行政院國家科學委員會專題研究計畫 成果報告
以 CEFR 為基礎之數位華語文行動學習載具之研發
研究成果報告(精簡版)
計 畫 類 別 : 個別型 計 畫 編 號 : NSC 98-2631-S-003-007- 執 行 期 間 : 98 年 08 月 01 日至 99 年 07 月 31 日 執 行 單 位 : 國立臺灣師範大學應用電子科技學系 計 畫 主 持 人 : 何宏發 共 同 主 持 人 : 蔡忠霖 報 告 附 件 : 出席國際會議研究心得報告及發表論文 處 理 方 式 : 本計畫可公開查詢中 華 民 國 99 年 12 月 17 日
Chinese Word Learning System on Mobile Device with Dynamic
Timing of Review
Hong-Fa Ho
Department of Applied Electronics Technology National Taiwan Normal University, Taipei, Taiwan
Ping-Zong Lin
Department of Applied Electronics Technology National Taiwan Normal University, Taipei, Taiwan
Abstract
One of the most unmanageable parts of Chinese language learning and teaching for non-native Chinese speakers is the Chinese words teaching and learning. Not only the quantity of Chinese words is large but also Chinese words are not easy to be memorized. In this paper, a Chinese word learning system on a mobile device for non-native Chinese speakers is presented. The learning target is 2500 frequently used Chinese words. For managing Chinese word learning, a Chinese word quotient is
proposed. Based on the quotient, an estimation of “Chinese word quantity”, which
represents the ability of Chinese word recognition, is developed. For assessing the learning performance, thirty two test models for Chinese words are also studied. The Item Response Theory (IRT) is applied to analyze these thirty two test models. A Chinese word learning plan and a two-phase learning strategy are presented. By using the plan, teachers can easily manage the most unmanageable part of language instruction and students also have an arranged Chinese learning schedule. Finally, the method of dynamic timing of review is developed to overcome the forgetting curve of individual. The difficulty parameters of the thirty two test models have been well analyzed by IRT and therefore teachers can easily find the proper test models to test students or learners accordingly. The Chinese learning plan of 2500 words, the two-phase learning strategy, thirty two test models, and the dynamic timing of review will be implemented in a mobile device. With the mobile device, teachers can easily manage the part of Chinese words teaching and learners can learn efficiently and conveniently.
Keywords: Chinese word, the list of frequently used words in modern Chinese, IRT,
1. Introduction
In a decade, Chinese is regarded as an important language of communication. Chinese characters are invented by Chang-Jie (Zhang, 2005). He applies the special characteristics of animals, plants, and the natural phenomena he found to create Chinese characters. Chinese characters are radical (root character) or compound character which contains two or more radicals, not alphabetic characters. The government of the People's Republic of China approved pin-yin in 1958 and officially adopted by it in 1979 to represent Chinese characters for non-Chinese speakers. Pin-yin represents Chinese characters and their sounds using the Roman alphabet and a set of tonal symbols to represent their pitch (Wu and Miller, 2007). The test model must be considered in the context of how Chinese character differs from English and other alphabetic orthographies. Chinese is considered a logographic, or morph syllabic, system (DeFrancis, 1989) in which the units of the orthography (characters) correspond to both syllables and morphemes. The typical Chinese character is a square-shaped symbol that, with some exceptions, represents one pronunciation and one morpheme. The characters are composed of radicals. Some radicals are characters by themselves, and some are not (Liu, Wang, and Perfetti, 2007).
However, The Chinese script, due to its logographic nature, is considered the most difficult script to learn by non-native learners. A recent survey (Ke et al., 2001) regarding the most difficult challenges for students of Chinese as a foreign language in pre-college programs suggests that character learning is the greatest challenge. The difficulty liesin the retention in thelearner’slong-term memory and instant retrieval of the three attributes of the Chinese character –sound (pronunciation), shape (graphic structure), and meaning (Shen, 2004). Learning Chinese character in systematic manner over the long term is a labor-intensive endeavor, and one that places huge demands on their memories, time, and study capabilities (Everson, 1998).
Recently, there are many literatures which research how to learn Chinese. There are some good approaches to help learners study and apply Chinese well and memorize them. The following paragraphs will introduce them.
In Lam, Ki, Law, Chung, Ko, Ho, and Pun (2001), Lam et al. describe that printed or written forms of Chinese characters are composed from a limited number of
common components. They also use technology to enhance young children’s
understanding about the structural principles of Chinese characters. Furthermore, authors’literature reports on the design of CALL software based on a pedagogic method, helping students to develop the higher order skills, to analyze and categorize Chinese characters by using components. In Chung (2002), the aim of this study is to
examine whether temporal spacing of a character and its associated pin-yin and English equivalent prompts would enhance learning of meaning (English translation) and pronunciation relative to a condition where a character and its prompts were presented simultaneously. In addition, Chung investigated whether presenting the order from the character to the familiar prompts would improve the acquisition more than the order from the prompts to the target stimulus. In Shen (2004), author investigated how different encoding strategies affect retention of Chinese characters (words) as measured by recall of the sound and meaning of the characters. Three types of encoding strategies were investigated during character learning: rote memorization (shallow processing), student self-generated elaboration and instructor-guided elaboration (deeper processing). In Sun and Feng (2004), an intelligent tutoring system (ITS) was proposed for teaching students to write Chinese characters using correct stroke orders over the Internet. This system can efficiently help students to learn Chinese characters and to determine the correct stroke orders of Chinese characters more intelligently. Kuo and Hooper used posttests to explain what learning approach can achieve the best effect for learners of Chinese. These learning approaches include translation, verbal mnemonics, visual mnemonics, dual coding mnemonics, and self-generated mnemonics. The experiment result indicated participants who generated their own mnemonics achieve higher posttest performance than other approaches (Kuo and Hooper, 2004).
In Lam, Ki, Chung, Ko, Lai, Lai, Chou, and Lau (2004), the authors’objective was the notion of this variation-affording instructional software that allowed learners to attend to the essential aspects of what is to be learned. Furthermore, the idea of the learning object also differed from other instructional software in its small, self-contained and reusable nature, such that teachers could flexibly embed the learning objects into their own teaching materials. Wu and Miller analyzed the use of a tutoring package that consisted of modeling, hand prompts, and contingent praise or Chinese conversations with the tutor to increase the effectiveness of pin-yin in teaching correct tonal pronunciation to nonnative speakers learning Chinese. The
student’s pronunciation of Chinese characters could be improved by using the tutoring
package (Wu and Miller, 2007). In Liu, Wang, and Perfetti (2007), Liu, Wang, and Perfetti stated that an English speaker learning to read Chinese must acquire knowledge of the visual forms of characters, knowledge of the mappings of these forms to meaning and pronunciation, and knowledge of the language itself. Authors proposed an important assessment of the ability of learners of Chinese at the end of their first and second terms in a Chinese class. The examination included orthography, phonology, and semantics of Chinese. In Shen and Ke (2007), Shen and Ke provided a picture of a developmental continuum of radical awareness across instructional
levels among adult nonnative learners of Chinese. They also suggested that radical knowledge, radical perception skills, and radical knowledge application skills do not develop synchronously across learning levels, but rather that each of them shows a unique developmental trend. Chung (2007) examined the influence of different instructional presentations upon meaning and pronunciation acquisition in character learning. He also thought that the addition of color-coded prompts led to superior learning. Retention over two weeks was greater in the case of characters presented before prompts with color-coding. These experiment data were interpreted in terms of split attention, which arises when learners attend to multiple inputs simultaneously, and the beneficial effects of attending to a character prior to its prompts. The presentation of the Chinese character first and then its pinyin and color-coded English translation was recommended. In Allen (2008), author described that learning to write Chinese characters (hanzi, or in Japanese, kanji) from memory is an extremely inefficient use of time for students of Chinese as a foreign language—and this may be even more so for students of Japanese as a foreign language, because the time necessary to learn to write the characters is inversely proportionally to the usefulness of that skill. Author also integrated handwriting skills with the new electronic writing technologies to create an efficient and culturally sensitive program of instruction in
hanzi/kanji writing. In Ding, Richman, Yang, and Guo (2010), authors’purpose was to
evaluate rapid automatized naming skills (RAN) and immediate memory processes in
243 Chinese Mandarin–speaking elementary readers. The report pointed that poor
readers performed poorly on subtests involving a visual component and did relatively better on subtests involving verbal cues only, whereas a reversed pattern was shown in the group of good readers. The findings were interpreted to suggest that good and poor Chinese readers may be essentially different in applying visual strategies and verbal mediation during visual-verbal intra- and intermodal processing, and visual skills appear to be particularly important in reading of Chinese.
