Low-Power Techniques for Network Security Processors
∗Yi-Ping You
1, Chun-Yen Tseng
2, Yu-Hui Huang
1, Po-Chiun Huang
2, TingTing Hwang
1, and Sheng-Yu Hsu
3Department of Computer Science, National Tsing Hua University, Hsinchu, Taiwan
1Department of Electrical Engineering, National Tsing Hua University, Hsinchu, Taiwan
2Design Service Center, Industrual Technology Research Insitude, Hsinchu, Taiwan
3Abstract— In this paper, we present several techniques for low- power design, including a descriptor-based low-power scheduling algorithm, design of dynamic voltage generator, and dual thresh- old voltage assignments, for network security processors. The ex- periments show that the proposed methods and designs provide the opportunity for network security processors to achieve the goals of both high performance and low power.
I. INTRODUCTION
As the security issues involved in network-aware events be- come serious concerns of users, many security algorithms that require tons of computation are developed to provide adequate security. To deal with the large amount of data communica- tion and computation when processing the security operations, the idea of using network security processors is brought out to provide dedicated security processing and to accelerate these processes.
In addition to high performance, network security proces- sors are required to be low power consumption. High power consumption is translated to heat energy which makes the pro- cessor unstable and raises the cost of packaging and cooling systems. In addition, for embedded and mobile systems, the working time directly depends on the battery life. Therefore, the power dissipation becomes an important concern in the de- sign of network security processors.
In the previous work by Su et al. [1] and Hong and Wu [2], traditional low-power techniques were used to develop the net- work security processor proposed by Design Technology Cen- ter at National Tsing Hua University. With the help of com- mercial CAD tools, power optimization techniques including macro cell mapping, control bit encoding, don’t care optimiz- ing, path balancing, gate input ordering, and transistor sizing were utilized [3]. The cryptographic modules are redesigned with modified algorithms which cost less memory buffers and
∗This work was supported in part by Ministry of Economic Affairs under Grant No. 92-EC-17-A-03-S1-0002 and Industrial Technology Research In- stitute under Grant No. S3-93030-4 in Taiwan.
smaller die size with higher performance. However, such tech- niques are not sufficient enough for low power considerations.
In this paper, we focus on the issue of further low-power techniques at the design and architectural phases of the net- work security processor. We propose several techniques, in- cluding a descriptor-based variable-voltage scheduling algo- rithm, dynamic voltage generations, and dual-threshold volt- age techniques to provide advanced power optimizations. The variable-voltage scheduling algorithm schedules descriptors, which can be treated as tasks in network security processors, with variable operating voltage and even shuts down crypto modules when they are not in use. The dynamic voltage gen- erator proposed a closed-loop architecture to generate supply voltage from 1.0 to 2.0 V with four levels. Finally, the dual threshold voltage assignment helps solve the problem of leak- age power dissipation in the design network security proces- sors.
The rest of this paper is organized as follows. We intro- duce the architecture issues of security processors in Section II.
Next, we present a scheduling algorithm for descriptor-based security processor in Section III. Then, we describe voltage generation in Section IV. The dual threshold voltage technique is illustrated in Section V. Finally, concluding remarks and fu- ture work are drawn in Section VI.
II. REVIEW OFNETWORKSECURITYPROCESSORS
We construct a configurable architecture of descriptor-based security processor. To run this security processor, there should be a program disassembling the crypto operations into a list of descriptors. The descriptor contains the type of en-/de- cryption functions, the length of raw data, the key information, and the destination memory address of the result data. After settling descriptors in the memory, a trigger signal to the SP will be pulled up. Such architecture would start retrieving the descriptors, decode the crypto operations, and automatically fill data into its operation modules. When the crypto operations are finished, the result data will store back to the memory.
In our design, the architecture template (Figure1) is mainly assembled with a main controller, a DMA module, internal buses, and crypto modules. The main controller has a slave interface of external bus which accepts the control signals and returns the operation feedback via the interrupt port. Inside the main controller, there are a resource allocation module keep- ing the resource status table of external bus master interfaces, channels, transfer engines, internal buses, and crypto modules.
The process scheduler module and power manage module are
Int. Bus
DMA Module
... ... ...
Ext. Bus SlaveExt. Bus Master
Transfer Engine Transfer Engine Channel Channel
Channel
Int. Bus Master
Crypto Module Crypto Module
Crypto Module Int. Bus
Master Main Controller Process Scheduler
Power Management
Resource Allocation Module
Fig. 1.Security Processor architecture template
added in the main controller for performing the features of scheduling algorithm and low power control.
