具有強健性語音辨識的無線語音控制系統研製
91
0
0
全文
(2) 具有強健性語音辨識的無線語音控制系統研製. 指導教授:潘欣泰 博士 國立高雄大學資訊工程學系. 學生:蔡宜亨 國立高雄大學資訊工程學系. 摘要 本論文主要是以提升語音的辨識率與語音的抗雜訊能力。在提升語音辨識率方面, 是以模糊向量量化(Fuzzy Vector Quantization, FVQ)來建立離散隱藏式馬可夫模型 (DHMM)並用於語音模型的訓練,同樣以模糊向量量化(Fuzzy Vector Quantization ,FVQ) 用於輸入語音的辨識。而語音抗雜訊方面,是以經驗模態分解法(Empirical Mode Decomposition, EMD) 將含雜訊的語音訊號分解成多組本質模態函式(Intrinsic Mode Function, IMF),並以實數型基因演算法找出最佳 IMF 組合參數,再將分離出之 IMF 依 組合參數還原成語音。結合 FVQ 和 EMD 之特點,將使得具有雜訊的語音辨識率提升 很多。另外,我們在 FPGA 平台使用語音關鍵詞方式來控制清潔機器人。本論文透過無 線模組將 FPGA 的辨識結果傳送至清潔用機器人上的 AT89S51 處理器,來控制清潔機 器人的動作,讓清潔機器人可以在吵雜環境中執行正確的動作。. 關鍵字:語音辨識、經驗模態分解法、模糊向量量化、離散隱藏式馬可夫模型、基因演 算法、場域可程式閘極陣列。 I.
(3) Robust Speech Recognition on Wireless Speech Control System Advisor: Dr. Shing-Tai Pan Department of Computer Science and Information Engineering, National University of Kaohsiung Student: Yi-Heng Tsai Department of Computer Science and Information Engineering, National University of Kaohsiung. ABSTRACT This thesis is to enhance and improve speech recognition rate in noised environment. We use fuzzy vector quantization (FVQ) to improve the modeling of Discrete Hidden Markov Model (DHMM) and then to improve the speech recognition rate. The Empirical Mode Decomposition (EMD) is used to discompose some noised speech signals into several Intrinsic Mode Functions (IMF). These IMFs will be combined to recover the original speech by multiplying their corresponding weights which were trained by Genetic Algorithms (GA). After applying Empirical Mode Decomposition (EMD), we obtain a cleaner speech for recognition. Combining EMD and FVQ, we can improve the noised speech recognition rate. Besides, we utilize speech keywords to control the clean robot by using FPGA platform. So, the clean robot can perform the correct action in the noised environment. In this research, a wireless module is used to transmit the control comments form FPGA to the AT89S51 processer embedded in the clean robot to control the behavior of the robot.. Keywords: Speech Recognition, Empirical Mode Decomposition, Fuzzy Vector Quantization, Discrete Hidden Markov Model, Genetic Algorithms, Field Programmable Gate Array.. II.
(4) 致謝. 首先感謝我的指導老師潘欣泰教授,老師總是給予我實用的建議並指導我做研究方 式,讓我受益良多。尤其是在論文最後完稿階段,老師提出許多的建議,並耐心的指導, 讓這篇論文可以順利完成。 另外感謝葉瑞峰教授與賴智錦教授,在百忙之間抽空來當我的口試委員,並提出相 關建議與指正,讓我受益匪淺。 在研究所就讀的這段時間,我得到很多新的啟發,無論是知識取得或是研究態度都 讓我有著不同以往的認知,是十分珍貴的經驗。 最後感謝實驗室的學弟宏晉與英瑋,有你們在實驗室的事務上給予相關的支援,讓 我可以不受影響。謝謝我的家人總是默默的支持我關心我,讓我可以無後顧之憂的完成 研究所的學業。感謝所有幫過我的同學、學長與學弟,謝謝你們。. 蔡宜亨 於高雄大學資訊工程學系 中華民國 100 年八月. III.
(5) 目錄 第一章 緒論…………………………………………………………………………….…….1 1.1 研究動機與目的.........................................................................................................2 1.2 研究方法……………………………………………………………………….……3 第二章 語音訊號處理………………………………………………………………………..5 2.1 擷取語音之音框………………………………………………………………….…5 2.2 語音端點偵測…………………………………………………………………….…6 2.3 語音預強調……………………………………………………………………….….7 2.4 漢明窗…………………………………………………………………………….….8 2.5 整數快速傅立葉轉換……………………………………………………….……….8 2.6 特徵值擷取…………………………………………………………………………12 第三章 語音辨識結合 EMD 訊號分解……………………………………………………..15 3.1 瞬時頻率………………………………………………………………...................15 3.2 立方弧線與模態函數分解…………………………………………………………16 3.3 模態函數分解結合語音辨識………………………………………………………22 第四章 模糊向量量化與隱藏式馬可夫模型………………………………………………24 4.1 語音辨識系統………………………………………………………………………24 4.2 DHMM 模型訓練……………………….…………………………………………..26 4.3 模糊向量量化結合語音辨識系統與 DHMM 模型訓練………………………….29 4.4 語音辨識系統結合 FVQ、EMD 和 GA………………………………………….…35 第五章 實驗方式與結果………………………………………………………....................37 5.1 實驗語料……………………………………………………………………………37 5.2 實驗方法與數據…………………………………………………………………...40 5.2.1 以 DHMM(無 FVQ 與 EMD)的測試結果…………………………………….41 5.2.2 以 DHMM 結合 FVQ 的測試結果……………………………………………42 5.2.3 語音訊號以 EMD+GA 的測試結果…………………………………………..43 5.2.4 語音訊號以 FVQ+EMD+GA 的測試結果……………………………………45 5.2.5 語音以 CHMM、DHMM 與 FVQ+DHMM 在不同環境的辨識時間….....…46 5.3 實驗結果分析………………………………………………………………………49 5.3.1 針對 SNR 0 ~ 20dB 的平均辨識率分析………………………………………49 5.3.2 針對不同 SNR dB 值在不同測試環境之分析………..………………………52 5.3.3 針對不同 SNR dB 值辨識率提升幅度之分析……..…………………………57 5.3.4 針對 CHMM、DHMM 與 FVQ+DHMM 辨識速度分析………….…………62 第六章 以無線語音控制清潔機器人於嵌入式 FPGA 實作……….………………………64 6.1 FPGA 硬體平台…………………………………………………………………….65 6.2 語音辨識系統於 FPGA 平台之軟體架構與流程…………………………………67 6.3 清潔機器人……………………………………………………………...………….70 IV.
(6) 6.4 FPGA 平台控制清潔機器人……………………………………………………….71 第七章 結論…………………………………………………………………………………78 參考文獻……………………………………………………………………………………..80. V.
(7) 圖目錄 圖 2.1 圖 2.2 圖 2.3 圖 2.4 圖 2.5 圖 2.6 圖 2.7 圖 2.8 圖 2.9 圖 3.1 圖 3.2 圖 3.3 圖 3.4 圖 4.1 圖 4.2 圖 4.3 圖 4.4 圖 4.5 圖 4.6 圖 4.7 圖 5.1 圖 5.2 圖 5.3 圖 5.4 圖 5.5 圖 5.6 圖 5.7 圖 5.8 圖 5.9 圖 5.10 圖 5.11 圖 5.12 圖 5.13 圖 5.14 圖 5.15 圖 5.16. 語音特徵值擷取步驟................................................................................................5 50%音框重疊率.........................................................................................................6 端點偵測....................................................................................................................6 漢明窗………………..……………………………………………………………..8 8 個時間點輸入分解演算法………………………………..……………………..10 浮點數轉為整數建表……………………..……………………………………....10 N 點時間分解 FFT………………….…………………………………………..…11 梅爾尺度圖……………………..…………………………………………………12 梅爾倒頻率的過程……..………………………………………………………....14 立方弧線……………..…………………………………………………………....17 局部極大值與局部極小值以立方弧線連結而成的包絡線圖…..………..……..17 15dB 雜訊語音分解成 6 個 IMF 之分解圖………………….…...……………….21 模態函數分解結合語音辨識系統圖…………………………………..………....23 語音模型的訓練與語音辨識系統………..……………………………………....24 DHMM 語音模型………..…………………...…………………………………....25 DHMM 語音模型訓練流程圖………..…………………….………………..……28 特徵向量量化後於三角形歸屬函數圖……..……………………………..…..…30 FVQ 於三角形歸屬函數圖……..…………………………………………….…...32 DHMM 語音模型訓練結合模糊向量量化流程……..…………..………..…...…34 FVQ,EMD 與結合實數型 GA 的流程圖………………………………..………36 G712 與 MIRS 通道效應圖……..……………..………………………………..…37 八種不同的加成性雜訊圖……..…………………………………..…………..…38 SNR 為 0~20dB 在 A 組環境雜訊比較圖…………………….….……………..…50 SNR 為 0~20dB 在 B 組環境雜訊比較圖…………………………………………50 SNR 為 0~20dB 在 C 組環境雜訊比較圖……………………………….……...…51 SNR 為 0~20dB 環境雜訊辨識率提升幅度比較圖……………………………..51 A 組地下鐵在不同 SNR 之辨識率…………………………………….…….......53 A 組人聲在不同 SNR 之辨識率..............................................................................53 A 組汽車在不同 SNR 之辨識率…………………………………………………54 A 組展覽會館在不同 SNR 之辨識率…...………………………………………..54 B 組餐廳在不同 SNR 之辨識率……………………………………………..…….54 B 組街道在不同 SNR 之辨識率…..........................................................................55 B 組機場在不同 SNR 之辨識率………………………….…………………..…...55 B 組火車站在不同 SNR 之辨識率…………………………….……………….....55 C 組地下鐵在不同 SNR 之辨識率………………………………………………..56 C 組街道在不同 SNR 之辨識率...………………………………………………...56 VI.