Recently, there are some literatures which pointed out why students do not have a good English ability. The EFL vocabulary was by far the most unmanageable part of language instruction (Tsai and Chang, 2009). Moreover, a poor vocabulary was acknowledged by most students at all levels (Lin, 2002; Segler, Pain, and Sorace, 2002). Therefore, it is obvious that vocabulary learning plays an important role in English-language acquisition. In addition, one of the learning problems for students is to forget learned vocabulary (Chen and Chung, 2008; Ho, 2006).
A number of studies showed language learners typically have significant difficulty remembering large amount of vocabulary (Anderson and Freebody, 1981; Mezynski, 1983; Oxford, 1990; DeCarrico, 2001). Furthermore, it has been found that numerous learners think that memorizing English vocabulary is difficult, especially
long or infrequently used words.
Memory retention is an ability that preserves learned information (Wikipedia contributors, 2005). If a learner does not review the learned words, the memory of the learned words will decrease. Forgetting is common for people; however, the speed at which one forgets differs among learners. The review process is a good way to enhance memory retention (Waugh and Norman, 1965). Each person has different retention abilities, even when learners are learning the same material. Furthermore, pronunciation has an impact on learners. Young (1997) argued that listeners follow a pattern of procedures when listening to a text. Learners make use of their background knowledge to interpret what they may hear next. They might make a guess and/or draw upon an inference from a context. During the process of listening, learners might develop metacognitive strategies to monitor comprehension.
Many of students think that it is difficult to learn words and learning words is a time-consuming process and thus they give up English eventually (Lin, 2002; Segler, Pain, and Sorace, 2002). However, people are concerned about methods of how to
quickly, efficiently and easily learn and review words. According to Chen’s (Chen and
Chung, 2008) review method based on IRT, he provided personalized learning strategies. Sounds play an important role in learning languages (Young 1997).
According to the problems on studying English for students, the approaches of learning English, such as memorizing English vocabularies, arranging study plan, dynamic timing of review, etc., are proposed and very useful for learning language. In this paper, a Chinese word learning system on a mobile device for non-native Chinese speakers is presented. The concepts and approaches of English learning will be modified slightly and applied to develop Chinese learning. The learning target is 2500
frequently used Chinese words. An estimation of “Chinese word quantity”, which
represents the ability of Chinese word recognition, is developed. Thirty two test models for Chinese words are also studied. The Item Response Theory (IRT) is applied to analyze these thirty two test models. A Chinese word learning plan and a two-phase learning strategy are presented. Finally, the method of dynamic timing of review is developed to overcome the forgetting curve of individual. With the mobile device, teachers can easily manage the part of Chinese words teaching and learners can learn efficiently and conveniently.
The rest of this article is organized as follows. A Chinese word quotient based on IRT and an estimation of Chinese word quantity is proposed in Section 2. With these
two definitions, learners’ability of recognizing Chinese words can be assessed easily.
A learning plan of Chinese word and two phases of Chinese word learning strategy are developed in Section 3. The two-phase Chinese learning strategy makes Chinese words learning process easier and faster. Section 4 introduces the method of dynamic
timing of review. This method helps learners overcome the forgetting curve of individual when they are studying any language. Finally, conclusions are drawn in Section 5.
2. Chinese word Quotient and Estimating Chinese word Quantity
A Chinese word quotient for languages is proposed first, and thirty two test models are developed based on it, especially for Chinese language learning. The reliabilities and validities of thirty two test models are analyzed by IRT (Baker and Frank, 1992; Hambleton and Swaminathan, 1985). These thirty two test models will be implemented in the form of the mobile device software in the near future. According to the Chinese word quotient, an estimating Chinese word quantity is proposed.
2.1 Chinese ward Quotient based on IRT
A Chinese word quotient, in the abbreviation form of CWQ, is a set of quotients derived from several different standardized test models and designed to assess the ability of recognizing Chinese word.
Definition 1:
The Chinese word quotient is:
CWQ(p, m, L, t, z)={CWQi| 1≦i≦d }, where
p is the examinee,
m is the native language of p, such as English in this study, L is the set of Chinese words,
t is the date of the test, and
z is the number of tests for each test model and is a positive integer. In
addition, tests are selected randomly from L by using the uniform distribution random function,
CWQi is the quotient of the number of correct answers divided by z of some
specific test model i about Chinese words in L,
and d is the number of different test models and is a positive integer.
Definition 1 can be applied to any languages. Both L1L1 and L1L2 are suitable.
Different languages have different number of test models. CWQ is time-variable for individual. If the parameter z is larger, the accuracy of CWQ is higher. It spends more time in testing, however.
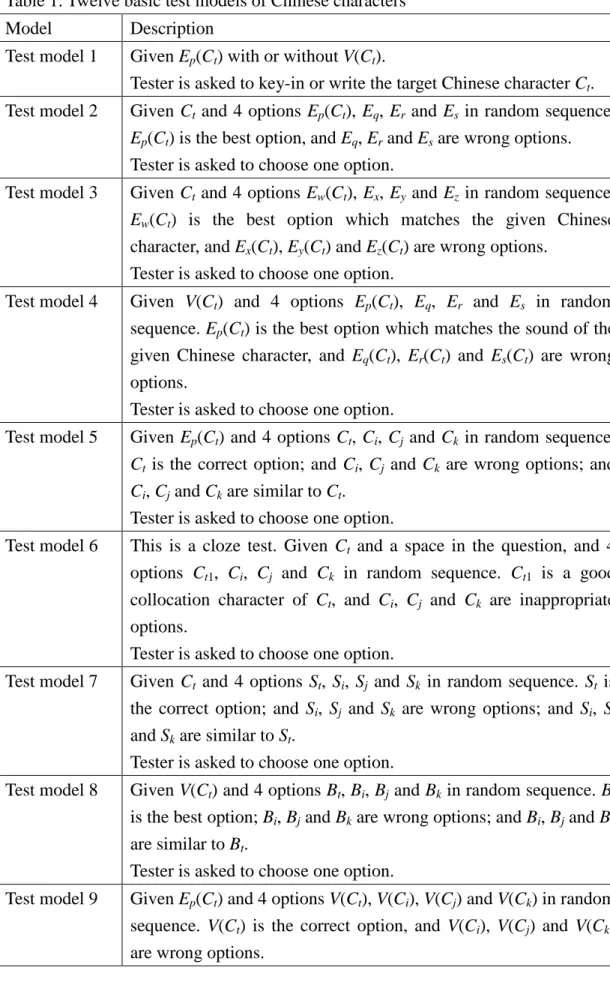
For Chinese as a Second language (CSL), especially for non-native Chinese learners, thirty two test models (d = 32) are proposed. They are described in Table 1. For reading easily and accurately, some symbols are defined in advance as follows.
Wt: the target traditional Chinese word;
Wi, Wj, and Wk: other traditional Chinese words, where t≠i≠j≠k;
Wa: the Chinese word whose pronunciation is the same as one of the target traditional
Chinese word;
Ci, Cj, Ck, Cm, and Cn: some traditional Chinese characters, where i≠j≠k≠m≠n;
St: the corresponding simplified Chinese word;
Si, Sj, and Sk: other simplified Chinese words, where t≠i≠j≠k;
Sent: a sentence using the target traditional Chinese word properly;
Seni, Senj, and Senk: other sentences using the target traditional Chinese word
improperly, where t≠i≠j≠k;
Ep(Wt): the corresponding English meaning of Wt;
Eq, Er, and Es: other English meanings, where p≠q≠r≠s;
Ew(Wt): the English vocabulary whose meaning consists with the target Chinese word;
Ex, Ey, and Ez: other English vocabularies, where w≠x≠y≠z;
Ec(Wt): the Chinese meaning of Wt;
Ed, Ee, and Ef: other Chinese meaning, where c≠d≠e≠f;
Bt: the corresponding phonetic transcription of Bopomofo of the target Chinese word;
Bi, Bj, and Bk: other phonetic transcription of Bopomofo of Chinese words, where t≠i
≠j≠k;
Pt: the corresponding phonetic transcription of pin-yin of the target Chinese word;
Pi, Pj, and Pk: other phonetic transcription of pin-yin of Chinese words, where t≠i≠j
≠k;
V(Wt): the pronunciation of Wt. Tester can hear the pronunciation from the speaker of
mobile device;
V(Wi), V(Wj), and V(Wk): the pronunciation of Wi, Wj, and Wk, respectively;
V(Ew(Wt)): the pronunciation of Ew(Wt);
V(Ex), V(Ey), and V(Ez): the pronunciation of Ex, Ey, and Ez, respectively.
Table 1. Thirty two test models of Chinese words
Model Description
Test model 1 Given Ep(Wt) with or without V(Wt).
Tester is asked to key-in or write the target of Chinese word Wt.
Test model 2 Given Wtand 4 options Ep(Wt), Eq, Er, and Esin random sequence.
Ep(Wt) is the best option, and Eq, Er, and Esare wrong options.