The DMA module integrates master interfaces of external bus, the channels containing the descriptor information, and the transfer engines. According the data in the channel, the transfer engine requests the external bus usage and transfers the processing data from memory. After that, the transfer engine passes the data on the dedicated crypto module via the internal bus.
The internal buses are designed to support multiple layers which will be needed for high speed data transmission. The crypto modules could be any type of cryptography functions;
for example, the RSA, AES, SH5, 3DES and more. The exe- cution time of the crypto module may be different. The crypto module will return a signal to main controller, when the en- /de-crypt operations are finished.
III. VARIABLE-VOLTAGESCHEDULING
As mentioned in Section II, the network security processor uses a descriptor-based model to proceed with encryption and decryption operations. The descriptor-based model makes it easier to distribute tasks at one’s own choice: for instance, one could allocate a specific task to be run on a certain process- ing unit or assign the operating voltage for a task simply by descriptors. In this section, we propose a real-time variable- voltage scheduling algorithm that scales the operating voltages of crypto modules of the network security processor dynami- cally by scheduling descriptors and evaluate the proposed ap- proach in the end of this section. A more generic schedul- ing algorithm has been proposed in [4]. We assume that the descriptor-based network security processor contains several major crypto modules (CMs) which are capable of K-level supply voltages and power-gating (PG) mode.
A. Scheduling Algorithm
The proposed scheduling algorithm is based on the well- known earliest deadline first (EDF) algorithm [5]. Figure 2 lists the algorithm. Assume there are n descriptors to be sched- uled. First, we sort descriptors in ascending order by deadlines, namely D1, D2, . . . , Dn, and put them in a list of unscheduled descriptors, i.e., the reservation list. We then extract each de- scriptor from the list on the basis of the schedule. Suppose the system provides m crypto modules, and each processing element is capable of K-level supply voltages, where level 1 represents the lowest voltage and level K represents the high- est voltage. Steps 1–3 in Figure 2 describe these procedures.
Real-Time Variable-Voltage Scheduling Algorithm with Reservation Lists in Multiple Crypto Modules Input: n unscheduled descriptors and m CMs
Output: Schedule of power-gating commands and the n descriptors with variable supply voltages at CM1...m
1. Sort descriptors by deadlines in ascending order; i.e., D1, D2, ..., Dn. 2. Put them in a list, called the reservation list of the target processing element
CMj. In the beginning, j=1.
3. Remove the first descriptor, namely Di, which has the earliest deadline, from the reservation list. Repeat steps 3–6 while the list is not empty.
4. Compute the slack time for descriptor Diwith both the highest- and lowest- voltage pseudo schedulers; i.e., δi(VH) and δi(VL).
5. Compute the computation time of Diat the highest- and lowest-voltages; i.e., ci(VH) and ci(VL).
6. Let Oibe the time overhead of voltage scaling for Di. Schedule Diin the following rules:
- If ci(VL) + Oi≤ δi(VL), schedule Diat CMjwith VLif possible†. - If δi(VL) < ci(VL) + Oi≤ δi(VH), call the decision algorithm.
- If ci(VL) + Oi> δi(VH) and
- if ci(VH) + Oi≤ δi(VH), schedule Diat CMjwith VH. - if ci(VH) + Oi> δi(VH), put Diin a new list.
7. Insert power-gating commands at the beginning and the end of idle period for CMjif deserving.
8. If CMjis the last available CM and the new list is not empty, then report the possible failure of real-time scheduling.
9. If the new list is not empty, let j = j + 1, use the new list as the reservation list of the target CMj, and go to step 3.
10.If j < m, then gate off the power of CMj+1. . . CMmall the time.
†Schedule Diat VLif deadline is met and energy overhead is deserving.
Fig. 2.Reservation-list scheduling algorithm for variable-voltage problems in multiple CMs.
