國立政治大學資訊科學研究所
Department of Computer Science
National Chengchi University
碩士論文
Master’s Thesis
模組化之安全多方計算領域專屬腳本語言
A Modular Scripting Language for Secure
Multi-Party Computation
研究生:翁宸暉
指導教授:陳恭
中華民國 102 年七月
July 2013
模組化之安全多方計算領域專屬腳本語言
A Modular Scripting Language for Secure
Multi-Party Computation
研究生:翁宸暉
指導老師:陳恭
Student: Cheng-Hui Weng
Advisor: Kung Chen
國立政治大學
資訊科學系
碩士論文
A Thesis
Submitted to Department of Computer Science
National Chengchi University
in partial fulfillment of Requirements
for the degree of
Master
in
Computer Science
中華民國 102 年七月
July 2013
模組化之安全多方計算領域專屬腳本語言
摘要
安全多方計算的研究主要是針對在分散環境下的兩造(或多方)之間,如何 在不透露彼此私有的資料的情況下,計算一個約定函數的問題,並要確保除了 計算結果及其可能推導出的資訊,不會洩漏額外的私有資料。依此要求設計出 來的函數算法,稱為安全的多方計算協定。 本研究室曾根據一套基於向量內積運算發展出的多方安全計算方法,設計 了一個分散式系統框架與符合安全需求的函式庫。其後再以自動化使用這套函 式 庫 的 動 機 出 發 , 開 發 出 多 方 安 全 計 算 語 言 smcSL (secure multiparty computation Scripting Language)。然此套語言目前尚缺作為使用者表述與解 決問題重要工具的自定函式功能,以及模組化相關功能。本研究即於現有 smcSL 的基礎,在安全性受到保證的情況下,允許使用者於程式中自定函式與模組, 使編寫更複雜且實際的應用成為可能,並在設計上希望能達到下列四點目標 一、 保持原有 smcSL 之安全特性:包括對於各變數存取權限的檢查,以及相應 產生程式碼在防止資訊洩漏上的安全考量。 二、 函式導向的語言設計原則:引入函式的同時,也代表引入所謂的變數作用 區域,以及相應的特性。因此像變數遮蔽(Variable Shadowing)、全域變 數、區域變數、傳值或傳參等議題,皆是設計上的要點。 三、 相容現有成果:在 smcSL 語言正在持續發展的階段,維持執行環境的相容 是必要的。最理想的情況是不修改而只是增加原有執行環境的功能,就可 以使新特色運作順暢。 四、 擴充與靈活性:在 smcSL 持續發展的情況下,有必要為了可預見的需求留 下設計擴充的餘地。因此在實作與設計上,帶有新特色的 smcSL 語言編譯 器,以及其他組件,都會遵循此原則進行。A Modular Scripting Language for Secure
Multi-Party Computation
Abstract
Recently, language-based tools are emerging to better support the systematic development of secure multiparty computation (SMC) protocols. In particular, our colleagues had developed a scripting language for automating the development of complex protocols for a commodity-based approach to SMC.
The implementation of the language consists of two parts, namely a distributed runtime environment and library of SMC protocols in the Ruby language and a compiler to translate a SMC script to executable Ruby code exploiting the distributed SMC runtime environment.
The basic constructs of our scripting languages are pretty common, such as variables, data types, expressions, assignment statements and for-loops. The salient features of our language are a symmetric view of all participating parties and a three-level data security attributes, namely public, private, and shared, that users can employ to express their security requirements by associating variables with these attributes in a declarative manner. Furthermore, these security attributes also direct how our compiler should perform security check as well as code generation.
However, currently the scripting language lacks of modular constructs such as functions and modules found in most programming languages, thus making it difficult for developers to compose large programs without redundant code. To make our language more flexible and practical, this thesis presents an enhancement of smcSL with functions and a basic module facility, and discusses how and why their design and implementation can still follows the security requirements, which ensures our new features not only make developers apt to construct large programs, but also keep them secure.
誌謝辭
從一個非資科背景出身的學生,轉而開始學習函數式程式設計、人機介面、 編譯器設計,以及其他作為資訊核心領域的知識,這個過程讓人不得不說是充滿 挑戰。更不用說在這個網路作為資訊學習載體式如此方便,卻又充分讓人體認到 生也有涯而知也無涯的時代,是如此容易對於自己學過與未學的差距常常感到焦 慮。感謝 神在這個過程中安排了如此長時間中,能與我共同走過學習思考與閒 暇時間的研究室同學。雖然我們在各樣興趣與對事物的看法常常有所不同,但卻 因此能發揮出更好的協調性,並使得研究室生活充滿樂趣。我認為這是除了我所 成就與應付研究、學習與每日事物之所得外,最能讓我深刻體認到作為研究生兩 年是如此珍貴時光的回憶。 感謝李明憲學長在我尚處於新生階段的諸多幫助,尤其是做為學長所能提供 的各種經驗談,讓我能有效的處理身為學生與研究室的各種事務。感謝林子文同 學在我們研究計畫的共同領域中所作出至關重要的貢獻,以及所有我們參與並決 定研究走向的討論。感謝范佐玄同學在每日研究室生活中所增潤的色彩,實在不 能想像沒有你的研究室會缺乏何種的熱度;當然也包括各種常常能帶來各種突破 點的談話內容。另外也感謝陳昱孙同學作為研究室帳目與庶務的管理者,讓我可 以在處理這些事務上獲得幫助,並省下不少時間繼續學習與研究。李家孙則作為 一位有著相似研究生路線的同學,希望我所留下的研究材料能足夠幫助你完成接 下來的計畫。最後則是要感謝作為專題生卻惠我良多的李致緯與蘇苑霖同學,因 為你們不時所帶來與外界社群、業界相關的各種知識與作法,讓我,以及我們研 究室不僅僅侷限在學校所能傳達與發展的方向上,而能夠充分與這些更廣闊的知 識,和各種自由軟體、開放原始碼、社群等事務進行理解、詴驗、交流與投入, 也因為這樣而我能順利的獲得實習與工作機會,並擁有有著共同熱忱的夥伴。 不過,在這整個研究與學習的過程中,如果沒有陳恭老師的淵博知識與管理 方式,以及對各種新作法、新知識的開放態度,我想我,以及我們研究室,將不 可能取得像現在這樣的成果。感謝老師對於研究與學習的要求,以及不時與國外 的比較,讓我充分覺得自己不能僅滿足所謂國內或普通的標準,而是應該在這個 充滿學習機會的時代,多擴增並磨練自己在思考、知識與技能上的成長。此外有 時可能因為在知識上的不足,或是過分的執著於特定方向,也是老師常常在一句 話中讓研究與學習得以清除原本難以理解的障礙。我想在我以往求學的過程中, 還沒有一位如此能指引我方向的老師。 最後則是要感謝我的家人能支持我在兵役結束後,還能在心理與資源上支持 我就讀研究所這個決定。如果沒有你們的支持,我想我不可能走完這兩年的路, 也不可能獲得今天所能時常為之感謝的一切。目 錄