(8) 圖 5.17 圖 5.18 圖 5.19 圖 5.20 圖 5.21 圖 5.22 圖 5.23 圖 5.24 圖 5.25 圖 5.26 圖 5.27 圖 5.28 圖 5.29 圖 6.1 圖 6.2 圖 6.3 圖 6.4 圖 6.5 圖 6.6 圖 6.7 圖 6.8 圖 6.9. A 組地下鐵於不同 SNR 下辨識率提升幅度……………………………….….....57 A 組人聲於不同 SNR 下辨識率提升幅度……………………..…………..……..58 A 組汽車於不同 SNR 下辨識率提升幅度...……………………………...............58 A 組展覽會館於不同 SNR 下辨識率提升幅度………………………...…..….....58 B 組餐廳於不同 SNR 下辨識率提升幅度………………………………………..59 B 組街道於不同 SNR 下辨識率提升幅度...………………………………….......59 B 組機場於不同 SNR 下辨識率提升幅度…………………….……………….....59 B 組火車站於不同 SNR 下辨識率提升幅度……………………………………..60 C 組地下鐵於不同 SNR 下辨識率提升幅度...………………………...................60 C 組街道於不同 SNR 下辨識率提升幅度...……………………….......................60 0~20dB 平均 SNR 在不同的測試環境........................……………………….......61 CHMM、DHMM 與 FVQ+DHMM 在不同測試環境平均語音辨識時間..............62 CHMM、DHMM 與 DHMM+FVQ 在乾淨語音下辨識率比較圖..........................62 FPGA 以無線方式控制清潔機器人系統方塊圖…………………………...….…64 DE2-70 開發板………………..……………..………………………………….....65 語音辨識系統的 SOPC 圖………………………………………..…………….....66 語音辨識系統於 FPGA 平台之軟體架構圖……………………………...…...….68 語音辨識系統於 FPGA 平台之軟體流程圖………………………...………...….69 清潔機器人系統方塊圖…………..……………………………………………....71 無線發射模組電路圖………………………………..………………………...….73 無線接收模組電路圖………………………………..………………………...….75 以 FPGA 平台在不同噪音環境下辨識結果圖………………………..……...….77. VII.
(9) 表目錄 表(5-1) 表(5-2) 表(5-3) 表(5-4) 表(5-5) 表(5-6) 表(5-7) 表(5-8) 表(5-9) 表(5-10) 表(5-11) 表(5-12) 表(5-13) 表(5-14) 表(5-15) 表(5-16) 表(5-17) 表(5-18) 表(5-19) 表(5-20) 表(5-21) 表(5-22) 表(5-23) 表(6-1) 表(6-2) 表(6-3). Aurora2 語音之訓練組合…………..………………………………………...….39 Aurora2 語音之測試組合…………………..………………………………...….39 無 FVQ 與 EMD 於 A 組環境雜訊之辨識果………………………………....….41 無 FVQ 與 EMD 於 B 組環境雜訊之辨識果…………………………….……....41 無 FVQ 與 EMD 於 C 組環境雜訊之辨識果………………………….………....42 DHMM+FVQ 在 A 組環境雜訊之辨識果…………………………………..…..42 DHMM+FVQ 在 B 組環境雜訊之辨識果………...………………………….….43 DHMM+FVQ 在 C 組環境雜訊之辨識果……………...…………………….….43 DHMM+EMD 在 A 組環境雜訊之辨識結果……...……………………….……44 DHMM+EMD 在 B 組環境雜訊之辨識結果…………………………………...44 DHMM+EMD 在 C 組環境雜訊之辨識結果…………………………………...44 DHMM+FVQ+EMD 在 A 組環境雜訊之辨識結果……………………………45 DHMM+FVQ+EMD 在 B 組環境雜訊之辨識結果………………………….…45 DHMM+FVQ+EMD 在 C 組環境雜訊之辨識結果………………………….…46 CHMM 在 A 組環境雜訊之辨識時間…………………………………………...46 CHMM 在 B 組環境雜訊之辨識時間..………………….………………………47 CHMM 在 C 組環境雜訊之辨識時間……………………..………………….…47 DHMM 在 A 組環境雜訊之辨識時間……………………..………………….…47 DHMM 在 B 組環境雜訊之辨識時間..………………….………………………48 DHMM 在 C 組環境雜訊之辨識時間……………………..………………….…48 FVQ+DHMM 在 A 組環境雜訊之辨識時間….…………..………………….…48 FVQ+DHMM 在 B 組環境雜訊之辨識時間..…..……….………………………49 FVQ+DHMM 在 C 組環境雜訊之辨識時間…..…………..………………….…49 FPGA 平台未加入 FVQ 與 EMD 並在不同噪音環境之辨識結果…..…………76 FPGA 平台加入 FVQ 與 EMD 並在不同噪音環境之辨識結果…………......…76 FPGA 平台加入 FVQ 與 EMD 在不同噪音環境辨識率提升程度……..…....…76. VIII.
(10) 第一章 緒論 由於科技得進步,讓我們生活變的方便,同時對於電子產品也越來越依賴,人們與 電子產品之間的互動越來越平凡,所以人機介面因而產生。語音一直是人與人之間的溝 通方式,如果可以用語音與電子產品做溝通,對使用者來說,是最方便也比較實用。在 實際狀況下,電子產品要和人溝通就要運用語音辨識系統。語音辨識領域發展時間已經 經過 20~30 幾年了,所包含的領域也非常廣泛,研究方式也非常多元[1-5]。 語音辨識從早期的動態時軸校正(Dynamic Time Warping)[6-7],其方式是將語音以 動態規劃演算法去和語音樣本做比較,找出最相近的語音。再來是以類神經網路[8-9] 來做語音辨識,由於類神經網路架構訓練後不可任意變更,導致語者說話速度會影響到 其辨識率。本論文以隱藏式馬可夫模型(Hidden Markov models, HMM)[10-11]作為語音 辨識系統,而 HMM 以統計方式來做語音辨識,除了完全解決語者說話速度問題,還可 以做到語意的辨識,目前以 HMM 運用於語音辨識方面的研究[12-16]數量也不在少數。 模糊向量量化[17-18](Fuzzy Vector Quantization ,FVQ)於本論文主要是用來提升語 音辨識系統的辨識率。在語音辨識系統的訓練方面以 FVQ 建立 DHMM[7]模型並做 DHMM 模型的訓練,而在語音辨識系統的辨識方面以模糊集合找出特徵向量與特徵向 量之間的比例並代入以 FVQ 建立 DHMM 的訓練模型,以此方式來提升語音辨識率。 經驗模態分解法(Empirical Mode Decomposition, EMD)是黃鍔博士(Dr. Norden Huang)於 1998 年所提出的數據分析方法[19],大多被應用於地球科學上的信號分析。 EMD 可適用於分析非線性(non-linear)和非穩態(non-stationary)的訊號,所以 EMD 對於. 1.
(11) 複雜的訊號有很好的解析。EMD 於本論文是用來分解含雜訊的語音訊號,為強健行語 音辨識的方法之ㄧ,關於強健性語音辨識研究也有不同方法被提出[4][20]。 基因演算法[21]運用範圍廣泛,只要能將需要解決的問題轉成找出最佳解問題都可 以套用基因演算法來求解,針對不同問題,基因演算法形式上也有些不同,例如染色體 編碼方式不同,交配方式不同,突變機率不同等等,原理是利用機率來找出最佳解。本 論文將以實數型基因演算法結合 EMD 做為語音抗雜訊系統。. 1.1 研究動機與目的 本論文將著重於語音辨識的辨識率與語音的抗雜訊能力,並實現智慧生活空間。因 為 HMM 對於語音辨識的速度與在嵌入式 FPGA 平台上效能發揮非常不利,所以本論文 採用了 DHMM 來做語音辨識系統並於語音辨識系統加入模糊向量量化(FVQ)來提升語 音的辨識率,如此一來不但可以加快辨識速度並運用於嵌入式 FPGA 平台,對於提升語 音的辨識率也很有助益。 乾淨語音的辨識以目前的技術來說,辨識率是可以超過 90%以上,但是如果語音訊 號加入雜訊那麼辨識率將會大打則扣,為了提升語音抗雜訊能力,本論文運用 EMD 做 為雜訊分離的工具,並且結合基因演算法將分解後的訊號依權重值做結合,來增強語音 抗雜訊能力。 最後透過嵌入式 FPGA 平台及無線收發模組來進行智慧家電的控制,並以清潔機器 人為例,實現智慧生活空間。本論文以嵌入式 FPGA 平台實現了語音辨識系統與抗雜訊. 2.
(12) 系統,並在嵌入式 FPGA 平台上安裝無線發射模組,且在家電上加入無線接收模組,如 此一來即以嵌入式 FPGA 平台來控制家電並應用於吵雜的環境中。在未來的其他應用 上,如語音的輪椅控制,語音辨識智慧鎖,車用語音辨識,自動語音取票系統等皆可套 用。. 1.2 研究方法 本論文之研究方法將分成提升語音辨識率,提升語音抗雜訊能力以及利用嵌入式 FPGA 平台實現智慧型家庭控制,說明如下。 在提升語音辨識率上,可以分為語音辨識與語音模型訓練兩部分。在語音模型訓練 上,我們以模糊向量量化(Fuzzy Vector Quantization ,FVQ)方式建立離散隱藏式馬可夫模 型(DHMM),並將結果用來做語音模型建立與訓練。在語音的辨識部分,我們把輸入語 音特徵向量做模糊向量量化,並將模糊向量量化後的觀察結果代入訓練後的語音模型, 達成較高的語音辨識效果。 在抗雜訊語音辨識部分,我們使用中研院黃鍔院士的經驗模態分解法(Empirical Mode Decomposition, EMD),將含雜訊的語音訊號分解成多組本質模態函式(Intrinsic Mode Function, IMF)[19],再以實數型基因演算法[21]找出最佳 IMF 組合參數,並將分 離出之 IMF 依組合參數還原成語音,達到語音抗雜訊的能力。 在實際應用上則是將語音辨識系統和語音抗雜訊系統加到嵌入式 FPGA 平台,並在 FPGA 平台上加入無線發射模組。再將清潔機器人加入無線接收模組,即可以用 FPGA. 3.
