國 立 交 通 大 學
電信工程研究所
碩 士 論 文
考慮語速影響與詞綴構詞之中文語音辨認系統
A Mandarin Speech Recognition System Incorporating with
Speaking Rate Modeling and Word Construction
研 究 生:林俊翰
指導教授:陳信宏 教授
考慮語速影響與詞綴構詞之中文語音辨認系統
A Mandarin Speech Recognition System Incorporating with
Speaking Rate Modeling and Word Construction
研 究 生: 林俊翰 Student:Jun-Han Lin
指導教授: 陳信宏 博士 Advisor:Dr. Sin-Horng Chen
國 立 交 通 大 學
電信工程研究所
碩 士 論 文
A Thesis
Submitted to Institute of Communication Engineering
College of Electrical and Computer Engineering
National Chiao Tung University
in Partial Fulfillment of the Requirements
for the Degree of
Master of Science
in Communication Engineering
July 2012
Hsinchu, Republic of China
I
考慮語速影響與詞綴構詞之中文語音辨認系統
研 究 生:林俊翰 指導教授:陳信宏
博士
國立交通大學電信工程研究所碩士班
中文摘要
本研究提出一個新的中文大詞彙連續語音辨認方法來考慮綴詞的辨認及語速對辨認的影 響,首先針對綴詞,從構詞學的角度出發,利用綴詞具有的規則特性將它們拆解成 sub-word 單元,再建構出一個詞群語言模型來描述它們和其他詞的關係,研究目標在於藉由增加 word lattice 的正確詞涵蓋率來降低 OOV(out-of-vocabulary)的影響,實驗結果顯示可以降低詞(word)、 字(character)及基本音節(base-syllable)的絕對錯誤率分別達到 0.37%、0.27%及 0.26% (或是降低 相對錯誤率達到 2.64%、2.56%及 3.38%);其次,本論文探討語速對語音辨認的影響,做法是 藉由建立一個語速控制的階層式韻律模型來描述語速對語音韻律聲學參數的影響,並將其用來 協助語音辨認。實驗結果顯示所提出的考慮語速的語音辨認方法可以降低詞、字及基本音節的 絕對錯誤率分別達到 1.67%、1.45%及 1.02% (或是降低相對錯誤率達到 12.25%、14.09%及 13.55%),因此這是一個不錯的方法。II
A Mandarin Speech Recognition System Incorporating with
Speaking Rate Modeling and Word Construction
Student:Jun-Han Lin Advisor:Dr. Sin-Horng Chen
Institute of Communication Engineering
National Chiao Tung University
Abstract
The thesis presents a new Mandarin-speech recognition approach to considering the recognition of
affix-words and the effect of speaking rate. First, the recognition of affix-words is realized via
decomposing them into sub-word units. A class-based language model is then employed to describe their
relations with other words. The study aims at decreasing the effect of out-of-vocabulary (OOV) words by
increasing the coverage of the word lattice generated by a lexicon with size limited to 60,000.
Experimental results showed the reductions of word, character, and base-syllable error rates by 0.37%,
0.27% and 0.26% absolutely (or 2.64%, 2.56%, and 3.38% relatively). Then, the effect of speaking rate
on speech recognition is discussed. A speaking rate-dependent hierarchical prosody model which
describes the influences of speaking rate on prosodic-acoustic features are constructed and used to assist
in speech recognition. Experimental results showed that the approach of considering speaking rate in
ASR leads to the reductions of word, character, and base-syllable error rates by 1.67%, 1.45% and 1.02%
III
致謝
就讀研所兩年期間,非常感謝陳信宏老師時時刻刻關心我的研究進度,在研究上不斷地給 與指導,引領我的研究方向,使我能夠順利畢業。感謝王逸如老師,碩一時教導我語音的基本 觀念與做研究的態度與方法,使我從一個懵懵懂懂的大學生領悟到如何成為一位真正的研究生。 感謝振宇學長、智合學長、阿德學長與希群學長在研究上給予我許多幫助,一路指導我的 研究,在我迷惘有困難時,願意花時間與我討論,提供建議與意見,使我能夠走向正確的道路 上;感謝文良、大胖、小蝦、智障、豆腐、進竹、冠譯與銘傑學長,在研究上給予建議,生活 上也非常照顧我們這屆學弟妹,由其感謝銘傑學長,感謝你一步一步地教導我,使我能夠迅速 地了解我的研究;感謝人生勝利組的小邱、研究與籃球一把罩的 kiwi 以及又帥又白的睿詮, 在研究上或生活上,都受到你們很大的照顧,感謝學識淵博的企鵝,觀念成熟的昂星,樂觀開 朗的昌祐,好相處的雅婷以及多才多藝的秘書靖觀,感謝你們兩年來對我的包容;感謝下一屆 學弟妹,很古意的阿龐,又聰明又會講話的子睿,排球超強、身材超好的奕勳,高手等級的良 基與個性活潑的婉君,期許你們明年順利畢業。 最後感謝我的父母親,謝謝您們一路上的支持,使我在人生道路上走得更加堅定,一路堅 持往前邁進,謝謝您們。IV
目錄
中文摘要... I Abstract ... II 目錄... III 表目錄... VII 圖目錄... IX 第一章 緒論... 1 1.1 研究動機... 1 1.2 文獻回顧... 1 1.3 研究方向... 2 1.4 章節概要說明... 3 第二章 階層式語言模型... 4 2.1 語料庫簡介... 4 2.2 聲學模型與語言模型之架構及建立... 5 2.2.1 聲學模型之建立... 5 2.2.2 文字資料庫介紹... 6 2.2.3 辨識詞典選詞方式... 7 2.2.4 語言模型的建立... 9 2.3 綴詞語言模型的訓練... 10 2.3.1 綴詞的選擇與拆解... 10 2.3.2 綴詞語言模型之建立... 10 2.4 階層式語言模型辨認器... 13 2.5 結果分析... 13 2.5.1 語言模型評估... 14V 2.5.2 綴詞於 word lattice 上之涵蓋率 ... 14 2.5.3 辨識效能結果... 15 2.5.4 辨識結果之細部剖析... 16 第三章 加入語速影響之韻律模型於中文大辭彙語音辨認系統... 17 3.1 中文語音韻律模型階層式架構... 17 3.2 階層式韻律模型之修正及設計... 19
3.2.1 Break Syntax Model ... 21
3.2.2 韻律狀態模型... 22
3.2.3 音節韻律模型... 22
3.2.4 停頓聲學模型... 24
3.3 加入韻律訊息於 two-stage 語音辨認系統... 25
3.3.1 Joint Syntax Model 之架構與建立 ... 26
