基於三元化特徵描述子之行動影像識別機制 - 政大學術集成
72
0
0
全文
(2) 致謝 首先感謝廖文宏老師在兩年半的時間中,總是不厭其煩,並且親切的指導給 予我指導,更在我遭遇到困難和瓶頸時給予我學術和思考上的幫助,讓我能夠在 學業上更為精進,此外也感謝李遠坤教授和紀明德教授兩位口委老師,提供我在 論文的修改上許多寶貴的意見,使我的論文更加完整。 也感謝在 VIPL 的每一位同學,嘉瑜在各方面的經驗總是提醒我做人處事的 原則,志毓也總是為實驗室的大家帶來歡樂的氣氛,也謝謝兩位同屆的同學每每 在我提議下陪我上山下海,騎單車環島等,這些都是難忘可貴的經驗。感謝明慶. 政 治 大 建堡和浩偉學長,讓我在剛進實驗室的時候讓我快速的融入大家和訴說各種大小 立 時常為我們這些學弟們處理各種實驗室的事務,另外也感謝冠智、柏銘、政明、. ‧ 國. 學. 的奇聞軼事,還有仁和學長帶領實驗室的大家爬山涉水,親身體驗台灣的美麗, 除此之外還要感謝實驗室的學妹們,交大新垣結衣苡甄、神隱少女苡萱、呼吸就. ‧. 會笑的育如還有任勞任怨、每晚奮鬥不懈的新守門員雅阿和家禎,實驗室有學妹. sit. y. Nat. 們的加入,帶來不少有趣的互動。此外也要感謝攝影社的冠淵、律鈞,讓我在攝. n. al. er. io. 影這方面也學習到了很多知識和技術,更有講不完的話題,還有力心、盈盈、婉. i Un. v. 婷、孟璟從你們照片的故事中我獲得的許多靈感,而政陞在考試的忙碌中依然排. Ch. engchi. 出時間跟我敘舊,大學的同學們:聖堯、柏榕、昱維也不忘在回國後相約暢談新 舊往事,珮瑜對我總是用心的解惑和照顧,還有總是半夜話題談不完的前室友峻 宏,很多在背後從不同領域和在我需要幫助的時伸出援手的朋友:忻恬、亦婷、 愛德、婷瑛、敬博、雅琇、雅如。 最後感謝我的家人,在我低潮時永遠給予我鼓勵和支持,讓我能夠有動力繼 續在研究上努力不懈,而王璿總是隨時地關心我的身體狀況和進度,還有許多幫 助我沒列出來的許多朋友們,在政治大學念研究所的這段時間,是你們使我過這 麼充實又豐富,這是一段難忘也不會忘的求學經驗,最後再謝謝廖老師當初從我 進實驗室以來非常照顧和提拔我,讓我得到許多寶貴的經驗。.
(3) 基於三元化特徵描述子之行動影像識別機制 中文摘要 近來因資訊和通信技術的快速發展,使行動裝置變得普及,智慧型手 機上的各類應用如雨後春筍般相繼出現,行動影像辨識是當中具代表 性的一種。本論文針對在有限的計算和儲存資源的移動裝置平台上進 行物體的偵測與追踪。為了達到此一目標,我們提出了一個型態的圖. 政 治 大. 像特徵,稱為區域三元描述子(Local Ternary Descriptors) ,期望在時. 立. 間複雜度、抗噪性和準確率各個面向取得一個較佳的平衡。LTD 是基. ‧ 國. 學. 於區域二元描述子(Local Binary Descriptors)所衍生出來的方法,如. ‧. BRIEF,BRISK,FREAK。而使用三進位制編碼方法的動機在於,三. Nat. io. sit. y. 元化處理可以減輕因在 LBD 的簡單 threshold 處理過後所產生的一些. al. er. 問題。而類似於 LBD 地方在於,LTDS 之間的距離可以很容易地使用. n. iv n C hengchi U Hamming distance 計算。實驗數據及比較分析後證明,本論文提出的 區域三元描述子可以在雜訊環境的條件下表現出優異的效果。. 關鍵字:三元化特徵描述子、二元化特徵描述子、行動影像辨識.
(4) Image Recognition on Mobile Devices Using Ternary Feature Descriptors. Abstract The rapid advances of information and communication technology have brought about the prevalence of mobile devices. Diverse applications on smartphones have emerged accordingly. Mobile image. 政 治 大 this thesis, we address立 the detection and tracking of objects on mobile. recognition is one of the novel functions that have seen great potential. In. ‧ 國. 學. platforms with limited computation and storage resources. To strike a good balance among feature complexity, noise immunity and detection. ‧. rate, we propose a novel class of image feature known as local ternary. y. LTDs are extensions of local binary descriptors. sit. Nat. descriptors (LTD).. er. io. (LBD) such as BRIEF, BRISK, and FREAK. The motivation for using. n. a l in the observation that the ternary representation lies i v ternarization process C. Un. e n g cbyh isimple thresholding in LBD. can alleviate some problemshcaused Similar to LBD, the distance between two LTDs can be easily computed using Hamming distance. Experimental results and comparative analysis indicate that the proposed descriptor can achieve superior performance under noisy conditions. Keywords: ternary feature descriptors, binary feature descriptor, mobile image recognition..
(5) 目錄 第一章 緒論 ................................................................................................................ 1. 1. 1.1. 研究背景.................................................................................................................. 1. 1.2. 研究目的.................................................................................................................. 2. 1.3. 流程架構與方法...................................................................................................... 2 第二章 相關研究 ........................................................................................................ 5. 2.. 特徵擷取.................................................................................................................. 5. 2.1. 2.1.1.. SUSAN(Smallest Univalue Segment Assimilating Nucleus) .............................. 6. 2.1.2.. FAST (features from accelerated segment test) ................................................... 7. 政 治 大 高斯拉普拉斯轉換 (The Laplacian of Gaussian, LoG)..................................... 8 立. 區域興趣點偵測 (regions of interest or interest points) ........................................ 8. 2.2.1.. 高斯差 (Difference of Gaussians, DoG) .......................................................... 10. 學. 2.2.2.. ‧ 國. 2.2.. 特徵描述子............................................................................................................ 10. 2.3.. 尺度不變特徵轉換 (Scale-invariant feature transform, SIFT) ........................ 11. 2.3.2.. PCA-SIFT (Principle Component Analysis-SIFT) ............................................ 13. 2.3.3.. GLOH (Gradient Location-Orientation Histogram) .......................................... 13. 2.3.4.. SURF (Speeded Up Robust Features) ............................................................... 14. 2.3.5.. BRIEF (Binary Robust Independent Elementary Features)............................... 16. 2.3.6.. ORB (Oriented FAST and Rotated BRIEF) ...................................................... 17. 2.3.7.. BRISK (Binary Robust Invariant Scalable Keypoints) ..................................... 18. 2.3.8.. Fast Retina Keypoint (FREAK)......................................................................... 20. ‧. 2.3.1.. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 第三章 區域三元化描述子 .................................................................................... 24. 3. 3.1.. 二元化特徵值討論歸納........................................................................................ 24. 3.2.. 二元化特徵值實驗分析........................................................................................ 27. 3.3.. 區域三元化圖型.................................................................................................... 28 第四章 實驗結果與分析 ........................................................................................ 32. 4. 4.1.. 影像雜訊................................................................................................................ 32. 4.2.. 抗噪性測試............................................................................................................ 37.
(6) 4.3.. 演算法三元化特徵值套用實驗 ............................................................................ 44. 4.4.. 實驗統整分析........................................................................................................ 56. 5.. 第五章 擴增實境應用 ............................................................................................ 57. 6.. 第六章 結論與未來研究方向 ................................................................................ 59. 參考文獻 ................................................................................................................................. 60 附錄 ............................................................................................................................ 62. 立. 政 治 大. 學 ‧. ‧ 國 io. sit. y. Nat. n. al. er. A.. Ch. engchi. i Un. v.
(7) 圖表目錄 圖 1-1 為本研究之研究架構,主要流程如下: .................................................................................. 2 圖 2-1 周圍 16 點遮罩示意圖 ................................................................................................................ 7 圖 2-2 利用微分尋找過零點示意圖 ...................................................................................................... 9 圖 2-3 指定特徵值的方向.................................................................................................................... 12 圖 2-4 特徵方向降維............................................................................................................................ 13 圖 2-5 放射狀同心圓的 17 LOCATION BINS .......................................................................................... 14 圖 2-6 利用加總方式計算主向量 ........................................................................................................ 15 圖 2-7 利用金字塔梯度做 SCALE 取樣 ................................................................................................ 19 圖 2-8 KEY POINT 取樣分布 ................................................................................................................... 20 圖 2-9 FREAK 特徵點區域示意圖 ...................................................................................................... 21 圖 2-10 用二進位的方式表示視網膜神經的訊號............................................................................... 21. 政 治 大 圖 2-12 SURF 以及 FREAK 的平均偵測時間..................................................................................... 22 立 圖 2-13 D 數量和總時間的關係 ......................................................................................... 23 圖 2-11 13 個測試中,SURF 以及 FREAK 的總共花費時間,DETECTOR 使用相同的取樣法 ...... 22. ESCRIPTOR. ‧ 國. 學. 圖 3-1 計算L𝑝𝑖,D=2 的情況,各紅色區域的高斯平均是再減去相對應的綠色區域的高斯平均 24 圖 3-2 在一個 KEY POINT 內,取一個區域進行隨機的點對點的灰階亮度值比較,194-218 得 0,. ‧. 170-179 得 0,171-21 得 1 依此進行,重複直到取滿所需的位元數為止 .............................. 25 圖 3-3 區域三元化示意圖.................................................................................................................... 29. y. Nat. 圖 4-1 高 ISO 影像以及局部放大圖 ................................................................................................... 33. sit. 圖 4-2 長時間曝光所產生的熱噪點現象(ISO 800 曝光時間 980S F2.8) ........................................... 33. al. er. io. 圖 4-3 不同裝置的 COMS 大小(一般常見的行動裝置為 1/2.5”,單眼相機為 24*16MM) ............. 34. v. n. 圖 4-4 低光源下行動裝置所擷取到的圖形圖 4-5 各種不同 ISO 狀況下的圖形............................. 34. Ch. i Un. 圖 4-6 同一場景,利用單眼相機以及行動裝置在低亮度環境下所取得的高 ISO 影像................. 35. engchi. 圖 4-7 模擬各種不同 ISO 情況下所產生的雜訊(數字為 PSNR) ....................................................... 36 圖 4-8 實驗的畫作示意圖 .................................................................................................................... 38 圖 4-9 晨光中盧昂主教堂正門以及不同雜訊程度的局部放大圖 ..................................................... 55 圖 4-10 卡薩爾基號與阿拉巴馬號之戰以及不同雜訊程度的局部放大圖 ....................................... 55 圖 5-1 使用 BINARY-LIKE DESCRIPTOR 應用 AR .................................................................................. 58 圖 5-2 行動裝置 AR 實際應用辨識 ..................................................................................................... 58.
(8) 1. 第一章. 緒論. 1.1 研究背景 隨著科技的進步,資訊以及通訊技術越來越貼近人們的生活,現今手上的手 機運算效能突飛猛進,而每個人每天使用手機的時間越來越長,能夠做的事情也 越來越多,舉凡上網、收信、導航、繪圖、社群運算等功能,讓行動運算的應用 越來越多樣化與生活化。 由於國民教育水平提升,人文素養也隨之提高,藝術品的展覽和創作因而逐. 政 治 大 要方式,但是在這之間往往創作的理念和背後的思考並不是簡單的幾個字可以清 立 漸熱絡起來,而創作者和觀賞者之間通常以簡短的幾個小看板來做傳達理念的主. ‧ 國. 學. 楚表達的,所以就會有一些輔助的裝置或是導覽人員來輔助講解。但是這些幫助 依然有限,除了時間以外,也有可能限於成本考量,在數量上和內容上有所限制。. ‧. 因為手持裝置的進步,現今的導覽裝置也以其他非硬體結合方式出現在智慧. sit. y. Nat. 型手機上,利用手持裝置本身就擁有的硬體配備,例如攝影機鏡頭或行動網路來. n. al. er. io. 增進導覽的互動體驗。目前常見的有 QR (Quick Response) code,利用行動裝置. i Un. v. 的鏡頭,搭配手機內的 QR code 解碼軟體,對著 QR code 掃描,解碼軟體會自動. Ch. engchi. 解讀此訊息,顯示於手機螢幕上面進行數位內容下載或是網址頁面的連結;另外 一個是較為直接的方式,直接對著被辨識物體擷取圖形影像以後,做特徵值得取 得辨識,透過網路的方式由遠端伺服器做運算,最後再將結果回傳到使用者的行 動裝置上,利用這樣的方式也可以達成不需要製作額外的標籤或是辨識物,來實 現行動裝置上的輔助資訊顯示。 雖然隨著科技的進步,使用者端的行動裝置運算能力日趨強大,各式各樣應 用程式也隨之發展,但在不同條件下必須考慮的環境變數也越來越多,如:光源 環境、網路訊號、室內定位等,因此本論文的主要目標著重於降低外在環境影響 的因素,希望在不同操作條件下,也能維持穩定的辨識結果。 1.
