第二章 文獻探討
第一節 資料庫儲
一、 資料倉儲定義
資料倉儲的概念大約起源於60年代美國麻省理工學院為研究計量經 濟學(econometrics) 而發明的多維式模組(multidimensional modeling),關 於資料倉儲的定義與研究,因不同研究者的研究重點及動機不同而有不同 的看法,整理如表 2-1 所示。
表 2-1 資料倉儲定義整理表
作者 內容綱要
Inmon(1996) 「資料倉儲是以主題導向、整合性、非揮發性及時 間變異性所聚集之資料,以支援管理決策
Kimball(1996)
資料倉儲是一群靜態的資料,由日常的交易系統中 取得,另外形成一個倉儲,因此資料倉儲可說是支 援決策的資料庫
Hoven(1998)
資料倉儲是一套經過改良的決策支援系統,它產生 高階的、整合的、系統的、結構化的資料,使其可 以被解釋、查詢、報告、分析以協助商業的決策 Murtaza(1998) 資料倉儲可以產生整合性、非揮發性的組織資料,
並轉換成提供決策支援的資訊。
Lewis & Bernstein & Kifer (2001)
通常是非常大型的,資料的取得包括了數個不同時 間的資料庫來源
資料來源:本研究自行整理
綜合上述觀點,資料倉儲可定義為有系統的蒐集歷史資料,這些資料
具有時間性與整合性,並依據特定研究主題來整合,可進一步利用線上分
析、資料挖掘各項知識發現工具,提供決策者或研究者快速、整合性、視
覺化且具分析性的資訊,以提供精確之決策與分析之用。
二、 資料倉儲特性
資料倉儲大師Bill Inmon(1996)在「建構資料倉儲(Building the Data Warehouse)」一書中之描述,資料倉儲包含以下四個主要特性:主題導 向、整合性、非揮發性及時間變異性,以下分別說明其意義 (Kimball, 1996) 。
(一)主題導向(subject oriented)
資料的組織結構是依據研究者所設定之主題來做安排,而非應用層面 來做安排,倉儲內的資訊是提供作決策支援與資訊運用的來源。
(二)整合性(integrated)
資料倉儲內的資料是一具整合性、穩定性、安全性且清洗過的資料。
各個不同資料來源的資料放入倉儲內時,需要轉換為一致的表示方式 及儲存方式。
(三)非揮發性(non-volatile)
資料放入資料倉儲後,即不允許輕易改變或更新,資料僅可被載入及 讀取用。
(四) 時間變異性(time variant)
資料倉儲的觀念建構於歷史資料模型的基礎之上,在倉儲中存放長期 歷史的資料,供分析、比較、趨勢預測等運用。
Codd於1993 年提出了資料倉儲具有以下特性:
(一)多維度概念(multidimensional conceptual view)
(二)無限制維度與集合層級(unlimited dimensions and aggregation level)
(三)無限制跨維度作業(unrestricted cross-dimensional operations)
(四)動態稀疏矩陣處理(dynamic sparse matrix handling)
(五)主從式架構(client-server architecture)
(六)支援多使用者(multi-user support)
(七)可存取性(accessibility)
(八)透通性(transparency)
(九)直覺的資料處理(intuitive data manipulation)
(十)一致性的報表績效(consistent reporting performance)
(十一)彈性化報表(flexible reporting)
林東清(民92)則提出了資料倉儲具有以下特性:
(一)主題導向(subject oriented)
資料倉儲主要可快速支援決策,而決策本身則包含了許多問題的分析 與評估,這些問題的分析與評估即所謂的主題。
(二)多維度的資料結構(multidimensional data structure)
資料倉儲依主題需求來設計多維度的資料結構,能夠提供更詳細、明 確、多種不同角度的意見來做支援決策用。
(三)整合性(integrated)
資料倉儲的目的在於支援多維度的決策,所需的資料廣度、深度都必 須夠大才能適時的支援,所以它必須是一個大型的、整合內外、不同 時間、蒐集各種不同來源資料。
(四) 資料的一致性
為了提供一個資訊品質良好的資料倉儲環境,必須把不同來源資料,
經過整理、篩選後,統一為具有一致性的資料型態、定義、格式的內 容放在單一的資料倉儲中。
(五)時間變異性(time variant)
支援決策一定要能支援預測分析,故資料倉儲中資料常存放5~10年不 同時期的歷史資料,作為趨勢分析、預測、比較之用。
(六) 不變動性(nonvolatile)
資料存入資料倉儲後便不能更改,因為提供趨勢分析,故每一筆資料 儲存進入後即不再更改,只提供查詢用。
(七) 主/從式架構(client/server structure)
為提供使用者容易使用的介面,以主/從式架構為主,同時也逐漸轉 型為web-based架構。
綜合以上學者所提出之觀點,可以歸納出資料倉儲乃是具有主題導 向、整合性、非揮發性及時間變異的特性,並具備多維度的資料結構及主 從式架構,由上述特性提供研究者做趨勢分析、預測、比較等多用途時,
最基礎、最根本、也是最重要的資料倉儲架構。
三、 資料倉儲架構
資料放入資料倉儲前必須先做適當的加工處理,包括篩選、萃取、轉 換、整合、維運五個動作 (林東清,民 92)。
(一) 篩選(filtering)
根據決策需求的規劃,在不同的資料來源中篩選出所需的資料後再進 行載入的動作。
