運用資料探勘與社會網路分析支援問題管理
79
0
0
全文
(2) `. 運用資料探勘與社會網路分析支援問題管理 Application of Data Mining and Social Network Analysis. to Support Problem Management. 研 究 生:阮淑婷. Student:Shu-Ting Juan. 指導教授:劉敦仁 博士. Advisor:Dr. Duen-Ren Liu. 國 立 交 通 大 學 管理學院(資訊管理學程)碩士班 碩 士 論 文 A Thesis Submitted to Institute of Information Management College of Management National Chiao Tung University In Partial Fulfillment of the Requirements For the Degree of Master of Science in Information Management June 2008 Hsinchu, Taiwan, the Republic of China. 中. 華. 民. 國. 九. 十. 七. 年 六 月.
(3) `. 運用資料探勘與社會網路分析支援問題管理 研究生:阮淑婷. 指導教授:劉敦仁 博士. 國立交通大學管理學院(資訊管理學程)碩士班. 摘要 企業導入資訊系統協助企業運作流程之自動化以獲取最大利潤,然而企業導入越多 IT系統,要處理的問題也就越多。因此,從IT服務管理之角度導入IT系統以支援企業運 作更為重要。本研究主要是運用資料探勘與社會網路分析支援IT服務管理中的問題管 理;運用關聯規則探勘,從歷史問題處理資料庫發掘相關的問題管理規則,進而找出問 題發生的主因;此外,本研究運用社會網路分析方法發掘出相似工作者與相關問題解決 專家的關係,從所建構之社會網路,使用者可尋找專家或與相似的工作者溝通合作以解 決問題。最後,本研究實作一個Web系統以驗證所提方法的可行性。. 關鍵字: 資訊技術基礎架構庫、問題管理、資料探勘、關聯規則、社會網路分析. I.
(4) `. Application of Data Mining and Social Network Analysis to Support Problem Management Student:Shu-Ting Juan. Advisor:Dr. Duen-Ren Liu. Institue of Information Management National Chiao Tung University Hsinchu, Taiwan, Republic of China. Abstract IT (Information Technology) systems are often implemented to assist enterprises in automating their business operations to maximize business profit. With the more IT systems implemented, the more issues generated accordingly. Thus, it is very important to implement IT systems to support business operations from the view of IT service management. This research applies data mining and social network analysis to support problem management. Association rule mining is employed to discover the rules of problem management from the database of historical problems, and then find out the root causes. Moreover, social network analysis is used to discover the relationship between users and the specialists that can resolve the problems. According to the constructed Social Network, users can find specialists / similar workers, and cooperate with them to resolve the problems. Finally, a Web-based prototype system is implemented to evaluate the feasibility of the proposed work.. Keyword: IT Infrastructure Library (ITIL), Problem Management, Data Mining, Association Rule, Social Network Analysis. II.
(5) `. 誌謝 呼~,該是邁入下一個階段的時候,回想貣研究所求學過程的點點滴滴,一幕幕就 像剛剛發生一樣,那樣的深刻、鮮明。 學分班時,那股想唸交大資管所的熱忱;剛考上研究所,那興奮溢於言表的心情; 當新生時,那努力讀書、快樂出遊的生活;到現在寫論文,那戰戰兢兢、如履薄冰的努 力;就只為一個共同的目的,讓自己的生活多采多姿。 在這兩年的研究所求學過程,最先要感謝的就是我的指導教授劉敦仁,就如同他的 名字一樣,敦敦教誨、實實在在地指導學生的態度,讓我了解如何做學問及寫出嚴謹的 文章,真是非常感謝;再來要感謝,口詴的評審委員們,羅濟群教授、吳美玉教授,在 口詴期間給予我許多寶貴的意見和指導,讓我的論文能更加完善;也感謝公司長官貞 維、平一、子明的支持及同事們大欣、怡亭、向陽、筱琳、瑞婷、茗菁、家彰、國明、 達榮的幫忙,有你們的支持和鼓勵,讓我的研究所求學過程走得更順遂。 還要感謝的我的同學們,瓊文、雅坪、淑君、國勳、文量,大家為了論文的撰寫, 雖然是不同實驗室,但是大家也非常齊心一致的努力,每個星期六都在一貣寫論文,那 段日子過得辛苦,但也充實;還要感謝同實驗室的學長姐,志偉及同學們,權龍、勝凱、 信智、瓊文、健誠、振東,大家互相幫忙、加油打氣;還有一同修課的同學們,乃鈞、 忠明等;還有資管所的教授們及助理欣欣,真是非常感謝你們。 再來,要感謝的是我親愛的家人,奶奶、爸爸、媽媽、姐姐、姐夫、弟弟、妹妹, 還有我那2個可愛的小姪子,給予我精神上的支持,讓我在研究所的求學路上無後顧之 憂;再來感謝一直陪伴在身邊的泰瑋,感謝你幫我潤稿及提供新的想法,因為你的耐心、 貼心,讓我走過這一段難熬的階段;也感謝泰瑋爸爸、媽媽的關心及支持。 最後,我想告訴你們的是「有你真好」,我會懷著感恩的心情,朝著另一段旅程邁 進,迎接新的挑戰。 淑婷 III. 2008/6/20.
(6) `. 目錄 摘要 ............................................................................................................................................ I ABSTRACT............................................................................................................................... II 誌謝 .......................................................................................................................................... III 目錄 ......................................................................................................................................... IV 表目錄 ..................................................................................................................................... VI 圖目錄 .................................................................................................................................... VII 一、緒論 ....................................................................................................................................1 1.1 研究背景及動機 ......................................................................................................1 1.2 研究目的..................................................................................................................2 1.3 論文架構..................................................................................................................3 二、文獻探討.............................................................................................................................4 2.1 資訊技術基礎架構庫(ITIL) ...............................................................................4 2.1.1 ITIL的架構 .....................................................................................................5 2.1.3 ITIL的服務管理(Service Management) .....................................................6 2.1.4 ITIL的問題管理(Problem Management) ...................................................7 2.2 資料探勘(DATA MINING) ....................................................................................8 2.2.1 關聯規則(Association Rule) .....................................................................9 2.2.2 資料探勘應用程式開發 .............................................................................. 11 2.3 社會網路分析(SOCIAL NETWORK ANALYSIS) .................................................... 14 2.2.1 社會網路的繪製工具 - Graphviz ............................................................ 16 三、服務導向的問題管理架構................................................................................................ 18 3.1 事件處理模組(INCIDENT PROCESS MODULE) ..................................................... 19 3.1.1 事件新增(Incident Created) .................................................................... 20 3.1.2 知識支援(Knowledge Support) ............................................................... 21 3.2 資料探勘模組(DATA MINING MODULE) ............................................................ 22 3.3 推論模組(INFERENCE MODULE) ...................................................................... 25 IV.
(7) `. 3.4 社會網路模組(SOCIAL NETWORK MODULE) ...................................................... 29 3.4.1 尋找專家 ..................................................................................................... 30 3.4.2 尋找相似工作者 .......................................................................................... 32 四、雛型系統建置及實作 ....................................................................................................... 34 4.1 系統的開發工具與平台......................................................................................... 34 4.2 系統設計................................................................................................................ 35 4.3 系統實作................................................................................................................ 36 4.3.1 4.3.2 4.3.3 4.3.4 4.3.5. 公用模組實作.............................................................................................. 36 事件處理模組實作(Incident Process Module) ........................................ 40 資料探勘模組實作(Data Mining Module) ..............................................42 推論模組實作(Inference Module)........................................................... 46 社會網路模組實作(Social Network Module) ......................................... 53. 4.4 實例展示................................................................................................................ 57 五、結論及未來方向 ...............................................................................................................64 5.1 結論 ....................................................................................................................... 64 5.2 未來研究方向 ........................................................................................................ 65 參考文獻 .................................................................................................................................. 66. V.
(8) `. 表目錄 表 1 : 關聯規則指標.......................................................................................... 13 表 2:A & B的社會網路關係圖 ........................................................................ 14 表 3 : 事件的資料表欄位 .................................................................................. 20 表 4:知識庫的資料表欄位 .............................................................................. 21 表 5 : 事件資料明細.......................................................................................... 22 表 6: 事件資料明細-Apriori-1 ........................................................................... 23 表 7: 事件資料明細-Apriori-2 ........................................................................... 23 表 8: 事件資料明細-Apriori-3 ........................................................................... 23 表 9 : 規則庫的資料表欄位 .............................................................................. 24 表 10 : 關聯規則指標-事件資料 ....................................................................... 27 表 11: 關聯規則指標-事件資料-例子 ............................................................... 28 表 12 : 以印表機分類的專家積分計算 ............................................................. 30 表 13 : 相似工作者的相似度計算 .................................................................... 33 表 14:雛型系統的開發工具與平台 ................................................................. 34. VI.
(9) `. 圖目錄 圖 1:論文架構 .................................................................................................... 3 圖 2:ITIL的主體框架圖 ..................................................................................... 5 圖 3:條件機率示意圖 ........................................................................................ 9 圖 4:Graphiviz繪製的有向圖 ........................................................................... 17 圖 5:服務導向的問題管理架構 ....................................................................... 18 圖 6:事件處理模組 .......................................................................................... 19 圖 7:資料探勘模組 .......................................................................................... 22 圖 8:推論模組 .................................................................................................. 25 圖 9:社會網路模組 .......................................................................................... 29 圖 10:印表機分類的社會網路圖 ..................................................................... 31 圖 11:0002的相似工作者社會網路圖 ............................................................. 33 圖 12:系統功能結構圖 .................................................................................... 35 圖 13:使用者登入系統畫面 ............................................................................. 36 圖 14: 系統首頁 ................................................................................................. 37 圖 15: 熱門問題的程式碼 ................................................................................. 38 圖 16:使用者的主版畫面................................................................................. 39 圖 17:事件輸入畫面 ........................................................................................ 40 圖 18:依分類找出的知識集合 ......................................................................... 41 圖 19:資料表關聯呈現 .................................................................................... 42 圖 20:採礦模型檢視器-項目集 ..................................................................... 43 圖 21:採礦模型檢視器-規則 ......................................................................... 44 圖 22:採礦模型檢視器-相依性網路 ............................................................. 45. VII.
