記憶體空間的浪費,這也是眾多研究的議題之一。. 2.2.12 Aggregated Bit Vector Aggregated Bit Vector(ABV) [12]是 bit –map intersection 演算法的改良,主要 著重於規則表中能與封包相符合的頻率較為稀少的規則,以及位元向量中散佈較 為稀疏的位元集合,並採用了位元向量的聚集以及規則的再排列兩種技術來達 成,聚集乃是藉由建立一小型的位元向量(稱為 ABV)來紀錄部分位元向量的資訊 以減少記憶體的存取,然而卻也會產生不良的影響,當對 ABV 做聯集取得最理 想結果時,有可能會發生規則配對錯誤的情形,造成更多的記憶體存取次數,而 規則的在排列便能減輕這樣的錯誤情形,雖然 ABV 在記憶體存取次數上勝於 bit–map intersection,但它卻也無法改良 bit –map intersection 的問題,甚至增加 了些許的不良情況。. 2.3 演算法之比較 表 2-2 列出了上述所提的各個演算法在最糟情況下的搜尋時間複雜度,更新 時間複雜度以及儲存空間複雜度 [13],其中 N 為規則的個數,d 為規則所包含的 維度數目,W 是每一維度的位元長度,T 維區間搜尋之時間。然而有些更新時間 複雜度未獲取,便以 N/A 表示:. 11.
(25) Algorithm. Search time complexity. Update time complexity. Storage complexity. Linear Search. N. log N. N. Hierarchical tries. Wd. d2W. NdW. Set-pruning tries. dW. Nd. NddW. Grid of tries. 2W. NW. NW. Cross-producting. dW αW. NW α√N. Nd. Hierarchical Cuttings. D. N/A. Nd. Recursive Flow Classification. D. N/A. Nd. d(T+N/W). N/A. dN2. Area-based QuadTree. Bit-map intersection. 表 2-2:封包分類演算法之複雜度比較。. 12. N.
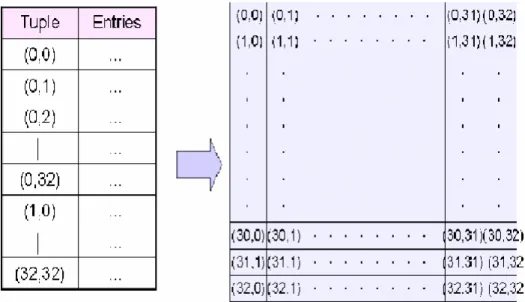
(26) 第三章 相關研究. 在這一章節中,我們將介紹 Tuple space 之定義以及作為我們所提出演算法 之基礎的二個使用 Tuple space 為概念的搜尋演算法。. 3.1 Tuple Space. 3.1.1 Tuple Space 之定義 每個規則都有定義各自的 source specified bits,destination specified bits 以及 所涵蓋的範圍,而 source specified bit 個數及 destination specified bit 個數卻只分布 於 0~32 等 33 種長度,藉由 source specified bit 個數及 destination specified bit 個數 的配對可以產生共 33X33 種組合。這使得對規則的搜尋可以先透過簡單的分群而 減少所需搜尋規則之數量。因為在同一群組中的規則都擁有相同的 specified bit 個數,我們便可以利用 specified bit 個數之值作為 hash key 值來檢索所欲搜尋的 specified bit 是否存在於規則資料庫中,因此透過 hash table 的建立以及 hash key 的檢索,使得群組間的搜尋僅需 O(w),w 為 specified bit 之長度。 Tuple space search [14]最早是由 Srinivansan et al.所提出的,利用 Prefix specification 來處理多維度封包分類的問題。由於作為 hash key 值的是規則的 source specified bit 個數及 destination specified bit 個數,因此整個 Hash table 可以 視為二維空間,如表 3-1 的例子便是依據 rule 中每一層維度的 specified bit 的個數 對應至相對應的 tuple 欄位,R2 的 specified bite 個數分別為 1 與 2,便對應至 tuple(1,2)這一欄位中;R3 的 specified bite 個數分別為 1 與 1,便對應至 tuple(1, 1)這一欄位中。表 3-2 則是整個 tuple space 的資訊,表示出全部的 tuple 以及每個. 13.
(27) tuple 欄位所包含的規則的編號,接著當封包需要進行規則的比對時便是使用對雜 湊表進行索引的方式來找出特定的 tuple 並從中得知所配置的每一個規則,繼而進 行規則的比對。 由於 tuple space 使用了雜湊表索引的概念,因此封包分類的問題便由對每一 個規則作比對的問題壓縮成對每一個 tuple 做比對的問題,再比對其中的每一個規 則,相較於其他使用規則來做分類的演算法,採用 tuple space 的演算法更能擁有 較快的平均搜尋時間以及較佳的更新時間。現今引用 tuple space 概念的演算法, 多是採用二維空間作為處理的途徑(圖 3-1),亦即使用(Source specified bits, Destination specified bits)當作 Hash key 來檢索每一個 tuple,然而 tuple 與 tuple 間 除了二個欄位的 specified bit 個數之外並無任何直接及間接的關聯性可供快速的 檢索,因此如何正確、有效的檢索出理想的 tuple 以找出最恰當的規則,便是眾多 使用 tuple space 的演算法,以及本篇論文的議題所在。 Rule. Specification. Tuple. R1. (00*,00*). (2,2). R2. (0**,01*). (1,2). R3. (1**,0**). (1,1). R4. (00*,0**). (2,1). R5. (0**,1**). (1,1). R6. (***,1**). (0,1). 表 3-1:規則對應至 Tuple 之範例。 Tuple. Hash Table Entries. (0,1). { R6 }. (1,1). { R3, R5}. (1,2). { R2 }. (2,1). { R4 }. (2,2). { R1 }. 表 3-2:表 3-1 所建立之 Tuple space。. 14.
