一個使用雙分群演算法進行智慧型手機應用程式推薦之框架 - 政大學術集成
82
0
0
全文
(2) 一個使用雙分群演算法進行智慧型手機應用程式推薦 之框架 A Framework for Using Co-Clustering Algorithms to Recommend Smartphone Apps 研 究 生:葉思妤 指導教授:徐國偉. 政 治 大 國立政治大學 資訊科學系. Nat. sit. y. ‧. 碩士論文. 學. ‧ 國. 立. Student:Szu-Yu Yeh Advisor:Kuo-Wei Hsu. n. er. io. A Thesis submitteda to Department of Computer Science v i l n National C h Chengchi University i U e h n c g in partial fulfillment of the Requirements for the degree of Master in Computer Science. 中華民國一百零三年七月 July 2014.
(3) 摘要 近年來,智慧型手機(Smartphone)的銷量超過其他型式手機。智慧型 手機具有更先進、更開放的行動作業系統,可允許使用者自行安裝應用程 式軟體(Application)來擴充手機功能。目前市面上的應用程式數量非常龐 大,在眾多的應用程式和有限的時間下,使用者不太可能將所有的應用程 式下載試用,所以對使用者而言,找出自己所想要和需要的應用程式,是. 政 治 大. 個困難的問題。推薦系統可依照使用者的喜好,或是準備推薦項目的相似. 立. 程度來做推薦,讓使用者能較快得到想要的資訊,目前主要的方式有協同. ‧ 國. 學. 過濾(Collaborative Filtering, CF)、內容過濾(Content-Based Filtering, CBF), 還有結合前述兩種方式的混和式推薦(Hybrid Approach)。. ‧. 本研究所使用的資料集是由政治大學資訊科學系所開發的實驗平台蒐. y. Nat. io. sit. 集而來。資料以側錄的方式,將使用者實際操作手機應用程式的狀況記錄. er. 下來,其中包含了 25 位使用者和 1125 個應用程式。我們將原始資料集以. n. a. v. l C 三種方式整理成三個資料集:一、是否使用應用程式;二、使用應用程式 ni. hengchi U. 的次數;三、使用應用程式的頻率,其值表示使用者在該應用程式的使用 狀況。我們並將資料分成前段與後段時間兩部分,以前段時間的資料當作 基準,推薦最多同群使用者使用的應用程式、同群使用者使用次數最多的 應用程式,以及同群使用者最常使用的應用程式,然後以後段時間的資料 做驗證,計算推薦結果的準確率與召回率加以比較。 我們使用知名的 Information Theoretic Co-Clustering Algorithm 和兩種 基於 Minimum Squared Residue Co-Clustering Algorithm 的演算法將使用者 與應用程式分群,利用分群結果做計算,推薦應用程式給使用者。實驗發 I.
(4) 現三種演算法在第一個資料集的準確率與召回率表現最好,此資料集以 0 和 1 的值,來紀錄使用者在各應用程式的使用狀況。實驗比較三個演算法 的結果,在大部分的情況之下,一個基於 Minimum Squared Residue CoClustering Algorithm 的演算法,給出的結果較好。 此外,我們也發現應用程式開發者將應用程式上架提供下載時,以個 人主觀想法對該應用程式定義其分類,與我們利用雙分群方法,以使用者 實際操作的情況將應用程式分類的結果有些差異,或許在 Google Play 的 分類上可做調整。. 立. 政 治 大. ‧ 國. 學. 本研究提出推薦系統的框架具有彈性,未來可以使用不同的雙分群演 算法做分群,也能套用其他的推薦方式。. n. al. er. io. sit. y. ‧. Nat. 關鍵字:雙分群、智慧型手機應用程式、推薦系統. Ch. engchi. II. i n U. v.
(5) Abstract. With the rapid evolution of smartphone devices, tens of thousands applications have been supplied on online stores such as App Store (operated by Apple Inc.) and Google Play (operated by Google Inc.). Since there are many applications, recommending applications to users becomes an important topic. In this thesis, we present a framework for using a co-clustering algorithm to. 政 治 大 People usually rely on some external knowledge to make informed decisions 立. recommend applications to users. Recommendations are a part of everyday life.. ‧ 國. 學. about a particular artifact or action. Using recommender systems is one of. general approaches that help people make decisions. There are three common. ‧. types of recommender systems, namely collaborative filtering, content-based filtering, and hybrid recommender systems.. y. Nat. io. sit. In this thesis, we use the dataset that was collected by a tool developed by. er. the Department of Computer Science at the National Chengchi University. It. n. a. v. i smartphones. We l Cwhen they were usingn their recorded the users’ behavior. i U. h. h of datasets: 1) indicating whether n g ctypes transform the original dataset intoethree a user used an application; 2) indicating the number of uses made by a user for an application; 3) indicating the frequency of uses made by a user for an application. Furthermore, we divide each dataset into two parts: The first part. containing data for the early time period is used as the recommending base, and the second part containing data for the late time period is used for verifying the results. We utilize three famous co-clustering algorithms, which are the Information Theoretic Co-Clustering Algorithm and two algorithms based on. III.
(6) the Minimum Squared Residue Co-Clustering Algorithm, in the proposed framework. According to the clusters given by a co-clustering algorithm, we recommend top five applications to each user by referring to the maximum number of users, the maximum number of uses, and the most frequently used applications that are in the same cluster. We calculate the precision and recall values to compare the results. From the experimental results, we find that the. 治 政 algorithms based on the Minimum Squared Residue 大 Co-Clustering Algorithm is 立 better than the other two algorithms in terms of the precision and recall values. best result corresponds to the first type of dataset and also that one of the. ‧ 國. 學. From the clusters of applications, we obtain some interesting insights into. ‧. the categories of applications. The categories of applications are set by their developers, but the users may not totally agree with the settings. There might be. y. Nat. er. io. sit. space for improvement for the categories of applications on the online store. In the future, we can utilize different co-clustering algorithms and other. n. a. recommended methods inlthe ni Cproposed framework.. hengchi U. v. Keyword: Co-clustering、Smartphone、Mobile Application、Recommender System. IV.
(7) 致謝 本論文可以順利完成,首先要感謝我的家人,讓我在研究所學習的這 段期間,不用擔心其他事務,能放心的將學業完成,親愛的爸爸、媽媽總 是相信我的決定,給我很大的支持與幫助。 感謝我的好朋友,辰輝、佳妤、曉吟、嬴爵、鈺婷,在我壓力大時總 是傾聽我的想法,適時的提供建議,並和我一起討論和解決問題。感謝趨 勢科技的同事們,總是默默的關心著我,幫忙我工作上的困難,特別是在 怡、語婷,常陪我聊天。感謝和平高中的好朋友淇秝、嘉玲,一直以來陪 伴著我,聽我訴苦。 最要感謝的是我的指導教授徐國偉老師,可以成為老師的學生真的非 常幸運,每次在討論論文時,給予我許多寶貴的意見與信心,也非常有耐 心的給我很多指導以及鼓勵,讓我能夠按照進度至最後完成論文。 最後,感謝所有關心、幫助我的人。. 立. 政 治 大. ‧. ‧ 國. 學. y. Nat. sit. n. al. er. io. 葉思妤 謹誌 國立政治大學 資訊科學學系研究所 民國 103 年 7 月. Ch. engchi. V. i n U. v.
(8) 目錄 第一章 緒論 ................................................................................................................................................................... 1 1.1 前言 ...................................................................................................................................................................... 1 1.2 研究動機 .............................................................................................................................................................. 1 1.3 研究目的 .............................................................................................................................................................. 4 1.4 論文架構 .............................................................................................................................................................. 5 第二章 文獻探討 ........................................................................................................................................................... 6 2.1 推薦系統 .............................................................................................................................................................. 6 2.1.1 協同過濾 ...................................................................................................................................................... 6 2.1.2 內容過濾 ...................................................................................................................................................... 7 2.1.3 混合式推薦系統 .......................................................................................................................................... 7 2.2 CO-CLUSTERING (雙分群) .................................................................................................................................... 8 2.2.1 Information Theoretic Co-Clustering Algorithm .......................................................................................... 9 2.2.2 Minimum Squared Residue Co-Clustering Algorithm ................................................................................. 9 2.3 如何使用 CO-CLUSTERING 做推薦系統 ............................................................................................................ 10 2.4 總結 .................................................................................................................................................................... 10 2.4.1 電影 ............................................................................................................................................................ 11 2.4.2 景點/餐廳 ................................................................................................................................................... 13 2.4.3 電子商務 .................................................................................................................................................... 14 2.4.4 文本資料 .................................................................................................................................................... 15 2.4.5 健保 ............................................................................................................................................................ 16 2.4.6 社群網路服務 ............................................................................................................................................ 16 2.4.7 手機應用程式 ............................................................................................................................................ 16. 立. 政 治 大. ‧. ‧ 國. 學. er. io. sit. y. Nat. al. n. iv n C 第三章 基於雙分群的推薦框架 ................................................................................................................................. 18 hengchi U 3.1 總覽 .................................................................................................................................................................... 18 3.2 實際運作範例 .................................................................................................................................................... 20 3.2.1 以使用者是否使用應用程式做推薦......................................................................................................... 20 3.2.2 以使用應用程式之次數做推薦 ................................................................................................................ 22 3.2.3 以使用者使用應用程式的頻率做推薦..................................................................................................... 24. 第四章 實驗 ................................................................................................................................................................. 27 4.1 環境與流程 ........................................................................................................................................................ 27 4.1.1 實驗環境 ......................................................................................................................................................... 27 4.1.2 實驗流程 ......................................................................................................................................................... 27 4.2 資料集 ................................................................................................................................................................ 34 4.3 實驗結果(一) ..................................................................................................................................................... 39. VI.
