最佳实践
文档版本 06
发布日期 2021-12-16
版权所有 © 华为技术有限公司 2021。 保留一切权利。
非经本公司书面许可,任何单位和个人不得擅自摘抄、复制本文档内容的部分或全部,并不得以任何形式传 播。
商标声明
和其他华为商标均为华为技术有限公司的商标。
本文档提及的其他所有商标或注册商标,由各自的所有人拥有。
注意
您购买的产品、服务或特性等应受华为公司商业合同和条款的约束,本文档中描述的全部或部分产品、服务或 特性可能不在您的购买或使用范围之内。除非合同另有约定,华为公司对本文档内容不做任何明示或暗示的声 明或保证。
由于产品版本升级或其他原因,本文档内容会不定期进行更新。除非另有约定,本文档仅作为使用指导,本文 档中的所有陈述、信息和建议不构成任何明示或暗示的担保。
目 录
1 导入导出...1
1.1 导入数据最佳实践... 1
1.2 GDS 实践指南... 2
1.3 教程:从 OBS 导入数据到集群...4
1.4 教程:使用 GDS 从远端服务器导入数据... 8
1.5 教程:导入 MRS 数据源...13
1.6 教程:导入远端 DWS 数据源... 22
2 开发设计...29
2.1 表设计最佳实践... 29
2.1.1 学习“教程:调优表设计”... 29
2.1.2 选择存储模型... 29
2.1.3 选择分布方式... 29
2.1.4 选择分布列... 30
2.1.5 使用分区表... 31
2.1.6 使用局部聚簇... 31
2.1.7 选择数据类型... 31
2.2 教程:调优表设计... 32
2.2.1 教程指引... 32
2.2.2 本教程所用表模型... 32
2.2.3 步骤 1:创建初始表并加装样例数据...33
2.2.4 步骤 2:测试初始表结构下的系统性能并建立基线... 37
2.2.5 步骤 3:选择存储方式和压缩级别... 40
2.2.6 步骤 4:选择分布方式...41
2.2.7 步骤 5:选择分布列... 42
2.2.8 步骤 6:创建新表并加载数据...43
2.2.9 步骤 7:测试新的表结构下的系统性能... 45
2.2.10 步骤 8:评估结果... 47
2.2.11 步骤 9:清除资源... 49
2.2.12 总结... 49
2.2.13 附录:表创建语法... 49
2.2.13.1 附录使用说明... 49
2.2.13.2 初始表创建...49
2.2.13.3 设计调优后二次表创建... 53
2.2.13.4 外表创建... 56
3 模拟数据分析...63
3.1 交通卡口通行车辆分析... 63
3.2 供应链需求分析(TPC-H 数据集)... 68
3.3 零售业百货公司经营状况分析... 76
3.4 导入 TPC-DS 样例数据并测试 GaussDB(DWS)性能... 84
4 数据库管理...87
4.1 工作负载管理优秀实践... 87
4.2 SQL 查询优秀实践... 91
4.3 分析正在执行的 SQL... 92
4.4 数据倾斜查询优秀实践... 95
4.4.1 导入过程存储倾斜即时检测... 95
4.4.2 快速定位查询存储倾斜的表... 96
4.5 用户管理优秀实践... 97
4.6 查看表和数据库的数据量大小...100
1 导入导出
1.1 导入数据最佳实践
从 OBS 并行导入数据
● 将导入数据拆分为多个文件
导入大数据量的数据时通常需要较长的时间及耗费较多的计算资源。
从OBS上导入数据时,如下方法可以提升导入性能:将数据文件存储到OBS前,
尽可能均匀地将文件切分成多个,文件的数量以DN的整数倍更适合。
● 在导入前后验证数据文件
从OBS导入数据时,首先将您的文件上传到OBS存储桶中,我们建议您列出存储 桶的内容,然后验证该存储桶是否包含所有正确的文件并且仅包含这些文件。
在完成导入操作后,请使用SELECT查询语句以验证所需文件是否已导入。
● OBS导入导出数据时,不支持中文路径。
使用 GDS 导入数据
● 数据倾斜会造成查询表性能下降。对于记录数超过千万条的表,建议在执行全量 数据导入前,先导入部分数据,以进行数据倾斜检查和调整分布列,避免导入大 量数据后发现数据倾斜,调整成本高。详细请参见查看数据倾斜状态。
● 为了优化导入速度,建议拆分文件,使用多GDS进行并行导入。另外,单个导入 任务可以拆分成多个导入任务并发执行导入,多个导入任务使用同一GDS时可以 使用-t参数打开GDS多线程并发执行导入。GDS建议挂载在不同物理盘以及不同网 卡上,避免物理IO以及网络可能出现的瓶颈。
● 在GDS IO与网卡未达到物理瓶颈前,可以考虑在GaussDB(DWS)开启SMP进行加 速。SMP开启之后会对对应的GDS产生成倍的压力。需要特别说明的是:SMP自 适应衡量的标准是GaussDB(DWS)的CPU压力,而不是GDS所承受的压力。有关 SMP的更多信息请参见SMP手动调优建议。
● GDS与GaussDB(DWS)通信要求物理网络畅通,并且尽量使用万兆网。千兆网无 法承载高速的数据传输压力,极易出现断连。即使用千兆网时GaussDB(DWS)无 法提供通信保障。满足万兆网的同时,数据磁盘组I/O性能大于GDS单核处理能力 上限(约400MB/s)时,方可寻求单文件导入速率最大化。
● 并发导入场景,与单表导入相似,至少应保证I/O性能大于网络最大速率。
● GDS跟DN的数据比例建议在1:3至1:6之间。
● 为了优化列存分区表的批量插入效率,在批量插入过程中会对数据进行缓存后再 批量写盘。通过GUC参数“partition_mem_batch”和
“partition_max_cache_size”,可以设置缓存个数以及缓存区大小。这两个参 数的值越小,列存分区表的批量插入越慢。当然,越大的缓存个数和缓存分区,
会带来越多的内存消耗。
使用 INSERT 多行插入
如果不能使用COPY命令,而您需要进行SQL插入,可以根据情况使用多行插入。如果 一次只添加一行或几行,则数据压缩效率低下。
多行插入是通过批量进行一系列插入而提高性能。下面的示例使用一条INSERT语句向 一个三列表插入三行。这仍属于少量插入,只是用来说明多行插入的语法。创建表的 步骤请参考创建表。
向表customer_t1中插入多行数据:
INSERT INTO customer_t1 VALUES (6885, 'maps', 'Joes'),
(4321, 'tpcds', 'Lily'), (9527, 'world', 'James');
有关更多详情和示例,请参阅INSERT。
使用 COPY 命令导入数据
COPY命令从本地或其它数据库的多个数据源并行导入数据。COPY导入大量数据的效 率要比INSERT语句高很多,而且存储数据也更有效率。
有关如何使用COPY命令的更多信息,请参阅使用COPY FROM STDIN导入数据 。
使用 gsql 元命令导入数据
\copy命令在任何psql客户端登录数据库成功后可以执行导入数据。与COPY命令相比 较,\copy命令不是读取或写入指定文件的服务器,而是直接读取或写入文件。
这个操作不如SQL COPY命令有效,因为所有的数据必须通过客户端/服务器的连接来 传递。对于大量的数据来说SQL命令可能会更好。
有关如何使用\copy命令的更多信息,请参阅使用gsql元命令导入数据 。 说明