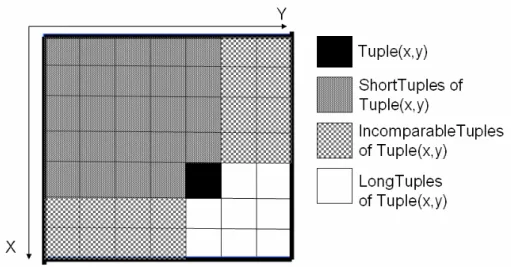
(28) 圖 3-1:Tuple space 可視為一二維空間。. 3.1.2 Tuple Relationship 任一 tuple 與 tuple 之間存在著三者關係:ShorterTuple,LongerTuple,以及 IncompatibleTuple,假設存在二個 tuple: Ta 及 Tb,則其關係的定義如下所敘: z z z. 若 ∀ i,1 ≤ i ≤ d,Ta[i] ≤ Tb[i],而且至少存在一個 i 使得 Ta[i] ≠ Tb[i],則 定義 Ta 屬於 Tb 的 ShorterTuple。 若 ∀ i,1 ≤ i ≤ d,Ta[i] ≥ Tb[i],而且至少存在一個 i 使得 Ta[i] ≠ Tb[i],則 定義 Ta 屬於 Tb 的 LongerTuple。 若 Ta 既非 Tb 的 ShorterTuple,也不是 Tb 的 LongerTuple,則定義 Ta 屬 於 Tb 的 IncompatibleTuple。 由上述的定義,我們可以知道 tuple(1,2)是 tuple(3,4)的 ShorterTuple,. 因 1 ≤ 3, 2 ≤ 4;tuple(5,6)是 tuple(3,4)的 LongerTuple, 因 5 ≥ 3, 6 ≥ 4; tuple(2, 5)是 tuple(3,4)的 IncompatibleTuple,因 2 ≤ 3,5 ≥ 4。圖 3-2 即為二維空間中 tuple(x, y)的範圍分布。. 15.
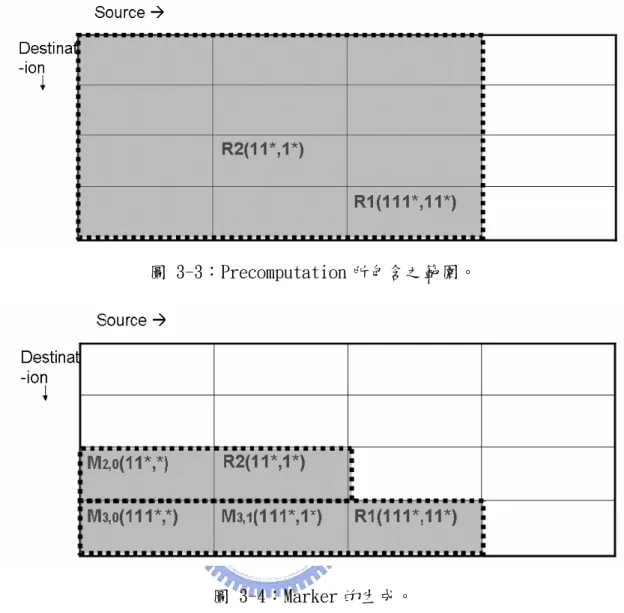
(29) 圖 3-2:tuple(x,y)與其他 tuple 之關係之二維空間表示圖。 當一個封包能擁有二個以上的規則滿足封包的配對,則根據每一個規則所配 對的 tuple 之間的 ShorterTuple,LongerTuple,以及 IncompatibleTuple 三種關係, 可以發展出規則與規則之間的三種關係: specific, general 以及 conflicting,假 設當一封包 P 能滿足二個規則:Ra 及 Rb 分別對應 Ta 及 Tb,則 Ra 與 Rb 間的關 係定義如下所敘: z. z. z. 若 Ta 是 Tb 的 ShorterTuple,則我們稱 Ra 較 Rb 更為 general,亦即當 Rb 能滿足封包的配對時,Ra 亦能滿足封包的配對,反之當 Rb 無法滿足時, Ra 卻有可能滿足配對。 若 Ta 是 Tb 的 longerTuple,則我們稱 Ra 較 Rb 更為 specific,亦即當 Rb 能滿足封包的配對時,Ra 未必能滿足封包的配對,反之當 Rb 無法滿足 時,Ra 必定也無法滿足配對。 若 Ta 與 Tb 互為 IncompatibleTuple,則我們稱 Ra 與 Rb 互為 conflicting, 當 Rb 能滿足封包的配對時,Ra 未必能滿足封包的配對,反之當 Rb 無 法滿足時,Ra 卻有滿足配對的可能性。. 3.1.3 Marker 與 Precomputation Srinivansan et al.提出了 Rectangle search 演算法並提出了 precomputation 以及 marker 的概念來解決 tuple space 中 tuple 與 tuple 間毫無關聯的問題 [14]: Marker 主要目的在於能為某些 tuple 的集合建立起關聯性,一般來說規則能 夠在它的 ShortTuple 生成自己的 marker,而 marker 除了 specified bit 需與所對應 16.
(30) 的 tuple 相同之外,其他資訊都與原來的規則相同,而隨著演算法的不同,marker 的生成也有著不同的方式。在 Rectangle search 中,對每一個規則而言,都必須不 斷向左設置一個自己的 marker,如圖 3-4 所示,每一個規則都會向左邊的 tuple 生成一個 marker,R1 在(3,1)的 marker 便為(111*,1*),在(3,0)的 marker 便為 (111*,*),R2 在(2,0)的 marker 便為(11*,*),因此我們可以將每個規則的 marker 視為較該規則更為 generic,當封包對某個 marker 比對失敗時,同時也意味著生 成該 marker 的規則亦無法比對成功,因此可以延伸出當對某個 tuple 搜尋失敗, 該 tuple 的右邊區域皆不可能有會符合的規則存在,因不可能發生不滿足 marker 卻滿足規則的情形發生,另外,根據每一個演算法的需要,每一個規則並不限定 只向左邊的 tuple 生成 marker,而是會有向上方,向左上方等不同方向的可能產 生。 Precomputation 主要的目的在於能為每一個規則找出包含它自身以及該規則 所對應 tuple 的所有 ShorterTuple 中擁有最高優先權(最佳選擇)的規則,如圖 3-3 所示,灰色區域便是 R1 的 precomputation 範圍(自己所對應的 tuple 以及 ShorterTuple),在這範圍之中搜尋出與 R1 相同或是比 R1 更為 general 的規則,結 果找出 R1 與 R2 這二個規則,若 R1 的優先權高於 R2,則我們便紀錄 R1 為 R1 這個規則所能對應到的最佳選擇,反之則紀錄 R2 為 R1 這個規則所能對應到的最 佳選擇。 由於封包的搜尋動作會受到 marker 所引導,然而當封包能與 marker 配對卻 不一定表示能與規則配對,因此當發生此一情形時便會造成整各搜尋演算法因為 受到錯誤的規則所引導,導致無法找出最理想的規則,所以此一動作的優點便是 當我們能找到一 marker 與封包相配對時,我們能自然的得到包含該 tuple 以內的 所有 ShorterTuple(如圖 3-3 所示為該 tuple 的左上方塊)的最佳規則,無須再去顧慮 發生上述錯誤情況時的處理。. 17.