(9) 4.3.1 以使用者是否使用應用程式做推薦(YN) ................................................................................................ 41 4.3.2 以使用者使用應用程式的次數做推薦(Count) ........................................................................................ 42 4.3.3 以使用者使用應用程式的頻率做推薦(Frequency) ................................................................................. 45 4.3.4 小結 ............................................................................................................................................................ 48 4.4 實驗結果(二) ..................................................................................................................................................... 55 4.4.1 以使用者是否使用應用程式做應用程式分群(YN) ................................................................................ 56 4.4.2 以使用者使用應用程式的次數做應用程式分群(Count) ........................................................................ 58 4.4.3 以使用者使用應用程式的頻率做應用程式分群(Frequency).................................................................. 60 4.4.4 小結 ............................................................................................................................................................ 62 第五章 結論與未來可能研究方向 ............................................................................................................................. 63. 政 治 大. 5.1 結論 .................................................................................................................................................................... 63 5.2 未來可能研究方向..................................................................................................................................................... 64. 立. 參考文獻 ...................................................................................................................................................................... 65. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. VII. i n U. v.
(10) 表目錄 表 1 推薦系統文獻整理.............................................................................................................................................. 11 表 2 本實驗使用之參數說明 ...................................................................................................................................... 33 表 3 使用者操作行為紀錄(範例) ............................................................................................................................... 34 表 4 手機應用程式分類說明(範例) ........................................................................................................................... 35 表 5 實驗使用之資料集及其結果說明 ...................................................................................................................... 37. 政 治 大. 表 6 稀疏矩陣檔案說明.............................................................................................................................................. 39. 立. 表 7 Confusion Matrix 說明 ........................................................................................................................................ 39 表 8 使用者只在後段時間所使用的應用程式個數 .................................................................................................. 40. ‧ 國. 學. 表 9 實驗 4.3.1,以使用者是否使用應用程式資料做推薦,準確率、召回率及 F-measure 比較表 ................... 41 表 10 實驗 4.3.1,平均準確率及召回率 ................................................................................................................... 42. ‧. sit. y. Nat. 表 11 實驗 4.3.2,以使用者使用應用程式的次數資料,推薦使用人數最多的 App,準確率、召回率及 Fmeasure 比較表................................................................................................................................................... 43. io. er. 表 12 實驗 4.3.2,推薦使用人數最多,App 的平均準確率及召回率 ................................................................... 43 表 13 實驗 4.3.2,以使用者使用應用程式的次數資料,推薦使用次數最高的 App,準確率、召回率及 Fmeasure 比較表................................................................................................................................................... 44. n. al. Ch. engchi. i n U. v. 表 14 實驗 4.3.2,推薦使用次數最多,App 的平均準確率及召回率 ................................................................... 45 表 15 實驗 4.3.3,以使用者使用應用程式的頻率資料,推薦使用人數最多的 App,準確率、召回率及 Fmeasure 比較表................................................................................................................................................... 46 表 16 實驗 4.3.3,推薦使用人數最多的 App,平均準確率及召回率 ................................................................... 46 表 17 實驗 4.3.3,以使用者使用應用程式的頻率資料,推薦使用頻率最高的 App,準確率、召回率及 Fmeasure 比較表................................................................................................................................................... 47 表 18 實驗 4.3.3,推薦使用頻率最高的 App,平均準確率及召回率 ................................................................... 48 表 19 以最多人使用的應用程式排名,使用是否使用應用程式資料集中做推薦................................................. 49 表 20 以最多使用次數的應用程式排名,以使用應用程式次數資料集做推薦..................................................... 50. VIII.
(11) 表 21 以使用頻率最高的應用程式排名,以使用應用程式頻率資料集做推薦..................................................... 51 表 22 以最多人使用的應用程式排名,使用是否使用應用程式資料集中做推薦................................................. 52 表 23 以最多人使用的應用程式排名,以使用應用程式次數資料集做推薦 ........................................................ 52 表 24 以最多使用次數的應用程式排名,以使用應用程式次數資料集做推薦..................................................... 53 表 25 以最多人使用的應用程式排名,以使用應用程式頻率資料集做推薦 ........................................................ 53 表 26 以使用頻率最高的應用程式排名,以使用應用程式頻率資料集做推薦..................................................... 54 表 27 準確率平均值比較表........................................................................................................................................ 55. 政 治 大. 表 28 應用程式群集數量............................................................................................................................................ 56. 立. 表 29 Sudoku 相關應用程式資料 ............................................................................................................................... 56. ‧ 國. 學. 表 30 旅遊及交通相關應用程式 ................................................................................................................................ 56 表 31 各群集中,應用程式數量 ................................................................................................................................ 57. ‧. 表 32 各演算法中,四個 Sudoku 相關 App 的分類情形 ......................................................................................... 57. sit. y. Nat. 表 33 各演算法中,五個旅遊與交通相關 App 的分類情形.................................................................................... 58. io. er. 表 34 各群集中,應用程式數量 ................................................................................................................................ 59 表 35 各演算法中,四個 Sudoku 相關 App 的分類情形 ......................................................................................... 59. n. al. Ch. i n U. v. 表 36 各演算法中,五個旅遊與交通相關 App 的分類情形.................................................................................... 60. engchi. 表 37 各群集中,應用程式數量 ................................................................................................................................ 61 表 38 各演算法中,四個 Sudoku 相關 App 的分類情形 ......................................................................................... 61 表 39 各演算法中,五個旅遊與交通相關 App 的分類情形.................................................................................... 62. IX.
(12) 圖目錄 圖 1 本研究推薦流程 .................................................................................................................................................. 18 圖 2 實際運作範例中應用程式被使用者使用情形 .................................................................................................. 21 圖 3 範例一,使用 Information Theoretic Co-Clustering Algorithm ......................................................................... 21 圖 4 範例一,使用 Minimum Squared Residue I Co-Clustering Algorithm .............................................................. 21 圖 5 範例一,使用 Minimum Squared Residue II Co-Clustering Algorithm ............................................................. 22. 政 治 大. 圖 6 使用者使用應用程式的次數示意圖 .................................................................................................................. 23. 立. 圖 7 範例二,使用 Information Theoretic Co-Clustering Algorithm ......................................................................... 23 圖 8 範例二,使用 Minimum Squared Residue I Co-Clustering Algorithm .............................................................. 23. ‧ 國. 學. 圖 9 範例二,使用 Minimum Squared Residue II Co-Clustering Algorithm ............................................................. 24 圖 10 使用者使用應用程式的頻率示意圖 ................................................................................................................ 25. ‧. 圖 11 範例三,使用 Information Theoretic Co-Clustering Algorithm ....................................................................... 25. y. Nat. sit. 圖 12 範例三,使用 Minimum Squared Residue I Co-Clustering Algorithm ............................................................ 25. er. io. 圖 13 範例三,使用 Minimum Squared Residue II Co-Clustering Algorithm ........................................................... 26. al. n. iv n C 圖 19 使用者使用應用程式個數 ................................................................................................................................ 35 hengchi U 圖 18 實驗流程圖 ........................................................................................................................................................ 29. 圖 20 應用程式在各分類的分布 ................................................................................................................................ 36 圖 21 各使用者使用應用程式的總次數 .................................................................................................................... 38. X.
(13) 第一章 緒論 1.1 前言 近年來,智慧型手機(Smartphone)的銷量已經超過了市場上的其他手機。智慧型手機 具有獨立的行動作業系統,可透過安裝應用軟體(Application,簡稱 App)、遊戲等程式來 擴充手機功能。目前市面上的應用程式數量非常龐大,使用者可能在不清楚應用程式的情 況下,下載了不適用的應用軟體,往往浪費許多時間和金錢。在此,我們使用雙分群(Co-. 政 治 大. Clustering)方法來建置推薦系統(Recommender System),讓使用者可以在較短的時間內,. 立. 找到自己所需的應用程式。. ‧. ‧ 國. 學. 1.2 研究動機. sit. y. Nat. 全球的科技持續且迅速的發展,人們在日常生活中已經跟手機有著密不可分的關係。. io. er. 伴隨著智慧型手機科技的發展,手機的功能也越來越多,其中最熱門的討論話題,莫過於 手機上使用的應用程式軟體。聯合新聞網報導,根據 Google 調查,台灣智慧型手機使用. n. al. Ch. i n U. v. 者平均安裝 30 個應用程式,超過美國和中國,顯示民眾對行動裝置相當依賴。當 Apple. engchi. 的 App Store 與 Google 的 Play Market(之前稱為 Android Market)陸續登場,我們感受到了 App 的狂潮。在短短四年內,在這兩個最主要市集上累積的 App 數量,已經跨越了 100 萬 的規模門檻1。 Android 是一個以 Linux 為基礎的半開放原始碼作業系統,主要用於行動設備,由 Google 成立的 Open Handset Alliance 持續領導與開發中。Android 系統由安迪·魯賓(Andy Rubin)開發製作,最初主要支援手機,於 2005 年 8 月被 Google 收購。2007 年 11 月,. 1. 資料來源:http://mag.udn.com/mag/digital/storypage.jsp?f_ART_ID=422828. 1.