緒論 ... 1 1-1 研究背景與動機 ... 1 1-2 研究目標 ... 4 1-3 研究貢獻 ... 4 1-4 論文結構 ... 4 既有研究成果介紹 ... 5 2-1 自動化多方安全協定函式庫的使用 ... 5 2-2 本機與分散式運算 ... 5 2-3 存取權限對 SMCSL 變數的重要性 ... 6 2-4 SMCSL 程式編譯與執行的環境與流程... 7 2-4-1 基礎環境 ... 8 2-4-2 撰寫與編譯 smcSL 程式 ... 8 2-4-3 執行中:各機器間的互動 ... 9 2-4-4 計算完的處理 ... 9 2-5 相關研究的概況與評述... 10 研究方法與標的 ... 11 3-1 原SMCSL 文法因應新增函式功能之變更 ... 11 3-2 函式文法介紹 ... 15 3-3 函式檢查規則 ... 19 3-3-1 函式作用區域檢查 ... 19 3-3-2 缺少回傳陳述式 ... 20 3-3-3 回傳值與宣告不一致 ... 20 函式生成規則 ... 21 4-1 SMCSL 函式生成原則與實例 ... 21 4-2 存取權限轉換於函式方面的議題 ... 27 SMCSL 編譯器設計原則與實作 ... 29 5-1 SMCSL 編譯器語法層面處理流程 ... 29 5-2 抽象語法樹的檢查階段 ... 34 5-2-1 變數與函式作用區域檢查 ... 34 5-2-2 型別檢查 ... 36 5-2-3 存取權限檢查 ... 37 5-3 SMCSL 編譯器安全檢查設計原則與實作 ... 385-4 SMCSL 編譯器目的碼產生設計原則與實作 ... 39 研究成果討論 ... 42 6-1 向後相容並適度更新... 42 6-2 低耦合設計之必要性與成本討論 ... 44 6-3 模組化SMCSL 程式之開發方式 ... 46 結論 ... 50 7-1 本研究貢獻 ... 50 7-2 未來研究 ... 50 參考文獻 ... 54 附錄………...58
圖目錄
圖 1-1:百萬富翁問題示意圖 ... 1 圖 1-2:兩類多方安全計算的模型 [15] ... 2 圖 1-2:smcSL 發展抽象層次示意圖 ... 3 圖 2-1:百萬富翁問題中的本機與分散式運算 ... 5 圖 2-2:smcSL 撰寫百萬富翁問題中的變數宣告段 ... 6 圖 2-3:安全權限結構示意圖 ... 7 圖 2-4:基礎環境 ... 8 圖 2-5:smcSL 程式的撰寫與編譯、遞交 ... 8 圖 2-6:執行中各機器的互動 ... 9 圖 3-1:百萬富翁問題使用原 smcSL 與函式版本之對比 ... 11 圖 3-2-1:使用 smcSL 函式功能解決線性迴歸問題(第一部分) ... 12 圖 3-2-2:使用 smcSL 函式功能解決線性迴歸問題(第二部分) ... 13 圖 3-3:線性迴歸方程式 ... 13 圖 3-4:最小平方向量求算公式 ... 14 圖 3-2:函式宣告圖解 ... 15 圖 3-2:百萬富翁問題比較函式範例 ... 15 圖 3-3:區域變數宣告方式圖解 ... 16 圖 3-4:區域變數宣告方式圖解 ... 16 圖 3-5:函式回傳值的自動轉換 ... 17 圖 3-6:具函式呼叫的百萬富翁問題主函式本體 ... 17 圖 3-7:函式呼叫文法圖解 ... 18 圖 3-8:以函式功能解決百萬富翁問題 smcSL 程式碼 ... 18 圖 3-9:函式存取作用區域中不存在變數造成錯誤範例 ... 19 圖 3-10:違背安全描述之函式回傳值 ... 20 圖 4-1:Public 級別函式拆分範例原始檔 ... 23 圖 4-2:Public 函式拆分範例生成 Ruby 程式碼 ... 23 圖 4-3:內含其他級別陳述式的 Public 函式 ... 24 圖 4-4:內含其他級別陳述式的 Public 函式生成結果 ... 24 圖 4-5:Private 並為 Alice 級別函式拆分範例原始檔 ... 25圖 4-6:Private 並為 Alice 級別函式拆分範例生成 Ruby 程式碼 ... 25
圖 4-7:Shared 級別函式拆分範例原始檔 ... 26
圖 4-8:Shared 級別函式拆分範例生成 Ruby 程式碼 ... 26
圖 4-9:允許與不允許級別轉換的賦值陳述式範例 ... 27
圖 4-10:賦值式存取權限轉換之檢查規則 ... 27
圖 4-12:函式參數與回傳值中不允許的級別轉換 ... 28 圖 5-1:smcSL 編譯器編譯流程示意圖 ... 29 圖 5-2:smcSL 語法掃描與剖析器與編譯器介接方式示意圖 ... 30 圖 5-3:smcSL 語法掃描與剖析階段內部流程圖 ... 31 圖 5-4:smcSL 語法掃描與剖析器產生 S-expression 格式範例 ... 31 圖 5-5:smcSL 前處理器針對常數區段處理範例 ... 33 圖 5-6:函式抽象語法樹節點進行變數區域檢查 ... 34 圖 5-7:帶 Accessor 資訊之函式識別符範例 ... 35 圖 5-8:smcSL 編譯器檢查未定義模組之處理流程 ... 36 圖 5-9:smcSL 編譯器所實作的安全層級關係 ... 37 圖 5-10:smcSL 編譯器檢查組件運作方式示意圖 ... 38
圖 5-11:Strategy Pattern UML 表示圖 ... 39
圖 5-12:smcSL 抽象法樹複製變形示意圖 ... 40 圖 6-1:smcSL 編譯器具目的碼生成相容能力示意圖 ... 43 圖 6-2:smcSL 編譯器產生目的碼組件解說 ... 44 圖 6-3:smcSL 編譯器各組件綜覽圖 ... 45 圖 6-4:模組提供共用功能示意圖... 46 圖 6-5:模組與定義檔案之關係示意圖 ... 47 圖 6-6:模組與函式文法差異 ... 48 圖 6-7:import 關鍵字作用區域示意圖 ... 48 圖 6-8:smcSL 模組化程式建構概念圖 ... 49 圖 7-1:無函式樣板之矩陣乘法定義範例 ... 51 圖 7-2:採函式樣板設計之通用矩陣乘法範例 ... 52 圖 7-3:smcSL 語言未來可能發展階段圖 ... 53
表目錄
表 4-1:根據函式不同回傳值對應雙方不同生成方式 ... 21緒論
1-1 研究背景與動機
安全多方計算 (Secure multi-party computation, SMC)的研究議題貣源 於 1982 年中研院姚期智院士所發表論文中的百萬富翁問題 [1],這個問題中有 兩個富翁,兩人想比一比,究竟是誰比較有錢,但又不想透露自己的財產數據 給對方知道。其問題情狀如圖 1-1 所示。 圖 1-1:百萬富翁問題示意圖 自此以後,許多學者對此進行研究,從而出現針對個別問題設計安全多方 協定的成果,也有將此類問題定義一般化並提出通用解決方案的研究[2][3][4]。 由這些研究所導出的安全多方計算協定,則可以應用於電子拍賣[5]、醫療資料 分類[6]、臉部辨識 [7]與保留隱私之資料擷取[8]與探勘[9]等課題[10]。然而 不管應用層面如何廣闊,概略來說,此類問題的核心都在各個參與方之間,要 如何不向對方或第三方透漏彼此私有資料,又能彼此進行合作計算解決問題。 在計算協定的設計方向上,較早開始且僅需於參與雙方間進行計算的方式 是 從 計 算 上 安 全 的 角 度 出 發 (computationally secure) , 採 用 混 淆 電 路 (garbled circuits) [3] 或同代編碼(homomorphic encryption) [11][12][13] 所設計的密碼協定(cryptographic protocols)。這種作法需要面對複雜的計算 與隨之而來的效率問題。而另一種設計方式則是從資訊理論上安全的角度出發 (information-theoretically secure),在資料擁有的各方之外,引入一個第 三方的公正伺服器(commodity server)[14],在不介入各方的計算的前提下, 提供亂數等的服務來協助各方隱藏其資料,進而完成安全的計算協定 [15]。此 A 方資產 B 方資產 A 方私有資訊 雙方參與但不洩漏各自資訊 B 方私有資訊 誰較富有
種方式可以從資訊理論上證明不會外洩資料,計算成本也比較低,但必頇有第 三方伺服器的協助。(如圖 1-2 所示)[10]。 圖 1-2:兩類多方安全計算的模型 [15] 在前述第二種由三方參與的計算模型基礎上,中央研究院資訊科學所的巨 量資料運算研究室已發展出一套安全多方計算協定發展方法 [16][17][18],亦 證明了這類的基礎協定能在保持安全性的前提下,以特定組合方式構成更大的 計算協定。在這些包括但不限於整數與浮點數的四則運算,以及衍生出來的矩 陣運算基礎上,本研究室與前述中研院方合作開發出了一套分散式的通訊協定 函式庫(Secure Multiparty Computation Protocols, SMC-Protocol)[19],並 以一般普遍被使用的程式語言實作之。此函式庫為開發者提供了解決多方安全 計算一套工具,並已透過實際的案例去探討其可應用的方式與發展的潛力。 然而該函式庫的使用,會要求開發者需針對參與計算的雙方分別撰寫不同 的程式碼,並處理各種繁瑣的細節。為了使開發者可以更專注於描述與解決問 題,並減少處理過多細節可能帶來的錯誤與安全隱憂,本研究室提出了自動化 該函式庫使用之腳本語言,即多方安全計算語言 smcSL (Secure Multiparty Computation Language)的概念[20]。此語言允許開發者撰寫與一般程式語言差 異不大的程式,其中可以包含有前述數值計算以及流程控制、輸入輸出等命令 去描述問題與解法。而後再透過編譯之安全檢查與生成目的碼的階段,自動處 理諸如使用安全協定、資料傳輸、參與雙方之程式碼分割、擷取第三方伺服器 資料等細節。不過該語言在表述問題與解法的機制上,還缺乏自定函式功能。 這使得一定規模的程式中將會有許多重複程式碼,以及表達不清楚等缺乏模組 化特性造成的問題。因此,本論文即是在保持原有 smcSL 安全性的前提下,