(13) 平台在有噪音的環境中控制清潔機器人。. 4.
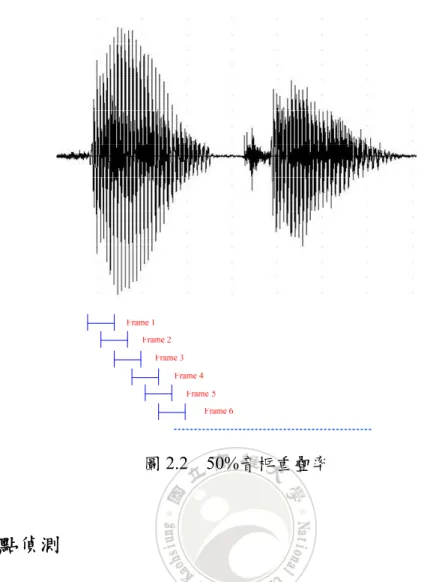
(14) 第二章 語音訊號處理 原始語音訊號都是類比訊號,因此要對類比訊號做運算就必須將類比訊號轉成數位 訊號,而取樣的頻率對於語音的失真與否有很大的關係,如果取樣頻率太低會造成語音 失真,若取樣頻率太高則計算量變大。由於語音會在不同的時間產生不同的訊號,而且 每個人的語音訊號也不會相同,所以必須將要辨識的語音訊號作處理,得到語音的特徵 值,再以語音訊號特徵值來執行辨識動作。下圖 2.1 為語音特徵值擷取步驟。. 語音輸入. 擷取語音之 音框. 語音端點偵 測. 快速傅利葉 轉換. 特徵值擷取. 圖 2.1. 語音預強調. 漢明窗. 語音特徵值擷取步驟. 2.1 擷取語音之音框 語音訊號會在不同時間有不同的變化,所以將語音訊號分成一段、一段的短時距 (short time period),這些短時距(short time period)即是音框(frame)。取音框的方式不是以 一段結束再接著另外一段開始,是以重疊方式來取音框。音框的重疊方式會對語音特徵 值有所影響,高重疊率可以得到高解析度的特徵值變化,但是高重疊率會增加運算量, 而低的音框重疊率會得到較低解析度的特徵值也會降低語音的辨識率,相對的運算量也 會減少。因此本論文採用較常用 50%音框重疊率(如圖 2.2)。 5.
(15) 圖 2.2. 50%音框重疊率. 2.2 語音端點偵測 由開始錄音到結束我們所錄得的資料並不完全是我們要辨識的語音,一開始一定會 有一段非語音部份,一般來說是靜音的部份,接著才開始講話部份,之後再接一段靜音 部份才結束。因此我們必須把非語音的靜音部份去除以減少不必要的資料運算量,並避 免影響到語音的辨識率,如圖 2.3 所示。. 圖 2.3. 語音端點偵測 6.
(16) 本論文採用的方法為能量偵測法,其做法是先求出每個音框的能量,其數學式子如(2-1). E ( m) =. m * L + L −1. ∑. S ( n). 2. (2-1). n = m* L. E (m) 為第 m 個音框的能量, L 代表音框的長度, n 為語音信號的索引值, S (n) 為原始 的聲音信號,求出所有音框能量後,取最大能量 E (m) 的 7.5%加上前 K 個音框能量的平 均做為門檻值公式如下。. Thr = 7.5% * max[ E (m)] +. 1 K. K −1. ∑ E (i), 0 ≤ m ≤ N − 1. (2-2). i =0. 其中 Thr 為門檻值。 計算出門檻值之後,從第一個音框依序向後比較,若連續多個音框超過門檻值,則可判 定語音的開始,同理由尾端方向比照公式(2-2)可算出尾端之門檻值接著從最後一個音框 依序向前比較,連續多個音框大於門檻值則判定為語音的尾端,經判斷非語音的部分即 捨棄不用。. 2.3 語音預強調 聲音在空氣中傳輸時,高頻的聲音會衰減,為了彌補高頻的衰減,必須將語音做預 強調處理,我們將原始語音輸入一個 FIR 的高通濾波器,公式如下: X (n) = S (n) − 0.95 * S (n − 1), 1 ≤ n ≤ L. (2-3). 式子(2-3)中, X (n) 為預強調後之訊號, S (n) 為原來之語音, L 為語音長度。. 7.
(17) 2.4 漢明窗 語音加上漢明窗的目的為要加強音框兩端的連續性,因為連續的音框中頭尾的數值 不一定相同,這會造成分析上的誤差。為了讓音框和音框之間更連續,並加強音框中間 值的特性,所以我們將每個語音之音框加上漢明窗,公式如下:. 2nπ ⎧ ), 0 ≤ n ≤ N − 1; ⎪0.54 − 0.46cos( W (n) = ⎨ N −1 ⎪⎩0, otherwise. (2-4). F ( n) = W ( n) × S ( n);. (2-5). 公式(2-4)中,N 為音框長度, n 為音框的 index。公式(2-5)中, S (n) 為音框訊號, F (n) 乘上漢明窗的語音訊號。圖 2.4[7]為取 256 點的漢明窗: 1 0.8 0.6 0.4 0.2 50. 100. 150. 200. 250. 圖 2.4 256 點的漢明窗[7]. 2.5 快速傅立葉轉換(Fast Fourier Transform ,FFT) 語音辨識中是採用頻域方式來取特徵值,而語音加上漢明窗後是以時域方式呈現, 因此語音的音框必須執行傅立葉轉換 [22]將音框時域訊號轉換成頻域訊號,如公式. (2-6)。 8.
(18) N −1. X [ k ] = ∑ x[ n]W Nkn , 0 ≤ k ≤ N − 1;. (2-6). n=0. 其中. WN = e. − j 2π N. 公式(2-6)為傳統的傅立葉轉換,N 為資料總數,由式子可以看出運算複雜度為 N 2 , 將語音音框代入傳統傅立葉公式,每個音框都做傅立葉轉換,這些運算會用到大量的浮 點數運算,所以執行時間會相當大,所以採用快速傅立葉轉換[23]。 假設 N 為偶數,定義:. f [n] = x[2n], 為x[n]偶數取樣點 g[n] = x[2n + 1], 為x[n]的奇數取樣點 並將公式(2-6)改為公式(2-7):. X [k ] =. N −1 2. ∑ f [ n ]W n=0. nk N /2. N −1 2. + W Nk ∑ g [ n ]W Nnk/ 2 = F [ k ] + W Nk G [ k ]. (2-7). n=0. 公式(2-7)中的 F [k ] 與 G[k ] 為 f [n] 和 g[n] 的. N N N 個取樣點,而 0 ≤ k < ,如果 也 2 2 2. 是偶數, f [n] 和 g[n] 可以分為偶數與奇數部分,然後可以用一樣的方法計算各別的 FFT。由於每階段的 N 分割後要為偶數,所以原本資料就為 N 的 2 次方,藉由此方式可. 將時間複雜度降為. N log 2 N ,圖 2.5[23]為 8 個時間輸入的分解演算法。 2. 9.
(19) W80 W81 W82. W83. 圖 2.5 8 點時間 FFT 演算法. 雖然快速傅立葉轉換加快了傳統傅立葉轉換的速度,但是我們的目標是要將語音辨 識系統實作在速度較慢的嵌入式系統上,故使用整數快速傅立葉轉換[24]來加快運算。 首先將浮點數轉為整數並利用查表方式將結果取出如圖 2.6 所示:. 112π sin( ) = 0.98 256. truncate( SF * 0.98) = 1003 truncate( SF * 0.195) = 199. 112π ) = 0.195 cos( 256. Re[112] = 199. Im[112] = 1003. 圖 2.6 浮點數轉為整數的查表方式. 10.
(20) 圖 2.6 說明對 FFT 運算中第一次遇到之 sin 與 cos 函式時先將它們左移 10bit,接著 捨棄小數位元轉成整數後建表,爾後遇到相同 sin 或 cos 則可直接查表。再將公式(2-7) 的 G[k ] 與 WNK 分解為下面式子: G[k ] = Re[G[ k ]] + j Im[G[k ]]. (2-8). ⎛ 2πk ⎞ ⎛ 2πk ⎞ WNk = cos⎜ − ⎟ + j sin⎜ − ⎟ ⎝ N ⎠ ⎝ N ⎠. (2-9). 經式子(2-8)與式子(2-9)將式子(2-7)改為下列算式: F [k ] + G[k ] *WNk = F [k ] + (c Re[G[k ]] − s Im[G[k ]]) * SF +. (2-10). j (( s Re[G[k ]] + c Im[G[k ]]) * SF ). 其中 SF 為我們將小數放大所要乘得值,cos 和 sin 乘上 SF 變成整數,經過所有運算後 再除以 SF,圖 2.7[24]為運算流程,經過圖 2.7 運算後,就可以將語音訊號由時域訊 號轉換成頻域訊號。. cRe[G[k]]-sIm[G[k]]*SF. 1 SF. Re[G[K]]. s*SF. c*SF. G[K]. G[k ] * W NK. -s*SF. c*SF. j. Im[G[k]]. cRe[G[k]]-sIm[G[k]]*SF 圖 2.7 複數乘法圖. 11. 1 SF.