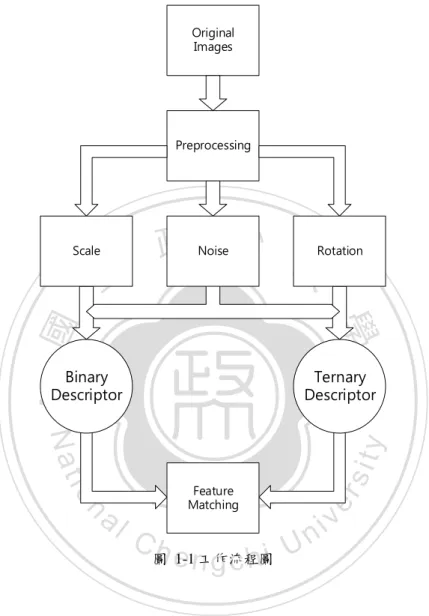
(9) 1.2 研究目的 本研究的主要目的是發展一個本機端的行動影像辨識機制,本論文所設定的 應用主要是藝術品導覽,在現行的方式大多都是以 QR 的標籤用來輔助資訊顯示, 除了需要針對每一項展品製作一個 QR 標籤,另外使用 QR code 也有一些問題, 如:連結網址改變則要重製,沒有網路的環境則無法使用,因此希望使用一個無 標籤的方式(markless)的方法,只需要對著作品,而不需要另外製作標籤來供辨 識使用,另外為了避免網路連線品質不佳或是遠端伺服器出現連線問題,也需要 使用不會使行動裝置增加計算負擔,並且能夠在裝置端存放夠多的辨識資料。. 政 治 大 的情況下也能準確辨識目標物,因在行動裝置上的效能有其限制和瓶頸,我們利 立. 因此本研究有兩個主要目標:第一個目標是在不依靠額外裝置或是網路連結. ‧ 國. 學. 用 light weight 的辨識方式將展覽內的特徵輸入至軟體內,試圖降低圖形別運算 負荷,如此一來便不需要依靠網路來回傳訊息或是內容資訊,可以離線使用,另. ‧. 外也可以藉此降低因為運算需求所增加的儲存空間的要求。. sit. y. Nat. 而在行動裝置上,因為礙於裝置體積上的原因,大多裝置的影像感光元件面. n. al. er. io. 積並不會太大,直接影響到了其影像的呈現能力,且容易產生噪點和雜訊,間接. i Un. v. 地影響到取得影像的品質,因此本論文的第二個目標是試著針對二元化特徵值加. Ch. engchi. 以改良成為三元化特徵值,期望在高雜訊的影像品質下能比二元化的特徵值有更 好的抗雜訊能力。. 1.3 流程架構與方法 基於前面所提出來的概念,我們會將會做不同的測試來比較各種狀況下的差 異值和速度、空間負荷等,進行將來行動裝置端的模擬試驗。 圖 1-1 為本研究之研究架構,主要流程如下: 1.. 影像首先會經過前置處理,之後將影像作放大、增加雜訊旋轉等變因以 利後續的實驗測試。 2.
(10) 2.. 將影像分別用不同的特徵表示法來分別取出所需要的特徵點. 3.. 得到特徵點以後,再利用各種不同的比對方法得到運算的結果. Original Images. Preprocessing. Scale. 立. 政 治 大 Noise. Rotation. ‧ 國. 學 Ternary Descriptor. ‧. Binary Descriptor. n. engchi. 圖 1-1 工作流程圖. er. io. Ch. sit. y. Nat. al. Feature Matching. i Un. v. 本論文的主要貢獻的是在行動裝置上提供一個 light-weight 演算法,在不依 賴網路數據環境下成功地進行辨識,並且能夠克服在低光源環境下硬體因素所產 生的先天限制,使擷取的圖片品質和雜訊的影響降至最低。. 本論文共分成六個章節,各章節的內容分別敘述如下:第一章針對研究主題 做概略的介紹,分別針對研究主題的背景條件,研究目的,以及研究的流程架構 等加以敘述與說明,讓讀者可以清楚地瞭解本論文的基本架構與主要目標。第二 3.
(11) 章對於現行主要的特徵描述子以及特徵擷取相關的文獻做收集整理以及分析,並 說明其定義、方法和比較不同方法間個別的差異。第三章說明本研究之主要研究 方法,從區域二元化特徵描述子開始做分析以及相關整理,到從區域二元化所衍 生出來區域三元化特徵描述子的方法其間的差異和改良。第四章針對行動裝置上 的環境作分析,並以此為基準而著力於在各種演算法使用區域三元化之後的測試 效果,以及各種不同的測試環境下所得到的個別差異和效能。第五章利用本研究 所提到的演算法,發佈到行動平台上,分析擴增實境及行動辨識等應用討論其效 果和可行性。第六章針對本論文「基於三元化特徵描述子之行動影像識別機制」, 提供後續研究與未來可行的應用發展提供建議。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 4. i Un. v.
(12) 2. 第二章. 相關研究. 影像資訊的處理可分為色彩與邊緣兩大類,由於攝影機的感光元件通常非 常依賴光源,依光源不同的變化色彩資訊變化相對較大,因此我們所探討的是如 何轉換這些影像資料是相對外在環境變化而較為不受影響,色彩的資訊相對是比 較薄弱的,所以我們重點在於特徵點的處理,從圖像中取出可靠的關鍵並且加以 比對和利用,讓物件辨識的結果更加穩定。 我們將會在 2.1、2.2 提到最各種根據不同原理的基本特徵擷取概念,接下 來在 2.3 的部分我們會進一步介紹主要兩種不同方式的描述特徵值,包含 SIFT. 政 治 大. 和 BRIEF 以及其各種衍生方法,最後 2.4 的部份我們會進行一個簡單的比較實驗. 立. 來測試兩種不同方式的描述值其辨識差異。. ‧ 國. 學 ‧. 2.1. 特徵擷取. sit. y. Nat. 特徵擷取是在圖形處理中一個初步的運算,根據不同的演算法來判斷是否為. io. er. 稍後辨識特徵演算法所需要的特徵,從種類來說有不同的特徵擷取方式,從發展 歷史來看依序有邊緣偵測(edge detection)、角偵測(corner detection)、區域偵測. al. n. iv n C detection)等方法,主要是進行降維後,將原始樣本投影到一個低維的特 hengchi U. (region. 徵空間,得到最能反應樣本本身或進行樣本區分的低維樣本特徵,篩選出合適的 特徵點再作進一步的處理,最後再透過分類器進行比對。由於許多電腦視覺演算 法使用特徵擷取作為其計算步驟的第一項,因此有大量的特徵擷取演算法被發展, 所擷取的特徵各式各樣,其計算複雜性和可重複性也非常不同,大致可以分為以 下四類:直觀性特徵、灰階統計特徵、變換係數特徵與代數特徵。 早期邊緣偵測的代表有 Canny[1]和 Sobel[2]方法,最主要的運算是先透過高 斯模糊去雜訊後,再轉換成灰階對圖像進行矩陣運算後得到的結果。接著有 Harris[3]、SUSAN[4]和 FAST[5]等作角偵測,核心的想法為透過一個自定範圍的. 5.
(13) 遮罩(mask),對遮罩中所涵蓋的範圍內的像素,來比較局部區域內的像素相似度 來找出可用的特徵點,除此以外還能得到方向向量的資訊。最後區域偵測的方法 常用的也有 LoG 和 HoG 方法,這兩種方法大同小異,主要是對灰階圖做微分變 換後,得到過濾過的訊號來做更精確的取樣。 而根據不同的演算法以及偵測方式,所得出的效果以及所需的時間也不盡相 同,且根據所得到的特徵值在不同場合上的利用或是各種不同情況狀況下的識別 也有不一樣的結果和辨識率,接下來將簡單介紹上述幾種常見取特徵點的方法, 包含邊緣偵測、角偵測、區域偵測。. 2.1.1. SUSAN(Smallest Univalue Segment Assimilating Nucleus). 治 政 SUSAN 是 S.M.Smith 和 J.M.Brady 提出的一種圖像處理方法 ,可以用來找出 大 立 物件的角點以及邊緣,SUSAN 角點偵測主要基本原理為搜尋局部區域內具有相 ‧ 國. 學. 同亮度的像素點,利用一個圓形遮罩來比較局部區域內的像素相似度。. ‧. 通常圓形遮罩半徑設定約為 3 至 4 像素,圓形遮罩中的中心稱為核心(nucleu),. sit. y. Nat. 將核心對準影像上每個像素,當核心經過影像上的像素時便計算遮罩內所有點的. io. er. 灰階值與核心灰階值的相似度,這區域的表示稱為 USAN(univalue segment. al. assimilating nucleus),並依據其局部區域的灰階值分布情形來判斷是否為角點,. n. iv n C 而其優點相較於邊緣偵測則是角點偵測效果比邊緣偵測好而不需計算影像梯度 hengchi U 值,速度快另外抗雜訊強且具有方向性。 首先對每個像素放置圓形遮罩並且計算他的 USAN 權重如( 2.1 ). n(𝑟𝑜 ) = ∑ compare(𝑟, 𝑟0 ). ( 2.1 ). 𝑟. 其中(𝑟, 𝑟𝑜 )定義如,設一個門檻值 T,當核心與遮罩上的任一點亮度相減時,若 相減小於 T,則假定這兩點的亮度將近將之設為 1,反之設為 0 如( 2.2 )所示. 6.
(14) compare(𝑟, 𝑟𝑜 ) = {. 1, 0,. 𝑖𝑓|𝐼(𝑟) − 𝐼(𝑟0 )| ≤ 𝑇 𝑖𝑓|𝐼(𝑟) − 𝐼(𝑟0 )| > 𝑇. ( 2.2 ). 得到 USAN 值以後,再利用一個固定的門檻值 G 來做比較,計算其邊緣強度, 通常 G 設為圓形遮罩的 1/2(小於 180 度),若要得到 USAN 值小於 G 值且核心點 附近也有與核心點亮度相似的像素,即可判斷此點是否為角點(corner)。. 2.1.2. FAST (features from accelerated segment test) FAST 是由 Rosten 與 Drummond 在 2006 年所提出的一種快速角點偵測法。 該方法的觀念是以待測點 p 為中心定義一個 7X7 遮罩,以遮罩內最大圓圈上的. 政 治 大 corner 的定義,這個定義基於特徵點周圍的圖像灰階值,檢測候選特徵點周圍一 立 16 像素之灰階判斷該中心點是否為角點,如圖 2-1 所示。此特徵檢測算法來源於. ‧ 國. 夠大,則認為該候選點為一個特徵點,如( 2.3 )所示。. 學. 圈的像素值,如果候選點周圍領域內有足夠多的像素點與該候選點的灰階值差別. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 圖 2-1 周圍 16 點遮罩示意圖[5]. N=. ∑. |𝐼(𝑥) − 𝐼(𝑝)| > 𝜀𝑑. ( 2.3 ). 𝑋∀(𝑐𝑖𝑟𝑐𝑙𝑒(𝑝)). 其中𝐼(𝑥)為圓周上任意一點的灰階值,𝐼(𝑝)為圓心的灰階值,𝜀𝑑 為灰階值 差得到一個門檻值,如果 N 大於預設的門檻值,一般為周圍圓圈點的四分之三, 則認為 p 是一個特徵點。 7.