設計並於編譯器中實作出函式相關功能,允許開發者發展更為實際的應用程式, 並提升 smcSL 解決複雜多方安全計算問題之能力。
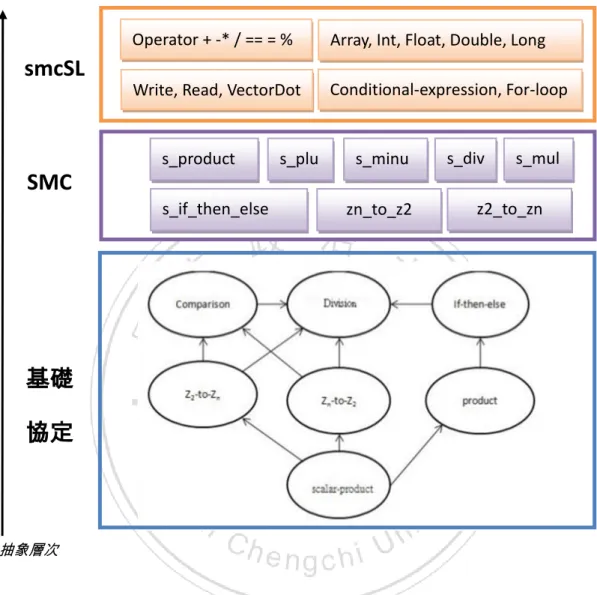
圖 1-2:smcSL 發展抽象層次示意圖
Operator + -* / == = % Array, Int, Float, Double, Long
Conditional-expression, For-loop Write, Read, VectorDot
smcSL
s_product s_plu s s_minu s s_div s_muls_if_then_else zn_to_z2 z2_to_zn
SMC
基礎
協定
1-2 研究目標
本研究之目標在於拓展前述 smcSL 語言,增加函式功能,並在設計上希望 能達到下列四點目標 一、 保持原有 smcSL 之安全特性:包括對於各變數存取權限的檢查,以及相應 產生程式碼在防止資訊洩漏上的安全考量。 二、 函式導向的語言設計原則:引入函式的同時,也代表引入所謂的變數作用 區域,以及相應的特性。因此像變數遮蔽(Variable Shadowing)、全域變 數、區域變數、傳值或傳參等議題,皆是設計上的要點。 三、 相容現有成果:在 smcSL 語言正在持續發展的階段,維持執行環境的相容 是必要的。最理想的情況是不修改而只是增加原有執行環境的功能,就可 以使新特色運作順暢。 四、 擴充與靈活性:在 smcSL 持續發展的情況下,有必要為了可預見的需求留 下設計擴充的餘地。因此在實作與設計上,帶有新特色的 smcSL 語言編譯 器,以及其他組件,都會遵循此原則進行。 藉由本研究達成以上四個目標,將可使 smcSL 在未來發展實際複雜應用的 前景上更近一步。尤其在未來以模組化程式設計為基礎,將可以持續發展出必 備的公用函式庫,乃至應用程式框架,去提供開發者更好的工具以解決各種多 方安全計算之問題。1-3 研究貢獻
本研究依據前述原則,完成了整套語言編譯器的修改與擴增。並且在不大 幅變動原有研究成果的情況下,重新組織了整個軟體的架構,呈現出無論是對 使用者或開發者都更為友善,以利持續使用與開發的成果。1-4 論文結構
本論文於第二章進行以往研究成果簡介,即介紹 smcSL 語言原本的特性。 第三章從文法開始提出為何函式對本語言而言是必頇增加的功能,以及新文法 將如何表達 smcSL 程式。第四章介紹編譯時產生程式碼之階段,因為增加函式 的緣故而衍生的各種議題。第五章介紹設計原則與實作方式。第六章提出對此 研究成果的討論。第七章做出結論與未來工作指引。最後附錄完整的 smcSL 語 法、分析與語言轉換規則。既有研究成果介紹
因本研究是基於 smcSL 語言拓展出函式之功能,因此需要簡單針對 smcSL 語言所擁有的功能與特色做介紹。2-1 自動化多方安全協定函式庫的使用
smcSL 目的上即是為使用者隱藏多方安全協定函式庫,於撰寫程式碼中需 要注意的安全細節而生。因為此函式庫需要使用者親自處理「此運算該位於哪 一伺服器」等細節,而不能專注於實現其解決問題的演算法上。因此,smcSL 語 言即是透過使用傳統的語言分析工具,以及編譯器的語言轉換技巧,以期能自 動將使用者書寫的運算程式轉換成有效率的實作程式,並兼具安全檢查之效。2-2 本機與分散式運算
由於多方安全計算是牽涉到各方參與的過程,因此這些需要合作計算的運 算就被稱為分散式( distributed ) 運算。最明顯的例子是百萬富翁問題中, 要透過多方安全協定進行比較雙方金額時的動作,一定是雙方必頇參與進行的 運算式。相對的,在進行這些分散式運算的過程前後,可能各自的資料需要一 些準備或事後處理的動作。這些動作無需雙方共同參與,因此可稱為本機 ( local ) 運算。例如百萬富翁問題中,雙方需要將自己的資料先讀入程式執 行環境,以備後續比較程式的執行,即是本機運算。 圖 2-1:百萬富翁問題中的本機與分散式運算 A 方資產 A 方伺服器 雙方參與但不洩漏各自資訊 B 方伺服器 分散式運算 誰較富有 本機運算 讀入 A 方 資產資料 B 方資產 本機運算 讀入 B 方 資產資料像這樣區分每個運算與陳述式為分散式或本機運算,是 smcSL 對使用者自 動隱藏,使其無需判斷的一個特色。因此 smcSL 中,每個語句對使用者看貣來 都與一般算術與其他普通運算無異,直至編譯過程才會靠編譯器自動按照所制 定的規則去區分。而這個編譯動作所依靠的,即是使用者對其每個變數所加上 的存取權限( Access Level)
2-3 存取權限對 smcSL 變數的重要性
在 smcSL 中,使用者需要為每個變數先宣告其資料型別與存取權限。此權 限代表了該變數是如何為各方所持有。現先假設先於 smcSL 中宣告兩參與方為 Alice 與 Bob ,將以下列簡短範例解釋變數不同宣告的存取權限與其意義:1 Party: Alice, Bob 2 Public: 3 Var n: Int 4 Alice: 5 Var asset_a:Int 6 Bob: 7 Var asset_b:Int 8 Shared:
9 Var richest: Int
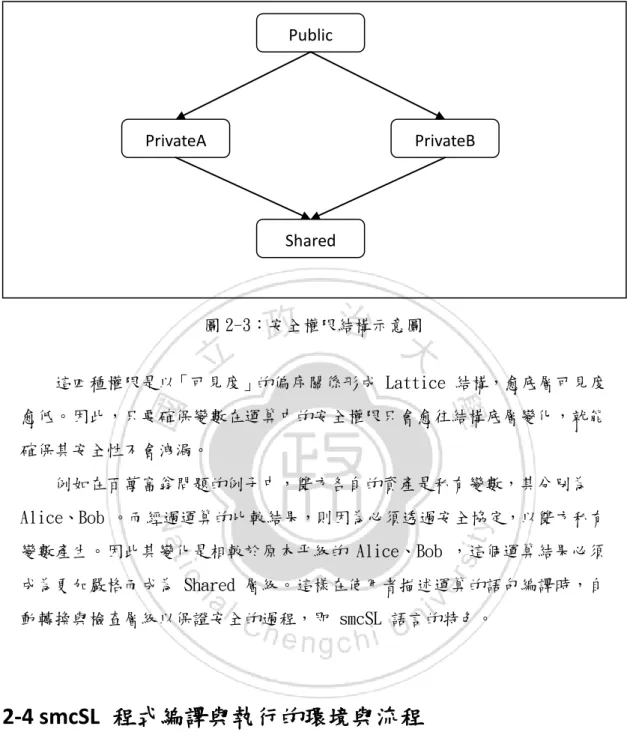
圖 2-2:smcSL 撰寫百萬富翁問題中的變數宣告段 Party 的作用在於宣告參與的雙方,使用者可以易記的方式分別為兩個參 與者命名。其後,如第一個區段中,參數之存取權限皆為 Public 所示,這些 變數是雙方皆可得知的變數,其值為雙方都得知並無影響。 而其後以 Alice、Bob 為存取權限的各變數,代表這些其是雙方各自私有, 不應讓對方知悉的變數。最後以 Shared 為存取權限者,則代表了「分持」的 變數,亦即其產生與更動將是透過多方安全協定,雙方參與運算後產生。這些 變數將是為雙方所分持持有。以下圖 2-3 是這四種權限的關係圖
圖 2-3:安全權限結構示意圖 這四種權限是以「可見度」的偏序關係形成 Lattice 結構,愈底層可見度 愈低。因此,只要確保變數在運算中的安全權限只會愈往結構底層變化,就能 確保其安全性不會洩漏。 例如在百萬富翁問題的例子中,雙方各自的資產是私有變數,其分別為 Alice、Bob 。而經過運算的比較結果,則因為必頇透過安全協定,以雙方私有 變數產生。因此其變化是相較於原本平級的 Alice、Bob ,這個運算結果必頇 成為更加嚴格而成為 Shared 層級。這樣在使用者描述運算的語句編譯時,自 動轉換與檢查層級以保證安全的過程,即 smcSL 語言的特色。
2-4 smcSL 程式編譯與執行的環境與流程
smcSL 語言提供使用者專注在描述與解決問題的抽象層,而其背後仍是在 執行多方安全計算。因此,從編譯到執行所需的環境與流程與一般程式有所不 同,以下分為基礎環境、撰寫與編譯、執行前、執行中與執行後四個階段描述。 Public PrivateA PrivateB Shared2-4-1 基礎環境
在進行計算前先架設環境。這包括參與雙方與使用者的機器必頇先裝好安 全多方執行環境,以及必頇有一台專門發送隨機變數的 Commodity Server。 圖 2-4:基礎環境2-4-2 撰寫與編譯 smcSL 程式
使用者撰寫 smcSL 程式後,透過編譯器,自動編譯並拆分出計算雙方應持 有的 SMC 程式碼。以圖中為例,「foo.smcl」將自動編譯成兩份,這兩份程式 碼將可以在準備好的 SMC 執行環境下,在使用者與 Alice, Bob 中配合執行。 圖 2-5:smcSL 程式的撰寫與編譯、遞交 User ServerA ServerB Commodity Server smcSL Runtime smcSL Runtimefoo_A.rb smcSL Compiler foo_B.rb
User ServerA ServerB Commodity Server smcSL Compiler smcSL Runtime smcSL Runtime
2-4-3 執行中:各機器間的互動
準備好完成安全計算後,使用者端會對雙方伺服器發出安全計算的需求。 而當伺服器接收到該需求後,便會按照該次需求的 SMC 程式碼,去與另一方以 SMC 協定互動,並計算出該方所得到的最終結果,再輸出至其本機的檔案中。 這樣做的用意是因為透過網路傳輸最終結果有可能被攔截,因此以檔案輸出為 取得安全計算的最終方式。 圖 2-6:執行中各機器的互動2-4-4 計算完的處理
計算完後,各伺服器擁有的輸出檔案可以被其各自檢查並無洩漏,最後再 以安全的方式交遞給使用者。使用者合併雙方所分持的內容,就可以得出安全 計算的最終結果。 User ServerA ServerB Commodity Server smcSL Runtime smcSL Runtime 提供隨機變數 提供隨機變數 SMC Protocol smcSL Compiler 進行「foo」計算 進行「foo」計算2-5 相關研究的概況與評述
以領域專屬語言角度發展適用於安全多方計算工具與系統的研究首見於 Malkhi et al. [21],他們發展的 Fairplay 系統內含兩個語言:高階的 Secure Function Description Language (SFDL) 和 低 階 的 Secure Hardware Description Language (SHDL),搭配的編譯器將 SFDL 程式翻譯成混淆電路 (garbled circuit),透過 Java 開發的電路模擬器來執行。
