國立臺灣大學工學院工程科學及海洋工程學系 碩士論文
Department of Engineering Science and Ocean Engineering College of Engineering
National Taiwan University Master Thesis
基於深度學習之老鼠腦部磁振影像 中風區域分割研究
Stroke Lesion Segmentation in Rat Brain MR Images Based on Deep Learning
何世馨 Shih-Hsin Ho
指導教授:張恆華 博士 Advisor: Herng-Hua Chang, Ph.D.
中華民國 109 年 7 月
July 2020
致謝
感謝張恆華教授,感謝我的電腦,感謝大家。
中文摘要
腦中風長期是造成人類死亡的主要原因之一,依型態可以分為腦缺血及腦 出血兩大類,而磁共振成像 ( Magnetic Resonance Imaging, MRI ) 之影像可以作 為初步之腦中風判讀依據。在相關實驗中,齧齒動物老鼠時常選擇為實驗動物,
以其中風腦部影像作為研究基礎。而在研究上,腦中風影像之中風區域選取及判 讀需要腦神經專家處置,這是一件繁鎖且耗時的任務,並有標準一致性上的問題。
本研究以深度學習為基礎,針對磁共振成像中 T2 加權成像及擴散加權成像 ( Diffusion Weighted Imaging, DWI ) 之影像,開發腦中風影像自動分割中風區域 之模型。透過全卷積神經網路為基礎架構,當中加入本研究所提出之混合殘差塊,
並使用 3528 張 T2 和 3024 張 DWI 增強後之影像分別進行訓練。檢視實驗 結果,以本架構針對兩種影像各別訓練之模型,能在訓練資料以外之測試資料有 優異的分割結果。在分割 T2 影像中風區域中達到 86.84% 的準確度,並在 DWI 影像中達到了 87.36% 的準確度。
關鍵字:深度學習、卷積神經網路、磁共振成像、缺血型腦中風、影像分割
Abstract
Stroke has been one of the main causes of human deaths for a long time. Stroke can be divided into two types: ischemic and hemorrhagic. Magnetic Resonance Imaging (MRI) can be used as a preliminary interpretation basis for stroke. In related experiments, mice are often selected as experimental animals, and their brain images are used for research. Usually, the determination and segmentation of stroke areas in rat brain stroke images requires manual processing by neurological experts. This process is complicated and time-consuming, and may have different standards. This thesis develops a model based on deep learning for automatically segmenting stroke regions in T2 Weighted and Diffusion Weighted image (DWI) images. Into the fully convolutional network as the basic structure, the mix block proposed by this thesis is incorporated. The network is trained using 3528 T2 and 3024 DWI augmented images.
The experimental results show that the two models trained separately for the two types of rat images with this architecture have excellent stroke segmentation results in the test data. The T2 image segmentation result has 86.84% accuracy, and the DWI image achieved 87.36% accuracy.
Keywords: deep learning, convolutional neural network (CNN), magnetic resonance imaging (MRI), ischemic stroke, image segmentation
目錄
致謝 ... i
中文摘要 ... ii
Abstract ... iii
目錄 ... iv
圖目錄 ... vii
表目錄 ... x
第 1 章 緒論 ... 1
1.1 研究背景 ... 1
1.2 研究動機 ... 2
1.3 研究目的 ... 2
1.4 論文架構 ... 2
第 2 章 文獻探討 ... 3
2.1 卷積神經網路 ... 3
2.1.1 神經元 ... 3
2.1.2 卷積層 ... 5
2.1.3 池化層 ... 6
2.2 神經網路訓練 ... 6
2.2.1 前饋 ... 7
2.2.2 反傳遞演算法 ... 7
2.2.3 自適應矩估計優化器 ... 8
2.3 全卷積網路 ... 9
2.3.1 編碼-解碼模型 ... 9
2.3.2 U 型網路 ... 11
2.4 殘差學習 ... 12
2.5 批量標準化 ... 13
2.6 不同網路架構核心 ... 14
2.6.1 Dense block ... 14
2.6.2 Inception module ... 14
2.6.3 倒置殘差塊 ... 15
2.6.4 Squeeze-and-Excitation block ... 16
2.6.5 ResNeXt block ... 17
第 3 章 研究設計與方法 ... 18
3.1 研究流程 ... 18
3.2 資料前處理 ... 19
3.3 資料增強 ... 19
3.4 卷積神經網路架構 ... 21
3.4.1 殘差塊 ... 21
3.4.2 混合殘差塊 ... 22
3.4.3 卷積層架構 ... 24
3.4.4 卷積核初始化 ... 24
3.4.5 其他網路架構 ... 24
第 4 章 實驗結果 ... 25
4.1 老鼠腦部 MR 影像資料集 ... 25
4.2 神經網路訓練模型 ... 26
4.2.1 實驗環境 ... 26
4.2.2 神經網路訓練參數 ... 26
4.3 實驗結果評估標準 ... 27
4.3.1 一致度 ... 28
4.3.2 敏感度 ... 29
4.3.3 識別度 ... 29
4.3.4 戴斯係數 ... 29
4.3.5 雅卡爾指數 ... 29
4.4 T2 影像實驗結果 ... 30
4.4.1 神經網路模型預測結果 ... 30
4.4.2 其他方法比較 ... 41
4.5 DWI 影像實驗結果 ... 49
4.5.1 神經網路模型預測結果 ... 49
