Knowledge Annotation and Discovery for Patent Analysis
6
0
0
全文
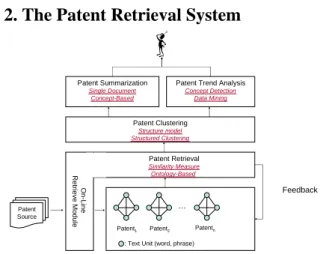
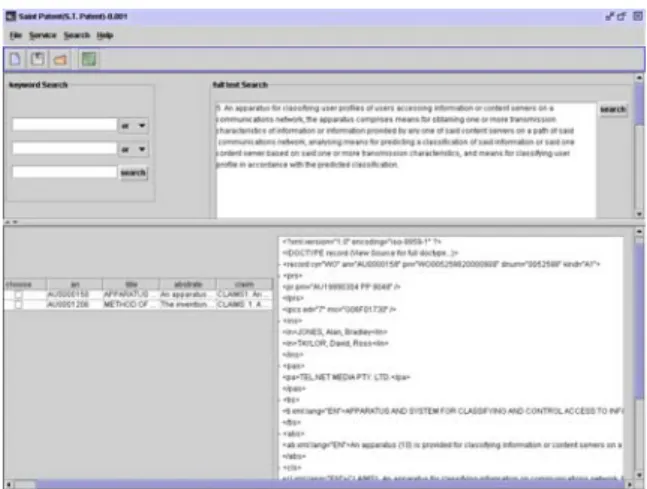
(2) Int. Computer Symposium, Dec. 15-17, 2004, Taipei, Taiwan.. Our system refines user’s query by expanding query concept. In the feedback process, the user chooses appropriate concepts from “concept clusters” to compare with connected concept units. The concepts connected with chosen clusters denote related ideas with user’s query and can be used to expand the query. Moreover, user query is also expanded by domain ontology. By comparing with the ontology tree, different words contained in the same ontology group can be identified as related. Fig. 3 displays the interface of the ontology-based patent search. A user can specify keywords or fulltext document to search patents. After analyzing concepts, the search result shows the patent content and concepts extracted from the patent.. retrieving documents from the patent sources. The retrieved documents are firstly analyzed in the patent database to extract patent concepts and construct domain ontology. In the meanwhile, the user can preview and choose patent concepts to rebuild his query and extend the search scope by domain ontology. The search result is then classified in the patent clustering module. Finally, the clustering results are consequently summarized and analyzed to track the trend. The architecture of the patent retrieval system is depicted in Fig. 1. The system contains four main parts: 1) the online patent search, 2) the structure clustering of patents, 3) the patent summarization, and 4) the patent trend tracking. The whole system is developed in Java SDK 1.4.2. and available in http://www.database.cis.nctu.edu.tw/. 2.1. Concept and ontology construction In our system, retrieved patents are analyzed for extracting connected concept units that are the basis to measure patent similarity. Each unit represents an independent concept. Two or more units are connected when they co-occur frequently. Concept units are segmented from sentences of patents; a single sentence can contain multiple concepts. Additionally, similar concepts are grouped into “concept clusters”. The search feedback exploits the clusters to refine user’s query. Ontology is referred to extend the search scope and is beneficial to search. There are two types of ontology in the system: y Domain knowledge from patents y External ontology The first ontology is obtained by calculating the most frequent TF*IDF of uni-, bi- and tri-grams terms from the patents. The relations among concepts in the ontology are determined by domain experts. The second one comes from the existent ontologies. Our system refers to WordNet to extend ontology. For example, “Algorithm”, “Algorithmic Rule”, “Algorithmic Program” and “Formula” are in the same ontology tree. (Fig. 2). Figure 3. Ontology-based patent search. 3. Structured Clustering of Patents The patents with related concepts are returned in the preceding step. Our system provides a clustering module that is used in the patent summarization and topic tracking service. However, a single patent may contain multiple concepts in its content and hence decrease the performance of clustering. Therefore, the clustering of patents must provide finer-level granularity to improve clustering efficiency. In this paper, we propose a clustering method considering the structures of patents. Each patent is divided into hierarchical sub-structures (like Claim, Description, paragraphs in a claim, etc.). Concept contains in sub-structures of patents are clustered individually and furthermore the whole patents are clustered according to the sub structure. Clustering according to structure is called structured clustering [6][7][8]. The distinction between structured and conventional clustering is the former provides finer granularity like sentences and paragraphs to obtain better clustering results. Writing a patent document is required to obey particular convention and style. Therefore, structure in patents can be analyzed heuristically. The analysis. Figure 2. The Ontology tree. 2.2. Query expansion. 2 16.
