國
立
交
通
大
學
資訊科學與工程研究所
碩
士
論
文
在無線隨意網路中使用完美雜湊族的高效率秘密
更新協定設計
Efficient Share Renewal Protocol Design for
Mobile Ad Hoc Network using Perfect Hash
Families
研 究 生:許鴻祥
指導教授:葉義雄 教授
在無線隨意網路中使用完美雜湊族的高效率秘密更新協定設計
研究生:許鴻祥
指導教授:葉義雄 博士
國立交通大學資訊科學與工程研究所碩士班
摘要︰
由於無線隨意行動網路 (Mobile Ad Hoc Network) 的一些先天特
性,例如不可靠的無線環境、節點的移動性、不需要任何基地台或移動
轉換中心的協助等等,使得提供安全通訊成為一個很大的挑戰。然而,
一般用在有線網路上的 PKI 架構也無法直接移植到無線隨意行動網路的
環境下,因為一個集中式 CA 是很難建構在無線隨意行動網路中。因此我
們必須解決此集中式的現象。
本論文提出一個利用「完美雜湊族」(Perfect Hash Families)的模
式來實現(
n
,
k
)閥值祕密共享,將私密的金鑰分散給在網路上的每個節
點,由一定個數的節點共同做簽章的動作,並且採用預防式祕密共享來
更新私密金鑰,以避免長時間擁有相同的金鑰,增加攻擊者攻擊的難度。
此外,我們利用完美雜湊族的特性,使得更新金鑰的程序更加有效率。
最後,我們會分析此方法與前人所提的各式方法的差異以及效能比較。
關鍵字︰隨意行動網路、(
n
,
k
)閥值祕密共享、預防式祕密共享、完美雜
湊族。
Efficient Share Renewal Protocol Design for Mobile Ad Hoc Network using
Perfect Hash Families
Student:Hung-Hsiang
Hsu
Advisor:Dr. Yi-Shiung Yeh
Institute of Computer Science and Information Engineering National Chiao
Tung University
Abstract︰
Due to the inherent characteristic, such as unreliable wireless media, host
mobility and lack of infrastructure, providing a secure communication
platform in a mobile ad hoc network is a big challenge. However, common
authentication schemes like PKI, which is used extensively in wired network,
are not applicable in the ad hoc network environment because public key
infrastructure with a centralized certification authority is rather difficult to
deploy here. Thus, the centralized circumstance needs to be solved.
This thesis propose a scheme using the perfect hash families to
implement the (n, k) threshold secret sharing. We separate the private keys
into several shares and distribute them to every node in the mobile ad hoc
network. Only a fixed number of nodes can sign the signature collaboratively.
We also use the proactive secret sharing to update the private shares. It can
avoid one node holding the same secret share for a long time and can increase
the difficulty to being attacked. Moreover, we use the property of a PHF to do
the proactive secret sharing, resulting in a more efficient update procedure.
Finally, we analyze the performance of this scheme and compare our system
with other previously mentioned methods.
Key words: Mobile Ad Hoc Network, (n, k) threshold secret sharing,
Proactive Secret Sharing, Perfect Hash Families.
致 謝
這篇論文能夠順利的完成,首先我必須感謝我的指導教授,葉義雄教
授,這兩年來敎了我許多,不論是在學問上或是待人處事方面都令我獲
益良多。接著很感謝的是高銘智學長,在我遇到瓶頸時,給了我很多的
寶貴意見以及協助;還有,也謝謝實驗室裡的各位學長姊、同學與學弟
妹,小白、阿甘、昇哥、英宗、雅婷、伯昕與 Gobby,大家平日的相互勉
勵與學習,讓我成長許多;尤其是雅婷,在期間幫我一起跑程式,讓我
因此節省許多寶貴的時間,真是太感謝了。此外,還要感謝在美國的怡
君,特地撥時間幫我修改英文寫作,改正了我許多寫作的問題與錯誤。
最後,要謝謝我的父母,由於你們多年來的栽培與支持,才會有今天
的我,真的非常非常的感謝你們。
謹將我這篇論文獻給所有關心我與支持我的人,謝謝你們。
許鴻祥
中華民國九十五年七月
Contents
摘要︰...ii
Abstract︰ ...iii
致 謝... iv
Figure List ...vii
Table List ...viii
Chapter 1 Introduction ... 1
1.1 Background... 1
1.2 Motivation ... 3
1.3 Related Work ... 4
1.4 Organization ... 7
Chapter 2 Related Knowledge ... 8
2.1 Network Security... 8 2.1.1 Requirement ... 8 2.1.2 Types of Attacks ... 10 2.2 Fundamental of Cryptography... 12 2.2.1 Symmetric Cryptography ... 13 2.2.2 Asymmetric Cryptography ... 14
2.3 Public Key Infrastructure ... 16
2.3.1 PKI overview... 18
2.3.2 Certificate and Certification Authority... 20
2.4 (n, k) Threshold Secret Sharing ... 21
2.5 Proactive Secret Sharing... 22
2.6 Combinatorial Object ... 24
2.6.1 Introduction to Perfect Hash Families... 25
2.6.2 Propositions of Perfect Hash Families ... 27
2.6.3 Construction methods of Perfect Hash Families ... 28
2.7 Fundamentals of Mobile Ad Hoc Network ... 33
2.7.1 Mobile Ad Hoc Network ... 34
2.7.2 Characteristics of Mobile Ad Hoc Network ... 34
2.7.3 Security challenges of Mobile Ad Hoc Network... 35
Chapter 3 System Architecture... 37
3.1 Concept... 37
3.1.1 Construction ... 37
3.1.2 Partition ... 41
3.1.3 Conceptual Building Blocks... 43
3.2 System Assumption ... 44
3.2.2 Trusted dealer ... 45
3.3 Details and Protocols... 45
3.3.1 System initialization ... 45
3.3.2 Certification service... 47
3.3.3 Updating the Secret Shares... 49
Chapter 4 Evaluation and Analysis ... 54
4.1 Evaluation... 54 4.2 Analysis ... 56 4.3 Discussion... 61 Chapter 5 Conclusion... 63 References: ... 64 Appendix A... 66 Appendix B... 70
Figure List
Figure 2.1.1 Passive Threats... 10
Figure 2.1.2 Active Threats ... 11
Figure 2.2.1 Symmetric Cryptography ... 14
Figure 2.2.2 Asymmetric Cryptography ... 15
Figure 2.3.1 Man-in-the-middle Attack... 17
Figure 2.3.2 Components and Process of PKI ... 19
Figure 2.7.1 Mobile Ad Hoc Network... 34
Figure 3.1.1 Finding the minimal prime power q ... 38
Figure 3.1.2 Construction Algorithm of PHF ... 38
Figure 3.3.1 Construction Algorithm of the whole Network... 46
Figure 3.3.2 Request for Certification... 49
Figure 3.3.3 Certification Service ... 49
Figure 3.3.4 Algorithm of Changing the Partition Header ... 50
Figure 3.3.5 Share Refreshing... 52
Figure 4.2.1 PHF, q = 3 ... 57 Figure 4.2.2 PHF, q = 4 ... 58 Figure 4.2.3 PHF, q = 5 ... 58 Figure 4.2.4 PHF, q = 3 ... 59 Figure 4.2.5 PHF, q = 4 ... 59 Figure 4.2.6 PHF, q = 5 ... 60 Figure 4.2.7 PHF, q = 7 ... 60
Table List
Table 2.6.1 PHF(4; 9, 3, 3) ... 26
Table 2.6.2 Construction Methods... 29
Table 3.1.1 A PHF(4; 9, 3, 3)... 40
Chapter 1
1.1
Introduction
Background
In the recent decades, with the development of science and technology, the internet has clearly become an indispensable part of our lives. A wide variety of applications and services are offered through the internet. For example, through the internet libraries can establish joint borrowing and returning systems, and we can also make flight and hotel reservations for destinations worldwide in advance. By using the internet, it is more convenient and easy to communicate with one another. Through some simple internet applications such as e-mail and instant messenger, we can easily transmit messages or even files to another party of the communication. The internet has helped bridge the barriers of time and distance through enabling communication with virtually no boundaries. In addition, a current trend is the rapid growth and development of wireless network, as evidenced in the increased numbers of
wireless related applications. Without any wired help, users can now use their wireless devises, such as PDAs and laptops, to connect to the internet via various wireless transmission
protocols including, for example, 802.11b and Bluetooth. Wireless network provides users with greater flexibilities and convenience. However, as an increasing amount of sensitive and important information being transmitted electronically, network security is an increasing concern. Thus, in order to ensure the integrity and confidentiality of transmitted data, people are paying more attention to network security related issues.