4.5.2 其他方法比較 ... 60
第 5 章 結論及未來展望 ... 68
5.1 結論 ... 68
5.2 未來展望 ... 69
附錄 ... 70
參考文獻 ... 72
圖目錄
圖 1-1 圖為擴散加權成像 ... 1
圖 1-2 圖為 T2 加權成像 ... 1
圖 2-1 神經元 ... 3
圖 2-2 線性整流函數 ... 4
圖 2-3 圖為 Sigmoid 函數 ... 4
圖 2-4 圖為 tanh 函數 ... 5
圖 2-5 輸入經過卷積運算得到輸出 ... 5
圖 2-6 最大值池化 ... 6
圖 2-7 多層神經網路 ... 7
圖 2-8 全卷積網路[16] ... 10
圖 2-9 上採樣 - 填滿 ... 10
圖 2-10 上採樣 - 位置 ... 10
圖 2-11 圖為 U 型網路結構[18] ... 11
圖 2-12 淺層與深層網路[20] ... 12
圖 2-13 殘差塊[20] ... 12
圖 2-14 批量標準化[21] ... 13
圖 2-15 圖為 Dense block [22] ... 14
圖 2-16 圖為 Inception module [23] ... 15
圖 2-17 圖 a 為傳統殘差塊, b 為 Separable 卷積塊[25] ... 16
圖 2-18 圖 a 為傳統殘差塊, b 為倒置殘差塊[25] ... 16
圖 2-19 圖為 Squeeze-and-Excitation block [27] ... 16
圖 2-20 圖為 ResNeXt block [29] ... 17
圖 3-1 研究流程 ... 18
圖 3-2 過擬合示意圖 ... 19
圖 3-3 資料集影像擴充 ... 20
圖 3-4 不同結構之殘差塊[32] ... 22
圖 3-5 混和殘差塊 ... 22
圖 3-6 本研究之 Rat-Unet 網路架構 ... 23
圖 3-7 卷積層架構 ... 24
圖 4-1 結果評估示意圖 ... 28
圖 4-2 測試之 T2 影像分割結果柱狀圖 ... 31
圖 4-3 測試之 T2 影像分割結果誤差比例柱狀圖 ... 32
圖 4-4 測試之 T2 資料集編號 141 之中風區域預測區域 ... 33
圖 4-5 測試之 T2 資料集編號 141 之中風區域正確區域 ... 34
圖 4-6 測試之 T2 資料集編號 141 之中風區域正確與預測區域 ... 35
圖 4-7 測試之 T2 資料集編號 141 之中風區域三維正確與預測區域 ... 36
圖 4-8 測試之 T2 資料集編號 142 之中風區域預測區域 ... 37
圖 4-9 測試之 T2 資料集編號 142 之中風區域正確區域 ... 38
圖 4-10 測試之 T2 資料集編號 142 之中風區域正確與預測區域 ... 39
圖 4-11 測試之 T2 資料集編號 142 之中風區域三維正確與預測區域 ... 40
圖 4-12 測試之 T2 資料集中風區域預測誤差較大圖例 ... 41
圖 4-13 測試之 T2 資料集編號 118 之中風區域其他方法預測 ... 42
圖 4-14 測試之 T2 資料集編號 118 之切片 10 中風區域其他方法預測 ... 43
圖 4-15 測試之 T2 資料集編號 141 之中風區域其他方法預測 ... 44
圖 4-16 測試之 T2 資料集編號 141 之切片 14 中風區域其他方法預測 ... 45
圖 4-17 測試之 T2 資料集編號 142 之中風區域其他方法預測 ... 46
圖 4-18 測試之 T2 資料集編號 142 之切片 12 中風區域其他方法預測 ... 47
圖 4-19 測試之 DWI 影像分割結果柱狀圖 ... 50
圖 4-20 測試之 DWI 影像分割結果誤差比例柱狀圖 ... 51
圖 4-22 測試之 DWI 資料集編號 141 之中風區域正確區域 ... 53
圖 4-23 測試之 DWI 資料集編號 141 之中風區域正確與預測區域 ... 54
圖 4-24 測試之 DWI 資料集編號 141 之中風區域三維正確與預測區域 ... 55
圖 4-25 測試之 DWI 資料集編號 142 之中風區域預測區域 ... 56
圖 4-26 測試之 DWI 資料集編號 142 之中風區域正確區域 ... 57
圖 4-27 測試之 DWI 資料集編號 142 之中風區域正確與預測區域 ... 58
圖 4-28 測試之 DWI 資料集編號 142 之中風區域三維正確與預測區域 ... 59
圖 4-29 測試之 DWI 資料集中風區域預測誤差較大圖例 ... 60
圖 4-30 測試之 DWI 資料集編號 141 之中風區域其他方法預測 ... 61
圖 4-31 測試之 DWI 資料集編號 141 之切片 12 中風區域其他方法預測 ... 62
圖 4-32 測試之 DWI 資料集編號 142 之中風區域其他方法預測 ... 63
圖 4-33 測試之 DWI 資料集編號 142 之切片 6 中風區域其他方法預測 ... 64
圖 4-34 測試之 DWI 資料集編號 146 之中風區域其他方法預測 ... 65
圖 4-35 測試之 DWI 資料集編號 146 之切片 10 中風區域其他方法預測 ... 66
表目錄
表 4-1 資料集 ... 25
表 4-2 電腦環境 ... 26
表 4-3 訓練參數 ... 27
表 4-4 學習率調整 ReduceLROnPlateau 參數 ... 27
表 4-5 自適應矩估計優化器參數 ... 27
表 4-6 區域分類 ... 28
表 4-7 測試之 T2 影像分割結果 ... 31
表 4-8 測試之 T2 影像分割結果分析 ... 32
表 4-9 測試之 T2 影像分割結果與其他方法比較 ... 48
表 4-10 測試之 T2 影像模型訓練時間與其他方法比較 ... 48
表 4-11 測試之 DWI 影像分割結果 ... 50
表 4-12 測試之 DWI 影像分割結果分析 ... 51
表 4-13 測試之 DWI 影像分割結果與其他方法比較 ... 67
表 4-14 測試之 DWI 影像模型訓練時間與其他方法比較 ... 67
第 1 章 緒論
1.1 研究背景
腦中風長期是造成人類死亡的主要原因之一[1]。腦中風依型態可以分為缺 血型及出血型兩大類,而其中大部分是由於腦血管阻塞所造成之缺血型腦中風。
在判讀腦中風或是腦中風之程度,磁共振成像 ( Magnetic Resonance Imaging, MRI ) 之影像可以作為初步之依據[2]。其中磁共振成像有不同類別,包括 T1 加 權成像、 T2 加權成像及擴散加權成像 ( Diffusion Weighted Imaging, DWI ) 等 成像方式。本研究所使用之資料集影像成像為 T2 加權成像及擴散加權成像 ( DWI ) 。在實驗上,齧齒動物老鼠時常選擇為實驗動物,其與人類同為哺乳動 物,並與人類有 90% 的基因序列相似度[3],且容易飼養也相對穩定。老鼠也可 以運用在腦中風實驗上,透過磁共振成像檢視老鼠腦中風的情況,如圖 1-1 及圖 1-2,未來便能以此為基礎延伸至人類研究[4]。
圖 1-1 圖為擴散加權成像
圖左為原影像,圖右藍色區域為腦中風區域
圖 1-2 圖為 T2 加權成像
圖左為原影像,圖右藍色區域為腦中風區域
1.2 研究動機