For utilizing power gating capabilities, we shall try to make tasks run successively without intermission and let idle time be together because power gating mechanisms cost much more expense than DVS does in performance and power. Next, in step 4, we compute the slack time for descriptor Diwith both the highest- and lowest-voltage pseudo schedulers, denoted as δi(VH) and δi(VL). The slack time δi(V ) represents the max- imum time interval allowed for descriptor Dito execute while all the remaining descriptors in the reservation list are sched- uled in reverse order with supply voltage V . In step 5, we com- pute the computation time of descriptor Diat both the highest- and lowest-voltages, denoted as ci(VH) and ci(VL). In step 6, we compare ci(VH) and ci(VL) with δi(VL) and δi(VH) to decide which voltage should be applied to the descriptor. This algorithm results in the following three possible scenarios:
(a) ci(VL) plus time-overhead of voltage-scaling (Oi) is smaller than or equal to δi(VL). If energy-overhead of voltage-scaling is less than energy-saving, we can schedule descriptor Diat the lowest voltage without affecting any descriptor in the future be- cause there are no overlaps between descriptor Diand the un- scheduled descriptors while those descriptors are assumed to be executed at the lowest voltage.
(b) ci(VL) plus time-overhead of voltage-scaling is larger than δi(VL) and smaller than or equal to δi(VH). If this happens, we call a decision algorithm to decide at which voltage descrip- tor should Dibe scheduled. The decision algorithm weights the alternatives to optimize the overall costs and selects a appropri- ate operating voltage level for Di, using a criterion such as the power or energy consumption.
(c) ci(VL) plus time-overhead of voltage-scaling is larger than δi(VH). This means it is impossible for descriptor Dito com- plete its execution by its deadline at any voltage lower than the highest voltage, and hence we must schedule it at the highest voltage for its deadline to be met. If descriptor Diis unschedu- lable for current CM, we put it in a new list that contains all unschedulable descriptors.
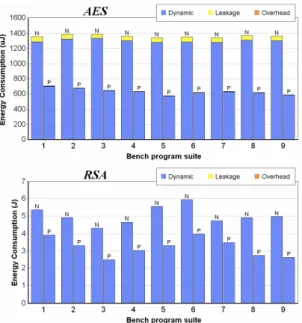
Fig. 3.Energy consumption of AES and RSA cypto modules
In step 7, we check the remained idle time between the sched- uled descriptors in the current CM and determine power gat- ing commands to be inserted if they are deserving of energy- saving. In step 8 and step 9, if the new list generated in step 6 is not empty, we use the list as the reservation list for the next available CM and schedule it by the same procedures in steps 3–6. If no CM is available for scheduling, the scheduler should report the failure. At the last step, we will turn off all unused CMs by power-gating to minimize both static and dy- namic power savings.
B. Experimental Results
The benchmark suites in the experiment are generated with a randomized descriptor generator which generates descriptors
— the ratio of AES to RSA descriptors is 60 to 1 — in uni- form, normal, or exponential distributions in terms of arrival and deadline time. The benchmark suites numbered with 1–3, 4–6, and 7–9 are generated with uniform, normal, and expo- nential distribution, respectively. We generated 500 distinct descriptor files for each suite and computed their average en- ergy consumptions of different components from the results of the simulator, as shown in Figure 3. The bars labeled by N are the scheduling results without power management and others labeled by P are the results with enabling our proposed power management. The energy-overhead of applying volt- age scaling and power gating is too few to be exhibited clearly on the charts, and so does the leakage of RSA modules. The left chart gives the energy consumption of AES modules, and the right chart gives that of RSA modules for all benchmark suites. The final results with latency approximation are also confirmed by the simulator that no deadline missing is reported in all benchmarks. Although the most energy consumptions are dominated by RSA operations in our experimental architec- ture and workload, the charts show that our scheme performs well for all components in the system. The summary in these figures present that the average energy reduction of AES and RSA modules are 54% and 36%, respectively.
Control circuit
Critical patch replica ckt (Dynamic monitor )
freq2digital Buck
core
ACP#1 AES#1
RNG#1 HMAC#1 buffer buffer
buffer buffer AHB Slave
interface Main
Controller Channel #1
Channel #2
AHB Master interface Channel #N
AHB Master interface
Transfer Engine Transfer Engine
Inte rnal AH B
Feedback
Signal Variable Vdd
System command frequency
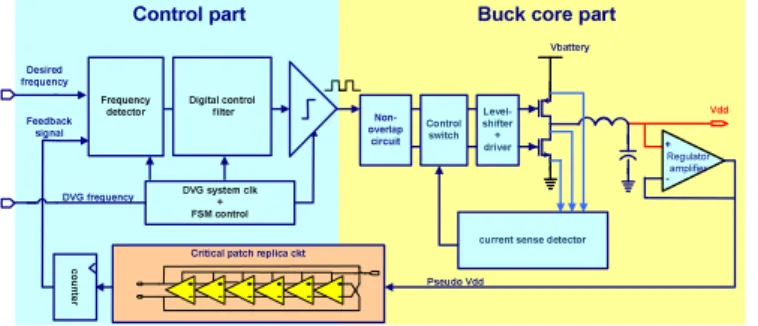
Fig. 4.The Proposed FLL-based Voltage Generation Architecture
IV. DYNAMICVOLTAGEGENERATOR
The dynamic power dissipation per switching event of a CMOS circuit is given by
Pdynamic= λCtotalV2fclk (1) where λ is the transition factor, Ctotalis the load capacitance, V is the supply voltage, and fclkis the the clock frequency.
