i
國立臺灣大學工學院土木工程學系 碩士論文
Department of Civil Engineering College of Engineering
National Taiwan University Master Thesis
運用特定領域文件集合進行自我學習之知識本體增補 技術
A Self-Learning Method for Enhancing Ontology from Domain-Specific Documents
金育暉 Yu-Huei Jin
指導教授:謝尚賢 博士
Advisor: Shang-Hsien Hsieh, Ph.D.
中華民國 101 年 8 月
August, 2012
ii
iii
誌謝
在 CAE 的兩年奮鬥,終於走到了這一頁,雖然這是論文的開頭,
卻是整個碩士生活的結尾。一路走來顛顛簸簸,受到了許多人的幫助 與指導,要說聲感謝的人的不計其數。而最為感謝的人則是一路給予 我指導的謝尚賢老師,謝老師從我大四修學士論文開始,一路給我研 究上的指導並告訴我研究上所需注意的事項。謝老師也相當關心我的 生活,讓我在碩士生活中得以安心地做研究,在此深深的感謝他。而 在口試時不吝給予我意見的王明德老師、郭榮欽老師、吳翌禎老師也 要深深感謝,三位老師都對於我的研究給了很多有用的意見,讓這一 篇論文更加完整,並感謝國科會研究計畫(NSC 100-2221-E-002 -224 -MY2)對研究經費上的補助。
同時也要感謝在研究路上一直給予我幫助的乃文學長,他讓我從 一個不懂資訊檢索的學生到以資訊檢索作為研究的題目並順利的畢 業,這一路有了他的指導讓我少走了許多彎路,也少做了許多無用之 功。另外還要特別感謝孟涵學姊,除了對於我的研究提供了許多建議,
她還會三不五時對我在研究生活中所需要注意的事項給予提醒,也常 常提供了不同的思維給我,讓我對於生活有了新的想像與想法。
iv
再來要感謝 R99 的夥伴們,蔡承諺、jacob、matthew、小古、郭 品岑、劉柔君、義彬、南同學、BK、三凱、瀚嶸,我們一起奮鬥了 兩年,製造了許多笑點,讓兩年生活不只有研究的苦悶,而是還有許 多與你們一起分享的歡樂。而在這兩年認識的 CAE 學長學弟們也都 非常感謝,像是奕竹總是被我以奇奇怪怪的問題騷擾、pattern 不斷地 嗆飛我、KID 抓我去打羽球、濟華大大不斷幫我製造新的封號……等 等,湘如跟銘峰也幫我解決了許多有的沒有的事情。總之在 CAE 的 兩年認識了許多有趣的學長學弟學姊學妹,讓這兩年的歡樂無限。
最後要感謝高中的那群,這兩年來跟你們的每次聚會都是一種充 電,讓我又有了繼續往前的動力,那群中有人的研究生活太好命,有 人的研究生活太悲慘,所以我知道我不是孤獨走在這條路上的。而在 那群中要特別感謝黃群凱,除了平常他的多所照應,在研究生活的最 後一段路是因為有他的支持,我才能走到今天這個終點,也才有了這 一頁的誕生。
v
摘要
知識本體(Ontology)是一種用來表達知識的方式,其被廣泛的 應用於各種領域中。知識本體利用簡潔的方式表示該領域中所含有的 知識概念以及知識概念相互之間的關係,讓知識本體可以被電腦解讀 並加以使用。然而目前在建置知識本體的流程上,並未有統一的標準 與方法,且在建置知識本體的過程中,需要大量領域專家的投入,並 隨著領域中知識的發展,必須不斷對知識本體進行增補。因此如何以 自我學習的方式來建議知識本體的增補內容,以減少領域專家人力的 參與,是建置知識本體時的重要議題。
本研究的主要目的為縮短增補特定領域的知識本體內容時,所需 花費的時間與人力。為此在本研究中選定「建築資訊塑模(Building Information Modeling)」領域作為研究的特定領域,由分析塑模領 域的文獻開始,收集文獻中所整理的知識概念以建置塑模領域的基本 知識本體,並建立該領域的文件集合,以驗證使用知識本體的資訊檢 索技術之成效表現乃優於使用向量空間模型的資訊檢索技術,再針對 資訊檢索的檢索結果進行知識概念擷取,來對知識本體的內容進行補 充。本論文將詳述各步驟所進行之研究內容,並先透過實驗來驗證應 用知識本體進行資訊檢索確實能提高資訊檢索的成效表現,再驗證經 過資訊檢索技術所增補的知識本體亦能提高資訊檢索之成效。
關鍵字:知識本體、建築資訊模型、建築資訊塑模、資訊檢索
vi
ABSTRACT
Ontology, which has been widely used in different domains, concisely represents the knowledge as a set of concepts and the relations of those concepts. However, with the growth of the domain knowledge and its lack of unified standards, building and revising the ontology is not only time-consuming but also requires a large amount of manpower. For making the process more efficient, this research proposed a self-learning method to suggest the enhancement of the ontology on a specific domain.
In this research, the specific domain is focused on building information modeling (BIM). There are three steps of the research progress. First, collect concepts from the related researches as reference to build the base ontology. Then, propose an ontology-based retrieval model to improve the retrieval effectiveness. Finally, propose a methodology to extract the concepts from the ontology-based retrieval results. According to the experiment results, using the enhanced ontology to the ontology-based retrieval could improve the retrieval effectiveness.
The enhanced ontology can also help learning and sharing the domain knowledge.
Keyword: Ontology, Building Information Model, BIM, Building Information Modeling, Information Retrieval
vii
目錄
誌謝 ... iii
摘要 ...v
ABSTRACT ... vi
目錄 ... vii
圖目錄 ... ix
表目錄 ... xi
第一章 緒論 ...1
1-1 研究背景與動機 ... 1
1-2 研究目的及範圍 ... 1
1-3 研究方法及步驟 ... 2
1-4 論文架構 ... 3
第二章 建立特定領域之知識本體 ...5
2-1 知識本體簡介 ... 5
2-2 以特定領域之知識來源建置知識本體 ... 7
2-2-1 建築資訊塑模簡介... 8
2-2-2 收集特定領域之知識概念 ... 10
2-2-3 建立階層與關聯性... 12
2-2-4 知識本體展示 ... 15
第三章 特定領域之資訊檢索 ...18
3-1 資訊檢索簡介 ... 18
3-2 建立特定領域之測試文件集 ... 20
3-2-1 選擇與準備文件 ... 21
3-2-2 定義資訊需求 ... 22
viii
3-2-3 評估文件相關度 ... 22
3-3 運用知識本體於特定領域資訊檢索之成效評估 ... 26