老鼠缺血型腦中風在磁共振成像之腦部影像中,對中風區域分割並對結果進 行分析,需要腦神經專家對各張影像進行手動分割。在不同權重之成像上,同隻 老鼠可能會有些許不同之結果,這樣的工作流程是較為繁鎖及費時。故本研究提 出對 T2 加權成像及擴散加權成像 ( DWI ) 之腦部影像進行自動化分割腦中風 區域之深度學習模型,在維持一定分割結果精準度上簡化此流程。
1.3 研究目的
本研究目的為,分割老鼠缺血型腦中風在磁共振成像上 T2 加權成像及擴 散加權成像 ( DWI ) 之腦部影像上之中風區域。透過卷積神經網路對現有資料 集進行訓練並學習出適當之模型,並應用於訓練資料集外之測試資料且分析結果,
以便進一步運用於大量之鼠腦影像,協助醫師及專家進行研究及判讀。
1.4 論文架構
本論文包含五個章節。
第一章,緒論,闡述研究之背景及動機,並說明研究之目的。
第二章,文獻探討,說明卷積神經網路之架構,並探討以此為延伸之相關研 究及應用。
第三章,研究設計與方法,展示本研究之研究流程及所提出之神經網路架構,
並就各流程進行說明。
第四章,實驗結果,針對實驗結果進行分析,其中包含實驗環境及結果分析 之指標說明。
第五章,結論及未來展望,對於本論文之總結,並提出未來期許及可能之研 究方向。
第 2 章 文獻探討
2.1 卷積神經網路
神經網路之研究近期在電腦科學領域蓬勃發展,而其中卷積神經網路 ( Convolutional Neural Networks, CNN ) 為其大宗[5],目前被廣泛應用於電腦視 覺領域,並且在某些領域之應用上擁有超越人類判斷的精準度[6]。卷積神經網路 中透過卷積層,以卷積運算對輸入資料進行特徵提取,並加入池化層減少資料量 及保留特徵,最後將結果輸出[7]。以下將對神經網路及卷積神經網路架構進行說 明。
2.1.1 神經元
神經網路之單元可以稱作神經元 ( Neuron ) ,如圖 2-1,發想來自生物中神 經元構造[8],深度神經網路包含了數個神經元。
圖 2-1 神經元 其計算公式可以表示如下:
𝑦𝑘 = 𝜑(∑ 𝑥𝑖𝑤𝑘𝑖 + 𝜃𝑘
𝑛
𝑖=1
) ( 1 )
其中 𝑖 表示神經元的第 𝑖 個元素, 𝑘 表示第 𝑘 個神經元。 𝑥 為神經元的多 個輸入,與權重 𝑤 相乘並與偏差值 𝜃 相加後作為訊號。最後訊號透過激勵函 數 𝜑 可以得到輸出 𝑦 。
當中激勵函數特性為非線性函數,可視為對神經元中之刺激訊號。透過非線 性轉換,使得神經網路能解決非線性問題。目前神經網路架構中,大多使用線性 整流函數 ( Rectified Linear Unit, ReLU ) [9]作為激勵函數,公式如下:
𝑓(𝑥) = 𝑚𝑎𝑥(0, 𝑥) ( 2 )
將輸入小於 0 的值設為 0 並保留大於 0 的值,停止傳遞不必要的特徵,
減緩過擬合的發生,再作為下一層之輸入,如圖 2-2,過擬合現象會在第 3 章中 說明。
圖 2-2 線性整流函數
而其他常見之激勵函數,Sigmoid 式( 3 ) 及 tanh 函數 式( 4 ) [10],其函式 可繪製為圖 2-3 及圖 2-4。
𝑓(𝑥) = 1
1 + 𝑒−𝑥 ( 3 )
𝑓(𝑥) = 𝑒𝑥− 𝑒−𝑥
𝑒𝑥+ 𝑒−𝑥 ( 4 )
圖 2-4 圖為 tanh 函數
由圖 2-3 和圖 2-4,可以發現在左右兩側之飽和區導數接近 0 ,會使得反 傳遞中訊息消失,無法順利更新參數,而整流線性單位函數之導數在輸入大於 0 的情況下為 1 反之為 0 ,避免了上述的現象。
2.1.2 卷積層
卷積神經網路能處理電腦視覺問題,當中卷積層 ( Convolution layer ) 為重 要因素。卷積層將輸入透過卷積運算產生輸出,如圖 2-5,將輸入經由步伐 ( Stride ) 與權重矩陣求得哈達瑪積 ( Hadamard product ),圖中 ∘ 運算子表示對 兩個矩陣各元素相乘得到哈達馬乘積,一個卷積層中會依需求給定多個權重矩陣。
圖 2-5 輸入經過卷積運算得到輸出
權重矩陣可以稱為過濾器 ( Filter ) 或是卷積核 ( Kernel ) ,透過卷積運算,
多個過濾器能將輸入之不同特徵提取,過濾出符合如此特徵之區塊,並保留空間 上的訊息。而輸出則稱為特徵地圖 ( Feature Map ) 。
2.1.3 池化層
卷積神經網路中加入池化層 ( Pooling layer ) ,可以降低資料維度以減少資 料量並進行特徵地圖的提取保留,而此操作稱為對資料進行編碼。常見池化有最 大值池化 ( Max pooling ) ,或是平均池化 ( Average pooling ) 。最大值池化保留 範圍內最大值,並根據範圍及步伐進行運算,如圖 2-6,公式如下:
𝑦 = 𝑚𝑎𝑥𝑖,𝑗=1 ℎ,𝑤 𝑋𝑖,𝑗 ( 5 )
公式中 ℎ 及 𝑤 表示為最大池化的範圍, 𝑋 為欲進行運算之矩陣。而平均池化 則是取範圍內數值之平均值。
圖 2-6 最大值池化
2.2 神經網路訓練
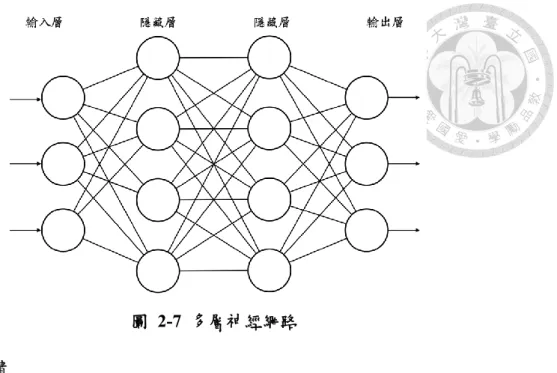
多個層透過連結便組合成網路,輸入及輸出層是將資料輸入及產生結果,當 中透過隱藏層進行運算,如圖 2-7。而其中各層的權重便是透過神經網路反覆進 行前饋及反傳遞演算法所調整,稱為學習[11],並期望達到最佳準確度。
圖 2-7 多層神經網路
2.2.1 前饋
在前饋中,將輸入資料透過各層的連接及運算,最終輸出結果,結果可視為 以多權重所組成之函式。而以圖 2-7 為例之含兩層隱藏層之神經網路公式如下:
𝑦 = 𝜑 (
∑ ∑ 𝑤3,𝑦,𝑧
3
𝑧 4
𝑦
𝜑 (∑ ∑ 𝑤2,𝑥,𝑦
4
𝑦 4
𝑥
𝜑 (∑ ∑ 𝑥𝑖𝑤1,𝑖,𝑥
4
𝑥 3
𝑖
)) )
( 6 )
組合與 式( 1 ) 相似之算式。 𝑥 為神經網路的輸入, 𝑖 為第 𝑖 個輸入,與權重 𝑤 相乘作為訊號,權重 𝑤 下標之 3 個參數分別為層、第幾個輸入及第幾個輸 出,將輸出之各訊號加總後透過激勵函數 𝜑 作為下一層之輸入,最後輸出為 𝑦 。
2.2.2 反傳遞演算法
神經網路透過反傳遞演算法 ( Backpropagation ) 來更新權重,以最小化輸出 之誤差。誤差可以透過所選用之損失函數 ( Loss function ) 來計算。而透過更新 權重來降低誤差,需知道該權重對於誤差之影響,而這個影響力可以透過偏微分 及鍊鎖率 ( Chain Rule ) 來計算,公式如下:
𝜕𝑙𝑜𝑠𝑠
𝜕𝑤𝑘𝑖 =𝜕𝑙𝑜𝑠𝑠
𝜕𝑜𝑢𝑡 ∗𝜕𝑜𝑢𝑡
𝜕𝑧𝑘 ∗ 𝜕𝑧𝑘
𝜕𝑤𝑘𝑖 ( 7 )
公式表示權重 𝑤𝑘𝑖 對於誤差之影響,當中 𝑘 和 𝑖 代表在 𝑘 層的第 𝑖 個權重,
而當中 𝑧 表示經過激勵函數之輸出。如此得到了誤差在該權重上的梯度,再根 據此數值去更新權重,優化目前的模型。
2.2.3 自適應矩估計優化器
在得到誤差在該權重上的梯度後,模型需要根據此梯度去更新權重,優化整 個模型。而自適應矩估計優化器 (Adaptive Moment Estimation, Adam) [12]是目前 被大量使用的優化演算法[13],該演算法結合了其他優化器 Momentum 演算法 [14]及 RMSprop ( Root Mean Square prop ) 演算法[15]。此演算法會先計算出與 前一次梯度更新方向相關之參數 𝑚𝑡 與 𝑣𝑡 ,公式如下:
𝑚𝑡= 𝛽1𝑚𝑡−1+ (1 − 𝛽1)𝑔𝑡 ( 8 )
𝑣𝑡 = 𝛽2𝑣𝑡−1+ (1 − 𝛽2)𝑔𝑡2 ( 9 )
𝛽1 與 𝛽2 為指數衰退率, 𝑔𝑡 為此次梯度。
𝑚𝑡 類似 Momentum 演算法, 𝑚𝑡−1 為之前的梯度所計算出的方向,在與 當前梯度相加,如此可以考慮到整個梯度的運動方向。類似慣性的概念,若前一
次梯度與此次是同方向,就加強這方向的移動 ,反之則減緩。而 𝑣𝑡 類似