(21) 2.6 特徵值擷取 人耳對於頻率感知並非線性,以正常狀況來說,只對低頻有較高解析,對於高頻解 析就不如低頻明顯。根據人耳特性可以使用梅爾尺度圖,如圖 2.8[7],由圖 2.8 可以看 出 1KHZ 以下為線性遞增,超過 1KHZ 為對數關係。因為梅爾頻率是根據人類的聽覺 特性而定義,Mel 為人類聽覺頻率的感知單位,公式(2-11)為頻率和 Mel 頻率的關係式 [7]。 Mel ( f ) = 2595 * log10 (1 +. f ) 700. (2-11). 圖 2.8 梅爾尺度圖. 本論文以梅爾倒頻譜[7]做特徵值的擷取,因為梅爾頻率的特性較能符合人類聽覺 上的效果,因此將語音的音框經過快速傅立葉轉換後,得到的每個頻率的能量將乘上梅 爾三角濾波器,濾波器算式[7],如公式(2-12):. 12.
(22) ⎧0, k < f m −1 ⎪k− f m −1 ⎪ , f m −1 ≤ k ≤ f m f f − ⎪ m m −1 Bm (k ) = ⎨ ⎪ f m +1 − k , f ≤ k ≤ f m +1 ⎪ f m +1 − f m m ⎪ ⎩0, f m +1 < k. ,1 ≤ m ≤ M. (2-12). 其中 M 為濾波器數目, f m +1 和 f m −1 為上下截止頻率。 另外 f m 為梅爾三角慮波器的中心頻率,如公式(2-13):. f ( m) =. N mel ( f h ) − mel ( f l ) * f (mel ( f l ) + m * ) fs M +1. (2-13). 其中 N = frame size, f h 為濾波器最高頻率, f l 為濾波器最低頻率, f s 為取樣頻率, mel. mel = 2595 * log(1 +. f ) , f = 700 * (10 2595 − 1) 700. 將每個頻率的能量乘上梅爾三角濾波器累加之後取對數,如公式(2-14):. ⎧ fm+1 ⎫ Y (m) = log⎨ ∑ X (k ) Bm (k )⎬. ⎩k = fm−1 ⎭. (2-14). 則 Y (m) 為第 m 的三角濾波器輸出的能量和,再對 M 個 Y (m) 做離散餘弦轉換如公式 (2-15): 1 c x ( n) = M. 1 πn(m − ) 2 ) Y (m) cos( ∑ M m =1 M. (2-15). 最後公式(2-15)的結果即為梅爾倒頻譜參數,也就是語音音框之特徵參數。本論文 取前面 13 筆資料作為特徵參數,圖 2.9 為梅爾倒頻率的過程。. 13.
(23) 圖 2.9 梅爾倒頻率運算流程. 14.
(24) 第三章 語音訊號結合 EMD 訊號分解 經驗模態分解(Empirical Mode decomposition , EMD)是黃鍔博士(Dr. Norden Huang) 於 1998 年所提出的數據分析方法, EMD 可適用於分析非線性 (non-linear) 和非穩態 (non-stationary)的訊號,所以EMD對於複雜的訊號有很好的解析。EMD會將訊號分解成. 許多個內建模態函數(Intrinsic mode function,簡稱IMF)[17]的線性疊加,而分離出的IMF 都有它的物理特性。將分離出的IMF結合「希爾伯特─黃轉換」(Hilbert-Huang transform, 簡稱HHT)[19]即可求得舜時頻率與振幅。本論文利用HHT中將分離IMF的方式將語音分 解成多個IMF,再將分離的IMF組成語音,期望可以降低雜訊。. 3.1 瞬時頻率 EMD與傳統傅利葉分析的不同之處為EMD並不需要事先定義基底函數就可直接根. 據訊號本身的性質(局部極大值與局部極小值)自動地將訊號分解成多個IMFs的線性疊 加。傳統的傅利葉分析就是一把不會變的尺,無法適應各種不同的複雜訊號;而EMD 就 好像是一把具有彈性的尺,可以為各種不同的複雜訊號量身訂做一把適合的尺。因此將 IMFs 從時間域或空間域轉換至頻率域後,會比使用快速傅利葉轉換 (Fast Fourier transform, 簡稱FFT)得到更詳細的頻譜資訊,黃鍔博士在1998年所發表的同一篇論文中 [19],另有提出IMFs的轉換公式,其名稱被命名為「希爾伯特─黃轉換」(Hilbert-Huang transform,簡稱HHT)。而HHT的公式定義如下所示:. Y (t ) =. ∞ X ( τ) 1 CPV ∫ dτ −∞ t − τ π. (3-1). 15.
(25) 其中,CPV為柯西主值(Cauchy principle value),利用 y (t ) 和 x(t ) 可組成一個解析 z (t ) 公式如下: z (t ) = x(t ) + jy (t ). (3-2). 其中: 1 2 2. a (t ) = z (t ) = ( x + y ) 2. θ(t ) = tan −1. (3-3). y (t ) x(t ). (3-4). 舜時頻率: f (t ) =. 1 1 d w(t ) = θ(t ) 2π 2π dt. (3-5). 3.2 立方弧線(Cubic Spline)與模態函數(Intrinsic mode function ,IMF)分解 EMD 將訊號分解成許多個內建模態函數 (IMF) ,並將 IMF 的局部極大值以包絡線 (envelope)連接成為上包絡線,局部極小值以包絡線(envelope)連接成為下包絡線。包絡. 線是採用立方弧線[25],為了達到立方弧線通過所有資料點的特性(如圖3.1所示),必須 每二個資料點之間就建構一個多項式函數,假設有n+1個資料點,立方弧線就會有公式 (3-6)的數學形式。 ⎧ g1 ( x), ⎪ ⎪ g 2 ( x), ⎪ G ( x) = ⎨ g3 ( x), ⎪ ⎪ ⎪ g n ( x), ⎩. x1 ≤ x < x2 x2 ≤ x < x3 x3 ≤ x < x4. (3-6). . . .. xn ≤ x < xn +1. 16.
(26) G (x). g1 (x). g4 (x). g2 (x). gn−1(x). gn−3(x). g3 ( x). gn (x). gn−2(x). x x1. x2. x3. x4. x5. xn−3 xn−2 xn−1. xn xn+1. 圖3.1 立方弧線 圖3.2為IMF的局部極大值與局部極小值以立方弧線連結而成的包絡線,其中以局部 極大值連結而成的是上包絡線,局部極小值連結而成的是上包絡線。. 局部極大值. 局部極小值 圖3.2 IMF局部極大值與局部極小值以立方弧線連結而成的包絡線圖. 17.
(27) EMD將訊號分解成許多個內建模態函數(IMF),而一個函數必須滿足下列二個條件. 才能被定義成IMF: (a) 極值(局部極大值與局部極小值)的數目與跨零點的數目必須相等或最多相差一個。 (b) 局部極大值的包絡線(envelope)與局部極小值的包絡線,在任一點其兩者的平均必須. 為零。 以下為模態函數(IMF)的分解方式分為4個步驟如下: 步驟1: (1) 尋找訊號中所有的局部極大值,然後採用立方弧線把它們連接起來當作上包絡線,. 命名為 hup (t ) 。 (2) 尋找訊號中所有的局部極小值,然後採用立方弧線把它們連接起來當作下包絡線,. 命名為 hlow (t ) 。 (3) 然後,計算局部極大值包絡線與局部極小值包絡線的平均包絡線(mean envelope),. 命名為 mean1 (t ) 。 mean1 (t ) =. hup (t ) + hlow (t ) 2. (3-7). (4) 原來訊號(假設為 f (t ) )與平均值包絡線之差即為IMF,命名為 h1 (t ) 。 h1 (t ) = f (t ) − mean1 (t ). (3-8). 步驟2: 如果 h1 (t ) 不符合IMF的條件,則把 h1 (t ) 當作是下一步驟的輸入,回到步驟1重新計算, 直到 h1k (t ) 滿足IMF 的條件。. 18.
(28) h11 (t ) = h1 (t ) − mean11 (t ) • • h1k (t ) = h1k −1 (t ) − mean1k (t ). 步驟3: (a) 指定 h1k (t ) 為訊號中的第一個IMF。 imf1 (t ) = h1k (t ). (3-9). (b) 從原始訊號中分離 imf1( t ) ,得到餘數函數(residue function),命名為 r1( t ) 。 r1 (t ) = f (t ) − imf1 (t ). (3-10). (c) 然後,再把 r1 (t ) 當成新的訊號,回到[step 1],直到 rn (t ) 變成單調函數(monotonic),. 沒有IMF 可以再分解出即停止。. r2 (t ) = r1 (t ) − imf 2 (t ) • • rn (t ) = rn −1 (t ) − imf n (t ) 步驟4: 最後,原始訊號 f (t ) 即可被表達成多個IMFs 與一個餘數函數(residuefunction)的線性疊 加。 n. f (t ) = ∑ imfi + rn (t ). (3-11). i =1. 在實際的運作中,理論上要讓 hij (t ) 完全符合模態函式的定義才能算分離出一個模 態函式,IMF定義1很容易達成,但是定義2在實際上不容易達到,需經過長時間的分解. 19.
(29) 才會達到,因此定義一個新的條件[19]如下: T. SDik =. ∑h t =0. i ( k −1) T. (t ) − hi (t ). ∑h t =0. 2 i ( k −1). 2. (3-12) (t ). 其中分子部分即為 meanik (t ) 的平方和,若 SDik 等於0即符合IMF定義2,一般會將 SDik 設 定為0.2~0.3之間為停止條件。 圖3.3為含15dB噪音的語音訊號與經過EMD的分解後的例子,IMF1~IMF6為依序產 生的六個IMF。. 20.
(30) 圖3.3 15dB雜訊語音分解成6個IMF之分解圖 21.
