以實驗計劃法與類神經網路建構混凝土的坍流度模型
葉怡成 陳家偉
中華大學土木系
摘 要
在混凝土科技中,工作度的重要性是明顯的。在規範與標準中,用以估計 工作度的經驗圖表是基於未添加強塑劑與礦物攙料(如飛灰與爐灰)等材料的混 凝土。對添加這些材料的混凝土,這些關係之妥當性應該要加以研究。由於這 些關係的高度複雜性,傳統的迴歸分析可能不足以建構精確的模型。類神經網 路是建構非線性模型的有效工具。因此,本研究以實驗計劃法與類神經網路建 構一個坍流度模型。在這個模型中,坍流度是混凝土所有成份用量的函數,包 括水泥、飛灰、爐灰、水、強塑劑、粗骨材,與細骨材。本研究導出下列結論:
(1) 利用雛形模式找出可疑的實驗數據,並予以重新實驗,對建構精確之模型 有非常顯著的助益。(2) 類神經網路可以建構一個比二階多項式迴歸分析更精 確的坍流度模型。
關鍵詞:混凝土、坍流度、實驗設計、模式化、類神經網路。
MODELING WORKABILITY OF CONCRETE USING DESIGN OF EXPERIMENTS AND ARTIFICIAL NEURAL NETWORKS
I-Cheng Yeh Jia-Wei Chen Department of Civil Engineering,
Chung-Hua University, Hsin Chu, Taiwan 300, R.O.C.
Key Words: concrete, slump flow, design of experiment, modeling, artificial neural networks.
ABSTRACT
The significance of workability in concrete technology is obvious. The current empirical diagrams and tables presented in codes and standards for estimating workability are based on tests of concrete without supplementary cementitious materials (fly ash, blast furnace slag, etc.). The validity of these relations for concrete with supplementary cementitious materials should be investigated. Because of the high complexity of these relations, conventional regression analysis is not sufficient to build an accurate model.
The artificial neural network (ANN) is a powerful tool for modeling complex nonlinear models. Therefore, in this study, a slump flow model has been built using design of experiments (DOE) and ANN. In this model, the slump flow is a function of the content of all concrete ingredients, including cement, fly ash, blast furnace slag, water, superplasticizer, coarse
aggregate, and fine aggregate. This study led to the following conclusions:
(1)Discovering doubtful experimental data produced by using the prototype model and repeating these experiments is very significantly beneficial for building a reliable model. (2) ANN can build a more accurate slump flow model than a 2-order polynomial regression can.
一、前 言