RMSprop 演算法當中之參數,計算之前梯度的平方和,但是會與指數衰退率相 乘,可以調整欲參考之梯度的重要程度。
由於在初始時參數會設定為 0,導致前期計算時與期望之參數的偏差過小,
因此計算出參數後,會通過偏差校正來校正參數,公式如下:
𝑚̂ =𝑡 𝑚𝑡
(1 − 𝛽1𝑡) ( 10 )
𝑣̂ =𝑡 𝑣𝑡
(1 − 𝛽2𝑡) ( 11 )
最後便可以對權重進行更新,公式如下:
𝜃𝑡+1= 𝜃𝑡+1− 𝜂
√𝑣̂ + 𝜖𝑡 𝑚̂ 𝑡 ( 12 )
其中 𝜃 為權重, 𝜖 為常數以防止除 0 , 𝜂 為學習率,學習率越大,則權重的 更新也較大,但有可能會導致錯過最佳解,而過小則可能更新過慢,或是無法找 到最佳解之方向,故學習率參數需視神經網路模型之學習過程手動調整。
2.3 全卷積網路
全卷積網路 ( Fully Convolutional Networks, FCN ) [16]可以用來處理語意分 割 ( Semantic segmentation ) 問題,語意分割是對輸入資料的各數值或是圖片中 像素點進行分類,以圖片為概念便是能將圖片中的目標物體位置分割出來。以下 對全卷積網路進行說明。
2.3.1 編碼-解碼模型
卷積神經網路中池化層可以視為進行編碼,而傳統卷積神經網路在解決分類 問題時會在最後加上全連接層來處理分類[17]。全卷積網路中則沒有全連接層,
而是在編碼後,加入上採樣層 ( Upsampling layer ) 如圖 2-8 或反卷積層進行卷 積運算,以解碼還原至原大小。並解碼時可加入先前網路中對應之池化層訊息,
以處理像素點分類問題,稱之為編碼-解碼模型 ( Encoder-Decoder Model ) 。
圖 2-8 全卷積網路[16]
上採樣層將特徵地圖還原至原大小,同時達成解碼。上採樣有不同還原方式,
常見是將放大後區塊填滿,如圖 2-9,或是放置於進行編碼池化前資料所在位置 等等,如圖 2-10。
圖 2-9 上採樣 - 填滿
圖 2-10 上採樣 - 位置
完成解碼後,再將特徵地圖與先前進行編碼前相同大小之特徵地圖中各像素 點相加,利用編碼前較清晰之特徵來加強解碼後之還原能力,並依需求決定還原 時所加入之編碼訊息尺度,調整重複上述步驟之次數。
2.3.2 U 型網路
U 型網路 ( U-net ) [18],是針對生物醫學影像分割所提出的一種全卷積網 路,在小資料量的訓練上有優異的表現,結構如圖 2-11。
圖 2-11 圖為 U 型網路結構[18]
如同編碼 - 解碼模型,以池化層進行編碼,但在解碼階段與全卷積網路所 提出之方法有不同之處。 U 型網路在進行解碼時同樣可使用上採樣層或反卷積 層將資料還原,但接下來並不是與對應之特徵地圖將各像素點相加,而是將之合 併 ( Concatenate ) ,形成更厚的特徵地圖後加入卷積層,調整至適當厚度,再重 複進行此解碼過程。
2.4 殘差學習
許多研究顯示[19],網路深度對於訓練結果有重要影響。但是當神經網路到 達一定的深度時,卻可以發現較深層的網路比淺層的網路有更低的準確度,準確 度在淺層網路達到了飽和,如圖 2-12 所示。何愷明的研究[20]指出,這並非由過 擬合及網路無法收斂而產生,並將這樣的現象稱為退化 ( Degradation ) ,同時提 出了解決辦法,殘差學習 ( Residual Learning ) ,使神經網路能輕易地加深,克 服了深層網路難以訓練的問題。
圖 2-12 淺層與深層網路[20]
殘差學習中的殘差塊,如圖 2-13,加入了捷徑 ( Shortcuts ) ,在輸出時將輸 入與之相加。
圖 2-13 殘差塊[20]
輸入 𝑥 經過卷積後得到輸出 𝐹(𝑥) ,而目標輸出可表示為 𝐻(𝑥) ,因此 𝐹(𝑥) 可稱為殘差 ( Residual ) ,代表兩者差距,公式如下:
𝐹(𝑥) = 𝐻(𝑥) − 𝑥 ( 13 )
目標輸出為殘差與輸入之加總,公式如下:
𝐻(𝑥) = 𝐹(𝑥) + 𝑥 ( 14 )
殘差學習中神經網路所需學習的為殘差 𝐹(𝑥) ,而不需要學習整個目標 𝐻(𝑥) 。在如此情況下加深網路深度,當學習過程中網路深度已經達到飽和時,
殘差變小,輸入會趨近於輸出,如此網路比較不會出現退化的情形,使得深層網 路容易訓練。
2.5 批量標準化
批量標準化 ( Batch Normalization ) [21],神經網路將資料分批進行訓練,並 將此批資料在訓練過程中進行標準化,使得輸出平均值為 0 標準差為 1,並會 再給予調整的參數,用以改變或減低標準化的影響,而調整參數是藉由網路學習 自行調整,公式如圖 2-14。批量標準化使得下一層之輸入變的穩定,透過標準化 降低了前一層權重改變時的輸出敏感度,緩解權重的更新對於整體網路模型的影 響,並使得網路能更加快速的收斂。
圖 2-14 批量標準化[21]
2.6 不同網路架構核心
本節介紹其他研究所提出之網路架構其核心,透過核心之組合,可以進一步 建構所需之卷積神經網路亦或是全卷積網路,本論文之實驗結果也將與本節介紹 之方法進行比較。
2.6.1 Dense block
Dense block 於 2016 年所提出[22],如圖 2-15,其研究中將使用 Dense block 組成之網路架構稱為 DenseNet 。殘差塊只於最終輸出時與輸入相加,而 Dense block 中各層之輸入為前面各層輸出之合併,透過密集之連接,使得各層 能使用前面層之特徵,運用重複使用之特徵以學習出其神經網路所需之權重。
圖 2-15 圖為 Dense block [22]
2.6.2 Inception module
Inception module 為 Google 於 2014 年所提出[19],其所組成之網路架構可 稱為 InceptionNet , Inception module 之組合將網路拓寬,透過不同尺度之特徵 來進行特徵提取,包含池化層及不同大小之卷積層等,並將輸出再進行合併,
Inception module 於 2015 有經過改良[23],如圖 2-16,並且其中可以加入殘差 捷徑,以其為核心所架構之網路,可稱為 InceptionResNet [24]。
圖 2-16 圖為 Inception module [23]
2.6.3 倒置殘差塊
倒 置 殘 差 塊 ( Inverted residual block ) 為 2018 年 所 提 出 [25] , 其 為 MobileNetV2 之核心,其中運用了 MobileNets [26]中將傳統卷積層以 Depthwise 卷積及 Pointwise 卷積兩個步驟取代,稱為 Separable 卷積塊,如圖 2-17。
Separable 卷積塊對輸入之各特徵地圖先進行卷積運算,再將其組合後,透過 1×1 之卷積核及所設定之數量進行卷積運算。透過 Separable 卷積塊,能夠減少 傳統卷積之計算量。而倒置殘差塊中除了運用 Separable 卷積塊,不同於傳統殘 差 塊 將 輸 入 降 低 維 度 , 其 卷 積 層 會 將 輸 入 之 維 度 提 升 , 因 此 稱 之 為 倒 置 ( Inverted ) ,如圖 2-18,並於輸出時降低維度且不加入 ReLu 激勵函數,因研 究認為在低維度時使用 ReLu 激勵函數會有特徵上的損失。
圖 2-17 圖 a 為傳統殘差塊, b 為 Separable 卷積塊[25]
圖 2-18 圖 a 為傳統殘差塊, b 為倒置殘差塊[25]
2.6.4 Squeeze-and-Excitation block