3.3.2 特徵參數正規化... 28
3.3.2.1 音節長度之語速正規化... 28
3.3.2.2 停頓長度之語速正規化... 29
3.3.2.3 音節音高軌跡之語速正規化... 29
3.3.2.4 音節能量強度之語速正規化... 30
3.3.3 The Second Stage 之實作 ... 31
3.3.3.1 第一階段:加入多種語言資訊... 31 3.3.3.2 第二階段:加入韻律邊界停頓資訊... 32 3.3.3.3 第三階段:加入音節韻律狀態資訊... 33 3.4 鑑別式模型組合... 34 第四章 實驗結果與分析... 36 4.1 階層式韻律模型之訓練... 36
4.1.1 Break Syntax Model ... 36
4.1.2 停頓聲學模型... 38
VI 4.2.1 詞性(POS)辨認率算法... 42 4.2.2 標點符號( PM)辨認率算法 ... 42 4.3 辨識結果分析與比較... 42 4.3.1 各級辨認結果之比較... 43 4.3.2 傳統韻律模型與考慮語速影響之韻律模型之比較... 45 第五章 結論與未來展望... 46 5.1 結論... 46 5.2 未來展望... 46 參考文獻... 48 附錄:決策樹之問題集... 50
VII
表目錄
表 2.1:TCC-300 語料庫統計表 ... 5 表 2.2:MFCC 參數抽取設定檔 ... 6 表 2.3:TF-IDF 方法剔除的詞條例 ... 8 表 2.4:經由 TF-IDF 方法加入的詞條例 ... 8 表 2.5:混淆度(Perplexity) ... 8 表 2.6:綴詞拆解範例 ... 10 表 2.7:詞幹詞性範例 ... 11 表 2.8:詞典涵蓋率 ... 13 表 2.9:TCC300 測試語料的詞類統計 ... 14 表 2.10:語言模型混淆度 ... 14 表 2.11:word lattice 上綴詞涵蓋率 ... 15 表 2.12:搭配語言模型之詞辨認率 ... 15 表 2.13:搭配語言模型之字元辨認率 ... 15 表 2.14:搭配語言模型之音節辨認率 ... 15 表 2.15:word lattice 之詞、字及音節涵蓋率 ... 16 表 2.16:綴詞辨識情況 ... 16 表 3.1:韻律結構之停頓標記 ... 19 表 3.2:韻律標記、聲學參數以及語言參數之數學符號 ... 20 表 3.3:文本處理 ... 27 表 4.1:詞(word)辨認率 ... 40 表 4.2:字(character)辨認率 ... 40 表 4.3:音節(syllable)辨認率 ... 41 表 4.4:詞性(POS)辨認率 ... 41VIII 表 4.5:標點符號(PM)辨認率 ... 41 表 4.6:搶詞狀況的改善 ... 43 表 4.7:一字詞辨認的改善 ... 44 表 4.8:聲調的修正 ... 44 表 4.9:加入語速影響的結果改善 ... 45
IX
圖目錄
圖 2.1:語言模型訓練流程 ... 6 圖 2.2:文本前處理流程 ... 7 圖 2.3:新辨識路徑 ... 11 圖 2.4:階層式系統架構 ... 13 圖 3.1:中文語音韻律之階層式架構 [9] ... 17 圖 3.2:本研究所採用的階層式韻律架構 ... 18 圖 3.3:以 two-stage 方式之韻律輔助中文語音辨認系統流程圖... 25圖 3.4:factored POS model 的 backoff 路徑 ... 26
圖 3.5:factored PM model 的 backoff 路徑 ... 27
圖 3.6:factored model 訓練架構流程圖 ... 27
圖 3.7:辨認器第二級三階段實作流程圖 ... 31
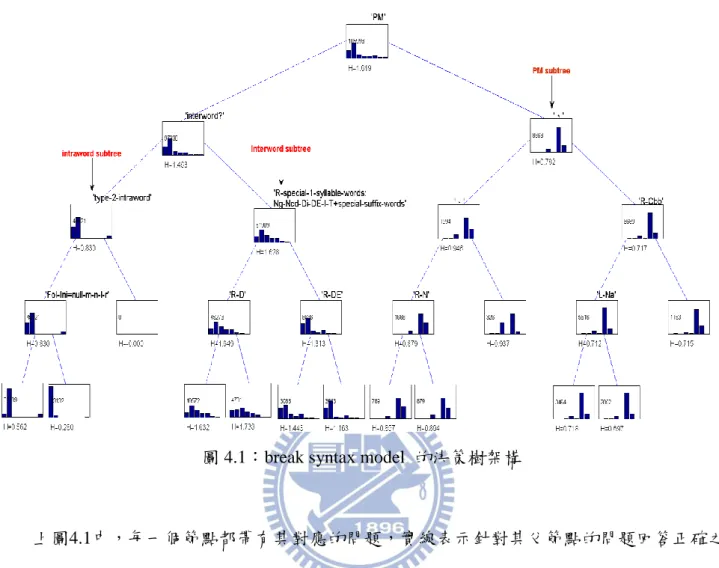
圖 4.1:break syntax model 的決策樹架構 ... 37
圖 4.2:interword subtree 架構更深層部分 ... 38
圖 4.3:(a)音節停頓時長,(b)正規化音節延長因子 1,(c)正規化音節延長因子 2,(d)音節間 能量低點,(e)正規化基頻跳躍值之決策樹根節點之機率分佈圖 ... 39
1
第一章 緒論
1.1 研究動機
近年來,電子產品不斷推陳出新,人們愈來愈注重其產品實用性與使用的便利性,而語音 是人類最直接且最便利的溝通方式,以語音取代複雜的鍵盤輸入做為與機器溝通的媒介已經成 為一種近代的發展趨勢。 針對中文語音辨識而言,中文詞彙不同於其它拼音語系,詞彙的邊界相當模糊、數量繁多 且變化複雜,詞與詞之間也可再組合成新的詞彙,這些多元的變化造成詞彙定義上的困難,然 而在傳統大詞彙語音辨認中,受限於詞典詞條數的限制,無法收錄所有中文詞彙可能的組合, 使得詞典的涵蓋率不足,在進行語音辨認時,落在詞典外的詞彙(out-of-vocabulary, OOV)將無 法被辨識出來。因此本研究將探討中文特性,針對若干具有較明顯的構詞規則的詞彙進行分析 討論,藉此增進詞典的涵蓋率,進而解決 OOV 問題。 韻律訊息在口語中扮演著很重要的角色,能幫助人們辨認每一個詞以及整段句子的結構。 其中說話速度更是一個很重要的韻律參數,它可以影響許多語音的現象,像是音節長度、停頓 長度、基頻軌跡等等...,更有相關的研究指出,慢速或快速語音辨認時會造成較大的詞錯誤 率(word error rate, WER),故本研究將考慮語速對中文語音韻律的影響。1.2 文獻回顧
在大詞彙語音辨認系統(large vocabulary continuous speech recognition, LVCSR)中,N 連語 言模型(n-gram language model)最常被使用,其原理為藉由統計各種詞彙出現在文本的次數來 描述詞與詞之間相接的機率,但隨著 N 值的升高,訓練語言模型時會發生資料稀疏(Data Sparseness)的問題,導致機率預估的不準確。而後為增進辨識系統效能,有許多學者提出方法
2
言模型(Class-based n-gram language model),透過加入類別資訊來訓練語言模型,則資料的預 估由詞彙組合數降低為類別的組合數,進而改善資料稀疏的問題。
中文詞彙數量繁多且變化複雜,辨識詞典無法收錄所有中文詞彙可能的組合,Jou [2]、Yang [3]在其論文中提出階層式辨識系統,以構詞學的角度出發,針對人名、定量複合詞與詞綴三
個類別依照其特性將之拆解進而提升詞的涵蓋率。
在自動語音辨識系統(Automatic Speech Recognition, ASR)上已有相關研究在探討語速對 於辨識效能的影響:Siegler [4]等人發現快語速的語音會提高其辨識上的錯誤,並提出三種方 法改進快語速語音的辨識準確率,分別是 Baum-Welch codebook 的調適、HMM 狀態轉移機率 的調適以及藉由加入複合詞(Compound Words)以及利用規則法改善發音詞典,實驗結果顯示第 二種方法降低了 4-6%的相對錯誤率。Martinez [5]等人討論語速與聲學參數的相關性,並將語 速加入辨識考量中,實驗結果顯示慢語速的部分詞錯誤率可以有效地降低。Pfau [6]提出語速 正規化的方法,其原理為透過動態調整音素(phone)長度,來消除語速對辨識系統的影響。
1.3 研究方向
本研究首先在語言模型層進行改良,更改選詞方式並考慮中文詞彙中若干具有規則特性的 詞彙,藉由語法資訊進行拆解,以便提升詞典涵蓋率、降低 OOV 的問題。第一步將產生一組 高涵蓋率的詞圖(word lattice),第二步在此涵蓋率高的 word lattice 上將符合規則的較小單元重 新進行構詞,並利用更精細的語言模型重新配置語言模型的分數,藉此壓抑不合理的路徑,加 強可靠的路徑的機率值。本研究將使用韻律模型,利用 Jiang [7]提出的非監督式中文語音韻律標記及韻律模式 (Unsupervised Joint Prosody Labeling and Modeling, PLM)演算法,從大量未經標記的語料中訓練
各種韻律模型,描述韻律邊界停頓、音節韻律狀態這兩種韻律標記與語言參數及韻律聲學參數 三者之間的關係,並加入語速變數將其引入韻律模型當中,使其與語速相關,最後應用到語音 辨認中,期許能進一步提升辨識效能,並解碼出詞(Word)序列、詞性(POS)序列、標點符號序 列(PM)等多種語言參數序列及代表韻律架構的兩種韻律標記資訊。
3
1.4 章節概要說明
本論文一共分為五章,其各章節內容分配如下: 第一章:緒論。 第二章:階層式語言模型。 第三章:加入語速影響之韻律模型於中文大詞彙語音辨認系統 第四章:實驗結果及分析。 第五章:結論與未來展望。4
第二章 階層式語言模型
基本語音辨認器中包含聲學模型與語言模型,聲學模型是以隱藏式馬可夫模型(HMM, Hidden Markov Model)呈現,透過該機率模型,描述發音過程之狀態轉移現象和輸出結果,語