As we continue to expand on the conceptual framework for guiding further development in network security, we need to understand the different types of attacks. Attacks can
when adversaries simply want to obtain information off the network; it includes, for example, eavesdropping and peep. An active attack, on the other hand, is when adversaries not only read information off the network but also want to modify or write data to the network; it includes, for instance, masquerade, replay attack, and denial of service.
In order to resist aforementioned attacks, a security mechanism should satisfy following requirements: confidentiality, authentication, integrity, non-repudiation, access control, and availability [1][2]. These requirements can be supported by cryptography including both symmetric and asymmetric approaches. In addition to the cryptography technology, a suitable infrastructure also needs to be constructed. Public key infrastructure (PKI) is one of such structures. PKI supports a trusted third party called Certification Authority (CA) [3]. CA has its own key pair (public key / private key). CA uses its private key to sign the digital
certificate, and the certificate then includes the user’s identity and his corresponding public key. Other people can verify the certificate by using the CA’s public key. If the certificate is valid, it can then be concluded that the content of the certificate is indeed valid. Depending on the certificates, users can authenticate the identity and transmit the data safely.
However, deploying security mechanisms is rather difficult due to the inherent properties of ad hoc networks, such as the high dynamics of their topology, limited resources of end systems, or bandwidth constraints and possible asymmetrical communication links. Any centralized design entity of security service is not practical in the ad hoc network because such entities would obviously become the targets of attack. Therefore, it is impossible to implement a centralized CA for managing public keys of the participants, because if the centralized CA is compromised, the attackers would be able to obtain much useful and sensitive information. The attackers can even impersonate a valid CA and consequently issue the certificate to the users. In this case, intruders can steal the transmitting data easily.
Furthermore, due to the high mobility of each node, if the node, playing the role of CA, leaves the network, then other users would not be able to find the CA. Therefore, they cannot apply
for a certificate or manage the certificate. In this case, the entire network system may crash. Hence, a distributed solution must be found instead.
One popular method to achieve the distribution condition is to implement the (n, k) threshold secret sharing [4]. In fact, there has been much research focused on using the (n, k) threshold secret sharing method to construct the distributed CA. In this paper, we propose and evaluate a new architecture for securing communication in the mobile ad hoc network. More specifically, we use the perfect hash families (PHF) [5][6] approach to construct the network along with the threshold method. Also, we distribute the CA function and network secret to multiple nodes. Furthermore, we adopt proactive secret sharing [7] to improve network security. By using the characteristics of the PHF, we can make the proactive secret sharing more efficient and also enhance the effectiveness of this approach in the event when some nodes are unavailable. Moreover, the extra overhead of doing secret shares updating can be shared among a group of nodes.
1.2
Motivation
As wireless technology and applications continue to develop and gain popularity, there is a high demand in developing a secure wireless network. Considering some inherent limits in the mobile ad hoc network, the traditional PKI cannot be directly applied to the mobile ad hoc network without any modification. Therefore, our goal is to make some changes to the
traditional PKI and ultimately implement it in the mobile ad hoc network.
The most important component in the PKI structure is the CA. In order to ensure
availability and high survivability, we implement a decentralized CA by distributing the CA’s functionality to many nodes. We use Adi Shamir’s (n, k) threshold secret sharing to do it. The CA has a key pair (public key / private key). The secret key is divided into n shares, and these shares are owned by n nodes. Only when k or more than k nodes combine their own secret
shares cooperatively, they can collectively function as the role of CA. The original secret key is, however, not visible or known by any component of the network except at the system bootstrapping phase. Then these k nodes sign the certificate collectively and issue it to the user. The CA’s public key is public in the network, so every user can easily verify the validity of a certificate. Users can then use the certificates to authenticate others’ identities and
communicate securely. We construct the (n, k) threshold secret sharing by using the PHF. Then we use the partition characteristic of the PHF to divide the entire network into several disjoint partitions. We use the partition point of view to do the proactive secret sharing. In this way, we can update the secret shares at a lower communication cost. Additionally, we can ensure a higher rate of success in doing the secret shares updating. Moreover, since our system does not require the synchronization of the network in the update process, we can prevent some attacks of synchronization. Finally, we can also securely transmit the new shares to each participant who needs it.
1.3
Related
Work
There has been much research focused on the mobile ad hoc network security. In [8], Zhou and Hass proposed a secure key management scheme. They used (n, k) threshold cryptography to distribute trust among a set of servers. They focused on the security of the shared secret in the presence of possible compromises of secret share holders. The system can tolerate k-1 compromised servers. However, they did not provide any specific explanation for how a node can make contact to sufficient servers, especially when the servers are spread across a large area. The authors also proposed to employ proactive schemes to achieve share refreshing to counter mobile adversaries. Yet, their solution assumed the group of servers with rich connectivity. It is not suitable for ad hoc environments. The authors also did not address the issue of how to distribute the update shares to the server nodes efficiently and securely.
In [9], Kong et al. also used threshold secret sharing mechanism to distribute the
functions of CA to some nodes. In order to ease the difficulty of contacting server nodes, they employed localized certification schemes. In other words, each entity holds a secret share, and multiple entities in a local neighborhood then jointly provide complete services. This method also can enhance the service efficiency for users. The authors noted that k is the balance point between service availability and intrusion tolerance. However, in their scheme the threshold value k is difficult to set. It is known that if k is too small, the probability of a global secret key being compromised is quite high. On the other hand, if k is big, although we can resist more compromises, it is relatively harder to find k one-hop legitimate neighboring nodes. Another problem is that they also did not address the issue of how to distribute the update shares to the server nodes efficiently and securely. [10] is an extension of [9] because the authors proposed the parallel share updates to prevent from emulating a coalition of k nodes to fake share updates. Yet, this method requires a much higher communication cost due to the fact that each update polynomial function has to be generated by k nodes collaboratively. After the polynomial function is generated, each node that wants to do the update procedure would be required to ask k nodes again to decrypt the polynomial function, then to complete the update. The authors also implemented a localized certification service to enhance service availability for mobile nodes and robustness against DoS attacks. However, this localized certification service operates under the assumption that each node has at least k legitimate neighbors; it surely has some difficulties to ensure that in a mobile ad hoc network
environment.