(14) Google 與多家硬體製造商、軟體開發商及電信營運商成立開放手持設備聯盟來共同研發改 良 Android 系統,隨後,Google 以 Apache 免費開源許可證的授權方式,發佈了 Android 的原始碼,讓生產商推出搭載 Android 的智慧型手機,而 Android 作業系統後來更逐漸拓 展到平板電腦及其他領域上。目前使用 Android 系統的手機的大廠,依字母順序排列,包 含 Acer、Asus、Google、HTC、Samsung、Sony 等;平板電腦則有 Acer、Asus、Cisco、 Dell、HTC、Samsung、Sony 等2。Google Play 是由 Google 為 Android 所開發的應用程式 發行平台,於 2008 年 8 月 28 日公開發表並於 2008 年 10 月 22 日正式上線,截止目前,. 政 治 大. 應用程式中的付費服務共支援過一百個國家3,Google Play 上頭有超過 80 萬個 App,而總. 立. 下載次數已超越 250 億次之多4。. ‧ 國. 學. App Store,是蘋果公司為其 iPhone、iPod Touch 以及 iPad 等產品創建和維護的數位應 用發佈平台,允許使用者從 iTunes Store 瀏覽和下載一些由 iOS SDK 或者 Mac SDK 開發. ‧. 的應用程式。根據應用程式發佈的情況,使用者可以付費或者免費將應用程式直接下載到. y. Nat. iOS 設備,也可以透過 Mac OS X 或者 Windows 平台下的 iTunes 下載到電腦中。蘋果的. sit. App Store 於 2008 年 7 月份上線,第三方開發者將 App 提供給蘋果公司審核,發佈後供使. er. io. 用者下載。截至 2012 年底,App Store 服務於全球 155 個國家,總體 App 數量超過 80 萬. n. al. i n C 萬個,並且下載次數超過 500 億次h 。e n gchi U. v. 個,適於 iPad 的 App 30 萬個,下載次數突破 400 億次5。2013 年,App 數量更是超過 90 6. 2. 資料來源:http://zh.wikipedia.org/wiki/Android. 3. 資料來源: http://zh.wikipedia.org/wiki/Google_Play. 4. 資料來源:http://www.bnext.com.tw/article/view/cid/0/id/26012. 5. 資料來源:http://technews.tw/2013/01/08/ios/. 6. 資料來源: http://en.wikipedia.org/wiki/App_Store_(iOS). 2.
(15) 2010 年 10 月 11 日,微軟(Microsoft)正式發佈了智慧型手機作業系統 Windows Phone。 2011 年 2 月,諾基亞(Nokia)與微軟合作研發。目前使用 Windows Phone 系統的行動裝置, 除了 Windows Phone,還有 Acer、Nokia 等品牌。Windows Phone Store(前身為 Windows Phone Marketplace)是由微軟提供的一個針對 Windows Phone 平台的服務,允許使用者能夠 下載由第三方開發的應用軟體。Windows Phone Store 與 Windows Phone 於 2010 年 10 月上 線。截至 2012 年 12 月 31 日,Windows Phone Store 擁有超過 15 萬項應用程式可供使用者 7. 使用 。. 政 治 大. BlackBerry World 是一個由 BlackBerry 公司為 BlackBerry OS 創建的服務,於 2009 年. 立. 4 月 1 日創立,允許使用者下載一些由第三方開發商開發的應用程式。BlackBerry World. ‧ 國. 學. 於 2009 年 4 月上線,目前有超過 10 萬個應用程式可供使用者使用8。於 2013 年 1 月底發 佈的 BlackBerry 10 手機系統平台是開放的,支援以不同方式寫 App 。BlackBerry 10 的開. ‧. 發工具當中,有一個特別的功能叫 Android Runtime,可以直接把 Android 上的 .apk 轉為. y. Nat. BlackBerry 10 上使用的 .bar 檔,簡單來說就是把整個 APP 完全移植到 BlackBerry 10 平台. er. io. sit. 上9。此功能的開發或許可以促使 BlackBerry 的應用程式數量更快速地增加。 目前應用程式軟體,除了可以在智慧型手機上應用之外,在智慧電視(Smart TV)上也. n. al. Ch. i n U. v. 可以下載使用。以往對於大多數使用者在使用電視時,最常使用的功能一定是觀賞電視節. engchi. 目,或是接上影音周邊設備來觀看 DVD 或是藍光光碟。在網路普及化的時代來臨之後, 智慧電視也增添了許多智慧連網的功能。智慧電視可以執行完整的作業系統,並提供一個 軟體平台,供應用軟體開發者,開發他們自己的軟體,並在智慧電視之上執行,讓使用者 除了使用電視原有的功能之外,又多了上網瀏覽網頁、下載應用程式、連結臉書社群網站. 7. 資料來源:http://zh.wikipedia.org/wiki/Windows_Phone_Store. 8. 資料來源: http://en.wikipedia.org/wiki/BlackBerry_World. 9. 資料來源: http://www.eprice.com.hk/mobile/talk/3475/49038/. 3.
(16) 等附加功能。各 Smart TV 也有相對應的 App 可以下載使用,例如 Samsung 有特別針對電 視設計的應用程式。 應用程式的數量持續不斷的增加,使用者的選擇越來越多,如何在有限的時間和預算 中,找到最適合自己的 App,成了值得關注的課題。. 1.3 研究目的. 政 治 大. 目前推薦 App 的網站有許多,像是德國的 AndroidPIT 網站(www.androidpit.com),就 是一個推薦使用者 Android 作業系統 App 的網站。使用者可以在這裡尋找適合的應用程式,. 立. 應用程式開發者也可以在此發佈自己的 App。當使用者尚未輸入任何資訊時,網站會依照. ‧ 國. 學. 目前最熱門的 App 做推薦,也可以針對使用者自訂的條件,例如評分(Ratings)、時間 (Time)、下載次數(Installations)等篩選條件做推薦。. ‧. 台灣 APPGuru 網站(www.Appguru.com.tw)的目標,是讓每個人都能找到適合自己用的. sit. y. Nat. App,此網站以收集完整、實用的 App 情報為宗旨。推薦方式以作業系統區分為 Android. io. er. 及 iOS 兩種,並將 App 做分類,分成工具、遊戲、旅遊、攝影等項目,方便使用者尋找。. al. n. iv n C 據。因此,我們想利用使用者平時使用 App。我們利用 h e nAppg的習慣,推薦使用者想要的 chi U. 在眾多的 App 推薦網站下,目前沒有發現依據使用者的喜好及使用習慣做為推薦的依. Co-Clustering 可以同時對資料矩陣的行與列作分群的特性,提出一個彈性的雙分群框架, 對不同的資料集來做分群,並且以分群的結果對使用者做推薦。我們探討不同 CoClustering 演算法在各個不同設定的資料集的推薦結果,計算準確率、召回率以及 F 度量. 作分析及比較。本研究所使用的資料,並非來自傳統的問卷調查,而是由側錄方式直接取 得的資料,所以,可以確保使用者一定有下載並且使用有出現在資料集內的 App。收集資 料的對象是台灣大學校園內使用智慧型手機的族群,而他們所使用的是 Android 作業系統 的手機。. 4.
(17) 1.4 論文架構 本論文分為五個部分,第一章為本篇論文的緒論,包含研究動機、研究目的及論文架 構。在第二章為文獻探討,內容涵蓋本研究相關技術,包含推薦系統與技術、CoClustering,及其相關應用。第三章為本研究之技術探討。實驗結果整理於第四章,用以驗 證本論文中所提出的作法的可行性,而第四章也包含針對實驗結果的討論。第五章對本研. 政 治 大. 究做一個結論,並探討未來可能的研究方向。. 立. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 5. i n U. v.