稍後,Nielsen and Schwartzbach[22] 以 Python 語言為基礎,發展了名 為 SMCL 的領域專屬語言,實作上翻譯成同代編碼的安全程式庫來執行。他們並 與其他研究團隊開發了一套用於丹麥甜菜拍賣的安全多方計算系統[23]。最近, 德國的一個團隊推出了名為 TASTY 的安全多方計算語言語系統[24],其特色是 可以將安全協定程式編譯成混淆電路或是同代編碼的安全程式庫來執行,由使 用者是應用需要自行選定標的程式庫。 上述幾套系統都是依據計算安全的密碼協定發展,我們的系統則是採用資 訊理論上安全的方式來進行。即在假設計算雙方是可被部分信任(semi-trusted) 會遵孚運算規則的情況下,引入不接收資訊而只負責發送隨機數之第三方伺服 器。其後再利用這些隨機數參與、混淆本就拆分過的計算中間產物在雙方間傳 遞,以避免合作計算時有洩漏的危險。此方式最早是由 Beaver [25]所提出一 種離線方式取得所需加密資源,參與各方則能以此進行計算之研究。其後 Du 與 Zhan 兩位學者[26]進行了 SMC 版的向量內積研究,並經由 Chiang 與其同事 [27][28]發展出的資訊洩漏度量方式進行了分析。後者更進一步將向量內積當 成系統的基本演算邏輯單元(building blocks),引入組合的方式讓此一基本運 算可以往上架構出更複雜的運算協定,並於該第三方伺服器參與的雙方運算架 構中保持資訊安全[17]。這些運算架構的運作方式即如前揭章節所展示。 最後,本研究之先導研究即是在該架構上所建立,目前有整數版與浮點數 版的安全程式庫[19],以及為了簡化使用者開發多方安全計算程式負擔之 smcSL 語言[20]。
研究方法與標的
3-1 原 smcSL 文法因應新增函式功能之變更
為了在現有的 smcSL 基礎上增加自定函式功能,首先需要對現有無函式的 文法進行一些修改。這是因為函式這個運算單元的概念,並非只是將原本的表 達式用函式文法包貣來而已。作為語言中一種可定義、執行與重用的單元,函 式的使用會讓整個程式的主要執行過程,就是在定義好的函式中流轉,最後回 傳經過這些函式運算後的結果。因此從以往只有單一程式區塊中,去執行一大 段陳述式的程式,變成具有多個小單元並互相串連執行的風貌。 而這些單元本身也具有部分的獨立性。首先函式會具有所謂區域變數與參 數兩種變數。這兩種變數除了在該函式中可被識別與操作之外,一旦函式執行 完畢,其生命期就結束,不會影響下次這個函式重新執行時的狀態。而且其他 函式也不能直接存取該函式中的變數與參數,因此確保了函式之間的獨立性。 因為每個函式基本上都是透過區域變數,以及參數取得可運算的值,使得 以往 smcSL 中的全域變數以及相關的宣告段不再是必要功能。而且此等全域性 質的變數往往具有安全性的隱憂。故此 smcSL 現已經取消了宣告段,只保留為 了方便且不會有問題的常數宣告區段,一個簡單的對比範例如下 原本帶宣告段之百萬富翁問題程式 使用函式之參數與區域變數改寫者 1 Party: Alice, Bob 1 Party: Alice, Bob2 Const p = 2 2 Const p = 2 3 Public: 3
4 Var n: Int 4 fun main( ): Shared Int 5 Alice: 5 {
6 Var asset_a:Int 6 Var asset_a: Alice Int , 7 Bob: 7 asset_b: Bob Int , 8 Var asset_b:Int 8 richest: Shared Int , 9 Shared: 9 n: Public Int 10 Var richest: Int 10
11 Computation 11 // Do computation 12 { // Do computation… 12
13 richest 13 return richest 14 } 14 }
以下舉另一個範例,展示如何使用函式解決線性迴歸的問題。此完整解決 一個較複雜問題的範例,可以充分表現現在 smcSL 新文法的特色
1 Party: Alice, Bob 2 Const N = 10 3 Const n = 4 4 Const m = 6 5 Const M = n+m
6 fun main(): Shared Float 7 {
8 Var i: Public Int,j: Public Int,k: Public Int,
9 A : Array [N][n] of Alice Float , B: Array [N][M] of Bob Float, 10 X : Array [N][M] of Shared Float, Y: Array [N][1] of Public Float, 11 XT : Array [M][N] of Shared Float,XTXI : Array [M][M] of Shared Float, 12 XTX : Array [M][M] of Shared Float,XTY : Array [M][1] of Shared Float, 13 Beta : Array [M][1] of Shared Float
14 for i in 0 .. N 15 Read(Y[i][0]) 16 for j in 0 .. n 17 Read(A[i][j]) 18 X[i][j] = A[i][j] 19 XT[j][i]= A[i][j] 20 end 21 for j in n .. m 22 Read(B[i][j]) 23 X[i][j] = B[i][j] 24 XT[j][i]= B[i][j] 25 end 26 end 27 29 XTY = multiply(M, N, 1, XT, Y) 31 XTX = multiply(M, N, M, XT, X) 32 XTXI = inverse(M, XTX)
33 Beta = multiply(M, M, 1, XTXI, XTY) 34 return Beta
35 } 36
37 fun multiply( x:Pub Int, y:Pub Int, z:Pub Int,
38 P : Array of Shared Float, Q : Array of Shared Float, 39 ): Array of Shared Float
40 {
41 Var i: Pub Int, 42 j: Pub Int, 43 k: Pub Int
44 PQ: Array [][] of Shared Float = dim [x][y] 45 for i in 0 .. x
46 for j in 0 .. z 47 for k in 0 .. y
48 PQ[i][j] = P[i][j] + P[i][k] * Q[k][j] 49 end 50 end 51 end 52 return PQ 53 } 圖 3-2-2:使用 smcSL 函式功能解決線性迴歸問題(第二部分) 所謂線性迴歸問題是指,給定一組實際二維資料在平面上呈現的點,計算 最合乎這些資料的趨勢直線並得出其公式,從而能詴圖透過計算預測未來資料 的值以及成長趨勢等。此方法可以用來預測例如食用澱粉多少對體重增加影響, 或是提高利率對房價價格變動,類似此種以一因素影響另一值的統計資料都可 以用此方式詴圖算出最接近的線性迴歸公式。而此問題使用 smcSL 來解的價值 在於因素與可能受影響的值之間,可以等同兩方不互相洩漏而又能合作計算出 迴歸公式的參與者。因此再也不需要讓其中一方或一第三方獲知全部資料。 在上述例子中,首先第 9 行的 A、B 矩陣各別代表了雙方不公開的資料,而 另一個向量 Y 則是雙方皆可知。這三者構成了整體資料集 M (透過 A:B:Y)。而 線性迴歸的問題,即是在尋找一道線性方程式,算出 X (透過 A:B 構成)與 Y, 之間的關係,是如何最接近整體資料集的分布情形。也就是欲求出下列方程式 圖 3-3:線性迴歸方程式 最重要的就是向量Β,最小平方向量。本程式主要功能即是在求算該值。
此問題即使使用其他一般語言也可以解決。可是一般的作法會需要在建構 矩陣 X 時,公開的讀取雙方資料。這樣會破壞 A、B 間希望互相保持機密的需求。 smcSL 的原則就是希望能達成類似的合作計算,但又能保持雙方彼此資料的隱 密性。因此在第 10 行中,本例透過存取權限的方式將矩陣 X 設定為 Shared, 代表所有針對 X 的操作,包括將雙方的值設定給 X 的動作,在底層都是利用 SMC 協定進行,因此就能確保對其進行運算的過程不會產生機密洩漏的問題。 而 在 前 述 求 最 小 平 方 向 量 的 過 程 中 , 本 程 式 是 依 據 下 列 虛 擬 反 矩 陣 (Moore-Penrose pseudoinverse)的公式進行計算 圖 3-4:最小平方向量求算公式 由此公式可以看出本例中,包括 XTX、XTXI、XTY 等變數都是在計算中所需 要的臨時變數。另外值得注意的是,除有定義的 multiply 函式外,第 32 行 inverse 函式看似沒有定義,事實是本函式為一內建函式,專門處理建立反矩 陣之運算。 就文法特色的展示而言,線性迴歸問題中,語言的特色在於如何處理陣列 乃至矩陣的各種作法。目前在 smcSL 函式中,對陣列的處理有下列幾個原則 一、 陣列傳入與傳出為 call-by-reference。也就是在函式中更改傳入的陣 列,其改變將會直接反映在陣列所配置記憶體上的值 二、 允許多維陣列。各維度內容長度可以宣告時配置,如 9-13 行;或採 動態配置,如 44 行所示 三、 陣列中所包含的值皆需初始化後方可使用
3-2 函式文法介紹
前面所介紹過的百萬富翁問題也是一個長度適當的例子,可以突顯呈現一 個函式需要哪些元素。首先就取代 Computation 區段的 main 函式來看,文法 上宣告一個新的函式需要使用 fun 關鍵字開頭,其後則是該函式的名稱、參數 宣告,以及最後宣告此函式回傳值的資料型別與存取權限,也就是安全描述 fun main ( ) : Shared Int 關鍵字 函式名 參數列 回傳值安全描述 圖 3-2:函式宣告圖解 因為 main 函式為程式的進入點,會被 smcSL 執行環境執行,就目前的方式 而言不會傳入任何參數。若是其他一般的函式,則會以下方式宣告參數1 fun compare( asset_a: Alice Int, asset_b: Bob Int ): Shared Int