(15) 候選點周圍的圓的選取半徑是一個很重要的參數,為了提高比較的效率,通 常只使用 N 個周邊像素來比較(FAST-N);另外為了獲得更快的結果,還採用了 額外的加速辦法,如果測試了候選點周圍每隔 90 度角的 4 個點,應該至少有 3 個和候選點的灰階值差夠大,否則不用再計算其他點,直接認為該候選點不是特 徵點。在 FAST-9 方法中,可以先判斷位置 1,5,9,13 像素的狀態;如果這些像素 中,有連續 2 個狀態相同,才執行連續 9 個像素的判定。在 FAST-12 方法中, 一樣先判斷位置 1,5,9,13 像素的狀態;如果這些像素中,有連續 3 個狀態相同, 才執行連續 12 個像素的判定。. 政 治 大 2.2. 區域興趣點偵測 (regions of interest or interest points) 立. ‧ 國. 學. 與角不同的是區域描寫一個圖像中的一個區域性的結構,但是區域也可能僅 由一個像素組成,因此許多區域檢測也可以用來辨識角點,而區域偵測器會檢測. ‧. 圖像中一個相對於角偵測器來說太平滑的區域。區域偵測可以被想像為把一張圖. sit. y. Nat. 像縮小,然後在縮小的圖像上進行角偵測。以下介紹較為常用的 Laplacian of. n. al. er. io. Gaussian (LoG)和 Difference of Gaussians (DOG)[6]方法。. i Un. Ch. v. n g c h iof Gaussian, LoG) 2.2.1. 高斯拉普拉斯轉換 (TheeLaplacian 在一維的訊號裡,一次微分(1st derivative)表示斜率(可正、可負),斜率的 絕對值出現 local optimum 時(灰階變化最劇烈的位置)往往就是物件的邊緣(edge) 或雜訊。二次微分(2nd derivative)相當於連續兩個一次微分;二次微分沒有方向性, 通常不會將結果看成向量,而是直接表示為純量的和 (sum);也就是兩個方向之 “二次微分”和,如( 2.4 )所示 𝐷𝐿 𝑓 = Δ𝑓 = ∇ ∙ ∇𝑓 = ∇2 𝑓 = 𝑓𝑥𝑥 + 𝑓𝑦𝑦 =. 8. 𝜕 2𝑓 𝜕 2𝑓 + 𝜕𝑥 2 𝜕𝑦 2. ( 2.4 ).
(16) 這個運算稱為拉普拉斯運算(Laplacian operator),如( 2.5 )所示 0 1 0 𝐷𝐿 = 𝑓𝑥𝑥 + 𝑓𝑦𝑦 = [1 −4 1] 0 1 0. ( 2.5 ). 此外二次微分表示斜率的變化,且「2nd derivative=0」時代表斜率函數的極 大值或極小值。從極大值跨到極小值或從極小值跨到極大值都會經過 0,而該 0 點剛好就是邊界的最中央位置。所以若是我們在二次微分的結果中尋找跨過 0 的位置,那麼就可以找到最準確的邊界點位置,如圖 2-2 所示;這個位置就稱為 過零點 (zero-crossing)。. 立. 政 治 大. ‧ y. sit. ‧ 國. 學. Nat. 圖 2-2 利用微分尋找過零點示意圖. io. er. 但是微分會將雜訊訊號放大,而二次微分因為經過運算兩次,所以比一次微 分還要容易受到雜訊干擾,所以為了抑制被強化出來的雜訊,做二次微分前先做. al. n. iv n C 高斯模糊。二次微分與高斯模糊亦可結合在一起變成一個運算子如( 2.6 ) hengchi U ∇2 (ℎ 𝑓(𝑥, 𝑦)) = (∇2 ℎ)𝑓(𝑥, 𝑦). 其中 h 為高斯模糊遮罩 ℎ(𝑥, 𝑦) = exp(−. 𝑥 2 +𝑦 2 2𝛿 2. ( 2.6 ). ),𝛿是高斯分布的標準差(standard. deviation)。因此二次微分和高斯模糊結合在一起的遮罩為 LoG 如( 2.7 )所示 ∇2 ℎ = (. 𝑟 2 −𝛿 2 𝛿4. 𝑟2. )exp(− 2𝛿2 ),𝑟 2 = 𝑥 2 + 𝑦 2. 9. ( 2.7 ).
(17) 2.2.2. 高斯差 (Difference of Gaussians, DoG) 將一個原始灰階圖像的模糊圖像從另一幅灰階圖像進行增強的演算法,通過 DoG 以降低模糊圖像的模糊度。這個模糊圖像是通過將原始灰階圖像經過帶有 不同標準差的高斯模糊進行相減後所得到的。高斯模糊只能降低高頻訊號。從一 幅圖像中減去另一幅可以保存在兩幅圖像中所含的訊號中含有的空間。這樣的話, DoG 就相當於一個能夠去除除了那些在原始圖像中被保留下來的頻率之外的所 有其他頻率訊號的帶通濾波器 (band-pass filter),如( 2.8 )所示 𝑢2 +𝑣 2 𝑢2 +𝑣 2 1 1 − − 2 2 2 𝑓(𝑢, 𝑣, 𝜎) = 𝑒𝑥𝑝 2𝜎 − 𝑒𝑥𝑝 2𝐾 𝜎 2πσ2 2π𝐾 2 σ2. 治 其中 r 是模糊半徑 (𝑟 = 𝑢 政 + 𝑣 ),σ 是常態分佈的標準偏差 大 立 2. 2. ( 2.8 ). 2. ‧ 國. 學. 事實上,DoG 演算法作為兩個多元常態分佈的差通常總額為零,當 K 約等 於 1.6 時它近似高斯拉普拉斯轉換(Laplacian of Gaussian, LoG),當 K 約等於 5 時. ‧. 又近似視網膜上神經節細胞的視野。. y. Nat. er. io. sit. 2.3. 特徵描述子. 在影像辨識中,在特徵值偵測完以後,接下來就是使用得到的特徵值用法,. al. n. iv n C 並將其描述出來以利之後的配對,現下有兩種常用的特徵描述子的類別 hengchi U 1. SIFT-like(1999~) 2. Local Binary Descriptors(2010~). SIFT-like 是先將特徵值標示出來並且針對其特徵向量做強化,而 SIFT 是在 這之中首先發表的,之後發表的大多使改良其方法或是描述式,故以此稱之,在 這之中有 SIFT[7]、PCA-SIFT、GLOH、SURF[8]、PCA-SURF 等,稍後將會簡 述。另外一個是近年來發表的新方法:二元化敘述方法(Binary descriptors),主要 的做法以二元字串作為其特徵值,並計算 Hamming distance(漢明距離)來比對特 徵間的差異,BRIEF[9]、ORB[10]、BRISK[11]、FREAK[12]等均屬此類。. 10.
(18) 2.3.1. 尺度不變特徵轉換 (Scale-invariant feature transform, SIFT) SIFT 是設計用來偵測與描述影像中的局部性特徵,它在空間尺度中尋找極 值點,並提取出其位置、尺度、旋轉不變數,局部影像特徵的描述與偵測可以幫 助辨識物體,其特徵是基於物體上的一些局部外觀的興趣點而與影像的大小和旋 轉無關。 而在 SIFT 中,關鍵點是在不同尺度空間的圖像下偵測出的具有方向資訊的 局部極值點,涉及到的最重要的兩步是構建尺度空間以及關鍵點檢測。 1. 構建尺度空間: 在 SIFT 中 Lowe 教授採用了尺度空間理論。其主要思想是透過對原始圖. 治 政 像進行尺度變換,獲得圖像多尺度下的尺度空間表示序列,並檢測這個序列 大 立 中的關鍵點。這樣圖片就被映射為多個尺度上的關鍵點資訊,儘管兩幅圖片 ‧ 國. 學. 是處於不同的尺度,但卻可以提取出在尺度變換中沒有改變的關鍵點,從而. ‧. 進行關鍵點配對,進而識別出物體。. sit. y. Nat. 因此在 SIFT 中構建了高斯金字塔,接著對圖像做高斯平滑以及對圖像做. io. er. 降維取樣(減小計算量)。一幅圖像可以產生幾組(octave)圖像,一組圖 像包括幾層(interval)圖像。為了讓尺度體現出連續性,相鄰兩層圖像間的. al. n. iv n C 尺度為 k 倍的關係,同時相鄰兩組的同一層尺度為 h e n g c h i U 2 倍的關係。 2. 關鍵點偵測:. 尺度規範化的 LoG 算子具有真正的尺度不變性。即我們可以在不同尺度 的圖像(已經經過高斯卷積)上進行拉普拉斯運算(二階導數),並求極值 點,從而求出關鍵點。但這樣做的運算量很大,於是 SIFT 中進行了近似處 理:利用 DoG 建立 scale-space,每一層在經過高斯模糊後,把所得的圖像 相減所產生的圖像成為一個新的空間集,之後就在這個空間上面做運算,接 著做 extremum 也就是這個像素(x, y)在 26 個鄰居裡面(上一個 scale 的 9 個點 +這個 scale 的 8 個點+下一個 scale 的 9 個點),它必須要是 local maximum. 11.
(19) 或 minimum。因此在第一個步驟裡面,我們就可以把所有是 local extremum 的點給選出來,當作是候選的興趣點(candidates)。. 接下來的第三個步驟就是指定特徵值的方向,這是為了接下來要拿來做比對 (matching)用的。最重要的是找出主要方向(major orientation),找到了主要方向之 後如果要做比對的話,就可以把所有的圖像轉到這個local frame,這樣就可以達 到旋轉不變量(rotation-invariant)的目的。 因此對於每一個特徵點我們要去計算它梯度(gradient)的大小和方向。這裡所 採用的方法是方向統計的直方圖(orientation histogram),主要是將對於每一個特. 治 政 徵點,去考慮它臨近周圍一個視窗內的點的梯度方向,統計最多的方向就當作主 大 立 要方向如圖 2-3。而每個鄰近的點對中央這個像素的權重,就是利用高斯分布 ‧ 國. 學. (Gaussian distribution)再乘上該點的梯度大小來決定。. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 圖 2-3 指定特徵值的方向[7]. 根據方向統計,把一個像素附近8*8這個是視窗切成2*2的子視窗,然後去統計每 個子視窗的方向統計,因此這每個子視窗的方向就由4*4的方向用之前的方法來 決定。每個方向是8個bits,如此一來每個像素就會有4*8=32個維度,圖 2-4所示. 12.
(20) 圖 2-4 特徵方向降維[7]. 對於光線、雜訊、些微視角改變的容忍度也相當高,對於部分物體遮蔽的偵 測率也相當高,甚至只需要 3 個以上的 SIFT 物體特徵就足以計算出位置與方位。. 政 治 大 很容易辨識物體而且鮮有誤認。 立. 基於這些特性,它們是高度顯著而且相對容易擷取,在母數龐大的特徵資料庫中,. ‧ 國. 學. 2.3.2. PCA-SIFT (Principle Component Analysis-SIFT). ‧. 改變原來 SIFT 中的方向統計步驟,在特徵空間周圍 41x41 的區域中去計算. sit. y. Nat. 它的 principle components (原因是特徵點它具有特殊的性質,不是任意 41x41 的. n. al. er. io. 區域皆可形成特徵點,因此存在有更精簡的表示方法)。PCA-SIFT 將原來的. i Un. v. 2x39x39=3042 維的向量(方框的上下左右邊界不看,所以是 39),降成 20 維(SIFT. Ch. engchi. 要 128 維)以達到更精簡的表示方式。. 2.3.3. GLOH (Gradient Location-Orientation Histogram) 是把原來 SIFT 中 4x4 棋盤格的 location bins 改成用放射狀同心圓的 17 location bins 來表示,圖 2-5 為示意圖,並計算其中的 gradient orientation histogram (orientation 的方向分類為 16 種),因此總共是 16x17=272 維度的表示方式,之後 再做 PCA 將之降維成 128 維的資訊,因此保有跟 SIFT 一樣精簡的表示方法,但 比 SIFT 有更佳的效能。. 13.