(10) `. 圖 23:待辦問題 ................................................................................................ 47 圖 24:問題關聯 ................................................................................................ 48 圖 25 : 待辦問題的程式碼 ................................................................................ 49 圖 26 : 推論模組的程式碼 ................................................................................ 49 圖 27:下拉選單組成Select子句 ....................................................................... 50 圖 28:「查詢」檢視模式 ................................................................................... 51 圖 29:「結果」檢視模式 ................................................................................... 52 圖 30 : 尋找專家的社會網路............................................................................. 53 圖 31 : 尋找專家的程式碼 ................................................................................ 54 圖 32: 尋找相似工作者的社會網路 .................................................................. 55 圖 33 : 尋找相似工作者的程式碼 ..................................................................... 56 圖 34:「無法使用印表機」-事件新增 ............................................................ 58 圖 35:「無法使用印表機」-列出相關知識供參考 ......................................... 59 圖 36:「無法使用印表機」-待辦問題 ............................................................ 60 圖 37:「無法使用印表機」-推論結果 ............................................................ 61 圖 38:以「印表機」為分類的社會網路 ......................................................... 62 圖 39:與「0002」使用者之相似工作者 ......................................................... 63. VIII.
(11) `. 一、緒論 1.1 研究背景及動機. 企業導入資訊系統, 主要目的為協助企業運作流程之自動化以獲取最大利潤,但只 是輔助企業營運所需,並不能滿足企業提昇競爭優勢的需求,故資訊科技的管理需與企 業的商務活動緊密的結合,才能發揮此功效,進而達到企業的組織目標。近年來,資訊 科技的管理,慢慢地朝向以「服務」導向為基礎,主要將資訊產業的流程分割成各種「服 務」,再整合於整個組織,以協助企業每個部門規劃並執行整體的資訊流程,以達到一 次 性 的 設 計 資 訊 流 程 , 這 就 是 「 資 訊 技 術 基 礎 架 構 庫 」 (Information Technology Infrastructure Library,ITIL)[27]。. ITIL的主要核心服務管理(Service Management) ,包含二個模組,服務支援(Service Support)[29]及服務提供(Service Delivery)[30]。這兩個模組的重點分述如下,服務支 援(Service Support) ,主要用來保證使用者能使用適當的服務來滿足商業功能(Business Function ), 基 於 上 面 的 目 的 , 定 義 了 下 列方 法 來 支 援 , 包 括 事 件 管 理( Incident Management) 、問題管理(Problem Management) 、變更管理(Change Management) 、上 線管理(Release Management)、組態管理(Configuration Management);而服務提供 (Service Delivery) ,則是以高品質且高成本效益比的服務來提供給使用者,包括IT服務 永 續 性 管 理( IT Service Continuity Management )、 服務水準管理(Service Level Agreement Management , SLA )、 容 量 管 理 ( Capacity Management )、 可 用 性 管 理 (Availability Management)、IT服務財務管理(Financial Management for IT services), 最後,再以服務台(Service Desk),作為使用者與資訊系統的聯繫窗口。. 1.
(12) `. 問題管理(Problem Management),主要為了降低因IT基礎架構錯誤而引發的事件與 問題對於企業的負面衝擊,避免相關錯誤所引發的事件重複發生,故將分析事件資料庫 中的問題資料,詴著從可能的原因清單中,找出根本的主因(Root Cause) ,為完整的解 決方法(Long Term Solution)。. 本研究主要是運用資料探勘(Data Mining)與社會網路分析(Social Network Analysis) 支援IT服務管理中的問題管理(Problem Management);藉由資料探勘(Data Mining)的技術 來發現問題的關聯性,以提供解決問題的參考,進而幫助資訊人員找出問題的主因,根 本地解決問題;另外,透過社會網路分析(Social Network Analysis)方法,找出工作性質 相似的工作者及解決問題的專家,提供資訊人員問題解答的詢問對象,加速問題的處理 速度。最後,本研究實作一個Web系統以驗證所提方法的可行性。. 1.2 研究目的. 根據以上的研究背景及動機,本研究希望達到下列的研究目的,第一,做為企業導 入ITIL 問題管理(Problem Management)的參考依據;第二,利用社會網路分析(Social Network Analysis)方法,找出工作性質相似的工作者及解決問題的專家,提供資訊人員 問題解答的詢問對象,加速問題的處理速度;第三,使用資料探勘技術,從歷史的問題 資料庫中,找出問題可能原因,提供資訊人員尋找問題主因的參考依據,以減少資訊人 員解決問題所需的時間,增加資訊人員的生產力;第四,利用Web介面的瀏覽方式,建 置一套雛型系統以驗證所提方法的可行性。. 2.
(13) `. 1.3 論文架構. 本篇論文主要分為五個章節,第一章為緒論,主要說明本研究的背景、動機、目的 及論文架構。第二章為文獻探討,主要整理相關文獻的定義、理論,包括,資訊技術基 礎架構庫(Information Technology Infrastructure Library,ITIL)、社會網路分析(Social Network Analysis) 、資料探勘(Data Mining)中的關聯規則(Association Rule)等技術。 第三章,主要依據第二章的理論基礎,設計一個「服務導向的問題管理架構」,並說明 此架構中各模組的功能及其設計方法。第四章為系統開發,利用C#、SQL Server 2005、 DMX、Graphivz 等技術,設計一套雛型系統以驗證所提方法的可行性。最後在第五章, 提出結論及未來方向的建議。研究流程如圖1所示。. 圖 1:論文架構. 3.
(14) `. 二、文獻探討 本研究主要在ITIL[27]服務管理的環境中,針對問題管理的部份,加以探討,並搭 配社會網路分析(Social Network Analysis)的觀念,讓資訊人員能找到專家及相似工作 者來合作解決問題。並採用資料探勘的技術來分析資料,找出事件的關聯性,以提供資 訊人員做為解決問題的參考。本章將針對相關主題進行探討。. 2.1 資訊技術基礎架構庫(ITIL). ITIL 是由英國組織OGC(Office of Government Commerce,OGC)[27]於1980年所 提出的一套IT服務管理的方法論,主要是由政府組織或私人機構,針對IT服務管理所做 的最佳化實務(Best Practice)。ITIL包含一系列的叢書,重點在於闡述服務管理的概念, 並詳細說明如何透過流程導向的管理架構,提高企業IT服務的品質,使資訊科技與企業 的營運流程能成功地結合。. 4.
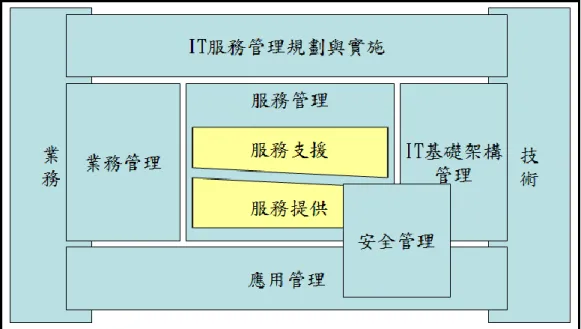
(15) `. 2.1.1 ITIL的架構. 資訊科技基礎架構庫(ITIL) ,主要包含六塊主要模組,分別為業務管理(Business Management)、服務管理(Service Management)、資訊與通信技術基礎設施管理(ICT Infrastructure Management) 、應用管理(Application Management) 、IT服務管理規劃與實 施(Planning To Implement Service Management)及安全管理(Security Management)。 架構中的核心模組為服務管理中的服務支援模組(Service Support)[29]及服務提供模組 (Service Delivery)[30]。圖2為ITIL的主體框架圖。. 圖 2:ITIL的主體框架圖. 5.
(16) `. 2.1.3 ITIL的服務管理(Service Management). ITIL的主要核心服務管理(Service Management) ,包含二個模組,服務支援(Service Support)及服務提供(Service Delivery) 。這兩個模組的重點分述如下,服務支援(Service Support) ,主要用來保證使用者能使用適當的服務來滿足商業功能(Business Function), 基於上面的目的,定義了下列方法來支援,包括事件管理(Incident Management) 、問題 管理(Problem Management)、變更管理(Change Management)、上線管理(Release Management) 、組態管理(Configuration Management) ;而服務提供(Service Delivery), 則是以高品質且高成本效益比的服務來提供給使用者,包括IT服務永續性管理(IT Service Continuity Management)、 服務水準管理(Service Level Management,SLA) 、 容量管理(Capacity Management) 、可用性管理(Availability Management) 、IT服務財務 管理(Financial Management for IT services)。最後,再以服務台(Service Desk),作為 使用者與資訊系統的聯繫窗口。由於ITIL服務管理的範圍過於廣大,在本研究中,僅就 問題管理(Problem Management)作深入的探討。. 6.
(17) `. 2.1.4 ITIL的問題管理(Problem Management). 在解釋問題管理(Problem Management)前,先說明一般人常會混淆的兩個模組, 事件管理(Incident Management)及問題管理(Problem Management) 。以目的不同來看, 事件管理(Incident Management) ,主要是使用各種可能的方法,讓問題快速的解決,可 看作短暫的解決方法(Short Term Solution) ;問題管理(Problem Management) ,即為分 析事件資料庫中的問題資料,詴著從可能的原因清單中,找出根本的主因(Root Cause) , 為完整的解決方法(Long Term Solution)。. 引用ITIL 出版品「服務支援」中說明,「問題管理」的目標在於降低因IT基礎架構 錯誤而引發的事件與問題對於商務的負面衝擊,並避免相關錯誤所引發的事件重複發 生。為了達到這個目標,「問題管理」旨在尋求「事件」的根本原因,然後採取行動來 改善情況或更正錯誤[15]。. 7.