3-3-1 向量空間模型簡介... 26
3-3-2 以知識本體為基礎之資訊檢索方法 ... 27
3-3-3 資料檢索成效評估... 31
第四章 以資訊檢索技術增補知識本體 ...33
4-1 增補知識本體之流程 ... 33
4-1-1 擷取知識概念 ... 35
4-1-2 自動化增補知識本體 ... 41
4-1-3 領域專家協助修訂... 46
4-1-4 領域知識本體 ... 46
4-1-5 系統建置與限制 ... 47
4-2 自動化增補知識本體之成效評估 ... 48
4-2-1 自動化增補知識本體流程之參數設定 ... 48
4-2-2 自動化增補知識本體展示 ... 55
第五章 結論與建議 ...60
5-1 結論 ... 60
5-2 未來研究方向建議 ... 61
參考文獻 ...63
ix
圖目錄
圖 1 本研究之進行步驟 ... 3
圖 2 建置知識本體之流程[5] [6] ... 7
圖 3 BIM 基本知識本體 ... 14
圖 4 擴展後的 BIM 基本知識本體 ... 15
圖 5 中文版 BIM 基本知識本體 ... 17
圖 6 資料檢索流程圖[18] ... 19
圖 7 研討會文件掃描檔 ... 21
圖 8 測試文件集範例 ... 22
圖 9 向量空間模型資訊檢索系統 ... 27
圖 10 知識本體資訊檢索系統 ... 28
圖 11 概念分層架構 ... 29
圖 12 權重地圖 ... 30
圖 13 運用資訊檢索技術增補知識本體之流程 ... 34
圖 14 bigram 切分結果 ... 36
圖 15 trigram 切分結果 ... 36
圖 16 自動化增補知識本體之流程 ... 42
圖 17 中文版 BIM 基本知識本體 ... 43
圖 18 K=3 時,不同 N 值的平均求準率 ... 50
圖 19 K=4 時,不同 N 值的平均求準率 ... 51
圖 20 K=5 時,不同 N 值的平均求準率 ... 51
圖 21 N=3 時,不同 K 值的平均求準率 ... 52
圖 22 N=4 時,不同 K 值的平均求準率 ... 53
圖 23 N=5 時,不同 K 值的平均求準率 ... 54
x
圖 24 N=3、K=4 的平均求準率 ... 55
圖 25 第一次增補後的知識本體 ... 56
圖 26 第二次增補後的知識本體 ... 57
圖 27 第三次增補後的知識本體 ... 58
圖 28 第四次增補後的知識本體 ... 59
xi
表目錄
表 1 BIM 應用項目使用分類[11] ... 11
表 2 BIM 工具使用分類[12] ... 12
表 3 專家評估結果 ... 23
表 4 Cohen’s Kappa measure 計算結果 ... 24
表 5 overlap value 計算結果 ... 24
表 6 兩種不同資訊檢索模型的平均求準率 ... 32
表 7 文件關鍵字排名表 ... 39
表 8 知識概念關鍵字排名表 ... 44
表 9 「規劃與設計」的平均求準率 ... 49
表 10 「營運」的平均求準率 ... 49
1
1 第一章 緒論
1-1 研究背景與動機
知識本體(Ontology)是一種用來表達知識的方式,其被廣泛的 應用於各種領域中,如生醫領域用知識本體表達蛋白質相關知識[1];
地球科學領域的 SWEET(Semantic Web for Earth and Environmental Terminology)計畫[2]。因為知識本體利用簡潔的方式表示該領域中 所含有的知識概念與知識概念相互之間的關係,讓知識本體可以被電 腦解讀並加以使用,因此在不同的專業領域上,都會有建置與使用知 識本體的需求。
然而目前在建置知識本體的流程上,並未有統一的標準與方法,
且在建置知識本體的過程中,需要大量領域專家的投入。並隨著領域 中知識的發展,必須不斷對知識本體進行修正。因此如何有效的以自 動化的方式來進行知識本體的增補,以減少領域專家人力的參與,是 建置知識本體時的重要議題。
1-2 研究目的及範圍
本研究的主要目的為縮短建置特定領域的知識本體時,所需花費 的時間與人力,因此本研究提出以自動化方式從特定領域文件集合中,
擷取文件中的知識概念,進行知識本體內容增補之方法,並利用知識 本體技術改善資訊檢索技術之成效表現。
本研究中選定「建築資訊塑模(Building Information Modeling)」
領域作為研究的特定領域。而在改善資訊檢索的成效表現上,則是以 搜尋結果的準確率為優先考慮的準則,而不以檢索過程所耗費的時間 作為評估的標準。
2
1-3 研究方法及步驟
本研究步驟如圖 1,共分為四個步驟,各步驟的內容與採用之方 法如下:
1. 建置特定領域之基本知識本體
本研究由特定領域相關的文獻資料中,整理並分析該領域中 的知識概念,並將這些知識概念建置成該特定領域的基本知 識本體。
2. 建立特定領域測試文件集
因選用的建築資訊塑模領域,目前並無合適的測試文件集,
因此在這個步驟中先建置所需的測試文件集,以進行資訊檢 索的成效評估。
3. 利用知識本體進行資訊檢索之成效評估
使用第二個步驟中所建置的測試文件集,測試以知識本體進 行資訊檢索方法與一般資訊檢索方法之間的成效比較,以驗 證使用知識本體技術進行資訊檢索可改善特定領域的資訊 檢索成效。
4. 利用資訊檢索技術增補知識本體
利用以知識本體進行資訊檢索的檢索結果進行分析,來增補 基本知識本體的內容,並將增補後的知識本體再次進行使用 知識本體的資訊檢索方法。將其檢索結果與只使用基本知識 本體的資訊檢索結果及未使用知識本體的資訊檢索結果進 行成效比較,以驗證增補過後之知識本體確能提高資訊檢索 的成效表現。
3
1-4 論文架構
本文的內容依照實作流程整理成以下章節:
第二章 建立特定領域之知識本體
本章將簡介知識本體與選用的特定領域:建築資訊塑模,並說明 目前知識本體於建築資訊塑模的應用以及說明本研究所使用的 特定領域之基本知識本體。
第三章 特定領域之資訊檢索
本章將說明如何建置特定領域之測試文件集,並利用特定領域文 件集合進行以知識本體技術進行的資訊檢索,並與向量空間模型 的資訊檢索方式進行成效比較。
圖 1 本研究之進行步驟
建置特定領域 基本知識本體
建立特定領域 測試文件集
利用知識本體進行 資訊檢索成效評估
利用資訊檢索技術 增補知識本體 1
2
3
4
4
第四章 以資訊檢索技術增補知識本體
本章利用第三章以知識本體進行資訊檢索的檢索結果進行分析,
擷取出特定領域文件集合中的知識概念,以藉此增補知識本體中 的知識概念,並利用增補後的知識本體再次進行資訊檢索並與第 三章的結果進行成效比較。
第五章 結論與建議
對於本研究實作與分析結果做出結論,並針對所面臨之問題提出 改善之建議。
5
2 第二章 建立特定領域之知識本體
2-1 知識本體簡介
知識本體為一種整理與儲存知識的方式,其定義為將一知識內容 用清楚並標準化的方式「概念化」[3],而其中「概念化」的含意為將 知識內容以不失原意的方式將其內容簡化。因此使用知識本體的方式 為當獲得一個知識時,將其知識內容簡化成一知識概念,接著將該知 識概念跟其他原有的知識概念進行連結。此項連結可能會包含有此知 識概念為另一知識概念的實例,或是此知識概念是另一知識概念的解 釋,或更多不同的關聯性。利用這樣的方式,將不同知識概念進行連 結。更重要的是可以藉由這樣的連結關係,去推論出兩個未有直接連 結的知識概念之間的關係。而將知識本體以 OWL (Web Ontology Language)[4]的格式儲存後,就可以使電腦理解並儲存知識概念。更 進一步的可以讓電腦利用知識本體的內容來進行知識概念之間的邏 輯推論。
由於每個知識領域對於知識本體的運用方式不同,所以知識本體 就需要依照每個知識領域的使用目的進行建置,因此在建置知識本體 時的步驟就會有所不同。如圖 2 左為 Noy 與 McGuinness 對於他們所 設計的知識本體建置軟體 Protégé,在進行知識本體建置時建議的操 作步驟[5],共分為六個步驟,由決定知識領域範圍開始,先使用已存 在的知識本體作為基礎,接著列舉重要的知識概念並定義知識概念彼 此之間的關係與屬性。而圖 2 右則為 Uschold 與 Gr¨uninger 對於在 進行知識本體建置時的所建議的步驟[6],共分為四個步驟,首先為確 定知識本體的使用目的與應用範圍,再進行知識本體內容的抓取,接 著將知識本體編碼儲存後,融入現有知識本體。