\COPY只适合小批量,格式良好的数据导入,容错能力较差。导入数据应优先选择GDS或 COPY。
1.2 GDS 实践指南
● 安装GDS前必需确认GDS所在服务器环境的系统参数是否和数据库集群的系统参 数一致。
● GDS与GaussDB(DWS)通信要求物理网络畅通,尽量使用万兆网。因为千兆网无 法承载高速的数据传输压力,极易出现断连,使用千兆网时GaussDB(DWS)无法 提供通信保障。满足万兆网的同时,要求数据磁盘组I/O性能大于GDS单核处理能 力上限(约400MB/s),才能保证单文件导入速率最大化。
● 提前做好服务部署规划,数据服务器上,建议一个Raid只布1~2个GDS。GDS跟 DN的数据比例建议在1:3至1:6之间。一台加载机的GDS进程不宜部署太多,千兆 网卡部署1个GDS进程即可,万兆网卡机器建议部署不大于4个进程。
● 提前对GDS导入导出的数据目录做好层次划分,避免一个数据目录包含过多的文 件,并及时清理过期文件。
● 合理规划目标数据库的字符集,强烈建议使用UTF8作为数据库的字符集,不建议 使用sql_ascii编码,因为极易引起混合编码问题。GDS导出时保证外表的字符集和 客户端字符集一致即可,导入时保证客户端编码,数据文件内容编码和客户端一 致。
● 如果存在无法变更数据库,客户端,外表字符集时,可以尝试使用iconv命令进行 手动转换。
#注意 -f 表示源文件的字符集,-t为目标字符集 iconv -f utf8 -t gbk utf8.txt -o gbk.txt
● 关于GDS导入实践可参考使用GDS导入数据。
● GDS支持CSV、TEXT、FIXED三种格式,缺省为TEXT格式。不支持二进制格式,
但是可以使用encode/decode函数处理二进制类型。例如:
对二进制表导出:
--创建表。
CREATE TABLE blob_type_t1 ( BT_COL BYTEA
) DISTRIBUTE BY REPLICATION;
-- 创建外表
CREATE FOREIGN TABLE f_blob_type_t1( BT_COL text ) SERVER gsmpp_server OPTIONS (LOCATION 'gsfs://127.0.0.1:7789/', FORMAT 'text', DELIMITER E'\x08', NULL '', EOL '0x0a' ) WRITE ONLY;
INSERT INTO blob_type_t1 VALUES(E'\\xDEADBEEF');
INSERT INTO blob_type_t1 VALUES(E'\\xDEADBEEF');
INSERT INTO blob_type_t1 VALUES(E'\\xDEADBEEF');
INSERT INTO blob_type_t1 VALUES(E'\\xDEADBEEF');
INSERT INTO f_blob_type_t1 select encode(BT_COL,'base64') from blob_type_t1;
对二进制表导入:
--创建表。
CREATE TABLE blob_type_t2 ( BT_COL BYTEA
) DISTRIBUTE BY REPLICATION;
-- 创建外表
CREATE FOREIGN TABLE f_blob_type_t2( BT_COL text ) SERVER gsmpp_server OPTIONS (LOCATION 'gsfs://127.0.0.1:7789/f_blob_type_t1.dat.0', FORMAT 'text', DELIMITER E'\x08', NULL '', EOL '0x0a' );
insert into blob_type_t2 select decode(BT_COL,'base64') from f_blob_type_t2;
SELECT * FROM blob_type_t2;
bt_col --- \xdeadbeef \xdeadbeef \xdeadbeef \xdeadbeef (4 rows)
● 对同一张外表重复导出会覆盖之前的文件,因此不要对同一个外表重复导出。
● 若不确定文件是否为标准的csv格式,推荐将quote参数设置为0x07,0x08或0x1b 等不可见字符来进行GDS导入导出,避免文件格式问题导致任务失败。
CREATE FOREIGN TABLE foreign_HR_staffS_ft1 ( MANAGER_ID NUMBER(6),
section_ID NUMBER(4)
) SERVER gsmpp_server OPTIONS (location 'file:///input_data/*', format 'csv', mode 'private', quote '0x07', delimiter ',') WITH err_HR_staffS_ft1;
● GDS支持并发导入导出,gds -t参数用于设置gds的工作线程池大小,控制并发场 景下同时工作的工作线程数且不会加速单个sql任务。gds -t缺省值为8,上限值为 200。在使用管道功能进行导入导出时,-t参数应不低于业务并发数。
● GDS外表参数delimiter是多字符时,建议TEXT格式下字符不要完全相同,例如不 建议使用delimiter '---'。
● GDS多表并行导入同一个文件提升导入性能(仅支持text和csv文件)。
-- 创建目标表。
CREATE TABLE pipegds_widetb_1 (city integer, tel_num varchar(16), card_code varchar(15),
phone_code vcreate table pipegds_widetb_3 (city integer, tel_num varchar(16), card_code varchar(15), phone_code varchar(16), region_code varchar(6), station_id varchar(10), tmsi varchar(20), rec_date integer(6), rec_time integer(6), rec_type numeric(2), switch_id varchar(15), attach_city varchar(6), opc varchar(20), dpc varchar(20));
-- 创建带有file_sequence字段的外表。
CREATE FOREIGN TABLE gds_pip_csv_r_1( like pipegds_widetb_1) SERVER gsmpp_server OPTIONS (LOCATION 'gsfs://127.0.0.1:8781/wide_tb.txt', FORMAT 'text', DELIMITER E'|+|', NULL '', file_sequence '5-1');
CREATE FOREIGN TABLE gds_pip_csv_r_2( like pipegds_widetb_1) SERVER gsmpp_server OPTIONS (LOCATION 'gsfs://127.0.0.1:8781/wide_tb.txt', FORMAT 'text', DELIMITER E'|+|', NULL '', file_sequence '5-2');