言模型則經由大量文字資料訓練出一個涵蓋範圍廣泛、適用於各種領域的語言模型,期許在加 入語言模型幫助下提升語音辨識率。 然而在傳統語音辨識上,辨識率一直受限於詞典大小,而中文詞彙數量繁多且變化複雜, 詞與詞之間也可再組合成新的詞彙,在這其中許多詞類為 open set,諸如數詞(Neu)、專有名詞 (Nb)、綴詞(MD)…等,由於詞典有其詞彙量的限制下,無法收錄所有中文詞彙可能的組合, 使得詞典的涵蓋率降低,落在詞典外的詞彙將無法被辨識出來,語音辨識效能因此成長有限。 為突破此困境,本研究針對 open set 中具有較明顯的構詞規則的若干詞彙進行處理,綴詞 富有其規則特性,可視為「詞幹(stem)」與「詞綴」的組合,故將其拆解成較小的單位,以收 錄較少的數量來降低 OOV 的問題,在此我們將每一種詞綴各自視為不同的類別,訓練出詞綴 類別與前後詞之間的機率,加上對各自類別內的單元組合訓練出語言模型,最後整合這兩個語 言模型經由重新評分得出最佳的辨識結果並進一步減少一字詞的錯誤率。 2.1 節中將對實驗所使用之語料庫做基本的介紹;2.2 節中將簡介聲學模型與語言模型之架 構及建立;2.3 節將介紹如何針對綴詞訓練出語言模型;2.4 節將介紹辨認系統的整體架構;2.5 節將分析此系統的辨識結果。
2.1 語料庫簡介
本研究是使用 TCC-300 麥克風語音資料庫,它由國立台灣大學、國立成功大學及國立交 通大學所共同錄製,此語料庫屬於麥克風朗讀語音,檔案統計資料如表 2.1 所示。每個學校之 語句取樣頻率皆為 16,000 赫茲(Hertz),取樣位元數為 16 位元。音檔檔頭為 4096 位元組(byte), 副檔名為*.vat。5 表 2.1:TCC-300 語料庫統計表 學校名稱 文章屬性 語者總數 總音節數 音檔總數 台灣大學 短文 男 50 男 27541 男 3425 女 50 女 24677 女 3084 總數 100 總數 52218 總數 6590 交通大學 長文 男 50 男 75059 男 622 女 50 女 73555 女 616 總數 100 總數 148614 總數 1238 成功大學 長文 男 50 男 63127 男 588 女 50 女 68749 女 582 總數 100 總數 131876 總數 1170 依據表 2.1,本研究會對上述內容以長句為主的語料庫分為訓練語料及測試語料,其中訓 練語料的部分大約占 90%,共包含 274 位語者,長度一共約 23 小時,音節總數量為 300,836; 測試語料的部分大約占 10%,共包含 19 位語者,長度一共約 2 小時,詞總數量為 15,461,音 節總數量則為 26,357,此外本研究所使用的韻律模型,是從訓練語料中挑選 164 位語者,音檔 長度 8.3 小時,音節總數量為 106,955 的語料來進行訓練。
2.2 聲學模型與語言模型之架構及建立
2.2.1 聲學模型之建立
由於語音訊號在頻譜上具有短時間穩定的特性及考慮到人耳聽覺效應的補償作用,本研究 使用的參數為 MFCC (Mel-Frequency Cepstral Coefficients, 梅爾倒頻譜參數),以 32 毫秒之漢明 窗(Hamming Window)及每次位移 10 毫秒取出一筆資料,其成分包含 12 維 MFCC 加上 1 維能 量共 13 維,取其一階變化量(delta term)和二階變化量(delta-delta term),最後扣掉能量參數, 參數一共 38 維做為本研究之發音聲學參數。其系統相關設定如表 2.2 所示。此外,聲學模型6 為 411 個音節,每一個音節使用 8 個狀態的隱藏式馬可夫模型(HMM),使用 MMI 鑑別式訓練得到。 表 2.2:MFCC 參數抽取設定檔 音框長度 32ms 音框平移 10ms Filter bank 個數 24 取樣頻率 16kHz
Pre-emphasis Filter First order with coefficient 0.97
2.2.2 文字資料庫介紹
辨認系統之語言模型,通常必須先具備大量的文字資料庫,利用大量的文字資料訓練出一 個涵蓋範圍廣泛、適用於各個領域的語言模型,本研究使用的文字資料庫共有下述四種來源: 1.)光華雜誌(Sinorama):內容為一般雜誌的文章,蒐集的年代範圍介於 1976 年到 2000 年之間。 2.) NTCIR:為一個建立資訊檢索系統的標竿測試集,其內容由數種不同學科領域文章構成。 3.)中研院平衡語料庫(Sinica):它是一套由中研院錄製,內容包含多種主題,以語言分析研究 為目的的資料庫。4.) Chinese Gigaword:由 Linguistic Data Consortium (LDC)整合發行,內容包含台灣中央社、
北京新華社等國際新聞。 在訓練語言模型之前,須先對語料庫的文章進行前處理,將文章中會影響辨認效能的內容 移除或修改,經由文本前處理後,得到詞的總數量為 382,921,251 個,之後再以統計方式選擇 詞典,這裡一共納入了 60,000 個常見詞彙,將常出現、較重要的詞收錄在詞典內以便訓練出 語言模型,圖 2.1 為語言模型訓練流程: 文字語料庫 文本前處理 建立辨識詞典 N-gram training 圖 2.1:語言模型訓練流程
7 其中文本前處理的步驟又可以再細分為以下數個步驟: 文字語料庫 CRF斷詞 文字正規化 訓練語料 圖 2.2:文本前處理流程
2.2.3 辨識詞典選詞方式
對於建立一個完善的語言模型而言,有一項重要的關鍵在於詞典的選擇,由於受限於記憶 體的大小,有別於傳統方式為直接收錄語料庫中高詞頻的六萬筆詞條,但某些詞條可能只出現 在特定文章中,在此為了讓收錄的詞條為一般常見的詞語,也就是說:必須找到廣泛出現在各 個文章中的詞,因此我們使用 TF-IDF (term frequency–inverse document frequency)方法來幫助 我們進行選詞。TF-IDF 是一種用於資訊檢索(IR - Information Retrieval)的常用加權技術。它是一種統計方
法,用於評估一個詞對於一個文件集或一個語料庫中的其中一份文件的重要程度。TF 表示該 詞條在語料庫中出現的頻率,代表其詞條的重要性隨著在語料庫出現的總次數成正比增加; IDF 則表示一個詞條普遍重要性的度量,代表其詞條類別區分能力隨著在語料庫各文章中出現 的頻率成反比下降。 我們可以使用(2.1)式算出每個詞條對應的 IDF 值: log { : } i i D idf d d t (2.1) (2.1)式中 D 表所有文件的集合,分子 D 表示語料庫中的文件總數,d 表文件,ti表正在處理的 詞條,分母則表示包含該詞條 ti的文件數目。 在進行大詞彙辨認時,我們欲收錄的詞是一般常見的詞語,觀察(2.1)式中,由於“出現的 文章數”在分母項,因此我們將挑選 IDF 分數低的詞收錄進詞典中。 比較藉由 TF-IDF 方法重新計算收錄的優先順序與直接收錄高詞頻的傳統方式,發現使用
8 TF-IDF 選詞而更動的詞數大多為人名,這些人名因為本身出現次數高而被收錄進原先高詞頻 的詞典中,但因僅僅出現在少數的文件中而遭到 TF-IDF 方法剔除,如下表 2.3 與表 2.4 所示, 由此可知,TF-IDF 選詞方式能使詞典收錄到較廣泛的詞條。表 2.5 並比較直接收錄高詞頻的 傳統方式與經由 TF-IDF 選詞方式來計算其混淆度(Perplexity),計算的對象為 TCC-300 的測試 語料,發現經由 TF-IDF 選詞方式能夠有較低的混淆度。 表 2.3:TF-IDF 方法剔除的詞條例 被剔除的詞 詞頻 出現文章數 IDF 值 黃乃宣 996 63 2.124 韋殿剛 1013 69 2.085 吳憶樺 1081 56 2.175 表 2.4:經由 TF-IDF 方法加入的詞條例 取代的新詞 詞頻 出現文章數 IDF 值 協商會 147 121 1.841 酒氣 147 121 1.841 崇洋 147 118 1.852 表 2.5:混淆度(Perplexity) Lexicon Order ppl ppl1 傳統方式 3 109.712 117.745 TF-IDF 方法 3 109.311 117.301
9
2.2.4 語言模型的建立