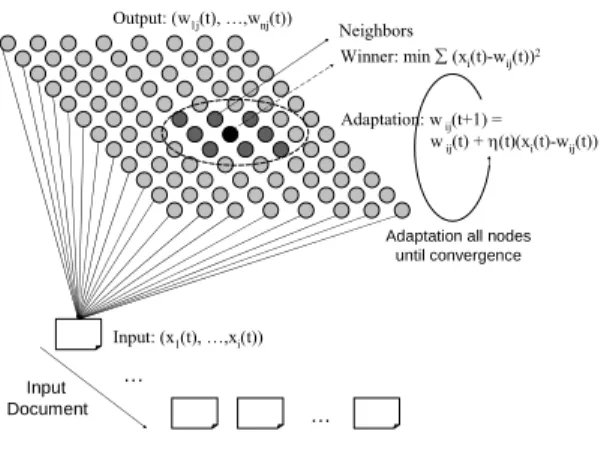
(3) Int. Computer Symposium, Dec. 15-17, 2004, Taipei, Taiwan.. of patent structure finds in some literatures [4][5]. In our system, patent structure among sentences is analyzed especially in “Claim” and “Description” sections.. 3.. 3.1. Structure model. 5.. 4.. We model a patent document into Directed Acyclic Graph (DAG). Each “node” in DAG represents a paragraph or sentence in the patent and an arrow denotes a structure relationship. Assuming the sequence to fill nodes is breadth first search, the structure of Node S can be represented as follows: NodeS:(VNode S, Node1, ..., NodeN) ..............Eq. 1 where VNode S is the feature vector of Node S. Nodeii≤N are the coordinate of branches of Node S. N is the maximum number of branches in all nodes. Fig. 4 illustrates a Chinese patent with analyzed structure. As shown in Fig. 4, if the maximum number of branches is 3, the Node S is represented as Nodes:(VNodes, Node1, Node6, NULL). Node 1 is Node1:(VNode1, Node2, Node3, Node5).. Compute the distance between the input document and all nodes in the map and select the closest node as the winner. Update the weights of the winner node and its neighbors. Repeat step 3-4 to other documents and iterate all inputs until convergence. Label the regions of the final map to represent the clustering result.. SOM Output Map Output: (w1j(t), …,wnj(t)). Neighbors Winner: min ∑ (xi(t)-wij(t))2 Adaptation: w ij(t+1) = w ij(t) + η(t)(xi(t)-wij(t)). Adaptation all nodes until convergence. Input: (x1(t), …,xi(t)) Input Document. … …. Figure 5. SOM. s. 1. The training of SOM is illustrated in Fig. 5. Adding structures in SOM requires some changes. Assume the dimension of SOM is 2 and the maximum number of branches is 3. The output nodes are represents as:. 2 3. 4. 5 6. 2. dx,y = (Vdx,y, (x1 ,y1), (x2, y2), (x3,y3)) ……….Eq.. where (xi, yi) is the coordinates of nodei and Vdx,y is the feature vector of (x, y). The distance of input and output nodes requires the original distance and the distances of all sub-structure nodes. By referring to Eq. 2 and 3, the distance of the example in Fig. 3 is calculated as follows:. Figure 4. Patent Structure. 3.2. Self-organizing map with sructure The structured clustering in our system refers to Hagenbuchner’s Self-Organizing Map (SOM) clustering algorithm in structured data [9]. SOM provides unsupervised neural network clustering and maps high-dimension data into a low-dimension map (usually two). In SOM, closer nodes in the map imply shorter distance in real data. SOM applies in many domains, like bio-structure clustering, graph structure clustering and audio-pattern clustering, etc., and receives good performance. We apply SOM in patent documents clustering with structure considering. There are five steps to train SOM. 1. Initialize weight vectors of output map as the same number features with input document vector. 2. Present input documents in order.. d = (VNode1 − Vdx, y ) + VNode2 − Vdx1, y1 + V Node6 − Vdx 2, y 2 + NULL− Vdx3, y 3 2. ………………………………………………….Eq. 3 where |VNodei-Vdxj,yj| is the distance between input Node i and output node (x, y). The adaptation of structure nodes needs to update root and all substructure nodes. The formula is shown in Eq. 4: wdx,y (t+1) = wdx,y(t) + η(t)*|VNode1-Vdx,y | wdx1,y1(t+1) = wdx,y(t) + η(t)*|VNode2-Vdx1,y1| wdx2,y2(t+1) = wdx,y(t) + η(t)*|VNode6-Vdx2,y2| ………………………………………………….Eq. 4 Eq. 4 updates the root and the sub-nodes Node 2 and 6. η(t) is the learning rate. The adaptation of Node 2 and 6 is cascadedly propagated to the substructures of Node 2 and 6.. 3 17.