6
分析兩者建置知識本體的步驟後,可以發現兩者有相似之處,在 圖 2 中以虛線註明並進行對照,因此可以統整出在建置知識本體的 過程中重要步驟,共有三個部分:
確認知識本體所涵蓋的領域範圍
確認想要建置的知識本體的領域,並對該領域有一明確定義 並限定該領域的範圍。
知識概念擷取與知識概念的關聯性建置
將在限定範圍內的知識概念擷取出來並定義不同知識概念 之間的關聯性。
將知識本體的內容轉換為電腦可閱讀之格式
將知識本體中的知識概念與其相互之間的關係,依造電腦可 閱讀的格式進行儲存。
根據以上所統整的知識本體建置流程,第一個與第二個步驟皆需 要許多領域專家參與協助,其中又以第二步驟需要領域專家投入許多 時間進行,以確認何項知識概念是屬於欲建置的知識本體的範圍內。
且根據 Noy 與 McGuinness 的建議,建置知識本體為一不斷循環的流 程,因此領域專家須不斷對知識本體的內容進行修訂,以增加該知識 本體的內容與完善性。但如此一來在建置知識本體時將耗費大量的人 力與時間,所以如何減少領域專家在建置知識本體時所參與的工作量,
是本研究的主要目標。
2-2
Inf 新興 訊塑
2 以特定
在 本 研 formation 興領域,因 塑模領域中
定領域之知
研 究 中 所 n Modeli 因此以下內
中已有的 圖
知識來源
選 定 的 特 ng),建築 內容將從 的知識來源
圖 2 建置
7
源建置知識
特 定 領 域 築資訊塑模 從介紹建築
源,建置建 置知識本體
識本體
域 為 建 築 模領域為 築資訊塑模 建築資訊塑
體之流程[
資 訊 塑 模 為土木營建
模開始,說 塑模的基本
[5] [6]
模 (Build 建工程領域 說明由建築 本知識本體
ding 域之 築資 體。
8
2-2-1 建築資訊塑模簡介
建築資訊塑模其主要的表現方式為在三維虛擬空間中的立體模 型,但其真正的意義為一整套與生產、溝通、分析相關的 3D 模型技 術[7]。因此,建築資訊塑模的使用時間包含了整個建物的生命週期,
從規劃設計到現場施工再到建物完成後的營運維護。
而使用建築資訊塑模所帶來的好處,也已經有相關研究[8],分別 有以下幾點:
更快與更有效率的流程(Faster and more effective processes) 建物相關的資訊可以更容易分享、加值與重複使用。
更好的設計(Better design)
在初期設計時,建物可以得到更嚴謹且更快的分析,因此可 以在初期設計階段時使用更多不同的設計。
包含整個生命週期的成本與環境資料
(Controlled whole-life costs and environmental data)
環境對建物的影響更容易預測,對於建物生命週期中所需要 的各項花費更加清楚。
更好的文件品質(Better production quality)
在建物的生命週期內所需要的相關文件的可以自動化產出 並更加彈性。
更好的客戶服務(Better customer service)
經由 3D 模型的展示,業主可以更輕易的理解建物的設計與 施工過程。
包含整個生命週期的資料(Lifecycle data)
所有建物的相關資訊,可以持續使用到營運維護上。
9
由 以 上 幾 點 , 可 以 知 道 一 個 完 整 的 建 築 資 訊 模 型 (Building Information Model),其所包含的資料量會相當的龐大。因此,BIM Handbook[9]一書提供 M.A. Mortenson Company 所定義的一個良好的 建築資訊模型必須包含六個要點:
數位的(Digital)
其儲存資料的方式要以數位資料方式儲存。
空間的(Spatial)
其數位模型資料需以虛擬三維(3D)的方式呈現。
可量測的(Measurable)
在數位模型資料中的資料是數值化並可計算的,如在模型中 有樑的尺寸、數量,並可對各種樑的數值進行計算。
完整的(Comprehensive)
在數位資料中不只含有建物模型的數值資料,並包含有建物 在規劃設計階段、現場施工階段等,不同階段中與該建物相 關的資訊。
易取得的(Accessible)
其儲存的資料格式必須是不受限於單一電腦軟體或硬體,其 資料檔案可在不同的軟硬體間交換,
持久的(Durable)
其資訊必須可以長時間保存並維持一致性於整個建物生命 週期。
由此可知建築資訊塑模為運用於建物完整生命週期之技術,且其 在三維虛擬空間的表現方式,讓過去在使用平面圖來表達建物設計上,
因誤解圖面表示方式而導致物件互相衝突的狀況大量減少,並讓不同 階段的參與者,經由建築資訊模型能有更好的溝通方式。
10
2-2-2 收集特定領域之知識概念
由於所需使用的基本知識本體,其領域範圍已限定在建築資訊塑 模領域中,而目前在建築資訊塑模領域中,已經有許多文獻對於建築 資訊塑模領域的內容進行整理與分析,因此在進行知識概念的收集時,
即可根據這些文獻的內容,來整理出建築資訊塑模領域中較為重要的 知識概念。因此在此節中將回顧建築資訊塑模的相關文獻,以收集建 築資訊塑模領域的知識概念。
由美國國家建築科學研究院(NIBS/National Institute of Building Sciences) 所公布的美國國家 BIM 標準(NBIMS-US/The National BIM Standard-United States)第二版中[10],在 Term and Definitions 章節裡,
有對於建築資訊塑模領域中各式詞彙進行說明,其內容包含有該詞彙 的縮寫與定義,如 Component 此詞彙在該書中的定義為,在建築物中 的各項設備與該設備在虛擬三維空間中的位置。因此根據此章節的內 容,就可收集到在建築資訊塑模中較為重要的知識概念。
而由 buildingSMART 於 2010 年發行的 BIM Project Execution Planning Guide 一書中[11],其第二章(Identifying BIM Goals and Uses For a Project)的內容為針對建築物不同生命週期所使用的各種應用項 目進行說明,總共提出二十五個應用項目,其內容整理後如表 1。其 每個應用項目所使用的階段皆有所不同,並在該書的附錄 B 中,有針 對每個項目的詳細內容進行描述,因此這些應用項目,可視為目前在 建築資訊塑模領域進行應用的各項知識概念。
11
表 1 BIM 應用項目使用分類[11]
PLAN DESIGN CONSTRUCT OPERATE
Existing Conditions Modeling Cost Estimation
Phase Planning
Programming
Site Analysis
Design Reviews
Design Authoring
Energy Analysis
Structural Analysis
Lighting Analysis
Mechanical Analysis
Other Eng. Analysis
LEED Evaluation
Code Validation
3D Coordination
Site Utilization Planning
Construction System Design
Digital Fabrication
3D Control and Planning
Record Model
Maintenance Scheduling
Primary BIM Uses Building System Analysis Secondary BIM Uses Asset Management
Space Mgmt/Tracking
Disaster Planning
另一項資料來源則為 Eastman 所編寫的 BIM Handbook[9],其為 建築資訊塑模領域的資訊手冊,該書的內容對建築資訊塑模有詳細的 介紹,並針對在建物生命週期中的擔任不同工程角色時,所會面臨到 的問題一一列舉與說明。而在該書中的 Glossary 章節有對於建築資訊 塑模領域中相關的知識概念進行介紹,並對不同知識概念之間的相關 性進行說明。
12