(21) 圖 2-5 放射狀同心圓的 17 location bins. 政 治 大. 2.3.4. SURF (Speeded Up Robust Features). 立. 此演算法是根據 SIFT 演算法改良而來。SURF 標準的版本比 SIFT 要快數倍,. ‧ 國. 學. 並且在生成不同變換的圖像換方面比 SIFT 更加穩定。SURF 基於近似二維的小 波轉換(Haar wavelets)和並且有效地利用了積分圖像。. ‧. SURF 創建一個在金字塔高階層取樣中不使用 2:1 降維取樣法的「堆疊」 ,而. y. Nat. io. sit. 是使用與圖像相同的解析度。由於使用積分圖像接著建立 Hessian 矩陣,SURF. n. al. er. 濾鏡使用一個帶通濾鏡近似二階高斯偏微分。因此積分圖像可以用矩形框過濾器. Ch. 在幾乎一定的時間內計算完成,如( 2.9 )所示. 𝐻(𝑥, 𝜎) = [. 𝐿𝑥𝑥 (𝑥, 𝜎) 𝐿𝑥𝑦 (𝑥, 𝜎). engchi. i Un. v. 𝐿𝑥𝑦 (𝑥, 𝜎) 𝜕2 ] In which 𝐿𝑥𝑥 (𝑥, 𝜎) = 𝜕𝑥 2 𝑔(𝜎) ∗ 𝐼(𝑥, 𝑦) 𝐿𝑦𝑦 (𝑥, 𝜎). ( 2.9 ). 𝑎𝑛𝑑 𝑔(𝜎) is a Gaussian distribution function. 為了達成旋轉不變量,SURF 對每個特徵點訂出一個方向性。如果某特徵點 被找到的 scale 為 s,再以特徵點為中心,半徑 6s 的圓形範圍內計算此區域的 Haar wavelet transform,且 wavelet 邊長為 4s。轉換完成後再乘上以特徵點為中心,σ 為 2s 的 Gaussian weight。結果可得到 x 與 y 方向的變化情況,此特徵點的方向. 14.
(22) 即為合成向量的方向。 ( 2.10 )為 Haar wavelet transform (哈爾小波轉換) :設轉換的目標為矩陣為 A, Haar matrix 為 H,則轉換後結果為:𝐻 𝑇 𝐴𝐻 1 ; 0 ≤ 𝑡 < 1/2, Haar wavelet function:𝜑(𝑡) = {−1 ; 1/2 ≤ 𝑡 < 1, 0 ; 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒. ( 2.10 ). 圖 2-6 表示方形區域大小為 8x8,每 2x2 的區域為一個 sub-region 針對每個子區 域,計算它的 Haar wavelets transform 得到相對於主向量垂直與平行的變量 dx、 dy 所有子區域裡的 dx、dy 都乘上中心為特徵點,σ 為 3.3s 的 Gaussian weight。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. i Un. 圖 2-6 利用加總方式計算主向量[8]. engchi. v. 之後將單一 sub-region 中的 dx、dy 分別加總與取絕對值,得到:v 即為此 sub-region 的 特 徵 向 量 。 整 個 特 徵 點 方 形 區 域 含 有 4x4 個 特 徵 向 量 𝑣 = (∑ 𝑑𝑥, ∑ 𝑑𝑦 , ∑|𝑑𝑥|, ∑|𝑑𝑦|) , 特 徵 總 長 為 64 , 將 它 正 規 化 為 單 位 向 量 變 成 contrast-invariant 得到 interest point descriptor vector。 相對於 SIFT 而言,使用 SURF 所需的運算資源負荷較低,而在我們的研究 過程中也順利的將 SURF 移置到行動裝置上做運算並可成功辨識,但資源消耗對 於行動平台的負擔還是有點負荷,所以必須在找一個更輕量的運算法來實現本研 究,因此我們轉而尋找有別於 SIFT 的特徵子的辨識方法,下面我們將繼續介紹 此種方法,即區域二元化描述子(Local Binary Descriptor)。 15.
(23) 2.3.5. BRIEF (Binary Robust Independent Elementary Features) BRIEF 所使用的特徵點擷取算法與 SIFT 一致,也可以仿照 SURF 算法。描 述子的建立過程:選定建立描述子的區域(特徵點的一個正方形鄰近區域)對該 區域用 σ=2 的高斯模糊,以消除部分雜訊。之後在這個區塊用 p 表示,它的大小 是 SxS 像素,在 p 上面提取 BREIF 特徵。定義一個τ測試如( 2.11 ):x,y 是 p 內 的兩個像素位置,實際上 x 是形如[u, v]的二維坐標,p(x)和 p (y)是像素位置 x 和 y 的亮度。以一定比率的隨機算法生成點對<x,y>1,若點 x 的亮度小於點 y 的 亮度,則返回值 1,否則返回 0。 1 τ(𝑝, 𝑥, 𝑦) = { 0. 立. 𝑖𝑓 𝑝(𝑥) < 𝑝(𝑦) 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒. 政 治 大. ( 2.11 ). ‧ 國. 學. 重複上述公式數次(如 512 次),就會得到一個 512 位的二進制編碼,即該特徵 點的描述子。如( 2.12 )所示:. ‧. 𝑓𝑛𝑑 (𝑝) = ∑ 2𝑖−1 𝜏(𝑝, 𝑥𝑖 , 𝑦𝑖 ). ( 2.12 ). io. sit. y. Nat. 1≤𝑖≤𝑛𝑑. n. al. er. 從這個公式可以看出,建立一個 512 個 bit 的 BRIEF,就需要 512 對<x,y>,. Ch. i Un. v. 且需要注意的是它們是有序排列的,每次計算位置都相同,否則將會影響最終結. engchi. 果。也就是說,一旦選定了 512 對<x,y>,那麼無論是提取特徵還是匹配特徵, 都要按照這 512 對的次序進行計算,而存儲 BRIEF 所需的 BYTE 數為 512/8=64, 所以 512 個 bit 的 BRIEF 又稱作 BRIEF-64。 而二元化特徵演算法比起之前的演算法快速的主因是在於利用配對時只需 計算兩特徵點描述子的 Hamming distance。而判斷是否配對成功的依據在經過大 量實驗數據測試,不能配對的特徵點描述子的 Hamming 距離在 128 左右,而配. 1. 原論文中在取法上做了五種不同的測試:在區域內平均取 pair、等方向性的高斯分布、兩段式 的高斯分布(權重改變)、隨機不相近的兩點、在區域內取對稱的點對,最後是隨機的兩點效果最 佳。 16.
(24) 對點對描述子的 Hamming 距離則遠小於 128。 因為 BRIEF 的步驟相對來的單純,如此一來只有兩個關鍵步驟是最重要的: 一為如何對圖像對平滑處理,另外則是如何選擇[x,y]對,由於τ測試是根據單一 一個像素的亮度進行判別,非常容易被雜訊影響,做圖像平滑可以消除雜訊影響, 但是相反的越平滑的圖像要配對的難度也越大,所以如何在圖像的平滑和去雜訊 中取得平衡也很重要。另外 BRIEF 不考慮特徵的方向(即旋轉不變量),也不考慮 多重解析度。. 2.3.6. ORB (Oriented FAST and Rotated BRIEF). 治 政 BRIEF 的優點在於速度,而缺點先前提到過的缺乏旋轉不變性、容易被雜訊 大 立 影響、不具備尺度不變性。而 ORB 就是試圖解決上述缺點其中的二點;在 ORB ‧ 國. 學. 的方案中,採用了 FAST 作為特徵點採取運算來解決旋轉不變性,如此增加了計. ‧. 算特徵點的角點方向,而找出 key point 的位置後,對於 key point 用 Harris 角點. sit. y. Nat. 檢測,選取前 N 個最好的點。因為 FAST 算法本身就不能處理多尺度圖像,如果. io. er. 需要處理多尺度的話,就對原來的圖像作金字塔,然後對每張圖都再進行 FAST 和 Harris 處理。接著將特徵點的主方向利用 moment 計算而來,公式如( 2.13 ):. n. al. i n C 𝑖 𝑗 U M𝑖𝑗 = ∑ h ∑ 𝑥 𝑦 𝐼(𝑥, 𝑦) e𝑦n gchi 𝑥. v. ( 2.13 ). 得到 Moment 之後接著進行 Corner orientation 運算如( 2.14 ): 𝑐𝑥 =. 𝑐𝑦 𝑀10 𝑀01 , 𝑐𝑦 = , 𝐶𝑜𝑟𝑖 = tan−1 ( ) 𝑀00 𝑀00 𝑐𝑥. ( 2.14 ). 有了主方向之後,就可以依據該主方向提取 BRIEF 描述子。但是由此帶來的問 題是,由於主方向會發生變化,隨機取得的 pair 相對的也會被影響,從而降低描 述子的判別性。解決方案也很直接地採取 greedy 的方法找到相關係數較低的隨 機點對,設定一個 threshold 直到取滿位元數。 關於雜訊影響的問題,由於 BRIEF 使用的是 pixel 跟 pixel 的大小來構造描 17.
(25) 述子的每一個 bit,這樣的後果就是容易被雜訊影響。因此,在 ORB 的方案中, 做了以下的改進:不再使用 pixel-pair,而是使用 5×5 的 patch-pair,也就是說,對 比 patch 的像素值之和。(可以使用積分圖快速計算)。 然而 ORB 沒有試圖解決尺度不變性,就如先前章節所提到的,因為 FAST 本身就不具有尺度不變性,但是對於這樣只求速度的特徵描述法,一般都是應用 在即時的影像處理中的,所以只能透過跟蹤或是其他補償的方法來解決尺度不變 性的問題。. 2.3.7. BRISK (Binary Robust Invariant Scalable Keypoints) 首先建尺度空間的金字塔,一個 n 個 octave 層,用 ci 表示;n 個 intra-octave. 治 政 層,d (見圖 2-7)。c 即是原始圖像,c ,c ,c 依次是對上一層 half-sampling 降低 大 立 取樣率。d 層在 c 和 c 層之間,d 是對原圖 1.5 倍下取樣,d 是對原圖 1.5*2^i i. 0. i. i+1. 2. 3. 0. i. 學. ‧ 國. i. 1. 倍下取樣。再用 9-16FAST 對每層(ci/di)提取 key point,都用一樣的閾值 T,. ‧. 找到興趣區。再對這些點進行尺度空間的非極大值抑制。. sit. y. Nat. 而討論的點要是同層周圍八個相鄰點中有最大的 FAST score 的,這個分數 s. io. er. 定義為最大值閾值。在此層的上、下兩層中的 scores 都要進行抑制(變小)。 c0 上的特殊處理:用 FAST5-8 對原圖檢測得到虛擬層 d(-1)上點的分數,作為 c0. n. al. 的下一層。. Ch. engchi. 18. i Un. v.
(26) 學. 2.key point 描述. 圖 2-7 利用金字塔梯度做 scale 取樣[11]. ‧. ‧ 國. 立. 政 治 大. 首先是方向的表達,可能的取樣點是圍繞 keypoint 的一個個同心圓分布上的. y. Nat. io. sit. 60 個點(圖 2-8)。另外然後對 60 個點兩兩選取組成點對(60-1)*60/2 個 pair,計算. n. al. er. 其高斯平均後的差異值後得到二元編碼,接著進行計算兩點之間的距離,而在原. Ch. i Un. v. 論文中指出超過 13.67t(t 為 scale)距離的長 pair 對較具代表性。最後在定義完關. engchi. 於一個取樣點對的局部梯度,然後定義各點對中兩點的距離長或短的差異,然後 全部 pattern 的方向就等於由這些長距離點對的梯度之和的平均,最後利用類似 BRIEF 的編碼加上角旋轉的敘述。. 19.
(27) 圖 2-8 key point 取樣分布[11]. 3.特徵點的配對還是用簡單有效的 Hamming distance。. 政 治 大. 2.3.8. Fast Retina Keypoint (FREAK). 立. 而 FREAK 主要是利用之前所提到的 FAST 來做提取主要的特徵方式,利用. ‧ 國. 學. 人類視網膜對於光線接受的敏感度分布的方式,以不同大小的圓圈圖案作為 pairs 的取樣方式,從中央小圈到外部大圈是由排列緊密到排列稀疏,以此作為有效率. ‧. 的取樣方式,使用高斯差(DoG)的方法來針對區域內不同部分的加權(如圖 2-9. y. Nat. n. er. io. al. sit. 所示),最後再將收到的訊號成二元制(如圖 2-10)。. Ch. engchi. 20. i Un. v.