(31) 3.3 模態函數分解結合語音辨識 包含噪音的語音訊號經EMD分解成多個IMF後,其中IMF1訊號主要成分為噪音, IMF2與IMF3訊號成份才是乾淨語音,而IMF4與IMF5也含有少數語音成份,可由圖3.3. 看出。但是IMF1並不全部的成分皆為雜訊,也包含少數語音成份,同樣的,IMF2與IMF3 也包含少數雜訊,不可能都為語音訊號成份。因此本論文使用基因演算法來找出每個 IMF 的權重值,再根據每個 IMF 的權重值將訊號還原成強化後的語音信號。如公式 (3-13)。 ∧. n. X (t ) = ∑ wi ⋅ imfi (t ). (3-13). i =1. ∧. 其中 X (t ) 為EMD處理後按照組合權重 wi 重組後的語音信號, wi 是由基因演算法求得。 本論文以實數型基因演算法找出公式(3-13)中最佳IMF權重值 wi 後,並依每IMF的權重 值 wi ,將IMF重組成強化的語音訊號,圖3.4為模態函數分解結合語音辨識系統圖。實 數型基因演算法參數設定如下: 1.每代染色體數16。. 2.每條染色體有5個實數基因,分別對應至IMF1~IMF5。 3.染色體存活率為0.5和突變率為0.05。 4.交配方式為隨機配對,演化代數500。. 22.
(32) Speech samples. imf1 imf2 IMFs weighting. EMD. ( w1 w2 L wn ). imfn. Feature extraction by. Train. MFCC. codebook. testing features DHMM. GA. modeling modify GA. N. END. Y. Acceptable. Speech recognition. recognition rate?. test. 圖3.4 模態函數分解結合語音辨識系統圖. 23.
(33) 第四章 模糊向量量化與隱藏式馬可夫模型 經過語音前置處理,每一個音框會產生一個 13 維的特徵向量。本論文將音框的特 徵向量做模糊向量量化,再將模糊向量產生的觀察向量輸入語音辨識平台做最後的辨 識。同樣以模糊向量量化來建立離散的隱藏式馬可夫模型(DHMM)並對 DHMM 作訓 練。完成訓練後,每一個語音會產生一個對應的 DHMM 語音模型,在辨識時計算每一 個語音模型產生該語音的機率,機率最高之模型為辨識的結果,語音模型的訓練與語音 辨識系統如圖 4.1。 Training :. Speech Features. Recognition :. Fuzzy Vector Quantization. Train codebook by LBG algorithm. The DHMM model. λ ={A, B,π, S,V}. Fuzzy Vector Quantization. Speech Features. The DHMM model. λ ={A, B,π, S,V}. Recognition results. 圖 4.1 語音模型的訓練與語音辨識系統. 4.1 語音辨識系統 在介紹語音辨識系統前,我們先對 HMM 作簡介,HMM 主要是根據觀察結果估計 出其隱藏的狀態轉移,此結構剛好可以用於描述語音的特性,一連串的音框可以代表著 一連串的觀察結果,而觀察結果的狀態變化對應到隱藏的狀態轉移。對於每個語音模 型,我們需要訓練的參數為每個狀態下產生各觀察結果之機率和各狀態轉移之機率,由. 24.
(34) 於設定模型皆由第一個狀態開始,故初始狀態機率不需要訓練。說明訓練方式前,須先 對 HMM 做一個定義和介紹:. λ = { A, B, π} : HMM模型 π = {πi }, πi = P (q1 = si ), 1 ≤ i ≤ N : 初使狀態機率向量 A = {aij }, aij = P(qt = s j | qt −1 = si ) : 狀態轉移機率矩陣 B = {b j (k )}, b j (k ) = P(ot = vk | qt = s j ) : 各狀態的輸出機率矩陣 O = {o1 , o2 , ..., oT } : 事件觀察結果序列 Q = {q1 , q2 , ..., qT } : 隱藏狀態序列. 在語音模型方面,本文採用 7 個隱藏狀態,所有可能的觀察結果為 64 種,每個狀 態跳躍方式如圖 4.2 所示:. 圖 4.2 DHMM 語音模型. 25.
(35) 根據 A 、 B 、 π 三個機率集合,我們可以算出一個模型 λ 產生一個觀察結果序列 O 的機率 P (O | λ) 如下, P(O | λ) = ∑ P(O, Q | λ) allQ. =. ∑ πq1 ⋅ bq1 (o1 ) ⋅ aq1q 2 ⋅ bq 2 (o2 ) ⋅ aq 2q3 ⋅ ⋅ ⋅aqT −1qT ⋅ bqT (oT ). (4-1). q1, q 2 ,..., qT. 由於上式計算之時間複雜度太高,共 N T 個浮點數乘法和 N T − 1 個浮點數加法,為了節 省計算時間,定義 Forward variable 式子如下: α t (i ) = P (o1 , o2 , ..., ot , qt = si | λ). (4-2). 起始: α1 (i ) = πi ⋅ bi (o1 ), 1 ≤ i ≤ N 為N *1矩陣. (4-3). 遞迴運算 N. α t +1 ( j ) = [∑ αt (i ) ⋅ aij ] ⋅ b j (ot +1 ), 1 ≤ j ≤ N , t = 1, 2, ..., T − 1. (4-4). i =1. 結束: N. P (O | λ ) = ∑ αT (i ). (4-5). i =1. 此演算法所需乘法數為 (T − 1) N 2 + N 個,加法為 T ⋅ N 個,大幅降低運算複雜度。公式(4-5) 即為語音辨識的結果。. 4.2 DHMM 模型訓練 再進入 HMM 模型訓練前,必須找出先對下列變數做說明: uij 標示由狀態si到狀態s j 26.
(36) ui • 標示由狀態si出來 u• j 標示進入狀態s j n(uij ) 由狀態si出來,然後進入狀態s j的次數 n(ui • ) 由狀態si出來的次數 n(u• j ) 進入狀態s j的次數 n(u• j , o = vk ) 進入狀態s j時產生觀察結果符號vk的次數. 本論文先以維特比[7]演算法來求得最佳狀態序列,方式如下: 起始: δ1 (i ) = πi ⋅ bi (o1 ), 1 ≤ i ≤ N 為N * 1矩陣. (4-6). ψ1 (i ) = 0. (4-7). 遞迴運算 N. δt ( j ) = max[∑ δt −1 (i ) ⋅ aij ] ⋅ b j (ot +1 ), 1 ≤ j ≤ N , t = 1, 2, ..., T − 1. (4-8). i =1. N. ψ t ( j ) = arg max[max ∑ δt −1 (i ) ⋅ aij ], 1 ≤ j ≤ N , t = 1, 2, ..., T − 1. (4-9). i =1. 結束: P ∗ = max[δT (i )], 1 ≤ i ≤ N. (4-10). qT∗ = arg max[δT (i )], 1 ≤ i ≤ N. (4-11). 回溯: qt∗ = ψ t +1 (qt*+1 ), t = T − 1, T − 2, ...1. (4-12). 語音模型訓練的流程是先收集該聲音的集合,將語音一筆一筆帶入初始的 HMM 模 型找出每筆語音的最佳狀態序列公式(4-12),根據猜測的狀態序列和觀測序列,我們可 27.
(37) 以統計出 n(uij ) 、 n(ui • ) 、 n(u• j ) 、 n(u• j , o = vk ) ,當統計完所有筆數的語音後,即可更新 參數,然後再以新的參數之模型重複做上述猜測狀態序列和統計更新的動作,直到模型 參數沒變化,即可結束而得到該聲音的模型參數。經統計我們可以重新更新參數如式子 (4-13)、(4-14),圖 4.3 為 DHMM 語音模型訓練流程圖。. 圖 4.3 DHMM 語音模型訓練流程圖 28.
(38) a=. n(uij ). (4-13). n(ui • ) n(u• j , o = vk ) b (k ) = n(u• j ). (4-14). 該模型參數即代表此聲音模型,可藉由訓練好的參數,計算該模型產生目標聲音的 機率,機率越高代表該模型越有可能為目標聲音的模型,當計算完所有模型機率後,機 率最高之語音模型所代表的音為辨識的結果。. 4.3 模糊向量量化結合語音辨識系統與 DHMM 模型訓練 由於我們採用離散的隱藏式馬可夫模型做為語音模型,其觀察結果為一個有限的集 合,為了將擷取出來的特徵向量分類為觀察結果集合中的一類,我們需對向量作量化的 動作[26]。 首先算出所有語音訓練樣本中每個音框的特徵向量,接著根據要分類的數目,隨機 產生相同數目的特徵向量當作初始碼簿(codebook)。隨機產生的初始碼簿是從語音訓練 樣本依比例來隨機產生,所以碼簿中的各向量代表著不同的類別。取得初始碼簿後,將 每個音框的特徵向量根據碼簿做分類,藉由公式(4-15),可以計算出該特徵向量和碼簿 中第 k 個向量的 d k 距離。 d k (v ) =. 13. ∑ (v i =1. i. − V ki ) 2. (4-15). 其中 k 表示碼簿中向量的編號,而 i 表示該向量中維度的索引,算出碼簿中所有 d k 後,即可將 v = [v1 , v2 ...v13 ] 歸類為 d k 最小的那一類,重複上述步驟可將所有音框的特徵向 量做出分類的動作。 29.