所有的語言都有其文法規則,利用文法規則所建立出的機率模型稱為語言模型。在大詞彙 連續語音辨認時,會利用語言模型,考慮前後詞彙的關連性,期望能使輸入的語音辨認出合理 且有意義的詞串。在本研究中使用了日前運用廣泛的 n-gram 語言模型,此模型假設任一個詞 在詞串中只受到前 n-1 個詞的影響。 假設有一詞串共有 N 個詞,也就是W w w1 2...wN,其中「wi」代表句子中的第 i 個詞,則 產生這個句子所對應的機率,可以拆解成以下一連串的條件機率之連乘: 1 2 1 1 1 1 1 ( ) ( ) ( | )... ( i| i n ... i )... ( N | N n ... N ) P W P w P w w P w w w P w w w (2.2) where 1 1 1 1 1 ( ,..., ) ( | ,..., ) ( ,..., ) i n i i i n i i n i Count w w P w w w Count w w (2.3) 由於 n-gram 語言模型是統計式的模型,如果訓練語料中沒出現該詞語組合,就無法預估 其機率,且隨著 n 值上升,所需的訓練語料也呈指數成長。為了解決這些問題,我們以後撤平 滑化(back-off smoothing)來調整模型的機率分佈。機率預估式改寫如下: 1 1 2 1 1 1 1 1 1 1 1 1 ( ,..., ) ( | ,..., ), ( ,..., ) 0 ( ,..., ) ( | ,..., ) , 1 ( ,..., ) ( ,..., ) ( ,.. i n i i i n i i n i i n i i i n i a i n i i n i i n a w w P w w w Count w w Count w w P w w w d Count w w k Count w w Count w 1 1 1 ., ) , ( ,..., ) ( ,..., ) i i n i i n i w Count w w k Count w w (2.4) (2.4)式中後撤加權值a w( i n 1,...,wi1)需經過正規化(normalization)處理,且滿足以下條件式: 1 1 ( i | i n ,..., i ) 1 w V P w w w w
(2.5) 另外,當Count( ) 的數值很小時,可能造成預估的不準確,則將原始的 n-gram 機率乘上一個小於 1 的值d (Discount Coefficient Factor)來進行平滑化,a d 依據 Good-Turning discountinga
10
2.3 綴詞語言模型的訓練
2.3.1 綴詞的選擇與拆解
綴詞的組合結構可拆解為「詞幹」與「詞綴」的組合,拆解方式如表 2.6 所示,依中研院 所統計的詞綴數量太過龐大,在此我們參照中文資訊處理分詞規範中,僅收錄常出現的衍生詞 綴、語法詞綴與名詞性接尾詞,總計共 148 個後詞綴。 為避免辨認詞典收錄過多的短詞,反而犧牲掉原先未經拆解即可收錄之高詞頻一般詞的空 間,故將詞頻高的詞彙保留其長詞型式。在此綴詞將依照詞頻高低以兩種型式收錄於詞典當中: 第一種為出現次數於前 50,000 詞內的高詞頻綴詞直接收錄於詞典;第二種為出現次數於 50,000 詞之外的綴詞均拆解為詞幹與綴詞收錄在詞典裡。 表 2.6:綴詞拆解範例 綴詞 詞幹 詞綴 靈敏度 靈敏 度 視覺系 視覺 系 拋棄式 拋棄 式 經由上述拆詞過程之後,在原先出現次數 50,000 到 60,000 的詞彙中,一共拆解了 957 個 綴詞,其中 919 個詞幹已收錄在前 50,000 詞,屬於高詞頻一般詞部分,故在此綴詞 subword 只新增了 38 個,而其詞典剩餘空間則收錄原先不在詞典中其餘高詞頻一般詞,直至到達詞典 容量上限為止,藉此提高詞典涵蓋率,降低 OOV 的數量。2.3.2 綴詞語言模型之建立
綴詞的分群原則是以詞綴做為區分,相異的綴詞各有其不同的涵義,與詞綴相關聯的詞幹 也有其相關詞性(POS),其詞性如表 2.7 所示,故針對目前所收錄的 148 個常見詞綴各自視為11 不同的類別比視為一個大類別來的適當,以其訓練詞彙間的機率來的更加可靠。 表 2.7:詞幹詞性範例 綴詞類別 詞幹詞性(46 類) 範例 們 Na 親友們、情侶們 記、物 Na、VA、VB、VC、VE、VH、VK 復仇記、漂遊記 賽、會、制、式 Na、VA、VC、VE、VG 邀請賽、責任制 本研究中會先對目前所收錄的 146 個常見詞綴建構出一個綴詞表,之後在 word lattice 上 透過查表方式(綴詞表與詞性表)判斷哪些詞彙可以重新構回綴詞。如圖 2.3 觀察到當 lattice 上 的「鄉親」與「們」經由綴詞表發現可組合成「鄉親們」並且「鄉親」符合該詞綴類別的詞性 表,此時將會產生新的辨識路徑,而後將重新計算該詞與前後詞彙間的機率,即統計圖 2.3 中 新路徑實線的機率分佈。 相信 鄉親 們 可以 鄉親 們 諒解 總統 原始路徑 構詞後路徑 圖 2.3:新辨識路徑 我們依 148 個常見詞綴各自分為 148 個類別,將具有相同詞綴的新詞放置同一類別中,綴 詞則依據其詞綴代表的類別做取代,最後透過一般詞與類別間的機率與在其類別內出現新詞之 機率,藉由這兩種外部機率(Inter-word probability)和內部機率(Intra-word probability)來重新配 置語言模型分數。原先 tri-gram 的機率預估式如下式(2.6)所示,bi-gram 與 uni-gram 類推之:
12 1 2 1 1 2 3 ( ) ( ) ( | ) ( | , ) N i i i i P W P w P w w P w w w
(2.6) 利用下式(2.7)將重新計算綴詞語言模型分數: 2 1 2 1 2 1 ( | ) ( | ) if ( | ) ( | ) 1 otherwise n n n n n n n n n n n n P C W W P W C W MD P W W W P W W W (2.7) 以下我們將深入探討這兩種外部機率和內部機率的計算方式: 1.) 外部機率(Inter-word probability)的預估:P C W W( n| n2 n1) 我們將綴詞依據其詞綴代表的類別標記,透過統計類別與前後詞彙的關聯性,採用 tri-gram 模型預估之,可得到所有詞彙的機率值,在此會產生 8 種不同的情況,包括如:詞與類別之間、 類別與類別之間、詞與詞之間的 class tri-gram 機率,如下式(2.8)所示。 2 1 1 2 2 1 2 2 1 1 2 1 2 1 2 1 1 2 2 1 2 ( | ) if , , ( | ) if , ( | ) if , ( | ) if ( | ) ( | ) if , ( | ) if ( | n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n n P C C C W W W MD P C C W W W MD P C W C W W MD P C W W W MD P W W W P W C C W W MD P W C W W MD P W 2 1 1 2 1 ) if ( | ) otherwise n n n n n n W C W MD P W W W (2.8) 2.) 內部機率(Intra-word probability)的預估: (P W Cn| n) 統計綴詞在該所屬類別內出現的機率,在此採用 uni-gram 模型預估之,搭配 good-turing smoothing 作為此內部機率,若為高詞頻的綴詞與一般詞情況下,則此內部機率為 1,如下式 (2.9)所示。 ( | ) if ( | )= 1 otherwise n n n n n P W C W MD P W C (2.9)13
2.4 階層式語言模型辨認器
Viterbi Decoder Lattice Expansion Replace LM score Syllable Acoustic Model Bigram Wordnet Trigram Language Model MD table MD Model Speech Signal WordLattice ExpansionLattice
Results POS Model Lattice Recoring Lattice with New Score 圖 2.4:階層式系統架構 圖 2.4 為此階層式系統的整體架構,首先第一級中先利用文字規則特性找出綴詞的文字規 則並依據此規則針對綴詞進行拆解以便提高詞典涵蓋率,如表 2.8 所示,之後在 word lattice 上透過查詞綴表方式與判斷詞幹本身所屬的詞性查詢哪些詞彙可再構回成綴詞,避免產生「過 份構詞」導致錯誤辨識結果的發生性。 表 2.8:詞典涵蓋率 拆詞前 97.13% 拆詞後 97.17% 第二級中本研究首先對綴詞建立一個更精細的語言模型,採用 class-based approach 的構想, 對綴詞進行分類,依據不同詞綴建立不同的類別,將綴詞分類細緻化,同類別內的詞彙共用相 同的外部機率,解決了部分詞彙出現次數稀疏的問題,最後在 word lattice 上,將分數替換成 此語言模型的分數,進行重新辨識找出最佳的辨識結果。
2.5 結果分析
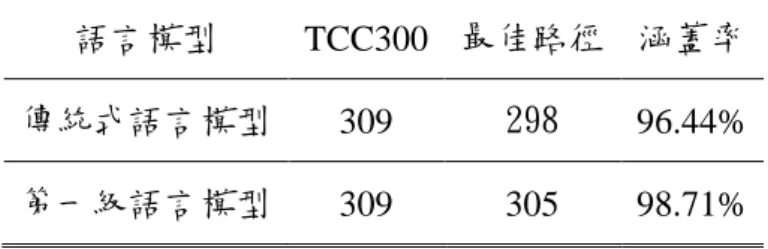