(二) 萃取(extract)
將資料倉儲內資料萃取與轉換,同時進行資料清洗(Cleaning)的工作。
(三) 轉換(transform)
將所有需要的資料全部進行轉化,統一為具有一致性的資料型態、定 義、格式的內容。
(四) 整合(integration)
若使用資料倉儲做為多維度工具時,則需先將資料載入資料倉儲內的 多維度結構中,整合成資料倉儲的結構。
(五) 維運(maintain)
定期做資料的載入、修改、更新動作,以符合不斷產生的研究新需求。
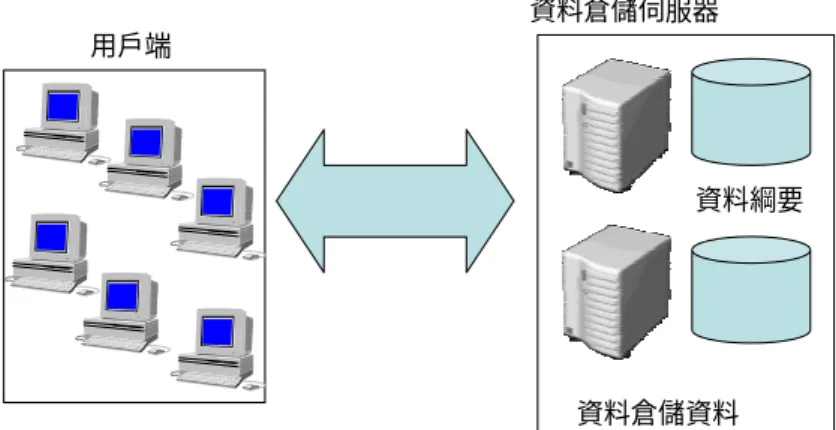
資料倉儲架構上大致可以分為為二種。
(一) 二層式資料倉儲架構:
兩層式資料倉儲,優點為硬體需求較小,並且架構簡單而容 易建置。但日後擴充規模的彈性不大,擴充性與彈性都受侷限,
將來新資料超市與既有資料超市的資料整合也是一大問題
(Berson, Smith, Thearling, 1999)。
用戶端
資料倉儲伺服器
資料綱要
資料倉儲資料
資料來源:(see Berson, et al.,1999)
圖 2-1 二層式資料倉儲架構圖
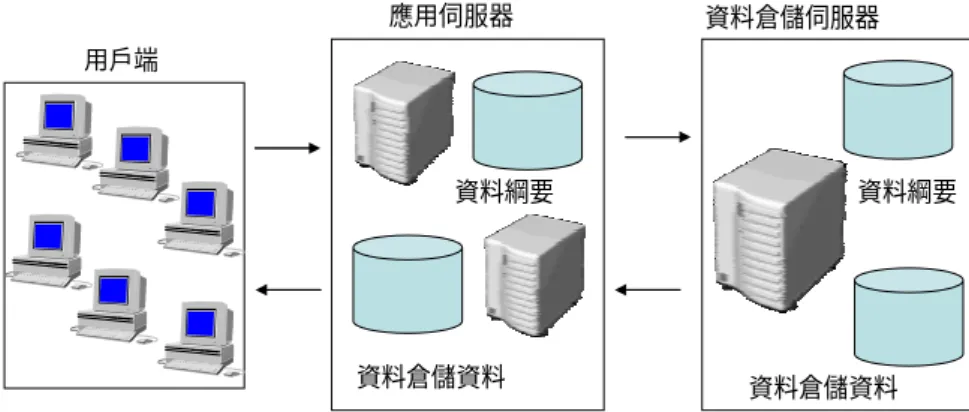
(二) 多層式資料倉儲架構:
在多層式的架構中,以 Jiawei Han在2001年提出的三層式架
構來建立資料倉儲的方式最為廣泛,分為資料來源、資料倉儲及
資料超市 (data mart)三層。資料來源端將這些資料可能分散在各個
不同的地理區域,或學校等資料,做前置處理的動作,確保資料
的純化與正確性後,整合後再匯入資料倉儲系統中。所以資料倉
儲系統可以說是資料的彙總處,提供一個日後線上分析處理的基
礎。因此可將資料倉儲系統的資料再分成若干個資料超市,資料 倉儲著重於資料的整合,而資料超市則著重於使者分析查詢的需 要。三層式的架構最主要的缺點在於系統建置初期的成本過高,
因此較不適合小規模的企業,以及一些先期的開發研究。
Ponniah (2001)也將資料倉儲的架構簡化為三個主要部分:資 料的取得、資料的儲存和資訊的萃取。如圖 2-2 所示。
用戶端
應用伺服器 資料倉儲伺服器
資料綱要
資料倉儲資料 資料綱要
資料倉儲資料
資料來源:(see Berson, et al.,1999)
圖 2-2 多層式資料倉儲架構圖
四、 資料倉儲綱要
資料倉儲的資料模式可分為三種綱要 ( Lewis, et al., 2001) ,第一種架構
為星狀綱要,以事實表格為中心,維度表格以事實表格為中心成放射狀的
模型。第二種架構為雪花狀綱要,仍以事實表格為中心,有些維度經第三
正規化後,進一步分裂成新增表格。第三種綱要為星座綱要,事實表格經
正規化後,成為多元事實表格共用維度表格,這三種網要皆由事實表格與
維度表格所組成。
(一) 事實表格與維度表格 1. 事實表格(fact table)
事實表格是多維式資料庫中最重要的核心表格,儲存各個維 度資料表的主鍵,以及欲觀察的測量值(measure)。通常是儲存 已量化的數值資料,也包含關於事實表格內管理主題內容的可測 量數值。主鍵是由兩個或更多個維度的外來鍵所構成,經常是一 對多的關係。事實表格的內容非常大,為了效率考量,通常不會 對它作正規化。
2. 維度表格(dimension tables)
維度表格與事實表格最大的差別在於維度表格內存放的是 文字性、階層性及類別性資料,作為結構查詢語言之限制條件,
其屬性描述事實表格中每一個列的資訊,並作事實表格與聚合維 度表格之間的連接。記錄各個資料表中的所有屬性,能很有彈性 的提供使用者從不同的角度來觀察欲分析的資料。維度表格有時 候也會進一步作正規化,再切成兩個以上的關聯表,並以外來鍵 相互連接,使得以事實表格為主的星狀結構變成有延長的產生,
稱之為「雪花狀」(snowflake)。
(二) 資料倉儲的三種綱要
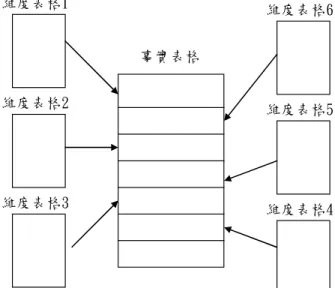
1. 星狀綱要(star schema):
為最常見被採用的模式,其架構由一個事實表格及多個維度 資料表格組成,事實表格每一筆記錄由指向每一個維度資料表之 座標及此座標之測量值組成,每一個維度資料表格由此維度之屬 性欄位組成,星狀綱要做為資料倉儲之特點是以空間換取時間,
此種綱要維度資料表就像星星的光芒,圍繞著事實資料表,看似
星星狀,故稱之為星狀綱要。
事實表格 維度表格1
維度表格2
維度表格3
維度表格6
維度表格5
維度表格4
資料來源:(see Lewis et al.,2001)
圖 2-3 星狀綱要架構圖
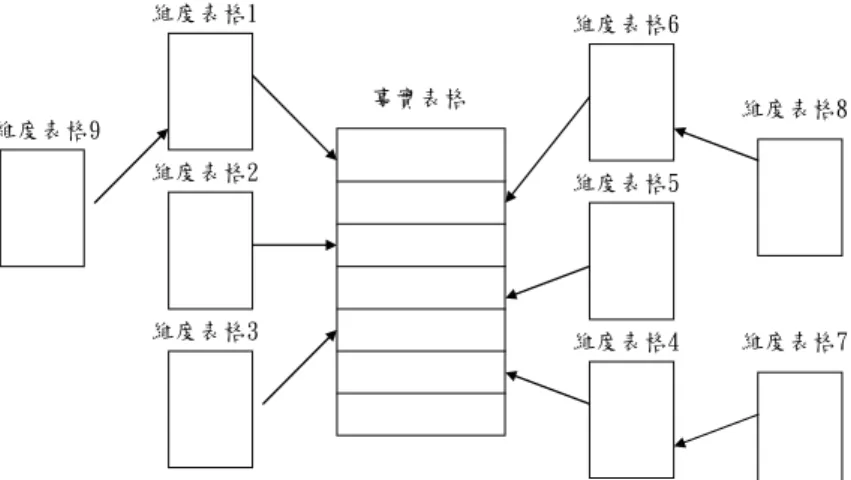
2. 雪花狀綱要(snowflake schema):
為星狀綱要的變型,有些維度表格經正規化後,進一步分裂
成新增加表格,其圖型形成類似雪花狀,由事實表及維度資料表
格所組成,結構上較星狀結構較複雜,雪花型結構能明白地顯示
出經由正規化後,維度階層之關係,優點是維度資料表容易維
護,但在查詢時須作很多合併作業,以致減少瀏覽的效率,且對
系統執行效率反而有不利地影響。系統執行的效能上比星狀結構
略差,其特點為減少資料重複性的問題。
事實表格 維度表格1
維度表格2
維度表格3
維度表格6
維度表格5
維度表格4
維度表格9 維度表格8
維度表格7
資料來源:(see Lewis et al.,2001)
圖 2-4 雪花狀綱要架構圖
3. 星座綱要(constellation schema):
星座綱要看似星狀的收集,事實表格經正規化之後,類似天 空中的銀河,因此稱為銀河綱要( galaxy schema)或稱為星座