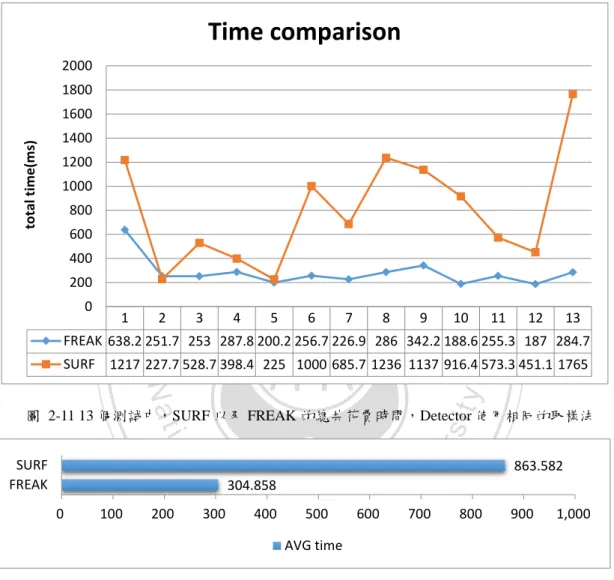
(28) 圖 2-9 FREAK 特徵點區域示意圖[12] (左上)視網膜的區域以及命名 (右上)視網膜內視神經的分布數量 (左)根據不同的區域和視神經分布數量所劃 分的描述區域. 立. 政 治 大. ‧. ‧ 國. 學 sit. y. Nat. io. er. 圖 2-10 用二進位的方式表示視網膜神經的訊號[12]. 跟 SIFT 和 SURF 不同的是,FREAK 採用了二元化的編碼方式並且將所取得. al. n. iv n C 的特徵以 Hamming distance 的方式描述,大幅降低中間的運算成本,為了得知此 hengchi U 兩類特徵編碼方式不同以及效果,我們在這裡抽出隨機的測試樣本用 FREAK 以 及 SURF 來做比較 (如圖 2-11 圖 2-12 所示)。 另外我們也注意到在第 2 個樣本以及第 5 個樣本中所呈現出來的數據,兩種 演算法其所需要的時間非常接近,探究其原因是辨識目標因本身可以取樣的特徵 點過少,例如沒有任何裝飾、同顏色或者邊界不明顯,都有可能導致可用特徵子 過少,如此一來就有會影響正確的辨識率。 根據這個實驗所做出來的結果,在上述兩個演算法當中,在取得特徵值一樣 使用 FAST 的方式下來做比較,這兩種描述的方式後者平均時間大約為前者的. 21.
(29) 1/3,而利用二元化方法比較能夠降低計算成本也就是在 local 端的計算負荷較另 外一個方法來得低,而 SURF 雖然從比較的準確度相對來說較為準確,但相對於 其他的描述比較方式需要最多的比較運算和負荷,因此本實驗將從此二元化出發, 並且針對其抗噪性提出新的方法試著加以改良。. Time comparison 2000 1800. total time(ms). 1600 1400 1200. 政 治 大. 1000 800. 立. 600 400. ‧ 國. 0. 學. 200. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. ‧. FREAK 638.2 251.7 253 287.8 200.2 256.7 226.9 286 342.2 188.6 255.3 187 284.7 SURF 1217 227.7 528.7 398.4 225 1000 685.7 1236 1137 916.4 573.3 451.1 1765. sit. y. Nat. io. v ni. n. al. er. 圖 2-11 13 個測試中,SURF 以及 FREAK 的總共花費時間,Detector 使用相同的取樣法 SURF FREAK 0. 100. 200. 300. Ch. 304.858. i U 700 e n 500 g c h600. 400. AVG time 圖 2-12 SURF 以及 FREAK 的平均偵測時間. 22. 800. 863.582 900. 1,000.
(30) 2000. 600. 1800. 400. 1200 1000. 300. 800. 200. 600 400. 100. 200 0. 0 1. 2. 3. 4. 5. 6. 7. Descriptors. 8. 9. 10. 11. 12. 13. total time. 圖 2-13 Descriptor 數量和總時間的關係. 立. 政 治 大. 學 ‧. ‧ 國 io. sit. y. Nat. n. al. er. Descriptors Number. 1400. Ch. engchi. 23. i Un. v. Cost time (ms). 500. 1600.
(31) 3. 第三章. 區域三元化描述子. 在本章節中將針對區域二元化和區域三元化圖形這兩類特徵描述子,以實例 分析各類型的不同,並討論其限制與可能的解決方案。. 3.1. 二元化特徵值討論歸納 因為早期的 SIFT-like 的 Descriptor 已成為視覺辨識的基礎和主流,近年來多 項研究都專注在提高效率這方面的改進,而在最近則有研究學者提出了二元化描 述子概念的 BRIEF,也就是 LBD(Local Binary Descriptor)。 LBD 的主要步驟是將感興趣的區域,經過 pixel-wise 或是 patch-wise 的差. 治 政 異後,來取得這個興趣點的特徵編碼。而 LBD 的進行主要有兩個步驟:首先定義 大 立 一塊圖形中的區域為 p,編碼的長度為 d,則計算如下式( 3.1 ) ‧ 國. 學. L(𝑝)𝑖 = ⟨𝑔𝑥𝑖 ,𝜎𝑖 , 𝑝⟩ − ⟨𝐺𝑥𝑖′ ,𝜎𝑖′ , 𝑝⟩. ( 3.1 ). ‧. sit. y. Nat. 𝑔𝑥,𝜎 是以 x 做中心點,σ為高斯的標準差,而⟨∙,∙⟩為普通的乘積,接下來量化. io. er. 的步驟則透過簡單的 threshold:當L(𝑝)𝑖 為一正數時則Q(𝑝𝑖 ) = 1,反之則Q(𝑝𝑖 ) = 0, 如此反覆進行後就會得到一組二元化編碼字串,即為此區域的特徵描述。. n. al. Ch. engchi. i Un. v. 圖 3-1 計算L(𝑝)𝑖,d=2 的情況,各紅色區域的高斯平均是再減去相對應綠色區域的高斯平均[17]. 基本上,一個 32X32 的區域大小在進行編碼後就會有 d=512 的長度編碼 (64Byte),最後只要利用 XOR 的方式將一個選定的區域進行 Hamming distance 的 比較,如此可以降低所需的空間以及計算量。 24.
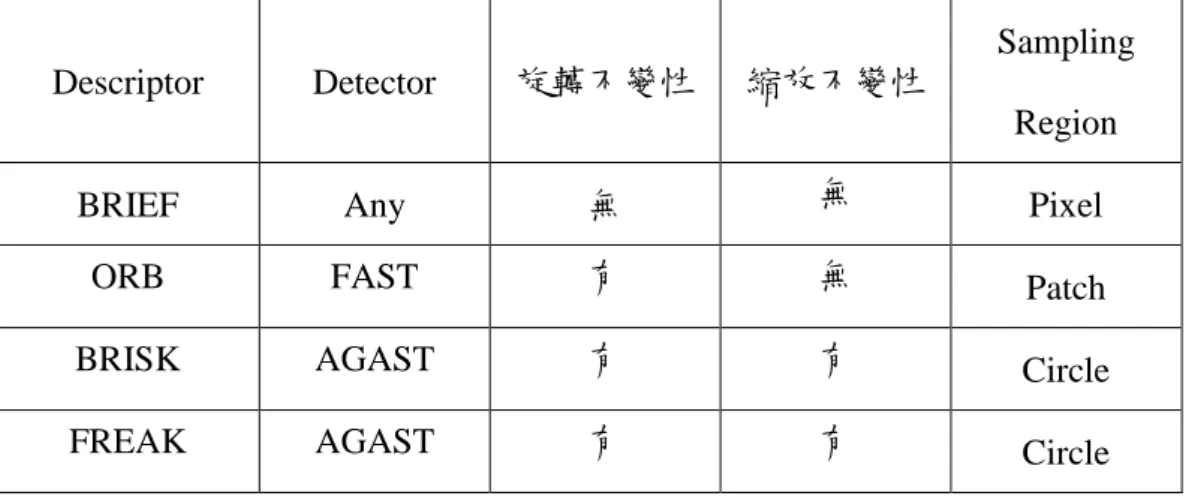
(32) 以 BRIEF 為例,圖 3-2 為簡單的示意圖,針對區域內的各點做比較,最後 得到 512bit(BRIEF-64)。. 立. 政 治 大. ‧ 國. 學. 圖 3-2 在一個 key point 內,取一個區域進行隨機的點對點的灰階亮度值比較,194-218 得 0,. ‧. 170-179 得 0,171-21 得 1 依此進行,重複直到取滿所需的位元數為止. sit. y. Nat. io. er. 在這裡稍微對 binary descriptor 做個整理,表 3-1 為各 descriptor 的比較, 上述所提到的四種 binary descriptor : BRIEF、ORB、BRISK、FREAK,所共同的. n. al. 特性有下列幾點:. Ch. engchi. i Un. v. 1. 特徵點是建立在一個群集中緊密成對的比較而來的 2. 在特徵點當中,每個位元所代表的正好就是比較後的結果 3. 都使用 Hamming distance 來做為測量的方法. 25.
(33) Sampling Descriptor. Detector. 旋轉不變性. 縮放不變性 Region. BRIEF. Any. 無. 無. Pixel. ORB. FAST. 有. 無. Patch. BRISK. AGAST. 有. 有. Circle. FREAK. AGAST. 有. 有. Circle. 表 3-1 各 descriptor 的比較. 接著分析各類 descriptor 不同之處:. 治 政 大 SURF 來做比較,但 分別可得到 128,256,512 個位元,雖然在原論文中提到是與 立. BRIEF 從可能的特徵點取高斯分布隨機取樣採 128,256,512 對的比較方式,. 間,BRIEF 具有最低的計算和儲存要求。. 學. ‧ 國. 是其實 BRIEF 可以跟任何一種 detector 做配合,由於其結構簡單和壓縮的儲存空. ‧. ORB 在 BRIEF 提出之後為了解決其不具旋轉不變性的缺點,而提出來的一. sit. y. Nat. 個改良性方法,透過計算局部特徵點的主向量利用一個加權平均像素強度假設在. io. er. 一個小區域內不是都集中在中心,而對一小塊區域進行平均後取 256 對比較結果,. al. 而對旋轉問題 ORB 使用 FAST 來尋找方向向量,但是 FAST 對於衡量 cornerless. n. iv n C 的圖表現較差和缺乏多尺度特徵的穩定性。為了解決這個問題,則使用了 Harris hengchi U 方法用於各 key point 的位置,用金字塔的方式逐一重複方式以提供非最大值抑 制圖像內的和有限的圖像檢測 key point 大小。 BRISK 不同於 BRIEF 可同時提供縮放和旋轉不變性。為了來計算特徵的位 置,它使用 AGAST 的角點偵測(FAST 為近似三元決策樹,而 AGAST 為二元決 策樹)來增進 FAST 的角點偵測,在增加速度同時保持也相同的檢測性能。對於 尺度不變性,FAST key point 在尺度空間金字塔,在所有尺度上進行非極大值抑 制和內插。而在描述特徵點的方式上,跟 BRIEF 以及 ORB 所採取的隨機採樣方 式不同,而是使用對稱式的取樣,取樣點的位置是以同心圓的方式圍繞在特徵周 26.
(34) 圍圓,每個取樣點的高斯模糊是相對於其周圍像素而來,而模糊的標準偏差是從 中心的距離開始逐漸增加。 在建立方向上,利用幾個長距離的樣本來做比較決定(例如在 descriptor pattern 的相反邊上做取樣),對於每一個長距離相比較而言,取樣點之間的向量 被加權後並儲存成二元化的強度差異,之後利用這些向量的平均值,確定主向量 的方向,如此可以將次特徵點建立起多尺度縮放和旋轉的不變性,而另用 512 對的短距離取樣,建立此特徵值的描述。 最後 FREAK 是改良了 BRISK 的方法,把取樣區域模擬成近似人類視網膜 的方式分布,越接近興趣點的地方權重就越重,區域也越密集,而取樣區域也減. 治 政 少至 43 個進一步的降低取樣後的維度。 大 立 總體而言,FREAK 或是 BRISK 比起 BRIEF 或是 ORB 顯著的需要更多的計 ‧ 國. 學. 算時間和稍多的儲存空間,但是所獲取的效果和穩定性卻是更高。. ‧. 3.2. 二元化特徵值實驗分析. sit. y. Nat. 因為本實驗是以未來可以在行動裝置上運行程式作為最終目標,而行動裝置. n. al. er. io. 運算儲存資源有限,並不會將過量的資訊將之導入導致負擔過重,所以這裡我們. i Un. v. 準備圖形樣本,畫作共 274 幅來進行測試。各描述值和偵測子的綜合測試表現的. Ch. engchi. 結果將附於附錄 A 中,為描述子在預設的條件下進行圖形識別所得到的平均配 對時間(包含 detection time, extraction time, matching time)以及平均特徵數如圖表 3-2 所示。. Descriptor. Detector. Avg Numbers of. Avg. Time. Features. (ms). Bytes. SIFT. SIFT. 64. 4788. 2095. SURF. SURF. 128. 3765. 390. ORB. ORB. 32. 13457. 370. 27.