CREATE FOREIGN TABLE gds_pip_csv_r_3( like pipegds_widetb_1) SERVER gsmpp_server OPTIONS (LOCATION 'gsfs://127.0.0.1:8781/wide_tb.txt', FORMAT 'text', DELIMITER E'|+|', NULL '', file_sequence '5-3');
CREATE FOREIGN TABLE gds_pip_csv_r_4( like pipegds_widetb_1) SERVER gsmpp_server OPTIONS (LOCATION 'gsfs://127.0.0.1:8781/wide_tb.txt', FORMAT 'text', DELIMITER E'|+|', NULL '', file_sequence '5-4');
CREATE FOREIGN TABLE gds_pip_csv_r_5( like pipegds_widetb_1) SERVER gsmpp_server OPTIONS (LOCATION 'gsfs://127.0.0.1:8781/wide_tb.txt', FORMAT 'text', DELIMITER E'|+|', NULL '', file_sequence '5-5');
--将wide_tb.txt并发导入到pipegds_widetb_1。
\parallel on
INSERT INTO pipegds_widetb_1 SELECT * FROM gds_pip_csv_r_1;
INSERT INTO pipegds_widetb_1 SELECT * FROM gds_pip_csv_r_2;
INSERT INTO pipegds_widetb_1 SELECT * FROM gds_pip_csv_r_3;
INSERT INTO pipegds_widetb_1 SELECT * FROM gds_pip_csv_r_4;
INSERT INTO pipegds_widetb_1 SELECT * FROM gds_pip_csv_r_5;
\parallel off
file_sequence参数详细内容,可参考CREATE FOREIGN TABLE (GDS导入导 出)。
1.3 教程:从 OBS 导入数据到集群
教程指引
本教程旨在通过演示将样例数据上传OBS,及将OBS的数据导入进GaussDB(DWS)上 的目标表中,让您快速掌握如何从OBS导入数据到GaussDB(DWS)集群的完整过程。
在本教程中,您将:
● 生成CSV格式的数据文件。
● 创建一个与GaussDB(DWS)集群在同一区域的OBS存储桶,然后将数据文件上传 到该存储桶。
● 创建外表,用于引流OBS存储桶中的数据到GaussDB(DWS)集群。
● 启动GaussDB(DWS)并创建数据库表后,将OBS上的数据导入到表中。
● 根据错误表中的提示诊断加载错误并更正这些错误。
估计时间:30分钟
准备数据源文件
● 数据文件“product_info0.csv”
100,XHDK-A,2017-09-01,A,2017 Shirt Women,red,M,328,2017-09-04,715,good!
205,KDKE-B,2017-09-01,A,2017 T-shirt Women,pink,L,584,2017-09-05,40,very good!
300,JODL-X,2017-09-01,A,2017 T-shirt men,red,XL,15,2017-09-03,502,Bad.
310,QQPX-R,2017-09-02,B,2017 jacket women,red,L,411,2017-09-05,436,It's nice.
150,ABEF-C,2017-09-03,B,2017 Jeans Women,blue,M,123,2017-09-06,120,good.
● 数据文件“product_info1.csv”
200,BCQP-E,2017-09-04,B,2017 casual pants men,black,L,997,2017-09-10,301,good quality.
250,EABE-D,2017-09-10,A,2017 dress women,black,S,841,2017-09-15,299,This dress fits well.
108,CDXK-F,2017-09-11,A,2017 dress women,red,M,85,2017-09-14,22,It's really amazing to buy.
450,MMCE-H,2017-09-11,A,2017 jacket women,white,M,114,2017-09-14,22,very good.
260,OCDA-G,2017-09-12,B,2017 woolen coat women,red,L,2004,2017-09-15,826,Very comfortable.
● 数据文件“product_info2.csv”
980,"ZKDS-J",2017-09-13,"B","2017 Women's Cotton Clothing","red","M",112,,, 98,"FKQB-I",2017-09-15,"B","2017 new shoes men","red","M",4345,2017-09-18,5473
50,"DMQY-K",2017-09-21,"A","2017 pants men","red","37",28,2017-09-25,58,"good","good","good"
80,"GKLW-l",2017-09-22,"A","2017 Jeans Men","red","39",58,2017-09-25,72,"Very comfortable."
30,"HWEC-L",2017-09-23,"A","2017 shoes women","red","M",403,2017-09-26,607,"good!"
40,"IQPD-M",2017-09-24,"B","2017 new pants Women","red","M",35,2017-09-27,52,"very good."
50,"LPEC-N",2017-09-25,"B","2017 dress Women","red","M",29,2017-09-28,47,"not good at all."
60,"NQAB-O",2017-09-26,"B","2017 jacket women","red","S",69,2017-09-29,70,"It's beautiful."
70,"HWNB-P",2017-09-27,"B","2017 jacket women","red","L",30,2017-09-30,55,"I like it so much"
80,"JKHU-Q",2017-09-29,"C","2017 T-shirt","red","M",90,2017-10-02,82,"very good."