Squeeze-and-Excitation block 於 2017 年所提出[27],簡稱 SE block ,此核 心透過 Global pooling 達到該研究中所稱之 Squeeze 操作,再透過兩層全連接 層進行 Excitation ,如圖 2-19,其所得出之結果會再乘上輸入,使重要特徵增
強並減低不重要之特徵,而 SE block 能夠與其他不同網路架構核心組合,於
2019 年所提出之 EfficientNet [28],其核心便是倒置殘差塊並加入 SE block 。
圖 2-19 圖為 Squeeze-and-Excitation block [27]
2.6.5 ResNeXt block
ResNeXt block 為 2017 年所提出[29],其為不同版本之殘差塊,類似 Inception module 的概念,將輸入分為不同之通道,於最後做相加,如圖 2-20,
可以取得不同之特徵,再透過學習調整不同通道之權重。
圖 2-20 圖為 ResNeXt block [29]
第 3 章 研究設計與方法
本章詳細介紹本論文之研究設計與方法。首先介紹研究流程,接下來詳細說 明流程中之步驟,以展示研究方法,包含資料集處理及所提出之卷積神經網路架 構,並將此神經網路架構命名為 Rat-Unet 。
3.1 研究流程
本研究可分為兩大部分,卷積神經網路模型訓練及老鼠腦部 MR 影像中缺 血型中風區域分割。如圖 3-1,以下對流程進行更詳細之說明。
圖 3-1 研究流程
3.2 資料前處理
在 資 料 前 處 理 , 會 對 資 料 集 使 用 標 準 分 數 正 規 化 ( Standard Score Normalization ) [30]的運算以使資料集符合標準常態分佈。儘量避免神經網路受 到範圍較大卻不重要的特徵影響,以較快並且貼近最佳解的方向進行權重調整。
進行標準分數正規化,先計算所有欲輸入模型之影像資料集中所有像素值的 平均值 𝑋𝑚𝑒𝑎𝑛 與標準差 𝑋𝑠𝑡𝑑 後,再對所有像素值分別減去 𝑋𝑚𝑒𝑎𝑛 後再除 𝑋𝑠𝑡𝑑 。經過標準分數正規化的資料集,平均數為 0 ,並且標準差為 1 ,公式如 下:
𝑧 =𝑥 − 𝑋𝑚𝑒𝑎𝑛
𝑋𝑠𝑡𝑑 ( 15 )
3.3 資料增強
本研究用於訓練之資料集影像數量, T2 有 588 張及 DWI 有 504 張,在 第 4 章會進一步說明資料集。而這樣的資料數量對於深度學習之模型訓練來說 是相對少的。若單純以這些資料給予神經網路進行訓練,訓練出來的權重,可能 會對於訓練資料集有非常優異表現,但對於訓練資料集外的資料集會發生失準,
這種過度擬和於訓練資料集的情況稱做過擬合 ( Overfitting ) 。而我們所期望的 權重,應該要符合資料集整體的走向,如圖 3-2。
圖 3-2 過擬合示意圖 圖左為期望函式,圖右為過擬合
在面對資料規模較小的情況,研究及實驗指出[7, 17, 18],適當地以原資料透 過轉換以擴充資料集,能有效地提升深度學習之模型在未知資料的判斷準確度,
減低過度擬和的現象。
本研究將資料集影像數量擴充至 6 倍。並對資料進行以下四種轉換。
1. 影像旋轉:隨機旋轉整影像 ± 30 度。
2. 水平翻轉:隨機沿著水平方向翻轉影像。
3. 推移變換:隨機推移比例 0.3 。
4. 縮放變換:隨機調整影像大小至原圖之 80% 至 120% 。 樣本增強結果顯示如圖 3-3。
3.4 卷積神經網路架構
本研究之卷積神經網路架構 Rat-Unet ,為編碼-解碼模型 ( Encoder-Decoder Model ) 之全卷積網路 ( FCN ) ,於解碼步驟時結合相對應之編碼層,以得到影 像分割之預測結果。
Rat-Unet,是以 U 型網路為基礎。包含 5 個最大值池化層與 5 個上採樣 層。以最大值池化層進行編碼,再以上採樣層解碼還原至原大小,並將輸出與對 應之編碼層進行合併。
本研究中於編碼步驟,以殘差塊 ( Residual block ) [20]加深網路深度,於第 一及第二最大值池化層之前,各加入兩個卷積層。而於第三至第五最大值池化層 之前,加入本研究所提出之混合殘差塊,通過兩個不同結構之殘差塊取得不同尺 度之特徵地圖,並進行合併。最後,使用 Sigmoid 函數將特徵地圖輸出值壓縮 至0 至 1 中,作為像素分類問題中為分割目標的機率,架構如圖 3-6。
3.4.1 殘差塊
在殘差學習中,除了基本的殘差塊 ( Basic block ) ,研究中[20]提出了殘差 瓶頸塊 ( Bottleneck block ) 減少了計算量,並在 2016 年將兩種殘差塊加以改良 [31] , 本 研 究 使 用 改 良 後 之 殘 差 瓶 頸 塊 及 2019 年 提 出 之 Res2Net 單 元 ( Res2Net block ) [32]做為神經網路之部分,上述殘差塊如圖 3-4。
Res2Net 單元,是取材殘差瓶頸塊,將第二層 3 × 3 的卷積層以卷積組 ( Group convolution ) 取代,可以讓神經網路觀察不同尺度的訊息,使神經網路 能在多個尺度中進行學習。
圖 3-4 不同結構之殘差塊[32]
圖中 BN 為 Batch Normalization
3.4.2 混合殘差塊
本研究提出混和殘差塊 ( Mix Block ) ,結合 Res2Net 單元與殘差瓶頸塊,
並將輸出合併後加入卷積層及殘差捷徑,結構如圖 3-5。
圖 3-5 混和殘差塊
以 Res2Net 單元結合殘差瓶頸塊,能保留 Res2Net 單元所取得之多尺度信 息,並同時加入殘差瓶頸塊以單層卷積層處理所獲取信息,再透過網路學習並使
3.4.3 卷積層架構
在 Rat-Unet 中大部分卷積層前,會加入批量標準化後再使用整流線性單位 函數,最後才為卷積層。如此順序是經由實驗後發現如此搭配在訓練上能有比較 好的表現,如圖 3-7。
圖 3-7 卷積層架構
3.4.4 卷積核初始化
神經網路透過權重進行運算,再透過學習來更新權重,而在開始時需要給定 權重之初始化值。給定方式目前常見為 Xavier 初始化[33],此初始化方式使輸 入與輸出之標準差保持相似,適合在使用 Sigmoid 及 tanh 函數為激勵函數時 保持梯度穩定。而本研究使用整流線性單位函數,在輸入小於 0 時會設置為 0 , 因此約有一半值消失,並不適合使用 Xavier 初始化,而研究指出[34],簡單的 改良 Xavier 初始化,將其變異數調整為 Xavier 初始化之變異數約兩倍,並於 截斷常態分布中取值,此初始化後之權重,於使用整流線性單位函數之網路中也 能保持梯度穩定。因此本研究使用上述 Xavier 初始化改良後之版本。
3.4.5 其他網路架構
實驗中也有建構 Rat-Unet 以外之神經網路架構,但其結果不如 Rat-Unet 。 於第四章實驗結果比較中,稱之為 Proposed 2 ,詳如附錄。
第 4 章 實驗結果
本章節說明研究中所使用之資料集及實驗環境,並說明 Rat-Unet 網路架構 所訓練之模型設定,及其對於老鼠腦部 MR 影像缺血型中風區域之分割結果。
4.1 老鼠腦部 MR 影像資料集
提供本論文使用之老鼠腦部 MR 影像資料集,來自臺大醫院神經科葉馨喬 醫師所提供之 T2 及 DWI 鼠腦影像,並使用葉醫師所分割之真實腦部影像進 行分析。本研究將 T2 及 DWI 資料集分別分為訓練資料及測試資料。訓練資料 用於訓練卷積神經網路模型,而測試資料用於檢視與評估模型結果。資料及詳細 情形如表 4-1。
表 4-1 資料集
T2 DWI
老鼠數量 65 57
腦部影像切片 15 15
影像總數 975 855
影像大小 256 × 256 128 × 128
訓練資料老鼠數量 49 42
訓練資料影像總數 588×6 504×6