2 { // 函式定義開始
3 Var a_lt_b: Shared Boolean,// 區域變數宣告段 4 a_gt_b: Shared Boolean
5 // 分隔宣告段之空行
6 a_lt_b = asset_a<asset_b// 函式本體 7 a_gt_b = asset_a>asset_b
8 return ((a_lt_b) ? 1 : ( (a_gt_b) ? 2 : 3 ) )// 函式回傳 9 } // 函式定義結束 圖 3-2:百萬富翁問題比較函式範例 在這個範例中,可以看出 compare 函式有兩個參數,分別是 asset_a 與 asset_b 。而每個參數後面,與函式回傳值類似,都需要使用冒號分隔其名稱 與安全性描述的部分。需要說明的是,參數可以被省略,但函式的回傳值宣告 是不可省略的。每個函式都應該具有回傳值。 函式的宣告區域完成後,使用兩個大括號把函式本體內部的陳述式包裹住。 接下來第一個區段是可省略的區域變數宣告區段,其文法範例如下 Var
關鍵字 變數名 安全描述 分隔符 圖 3-3:區域變數宣告方式圖解 使用者必頇在整個區域變數宣告段開始時,以 Var 關鍵字宣告區段開始。 這之後,每一行都是一個區域變數的宣告行,並且行末使用逗號做分隔。只有 最後一行是以省略逗號的方式作結。而在整個區段結束前,需要在開始描述函 式本體前留下一空行表示區域變數宣告結束,如圖 3-2 的第 5 行所示。 需要注意的是,函式中所有區域變數都必頇在使用前宣告,而且一個函式 只能有一個區域變數宣告段。這代表使用者不可以把宣告段放在函式本體之後, 或是擺放任意數量與位置的區域變數宣告段。 區域變數宣告結束後就開始了函式本體。這個部分所有的陳述式語法都與 此前 smcSL 中,Computation 所使用的文法相近,只一些比較細微的調整,因 此不再此贅述。唯一新增加的是 return 這個陳述式,由上述範例可說明如下
return ( ( a_lt_b ) ? 1 : ( (a_gt_b) ? 2 : 3 ) )
關鍵字 任意 smcSL 運算式 圖 3-4:區域變數宣告方式圖解 關於 return 陳述式要注意的是,其回傳值型別必頇嚴格吻合先前宣告的 函式回傳值描述。也就是如果使用者宣告該函式將回傳整數型別,就不可以回 傳浮點數,這是目前為確保安全而採取的措施。相較之下,目前因為存取權限 的位階與轉換經研究是可以確保安全的,因此允許級別較寬鬆的回傳值(如
Public Int ),透過宣告與回傳的方式轉成比較嚴格的級別(如 Shared Int )
並傳出去。這部份後面會詳加說明,此處只先舉一個簡單範例,如下圖所示。
1 fun convert(): Shared Int 2 {
3 Var p : Public Int 4
5 p = 13
7 }
圖 3-5:函式回傳值的自動轉換
在這個範例中可以看出,原本宣告為回傳 Shared Int 的函式 convert, 最後卻在 return 陳述式中回傳了一個 Public Int 。而根據安全級別的關係 描述,Public 比 Shared 寬鬆,轉成較嚴格的級別只會減少資訊洩漏的可能, 並不會增加,因此允許透過呼叫此函式時回傳並取得此 Shared Int 值。 除了前述函式、區域變數宣告,與函式回傳的新文法外,最後一個因為加 入函式功能而產生變化的 smcSL 文法是運算式的部份。在以前,運算式中允許 出現的元素大致為變數、一元、二元、條件運算式等。而在現在的 smcSL 中, 新增加允許函式呼叫的文法規則。其範例與圖解如下所示
1 fun main( ): Shared Int 2 {
3 Var asset_a: Alice Int , 4 asset_b: Bob Int , 5 richest: Shared Int , 6 n: Public Int 7
8 richest = compare(asset_a, asset_b) // 函式呼叫 9 return richest 10 } 圖 3-6:具函式呼叫的百萬富翁問題主函式本體 需注意的是雖然此例中,第 8 行的賦值陳述式只有一個函式呼叫的式子, 但事實上同一陳述式中,函式呼叫可以出現多個,並與其他運算子混用,也可 成為迴圈範圍的貣始或終止條件值。 對於函式呼叫的文法,其參數可以是變數,也可以是另一個運算式。只要 合乎安全描述的規範,以及函式宣告的規範,並前述轉型相關的規則,就可以 被接受並傳入成為函式運算的一部分。
函式名 合乎函式宣告個數與安全描述的參數列 圖 3-7:函式呼叫文法圖解 最後就是被執行的函式雖然要宣告,但不見得在一定先於呼叫者的位置。 也就是一個函式宣告的位置不影響其被執行是否會錯誤。 針對以上基本的函式文法介紹,下面展示了完整使用函式功能解決的百萬 富翁問題,作為本節的結束。
1 Party: Alice, Bob 2
3 fun main( ): Shared Int 4 {
5 Var asset_a: Alice Int , 6 asset_b: Bob Int , 7
8 Read(asset_a) 9 Read(asset_b) 10
11 return ( aLTb( asset_a, asset_b ) ? 1 : ( ( bLTa( asset_b, asset_a)) ? 2 : 3) ) 12 }
13
14 fun aLTb( asset_a: Alice Int, asset_b: Bob Int): Shared Boolean 15 {
16 return asset_a<asset_b 17 }
18
19 fun bLTa(asset_b: Bob Int, asset_a: Alice Int,): Shared Boolean 20 {
21 return asset_b<asset_a 22 }
3-3 函式檢查規則
函式的檢查可以分為宣告與執行的檢查。前者是檢查宣告的函式,是否有 使用不存在作用範圍內的變數,或是缺少回傳陳述式,又或是最後回傳值的安 全描述與宣告時的描述不合。這部份將按正常一個程式單元被編譯時檢查的流 程,分為三小節介紹。3-3-1 函式作用區域檢查
對於一個函式而言,因為所有變數都來自於參數或區域變數宣告,因此不 能使用這兩塊區域所未宣告的變數。若是函式存取這兩者以外的變數,除了較 特殊的常數外,都會產生編譯錯誤。下例是一個使用不存在變數而錯誤的例子1 Party: Alice, Bob 2 Const PI = 3.14 3
4 fun R2(): Public Int 5 {
6 Var pi2: Public Int 7
8 pi2 = PI * 2 // 常數 9 return pi2
10 } 11
12 fun illegal(rd: Public Int): Public Int 13 {
14 Var area: Public Int 15
16 area = rd * pi2 * 2 // 不存在的變數 pi2 17 return area 18 } 圖 3-9:函式存取作用區域中不存在變數造成錯誤範例 在這個範例中,illegal 函式存取了並非參數,也非區域變數的 pi2 變數。 這個變數對該函式而言是未宣告變數,因此將會出錯。相較之下,在函式 R2 中,使用了 PI 這個常數變數,雖然在該函式之外但並非錯誤。
3-3-2 缺少回傳陳述式
目前所有的 smcSL 函式都必頇具備回傳值。因為就安全方面的考量,目前 使用者自定函式,除了 main 函式外不開放諸如 Read/Write 等有副作用,能改 變執行狀態但不透過回傳值表達的陳述式。因此,若一個函式沒有回傳任何值, 就等於沒有意義。因為其所運算的結果不能再被使用。3-3-3 回傳值與宣告不一致
這個部分是因為 smcSL 程式的安全分析,是建立在一致與允許部分轉換的 原則上。若函式回傳違背自己所宣告,應該會回傳的型別與安全級別時,就是 不合法的函式。像是一個宣告自己會傳出公開( Public ) 級別變數的函式,若 最後卻傳出某私有方的資料,這樣就會造成洩漏。以下就是一個有問題的例子1 Party: Alice, Bob
2 fun main(): Public Boolean 3 {
4 Var is_10: Public Boolean, 5 ai: Alice Int
6
7 Read(ai)
8 is_10 = (10 == illegal(ai)) ? True : False 9 return is_10
10 } 11
12 fun illegal(ai: Alice Int): Public Int 13 {
17 return ai// ai::Alice → Public,回傳私有變數且轉成公開變數 18 } 圖 3-10:違背安全描述之函式回傳值 上述例子中,第 17 行將本屬於 Alice 私有的 ai 變數,經過 illegal 函式 回傳安全級別會從私有變成公開,因此兩方於後續的操作就都可以知道該變數 的值。這種漏洞目前是會被檢查並禁止的,並只允許函式回傳時所傳出的運算 式,其安全級別比貣宣告相等或更寬鬆。然後編譯器會在將這比較寬鬆的級別, 自動轉成宣告時使用並較嚴格的級別。例如從 Public 轉成 Shared。
函式生成規則
經過前述文法與安全規則檢查後,已經確保這份程式不會發生資訊外洩的 問題。因此可以開始進行將程式拆分並轉換成目的碼之流程。這部份目前編譯 器設計成具有彈性,可以視執行環境使用的語言不同,實作並新增產生不同目 的碼生成的機制。不過因為此前的成果皆是以 Ruby 程式語言為主,所以本論文 中所提及的目的碼格式皆為 Ruby 程式。4-1 smcSL 函式生成原則與實例