(18) `. 2.2 資料探勘(Data Mining). 資料探勘[24]的定義如下:利用統計及機械學習的演算法,從龐大的資料中尋找隱 藏於資料下,具有商業價值的知識與規則,以作為自動化商業策略之應用。主要由下列 幾種模式組成,分類(Classification),根據已知的特徵作分類;分群(Clustering),確 定資料要分為幾群,然後從中找出同一群組的相似性;關聯規則(Association Rule) [18][19],找出某一事件或資料中,會同時出現的東西;序列(Sequence) ,類似關聯規 則(Association Rule),主要是以時間為主;迴歸分析(Regression),使用一系列的數 值 , 來 預 測 一 個 連 續 數 值 的 可 能 性 ; 時 間 序 列 ( Time Serious ), 類 似 迴 歸 分 析 (Regression),但分析的數值皆為時間。. 本研究僅針對有使用到的資料探勘技術-關聯規則(Association Rule),加以詳細 討論。. 8.
(19) `. 2.2.1 關聯規則(Association Rule). 關聯規則為資料探勘的演算法之一,最有名的例子,莫過於「啤酒與尿布」,一家 連鎖店利用資料探勘來挖掘資料隱藏的規則時,發現小孩尿布和啤酒之間有著一定的關 聯,之後探討,原來購買尿布的父親中,有30% ~ 40%的人,同時會買啤酒,因為在照 顧小孩之餘,還會看球賽及喝啤酒,於是,這間店依據這條規則,調整了貨架的擺放, 把尿布和啤酒擺在一貣,明顯地增加了銷售額。從這個例子了解,關聯規則的主要應用 為「條件機率」。典型的關聯規則形式如下:. 假如購買A,則有X%的機率也會同時購買B. 利用一個簡單的圖形來說明上述規則如何計算。假設在某段期間中,購買A商品的 顧客共有100名,而購買B商品共有50人,而兩者交集(同時購買A以及B的顧客,也就 是圖形中重疊區域)共有40人,如圖3。因此可以計算出兩條關聯規則:. 假如購買A,則有40%的機率也會同時購買B。(40/100=0.4). 假如購買B,則有80%的機率也會同時購買A。(40/50=0.8). 圖 3:條件機率示意圖. 9.
(20) `. 關聯規則的好壞,可由下列兩個指標來說明,信心水準(Confidence) [2][3],等於在 A條件下發生B的可能性,可以用下列公式表示,Confidence (A => B)= P( B | A),其義意 為規則準確度的高低,信心水準越高代表規則越有參考價值;支持度(Support) [2][3], 代表A與B同時發生的機率。公式如下,Support (A => B)= P( A∩B),為支援這個規則的 交易次數的百分比;所以,為了篩選出有效的規則,會先定義出最小信心水準門檻值 (Minimum Confidence),及最小支持度門檻值(Minimum Support),來預先剔除不合格的 規則。. 10.
(21) `. 2.2.2 資料探勘應用程式開發. 在SQL Server 2005的資料開發中,主要可以透過兩種API來實作:ADOMD.NET以 及OLE DB[2][3]。本研究採用ADOMD.NET,因為它是一個標準的.NET資料提供者,用 來存取資料探勘以及多維度資料,因此,開發人員可以透過ADOMD.NET定義的類別 庫,自行撰寫實作程式,以處理較複雜的計算邏輯。. 根據微軟定義,資料探勘模型是一種特殊型態的資料表。因此,整個模型從建置、 訓練到預測,都可以透過結構化查詢的方式來完成,這個語言微軟稱之為資料探勘延伸 語言 (Data Mining Extension,DMX) [2][3]。根據功能性可分成兩大類,一類是內容查 詢(Content Query),包括了一系列資料定義語言以及操作語言,用來新增、修改、刪 除、調整資料探勘模型;另一類則主要用來產生預測結果,稱之為預測查詢(Predication Query)。下列針對使用到的預測查詢(Predication Query),做一簡單的說明。. 預測查詢(Predication Query)的形式就像是傳統T-SQL中SELECT–JOIN-ON的語 法,但在資料探勘下,JOIN聯結的不是兩個關聯式資料表,而是連結一個資料探勘模型 以及欲預測資料來源。DMX標準預測查詢語法結構如下。 SELECT [FLATTENED] <SELECT陳述式> FROM <資料採礦模型名稱> PREDICTION JOIN <來源資料查詢> ON <連結條件> WHERE <陳述式>. 11.
(22) `. 除了單純的DMX預測查詢語法外,也提供額外的資料探勘函數,主要用來提供更 多 的 預 測 資 訊 ; 其 相 關 預 測 函 數 包 括 ClusterProbability 、 PredictSequence 、 PredictionAssoication 等 [2][3] , 本 研 究 因 採 用 關 聯 規 則 演 算 法 , 所 以 使 用 PredictionAssoication預測函數,其語法結構如下。 PredictionAssocation(<Table column reference> [,INCLUSIVE | EXCLUSIVE | INPUT_ONLY] [,INCLUDE_STATISTICS][,INCLUDE_NODE_ID][,<n-items> ] 關聯規則 預測 函數(PredictAssociation)的各個參數說明如下,<Table column reference> 為 資料探勘模型 中的資料表名 稱 ; INCLUSIVE 為預測結果包含空值; EXCLUSIVE為預測結果排除空值,此參數為預設值;INPUT_ONLY為不預測,只傳回 這 個 鍵 值 購 買 過 的 商 品 ; INCLUDE_STATISTICS 是 預 測 結 果 會 自 動 傳 回 支 持 度 (Support)、機率(Probability)、調整後機率(Adjusted Probability)三個統計資訊欄位; INCLUDE_NODE_ID為預測結果會在回傳時加入$NodeId欄位,以顯示推薦這個商品是 根據哪一條規則;<n-items>列出前n項機率最高的預測商品。. 12.
(23) `. 利用DMX及資料探勘函數 PredictionAssoication 預測出來的資料,包括支持度 (Support)、機率(Probability)、調整機率(Adjusted Probability),可依數值高低來分 析預測結果,如表1說明 ,其中支持度(Support)在Microsoft SQL Server2005內,將會 以符規則的交易次數呈現,並非由交易次數的百分率來看,其交易次數越多越有代表性。. 表 1 : 關聯規則指標. 欄位. 說明 代表A與B同時發生的機率. Support(支持度) Support (A => B)= P( A∩B) Probability(機率). 信心水準,代表規則中有A的條件下會有B的機率 Confidence (A => B)= P( B | A) 此屬性與「Important」為正相關 Importance(重要性),用來判斷此規則是否有意義。 (A => B) = log (p(B|A)/p(B|not A)) = 0:表示A和B沒有關聯性。. Adjusted Probability. > 0:表示一旦擁有A則再擁有B的概率會增加。. (調整後的機率). < 0:表示一旦擁有A則再擁有B的概率會降低。 例如:有A的條件下會有B的機率 : 80%, 但在這兩種情況,就會有不一樣的結果 B的機率若為20%,則判定為有意義規則 B的機率若為90% ,則判定為無意義規則. 13.
(24) `. 2.3 社會網路分析(Social Network Analysis). 社會網路為社會科學的分支,目的在於檢視人們於社會、經濟、文化等框架 (Framework)中所扮演的角色。以人為節點(Vertices),框架中的關係做為連結(Edges) 以建構社會關係的模型。並藉此分析個體與個體、個體與群體、群體與群體之間互動關 係及影響[16]。. 社會網路的定義, 包含一組客體(Objects) (以數學上的術語稱為Node), 以及客體兩 者之間關係。最簡單的網路包括A及B兩個客體及聯結兩者的關係[11]。例如, A及B 可 能為兩人, 聯結兩人的關係可能為一間辦公室,如表2。. 表 2:A & B的社會網路關係圖. 編號. 關係圖. 說明. 1. A. B. 兩人的可能站在同一間辦公室. 2. A. B. A認識B (單向的箭頭關係). 3. A. B. A及B互相認識對方 (雙向的關係). 14.
(25) `. 社會網路分析的意義在於,它可以對各種關係進行精確的量化分析,主要有點、關 係及聯繫三種[9][25]。分別說明如下,點(Node),社會網路分析著重在行動者之間的 關係,而其最基本的成分就是點與線(Node and Link),點代表行動者,而線代表行動 者之間的關係或是聯繫;關係(Relation),關係的特徵可經由四個部分來說明,分別 為內容、方向、強度、主動或被動關係;內容,內容就是指兩行為者間之關係產生原因 與關係建構基礎,例如:兩行為者因為共同解決同一事件而產生關係;方向,關係可分 成有方向性(Directed)及無方向性(Undirected)。例如0001與0002為同一公司的員工, 但兩人互不認識,此種關係便是無方向性的關係。強度,關係也有著程度不同的強度。 其衡量方式可能因為不同的關係型態與研究主題而有不同的變化,譬如相似工作者關 係,便以相同專長及是否為曾經參與過同一專案來衡量。主動關係或被動關係,關係產 生時,因為行為者本身意向之主被動的不同,也是一種關係的特徵,例如資訊人員與相 似工作者的關係,行為者本身對這個關係的發生,是處於被動的情況;聯繫(Tie), 所謂的聯繫是指兩行動者之間的關係組合。其聯繫所含的關係可能只有一種、也有可能 由多種的關係組合而成,例如兩人彼此有商業合作、資訊交換、學術交流等關係。而聯 繫的「強弱」又可分成弱聯繫(Weak Ties)及強聯繫(Strong Ties)兩種觀念[33],簡 單來說,強聯繫和弱聯繫的定義如下,強聯繫,代表關係是親近、特別的,會自發性的 維護聯繫,會常透過各種不同的關係來達到彼此之間長時間的互動;弱聯繫,彼此之間 比較少有關係或是親近的接觸,且彼此之間很少提及個人的經歷、很少談論彼此不曾接 觸的事情。. 本研究主要利用社會網路概念,來分析專家及相似工作者的社會網路,協助資訊人 員解決問題。. 15.