驗證資料影像總數 147 126
測試資料老鼠數量 16 15
測試資料影像總數 240 225
訓練-驗證-測試資料比例 3528:147:240 3024:126:225
4.2 神經網路訓練模型
以下說明本研究之神經網路模型訓練之參數設置及實驗環境。
4.2.1 實驗環境
本研究之實驗電腦環境如表 4-2。並使用 Python3.5.7 [35]作為開發之程式語 言,套件使用 Keras 2.2.4 [36]並搭配 tensorflow-gpu 1.15.2 [37]。
表 4-2 電腦環境
4.2.2 神經網路訓練參數
在 T2 及 DWI 分割任務的模型訓練中,皆設置了 200 次的訓練週期 ( Epoch ) 與 8 的批次大小 ( Batch size ) ,以戴斯係數 ( Dice coefficient ) [38]與 1 之差距作為損失函數。並將訓練資料集中 20 % 作為為驗證資料 ( Validation data ),如表 4-1,訓練過程中只將在驗證資料上準確度最高的模型儲存,並在驗 證資料上的準確度連續 15 個週期沒有提升的情況下停止訓練,如表 4-3。學習 率調整上,在前面週期設置較大學習率,加速神經網路的學習,後期使用較小學 習率,使網路學習較為平穩並接近最佳結果,使用 Keras 之 ReduceLROnPlateau 函式做調整,如表 4-4。而自適應矩估計優化器[12]的參數設置則如表 4-5。於測 試資料分割時,以預測結果大於固定閥值時判斷為中風區域,實驗時過程中以 0.002 至 0.6 之閥值範圍進行測試,並以 0.5 為基準。
CPU Intel(R) Xeon(R) CPU E5-2620 v3 @ 2.40GHz × 4
GPU NVIDIA Tesla K40c
RAM Samsung DDR4 ECC REG 2133 8G × 2, 4G × 2
作業系統 Ubuntu 18.04.3 LTS
表 4-3 訓練參數
表 4-4 學習率調整 ReduceLROnPlateau 參數
表 4-5 自適應矩估計優化器參數
4.3 實驗結果評估標準
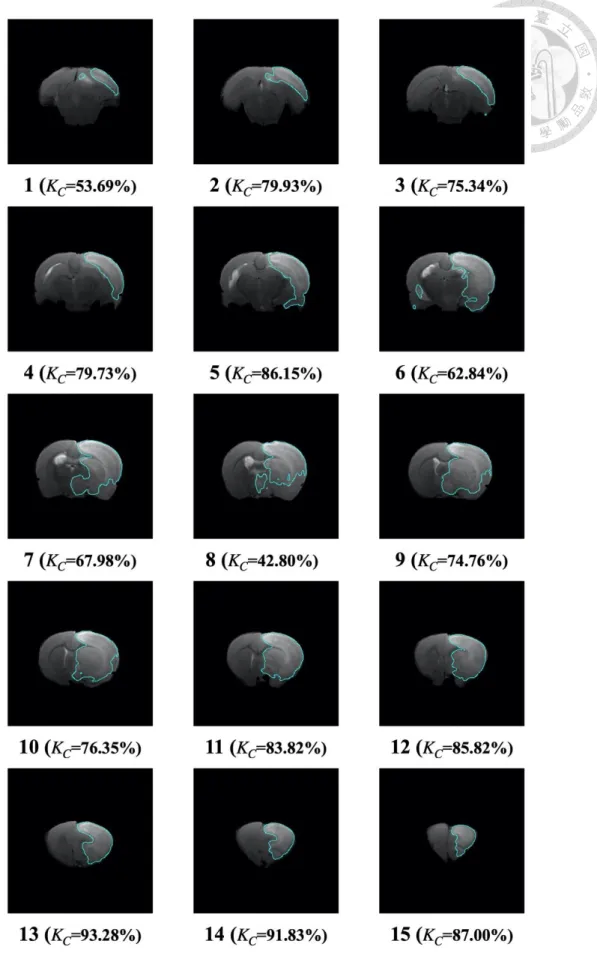
將模型訓練後,便可將模型運用於影像中缺血型中風區域之分割,而在評估 分割的結果與醫生所提供之正確區域的差距,本研究以五種指標作為評斷標準,
分 別 為 一 致 度 ( Conformity, 𝜅𝑐 ) 、 敏 感 度 ( Sensitivity, 𝜅𝑠𝑡 ) 、 識 別 度 ( Sensibility, 𝜅𝑠𝑏 ) [39]、 戴斯係數 ( Dice coefficient, 𝜅𝐷 ) [38],及雅卡爾指數 ( Jaccard similarity coefficient, 𝜅 ) [40],接下來將說明以上指標。
Epoch 200
Batch size 8
Validation split 20%
Early stop patience 15
Init learning rate 1e-03
monitor val_loss
factor 0.5
patience 10
Min learning rate 1e-04
𝜷𝟏 0.9
𝜷𝟐 0.999
𝝐 1e-07
圖 4-1 結果評估示意圖
如圖 4-1, X 圓區域視為本研究之模型所分割出來之預測區域, Y 圓區域 則視為醫師所提供之正確區域。以此示意圖,可以將兩者所佔區域進行分類,如 表 4-6。
表 4-6 區域分類
TP 代表預測區域與正確區域相同之區域, FP 代表所預測之區域不在正確 區域中,而 FN 代表正確區域中沒有被預測之區域。將結果分類為上述區域,便 可進行評斷標準之五項指標計算。
4.3.1 一致度
一致度 ( Conformity, 𝜅𝑐 ) 可以評估預測正確中預測錯誤的比例關係,可以 了解預測結果與正確結果之差異性,公式如下:
𝜅𝑐 = 1 −𝐹𝑃 + 𝐹𝑁
𝑇𝑃 × 100% ( 16 )
符號 TP FP FN
意義 X∩Y X∩~Y ~X∩Y
區域 B A C
4.3.2 敏感度
敏感度 ( Sensitivity, 𝜅𝑠𝑡 ) 評估正確結果中預測正確的比例,能夠了解預測 正確的情形,公式如下:
𝜅𝑠𝑡 = 𝑇𝑃
𝑇𝑃 + 𝐹𝑁× 100% ( 17 )
4.3.3 識別度
識別度 ( Sensibility, 𝜅𝑠𝑏 ) 則是評估正確結果中將錯誤預測為正確的比例,
能夠了解預測中誤判的情形,公式如下:
𝜅𝑠𝑏 = 1 − 𝐹𝑃
𝑇𝑃 + 𝐹𝑁× 100% ( 18 )
4.3.4 戴斯係數
戴斯係數 ( Dice, 𝜅𝐷 ) 是廣泛使用的評估指標,能夠評估預測正確的比例,
並給予預測正確較高權重,可以了解當中與正確結果的誤差,也是本研究中所重 視的指標,公式如下:
𝜅𝐷 = 2 × 𝑇𝑃
2 × 𝑇𝑃 + 𝐹𝑁 + 𝐹𝑃× 100% ( 19 )
4.3.5 雅卡爾指數
雅卡爾指數 ( Jaccard, 𝜅𝐽 ) 與戴斯係數 ( Dice ) 類似,不同之處在於預測 正確部分並未給予權重,公式如下:
𝜅𝐽 = 𝑇𝑃
𝑇𝑃 + 𝐹𝑁 + 𝐹𝑃× 100% ( 20 )
4.4 T2 影像實驗結果
本節展示 Rat-Unet 模型在 T2 影像中對於測試資料之分割結果,並與其他 方法進行比較及分析。
4.4.1 神經網路模型預測結果
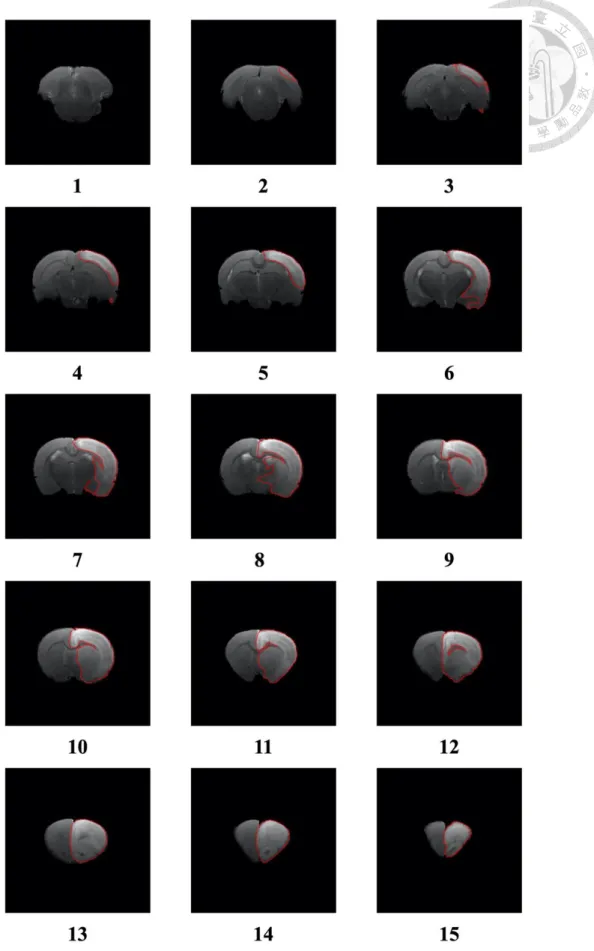
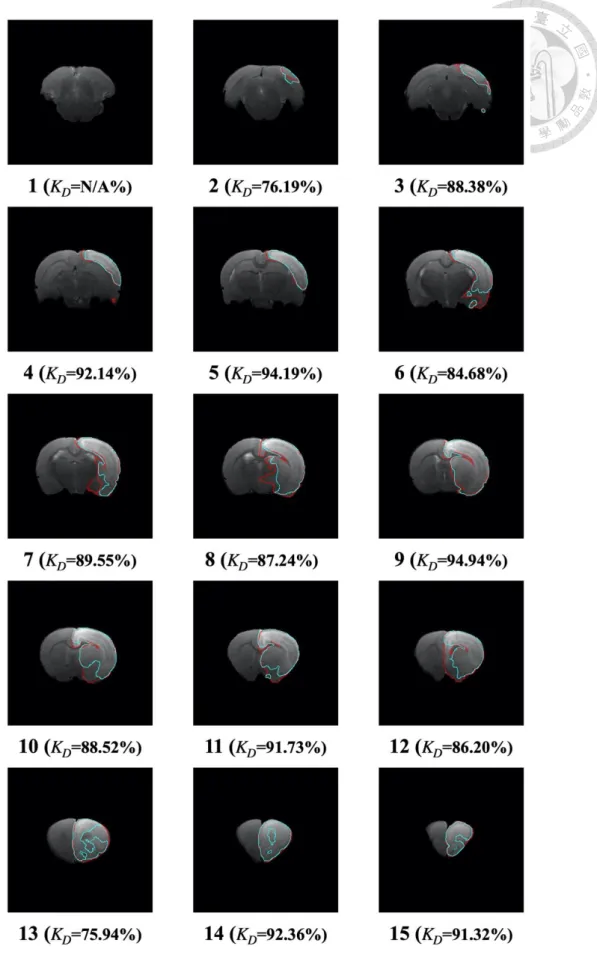
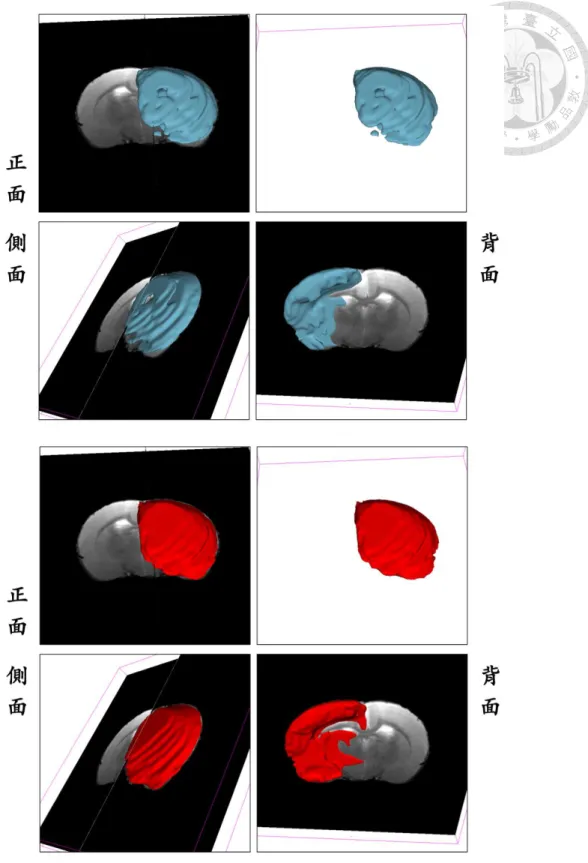
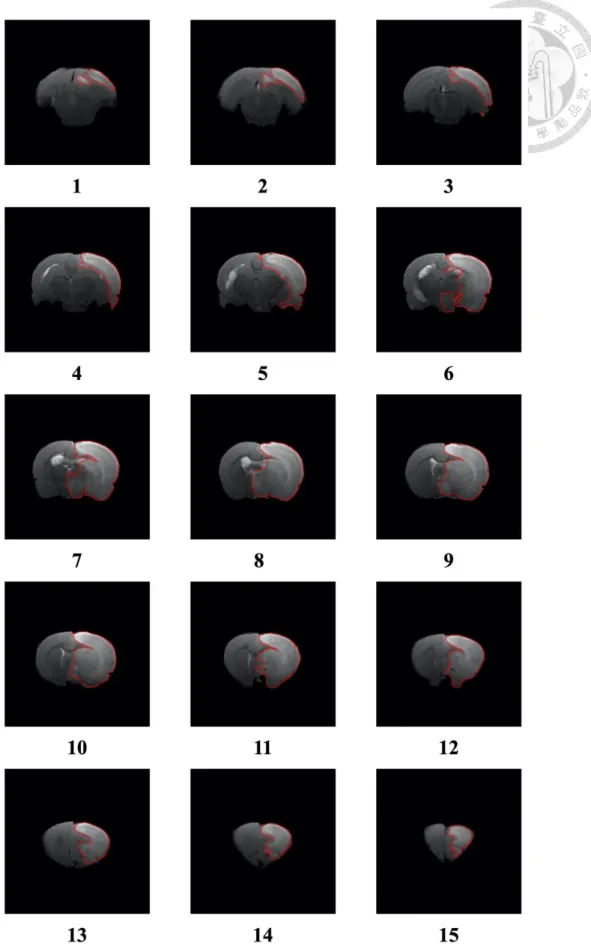
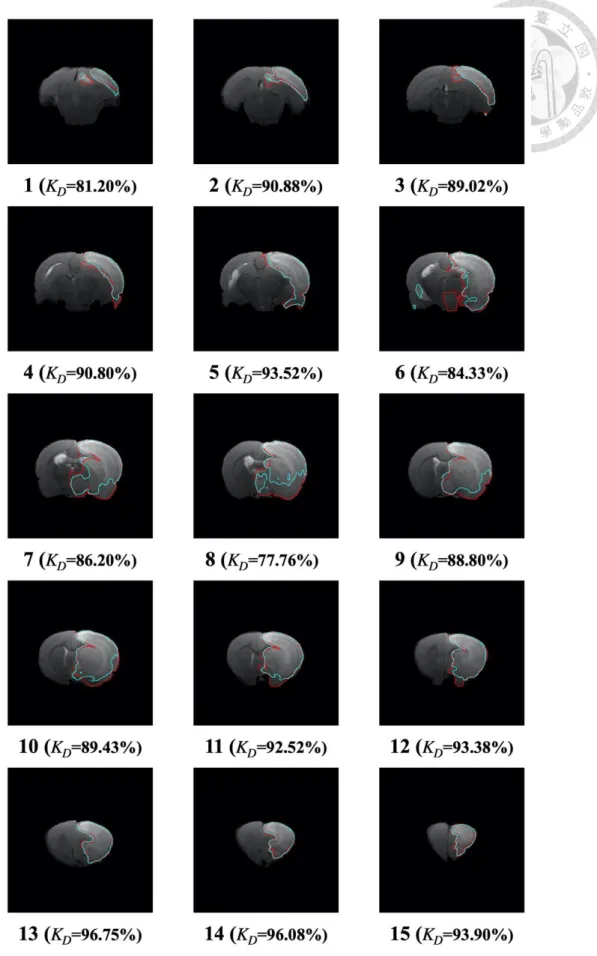
表 4-7 及表 4-8 為測試之 T2 資料集中,各老鼠的中風區域分割預測結果 與正確結果比較。並附上編號 141 及 142 之結果圖,結果圖包括預測結果、正 確結果及合併結果,同時附上在三維空間之分割結果,三維空間結果展示預測結 果與正確結果在三維空間中正面、側面及背面之不同視角圖像以供檢視與比較,
如圖 4-4 至圖 4-11。檢視上述結果圖,可以發現在這兩組資料集中,本研究之 模型多數能判斷正確之位置及輪廓,可以觀察預測之結果與正確結果是接近的。
表 4-7 測試之 T2 影像分割結果
圖 4-2 測試之 T2 影像分割結果柱狀圖
編號 𝜿𝒄(%) 𝜿𝒔𝒕(%) 𝜿𝒔𝒃(%) 𝜿𝑫(%) 𝜿𝑱(%)
118 74.53 82.79 96.12 88.70 79.70
141 74.81 82.34 96.91 88.81 79.88
142 74.76 83.10 95.92 88.79 79.85
146 85.01 92.89 93.18 93.03 86.96
149 67.16 77.41 97.17 85.89 75.28
154 67.96 82.45 91.13 86.19 75.73
159 74.61 86.02 92.14 88.74 79.75
267 80.01 86.84 95.80 90.91 83.34
268 74.95 82.92 96.31 88.87 79.97
275 63.74 77.38 94.57 84.65 73.39
280 58.77 76.29 92.26 82.91 70.81
284 67.18 83.65 88.90 85.90 75.29
286 33.03 61.99 96.50 74.91 59.89