由於 Ruby 語言本身已經有函式的概念,所以編譯器在轉換時,基本原則就 是直接把一個 smcSL 函式對應到一個 Ruby 函式。只是 smcSL 的生成,是把一份 smcSL 程式碼拆分成兩份程式碼,而兩個參與者分別拿到不同的版本,以避免 洩漏各自資訊。因此這個一對一到 Ruby 函式的概念,將有下列拆分方式的不同 smcSL 函式最終回 傳 Alice 方生成 Bob 方生成 Public 雙方都具該生成後 Ruby 函式 Alice 具生成後 Ruby 函式 無 Bob 無 具生成後 Ruby 函式 Shared 雙方都具該生成後 Ruby 函式 表 4-1:根據函式不同回傳值對應雙方不同生成方式 要注意目前 smcSL 允許宣告級別比回傳值時嚴格。例如宣告回傳 Shared 但函式中最後回傳出 Public,則該函式還是以 Shared 作為其級別。所以這邊 所謂「smcSL 函式最終回傳」,指的是考慮這樣的轉換後取得的級別。另外本表 所表示的是該函式會不會出現在該方所取得的程式碼中,而不是程式本體個陳 述式拆分的情況。像雖然該函式為 Public 與 Shared 時,雙方程式中都會有該 函式對應的 Ruby 版本,但內容卻因著各陳述式的拆分法不同而有所不同。所以 嚴格說來本研究除增加了後面會提及的函式呼叫的部份外,並沒有大幅改寫過 往 smcSL 的拆分方式。 下面數個例子包含了四種級別的函式各一,並且隨附上編譯器產生後的兩 份程式碼。讀者可以由此理解函式拆分的主要結果1 Party: Alice, Bob
2 fun public_pow(pi: Public Int, pj: Public Int): Public Int 3 {
4 Var i: Public Int, 5 sum: Public Int 6 7 for i in 0..pj 8 sum = sum + pi * pi 9 end 10 11 return sum 12 } 圖 4-1:Public 級別函式拆分範例原始檔
編譯後 Alice 端 Ruby 程式碼 編譯後 Bob 端 Ruby 程式碼 1 def main_public_pow(pi,pj) 1 def main_public_pow(pi,pj) 2 i = smcSL_IO.initValue(:SMCInt) 2 i = smcSL_IO.initValue(:SMCInt) 3 sum = smcSL_IO.initValue(:SMCInt) 3 sum = smcSL_IO.initValue(:SMCInt)
4 4
5 for i in 0..pj 5 for i in 0..pj 6 temp_0 = pi * pi 6 temp_0 = pi * pi 7 temp_1 = sum+temp_0 7 temp_1 = sum+temp_0 8 sum = temp_1 8 sum = temp_1
9 end 9 end
10 10
11 return sum 11 return sum 12 end 12 end 圖 4-2:Public 函式拆分範例生成 Ruby 程式碼 從上例可以看出,安全級別為 Public 的函式,在生成時的原則是雙方將持 有同樣的函式。這是因為這類函式可能會被雙方各自執行,因此需要讓雙方都 持有該函式。值得注意的一點是因為 Public 函式意味著所傳出的值只能是 Public,而非其他級別的值,因此函式本體的陳述式通常不會有其他級別的運 算,因此生成的程式碼也按 Public 處理方式拆分,而顯得相同。但事實上函式 級別不代表所有內部陳述式級別。有可能內部依然有其他級別的陳述式,採該 級別方式拆分,如下例
1 Party: Alice, Bob
2 fun plus (pi: Public Int, pj: Public Int): Public Int 3 {
4 Var ai: Alice Int, 5 bi: Bob Int, 6 si: Shared Int 7
8 ai = 4 // Alice 9 bi = 5 // Bob 10 si = ai + bi // Shared 11 return pi+pj // Public 12 }
圖 4-3:內含其他級別陳述式的 Public 函式
上例中,雖然宣告與最後回傳的級別都是 Public,但從第 8 至第 10 行有 一些陳述式是屬於 Public 以外的級別。因此最後產生程式碼時,這部份將按照 各自的規則進行拆分,而非隨同函式的 Public 級別拆分。結果如下
編譯後 Alice 端 Ruby 程式碼 編譯後 Bob 端 Ruby 程式碼 1 def main_plus(pi,pj) 1 def main_plus(pi,pj)
2 ai= smcSL_IO.initValue(:SMCInt) 2 bi = smcSL_IO.initValue(:SMCInt) 3 si_A = smcSL_IO.initValue(:SMCInt) 3 si_B = smcSL_IO.initValue(:SMCInt)
4 4
5 ai = 4 5 bi = 5
6 temp_0 = s_plus(ai, 0, $BASE) 6 temp_0 = s_plus(0, bi, $BASE)
7 si_A = temp_0 7 si_B = temp_0
8 temp_1 = pi+pj 8 temp_1 = pi+pj 9 return temp_1 9 return temp_1 10 end 10 end 圖 4-4:內含其他級別陳述式的 Public 函式生成結果 可以注意這邊屬於雙方各自級別的程式碼,以及分持 Shared 級別的運算, 拆分依然遵循各自規則。但因為最終回傳與宣告皆為 Public,因此此函式級別 仍然算為 Public。且由於一般 smcSL 使用者自訂函式不允許 IO,這些非回傳的 陳述式事實上不會發生任何效用,而只是展示此種情況的生成情形。
1 Party: Alice, Bob
2 fun alice_pow(ai: Alice Int, pi: Public Int): Alice Int 3 {
4 Var i: Public Int, 5 sum: Alice Int 6 7 for i in 0..pi 8 sum = sum + ai * ai 9 end 10 11 return sum 12 } 圖 4-5:Private 並為 Alice 級別函式拆分範例原始檔
編譯後 Alice 端 Ruby 程式碼 編譯後 Bob 端 Ruby 程式碼 1 def main_alice_pow(ai,pi) 1 2 i = smcSL_IO.initValue(:SMCInt) 2 3 sum = smcSL_IO.initValue(:SMCInt) 3 4 4 5 for i in 0..pi 5 6 temp_0 = ai * ai 6 (不產生對應函式) 7 temp_1 = temp_0+sum 7 8 sum = temp_1 8 9 end 9 10 return sum 10 11 end 11
圖 4-6:Private 並為 Alice 級別函式拆分範例生成 Ruby 程式碼
可以看出當該函式為私有一方時,另一方將不會產生對應的函式。在這種 情況下,該函式所執行的運算事實上將全部依賴該方的資源,因此產生對方函 式是毫不合理且無意義的行為。這對於兩方私有級別而言都是一致的規則,因 此在此不舉另一方的例子。
1 Party: Alice, Bob
2 fun shared_pow(ai: Alice Int, bi: Bob Int, pi: Public Int): Shared Int 3 {
4 Var i: Public Int, 5 sum: Shared Int 6 7 for i in 0..pi 8 sum = sum + ai * bi 9 end 10 11 return sum 12 } 圖 4-7:Shared 級別函式拆分範例原始檔
編譯後 Alice 端 Ruby 程式碼 編譯後 Bob 端 Ruby 程式碼 1 def main_shared_pow(ai,pi) 1 def main_shared_pow(bi,pi) 2 i = smcSL_IO.initValue() 2 i = smcSL_IO.initValue() 3 sum_A = smcSL_IO.initValue() 3 sum_B = smcSL_IO.initValue()
4 4
5 for i in 0..pi 5 for i in 0..pi
6 temp_0= s_product(ai, 0, $BASE) 6 temp_0 = s_product(0, bi, $BASE) 7 temp_1 = s_plus(sum_A, temp_0, 7 temp_1= s_plus(sum_B, temp_0,
8 $BASE) 8 $BASE)
9 sum_A = temp_1 9 sum_B = temp_1 10 end 10 end
11 11
12 return sum_A 12 return sum_B 13 end 13 end
圖 4-8:Shared 級別函式拆分範例生成 Ruby 程式碼
上例中可以看出,Shared 函式的拆分也是雙方都會持有該函式。就函式的 拆分原則並無不同,當然內部各陳述式因為基於 Shared 運算的方式會與 Public 的拆分法不同。
4-2 存取權限轉換於函式方面的議題
就如同前面所提到的,目前 smcSL 中的變數允許存取權限的轉換。原則是 允許較寬鬆的級別,例如 Public 變數,透過賦值陳述式轉成例如 Private 或 Shared 等較嚴格的級別。這個過程並不會產生資訊洩漏,故被允許用於需要的 場合上。
1 Party: Alice, Bob
2 fun level_ups( pi: Public Int): Shared Int 3 {