Test model 3 Given Ep(Wt) and 4 options Wt, Wi, Wj, and Wk in random
sequence. Wt is the correct option; Wi, Wj, and Wk are wrong
options; and Wi, Wj, and Wkare similar to Wt.
Tester is asked to choose one option.
Test model 4 Given Wtand 4 options Ew(Wt), Ex, Ey, and Ezin random sequence.
Ew(Wt) is the best option, and Ex, Ey, and Ezare wrong options.
Tester is asked to choose one option.
Test model 5 Given Ew(Wt) and 4 options Wt, Wi, Wj, and Wk in random
sequence. Wt is the correct option, and Wi, Wj, and Wk are wrong
options.
Tester is asked to choose one option.
Test model 6 Given Ec(Wt) and 4 options Wt, Wi, Wj, and Wk in random
sequence. Wt is the correct option, and Wi, Wj, and Wk are wrong
options.
Tester is asked to choose one option.
Test model 7 Given Wt and 4 options Ec(Wt), Ed, Ee, and Efin random sequence.
Ec(Wt) is the best option, and Ed, Ee, and Efare wrong options.
Tester is asked to choose one option.
Test model 8 Given Wtand 4 options Pt, Pi, Pj, and Pkin random sequence. Pt is
the correct option, and Pi, Pj, and Pkare wrong options.
Tester is asked to choose one option.
Test model 9 Given Wtand 4 options Bt, Bi, Bj, and Bkin random sequence. Bt is
the correct option, and Bi, Bj, and Bkare wrong options.
Tester is asked to choose one option.
Test model 10 Given Pt and 4 options Wt, Wi, Wj, and Wk in random sequence. Wt
is the correct option, and Wi, Wj, and Wkare wrong options.
Tester is asked to choose one option.
Test model 11 Given Bt and 4 options Wt, Wi, Wj, and Wk in random sequence. Wt
is the correct option, and Wi, Wj, and Wkare wrong options.
Tester is asked to choose one option.
Test model 12 Given Ew(Wt) and 4 options Pt, Pi, Pj, and Pk in random sequence.
Ptis the correct option, and Pi, Pj, and Pkare wrong options.
Tester is asked to choose one option.
Test model 13 Given Ew(Wt) and 4 options Bt, Bi, Bj, and Bk in random sequence.
Btis the correct option, and Bi, Bj, and Bkare wrong options.
Tester is asked to choose one option.
Test model 14 Given Pt and 4 options Ew(Wt), Ex, Ey, and Ezin random sequence.
Tester is asked to choose one option.
Test model 15 Given Bt and 4 options Ew(Wt), Ex, Ey, and Ezin random sequence.
Ew(Wt) is the correct option, and Ex, Ey, and Ezare wrong options.
Tester is asked to choose one option.
Test model 16 This is a cloze test. Given Cmand a space, and 4 options Cn, Ci, Cj,
and Ck in random sequence. Cnis the fitting option that Cmand Cn
can be combined to product a correct word Wt., and Ci, Cj, and Ck
are inappropriate options.
Tester is asked to choose one option.
Test model 17 Given Wt and 4 options Sent, Seni, Senj, and Senk in random
sequence. Sent is the correct option, and Seni, Senj, and Senk are
wrong options.
Tester is asked to choose one option.
Test model 18 Given Wt and 4 options St, Si, Sj, and Sk in random sequence. St is
the correct option; Si, Sj, and Sk are wrong options; and Si, Sj, and
Skare similar to St.
Tester is asked to choose one option.
Test model 19 Given Wt and 4 options V(Wt), V(Wi), V(Wj), and V(Wk) in random
sequence. V(Wt) is the correct option, and V(Wi), V(Wj), and V(Wk)
are wrong options.
Tester is asked to choose one option.
Test model 20 Given Bt and 4 options V(Wt), V(Wi), V(Wj), and V(Wk) in random
sequence. V(Wt) is the correct option, and V(Wi), V(Wj), and V(Wk)
are wrong options.
Tester is asked to choose one option.
Test model 21 Given Pt and 4 options V(Wt), V(Wi), V(Wj), and V(Wk) in random
sequence. V(Wt) is the correct option, and V(Wi), V(Wj), and V(Wk)
are wrong options.
Tester is asked to choose one option.
Test model 22 Given Ew(Wt) and 4 options V(Wt), V(Wi), V(Wj), and V(Wk) in
random sequence. V(Wt) is the correct option, and V(Wi), V(Wj),
and V(Wk) are wrong options.
Tester is asked to choose one option.
Test model 23 Given Ep(Wt) and 4 options V(Wt), V(Wi), V(Wj), and V(Wk) in
random sequence. V(Wt) is the correct option, and V(Wi), V(Wj),
and V(Wk) are wrong options.
Tester is asked to choose one option.
sequence. Ep(Wt) is the correct option, and Eq, Er, and Esare wrong
options.
Tester is asked to choose one option.
Test model 25 Given V(Wt) and 4 options, Ew(Wt), Ex, Ey, and Ez in random
sequence. Ew(Wt) is the correct option, and Ex, Ey, and Ezare wrong
options.
Tester is asked to choose one option.
Test model 26 Given V(Wt) and 4 options, Bt, Bi, Bj, and Bk in random sequence.
Btis the correct option, and Bi, Bj, and Bkare wrong options.
Tester is asked to choose one option.
Test model 27 Given V(Wt) and 4 options, Pt, Pi, Pj, and Pk in random sequence.
Ptis the correct option, and Pi, Pj, and Pkare wrong options.
Tester is asked to choose one option.
Test model 28 Given V(Ew(Wt)) and 4 options, Wt, Wi, Wj, and Wk in random
sequence. Wt is the correct option, and Wi, Wj, and Wk are wrong
options.
Tester is asked to choose one option.
Test model 29 Given V(Ew(Wt)) and 4 options, Bt, Bi, Bj, and Bk in random
sequence. Bt is the correct option, and Bi, Bj, and Bk are wrong
options.
Tester is asked to choose one option.
Test model 30 Given V(Ew(Wt)) and 4 options, Pt, Pi, Pj, and Pk in random
sequence. Pt is the correct option, and Pi, Pj, and Pk are wrong
options.
Tester is asked to choose one option.
Test model 31 Given Wt and 4 options Wa, Wi, Wj, and Wk in random sequence.
Wais the best option that its pronunciation consists with one of the
given Chinese word, and Wi, Wj, and Wkare wrong options.
Tester is asked to choose one option.
Test model 32 This is a cloze test of a sentence. Given a sentence with a space
and 4 options Wt, Wi, Wj, and Wk in random sequence. Wt is the
fitting option to complete the sentence, and Wi, Wj, and Wk are
inappropriate options.
Tester is asked to choose one option.
The aim of these aforementioned test models is to find out different perspectives about the ability of recognizing Chinese word for non-native Chinese speakers. The purpose of Test model 1 is to find out if tester can write or spell a word correctly with
or without pronunciation. Using a computer to key in the correct answer for test model 1 is another kind of test. The latter is easier than the former if testers understand the phonetic transcription of Bopomofo or pin-yin. Test models 2 to 7 are to find out whether tester understands the meaning of the target Chinese word or not, and examine testers the ability of translating language between Chinese and English. Test models 8 to 15 are to examine testers’comprehension and ability of using the phonetic transcription which includes Bopomofo and pin-yin. The ability of correct usage of Chinese words can be judged by using Test model 16. Test models 17 is to find out whether tester comprehends the meaning of the target Chinese word or not, and examine testers the ability of making a proper sentence. Test model 18 is to examine if learner has understood the difference between Traditional and Simplified Chinese font. With some Chinese words, English vocabularies, and phonetic transcription prompts, test models 19 to 30 are to examine tester the listening ability. The pronunciation ability is tested by test model 31. Finally, test model 32 is to examine the comprehension of the meaning of Chinese words and the ability of making a proper sentence.
Basically, Chinese characters are invented by Chang-Jie (Zhang, 2005). He applies the special characteristics of animals, plants, and the natural phenomena he found to create Chinese characters. It is obvious that studying Chinese is a difficult work even if there are the auxiliaries of pronunciation and phonetic alphabets. In this
study, learner’s native language m is English; however, m can also be Japanese,
Korean, and others.
For learners who are non-native Chinese speaker, CWQ is a function of thirty two tuples in this study.
CWQ(p, m, L, t, z)=<CWQ1, CWQ2, ... , CWQ31, CWQ32>, (1) where m is English or other language, but not Chinese; L is Chinese word; |L| is 2500;
z is 20; and d=32 in this study. The original score of every test model can be obtained
by z multiplied by CWQi. That is, Original score of a test model = z * CWQi. Thirty
two test models are evaluated by Item Response Theory as following.