(18) 第二章 文獻探討 2.1 推薦系統 在現實生活中每個人對每件事會有不同的觀點,這樣的觀點有時很抽象。使用者無法 使用一串關鍵字來正確表達它,推薦系統(Recommender System)就是一個針對個人化問題 發展出來的智慧型系統[3],它能幫助我們快速找尋到我們有興趣的資料或商品,若消費者 覺得購買的商品很符合自己的習性,以後便會增加對系統的信賴度,更常使用系統來消費,. 政 治 大. 而系統能準確預測出消費者對於購買商品的偏好,便能促進電子商品的交易買賣還有增加. 立. 公司的銷售量。可以達到使用者和系統雙贏的目標。對於資訊過量的問題,也有研究[3]指. ‧ 國. 學. 出可以用推薦技術能解決。. 推薦系統目前主要的方式有幾類,其中以協同過濾(Collaborative Filtering,簡稱為 CF). ‧. 和內容過濾(Content-Based Filtering,簡稱為 CBF)為主,前者是利用前人的經驗所給予的. sit. y. Nat. 推薦,而後者是針對個人對某些商品的特徵點計算出這個人對各特徵點的重視程度,進而. io. n. al. er. 做出預測。另外也有混合這兩者的混合式推薦系統(Hybrid Recommender Systems)。. 2.1.1 協同過濾. Ch. engchi. i n U. v. 協同過濾(Collaborative Filtering)推薦系統,是利用有共同經驗之群體的喜好,來推薦 使用者可能會感興趣的資訊,而每個使用者透過合作機制,給予所推薦的資訊相當程度的 回應(如評分),進而幫助別人篩選資訊。協同過濾的原理來自於使用者會喜歡參考有相同 品味或想法的人的建議,透過找出與某使用者行為相似的一群人,然後用這群人過去的記 錄,預測該使用者對於新商品(推薦項目)的喜好程度,進而推薦喜好程度最高的商品給該 使用者。以 Amazon 為例,該公司掌握了客戶過去的歷史購買資訊,累積資訊的結果可以 發現使用者購買商品之相關性,這樣的相關性就成為他推薦的主要依據[4]。. 6.
(19) 協同過濾又可分為評比(Rating)或者群體過濾(Social Filtering)。其後成為電子商務當中 很重要的一環,即根據某顧客以往的購買行為以及從具有相似購買行為的顧客群的購買行 為去推薦這個顧客可能喜歡的品項,也就是藉由社群的喜好提供個人化的資訊、商品等的 推薦服務10。然而協同式推薦系統還是有他的侷限性在,例如像是稀疏性(Sparsity)的問題, 當商品數量超出使用者,兩者的比例十分懸殊時,系統就無法找到適合的推薦者來進行推 薦。另外可能有擴充性(Scalability)的問題,當使用者及物品數量越來越大時,可能會影響 到運算速度。. 立. 2.1.2 內容過濾. 政 治 大. ‧ 國. 學. 內容過濾(Content-Based Filtering)推薦系統,依據的基礎是對物品內容的分析,而不是. ‧. 使用者所給予的評價。內容過濾推薦系統會預測使用者對內容的喜愛程度,再找出使用者 可能會感興趣的特徵,進而找出使用者喜歡的物品。因為內容過濾推薦系統是針對物品內. y. Nat. sit. 容去做分析,進而推薦使用者,而它的缺點,主要是較難處理聲音、圖片、藝術品、影像. n. al. er. io. 等不容易被找出特徵的內容。另外,由於內容過濾僅對內容做處理,使用者只能看到與過. i n U. v. 去經歷類似的推薦項目,這樣可能會失去許多的潛在推薦。. Ch. engchi. 2.1.3 混合式推薦系統 混合式推薦系統(Hybrid Recommender Systems)是使用兩種以上推薦系統,它可以針對 問題的特性,結合不同推薦系統的優點,以彌補各推薦系統在特定問題的不足。. 10. 資料來源:http://en.wikipedia.org/wiki/Collaborative_filtering. 7.
(20) 2.2 Co-Clustering (雙分群) 分群(Clustering)指的是按照資料之間的差異性,將資料分組。一筆資料只屬於某一組, 相似資料歸類於同一組,每一組稱作一個群集(Cluster)。Co-Clustering,又稱為 Biclustering 或 Two-Mode Clustering11。Co-Clustering 是一種資料探勘的技術,它將資料儲 存在矩陣的行和列中,並且進行排序。目前有數種 Co-Clustering 演算法,像是 Block Clustering、The Plaid Model、Coupled Two-Way Clustering、 Interrelated Two-Way. 政 治 大. Clustering12、Information Theoretic Co-Clustering Algorithm[7]、Minimum Squared Residue Co-Clustering Algorithm[8]。. 立. ‧ 國. 學. 一般資料探勘的過程中,通常在同一時間下,只會考慮資料矩陣的行或列其中之一, Co-Clustering 則是將資料矩陣的行與列同時考慮,但取決於所使用的特定演算法,可能會. ‧. 產生不同的結果。. y. Nat. 最早將 Co-Clustering 公式化的研究,是由 Hartigan 提出的,在[4]中稱為直接群集. sit. (Direct Clustering)。Hartigan 提出多種 Co-Clustering 的方法和模型,並在階層化的 Co-. n. al. er. io. Clustering 模型中,使用一個貪婪算法(Greedy Algorithm),使其中的行和列分區可以以分. i n U. v. 層的方式,用樹(Tree)加以說明。分群問題的研究如[5],該文研究文件與文字分群的問題,. Ch. engchi. 提出了 Spectral Algorithm,使用 Co-Clustering 技術,同時考慮了文件和文字,將文件和文 字分群。研究[aa55]提出基因表達資料的雙分群方法,他們使用一個考慮平方差的方法去 衡量分群的品質。[7]提出了一種基於資訊理論的雙分群演算法,該研究利用遞減函數將兩 個互相影響的行與列同時做文字的分群,並使用資訊理論解決受限於行和列群集數目的問 題,[7]的實驗結果顯示該演算法在稀疏與高維的資料集中有良好的運作。. 11. 12. 資料來源:http://en.wikipedia.org/wiki/Biclustering 資料來源:http://www.wisegeek.com/what-is-biclustering.htm. 8.
(21) 大多數現有的推薦系統中使用任何內容或基於協同過濾的方法,而研究[9]考慮到使用 者和推薦項目的個人偏見,提出一種新的協同過濾方法來做推薦。 以下介紹本研究所使用的 Co-Clustering 演算法。. 2.2.1 Information Theoretic Co-Clustering Algorithm. 治 政 大 支,由 Claude E. Shannon 開發,目前應用在許多的領域,包含統計、自然語言處理、密碼 立 學、神經生物學等。Information Theoretic Co-Clustering Algorithm 由 Inderjit S. Dhillon 等人 Information Theoretic 是應用數學、電氣工程、電腦科學中涉及訊息進行量化的一個分. ‧ 國. 學. 提出,[7]提出一個雙分群演算法,類似 K-Means 和 EM 的精神,使用康乃爾大學提供的 新聞資料(NG20),利用遞減函數將兩個互相影響的行與列同時做文字的分群,實驗證明了. ‧. 該演算法在稀疏與高維的資料集中有良好的運作,該演算法流程為:輸入矩陣資料集欲取. sit. y. Nat. 得的行與列 Cluster 數量,將 Matrix 隨機切區塊,當作 Row Cluster 的雛型,使用 K-L 距離 計算並分配 Row 為最近 Cluster,利用分配過的 Row 資料,將 Matrix 隨機切區塊,計算. io. n. al. er. Column Cluster 的雛形,再使用 K-L 距離計算並分配 Column 為最近 Cluster,之後重複計. i n U. v. 算產生新的 Row 和 Column 的 Cluster,直到收斂為止,最後輸出行與列的分群。. Ch. engchi. 2.2.2 Minimum Squared Residue Co-Clustering Algorithm Co-Clustering Software 所使用的 Minimum Squared Residue Co-Clustering Algorithm[8] 主要是由 Hyuk Cho 等人提出的方法,研究中表明該雙分群演算法在基因分群的實驗是有 效的。使用 Iterative Algorithms 解決剩餘最小矩陣的 NP-hard 問題。提出兩種計算方式來 評估 Co-Cluster 的同質性,分別為一、計算群集中每個項目與其平均值的差值之平方和。 二、計算群集中每個項目與其對應的行與列的差值之平方和,群集的平均值需保有對稱性。. 9.
(22) 本研究也使用了 Hyuk Cho 等人所提出的兩種計算方式進行實驗。使用該演算法需要先輸 入矩陣資料集欲取得的行與列 Cluster 數量,使用 Batch Iterative Algorithms,利用所提的 兩種方法,先計算 Column 的 Cluster,再計算 Row 的 Cluster,直到收斂為止,最後輸出 行與列的分群。. 2.3 如何使用 Co-Clustering 做推薦系統. 政 治 大. 現今,Co-Clustering 在演算法的開發及應用上受到關注,研究範圍相當廣,其中較廣. 立. 為人知的,是在癌症基因上的研究。除了在醫學方面的研究外,Co-Clustering 也被使用在. ‧ 國. 學. 其他的研究,例如推薦系統。研究[9]就是以加權 Co-Clustering 演算法,在做推薦預測時, 同時考慮到使用者和推薦項目的個人偏見,該研究並提出一個新的協同過濾推薦方法。而. ‧. [10]則是結合了協同定位建議(Collaborative Location Recommendation)的框架做推薦。研究. y. Nat. [a55]運用協同過濾推薦系統,同時結合了使用者喜好進行推薦演算法、廣告的受歡迎程度. n. al. 2.4 總結. Ch. engchi. er. io. 同時應用多重矩陣之間的資訊而能夠產生更佳的結果。. sit. 進行推薦演算法與考慮擴充矩陣的雙分群演算法,顯示出在缺乏已知資料的議題上能藉由. i n U. v. 總結上述討論,整理了表 1。如下,橫軸表示推薦系統的應用,縱軸則呈現其使用技 術,依照類別在以下各小節做說明。. 10.