(26) `. 2.2.1 社會網路的繪製工具 - Graphviz. Graphviz[14]是一套圖形抽象化的軟體,由AT&T所開發。您可以透過編輯其程式語 言,來表達節點的特性與節點之間的關係,就可以輕鬆的畫出一張關係圖出來,也可以 應用在網頁設計(SiteMap) 、軟體工程、網路、資料庫等。是一個畫程式流程圖、ER 圖 不可多得的好幫手。現已支援中文UTF-8。. 對於很多圖形來說,差異只是在於箭號的有無,一般來說,如果你的圖中包括箭號, 那就是有向圖(Directed Graph) ,代表著會有單、雙向的關係,否則就是無向圖(Undirected Graph)。. 如果為有向圖,語法[13]就是,digraph G{…} ,且解譯程式為 dot language,,其解 譯 的 方 式 為 dot. -T[output_filetype]. [-G[option_name]]. -o. [output_filename]. [input_filename] ,舉例如下, dot -Tpng -o output.png input.dot ;若為無向圖,語法就 是:graph G{…},且編譯程式為neato language,其解譯的方式為neato -T[output_filetype] [-G[option_name]] -o [output_filename] [input_filename] ,例如, neato -Tpng -o output.png input.dot。. 16.
(27) `. 圖形中點和點的關係,主要用「-」和「->」來區分,例如:「A — B」,即為無 向圖的連結;若為「A -> C」則代表有向圖的連結。舉例說明,若資料的關係如下, 0001 -> 0002 ,0002 ->0003, 0003 -> 0002,則代表此圖為有向圖,而0001 和 0002 為 單 向 關 係 , 0002 和 0003 為 雙 向 關 係 , 而 畫 圖 的 程 式 碼 為 , digraph G { 0001 -> 0002;0002 -> 0003;0003 -> 0002;},其繪製出來的圖如圖4。. 圖 4:Graphiviz繪製的有向圖. 本研究透過Graphiviz軟體繪製問題分類與專家的社會網路圖及相似工作者的社會 網路圖。. 17.
(28) `. 三、服務導向的問題管理架構 本研究提出一個以服務導向的問題管理架構,在ITIL的問題管理概念下,根據事件 資料庫中的資料,利用資料探勘的方法,從中挖掘出事件的關聯規則,做為解決問題的 參考依據,協助資訊人員,找出問題的主因;也利用社會網路分析方法,從員工的資料 庫中,找出工作性質相似的員工及有能力解決問題的專家,建立貣問題管理的社會網 路;最後,本研究實作一個Web系統以驗證所提方法的可行性。. 為了達到上述目的,我們提出如圖5服務導向的問題管理架構。主要分為四個模組, 分別介紹如下:. 圖 5:服務導向的問題管理架構. 18.
(29) `. 3.1 事件處理模組(Incident Process Module). 事件處理模組,如圖6所示,當使用者向Help Desk反應問題時,Help Desk將使用者 反應的事件,透過系統來建立、儲存,此時系統會依新事件的分類,從知識庫中,找出 相關的事件及解決方案,提供給Help Desk,做為解決問題的參考。. 圖 6:事件處理模組. 在這個模組中,主要有兩個目的,第一是記錄事件發生時的狀態與特徵,提供給資 料探勘模組使用。第二是透過事件的分類,從知識庫中尋找出相關知識解答來協助 Help Desk 做事件處理。. 19.
(30) `. 3.1.1 事件新增(Incident Created). 事件新增中記錄了事件的完整資訊,也就是資料探勘的資料來源;下面就事件新增 的欄位,解釋如下,如表3,包括事件編號(Event_No),即事件的流水號;提問者 (User_ID),為提出此問題的使用者員工編號;紀錄者(Rec_ID),為記錄此問題的Help Desk員工編號;分類(Category),描述事件的分類情況;紀錄日期(Rec_Date),使用者 提問給Help Desk的日期;結束日期(Done_Date),為事件處理完畢的日期;狀態(Status), 描述事件處理的情況;問題描述(Event),描述使用者遭遇到問題的情況;物件(Object), 使用者遭遇到問題的相關可能物件;特徵(Symptom),使用者遭遇到問題相關可能物件 的情形;問題原因(Cause),即為發生此問題的主要原因。. 表 3 : 事件的資料表欄位. Event_No User_ID Rec_ID Category Rec_Date Done_Date. 101 0001 0005 網路 2008/6/25 2008/6/26. Status Event Object Symptom Cause. 20. 處理中 印表機無法列印 印表機 連接失敗 網路中斷.
(31) `. 3.1.2 知識支援(Knowledge Support). 就知識支援來說,系統將會在Help Desk建立完事件記錄之後,透過事件的分類,自 動提供相關知識資料,協助Help Desk 作事件的處理;例如,若事件分類(Category)為網 路的話,系統就會從知識庫中找出以網路為分類的相關事件知識。. 知識庫的資料表欄位,如表4,包括,事件編號(Event_No) ,為事件的流水號;問 題描述(Event),描述使用者遭遇到問題的情況;問題原因(Cause),即為發生此問題 的主要原因;解決方案(Solution),解決此問題的方法;分類(Category) ,描述事件的分 類情況。. 表 4:知識庫的資料表欄位. Event_No 1. Event 印表機無法列印. Cause 網路中斷. 本研究,將開發一個事件描述的介面,來讓Help. Solution 更換新的網路線. Category 網路. Desk填寫事件編號(Event_No)、. 提問者(User_ID)、紀錄者(Rec_ID)、分類(Category)、紀錄日期(Rec_Date)、結束日 期(Done_Date)、狀態(Status)、問題描述(Event)、物件(Object)、特徵(Symptom)、問題原 因(Cause),以達到問題資料的處理,並在填完事件記錄後,秀出相關解決方法的知識資 料,作為解決問題參考。. 21.
(32) `. 3.2 資料探勘模組(Data Mining Module). 資料探勘模組,如圖7所示,主要負責從事件資料庫的歷史資料中,使用關聯規則 探勘的技術,對資料做關聯分析,找出有用的知識樣板(Knowledge Pattern) ,儲存至規 則庫中,提供推論模組分析時,所需用到的規則來源。. 圖 7:資料探勘模組. 本系統採用Microsoft SQL Server. 2005中的關聯規則演算法,因此採用的演算法為. Apriori,主要根據事件資料明細做為基礎,遞迴計算候選的物件組以及規則組合。以本 研究來說,主要目標為針對每個事件中,找出相關聯物件。因此,本研究的資料探勘資 料為事件資料明細。下面利用個例子,如表5,說明實際的運算流程:. 表 5 : 事件資料明細. 事件編號 1 2 3 4 5 6. 相關物件 印表機、網路 網路 印表機 印表機、網路、印表機伺服器 印表機伺服器、印表機 印表機 22.
(33) `. 首先演算法掃描過全部事件紀錄,產生事件資料中所包含的所有單一物件數的所有 物件組合(Item Sets) ,並計算各單一物件組的案例數(支持度)(表6);繼續產生2個物 件組合(2-item Itemsets),並計算2個物件組的案例數(支持度)(表7);一直反覆以上 的步驟,直到產生出包含「最大規則物件數」+ 1個物件的物件組為止或者產生符合最 小支持度物件組數為0時,系統也會中止物件組搜尋。將物件組排列組合,計算所有的 可能規則,同時計算規則的支持度、信心水準;過濾掉不符合最小支援度以及信心水準 的規則,此時即完成Apriori演算法的計算過程(表8)。. 表 6: 事件資料明細-Apriori-1. 物件組內容 印表機 網路 印表機伺服器. 支持度 5 3 2 表 7: 事件資料明細-Apriori-2. 物件組內容 印表機、網路 印表機、印表機伺服器 網路、印表機伺服器. 支持度 2 2 1 表 8: 事件資料明細-Apriori-3. 物件組內容 印表機、網路、印表機伺服器. 支持度 1. 23.
(34) `. 關聯規則的資料表,包括事件(Event)和事件明細(EventDetail),事件主檔(Event), 為案例 資料表 ,記 錄了事 件編 號 (Event_No)、使用 者編號(User_ID) 、紀錄 者編號 (Rec_ID)、記錄日期(Rec_Date)、結束日期(Done_Date)、狀態(Status)、問題描述(Event)、 原 因 (Cause) 、 分 類 (Category) , 以 事 件 編 號 (Event_No) 為 主 鍵 值 ; 事 件 明 細 檔 (EventDetail),為巢狀資料表,記錄相關物件及特徵,包括事件編號(Event_No)、物件 (Object)、特徵(Symptom)等欄位,利用事件編號(Event_No)做為外來鍵與事件主檔(Event) 做連結。其輸入及輸出變數皆為物件(Object)。. 透過關聯規則演算法找出來的相關規則,將會儲存於規則庫中,其規則庫的欄位, 包括如下,Model_Catalog,為資料探勘的專案名稱;Model_Name,為資料探勘的模組 名稱; Node_Rule,資料探勘出來的規則;Node_Probability,為資料探勘出來的機率, 如表9。. 表 9 : 規則庫的資料表欄位. Model_Catalog. Analysis Services-isMine. Model_Name. isMine <AssocRule support="1" confidence="1" length="2". Node_Rule Node_Probability. rule="網路 ->印表機"/> 1. 24.