(31) 圖 3-3:Precomputation 所包含之範圍。. 圖 3-4:Marker 的生成。. 3.2 Rectangle Search 利用 precomputation 以及 marker 的觀念,便發展出 rectangle search 演算法 [15]:當被給予一封包 P,便從整個 tuple space 的最左下方((32,0)的位置)開始進 行探測,若能找到至少一個規則或是 marker 能與 P 相配對,則表示該 tuple 的所 有 LongerTuple 有可能存在更為 specific 的規則,因此繼續向右一行的 tuple 進行 搜尋,否之無法找到任一個規則或是 marker 與 P 相配對,表示不存在更 specific 的規則可與之配對,此時向上一列的 tuple 進行搜尋。 如圖 3-5 所示,R1 至 R5 生成各自的 marker,當根據封包 P 的表頭資訊內. 18.
(32) 容(0000,0000)開始進行 rectangle search 時,首先先由最左下角的 tuple(4,0)開 始,因能夠找到 marker 與 P 符合,所以向右一列的 tuple(4,1)繼續進行搜尋,並 紀錄由 marker 得知的此時最佳符合規則為 R6,同樣的在 tuple(4,1)能找到 R2 配 對,所以繼續向右一列的 tuple(4,2)進行搜尋,而由於 R2 的優先等級較 R6 高, 因此符合封包 P 的最佳符合便由 R2 取代,而在 tuple(4,2)因為無法找到能夠與 P 配對的規則或 marker,所以往上一行的 tuple(3.2)繼續進行搜尋,如同圖 3-5 箭頭 的搜尋過程,最後會結束於 tuple(0,3),封包 P 所能配對到的最佳規則為 R1。. 圖 3-5:Rectangle search 之範例。 然而我們也可以由圖 3-6 看出 rectangle search 的問題,當一封包在 tuple space 之中對 tuple 的比對路徑如圖所示時,此演算法需要對(2w-1)個 tuple 做檢測,亦 及對雜湊表做了(2w-1)次的存取,即使在最佳狀況(對每個 tuple 都能找到配對的 規則或 marker 的情況或對每個 tuple 都無法找到可配對規則或 marker 的情況)下也 需要高達 w 次的存取,同時每一個規則都會像左生成 marker,這結果造成 marker 的數量遠大於規則的數量的幾十倍以上,假設 tuple space 有 n 各規則,則最糟情 形為每個規則都分別向左生成(w-1)個 marker,共須 n+nx(w-1)=nw 的儲存空間需 求。因此 rectangle search 在搜尋時間 O(w)及記憶體空間的表現 O(nw)上都不甚想. 19.
(33) 理。. 圖 3-6:Rectangle search 之最糟情形。. 3.3 Diagonal Tuple Space Search 為了解決 Rectangle search 對 tuple 搜尋次數過多的問題,Mikko Alutoin 和 Pertti Raatikainen 共同提出了 Diagonal tuple space 的概念 [16],在這演算法中, marker 的生成方向如圖 3-7 所示,對任一個 tuple(i,j), 0 ≤ i,j ≤ 32,可以有以 下的三種生成 marker 的情形: z z z. 當 i<j,則 tuple(i,j)的每一個規則都要向上增加自己的 marker 直至 tuple(j,j)為止。 當 j<i,則 tuple(i,j)的每一個規則都要向左增加自己的 marker 直至 tuple(i,i)為止。 當 i=j,則 tuple(i,j)的每一個規則都要向左上方增加自己的 marker 直至 tuple(0,0)為止。. 20.
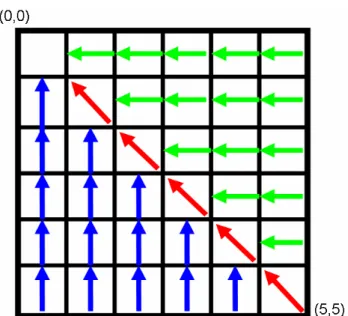
(34) 圖 3-7:Diagonal tuple space search 之 marker 生成方向。 因此我們能夠觀察到對每一列或是每一行而言,他們之間的關聯性只有靠位 於對角線的 tuple 所生成的 marker 來建立,而在 diagonal tuple search 中使用了" 映射"作為搜尋方式,當找到位於某對角線上的 tuple(d,d)時,需要分別對 tuple[d,y ≥ d]以及 tuple[d,x ≥ d]再多做二次的二元搜尋,而決定 tuple(d,d)的位 置又再多需一次 binary search,因此整個 diagonal tuple search 更需三次的 binary search,使得在搜尋上的時間複雜度僅須 O(log w),然而"映射"會對一些衝突的 規則或是 IncompatibleTuple 造成誤判的錯誤,因此為了使搜尋能夠更為完整與正 確,在 precomputation 需具備增加 mirrir rule 的動作,當規則 R 在其 IncompatibleTuple 的對角線 tuple 找到一 marker M,使得規則 R 會與 marker M 產 生衝突的問題,則必須在規則 R 與 marker M 的連結位置產生一 mirror rule,若規 則 R(111***,11111*)與 marker M(1111**,1111**),則產生的 mirror rule 為 (1111**,11111*)。 在搜尋上需要三次二元搜尋,首先根據被給予的封包 P 針對 tuple space 對角 線上的 tuple 做第一次二元搜尋以找出 tuple(d,d),以能夠找到最大的 d 值為優先, 若是 tuple(d,d)上的規則與 P 相符合,可以得之封包 P 所能找到的最佳符合為該 規則,回傳該規則而後結束搜尋;若是 tuple(d,d)上的 marker 與 P 相符合時,則. 21.
(35) 分別對 tuple[d,y ≥ d]以及 tuple[d,x ≥ d]坐二元搜尋,同樣的以找到最大值為優先, 而後再選擇出擁有最大優先權的規則或是 marker 中的最佳符合規則,即可完成封 包 P 的搜尋動作,如圖 3-8 所示,R1 向左生成 marker 直至 tuple(1,1)為止,R2 向上生成 marker 直至 tuple(1,1)為止,R3 向左生成 marker 直至 tuple(0,0)為止, R4 及 R5 向左上生成 marker 直至 tuple(0,0)為止,當給予一封包 P 之後,對對角 線的 tuple 做第一次的二元搜尋,最初是 tuple(2,2)檢測失敗後再對 tuple(1,1) 進行搜尋,爾後發現有 marker 與 P 相符合之後,接著針對 tuple(1,1)右邊以及下 面的 tuple 各自進行二元搜尋,分別找到 R1 及 R2 兩個可以符合的規則,最後依 據優先權的比較,可以得知封包 P 能夠分類至 R1。. 圖 3-8:Diagonal tuple search 之範例。 由於至多使用了三次的二元搜尋來完成整各封包分類,因此在搜尋時間上能 壓縮至O(log w),若有n各規則存在於tuple space,當一對角線tuple(x,x)以及. d-x. IncomparableTuple的某一規則產生衝突時,可能會生成 2. 個marker以解決衝突. w. 問題,因此最糟情形需要O(n2 w)的儲存空間需求,然而在此情況下產生衝突的 列或行因為會有marker重複的情形,因此至多只需生成logw個marker即可,使得 22.