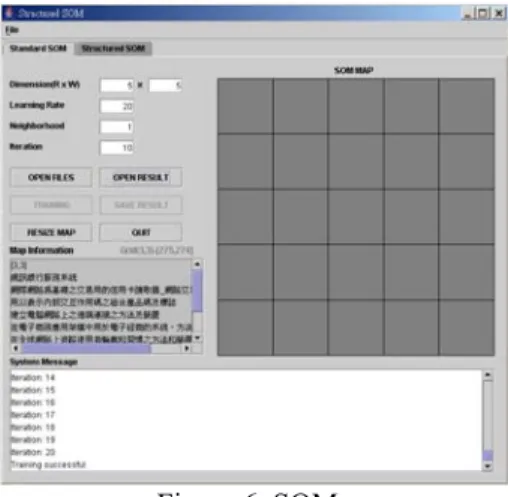
(4) Int. Computer Symposium, Dec. 15-17, 2004, Taipei, Taiwan.. Fig. 6 illustrates the clustering result after structured clustering of patents. The attributes to train SOM are set in the top-lest area. The right map displays the clustering result and each grid contains the clustering patents shown in the left text area.. The front five terms “Labor Party on Saturday backed” and the back five terms “requests to question former Chilean” determine the concept of the noun phrase “Spanish”. Consequently, the process of summarization has five steps: 1. Find noun phrases with high score in TF*IDF. 2. Represent a noun phrase by a feature vector in front/back of N words 3. Cluster the vectors of noun phrases by kmeans clustering. 4. Determine the weight of a noun phrase by comparing the clusters in step 3. 5. Sort the sentences in all documents and summarize the top-k ones with the highest weight. Fig. 7 depicts the process of summarization. The incoming patents are processed by natural language processor and put them into a temporary database. Each feature in vector is calculated by tf*idf (as shown in Eq. 5). In step 1, stop-words are eliminated according to stop-word list. Additionally, the clustering of vectors in step 3 is to find out the concept to represent similar vectors. In step 5, the top-k sentences depend on the compression ration selected. The larger ratio produces the longer summary.. Figure 6. SOM. 4. Patent Summarization To defense IP accusation, people need to read a lot of patents and find related ones in short time. This process costs a lot of effort and has poor productivity. Therefore, automatically summarizing patents is required to help people preview patents fast. Literature on summarization focuses on syntactic and semantic analysis to automatically produce patent summarization [10][11]. Generally speaking, the summarization process is to pick up key sentences in an original patent and eventually combine these sentences into a summarization.. tfi , j =. freqi , j max freql , j. idf i = log. 2. N ni. …………Eq. 5. After the k-means clustering, each sentence is give a score with each cluster (as shown in Eq. 6) n. ∑ [ clusters. Wp =. _ weight × sentence. _ weight ]. 0. =. n. ∑ [# ( cluster. _ i ) × match _ term / length _ of _ sentence ]. 0. Tokenization. WIPO. XML parser ODBC. Structured data. MySQL. MySQL. Stop-word Filtering POS tagging NLP V 3.8. Structured data. DMAS. Generate Vectors. Files to Database. K-Means cluster 20 clustering. ………………………………………………….Eq. 6 where #(Cluster_i) represents how many vectors in cluster I; match_term is the number of terms in sentence P; length_of _sentence indicates the length of sentence p.. Tf * IDF. Mapping. Sentence ranking Summary Duplicate sentence. Cluster Data. Figure 7. Patent Summarization The proposed summarization is to extract important noun phrases according to the context near them. For example, An influence lawmaker from the governing Labor Party on Saturday backed Spanish requests to question former Chilean dictator Gen.. Figure 8. Patent summarization. 4 18.