(35) `. 3.3 推論模組(Inference. Module). 推論模組,當資訊人員尋求事件解答時,可透過推論模組的推論引擎,依據事件的 分 類 , 推 論 出 其 他 最 有 可 能 同 時 發 生 的 相 關 物 件 及 其 支 持 度 (Support) 、 機 率 (Probability)、調整後機率(Adjusted Probability),提供給資訊人員,做為解決問題的參考 依據;當問題解決之後,則將此知識儲存於知識庫中,以供下次解決問題之參考,如圖 8所示。. 圖 8:推論模組. 事件分類定義,即Help Desk人員針對該事件發生時的屬性及特徵來分門別類;相關 物件定義,即為事件發生後,連帶影響該事件的其他分類,例如,「印表機無法列印」 的事件,其事件分類為印表機,相關物件為網路、印表機伺服器等。. 25.
(36) `. 本研究採用資料探勘延伸語言 (Data Mining Extension,DMX)預測查詢的語法,搭 配關聯規則預測函數(PredictAssociation) ,再依據事件的分類,即可預測出其他最有可 能同時發生的相關物件及其支持度(Support)、機率(Probability)、調整後機率(Adjusted Probability)。關聯規則預測函數(PredictAssociation),主要是用來讀取事件資料表的事 件分類,比對所有關聯規則之推薦物件,並剔除已發生物件,以產生推薦物件,其語法 如下, PredictionAssociation(<Table column reference> [,INCLUSIVE | EXCLUSIVE | INPUT_ONLY] [,INCLUDE_STATISTICS][,INCLUDE_NODE_ID][,<n-items> ] 關聯規則 預測 函數(PredictAssociation)的各個參數說明如下,<Table column reference> 為 資料探勘 模型 中的資料表 欄 位 ;INCLUSIVE 為預測結果包含空值; EXCLUSIVE為預測結果排除空值,此參數為預設值;INPUT_ONLY為不預測,只傳回 事件記錄中有發生過的物件;INCLUDE_STATISTICS是預測結果會自動傳回支持度 (Support)、機率(Probability)、調整後機率(Adjusted Probability)三個統計資訊欄位; INCLUDE_NODE_ID為預測結果會在回傳時加入$NodeId欄位,以顯示推薦這個物件是 根據哪一條規則;<n-items>列出前n項機率最高的預測物件。. 26.
(37) `. 利用DMX及資料探勘函數 PredictionAssoication 預測查詢出來的資料,包含4個欄 位,物件 (Object)、支持度(Support)、機率(Probability)、調整後的機率(Adjusted Probability),分別說明如下表10 ,其中支持度(Support)在Microsoft SQL Server2005 內,將會以符規則的交易次數呈現,並非由交易次數的百分率來看,其交易次數越多越 有代表性。. 表 10 : 關聯規則指標-事件資料. 欄位. 說明 事件發生後,連帶影響該事件的其他分類,例如, 「印. Object(相關物件). 表機無法列印」的事件,其事件分類為印表機,相 關物件為網路、印表機伺服器等。 代表A與B同時發生的機率. Support(支持度) Support (A => B)= P( A∩B) Probability(機率). 信心水準,代表規則中有A的條件下會有B的機率 Confidence (A => B)= P( B | A) 此屬性與「Important」為正相關 Importance(重要性) ,用來判斷此規則是否有意義。 (A => B) = log (p(B|A)/p(B|not A)) = 0:表示A和B沒有關聯性。. Adjusted Probability. > 0:表示一旦擁有A則再擁有B的概率會增加。. (調整後的機率). < 0:表示一旦擁有A則再擁有B的概率會降低。 例如:有A的條件下會有B的機率 : 80%, 但在這兩種情況,就會有不一樣的結果 B的機率若為20%,則判定為有意義規則 B的機率若為90% ,則判定為無意義規則. 27.
(38) `. 舉例說明,當發生事件「印表機無法列印」時,其事件分類為印表機,透過推論模 組,依「印表機」的事件分類推論出與「印表機」相關聯的物件有網路、電子郵件、郵 件伺服器,如表11,其支持度(Support)分別為6、3、2,代表著在「印表機」的事件分 類下,網路發生問題的頻率最高,其值為6;機率(Probability)分別為0.7、0.3、0.2, 代表著在「印表機」的事件分類下,網路發生問題的機率為0.7;調整後的機率(Adjusted Probability)分別為0.52、0.26、0.18,皆大於0,代表網路、電子郵件、郵件伺服器皆與 事件分類印表機呈現正相關;而這三個物件中,以網路的關聯性最高,故可得知在處理 此問題時,可先從網路開始著手,以加快解決問題的速度。. 表 11: 關聯規則指標-事件資料-例子. 物件 (Object) 網路 電子郵件 郵件伺服器. 支 持 度 (Support) 6 3 2. 機 率 (Probability) 0.7 0.3 0.2. 28. 調整後的機率 (Adjusted Probability) 0.52 0.26 0.18.
(39) `. 3.4 社會網路模組(Social Network Module). 社會網路模組,如圖9,主要從員工資料庫中,找出相同工作性質的員工及擁有解 決問題能力的專家,並將其社會網路的關係呈現於雛型系統,讓資訊人員在解決問題遭 遇瓶頸時,能有額外的資源使用,進而更加快速地解決問題。. 圖 9:社會網路模組. 尋找專家的做法,在各個事件分類下,資訊人員將依據各專家所回答問題的解答之 有效程度給予評分,並將各事件分類下專家解決問題的總積分算出,分數越高,代表解 決問題的能力越高。最後再畫出此事件分類與專家的社會網路圖,此關係圖可提供給資 訊人員,當作額外的詢問及解決問題的管道。更進一步,當專家有事,無法解決問題時, 可尋求其他專家幫助,建立貣專家們的代理機制。. 尋找相似工作者的做法,主要將員工專長及工作經歷與使用者互相比較,計算出擁 有相同專長及執行過相同專案的總次數,數值越高,代表相似程度越高。最後,再將相 似工作者的社會網路關係圖畫出,提供給資訊人員參考。. 29.
(40) `. 3.4.1 尋找專家. 專家的定義,幫助資訊人員解決問題的人;專家的認定,依問題的分類,來累積解 答的分數,依分數的高低來認定專家的經驗值,累積的分數越高,代表專家對於此事件 分類的問題越有處理能力;分數的評斷,則請資訊人員來評分,分數的區間為1~10分, 分數越高,表示此專家的解答,越能有效解決問題;最後,依每種事件分類中,專家們 各自的積分畫出屬於此事件分類的社會網路圖。. 利用表12的例子,解釋繪製專家社會網路圖的計算過程。在「印表機」的事件分類 中,共有3個事件發生,事件的編號為1、2、3,員工0001、0005、0007,分別對這3個 事件給予解答,資訊人員依員工所給的解答給予評分,給員工0001的評分為8、8、6, 積分總和為22,給員工0005的評分為5、3、7,總積分為15,給員工0007的評分為2、3、 4,總積分為9,故對於「印表機」事件分類來說,員工0001的解決問題能力大於員工0005 及0007。. 表 12 : 以印表機分類的專家積分計算. 分類 印表機 印表機 印表機 印表機 印表機 印表機 印表機 印表機 印表機. 員工 0001 0001 0001 0005 0005 0005 0007 0007 0007. 事件 1 2 3 1 2 3 1 2 3. 資訊人員給的評分 8 8 6 5 3 7 2 3 4. 30. 積分總和 22. 15. 9.
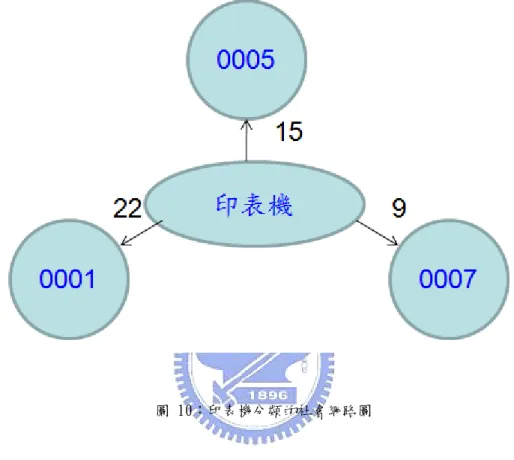
(41) `. 依上面例子,畫出以「印表機」事件分類的專家社會網路圖。中間的圓,代表「印 表機」事件分類;四周的圓為「專家的編號」;其連接線旁的數值代表「此印表機分類 中,專家們的總積分」 ,分數越高,表示此專家的解答,越能有效解決問題,如下圖10。. 圖 10:印表機分類的社會網路圖. 31.
(42) `. 3.4.2 尋找相似工作者. 相似工作者的定義,對於使用者來說,代表工作性質非常相近的員工;本研究,採 用比對使用者與企業員工的專長及工作經歷,若專長有1個相同,即相同專長的計算次 數加1次,若以工作經歷來看,曾有在一貣工作者,如執行相同專案,即認定為工作經 歷相同,相同工作經歷的計算次數加1次,最後,再將此相同專長及相同專案的次數加 總,用以計算使用者與其他工作者的相似程度,再畫出以使用者為主的相似工作者社會 網路關係圖。. 利用表13的例子,解釋繪製相似工作者社會網路的計算過程。以工作經歷來看,使 用者0002,曾經參與的專案有A、B、C、D、E的專案;員工0002,曾經參與的專案有A、 B、C、W、X專案;員工0006,曾經參與的專案有A、B、M、N、O專案,故與使用者 002有相同專案個數;員工0006有3個,分別為A、B、C專案;員工0008有2個,分別為 A、B專案;以專長來看,使用者0002的專長,包括Java、Oracle、印表機、網路、郵件 伺服器,員工0006的專長,包括Java、Oracle、印表機、網路、MES,員工0008的專長, 包括印表機、網路、C#、VB、PC,故與使用者0002有相同專長的個數,員工006有4個, 分別為Java、Oracle、印表機、網路,員工0008有2個,分別為印表機、網路。則將相同 的專長及工作經歷次數加總,即可得知員工0006與0002相似程度的總和為7,員工0008 與0002相似程度的總和為4,以相似程度較高的員工0006,為使用者0002最相似工作者。. 32.