(36) w. diagonal tuple search需要O(n2 log w) 的儲存空間,比起rectangle search更為不理 想。. 23.
(37) 第四章. Advanced Regional Diagonal Tuple Space Search. 4.1 動機 一般來說,真實網路環境下的規則在 tuple space 的分布情形大致上如圖 4-1 所示,整個 tuple space 以二維空間所表示,顏色越深之區域表示所對應的規則數 量越多,反之顏色越淺或接近白色表示該格所對應的規則稀少或無。其中以 tuple[16~32,16~32]這一區間分布的最為密集,亦或是在 wildcard 區域([0,0~32] 或[0~32,0])有較為顯注的密度集中於此,考慮這樣的情況下,使用 Diagonal tuple space search 便有明顯的空間的浪費以及搜尋次數的增加。. 圖 4-1:真實網路環境的規則配置情形 [17]。 z. 空間的浪費:. (1)、在 Diagonal tuple space 定義中,每一條規則皆會朝著 tuple(0, 0)的方 向增加 marker,可能造成 tuple(0,0)~tuple(15,15)這些對角線位置的 tuple 由於 這些規則的存在而生成大量的 marker,但這些對角線 tuple 的右邊及下面卻可能 沒有或僅只有極為稀少量的規則被配置,因此對這些區域的 tuple 來說,它們可能 只需要配置及少量的空間比例來儲存這些來自右方及下方的規則所生成的. 24.
(38) marker,卻需要極大量的空間比例來儲存來自於右下方的規則所生成的 marker。 (2)、同時對這些極少量的規則來說,它們仍需要朝向對角線位置生成 marker,如存在於 tuple(32,5)的規則得對 tuple(5,5)至 tuple(31,5)等 27 個 tuple 分別生成該規則的 marker,在空間的使用上是極為可觀的。 z. 存取次數的增加:. 由於空間的浪費的第二點所述,若當第一次二元搜尋所能找到最深的 tuple 是介於 tuple(0,0)~tuple(15,15)等規則分佈較為稀少之區域時,卻有可能因為該 tuple 的右邊或下方僅存在一條規則而多需要二次的二元搜尋,逐次的藉由 marker 的指引才能找到該規則所對應的 tuple,但所搜尋的區域可能並不存在其他的規則 或 marker,過多的 marker 的指引反而造成不必要的搜尋。如上例中欲搜尋 tuple(32,5)的規則,我們必須由 tuple(5,5)出發,分別對 tuple(i,5),5≦i≦32 以及 tuple(5,j),5≦j≦32 做二元搜尋,其中必須搜尋(5,18)、(5,25)、(5,29)、 (5,31)、(5,32)以及(18,5)、(11,5)、(7,5)、(5,5),但可能這些 tuple 只存在 該規則所對應的 marker 甚至無任何規則與 marker 存在。 因此為了解決 Diagonal tuple space search 不符合真實網路環境的問題,我們 便提出了幾點想法: z. z. z. 若對應於 tuple[16~32,16~32]的規則僅需生成 marker 至一定範圍的 tuple,而無須朝著 tuple(0,0)的方向逐漸生成,則 tuple(0,0)~tuple(15, 15)等左上段對角線 tuple 的 marker 必能減少許多,同時也能使得搜尋所 需的存取次數下降。 Diagonal tuple space search 需要至少三次的二元搜尋是因為對應於對角 線 tuple 上的 marker 無法告訴我們來自於哪個方向,因此第二次以及第 三次的二元搜尋得分別往右以及往下做搜尋以進行確認。若我們能建立 起方向性,便能依據方向性朝著正確的方向進行一次的二元搜尋即可。 若對某些 marker 建立起類似指標之性質,則透過這些 marker 的指引便 能直接對生成該 marker 的規則所對應的 tuple 做搜尋,如此在規則散佈 密度稀散的區域,便無須作多次累贅的搜尋。 為了達成以上三點的想法,我們嘗試改變規則及 marker 的資料結構,. 25.
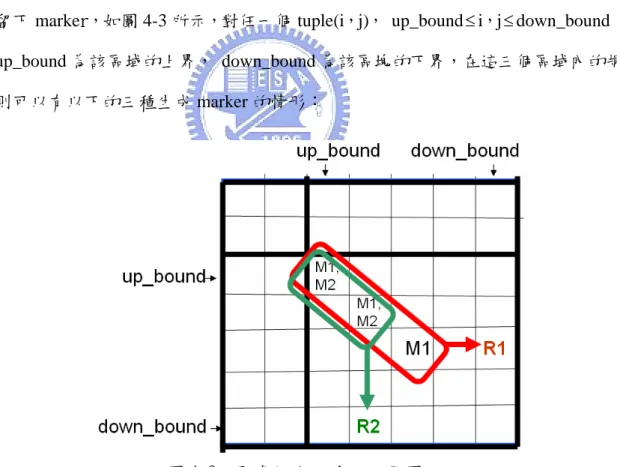
(39) 並進而提出了以下的方法來加以改良,使得 marker 的生成數量得以減少,並在搜 尋時增添一變數輔助,已達成第一次二元搜尋之後僅需往單一方向做深入搜尋的 想法,必藉此減少存取的次數。 在 Section 4.2 中,我們將介紹規則與 marker 的資料結構;在 Section 4.3 中, 我們將加以描述整個 tuple space 的 marker 生成流程;在 Section 4.4 中針對一些渴 能發生的問題做進一步處理;在 section 4.5 中,我們將描述整個初始化動作之流 程以及搜尋流程,並以簡單的例子做說明; Section 4.6,我們將證明整個搜尋演 算法的可行性;而最後的 Section 4.7 中將以簡單的例子說明整個搜尋流程。. 4.2 資料結構的描述 我們對規則及 marker 額外增設了二個欄位,用來記錄該 marker 是由哪一個 tuple 生成而來,我們稱之為來源資訊(Source information),如 R(11111,1111*)在 tuple(2,3)生成了 marker(11***,111**),則該 marker 的來源資訊便填入(5,4)。 由於在 marker 生成階段時可能因為與某些規則相重複而不被生成,便改為對與該 marker 重複的規則填入來源資訊,另外由於 Precomputation 在我們的演算法中仍 是有必要的,因此一個 marker 的資料結構便為: Marker(Source specified bits,Destination specified bits, Best matching rule,Source information). 而一個規則的資料結構便為: Rule(Source specified bits,Destination specified bits,Source information). 增設此來源資訊欄位的目的有二: z. 為二元搜尋增加方向性,並限定二元搜尋範圍。對位於 tuple(5,5)的 marker 來說,若來源資訊為(5,10),我們便可得知該 marker 來自於右 方的 tuple 的某一規則所生成的。一般來說位於對角線的規則或 marker 的來源資訊可分為三種資料型態:. NULL,來源資訊填入(Null,Null)。 26.