步骤1 新建文本文档并使用notepad++打开后,将示例数据拷贝进文本文档中。
步骤2 选择“格式>以UTF-8无BOM格式编码”。
步骤3 选择“文件>另存为”。
步骤4 在弹出的对话框中输入文件名后,将文件后缀设为.csv,单击“保存”。
----结束
上传数据到 OBS
步骤1 将上面准备的3个CSV格式的数据源文件存储到OBS桶中。
1. 登录OBS管理控制台。
单击“服务列表”,选择“对象存储服务”,打开OBS管理控制台页面。或者,
您也可以通过访问以下地址登录OBS管理控制台:https://
storage.huaweicloud.com。
2. 创建桶。
如何创建OBS桶,具体请参见《对象存储服务》“快速入门”中的创建桶章节。
例如,创建以下两个桶:“mybucket”和“mybucket02”。
须知
确保这两个桶与GaussDB(DWS)集群在同一个区域,本教程以"华北-北京四”区 域为例。
3. 新建文件夹。
具体请参见《对象存储服务控制台指南》中的新建文件夹章节。
例如:
– 在已创建的OBS桶“mybucket”中新建一个文件夹“input_data”。
– 在已创建的OBS桶“mybucket02”中新建一个文件夹“input_data”。
4. 上传文件。
具体请参见《对象存储服务控制台指南》的上传对象章节。
例如:
– 将以下数据文件上传到OBS桶“mybucket”的“input_data”目录中。
product_info0.csv product_info1.csv
– 将以下数据文件上传到OBS桶“mybucket02”的“input_data”目录中。
product_info2.csv
步骤2 为导入用户设置OBS桶的读取权限。
在从OBS导入数据到集群时,执行导入操作的用户需要取得数据源文件所在OBS桶的 读取权限。通过配置桶的ACL权限,可以将读取权限授予指定的用户帐号。
具体请参见《对象存储服务控制台指南》中的配置桶ACL章节。
----结束
创建外表
步骤1 连接GaussDB(DWS)数据库。
步骤2 创建外表。
说明
● ACCESS_KEY和SECRET_ACCESS_KEY
用户访问OBS的AK和SK,请根据实际替换。获取访问密钥,请登录管理控制台,将鼠标移至 右上角的用户名,单击“我的凭证”,然后在左侧导航树单击“访问密钥”。在访问密钥页 面,可以查看已有的访问密钥ID(即AK),如果要同时获取AK和SK,可以单击“新增访问 密钥”创建并下载访问密钥。
DROP FOREIGN TABLE IF EXISTS product_info_ext;
CREATE FOREIGN TABLE product_info_ext ( product_price integer not null, product_id char(30) not null, product_time date , product_level char(10) , product_name varchar(200) , product_type1 varchar(20) , product_type2 char(10) , product_monthly_sales_cnt integer , product_comment_time date , product_comment_num integer ,
product_comment_content varchar(200) ) SERVER gsmpp_server
OPTIONS(
LOCATION 'obs://mybucket/input_data/product_info | obs://mybucket02/input_data/product_info', FORMAT 'CSV' ,
DELIMITER ',', ENCODING 'utf8', HEADER 'false',
ACCESS_KEY 'access_key_value_to_be_replaced',
SECRET_ACCESS_KEY 'secret_access_key_value_to_be_replaced', FILL_MISSING_FIELDS 'true',
IGNORE_EXTRA_DATA 'true' )READ ONLY
LOG INTO product_info_err PER NODE REJECT LIMIT 'unlimited';
返回如下信息表示创建成功:
CREATE FOREIGN TABLE
----结束
执行数据导入
步骤1 在GaussDB(DWS)数据库中,创建一个名为product_info的表,用于存储从OBS导入的 数据。
DROP TABLE IF EXISTS product_info;
CREATE TABLE product_info
( product_price integer not null, product_id char(30) not null, product_time date , product_level char(10) , product_name varchar(200) , product_type1 varchar(20) , product_type2 char(10) , product_monthly_sales_cnt integer , product_comment_time date , product_comment_num integer ,
product_comment_content varchar(200) ) WITH (
orientation = column, compression=middle
) DISTRIBUTE BY hash (product_id);
步骤2 执行INSERT命令,通过外表product_info_ext将OBS上的数据导入到目标表 product_info 中:
INSERT INTO product_info SELECT * FROM product_info_ext;
步骤3 执行SELECT命令查询目标表product_info,查看从OBS导入到GaussDB(DWS)中的数 据。
SELECT * FROM product_info;
查询结果的结尾将显示以下信息:
(20 rows)
步骤4 对表product_info执行VACUUM FULL。
VACUUM FULL product_info VACUUM
步骤5 更新表product_info的统计信息。
ANALYZE product_info;
ANALYZE
----结束
清除资源
步骤1 如果执行了导入数据后查询数据,请执行以下命令,删除目标表。
DROP TABLE product_info;
当结果显示为如下信息,则表示删除成功。
DROP TABLE
步骤2 执行以下命令,删除外表。
DROP FOREIGN TABLE product_info_ext;
当结果显示为如下信息,则表示删除成功。
DROP FOREIGN TABLE
----结束
1.4 教程:使用 GDS 从远端服务器导入数据
教程指引
本教程旨在演示使用GDS(General Data Service)工具将远端服务器上的数据导入 GaussDB(DWS)中的办法,帮助您学习如何通过GDS进行数据导入的方法。
在本教程中,您将:
● 生成本教程需要使用的CSV格式的数据源文件。
● 将数据源文件上传到数据服务器。
● 创建外表,用于对接GDS和GaussDB(DWS),及将数据服务器上的数据引流到 GaussDB(DWS)集群中。
● 启动GaussDB(DWS)并创建数据库表后,将数据导入到表中。
● 根据错误表中的提示诊断加载错误并更正这些错误。
准备 ECS 作为 GDS 服务器
购买Linux弹性云服务器的操作步骤,请参见《弹性云服务器快速入门》中的自定义购 买弹性云服务器。购买后,请参见登录Linux弹性云服务器进行登录。
说明
● ECS操作系统必须是GDS工具包所支持的操作系统。
● ECS与DWS处于同一区域、同一虚拟私有云和子网。
● ECS安全组规则需放通DWS集群的访问,即安全组入规则:
● 协议:TCP
● 端口范围:5000
● 源地址:选择“IP地址”,输入GaussDB(DWS) 集群地址,例如
“192.168.0.10/32”。
● ECS内部如果启用了防火墙,需要保证防火墙打开了GDS服务的监听端口:
iptables -I INPUT -p tcp -m tcp --dport <gds_port> -j ACCEPT
下载 GDS 工具包
步骤1 登录GaussDB(DWS)管理控制台。
步骤2 在左侧导航栏中,单击“连接管理”。
步骤3 在 “客户端”的下拉列表中,选择对应版本的GaussDB(DWS) 客户端。
请根据集群版本和安装客户端的操作系统,选择对应版本。
说明
客户端CPU架构要和集群一致,如果集群是X86规格,则也应该选择X86客户端。
步骤4 单击“下载”。
----结束
准备数据源文件
● 数据文件“product_info0.csv”
100,XHDK-A,2017-09-01,A,2017 Shirt Women,red,M,328,2017-09-04,715,good!