高性能混凝土[1,2]發展至今已有十多年之久,卻尚未 有一套精確之配比設計方法,供設計者能準確地控制其所 需之性質,尤其是工作度,因強塑劑與礦物攙料之添加,
其性質更是難以捉摸。故大部分高性能混凝土配比需在配 比設計完成後,進行試拌,再予以調整。本研究目的之一,
即是試圖建構工作度之經驗模型。一般建構經驗模式之主 要工具為迴歸分析。然由於高性能混凝土配比一般有七種 材料,加上材料用量與工作度之關係十分複雜,迴歸分析 可能不足以建構準確之模型,因而本研究使用為類神經網 路建構高性能混凝土工作度模型。
類神經網路常應用於預測、決策與診斷問題 [3]。發 展至今已有相當之研究應用於混凝土,然其重點多著重於 強度預測模型[4-9],很少工作度預測模型之研究。先前之 研究指出,以類神經網路建構工作度預測模型,優於迴歸 分析所建構之模型 [10]。惟所建構模型誤差仍相當大,尚 有可改進之空間。故本研究之另一目的即改進實驗設計方 法,導入篩選問題實驗之方法,以得更精確之實驗數據,
建構更精準之預測模型。
本研究與先前研究[10]主要相異之處為本研究導入篩 選問題實驗之方法,針對問題實驗進行重複實驗,其後更 進行第二次篩選,以決定需進行第二次重複實驗之配比。
本研究之研究過程主要分五個階段:
(一) 以實驗設計取得實驗數據: 本研究採用之實驗設計方 法為單體形心設計,輔以軸回合擴充設計[11-13],另 依規範及經驗公式訂定設計限制,共有二項詳列如 下:(1) 各成份上下限限制;(2) 各成份間比例限制。
經由上述之限制,可使設計出之各材料使用量較為合 理、可行,同時能建構較為精準之模型。又為了排除 氣溫、濕度等不可控制因子之影響,將實驗順序予以 隨機化。實驗實施之過程係依照實驗設計所得之配比 進行拌合實驗,試驗方法則參考CNS 1176 混凝土坍 度試驗法施行之。坍流度為混凝土坍流範圍的平均直 徑。
(二) 以初始實驗數據建構模型: 待實驗全數完成後,隨之 將第一次試驗結果以類神經網路建構模型雛形。模型 以各材料用量為輸入變數,共有七項,分別是水泥、
飛灰、爐石、水、強塑劑、粗骨材、細骨材及強塑劑
之用量;輸出變數則為坍流度試驗結果。
(三) 以初始模型診斷實驗數據: 以初始模型對所有實驗配 比進行坍流度預測後,篩選出誤差偏大的可疑實驗數 據,並進行重複實驗,確認實驗數值,以使實驗數據 更為可靠。
(四) 以修正實驗數據建構模型: 用經過重複實驗確認與修 正後之實驗數據以類神經網路建構模型。
(五) 比較初始模型與修正模型: 比較以初始實驗數據及修 正實驗數據為基礎的這二種方式對模型殘差評估的影 響。
本文第二節為文獻回顧;第三節以實驗設計取得實驗 數據;第四節以初始實驗數據建構模型;第五節以初始模 型診斷實驗數據;第六節以修正實驗數據建構模型,並比 較初始模型與修正模型;第八節為驗證實驗,以及第九節 為結論與建議。
二、文獻回顧
1. 實驗設計
傳統品質管理強調品質管制,然此僅為揚湯止沸,並 不能有效改善品質且較浪費成本。故現今之品質管理乃強 調品質設計之觀念,亦即品質係可經由設計獲得而非篩 選,品質設計係以追求品質更高、成本更低及開發更快為 目標,因此品質設計係產業界競爭之重要技術。
實驗設計即為品質設計中重要之過程,由於實驗係有 成本考量,故如何以最少量之實驗,獲得最大量有用之品 質特性資訊,即是實驗設計問題。有系統地選擇獨立變數 組合,進行實驗並記錄反應值,以收集建立系統模型所需 數據之程序即為實驗設計。故實驗設計之目的係以最少之 實驗次數及適當之分析技術,獲得最多有用之系統資訊 [11-13]。
由於高性能混凝土之各品質因子水準間具有總和限 制,體積總和必須為1 立方公尺,故其為配比設計,因此 並不適宜用直角座標系來表達其設計空間,一般常用單體 座標系來表達之,如圖1 所示 [11]。
配比設計問題雖然也是採用反應曲面法的設計理念,
但因各品質因子的水準間有總和限制,故其實驗設計、模 型建構與參數優化等三個程序之技術均與一般的品質設計 問題有所不同 [11]。
圖 1 單體座標系示意圖
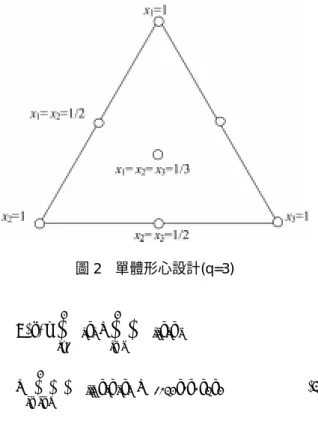
配 比 設 計 常 用 之 實 驗 設 計 方 法 有 單 體 格 子 設 計 (simplex lattice design)與單體形心設計(simplex centroid design)[11]。本研究採用單體形心設計,故以下簡略介紹單 體形心設計過程。
在一個q 種成份的單體形心設計中,共有 2q-1 個實驗 點,包括