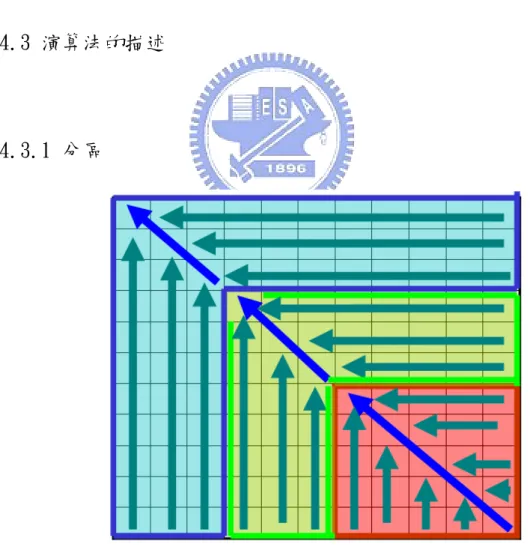
(40) 單方向,當該 marker 僅是來自於右方或下方其中之一時,此時紀錄來源的 tuple 位址,來源資訊填入(Source specified bits length,Destination specified bits length)。 雙方向,當該 marker 同時為來自兩方的規則所生成,如 R1(11***,1111*) 與 R2(1111*,11***)在 tuple(2,2)所生的 marker 皆是(11***,11***),此時記錄 marker 所在的 tuple 與ㄧ空值,即(2,Null)。 z. 具備指標之功能。由於來源資訊記錄著生成該 marker 的規則所對應的 tuple 位址,因此我們可以透過來源資訊的紀錄直接對相對應的 tuple 做 搜尋即可。. 4.3 演算法的描述. 4.3.1 分區. 圖 4-2:Advanced Diagonal Tuple Space 的區域配置圖示。 如 Section 4.1 小節所描述,一般的規則在 tuple space 的分布情形大致可分為. 27.
(41) 三大類: tuple[16~32,16~32]等較密集區域,wildcard 區域(tuple[0,0~32]或 tuple[0~32,0])以及其他較為疏散區域,而為了避免位於對角線上的 tuple 對又下 方的規則生成過多的 marker,因此我們可以將整個 tuple space 分為三各區域,如 圖 4-2 所示,區域與區域之間的間隔可以為 0~7,8~15 及 16~32 等三大塊,而在 每各區域內的所有的規則都能再對該區域進行搜尋時有機會被檢索,而區域以 0~7,8~15,16~32 之分區法正如同二元搜尋之順序般,當逐漸由最下層區域往上 層區域進行搜尋時,正如同 Diagonal search 之第一次二元搜尋失敗時地向左上深 入搜尋。 每一層區域的對角線 tuple 必須能夠配置該區域內規則的 marker,使能夠藉 由該 marker 搜尋至該規則,因此每一個規則都必須在相對應的對角線位置之 tuple 留下 marker,如圖 4-3 所示,對任一個 tuple(i,j), up_bound ≤ i,j ≤ down_bound, up_bound 為該區域的上界, down_bound 為該區塊的下界,在這三個區域內的規 則可以有以下的三種生成 marker 的情形:. 圖 4-3:區域內的 marker 配置圖示。 Case 1:如圖 4-3 的規則 R2 所示,當 j<i,則 tuple(i,j)的每一個規則都要向 上在 tuple(j,j)增加自己的 marker,接著再向左上方增加自己的 marker 直至 tuple(up_bound,up_bound)為止。而後,我們會對位於 tuple(j,j)所生成的 marker. 28.
(42) 增設來源資訊已建立起方向性,若該 marker 因與其他的規則或 marker 重複而不 被生成,則對被重複的規則或 marker 填入來源資訊。 Case 2:如圖 4-3 的規則 R1 所示,當 i<j,則 tuple(i,j)的每一個規則都要向 左於 tuple(i,i)增加自己的 marker,接著再向左上方增加自己的 marker 直至 tuple(up_bound,up_bound)為止。而後,我們會對位於 tuple(j,j)所生成的 marker 增設來源資訊已建立起方向性。若該 marker 因與其他的規則或 marker 重複而不 被生成,則對被重複的規則或 marker 填入來源資訊。 Case 3:當 i=j,則 tuple(i,j)的每一個規則都要向左上方增加自己的 marker 直至 tuple(up_bound,up_bound)。 藉由如此的 marker 生成方式使得每一個對角線上的 tuple 都有來自其右方以 及下方的規則所生成的 marker,每一個區域內的規則亦不會在其他的區域生成任 何的 marker,因此區域與區域之間可以說是互相獨立的,當最右下方的區域在最 左上角的 tuple 生成大量的 marker 時,並不會影響到另外二個區域內的 marker 生 成,這二個 Diagonal tuple space 也因此不再有來自右下方區域的規則所生成的 marker 的空間負擔。 另一方面,由於每一個規則最終都會生成 marker 於 tuple(up_bound, up_bound),亦即該規則所屬區域的最左上角的 tuple,藉由透過每一個區域的最 左上方的 tuple( tuple(up_bound, up_bound) )的檢查,若檢查失敗則表示該區域 並無任何可能會與封包相配合的規則存在,換至下一各區域做相同的檢查;當檢 查成功,我們便能得知該區域可能存在著能與封包相配合的規則。因此對每一塊 正方形區域搜尋的順序為最右下方區域開始,當最右下方區域的最左上方 tuple 無任何規則或 marker 能與封包配對時,便跳往上一層的區域的最左上角 tuple 做 相同的檢察,直至 tuple(0,0)所屬的最上一層區域為止;若區域的最左上方 tuple 存在著能與封包配對的規則或 marker 時,便能對該區域進行內部的搜尋,若搜尋. 29.