In [11], Bechler et al. proposed and evaluated a clustered architecture for securing communication in mobile ad hoc networks. They divided the network into clusters and used threshold cryptography to implement a decentralized CA. The authors further separated the cluster internal traffic from the network-wide traffic. For cluster internal traffic, they used the symmetric encryption. For network-wide traffic, they used public key cryptography. There are,
however, two major problems with their proposed architecture: (1) with its log-on procedure and (2) with its sharing update. First, they did not specify how to find the warrant nodes, and also the number of warrant nodes is indeterminate. Second, they used proactive secret sharing without any modification. Therefore, the communication overhead is too high for the wireless channel.
In [12], Zhu et al. proposed a novel key management scheme based on the hierarchical structure and secret sharing to distribute cryptography keys and to provide certification services, called the Autonomous Key Management (AKM). AKM is a logical tree, in which all the left nodes represent real wireless nodes, while all the branch nodes only exist logically. AKM can achieve flexibility and adaptivity by issuing certificates with different levels of assurance and can handle the mobile ad hoc network (MANET) with a large number of nodes. They further proposed two algorithms, which are based on threshold cryptography and
Verifiable Secret Sharing (VSS). These algorithms can resist active attacks targeting
certification services. The disadvantage of AKM is that if we want to change the configuration of (n, k) to (n’, k’), it would require a significant cost. Under their “join operation,” when one real node wants to join a region, the system would choose a group of k nodes randomly. The authors assumed that each node in that group should know the identity of one another. However, their assumption is not sound, since each node is randomly chosen.
In [13], Wu et al. also adopted the threshold cryptography to distribute the private key share to shareholders. The major difference in this presented model is that the shareholders form a special group, called the server group. In the pervious approach the shareholders are all independent; users must communicate with each server node individually. In contrast, here a user only needs to communicate with one member of the server group, then that server node will send the information to other server nodes automatically. The advantage of this method is that it is easier for a node to request service from a well maintained group rather than from multiple “independent” service providers, which may spread across a large area. Furthermore,
the server group does not have to include all shareholders; it takes the soft state maintenance to ensure a number of shareholders. In sum, the benefits include communication-efficiency, bandwidth-saving, and easy management. However, the size of a server group is the
determinant of the entire network performance. That is, if the server group is small, it is then relatively easier to respond and manage. Yet, this kind of small server groups may not have the ability to serve a large network. On the other hand, if the group is big, the response rate would, as expected, be slower and thus would have an impact on the entire network
performance. Therefore, how to decide on the size of a server group would be key in determining the quality of network performances.
1.4
Organization
This thesis is organized as follows. First, it begins with a brief overview of related knowledge in chapter 2. Specifically, it includes backgrounds on cryptography and security, mobile ad hoc network concepts, principles of secret sharing, and some combinatorial objects. Then chapter 3 focuses on the specific concepts and describes the detailed protocol of our scheme. In chapter 4, we present the analysis of mobile ad hoc network that uses our scheme in order to show its availability and performance. Results and related parameters are also discussed in this chapter. Finally, chapter 5 provides conclusions pertaining to the proposed scheme and results and suggestions for some future research directions based on this thesis.
Chapter 2 Related Knowledge
2.1
Network
Security
2.1.1 Requirement
Network security is an increasingly important issue, especially for those
security-sensitive applications. In order to ensure the safety of data transmission process in the network, the following attributes need to be considered [1][2]:
Confidentiality Authentication Integrity Non-repudiation Access control Availability
Below is a description for each requirement. (1) Confidentiality
Confidentiality is the protection of transmitted data from passive attacks. It ensures that the data only be accessible by authorized entities. The other aspect of confidentiality is the protection of traffic flow from analysis. Network applications with sensitive information transmission require confidentiality. If such kinds of information are leaked out to the adversaries, it may result in devastating consequences.
(2) Authentication
Authentication is the process that enables a node to ensure the identity of the peer node that it is communicating with. Without authentication, adversaries could masquerade a node and thus obtain unauthorized access to resource and sensitive information.
(3) Integrity
Integrity is the measure of ensuring the correctness and completeness of transmitted information. It guarantees that data are received as sent, with no insertion, modification, reordering, or corruption.
(4) Non-repudiation
Non-repudiation prevents either sender or receiver from denying a transmitted message. Also, the sender and receiver have ways to prove that they actually have sent and received the message respectively. Essentially, non-repudiation is the process that holds senders and receivers accountable for sending or receiving any data. Non-repudiation is also useful for detecting and isolating compromised nodes. When node A receives an erroneous message from node B, non-repudiation allows A to accuse B for sending the message and to convince other nodes that B has, indeed, been compromised.
(5) Access control
Network resources are limited. If unauthorized nodes use the network resources unrestrictedly, it may endanger the entire network. Therefore, access control is the ability to permit or deny the access to network resources. To achieve this control, each entity has to obtain authorizations prior to any use of the resources.
(6) Availability
Availability ensures the survivability of the network service. Many kinds of attacks can result in loss or reduction in the availability of services. Thus, there is a strong need for finding solutions to deal with this situation and to let only authorized nodes get the service easily.
2.1.2 Types
of
Attacks
Generally speaking, attacks can be classified into two categories: passive attack and active attack. Below is a description of these two types of attacks [1]:
(1) Passive attack
A passive attack is an attack where an unauthorized attacker monitors or listens to the communication between two parties. Figure 2.1.1 shows the two different types of passive attacks.
Figure 2.1.1 Passive Threats
Another type is the traffic analysis threat, which is much more subtle. It means that encryption masks the content of the transmitted message, so even if captured by attackers, they would be unable to read the content of the message. Although the attackers cannot see the content, they nevertheless could determine the location of the sender or some other important information, such as the communication model.
Passive attacks are very difficult to detect because they do not involve any alteration of the data or message. Due to the difficulty in detecting passive attacks, the primary defense strategy is in prevention rather than detection.
(2) Active attack
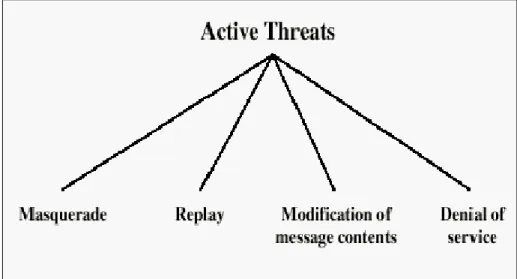
In active attacks, adversaries may modify the data stream or create a fake reply. The attacker may also transmit data to one or both parties, or block the data stream in one or both directions. It is also possible that an attacker could deceive user A into believing he is user B and could deceive user B into believing he is user A. In other words, users A and B do not know that the communication link between them has been compromised. Figure 2.1.2 shows various types of active attacks.
Masquerade is an attempt to act like or to impersonate someone else or some other
system.
Replay attack means that attackers first intercept the valid data and then subsequently
retransmit the data to fulfill their illegal intention.
Modification of message contents simply means to produce an unauthorized effect by
altering or reordering some portions of the message.
Denial of service (DoS) attacks lead to a loss of services and resources to legitimate
users in the system.
In general, it is also quite difficult to prevent active attacks because it would require a complete protection of all communication facilities to do so. Contrary to passive attacks, the primary defense strategy to active attacks is to detect them and recover any disruption or delay caused by them.
2.2 Fundamental of Cryptography
Cryptography is the science of keeping secrets secret. The origin of cryptography traces back millenniums ago. When humans had learned how to communicate with one another, they had no choice but to find methods to keep their private messages secret. Therefore,
cryptography is the science of encoding a message such that only the sender and the intended recipients are able to understand it. “Plaintext” refers to a message before encryption, and after the encryption, the corresponding message is known as the “ciphertext.”