(39) 將所有音框分類後,根據每ㄧ類別內所有的特徵向量計算新的中心點,所有新計算 出來的中心點則取代舊的碼簿成為更新後的碼簿,公式(4-16)為中心點的計算: 1 Nk Vk = × ∑ vkn N k n =1. (4-16). 其中 Vk 為第 k 類新的中心點向量,vk = [vk 1 , vk 2 ...vkn ] 為屬於第 k 類的特徵向量,N k 為 歸類為第 k 類的特徵向量數。藉由重複上述兩個分類和計算中心點的疊代動作。可對碼 簿做訓練,當碼簿不再變動時則代表碼簿已訓練完成。在碼簿完成後即可根據碼簿對音 框的特徵向量做量化,量化後的特徵向量即為觀察向量。 由於音框與音框之間是有關聯性的,但是碼簿對音框特徵向量做量化後有贏者全拿 的特性,如果以向量量化對音框的特徵向量做量化動作,會造成只會選取到碼簿中的一 個分組特徵向量,為了改善向量量化只選取到一個分組特徵向量,因此使用了模糊集合 (Fuzzy Set)的三角形歸屬函數(Triangular Membership Function)對量化後的音框特徵向. 量做模糊處理,如圖 4.4 。在圖 4.4 中 vi , i = 1...n , vi 為量化後的音框特徵向量, Ai , i = 1...n , Ai 為三角形歸屬函數。. μA ( x ) i. A1. Ai. Ai + 1. v1. vi. vi +1. 圖 4.4 特徵向量量化後於三角形歸屬函數圖. 30. x.
(40) 三角形歸屬函數的隸屬程度(Degree of Membership),如公式(4-17)。. [. ⎧ x − vi −1 ⎪ v − v , ∀x ∈ vi −1 , vi ⎪ i i −1 μ Ai ( x) = ⎨ ⎪ vi +1 − x , ∀x ∈ v , v i i +1 ⎪⎩ vi +1 − vi. [. ] (4-17). ]. 音框的特徵向量量化後,經三角形歸屬函數做運算,即可將量化後的特徵向量分成 兩組觀察向量,如圖 4.5。因此將音框特徵向量代入算式(4-15),即可求出音框之特徵向 量經 codebook 量化後的觀察向量分組距離( d k )與觀察向量分組( d k (v) )。再把特徵向量 量化後的觀察向量分組與觀察向量分組距離做排序,即可找出最小觀察向量分組與觀察 向量距離和倒數第二小的觀察向量分組與觀察向量距離,再以最小觀察向量分組與觀察 向量距離和倒數第二小的觀察向量分組與觀察向量距離來做 FVQ 的運算。 有關圖 4.5 的變數敘述如下: vo : 音框的特徵向量 vd 1 :特徵向量 vo 在 codebook 中的最短觀察向量分組距離 vd 2 :特徵向量 vo 在 codebook 中的倒數第二短觀察向量分組距離. p1 :特徵向量 vo 於三角形歸屬函數 A1 的隸屬程度(Degree of Membership)。 p 2 :特徵向量 vo 於三角形歸屬函數 A2 的隸屬程度(Degree of Membership)。. 31.
(41) μ A (x). p1 = μ A1 ( vo ) p 2 = μ A2 ( vo ). vd 1. vo. vd 2. x. 圖 4.5 FVQ 於三角形歸屬函數圖 圖 4.5 可以將為 vo 表示為下面公式, vo = vd 1 * p1 + vd 2 * p 2. (4-18). 為了避免向量量化的贏者全拿的特性,因此本論文使用模糊向量量化,讓向量量化 結果更合理也比較準確。最後將語音辨識系統結合模糊向量量化(FVQ)則可把 Forward variable 演算法的起始公式(4-3)結合(4-18)改為公式(4-19),遞迴運算公式(4-4)結合(4-18). 改為公式(4-20),下列式子為模糊向量量化結合 Forward variable 演算法之算式。 起始: α1 (i ) = πi ⋅ bi (v0 ), 1 ≤ i ≤ N為N * 1矩陣. (4-19). 其中 v0 = vd 1 * p1 + vd 2 * p 2 遞迴運算 N. α t +1 ( j ) = [∑ α t (i ) ⋅ aij ] ⋅ bi (vt +1 ), 1 ≤ j ≤ N , d = 1,2,..., t − 1 i =1. 其中 vt = vd 1 * p1 + vd 2 * p 2 結束:. 32. (4-20).
(42) N. P (O | λ ) = ∑ αT (i ). (4-21). i =1. 公式(4-21)即為語音辨識系統結合模糊向量量化(FVQ)的辨識結果。 同樣以模糊向量量化結合維特比演算法來求得最佳狀態序列,因此把維特比演算法 的起始公式(4-6)結合(4-18)成為公式(4-23),遞迴運算公式(4-8)結合(4-18)成為公式 (4-24),下列式子為模糊向量量化結合維特比演算法之算式。. 起始: ψ1 (i ) = 0. (4-22). δ1 (i ) = πi ⋅ bi (v0 ), 1 ≤ i ≤ N為N * 1矩陣. (4-23). 其中 v0 = vd 1 * p1 + vd 2 * p 2 遞迴運算 N. δt ( j ) = max[∑ δt −1 (i ) ⋅ aij ] ⋅ bi (vt ), 1 ≤ j ≤ N , t = 1, 2, ..., t − 1. (4-24). i =1. N. ψ t ( j ) = arg max[max ∑ δt −1 (i ) ⋅ aij ],1 ≤ j ≤ N , t = 1, 2, ..., t − 1. (4-25). i =1. 其中 vt = vd 1 * p1 + vd 2 * p 2 結束: P ∗ = max[δT (i )], 1 ≤ i ≤ N. (4-26). qT∗ = arg max[δT (i )], 1 ≤ i ≤ N. (4-27). 回溯: qt∗ = ψ t +1 (qt*+1 ), t = T − 1, T − 2, ...1. (4-28). DHMM 模型訓練結合模糊向量量化的流程是先收集該聲音的集合,將語音一筆一筆. 33.
(43) 帶入初始的 DHMM 模型找出每筆語音的最佳狀態序列公式(4-28),當統計完所有筆數 的語音後,即可更新參數,然後再以新的參數之模型重複做上述猜測狀態序列和統計更 新的動作,直到模型參數沒變化時即可結束而得到該聲音的模型參數。經統計我們可以 重新更新參數如式子(4-13)、(4-14),即完成以 FVQ 訓練 DHMM 模型的過程。圖 4.6 為 DHMM 語音模型訓練結合模糊向量量化流程圖。. 圖 4.6 DHMM 語音模型訓練結合模糊向量量化流程圖. 34.
(44) 4.4 語音辨識系統結合 FVQ、EMD 和 GA 為了提升語音辨識系統的辨識率,本論文在 DHMM 模型的訓練上加入了 FVQ,同 樣將 FVQ 加入語音辨識系統上。在語音的抗雜訊方面以 GA 結合 EMD 來分離雜訊, 讓語音辨識系統有更好的抗雜訊能力,最後我們將 FVQ,EMD 結合實數型 GA 和語音 辨識系統做結合,使得語音辨識系統有更好的辨識率與抗雜訊能力。 圖 4.7 為本論文語音辨識系統加入 FVQ,EMD 與結合實數型 GA 的流程圖,圖 4.7 中(a)為語音辨識,其步驟是先將輸入語音做語音端點偵測取出語音資料,再以 EMD 結 合 GA 將雜訊分離,然後經語音預強調、語音加上漢明窗、快速傅利葉轉換來取得語音 的音框特徵向量,再將音框特徵向量結合 FVQ 並代入以 FVQ 訓練的 DHMM 模型,最 後得到語音辨識結果。 圖 4.7 中(b)為語音 DHMM 模型得訓練,其步驟是先將輸入語音做語音端點偵測取 出語音資料,經語音預強調、語音加上漢明窗、快速傅利葉轉換來取得語音的音框特徵 向量,再將音框特徵向量做向量量化動作並練成 codebook,以 FVQ 來取得觀察向量, 代入 DHMM 模型並對 DHMM 模型做訓練,最後完成 DHMM 語音模型訓練。圖 4.7 為 語音辨識系統結合 FVQ,EMD+GA 圖。. 35.
(45) 輸入語音. 快速傅利葉轉 換. 輸入語音. 特徵向量擷取. 語音端點偵測. 特徵向量擷取. 語音端點偵測. Codebook 訓 練. EMD+GA. FVQ. 語音預強調. Viterbi +FVQ. 語音預強調. 以FVQ訓練的 DHMM模型. 漢明窗. DHMM Modeling. 漢明窗. 辨識結果. 快速傅利葉轉 換. (a) 語音辨識. (b) 語音DHMM模型訓練. 圖 4.7 FVQ,EMD 與結合實數型 GA 的流程圖,(a)語音辨識,(b)語音 DHMM 模型訓 練. 36.
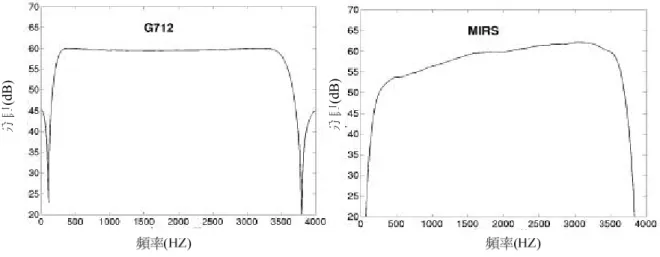
(46) 第五章 實驗方式與結果 5.1 實驗語料 本論文採用 Aurora2 database[30]作為語音測試與訓練的基礎,Aurora2 所使用的語 料為歐洲電信標準協會 (European Telecommunications Standards Institute, ETSI) 所發行 的語料。它是一套含雜訊的英語連續數字語料,而實驗的環境與實驗語者皆是美國成年 人,由 TIDigits 這套不含雜訊的英語連續數字語料的部分內容加上雜訊而成的。每個乾 淨不含雜訊的音段(utterance)先通過特定的通道效應 G.712 與 MIRS,其中 G.712 通道效 應描述的是傳統電話線使用之脈碼調變(Pulse Code Modulation, PCM)的頻道特性;而 MIRS 通道效應則是類似手機上 GSM(Global System of Mobile Communications)的頻道. 特性,如圖 5.1。各種訊噪比加上八種不同的加成性雜訊(圖 5.2),並以測試語料通過的 通道效應及加成性雜訊的種類,分成 A、B、C 三種測試組合(testing set),表 5-1 為 Aurora2. 分貝(dB). 分貝(dB). 語音的訓練組合,表 5-2 為 Aurora2 測試的語音組合。. 圖 5.1 G712 與 MIRS 通道效應. 37.