4 Var ai: Alice Int, 5 bi: Bob Int, 6 si: Shared Int 7 8 ai = pi // Public → Alice 9 bi = pi // Public → Bob 10 si = pi // Public →Shared 11 si = ai // Alice→Shared 12 ai = bi // Forbidden 13 pi = ai // Forbidden 14 pi = si // Forbidden 15 return si 16 } 圖 4-9:允許與不允許級別轉換的賦值陳述式範例 如上述範例所示,級別的轉換不會允許較嚴格的級別轉成較寬鬆級別的情 況出現,以此避免資訊外洩。前例中,12-14 等行將會在編譯時引發錯誤。此 錯誤之規則如下所示 圖 4-10:賦值式存取權限轉換之檢查規則
存取權限的轉換除影響賦值外,還會影響函式的回傳值與參數。目前 smcSL 允許這兩者以級別轉換的方式,將原本較寬鬆的參數或回傳值,轉成較嚴格的 級別,如下例所示
1 Party: Alice, Bob
2 fun level_up_fn( ai: Alice Int): Shared Int 3 {
4 return ai // ai::Alice → Shared
5 }
7 fun main(): Shared Int 8 {
9 Var pi: Public Int 10
11 pi = 5
12 return level_up_fn( pi ) // pi::Public → Alice
13 }
圖 4-11:函式參數與回傳值中的級別轉換
如上所示,函式 level_up_fn 的參數級別應該是 Alice,但在 main 函式 中卻給予了一個 Public 值。此值將自動在 level_up_fn 函式中轉成 Alice 的變 數後才運算。而後,雖然該函式回傳宣告為 Shared,但最後面的回傳陳述式卻 是將 Alice 的變數直接回傳,因此這裡也隱含了一個將回傳變數級別轉換成 Shared 的過程。此外,函式參數與回傳值的級別轉換,依然要遵孚此前所述, 僅允許較寬鬆者轉換成較嚴格者的規則。下面就是一個會發生錯誤的例子
1 Party: Alice, Bob
2 fun error_fn( ai: Alice Int): Public Int 3 {
4 return ai // Forbidden: pi::Alice → Public 5 }
7 fun main(): Shared Int 8 { Var ai: Alice Int, 9 bi: Bob Int
10 return error_fn(ai + bi ) // Forbidden: ai+bi::Shared → Alice 11 }
smcSL 編譯器設計原則與實作
前面所介紹的,是從比較單純的輸出輸入,來看待編譯器從文法到產生目 的碼的規則與結果。而實際上的功能,則是透過落實各設計思想的實作達成。 以下將介紹此階段編譯器是如何轉換原始碼所產生出的抽象語法樹(Abstract Syntax Tree, AST),到最終目的碼生成的過程。並介紹現今 smcSL 編譯器在設 計與實作中的原則和特色。
5-1 smcSL 編譯器語法層面處理流程
首先 smcSL 編譯器一如一般編譯器原理,也有包含如下圖所示那樣的語法 剖析,到產生目的碼的過程。一個比較特別的地方在於,smcSL 基於安全性的 原因會將一份原始碼編譯後產生兩份目的碼,此特點將有別於其他一般語言。 圖 5-1:smcSL 編譯器編譯流程示意圖就實作細節而言,如果從語法處理的前階段來看,本研究與之前版本的編 譯器差別在於,新增了基於標準 Lex&Yacc 所開發出來的 C/C++語法掃描與剖 析器。此前的版本實際上是使用本編譯器的開發語言,即 Ruby 本身內建的 Meta-Programming 技術去進行掃描原始檔與建構抽象語法樹的工作。這樣的作 法固然能快速開發,但在後續的語言擴展與維護過程中,有發現部分新功能與 設計會受到限制的問題。因此,目前採取的策略,是編譯器在接收原始檔後, 會透過系統呼叫事實上為獨立外部組件的語法掃描與剖析器,並將整份 smcSL 原始碼轉換成抽象語法樹所使用的格式,再由編譯器接收字串輸出結果後進行 後續處理。此處編譯流程如下所示 圖 5-2:smcSL 語法掃描與剖析器與編譯器介接方式示意圖 也因為語法掃描與剖析器並不是使用 Ruby 實作,且其於編譯器之外,是可 以獨立執行的程式,因此現在的 smcSL 編譯器相較於以往的版本,系統可移植 性(Portable)上有比較多的限制。但此種作法方能最大的發揮語言擴展的可能 性並符合本研究的需求。 而在語法掃描與剖析器這邊的特色而言,本研究為了顧及未來語言的變動 可能,以及保持結構靈活可擴充的特色,特地將原始碼的剖析與產生抽象語法 樹兩者功能做切割。具體而言,現在的實作上分為 Lexer& Parser、Builder 與 AST Template 三部組件。其中 AST Template 指的是要如何從剖析出來的 節點輸出成 AST 所使用的 S-expression 格式,其將透過 Builder 填入必要資訊 的樣板檔。而 Lexer& Parser 的角色簡化到只有在遇見特定節點時,一一呼叫 相關 Builder,由後者執行填入樣板變數的動作。其流程示意圖如下所示 系統呼叫 系統回傳 編譯前階段 後續編譯流程 分析 檢查 產生 目的碼 目的碼 smcSL 語法掃描與剖析
31
圖 5-3:smcSL 語法掃描與剖析階段內部流程圖
至於在設計上為何要將 Builder 與 AST Template 從 Lexer& Parser 中抽出, 這是考慮到將來語言增加新特性,例如在可預見的未來增函式樣板(Template) 的功能時,可以比較清楚且快速的增加與更改所對應的 S-expression 格式。 相較於以往的 smcSL 編譯器是將產生 S-expression 的功能寫在剖析器的程式 碼中,隨時間修改後沒有一份即時且統一的文件描述每個抽象語法樹節點是如 何對應到 S-expression;今此功能以 AST Template 方式提供後就可以很自然 的 將 增修 程式 與 更新文 件 兩者 行為 統 一,日 後 要檢 視全 部 節點對 應 到 的 S-expression,只要檢視 AST Template 即可。
另外前述所謂 S-expression 格式,是指為了要使透過剖析,已經是結構化 的抽象語法樹,可以順利輸出並為編譯器所接收而使用的序列化(Serialized) 格式。其源頭是來自 Lisp 語言表達程式結構的類似概念,並輕微變形成 Ruby 可以接收並輕易轉為 Ruby 程式結構的格式。S-expression 範例如下
圖 5-4:smcSL 語法掃描與剖析器產生 S-expression 格式範例
[:program, [:modules, [:list, [:module, [:name, :main], [:list], [:list, [:fn, [:name, :main], [:list], [:stmts, [:stmts, [:stmts, [:stmts, [:stmts, [:stmts, [:noop], [:write, :SMC_PRIVATE_A, [:str, "How much money do you have?\n"]]], [:write, :SMC_PRIVATE_B, [:str, "How much money do you have?\n"]]], [:read, [:idrefer, [:name, :asset_a], [:list]]]], [:read, [:idrefer, [:name, :asset_b], [:list]]]], [:asn, [:id, [:name, :empty], [:accessor]], [:call, [:id, [:name, :empty_fn], [:accessor, [:id, [:name, :main], [:accessor]]]], [:list, [:id, [:name, :empty], [:accessor]]]]]], [:return, [:call, [:id, [:name, :compare], [:accessor, [:id, [:name, :main], [:accessor]]]], [:list, [:id, [:name, :asset_a], [:accessor]], [:id, [:name, :asset_b], [:accessor]]]]]], [:list, [:return, [:call, [:id, [:name, :compare], [:accessor, [:id, [:name, :main], [:accessor]]]], [:list, [:id, [:name, :asset_a], [:accessor]], [:id, [:name, :asset_b], [:accessor]]]]]], [:sig, [:id, [:name, :main], [:accessor]], [:list,
[:sigdecl, :SMC_SHARED, :SMC_INT__0]]], [:list, [:vardecl, [:id, [:name, :asset_a], [:accessor]], :SMC_PRIVATE_A, :SMC_LONG__0, [:list]], [:vardecl, [:id, [:name, :asset_b], [:accessor]], :SMC_PRIVATE_B, :SMC_LONG__0, [:list]], [:vardecl, [:id, [:name, :empty], [:accessor]], :SMC_PRIVATE_B, :SMC_INT__0,
smcSL Lexer& Parser Function Variable Expression
...