205,KDKE-B,2017-09-01,A,2017 T-shirt Women,pink,L,584,2017-09-05,40,very good!
300,JODL-X,2017-09-01,A,2017 T-shirt men,red,XL,15,2017-09-03,502,Bad.
310,QQPX-R,2017-09-02,B,2017 jacket women,red,L,411,2017-09-05,436,It's nice.
150,ABEF-C,2017-09-03,B,2017 Jeans Women,blue,M,123,2017-09-06,120,good.
● 数据文件“product_info1.csv”
200,BCQP-E,2017-09-04,B,2017 casual pants men,black,L,997,2017-09-10,301,good quality.
250,EABE-D,2017-09-10,A,2017 dress women,black,S,841,2017-09-15,299,This dress fits well.
108,CDXK-F,2017-09-11,A,2017 dress women,red,M,85,2017-09-14,22,It's really amazing to buy.
450,MMCE-H,2017-09-11,A,2017 jacket women,white,M,114,2017-09-14,22,very good.
260,OCDA-G,2017-09-12,B,2017 woolen coat women,red,L,2004,2017-09-15,826,Very comfortable.
● 数据文件“product_info2.csv”
980,"ZKDS-J",2017-09-13,"B","2017 Women's Cotton Clothing","red","M",112,,, 98,"FKQB-I",2017-09-15,"B","2017 new shoes men","red","M",4345,2017-09-18,5473
50,"DMQY-K",2017-09-21,"A","2017 pants men","red","37",28,2017-09-25,58,"good","good","good"
80,"GKLW-l",2017-09-22,"A","2017 Jeans Men","red","39",58,2017-09-25,72,"Very comfortable."
30,"HWEC-L",2017-09-23,"A","2017 shoes women","red","M",403,2017-09-26,607,"good!"
40,"IQPD-M",2017-09-24,"B","2017 new pants Women","red","M",35,2017-09-27,52,"very good."
50,"LPEC-N",2017-09-25,"B","2017 dress Women","red","M",29,2017-09-28,47,"not good at all."
60,"NQAB-O",2017-09-26,"B","2017 jacket women","red","S",69,2017-09-29,70,"It's beautiful."
70,"HWNB-P",2017-09-27,"B","2017 jacket women","red","L",30,2017-09-30,55,"I like it so much"
80,"JKHU-Q",2017-09-29,"C","2017 T-shirt","red","M",90,2017-10-02,82,"very good."
步骤1 新建文本文档并使用notepad++打开后,将示例数据拷贝进文本文档中。
步骤2 选择“格式>以UTF-8无BOM格式编码”。
步骤3 选择“文件>另存为”。
步骤4 在弹出的对话框中输入文件名后,将文件后缀设为.csv,单击“保存”。
步骤5 以root用户登录GDS服务器。
步骤6 创建数据文件存放目录“/input_data”。
mkdir -p /input_data
步骤7 使用MobaXterm将数据源文件上传至上一步所创建的目录中。
----结束
安装并启动 GDS
步骤1 以root用户登录GDS服务器,创建存放GDS工具包的目录/opt/bin/dws。
mkdir -p /opt/bin/dws
步骤2 将GDS工具包上传至上一步所创建的目录中。
以上传redhat版本的工具包为例 ,将GDS工具包“dws_client_8.1.x_redhat_x64.zip”
上传至上一步所创建的目录中。
步骤3 在工具包所在目录下,解压工具包。
cd /opt/bin/dws
unzip dws_client_8.1.x_redhat_x64.zip
步骤4 创建用户gds_user及其所属的用户组gdsgrp。此用户用于启动GDS,且需要拥有读取 数据源文件目录的权限。
groupadd gdsgrp
useradd -g gdsgrp gds_user
步骤5 修改工具包以及数据源文件目录属主为创建的用户gds_user及其所属的用户组 gdsgrp。
chown -R gds_user:gdsgrp /opt/bin/dws/gds chown -R gds_user:gdsgrp /input_data
步骤6 切换到gds_user用户。
su - gds_user
若当前集群版本为8.0.x及以前版本,请跳过步骤7,直接执行步骤8。
若当前集群版本为8.1.x版本,则正常执行以下步骤。
步骤7 执行环境依赖脚本。(仅8.1.x版本适用)
cd /opt/bin/dws/gds/bin source gds_env
步骤8 启动GDS。
/opt/bin/dws/gds/bin/gds -d /input_data/ -p 192.168.0.90:5000 -H 10.10.0.1/24 -l /opt/bin/dws/gds/
gds_log.txt -D
命令中的斜体部分请根据实际填写。
● -d dir:保存有待导入数据的数据文件所在目录。本教程中为“/input_data/”。
● -p ip:port:GDS监听IP和监听端口。默认值为:127.0.0.1,需要替换为能跟 GaussDB(DWS)通信的万兆网IP。监听端口的取值范围:1024~65535。默认值 为:8098。本教程配置为:192.168.0.90:5000。
● -H address_string:允许哪些主机连接和使用GDS服务。参数需为CIDR格式。此 参数配置的目的是允许GaussDB(DWS)集群可以访问GDS服务进行数据导入。所 以请保证所配置的网段包含GaussDB(DWS)集群各主机。
● -l log_file:存放GDS的日志文件路径及文件名。本教程为“/opt/bin/dws/gds/
gds_log.txt”。
● -D:后台运行GDS。仅支持Linux操作系统下使用。
----结束
创建外表
步骤1 使用SQL客户端工具连接GaussDB(DWS)数据库。
步骤2 创建如下外表:
注意
LOCATION:请替换成实际的GDS地址和端口。
DROP FOREIGN TABLE IF EXISTS product_info_ext;