(23) 表 1 推薦系統文獻整理. 內容過濾 Content-Based Filtering 混合式推薦 Hybrid. 電子商務. 文本資料. [11] [12] [13] [14] [15] [16] [17] [18] [19]. [10] [26]. [9] [30] [31] [32] [33] [34]. [39]. [27]. [35] [36]. [20] [21] [23] [24] [19] [25]. [28] [29]. 立. 健保. [43]. 社群網路服務. 手機應用程式. [45] [46]. [48] [49] [50] [51]. [47]. 政 治 大 [37] [38]. [40] [41] [42]. [44]. ‧. 2.4.1 電影. 景點/餐廳. 學. 其他 Misc. 電影. ‧ 國. Recommender Systems 協同過濾 Collaborative Filtering. Nat. sit. y. 在電影相關研究中,有許多是以 MovieLens 或 NetFlix 的資料來做實驗。. er. io. MovieLens(http://grouplens.org/datasets/movielens/)是由美國明尼蘇達大學電腦科學與工程. al. iv n C 2007 年舉辦了一個 是一家網路串流媒體的供應商,在h e n g c h i UNetflix Prize 的競賽 n. 學系的 GroupLens 研究小組,針對研究用途所提供之網站的電影評分資料。NetFlix 公司. (http://www.netflixprize.com/),利用客戶的資料,希望能找出最好的影片推薦方法,2009 年九月,由 BellKor’s Pragmatic Chaos 團隊拿下了首獎。然而,由於隱私權問題備受爭議,. NetFlix 公司已在 2010 年取消這個比賽13。 以協同過濾方法做研究,使用 MovieLens 資料的文獻如[11],對 Apache Mahout 實作, 使用的 Mahout Distributed Item Base Recommendation System 進行分析,修改的該實作中花 費較多執行時間的 Similarity Matrix 計算部分進行修改,實作出兩個 Distributed 13. 資料來源:http://en.wikipedia.org/wiki/Netflix. 11.
(24) Collaborative-Based Recommendation Systems,經實驗證實該論文所實作的系統在 Performance 和 Accuracy 的表現都優於原系統。[12]提出一個新的方法於動態協同過濾法 (Dynamic Similarity Collaborative Filtering,DSCF)上,衰減人與人之間的相似度,並比較 預測值與實際值的結果,讓每個使用者在不同時間點,都有適合個人的相似度衰減值。實 驗證明該方法更符合人們的行為,且在執行時間上,有很大的改進。[13]和[14]在群體推 薦演算法中,分別以基因演算法及皮爾森係數(Pearson Correlation Coefficient)和餘弦相似 性(Cosine Similarity)做實驗,發現群體推薦結果能作為群體決策時的一個參考,更能滿足. 政 治 大 會犧牲預測的涵蓋範圍。[15]提出整合分群與包含啟發式搜尋的特徵選取法,可根據資料 立. 一般使用者在從事群體活動時的需求,也證實該方法可以提高偏好預測時的準確度,且不. ‧ 國. 學. 分群結果動態地搜尋最佳特徵子集,用以改善分群結果。實驗使用基因演算法做計算,結 果顯示該研究提出之特徵選取法確實能有效提高推薦系統之效能。[16]使用統計特徵距離. ‧. (Statistical Attribute Distance,SAD)的 Multi-Tier Granule Mining Algorithm 方法,提出一個 回饋推薦機制架構在協同過濾器下的推薦系統。[18]是在 CF 框架下,透過實驗,在不同. Nat. sit. y. 的組合中發現,使用結合個人的資訊和社群的意見,能產生更好的推薦。[17]分析了不同. al. er. io. 的基於項目(Item-Based)的推薦演算法,透過實驗使用不同的技術(Basic Cosine/Adjusted. n. Cosine/Correlation)來計算項目項相似之處並做評估,與基本的 K-Nearest Neighbor 方法比. Ch. i n U. v. 較,發現基於物品(Item-Based)的算法比基於用戶(User-Based)的算法,有更好的性能。[20]. engchi. 則是使用 Netflix 的資料,提出一個考量多種類型多樣性的混合型推薦系統,會預先算好 所有類型項目的多樣性權重並將這些多樣性因素結合混合式推薦系統,達到各種多樣性類 型的效果,實驗結果表示該系統可改善並考量到多樣性來滿足使用者的興趣。 混合式推薦系統中,以 MovieLens 的資料做實驗的研究,如[21],使用一個混合式的 推薦系統,來整合以使用者為基礎的協同過濾演算法,加上雲模型(Cloud Model)協同過濾 演算法,來預測結果。實驗證實混合式的推薦系統可改善稀疏性的問題。在[23]當中,實 驗使用 Bayesian Learning 和 Decision Tree Learning 方法,發現基於案例推理(Case-Based) 能夠提供比由專家使用以規則基礎(Rule-Based)的預測更加準確,並且可以擴充系統。[24]. 12.
(25) 則是使用 Compaq Systems Research Center 提供的 EachMovie1 資料,採用基於內容的預測, 使用 Neighborhood-Based Algorithm 以加強現有的使用者資料,然後透過協同過濾,使用 Bag-Of-Words Naive Bayesian Text Classifier,提供個性化建議。 [19]使用了 MovieLens 的資料,提出兩個方法,一為考慮個別商品內容差異性的協同 過濾推薦技術,解決傳統協同過濾技術不考慮商品異質性的缺點,研究結果顯示,可以提 高準確度,另一個則是結合傳統協同過濾技術的混合方法,其實驗顯示該方法可以達到與. 政 治 大 [25]提出了一種歸納學習方法(Inductive Learning),即能夠同時使用評比的資訊和其他 立. 傳統協同過濾技術相同的可預測涵蓋範圍,且有較佳的推薦效果。. 形式的資訊,預測用戶的偏好。. ‧. ‧ 國. 學. 2.4.2 景點/餐廳. y. Nat. sit. 推薦系統文獻中,也有以地點相關做的研究。例如[26]使用協同過濾方法,採用公式. er. io. 計算使用者之間的興趣相似程度,配合各相對年齡層做不同權重值分數評價調整,以花蓮. al. n. iv n C 規劃旅遊行程之整合型推薦系統。[10]提出了協同定位建議(Collaborative Location hengchi U. 為主要推薦旅遊景點,並且嵌入 Google Map API 作為旅途路徑規劃,是一套景點查詢及. Recommendation(CLR))的框架做推薦。在推薦過程中考慮了活動(例如:喜好)和不同的使 用者類別(例如:一般使用者或旅行中的使用者),CLR 能夠產生更精確和完善的建議。此 外,CLR 採用動態分群演算法 CADC,當新的 GPS 軌跡資料產生時,可以有效的將資料 做分類,該研究也證明的 CLR 的方法較一般方法更能提出精確的推薦。 在內容過濾的基礎下,[27]使用 Facebook 建構了一個即時餐飲商店推薦系統,以機器 學習法,在多為空間中以分群法,推薦適合的餐飲商店。. 13.
(26) [28]提出一個以標籤為基礎之混合式推薦系統,資料採用於文化資產與歷史古蹟資料 庫,建議適合使用者參訪的景點和觀覽路徑。[29]使用一種新的方法 EntreeC,結合了基 於知識(Knowledge-Based)推薦和協同過濾(Collaborative Filtering),使用 KDD 資料庫中的 Entrée 資料,做餐館的推薦。. 2.4.3 電子商務. 政 治 大. 電子商務方面,使用協同過濾方法的研究如[30],該研究以一著名的網路音樂 CD 販. 立. 售網站 Joy Audio (http://www.joyaudio.com.tw/)為例,先將音樂進行屬性建置成模糊語意知. ‧ 國. 學. 識庫,收集買方每次的音樂採購偏好,開發出音樂推薦系統的雛形。研究使用歐幾里德距 離(Euclidean Distance)公式計算離異度,結果顯示,使用模糊語意法進行產品推薦之動作,. ‧. 可提供使用者在音樂產品上做良好的選擇。[31]根據一個音樂推薦系統 RINGO(A Personalized Music Recommendation System),利用其網站使用者資料,並使用四個演算法. y. Nat. sit. 進行實驗,發現 The Constrained Pearson R Algorithm 表現最好。[32]使用自動產生評比的. er. io. 機制,利用使用者的網頁瀏覽紀錄,由實驗觀察,發現該研究所使用隱藏式評比(Implicit. al. n. iv n C hengchi U [33]不同於傳統兌換商品的系統,將網頁伺服器及資料庫和網路作結合,並加入協同過濾. Rating)之協同過濾機制所得之結果較前人研究使用明顯是評比(Explicit Rating)的結果佳。. 推薦機制及個人化的技術,透過分析每位消費者察看及兌換商品的紀錄,找出其個人的偏 好,並為其建立一個專屬的個人化推薦機制。[34]探討 Amazon 網站使用 Item-To-Item Collaborative Filtering 推薦的方法與技術。 使用內容過濾法的研究如[35],該研究探索電子商務模型,透過問卷調查方式了解線 上消費者的行為,運用資料探勘決策樹方法,去探索蒐集到的問卷資料,並將商品推薦分 為「一般商品推薦」及「互補商品推薦」計算模型,計算消費者對商品的喜好,進而推薦 商品給使用者。[36]探索基於內容過濾的書籍,透過應用自動化的文本分類方法,從網上. 14.