( constellation)。星座綱要最主要的目的在考慮多元的事實表格 共用維度表格資料,使用到多個事實表格及需要不同階層的彙總 資料。
事實表格1 維度表格1
維度表格2
維度表格3
維度表格4 事實表格2
資料來源:(see Lewis et al.,2001)
圖 2-5 星座綱要架構圖
4. 三種綱要的比較
由上述三種綱要的敍述,可以做一個整理如表2-2所示。
表 2-2 三種綱要的比較表
優點 缺點
星狀綱要
容易瞭解。
容易定義階層。
減少實體合併數目,增加 執行效率。
低維護成本。
簡單的詮釋資料
龐大的維度表格。
雪花狀綱要
節省磁碟空間。
瀏覽單一屬性。
增加合併(join)的數目 瀏覽跨屬性速度較慢。
特別的查詢較為複雜。
資料載入、綱要、詮釋資 料、維護等較具複雜性。
星座綱要
維度表格中不需要有"層 次" 表示,在低層次的細 部不需儲存任何聚集資 料。
維度表格很大時,會降低 執行效率。
需要更複雜的詮釋資料。
資料來源:(see Lewis et al.,2001)
(三) 資料倉儲綱要小結:
三種資料倉儲綱要各有其優缺點,本研究考量資料庫架構簡單、儲存 空間不受限、可增加執行效率、低維護成本、且容易瞭解等諸多優點,
故採以星狀架構做為本研究資料倉儲綱要之設計方式。
五、 資料超市(Data Marts)
關於資料超市的定義與研究,因不同研究者的研究重點及動機不同而 有不同的看法,整理如表2-3所示。
表 2-3 資料超市的定義與研究整理表
作者 內容綱要
Lin & Kuo (2000)
資料超市是企業資料倉儲的子集合,提供特定的某 一群使用者或某一部門使用,為某一特定部門的決 策支援系統(DSS)之程序需求而量身收集的
Rob & Coronel (2004)
在資料倉儲中若要聚焦在某持殊的小型的群體組 織中,這些小型資料儲存的倉庫可以稱為“資料超 市”它具有:小型的、主題導向的資料倉儲子集 合,在一個小型的集合之中它可以提供做為決策支 援系統所用。
林東清(民 92)
資料超市為資料倉儲中複製的一部份子集合之資 料的組合,是專門為支援某些特定的部門或特定的 地區。
資料來源:本研究自行整理
資料超市可定義為:一個良好的資料倉儲的組織架構其核心部份需有 資料超市做分類、整理、儲存。資料超市是資料倉儲的子集合,提供特定 的某一群使用者或某一需求使用,為某一特定需求的決策支援系統而量身 收集的。其範圍局限於特定主題,資料超市的資料通常只有特定主題的彙 總或詳細資料( Lin, et al., 2000) 。
資料超市的資料通常是彙總過的,多是由資料倉儲傳送到資料超市時 經重新排列、整合而成的。因此許多資料超市都是附屬於資料倉儲系統中
(嚴紀中;古政元,2000)。一般而言,資料超市之間的資料幾乎很少交
換,欲交換的資料首先傳遞並儲存在資料倉儲中,資料一經儲存在資料倉
儲後,再傳遞給想要分享資料的資料超市,資料的一致性便遵循此架構來
維護。
資料超市就資料來源可分為獨立資料超市(independent data mart)及 相依資料超市(dependent data mart),獨立資料超市的資料來源是從一個以 上作業系統或外部的資訊供應來源,或是從特定的地方而來;相依資料超 市的資料來源是由資料倉儲直接產生而來。
總結前述,資料倉儲指的是整個廣域資料,而資料超市指的是一個具
有特定相關資料的集成,因此也可說資料倉儲是多個資料超市之組成,資
料市集的儲存可以分散儲存於不同的伺服器上,以提供特定性質的資料需
求。資料超市的優點為部門可以掌控在資料超市內的資料與處理程序,所
花費的成本遠低於資料倉儲,資料由資料倉儲傳遞到資料超市時,已成為
符合特殊需求之集合。至於缺點則是就資料而言,和資料倉儲相比較之
下,資料超市的環境顯得相對小些,且資料超市只與特定主題有關。
第二節 資料挖掘
知識的貢獻大於資訊,資訊的貢獻大於資料,資料挖掘就是從大型的 資料庫中萃取出隱藏的預測資訊,在商業上可以有效地協助企業利用資料 倉儲做為預測未來的趨勢以及行為分析,也是建立企業智慧最主要的方法 之一,因此有人稱之為資料庫的知識挖掘(Knowledge Discovery in
Database, KDD)、資料考古學(data archaeology)或資料型態分析(data pattern analysis) (梁定澎,2004)。若能由資料中找出顯著且有用的決策 模式或決策法則,進而正確地預測未來的行為,將能增加更多企業智慧,
資料挖掘可以創造出許多新的知識,透過這些知識的發現、儲存、分享、
利用,是重要的知識產生工具。
一、 資料挖掘定義
關於資料挖掘的定義與研究,因不同研究者的研究重點及動機不同而 有不同的看法,整理如表2-4所示。
表 2-4 資料挖掘的定義與研究整理表
學者(年代) 資料挖掘的定義 Frawley(1991) 從資料中萃取出隱藏的、先前未知的
有用資訊
Gnardellis & Boutsinas(2001) 認為資料挖掘為資料庫中知識發掘過 程的一個步驟
Fayyad(1996)
可萃取出資料中有效的、嶄新的、具 潛在效益的資訊之非細瑣過程,其最 終目標是瞭解資料的型態
Berry & Linoff(1997)
為了發現有意義的模式或規則,以自
動或半自動的方式,來勘查、分析大
量資料所進行的流程
Lewis & Bernstein & Kifer (2001)
資料挖掘是一個發掘知識的過程,可 以在一個大型資料集合結構中找到所 需要的特徵知識
Berson & Smith & Thearling (1999)
在一個資料倉儲的數個資料倉庫中,