CREATE FOREIGN TABLE product_info_ext ( product_price integer not null, product_id char(30) not null, product_time date , product_level char(10) , product_name varchar(200) , product_type1 varchar(20) , product_type2 char(10) , product_monthly_sales_cnt integer , product_comment_time date , product_comment_num integer ,
product_comment_content varchar(200) ) SERVER gsmpp_server
OPTIONS(
LOCATION 'gsfs://192.168.0.90:5000/*', FORMAT 'CSV' ,
DELIMITER ',', ENCODING 'utf8', HEADER 'false',
FILL_MISSING_FIELDS 'true', IGNORE_EXTRA_DATA 'true' )READ ONLY
LOG INTO product_info_err PER NODE REJECT LIMIT 'unlimited';
返回如下信息表示创建成功:
CREATE FOREIGN TABLE
----结束
导入数据
步骤1 使用如下语句在GaussDB(DWS)中创建目标表product_info,用于存储导入的数据。
DROP TABLE IF EXISTS product_info;
CREATE TABLE product_info
( product_price integer not null, product_id char(30) not null, product_time date , product_level char(10) , product_name varchar(200) , product_type1 varchar(20) , product_type2 char(10) , product_monthly_sales_cnt integer , product_comment_time date , product_comment_num integer ,
product_comment_content varchar(200) )
WITH (
orientation = column, compression=middle
) DISTRIBUTE BY hash (product_id);
步骤2 将数据源文件中的数据通过外表“product_info_ext”导入到表“product_info”中。
INSERT INTO product_info SELECT * FROM product_info_ext ;
出现以下信息,说明数据导入成功。
INSERT 0 20
步骤3 执行SELECT命令查询目标表product_info,查看导入到GaussDB(DWS)中的数据。
SELECT count(*) FROM product_info;
查询结果显示结果如下,表示导入成功。
count --- 20 (1 row)
步骤4 对表product_info执行VACUUM FULL。
VACUUM FULL product_info VACUUM
步骤5 更新表product_info的统计信息。
ANALYZE product_info;
ANALYZE
----结束
停止 GDS
步骤1 以gds_user用户登录安装GDS的数据服务器。
步骤2 请使用以下方式停止GDS。
1. 执行如下命令,查询GDS进程号。其中GDS进程号为128954。
ps -ef|grep gds
gds_user 128954 1 0 15:03 ? 00:00:00 gds -d /input_data/ -p 192.168.0.90:5000 - l /opt/bin/gds/gds_log.txt -D
gds_user 129003 118723 0 15:04 pts/0 00:00:00 grep gds
2. 使用“kill”命令,停止GDS。其中128954为上一步骤中查询出的GDS进程号。
kill -9 128954
----结束
清除资源
步骤1 执行以下命令,删除目标表product_info。
DROP TABLE product_info;
当结果显示为如下信息,则表示删除成功。
DROP TABLE
步骤2 执行以下命令,删除外表product_info_ext。
DROP FOREIGN TABLE product_info_ext;
当结果显示为如下信息,则表示删除成功。
DROP FOREIGN TABLE
----结束
1.5 教程:导入 MRS 数据源
大数据融合分析时代,GaussDB(DWS)如需访问MRS数据源,可通过远程读取MRS集 群Hive上的ORC数据表完成数据导入DWS。
点击观看视频。
准备环境
已创建DWS集群,需确保MRS和DWS集群在同一个区域、可用区、同一VPC子网内,
确保集群网络互通。
基本流程
本实践预计时长:1小时,基本流程如下:
1、创建MRS分析集群(选择Hive、Spark、Tez组件)。
2、通过将本地txt数据文件上传至OBS桶,再通过OBS桶导入Hive,并由txt存储表导 入ORC存储表。
3、创建MRS数据源连接。
4、创建外部服务器。
5、创建外表。
6、通过外表导入DWS本地表。
创建 MRS 分析集群
步骤1 登录华为云控制台,选择“大数据 > MapReduce服务”,单击“购买集群”,选择
“自定义购买”,填写软件配置参数,单击“下一步”。
表1-1 软件配置
参数项 取值
区域 华北-北京四
集群名称 mrs_01
集群版本 MRS 1.9.2(主推)
说明如果当前用户使用的MRS集群版本为1.6.x、1.7.x、1.8.x、1.9.x和 2.0.x,本教程也同样支持。
集群类型 分析集群
步骤2 填写硬件配置参数,单击“下一步”。
表1-2 硬件配置
参数项 取值
计费模式 按需计费
可用区 可用区2
虚拟私有云 vpc-01 子网 subnet-01
安全组 自动创建
弹性公网IP 10.x.x.x 企业项目 default
Master节点 打开“集群高可用”
分析Core节点 3 分析Task节点 0
步骤3 填写高级配置参数如下表,单击“立即购买”,等待约15分钟,集群创建成功。
表1-3 高级配置
参数项 取值
标签 test01
委托 保持默认即可
告警 保持默认即可
规则名称 保持默认即可
主题名称 保持默认即可
参数项 取值 Kerberos认证 默认打开
用户名 admin
密码 设置密码,例如:Huawei@12345。该密码用于登录集群管 理页面。
确认密码 再次输入设置admin用户密码
登录方式 密码
用户名 root
密码 设置密码,例如:Huawei_12345。该密码用于远程登录ECS 机器。
确认密码 再次输入设置的root用户密码 通信安全授权 勾选“确认授权”
----结束
准备 MRS 的 ORC 表数据源
步骤1 本地PC新建一个product_info.txt,并拷贝以下数据,保存到本地。
100,XHDK-A-1293-#fJ3,2017-09-01,A,2017 Autumn New Shirt Women,red,M,328,2017-09-04,715,good 205,KDKE-B-9947-#kL5,2017-09-01,A,2017 Autumn New Knitwear Women,pink,L,584,2017-09-05,406,very good!