Cryptography is fundamental to the network security. All of the security requirements discussed in the earlier section of this text can be achieved by relying on cryptography algorithm. Cryptography algorithm could involve some replacement or permutation
techniques. It also could be based on some kinds of mathematical function operations. With the participation of some secret information, usually referred to as a "secret key," we use the
cryptography algorithm to transform the plaintext into unreadable ciphertext, which is something unintelligible to anyone other than an authorized recipient.
Generally speaking, depending on how the secret key is used, cryptography can be classified into two categories: symmetric cryptography and asymmetric cryptography. The following is an introduction of each cryptography approach [14][15].
2.2.1 Symmetric
Cryptography
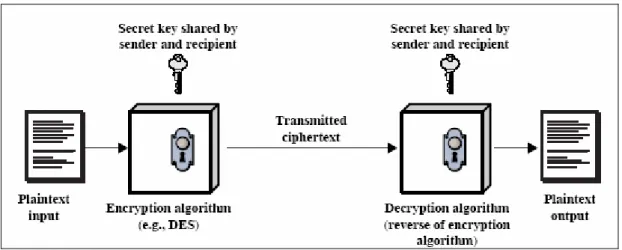
Symmetric cryptography uses the same symmetrical key for both encryption and decryption. Without the secret key, it is impossible to recover ciphertext back to its original plaintext. Therefore, the secret key has to be stored secretly. Two popular symmetric
cryptography techniques are DES and AES. There are several weaknesses associated with the symmetric cryptography approach: 1. The fact that encryption and decryption parties share a same key, before transmitting any data, the secret key must be securely sent to both parties first. However, how key exchange process can be kept secret is a major problem. 2. Another weakness is related to the difficulties in managing the key, as one secret key is shared by users altogether. 3. Lastly, if a secret key is compromised, then the key must be destroyed and replaced with a new one. The effort to distribute the new secret key to all users would be enormous. Despite its disadvantages, symmetric cryptography is nonetheless an efficient approach to encrypt and decrypt messages.
Figure 2.2.1 illustrates the operation of symmetric cryptography. The sending party and the receiving party use the same secret key and the same encryption model to do the
Figure 2.2.1 Symmetric Cryptography
2.2.2 Asymmetric
Cryptography
Asymmetric cryptography, also known as public-key cryptography, is perhaps the most important development in the history of cryptography. Introduced by Whitfied Diffie and Martin Hellman in 1976, the concept of public-key cryptography was specifically
developed to solve problems related to the secret key distribution and management in symmetric cryptography. Public-key cryptography has, in fact, taken cryptography
development to a new direction and network security to a new level. First, the asymmetric algorithms are based on mathematical functions instead of replacement or rearrangement techniques. Then, most importantly, the asymmetric cryptography uses two asymmetric keys. Asymmetric cryptography uses one key for encryption and a different, but relative, key for decryption. The concept of public-key cryptography is built upon the idea that it might be possible to find a cryptosystem where it is computationally infeasible to determine dK given eK. If that is the case, then according to the encryption rule, eK is a
public key, which can be published in the world, and dK is a secret key, which has to be
(a) Encryption and Decryption
(b) Authentication
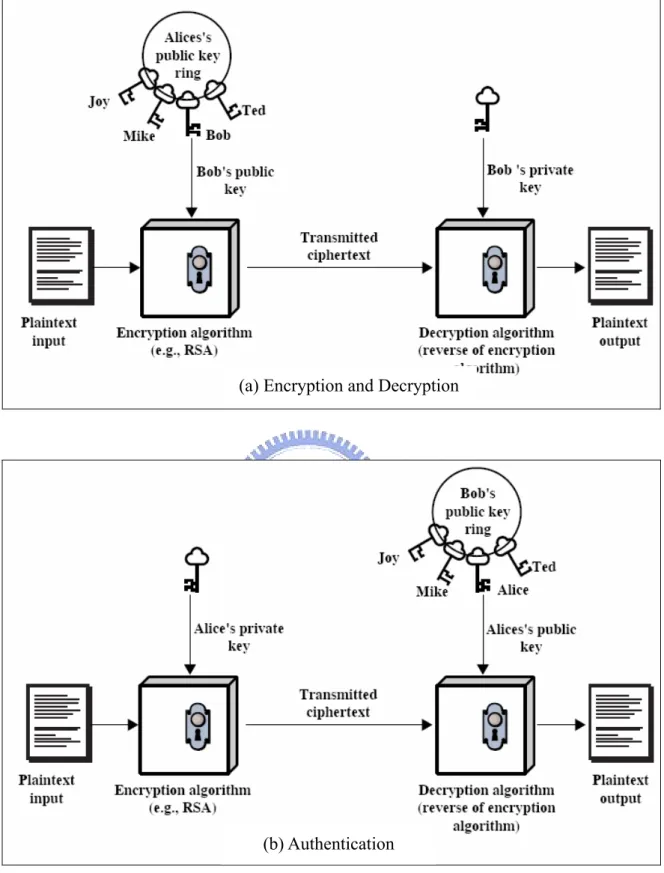
Figure 2.2.2 Asymmetric Cryptography
As Figure 2.2.2(a) shows, when Alice wants to transmit a message to Bob, Alice uses Bob’s public key to encrypt the message. Then, instead of the original message, she
transmits the ciphertext to Bob. When Bob receives the ciphertext, he uses his own private key to recover the message. From the example above, it clearly shows that only when we have Bob’s private key, then are we capable of recovering the ciphertext back to its original state. Thus, an advantage of the public-key cryptography is that even if other people were to intercept the transmitting ciphertext, they would not be able to recover the message without Bob’s private key.
As Figure 2.2.2(b) illustrates, the public-key cryptography can also be used for identity authentication. Alice uses her secret key to encrypt the message that she wants to send to Bob. When Bob receives it, he can use Alice’s public key to decrypt the message. Because this message is encrypted by Alice’s secret key, only Alice could generate this message. Thus, the entire message itself can also serve as a digital signature. Additionally, the person who sends this encrypted message can be authenticated. This achieves the identity authentication.
Asymmetric cryptography solves the key management and key distribution problems successfully. However, the fact that asymmetric approach involves relatively more
complicated algorithms as compared to the symmetric approach, the efficiency in encryption and decryption is then not as good as that of the symmetric approach.
In the current thesis, both symmetric and asymmetric cryptography are used.
Specifically, we use the asymmetric method for getting the signatures to verify the identities of the node and of the corresponding public key. Then, when each node has the same
symmetric key, we encrypt the transmitting message by using the symmetric algorithm. Therefore, not only can our approach solve the key distribution problem but also achieve high transmission efficiency.
2.3
Public
Key
Infrastructure
science of cryptography, but these algorithms do not guarantee a carefree crypto life. Problems with asymmetrical algorithms stem from their practical applications, and these problems can only be avoided by constructing a suitable infrastructure. Problems with asymmetrical algorithms are summarized in the following section [3].