一元混合:(1,0,0,…,0),(0,1,0,…,0),…,(0,0, 0,…,1)等設 計。
二元混合:(1/2,1/2,0,0,…,0),(1/2,0,1/2,0,…,0)等由 1/2 與 0 組成的設計。
三元混合:(1/3,1/3,1/3,0,0,…,0),(1/3,1/3,0,1/3, 0,…,0)等由 1/3 與 0 組成的設計。
q 元混合:(1/q,1/q,…,1/q)之中心點設計。
一個三成份的單體形心設計其實驗點在單體座標系的 分佈如圖2 所示。
單體形心設計所對應的多項式函數通式如下:
∑∑
∑
= <+
= q
j i
j i ij q
i i
ix xx
y
E β β
1
) (
q k
j i
q k
j i
ijkxx x L 12L x1x2Lx
∑∑∑
<<
+ +
+ β β (1)
例如當q=3 時,上式簡化為
E(y)=β1 x1 + β2 x2 + β3 x3 + β12 x1 x2+
β13 x1 x3 + β23 x2 x3 + β123 x1 x2 x3 (2)
當q=4 時,上式簡化為
圖 2 單體形心設計(q=3)
∑∑
∑
= <+
= 4 4
1
) (
j i
j i ij i
i
ix xx
y
E β β
∑∑∑<
< +
+ 4 1234 1 2 3 4
k j
i βijkxixjxk β xx x x (3) 由於上述的單體設計大多數之實驗點都是在邊界上,
因此這些實驗點最多只包含了q-1 種成份。一般都希望以 增加內部點(用到全部的 q 種成份)來擴大「單體格子設計」
或「單體形心設計」,以能更精確地估計完全混合配比之性 質,因此應在單體設計中增加內部點的數目。一般而言,
內部點的選擇可放置於形心點與頂點的中間 [11],而這也 就是軸回合擴充設計。
2. 類神經網路
類神經網路是「一種基於腦與神經系統研究所啟發的 資 訊 處 理 技 術 」, 利 用 大 量 簡 單 且 相 連 的 人 工 神 經 元 (artificial neuron)來模仿生物神經網路之能力[3]。其可以利 用一組範例(即系統輸入與輸出所組成之資料)建立系統 模型(輸入與輸出間之關係),而可用於預測、決策與診斷 問題。
一個類神經網路係由多個人工神經元所組成,人工神 經元又可稱為處理單元,每一個處理單元之輸出以扇狀送 出,成為其他處理單元之輸入;而介於處理單元間之訊號 傳遞路徑則稱為連結,每一個連結上有一個數值的加權值 Wij,表示第i 個處理單元對第 j 個處理單元之影響強度。
類神經網路之網路架構可分為:前向式架構與回饋式 架構。其中以前向網路應用最為普遍。一個前向網路包含 許多層,每一層包含若干個處理單元,輸入層處理單元用 以輸入外在環境之訊息,輸出層處理單元用以輸出訊息給 外在環境。此外,一個層狀類神經網路經常包含若干層隱 藏層,其功能係提供類神經網路表現處理單元間之交互作 用,與問題內在結構之能力。
表一 各成份之下限限制值 材料
名稱
重量 (公斤)
比重 (公斤/公升)
體積 (公升)
水泥 150 3.15 47.62
飛灰 0 2.22 0
爐粉 0 2.85 0
水 125 1 125
強塑劑 3.5 1.2 2.92
粗骨材 850 2.645 321.36 細骨材 675 2.66 253.76
類 神 經 網 路 運 作 的 主 要 方 式 為 學 習(learning) 與 回 想 (recalling)。學習乃利用經由訓練範例調整網路之連結加權 值,使得網路推論輸出值趨近於目標輸出值。回想是利用 學習後之網路連結加權值與網路輸入值來推論網路輸出 值。當學習策略為自問題領域中取得訓練範例,學習輸入 變數與輸出變數的內在對應規則,以應用於只有輸入值而 需推 論輸出值 的新案例 時,此種 學習稱為 監督式學習 (supervised learning)。監督式學習適合分類(診斷、決策)、
預測(函數合成)方面之應用,監督式學習中應用最廣且最 具代表性首推倒傳遞網路[3],本研究即採用此種網路。
倒傳遞類神經網路係現今應用最普遍且最具代表性之 類神經網路學習模式,已發表之相關應用為數數千個以 上。其基本觀念係運用最陡坡降法之觀念,將誤差函數最 小化[3]。其網路架構如圖 3 所示。
應用類神經網路於混凝土強度預測的文獻已相當豐 富,例如文獻[4-9],這些文獻均顯示,以類神經網路建構 強度模型係一可行之研究,且模型具相當之準確性。但應 用在工作度預測的文獻卻相當稀少,例如文獻[10]。
三、以實驗設計取得實驗數據