(5) Int. Computer Symposium, Dec. 15-17, 2004, Taipei, Taiwan.. Fig. 8 displays the result of patent summarization. The left text area shows the original patents to be summarized. Each paragraph indicates a patent. The right text area is the summarized text. The user can adjust the compression ratio to expand or shrink the summarization.. The extracted terms are given significance to represent their patency. The significance is calculated by Swan’sformula in Eq. 7. [13]. Section a, b, c, d are expressed in Fig. 10. x2 =. N ( ad − bc ) 2 ( a + b)( a + c )(b + c )(b + d ). 5. Patent Trend Tracking t∈t0 t∉t0. For general users, to visualize patent knowledge using maps (called patent map) is beneficial to overview the trends of patents. Many types of patent trends can be visualized by patent maps. A majority of patent maps provide statistical information such as the statistics of patent counts with respect to companies, and the statistics of patent counts with respect to inventors [12]. However, exploiting patent maps to visualize latent knowledge like technology trends proposed in patents in some period of time is rarely studied because it is hard to obtain. To extract implicit knowledge in patents requires advanced information technologies to overcome two main tasks. The first task is to precisely extract the main techniques proposed in patents. This task relies on textual analysis to extract terms that can express the technique. The second task is to correlate the technique with time. This task relies on statistic analysis to find the significance of the technique in some period of time. Swan proposed a method to detect the significance of terms in some period of time [13]. Clustering the terms obtains the tendency of patents.. In Fig. 10, t represent the time and e represent the document set. The meaning of each section is as follows: y Section “a” is # of documents that the term appears in time t y Section “b” is # of documents that the term doesn’t appear in time t y Section “c” is # of documents that the term appears except time t y Section “d” is # of documents that the term doesn’t appear except time t The concepts with high significance are the trend of patents in time t. As shown in Fig. 11, the interface shows patent trend with time. The X axis is the time period and the Y axis displays the significance of techniques. Different techniques are shown in different bars in each time period. The color of the technique can be set to represent the number of documents. Alternatively, the color of the techniques can also be set to the similarity among techniques. We also can set the label beside bar as name of technique concept or number of documents. Users can select the displayed techniques and time period. The patent trend tracking provides overview to patents with time and assists users to track the development of patents efficiently.. Data Cleaning Part of speech Tagging Part of speech Selection. Textual Analysis Clustering Hierarchical Clustering. Text Mining Concept Database. ē b d. Figure 10. The significance of terms. Patent. Document Database. e a d. ……………..Eq. 7. Data MiningApriori. Statistical Analysis R a n k. User can choose what the color means,now it show the percentage of documents. Visualization. Time. Figure 9. Patent trend tracking process Choose the information of label. The patent trend tracking process is shown in Fig. 9. Patents are cleaned in advance and sent to “Apriori” to mine important terms [14]. In our system, the “Apriori” data mining algorithm is adapted to extract associated terms that can express techniques. Each sentence is a transaction and large item sets are mined to discover associated terms in a sentence. The associated terms are treated as concept of techniques.. Choose the interval to analyze. Figure 11. Paten Trend Tracking. 5 19.