300,JODL-X-1937-#pV7,2017-09-01,A,2017 autumn new T-shirt men,red,XL,1245,2017-09-03,502,Bad.
310,QQPX-R-3956-#aD8,2017-09-02,B,2017 autumn new jacket women,red,L,411,2017-09-05,436,It's really super nice
150,ABEF-C-1820-#mC6,2017-09-03,B,2017 Autumn New Jeans Women,blue,M,1223,2017-09-06,1200,The seller's packaging is exquisite
200,BCQP-E-2365-#qE4,2017-09-04,B,2017 autumn new casual pants men,black,L,997,2017-09-10,301,The clothes are of good quality.
250,EABE-D-1476-#oB1,2017-09-10,A,2017 autumn new dress women,black,S,841,2017-09-15,299,Follow the store for a long time.
108,CDXK-F-1527-#pL2,2017-09-11,A,2017 autumn new dress women,red,M,85,2017-09-14,22,It's really amazing to buy
450,MMCE-H-4728-#nP9,2017-09-11,A,2017 autumn new jacket women,white,M,114,2017-09-14,22,Open the package and the clothes have no odor
260,OCDA-G-2817-#bD3,2017-09-12,B,2017 autumn new woolen coat women,red,L, 2004,2017-09-15,826,Very favorite clothes
980,ZKDS-J-5490-#cW4,2017-09-13,B,2017 Autumn New Women's Cotton Clothing,red,M, 112,2017-09-16,219,The clothes are small
98,FKQB-I-2564-#dA5,2017-09-15,B,2017 autumn new shoes men,green,M,4345,2017-09-18,5473,The clothes are thick and it's better this winter.
150,DMQY-K-6579-#eS6,2017-09-21,A,2017 autumn new underwear men,yellow, 37,2840,2017-09-25,5831,This price is very cost effective
200,GKLW-l-2897-#wQ7,2017-09-22,A,2017 Autumn New Jeans Men,blue,39,5879,2017-09-25,7200,The clothes are very comfortable to wear
300,HWEC-L-2531-#xP8,2017-09-23,A,2017 autumn new shoes women,brown,M,403,2017-09-26,607,good 100,IQPD-M-3214-#yQ1,2017-09-24,B,2017 Autumn New Wide Leg Pants Women,black,M,
3045,2017-09-27,5021,very good.
350,LPEC-N-4572-#zX2,2017-09-25,B,2017 Autumn New Underwear Women,red,M,239,2017-09-28,407,The seller's service is very good
110,NQAB-O-3768-#sM3,2017-09-26,B,2017 autumn new underwear women,red,S, 6089,2017-09-29,7021,The color is very good
210,HWNB-P-7879-#tN4,2017-09-27,B,2017 autumn new underwear women,red,L,3201,2017-09-30,4059,I like it very much and the quality is good.
230,JKHU-Q-8865-#uO5,2017-09-29,C,2017 Autumn New Clothes with Chiffon Shirt,black,M, 2056,2017-10-02,3842,very good
步骤2 登录OBS控制台,单击“创建桶”,填写以下参数,单击“立即创建”。
表1-4 桶参数
参数项 取值
区域 华北-北京四
数据冗余存储策略 单AZ存储 桶名称 mrs-datasource
默认存储类别 标准存储
桶策略 私有
默认加密 关闭
归档数据直读 关闭
企业项目 default
标签 -
步骤3 等待桶创建好,单击桶名称,选择“对象 > 上传对象”,将product_info.txt上传至 OBS桶。
步骤4 切换回MRS控制台,单击创建好的MRS集群名称,进入“概览”,单击“IAM用户同 步”所在行的“同步”,等待约5分钟同步完成。
步骤5 回到MRS集群页面,单击“节点管理”,单击任意一台master节点,进入该节点页 面,切换到“弹性公网IP”,单击“绑定弹性公网IP”,勾选已有弹性IP并单击“确 定”,如果没有,请创建。记录此公网IP。
步骤6 下载客户端。
1. 回到MRS集群页面,单击集群名称进入“概览”,单击“前往Manager”,如果 提示绑定公网IP,请先绑定公网IP。
2. 输入MRS Manager的用户名admin和密码,密码为创建MRS集群时输入的admin 密码,本实践为Huawei@12345。
3. 登录成功后,选择“服务管理 > 下载客户端”,“客户端类型”选择“仅配置文 件”,“下载路径”选择“服务器端”。单击“确定”。
步骤7 确认主master节点。
1. 使用SSH工具以root用户登录以上节点,root密码为Huawei_12345,切换到omm 用户。
su - omm
2. 执行以下命令查询主master节点,回显信息中“HAActive”参数值为“active”
的节点为主master节点。
sh ${BIGDATA_HOME}/om-0.0.1/sbin/status-oms.sh
步骤8 使用root用户登录主master节点,并更新主管理节点的客户端配置。
cd /opt/client
sh refreshConfig.sh /opt/client 客户端配置文件压缩包完整路径 本例命令为:
sh refreshConfig.sh /opt/client /tmp/MRS-client/MRS_Services_Client.tar 步骤9 切换到omm用户,并进入Hive客户端所在目录。
su - omm cd /opt/client
步骤10 在Hive上创建存储类型为TEXTFILE的表product_info。
1. 在/opt/client路径下,导入环境变量。
source bigdata_env 2. 登录Hive客户端。
beeline
3. 依次执行以下SQL语句创建demo数据库及表product_info。
CREATE DATABASE demo;
USE demo;
DROP TABLE product_info;
CREATE TABLE product_info (