For test model 1, two-parameter logistic model is considered since there is no chance to guess the answer. The formula for the item characteristic function with two parameters is ) ( ) ( 1 ) ( i i i i b a b a i e e P i1,2,,z, (2)
where Pi() stands for the probability of any tester with ability correctly answer
test i; ai stands for item discrimination parameter; bi stands for difficulty
parameter; and z is the number of tests. According to Chen and Chung (2008), a is ai
Considering b in (2), there are two cases in the test model 1. In case 1, with ori
without pronunciation, testers use the keyboard of a computer to key in the target Chinese word. In case 2, with or without pronunciation, testers have to write or spell the target Chinese word on the paper. However, Chinese words are not alphabetic words or phonetic words, test model 1 is not an easy test model whether it has pronunciation or not. Both Ho (2005, 2006) and Chen and Chung (2008) took the
length of English word as a factor of b . Chen & Chung also took phonetic andi
weight parameters of English word as two more factor of b . In addition, if ani
English word is brand new for the tester, it is very difficult to spell; if a word has been learned, it is easier. According to the aforementioned concept, the stroke-number and pronunciation of Chinese words will be as reference indexes to determine the value
i
b . Hence, the formula b of test model 1 for two cases are defined asi i
i i i
i L P G B
b for case 1, and
i i i i i i L P Q G B b for case 2
where Liis the stroke-number parameter of the ith test; Piis the pronunciation (or tone)
parameter of the ith test and the pronunciation is provided by a computer or a mobile
device; Qi is the parameter for writing or spelling a word; Gi is the weight parameter
about using frequency of Chinese words defined in the list of frequent characters in
modern Chinese; and Bi is the never-learned parameter of the Chinese word. If a
Chinese word is brand new for tester, for example, Bi=1; else Bi=10. If the
pronunciation of Chinese word is given, for example, Pi=0.2; else Pi=1. The values, Bi
and Pi, are determined by the designer. The difficulty of writing or spelling a word is
higher than one of keying in a word to computer if testers have an ability of using Bopomofo or pin-yin. Hence, there are five parameters to describe the difficulty in case 2.
For test models 2 to 32, three-parameter logistic model is considered since tester is able to guess the answer. The formula for the item characteristic function is
) ( ) ( 1 ) 1 ( ) ( i i i i b a b a i i i e e c c P i1,2,,z, (3)
where c stands for guessing parameter. If ai i=1.702 and ci=0.25, (3) becomes
one-parameter logistic model. The b for different test models are discussed asi
following. Considering b in (3), the stroke-number and pronunciation of Chinesei
word are not factors of difficulty since the purpose of these tests are not to examine
the ability of writing or spelling a word. The b of test models 2 to 32 are giveni
respectively in Table 2.
Test model The difficulty value bi
Test model 2 bi= Gq,i*Bq,i*Ki
Test model 3 bi= Go,i*Bo,i*Ki
Test model 4 bi= Gq,i*Bq,i*TCB
Test model 5 bi= Go,i*Bo,i*TCB
Test model 6 bi= Go,i*Bo,i*Ki
Test model 7 bi= Gq,i*Bq,i*Ki
Test model 8 bi= Gq,i*Bq,i*TP
Test model 9 bi= Gq,i*Bq,i*TB
Test model 10 bi= TP*Go,i*Bo,i
Test model 11 bi= TB*Go,i*Bo,i
Test model 12 bi= TB*TCB
Test model 13 bi= TP*TCB
Test model 14 bi= TP*TCB
Test model 15 bi= TB*TCB
Test model 16 bi= Gq,i* Go,i*Bq,i*Bo,i*RS
Test model 17 bi= Gq,i*Bq,i*Ki*F
Test model 18 bi= Gq,i*Bq,i*S
Test model 19 bi= Gq,i*Bq,i*H
Test model 20 bi= TB*H Test model 21 bi= TP*H Test model 22 bi= TCB*H Test model 23 bi= Ki*TCB*H Test model 24 bi= H*Ki*TCB Test model 25 bi= H*TCB Test model 26 bi= H*TB Test model 27 bi= H*TP
Test model 28 bi= TCB*Go,i*Bo,i
Test model 29 bi= TCB*TB
Test model 30 bi= TCB*TP
Test model 31 bi= Gq,i*Bq,i*Bo,i*C
Test model 32 bi= Go,i*Bo,i*F*Ki
Symbols in Table 2 are defined as following.
Gq,i is the weight parameter about using frequency of Chinese words defined in the
list of frequent characters in modern Chinese and given in the test model.
Go,i is the weight parameter about using frequency of Chinese words defined in the
list of frequent characters in modern Chinese and given in the test model.
Bo,iis the never-learned parameter of the Chinese word given in the test model.
Kiis the parameter about the proficiency level of the meaning of Chinese words.
TCB is the parameter of the ability of translating language between Chinese and
English.
TBis the weight parameter of the phonetic transcription and tone of Bopomofo.
TPis the weight parameter of the phonetic transcription of pin-yin.
RS is the weight parameter of recognizable Chinese word combined with both of test
model and option terms.
F is the parameter about the proficiency level of the meaning of the sentence.
S is the weight parameter of similarity between traditional and simplified Chinese
word.
H is the parameter of the listening ability. C is the parameter of tester’s pronunciation ability.
According to the aforementioned analysis of IRT, the reliability and validity of the practice tests can be obtained.
2.2 The Estimation of Chinese word Quantity
Based on the CWQ, the estimation of Chinese word quantity indicates the standard of the recognition of Chinese word of a person p with the native language m at the time t for the learning language L, and he/she had tested z questions. The definition of the estimation of Chinese word quantity is given as following.
Definition 2:
The estimation of Chinese word quantity is:
ECWQ(CWQ(p, m, L, t, z))= {ECWQi| 1≦i≦d }, where
ECWQi=CWQi* |L|;
|L| is the number of Chinese words in L; and
CWQ(p, m, L, t, z) and d are defined by Definition 1.
In this study, for learners whose native language is not Chinese, ECWQ is a function of thirty two tuples and defined as following.
ECWQ(CWQ (p, m, L, t, z))=<ECWQ1, ECWQ2, … , ECWQ31, ECWQ32> where m is English or other language but not Chinese, L is Chinese words, |L| is 2500,
z is 100, and d is 32 in this study.
Chinese words one knows. Based on ECWQ, a learning plan of Chinese words and a corresponding strategy is developed. ECWQ also helps people organize the previously most difficult part in language teaching.
3. Chinese word Learning Plan and Strategy
One of the major philosophies of Balance Scorecard (BSC) points out that only quantified indexes can be evaluated and quantified (Kaplan and Norton, 1996). Based on the concepts of management science, for examples Key Performance Indicators (KPI) and BSC, a feasible Chinese word learning plan is proposed. Teachers instruct learners to carry out the plan. Principals and directors manage and assess learners’ learning conditions of Chinese words. ECWQ acts as one of the KPI in language learning.
The pre-study (Ho, 2006) found that most learners gave up to fulfill the plan because of the loading and difficulties of spelling English words. To avoid this situation, two-phase vocabulary learning strategy is proposed. According to this learning strategy, the learning plan and strategy of learning Chinese words will be developed in the following sub-section.
3.1 Chinese word Learning Plan based on CWQ
The learning plan of Chinese words based on CWQ is proposed and can be regarded as a kind of the teaching strategy. For the teaching strategy of Chinese, Chinese word management system is suggested. Teachers and learners have clear steps and key index to follow through the plan. A learning plan of Chinese word for learners whose native language is not Chinese is presented in this paper.
Assume that there is a target set of Chinese words. There are 2500 Chinese words which are defined by the list of frequent characters in modern Chinese in the target set. Learners have to take 8 months to learn 2500 Chinese words. Suppose the 2500 Chinese words are denoted as W:
W={wi| 1≦i≦2500, i is the index of the sequence}
In the normal experience, choosing which Chinese character to learn first usually depends on the stroke-number, which means, the stroke number of the character defines the sequence of learning words. Learners’language interests will be attenuated because of the sequence of learning words. The sequence of learning words is determined by both the difficulty of character learning and the memory of individual. Learners learn Chinese words from the easiest words to the hardest words. Chen and Chung (2008) proposed personalized mobile English vocabulary learning
system based on item response theory and learning memory cycle. The concept of this system will be applied to the learning of Chinese.
Furthermore, learners have to study 2500 Chinese words among 3 periods. There is about 80 days for each period. Let
W={W1 ∪ W2 ∪ W3} where
W1={wi| 1≦i≦833},
W2={wi| 834≦i≦1666}, and
W3={wi| 1667≦i≦2500}.
W1 must be learned before the end of the first period. The ECWQ should be greater
than 833 before the end of the first period.
W2must be learned before the end of the second period. The ECWQ should be greater
than 1666 before the end of the second period.