使用「已經建立完成的統計方式」及
「機器學習技術」 ,找尋具有相互關 係、項目、趨勢預測等意義深遠的挖 掘處理過程
Jiawei Han(1997)
透過許多種資料分析的技術以發掘出 資料與資料之間的型態與關係的一種 過程。
梁定澎(2004)
資料挖掘就是從資料中發掘知識過 程,從大量資料中,找尋事前未知或 有效且可以付諸行動之規則或知識
林東清(民92)
資料挖掘指的是利用統計,人工智慧 (AI)或其他的分析技術,在大型資料 庫(倉儲)內挖掘與尋找未知的.有效 且可實行的資料間所隱藏的關係與規 則,可用來支援決策支援系統
資料來源:本研究自行整理
綜合以上各專家學者對於「資料挖掘」的定義後,可以發現和資料庫 知識發現流程(Knowledge Discovery in Database process, KDD process)有 關,Fayyad(1996)認為資料庫知識發現流程是說明在資料庫中取得知識 的過程,因此對於不確定、不完整及有干擾性的資料要預先處理,而資料 挖掘只是資料庫知識發現流程中的一步驟。從資料庫中找尋知識,不但結 合了資料庫、知識庫、而且也包括人工智慧、統計學等方面相關的應用。
透過知識的挖掘,從龐大的資料庫中挖掘出有意義的資訊,以幫助決策者
做最有利的決策(Berson, et al., 1997;楊琇媛、李維平,民91年)。
資料庫知識發現的流程,可包含下列幾個步驟(Fayyad,1996)。
1. 建立目標資料集合:應用先前相關知識,選擇與目標相關的資料。
2. 資料淨化與先前處理:過濾資料雜質、處理缺漏資料、定義資料 型態與綱要等。
3. 資料轉換:將資料範圍縮小資料,對目標及任務找出有用的代表 資料,並利用多維度法或資料轉換法來減少變數或找出不變的資 料。
4. 選擇資料挖掘模型與方法:找出資料關連性。
5. 資料挖掘:根據問題的種類進行資料挖掘。
6. 結果說明:對結果解釋與評估,決定結果呈現方式。
選擇
處理
轉換
資料挖掘
解釋/評估
資料
目標 資料
處理 資料
轉換 資料
特徵值 知識
資料來源:(see Liu, Z. & Guo, M., 2001)
圖 2-6 資料庫知識發現的流程圖
由圖 2-6可以清楚看出,整個資料庫知識發現的流程,是先將資 料選擇、清理、整合與轉換後,存放於資料倉儲中,再利用資料挖掘 技術萃取資料的型樣,最後評估型樣的實用性與呈現知識給使用者,
而資料挖掘乃是整個資料庫知識發現流程中的一個步驟。
二、 資料挖掘任務與技術
(一) 資料挖掘各項任務
資料挖掘是利用統計與人工智慧的演算法,從龐大的歷史資料中,找 出隱藏的規律及建立精準的模型,用以預測未來,在商業上可有效提供市 場行銷以及顧客管理所需根據之規則型態,根據Berry and Linoff (2000)在
“Mastering Data Mining“一書中,可將資料挖掘區分為六大任務。
1. 分類(classification)
由目前的分類推論出一套最有效的規則來識別群體的類型,從已 知類別的物件集合中,依據其屬性(可能影響物件類別的變數)建 立一個分類模式(如決策樹或決策法則)來描述物件屬性與類別 之關係,再根據這些特徵,對其他未經分類或是新的資料作預 測,分類的目的是產生一個分類模型來描述物件屬性與類別之間 的關係,事實上,分類不光是提供單純「會」或「不會」的答案 而已。還可以透過分類結果的純度(purity)來提供分類機率,這些 分類機率可以提供我們作為名單排序或是篩選顧客時的重要依 據。而分類模型最常使用的表示法包括類神經網路、決策樹 (decision tree)=>樹歸納法(decision tree)及決策法則(decision rules)=> 法則歸納法(rule induction)。
2. 推估(estimation)
推估與分類的差異在於分類問題是預測「類別變數」,而推估問
題主要是用來推估「連續變數」。透過輸入資料我們可以用來推
估一些未知的連續性變數,在商業上的應用例如信用額度等。
3. 預測(prediction)
預測與分類和推估相當接近,其差別在於預測是去推估未來的數 值及趨勢,以歷史資料來預測未來的走向,例如根據過的課程開 設來預測未來課程數量的趨勢是增加還是減少,藉以做為調整教 育資源分源參考資料。
4. 群集化(clustering)
利用一些特性的組合將這些物件分成集群的過程,根據物件的相 似性(或不相似性),將這些物件分成群集,使得每個群集內的成 員具有高度的相似性,而不同群集間之物件具有高度的不相似 性。但是與「分類」不同的是,群集不像分類問題中有那麼明確 的分析標的,必須透過各產業領域知識專家或是借用其他像敘述 統計或線上分析處理的工具,才能進一步找出這群相近的顧客 中,有哪些共同的特性。當中在群集化分析常用的演算法包括:
K-means、EM以及自我組織映射圖網路(SOM, self-organization map)。
5. 關聯分組(affinity grouping)
關聯分組就是從歷史資料中,找出哪些物件/事件總是相伴發 生,在大多數的時候我們會稱之為關聯規則或者是購物籃分析。
在關聯規則當中最有名的案例,就是NCR為美國最大的連鎖零售
商wal-mart所分析的案例,他們發現在星期四的晚上,大多數購
買尿布的消費者,也會一併購買啤酒。這個規則之所以有名其實
是在於它突顯出利用資料挖掘可以發覺出許多利用傳統行銷人
員經驗所無法找出的規律,而事後的研究發現,這些同時購買尿
布與啤酒的人,大多數是年輕的夫婦,趁週四買週末狂歡要用的 啤酒時,也順便購買安置家中幼兒的尿布。關聯分組可以成功的 找出事物之間隱藏的關聯性,而找出這種關聯性有助於我們研判 針對單一事物做改變時所帶來的整體影響。