(35) BRIEF. FAST. 32. 8141. 370. BRISK. FAST. 64. 7753. 524. FREAK. FAST. 64. 7977. 412. 圖表 3-2 各特徵值辨識所需之平均時間. 再針對各種不一樣的特徵值和描述式的組合來做比較,因為 SIFT 和 SURF 取樣的方式是取出以後再做向量強化方向,後來的二元化辨識方式都可以取用 SIFT 和 SURF 的描述式,不過效果並沒有如 FAST,ORB,BRISK 的二元化描 述式好,而 SIFT 和 SURF 的辨識法並不能使用其他三種二元描述值來做辨識,. 治 政 大 所以沒有列出數據,詳細的實驗結果將於附錄中呈現。 立. 綜合的觀察如下,SIFT 辨識率是最穩定的,但相對的時間和計算代價也是. ‧ 國. 學. 最高的,因此才有後面提出的各種方式做不同的嘗試,再來是 SURF,改進了 SIFT. ‧. 的效能,但是其實其儲存的空間使用卻相對的變多了一些,不過也因此在研究中. sit. y. Nat. 使用 OpenCV 上有許多的特徵值可以先藉由 SURF 方法辨識出再利用自己的演算. io. er. 法來作取出配對;而我們可以從上述的實驗得知,雖然 binary descriptor 可以從. al. SIFT 以及 SURF 方法來取得描述值,不過用 FAST 方式相對於來說更快,不過. n. iv n C 相對的缺點在前面的章節也提到過,對於視角的改變來說 Binary 在這方面的辨 hengchi U 識度表現還是相對低落(附錄圖表 A-3)。總體來說 SIFT 對於各種物體較為穩定, Binary 的方式在非平面物體的表現上,表現也比較弱了一點,但是尚在可接受範. 圍內,另外 Binary 的 match 的方式主要是使用 Hamming distance 來比對編碼的 結果,因為是有序對比對結果的關係,所以目前在不同的情況下再相互比對是不 具意義的,目前尚無法拿來另作他用。. 3.3. 區域三元化圖型 而區域二元化特徵值的優點,相對的也伴隨著缺點:容易被雜訊所干擾,這 將會大大的影響了辨識和編碼的結果,雖然說各個不同的演算法有針對此項缺點 28.
(36) 利用不同的方式,如高斯模糊、特徵點取樣區分佈、權重設定等,卻還是不能改 變其二元化非 0 即 1 的特性,尤其在面對本研究的主題,電子硬體所產生的雜訊 通常是 CMOS 因經過重重的電子訊號放大所得出來的影像訊號(下章節會有詳細 的解釋,見圖 4-1、圖 4-2),因此更容易被二元化的方式放大雜訊這個缺點。 在這裡我們提出了一個方法來改進二元化過程易受雜訊干擾這個缺點。原理 是我們在原本的二元化方法中,再增加一個判斷式,因此一個特徵區域將被切割 成三個區段來描述:大於、介於兩者之間的、小於,如此增加一個緩衝的區域, 讓雜訊影響辨識的程度獲得一些紓解。. 立. 政 治 大. 假設𝜃定為 10 198-195= 3 ≤ 10 … 1. ‧ 國. 學. 86-248 = -162 < -10 … 0. ‧. 52-46 = 6 ≤ 10 …1. 156-237 = -81 < -10 … 0. n. al. er. io. sit. y. Nat. …. Ch. n engchi U. 187-167 = 20 > 10 … 2 v i 96-46 = 50 > 10 … 2. 得到三元編碼 101…022 圖 3-3 區域三元化示意圖. 以 BRIEF 為例,方法是選定建立描述子的區域,對該區域用 σ=2 的高斯模 糊,以消除部分雜訊,之後在這個區塊用 p 表示,它的大小是 SxS 像素,在 p 上面提取特徵。定義一個τ測試如式( 3.2 ):x,y 是 p 內的兩個像素位置,實際上 x 是形如[u, v]的二維座標,p(x)和 p (y)是像素位置 x 和 y 的亮度。以一定比率的 隨機算法生成點對<x,y>,取一個𝜃再將點對 x,y 取亮度的差異,若相差𝜃以上則 為 2(在二元化中是為 1),若是比−𝜃小的話則是 0(與二元化的 0 相同),中間加入. 29.
(37) 了一個判斷式:如果差異是介於𝜃之間的話為 1(如圖 3-3 所示)。. 2, τ(𝑝, 𝑥, 𝑦) = {1, 0,. 𝑝(𝑥 − 𝑦) > 𝜃 𝑝(|𝑥 − 𝑦|) ≤ 𝜃 , 𝜃 = max{𝛼 × 𝜎 , 𝜃𝑚𝑖𝑛 } 𝑝(𝑥 − 𝑦) < −𝜃. ( 3.2 ). 重複上述公式數次(如 512 次),就會得到一個 512 位的三進制編碼,即該特徵 點的描述子。如( 3.3 )所示:. 𝑓𝑛𝑑 (𝑝) = ∑ 3𝑖−1 𝜏(𝑝, 𝑥𝑖 , 𝑦𝑖 ). 政 治 大. ( 3.3 ). 1≤𝑖≤𝑛𝑑. 立. ‧ 國. 學. 不過跟 BRIEF 不同的地方在於因為是三元化,所以要將所取出來的特徵用兩個 位元儲存一個 ternary 位元(210, 101, 000),因此相對來說 512 個 ternary digit. ‧. 相當於 1024 binary bit 所需要的儲存空間所需的 BYTE 數2。. sit. y. Nat. 利用公式( 3.3 )的定義,可以將 receptive field 平均亮度間的關係從原來的大. n. al. er. io. 或小(1 或 0)延伸為差不多(編碼為 1)、差異大過一個門檻(編碼為 2)或小於一個. i Un. v. 門檻值(編碼為 0)。如此一來將可降低兩個原本平均亮度非常接近的區域,因受. Ch. engchi. 些微雜訊干擾,致使編碼方式產生變動(由 01 或由 10)的機率。以公式( 3.3 ) 計算而得的三元編碼字串,仍可使用 Hamming distance 計算字串間的距離,如 ( 3.4 )。 𝑛=1. 𝐷(𝑥, 𝑦) = ∑|𝑥𝑖 − 𝑦𝑖 |. ( 3.4 ). 𝑖=0. 然而在儲存特徵時,然而這樣的編碼方式也產生了另一個問題,即是儲存空 間的增加,原本二元化的使用空間是一個 bit 可以儲存一個轉換後的像素編碼, 2. 實際上只要經過簡單的轉換,以二進位儲存後僅需 1.5 倍的容量。 30.
(38) 假使原本二元化所得到的編碼會是110100102 得到 8bit 的一組編碼,而轉換成三 元化編碼後是220100103,假如不作任何分類壓縮,用簡單的轉換成 2 進位儲存 空間則需要 16bit 的儲存空間的101000010000012 ,所需空間會增加(從原先的 0,1 變為 00, 01,10)為兩倍的空間,這是目前我們提出的修正方法比較不利之處。 另外如何訂定一個明確的 threshold,使三元化特徵描述能夠更準確的取得中間彈 性的部分,做出跟二元化的差異,又不能失去原本二元化的優點,也是需要研究 的部分。 針對上述定義的新形態圖像描述方法,有下列議題值得進一步探討: 1.. 門檻值的設定: 討論𝜎在固定與伴隨圖像內容變動的情況下,對於此三元特 徵描述法有怎樣的影響。. 立. 研究各式取樣(sampling)方法:較佳的取樣方法可能對於取較為重要 pairs 的. 學. ‧ 國. 2.. 政 治 大. 效率會有正面提升的效果,我們將研究常見的取樣方法作為參考。 成對(pairs)取樣的數量:以三元方式編碼,每個 pair 所帶進的資訊較多,是否. ‧. io. sit. y. Nat. 可因此降低 pair 的數量,將是一個重點討論問題。. n. al. er. 3.. Ch. engchi. 31. i Un. v.
(39) 4. 第四章. 實驗結果與分析. 本章節將先針對行動裝置上的環境狀況做介紹整理,並且點出主要可能遭遇 的問題和造成的影響,並且根據這些問題設計模擬的實驗圖像,利用前面所提到 的區域三元化特徵描述子,從不同的 threshold 至各個不同演算法的套用何差異, 實際進行實驗測試並且加以分析。. 4.1. 影像雜訊 在我們的設想中,要將此實驗設計成為行動裝置上的運算測試,因此考慮到. 治 政 行動裝置與一般相機所取得的影像不同,通常來說以擷取影像的元件 CMOS 會 大 立 有相當程度的影響,而 CMOS 的尺寸大小以及製程良率又會影響其最後的結果 ‧ 國. 學. 表現,在預設條件下的狀況底下攝影機為了在取得正常的曝光情況下,ISO 值(感. ‧. 光度)的表現將會直接影響最後的圖形結果(圖 4-1),而攝影機的感光元件在長久. sit. y. Nat. 的使用情況下,也會產生熱噪點現象(圖 4-2)。我們可以得知為了取得更明亮的. io. er. 影像提高 ISO 也不可避免地造成影像上的雜訊,如果雜訊超過一定程度的話, 便有可能影響到所取得的特徵效率,另外相對於專業相機高畫素以及其感光元件. al. n. iv n C 尺寸較大外,手機的感光元件是更小的(圖 h e n g c4-3),所以在同樣成像條件下,相對 hi U 於相機高畫素下,行動裝置的雜訊會更明顯(圖 4-6),。. 而在現今的器材中,在透過 CMOS 取得原始影像以後,還會透過相機或行 動裝置上的處理器來做雜訊消除以及影像最佳化的過程,這樣導致透過攝影機影 像已被經過一次加工並將雜訊與原圖形一同平滑化,尤其在低光源環境下更是能 夠嚴重影響其畫質,在本論文研究中我們探討的是行動裝置在一般低光源環境下 的表現,對於熱噪點以及拍攝移動所造成的模糊暫不在設想的情境中,因此我們 對於在低光源環境下取得的高 ISO 影像,試著用模擬的方式進行了不同的演算 法的抗噪性實驗。. 32.
(40) 圖 4-1 高 ISO 影像以及局部放大圖. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 圖 4-2 長時間曝光所產生的熱噪點現象(ISO 800 曝光時間 980s f2.8). 33.
(41) 立. 政 治 大. ‧ 國. 學 ‧. 圖 4-3 不同裝置的 COMS 大小(一般常見的行動裝置為 1/2.5”,單眼相機為 24*16mm). n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 圖 4-4 低光源下行動裝置所擷取到的圖形圖 4-5 各種不同 ISO 狀況下的圖形 34.
(42) 政 治 大. 立. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 圖 4-6 同一場景,利用單眼相機以及行動裝置在低亮度環境下所取得的高 ISO 影像 (上 HTC NEW ONE:ISO:1600,下 Canon 60D ISO:12800). 在此實驗步驟中,預設原本資料庫中的資料集為品質最佳的對照組來做之後 的模擬測試,因為相機本身的雜訊並不只有單純的噪點,所以我們先將影像加入 不同強度的高斯雜訊後,再進行高斯模糊做模擬測試,以求能夠得到接近行動裝 置上面的圖形樣本,如圖 4-7。 35.
(43) Original. 26.05 dB. 立. 政 治 大. ‧. ‧ 國. 學. 20.06 dB. 17.5 dB. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 15.4 dB 圖 4-7 模擬各種不同 ISO 情況下所產生的雜訊(數字為 PSNR). 36.