W3 must be learned before the end of the third period. The ECWQ should be greater
than 2500 before the end of the third period.
CWQ testing software can be used to examine and find out learners’ECWQ at
any time. If a learner’s ECWQ is higher than expected ECWQ, teacher could
encourage the learner to study the higher ECWQ level of Chinese. If a learner’s
ECWQ is lower than expected ECWQ, teacher could ask the learner to put more effort
into learning. Teachers are able to manage the learning condition of Chinese words. It
is ideal if all learners’ECWQ reach 2500 before the end of 8 month.
The number of Chinese words learning will affect learners’learning plan and their interest in CSL. When you learn many Chinese words in each study, your language interest will be attenuated gradually and your learning schedule will be postponed. Chinese word learning includes leaning the Chinese phonetic transcription, such as Bopomofo and pin-yin; how to write the character; pronunciation and meaning of Chinese word, etc. According to the number of Chinese words defined in the list of frequent characters in modern Chinese, a learner have to learn 12 Chinese words in a day during the period of 8 months. The load of each study should be
reasonable, and learners’language interest and schedule can be maintained.
3.2 Two-Phase of Chinese word Learning Strategy
For foreigners who study Chinese as a second language, there are two abilities that they have to possess. First, they need to recognize Chinese words and pronunciation by their eyes and ears, which mean they don't write Chinese words
correctly. Second, they need to not only recognize Chinese words and pronunciation but also write them correctly. Different demands lead to different ways to learn.
From foreign learner's point of view, there are two major concerns: 1) Is the study plan easy to follow through? 2) Can they spend less time studying every day but have high achievement? Writing or spelling a word is not an easy and time-consuming exercise. The ability of writing or spelling a word is not an essential condition for some foreigners. Thus, learning how to write or spell a word is ignored in the first
round. This way brings some benefits which match foreign learner’s concerns. The
Chinese word learning process becomes easy, fast and less time-consuming.
The proposed two phases of Chinese word learning process is described by pseudo-code as follows.
Algorithm 1: Two-Phase-Chinese-Word-Learning (W) {/* Learning brand new Chinese word in W.
/* Suppose there are 240 days and 12 Chinese words to study every day. For (j=0 to 239) do /* Phase 1 */
For (i=j*12+1 to j*12+12) /* learning process */ Let Wt=wi.
Learners should do following works:
(1). Listen to the pronunciation of the Chinese word V(Wt).
(2). Read the target Chinese word Wt.
(3). Read the meanings in learner’s native language E(Wt).
(4). Speak out the pronunciation of the Chinese word V(Wt) loudly.
(5). Read the usage and other information of the Chinese word if available. /* Writing or spelling a word must be avoided in this phase.
Next i
For (i=j*12+1 to j*12+12) /* testing process */ Let Wt=wi.
Test Wt by test models 2, 3, …, 32. /* Test models 2, 3, …, 32 are multiple
choice questions.
Learner practices all test models.
/* Writing or spelling a word must be avoided in this phase. Next i
Next j
If (Do not need to write or spell a word) = true, then stop; For (j=0 to 239) do /* Phase 2 */
For (i=j*12+1 to j*12+12) /* reviewing process */ Let Wt=wi.
Learners should do following works:
(1). Listen to the pronunciation of the Chinese word V(Wt).
(2). Read the target Chinese word Wt.
(3). Read the meanings in learner’s native language E(Wt).
(4). Speak out the pronunciation of the Chinese word V(Wt) loudly.
(5). Read the usage and other information of the Chinese word if available.
(6). Write or Spell the target Chinese word Wt. /* Writing or spelling a word is
asked in phase 2. Next i
For (i=j*12+1 to j*12+12) /* testing process */ Let Wt=wi.
Test Wtby test models 1, 2, … , 32. /* Test models 1 is necessary.
/* Test models 2, 3, … , 32 are multiple choice questions. Learner practices all test models.
Next i Next j
} /* end of Two-Phase-Chinese-Word-Learning().
The key features of the aforementioned algorithm are listed as follows.
1. Learn all brand new Chinese words without writing or spelling a word in Phase 1.
2. Learn how to write or spell words only in Phase 2. 3. Listening and speaking are important.
4. Doing tests are asked immediately after learning and reviewing.
The two-phase of Chinese word learning strategy are personalized. The number of Chinese word learning is adjustable. However, the problem of retention of Chinese words still exists.
4. Method of Dynamic Timing of Reviews
Algorithm 1 does not consider the forgetting curve of human being (Ebbinghaus, 1885). A method of memory was proposed by Ho, 2005, 2006. It is referred to as the method of Dynamic Timing of Reviews (DTR). DTR is a personalized review method. A modification of DTR is proposed in this paper. It asks people to review some parts of items. These items are memorized by reviewing and testing every day. If one fails to answer the item correctly, DTR assumes that one forgets it and arranges the next review is tomorrow. If one successfully answers the item correctly, DTR assumes that
one remembers it and arranges the longer period from this review to the next review. DTR can be used for other items which are memorized by human being. DTR assumes that one has learned some items which are memorized first. After the very moment one learned, DTR tests if one remembers the items correctly.
A review number series is defined for each item based on the stroke-number of
that item. For example, the item of Chinese word “務實”,itsreview numberseriesis
1, 4, 5, 9, 14, 23, 37, 60, ….Thesecond numberin thisseriesis4.Itstandsforthe timing of the next review is 4 days later. The third number is larger than the second, the fourth number is larger than the third, and so forth. For another example, the item
of Chinese word “加入”,itsreview numberseriesis1,7,8,15,23,38,61,99, ….
The stroke-number of the item is smaller than the former one; the span between two adjacent reviews is longer. The stroke-number of the item is bigger, the span between two adjacent reviews is shorter.
DTR selects all items which should be reviewed today automatically. It picks up the next number in the review number series of that item. One will be asked to review the item after longer period of days.
Assume d(wi) is the initial function of review periods of wi and is defined as
following. d(wi)=v1, if |wi|≦r1; d(wi)=v2, if r1<|wi|≦r2; d(wi)=v3, if r2<|wi|≦r3; … d(wi)=vm, if rm-1<|wi|, where |wi| is the stroke-number of wi, m≦|L|, m is a positive integer, v1≧v2≧v3≧…≧vm≧0, viis a numerical value, 0≦r1≦r2≦r3≦…≦rm-1, riis an integer.
d(wi) expresses that a large number of strokes of Chinese word has a smaller initial
value because of a large number of strokes of Chinese word with a shorter period to
review, and vice versa. Assume xi is an index of wi and xi =1 initially. The series of
review period, f(wi, xi) is defined as following.
f(wi, xi)=0, if xi≦0;
f(wi, xi)≦f(wi, xi+1), if xi>0,
where
f(wi, xi) expresses that a bigger index maps to a bigger value for each Chinese word
since a more familiar Chinese word needs a longer period to review. Different
Chinese words have different series. Combining with d(wi) and f(wi, xi), the DTR
series can be obtained. A simple example of DTR series is given as following.
f(wi, xi)=0, if xi<0; f(wi, xi)=1, if xi=0; f(wi, 1)= d(wi)+ε1; f(wi, 2)= d(wi)+ε2; f(wi, xi)=k1f(wi, 1)+ k2f(wi, 2)+…+ ki-1f(wi, xi-1), if xi>2, where
k1, k2, … , ki-1are arbitrary coefficients, and ε1and ε2are 0 or positive integers,
respectively.
It is obvious that the DTR series is determined by d(wi) and f(wi, xi); however,
the real decision maker of how long period of reviews is a learner. xiis determined by
a pseudo-code of a index rule according to a learner’s answers of tests.
If (all answers of selected test models of xiare correct) then xi= xi+1;
Else xi=0.
If all answers of selected test models of xi are correct, DTR assumes that learner is
familiar with xicurrently. The period of next review should be longer to save time and
to reduce loading. If answers are incorrect, DTR assumes that learner is not familiar
with xicurrently. xishould be reviewed tomorrow to enhance the retention.
Adding d(wi), f(wi, xi) and the index rule into Algorithm 1, DTR works with
two-phase of Chinese word learning strategy. Assume that DTR series for xiis (1, 5, 7,
12, 19, …). If one has learned xi, DTR tests user about xi immediately on date D (D
stands for today). If one fails to answer xicorrectly, the date of next review will be on
date D+1 (tomorrow). If one answers xi correctly, the date of next review will be on
date D+5.
Assume the date of the first review is D+5. Upon the first review, if one answers
xi correctly, the date of the second review will be D+5+7. Upon the second review, if
one answers xi correctly, the date of the third review will be D+5+7+12, and so forth.
Upon each review, if one answers xicorrectly, DTR picks up the larger number as the
next span. On the other hand, upon each review, if one fails to answer xi correctly, the
date of the next review is D+1.