6. 描述(description)
描述是資料挖掘過程中的重要附加價值的一種,通常在進行資料 挖掘的前置作時透過資料視覺化,能夠將資料特性呈現在資料挖 掘者的面前。人的眼睛有時候是最好的資料挖掘工具,透過良好 的資料視覺化程序,我們可以發覺許多演算法無法判別的規則型 態。
(二) 資料挖掘各項技術
在資料挖掘領域中最普遍使用的幾項技術,如表2-5所示 。 表 2-5 常見的資料挖掘技術整理表
技術 描述
購物籃分析
「同質分組」的一種形式,著眼點在於找出可以一起販 售的商品組合,它能顯示商品組合的售出率有多高並且 形成規則。當交易是非匿名時,它可以加上一個模組進 行跨時性分析。
記憶基礎理解
比對新資料和現存資料庫原有資料的相似度,以決定新 資料的類別或預測值的工作。它是以距離函數判斷資料 間的相似度,再以數個最相似的資料投票來決定歸類結 果。
群集偵測
針對要分析的資料,利用幾何學、統計、類神經網路等 方法,將資料分成多個群內同質、群間異質的群組,使 各群組的特徵能有效突顯出來。
連結分析 搜尋資料間的關聯,並且據此發展出分析模型,這是圖
像理論在資料挖掘中的應用。
決策樹
主要用在資料分類上,屬於監督式的資料挖掘方法。它 能將訓練資料集的紀錄區分為獨立的子群,每一子群都 有自己的規律,彼此是互斥的。同時在樹的發展過程中,
獲得清楚易懂的分類規則並找出關鍵屬性。
類神經網路
一種平行分散式的計算模式,以大量簡單的相連人工神 經元,模仿生物神經網路的資訊處理系統,使電腦能夠 模擬人類的神經系統結構,進行資料的處理。
基因演算法
應用選擇、雜交、突變等物競天擇和基因演化的機制,
將此機制結合電腦語言,經過世代繁衍,得到最後留下 的最佳方案,通常用在找尋預測功能的最佳參數。
資料來源:(see Berry, et al., 1997)
(三) 資料挖掘各項技術適用之任務整理:
上述多種技術各自適合達成不同的任務,在什麼時候要採用何種 資料挖掘技術,必須看特定資料挖掘所要達成的目的,及所要分析資 料的取得來決定,茲整理如下表2-6所示。
表2-6 資料挖掘各項技術適用之任務表
技術 分類 推估 預測 關聯
分組 集群 描述
傳統統計 ○ ○ ○ ○ ○ ○
購物籃分析 ○ ○ ○ ○
記憶基礎理解 ○ ○ ○ ○
群集偵測 ○
連結分析 ○ ○ ○
決策樹 ○ ○ ○ ○
類神經網路 ○ ○ ○ ○
基因演算法 ○ ○
資料來源:(see Berry, et al., 1997)
三、 資料挖掘應用
在大學課程網資料倉儲方面,希望找出課程的一些共同的特徵,藉此
預測未來的開課趨勢或是開設課程內容是否有變化,以幫助決策人員做出
正確的判斷。資料挖掘可以從現有課程資料中找出他們的特徵,再利用這 些特徵到資料庫裡去篩選隱藏其中的知識。為了實現這樣的目標,必須和 資料倉儲整合並且設計成具有彈性及互動式的分析工具。OLAP伺服器提 供使用者更豐富的觀察模式,其多維度的結構讓使用者能夠依據學年度、
課程或者是其它更為透徹的觀察角度來做統計,資料倉儲必須和OLAP server整合以便使分析融入其中。然後可以藉由報表工具(reporting tool)、
視覺化工具(visualization tool)以及分析工具(analysis tool) 來規劃未來的
決策和確認這些決策的影響。
第三節 線上分析處理
1993年,Codd認為OLTP已不能滿足終端用戶對資料庫查詢分析的需 要, SQL對大型資料庫進行的簡單查詢也不能滿足使用者分析的要求。用 戶的決策分析需要對關聯資料庫進行大量計算才能得到結果,而查詢的結 果並不能滿足決策者提出的需求。因此,Codd 提出了多維資料庫和多維 分析概念,即線上分析處理(Online Analytical Processing, OLAP)。
一、 線上分析處理定義
線上分析處理主要是結合資料倉儲,提供資料上鑽、深耕、切片、切 丁、轉軸的功能以進行多維度資料的查詢,是一個具備彈性、功能強、速 度快的資料分析工具,企業利用線上分析處理和資料倉儲結合,即時快速 地提供分析性的資訊來支援決策。 (林東清,民92)
其目標是滿足決策支援或多維環境特定的查詢和報表需求,它的技術 核心是“維度(dimension)”這個概念,提供一個線上支援決策分析工 具(Jiawei,1997; Chaudhuri, Dayal, 1997),能提供多維度以及快速查詢,
讓分析者可以輕易及有效率的建立符多維度的資料結構,提供互動式的操
作讓分析者從不同角度去分析資料,以滿足決策支援及多維環境特定的查
詢和報表需求,協助決策者了解與掌握問題。
Berry, et al.(1997)指出線上分析處理具備的優缺點:如表 2-7 所示。
表2-7 線上分析處理優缺點分析表
優點 缺點 是一個強大的虛擬工具
提供快速、互動反應時間少 在連續時間分析上時十分良好的 可以使用在分類和分群上
可以支援許多的使用者
設定一個 Cube 是困難的 在連續值的操作上是困難的 cube 可能很快的就過時 不是資料挖掘
和資料挖掘是互補的,不能自動找 到型態
資料來源:(see Berry, et al., 1997)
Rob, et al. (2004)在「資料庫系統」一書中提到,若將資料、資訊、知 識視為一個金字塔型時,依其重要性及處理的難易度,及其應用之領域和 適用分析工具及架構來看,可以如圖2-7所示。
處理層次 高
低
知識
資訊
資料 線上轉換處理 操作資料庫 資料挖掘
線上分析處理 決策支援系統
資料倉儲 人工智慧
知識發現流程 類神經網路, etc.