而由 IBC(Institute for BIM in Canada)組織於 Evironmental Scan of BIM Tools and Standards[12]報告中統計目前已存在的 BIM 工具,並 對每個 BIM 工具在建築資訊塑模中所應用的領域範圍進行統計,其 整理出的分類架構如表 2,此分類架構即是對建築資訊塑模領域中的 知識概念的整理。
表 2 BIM 工具使用分類[12]
Tool Category Areas of Use
Planning and Design
Site Modeling Spatial Programming Design Authoring Design Review Engineering Analyses Code Evaluation Cost Estimation
Construction
Sequential Planning
Construction Site Utilization Temporary Structure Design 3D Coordination
Site Analysis and Phase Planning Cost Estimation
Operation
Building Record Building Performance Space and Asset Management Disaster Planning
Maintenance Scheduling Building Analysis
2-2-3 建立階層與關聯性
在知識本體中,需定義不同知識概念之間的關係,所以由上節的 文獻回顧中,本研究選用 BIM Handbook 的 Glossary 章節,來做為 基本知識本體的主要知識來源。因該章節的內容除了對於知識概念的 說明以外,仍有針對不同知識概念之間的關係進行說明。
13
以下條例出本研究所選用的知識概念與其彼此之間的關係:
1. Building information modeling (BIM)
基本知識本體的領域範圍為 BIM,因此選用該知識概念作為基本 知識本體的最上層結構。
2. BIM system
其內容為整合 BIM 工具並提供平台讓不同工具進行連接,所以此 知識概念為 Building Information Modeling 的下層概念。
3. Building Model
其內容為可供 BIM 工具讀取與編輯的數位資料,所以此知識概念 為 Building Information Modeling 的下層概念。
4. BIM Process
為使用 BIM 工具處理建物生命週期中所遇到的各種工作事項,所 以此知識概念為 Building Information Modeling 的下層概念。
5. BIM application
其內容為工作團隊為某一種特定目的而對 Building Information Modeling 所採取的使用方式,此概念在 BIM system 中有提及並進 行描述,所以此概念為 BIM system 之下層知識概念。
6. BIM tool
其內容為可產生並操作 Building Information Model 的軟體。其概念 在 BIM system 中提及並進行描述,所以此知識概念為 BIM system 之下層知識概念。
7. Building objects
其定義為組成建築物的基本單位,如柱、梁、版、牆以及建築物 的空間概念。所以此知識概念為 Building Model 下層之知識概念。
Building m 其定義為 為物件式 念為 Buil Building D 其定義為 概念為 B 綜合以 訊塑模的知 關係為「包 識概念「包 子知識概念
而在 Pr
,而沒有全 ols and Sta
model rep 為儲存 Bui 式的儲存方
lding Mod Data Mod 為儲存 Bui Building M
以上 9 個知 知識本體 包含」,因 包含」了 念。
rocess 之下 全部列舉 andards 所
pository ilding Info 方式且具有
del 之下層 del
ilding Info Model 下層
知識概念以
,其內容如 因此根據圖
BIM Syst
下的知識概 舉。因此本
所提供的知 圖 3
14
ormation M 有檢索個別 層知識概念
ormation M 層知識概念 以及其相 容如圖 3。
圖 3 所表示 tem、BIM
概念,在 本研究參考
知識概念進 BIM 基本
Model 的資 別元件的 念。
Model 的檔 念,用來說 相互之間的 共為三層 示的基本 M Model 與
BIM Han 考了 Envir
進行知識本 本知識本體
資料庫,該 的功能。所
檔案格式 說明模型的 的關係可以 層架構,每 本知識本體
與 BIM Pro
ndbook 裡 onmental 本體的擴 體
該資料庫內 所以此知識
,所以此知 的檔案格式 以得到建築 每一層之間 體,BIM 此 ocess 共三
裡只有部分 Scan of B 擴展。
內容 識概
知識 式。
築資 間的 此知 三個
分舉 BIM
Environ ocess 分為
每一個部分 各項知識概 域的基本知 概念,其知 念。
2-4 知識 經過上兩 知識本體 其知識概念 知識概念進
nmental Sc 為三個部分 分有包含 概念添加 知識本體 知識概念之
識本體展示 兩節的整
,但由於該 念的內容 進行翻譯 圖
can of BIM 分:Plannin 含有各種子 加進目前 B 體就擴展為
之間的關係
示
整理之後,本 該基本知 容皆為英文 譯。
圖 4 擴展
15
M Tools a ng and De 子應用方向
BIM Proce 為圖 4。其
係為上層
本研究已 知識本體的
文。為將這 展後的 BIM
and Stand sign、Con 向。依造該 ess 知識概 其總共有四 層的知識概
已整理出建 的知識來源 這些知識概 M 基本知識
dards 此篇 nstruction、
該篇報告整 概念的下層
四層架構 概念包含有
建築資訊塑 源皆為英文 概念轉換成
識本體
篇報告將 B
、Operatio 整理之結果 層。因此 B
,共 27 個 有下層的知
塑模領域的 文的文獻 成中文,需
BIM on,
果,
BIM 個知 知識
的基
,因 需要
16
本研究首先採用 AEC-STIIRS 工具[13] 來進行翻譯,該工具提供 了在營建領域中各式詞彙的中英文版本。其資料來源有兩個部分:
CEDICT[14]與牛頓工程詞典[15]。CEDICT 為一般詞典,其中包含了 33000 組詞彙,牛頓工程詞典則為營建工程領域的專業詞典,共有 35000 組詞彙。
因此根據 AEC-STIIRS 工具可翻譯出部分知識概念,以下說明使 用該工具在翻譯時的三種狀況:
只有單一解釋,如「tool」此知識概念使用 AEC-STIIRS 工具查 詢後,其中文翻譯只有「工具」,而「工具」也符合此知識概念所表 達之含意,因此選用「工具」做為此知識概念的中文版本。
含有多種解釋,如「model」此知識概念,在使用 AEC-STIIRS 工具查詢後,其中文翻譯有「模型」、「模範」、「雛型」三種不同的解 釋,因此需根據此知識概念在知識本體中所表達的含意,來決定該知 識概念的中文翻譯,而在此例選用「模型」做為此知識概念的中文版 本。另一個相同的例子為「system」,其中文翻譯有「系統」、「制」、
「系」、「綱」、「法」、「式」共六個,本研究選用系統作為此概念的中 文翻譯。
未有直接翻譯,如「disaster planning」此知識概念在翻譯工具中 並無直接的翻譯,但在 AEC-STIIRS 工具中有一英文詞彙為「disaster prevention plan」,該詞彙的中文翻譯為「防災計畫」,其含意與「disaster planning」相同,因此可以將「disaster planning」翻譯為「防災計畫」。
由於仍有 分知識概念 實現營建協 為:代理者
ent、Colla sign revie llaborative
因此根據 為中文版本
有部分知 念參考前 協同設計 者、協同審
aborative ew 的 中
e 後可以知 據以上的 本的基本
圖