在這小節中,我們將以三種方式來評估傳統式語言模型(經由 TF-IDF 選詞方式選出六萬詞,14 但未對綴詞進行處理)與本研究所提出的階層式語言模型對於綴詞在辨認上的影響並進行說明。 首先,本研究針對 TCC300 測試語料中綴詞數量與其所占的比例,由此可以先行知道測試 語料中綴詞的正確辨識數量及上限。 表 2.9:TCC300 測試語料的詞類統計 TCC300 測試語料(226 個音檔) 詞條數 所佔比例 綴詞 309 2% total words 15461 100%
2.5.1 語言模型評估
我們以混淆度(Perplexity, PPL)來評估傳統式語言模型與第一級語言模型(拆詞過後)的複雜 程度,藉此判斷語言模型的好壞。語言模型帶有大量詞彙和詞彙相接的機率資訊,藉由透過這 些機率資訊來預估下一個詞彙,PPL 值高代表語言模型需要較多的預估次數才會命中,較不易 找到正確答案;反之,PPL 值低代表其語言模型較為單純,不需要過多的預估次數即可找出正 確答案,故於 PPL 值越低時進行語音辨認,語言模型可能會呈現較好的辨識效能。表 2.10 中 計算的對象為 TCC-300 的測試語料,可以發現到第一級語言模型擁有較低的混淆度。 表 2.10:語言模型混淆度 語言模型 Order ppl ppl1 傳統式語言模型 3 109.311 117.301 第一級語言模型 3 109.126 117.0992.5.2 綴詞於 word lattice 上之涵蓋率
針對傳統式語言模型與第一級語言模型產生的 word lattice 進行分析,統計在理想最佳路15 徑上有多少數量可以辨識回原先的綴詞,並加以計算其涵蓋率。 表 2.11:word lattice 上綴詞涵蓋率 語言模型 TCC300 最佳路徑 涵蓋率 傳統式語言模型 309 298 96.44% 第一級語言模型 309 305 98.71%
2.5.3 辨識效能結果
以下我們比較傳統式語言模型與階層式語言模型之辨識效能,分別以詞、字元、音節為辨 識單元來評估其辨識效能,並由第一級語言模型產生出來的 word lattice 觀察詞、字及音節之 涵蓋率。 表 2.12:搭配語言模型之詞辨認率Deletion Substitution Insertion Accuracy (%)
傳統式語言模型 269 1531 364 86.00%
階層式語言模型 273 1467 368 86.37%
表 2.13:搭配語言模型之字元辨認率
Deletion Substitution Insertion Accuracy (%)
傳統式語言模型 206 2453 138 89.44%
階層式語言模型 199 2384 142 89.71%
表 2.14:搭配語言模型之音節辨認率
Deletion Substitution Insertion Accuracy (%)
傳統式語言模型 212 1705 145 92.21%
16 表 2.15:word lattice 之詞、字及音節涵蓋率 詞(word) 93.72% 字(character) 93.72% 音節(syllable) 94.54%
2.5.4 辨識結果之細部剖析
在辨識結果中對綴詞進行分析,觀察傳統式做法與本研究所提出之方法對於綴詞在辨認上 的影響並進行說明,在此將對辨認結果分成三種不同情況來進行討論: 1.) Case A:正確答案應為綴詞,但辨識結果錯誤的部分。 2.) Case B:正確答案不為綴詞,但辨識結果判斷成綴詞的部分。 3.) Case C:辨識答案辨認出正確答案的部分。 表 2.16:綴詞辨識情況Case A Case B Case C
傳統式語言模型 27 6 282
階層式語言模型 6 11 303
觀察表 2.16 可得知,階層式語言模型比起傳統式語言模型多增加 21 個綴詞被正確地辨識 出來,雖然階層式語言模型也增加了 5 個判斷成錯誤綴詞的情況(Case B),但整體而言,綴詞 的辨認率(i.e., (Case C-Case B)/(綴詞總數 309))為 94.5%,比起使用傳統式語言模型的 89.3% 增加許多,由此可知,為綴詞建立其語言模型是有用的,不僅僅幫助綴詞本身之辨識而其鄰近 詞也更容易辨識正確。
17
第三章加入語速影響之韻律模型於中文
大辭彙語音辨認系統
所謂韻律就是連續語音中一種跨區段(supra-segmental)的特徵,其主要表現在語速(speaking rate)、停頓時長(pause duration)、音高軌跡(pitch contour)、音量大小(energy level)等因素上,本
研究考慮語速變數並且引入韻律模型當中,使其與語速相關,因此在本章節中,將會探討以下 幾點: 3.1 節介紹中文語音韻律階層式架構;3.2 節介紹本研究所使用的韻律模型;3.3 節將會說 明如何整合韻律模型以 two-stage 的方式加入到語音辨認中;3.4 節說明本研究如何使用鑑別式 組合(Discriminative Model Combination)處理重新評分過程中多個模型之權重問題。
3.1 中文語音韻律模型階層式架構
依據語言學家的研究發現[8,9]語音的韻律結構呈現階層式架構,[9]提出一個 5 階層的中文 語音韻律結構,如圖 3.1 所示: PG BG BG PPh PPh PPh PW PW PW PWSYL SYL B1/B0 SYL SYL SYL
B2 B3 B4 B5 B5 PPh PW SYL 圖 3.1:中文語音韻律之階層式架構 [9]
18
圖中最底層為音節層次(syllable layer, SYL),由於中文特性為一個音節一個字,故最底層 的韻律單元為音節;向上發展依序為韻律詞層次(prosodic word layer, PW),由雙音節或多音節 所構成的詞組,此詞組通常在句法和語意上關係緊密;韻律短語層次(prosodic phrase layer, PPh), 由一個或多個韻律詞所組成,結尾常會帶有不明顯但可察覺之停頓;呼吸組層次(breath group, BG),代表一個有音高及音長明顯變化的段落;最上層為韻律組句(prosodic phrase group),由
連續的呼吸組構成。這整體架構統稱「階層式多短語韻律句群(Hierarchical Prosodic Phrase Grouping,HPG)」架構[9]。
本研究以 HPG 架構為基礎,再進一步對其做修改,使用如圖 3.2 的 4 層結構,並使用兩 種韻律標記來代表這階層式的韻律架構,第一種是韻律邊界停頓標記,它是用來區分階層式韻 律架構中的各層韻律組成份子,如上圖 3.2 所示,本研究將 B1 細分為 B1-1、B1-2,其中 B1-1 代表 normal syllable boundary,不具有明顯停頓,B1-2 則代表詞內的音節邊界有較明顯的停頓。 B2 細分為 B2-1、B2-2、B2-3,其中 B2-1、B2-2、B2-3 分別代表明顯音高位置(pitch reset)之韻
律詞邊界、短停頓(short pause)之韻律詞邊界以及含有音節拉長效應(duration lengthening)後的 韻律詞邊界。接著將 B4、B5 合併為 B4,因為其描述的韻律特性相當相似,於是整個架構從 圖 3.1 的 5 層結構變回圖 3.2 的 4 層結構。 BG/PG PPh PW PW SYL B3 B2 B1/B0 PW PPh SYL B3 B3 B1/B0 SYL SYL SYL B2 B4 B4 B4 B4 B4 B4 B4 B4 圖 3.2:本研究所採用的階層式韻律架構 本研究採用這 8 種韻律邊界停頓(break type) B={B0, B1-1,B1-2, B2-1, B2-2, B2-3, B3, B4} 來標記四種韻律單元:音節(SYL)、韻律詞(PW)、韻律短語(PPh)、呼吸組/韻律句組(BG/PG), 其對應關係如表 3.1 所示。
19 表 3.1:韻律結構之停頓標記 韻律結構 停頓標記 意義 韻律群(PG) 或呼吸群(BG) B3 長停頓 B4 長停頓且含有明顯的基頻跳躍 韻律詞(PW) B2-1 相鄰兩音節具有明顯的基頻跳躍 B2-2 短停頓 B2-3 前一音節發生音節拉長 音節(SYL) B0 音節邊界相鄰兩音節是緊密連接(tightly coupling) B1-1 B1-2 音節邊界相鄰兩音節是普通連接(tightly coupling) 詞內的音節邊界有較明顯的停頓 至於另一種韻律標記是韻律狀態,針對音節音高、音長及能量共分成三種類型,用以描述 韻律架構中高層次組成份子對於音節韻律資訊帶來的影響。
3.2 階層式韻律模型之修正及設計