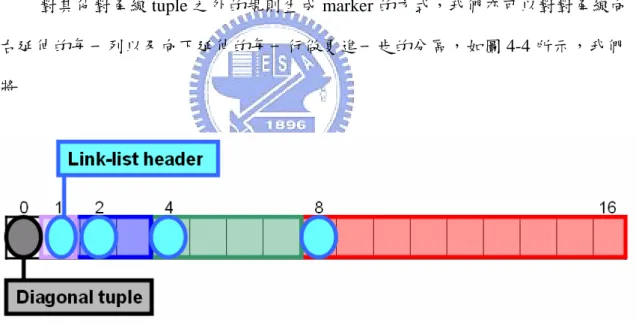
(43) 至最上層,由於 tuple(0,0)的規則必定能與封包符合,可直接對內部進行第一次 二元搜尋無須再檢察 tuple(0,0)是否符合。 第一次的二元搜尋範圍便為區域內的對角線,tuple(up_bound,up_bound)至 tuple(down_bound, down_bound),當找到最深的 tuple 時,又可分為二種情形, 若與封包相符合的規則或是 marker 所填入的來源資訊為單一方向之型式時,我們 便可以透過來源資訊得知可能在哪各方向(右方,下方)存在著某一條規則能與封 包相配合。. 4.3.2 Link-list 與 marker 生成 對其他對角線 tuple 之外的規則生成 marker 的方式,我們亦可以對對角線向 右延伸的每一列以及向下延伸的每一行做更進一歨的分區,如圖 4-4 所示,我們 將. 圖 4-4:Linklist 區間配置方式與 header tuple 之設置。 ㄧ列(或一行)分成若干小區塊,每一個小區塊的起始位置亦可以為二元搜尋 失敗時所需經過的 tuple,在圖 4-5 中便為編號 8、4、2、1 為各個區塊之起始位 置,這些 tuple 可以視為一個 link-list 之起頭,接著便可以由下列步驟來說明位於 非對角線 tuple 上的每各規則如何生成 marker: Step 1:若規則R對應於tuple(x,y)中,若x≠y,則規則R對應於非對角線之. 30.
(44) tuple。接著根據該規則R所對應的tuple位置,找出相對應於該列或該行的link-list header tuple位置,若y>x時,則所對應的link-list header位置為tuple(x,x + 2. |log2(y-x)|. |log2(x-y)|. );若x>y時,所對應的區域邊界位置為tuple(y + 2. ,y)。. Step 2:規則 R 在生成 marker 於所對應的 link-list header tuple 中,並填入來 源資訊為(x,y)。若該 marker 因與其他規則或 marker 發生重複而取消時,我們又 能夠分為三種情形: z z. Case 1:若該規則或 marker 尚未填入來源資訊,則填入(x,y)。 Case 2:若該規則或 marker 已填入來源資訊(x`,y`),則比較(x`,y`)與 (x,y),當 x`=x 且 y`<y,或是 x`<x 且 y`=y 時,我們可以得知規則 R 所 對應的 tuple 位置(x,y)與 link-list header tuple 間的距離較(x`,y`)與 link-list header tuple 間的距離遠,我們無須更動該來源資訊,接著規則 R 便在 tuple(x`,y`)位置生成 marker,marker 的來源訊息便為規則 R 的(x, y),若又存在重複的規則或 marker 使得規則 R 的 marker 不被生成,則 採用相同的步驟遞回進行,比較該規則或 marker 的來源資訊與規則 R 的位置,並做相同的處理。. z. Case 3:若該規則或 marker 已填入來源資訊(x`,y`),則比較(x`,y`)與 (x,y),當 x`=x 且 y`>y,或是 x`>x 且 y`=y 時,我們可以得知規則 R 所 對應的 tuple 位置(x,y)與 link-list header tuple 間的距離較(x`,y`)與 link-list header tuple 間的距離近,則 link-list header tuple 之 marker 或規 則的來源資訊便取代為(x,y),而原來位於 tuple(x`,y`)的規則 R`便生 成 marker 至 tuple(x,y)位置上,來源資訊填入(x`,y`),同樣的,若存 在重複的規則或 marker 存在使得規則 R`的 marker 不被生成,則採用相 同的步驟遞回進行,比較該規則或 marker 的來源資訊與規則 R`的位置, 並做相同的處理。. Step 3:當所有非對角線上之 tuple 的規則皆生成 marker 於相對應的 link-list header tuple 之後,我們便可以開始對對角線 tuple 上的每一個規則或是 marker 填 入相對應的來源資訊。對每一個對角線上的規則或 marker,都須向右以及向下檢 查每一個 link-list header tuple,若該 marker 或規則是由右方或下方的的某一規則 所生成而來,因該規則亦會對相對應的 link-list header tuple 生成 marker,因此原 則上這些對角線的規則或 marker 至少能找到一個 link-list header tuple 的規則或 marker 使得對角線之規則或 marker 能包含住 link-list header tuple 的規則或 31.
(45) marker。若能找到能包含的 link-list header tuple 之規則或 marker 時,則此一對角 線之規則或 marker 的來源資訊則填入該 link-list tuple header 之位置。若存在二各 以上不同位置的 link-list header tuple 滿足此一情形時,澤我們需判斷這些 link-list header tuple 是否都在同一端(都在右端或都在下方):若是,選擇距離對角線位置 最遠之 link-list header tuple 為來源資訊位置;若是不同端時,此時便會產生雙方 向衝突,我們暫時將來源資訊填為(d,-),d 為對角線之位置。 圖 4-5 為非對角線 tuple 之規則生成 marker 的簡單範例,其中(2,3)與(2,5) 皆為 link-list header tuple,圖 4-5.a 加入 R1,因已在所對應的 link-list header tuple, 故無須生成 marker,圖 4-5.b 加入 R2,在對應的 link-list header tuple(2,5)內生成 marker 並填入來源資訊為(2,7),圖 4-5.c 加入 R3,由於 R3 所對應的 link-list header tuple(2,5)已存在 marker 且該 marker 的來源資訊(2,7) 較 R3 所對應的 tuple(2, 6)距離對角線更遠,因此將該 marker 的來源資訊更新為(2,6),並找出 tuple(2, 7)的規則或 marker 再生成 marker 於 tuple(2,6)上,填入來源資訊(2,7)。. 圖 4-5.a:簡單的非對角線 tuple 之 marker 生成流程範例,加入 R1。. 32.
(46) 圖 4-5.b:簡單的非對角線 tuple 之 marker 生成流程範例,加入 R2。. 圖 4-5.c:簡單的非對角線 tuple 之 marker 生成流程範例,加入 R3。 透過 Step 2 的處理之後,我們可以知道每一個位於 link-list header tuple 之規 則或 marker 都是一個 link-list 起點,當該 tuple 存在越多的規則或 marker 即表示 存在越多的 link-list,我們可以以一樹狀圖來表示之:. 33.