Active-idle and frequency scaling are two common methods to get compromise between peak power dissipation and speed.
But for efficient energy usage, circuit should be operated under the optimal supply voltage. In this section a voltage generator which can dynamically provide voltage level according to the decision of system scheduler is proposed. This voltage scal- ing technique is expected to supply the critical function block, like encryption engines in this design, with adjustable voltage rather than fixed level to achieve better power efficiency.
A. FLL-based Voltage Generation Architecture
Figure 4 shows the proposed dynamic voltage generator ar- chitecture associated with the encryption processor. The volt- age generator is composed three parts: frequency to digital conversion, pulse-width modulation (PWM) controller, and bulk converter core. The two inputs, one is from system com- mand and the other is from processor feedback, represent the target frequency that the system desires and the speed that the system now is working. These two frequencies are compared then converted as a digital code by first frequency to digital converter. This code then be modulated as PWM format in dig- ital domain to control the on-off timing of power FETs. Bulk converter is adopted in voltage generation as it can reach higher power efficiency compared with the linear regulation approach, although it needs external LC components for filtering.
Unlike the conventional voltage downconveters or regula- tors, the proposed architecture is a closed-loop system. Its concept is like a frequency-locked loop (FLL) [6]. By this approach the output voltage herein is no longer a constant. In- stead, the output voltage is dynamically adjusted to support processor operated at the target speed. As shown in Figure 4, a critical path replica circuit in processor is employed as the
Digital control filter
Critical patch replica ckt coun
ter Frequency
detector
+ -
Pseudo Vdd
Vdd Regulator
amplifier DVG system clk
FSM control+
Level- shifter driver+ Control switch
current sense detector Vbattery
Control part Buck core part
overlapNon- circuit Desired
frequency Feedback signal
DVG frequency
Fig. 5.Block Digram of the Proposed Dynamic Voltage Generator
speed monitoring block, which feeds back the system speed information under the voltage at the moment. After three stage processing as mentioned, the loop will generate the voltage level that provides the processor power with its speed equal to the system requirement. Compared to the fixed voltage gen- eration, the proposed structure achieves higher yield, since the dynamically adjustable nature of closed-loop system can com- pensate the variations from process or environment.
B. High Efficiency Hybrid Feedback-Controlled Loop A new design approach for high efficiency dynamic supply voltage generation is presented in Figure 5. This design intro- duces hybrid analog and digital signal processing to realize the PWM function with small power consumption and chip area.
In conventional analog techniques, a PWM signal is created by comparing a ramp signal to a reference value. However this method requires a steady dc current flowing into an accurate capacitor to generate the voltage ramp. That will be power- hungry. To alleviate this problem, a digital PWM structure is developed. This digital PWM is achieved by counting the feed- back path speed using a high speed counter. Its digital output then be used to calculate the on-off pulse width to control the switching activity of power FETs.
In the proposed digital PWM structure the power dissipation penalty is on the high speed counter. To achieve high resolu- tion for pulse width control, the counter speed must be high.
But increase counter speed unavoidably increase power. To re- duce the power while keep the resolution system required, a digital dither is developed. At most four extra phases can be interpolated into the original duty cycle. With the aid of dither- ing technique, the operation speed on counter can be reduced.
The power budget due to high speed operation demand is re- leased therefor.
The precise control of power FETs conducting cycle is an- other crucial factor for power waste minimization. This is due to power leakage if either N- or P- MosFET is conducted more than expected. To keep the power FETs operated off this re- gion, a detection and adjustment loop is constructed around these devices. It is in analog domain as the speed must be fast.