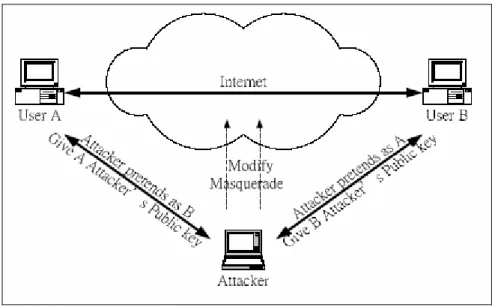
(1) Authenticity of the key: In an asymmetric cryptosystem, how can one tell a public key belongs to whom? In other words, an attacker can easily use a man-in-the-middle attack to cheat both the sender and the receiver, as depicted in Figure 2.3.1. This is a scenario when user A wants to communicate with user B secretly. First, they exchange their public keys with each other. If there is an attacker that tells A that he is B and also tells B that he is A, and in the event that both users A and B were to believe the identity of this “middle-man,” they would then share their public keys with the attacker. Upon receiving A and B’s public keys, the attacker would then send his public key to both users, pretending that this was, in fact, the public key of their communication partners. Then A and B use the attacker’s public key to encrypt the message that they want to send and think that it is secure. What A and B do not realize is that the attacker can, in fact, use his public key to decrypt the message. This is called the man-in-the-middle attack.
Figure 2.3.1 Man-in-the-middle Attack
immediately generated a new key pair to replace the old private key. But then how can others know that his old private key has been revoked? In other words, it is not possible to tell from a public key itself whether it has been revoked or not.
(3) Non-repudiation: The purpose of digital signature is to ensure that the individual sending the message is indeed who he claims to be. If one, however, keeps his private key secret, and he simply denies that the key used in the signature was his, no one can challenge him. Since no one can forge his key, the problem then is how to prove that a particular key belongs to whom?
Therefore, a suitable structure must be constructed to address these problems. Such a structure is called a public key infrastructure (PKI).
2.3.1 PKI
overview
PKI has more than twenty years of history in development. The concept of the
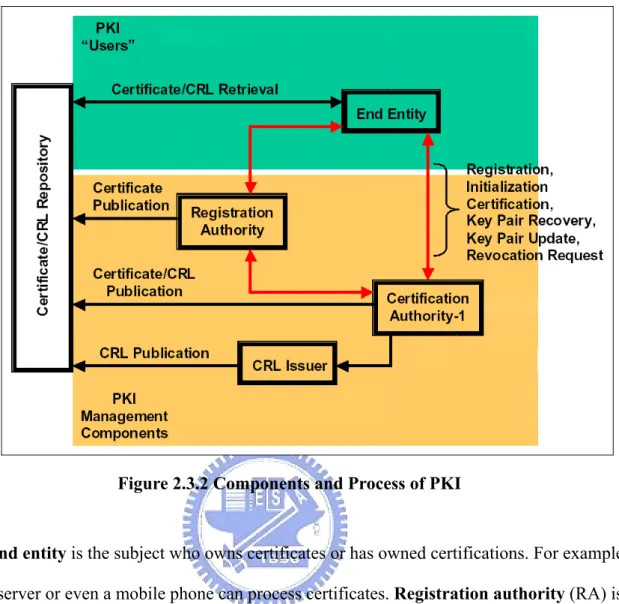
public-key cryptography was first introduced by W. Diffieand and M. Hellman in 1976. Two years later, computer scientists proposed the concept of public-key digital certificates. In 1988, the first certificate standard X.509 was developed. In 1993, the first IETF certificate was introduced to the public. In short, the technology of PKI refers to the framework that uses asymmetric approach to generate digital signatures and that provides a highly secure service platform for network transactions. The major goal of PKI is to construct trust relationships among individuals. Establishing trust relationships is fundamental to the implementation of information security. Major components of a PKI are shown in the next illustration, Figure 2.3.2.
Figure 2.3.2 Components and Process of PKI
End entity is the subject who owns certificates or has owned certifications. For example,
a web server or even a mobile phone can process certificates. Registration authority (RA) is the administrative center where an end entity can apply for certificates. The RA may be authenticated face to face by the certification authority (CA) and may then be trusted to perform face to face authentication for the end entity. The PKI standard does not strictly define the existence of RA. End entity can communicate with the CA directly. However, almost all PKI implementations are provided for an RA and actually do not allow any communication between an end entity and the CA.
The present thesis seeks to implement some roles for the CA. The relationship between the certificate and certificate authority is introduced in the following sub-section.
2.3.2
Certificate and Certification Authority
The certification authority (CA) plays the most important role in a trust center. By definition, a trust center without CA is not possible. The CA is the entity that issuescertificates. From the security perspective, CA is a highly crucial component. In particular, the CA’s private key has to be stored in a highly secure environment. In order to avoid attacks from the network, the computer running the CA software should, as a rule, not be connected to the internet.
The certificate issued by the CA is the solution to the aforementioned remaining
problems of asymmetric algorithms. The content of a certificate may consist of, for instance, issuer, user identity, a corresponding public key, valid period, and issuer’s signature. Often, the certificate has signature signed using the CA’s private key. As a result, if anyone wants to verify the certificate, he can use CA’s public key to do so. He can then trust that the public key inside of the certificate actually belongs to the corresponding user. This solves the authenticity of the key problem. A CA can also revoke a public key very well by signing a revocation list called Certificate Revocation List (CRL). The CRL contains the invalid certificates. One should download the CRL and check a certificate’s validity against the CRL before accepting it. Finally, because a CA issues digital certificates to all users, non-repudiation is much easier to guarantee. If one registers with a CA and is officially given a key pair, he can hardly have any dispute over his ownership at a later time.
In summary, there are several characteristics of using a CA: (1) Only CA can create, update, and revoke a certificate.
(2) Every user can verify whether the certificate is issued by the CA. (3) Every user can verify the correctness of a certificate.
(4) Every user can read the content of a certificate to determine its identity and the owner’s public key.
2.4
(n, k) Threshold Secret Sharing
Secret sharing means that a secret is divided into many shares, and these shares are distributed to a group of users. As a group, these people collectively share this secret. No one in the group knows or holds the complete secret, and no one can use his own partial share to retrieve the original secret. Only when enough partial shares are combined can we recover the original secret. The (n, k) threshold secret sharing means that we divide a secret into n shares and distribute the shares to n participators. Only when k participators (k ≤ n) collaboratively combine their own shares, then the secret can be recovered.
(n, k) threshold secret sharing was introduced by Adi Shamir in 1979 [4]. He used a polynomial function to generate a secret into n shares. After that, one can use the Lagrange interpolation method to recover the secret. Below is a step-by-step instruction of this method.
First, suppose that the secret we want to share is S, and there are n participators to share this secret. The identities of participators are denoted as ID1…n. Then there is a dealer, which
is trusted by all participators. Specifically, the dealer is responsible to perform the following actions and to distribute the shares to their corresponding participators.
(1) Give a prime number p, that p > max(S, n).
(2) Dealer chooses a polynomial function, f(x) = S + a1x + … + ak-1xk-1, that a0 = S and
choose a1…ak-1 from Zp.
(3) Compute share secret, Si = f(IDi)(mod p), for i = 1 ~ n.
(4) Distribute share secret Si to IDi.
In order to recover the original secret, Lagrange interpolation must be used. We must have k or more than k, use f(x) to construct f(0), and finally secret S is retrieved.
Lagrange interpolation: ) )(mod ( ) ( , 1 1 p x ID ID ID x S x f k i j j i j j k i i
∏
∑
≠ = = − − ⋅ =2.5 Proactive Secret Sharing
The secret sharing we mentioned above relies on the idea of distribution. We share the secret to many nodes, so if one node is compromised, the attacker still cannot retrieve the secret. The only way that an attacker can obtain the secret is to compromise at least k nodes. If each share is, however, never changed, an attacker may have ample time to compromise k nodes and ultimately retrieve the secret. This probability increases over time. Therefore, some people, such as A. Herzber, proposed proactive secret sharing in 1995[7]. The objective of this method is to decrease the likelihood of the abovementioned situation by using an update function to periodically calculate new share and distribute the new share to each node.