(27) 摘錄的半結構化文本,使用 LIBRA,提取網頁在 Amazon.com 的圖書資料庫,使用標題內 容的 Meta-Data,而不是圖書本身的實際文本,使用 Bayesian Learning 法,產生的最值得 推薦的結果。 混合式推薦的研究,則有[37],該文提出了一個混合推薦系統,結合了協同過濾和 Knowledge-Based 的方法,說明可以結合各種知識庫來做推薦系統。[38]則是結合協同過 濾和基於內容的方法,提出一種新的混合推薦系統,使用 Music Machines 的資料,透過實. 政 治 大. 驗證明新的方法比使用基於內容的建議或協同過濾推薦算法,更準確的預測和更適當的建 議。. ‧. ‧ 國. 學. 2.4.4 文本資料. 立. 推薦系統的文獻中,也有與文本資料相關的研究,[39]以協同過濾方法,使用銘傳大. sit. y. Nat. 學網路虛擬教室網站上的專家系統課程學生瀏覽記錄,提出階段式向前序列與興趣向量來. io. 效能。. er. 做為隱性評比的方式,並使用多種常見的相似度計算方式做實驗,比較其對推薦準確率的. al. n. iv n C 使用混合式推薦方法的研究,如[40],該研究提出一個混合式的文件推薦方法,使用 hengchi U. Digg.com 的資料,結合了共同興趣使用者的喜好與使用者原本的喜好來做推薦,第一階段 將使用者原本的喜好藉由協同過濾來拓展使用者的喜好,第二階段則是從拓展的喜好建立 使用者對文件字詞的喜好,再利用潛在語意檢索提高推薦結果的準確率,結果顯示該研究 所提的方法在實務上更具實用性。[41]提出一套個人化的學習系統,將學習測驗結果,應 用電腦適性化中試題反應理論,與學習歷程結果及問卷調查的個人偏好作為參考依據,來 做英文文章的推薦,幫助學習者增進興趣及學習效率。在[42]當中,使用 Fab System(Stanford University Digital Library Project),自行蒐集使用者看過的文件當作測試資 料,推薦其感興趣的文件。. 15.
(28) 2.4.5 健保 推薦系統研究,也有與健保相關的論文,如[43],該研究以內容過濾方法,結合資料 探勘的技術,使用決策樹做分類,開發營養資訊輔助推薦系統,將結果交由執行系統決策 的營養師,進行評估做決定,並結合雲端運算的技術,讓使用者可在任何時間、地點使用。 而[44]則是藉由患者知識本體的架構建立患者項目,利用多準則方法,將重要性的熵. 政 治 大. 量度運算將資料的用藥程度作出計算,使用藥品知識本體座結合排序並推薦適用的藥品類. 立. 型。. ‧ 國. 學 ‧. 2.4.6 社群網路服務. sit. y. Nat. 社群網路服務方面,利用協同過濾方式的研究,[45]結合 Facebook API 自行收集實驗. io. er. 資料,取得 135 使用者樣本資料,並分析使用者的社會網絡,經由分析社會網絡中成員的 偏好,運用正規概念分析(Formal concept analysis,FCA)關聯矩陣理論進行資料分析,預測. n. al. Ch. i n U. v. 使用者的潛在興趣。[46]使用協同過濾推薦系統,結合基於使用者的喜好、及基於廣告受. engchi. 歡迎程度,並考慮擴充矩陣的共分群演算法,該研究實驗的資料來源取自一個 Financial Social Web-Site - Ad$Mart,結果顯示出在缺乏已知資料的議題上能產生更佳的處理結果。 [47]使用 Facebook 的資料,結合 Co-occurrences Relationship 和 Mutual Friend Relationship,提出一個新穎的方法來對人臉標註做推薦,有別於其他方法中單純分析照片 上傳者在社群網站中與其他人的關係,該研究考慮了欲被標註的那群人臉之間的群組關係。. 2.4.7 手機應用程式. 16.
(29) 在智慧型手機發展下,手機應用程式的推薦研究,大多以協同過濾為基礎。如[48]提 出一個 AppFunnel,利用 App 安裝的次數、使用者是否使用過此 App、使用 App 的時間 (早/晚)、使用時是否正在移動及 App 的類型等資料,以 Appazaar Recommender System 的 資料做實驗,研究發現在 Short-Term Usage 上使用 Context-Aware Recommendation Engine 以及在 Long-Term Usage 使用 Non-Context-Aware Engine 效果較好。[49]提出了一個 AppJoy 程式,自行蒐集使用者資料,透過分析使用者如何實際使用所安裝的應用程序, 以 Item-Based Collaborative Filtering Algorithm 對個人做推薦。[50]提出一種基於 SPSO(Set-. 政 治 大 AppBrain 及 AppAware 網站的資料。[51]提出一個 EigenApp 的方法,它是一個改善 立. Based Particle Swarm Optimization)的新的方法-CF-SPSO,使用 Google Play Market 中. ‧ 國. PureSVD、EigenApp)做比較,使用 GetJar 的資料做實驗。. 學. Memory-Based 模型,該研究將四個模型(Non-Personalized (POP)、Memory-Based (MEM)、. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. 17. i n U. v.
(30) 第三章 基於雙分群的推薦框架 3.1 總覽 一般的推薦方式往往只考慮其中一種因素,根據使用者的相似度,或是項目的相似度 進行推薦。本實驗利用使用者及應用程式的資料,以 Co-Clustering 方法,分別將使用者及 應用程式做分群,再以結果進行推薦,流程如下:. 政 治 大. 立. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 1 本研究推薦流程. 目前許多研究使用了 NMF(Non-Negative Matrix Factorization14)的方法對矩陣做處理。 NMF 先將原本的矩陣拆解成兩個或兩個以上低維度的矩陣相乘,使用低維度矩陣做運算, 最後以重建的結果矩陣來做推薦。. 14. 資料來源:http://en.wikipedia.org/wiki/Non-negative_matrix_factorization. 18.
(31) 正規劃矩陣分解模型在推薦系統的應用上,已知能產生高品質的預測結果,但是在計 算之後產生的模型是靜態的,[52]建立了一個規範化的矩陣分解,當新使用者或新的項目 加入時更新矩陣,然而,最後輸出的結果矩陣,在重建與原先的矩陣比較之後,才能做推 薦。研究[53]是使用 MovieLens 的資料來做實驗,它提出方法改進原始的 NMF,實驗最後 輸出了兩個結果矩陣,必須將結果矩陣相乘,再與原先的矩陣做比較,才能抓取欲推薦的 結果。[54]提出了兩階段的評分預測算法,先以 Co-Clustering 演算法對原始的矩陣進行分 類,再以改進過的 NMF 方法來預測未知的評分,改進的方法為當有新的使用者對已存在. 政 治 大 以此進行推薦。[55]為解決 Missing Value Prediction 的問題,使用協同過濾推薦系統做實 立. 的物品進行評分,或是新的物品被既有的使用者評分之後,使用重新預測的結果重建矩陣,. ‧ 國. 學. 驗,採用 Co-Clustering 方法同時計算使用者和項目的群集,嘗試恢復資料的原始結構,使 得重建矩陣可以被用來預測結果。[56]將矩陣壓縮成一個 Codebook,提出了一個演算法來. ‧. 重建目標矩陣,實驗結果顯示,與其他方法比較,該方法可有效地解決資料稀疏性問題。. y. Nat. 上述的研究中,產生的結果矩陣數量,可能為兩個或兩個以上,必須將矩陣重建,與. sit. 原本的矩陣比對之後,才能找出欲推薦的項目。重建矩陣是利用矩陣相乘的方式,來得到. er. io. 目標矩陣。矩陣相乘由大量運算產生,這是非常耗費成本的。矩陣相乘時,若輸入兩個. al. n. iv n C U heng 的時間複雜度為 O(n );以演算法 Strassen Algorithm O(n c h i 來說,它的時間複雜度為. n×n 的矩陣,會輸出一個 n×n 的矩陣,以演算法 Schoolbook Matrix Multiplication 來說,它 3. 2.807. );. 以演算法 Coppersmith–Winograd Algorithm 來說,它的時間複雜度為 O(n2.807);以演算法 Williams Algorithm 來說,它的時間複雜度為 O(n2.373),當輸入的矩陣為一個 n×m 和一個 m×p 的矩陣做相乘時,會輸出一個的 n×p 矩陣,以演算法 Schoolbook Matrix Multiplication 來說,時間複雜度則為 O(nmp)。15 本研究所使用的方法,不需做重建矩陣的動作就可以對使用者做應用程式的推薦。. 15. 資料來源:http://en.wikipedia.org/wiki/Computational_complexity_of_mathematical_operations#Matrix_algebra. 19.