混凝土拌合試驗甚是勞心、勞力且耗時,倘若一組配 比僅作工作度試驗,尚須30 分鐘才可完成。故假設有 100 組配比需進行試驗,則需3000 分鐘,也就是 50 個小時方 可完成,然這也需試驗人員有充沛之體力,此則突顯了實 驗設計之重要性。
本研究之實驗設計過程主要可分為三個步驟:初步設 計、配比調整、配比篩選,以上三個步驟分述如下各節。
1. 初步設計
於實驗設計前,本研究以文獻配比為基礎,訂出配比 各材料用量之下限限制值,作為配比設計之參考。又混凝 土配比設計具有各材料體積總和為 1 立方公尺,即 1000 公升之限制,因此實驗配比的體積總和必須滿足下式:
圖 3 倒傳遞網路之網路架構
圖 4 初步設計之實驗設計的單體座標系示意圖
VC+VF+VS+VW+VSP+VCA+VFA=1000 (4)
其中VC,VF,VS,VW,VSP,VCA,VFA依序為水泥、飛灰、爐石粉、
水、強塑劑、粗骨材、細骨材之體積。
故以後之配比設計則以體積單位進行設計,待體積設 計結果出來,再轉換成重量:
Wi=Gi.Vi (5)
其中Vi,Wi,Gi分別表各材料之體積、重量與比重。
最後並將各材料之重量與體積下限值整理如表一所 示,這些下限的決定是基於一千多筆在文獻上找到的配比 統計的結果[6,7]。
完成上述之前處理工作後,接著應用單體形心設計與 軸回合擴充設計進行配比設計,其單體座標系之示意圖如 圖4 所示。
設計結果共得127 個實驗點,其結果如表二所示。表 中所顯示數字係虛擬變數之值,可藉由「反尺度化」之動 作獲得真值,而真值與虛擬變數之轉換公式如下式所示:
表二 以虛擬變數作配比設計之結果 水泥 飛灰 爐石 水 強塑劑 粗骨材 細骨材
1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 一元
混合
0 0 0 0 0 0 1
: : : : : : : : 七元
混合 1/7 1/7 1/7 1/7 1/7 1/7 1/7
表三 虛擬變數轉換為體積變數之配比設計之結果 各成份之體積 (公升)
序號
水泥 飛灰 爐粉 水 強塑劑 粗骨材 細骨材 體積 總和
1 296.96 0.00 0.00 125.00 2.92 321.36 253.76 1000 2 47.62 249.34 0.00 125.00 2.92 321.36 253.76 1000 3 47.62 0.00 249.34 125.00 2.92 321.36 253.76 1000 4 47.62 0.00 0.00 374.34 2.92 321.36 253.76 1000 5 47.62 0.00 0.00 125.00 252.26 321.36 253.76 1000
: : : : : : : : :
127 83.25 35.63 35.63 160.63 38.55 356.99 289.39 1000
表四 體積變數轉換為重量變數之配比設計之結果 各成份之重量 (公斤)
序號 水泥 飛灰 爐粉 水 強塑劑 粗骨材 細骨材 1 935 0 0 125 3.5 850 675 2 150 554 0 125 3.5 850 675 3 150 0 711 125 3.5 850 675 4 150 0 0 374 3.5 850 675 5 150 0 0 125 302.7 850 675
: : : : : : : : 127 262 79 102 161 46 944 770
i i i
i V V X
V = min+(1000−
∑
min)× (6) 由公式可知,當某一材料之虛擬變數為0 時,其體積為該材料之體積下限值;而當其虛擬變數為1 時,則其體 積為最大值。虛擬變數轉換回真值之結果如表三所示。
然混凝土之標準配比乃是以每一立方公尺多少公斤用 量來表示,故需以公式5 做轉換,轉換之結果整理如表四 所示。
2. 配比調整
待配比設計完成後,隨之進行配比調整之動作。此乃 因在單體形心設計中,強塑劑用量有八種:3.5、46.3、53.4、
63.4、78.3、103.3、153.2、302.8 kg/m3,除了3.5 kg/m3以
圖 5 調整後之實驗設計的單體形心座標系示意圖
外均超過一般常規使用量甚多,極不合理。因此需進行配 比調整步驟,使其不超過合理範圍。
調整之方法係將原設計配比之最大值302.7kg/m3映射 為強塑劑上限用量15.5kg/m3,此值是基於一千多筆在文獻 上找到的配比統計的結果而訂[6,7],最小值則維持不變為 3.5kg/m3,餘以內插法求得。惟如此調整後,將使原設計 配比之總體積和不足 1 m3,故需將其他材料做一放大計 算,以使總體積和維持為1 m3。計算方法如下:
(一) 計算調整強塑劑用量減少之體積,公式如下:
SP SP
sp W G
W
V = − ′ ÷
∆ ( ) (7)
(二) 計算其他材料體積放大係數,公式如下:
VSP
V V
− + ∆
=1
α (8)
(三) 調整其他材料之用量,公式如下:
α
×
′= i
i W
W (9)
(四) 檢合調整後體積是否符合體積總和限制,若否檢查是 否計算有誤或再進行調整。其調整後單體形心座標系 示意圖如圖5 所示。調整結果整理如表五所示。
3. 配比篩選
由於配比調整之過程僅針對強塑劑施行,惟尚有其他 不合理之配比,如水泥用量935 kg/m3等,為能剔除不合理 之配比,本研究以整理文獻所得之材料用量上限限制及材 料比例限制進行篩選之動作。其中上限限制整理如表六所 示[6,7]。
比例限制則是對水灰比、水膠比…等 9 種比例作上下 限之限制,公式如下:
表五 配比調整後之配比設計之結果 調整後各成份之用量 (公斤) 序
號 減少 體積
放 大 倍
數 水泥 飛灰 爐粉 水 強塑劑 粗骨材 細骨材 1 0.0 1.00 935 0 0 125 3.5 850 675 2 0.0 1.00 150 553 0 125 3.5 850 675 3 0.0 1.00 150 0 711 125 3.5 850 675 4 0.0 1.00 150 0 0 374 3.5 850 675 5 239.3 1.32 198 0 0 165 15.5 1122 891
: : : : : : : : : : 127 32.8 1.03 271 82 105 166 6.9 976 796
表六 材料用量之上限限制值 主要成份 用量上限(公斤)
水泥 350
飛灰 200
爐粉 260
水 240
強塑劑 12
粗骨材 1160
細骨材 980
表七 材料用量之比例限制值
材料比例 比例下限 比例上限
水灰比 0.37 1.46
水膠比 0.25 0.70
水固比 0.07 0.12
強塑劑對膠結料之比例 0.01 0.03
飛灰對膠結料之比例 0 0.55
爐粉對膠結料之比例 0 0.61
飛灰爐粉對膠結料之比例 0 0.68
骨材對膠結料之比例 2.72 6.86 細骨材對骨材總量之比例 0.39 0.51
水灰比=(WW +WSP) / WC (10)
水膠比=(WW +WSP) / (WC+WF+WS) (11)
水固比=(WW +WSP) / (WC+WF+WS+WCA+WFA) (12)
強塑劑與膠結料之比例
=WSP / (WC+WF+WS) (13)
飛灰佔膠結料之比例
=WF / (WC+WF+WS) (14)
圖 6 篩選後之實驗設計的單體座標系示意圖
圖 7 配比設計結果之單體座標系示意圖
爐石粉佔膠結料之比例
=WS / (WC+WF+WS) (15)
飛灰與爐石粉總量佔膠結料之比例
=(WF+WS) / (WC+WF+WS) (16)
粗骨材之總量對膠結料之比例=
=(WCA+WFA) / (WC+WF+WS) (17)
細骨材佔粗骨材總量之比例=
=WFA / (WCA+WFA) (18)
比例之上下限限制值整理如表七所示,這些上下限的 決定 是基於一 千多筆在 文獻上找 到的配比 統計的結果 [6,7]。
篩選後單體座標系示意圖如圖6 所示,配比設計最後 結果之單體座標系示意圖則如圖7 所示。
表八 初始模型之網路參數
網路參數 模型A 模型 B 模型 C 模型 D
隱藏單元數 7 6 6 8
訓練循環數 2200 2500 2000 1500 學習速率 2.0 1.0 1.0 2.0 慣性因子 0.5 0.5 0.5 0.5
表九 初始模型之建構結果 訓練範例 測試範例 模型 判定係數 誤差均方根
(公分)
判定係數 誤差均方根 (公分) 模型A 0.5435 11.47 0.3988 19.09 模型B 0.6546 10.20 0.2670 19.09 模型C 0.6574 10.55 0.3641 14.59 模型D 0.6061 11.31 0.2151 14.78
表十 初始模型之綜合結果 測試範例
判定係數 誤差均方根(公分)
坍流度 0.3067 16.89
配比篩選完成後,則對剩餘之實驗點進行重複與隨機 化,重複乃是針對中心點(七元混合)取重複實驗,其用 途為求得實驗誤差及獲得更精確之實驗數據;隨機化則是 將原本之序號重新以亂數排列,其目的係減少如溫濕度等 不可控制因子之影響,並確保觀測值或誤差為隨機變數 [11]。
4. 初始實驗數據之取得