知識概念在 前人的文獻 計審查之研 審查設計審
design rev 中 文 解 釋
知道 desig 的步驟,就 本知識本體
圖 5 中文
17
在 AEC-ST 獻進行翻譯 研究」[16]
審查、建築 view、BIM
為 協 同 審 gn review 就可將英文 體,其成果
文版 BIM
TIIRS 工具 譯。如在
中,其作 築資訊模型
M。由此可 審 查 設 計
的中文翻 文版本的基 果如圖 5。
基本知識
具中並沒有
「以 BIM 作者所定義
型;英文的 可以知道 C
計 審 查 , 翻譯為設計 基本知識本
。
識本體
有資料,因 與代理者 義的中文關 的關鍵字為 Collabora
, 而 扣 除 計審查。
本體(圖 4 因此 者技 關鍵 為:
ative 除 掉
4)翻
18
3 第三章 特定領域之資訊檢索
3-1 資訊檢索簡介
隨著資訊時代的發展,各式資料的電子化已經是進行知識管理的 必要程序。但隨著資料數量的增加,若無妥善的整理方式,則儲存的 資料裡所蘊含的知識就無法迅速的被找到,如此一來儲存的資料也無 法進行有效的應用,因此資訊檢索技術就應運而生。
資訊檢索(Information Retrieval)為在儲存的資料中迅速找到所需 要的相關資料的一種技術[17]。其最常見的形式就是網路上的各式搜 尋引擎,如 GOOGLE、YAHOO、BING……等。其運作方式為接收 到使用者的資訊需求(Information Needing)後,根據不同的資訊檢索模 型 (Retrieval Model) 進 行 資 訊 需 求 與 事 先 已 蒐 集 好 的 文 件 集 合 (Document Collection)的相關性計算,並依造相關性計算的結果,給 予使用者經過排序過後的檢索結果。
參考文獻[18]中所提供的資訊檢索流程,本研究進行整理後將資 訊檢索技術分為三個部分並繪製成圖 6,分別為圖 6 上方的使用者 介 面 (User Interface) , 圖 6 右 下 方 的 文 件 集 合 處 理 (Document Collection),圖 6 左下方的資訊檢索模型(Retrieval Model)。以下分別 說明各部分所進行的內容。
使用者介 處理使用 在文字檢索 檢索系統時 索系統也會 資料搜索的
文件集合 分析所儲 析方式為將 為表示該詞 索系統在進 型來建置完
介面 (User 用者的資 索中所代 時,會利用 會記錄使 的成效表 合處理 (Do
儲存的文 將文件中 詞彙在那 進行檢索 完整的資
r Interface 資訊需求,
代表的意義 用簡單的 使用者在搜 表現。
ocument C 文件集合中 中的詞彙擷 那一篇文件 索時的處理 資訊檢索系 圖 6 資
19
e)
延伸或擴 義就是檢索 的詞彙來表
搜尋結果中
Collection 中所有文件 擷取出來,
件中曾出現 理速度,而 系統。
資料檢索流
擴展使用者 索詞彙(Qu 表達自己的
中實際點選
n)
件包含的資 並將這些 現過的列表 而索引將會
流程圖[1
者的資訊需 uery),使用 的資訊需求
選的文件,
資訊。在文 些詞彙建置
表,其目的 會搭配不同
8]
需求。資訊 用者在使用 求。同時資
,來修正下
文字檢索中 置成索引 的為增加資 同的資訊檢
訊需 用資 資訊 下一
中其
,索 資訊 檢索
20
三. 資訊檢索模型 (Retrieval Model)
將資訊需求與處理好的文件透過資訊檢索模型進行相關性計算,
以找出較為符合資訊需求的文件,並依文件與資訊需求的相關程度,
對檢索結果進行排序,讓使用者能決定從那一個結果開始看起。
綜合以上回顧,資訊檢索技術能幫助使用者快速而正確的得到其 所需要的資訊需求,因此不論在何種專業領域內,都需要使用到資訊 檢索技術。而讓使用者選擇何種資訊檢索技術的關鍵在於,該資訊檢 索技術是否能檢索出使用者所需要相關資料,也就是說,資訊檢索的 成效表現才是使用者最關心的議題。因此本章節將導入上一章的基本 知識本體,來進行以知識本體為基礎的資訊檢索系統之建置,以改善 資訊檢索系統運用於建築資訊塑模領域的成效表現。
3-2 建立特定領域之測試文件集
資訊檢索的成效由測試文件集加以評估,測試文件集是具有「標 準答案」的文件集合,而標準答案的獲得方式為請專家判斷有哪些文 件與某一筆資料需求是確實相關的。因此,為評估資訊檢索系統之成 效,本研究建置了建築資訊塑模領域的測試文件集。
測試文件集由三個部分組成:文件集合、資訊需求、文件相關度 的「標準解答」。文件集合為最原始的文件資料,而為了後續的系統 建置的方便,需將實際的文件資料轉化成電子文件。資訊需求則為使 用者可能提出的檢索詞彙。文件相關度的標準解答則為文件集合中的 每一項文件與某一筆資訊需求的相關程度。以下小節解釋各步驟詳細 內容。
2-1 選擇 在準備文
、期刊或是 的豐富度上 路文件來源 考慮到內 於土木水利 的文章,實 的其中一篇
而為了讓 讀取文件 llection 時 使用的節點 者]、[Abst eference-參 英文兩種版 如圖 8。
擇與準備文 文件集合 是各式新聞
上各有不 源則數量 內容資料 利工程應 實際使用 篇文件。
讓後續的 件的設計 時所使用的
點分別為 tract-文件 參考文獻]
版本,則用 文件 合時,文件
聞。而不同 不同。如期 量眾多,但 料的正確與 應用研討會 用 117 篇文
的資訊檢索
。因此本 的文件格式
:[DOCN 件摘要]、[S
],其中 T 用 xml:lan
圖 7
21
件的資料來 同的資料 期刊的文件
但文件內容 與完整性,
會的所有論 文件作為文
索系統無須 本研究採用 式,將每一
O-文件編 Subject-關 Title、Au ng 標籤分
研討會文
來源有許多 料來源在文
件內容較為 容較為雜亂
本研究選 論文共 124 文件集合
須針對不 用文獻 [1 一份文件轉 編號]、[Titl
關鍵字]、[C uthor、Ab 分別註明。
文件掃描檔
多途徑。如 文件獲取難 為完整但數
亂。
選用了 100 4 篇,扣除
。圖 7 即
同的文件 3] 中 , 建 轉換為 XM
e-文件標題 Content-文
stract、Su 經轉換過 檔
如:現有的 難度與文件
數量較少
0 年電子計 除掉內容為 即為文件集
件檔案格式 建置 NCR
ML 格式 題]、[Auth 文件內容]
ubject,若 過的文章其
的書 件內
,而
計算 為英 集合
式進 REE
,而 hor- 、 若有 其內
式 與 Col 3-2
由所 行檢 領域 置了 基本
「營 合適 3-2
件 求的 出來 採用
根據以上 與 NCRE llection 的 2-2 定義
在大型的 所收集的文 檢索,並從 域,並無合 了一小型文 本知識本體 營運」來作 適性進行評 2-3 評估
當產生資
,來做為該 的相關性進 來的結果是 用的方法分
上所述,本 EE Collec 的內容,使 義資訊需求 的文件集 文件中相 從裡面剔除 合適的大型
文件集合 體,選取其 作為一開始
評估。
估文件相關 資訊需求 該文件集合
進行評估 是相同的 分別為 ov
本研究建 ction 相 符 使得土木營 求
集合中,定 相關的主題 除出現次 型文件集 合,而該文件
其中的三 始設定的
關度
求後,需評估 合的標準
,而為確保
,因此需對 verlap valu
圖 8
22
建置了一小 符 , 因 此 營建工程領
定義資訊需 題來直接定 次數過少的 集,因此經 件集合的 三個知識概 的資訊需求
估在文件 準答案,所 保不同專 對於專家 ue[19] 及 8 測試文件
小型文件集 此 該 文 件 集
領域的測試
需求的方式 定義資訊需 的主題。但 經由上一節 的資訊需求
概念:「規劃 求,並在下
件集合中與 所以須請專 專家對於同 家所評估的 及 Cohen’s 件集範例
集合,且因 集 合 能 增 試文件集
式通常有兩 需求,2.將 但由於本研 節收集相關 求則由上一 劃與設計 下一節對該
與該資訊需 專家針對文 同一個資訊 的結果進行 Kappa me 例
因所採用之 增 加 NCR 集更加豐富
兩種方式 將文件集合 研究所選定
關資料後 一章所建置 計」、「施工
該資訊需求
需求相關的 文件與資訊 訊需求所評 行一致性測 easure[20
之格 REE 富。
:1.