(47) 圖 4-6:每一列(行)可與 Diagonal tuple 組成 Link-list 樹狀圖。 圖 4-6 中假設以(0,0)為對角線 tuple,毎個矩形為 link-list header tuple,三 角型為該小區域內所生成之 link-list 之集合,越下方之三角型,所對應的區域長 度越長,因此有可能會形成越長串的 link-list。 當封包在第一次的二元搜尋中找到最深的對角線 tuple(d,d)時,透過與封包 相符合的規則或 marker 所填入的來源資訊(x,y)來判斷搜尋的範圍,當來源資訊 為雙方向時留至下一小節再加以討論,當來源資訊為單方向時,因記載著可能存 在著的小區域中最遠之ㄧ的來源位置,而較該小區域更遠的的其他區域因並無任 何的規則或 marker 能與封包相符合,便無須考慮那些區域內的規則是否與封包相 符合,所以接下來的搜尋範圍便跳至 tuple(x,y),以該 tuple 為起點首先先判對是 否該區域可能存在能夠與封包相符合之規則,若對 tuple(x,y)搜尋成功時,即可 對所在的區域進行進一歨的搜尋;反之若 tuple(x,y)搜尋失敗,我們必須跳至前 一個 link-list header tuple 進行相同的判斷,因此當不斷的搜尋失敗時,會有與二 元搜尋相同的表現效率。圖 4-7 即為圖 4-6 之搜尋方式,根據對角線上的來源資 訊跳至最遠的 link-list header tuple 進行檢查,當檢查成功則揩使向下對子樹進行 細部搜尋;若檢查失敗則跳往上層再進行相同之檢查。. 34.
(48) 圖 4-7:圖 4-6 之搜尋路徑圖。 接著我們將介紹對小區域內部如何進行細部的搜尋動作。透過上述步驟的鏈 結型式,我們能夠採取簡單的線性搜尋法來進行搜尋,當對某個 tuple 搜尋失敗便 可結束整個搜尋流程。然而這樣的配置方式卻有可能導致如圖 4-8 的問題,採用 上述所提的線性搜尋法時,若一封包 P(11111111111,1111111111)搜尋到 tuple(2, 4)比對到規則 R1 時,根據其來源資訊接下來搜尋 tuple(2,5)比對到規則 R2,再 根據 R2 的來源資訊比對 tuple(2,6)的 R3,以此類推再比較 R4 與 R5,共搜尋了 五個 tuple;但若採用二元搜尋的方式時,則僅只是從 R3 到 R4 到 R5,只需三次 的搜尋。因此當該列(該行)的規則散佈稀少時,使用線性搜尋的方式能取得較佳 的效果;若散佈密集時,使用二元搜尋能夠獲得較線性搜尋更理想的效果。然而 使用二元搜尋的方式時,則有必要將 tuple(2,4)之後的每個 tuple 內的規則向前生 成 marker 直至 tuple(2,4)為止,而若該區域之規則分布稀疏時,如圖 4-9 所示般 情形,使用二元搜尋之效率就不如線性搜尋般理想了。在圖 4-8 中採用二元搜尋 時,由於整個搜尋範圍為(2,4)至(2,9),因此我們必須找到標示著來源資訊為(2, 4)的 marker 或規則,將來源標示更新為(L_range,R_range),L_range 為二元搜尋 的左邊(或上面)邊界,R_range 為二元搜尋的右邊(或下面)邊界,在圖 4-8 中即為 (4,9),當找到的 marker 來源資訊為此一格式時,便為二元搜尋模式,即可在此 一範圍內展開二元搜尋。那麼如何選擇該使用線性搜尋或是二元搜尋便也影響了 35.
(49) 搜尋的效率。. 圖 4-8:二元搜尋較線性搜尋佳之例子。. 圖 4-9:線性搜尋較二元搜尋佳之例子。 在這問題中,我們採用透過遞迴的方式來判斷單一行(列)需採用的搜尋演算 法 [18]。由於線性搜尋不適用於規則散佈密集的情形,二元搜尋不適用於規則散 佈稀疏的情形,因此我們嘗試合併線性搜尋與二元搜尋演算法,利用遞迴的方式 動態地產生演算法,我們可以根據規則分配狀況來即時決定搜尋演算法,亦可以 在加入或刪除規則之後重新調整搜尋演算法。. 圖 4-10:動態決定區域搜尋演算法之流程圖。. 36.
(50) 圖 4-10 為整個演算法建立流程圖。當我們找到ㄧ位於 link-list header tuple 之規則或 marker 所建立的鏈結時,我們便從該鏈結所指向的第一個 tuple 開始進 行處理(非 link-list header tuple),首先依照 tuple 的先後順序,依序將最前方的 tuple 的所有規則加入,並計算每個規則的搜尋總次數。當加入一新的規則時,必須計 算新規則採用線性搜尋或採用二元搜尋,何者有較好的效果,則選擇較佳效果之 演算法;若次數相同時,則保留選取方式,並繼續加入下一個規則重複地計算, 若結束規則的增加時次數仍然相同,則選取線性搜尋方式,因線性搜尋所需生成 的 marker 個數少於二元搜尋。當整個列皆計算完畢之後,再與完全採用二元搜尋 的總次數做比較並選取較佳的演算法。若選取的是線性加二元搜尋混用演算法, 則必須將來源資訊為採用二元搜尋演算法的 tuple 更改為上述的格式。以下為圖 4-8 的演算法生成方式: Step 1:加入 R1,使用線性搜尋共需 1 次 ,使用二元搜尋共需 1 次 =>保留 Step 2:加入 R2,使用線性搜尋共需 1+2=3 次 ,使用二元搜尋共需 1+2=3 次 =>保留 Step 3:加入 R3,使用線性搜尋共需 1+2+3=6 次 ,使用二元搜尋共需 2+2+2=6 次 =>保留 Step 4:加入 R4 與 R5,使用線性搜尋共需 1+2+3+4+4=14 次 ,使用二元搜尋共需 3+2+2+3+3=13 次. 37.
(51) =>(2,4)至(2,8)間選取二元搜尋 Step 5:加入 R6,使用線性搜尋共需 3+2+2+3+3+4=17 次 ,使用二元搜尋共需 3+2+3+3+3+3=17 次 =>(2,4)至(2,9)間選取二元搜尋 而最後我們必須判斷完整只對 tuple(2,4)至 tuple(2,9)間使用二元搜尋之效 果是否會較動態演算法之效果佳,若是則由完整的二元搜尋所取代,因動態生成 演算法能適應最佳狀況但並非有最平均之表現。在圖 4-8 中與 Step 5 之後的結果 相同,故採用動態演算法對該區間做搜尋。當最終決定完演算法之後,我們必須 將二元搜尋範圍內非尾端的 tuple 所對應鏈結的規則或 marker 之來源資訊給取消 以避免誤導其他鏈結的搜尋動作,同時也向前生成 marker 直至二元搜尋之前端為 止,如圖 4-11 所示。. 圖 4-11:最後對二元搜尋範圍內鏈結之規則或 marker 之處理。 因此我們可以對非對角線 tuple 的規則或 marker 做檢查,當判斷 link-list headertuple 內的規則 R 或 marker M 填入來源資訊時,可以知道存在著一條以來 源資訊的位置為起點的 link list,便可以對該 link list 內所有比 R 或 M 更 specific 的所有規則做動態的處理,因此對每一行或每一列來說,有可能存在著二者以上 的不同搜尋演算法。 圖 4-12 為至此整個單方向搜尋的流程圖,首先我們根據毎個區域之最左上 方 tuple 的檢查來判斷是否可能存在能符合的規則,若檢查失敗則往上一層區域做 相同的檢查,當檢查成功或檢查至最上層便可直接進行二元搜尋,其範圍為該區 38.