(43) `. 表 13 : 相似工作者的相似度計算. 使用者 (0002) A專案 B專案 C專案 D專案 E專案. 專案. 與使用者0002有相同專案 的個數 Java Oracle 印表機 網路 郵件伺服器. 專長. 與使用者0002有相同專長 的個數 總和(相似程度). 員工 (0006) A專案 B專案 C專案 W專案 X專案. 員工 (0008) A專案 B專案 M專案 N專案 O專案. 3. 2. Java Oracle 印表機 網路 MES. 印表機 網路 C# VB PC. 4. 2. 7. 4. 從上面的例子繪製出與0002相似工作者社會網路圖,中間的圓為使用者0002;四周 的圓為相似工作者(0006、0008);連接線旁的數值,代表相似程度的高低,數值越高, 代表相似程度越高,反之亦然,如圖11。. 圖 11:0002的相似工作者社會網路圖 33.
(44) `. 四、雛型系統建置及實作 依據第三章所提的架構,設計出一個雛型系統,說明整個架構的運作方式。本章分 為四個部份,第一部份介紹系統的開發工具與平台;第二部份為系統設計的說明;第三 部份介紹系統實作;第四部份則是提出一個實際的例子,用以說明整個系統架構的運作 方式,幫助大家理解本系統的用途及功用。. 4.1 系統的開發工具與平台. 過去以統計出發的資料探勘工具,由於本身並沒有開發工具,因此所有的資料探勘 應用只能依附於既有的分析平台,根本無法將自身的工具整合於企業既存的資訊平台 中,而 Microsoft SQL Server 2005 能利用開發工具來開發屬於自己企業的資料探勘系 統,在本研究中,除了社會網路繪製工具,採用免費的軟體 Graphivz 以外,所有相關 開發工具皆採用微軟的產品。下表14,為本雛型系統的開發工具與平台。. 表 14:雛型系統的開發工具與平台. 系統平台. Operation System. Microsoft Windows Vista. Application Server. IIS. Database Server. Microsoft SQL Server 2005. 系統開發工具. .Net Framework 2.0. 系統開發語言. C#. 程式開發環境. Microsoft Visual Studio 2005. 資料探勘工具. Microsoft SQL Server 2005 Analysis Services. 資料探勘應用程式開發. ADOMD.NET、DMX. 社會網路繪製工具. Graphviz-2.18. 34.
(45) `. 4.2 系統設計. 系統主要由問題管理、社會網路及公用模組等三部份所組成。問題管理,主要包括 下列功能,事件新增、查詢及修改、待辦問題、問題的關聯規則、問題的知識管理;社 會網路,主要功能包括,查詢相似工作者的社會網路及尋找專家的社會網路;公共模組, 為設計系統的共用畫面,如系統登入、系統的主畫面、主版頁面的設計。. 系統功能結構介紹如下,如圖12,員工登入,主要認證使用者擁有哪些權限及功能; 問題管理,包括事件新增、修改,即為新增、修改事件的資料;待辦問題,即為列出重 複性事件;知識管理,即為列出知識庫中與事件分類相關的解決方法;社會網路,即為 找出相似工作性質的員工及擁有解決問題能力的專家,並將其社會網路的關係呈現於雛 型系統。. 圖 12:系統功能結構圖. 35.
(46) `. 4.3 系統實作. 系統的實作,主要分為5個部份,第一個部份為公用模組實作,例如:系統的登入、 系統首頁、主版頁面的實作及相關程式碼等;第二部份為事件處理模組實作,主要說明, 新產生的事件資料的處理介面及知識支援的相關程式碼及畫面;第三部份為資料探勘模 組實作,說明資料探勘模組實作的過程、畫面及程式碼;第四部份為推論模組實作,說 明如何將資料探勘後的規則,依資訊人員所需,提供給資訊人員;第五部份為相似工作 者及專家社會網路繪製的實作、畫面及程式碼。介紹如下:. 4.3.1 公用模組實作. 公用模組實作,設計系統的共用的畫面,如系統登入、系統首頁、主版頁面的設計 等。圖13,為使用者登入系統畫面,使用者輸入帳號及密碼,認證通過即可進系統的主 畫面。. 圖 13:使用者登入系統畫面. 36.
(47) `. 圖14,為系統首頁,包括三個部份,第一部份為「待辦問題」,主要列出重複發生 事件的清單;第二部份為「熱門問題」 ,依問題的熱門程度,以不同的文字大小來呈現, 愈熱門的問題,所代表的字體越大,附上其程式碼,如圖15;第三部份為最新的「社會 網路」。. 圖 14: 系統首頁. 37.
(48) `. 圖 15: 熱門問題的程式碼. 38.
(49) `. 為了讓網頁有一致的外觀,使用描述一致性外觀的網頁稱為Master Page,引用Master Page的網頁稱做Content Page,Master Page所扮演的角色就像是佈告欄的看板,而Content Page則扮演佈告欄中的公告。圖16,為使用者的主版設計畫面。下段附上片段的程式碼, 主要分為兩個部份,Master Page 及Content Page。Master Page的程式碼如下,<%@ Master Language="C#". AutoEventWireup="true". CodeBehind="UserMasterPage.Master.cs". Inherits="WebApplication_isMine.MasterPage" %>. ;而Content Page的程式碼如下,. <%@PageLanguage="C#"MasterPageFile="~/User/UserMasterPage/UserMasterPage.Master "AutoEventWireup="true"CodeBehind="User_index.aspx.cs"Inherits="WebApplication_isMi ne.User.User_index" Title="Content Page" %>,再利用Contetplaceholder來,放入想呈現的 內 容 , <asp:Content. ID="Content1"ContentPlaceHolderID="ContentPlaceHolder2". runat="server"></asp:Content>. 圖 16:使用者的主版設計畫面 39.
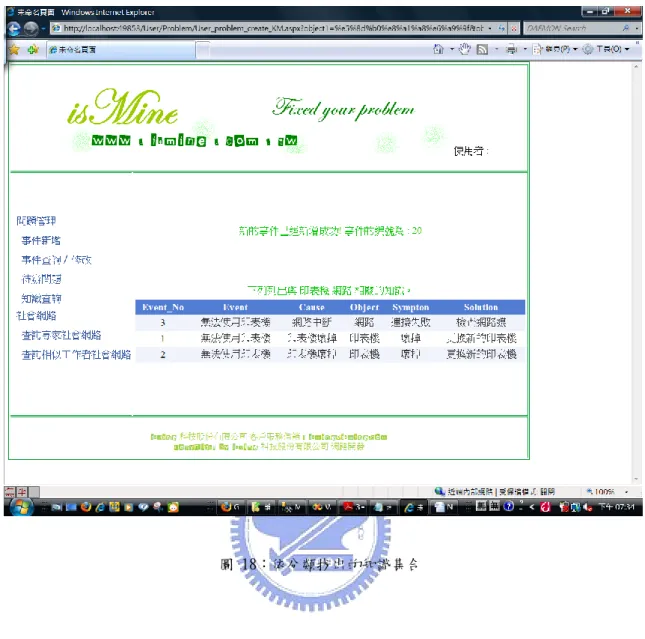
(50) `. 4.3.2 事件處理模組實作(Incident Process Module). 資料處理模組實作,主要實作事件輸入的功能,當收到使用者問題時,Help Desk 即記錄提問者、記錄者、問題發生的日期、問題結束的日期、問題描述、相關的物件、 相關物件的特徵、問題原因、分類、狀態等,如下圖17所示。當事件輸入完畢後,系統 會依事件分類,到知識庫中,找出相關事件分類的處理方法,以提供Help Desk問題處理 參考。如圖18。. 圖 17:事件輸入畫面. 40.
(51) `. 圖 18:依分類找出的知識集合. 41.
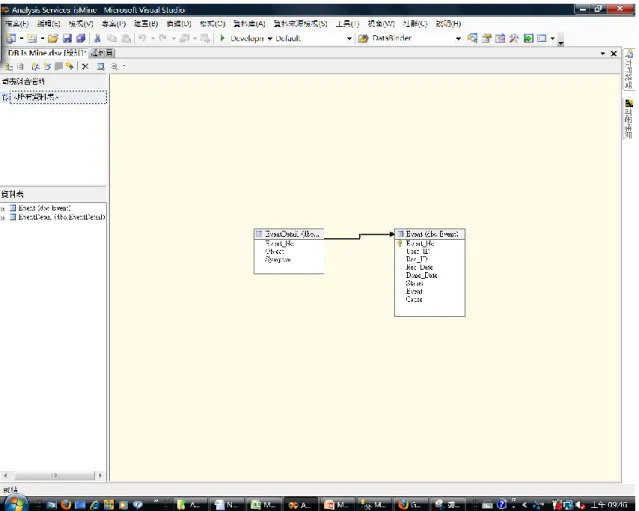
(52) `. 4.3.3 資料探勘模組實作(Data Mining Module). 資料探勘模組實作,主要利用Microsoft SQL Server 2005的資料探勘工具,實作問題 資料關聯規則的分析,找出問題的相關物件,提供使用者作為問題解決的參考,此資料 探勘模組需每天定時於後端執行,才可提供給推論模組使用。圖19,為實作資料探勘模 組於Microsoft Visual Studio中的部份實作畫面。. 圖 19:資料表關係呈現. 42.