合先 定之
,建 置的 工」、
求的
的文 訊需 評估 測試,
]。
23
為說明兩種方法的計算方式,假設表 3 為針對某一筆資訊需求,
兩專家評估每份文件之相關程度的結果。RR 為兩專家皆認為與該資 訊需求相關的文件數量,RN 為專家 B 認為相關但專家 A 認為不相關 的文件數量。NR 為專家 B 認為不相關的但專家 A 認為相關的文件數 量。NN 為專家 A 與專家 B 皆認為不相關的文件數量。
表 3 專家評估結果 專家 A
專家 B
相關 不相關
相關 RR RN
不相關 NR NN
根據表 3 計算 overlap value 方法可表示為:
overlap value RR
RR RN NR (公式 1) 其含義為兩專家評估為相關文件的交集除以兩專家評估為相關文件 的聯集,其值越高則代表兩專家所評估的結果一致性越高。
Cohen’s Kappa measure 則考慮到兩位專家所評估的一致性結果,可能 是偶然為一致性,因此將扣除偶然一致性的部分,其計算方式如下:
其中 P(A)為兩專家評估結果確實為一致性的機率,其計算方式為:
Kappa P A P E
1 P E (公式 2)
P A RR NN
SUM (公式 3)
24
而 P(E)則是兩專家評估結果偶然為一致性的機率,其計算方式為:
P E RR NR SUM
RR RN SUM
NN NR SUM
NN RN
SUM (公式 4) 其 中 SUM 所 代 表 的 意 義 為 搜 尋 結 果 的 總 文 件 數 量 , 即 為 RR+RN+NR+NN。因此依照 Cohen’s Kappa measure 的計算方式,即 可獲得扣除偶然一致性的一致性評估結果。
本研究對文件集合進行三個資訊需求的一致性評估。每個資訊需 求皆邀請了三位專家進行評估,而為了讓每一位專家的評估標準相同,
因此要求專家在進行評估時,其評估標準為判斷該文件內容是否與該 檢索詞彙所表達之生命週期階段的概念相關,如:「營運/Operation」
此資訊需求,若該文件內容與「營運/Operation」相關且與「建築資 訊模型/BIM」相關,則該文件與此資訊需求為相關。
將三位專家所評估的結果進行 overlap value、Cohen’s Kappa measure 的計算,但由於這兩種計算方式是比較兩位專家之間的評估 結果,因此每個檢索結果會有三筆數值,其結果如表 4 與表 5。
表 4 Cohen’s Kappa measure 計算結果 資訊需求 I & II II & III I& III 規劃與設計 1.009 10 0.615 -0.222
施工 0.368 0.300 0.300 營運 0.565 0.327 0.722
表 5 overlap value 計算結果 資訊需求 I & II II & III I& III
規劃與設計 0.353 0.667 0.421 施工 0.625 0.500 0.563 營運 0.556 0.417 0.727
25
參考文獻[19]統計 TREC topic 202-250 的 overlap value 的數值,
多落在 0.42 至 0.49 之間;文獻[21]則指出 Kappa 值在 0.67 以上即代 表兩位專家所評估的結果較為一致。但由於本研究所建置的文件集合 數量較少,因此對於此兩項數值所選定的門檻值調整為 Overlap 高於 0.5,Kappa 高於 0.6。在此門檻值之下,則有兩個資訊需求在兩位專 家的評估下符合要求,分別是「規劃與設計」及「營運」,因此選取 此兩筆資訊需求作為檢驗資訊檢索系統成效的指標。
26
3-3 運用知識本體於特定領域資訊檢索之成效評估
3-3-1 向量空間模型簡介
本研究的資訊檢索系統採用向量空間模型(Vector space model)進 行建置,向量空間模型為在資訊檢索技術中常見的檢索模型。其為將 文件與資訊需求都轉換為向量的表示方式,而在向量空間中,當兩向 量的夾角越小時,代表兩向量越為相似,因此利用轉換而成的向量可 以求出文件與資訊需求之間的相關程度[22]。
轉換文件向量的方式為向量的每一個維度代表在文件中每一個 詞彙的權重,其中詞彙的權重計算是以 tf-idf 方法[23]來進行計算,
其計算方法如下:
tf 目標詞彙在文件中出現的次數
文件的總詞彙數量 (公式 5)
idf log 文件集合中的文件總數
有出現過目標詞彙的文件數量 (公式 6)
tf 為 term frequency 之縮寫,其中文為詞頻,其含義為當目標詞 彙在某一文件出現越多次則 tf 值越高。idf 則為 inverse document frequency 的縮寫,其中文為逆向文件頻率,當目標詞彙在許多文件 皆出現時 idf 值越小,兩者相乘後則為在文件向量中某一個維度的詞 彙權重。計算完每一個詞彙的權重後,這些不同維度的權重就會組合 成該文件的向量,可表示成D。而當使用者提出資訊需求時,也對該 資訊需求用同一方式建置該資訊需求之向量,可表示成Q,接著在利 用向量內積來求其相關性,其式如下:
向量空間 需求與該文 向量內積的 可以將文件 使用者所需 3-2 以知
本研究運 9,將文件 odel)進行分 的檢索,以
間模型的 文件的相 的結果越 件集合中 需要的搜 知識本體為
運用向量 件集合(D
分析後,就 以得到該
圖 cos θ
的相關性計 相關性就越 越大的時候 中的文件依 搜尋結果。
為基礎之資 量空間模型
ocument C 就可對資訊 該資訊需求
圖 9 向量
27
D ∙ Q D Q
計算為當兩 越高,因此 候,則相關 依照與資訊
資訊檢索方 型進行資訊
Collection 訊需求(In 求的檢索結
量空間模型
兩向量所夾 此可利用向
關性越高。
訊需求的相
方法 訊檢索系統
n)以向量空 nformation 結果(Retrie
型資訊檢索
夾的角度越 向量內積來
因此根據 相關性進行
統建置,其 空間模型(
n Needing eval Resul
索系統
(公式
越小,則該 來進行計算 據向量空間 行排序,也
其檢索流程 (Vector Sp g)進行向量
lt)。
式 7)
該資 算,
間模 也就
程如 pace 量模
根據圖 後,向量空 行分析,而 訊需求的分 可以針對
,其流程如
因此,在 識來源,藉 者輸入「B 就會認為該 此知識本 容進行資訊 面層級的知 資訊。
9 向量空 空間模型的
而以知識本 分析上進
使用者所 如圖 10。
在運用知識 藉由該知識 BIM」、「營 該使用者
體資訊檢 訊需求的 知識概念
空間模型的 的資訊檢索
本體為基 進行擴充。
所輸入的資
。
識本體於 識本體對 營運」這兩 者是想要查
檢索系統就 的擴充。其擴 念皆補充到
圖 10 知
28
的資訊檢 索系統只 基礎的資訊
因為當擁 資訊需求依
於資訊檢索 對使用者的 兩個資訊 查找在 BIM
就會開始查 擴充的方 到資訊需求
知識本體資
索系統,
只會對使用 訊檢索方法 擁有知識本 依照知識
索上,本研 的資訊需求 訊需求時,
M 領域中 查找知識 方式為將在
求中,進而 資訊檢索系
當使用者 用者所輸入 法,其主要 本體後,資 本體的內
研究將知識 求進行擴充
知識本體 中與營運相 本體中與 在知識本體 而讓資訊需
系統
者輸入資訊 入的資訊需 要的內容是 資訊檢索系 內容去進行
識本體視為 充。例如當 體資訊檢索 相關的文件 與營運相關 體中屬於營 需求能包含
訊需 需求 是在 系統 行擴
為一 當使 索系 件,