本研究之工作度試驗目的在求得坍度、坍流度及坍流 時間三項數據,試驗方法則參考CNS 1176 混凝土坍度試 驗法施行,其步驟簡述如下:先潤濕模具後,分三層填入 搗實,每層搗實25 下,後以 5±2 秒等速提起模具 300mm,
待混凝土停止流動後,記錄坍度、流度及坍流時間。其中 坍度(mm)=300mm - 試體坍下後之高度,坍流度係量測試 樣之平均直徑,坍流時間則係試樣停止流動之時間。
實驗過程如下:
(一) 本研究屬七元配比設計,採用單體形心設計與軸回合 擴充設計,因此在初步設計時獲得127 個實驗點,並 針對強塑劑進行配比調整,接著針對材料用量上限限 制及材料比例限制進行篩選之動作。
(二) 篩選後之實驗設計共有 57 筆,然於進行拌合實驗時。
(三) 拌合實驗時,發現部分配比無法膠結,故對該部分配 比進行配比調整,如增加用水量或強塑劑用量等,使 其能膠結。最後結果共得109 筆實驗數據。
(四) 整理上述 109 筆實驗數據,經刪除拌合實驗時無法拌 合之配比,包括用水量不足致使無法膠結之配比,以 及嚴重泌水致使無法量測工作度等之配比,得可用之
圖 8 坍流度初始模型之訓練範例散佈圖 (單位: 公分)
數據共78 筆,此即為本研究用以建構工作度模型雛形 之初始實驗數據。
四、以初始實驗數據建構模型
本研究於模型建構前,先將全部78 筆初始實驗數據隨 機均分為A、B、C、D 四組。其中前三組各有 20 筆數據,
最後一組有18 筆數據。其中以 B、C、D 三組為訓練範例,
A 組為測試範例所建構之模型即為模型 A;若以 A、C、D 三組為訓練範例,B 組為測試範例所建構之模型即為模型 B,餘以此類推得 C、D 模型。待完成此分組動作後,即可 進行模型建構。
本研究之工作度模型係以七項材料水泥、飛灰、爐石、
水、強塑劑、碎石及砂之用量為輸入變數 x1∼x7,以坍流 度為輸出變數y 而建構之。
本研究使用CAFE[8]程式建構類神經網路模型,各步 驟之說明及結果分述如下:
(一) 變數統計:此步驟係統計各變數之最小值、最大值及 平均值等統計數據,以便尺度化之執行。
(二) 尺度化:此步驟係將原本之實驗數據(實際值)映射 為-1 至 1 之值,其中-1 代表最小值,1 代表最大值,
其餘則內插。
(三) 網路參數設定:此步驟係輸入網路訓練之參數,如輸 入層、隱藏層、輸出層、訓練循環、測試週期、訓練 範例數及測試範例數等。網路參數之詳細資料整理如 表八所示。
(四) 網路訓練:此步驟係根據設定之網路參數,進行類神 經網路之訓練與測試。
(五) 反尺度化:此步驟係將尺度化之預測值轉變回為實際 尺度預測值,同時求得模型訓練範例與測試範例之判 定係數與誤差均方根。初始模型之結果整理如表九所 示。此外並將此四個模型所得之預測值集合起來,稱 之為綜合模型結果,並計算其判定係數與誤差均方
表十一 修正模型之網路參數
網路參數 模型A 模型 B 模型 C 模型 D
隱藏單元數 8 5 7 7
訓練循環數 2300 2000 2600 2000 學習速率 1.0 2.0 1.0 1.0 慣性因子 0.5 0.5 0.5 0.5
表十二 修正模型之建構結果 訓練範例 測試範例 模型 判定係數 誤差均方根
(公分) 判定係數 誤差均方根 (公分) 模型A 0.8976 5.47 0.4960 9.93 模型B 0.8266 6.53 0.8127 9.10 模型C 0.8606 6.16 0.7751 7.51 模型D 0.8055 6.82 0.8032 8.14
根,如表十所示。
由表九可知,初始模型建構結果尚非良好,誤差仍相 當大。接著,將A、B、C、D 四個模型之散佈圖整理於同 一圖中,訓練範例及測試範例之結果,分別如圖8 及圖 9 所示。由圖可知,初始模型之預測點分佈分散而不密集,
顯示初始模型之準確性尚非十分良好。
五、以初始模型診斷實驗數據
1. 問題實驗篩選方法
重複實驗是尋求更精準實驗數據之方法,然若對全部 實驗進行重複實驗,勢必不符合經濟效益原則,因此如何 篩選出有進行重複實驗之需要的配比係一重要之課題。由 文獻 [11-13]知,當某數據之標準化殘差偏離 0 特別大時,
例如大於 3 或小於-3,則屬可疑的數據,可考慮檢查或刪 除該數據,或者重作該筆實驗。故本研究參考上述方法,
建立問題實驗之篩選方法。篩選之標準為坍流度之標準化 殘差,當某筆實驗數據的標準化殘差之絕對值大於2 時,
則視為問題實驗,需進行重複實驗。詳細步驟如下:
(一) 將各配比依上述工作度模型雛形計算得坍流度預測 值。
(二) 計算各配比之坍流度的標準化殘差。