(52) 域之上界至下界以找出最深的 tuple,若找到能符合的規則或 marker 存在來源資 訊時,若是單方向,便可直接跳至該來源資訊所指之 link-list header tuple 做檢查, 若檢查失敗則往上一層的 link-list header tuple 做檢查,若檢查成功則判斷符合的 規則或 marker 是否有來源資訊,若有且為二元搜尋模式時,則根據來源資訊所標 示的上限與下限間的範圍做搜尋,若為線性搜尋型式時則直接前往該來源資訊所 紀錄之 tuple 做檢查即可,若搜尋失敗或符合的規則或 marker 不再有來源資訊時 便可結束搜尋;若符合的規則或 marker 有標記來源資訊時則再次判斷是屬於二元 搜尋或是線性搜尋,一直遞迴。. 39.
(53) 圖 4-12:封包單方向搜尋之流程圖。. 40.
(54) 4.4 衝突(Conflict)的處理 在這一演算法中,我們將衝突的情況分為二種:單方向的衝突,以及雙方向 的衝突:. 4.4.1 單方向衝突的處理 當收到一封包對對角線間的 tuple 進行第一次二元搜尋時,若規則 R 向左在 對角線 tuple(k,k)生成 marker M,規則 R`向左在對角線 tuple(k`,k`)生成 marker M`,k`>k,marker M`的範圍能夠被 marker M 的範圍所覆蓋住,如此第一次二元 搜尋極有可能受到 marker M`的引導而搜尋至 tuple(k`,k`)而非 tuple(k,k)的位置, 儘管對封包來說規則 R 可能會是它的最佳符合規則,如圖 4-13 所示,此為單方向 衝突問題,當收到封包 P 進行二元搜尋,因 R2 生成 marker(11*,11*)導致封包 P 搜尋至該 tuple,然而進一步進行深入二元搜尋時卻會於 tuple(2,3)造成搜尋失敗 而無法理想地搜尋至 R1。. 圖 4-13:產生衝突的範例圖示。 為了解決這類的問題發生,如同 Diagonal tuple space search 般,每個規則必 須對存在於 IncompatibleTuples 的所有對角線 tuple 做檢查,若這些 tuple 的規則或 是 marker 可能與規則 R 產生衝突的情形,便需增加一條 Mirror rule [16]。假設規 則 R 位於 tuple(x,y),若 y>x 時,便須對 tuple(x+1,x+1)至 tuple(y-1,y-1)間的 每一個對角線 tuple 做檢查,若存在某一 tuple(k,k)的 marker 或規則使得該 marker 41.
(55) 或規則的前 x 個 source specified bits 與規則 R 的 source specified bits 相同,規則 R 的前 k 個 destination specified bits 與該 marker 或規則的 destination specified bits 相 同,便有可能產生單方向衝突問題;若 y<x 時,便須對 tuple(y+1,y+1)至 tuple(x-1, x-1)間的每一個對角線 tuple 做檢查,若存在某一 tuple(k,k)的 marker 或規則使得 該 marker 或規則的前 k 個 source specified bits 與規則 R 的 source specified bits 相 同,規則 R 的前 y 個 destination specified bits 與該 marker 或規則的 destination specified bits 相同,便有可能產生單方向衝突問題。 為了避免這種問題造成搜尋失誤,必須在規則 R 與 tuple(k,k)的聯集位置生 成 Mirror rule,亦即聯集規則。當 y>x,聯集規則位於 tuple(k,y);當 y<x,聯集 規則位於 tuple(x,k) 。根據聯集規則的位置而生成 marker 的方式則與一般的規 則無異,但聯集規則仍須與 marker 有著相同資料結構,即必須紀錄該位置的最佳 符合規則。 因此當收到封包進行第一次二元搜尋時,若規則 R 向左在對角線 tuple(k,k) 生成 marker M,規則 R`向左在對角線 tuple(k`,k`)生成 marker M`,k`>k,以及 marker M`的範圍能夠被 marker M 的範圍所覆蓋住,若封包能夠符合規則 R,當 第一次二元搜尋至 tuple(k`,k`)位置時,由於 k`>k,封包必能滿足規則 R 的 source specified bits,又由於聯集規則的 destination specified bits 與規則 R 相同,因此搜 尋必定能到達規則 R 與 marker M`的聯集位置甚至之後,如此便可解決單方向衝 突問題。如圖 4-14 所示,增加了 R3 這個聯集規則以及相對應的 marker 之後,封 包 P 便能搜尋至 R3 的位置並得知 R3 能與封包 P 相配合,再透過 R3 的最佳符合 規則便能獲得 R1。. 42.
數據
+7



相關文件
網路上進行天氣瓶購買的價錢的蒐尋,其造型有各式各樣,有些作成吊飾,有的可 以擺在桌上當擺飾品或夜燈,天氣瓶的商品琳瑯滿目(如下圖一、A-D),發現新台幣約 在
LED。Wii remote 裏的光學感應器,可以根據這些 LED 成像的
In particular, we present a linear-time algorithm for the k-tuple total domination problem for graphs in which each block is a clique, a cycle or a complete bipartite graph,
依序填入該學生社團負責人之相關資訊,並於下方
媒體可以說是內容、資訊最大的生產者,但受制於 國際社交媒體及搜尋平台的經營手法,本地主流媒 體在發展網上業務時,面對不公平的競爭。 這些
求出 Select Case 運算式之值,並逐一與 Case 運算式值串列比對,若符合則執行該 Case 之後的敘述區段。1. 如果所有的
疊對(overlay)的方式是指兩層的定位與相互考量的 x 和 y 方向,如果所有的疊對 層在晶圓上沒有偏移,亦即代表 overlay value=0 ,通常 overlay =0 是目標值。而 overlay
本章將對 WDPA 演算法進行實驗與結果分析,藉由改變實驗的支持度或資料 量來驗證我們所提出演算法的效率。實驗資料是以 IBM synthetic data generator