Without disclosing the service private key, proactive secret sharing allows the users to calculate the new shares from the old ones in collaboration. After the update, users remove the old shares and replace them with only the new ones. The fact that different time periods have different update shares and that they are completely independent of the old shares, there is no way to reconstruct the original secret by combining the new and old shares. Furthermore, no one can predict the new share value for each node after each update cycle – that is, it is completely random, not predictable.Thus, if an attacker wants to get the secret, he has to compromise at least k nodes during one point in time. Otherwise, after each update, any information he had previously obtained would clearly become useless. Share refreshing basically relies on the following homomorphic property.
If S’ is 0, then we get a new (n, k)
' ' ' '
1 2 1 2
If ( , , s s …, ) is a ( , ) sharing of secret and ( , , ..., ) is a ( , ) sharing of secret , sn n k S s s sn n k S
' ' '
1 1 2 2
then ( , , ..., ') is a ( ) sharing of , .
n n
sharing of S. Now, let’s turn our attention to how it does that.
First, for each node i, we must generate a new polynomial f(i)(x) to correspond with f(x). The constant term of f(i)(x) has to be 0 because we want the secret shared by this polynomial is 0. The method of updating share is shown as follows:
p ) x a x a (S f(x) k-k- mod 1 1 1 + + + = L number. random is b , , b mod i,1 i,k-1 1 1 1 + + … =(b x b x ) p, (x) f i, k-i, (i) L p x b a x b a S x f x f x f k k i k i k k i i k i i ( )) ( ( ) ( ) )mod ) ( ( ) ( 1 1 1 , 1 1 1 , 1 1 ) ( ' − = − − = =
∑
∑
∑
= + + + + + + = LThe update share for each node is computed by , for j = 1, …, k. Therefore, each participant first generates its own polynomial
) (ID f' j
(i)
f (x) . Then according to the polynomial, he
computes (i) j
f (ID ). After that, he sends these results securely to the corresponding node.
When a node receives the new share from other participants, he will add to the original share. The result of this addition is the new share.
A verification system must, however, be in place in order to prevent some nodes being compromised. A compromised node may not want to participate in the update process, or it may intentionally send incorrect update shares to other nodes. If other nodes use the incorrect shares to construct their new shares, the secret, which is recovered from the new shares, will then not be consistent with the original one. Hence, verifiable secret sharing is used to prevent this kind of attack. The method is detailed below.
(1) Prior to distributing the secret share to other nodes, the dealer publishes that are the witnesses of coefficients of the sharing polynomial.
1 1
0, a , , ak−
a g g
g L
(2) Each participant then receives its share and verifies it by calculating
1 1 1) ... ( ) ( ⋅ ⋅ − − ⋅ = k i k i i S a ID a ID S g g g g
2.6
Combinatorial
Object
We begin this section by first introducing some specific notations and their definitions [16].
Definition 2.6.1 Θ-notation [16]
For a given function g(n), we denoted by Θ(g(n)) the set of functions
1 2 0
(g(n)) = {f(n): there exists positive constants , and such thatc c n
Θ
1 2
0≤c ng( ) f( )≤ n ≤c g( ) for all n n n≥ 0} □
A function f(n) belongs to the set Θ(g(n)) if there exists positive constants c1 and c2 such that
it can be “sandwiched” between c1g(n) and c2g(n) for sufficiently large n.
Definition 2.6.2 O-notation [16]
For a given function g(n), we denoted by O(g(n)) the set of functions 0
(g(n)) = {f(n): there exists positive constants and such that
O c n
n0
0 f(n)≤ ≤cg(n) for all n≥ }
n n
□
We use O-notation to give an asymptotic upper bound on a function to within a constant factor.
Definition 2.6.3 Ω-notation [16]
For a given function g(n), we denoted by Ω(g(n)) the set of functions
0
(g(n)) = {f(n): there exists positive constants and such thatc n
Ω
0
We use Ω-notation to provide an asymptotic lower bound on a function to within a constant factor.
2.6.1
Introduction to Perfect Hash Families
Computer scientists have studied perfect hash families (PHF) for more than 15 years. Perfect hash families are basic combinatorial structures, and they have played many important roles in the field of computer science, such as in database management and compiler
constructions. Such hash functions should be easily computable, and only a minimal amount of memory would be required. Not until recently that the concept of perfect hash families has been applied to cryptography. For example, it can be seen used in the broadcast encryption schemes, secret sharing, and cover-free families. A perfect hash family can be defined as follows [5]:
Definition 2.6.4 [5]
A perfect hash family, denoted as PHF(F; A, B, ), should satisfy the following statements:
1. A and B are the finite non-empty set.
2. F is a finite set of hash functions from A to B such that
w
for each X⊆A if |X| =w, X
there exists at least one f∈F , where f | is injective. □
Note: In many situations, a perfect hash family can also be denoted as PHF(|F|; |A|, |B|, w).
According to the above definition, the notation ‘|X’ is used to denote the restriction to the
Note: We may also write f(A, B, ) as fw ∈F, f:A→ B, F { f(A, B, ) | f }.= w
Let N be the minimum number of functions such that a PHF(F; A, B, w) would exist. That is, N = min { |F| } is the optimal solution [5].
Below is a simple example of a perfect hash family – PHF(4; 9, 3, 3).
Example 2.6.1
We have a PHF(4; 9, 3, 3). Consider the matrix:
⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ = 2 1 3 1 3 2 3 2 1 1 3 2 2 1 3 3 2 1 3 2 1 3 2 1 3 2 1 3 3 3 2 2 2 1 1 1 M
Let A = {1, 2, 3, 4, 5, 6, 7, 8, 9} and B = {1, 2, 3}. Hence |A| = 9, |B| = 3. Let f be a set of hash functions fi, i = 1, 2, 3, 4, as shown in Table 2.6.1.
X 1 2 3 4 5 6 7 8 9 f1(x) 1 1 1 2 2 2 3 3 3 f2(x) 1 2 3 1 2 3 1 2 3 f3(x) 1 2 3 3 1 2 2 3 1 f4(x) 1 2 3 2 3 1 3 1 2 Table 2.6.1 PHF(4; 9, 3, 3)
From these four functions, we can see that for any subset of with |X| = 3, we have at least one function f
X⊆A
i that separates X. The verification of that F is a PHF(4; 9, 3, 3) has
been shown in [5]. □
In the next section, two propositions of perfect hash families are presented. These two propositions are used in our scheme later.
2.6.2
Propositions of Perfect Hash Families
Two propositions of perfect hash families are discussed here [5][6]. One is the partition characteristic offered by the perfect hash families. The other one is the corresponding matrix.
Definition 2.6.5 w-partition of A
i 1 2 |A| i
w
| A is a partition of A. P, , {P , P , , P |P | .
w Π ∈Π L }, = w
The order of each subset is .w □
Note: A set X A is separated by a partition of A if the elements of X are in
distinct part of .
π π
⊆
Proposition 2.6.6 [5][6]
Suppose that is a family of -partition of A with N. For all sets X A with X , X is seperated by at least one . Then there exists a PHF( ; , , ).
w
w π N
Π Π =
= ∈Π n m w
⊆
Conversely, a PHF( ; , , ) gives rise to such -partition set of A. N n m w w Π □
The proof for Proposition 2.6.6 is included in Appendix A. A simple example of Proposition 2.6.6 is given below.