關的 營運 含較
而由於在 相同,因此 權重,其權 概念開始分
為說明權 使用者輸入 往下找尋沒
、S、T、U 該節點的重 值初始化為
為 S、T 節點 K 的 予三節點的 為 0。其結
在知識本 此根據知識 權重分配方
分配權重 權重分配 入的資訊 沒有子節 U。因子節
重要程度 為 1。接著
、U 的父節 的權重為 2
的父節點 結果如圖
本體中不同 識本體的 方式為從 重。
配方式,假 訊需求為節 節點的節點
節點越多則 度也較高,
著將此節點 節點,因 2,節點 L
,因此節 12。
圖
29
同的層級的 的結構,每 從使用者所
假設目前的 節點 E,則其 點,依照此
則代表該 因此將這 點的權重 因此其權重
L 的權重為 節點 E 的權
11 概念分
的知識概 每一個補充
所輸入的資
的知識本體 其權重分 此例,無子節 該節點所蘊
這些沒有子 重賦予此節
重數值為 3 為 1,並再 權重為 6,
分層架構
念與營運 充的知識概
資訊需求開
體架構如圖 分配方式為
節點的節 蘊含的知識
子節點的節 節點的父節
3,依照相 再將 K、L 而其他所
運的相關性 概念皆有不 開始,往下
圖 11,且 為由節點 E 節點為 P、Q
識概念較多 節點,其權 節點,如節 相同計算方 L、M 的權 所有節點的
性不 不同 下層
且此 E 開 Q、
多,
權重 節點 方式 權重 的權
得到節點
:BIM,由 的重要性一 權重與節點 識概念,所 權重賦予給 需求的重要 所有權重加 根據以上 容進行補充 資訊需求向 需求的資訊
點 E 的權 由於 BIM 一樣重要 點 E 相等 所以在圖 給節點 A 要性都相 加總起來 上步驟,使 充,而增補 向量,並依 訊檢索結
權重地圖後 M 與節點 E
。因此將節 等。而因為 圖 11 的例
A,也就是 相等,因此 來為 1,以保
使用者所 補完的資 依照向量 結果。
圖
30
後,則需考 E 皆為使 節點 E 的 為 BIM 為 例子中節點 是節點 A 的 此將權重地
保持每一 所輸入的資 資訊需求,
量空間模型 圖 12 權重
考慮使用者 使用者輸入 的權重賦予 為整個知識 點 A 即為
的權重為 6 地圖進行正 一筆資訊需 資訊需求,
就可以轉 型的相關性
重地圖
者所輸入的 入的資訊需 予給 BIM,
識本體架構 BIM,因 6。而為了 正規化,讓 需求的重要 就可經由 轉換為向量 性評估方式
的另一資訊 需求,所以
,也就是 B 構中最上層 因此將節點 了使每一筆 讓權重地圖 要性相等 由知識本體 量空間模型 式,得出該
訊需 以兩 BIM 層的 點 E 筆資 圖上
。 體的 型中 該資
31
3-3-3 資料檢索成效評估
為評估向量空間模型檢索與以知識本體為基礎之資訊檢索方法 於資訊檢索系統之成效,因此本研究針對兩種檢索系統所返回之檢索 結果進行評估。所採取的評估標準分別是求全率與求準率,其計算方 式如下:
1. 求全率(Recall)
Recall 檢索結果中相關文件數量
文件集合內所有相關文件的總數 (公式 8)
2. 求準率(Precision)
Precision 檢索結果中相關文件數量
檢索結果的文件總數 (公式 9)
在評估資訊檢索系統的成效上,這兩項是最主要的指標,求全率 可以得知資訊檢索系統是否能將所有相關的文章檢出,而求準率可以 知道資訊檢索系統的精確程度。因此為了不偏重於其中一項指標,本 研究採用了平均求準率(AP/Average Precision)來做為評估資訊檢索系 統的成效表現的指標,其計算方法如下:
AP ∑ P i rel i
R (公式 10)
其中 R 為與該資訊需求相關的文件數量;P(i)為計算檢索結果中到第 i 名文件的求準率;rel(i)為第 i 名文件是否與資訊需求相關,若相 關則為 1,不相關為 0;N 為搜尋結果之總數。
32
而 根據資 訊檢索 領域的 重要國 際會議 TREC(Text Retrieval Conference)所提供的資訊檢索成效測試工具[24],平均求準率的計 算方式可簡化為當求全率的值為 0、0.1、0.2 至 1.0 時的求準率的平 均,其方法為在求全率與求準率的曲線圖上以內差的方式,求取這十 一個點的求準率數值。此種計算方式同時考慮了求全率與求準率的表 現,因此本研究根據此指標來評估資訊檢索系統成效。
根據以上評估方式,對兩種檢索方法使用上一節通過一致性分析 的資訊需求,並根據由專家所評估出來的標準答案,可得到使用向量 檢索模型與以知識本體為基礎的檢索技術的資訊檢索系統成效,其平 均求準率的數值如表 6。
表 6 兩種不同資訊檢索模型的平均求準率 檢索模型
資訊需求 Vector space model Ontology-based model
規劃與設計 0.528 0.554
營運 0.475 0.570
以表 6 的第一行為例,其所代表的意義為使用「規劃與設計」
做為資訊需求在兩個不同的資訊檢索模型中所得的平均求準率,如第 一行第一列的 0.528 即是使用向量空間模型進行資訊檢索後所得到的 平均求準率。若其值越高,則代表使用該資訊檢索模型的資訊檢索成 效表現越好。
因此根據表 6 的第一行的數值表現來看,使用知識本體進行資 訊檢索的平均求準率高於使用向量空間模型的平均求準率,而在第二 行的數值表現,使用知識本體進行資訊檢索的平均求準率也同樣高於 使用向量空間模型的平均求準率。所以在此兩項資訊需求的檢索結果 中,以知識本體進行資訊檢索確有改善資訊檢索系統之成效。
33
4 第四章 以資訊檢索技術增補知識本體
4-1 增補知識本體之流程
在第二章中,本研究建置了建築資訊塑模領域的基本知識本體,
並在第三章中利用該基本知識本體建置了以知識本體為基礎的資訊 檢索系統,同時對於該資訊檢索系統的成效與向量空間模型的資訊檢 索系統的成效進行比較,其結論為以平均求準率(average precision)作 為指標進行評估後,得出以知識本體為基礎的資訊檢索的成效較佳。
本章將延續上兩章的成果,對以知識本體為基礎的資訊檢索系統的檢 索結果進行分析,來對基本知識本體的內容進行增補。
本研究第三章所建置的資訊檢索系統可以得到每筆資訊需求的 檢索結果。在資訊檢索中檢索結果是與資訊需求相關的文件的排名順 序,若文件在檢索結果中的排名越高就代表該文件與該筆資訊需求越 相關。而因為該資訊檢索系統是使用知識本體來對資訊需求的內容進 行補充,因此在檢索結果中排名較高的文章,就是與知識本體中的知 識概念相關性較高的文件。
為了對知識本體的內容進行增補,本研究針對在檢索結果中排名 較高的文件進行分析。因為在同一篇文件中會包含許多知識概念,除 了與資訊需求相關的知識概念外,該文件仍會含有其他的知識概念,
而這些知識概念與資訊需求中的知識概念同時出現在同一篇文件中,
則代表這兩個知識概念之間相關性程度較高,因此應將這些知識概念 增補進知識本體中,所以藉由分析檢索結果中排名較高的文件中的知 識概念,就可以對知識本體的內容進行增補。
整理 流程 在於 知識
根據以上 理成圖 13 程(圖 10) 於知識本體 識本體」五
上概念將 3,其主體 ),其增加
體中?」、 五個部分
圖 13 運
將利用資訊 體流程延續 加的部分為
、「增補知 分,以下各
運用資訊
34
訊檢索技術 續第三章 為:「擷取 知識本體」
各小節分別
訊檢索技術
術對知識 以知識本 取知識概念
、「領域專 別說明各部
術增補知識
本體進行 本體為基礎 念」、「知識 專家協助修 部分之內容
識本體之流