在本研究中,要以能幫助於語音辨認的前提之下設計韻律模型,主要任務是在給定聲學參 數 a {X Xa, p}的條件下,找出最佳的語言參數序列 l {W POS PM 、韻律標記, , } p { , }B P 及 acoustic segmentation s,在數學式中可視為一種求取最佳參數解的過程,如下式(3.1)所示: , , , , , , arg max ( , , , , , | , ) arg max ( , , , , , , , ) l p s l p s l p s s a p s a p P P W POS PM B P X X W POS PM B P X X (3.1) (3.1) 式 中
1M w W 是 代 表 詞 序 列 ;POS{pos1M}是 詞 所 對 應 到 的 詞 性 序 列 ; 至 於 1 {pmM} PM 是代表標點符號序列;M 代表詞的全部數量;B{B1N}則是韻律邊界停頓標記序 列,它包含八種韻律邊界停頓標記:Bn{B0, B1-1,B1-2, B2-1, B2-2, B2-3, B3, B4},用來表示階 層式韻律架構中的各層韻律組成份子的邊界;P{ , , }p q r 則是音節韻律狀態序列,其代表的意 義分別為音節音高軌跡p{p1N}、音節長度 1 {qN} q 及音節能量強度r{r1N};N 代表音節的20
全 部 數 量 ; X 代 表 一 個 frame-based 頻 譜 參 數 序 列 (i.e., MFCCs 及 它 們 的 一 階 和 二 階a
derivatives);Xp { , , }X Y Z 則是一個韻律聲學參數序列,其中 X 代表音節韻律聲學參數,包含
了音節音高軌跡(sp)、音節能量強度(se)及音節長度(sd);Y 代表音節邊界參數,包含了音節間的 停頓長度(pd)及音節間的能量低點(ed);Z 代表差分韻律參數(differential prosodic feature),包含了 正規化的音節內基頻差(pj)及兩種正規化長度拉長因子 (dl and df)。其完整符號表整理於表 3.2。
表 3.2:韻律標記、聲學參數以及語言參數之數學符號
T: prosodic tag B: break type={B0, B1-1,B1-2 ,B2-1, B2-2, B2-3, B3, B4}
PS: prosodic state p: pitch prosodic state
q: duration prosodic state
r : energy prosodic state
A: prosodic feature X: syllable prosodic feature sp: syllable pitch contour
sd: syllable duration
se: syllable energy level
Y: inter-syllabic prosodic feature pd: pause duration
ed: energy-dip level
Z: differential prosodic features pj: normalized pitch jump
dl: normalized duration lengthening factor 1
df :normalized duration lengthening factor 2
SR: speaking rate
L: linguistic feature l: reduced linguistic feature set
t: syllable tone sequence
s: base-syllable type
f: final type
以下本研究將會提出下列五種假設,以方便設計韻律模型:
假設一:如同傳統的聲學模型,頻譜參數序列X 只會相依於詞序列 W。 a
21 假設三:音節韻律聲學參數序列 X 與音節邊界韻律參數序列 Y 及差分韻律參數序列 Z 彼 此間相互獨立。 假設四:韻律邊界停頓標記序列 B 相依於鄰近相關的語言參數序列l。 假設五:音節韻律狀態序列 P 相依於鄰近的韻律邊界停頓標記 B。 經由上述五種假設後,(3.1)式將會簡化成以下形式:
, , , , arg max ( , | ) ( , , ) ( | , ) ( | , ) ( | , , ) ( , | , , ) l p s l p s a s l s p l s p l P P P P P P X W W POS PM B SR P B SR X Y Z (3.2)(3.2)式中 (P Xa,s |W 代表聲學模型(AM);) P W POS PM( , , )則是 joint syntax model,它描述了
Word、POS 及 PM 彼此之間的關係; ( |P B l)是代表 break syntax model,它是利用語言參數
L{W POS PM, , }來預估隱含著階層結構資訊的韻律邊界停頓 B 的模式,P P B( | )稱為韻律狀 態模型,用來描述韻律狀態 P 是如何受到韻律邊界停頓 B 影響下發生轉移變化;P( |X s, p, l) 稱 為 音 節 韻 律 模型 ,用 來 說 明 音 節 韻律 參數 受 到 B 、 P 和 L 的 影 響 而 產 生 的變 化; ( , | s, p, l) P Y Z 稱為停頓聲學模型,用來說明在各個不同的韻律邊界停頓和語言參數之下, 音節內的聲學特性。以下我們將針對這四種韻律模型做更深入的探討。
3.2.1 Break Syntax Model
在相同語言參數之下,不同語速所產生的韻律邊界停頓 B 應會有所不同,故必須修正 Break Syntax Model,使其與語速相關,其數學式改寫如(3.3)式所示: 1 n 1 ( | ) ( , ) ( | L , ) N l l n n n P P P B SR
B B | SR (3.3) (3.3)式中P B( n| L ,n SR 是一個用來描述音節韻律邊界停頓與其相關的語言參數及語速資訊之n) 間關係的模型,其模型由兩個步驟建構而成,第一步:依據語言參數搭配問題集使用分類樹與 決策樹(CART)演算法訓練出一顆決策樹;第二步:對建構出來的決策樹之每一個終止節點(leaf22 node)其帶有的八種停頓標記,藉由線性迴歸的方式來模擬各種停頓標記的出現頻率與語速兩 者之間的相關性,其數學式如(3.4)式所示: , , Type# Type# , , 1 1 ( | L , ) ( | L , ) ( | L , ) k j n k j n n n n n n Break Break n n n b j n b j b b C SR D P B k SR P B k SR P B b SR C SR D
(3.4)3.2.2 韻律狀態模型
假設目前的韻律狀態只和前一個韻律狀態及前一個停頓標記有關,並以語速分 bin 來區分 語速不同時造成韻律狀態轉移機率不同的情況,故韻律狀態模型P P B( | )可以改寫並分解成三 個子模型,其數學式改寫如(3.5)式所示: 1 1 1 1 1 1 1 1 1 1 1 1 2 ( | ) ( , ) ( , ) ( , ) ( , ) ( | ( )) ( | ( )) ( | ( )) ( | , , ( )) ( | , , ( )) ( | , , ( )) N n n n n n n n n n n n n n P PP P P P p bin SR P q bin SR P r bin SR
P p p B bin SR P q q B bin SR P r r B bin SR
P B PS | B SR p | B SR q | B SR r | B SR (3.5)(3.5)式中P p( n |pn1,Bn1, bin(SRn))、P q( n |qn1,Bn1,bin SR( n))與P r r( |n n1,Bn1,bin SR( n))分別表
示各個不同韻律狀態,在給定音節邊界停頓Bn1及語速SR 的情況下,從第 n-1 個音節的韻律n 狀態到第 n 個音節韻律狀態的轉移機率。
3.2.3 音節韻律模型
音節韻律模型P( |X s, p, l)可以進一步分解成三個子模型,分別模擬音節音高軌跡序列 (sp)、音長序列(sd)以及音節能量序列(se),如(3.6)式所示: 1 1 1 1 ( | , , ) ( | , , , ) ( | , , , , ) ( | , , , , ) ( | , , ) ( | , , ) ( | , , ) s p l s s s N n n n n n n n n n n n n n n n P P P P P p B t P sd q s t P se r f t
X sp B p t sd B q t s se B r t f sp (3.6) 在第一個子模型 1 1 1 ( n| nn , n, nn ) P sp B p t 中,我們假設sp 會受到下列因素影響:分別是目前的音高韻n23 律狀態p 、目前的聲調n tn以及在給定韻律邊界停頓Bn-1和Bn時,前後各一個音節聲調tn-1和tn1 造成的連音影響,此處表示 n-1=( -1, ) n n n B B B , 1 -1 ( -1, , 1) n n n n n t t t t 。而 則為第 n 個音節音高軌跡,