(47) 地下鐵. 人聲. 分 貝. 分 貝. 頻率(HZ). 頻率(HZ). 展覽會館. 汽車. 分 貝. 分 貝. 頻率(HZ). 頻率(HZ). 街道. 餐廳 分 貝. 分 貝. 頻率(HZ). 頻率(HZ). 機場 火車站 分 貝. 分 貝. 頻率(HZ). 頻率(HZ). 圖 5.2 八種不同的加成性雜訊. 38.
(48) 表 5-1 Aurora2 語音的訓練組合 Aurora2(訓練部分). 取樣頻率: 8KHZ 語音內容: 英語數字 0 ~ 9 : one、two、three、four、five、six、seven、eight、 nine、 zero、oh, 共計十一種發音 乾淨語音來源: 55 男 55 女 音段數: 8440 通道效應: G.712 的通道效應 雜訊訊噪比: 無. 訓練模式:. 表 5-2 Aurora2 測試的語音組合 Aurora2(測試部分). 取樣頻率: 8KHZ. 測試組合. A組. B組. C組. 音段數: 28028. 音段數: 28028. 音段數: 14014. 通道效應: G.712 的通道效應. 通道效應: G.712 的通道效應. 通道效應: MIRS 通道效應. 加成性雜訊: -地下鐵雜訊 -人聲雜訊 -汽車雜訊 -展覽會館雜訊. 加成性雜訊: -餐廳雜訊 -街道雜訊 -機場雜訊 -火車站雜訊. 加成性雜訊: -地下鐵雜訊 -街道雜訊. 加成性雜訊之訊噪比: 20dB、15dB、10dB、 加成性雜訊之訊噪比: 加成性雜訊之訊噪比: 5dB、0dB、乾淨語音 20dB、15dB、10dB、 20dB、15dB、10dB、 5dB、0dB、乾淨語音 5dB、0dB、乾淨語音. 39.
(49) 5.2 實驗方法與數據 實驗方法: 1. 單純 DHMM(無 EMD 與 FVQ): 使用 Aurora2 database 的乾淨語音語料做訓練如表 5-1,測試語料如表 5-2,我們以乾淨語音表 5-1,訓練各個 DHMM 語音模型,再. 以測試語音表 5-2 做測試。 2. DHMM+FVQ: 將乾淨語音如表 5-1 以第 4.3 節所述之模糊向量量化(FVQ)建立 DHMM 並訓練各個 DHMM 語音模型,再將測試語音表 5-2 結合模糊向量量化 (FVQ)做測試。 3. DHMM+EMD: 將乾淨語音以表 5-1 建立 DHMM 並訓練各個 DHMM 語音模型,. 再將測試語音表 5-2 以第 3.3 節模態函數分解(EMD)加上基因演算法(GA)做測試。 4. DHMM+FVQ+EMD: 將乾淨語音如表 5-1 以模糊向量量化(FVQ)上來建立 DHMM. 並訓練各個 DHMM 語音模型,再將測試語音表 5-2 以模態函數分解(EMD)加上基 因演算法(GA)加上模糊向量量化(FVQ)做測試。 5. CHMM 與 DHMM 辨識速度之比較: 在 CHMM 方面,我們以乾淨語音表 5-1,訓. 練各個 CHMM 語音模型,再以表 5-2 統計語音辨識所花費的時間。在 DHMM 方 面,我們以乾淨語音表 5-1,訓練各個 DHMM 語音模型,再以表 5-2 統計語音辨 識所花費的時間。 6. 實數型 GA 參數設定:每代染色體數 16,每個染色體有 5 個實數基因,分別對應至 IMF1 到 IMF5 重組的權重 wi ,在染色體存活率為 0.5,突變率為 0.05,以隨機配. 40.
(50) 對作為選擇方法,交配方式為線性交配,演化代數為 500 代。. 5.2.1 以 DHMM(無 FVQ 與 EMD)的測試結果 使用 Aurora2 database 的乾淨語音作訓練如表 5-1,測試部分如表 5-2。表 5-3、表 5-4、表 5-5 為以 DHMM 無 FVQ 與 EMD 在不同測試環境之辨識結果。. 表 5-3 無 FVQ 與 EMD 於 A 組環境雜訊之辨識結果 A 組環境雜訊. 訊噪比. 地下鐵. 人聲. 汽車. 展覽會館. clean. 97.51. 97.28. 97.21. 97.63. 20db. 92.22. 84.82. 88.78. 89.49. 15db. 86.79. 72.4. 80.73. 84.79. 10db. 76.92. 50.6. 58.88. 70.66. 5db. 41.37. 20.2. 41.42. 37.29. 0db 0~20db 平均. 23.6. 11.47. 18.06. 21.9. 64.18. 47.898. 57.574. 60.826. 表 5-4 無 FVQ 與 EMD 於 B 組環境雜訊之辨識結果 B 組環境雜訊. 訊噪比. 餐廳. 街道. 機場. 火車站. clean. 97.1. 97.28. 97.1. 97.2. 20db. 85.95. 89.62. 87.12. 88.33. 15db. 74.33. 80.36. 77.63. 79.59. 10db. 54.1. 63.2. 51.23. 54.8. 5db. 20.43. 40.45. 23.62. 21.94. 0db. 13.53. 19.1. 12.82. 15.25. 0~20db 平均. 49.668. 58.546. 50.484. 51.982. 41.
(51) 表 5-5 無 FVQ 與 EMD 於 C 組環境雜訊之辨識結果 C 組環境雜訊. 訊噪比. 地下鐵(Test C). 街道(Test C). clean. 97.55. 97.63. 20db. 89.23. 90.1. 15db. 81.54. 80.9. 10db. 68.17. 64.78. 5db. 32.72. 34.97. 0db 0~20db 平均. 20.05. 21.76. 58.342. 58.502. 5.2.2 以 DHMM 結合 FVQ 的測試結果 我們將乾淨語音表 5-1 結合模糊向量量化(FVQ)建立 DHMM 並訓練每個 DHMM 語 音模型,再將測試語音表 5-2 結合模糊向量量化(FVQ)作測試,結果如下。表 5-6、表 5-7、表 5-8 為以 DHMM+FVQ 在不同測試環境之辨識結果。. 表 5-6 DHMM+FVQ 在 A 組環境雜訊之辨識結果 A 組環境雜訊. 訊噪比. 地下鐵. 人聲. 汽車. 展覽會館. clean. 98.53. 98.36. 97.85. 97.95. 20db. 94.04. 93.9. 95.68. 94.54. 15db. 92.2. 86.9. 86.1. 90.58. 10db. 80.8. 70.6. 60.8. 73.08. 5db. 43.39. 48.84. 46.4. 41.64. 0db 0~20db 平均. 25.86. 23.8. 23.65. 24.34. 67.258. 64.808. 62.526. 64.836. 42.
(52) 表 5-7 DHMM+FVQ 在 B 組環境雜訊之辨識結果 B 組環境雜訊. 訊噪比. 餐廳. 街道. 機場. 火車站. clean. 98.53. 98.36. 97.85. 97.95. 20db. 95.9. 93.34. 94.18. 93.71. 15db. 89.83. 85.05. 86.88. 87.25. 10db. 72.52. 67.06. 76.6. 73.66. 5db. 50.5. 41.56. 53.33. 49.24. 0db 0~20db 平均. 24.24. 24.12. 31.11. 29.62. 66.598. 62.226. 68.42. 66.696. 表 5-8 DHMM+FVQ 在 C 組環境雜訊之辨識結果 C 組環境雜訊. 訊噪比. 地下鐵. 街道. clean. 98.4. 98.6. 20db. 92.58. 96.1. 15db. 84.55. 84.68. 10db. 70.1. 68.06. 5db. 34.96. 44.09. 0db 0~20db 平均. 22.13. 23.75. 60.864. 63.336. 5.2.3 語音訊號以 DHMM+EMD+GA 的測試結果 我們將乾淨語音表 5-1 建立 DHMM 模型並訓練各個 DHMM 語音模型,再將測試 語音表 5-2 以模態函數分解(EMD)加上基因演算法(GA)作測試,結果如下。表 5-9、表 5-10、表 5-11 為以 DHMM+EMD 在不同測試環境之辨識結果。. 43.
(53) 表 5-9 DHMM+EMD 在 A 組環境雜訊之辨識結果 A 組環境雜訊. 訊噪比. 地下鐵. 人聲. 汽車. 展覽會館. clean. 97.3. 97.42. 97.31. 97.01. 20db. 93.1. 89.2. 95.92. 94.52. 15db. 88.9. 86.72. 86.62. 89.32. 10db. 86.2. 74.25. 70.12. 79.54. 5db. 60.26. 59.26. 55.1. 62.94. 0db. 30.8. 35.4. 36.8. 36.72. 0~20db 平均. 71.852. 68.966. 68.912. 72.608. 表 5-10 DHMM+EMD 在 B 組環境雜訊之辨識結果 B 組環境雜訊. 訊噪比. 餐廳. 街道. 機場. 火車站. clean. 97.22. 97.56. 97.4. 97.1. 20db. 93.2. 93.2. 91.33. 90.64. 15db. 89.96. 86.4. 85.1. 86.42. 10db. 80.1. 83.63. 77.1. 77.42. 5db. 56.24. 62.37. 63.9. 59.6. 0db 0~20db 平均. 36.52. 36.72. 38.3. 39.4. 71.204. 72.464. 71.146. 70.696. 表 5-11 DHMM+EMD 在 C 組環境雜訊之辨識結果 C 組環境雜訊. 訊噪比. 地下鐵. 街道. clean. 97.8. 97.88. 20db. 91.21. 95.2. 15db. 84.02. 84.24. 10db. 77.42. 77.8. 5db. 57.5. 58.77. 0db 0~20db 平均. 35.2. 37.34. 69.07. 70.67. 44.