295 64.51 82.90 87.68 84.93 73.81
304 83.15 86.48 98.95 92.23 85.58
307 61.78 76.00 94.95 83.96 72.35
表 4-8 測試之 T2 影像分割結果分析 表中誤差比例計算為誤差除以正確像素
編號 預測像素 正確像素 誤差 誤差比例 (%)
118 46400 40218 6182 13.32
141 45443 38823 6620 14.57
142 57197 49863 7334 12.82
146 34164 34065 99 0.29
149 56852 45616 11236 19.76
154 32371 29559 2812 8.69
159 40721 38230 2491 6.12
267 32293 29400 2893 8.96
268 25825 22365 3460 13.40
275 35104 29068 6036 17.19
280 26769 22495 4274 15.97
284 16254 15402 852 5.24
286 3512 2300 1212 34.51
295 17780 16929 851 4.79
304 40054 35060 4994 12.47
307 2871 2327 544 18.95
平均 12.94±7.94
圖 4-4 測試之 T2 資料集編號 141 之中風區域預測區域
圖 4-5 測試之 T2 資料集編號 141 之中風區域正確區域
圖 4-6 測試之 T2 資料集編號 141 之中風區域正確與預測區域
圖 4-7 測試之 T2 資料集編號 141 之中風區域三維正確與預測區域 上方藍色區域為預測區域,下方紅色區域為正確區域
(圖中三維空間結果為原結果加厚兩倍以利檢視)
圖 4-8 測試之 T2 資料集編號 142 之中風區域預測區域
圖 4-9 測試之 T2 資料集編號 142 之中風區域正確區域
圖 4-10 測試之 T2 資料集編號 142 之中風區域正確與預測區域
圖 4-11 測試之 T2 資料集編號 142 之中風區域三維正確與預測區域 上方藍色區域為預測區域,下方紅色區域為正確區域
(圖中三維空間結果為原結果加厚兩倍以利檢視)
除了上述編號 141 及 142 之外,有一些資料在預測上有失準的情形,如圖 4-12,在預測上有判斷出大略位置,但是在輪廓上與正確結果有較大的落差。由 圖中可以觀察到某些區域是看似比較不明顯的。
在中風區域之正確分割上,是會參考前後之中風情形,而本模型是以二維資 料為輸入,會將資料視為各別之輸入,並不會考慮前後張之關係。
圖 4-12 測試之 T2 資料集中風區域預測誤差較大圖例
圖中數字為資料編號及切片編號,藍色區域為預測區域,紅色區域為正確區域
4.4.2 其他方法比較
實驗以測試資料集作為比較標準,並以戴斯係數 ( Dice ) 及雅卡爾指數 ( Jaccard ) 為主要觀察指標。並附上其他方法於編號 118 、 141 及 142 之預測 結果之三維空間圖及其中切片之比較圖,如圖 4-13 至圖 4-18。結果顯示本研究 所提出之 Rat-Unet 在其他方法中有優異的表現,如表 4-9,在其他指標中也有 穩定及良好的預測結果。
圖 4-13 測試之 T2 資料集編號 118 之中風區域其他方法預測
圖 4-14 測試之 T2 資料集編號 118 之切片 10 中風區域其他方法預測
圖 4-15 測試之 T2 資料集編號 141 之中風區域其他方法預測
圖 4-16 測試之 T2 資料集編號 141 之切片 14 中風區域其他方法預測
圖 4-17 測試之 T2 資料集編號 142 之中風區域其他方法預測
圖 4-18 測試之 T2 資料集編號 142 之切片 12 中風區域其他方法預測
表 4-9 測試之 T2 影像分割結果與其他方法比較
表 4-10 測試之 T2 影像模型訓練時間與其他方法比較
𝜿𝒄(%) 𝜿𝒔𝒕(%) 𝜿𝒔𝒃(%) 𝜿𝑫(%) 𝜿𝑱(%) Unet 56.95±26.23 76.82±11.51 92.67±8.44 83.09±8.02 71.79±11.17 DenseNet -66.63±288.11 66.32±27.73 93.17±4.23 72.47±25.24 61.51±25.36 EfficientNet 43.73±49.53 72.13±17.09 95.08±3.46 80.26±12.32 68.52±15.44 InceptionResNetV2 60.35±20.40 77.96±10.22 92.96±4.97 83.97±6.48 72.85±9.26 MobileNetV2 8.10±133.18 68.22±21.94 93.61±4.70 75.83±18.00 63.73±19.68 ResNet 54.84±28.85 76.39±12.56 92.33±5.56 82.47±8.13 70.87±10.90 ResNeXt 44.31±49.55 71.85±14.35 94.43±3.51 80.13±10.76 67.95±13.22 Proposed2 51.92±47.02 75.89±15.60 94.19±2.67 82.57±11.18 71.58±14.19 Rat-Unet 69.12±12.24 81.34±6.78 94.28±3.13 86.84±4.32 76.97±6.51
一訓練週期訓練時間(秒)
Unet 2227
DenseNet 598
EfficientNet 477
InceptionResNetV2 1107
MobileNetV2 381
ResNet 371
ResNeXt 1016
Proposed2 1400
Rat-Unet 1033
4.5 DWI 影像實驗結果
本節展示 Rat-Unet 模型在 DWI 影像中對於測試資料之分割結果,並與其 他方法進行比較及分析。
4.5.1 神經網路模型預測結果
表 4-11 及表 4-12 為測試之 DWI 資料集中,各老鼠的中風區域分割預測 結果與正確結果比較。並同樣附上編號 141 及 142 之結果圖,結果圖包括預測 結果、正確結果及合併結果,亦附上在三維空間之分割結果,展示在三維空間中 正面、側面及背面之不同視角圖像,如圖 4-21 至圖 4-28。由上述結果圖中可以 發現本模型之預測亦與正確區域接近。
表 4-11 測試之 DWI 影像分割結果
圖 4-19 測試之 DWI 影像分割結果柱狀圖
編號 𝜿𝒄(%) 𝜿𝒔𝒕(%) 𝜿𝒔𝒃(%) 𝜿𝑫(%) 𝜿𝑱(%)
141 78.47 85.47 96.14 90.28 82.29
142 80.35 87.79 94.97 91.06 83.58
146 72.67 86.89 89.36 87.98 78.54
149 83.14 92.53 91.87 92.22 85.57
154 68.03 81.81 92.03 86.22 75.77
159 75.09 85.98 92.60 88.93 80.06
226 73.62 84.66 93.00 88.35 79.12
267 63.02 75.70 96.32 84.40 73.01
268 75.11 92.97 83.90 88.93 80.07
274 39.73 82.16 68.32 76.84 62.39
275 76.12 87.71 91.34 89.33 80.72
280 65.81 80.79 91.59 85.40 74.52
281 73.60 89.86 86.42 88.34 79.12