資料來源:(see Rob, et al.,2004)
圖 2-7 線上分析處理處理階層圖
總結上述文章所敍,線上分析處理可作為提供企業智慧最重要的分析 工具,它本身可以在這多維度的空間中,具備快速、有彈性地提供各種不 同的資訊轉換功能,可以依決策者的需求旋轉成不同的維度,切丁成個細 部範圍,也可以從三個不同的維度切片成二個維度,經由宏觀到微觀,或 由微觀到宏觀,這些都是決策者常用且必須用到的分析功能,因此線上分 析處理可定義是一個具備彈性、功能強、速度快的資料分析工具。
二、 線上分析處理維度 dimension 與立方體 cube
線上分析處理在進行多維度資料模型設計,具有維度和立方體的概 念,維度即為研究者對事物分析的角度,如:時間維度、課程維度等,如:
時間維度之階層關係經常為 月→季→年,因此在研究者經常透過維度的 調整,來了解維度之間的關係及維度產生之影響,然而研究者對資料的分 析行為經常是由粗而細漸層的分析,在分析的過程中來發現問題,但在分 析的過程中經由維度組合後的多維度資料表,經常是資料項目眾多,且經 過維度組合及不同階層產生資料的彙總。
在線上分析處理中有一個 cube 機制佔有十分重要的地位,cube 為資
料倉儲的一個子集合,是一種將資料事先進行整理、加總並儲存到多維式
結構的一種應用方式,可以讓存取資料倉儲的速度變快,不論是大量存
取、或是少量存取,都有非常好、一致性的存取速度( Corey,1998; Goil,
Choudhary, 1999 )。
三、 線上分析處理類型
線上分析處理常見有三種型式:多維式線上分析處理(MOLAP:multi - dimension OLAP)、關聯式線上分析處理(ROLAP:relational OLAP)及混 合式線上分析處理(HOLAP:hyper OLAP)三種(Kroenke, 2001)。
(一) 關聯式線上分析處理(relational OLAP)
關聯式線上分析處理則是以儲存資料倉儲資料的資料庫來存放彙總 性資料,因此只可用於不常被使用及查詢的cube;透過標準或擴充式 的關聯式資料倉儲管理系統來建置資料倉儲,以支援OLTP,資料儲 存在關連式資料庫中,透過SQL語法的查詢方式來讀取資料,關聯式 線上分析處理並不會預先將資料彙總,所以其所有的資料來自於資料 倉儲,線上分析處理伺服器只儲存其架構,使用資料倉儲中的表格來 儲存彙總資料及詳細資料,為傳統關聯式資料庫的延伸,較適合應用 在不常使用且大量的資料,如歷史性資料。
ROLAP 分析 處理邏輯 ROLAP資料
處理邏輯 資料倉儲
資料
操作性 資料
ROLAP 使用者介面 ROLAP 伺服器
ROLAP 使用者介面
ROLAP 使用者介面
ROLAP 使用者介面
資料來源:(see Rob, et al.,2004)
圖 2-8 關聯式線上分析處理架構圖
(二) 多維式線上分析處理(multi-dimensional OLAP)
多維式線上分析處理會預先將資料彙總並將其儲存在多維度資 料庫(multi-dimensional databases, MDDBs),故若要存取彙總性資料則 取自多維度資料庫,明細資料取自資料倉儲。適合應用在使用頻繁、
量小且的反應時間要求快的情況,亦可用於離線狀態。多維式線上分 析處理將多維度資料以特定的結構加以儲存,OLAP則直接在此特定 的資料結構上進行運作,複雜度較高,所需的建置時間較常,使用者 在進行分析時可以有較高的績效,系統可以提供更快速的回應時間。
MOLAP 分析 處理邏輯 MOLAP 資料
處理邏輯
資料倉儲 操作性 資料
資料
MOLAP 使用者介面
多維度資料庫 管理系統 資料立方體 多維度資料倉儲
關連度資料庫 管理系統
MOLAP 伺服器
MOLAP 使用者介面
MOLAP 使用者介面
MOLAP 使用者介面
資料來源:(see Rob, et al.,2004)
圖 2-9 多維式線上分析處理架構圖
(三) 混合式線上分析處理(hyper OLAP)
混合式線上分析處理則是前面兩者的混和體,彙總資料儲存於多
維式,而基本資料則儲存於資料倉儲的關連性資料庫之中,當用戶要
查詢彙總性資料時,會從多維式線上分析處理中找尋資料,而當使用
者觀看細部資料時,則從關連式線上分析處理中去找出所要的資料,
因此,會使用比多維式線上分析處理使用更少的空間,但會比關連式 線上分析處理有更好的查詢速度,這種特質適合於建立擁有大量資 料、但要求快速查詢的資料立方體。
(四) 三種類型分析比較
線上分析處理常見有三種型式分析比較如表2-8及圖2-10所示。
表2-8 資料挖掘各項技術適用之任務表
優點 缺點
多維式(MOLAP)
查詢速度極快
硬體設備要求相當低簡單、
好用、使用者不需有資訊技 術背景
分析、評比、數學功能強 易於維護
建檔速度慢,一般的多維式 資料庫不能太大
架構缺乏彈性,如果需變更 設計則必須重新建置資料庫 對資料比較挑剔,不是每種 資料都適用於MOLAP 資料重複性高,開放性差
關聯式(ROLAP)
彈性較佳,變更設計容易,
可支援中大型資料倉儲需求 對資料比較不挑剔
開放式技術
查詢速度較MOLAP慢 查詢語法需資訊背景人員 難以執行許多複雜的查詢 對硬體設備要求比較高
混和式(HOLAP)
查詢速度一般介於上述兩著 之間,建檔速度極快,擴展 性佳,可以支援大型資料庫 資料模組設計彈性佳,適用 ER Model
微觀查詢速度極慢
SQL 有其先天限制,難以執 行許多複雜查詢
資料來源:(see Berry, et al., 1997)
常見三種線上分析處理各有其優缺點,本研究考量關聯式線上分析處 理有彈性較佳、變更設計容易、可支援中大型資料倉儲需求等諸多優點,
應用多使用在大量的資料上,且其缺點可利用程式撰寫的方式克服及目前
電腦設備性能均可支援考量下,採關聯式線上分析處理做為設計方式。
應用 複雜度
應用效能 關連式
OLAP
混合式 OLAP
多維式 OLAP
資料來源: (see Berson, et al.,1997)
圖 2-10 線上分析處理常見三種型式之應用及效能比較圖
四、 線上分析處理特性
Rob, et al.(2004)提出線上分析處理主要具有以下四個主要的特性。
(一) 快速(fast):
具備特殊儲存格式、預先計算及特定硬體需求達到快速反應目的。
(二) 分析(analysis):
系統應能滿足各種研究分析需求。
(三) 共用(shared):
系統即使在多人使用時應能提供資料瀏覽權限,以保障機密資料之安 全性。
(四) 多維度(multi-dimensional):
系統必須提供一個可瀏覽多維度資料的環境,以符合多維分析特性。
(五) 資訊(information):
所提供之資訊是依據使用者需求,從資料倉儲中複製轉換而來。
林東清(民 92)在「資訊管理 e 化企業的核心競爭能力」一書中也提 到線上分析處理主要的特性與功用。
(一) 能即時地、快速地提供整合性的決策資訊
(二) 主要目的在支援決策資訊的分析而非線上交易處理 (三) 常需要擷取大量的歷史資料進行趨勢分析
(四) 常需對多維度的資料進行複雜的分析
(五) 常需用到整合的半成品資訊,及下拉的細部資料 (六) 常需要以不同時間來比較整合後的資料
(七) 常需利用運算公式來推算衍生的資訊 (八) 需快速回應使用者的決策需求
五、 線上分析處理操作
典型線上分析處理操作 ( Lewis et al., 2001) 包括上鑽、深耕、切片、切 丁、轉軸五種,圖2-11為原始資料立方體,以此說明五種分析方式,分述 如下:
課程 學院
時間
文學院 社會學院 理工學院
2002(90)
2003(91)
2004(92)
工藝 出版 品牌
……..