Once the bulk converter internal output beyond the specified value, the detection circuits will invoke the adjustment loop to control the conducting phase, thus the leakage power can be greatly reduced.
In the proposed prototype in Figure 5 a ring-type oscillator is employed as the equivalent to the critical path delay in pro-
1.2V 1.2V
1.5V
1.8V
Fig. 6.Closed-loop Transient Response
TABLE I PERFORMANCESUMMARY
Performance
Output loading 200mA
Level transition time 20µs - 30µs
Output ripple ≤ 15mV
Buck core frequency 1MHz
Efficiency 91 %
Process 0.18µm CMOS
cessor. The control signal of the ring oscillator is the power supply. This oscillator and a counter at output serve as a fre- quency to digital converter as the oscillating frequency is the function of supply voltage. This forms the feedback path of the proposed FLL-based voltage generation. Of course the os- cillator can be replaced with real critical path in processor to monitor the real system speed.
C. Experimental Result of the Proposed Voltage Generator A FLL-based voltage generation loop is proposed to attain both software-estimated power minimization and automatic voltage adjustment for yield improvement. In this loop hy- brid analog and digital signal processing can achieve high res- olution while minimize the power waste. Figure 6 is the loop transient simulation result when the request is stepping up. The proposed architecture can vary the supply voltage from 1.0 to 2.0 V with four level. The transition time penalty is smaller than 30µs. Power efficiency estimated can be up to 91% with its output loading current from 50mA to 200mA.
The prototype chip uses 0.18µm CMOS technology. The performance summary is listed in Table I.
V. DUALTHRESHOLDVOLTAGEASSIGNMENT
It is shown in [7] when the manufacturing technology scal- ing to 0.05 micron in the future, the static power will con- tribute to nearly 50% of the total power consumption. Several techniques to reduce subthreshold leakage current by multi- threshold voltage were reviewed in [8]. In dual V th fabrica- tion process, designers are provided with transistors that are either high threshold voltage (slow but low leakage) and low threshold voltage (fast but high leakage) by only an extra mask
1 Algorithm SE-DVA () 2 Input : Graph G = (V, E)
3 Output : Set of high-Vth gates, HList 4
5 For each node v, v∈V 6 If SL(v)≥Dif f D(v) {
7 Add node v to SList by its SL(v);
8 AllD(v) = 0;}
9 Construct Gmaxof Gs; 10 ε = SLmax− SLmax−1
11 While (ε6=0 and SList6=∅) { 12 /* Find MWIS in Gmax*/
13 Compute W (v) for each node v in Gmax
14 While Gmax6=∅ {
15 Select node v with maximum W (v) to MWIS;
16 Remove v and its neighbors in Gmax} 17 For all node v in MWIS do {
18 εε = min(ε, Dif f D(v) − AllD(v));
19 AllD(v) = AllD(v) + εε ; 20 If (AllD(v) = Dif f D(v)) then 21 Move node v from SList to HList;}
22 Update AT /RT /SL/ε for the graph G;}
Fig. 7.Single Execution of Dual-Vth Assignment
layer. In this section, we will describe our dual-Vth assignment algorithm [9]. Our algorithm is inspired by the maximum inde- pendent set based slack assignment (MISA) proposed in [10].
A. MISA-based Assignment Algorithm
The pseudo-code of our single execution of dual-Vth assign- ment algorithm is shown in Figure 7. Given the arrival time (AT), required time (RT), and slack (SL) for each node, first, we construct a SList(G) by SL(v), v∈V in decreasing order.
Note that for each node we compute the delay difference of the node working at low-Vth and high-Vth, Dif f D(v). If the slack is less than the difference, we will not put it into the candidate list, SList, for selection. The reason is that, in this situation, it is impossible to swap this node from low-Vth to high-Vth even if all slack is allocated to the node. Before we proceed the algorithm, we set the current allocated delay, AllD(v) to be zero, for all nodes in SList.
We first select the nodes which have the maximum slack and construct a transitive closure graph, Gmax, among these nodes. Then, we will find the maximum independent set in Gmax. Since the maximum independent set problem is NP- complete on general graph. We propose a heuristic to solve it.