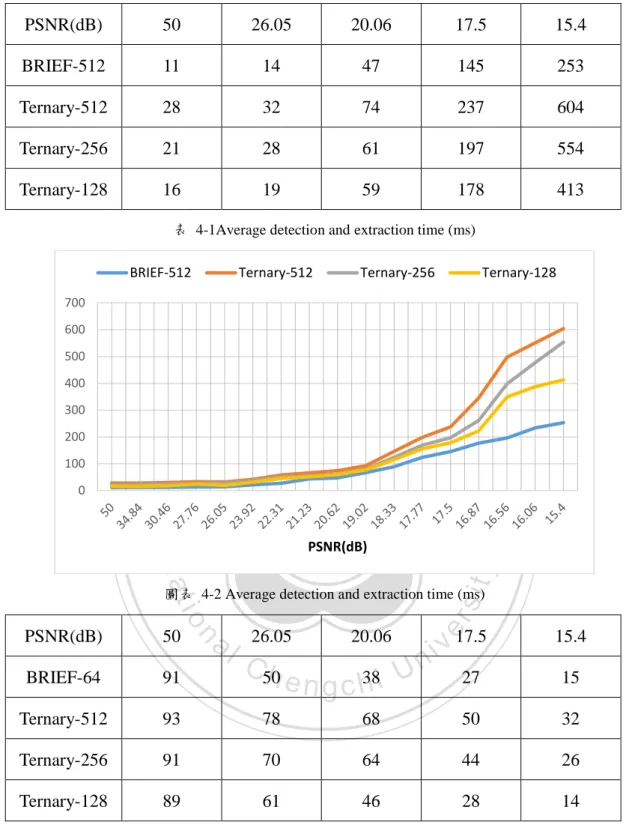
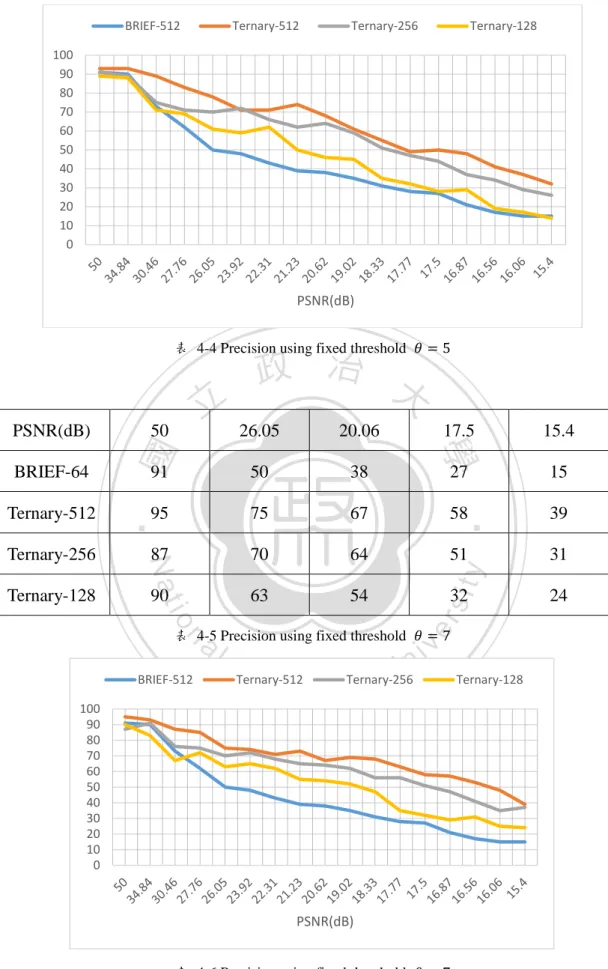
(44) 4.2. 抗噪性測試 在取得了模擬雜訊圖型影像後,這裡我們利用最基本的 BRIEF 定義以及稍 微修改成三元化的規則來做初步的測試和比較,在配對時只需計算兩特徵點描述 子的 Hamming distance,為了做跟 binary 的結果做比較,我們以 BRIEF-64(這裡 指的是 64 Byte,為了統一之後的單位將轉換成 bit 來計算也就是 512 bit)當作比 較的基準,之後將三元化的取樣長度做一個不同的測試,Ternary-512 是指取樣 長度共有 512 個三元化位元(如 012210…110 共 512 個位元),再將這些取樣所得 的特徵點相比較。. 政 治 大 討論,就抗雜訊的角度而言 𝜃 值的選擇會跟著雜訊的強度而有相關,其中一解是 立. 而在先前提到的三元化分類式中,關於門檻值 𝜃 的選擇其實需要更進一步的. ‧ 國. 學. 利用影像中較為平滑的區塊,計算其像素值的分布,而最直覺也是最簡單作法設 定一個固定的範圍,也就是在下式中取固定的 𝜃. ‧. ( 4.1 ). y. 𝑝(𝑥 − 𝑦) > 𝜃 𝑝(|𝑥 − 𝑦|) ≤ 𝜃 𝑝(𝑥 − 𝑦) < −𝜃. n. al. er. io. sit. Nat. 2, τ(𝑝, 𝑥, 𝑦) = { 1, 0,. i Un. v. 在本實驗中,我們除了從 Mikolajczyk and Schmid 所提供的 data set[17],另. Ch. engchi. 外也加入一些著名畫作來做進行本研究目的測試,例如莫內、梵谷,米勒,塞尚, 畢卡索等不同時期不同流派的作品來進行實驗,畫作共 274 幅。圖 4-8 為部分實 驗的畫作縮圖,實驗中將根據先前所提到的模擬方式將所收集來的各畫作,先進 行高 ISO 雜訊化後再進行實驗,並且得出結果後再將之平均。 而根據[17]所做的研究,先將𝜃 設定為一個固定值,接著去再將𝜃 設為不同 的門檻值來做測試,藉此來觀察不同門檻值的表現,觀察在何種情況下是最佳的 (見表 4-1 至錯誤! 找不到參照來源。,橫軸為 PSNR),再以此依據進行下一個 階段的演算法套用實驗。. 37.
(45) 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. 圖 4-8 實驗的畫作示意圖 38. v.
(46) PSNR(dB). 50. 26.05. 20.06. 17.5. 15.4. BRIEF-512. 11. 14. 47. 145. 253. Ternary-512. 28. 32. 74. 237. 604. Ternary-256. 21. 28. 61. 197. 554. Ternary-128. 16. 19. 59. 178. 413. 表 4-1Average detection and extraction time (ms) BRIEF-512. Ternary-512. Ternary-256. Ternary-128. 700 600 500 400. 立. 300. 0. ‧. ‧ 國. 100. 學. 200. 政 治 大. PSNR(dB). sit. y. Nat. io. al. 50. BRIEF-64. 91. C50 h. Ternary-512. 93. 78. Ternary-256. 91. Ternary-128. 89. n. PSNR(dB). 26.05. 20.06. er. 圖表 4-2 Average detection and extraction time (ms). v ni. 17.5. 15.4. 27. 15. 68. 50. 32. 70. 64. 44. 26. 61. 46. 28. 14. e n g c h38i U. 表 4-3 Precision using fixed threshold 𝜃 = 5. 39.
(47) BRIEF-512. Ternary-512. Ternary-256. Ternary-128. 100 90 80 70 60 50 40 30 20 10 0. PSNR(dB) 表 4-4 Precision using fixed threshold 𝜃 = 5. 91. 50. 38. 27. 15. 95. 75. 67. 58. 39. 87. 70. 64. 51. 31. 90. 63. 54. sit. 17.5. io. n. 表 4-5 Precision using fixed threshold 𝜃 = 7. BRIEF-512 100 90 80 70 60 50 40 30 20 10 0. 15.4. y. al. 32. er. Ternary-128. 20.06. Nat. Ternary-256. 26.05. ‧. Ternary-512. 50. ‧ 國. BRIEF-64. 立. 學. PSNR(dB). 政 治 大. i n CTernary-512 U h e n g c Ternary-256 hi. v. PSNR(dB) 表 4-6 Precision using fixed threshold 𝜃 = 7. 40. Ternary-128. 24.
(48) PSNR(dB). 50. 26.05. 20.06. 17.5. 15.4. BRIEF-64. 91. 50. 38. 27. 15. Ternary-512. 93. 78. 72. 57. 38. Ternary-256. 88. 74. 64. 44. 28. Ternary-128. 83. 65. 52. 29. 14. 圖表 4-7 Precision using fixed threshold 𝜃 = 10 BRIEF-512. 立. Ternary-256. Ternary-128. 政 治 大. ‧. ‧ 國. 學. 100 90 80 70 60 50 40 30 20 10 0. Ternary-512. PSNR(dB). Nat. sit. y. 表 4-8 Precision using fixed threshold 𝜃 = 10. n. al. er. io. 而就數據結果顯示,門檻值太低效果並沒有來得明顯有優勢,而將門檻值在. i Un. v. 往上提升一些在中雜訊的圖形中,辨識率較為穩定,但是在高雜訊的部分反而顯. Ch. engchi. 得不穩定,雜訊反而容易使變動程度更大,造成精準度下降。 PSNR(dB). 50. 26.05. 20.06. 17.5. 15.4. BRIEF-64. 91. 50. 38. 27. 15. Ternary-512. 95. 81. 76. 65. 47. Ternary-256. 91. 75. 68. 53. 34. Ternary-128. 90. 68. 59. 37. 27. 表 4-9 Precision using adaptive threshold. 41.
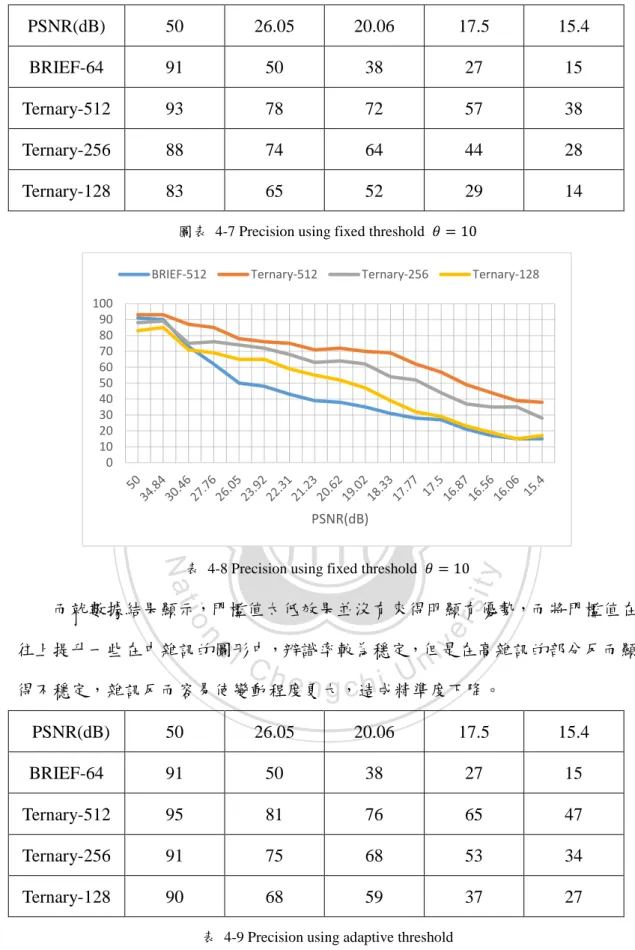
(49) BRIEF-512. Ternary-512. Ternary-256. Ternary-128. 100 90 80 70 60 50 40 30 20 10 0. PSNR(dB) 表 4-10 Precision using adaptive threshold. 50. BRIEF-64. 11. 145. 253. 93. 125. 191. 385. 772. 84. 112. 164. 324. 705. 74. 97. 153. 292. 543. y. sit. Nat. Ternary-128. 47. ‧. Ternary-256. 15.4. 14. ‧ 國. Ternary-512. 立. 17.5. 學. PSNR(dB). 治 政 26.05 20.06 大. io. al. n. BRIEF-512 800 700. Ternary-512. Ch. v ni. Ternary-256. engchi U. er. 表 4-11 Detection and extraction time using adaptive threshold (ms) Ternary-128. 600 500 400 300 200 100 0. PSNR(dB) 表 4-12 Detection and extraction time using adaptive threshold (ms). 42.