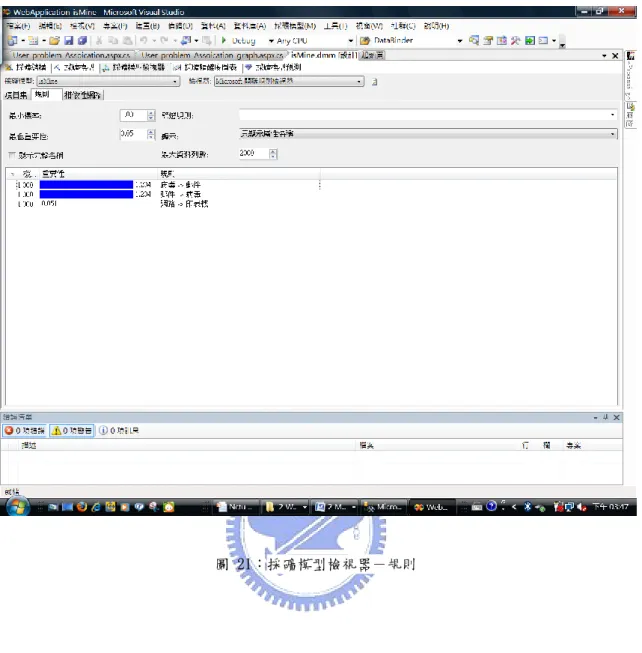
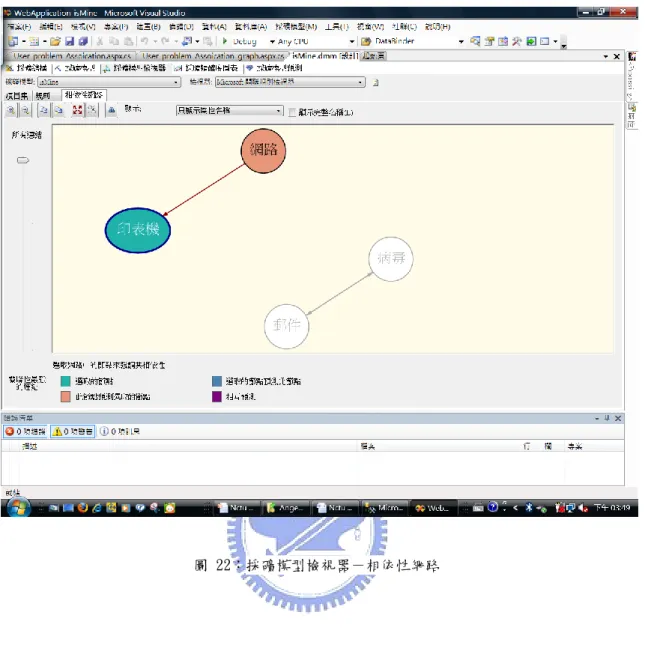
(53) `. 資料探勘的結果,可透過項目集檢視器,用來檢視Apriori演算法中產生的物件組內 容及其支持度(Support)。如圖20的第一項「印表機」的支持度(Support)為15;也可透過 規則檢視器可用來檢視Apriori演算法中產生的關聯規則,進而了解關聯規則內容及其信 心水準(機率,Probability)及重要性(Importance)。如圖21, 「網路->印表機」的機率 (Probability)為1,重要性(Importance)為0.051;透過相依性網路是為了讓使用者了 解變數之間關連性的圖形檢視。每一個箭頭連結代表著預測的關係(貣點為輸入變數, 箭頭端為輸出變數),同時,我們可根據每個箭頭連結的強弱來了解變數之預測關聯性 的強度,如圖22。. 圖 20:採礦模型檢視器-項目集. 43.
(54) `. 圖 21:採礦模型檢視器-規則. 44.
(55) `. 圖 22:採礦模型檢視器-相依性網路. 45.
(56) `. 4.3.4 推論模組實作(Inference Module). 利用資料探勘模組所產生的關聯規則,來做「探勘模型預測」 ,也就是說,透過DMX 的預測查詢語法,從規則資料庫中,依據事件的分類,推論出其他最有可能同時發生的 相關物件及其支持度(Support)、機率(Probability)、調整後機率(Adjusted Probability),提 供給資訊人員,做為解決問題的參考依據。. 點選「待辦問題」功能後,即可選擇要解決的問題,例如要解決「印表機無法列印」 的事件,資訊人員可以點選該事件「關聯物件」連結,如圖23;此時,推論模組會依據 該事件的分類,推論出其他最有可能同時發生的相關物件及其支持度(Support)、機率 (Probability)、調整後機率(Adjusted Probability),提供給資訊人員,做為解決問題的參考 依據。如圖24。. 46.
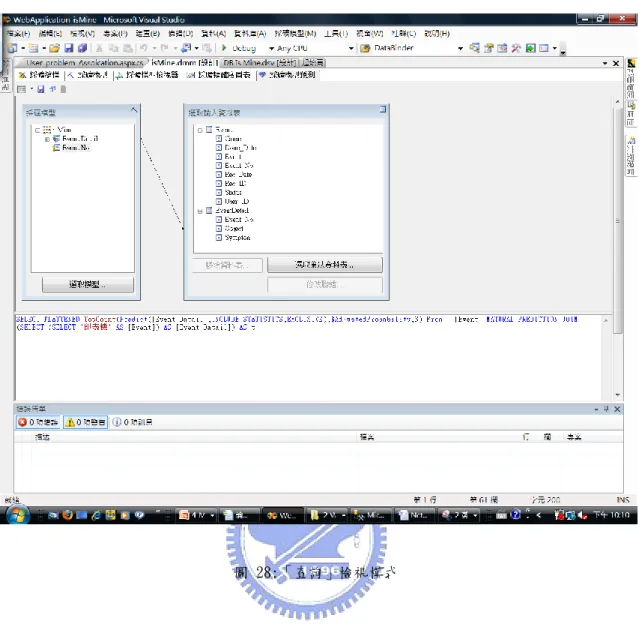
(57) `. 圖 23:待辦問題. 47.
(58) `. 圖 24:問題關聯. 如圖24的推論結果顯示,當發生事件「印表機無法列印」時,其事件分類為印表機, 透過推論模組,依「印表機」的事件分類推論出與「印表機」相關聯的物件有網路、電 子郵件、郵件伺服器,其支持度(Support)分別為6、3、2,代表著在「印表機」的事件 分類下,網路發生問題的頻率最高,其值為6;機率(Probability)分別為0.7、0.3、0.2, 代表著在「印表機」的事件分類下,網路發生問題的機率為0.7;調整後的機率(Adjusted Probability)分別為0.52、0.26、0.18,皆大於0,代表網路、電子郵件、郵件伺服器皆與 事件分類印表機呈現正相關;而這三個物件中,以網路的關聯性最高,故可得知在處理 此問題時,可先從網路開始著手,以加快解決問題的速度。. 48.
(59) `. 「待辦問題」的實作部份程式碼,如圖25,主要從事件資料表中,找出重複發生的 事件,呈現於畫面上。「推論模組」的實作部份程式碼,如圖26,則是透過DMX預測查 詢語法,從規則資料庫中,依據事件的分類,推論出其他最有可能同時發生的相關物件。. 圖 25 : 待辦問題的程式碼. 圖 26 : 推論模組的程式碼. 49.
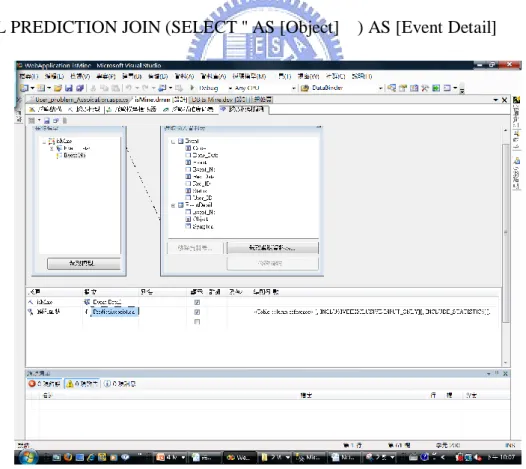
(60) `. DMX預測查詢語法,可由Microsoft Visual Studio的「探勘模型預測」功能產生, 其實作的步驟如下,首先,在探勘模型預測畫面的左方,選擇所要預測的資料探勘模型; 接下來,在探勘模型預測畫面右方,選擇「案例資料表」(Event)及「巢狀資料表」 (EventDetail);接著,透過由下方選單,組合DMX預測查詢語法,如圖27;設定完成後, 即可切換至「查詢」模式,此時下方視窗會自動產生完整的DMX預測查詢語法,如圖28。 確認語法無誤時,即可切換至「結果」模式,系統則會回傳預測結果,如圖29;產生的 語法如下。 SELECT FLATTENED PredictAssociation([isMine].[EventDetail],INCLUDE_STATISTICS,include_node_id) From [isMine] NATURAL PREDICTION JOIN (SELECT '' AS [Object]. ) AS [Event Detail]. 圖 27:下拉選單組成Select子句 50.
(61) `. 圖 28:「查詢」檢視模式. 51.
(62) `. 圖 29:「結果」檢視模式. 52.
(63) `. 4.3.5 社會網路模組實作(Social Network Module). 社會網路模組的實作,包括尋找專家、尋找相似工作者的實作,內容分別描述如下。. 4.3.5.1 尋找專家實作. 點選「查詢專家社會網路」功能後,即可在「事件分類」欄位內,輸入所要查詢的 資料,例如輸入印表機,按下「Submit」按鈕後,系統即可自動繪製出,印表機分類與 各專家的社會網路圖,並將各專家解決此分類問題的積分表及繪製專家社會網路的語 法,呈現於畫面上,如圖30。. 圖 30 : 尋找專家的社會網路 53.