(32) 3.2 實際運作範例 在此,我們使用部分資料做範例說明。我們將資料用四種方法做整理,分別在 3.2.1、 3.2.2、3.2.3、3.2.4 章節呈現實驗結果,其中資料包含 5 個使用者,以及 21 個應用程式。 以下以 ITCC 代表 Information Theoretic Co-Clustering Algorithm,以 MSRICC 代表 Minimum Squared Residue I Co-Clustering Algorithm,以 MSRIICC 代表 Minimum Squared. 政 治 大. Residue II Co-Clustering Algorithm。. 學. ‧ 國. 立. 3.2.1 以使用者是否使用應用程式做推薦. ‧. 此範例中,我們以使用者是否使用應用程式的標準來整理資料,若使用者有使用該應. sit. y. Nat. 用程式,則將其值設定為 1;若使用者未使用該應用程式,則將其值設定為 0。圖 2 呈現. io. er. 各應用程式是否被使用者使用的情形。其中 X 軸代表應用程式,Y 軸代表被使用的次數, 例如 App0006 在此範例中被 User_004 和 User_006 使用,而 App001、App002、App012、. n. al. Ch. i n U. v. App013、App014、App018、App019、App028、App047 沒有被這 5 個使用者所使用。. engchi. 20.
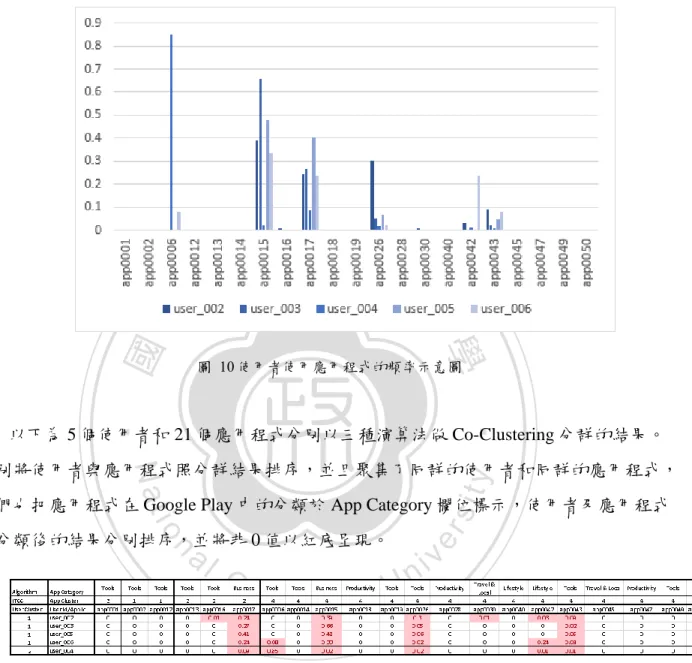
(33) 學. 圖 2 實際運作範例中應用程式被使用者使用情形. ‧. ‧ 國. 立. 政 治 大. 以下為 5 個使用者和 21 個應用程式分別以三種演算法做 Co-Clustering 分群的結果。. y. Nat. sit. 分別將使用者與應用程式照分群排序,並聚集了同群的使用者和同群應用程式聚集,我們. al. n. 類後的結果分別排序,並將非 0 值以紅底呈現。. Ch. engchi. er. io. 也把應用程式在 Google Play 中的分類於 App Category 欄位標示,使用者及應用程式以分. i n U. v. 圖 3 範例一,使用 Information Theoretic Co-Clustering Algorithm. 圖 4 範例一,使用 Minimum Squared Residue I Co-Clustering Algorithm. 21.
(34) 圖 5 範例一,使用 Minimum Squared Residue II Co-Clustering Algorithm. 由以上結果,在使用者分群的部份,我們發現使用 ITCC 和 MSRICC 所做的分群結果 相同,使用者 User_003 和 User_005 都被分在同一個群集,使用者 User_002、User_004、 User_006 被分在第二群,而 MSRIICC 則是將 User_002、User_003 和 User_005 分在同一. 政 治 大. 個群集,User_004、User_006 分在第二群。在應用程式分群的部份,使用 ITCC 和. 立. MSRICC 所做的分群結果也相同,而 MSRIICC 則是有較不同的分法。. ‧ 國. 學. 以 ITCC 和 MSRICC 的結果分析,在使用者群組 2 中,所有的使用者只有 User_002 並 未使用 App0006,所以我們會將 App0006 推薦給 User_002;同理,我們會將 App0030 推. ‧. 薦給 User_004、User_005,將 App0042 推薦給 User_003,將 App0045 推薦給 User_006,. sit. y. Nat. 將 App0049 推薦給 User_004。而 MSRIICC 的部分,我們會將 App0030 推薦給 User_004、. io. 給 User_006,將 App0049、App0050 推薦給 User_004。. n. al. Ch. engchi. er. User_005,將 App0040 推薦給 User_004,將 App0042 推薦給 User_003,將 App0045 推薦. i n U. v. 3.2.2 以使用應用程式之次數做推薦 此範例中,我們以使用者在資料集中,使用該應用程式的次數做為依據,其值表示使 用次數。圖 6 呈現各使用者在每個應用程式的使用次數統計,其中 X 軸代表應用程式及使 用者,Y 軸代表被使用的次數,以 User_004 使用 App0006 次數最多,為 2007 次。App001、 App002、App012、App013、App014、App018、App019、App028、App047 沒有被這 5 個 使用者所使用。. 22.
(35) 立. 政 治 大. ‧ 國. 學. 圖 6 使用者使用應用程式的次數示意圖. 以下為 5 個使用者和 21 個應用程式分別以三種演算法做 Co-Clustering 分群的結果。. ‧. 分別將使用者與應用程式照分群結果排序,並且聚集了同群的使用者和同群的應用程式,. sit. y. Nat. 我們也把應用程式在 Google Play 中的分類於 App Category 欄位標示,使用者及應用程式. io. n. al. er. 以分類後的結果分別排序,並將非 0 值以紅底呈現。. Ch. engchi. i n U. v. 圖 7 範例二,使用 Information Theoretic Co-Clustering Algorithm. 圖 8 範例二,使用 Minimum Squared Residue I Co-Clustering Algorithm. 23.
(36) 圖 9 範例二,使用 Minimum Squared Residue II Co-Clustering Algorithm. 由以上結果,在使用者分群的部份,我們發現三種演算法都將 User_004 分成一個群集, 另外四位使用者分在第二個群集。在應用程式分群的部份,使用 ITCC 和 MSRICC 所做的 分群結果相同,而 MSRIICC 則是較不同。. 治 政 以 ITCC 和 MSRICC 的結果分析,在使用者群組 1大 中,所有的使用者只有 User_005 並 立 未使用 App0030,所以我們會將 App0030 推薦給 User_005;同理,我們會將 App0042 推 ‧ 國. 學. 薦給 User_003。而 MSRIICC 的部分,我們會將 App0030 推薦給 User_005,將 App0042 推 薦給 User_003。. ‧. 從 3.2.1 和 3.2.2 兩個範例中,我們發現 ITCC 和 MSRICC 兩個演算法,在使用者和應. Nat. n. al. er. io. sit. y. 用程式的分群,皆得到相同的結果,而 MSRIICC 則是有不同的分群結果。. 3.2.3 以使用者使用應用程式的頻率做推薦 C. hengchi. i n U. v. 此範例中,我們以使用者在資料集中,使用該應用程式的頻率做為依據,其值表示使 用頻率,例如 User_004 總共使用了 2361 次的應用程式,其中 App0006 使用了 2007 次, 表示 App0006 佔總使用的百分之八十五,其值以 0.85 表示。圖 10 呈現各使用者在每個應 用程式的使用頻率統計,其中 X 軸代表應用程式及使用者,Y 軸代表被使用的頻率,以 User_004 使用 App0006 頻率最高,為 0.85。App001、App002、App012、App013、 App014、App018、App019、App028、App047 沒有被這 5 個使用者所使用。. 24.
(37) 立. 政 治 大. ‧ 國. 學. 圖 10 使用者使用應用程式的頻率示意圖. ‧. 以下為 5 個使用者和 21 個應用程式分別以三種演算法做 Co-Clustering 分群的結果。. sit. y. Nat. 分別將使用者與應用程式照分群結果排序,並且聚集了同群的使用者和同群的應用程式,. io. 以分類後的結果分別排序,並將非 0 值以紅底呈現。. n. al. Ch. engchi. er. 我們也把應用程式在 Google Play 中的分類於 App Category 欄位標示,使用者及應用程式. i n U. v. 圖 11 範例三,使用 Information Theoretic Co-Clustering Algorithm. 圖 12 範例三,使用 Minimum Squared Residue I Co-Clustering Algorithm. 25.