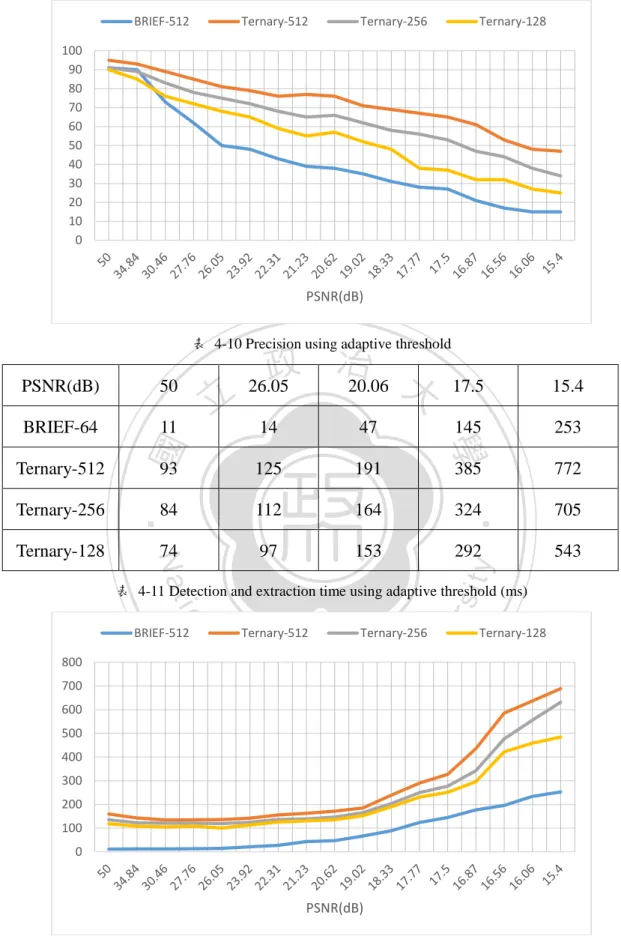
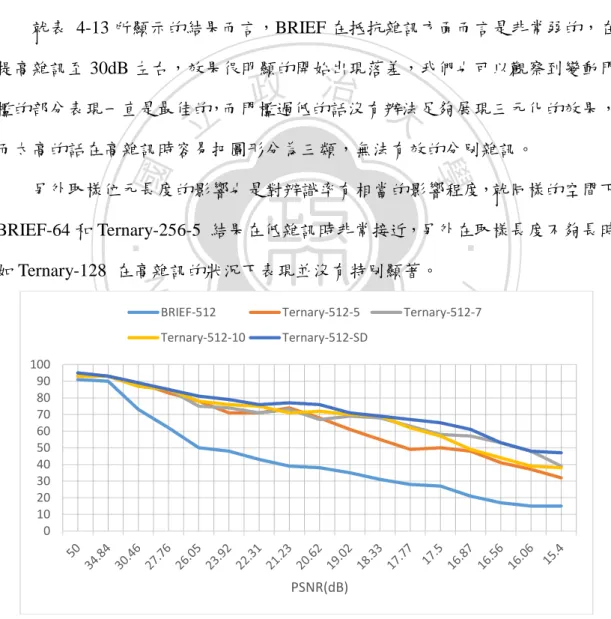
(50) 然而要如何取一個適當的門檻是要取決於圖形的平滑程度和雜訊強度是一 個問題,一個適合的門檻值在其他的測試圖中並不一定一樣有效。根據實驗室學 長所提出的方法是先計算參考點與其將測試的區域中心點建立平均分布的統計, 並取其標準差再乘上一個定數決定出各測試圖的最佳門檻值;在時間方面看得出 因為需計算標準差的關係必須先花上一部份的時間來計算(表 4-12),在高雜訊的 部分相對來說影響較小,但是所花的時間也因額外的計算相對地增加近一半以上 (平均變動幅度為 512B-151.6%、256B-161.8%、128B-185.2%)。 就表 4-13 所顯示的結果而言,BRIEF 在抵抗雜訊方面而言是非常弱的,在 提高雜訊至 30dB 左右,效果很明顯的開始出現落差,我們也可以觀察到變動門. 治 政 檻的部分表現一直是最佳的,而門檻過低的話沒有辦法足夠展現三元化的效果, 大 立 而太高的話在高雜訊時容易把圖形分為三類,無法有效的分別雜訊。 ‧ 國. 學. 另外取樣位元長度的影響也是對辨識率有相當的影響程度,就同樣的空間下. Ternary-512-5. io. Ternary-512-10. al. n. 100 90 80 70 60 50 40 30 20 10 0. Ternary-512-SD. Ch. engchi. Ternary-512-7. er. BRIEF-512. sit. y. Nat. 如 Ternary-128 在高雜訊的狀況下表現並沒有特別顯著。. ‧. BRIEF-64 和 Ternary-256-5 結果在低雜訊時非常接近,另外在取樣長度不夠長時. i Un. v. PSNR(dB) 表 4-13 Precision using different thresholds (𝜃 = 5, 7,10, 𝑎𝑑𝑎𝑝𝑡𝑖𝑣𝑒). 而在高雜訊下未針對特徵點的取樣做多餘的限制,因此在取樣的結果上將許 多不需要的特徵也一併計算進去,也因此大幅增加了計算其特徵點的時間。. 43.
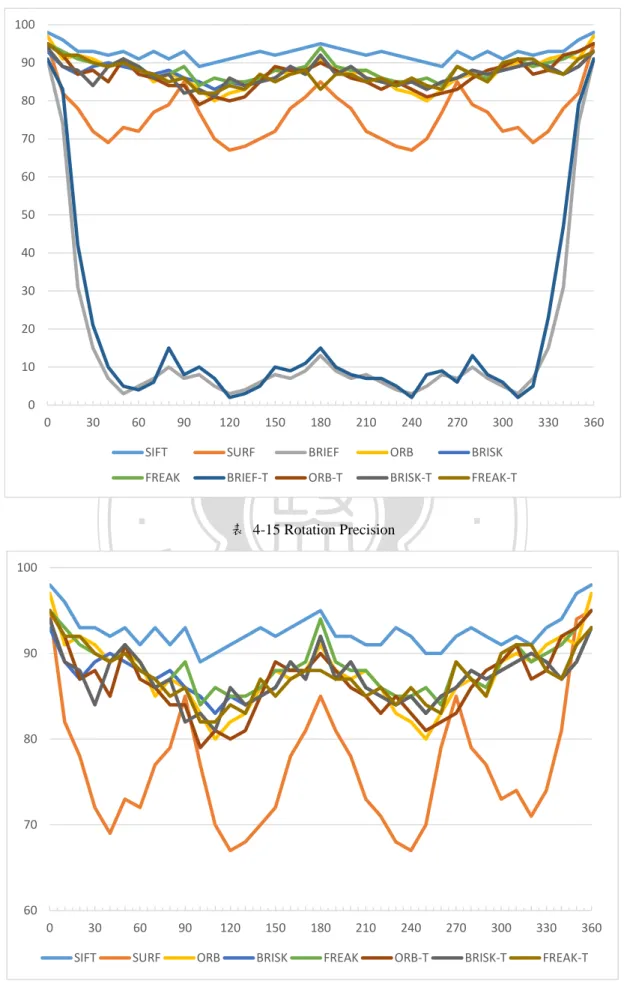
(51) 4.3. 演算法三元化特徵值套用實驗 在做完基本比較之後,接著我們將試著把其他二元化的演算法的編碼將其三 元化觀察其效果,因為在旋轉和縮放這兩個項目下其演算法影響的因素遠大於編 碼格式的差異,所以可以看到在這方面其實跟原本的演算法並沒有太大的差距以 及不同之處,實驗結果如表 4-14、表 4-17 所示。 在演算法方面 BRIEF 並沒有去處理縮放和旋轉這部分,另外 ORB 本身也沒 有針對縮放去做處理,所以在這一方面我們可以在稍後實驗的結果中明顯的看出 其差別和影響。. 政 治 大 SIFT 的準確率還是最高的,而 SURF 只對每 90 度的旋轉較為敏感,在剩餘的二 立. 在旋轉的部分,首先除去了 BRIEF 的演算法後,我們可以觀察表 4-16 發現,. ‧ 國. 學. 元化特徵子和三元化特徵子中,可以觀察到是在同一個群體區間內,代表了對原 本二元化特徵子做三元化編碼改變並不會去改變它原本的旋轉辨識結果。 135∘. 180∘. 98. 92. 93. 92. y. 95. 95. 69. 85. 68. sit. 85. 7. 7. 4. 13. 83. 91. n. al. er. 90∘. io. SURF. 45∘. Nat. SIFT. ‧. 0∘. i Un. v. BRIEF. 91. ORB. 97. Ch. 89. e n g c h86i. BRISK. 93. 90. 86. 84. 92. FREAK. 95. 89. 89. 85. 94. BRIEF-T. 91. 10. 8. 3. 15. ORB-T. 95. 85. 84. 81. 90. BRISK-T. 94. 89. 82. 84. 92. FREAK-T. 95. 89. 86. 83. 83. 表 4-14 Rotation Precision. 44.
(52) 100 90 80 70 60 50 40 30 20. 政 治 大. 10 0 30. 60. 90. 立. 120. 150. 180. 210. 240. SIFT. SURF. BRIEF. ORB. FREAK. BRIEF-T. ORB-T. BRISK-T. 330. 360. 330. 360. BRISK. ‧ y. sit er. io. al. n. 90. 300. FREAK-T. 表 4-15 Rotation Precision. Nat. 100. 270. 學. ‧ 國. 0. Ch. engchi. i Un. v. 80. 70. 60 0. 30 SIFT. 60 SURF. 90. 120 ORB. 150. 180. BRISK. 210. FREAK. 240 ORB-T. 表 4-16 Rotation Precision(without BRIEF) 45. 270. 300. BRISK-T. FREAK-T.
(53) 在 Scale 的測試中,明的可以看出 BRIEF 和 ORB 並沒有真的這部份去做保 持不變性,所以在經過縮放以後準確率下降的非常的快,同樣的我們將 BRIEF 和 ORB 演算法的結果除去後,也可以觀察到 SIFT 對於縮放的測試也是非常的 穩定,而其他的演算法並沒有特別突出或值得注意的表現。. 1.5. 2. 2.5. 3. 3.5. 4. SIFT. 98. 70. 50. 41. 33. 24. 20. SURF. 95. 68. 45. 33. 27. 20. 17. BRIEF. 91. 15. 1. 0. ORB. 97. 15. 立. 3 3 治 政 大2 3 2. 1. 0. BRISK. 93. 69. 45. 32. 24. 19. 16. 95. 70. 52. 43. 24. 12. 7. 91. 14. 3. 3. 2. ORB-T. 95. 14. 3. 1. 2. BRISK-T. 94. 66. 42. 27. 20. FREAK-T. 95. a70l. 43. 28. v ni. io. y. sit. Nat. n. Precision. ‧. BRIEF-T. er. FREAK. 4. 學. ‧ 國. 1. C表h4-17 Scale PrecisionU engchi. 17. 1. 0. 1. 0. 11. 6. 11. 6. 100 90 80 70 60 50 40 30 20 10 0 0. 0.5. 1. 1.5. 2. 2.5. 3. 3.5. Scale factor SIFT. SURF. BRIEF. ORB. BRISK. FREAK. BRIEF-T. ORB-T. BRISK-T. FREAK-T. 表 4-18 Scale Precision 46. 4.
數據

+7
相關文件
本案件為乳癌標準化化學藥物治療與個人化化學治 療處方手術前化學治療療效比較之國內多中心研 究,於 2008 年 8 月 1 日由
本系已於 2013 年購置精密之三維掃描影像儀器(RIEGL
全國人民代表大會常務委員會在徵詢其所屬的香港特別行政區基本法委
本書立足中華文化大背景,較為深入系統地分析研究了回族傳統法文化的形成基礎、發展歷
automated cartography 自動製圖 automated data processing 自動數據處理 automated digitising 自動數碼化 automated feature recognition 自動要素識別 automated
Intel-臺大創新研究中心(Intel-NTU Connected Context Computing Center)成立於2011 年。這是英特爾實驗室( Intel Labs)與世界頂尖大學進行的「英特爾合作研究機構(Intel
根據研究背景與動機的說明,本研究主要是探討 Facebook
在商學與管理學的領域中,電子化普遍應用於兩大範疇:一 是電子商務(E-Commerce),另一個為企業電子化(E-Business)。根 據資策會之 EC