3 11 0
4
6
5
17
0
1 1
0
13 0
0 0
0 0
0 0
資料來源: (see Dai, C. Y. & Hsu, M. J. & Lin, P. L.,2005)
圖 2-11 原始資料立方體圖
(一) 上鑽(rroll-up):縮小維度,顯示資料的彙總值。針對學院而言,
若欲觀察各個不同學院間的情形,須將學院的維度縮小,如此 就可觀察出欲觀看之特定學院與其他維度間的情形,如圖2-12 所示。
課程 學院
時間
2002(90)
2003(91)
2004(92) 文學院
理工學院
工藝 出版 品牌
3 11 0
4
6
5
17
0
1
1 13 0
0
0
資料來源:
(see Dai, et al., 2005)圖 2-12 原始資料立方體上鑽圖
(二) 深耕(drill-down):放開維度,顯示出資料的詳細值。針對時間
這個維度,若欲詳細觀察每學期情形,必須將時間維度的學年
層級向下展開成學年,可觀察學期與學院維度及課程維度之間
的情形,如圖2-13所示。
課程
時 間
2002(90) 第一學期
2003(91) 第一學期 2002(90) 第二學期
2003(91) 第二學期
2004(93) 第一學期
2004(93) 第二學期
學院
文學院 社會學院 理工學院
工藝 出版 品牌
資料來源:
(see Dai, et al., 2005)圖 2-13 原始資料立方體深耕圖
(三) 切片(slice):固定某一特定維度值。此處選擇作切片的處理,
如圖 2- 14所示。
課程 學院
工藝 出版 品牌
文學院 社會學院
理工學院
3 11 0
1 0
13 0
0 0
資料來源:
(see Dai, et al., 2005)(四) 切丁(dice):各維度限定一定範圍。經由切丁這個動作可觀看 特定的小範圍維度間關係,如圖2-15所示。
課程 學院
時間
2002(90)
2003(91)
10
工藝 出版
3 11
4 5
1 13
文學院 理工學院
資料來源:
(see Dai, et al., 2005)圖 2-15 原始資料立方體切丁圖
(五) 轉軸(pivot):針對不同的象限,作旋轉的動作,以不同面向的 方式呈現資料。如圖,將縱軸學院,橫軸課程,轉變成縱軸課 程,橫軸學院,如圖2-16所示。
課程
學院
工藝出版品牌
文學院
社會學院 理工學院
3
11
0 1
0
13 0
0 0
資料來源:
(see Dai, et al., 2005)圖 2-16 原始資料立方體轉軸圖
第四節 互動電視傳輸網路光纖課程
隨著技術的發展與演進,電視媒體所能提供的服務內容將越來越豐 富,畫面從黑白進步至彩色,信號傳送由無線、有線到衛星,內容也越來 越多元,數位化之後的內容再加上網路架構,電視未來將從單純單向提供 節目發展到能提供使用者雙向互動的服務。電視與網路媒體及通信本質上 是相異的,不同的媒介傳輸各自的內容,且媒介之間的藩籬,壁壘分明。
然而在新科技不斷的發展下,使得三者之間的界線越來越模糊,並得以匯 流(交通部電信總局,民91),原本不同的平台上可提供的服務內容也越 來越接近(Kűng, 2000)。
互動電視在國內互動電視服務仍處於一個剛被導入市場的「導入期」
(introduction)階段,故變動相當快速,產業不成熟也未成型。是一個未來 十分值得投入的「新興產業」,若能配合政府大力推展,極具發展潛力。
一個產業的成功與否,除了研發技術的進步、政府的大力支持、經費是否 充裕外,未來若台灣想在世界上互動電視領域佔一席之地,人才的培訓也 是不可獲缺的一環,國內在互動電視等相關產業人才培育的整體配合課程 開設情況調查或分析工作,目前尚付之闕如;且受到其他高科技產業吸引 影響,產業界對人才的需求及培訓可說是供不應求(詹睿然,民92) 。
一、 互動電視
傳統上電視媒體、電信業者、網路業者各自提供不同的服務及內容,
所擁有的市場及技術也各有所異(如表2-9所示),但隨著有線電視網路、
廣播電視、電信、網際網路等市場因數位匯流趨勢,以及對「跨業經營」
及「跨業擁有」之限制解除,不僅各項服務漸次呈現多元化發展趨勢,傳
統之角色亦日趨多元與不確定性,展現電信、廣播電視、網際網路、有線
電視網路業者之身分與界限會因數位化發展而日趨模糊(交通部電信總 局,民91;Kim, Sawhney, 2002),目前在內容服務方面,主要是提供三網 合一(triple-play)的服務,也就是將聲音、資料和影像以不同的波段在同 一條光纖中傳輸(鍾沛璟,民94a)。
表2-9 傳統電信產業所能提供的服務與技術一覽表
電視媒體(media) 電信(telecom) 網路(IT)
內容(content) ○ 包裝(packaging) ○
傳播(distribution) ○ ○
使用者線路(user conduit) ○ ○ 使用者介面(user interface) ○ ○
資料來源:(see Kim, et al., 2002)
而「互動電視」(interactive TV) 即為上述數位科技匯流以後的產物,
可視為傳統電視的「轉型」,或對於「電訊匯流」的回應,藉由數位科技 的發展,透過地面無線、有線電視、電信網路或衛星等寬頻網路(broadband network),傳輸數位化的影音與加值服務,是一種將電視與網路的互動 性結合在一起的新媒體。數位匯流後所能提供的應用與技術和傳統相較之 下也大不相同(如表2-10所示),它一方面提供使用者主動參與的視聽娛樂 經驗,另一方面對媒體產業內的經營者而言則是提供了一個新的事業機會
(Pramataris, Papakyriakopoulos, Lekako, Mylonopoulos, 2001)。