Example 2.6.2
Let A = {1, 2, 3, 4, 5, 6, 7, 8, 9}. Consider the PHF(4; 9, 3, 3) we constructed in Example 2.6.1, we can get the following results:
7}} 5, {3, 9}, 4, {2, 8}, 6, {1, { , 8}} 4, {3, 7}, 6, {2, 9}, 5, {{1, 9}} 6, {3, 8}, 5, {2, 7}, 4, {{1, 9}}, 8, {7, 6}, 5, {4, 3}, 2, {{1, 4 3 2 1 = = = = π π π π
1 2 3 4
Thus, Π ={π π π π, , , } is the most desired set of partitions of A. 1 2 3 4
Conversely, we can find a function family F {f , f , f , f , such that f (x) is denoted as and for each x A, labeling the part for each partition according to the given order.
i i i π π = } ∈ □ Proposition 2.6.7 [5][6]
Suppose that there exists a PHF( ; , , ). Then there exists an array M, where size is * and which has entries in a set B of size , such that for any subset
X of columns of M with X , th
N n m w
N n m
w
= ere is at least one row of M that seperates the subsex X of columns of M.
Conversely, such an array gives rise to a PHF( ; , , ). N n m w □
The proof of Proposition 2.6.7 is also included in Appendix A. Referring to the matrix provided in Example 2.6.1, it is obvious that it is an example of Proposition 2.6.7.
Next section provides a summary of construction methods of perfect hash families proposed in other studies. We also discuss some known bounds of N(n, m, w).
2.6.3
Construction methods of Perfect Hash
Families
In this section, we are more interested in the behavior of minimum N as a function of n when m and w are fixed. Bounds on N have been studied extensively (For examples, see [5][6][17][18][19]). In particular, in [19], it provides a proof that when m and w are fixed, N is Θ(log n). However, this existence is non-constructive. It is also believed that it is difficult to give explicit constructions that are as asymptotically good. Here, we introduce some explicit constructions and point out the bound on N in those constructions. Although these
reasonable.
There are many kinds of method to construct perfect hash families, such as using combinatorial structures and using algebraic structures. Table 2.6.2 lists the approaches included in the combinatorial and algebra structures.
Combinatorial Structures Algebra Structures
Design Theory Special Global Function Field Error-Correcting Codes Algebraic Curves
Recursive Constructions
Table 2.6.2 Construction Methods
In the combinatorial structures, we can use the design theory to construct perfect hash families. There are some set systems, such as the balanced incomplete block design (BIBD) and the separating resolvable block design (SRBD). The detail of this construction was introduced in [17]. According to their inference and proof, in the situation when m and w are fixed, the bound of N is Ω(n). Although these methods give simple constructions, they are limited in the sense that they cannot be applied to obtaining a PHF with an arbitrary m ≥w. In
other words, they cannot obtain a PHF in which m is O(w). In addition, in a construction of perfect hash families using Error-Correcting Codes, the bound of N is O(n). The restriction of this method is the same as using the design theory to construct it. It also cannot construct a PHF in which m is O(w). Finally, in [17], the authors proposed two kinds of recursive construction. First, they used an already existing PHF together with a (n, k, λ) - difference matrix to obtain another PHF with larger N and n. In this construction, the bound of N is
1 2 log( ) ((log ) w O n ⎛ ⎞+ ⎜ ⎟
⎝ ⎠ ) . Second, the authors used three already existing PHFs and combine them into a new PHF with larger N and n. The bound value of N in the second method is about the same as the first one, but the second method has a slightly larger constant term.
hash families. Specifically, they used an algebraic curve to construct a PHF. In this method, the bound of N is O(log n). Details of this kind of construction are not included in this text since algebra structures are not used in this thesis. (For more related information, see [18].)
In this thesis, the PHF is constructed by the affine plane and resolvable BIBD. Before we introduce the construction mechanism, we first give some definitions for affine plane and resolvable BIBD.
An affine plane is a PBD(P, B) with some specific properties[20]. Before we state the corresponding properties, PBD(P, B) is introduced first. A pairwise balanced design, referred to as the PBD, is an ordered pair (P, B). P is a finite set of symbols, and B is a collection of subsets of P called blocks, such that each pair of distinct elements of P occurs together in exactly one block of B. The properties of an affine plane are summarized below.
(1) P contains at least one subset of 4 points, and no 3 of which are collinear.
(2) Given a line h and a point p not on h, there is exactly one line of B containing p, which is parallel to h. Example 2.6.3 Affine plane. P = {1, 2, 3, 4} B = { {1, 2} {1, 3} {1. 4} {3, 4} {2, 4} {2, 3} } □
In an affine plane (P, B), the number of points in each block is called the order of the affine plane.
Definition 2.6.8 k-power set of X
P is the power set of X.
A is a -power set of X if Ak ⊆P and for each x A |x| ∈ =k. | |
We have X -power sets of X.k k
⎛ ⎞ ⎜ ⎟
⎝ ⎠ □
Definition 2.6.9 [5]
X is a non-empty set of points, and A is a subset of the k-power set of X called blocks. Let v, k, λ be positive integers such that v ≥ k ≥ 2. A (v, b, r, k, λ) – balanced incomplete block design (denoted as (v, b, r, k, λ) – BIBD) is a set system(X, A) such that the following properties are satisfied:
1. | X | = v,
2. Every point occurs in r blocks, and
3. Every pair of points occurs in exactly λ blocks. □
For simplicity, in the following examples, we write blocks in the form abc, rather than {a, b, c}. Example 2.6.4 A (10, 15, 6, 4, 2) – BIBD. X = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}, and A = {0123, 0145, 0246, 0378, 0579, 0689, 1278, 1369, 1479, 1568, 2359, 2489, 2567, 3458, 3467}. □
Theorem 2.6.10. [5][21]
1. A (v, b, r, k,λ)–BIBD follows from elementary counting that vr = bk and λ(v–1) =
r(k–1). □
The proof of Theorem 2.6.10 is included in Appendix A.
A parallel class in (X, A) is a set of blocks that forms a partition of the point set X. A BIBD is resolvable if A can be partitioned into r parallel classes, and each of which consists of v/k disjoint blocks. Obviously, a BIBD can have a parallel class only if v ≡ 0 mod k.
Example 2.6.5 A resolvable (6, 15, 5, 2, 1) – BIBD.
Let X = {0, 1, 2, 3, 4, 5}, and r = 5. Hence there are 5 parallel classes, and each consists of 3 blocks. So parallel classes = {01, 25, 34}, {02, 13, 45}, {03, 24, 15}, {04, 35, 12}, {05, 14, 23} □
It is well-known that an affine plane of order q is an (q2, q(q+1), q+1, q, 1) – BIBD. It is also a resolvable BIBD. Thus, the following theorem can be derived: For any prime power q, there exists an affine plane of order q. That is, there exists a (q2, q(q+1), q+1, q, 1) – BIBD.
Theorem 2.6.11. [5][18]
If there exists a resolvable (v, b, r, k, λ) – BIBD with , then there exists a PHF(r; v,
v/k, w). □
2
w r λ> ⎜ ⎟⎛ ⎞
⎝ ⎠
The above theory is derived and obtained from [5][18]. The proof is stated in Appendix A. Based on this theory and the above description, we then can derive the following corollary.
Corollary 2.6.12 [5]
Let w be an integer such that w ≥ 2. Suppose q is a prime power and . Then there exists a PHF(q+1; q 1 2 w q+ > ⎜ ⎟⎛ ⎞ ⎝ ⎠ 2, q, w). □
Therefore, we can use an affine plane to construct a PHF.