(38) 圖 13 範例三,使用 Minimum Squared Residue II Co-Clustering Algorithm. 由以上結果,在使用者分群的部份,我們發現 ITCC 和 MSRIICC 兩種演算法都將 User_004 分成一個群集,另外四位使用者分在第二個群集。在應用程式分群的部份,使用. 政 治 大. ITCC 和 MSRIICC 所做的分群結果相同,而 MSRICC 則是較不同。. 立. 以 ITCC 和 MSRICC 的結果分析,在第一個使用者群組中,有一半的使用者使用了. ‧ 國. 學. App0042,所以我們會將 App0042 推薦給 User_003 和 User_005。而 MSRIICC 的部分,我 們會將 App0016 推薦給 User_006,將 App0006 推薦給 User_002,將 App0030 推薦給. ‧. User_006。. sit. y. Nat. 由上述三個範例,我們發現各演算法在 App 分類時,不一定會把相同類別的 App 分在. io. 操作方式,稍做調整。. er. 同一個 Cluster。Google Play 的分類使由程式開發者主觀定義的,或許可以反應使用者的. al. n. iv n C 第三章範例主要解釋本研究如何做推薦,並非比較演算法之間的差異。詳見第四章更 hengchi U 大規模的實驗。. 26.
(39) 第四章 實驗 相較於第三章的實驗,本章實驗使用較大規模的資料集。資料集為 2010 年 9 月至 2011 年 3 月的使用紀錄,共 26 萬多筆資料,其中包含有 30 個使用者、1125 個手機應用 程式。. 4.1 環境與流程. 立. 4.1.1 實驗環境. 政 治 大. ‧ 國. 學. 本研究進行實驗時所使用的系統,硬體為一般個人電腦(單機),軟體環境則是簡述如. ‧. 作業系統,使用 Ubuntu v12.04. . 程式語言,使用 C++、Python. . 關聯式資料庫使用 MySQL (Workbench CE 6.0.8). y. sit. io. al. iv n C hengchi U Co-clustering 另外,本研究使用由德克薩斯州大學資訊科學學系所開發的 n. . Nat. . er. 下:. Software (Version 1.1)16進行雙分群. 4.1.2 實驗流程 此實驗為一個基於離線(Off-Line)及模型基礎(Model-Base)的架構。我們將資料集整理 成 CCS(Compressed Column Storage)檔,使用 Co-Clustering Software 三種演算法對使用者 16. 資料來源:http://www.cs.utexas.edu/Users/dml/Software/cocluster.html. 27.
(40) 及應用程式做分群,將三種演算法輸出的結果,分別以 Python17處理,轉換格式成 CSV(Comma Separated Value)檔並匯入資料庫,對每個 User,做不同的推薦。首先,我們 找出與此 User 相同群組的 User 名單,在各應用程式分類的群組中,使用三種方法計算同 群 User 的使用狀況,決定是否推薦此應用程式。 第一種方法,我們找出每個 App Cluster 中,應用程式被最多同群 User 使用的最優先 推薦。例如:App Cluster 是 1 的 App0050,在同群的 User 中有 5 位使用,他的分數就是 5;. 政 治 大. App Cluster 是 1 的 App0100,在同群的 User 中有 8 位使用,他的分數就是 8,所以我們會 優先推薦 App0100。若是遇到分數相同的情況下,我們會將兩個應用程式同時推薦給使用. 立. 者。. ‧ 國. 學. 第二種方法,我們將資料分別整理成以使用次數及使用頻率計算,推薦使用次數或頻 率最高的應用程式。使用次數的部分,我們找出每個 App Cluster 中,應用程式被同群. ‧. User 使用次數最多的優先推薦。例如:App Cluster 是 1 的 App0050,被 5 個同群的 User. sit. y. Nat. 分別使用 100 次,他的分數就是 500;App Cluster 是 1 的 App0100,被 2 個同群的 User 分. io. er. 別使用 200 次,他的分數就是 400,所以我們會優先推薦 App0050。另外,我們將每個使 用者在各應用程式的使用次數轉換為個人使用頻率,計算每個 App Cluster 中,應用程式. n. al. Ch. i n U. v. 被同群 User 使用頻率最高的優先推薦。例如:App Cluster 是 1 的 App0050,被 5 個同群. engchi. 的 User 使用的頻率分別是 0.39、0.36、0.09、0.12、0.06,那麼他的分數就是 1.02;App Cluster 是 1 的 App0100,被 2 個同群的 User 使用的頻率分別是 0.2、0.16,那麼他的分數 就是 0.36,所以我們會優先推薦 App0050。 我們將欲推薦的 User 從未使用過的應用程式列出來,並找出各應用程式的分數,再依 序找出此 App Cluster 裡分數最高的前五個應用程式,推薦給使用者。請注意,在我們的 實驗中,實際上沒有真正對使用者進行推薦,而是以模擬推薦的方式,驗證使用者是否用. 17. 參考網址:https://www.python.org/. 28.
(41) 到我們所推薦的應用程式;然而,使用者是否使用某應用程式,也不能完全代表他或她是 否喜歡該應用程式。圖 18 為實驗一流程說明。. 政 治 大. 立. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. C h 圖 14 實驗流程圖U n i engchi. 以下介紹實驗一所用的 SQL。. 29. v.
(42) SQL#1 找出與欲推薦 User 同一個 Cluster 其他 User,並以這些同群使用者的資料為基 準,其中 user_cluster_result 儲存了使用者分群的結果, $user_id$表示欲推薦的使用者。 SELECT user FROM user_cluster_result WHERE user_cluster = ( SELECT user_cluster FROM user_cluster_result WHERE User='$user_id$' ). 立. 政 治 大. SQL#2 取得 User 未使用過的 App 做為推薦候選名單,user_app_value 這個 Table 儲存. ‧ 國. 學. 了使用者對應用程式的操作狀況,app_cluster_result 儲存了應用程式分群的結果。. ‧. SELECT a.app_id, a.value, b.app_cluster. sit. y. Nat. FROM user_app_value a, app_cluster_result b. io. n. al. er. WHERE a.User='$user_ud$' and a.value='0' and a.app_id=b.app_id. Ch. engchi. 30. i n U. v.
(43) SQL#3.1 計算每個應用程式的分群$app_cluster$的使用人數,使用@row 語法依照人數 多少從高到低排序。 SELECT *,@row := @row + 1 as row FROM ( SELECT app_id, count(user) AS user_app_value,app_cluster FROM recommender_list a, ( SELECT @row := 0. 政 治 大 )r. 立. WHERE app_cluster=$app_cluster$ AND user_app_value <> 0. ‧ 國. 學. GROUP BY app_id ) b. ORDER BY user_app_value DESC. ‧. y. Nat. SQL#3.2 計算每個應用程式的分群$app_cluster$的使用次數/頻率,使用@row 語法依. al. SELECT *,@row := @row + 1 AS row FROM (. er. io. sit. 照使用次數/頻率多少從高到低排序。. n. iv n C SELECT app_id, SUM(user_app_value) AS user_app_value, app_cluster hengchi U FROM recommender_list a, (SELECT @row := 0) r WHERE app_cluster=$app_cluster$ GROUP BY app_id ) b ORDER BY user_app_value DESC. 31.
(44) SQL#4 推薦排名前 5 的應用程式。 SELECT * FROM recommender_result WHERE app_sequence<=5. 當我們在整理實驗所需的資料集時,發現類似的應用程式在 Google Play 的分類有些 特別,例如像是部分 Bus 相關的應用程式分類為 Transportation,而部分 MRT 相關的應用. 治 政 討應用程式在 Co-Clustering 做分類的結果,想了解 Google 大 Play 的分類情形是否可做調整。 立. 程式分類為 Travel & Local,我們設計了額外的實驗,從 User 使用應用程式的相似性,探. ‧ 國. 學. Co-Clustering Software 所提供的參數有許多,必要輸入的參數有演算法(–A)、行分群 數量(–C)、 輸入之資料(–I)、列分群數量(–R)四種。本研究所用的參數為-A、-C、-I、-R、. ‧. -O 五種,在演算法中,我們使用了三種演算法分別做實驗;以應用程式為列(Column),將 應用程式分成 30 個 Cluster;以使用者為行(Row),將使用者分為 2 個 Cluster。本實驗的. Nat. n. al. er. io. sit. y. 參數設定說明如表 2。. Ch. engchi. 32. i n U. v.
數據




+7


相關文件
國立政治大學應用數學系 林景隆 教授 國立成功大學數學系 許元春召集人.
MATLAB 程式使用 pass-by-value 的方 式,進行程式與函式間的溝通聯絡,當 程式呼叫函式時, MATLAB
聽、說、讀、寫,以 及分析、評價等能力 例:設計課業,讓學生 應用所學,並運用各
微算機原理與應用 第6
應用閉合電路原理解決生活問題 (常識) 應用設計循環進行設計及改良作品 (常識) 以小數加法及乘法計算成本 (數學).
又到了回顧年度成績的時刻,Google 於 12 月 1 日公布台灣「Google Play 2020 年 度最佳榜單」,總共有 16 款應用程式與 20 款遊戲上榜。因應
教師介紹投委會的「收支管家–錢家有 道」手機應 用程式 , 方 便學生實 踐所
活用建築物本身擁有的磁場特性進行定位 ,因此可用來解決 上述問題。利用實驗型App取得智慧型手機地磁場感應器的數據,接著