Builder Template Function =[‘fn’,<%= name %>, ..] Expression=[‘expr’, <%= op %>, ..] ... 抽象語法樹節點上例可以看出,整個 smcSL 程式經語法掃描與剖析後,產生的語法樹 以:program 為根,內中開始是:modules 到函式內部陳述式與運算式的元素,再 細至每個變數、每個常數。 至於 S-expression 的格式,在 smcSL 中並沒有程式性的規範,但有幾個 原則在設計與使用上必頇遵孚 一、 該節點的「型別」必頇位於第一個元素,例如 :program、:module 二、 帶有多個元素的串列,必頇用另一個 S-expression 的陣列包裹這些 元素。且該 S-expression 必頇以 :list 為其型別標示 三、 編譯器其他組件不應該直接操作陣列化的 S-expression,而應該透過 適當的轉換器 ,將每種 S-expression 轉成適切的抽象語法樹節點後, 方透過符合 Ruby 物件導向原則的方式對之進行操作 四、 前 述 的 轉 換 器 應 該 要 有 能 力 將 相 應 的 節 點 傾 印 (Dump) 回 S-expression,並保持所有資訊不在這過程中漏失 五、 S-expression 從語法掃描與剖析器產生後,應該儘量保持唯讀狀態。 也就是後續的操作除非有必要,否則不應該改變整個程式原始的抽象 語法樹 最後,從編譯流程上來看,由於 S-expression 在 Ruby 中就是普通的陣列 而已。因此在 smcSL 編譯器透過系統呼叫語法掃描與剖析器後,所接收到的系 統回傳就是這樣的字串,而後只要使用 eval 功能就可以取得前者所剖析出來的 抽象語法樹。而此處的抽象語法樹即是後續所有從分析到產生目的碼之基礎。
smcSL 編譯器於語法層面的處理,還有一個值得注意的特色是本研究中, 因 smcSL 語言之常數區段,實際上會有常數計算的需求。因此目前編譯器實際 上具備一個前處理器(Preprocessor)去處理這些常數區段中的計算,如圖所示 smcSL 原始檔常數區段範例 經前處理器處理之結果 1 Const pi = 3.14 1 2 Const tau = pi * 2 2 3 Const hello = “Hello, world !” 3
4 4
5 fun main(): Public Int { 5 fun main(): Public Int {
6 Write(Alice, hello) 6 Write(Alice, “Hello, World”) 7 return tau * tau 7 return 6.28 * 6.28
8 } 8 } 圖 5-5:smcSL 前處理器針對常數區段處理範例 目前前處理器所能處理的運算式,包括整數與浮點數運算。這些運算可以 含有透過四則運算子表達的算式,其中也可以含有由 Ruby 數學相關函式參與的 運算式。這使得前處理器所處理的內容近於在 C/C++中可見的 Macro,但本研究 針對此部份採取的設計原則比較單純,希望這些功能只是輔助開發者可以更加 方便開發程式,並不希望成為像 Macro 那樣功能繁多的語言特色。 smcSL 編譯器目前也有參數,可以允許附帶輸出前處理器所處理完原始檔。 這個功能在要針對語法掃描與剖析器進行開發除錯時特別有用,因為事實上語 法掃描與剖析器必頇接受已經由前處理器處理完的格式,而非原始的 smcSL 格 式。所以在這種情境下就可以先將一份除錯用的 smcSL 檔案,透過該參數編成 語法掃描與剖析器可以接收的格式,然後透過系統直接執行該獨立部分的程式, 就不用在針對該部分除錯時還要等候後續編譯階段的流程執行完畢,所產生的 除錯訊息也會比較單純。這也是另一個將語法掃描與剖析器獨立出編譯器而帶 來的好處之一。
5-2 抽象語法樹的檢查階段
透過前述語法階段的剖析,smcSL 編譯器現在要將整株抽象語法樹的每個 節點進行安全規則檢查。在設計上,這些檢查由三個組件構成,每個組件代表 一個獨立的檢查項目,包括 一、 變數與函式作用區域(Scope)檢查 二、 型別檢查 三、 存取權限檢查 每一個檢查項目都必頇通過,否則 smcSL 編譯器將停止整個流程,並將現 在產生錯誤的節點與相關錯誤訊息回報至系統的標準錯誤輸出。以下將一一介 紹每個檢查的實作方式與設計原則。5-2-1 變數與函式作用區域檢查
這部份主要的檢查是針對每個函式中,是否使用了不在區域內的名稱,也 就是含有不是函式參數、區域變數、模組成員函式,以及內建函式的識別符。 針對變數區域檢查的處理比較單純。在代表函式的抽象語法樹節點格式中, 就包含有語法剖析時所獲取的所有區域變數、函式參數之識別符。因此只要在 掃描函式本體時,比對每個遭遇的變數其識別符是否在前述的清單中即可。這 部份的檢查方式如下圖所示 圖 5-6:函式抽象語法樹節點進行變數區域檢查 ASTNode Function Variables[foo, bar, ai, richest, result...]
Functional Body Statements Statement Expression Expression Expression Used Variables foo, bar, result, ... 檢查 檢查 兩者比對
而在針對函式呼叫進行作用區域檢查時,編譯器的處理方式將較為複雜。 首先,如果該函式呼叫的識別符,不是跨模組呼叫而沒有帶有如下圖所示的 Accessor 資訊,而僅有單純函式名稱時,代表該函式可能是定義在當前編譯模 組內,也可能是內建函式。因此編譯器會先檢查該函式名稱是否出現在本模組 的定義函式內。如果不是,則再次檢查是否為內建函式。在這兩種情形都不符 合的情況下,代表該函式呼叫錯誤的引用了未經定義的函式,因而編譯器會終 止編譯並回報錯誤。 matrix
.
transpose 模組名 分隔符 函式名 圖 5-7:帶 Accessor 資訊之函式識別符範例 所謂的 Accessor 指的是位於函式名稱前面,以「.」為分隔符,一連串的 模組或其他上層結構名稱。然而目前 smcSL 模組設計僅有兩層,也就是模組-函式的結構,因此 Accessor 實際上可以代指模組名稱。 如果編譯器在做區域檢查時,所欲檢查的函式呼叫節點帶有 Accessor 資訊, 則會視現今編譯器是在進行單個模組編譯,抑或主程式編譯而有不同的檢查法。 首先如果編譯器處於編譯單個模組檔的模式,則在整個程式編譯單元找不到該 Accessor 所指出的模組名稱時,編譯器會忽略這個錯誤繼續向下檢查。但如果 是編譯整個主程式時,只要 Accessor 中所指稱的模組名稱沒有定義在 smcSL 程式單元中,檢查就出錯並終止執行。會有這樣的差異是因為,當編譯單個模 組時,有可能所指稱的其他模組並不在目前程式單元的可見範圍內,而是會透 過匯入(Import)功能連結在一貣。因此這樣的錯誤將被忽略,且延遲至等所有 模組單元都已匯入成一份主程式檔案時,才檢查每個被指稱的模組,在匯入完 成後是否於程式中有所定義。這部份如何處理錯誤的流程圖如圖 5-8 所示。 會有這樣忽略錯誤並延遲檢查的原因,最主要是因為在本研究中,模組的 設計與實作尚屬實驗性質。因此在編譯單個模組時,應要產生關於該模組連結 與其他資訊的模組標頭檔,以及其他相關的模組資訊檔還沒有完整的設計與實 作。這部份需要更多的討論與確認後才能進行。因此在現階段,其實編譯器會 在個別模組編譯以最後主程式編譯階段,針對同一段 smcSL 程式重複做檢查兩次。此乃不符合分別編譯的精神,但是是此過渡時期能先使用與評估模組功能, 而又不會違背安全原則的作法。 圖 5-8:smcSL 編譯器檢查未定義模組之處理流程 若是本研究中的模組功能經過討論、設計與實作較完整後,此種看似個別 編譯實際上卻要檢查兩次的臨時作法就可以取消,而是改以檢查個別編譯時所 產生出的模組標頭檔,去檢查所有匯入之模組資訊,就可以在個別編譯階段中, 揪出未定義模組函式之錯誤。而後於主程式編譯時,這些已經檢查過的模組就 無需再次被檢查,而只要檢查主程式中餘下未檢查的部份即可。
5-2-2 型別檢查
型別檢查在 smcSL 編譯器中比較單純。第一個原因是目前 smcSL 語言不允 許資料別的轉變,因此只要針對程式編譯單元中出現的每個變數,以及相應的 運算式、陳述式,去檢查是否切實符合到語言規則的要求即可。這方面的檢查 規則可見附錄。 不過對於語言使用者而言,要注意目前 smcSL 完全不允許資料型別的轉換, 因此浮點數、整數與長整數之間並不存在自動轉換的關係。忽略此特性可能對 語言使用者在開發某些數學函式時會造成困擾。會有這樣的限制主要是 smcSL所描述的 SMC 協定中,不同長度數值進行運算的函式,其會有所謂基底的差異。 因此並不如普通語言中,處理數字轉換只是記憶體位置使用的多寡問題。 另一個資料型別檢查中的實作特點在於,smcSL 語言的陣列是含有維度與 長度資訊的。而每個陣列的維度資訊就是記在其型別中。因此一個維度三的整 數陣列型別可能表達為 INT_3,而無維度的單純整數將表達成 INT_0。因此只要 透過檢查型別,就可揪出諸如將無維度整數賦值給一個具維度的陣列之錯誤。