First, we assign a weight to each node in the graph and then find the maximum weight independent set in the graph. The weight of a node v, W (v), is defined to reflect the gain of se- lecting a node to work at high-Vth:
W (v) = α ∗ P W (v) + β ∗ U W (v) + γ ∗ LW (v, dist) (2) The first term, P W , is defined to represent the effective power saving when εε slack is used. It is:
P W (v) = 4P (v)
εε × (1 + Adj(v)) (3) where 4P (v) is the power saving of node v when node v works at high-Vth, εε is min(ε, (Dif f D(v) − AllD(v)), and
Adj(v) denotes the number adjacent nodes to v in Gmax. Note that ε = SLmax− SLmax−1.
The second term, U W (v), in (2) is used to reflect how ur- gent of node v to be selected.
U W (v) = AllD(v)
Dif f D(v). (4)
In this equation, AllD(v), Dif f D(v) are the additional delay allocated to node v and the delay difference of v when working at high-Vth and low-Vth, respectively. The closer the delay for v to work at high Vth, the urgent the node will be selected.
The third term, LW (v, dist), in (2) is used to reflect the lo- cation information of the circuit. Since our proposed algorithm is called after the circuit has been placed. We can take cell lo- cation in the floorplan into account. When we select nodes to work at high-Vth, we can assign the nodes which have the most neighbors working at high-Vth a higher weight. This will bring nodes with high-Vth or low-Vth clustered in a region so as to have higher yield during fabrication process. LW (v, dist) is defined as follows.
LW (v, dist) = hnode (5)
where hnode is the number of nodes working at high-Vth that are within distance of dist from v. dist is a user defined pa- rameter. α, β, γ in (2) are the parameter to control the impor- tance of the three terms.
After the weight of node in Gmax is computed, the fol- lowing heuristic is used to find the maximum weight inde- pendent set (MWIS). The heuristic begins with selecting the node v with maximum W (v). Then node v is added to MWIS and v and all its neighbors are deleted from Gmax. This process repeats until Gmax = φ. After finding the MWIS, ε = SLmax − SLmax−1 is computed, and a small delay of constant εε = min(ε, (Dif f D(v) − AllD(v))) is added to AllD(v) for each node v in MWIS. If the delay added to node v is enough for it to work at high-Vth (i.e., AllD(v) = Dif f D(v)), we will select this node to work at high-Vth and add this node to HList, where HList is a list that store se- lected nodes that can work at high-Vth. If the current allocated delay of the selected node is not high enough to work at high- Vth, the node will remain in the list of SList. Finally, the timing information is updated for each sensitive nodes. This procedure repeats until SList = φ or SL(v) = 0, for all nodes in SList.
B. Experiment Flow for Dual Threshold Voltage
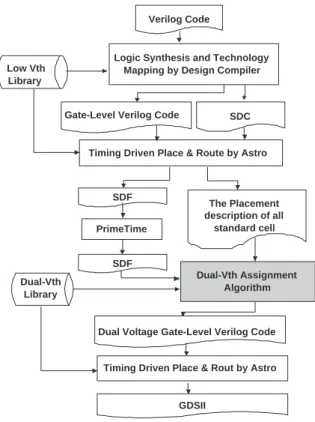
Our experiment flow will follows the flow suggested by TSMC Multiple Vt Flow for Leakage Power Reduction version 4.0 as shown in Figure 8 . In this experiment, TSMC 0.13µm lib was used.
At the beginning, an input design is synthesized using only low-Vth library by Design Compiler. Then this synthesized gate-level Verilog code is placed and routed using Astro. After finishing placement and routing, we use PrimeTime to output the timing information file, called SDF. In this file, we can get the accurate wire delay and cell delay. With this timing infor- mation, we calculate the arrival/required time of the circuit and analyze the timing slack. Then, dual threshold voltage assign- ment is performed. In our case, our Dual-V th Assignment
TABLE II CIRCUITDESCRIPTIONS
Cir. CN Characteristics
TOP 463 An Alarm Clock
MAC 2425 Multiplier and Accumulator GCC 8204 Gravity Center Calculator RSA 14815 Asymmetric Crypto-Processor AES 16824 Advanced Encryption Core
TABLE III
RESULT OFTSMCANDOURALGORITHM
Swap Rate % Power Reduction %
Cir. BP TSMC Ours Imp. TSMC Ours Imp.
TOP 5.1 66.1 93.7 27.6 38.0 80.4 42.4
MAC 37.4 79.1 96.7 17.6 60.0 81.1 21.1
GCC 97.1 80.6 86.3 5.7 47.8 59.0 11.2
RSA 201.0 94.6 98.3 3.6 78.3 83.8 5.6
AES 228.7 89.3 90.2 6.3 67.6 77.4 9.8
Avg. 80.9 93.0 12.2 58.4 76.4 18.0
algorithm implemented in C is called. In the flow suggested by TSMC, the following algorithm is performed.