是將音節音高軌跡進行正交展開(orthogonal expansion),投影到四個 Legendre 多項式基底所得 到的四維正交參數[10],其表示法如下所示: 1 1,n1 ,n n n n n n n r f b n n t p B t B t sp sp sp β β β β μ (3.7) 在(3.7)式中, n t β 及 n p β 分別是目前音節音調t 及目前音節韻律狀態n p 的影響因子(Affecting n Patterns, APs); 1, 1 n n n f B t β 及 ,n1 n n b B t β 分別是第 n-1 個和第 n+1 個音節所貢獻的前後音節影響效應的
APs;μsp是音高向量的總體平均值(global mean); r
n sp 是正規化後的 ,即為 扣除 n t β 、 n p β 、 1, 1 n n n f B t β 、 ,n1 n n b B t β 和μsp的殘餘值(residual)。藉由假設 r n sp 是一平均值為零的高斯隨機分布(normal distribution),即N(sprn;0,Rsp),則 1 1 1 ( n| nn , n, nn ) P sp B p t 可化解成(3.8)式: 1 1 1 1 -1 -1 , , ( | , , ) ( ; n n , ) n n n n n n n n f b n n n n n t p B t B t sp sp P p B t N R sp sp (3.8) 在建構第二個子模型 (P sdn|q s tn, , )n n 時,我們假設sd 會受到下列因素影響:分別是音節n 韻律狀態、基本音節類型及音節聲調,因此我們可以將觀察到的音節長度sd 表示成: n n n n r n n t s q sd sd sd (3.9) 在(3.9)式中 r n sd 是正規化後的sd ;n tn、sn及qn分別是目前音節音調、基本音節類型及目前
音節韻律狀態影響效應的 APs;sd是音節音長的總體平均值(global mean)。藉由假設 r
n sd 是一 平均值為零的高斯隨機分布(normal distribution),即 ( r;0, ) n sd N sd R ,則 (P sdn|q s tn, , )n n 可化解成 (3.10)式: ( | , , ) ( ; , ) n n n n n n n n t s q sd sd P sd q s t N sd R (3.10) 最後在建構第三個子模型 (P sen| ,r f tn n, )n 時,我們假設se 會受到下列因素影響:分別是音n n sp n sp spn
24 節韻律狀態、音節韻母類型及音節聲調,因此我們可以將觀察到的音節能量se 表示成: n n n n r n n t f r se se se (3.11) 在(3.11)式中 r n se 是正規化後的se ;n n t 、 n s 及 n q 分別是目前音節音調、目前音節韻母類型及
目前音節韻律狀態影響效應的 APs;se是音節能量的總體平均值(global mean)。藉由假設 r
n se 是 一平均值為零的高斯隨機分布(normal distribution),即 ( r; 0, ) n se N se R ,則 (P sen| ,r f tn n, )n 可化解 成(3.12)式: ( | , , ) ( ; , ) n n n n n n n n t f r se se P se r f t N se R (3.12)
3.2.4 停頓聲學模型
在此使用了音節邊界參數及差分韻律參數{Y, Z}={pd, ed, pj, dl, df}來描述韻律邊界的聲 學特性,並且假設五種韻律聲學參數間彼此互相獨立,則停頓聲學模型可以做進一步的分解, 如下所示:
, , , , , , , , , 1 2 , , , , , , 1 2 2 , , , , , , , , , , ( , | , , ) ( , , , , | , , ) ( ; , ) ( ; , ) ( ; , ) ( ; , ) ( ; , n l n n l n n l n n l n n l n n l n n l n n l n n l n s p l s p l N n B B n ed B ed B n n pj B pj B n dl B dl B n df B df P P g pd N ed N pj N dl N df
Y Z pd ed pj dl df
, 2 , , ) n l n B (3.13)在 (3.13) 式 中 pd 為 音 節 邊 界 的 停 頓 時 長 (pause duration) 在 這 裡 以 伽 瑪 隨 機 分 布 (gamma n
distribution)來模擬之;ed 為音節間的能量低點(energy dip),在這裡以高斯隨機分布(normal n
distribution)來模擬之;pj 為正規化的音節內基頻差序列(pitch jump),定義如下: n
1 1 ( (1) (1)) ( (1) (1)) n n n n t n t pj sp β sp β (3.14)
25 在(3.14)式中,spn(1)定義為第一維度的音節音高軌跡; (1) n t β 則定義為第一維度的聲調影響因 子。同樣的,在這裡以高斯隨機分布(normal distribution)來模擬之。最後,還有兩種正規化的 音節長度拉長因子 dl 和 df 定義為: 1 1 1 ( ) ( ) n n n n n n t s n t s dl sd sd (3.15) 1 1 1 ( ) ( ) n n n n n n t s n t s df sd sd (3.16) 這裡兩種因子我們都使用高斯隨機分布(normal distribution)來模擬。在實作過程中, ( , , , , | s, p, l) P pd ed pj dl df 是經由語言參數搭配問題集(附錄一)使用分類數與決策樹(CART)
推導出來,其節點的分類標準是依據最大概似函數增益(maximum likelihood gain),依據不同的
韻律邊界停頓同時將所有音節邊界的pd 、n ed 、n pj 、n dl 、n df 做好分類,並於決策樹的每個n 終止節點(leaf node)統計其參數分佈。
3.3 加入韻律訊息於 two-stage 語音辨認系統
Unlabeled Database Prosody modeling Syllable AM Syllable Prosodic acoustic model Break syntax model Syllable juncture Prosodic acoustic model Prosodic state model Factored LM Word trigram LM Word bigram LM Frame-based features extraction Viterbi search Prosodic acoustic features extraction rescoring Lattice ExpansionF0 & energy sequence
First Stage Second Stage
* * * , , l p s Word construction Syllable Segmentation information MD Model Word Lattice X,Y,Z Input Speech 圖 3.3:以 two-stage 方式之韻律輔助中文語音辨認系統流程圖
26
上圖 3.3 為本研究之系統流程圖,以下將對此系統的 second stage 做詳細介紹:
3.3.1 Joint Syntax Model 之架構與建立
由 3.2 小節可以發現到,韻律模型的建立需要給定語言參數資訊,其中包含詞性(POS)以 及標點符號(PM)這兩種語言參數資訊,本研究所使用的 joint syntax model 包含一個 trigram LM、 一個 factored POS model 與一個 factored PM model,在這裡我們使用 FLM approach[11]建構 factored POS model 和 factored PM model 其主要概念是利用其他相關資訊(factor)的輔助來預估
目標,所以這裡將充分利用到所有相關語言知識來提升預估 POS 或 PM 的準確性。
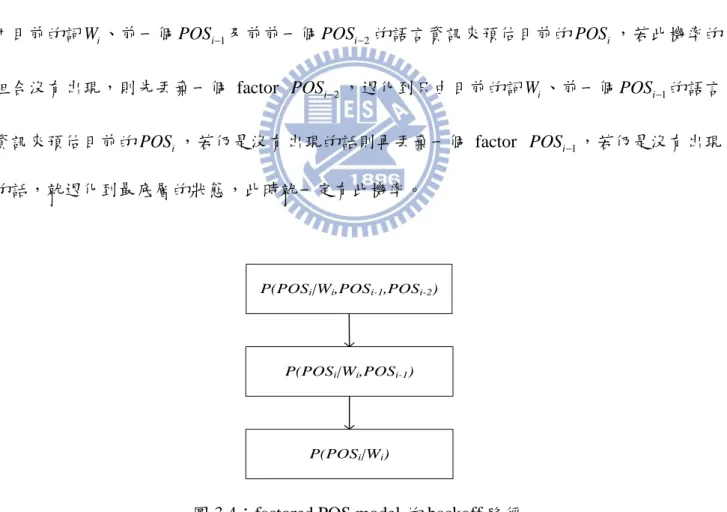
當使用多種語言資訊做預估時難免會面臨到資料量不足的問題,因此會採取退化(back 0ff) 的架構,在本研究中,factored POS model 其退化路徑如下圖 3.4 所示。在最上層的部分,使