(54) 5.2.4 語音訊號以 DHMM+FVQ+EMD+GA 的測試結果 我們將乾淨語音表 5-1 以模糊向量量化(FVQ)上來建立 DHMM 並訓練各個 DHMM 語音模型,再將測試語音表 5-2 以模態函數分解(EMD)加上基因演算法(GA)加上模糊向 量量化(FVQ)作測試,結果如下。表 5-12、表 5-13、表 5-14 為以 DHMM+FVQ+EMD 在不同測試環境之辨識結果。. 表 5-12 DHMM+FVQ+EMD 在 A 組環境雜訊之辨識結果 A 組環境雜訊. 訊噪比. 地下鐵. 人聲. 汽車. 展覽會館. clean. 98.31. 98.5. 98.12. 97.88. 20db. 96.96. 97.1. 96.9. 96.82. 15db. 95.52. 93.4. 92.22. 93.64. 10db. 88.12. 83.32. 84.1. 85.76. 5db. 66.2. 63.3. 60.62. 66.1. 0db 0~20db 平均. 43.86. 44.8. 43.24. 46.17. 78.132. 76.384. 75.416. 77.698. 表 5-13 DHMM+FVQ+EMD 在 B 組環境雜訊之辨識結果 B 組環境雜訊. 訊噪比. 餐廳. 街道. 機場. 火車站. clean. 97.56. 97.9. 97.24. 97.92. 20db. 96.9. 96.1. 96.2. 95.26. 15db. 94.52. 93.81. 94.3. 93.64. 10db. 86.83. 85.1. 85.99. 85.74. 5db. 66.54. 65.82. 67.34. 61.4. 0db 0~20db 平均. 45.4. 46.46. 44.2. 45.92. 78.038. 77.458. 77.606. 76.392. 45.
(55) 表 5-14 DHMM+FVQ+EMD 在 C 組環境雜訊之辨識結果 C 組環境雜訊. 訊噪比. 地下鐵. 街道. clean. 97.86. 98. 20db. 96.86. 97.6. 15db. 94.24. 95.2. 10db. 88.15. 89.62. 5db. 70.27. 71.8. 0db 0~20db 平均. 52.8. 51.12. 80.464. 81.068. 5.2.5 語音以 CHMM、DHMM 與 FVQ+DHMM 在不同環境的辨識時間 我們以表 5-2 作為測試語音,其中每一個測試環境包含了 6 種 SNR,分別為乾淨、 20dB、15dB、10dB、5dB 與 0dB,而每一個測試環境在一種 SNR 的語音數有 1001 個。. 我們以 CHMM、DHMM 與 FVQ+DHMM 計算各種環境在不同 SNR 的辨識時間。表 5-15、表 5-16、表 5-17 為以 CHMM 的在不同測試環境在不同 SNR 的辨識時間。表 5-18、. 表 5-19、表 5-20 為以 DHMM 的在不同測試環境在不同 SNR 的辨識時間。表 5-21、表 5-22、表 5-23 為以 DHMM+FVQ 的在不同測試環境在不同 SNR 的辨識時間。. 表 5-15 CHMM 在 A 組環境雜訊之辨識時間 A 組環境噪音辨識時間(秒). 訊噪比. 地下鐵. 人聲. 汽車. 展覽會館. clean. 28.066. 30.033. 33.102. 34.247. 20db. 41.175. 29.932. 40.612. 40.141. 15db. 42.64. 40.773. 40.255. 38.736. 10db. 47.123. 41.064. 39.864. 39.281. 5db. 40.212. 39.572. 40.879. 38.363. 0db 0~20db 平均. 42.047. 41.084. 39.922. 39.032. 42.6394. 38.485. 40.3064. 39.1106. 46.
(56) 表 5-16 CHMM 在 B 組環境雜訊之辨識時間 B 組環境噪音辨識時間(秒). 訊噪比. 餐廳. 街道. 機場. 火車站. clean. 35.963. 28.697. 33.319. 34.407. 20db. 39.997. 36.912. 38.059. 32.323. 15db. 36.353. 38.411. 39.962. 34.857. 10db. 38.81. 36.768. 36.998. 32.857. 5db. 38.57. 42.307. 35.855. 31.134. 0db 0~20db 平均. 39.81. 38.773. 37.498. 30.303. 38.708. 38.6342. 37.6744. 32.2948. 表 5-17 CHMM 在 C 組環境雜訊之辨識時間 C 組環境噪音辨識時間(秒). 訊噪比. 地下鐵(Test C). 街道(Test C). clean. 31.496. 31.011. 20db. 33.497. 31.467. 15db. 29.624. 31.202. 10db. 31.817. 33.71. 5db. 34.43. 33.484. 0db 0~20db 平均. 35.505. 31.756. 32.9746. 32.3238. 表 5-18 DHMM 在 A 組環境雜訊之辨識時間 A 組環境噪音辨識時間(秒). 訊噪比. 地下鐵. 人聲. 汽車. 展覽會館. clean. 20.7. 22.5. 24.4. 25.2. 20db. 32.8. 20.3. 31.1. 33.5. 15db. 34.8. 33.7. 33.5. 30.6. 10db. 39.3. 35.3. 33.4. 32.9. 5db. 33.2. 30.1. 32.8. 30.7. 0db 0~20db 平均. 31.5. 32.6. 30.2. 31.2. 34.32. 30.4. 32.2. 31.78. 47.
(57) 表 5-19 DHMM 在 B 組環境雜訊之辨識時間 B 組環境噪音辨識時間(秒). 訊噪比. 餐廳. 街道. 機場. 火車站. clean. 28.6. 21.7. 23.4. 26.3. 20db. 30.1. 28.2. 31.2. 25.4. 15db. 29.4. 29.1. 33.2. 28.8. 10db. 31.5. 28.7. 28.5. 26.7. 5db. 29.8. 34.3. 28.4. 23.2. 0db 0~20db 平均. 33.9. 30.7. 30.8. 23.3. 30.94. 30.2. 30.42. 25.48. 表 5-20 DHMM 在 C 組環境雜訊之辨識時間 C 組環境噪音辨識時間(秒). 訊噪比. 地下鐵(Test C). 街道(Test C). clean. 25.3. 24.6. 20db. 26.5. 26.5. 15db. 23.6. 25.3. 10db. 25.3. 28.5. 5db. 24.7. 27.4. 0db 0~20db 平均. 28.9. 23.6. 25.8. 26.26. 表 5-21 DHMM+FVQ 在 A 組環境雜訊之辨識時間 A 組環境噪音辨識時間(秒). 訊噪比. 地下鐵. 人聲. 汽車. 展覽會館. clean. 21.3. 23.1. 24.8. 25.9. 20db. 33.4. 20.9. 31.7. 34.2. 15db. 35.2. 34.1. 34.1. 31.2. 10db. 40.1. 35.9. 33.9. 33.5. 5db. 33.8. 30.7. 33.3. 31.4. 0db 0~20db 平均. 32. 33.1. 30.8. 31.8. 34.9. 30.94. 32.76. 32.42. 48.
(58) 表 5-22 DHMM+FVQ 在 B 組環境雜訊之辨識時間 B 組環境噪音辨識時間(秒). 訊噪比. 餐廳. 街道. 機場. 火車站. clean. 29.1. 22.1. 23.9. 26.9. 20db. 30.7. 28.8. 31.8. 26. 15db. 30.1. 29.7. 33.8. 29.3. 10db. 32. 29.5. 29.1. 27.4. 5db. 30.4. 34.9. 29. 23.8. 0db 0~20db 平均. 34.5. 31.1. 31.4. 23.9. 31.54. 30.8. 31.02. 26.08. 表 5-23 DHMM+FVQ 在 C 組環境雜訊之辨識時間 C 組環境噪音辨識時間 ( 秒 ). 訊噪比. 地下鐵 (Test C). 街道 (Test C). clean. 25.9. 25.2. 20db. 27.1. 27.2. 15db. 24.2. 25.9. 10db. 25.9. 29.3. 5db. 25.3. 28. 0db 0~20db 平均. 29.5. 24.5. 26.4. 26.98. 5.3 實驗結果分析 5.3.1 針對 SNR 0 ~ 20dB 的平均辨識率分析 圖 5.3、圖 5.4、圖 5.5 是由表 5-3 ~ 表 5-14 整理而成,為 Aurora2 database 在使用 DHMM+FVQ、DHMM+EMD+GA、DHMM+FVQ+EMD+GA 與單純 DHMM(無 EMD. 與 FVQ)在 SNR 為 0~20dB 與不同環境之比較:由圖可以看出使用 DHMM+ FVQ、 DHMM+EMD+GA 或 DHMM+EMD+FVQ+GA 辨識率都比單純 DHMM 高,尤其是使用 49.
數據


+7






相關文件
FPGA –現場可規劃邏輯陣列 (field- programmable
FPGA –現場可規劃邏輯陣列 (field- programmable gate
FPGA –現場可規劃邏輯陣列 (field- programmable
FPGA –現場可規劃邏輯陣列 (field- programmable
語文運用 留意錯別字 辨識近義詞及詞語 的感情色彩 認識成語
massive gravity to Ho ř ava-Lifshitz Stochastic quantization and the discrete quantization scheme used for dimer model and crystal melting. are
(1828) An American Dictionary of the English
加強「漢語拼音」教學,使學生掌握