First, a task checks if there is any timing violation path. Then, the following iterations start to swap cell.
Iteration(1) Swap all cells not in violation path to HVT.
Iteration(1+m) Swap cells in violation path to NVT.
Iteration(1+m+n) Swap cells in violation path to LVT.
After executing the dual threshold assignment algorithm, a Verilog code using cells from low-Vth and high-Vth library is produced. Finally, this Verilog code is used to instruct Astro to do ECO placement.
To demonstrate the effectiveness of our algorithm, 5 designs were selected for benchmarking process. The descriptions of these designs are shown in Table II. The columns labeled CN, and Characteristics are the cell number of the design, and the characteristics of the design, respectively.
The comparison results are shown in Table III. The column labeled BP is the original leakage power consumption in nano- watt (nW) of the circuit calculated by Design Compiler. The column labeled Swap Rate is the ratio of the swapped num- ber of cells to the total number cells. The cells were swapped from low to high Vt. The column labeled Power Reduction is calculated as dual−V th power
original power . The column labeled TSMC is the results of the circuit using TSMC tool. The column labeled Ours is the results using our algorithm. The column labeled Imp. is calculated as the subtraction of Ours and TSMC. It can be seen that out method can reduce on the average 18.0%
more leakage power than TSMC’s.
VI. CONCLUSIONS
In this paper, we have proposed several low-power tech- niques for network security processors, including a descriptor- based low-power scheduling algorithm, design of dynamic voltage generator, and dual threshold voltage assignments. The experiments have shown that the proposed designs are efficient in power reduction for network security processors.
Verilog Code
Logic Synthesis and Technology Mapping by Design Compiler Low Vth
Library
Gate-Level Verilog Code
Timing Driven Place & Route by Astro
SDF The Placement
description of all standard cell
Dual-Vth Assignment Algorithm
Dual Voltage Gate-Level Verilog Code
Timing Driven Place & Rout by Astro
GDSII Dual-Vth
Library
SDF
SDC
PrimeTime
Fig. 8.Design Flow for Dual-Vth
REFERENCES
[1] C.-P. Su, T.-F. Lin, C.-T. Huang, and C.-W. Wu, “A high- throughput low-cost AES processor,” IEEE Communications Magazine, vol. 41, no. 12, pp. 86–91, Dec. 2003.
[2] J.-H. Hong and C.-W. Wu, “Cellular array modular multiplier for the RSA public-key cryptosystem based on modified Booth’s algorithm,” IEEE Transactions on VLSI Systems, vol. 11, no. 3, pp. 474–484, June 2003.
[3] S. Devadas and S. Malik, “A survey of optimization techniques targeting low power VLSI circuits,” In Proceedings of the 32nd ACM/IEEE Conference on Design Automation, pp. 242–247, 1995.
[4] Y.-C. Lin, Y.-P. You, C.-W. Huang, J. K. Lee, W.-K. Shih, and T.T. Hwang, “Power-aware scheduling for parallel security pro- cessors with analytical models,” Submitted to The 17th Interna- tional Workshop on Languages and Compilers for Parallel Com- puting, 2004.
[5] C. L. Liu and J. W. Layland, “Scheduling algorithms for multi- programming in a hard read-time environment,” Journal of the ACM, 20(1):46–61, 1973.
[6] A. Stratakos, S. Sanders, and R. Brodersen, “A low-voltage CMOS DCDC converter for a portable battery-operated system,”
In Proceedings of IEEE Power Electronics Specialists Confer- ence, pp. 619–626, 1994.
[7] S. Borkar, ”Low power challenges for the decade,” In Proceed- ings of ASP-DAC, 2001.
[8] J. Kao, S. Narendra and A. Chandrakasan ”Subthreshold leakage modeling and reduction techniques,” In Proceddings of ICCAD, pp. 141-148, 2002.
[9] Y.-T. Ho, T.T. Hwang, ”Low power design using dual threshold voltage,” In Proceedings of ASP-DAC, pp. 205-208,2004.
[10] C. Chen, X. Yang and M. Sarrafzadeh, ”Potential slack: an ef- fective metric of combinational circuit performance,” In Proceed- ings of ICCAD, pp.198-201, 2000.