用目前的詞W 、前一個i POSi1及前前一個POSi2的語言資訊來預估目前的POS ,若此機率的i
組合沒有出現,則先丟棄一個 factor POSi2,退化到只由目前的詞W 、前一個i POSi1的語言
資訊來預估目前的POS ,若仍是沒有出現的話則再丟棄一個 factor i POSi1,若仍是沒有出現
的話,就退化到最底層的狀態,此時就一定有此機率。
P(POSi|Wi,POSi-1,POSi-2)
P(POSi|Wi)
P(POSi|Wi,POSi-1)
圖 3.4:factored POS model 的 backoff 路徑
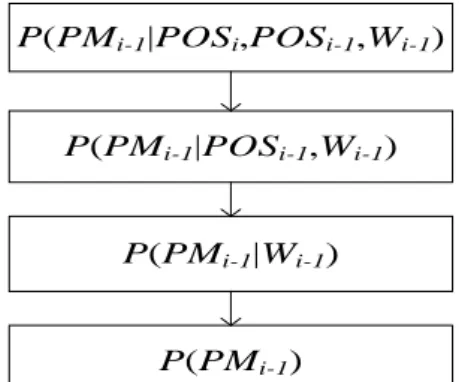
依此類推,factored PM model 亦是如此,其退化路徑如下圖 3.5 所示。在最上層的部分,
27
率的組合沒有出現,依序丟掉POS ,接著是i POSi1,然後Wi1,最終退化到P PM( i1),此時就
一定有此機率。
P(PMi-1|POSi,POSi-1,Wi-1) P(PMi-1|POSi-1,Wi-1)
P(PMi-1|Wi-1) P(PMi-1)
圖 3.5:factored PM model 的 backoff 路徑
其完整訓練流程圖如下圖 3.6 所示,需先對訓練文本做前處理,使其文本內所有的詞都帶有詞 性(POS)與標點符號(PM)的標記如下表 3.3 所示,接著使用 SRILM toolkit[12]及利用 Witten-Bell smoothing 的方式來訓練模型,其中 flm 檔案即為設定 factored model 內每一層 backoff 結構中
所需要考慮的 factor。
training data
fngram-count fngram-count
lexicon factor model flm file count file 圖 3.6:factored model 訓練架構流程圖 表 3.3:文本處理 Original_data: 目前為改善交通秩序,立體停車場已陸續興建,原狹窄街道亦逐步擴建。
28
FLM_data:
W-目前:P-Nd:M-NONE W-為:P-P:M-NONE W-改善:P-VC:M-NONE W-交通:P-Na:M-NONE
W-秩序:P-Na:M-COM W-立體:P-VH:M-NONE W-停車廠:P-Nc:M-NONE W-已:P-D:M-NONE
陸續:P-D:M-NONE 興建:P-VC:M-COM 原:P-D:M-NONE 狹窄:P-VH:M-NONE
W-街道:P-Na:M-NONE W-亦:P-D:M-NONE W-逐步:P-D:M-NONE W-擴建:P-VC:M-OTH
3.3.2 特徵參數正規化
針對圖 3.3 中第二級辨認器開始,工作過程中如有牽涉到音節能量、音節長度或音節音高 等韻律聲學參數時,必須要先經過正規化的步驟,藉此消除語速對於韻律聲學參數的影響,以 下我們將針對這四種韻律聲學參數介紹其語速正規化的方式。3.3.2.1 音節長度之語速正規化
中文中音節長度近似於高斯隨機分佈(normal distribution),故針對音節長度做高斯正規化: 對於音節長度的平均值使用一階多項式曲線來模擬,而對於音節長度的標準差則使用二階多項 式曲線來模擬,其正規化數學式如(3.17)式所示:
sd( )
sd( ( )) sd sd n n g g sd sd SR SR k (3.17) 其中sd 表示原始音節長度;n sdn表示語速正規化後的音節長度;sd(SR)SR為此語句的音節 長度平均值,我們將其當作此語句的語速SR;
2 1 1 1 ( ) sd SR a SR b SR c (3.18) 為平滑化後的標準差; sd g 和 sd g 分別為訓練韻律模型時所統計出的結果,代表所有語料庫音節 長度之總體平均值與平均標準差。29
3.3.2.2 停頓長度之語速正規化
停頓長度較近似於伽瑪隨機分布(gamma distribution),對於停頓長度的平均值與標準差皆 使用二階多項式曲線來模擬,其正規化數學式如(3.19)式所示: 1 = ( ( , pd( ( )), pd( ( ))), gpd, gpd) pd G G pd SR k SR k (3.19)其中G pd( , , ) 為伽碼分佈的累積密度函數(Cumulative Density Function, CDF);
2 2 ( ( )) ( ( ( ))) / ( ( ( ))) pd pd pd SR k SR k SR k (3.20) 及 2 ( ( )) ( ( ( ))) / ( ( )) pd pd pd SR k SR k SR k (3.21) 為平滑化後的停頓長度伽碼分佈的參數;
2 2 2 2 ( ) pd SR a SR b SR c (3.22) 及
2 3 3 3 ( ) pd SR a SR b SR c (3.23) 為語速控制的停頓長度平滑平均值和標準差; pd g 和 pd g 分別為訓練韻律模型時所統計出的停 頓長度伽碼分佈的參數平均值。3.3.2.3 音節音高軌跡之語速正規化
首先針對不同語者做 frame-based normalization 以消除不同語者先天發音上的差異,其正 規化數學式如(3.24)式所示: ( ) ( ) ( ) ( ) fsp fsp fsp n n fsp g g fsp k k fsp k k (3.24) 其中 k 為 speaker index, fsp 表示第 n 個音框的原始基頻對數值;n fspn表示第 n 個音框做完 frame-based normalization 的基頻對數值;gfsp和 fsp g 分別為訓練韻律模型時所統計出的結果,30
代表所有語料庫的基頻對數值之總體平均值與平均標準差,fsp
和fsp分別為第 k 個語者基頻
對數值的平均值和標準差。
接著再針對音節基頻軌跡進行正交展開(orthogonal expansion),投影到四個 Legendre 多項
式基底,用所得到的四維正交參數 0 1 2 3 T n a a a an n n n sp 表示其基頻軌跡,第一維正交參數代表 此基頻軌跡的平均值,後三維正交參數則用來描述此基頻軌跡分佈。由於基頻軌跡分佈相對於 聲調不同而有相異性,故我們在此將基頻軌跡依據不同聲調做正規化動作,其正規化數學式如 (3.25)式所示: ( ) ( ( ), , ) ( ) ( , ) ( , ) ( ( ), , ) sp sp sp n n n sp g n g n n sp i SR k t i sp i t i t i SR k t i (3.25) 其中t1 ~ 5表示聲調類型;i1 ~ 4表示維度;spn表示語速正規化後的第 i 維基頻軌跡參 數; 4 4 ( ( ), , ) ( , ) ( , ) sp SR k t i b t i SR c t i (3.26) 和 5 5 ( ( ), , ) ( , ) ( , ) sp SR k t i b t i SR c t i (3.27) 為語速控制的聲調及維度相依的基頻軌跡參數的平滑平均值和標準差; sp g 和 sp g 分別為訓練韻 律模型時所統計出的結果,代表所有語料庫中四維正交參數之總體平均值與平均標準差。
3.3.2.4 音節能量強度之語速正規化
音節能量強度與背景環境及錄音條件具有強大的相關性,而受語速的影響並不大。因此, 音節能量強度採用 Utterance-based normalization scheme,其正規化數學式如(3.28)式所示:( ) ( ) ( ) ( ) se se se n n se g g se k k se k k (3.28)
其中 k 為 utterance index;sen表示 normalized 後的音節能量強度數值; se
g
和 se g
31
律模型時所統計出的結果,代表所有語料庫的音節能量之總體平均值與平均標準差,se
和se
分別為第 k 個音檔音節能量強度的平均值和標準差。
3.3.3 The Second Stage 之實作
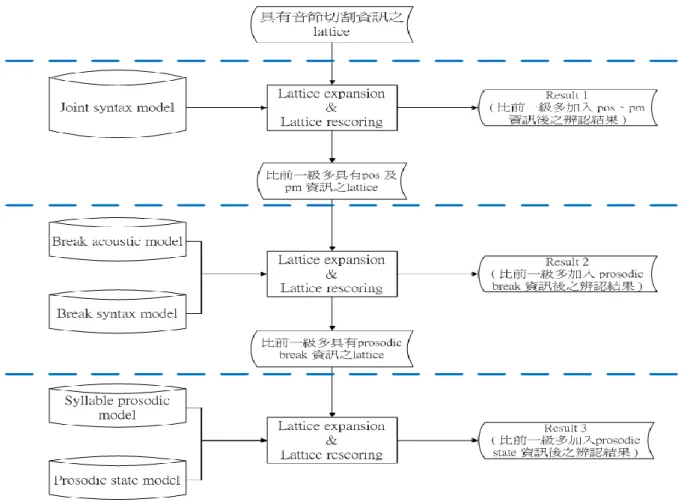
在第二個 stage 開始之後,加入的韻律模型及 joint syntax model 種類高達 16 種之多,為了 瞭解每個模型對於辨識系統的影響力,本研究將針對 the second stage 再細分成三個小階段,逐 次加入模型資訊並觀察實驗結果,其詳細流程圖如下所示:
圖 3.7:辨認器第二級三階段實作流程圖
3.3.3.1 第一階段:加入多種語言資訊
如圖 3.7 所示,辨認器第二級第一階段是引入多種語言參數資訊(POS 及 PM),在這裡需 要加入的模型為 joint syntax model,此時在 word lattice 上每個 node 所帶有的 word 資訊會根據