DTR automatically collects words which the learner should review every day. Up to now, a manageable plan, an easy learning strategy and a personalized review
method are proposed. Based on them, foreigners who are non-native Chinese speaker can achieve their study goal in a shorter period.
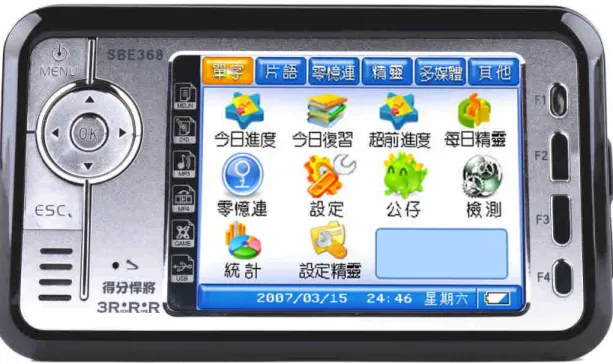
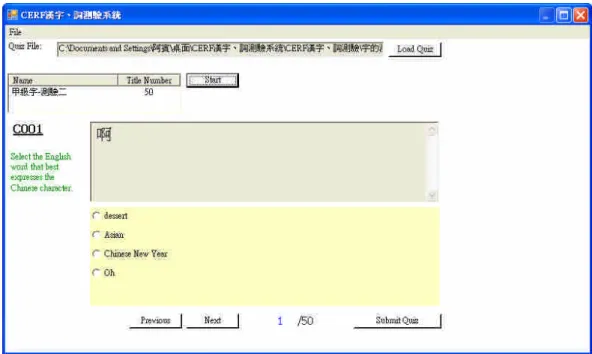
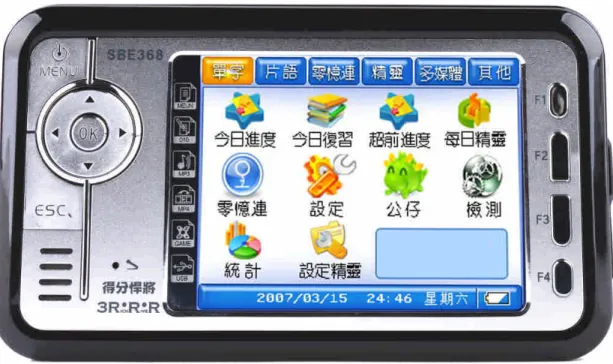
Based on the DTR, two-phase strategy and learning plan, a mobile product has been developed for learning English vocabulary. Figure 1 shows the picture of the mobile device. The software of learning Chinese words on this mobile device is under coding currently.
Fig. 1. The picture of mobile learning machine for learning English vocabulary
5. Conclusions
It is obvious that studying Chinese is a difficult work even if there are the auxiliaries of pronunciation and phonetic alphabets. In this paper, a Chinese word learning system on a mobile device for non-native Chinese speakers is investigated. According to the list of frequent characters in modern Chinese, an estimation of Chinese word quantity which assesses the ability of recognizing Chinese word is proposed. Furthermore, thirty two practice tests of Chinese words are also described briefly, and the reliability and validity of the practice tests are analyzed by the IRT. A learning plan of Chinese and a two-phase of learning strategy of Chinese are presented. The modification method of dynamic timing of review is also developed to overcome the forgetting curve of individual. Finally, the purpose of this paper is that learners who are non-native Chinese speaker can achieve their study goal according to the proposed approach by using the mobile device in the short period. The future work includes the software development for the learning machine and experiments of evaluating two-phase learning strategy, learning plan, and DTR for Chinese words.
References
Allen, J. R. (2008), Why Learning to Write Chinese is a Waste of Time: A Modest Proposal, Foreign Language Annuals, 41(2), 237-249.
Anderson, R. C. and Freebody, P. (1981), Vocabulary Knowledge, In J. T. Guthrie (Ed.), Comprehension and teaching: Research reviews (pp.77-117).Newark, NJ: International Reading Association.
Baker, F. B. (1992), Item Response Theory: Parameter Estimation Techniques, New York: Marcel Dekker.
Chen, C. M. and Chung, C. J. (2008), Personalized Mobile English Vocabulary Learning System Based on Item Response Theory and Learning Memory Cycle,
Computer and Education, 51, 624-625.
Chung, K. K. H. (2002), Effective Use of Hanyu Pinyin and English Translations as Extra Stimulus Prompts on Learning of Chinese Characters, Educational
Psychology, 22(2), 149-164.
Chung, K. K. H. (2007), Presentation Factors in the Learning of Chinese Characters: The order and position of Hanyu pinyin and English translations, Educational
Psychology, 27(1), 1-20.
DeCarrico, J. S. (2001), Vocabulary Learning and Teaching, In M. Celces-Murcia (Ed.), Teaching English as a second or foreign language (pp. 285-299), Boston: Heinle & Heinle Publishers.
DeFrancis, J. (1989), Visible Speech: The Diverse Oneness of Writing Systems, Honolulu: University of Hawaii Press.; Mattingly, I. G. (1992). Linguistic awareness and orthographic form. In R. Frost & L. Katz (Eds.), Orthography,
phonology, morphology and meaning (pp. 11–26). Amsterdam: Elsevier.
Ding, Y., Richman, L. C., Yang, L. Y., and Guo, J. P. (2010), Rapid Automatized Naming and Immediate Memory Functions in Chinese Mandarin — Speaking Elementary Readers, Journal of Learning Disabilities, 43(1), 48-61.
Ebbinghaus, H. (1885), Memory, A Contribution to Experimental Psychology, http://en.wikipedia.org/wiki/Forgetting_curve, German.
Everson, M. E. (1998), Word Recognition among Learners of Chinese as a Foreign Language: Investigating the Relationship between Naming and Knowing, The
Modern Language Journal, 82, 194-204.
Hambleton, R. K. & Swaminathan, H. (1985), Item Response Theory: Principles and
Applications. Kluwer-Nijhoff Publisher.
Ho, H. F. (2005), Patent Name: A Method of Automatic Adjusting the Timing of Review Based on a Microprocessor Built-in Device for User to Memory Strings,
Patent ID: [092134253].
Ho, H. F. (2006), A Scientific Method Of Memory, Proc. of International Conference
on Automation, Control and Instrumentation, Valencia (SPAIN).
Kaplan, R. S. and Norton D. P. (1996), Using the Balanced Scorecard as a Strategic Management System, Harvard Business Review, 75-85.
Ke, C., Wen, X., and Kotenbeutel, C. (2001), Report on the 2000 CLTA Articulation Project, JournaloftheChineseLanguageTeacher’sAssociation,36(3), 23-58. Kuo, M.-L. A. and Hooper, S. (2004), The Effects of Visual and Verbal Coding
Mnemonics on Learning Chinese Characters in Computer-Based Instruction,
Educational Technology Research and Development, 52(3), 23-38.
Lam, H. C., Ki, W. W., Chung, A. L. S., Ko, P. Y., Lai, A. C. Y., Lai, S. M. S., Chou, P. W. Y., and Lau, E. C. C. (2004), Designing Learning Objects that Afford Learners the Experience of Important Variations in Chinese Characters, Journal of
Computer Assisted Learning, 20(2), 114-123.
Lam, H. C., Ki, W. W., Law N., Chung, A. L. S., Ko, P. Y., Ho, A. H. S., Pun, S. W. (2001), Designing CALL for Learning Chinese Characters, Journal of Computer
Assisted Learning, 17(1), 115-128.
Liu, Ying, Wang, Min, and Perfetti, Charles A (2007), Threshold-style Processing of Chinese Characters for Adult Second-language Learners, Memory & Cognition, 35(3), 471-480.
Lin, Z. (2002), Discovering EFL Learners’Perception of Prior Knowledge and Its
Role in Reading Comprehension, Journal of Research in Reading, 25(2), 172-190. Mezynski, K. (1983), Issues Concerning the Acquisition of Knowledge: Effects of Vocabulary Training on Reading Comprehension. Review of Educational
Research, 53(2), 253-279.
Oxford, R. (1990), Language Learning Strategies: What Every Teacher Should Know. Boston: Heinle & Heinle Publishers.
Segler, T. M., Pain, H., and Sorace, A. (2002), Second Language Vocabulary Acquisition and Learning Strategies in ICALL Environment, Computer Assisted
Language Learning, 15(4), 409-422.
Shen, H. (2004), Level of Cognitive Processing: Effects on Character Learning among Non-native Learners of Chinese as a Foreign Language, Language & Education, 18(2), 167-182.
Shen, H. H. and Ke, C. (2007), Radical Awareness and Word Acquisition among Nonnative Learners of Chinese, Modern Language Journal, 91(1), 97-111.