表2-10 數位滙流後的應用服務一覽表 內容(content) 電視系統
遊戲軟體
電影 音樂錄製
包裝(packaging)
有線網路/寬頻網路 列印
服務
網路 電腦報導
傳播(distribution) 地球衛星 有線網路
電信與電影後製
使用者線路(user conduit)
地區性電信纜線 電子有線網路 網際網路 機上盒 使用者介面(user interface) 電視
電腦
個人化
資料來源:(see Kim, et al., 2002)
根據資策會亞洲資訊科技報告書(asia IT report)指出(Chang, 2001):
互動電視指經由衛星、線纜或地面無線等寬頻網路(broadband)傳送數 位化(digitalization)的加值節目(value-added program),透過人性化
(user-friendly)的介面設計,同時提供電視頻道與其他互動式的服務。
這些互動式服務包含了隨選視訊(video on demand;VOD)、電子節目選 單(electronic program guide;EPG)、個人數位電視錄影機(personal video recorder;PVR)以及先進電視(enhanced TV)諸多服務。
綜觀互動電視近年來在國外發展漸漸成形,市場研究公司strategy analytics 預測,2005年時全球將有6億2500萬的人口,透過電視平台網路 進行電子購物、銀行交易、線上遊戲、資訊搜尋以及互動式娛樂等服務。
調查報告中指出,至2001年底前,使用結合電視與眾多網路技術的互動式 數位電視服務的全球家庭數已達到3800 萬戶。這群「視聽戶」中,62%
分佈在西歐地區,北美佔18%,亞太佔10%,拉丁美洲佔1%;而使用者中74%
選擇以衛星(satellite)傳輸方式上網,另外由有線電視(cable)業者提供服 務功能者佔21%(陳怡伶,民90;林山霖,民91;鍾沛璟,民94b)。
二、 傳輸網路
在互動電視的網路傳輸系統方面,可分成兩大部分:一為核心網路,
使用於連接頭端、交換局和終端用戶之間的高速數位網路,將數個頭端和 集散中心相連,目前以同步光纖網路(synchronous optical network;SONET) 或是數位同步架構(SDH)上用ATM傳輸為主(程予誠,民88);另一為用 戶迴路,是用以連接頭端和終端用戶間之間的傳輸系統,其特色在於它是 方式為下行的傳輸量遠大於上行的傳輸量,即所謂的非對稱式的傳輸。使 視訊流能夠流暢的傳輸到家用戶中,因此必須透過寬頻(broadband)網 路進行(王國雍,民84),目前提供市場服務的三種寬頻網路技術以直播 衛星(direct PC)、傳統電話網路(ADSL)和有線電視纜線(cable modem)為 主(趙怡、陳駿德,民90)。
目前我國在互動電視的經營有三大業者:中華電信MOD、中嘉網路、
東森數位電視,各擁有優勢及其資源,考量目前傳輸網路的成本價格及經
濟效益下,目前中華電信在傳統的電信網路架構上採用(ADSL)為主要用
戶迴路,將光纖舖設到達用戶鄰近機房,再以電話網路將視訊信號送至用
戶家中,有線電視業者:中嘉網路和東森數位電視則以有線電視纜線(cable
modem)為主,並採用光纖和同軸混和式架構HFC(Hybrid Fiber-Coaxial
network)做為系統架構,使用部份的光纖代替同軸電纜作為網路傳輸的幹
線,到達用戶區域時再透過光電轉換方式以同軸電纜送至用戶家中,可使
傳輸的品質大幅提昇並可使系統的涵蓋面更廣泛(陳聰謀等.,民92;鄭允
達,民91)。
未來的互動電視在有線電視和電話公司的競爭中,關鍵的因素不是 技術、資金、法規,而是良好的互動內容與服務品質,以及推銷給消費 者的技巧(Daniel, David, 1997),而傳輸網路正是最為關鍵的基礎建設,
以光纖到家的技術可同時滿足距離與頻寬的需求(鍾沛璟,民 93),未來 在品質、頻寬及用戶要求諸多嚴厲挑戰下,加上科技的進步及成本不斷 降低,不論是核心網路或是用戶迴路,光纖(fiber)的大量使用與舖設 將成為網路傳輸系統中未來方向及趨勢之所在。
ADSL Cable Modem
FTTx (B/C/H)
資料來源:本研究整理
圖 2-17 網路傳輸系統中未來方向及趨勢圖
三、 光纖
使用光纖在信號傳輸的應用很多,具有下列諸多優勢(陳克任,民89;張 士行,民93;游明達、莊嘉琛,民92):
(一) 通信容量大,中繼距離長 (二) 體積小重量輕低衰減
(三) 保密性高且具電絕緣性,不愛電磁干擾
(四) 柔軟度與彈性系統易維修
光纖具有高頻寬、可雙向互動、資源豐富、體積重量輕巧、不受干擾 及長距離信號傳遞等優點,雖然有連接技術複雜及成本高等問題,但仍無 法掩蓋光纖網路將成為最重要的傳輸網路的事實。
光纖接入網路架構做到連分配線/餽線以及用戶迴路都使用光纖來接 取主要的三種型式為光纖到大樓(Fiber To The Building: FTTB)、光纖到近 鄰(Fiber To The Curb: FTTC)、光纖到用戶(Fiber To The Home: FTTH),
整理如表2-11所示。
表2-11 FTTx類別與所提供的服務一覽表
NIU放置位址 服務對象 所提供應用與服務 FTTC 道路、馬路旁 獨門獨院的用戶 VOD、寬頻上網、
互動電視
FTTB 公寓大樓 辨公大樓
中大型企業單位 及商業用戶
高速數據、電子商 務、視訊、線上醫 療、遠距教學 FTTH 住戶家中 家庭 VOD、居家購物、網
路遊戲
資料來源:(陳聰謀等.,2003)