(64) `. 從圖30看出,專家0001、0005、0007解決印表機分類問題的積分為22、15、9,其 中以專家0001的積分為最高,再來是專家0005、0007,代表著專家0001在印表機分類中, 為最有經驗的專家,此時,資訊人員可向專家0001請教問題或者從知識庫中,找出專家 0001曾經解決過印表機問題的相關文件來參考,還有,專家0005、0007,可視為專家0001 的代理人,當專家0001無法解決問題時,也能請教專家0005、0007。. 尋找專家實作的程式碼,如圖31,解釋如下,主要包括三個部份,第一部份,依照 「事件分類」來找出所有專家解決問題的總積分;第二部份,則是組合出印表機分類與 各 專 家 社 會 網 路 圖 的 語 法 , 程 式 碼 如 下 , digraph G { charset=big5; node [fontname=”simhei”];印表機 -> 0001 [label=22] ;印表機 -> 0005 [label=15] ; 印表 機 -> 0007 [label=9] ; };第三部份,則是顯示印表機分類與各專家的社會網路圖。. 圖 31 : 尋找專家的程式碼. 54.
(65) `. 4.3.5.2 尋找相似工作者實作. 點選「查詢相似工作者社會網路」功能後,即可在「員工編號」欄位內,輸入所要 查詢的使用者員工編號,例如輸入0002,按下「Submit」按鈕後,系統即可繪製出,使 用者0002與其他相似工作者的社會網路圖,並將使用者0002與其他員工的相似程度表及 繪製相似工作者社會網路的語法,呈現於畫面上,如圖32。. 圖 32: 尋找相似工作者的社會網路. 55.
(66) `. 從圖32看出,依工作經歷及專長的相似程度分析,得知使用者0002與員工0006、0008 的工作相似程度,分別為7、4,代表員工0006與使用者0002相似程度較高,此時,資訊 人員可依相似程度高低,依序詢問員工0006、0008,請教是否曾經遇過相同問題及解決 此問題的相關經驗,依此循環,直到收集足夠解決問題的相關資訊為止,以作為解決使 用者0002問題之輔助參考。. 尋找相似工作者實作的程式碼,如圖33,解釋如下,主要包括三個部份,第一部份, 從員工資料庫中,依「工作經歷」及「專長」分析使用者與其他員工的相似程度;第二 部份,則是組合出繪製使用者與相似工作者社會網路關係圖的語法,程式碼如下,digraph G { 0002 -> 0006[label=7] ; 0002 -> 0008[label=4] ; };第三部份,則是顯示使用者 與相似工作者的社會網路圖。. 圖 33 : 尋找相似工作者的程式碼. 56.
(67) `. 4.4 實例展示. 假設,使用者提出一個問題給Help Desk,報案說「無法使用印表機」 ,這時Help Desk 將問題描述、影響問題的物件、特徵、分類等,新增於事件資料庫內;此時系統會依事 件分類列出相關的知識集,Help Desk可立即採用既有解決方法,順利的解決問題;但是 相同的問題還是重複發生,系統會以待辦問題的方式,呈現給資訊人員,告知這些問題, 並未完全解決;系統會依事件分類推論出可供參考的關聯規則集,資訊人員可利用這些 關聯規則來解決問題;在這同時,資訊人員也可以利用事件分類到專家的社會網路中找 尋有經驗的專家們,向專家們請教問題或者從知識庫中,找出專家曾經解決過相似問題 的相關文件來參考;再者,為更了解使用者的想法,也能到相似工作者的社會網路中, 找出相同工作經驗的人,請教是否曾經遇過相同問題及解決此問題的相關經驗,以作為 解決使用者問題之輔助參考。(如圖34~ 圖39). 57.
(68) `. 圖34為Help Desk新增使用者的事件「無法使用印表機」的畫面;圖35為新增 「無 法使用印表機」事件後,產生相關解決方案的知識集。. 圖 34:「無法使用印表機」-事件新增. 58.
(69) `. 圖 35:「無法使用印表機」-列出相關知識供參考. 59.
(70) `. 圖36,資訊人員選擇「無法使用印表機」的待辦問題來處理;圖37,系統會依據「無 法使用印表機」事件的分類,推論出其他最有可能同時發生的相關物件及其支持度 (Support)、機率(Probability)、調整後機率(Adjusted Probability),提供給資訊人員,做為 解決問題的參考依據。. 圖 36:「無法使用印表機」-待辦問題. 60.
(71) `. 圖 37:「無法使用印表機」-推論結果. 61.
(72) `. 圖38,顯示以「印表機」事件分類的專家社會網路圖;圖39,顯示以使用者0002為 主的相似工作者社會網路關係圖。. 圖 38:以「印表機」為分類的社會網路. 62.
(73) `. 圖 39:與「0002」使用者之相似工作者. 63.
(74) `. 五、結論及未來方向 5.1 結論. 本研究主要是針對 ITIL 服務管理中的問題管理,提出一個服務導向的問題管理架構。 從歷史問題資料庫中挖掘出相關的問題管理規則,進而找出問題發生的主因以及問題解決 之參考依據。並建構問題管理的社會網路,運用社會網路分析方法找出相似的工作者及解 決問題之專家進而合作解決問題。最後,實作 Web 系統呈現研究成果,以確認問題管理 架構的可行性。. 本研究的主要貢獻如下,第一,做為企業導入 ITIL 問題管理(Problem Management) 的參考依據;第二,利用社會網路分析(Social Network Analysis)方法,找出工作性質相似 的工作者及解決問題的專家,提供資訊人員問題解答的詢問對象,加速問題的處理速度; 第三,使用資料探勘技術,從歷史的問題資料庫中,找出問題可能原因,提供資訊人員尋 找問題主因的參考依據,以減少資訊人員問題解決所需的時間,增加資訊人員的生產力。. 64.
(75) `. 5.2 未來研究方向. 基於公司機密考量及資料搜集不易等原因,本研究僅採用假設性的虛擬資料來實作此 服務導向的問題管理架構,未來可透過實際資料和環境建置,更完整的驗證本研究的可行 性。. 專家的認定,除了依據專家所提出問題解答的有效程度來評分外,還可參考專家對問 題解答的貢獻程度,也就是說,該問題解答實際被引用的次數或比例,如此更能顯示出專 家對於該領域的專業程度;相似工作者的認定,除了依據工作經歷及專長來找出相似程度 外,也可加上其他特徵、屬性來加強相似程度的辨識,例如,相似工作者所屬部門、職位 輪調資料、工作性質等。. 加強與知識管理的整合,例如,透過自動化推薦知識的方式,提高知識使用的效率與 問題解決的速度;另外,為了提高專家與相似工作者分享知識的動力,也可與績效系統結 合。. 最後,可整合資訊技術基礎架構庫的其他模組,例如,利用服務水準管理(Service Level Agreement Management,SLA)的模組,來定義事件服務的等級,提昇 IT 服務的品質與 水準,讓服務導向的問題管理架構更加完整。. 65.
(76) `. 參考文獻 中文部份 [1] 小家,「用SQL Server 2005的數據挖掘實現圖書館書目推薦服務」, http://www.cnblogs.com/wzjingwei/archive/2007/03/06/665780.html [2] 尹相志,2005,「Microsoft SQL Server 2005 資料採礦聖經」。 [3] 尹相志,2005,「Microsoft SQL Server 2005 Data Mining 資料採礦與Office 2007資料採礦增益集」。 [4] 李桄瑋,2005,「IT服務管理:運用主題地圖與資料探勘支援事件管理」,國立 交通大學資訊管理研究所,碩士論文。 [5] 李鴻生,2005,「探討企業採用資訊科技基礎架構庫因素之研究」,輔仁大學 碩士論文。 [6] 林立傑,2006,「《組織管理》ITIL資訊服務升級的關鍵指標 台灣產業漸由技 術導向轉型為服務導向」,工商時報/工商經營報 [7] 林佳瑩,2005,「社會網路. 經營知識 。. Social Networks」,政大圖書館每月專題介紹。. [8] 周柏村,2005,「IT服務管理:運用情境認知之知識支援於事件管理」,國立交 通大學資訊管理研究所,碩士論文。 [9] 徐慧成,2003 ,「利用網頁資訊建構多階層指導教授與研究生之網路關係」, 國立中山大學資訊管理研究所,碩士論文。 [10] 蔡坤家,“IT服務發展的趨勢及ISO20000標準” , http://dbmaker.syscom.com.tw/mag/114/coverstory_01.htm [11] 劉雅文、邱孙輝,「Business Models and Strategies for Social Networks」。 [12] 羅子文,「Web2.0概念的圖書館個人推薦系統」,國立交通大學資訊管理研 究所,碩士論文。 66.
(77) `. [13] Blake,「畫關係圖的小幫手 : graphviz」, http://greenisland.csie.nctu.edu.tw/wp/2007/04/13/989/ [14] DebianWiki,「graphviz. 介紹」,. http://wiki.debian.org.tw/index.php/graphviz [15] Malcolm Fry,「問題管理的目標」, http://www.nextslm.org/itil/books/goals-of-itil/tc/ch2.shtml [16] RedBug’s Home,「Social Network 介紹」, http://redbug.twbbs.org/index.php/2007/10/10/317 [17] Puma,「利用ASP.NET結合PowerShell的command,來取得Server端系統的 Process」 http://blog.blueshop.com.tw/hent/archive/2008/01/28/54199.aspx [18] UniMiner,「資料探勘Data Mining的介紹」, http://www.uniminer.com/center01.htm. 67.
數據
+7
相關文件
推理論證 批判思辨 探究能力-問題解決 分析與發現 4-3 分析文本、數據等資料以解決問題 探究能力-問題解決 分析與發現 4-4
回應電子平台問題 自主探索 考察點額外講解 支援學生.
熟悉 MS-OFFICE
Keywords: Mobile ad-hoc network, Cluster manager electing, Fuzzy inference rule, Workload sharing, Backup manager... 致謝 致謝
熟悉 MS-OFFICE
In our AI term project, all chosen machine learning tools will be use to diagnose cancer Wisconsin dataset.. To be consistent with the literature [1, 2] we removed the 16
We try to explore category and association rules of customer questions by applying customer analysis and the combination of data mining and rough set theory.. We use customer
資料探勘 ( Data Mining )