Sun, K. T. and Feng,D. S. (2004), A Distance Learning System for Teaching the Writing of Chinese Characters over the Internet, Journal of Distance Education
Tsai, C. C. and Chang, I. C. (2009), An Examination of EFL Vocabulary Learning Strategies of Students at the University of Technology of Taiwan, International
Forum of Teaching and Studies, 5(2), 32-38.
Waugh, N. C. and Norman, D. A. (1965), Primary Memory, Psychological Review, 72, 89-104.
Wikipedia contributors (2005). Memory Retention. Wikipedia, The free encyclopedia.
Retrieved January 18, 2006 from the World Wide Web:
http://en.wikipedia.org/w/index.php?title=Memory_retention&oldid=16865590. Wu, H. and Miller, L K. (2007), A Tutoring Package to Teach Pronunciation of
Mandarin Chinese Characters, Journal of Applied Behavior Analysis, 40(3), 583-586.
Young, M. Y. C. (1997), A Serial Ordering of Listening Comprehension Strategies Used by Advanced ESL Learners in Hong Kong, Asian Journal of English
Language Teaching, 7, 35-53.
Zhang, S.-D. (2005), A General History of Chinese Printing, Taipei: XingCai Literary Foundation, ch.3, sec.1. ISBN 957-99638-3-5.
Chinese Character Quotient based on Item Response Theory
Hong-Fa HoAssociate Professor
Department of Applied Electronics Technology
National Taiwan Normal University, Taipei, Taiwan, (R.O.C.)
Abstract
The Chinese character size of an individual is an import factor of reading and writing Chinese. Researchers and teachers used different testing methods to assess learners’Chinese character ability. Different testing methods not only focus on different aspects but also have different reliabilities and validities. Learning a large amount of Chinese characters is a major difficulty for non-native learners. For evaluating abilities of Chinese characters effectively and efficiently, a Chinese character quotient (CCQ) is proposed first. Based on the CCQ, an estimation of Chinese character quantity (ECCQ) which assesses the Chinese character size of an individual is proposed. Twelve test models of Chinese characters are also described. The Item Response Theory (IRT) is applied to analyze the proposed test models. By using the CCQ and ECCQ, the researchers and teachers can easily find out the Chinese character size of every learner and manage the most unmanageable part of the Chinese instruction.
Keywords: Chinese character, IRT, quotient
6. Introduction
In a decade, Chinese is regarded as an important language of communication. Chinese characters are invented by Chang-Jie (Zhang, 2005). He applied the special characteristics of animals, plants and the natural phenomena he found to create Chinese character. Chinese characters are radical (root character) or compound characters which contain two or more radicals, not alphabetic words. The government of the People's Republic of China approved pin-yin in 1958 and officially adopted by it in 1979 to represent Chinese characters for non-Chinese speakers. Pin-yin represents Chinese characters and their sounds using the Roman alphabet and a set of tonal symbols to represent their pitch (Wu and Miller, 2007). The question must be considered in the context of how Chinese character differs from English and other alphabetic orthographies. Chinese is considered a logographic or morphosyllabic system (DeFrancis, 1989) in which the units of the orthography (characters)
correspond to both syllables and morphemes. The typical Chinese character is a square-shaped symbol that, with some exceptions, represents one pronunciation and one morpheme. The characters are composed of radicals. Some radicals are characters by themselves, and some are not (Liu, Wang and Perfetti, 2007). The ability of Chinese characters is a fundamental ability of Chinese language.
However, Chinese is often regarded as the most difficult language for non-native Chinese speakers to learn for two reasons. First, Chinese characters are ideographs without individual characters that represent the component sounds of a word. Second, Chinese is a tonal language, because the same set of sounds can have different meanings depending on the tone with which they are spoken (Wu and Miller, 2007). A recent survey (Ke et al., 2001) regarding the most difficult challenges for learners of Chinese as a foreign language in pre-college programs suggests that character learning is the greatest challenge. Learning Chinese character in systematic manner over the long term is a labor-intensive endeavor, and one that places huge demands on their memories, time and study capabilities (Everson, 1998). Ho and Lin (2010) developed a Chinese character learning plan as a teaching strategy. And a two-phase learning strategy was designed to enhance both the learning efficiency and effectiveness. Different researches and teachers designed various test models to assess the ability of Chinese characters.
Recently, there were many literatures which study how to learn Chinese. There were some good approaches to help learners study and apply Chinese well and memorize them. The following paragraphs will introduce them. Note that different aspects of Chinese abilities were assessed by different test models. In addition, it is hard to compare various approaches since they used different test models.
In Lam, Ki, Law, Chung, Ko, Ho, and Pun (2001), Lam et al. described that printed or written forms of Chinese characters are composed from a limited number of
common components. They also used technology to enhance young children’s
understanding about the structural principles of Chinese characters. Furthermore, authors’literature reported on the design of CALL software based on a pedagogic method, helping learners to develop the higher order skills, to analyze and categorize Chinese characters by using components. In Chung (2002), the aim of this study was to examine whether temporal spacing of a character and its associated pin-yin and English equivalent prompts would enhance learning of meaning (English translation) and pronunciation relative to a condition where a character and its prompts were presented simultaneously. In addition, Chung investigated whether presenting the order from the character to the familiar prompts would improve the acquisition more than the order from the prompts to the target stimulus. In Shen (2004), author investigated how different encoding strategies affect retention of Chinese characters
(words) as measured by recall of the sound and meaning of the characters. Three types of encoding strategies were investigated during character learning: rote memorization (shallow processing), learner self-generated elaboration and instructor-guided elaboration (deeper processing). In Sun and Feng (2004), an intelligent tutoring system (ITS) was proposed for teaching learners to write Chinese characters using correct stroke orders over the Internet. This system could efficiently help learners to learn Chinese characters and to determine the correct stroke orders of Chinese characters more intelligently. Kuo and Hooper used posttests to explain what learning approach can achieve the best effect for learning Chinese. These learning approaches include translation, verbal mnemonics, visual mnemonics, dual coding mnemonics and self-generated mnemonics. The experiment result indicated participants who generated their own mnemonics achieve higher posttest performance than other approaches (Kuo and Hooper, 2004).
In Lam, Ki, Chung, Ko, Lai, Lai, Chou, and Lau (2004), the authors’objective was the notion of this variation-affording instructional software that allows learners to attend to the essential aspects of what is to be learned. Furthermore, the idea of the learning object also differs from other instructional software in its small, self-contained and reusable nature, such that teachers can flexibly embed the learning objects into their own teaching materials. Wu and Miller analyzed the use of a tutoring package that consisted of modeling, hand prompts, and contingent praise or Chinese conversations with the tutor to increase the effectiveness of pin-yin in teaching correct tonal pronunciation to non-native speakers learning Chinese. The
learner’s pronunciation of Chinese characters could be improved by using the tutoring
package (Wu and Miller, 2007). In Liu el al., (2007), authors stated that an English speaker learning to read Chinese must acquire knowledge of the visual forms of characters, knowledge of the mappings of these forms to meaning and pronunciation, and knowledge of the language itself. Authors proposed an important assessment of the ability of learners of Chinese at the end of their first and second terms in a Chinese class. The examination included orthography, phonology and semantics of Chinese. In Shen and Ke (2007), Shen and Ke provided a picture of a developmental continuum of radical awareness across instructional levels among adult non-native learners of Chinese. They also suggested that radical knowledge, radical perception skills, and radical knowledge application skills do not develop synchronously across learning levels, but rather that each of them shows a unique developmental trend. In Allen (2008), author described that learning to write Chinese characters (hanzi, or in Japanese, kanji) from memory is an extremely inefficient use of time for learners of Chinese as a foreign language—and this may be even more so for learners of Japanese as a foreign language, because the time necessary to learn to write the characters is
inversely proportionally to the usefulness of that skill. Author also integrated handwriting skills with the new electronic writing technologies to create an efficient and culturally sensitive program of instruction in hanzi/kanji writing.
Recently, there were some literatures which pointed out why learners do not have a good English ability. The EFL vocabulary is by far the most unmanageable part of language instruction (Tsai and Chang, 2009). Moreover, a poor vocabulary is acknowledged by most learners at all levels (Lin, 2002; Segler, Pain and Sorace, 2002). Therefore, it is obvious that vocabulary learning plays an important role in English-language acquisition. In addition, one of the learning problems for learners is to forget learned vocabulary (Chen and Chung, 2008; Ho, 2006).
A number of studies showed that language learners typically have significant difficulty remembering large amount of vocabulary (Anderson and Freebody, 1981; Mezynski, 1983; Oxford, 1990; DeCarrico, 2001). Furthermore, it has been found that numerous learners think that memorizing English vocabulary is difficult, especially long or infrequently used words. It showed that ability of Chinese characters is time-variant. An assessment of Chinese characters is proposed to examine learners’ Chinese character ability and quantity on different dates.