(三) 將坍流度標準化殘差大於 2 之配比篩選出來,進行重 複實驗。
待第一階段重複實驗之配比試驗完成後,因重複實驗 結果可能與原本實驗結果有所差距,倘若差距不大,表該 實驗非問題實驗,人為誤差影響不大,可直接取兩者之平 均值為最後實驗結果。然當差距大時,表其中之一為問題 實驗,為求得較準確之實驗數據,故需挑選出以進行第二
圖 9 坍流度初始模型之測試範例散佈圖 (單位: 公分)
階段重複實驗,此過程即為本研究之第二階段問題實驗篩 選方法。詳細步驟如下:(1) 計算重複實驗與初步實驗之 坍 流 度 差 異 絕 對 值 。(2) 如 果 坍 流 度 差 異值 小 於 等 於 10cm,則以二次實驗之平均值作為實驗值;如果大於 10cm 則再進行一次重複實驗確認之。
2. 修正實驗數據之取得
本研究之實驗結果共獲得 78 筆為具有工作性之可行配 比。經以類神經網路建構模型雛形獲得預測值,進而求得 標準化殘差。將標準化殘差之絕對值大於2 之 18 筆配比進 行重複實驗。第一階段重複實驗完成後,進行數據比較,
發現共有7 筆配比其第一階段重複實驗與初始實驗之坍流 度差值大於 10 cm,故需進行第二階段重複實驗。第二階 段重複實驗完成後,因7 筆配比之第二階段重複實驗值與 第一階段重複實驗值相較之差值均小於 10 cm,故無需第 三階段重複實驗,而以各實驗之較接近的二次實驗值之平 均值為各實驗之採用值。
六、以修正實驗數據建構模型
修正模型之建構過程同初始模型之建構過程。其中最 佳之網路參數整理如表十一所示。反尺度化後得模型建構 結果,整理如表十二所示。亦整合四個模型之預測值為綜 合模型,並計算其判定係數與誤差均方根,如表十三所示。
由表十二可知,單就訓練範例來看,每一模型皆有相當良 好之成果;若就測試範例比較,以模型A 之成果較差。此 外,將A、B、C、D 四個模型之散佈圖整理於同一圖中,
訓練範例及測試範例之結果,分別如圖10 及圖 11 所示。
由圖10 可知,訓練範例之模型預測值與實際值相差不大;
由圖11 可知,測試範例之模型預測值與實際值相較之誤差 略大於訓練範例者。
比較初始模型及修正模型之項目為兩者之綜合模型測 試範例之判定係數(R2)及均方根(RMS),整理如表十四所
表十三 修正模型之綜合結果 測試範例
判定係數 誤差均方根(公分)
坍流度 0.7240 8.51
表十四 初始模型與修正模型之比較 模型 判定係數 誤差均方根(公分)
初始模型 0.3067 16.89
修正模型 0.7240 8.51
表十五 類神經網路與二階多項式迴歸分析之比較 方法 判定係數 誤差均方根 類神經網路 0.7240 8.51(公分) 二階多項式迴歸分析 0.3230 15.57(公分)
圖 10 類神經網路之坍流度修正模型之訓練範例散佈 圖(單位: 公分)
圖 11 類神經網路之坍流度修正模型之測試範例散佈 圖(單位: 公分)
示。由表可知,修正模型與初始模型相較之下,不論是判 定係數,還是均方根皆有大幅之改進。就判定係數來看,
修正模型較初始模型多解釋了42%(0.7240-0.3067=0.4173
圖 12 二階多項式迴歸分析之坍流度修正模型之測試 範例散佈圖
圖 13 坍流度驗證實驗之散佈圖
=42%)的變異。就誤差均方根來看,修正模型較初始模型 減少 50%((初始模型之誤差均方根-修正模型之誤差均方 根) / 初始模型之誤差均方根)之誤差。推斷其因可能為,
有問題之實驗點使模型被扭曲,因而導致預測值與實際值 相差甚大。一旦有問題之實驗點被消除,則使模型不再被 扭曲,準確性便大幅提升。由此可知,本研究提出之篩選 問題實驗點之方法,對消除問題實驗點,提升模型準確性,
確實有其助益。
七、類神經網路與二階迴歸分析之比較
為比較類神經網路與第二節之二階多項式迴歸分析的精確 度,本研究將完全相同的實驗數據以二階多項式迴歸分析 建模,其測試範例之結果如圖12 所示,其誤差如表十五所 示。由表可知,類神經網路比二階多項式迴歸分析多解釋 了 40%(0.7240-0.3230=0.401=40%)左右之變 異,並減少 45%((15.57-8.5)/15.57)左右之誤差。顯見類神經網路遠比二 階多項式迴歸分析精確。
八、驗證實驗
為確認類神經網路模型之預測能力,在建構模型後,
額外進行25 次不同配方的坍流度實驗,其結果如圖 13 所 示。由圖可知實際值與預測值之間的判定係數高達0.84,
但由圖中的迴歸公式可知,坍流度的預測值比實驗值大約 低10.7 公分。原因可能是此批實驗的執行時間與原先用來 建構模型的實驗的執行時間約晚了一年,因此實驗的材 料、機具、人員均不相同,因此造成結果略有差異。但考 量實際值與預測值之間相當高的判定係數,此一模型仍然 十分具有預測能力。