In this thesis, we construct the perfect hash families according to Corollary 2.6.12. The detail of our construction is described in the next chapter. By observations, we find that formats of the BIBD and the PHF, which are constructed from an affine plane, are determined by only one parameter – prime power q. Thus, we give a special name for these kinds of BIBDs and PHFs – namely, (q, 1) – BIBD and (q, w) – PHF.
2.7 Fundamentals of Mobile Ad Hoc Network
In the last few years, computer scientists have shown growing interest in studying mobile ad hoc networks as they have tremendous military and commercial potential [22]. Security related issues in mobile ad hoc networks are also an important topic of research. Below is a brief introduction to the mobile ad hoc network [23].
2.7.1
Mobile Ad Hoc Network
Mobile ad hoc network for short is called MANET. It is a non-infrastructure network. MANET is consisted of a group of autonomous mobile nodes. Each node has the function of a router. They are able to communicate with each other without any support of wired
infrastructure. As long as they stay in the communication scope of each other, they can talk to each other by using the wireless link. Since the nodes have mobility, the network topology may change rapidly and unpredictably. Also, the network is decentralized; all network
activities, which include discovering the topology and delivering messages, must be executed by the nodes themselves. Nowadays, a mobile node can be a notebook, a PDA, or any other kinds of wireless device with mobility. Next figure illustrates a mobile ad hoc network constructed by many kinds of mobile node.
Figure 2.7.1 Mobile Ad Hoc Network
2.7.2
Characteristics of Mobile Ad Hoc Network
According to IETF RFC 2501[24], the characteristics of MANET include several parts, and they are outlined below.
may change randomly and rapidly at unpredictable times.
2. Bandwidth-constrained, variable capacity links: Compare to the wired network
environment, MANET is resource-constrained in bandwidth and link capacity. In addition, the realized throughput of wireless communications is often much less than a radio’s maximum transmission rate.
3. Energy-constrained operation: The power supply for some nodes in MANET is batteries or other exhaustible energy. Therefore, the consideration of limited battery power and life is also necessary.
4. Limited physical security: Wireless links are generally prone to more physical security threats than wired links. MANET suffers from, for example, passive eavesdropping, active impersonation, and denial-of-service attacks. As a benefit, though, the decentralized mechanisms in MANET have higher security.
2.7.3
Security challenges of Mobile Ad Hoc
Network
Due to the noticeable characteristics of mobile ad hoc networks, achieving the requirements of security mentioned in the earlier section can be rather challenging. First, compared with wired links, wireless links are generally more prone to link attacks because all the data are transmitted in the air. As a result, it is relatively easier to perform eavesdropping, impersonation, message replay and message distortion. The simplest way to protect the transmitting data is to encrypt it before sending it out. Certainly, in this way, we have to bear the overheads from encryption. Second, since each node has the mobility, it may roam to a dangerous environment. Some nodes may therefore be compromised. Thus, we should not only pay attention to the malicious attacks from the outside, but also, equally important,
watch out for the wrong information from the inside compromised nodes. The trust
relationship among nodes may change very often; for example, some nodes may have been detected as compromised nodes, so we have to authenticate the neighbor nodes periodically. Third, due to the high mobility, some roles that are responsible for authentication, such as CA, cannot be the central entities. In order to improve the survivability, the authenticator must use a distribution structure. Fourth, because of a rapid changing topology, a mobile node may only be able to perform effectively and have timely communication with its local neighbors but not with remote entities. For example, routing protocols may fail to establish robust
communication over multi-hop paths. Thus, it is imperative to localize the security service. Finally, an ad hoc network may consist of hundreds or even thousands of nodes. Therefore, the scalability and flexibility of security mechanisms are crucial properties.
Chapter 3 System Architecture
3.1
Concept
In this thesis, we distribute the CA’s functionality to many nodes in the network. In addition to using Shamir’s threshold secret sharing scheme, we also use perfect hash families’ properties to distribute the trust among a group of nodes. In this chapter, we discuss the concept behind the design of our protocol.
3.1.1 Construction
Initially, our network system is constructed from a special form of BIBD: (q2, q(q+1),
q+1, q, 1) – BIBD, and we call it (q, 1) – BIBD. From section 2.6.3, we know that for any
prime power q, there exists an affine plane of order q. Furthermore, an affine plane of order q can construct a (q, 1) – BIBD. Because q2 ≣ 0 mod q, it is also a resolvable BIBD. Let w be
an integer such that w ≥ 2. Suppose q is a prime power and . Then, based on Corollary 2.6.12, there exists a PHF(q + 1; q
1 2
w q+ > ⎜ ⎟⎛ ⎞
⎝ ⎠
2, q, w), and we call it (q, w) – PHF. When we
want to construct the system, we therefore first consider the security parameter w that we want to achieve and the system secret S. After both variables are determined, we then get a minimal random prime power q such that . Finally, we use this prime power q to create a (q, w) – PHF. The following two figures show the construction algorithm of this PHF. The program of the construction is appended in Appendix B. Figure 3.1.1 provides the
procedure of finding the minimal prime power q that satisfies the requirement . 1 2 w q+ > ⎜ ⎟⎛ ⎞ ⎝ ⎠ 1 2 w q+ > ⎜ ⎟⎛ ⎞ ⎝ ⎠
That is is a prime power and +1 > 2
min{ | w }
q= x x x ⎛ ⎞⎜ ⎟
⎝ ⎠ . Figure 3.1.2 then illustrates how the appropriate (q, w) – PHF is generated [20].
// Finding the minimal prime power q // Input: the security parameter w
// Output: prime power q
Finding_q( w ) w 1. q 2 2. q exists 3. q is a prime power 4. while if the ⎛ ⎞ ← ⎜ ⎟ ⎝ ⎠ q 5. 6. q q + 1 n return break else ←
Figure 3.1.1 Finding the minimal prime power q
// Construction algorithm of PHF // Input: the prime power q // Output: A (q, w) - PHF
Construct_PHF(q)
1 Use the prime power q to construct a finite field 2 Derive an affine plane of order q from the
.
. finite field
3. Map the affine plane to a (q, 1) - BIBD
4 Construct a (q, w) - PHF from the (q, 1) - BIBD 5 (q, w) - PHF
.
. return
The meaning of every parameter in the PHF(q + 1; q2, q, w) is explained as follows: q2 means the number of nodes owning the secret shares in our system. We call this kind of nodes as the server nodes. (q + 1) represents the number of secret shares each server node should hold. Besides, it also implies that this PHF has (q + 1) hash functions, and we have to create (q + 1) polynomial functions with degree (w - 1) for secret sharing. Each polynomial function has the same secret S. Also, a set of secret shares can be combined for every w server nodes to reconstruct the system secret S and use S as the secret key to sign a certification
collaboratively. In other words, w is the minimum number of server nodes required to retrieve the original S. Finally, q refers to the number of disjoint sets in each partition when we
partition q2 sever nodes. That is, each partition has q disjoint sets. Furthermore, it also implies the number of secret shares that each polynomial function has to generate.
When we divide the system secret S into several secret shares, we have to send these secret shares to the sever nodes. The coefficient of the corresponding hash functions determines which serve node gets which secret share.
Take the PHF(4; 9, 3, 3) we mentioned above for example. From this PHF, we know that the system has nine sever nodes. We denote them as from Ser1 to Ser9. Then we would
generate four polynomial functions with degree 2, and each would individually generate three secret shares. Each sever node would then have four secret shares from different polynomial functions. Any three randomly chosen server nodes could use a set of secret shares to
reconstruct the system secret. We distribute the secret shares to the nine server nodes according to the four hash functions, which is summarized below in Table 3.1.1.