Young (1997) argued that listeners follow a pattern of procedures when listening to a text. Learners make use of their background knowledge to interpret what they may hear next. They might make a guess and/or draw upon an inference from a context. During the process of listening, learners might develop metacognitive strategies to monitor comprehension. Sounds play an important role in learning languages. Test model is better if it includes the test of sounds of Chinese characters.
The rest of this article is organized as follows. A Chinese character quotient is proposed first in Section 2. Item characteristic functions of twelve test models are presented in Section 3. An estimation of Chinese character quantity is stated in Section 4. Section 5 illustrates twelve basic test models and the developed software tool. With these two definitions, the Chinese character ability of learners can be assessed easily. Finally, conclusions are drawn in Section 6.
7. Chinese Character Quotient
A Chinese character quotient, or in the abbreviation form of CCQ, is a set of quotients derived from several different standardized test models designed to assess the ability of Chinese characters.
Definition 1:
CCQ(p, m, L, t, z)={CCQi| 1≦i≦d }, where
p is the tester,
m is the native language of p, such as English, L is the set of Chinese characters,
t is the date of the test, and
z is a positive integer and the number of tests for each test model. In
addition, target Chinese characters are selected randomly from L by using the uniform distribution random function,
CCQi is the quotient of the number of correct answers divided by z of some
specific test model i about Chinese characters in L,
and d is the number of different test models and a positive integer.
Definition 1 can be applied to any languages. Both L1L1 and L1L2 are suitable.
Different languages have different number of test models. CCQ is time-variable for individual. The parameter z is larger; the accuracy of CCQ is higher. Testers will spend more time to accomplish tests, however.
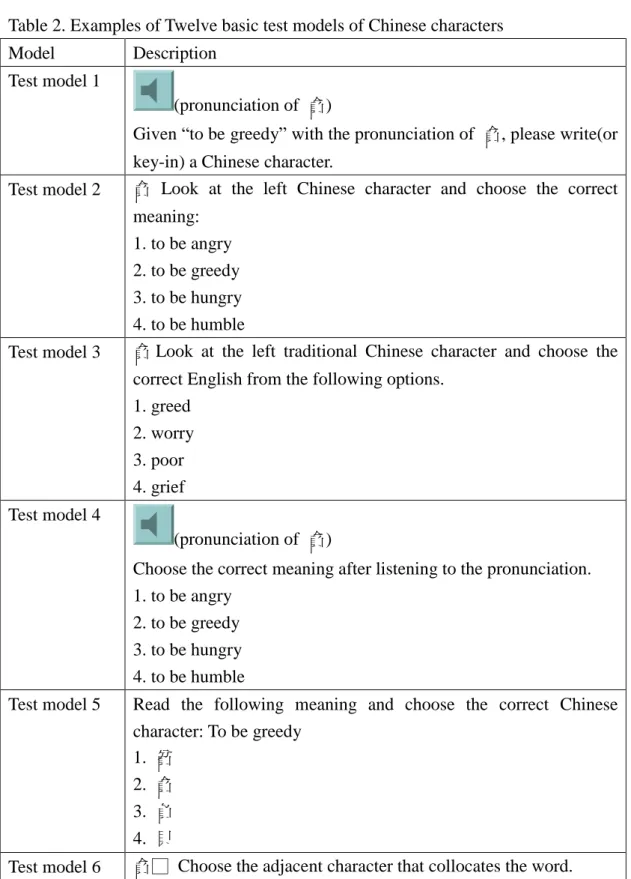
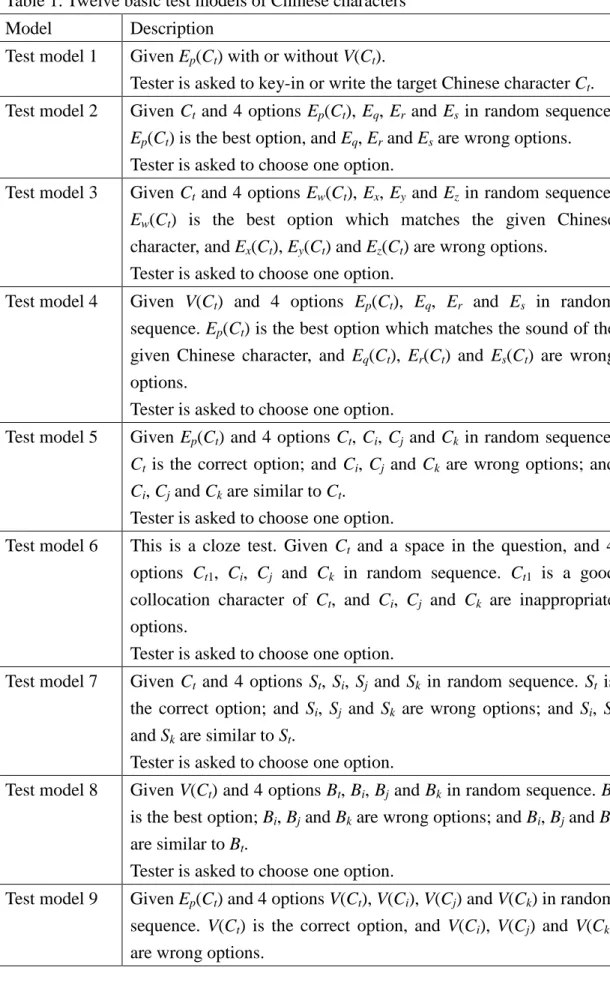
For Chinese as a Second language (CSL), twelve basic test models (d = 12) are proposed. They are described in Table 1.
For reading easily and accurately, some symbols are defined in advance as follows.
Ct: the target Chinese character;
Ct1: is a good collocation character of Ct;
Ci, Cj, and Ck: other Chinese characters, where t≠i≠j≠k;
St: Simplified Chinese for the target character;
Si, Sj, and Sk: other simplified Chinese characters, where t≠i≠j≠k;
Ep(Ct): English meaning of Ct;
Eq, Er, and Es: other English meanings, where p≠q≠r≠s;
Ew(Ct): English vocabulary which matches the target Chinese character;
Ex, Ey, and Ez: other English vocabularies, where w≠x≠y≠z;
Bt: the Bopomofo phonetic transcription for the target Character;
Bi, Bj, and Bk: other Bopomofo phonetic transcription for any character, where t≠i≠j
≠k;
V(Ct): the pronunciation of Ct. Tester can hear the pronunciation from the speaker of
the testing tool;
V(Ci), V(Cj), and V(Ck): the pronunciation of Ci, Cj, and Ck, respectively, where t≠i≠
j≠k;
Pt: the pin-yin phonetic transcription for the target Character;
k;
Table 1. Twelve basic test models of Chinese characters
Model Description
Test model 1 Given Ep(Ct) with or without V(Ct).
Tester is asked to key-in or write the target Chinese character Ct.
Test model 2 Given Ct and 4 options Ep(Ct), Eq, Erand Es in random sequence.
Ep(Ct) is the best option, and Eq, Erand Esare wrong options.
Tester is asked to choose one option.
Test model 3 Given Ct and 4 options Ew(Ct), Ex, Ey and Ez in random sequence.
Ew(Ct) is the best option which matches the given Chinese
character, and Ex(Ct), Ey(Ct) and Ez(Ct) are wrong options.
Tester is asked to choose one option.
Test model 4 Given V(Ct) and 4 options Ep(Ct), Eq, Er and Es in random
sequence. Ep(Ct) is the best option which matches the sound of the
given Chinese character, and Eq(Ct), Er(Ct) and Es(Ct) are wrong
options.
Tester is asked to choose one option.
Test model 5 Given Ep(Ct) and 4 options Ct, Ci, Cj and Ck in random sequence.
Ct is the correct option; and Ci, Cj and Ck are wrong options; and
Ci, Cjand Ckare similar to Ct.
Tester is asked to choose one option.
Test model 6 This is a cloze test. Given Ct and a space in the question, and 4
options Ct1, Ci, Cj and Ck in random sequence. Ct1 is a good
collocation character of Ct, and Ci, Cj and Ck are inappropriate
options.
Tester is asked to choose one option.
Test model 7 Given Ct and 4 options St, Si, Sj and Sk in random sequence. St is
the correct option; and Si, Sj and Sk are wrong options; and Si, Sj
and Skare similar to St.
Tester is asked to choose one option.
Test model 8 Given V(Ct) and 4 options Bt, Bi, Bjand Bk in random sequence. Bt
is the best option; Bi, Bjand Bk are wrong options; and Bi, Bjand Bk
are similar to Bt.
Tester is asked to choose one option.
Test model 9 Given Ep(Ct) and 4 options V(Ct), V(Ci), V(Cj) and V(Ck) in random
sequence. V(Ct) is the correct option, and V(Ci), V(Cj) and V(Ck)