(6) Int. Computer Symposium, Dec. 15-17, 2004, Taipei, Taiwan. [8] Alessandro Sperduti and Antonina Starita, “Supervised Neural Networks for Classification of Structures”, IEEE transaction on Neural Networks, 8(3), pp. 714735, 1997. [9] Markus Hagenbuchner, Alessandro Sperduti and Ah Chung Tsoi, „A Self-Organizing Map for Adaptive Processing of Structured Data“, IEEE Transactions on Neural Networks, 14(3), pp. 491-505, 2003. [10] E. Hovy, and C. Y. Lin (1999), "Automated Text Summarization in SUMMARIST," In I. Mani and M. Maybury (eds), Advances in Automated Text Summarization, MIT Press, pp. 81-94, 1999. [11] J. Y. Yeh, H. R. Ke, and W. P. Yang (2002), "Chinese Text Summarization Using A Trainable Summarizer and Latent Semantic Analysis," Proceedings of the 5th International Conference on Asian Digital Libraries, Singapore, 2002 [12] PatentGuider, Available at http://www.learningtech .com.tw/products/pg_function .aspx# [13] R.Swan and J.Allan, ”Automatic generation of overview timeliness,” Proceedings of the 23rd annual international ACM SIGIR conference on Research and development in information retrieval, Athen, Greece, 2000 [14] J. Han and M. Kamber, Data mining: concepts and techniques, San Mateo, CA, Morgan Kaufmann Publishers, 2001.. 6. Conclusions In this paper, a patent retrieval system is developed to annotate and discover knowledge from patents. The system contains an on-line retrieval module, structured patent clustering, patent summarization and patent trend tracking. In the online retrieval module, we apply ontology-based search and use concepts to extend search scope. We propose a structure model to analyze retrieved patent and apply structured clustering to patents. The clustering result is summarized according to the context of important noun phrases. Moreover, a visualization interface of for tracking patent trends is designed to overview the trends of patents developed in a period of time. The effectiveness of the proposed system relies on precise textual analysis. In both retrieval and trend tracking, the extraction of concept depends on a statistical algorithm and has limitation in the performance. We plan to adapt natural language processing like POS tagging, corpus training to improve the accuracy of concept extraction. Moreover, SOM clustering with structure of patents consumes more time and map space than traditional SOM. The future work is to reduce the map by adjusting the training weight of adaptation.. 7. Acknowledgement This research was supported by the Software Technology for Advanced Network Application project of Institute for Information Industry and sponsored by MOEA , R.O.C.. References [1] ACL Workshop on Patent Corpus Processing, Sappora, Japan, 2003. Available at http://acl.ldc.upenn.edu/ acl2003/patent/index.htm. [2] ACM SIGIR Workshop on Patent Retrieval, Athens, Greece, 2000. Available at http://research.nii.ac.jp /ntcir/sigir2000ws/., [3] L.S. Larkey, “A patent search and classification system,” Proceedings of the fourth ACM conference on Digital libraries, , pp.179-187, 1999. [4] A. Fujii and T. Ishikawa, “Document Structure Analysis in Associative Patent Retrieval”, NTCIR Workshop 4 Meeting Working Notes. Available at http://research.nii.ac.jp/ntcir-ws4/NTCIR4-WN/ [5] A. Shinmori, M. Okumura, Y. Marukawa and M.. Iwayama, “Can Claim Analysis Contribute toward Patent Map Generation”, NTCIR Workshop 4 Meeting Working Notes. Available at http://research.nii.ac.jp/ntcir-ws4/NTCIR4-WN/ [6] B.Hammer, B.J.Jain, “Neural methods for non-standard data”, , European Symposium at Artificial Neural Networks'2004, D-side publications, Verleysen, pp. 281-292, 2004. [7] Alessandro Sperduti, “Neural Networks for Adaptive Processing of Structured Data”, Lecture Notes in Computer Science, pp. 5-12, 2001.. 6 20.
(7)
數據
+2
相關文件
important to not just have intuition (building), but know definition (building block).. More on
It costs >1TB memory to simply save the raw graph data (without attributes, labels nor content).. This can cause problems for
Retrieval performance of different texture features according to the number of relevant images retrieved at various scopes using Corel Photo galleries. # of top
It is concluded that the proposed computer aided text mining method for patent function model analysis is able improve the efficiency and consistency of the result with
The phrase-based vector space model for automatic retrieval of free-text medical documents, Data & Knowledge Engineering, 61, 76-92,.. Pedersen, and Chen F., “A
Envelopment Analysis,” International Institute for Applied Systems Analysis(IIASA), Interim Report, IR-97-079/October. Lye , “Clustering in a Data Envelopment Analysis
The objective of this study is to analyze the population and employment of Taichung metropolitan area by economic-based analysis to provide for government
The results showed that, on the part of patent analysis, the United States in four categories of face recognition technology, they know one another on the patent number