九、結 論
本研究導出下列結論:
1. 利用雛形模式找出可疑的實驗數據,並予以重新實驗,
對建構精確之模型有非常顯著的助益。
2. 類神經網路可以建構一個比二階多項式迴歸分析更精 確的坍流度模型。
3. 由驗證實驗可知基於類神經網路的坍流度模型具有預 測能力。
誌 謝
本研究承國科會NSC-92- 2211-E-216-015 經費補助完 成,特表感謝。
符號索引
GSP 強塑劑之比重
V 原設計總體積(即 1000 公升) Vi 表各項材料之體積
Vmin 表各項材料之體積下限值 VSP 原設計SP 之體積(公升) Wi 第i 成份原設計用量 W'i 第i 成份調整後用量 WSP 原設計強塑劑重量 W'SP 調整後強塑劑重量
Xi
表各項材料之虛擬變數,值域為1 ≥ Xi ≥ 0,且 ΣXi=1
α 放大倍數
ΔV 強塑劑減少之體積(公升)
參考文獻
1. 陳振川,「高性能混凝土之定義與特性」,結構工程,第 九卷,第一期,第5-6 頁 (1994)。
2. 黃兆龍,混凝土性質與行為,詹氏書局,台北(1999)。
3. 葉怡成,應用類神經網路,儒林圖書公司,台北(2001)。
4. Kasperkiewicz, J., Racz, J., and Dubrawski, A., “HPC Strength Prediction Using Artificial Neural Network,”
Journal of Computing in Civil Engineering, ASCE, Vol. 9, No. 4, pp. 279-284 (1995).
5. Yeh, I. C., “Modeling Concrete Strength with Augment- Neuron Networks,” Journal of Materials in Civil Engi- neering, ASCE, Vol. 10, No. 4, pp. 263-268 (1998).
6. Yeh, I. C., “Modeling of Strength of High Performance Concrete Using Artificial Neural Networks,” Cement and Concrete Research, Vol. 28, No. 12, pp. 1797-1808 (1998).
7. Yeh, I. C., “Design of High Performance Concrete Mixture Using Neural Networks,” Jounal of Computing in Civil Engineering, ASCE, Vol. 13, No. 1, pp. 36-42 (1999).
8. 葉怡成、陳怡成、柯泰至、彭釗哲、柑俊晟、陳家偉,
「以類神經網路作高性能混凝土最佳配比設計之研 究」,技術學刊,第十七卷,第四期,第 583-591 頁 (2002)。
9. Yeh, I. C., “A Mix Proportioning Methodology for Fly Ash and Slag Concrete Using Artificial Neural Networks,”
Chung Hua Journal of Science and Engineering, Vol. 1, No. 1, pp. 77-84 (2003).
10. 柯泰至,「以類神經網路建構高性能混凝土工作度模型 之研究」,碩士論文,中華大學土木工程研究所,新竹 (2001)。
11. 葉怡成,實驗計畫法-製成與產品最佳化,五南圖書公 司,台北(2001)。
12. Montgomery, D. C., Design and Analysis of Experiments, Jone Wiley & Sons Inc., New York, USA pp. 12-14 (1997).
13. Myers, R. H., and Montgomery, D. C., Response Surface Methodology, John Wiley & Sons, Inc., New York, USA (1995).
2004 年 01 月 12 日 收稿 2005 年 01 月 13 日 初審 2005 年 05 月 06 日 複審 2005 年 05 月 10 日 接受