294 78.55 89.56 91.23 90.31 82.34
310 55.35 79.76 84.62 81.75 69.13
表 4-12 測試之 DWI 影像分割結果分析 表中誤差比例計算為誤差除以正確像素
圖 4-20 測試之 DWI 影像分割結果誤差比例柱狀圖
編號 預測像素 正確像素 誤差 誤差比例 (%)
141 9866 8813 1053 10.67
142 11765 10920 845 7.18
146 7310 7130 180 2.46
149 11274 11349 75 0.67
154 8296 7448 848 10.22
159 10795 10081 714 6.61
226 8125 7448 677 8.33
267 10204 8100 2104 20.62
268 7322 7986 664 9.07
274 7007 7977 970 13.84
275 9027 8700 327 3.62
280 9155 8166 989 10.80
281 8162 8442 280 3.43
294 10344 10171 173 1.67
310 8544 8129 415 4.86
平均 7.60±5.27
圖 4-21 測試之 DWI 資料集編號 141 之中風區域預測區域
圖 4-22 測試之 DWI 資料集編號 141 之中風區域正確區域
圖 4-23 測試之 DWI 資料集編號 141 之中風區域正確與預測區域
圖 4-24 測試之 DWI 資料集編號 141 之中風區域三維正確與預測區域 上方藍色區域為預測區域,下方紅色區域為正確區域
(圖中三維空間結果為原結果加厚兩倍以利檢視)
圖 4-25 測試之 DWI 資料集編號 142 之中風區域預測區域
圖 4-26 測試之 DWI 資料集編號 142 之中風區域正確區域
圖 4-27 測試之 DWI 資料集編號 142 之中風區域正確與預測區域
圖 4-28 測試之 DWI 資料集編號 142 之中風區域三維正確與預測區域 上方藍色區域為預測區域,下方紅色區域為正確區域
(圖中三維空間結果為原結果加厚兩倍以利檢視)
在 DWI 的預測中,與 T2 資料中相同,在某些資料上也有失誤的情形,如 圖 4-29,在位置判斷上大略有判斷正確,但是在區域之範圍上是與正確區域有 些差距,於圖中觀察,可以發現本模型之預測區域大致上是可以理解,但還是與 專家所分割之正確區域有所不同。
圖 4-29 測試之 DWI 資料集中風區域預測誤差較大圖例
圖中數字為資料編號及切片編號,藍色區域為預測區域,紅色區域為正確區域
4.5.2 其他方法比較
附上其他方法於編號 141 、 142 及 146 之預測結果之三維空間圖及其中 切片之比較圖,如圖 4-30 至圖 4-35。結果顯示,本研究所提出之 Rat-Unet 模 型在 DWI 影像分割,在其他方法之模型中表現出色並在各項指標上相對穩定,
如表 4-13,且其他方法對於 T2 及 DWI 兩種影像表現上有落差,而 Rat-Unet 所學習之模型是相對穩定的。
圖 4-30 測試之 DWI 資料集編號 141 之中風區域其他方法預測
圖 4-31 測試之 DWI 資料集編號 141 之切片 12 中風區域其他方法預測
圖 4-32 測試之 DWI 資料集編號 142 之中風區域其他方法預測
圖 4-33 測試之 DWI 資料集編號 142 之切片 6 中風區域其他方法預測
圖 4-34 測試之 DWI 資料集編號 146 之中風區域其他方法預測
圖 4-35 測試之 DWI 資料集編號 146 之切片 10 中風區域其他方法預測
表 4-13 測試之 DWI 影像分割結果與其他方法比較
表 4-14 測試之 DWI 影像模型訓練時間與其他方法比較
𝜿𝒄(%) 𝜿𝒔𝒕(%) 𝜿𝒔𝒃(%) 𝜿𝑫(%) 𝜿𝑱(%) Unet 63.93±12.95 80.73±7.42 90.89±6.05 84.95±4.49 74.08±6.65 DenseNet 21.59±119.54 72.57±20.96 91.88±6.18 78.37±17.08 66.90±18.94 EfficientNet 59.57±17.67 78.02±7.00 91.42±6.98 83.57±5.66 72.14±7.97 InceptionResNetV2 59.61±23.42 77.58±10.27 93.22±5.13 83.82±6.88 72.66±9.38 MobileNetV2 56.89±32.77 77.56±12.46 92.61±5.33 83.33±8.54 72.18±11.15 ResNet 54.95±34.83 78.54±13.04 89.89±8.19 82.75±8.63 71.32±10.89 ResNeXt 57.34±31.40 81.63±14.15 87.38±9.54 83.49±8.91 72.51±11.86 Proposed2 65.87±14.26 84.79±7.24 86.93±8.58 85.70±4.89 75.26±7.22 Rat-Unet 70.58±11.16 85.58±4.85 89.58±6.96 87.36±3.98 77.75±6.02
一訓練週期訓練時間(秒)
Unet 565
DenseNet 190
EfficientNet 144
InceptionResNetV2 415
MobileNetV2 123
ResNet 118
ResNeXt 343
Proposed2 358
Rat-Unet 279
第 5 章 結論及未來展望
5.1 結論
造成人類死亡的主要原因中,腦中風長期榜上有名,因此若是能在腦中風領 域能有突破性進展,勢必能提升人類之生活品質。而以齧齒動物老鼠做為腦中風 實驗對象時,磁共振成像之影像可以作為腦中風區域及程度之初步判讀依據,但 在影像上中風區域選取及判讀需要腦神經專家處置,以進一步探討及分析,這是 一項繁瑣的工作,並且不同專家分割上有標準一致性上之問題。因此本研究提出 腦中風影像自動分割中風區域之模型,以簡化及協助上述之研究流程。
在此分割任務上,本研究透過全卷積神經網路為架構,加入提出之混合殘差 塊,組成 Rat-Unet 網路架構。當中混合殘差塊以不同尺度之特徵給予神經網路 做抉擇,再以殘差學習避免網路在加深時退化之情形。並在訓練模型時對現有資 料集透過不同程度之旋轉、推移及縮放,進行資料增強以提升網路在測試資料上 之表現。
在實驗中,Rat-Unet 網路架構各以少量的 T2 中 588 張及 DWI 中 504 張原始訓練影像,增強後分別增加為 3528 及 3024 張,並以此進行模型訓練。
其所學習出之模型,分別在 T2 加權成像及擴散加權成像 ( DWI ) 之腦部影像 中風區域分割上,對於測試資料集都有優異的精準度。在分割 T2 影像中風區域 中達到 86.84% 的準確度,並在 DWI 影像中達到了 87.36% 的準確度。
以此模型為基礎,近一步運用於未來之資料集,分別能在 T2 及 DWI 影像 中產生腦中風區域之初步分割結果,輔助專家在研究時之目標區域選取及判讀,
簡化研究之流程。

![圖 2-17 圖 a 為傳統殘差塊, b 為 Separable 卷積塊[25]](https://thumb-ap.123doks.com/thumbv2/9libinfo/9604504.630683/27.892.191.782.105.578/圖217圖a為傳統殘差塊b為Separable卷積塊25.webp)