行增補的流 礎的資訊檢 識概念是否 修訂」、「領
容。
流程
流程 檢索 否存 領域
35
4-1-1 擷取知識概念
得到某一筆資訊需求的檢索結果後,對該檢索結果中排名較高的 文件進行知識概念的擷取。而在中文的文件中,代表該篇文件所包含 的知識概念則為該文件中的所出現的詞彙,因此為了擷取出每篇文件 的知識概念,就須對文件中的語句進行分析。所謂的語句的分析就是 如何將語句拆分成詞彙,在資訊檢索中此項技術稱之為「斷詞」。
斷詞技術為讓文件內容裡的語句依照正確的語意,以詞彙為單位 來進行儲存。但是如何將語句以正確的方式進行斷詞,在不同語言中 就有著不同的方式,因為每種語言在詞彙組合成語句的規則上並不相 同,例如,英文的詞彙是使用空白做為間隔,而中文的詞彙則是以連 續無間隔的方式來組成語句。
斷詞技術在中文上尤其困難,因為中文的詞彙在語句中並沒有明 顯的間隔,所以中文斷詞方法多是參考中文辭典,先行在語句中擷取 出在辭典中出現的詞彙,再分析語句中所剩下的內容,來得到斷詞結 果。此種方式的優點為在文件內容與該辭典所包含的領域相同時,斷 詞結果會較為準確,但若文件內容是屬於新發展或較為專業的領域時,
則會因為辭典中沒有與該領域的相關資料,而容易發生斷詞錯誤。
由於本研究所選定的特定領域為建築資訊塑模領域,其為新發展 的知識領域,因此本研究採用 n-gram 斷詞方法[25]對文章進行分析,
其優點為無需先建置辭典,而是直接針對文章的內容進行分析,來擷 取出文件中所出現的詞彙。因此 n-gram 方法在擷取新發展的知識領 域的詞彙時,就不會因新發展的知識領域的詞彙尚未被編進辭典中,
而無法對文件的內容進行正確的斷詞。
36
n-gram 方法為假設每個語句都存在有一個最小的表示單位,在中 文裡最小的表示單位為「字」,每個最小表示單位可以跟另一個最小 的表示單位合成為一個概念,也就是中文的「詞」。n-gram 方法並不 限定多少個最小表示單位來進行組合成一個概念。若只用一個最小表 示單位稱之為 unigram,以兩個單位的長度進行連接稱 bigram,以三 個單位的長度進行連結稱為 trigram。
在實際進行斷詞時需要多少個最小表示單位組合成一個概念,則 是由語言特性與文件內容來決定的。以下以「工程變更設計」此語句 為例,表示 bigram 與 trigram 的切分結果。
工 程 變 更 設 計 工程
程變
變更
更設
設計
圖 14 bigram 切分結果
工 程 變 更 設 計 工程變
程變更
變更設
更設計
圖 15 trigram 切分結果
37
對語句進行以 n-gram 方法的不同長度切分後,為得到這些詞彙 的重要程度,因此對這些詞彙進行詞頻計算,詞頻為計算每一個詞彙 在文件中所出現的頻率,其計算方式為該詞彙在文件中所出現的次數 除以整篇文件中的總詞彙數量:
詞頻 目標詞彙在文件中出現的次數
文件的總詞彙數量 (公式 11)
其中文件的總詞彙數量的計算方法,則是根據 n-gram 方法的不 同切分長度進行計算。每個詞彙在計算詞頻時的分母為該詞彙的切分 長度的總字彙數量。例如依照「工程變更設計」此語句,「工程」此 詞彙在計算詞頻的時候的分母為 5,因為該語句在兩個單位的長度下 被切分為 5 個詞彙;「工程變」此詞彙的分母則為 4,因為在三個單 位的長度下,該語句被切分為 4 個詞彙。因此切分長度較長的詞彙,
其分母就會較小,詞頻的數值就會較高,來凸顯長詞彙的重要性。
而由於在中文文件中,仍然會有許多專業詞彙以英文方式表示,
因此在進行實作時會將這些英文詞彙獨立抽出,再對剩下的中文詞會 進行 n-gram 方法分析,而英文詞彙的權重也是依照詞頻計算公式進 行計算,所以在本研究中同時也會分析在中文文件的英文詞彙的重要 程度。
利用 n-gram 方法與詞頻計算方法,就可以對文件集合中所有文 件的內容進行分析,來得到在每篇文件中詞頻表現較高的詞彙。其結 果如
38
表 7,該表為在文件集合中某五篇文件進行分析後,在該篇文件 中詞頻前十名的詞彙。
39
表 7 文件關鍵字排名表
排名 文件一 文件二 文件三 文件四 文件五
1 研究室 檢查 BIM BIM RFID
2 節能 檢查維護 Revit 專案經理人 讀取 3 誘導 消防安全設備 產出 執行流程 構件
4 用電 消防 施工圖 專案 BIM
5 誘導模式 檢查維護人員 圖面 建國工程 標籤
6 生態系 消防設備 日照 團隊協作 鋼構
7 虛擬生態系 BIM 日照輻射量 團隊 Tag
8 虛擬 設備 疑義 員工 驗收
9 虛擬對象 維護 日照輻射量分析 流程 鋼結構
10 回饋 管理權人 建築 營造公司 讀取器
從
40
表 7 中可以看出,每篇文章的前十名關鍵字就代表了這篇文件 中所蘊含的重要的知識概念,所以計算出每篇文件中關鍵字的排名順 序後,就可以對每個資訊需求的檢索結果進行關鍵字排序,再依據關 鍵字排名表中的關鍵字來對知識本體的內容進行增補。
41
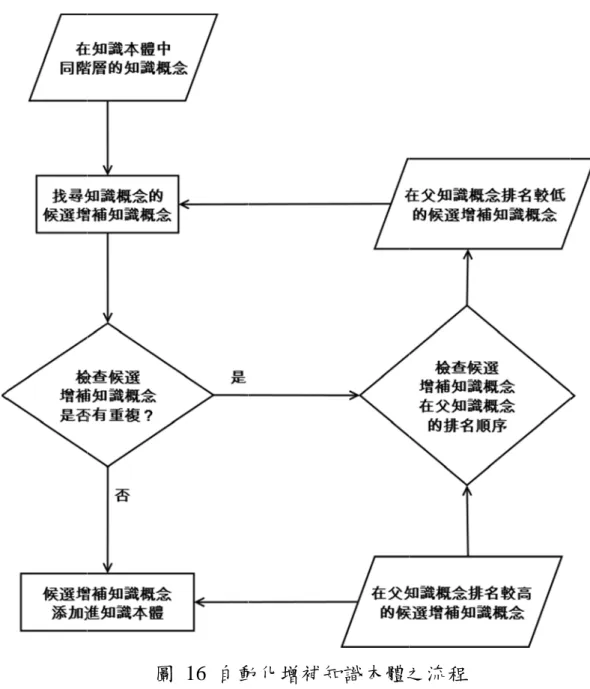
4-1-2 自動化增補知識本體
此小節包含知識本體增補流程的兩個部分:「知識概念是否存在 於知識本體」與「增補知識本體」。此兩部分為針對每一筆資訊需求 的檢索結果,選取在檢索結果中排名較高的文件的關鍵字後,對這些 關鍵字進行排序,接著判斷排名較高的關鍵字是否已在原本的知識本 體中,若關鍵字不存在於目前的知識本體中,則增加該關鍵字於知識 本體中。
由於增補知識本體的流程為等待終止條件的循環,因此為了能自 動化進行知識本體的增補,本研究建置了自動增補知識本體的系統。
其系統的運行流程如圖 16,分為「在知識本體中同階層的知識概念」、
「找尋知識概念的候選增補知識概念」、「檢查候選增補知識概念是否 有重複」、「候選增補知識概念添加進知識本體」、「檢查候選增補知識 概念在父知識概念的排名順序」以下分別說明各部分之內容。
圖
圖 16 自動
42
動化增補知知識本體之之流程
在知 自動化增 最下層的知 補流程後 整個知識本
以圖 17 計畫、施工 階層開始往 為第三層的 層的系統
知識本體中 增補知識 知識概念
,會再選取 本體中的 7 為例,在 工排程、防
往上進行 的應用程
、模型、
圖
中同階層的 識本體之流 念為起始,
取在知識 的知識概念
在知識本體 防災計畫 行增補流程 程式、元件 流程,再
圖 17 中文
43
的知識概 流程的初始
進行增補 識本體中上 念都已經進
體架構中 畫……等,
程,在第四 件、規劃與 再到最上層
文版 BIM 概念
始步驟。在 補知識本體 上一層的知 進行增補為 中,最下層
因此增補 四層的知識 與設計、施 層的建築資
M 基本知識
在本研究中 體之流程,
知識概念進 為止。
層的概念為 補知識本體 識概念增補 施工、營運
資訊模型
識本體
中由知識本
,結束該層 進行增補
為第四層的 體的流程將
補結束後 運……等
。
本體 層的
,直
的敷 將從
,依
,第
![表 1 BIM 應用項目使用分類[11]](https://thumb-ap.123doks.com/thumbv2/9libinfo/9601416.629019/22.892.105.793.144.787/表1BIM應用項目使用分類11.webp)
![表 2 BIM 工具使用分類[12]](https://thumb-ap.123doks.com/thumbv2/9libinfo/9601416.629019/23.892.220.638.301.816/表2BIM工具使用分類12.webp)