product_price int , product_id char(30) , product_time date , product_level char(10) , product_name varchar(200) , product_type1 varchar(20) , product_type2 char(10) , product_monthly_sales_cnt int , product_comment_time date , product_comment_num int ,
product_comment_content varchar(200) ) row format delimited fields terminated by ','
stored as TEXTFILE;
步骤11 将product_info.txt数据文件导入Hive。
1. 切回到MRS集群,单击“文件管理”,单击“导入数据”。
2. OBS路径:选择上面创建好的OBS桶名,找到product_info.txt文件,单击
“是”。
3. HDFS路径:选择/user/hive/warehouse/demo.db/product_info/,单击“是”。
4. 单击“确定”,等待导入成功,此时product_info的表数据已导入成功。
步骤12 创建ORC表,并将数据导入ORC表。
1. 执行以下SQL语句创建ORC表。
DROP TABLE product_info_orc;
CREATE TABLE product_info_orc (
product_price int , product_id char(30) , product_time date , product_level char(10) , product_name varchar(200) , product_type1 varchar(20) , product_type2 char(10) , product_monthly_sales_cnt int , product_comment_time date , product_comment_num int ,
product_comment_content varchar(200) ) row format delimited fields terminated by ','
stored as orc;
2. 将product_info表的数据插入到Hive ORC表product_info_orc中。
insert into product_info_orc select * from product_info;
3. 查询ORC表数据导入成功。
select * from product_info_orc;
----结束
创建 MRS 数据源连接
步骤1 登录DWS管理控制台,单击已创建好的DWS集群,确保DWS集群与MRS在同一个区 域、可用分区,并且在同一VPC子网下。
步骤2 切换到“MRS数据源”,单击“创建MRS数据源连接”。
步骤3 选择前序步骤创建名为的“mrs_01”数据源,用户名:admin,密码:
Huawei@12345,单击“确定”,创建成功。
----结束
创建外部服务器
步骤1 使用Data Studio连接已创建好的DWS集群。
步骤2 新建一个具有创建数据库权限的用户dbuser:
CREATE USER dbuser WITH CREATEDB PASSWORD "Bigdata@123";
步骤3 切换为新建的dbuser用户:
SET ROLE dbuser PASSWORD "Bigdata@123";
步骤4 创建新的mydatabase数据库:
CREATE DATABASE mydatabase;
步骤5 执行以下步骤切换为连接新建的mydatabase数据库。
1. 在Data Studio客户端的“对象浏览器”窗口,右键单击数据库连接名称,在弹出 菜单中单击“刷新”,刷新后就可以看到新建的数据库。
2. 右键单击“mydatabase”数据库名称,在弹出菜单中单击“打开连接”。
3. 右键单击“mydatabase”数据库名称,在弹出菜单中单击“打开新的终端”,即 可打开连接到指定数据库的SQL命令窗口,后面的步骤,请全部在该命令窗口中 执行。
步骤6 为dbuser用户授予创建外部服务器的权限,8.1.1及以后版本,还需要授予使用public 模式的权限:
GRANT ALL ON FOREIGN DATA WRAPPER hdfs_fdw TO dbuser;
GRANT ALL ON SCHEMA public TO dbuser; //8.1.1及以后版本,普通用户对public模式无权限,需要赋权,
8.1.1之前版本不需要执行。
其中FOREIGN DATA WRAPPER的名字只能是hdfs_fdw,dbuser为创建SERVER的用户 名。
步骤7 执行以下命令赋予用户使用外表的权限。
ALTER USER dbuser USEFT;
步骤8 切换回Postgres系统数据库,查询创建MRS数据源后系统自动创建的外部服务器。
SELECT * FROM pg_foreign_server;
返回结果如:
srvname | srvowner | srvfdw | srvtype | srvversion | srvacl
| srvoptions
---+---+---+---+---+---
+--- gsmpp_server | 10 | 13673 | | | |
gsmpp_errorinfo_server | 10 | 13678 | | | |
hdfs_server_8f79ada0_d998_4026_9020_80d6de2692ca | 16476 | 13685 | | | | {"address=192.168.1.245:9820,192.168.1.218:9820",hdfscfgpath=/MRS/8f79ada0-
d998-4026-9020-80d6de2692ca,type=hdfs}
(3 rows)
步骤9 切换到mydatabase数据库,并切换到dbuser用户。
SET ROLE dbuser PASSWORD "Bigdata@123";
步骤10 创建外部服务器。
SERVER名字、地址、配置路径保持与步骤8一致即可。
CREATE SERVER hdfs_server_8f79ada0_d998_4026_9020_80d6de2692ca FOREIGN DATA WRAPPER HDFS_FDW
OPTIONS
(address '192.168.1.245:9820,192.168.1.218:9820', //MRS管理面的Master主备节点的内网IP,可与DWS通讯。
hdfscfgpath '/MRS/8f79ada0-d998-4026-9020-80d6de2692ca', type 'hdfs'
);
步骤11 查看外部服务器。
SELECT * FROM pg_foreign_server WHERE
srvname='hdfs_server_8f79ada0_d998_4026_9020_80d6de2692ca';
返回结果如下所示,表示已经创建成功:
srvname | srvowner | srvfdw | srvtype | srvversion | srvacl
| srvoptions
---+---+---+---+---+---
+--- hdfs_server_8f79ada0_d998_4026_9020_80d6de2692ca | 16476 | 13685 | | | | {"address=192.168.1.245:9820,192.168.1.218:9820",hdfscfgpath=/MRS/8f79ada0-
d998-4026-9020-80d6de2692ca,type=hdfs}
(1 row)
----结束
创建外表
步骤1 获取Hive的product_info_orc的文件路径。
1. 登录MRS管理控制台。
2. 选择“集群列表 > 现有集群”,单击要查看的集群名称,进入集群基本信息页 面。
3. 单击“文件管理”,选择“HDFS文件列表”。
4. 进入您要导入到GaussDB(DWS)集群的数据的存储目录,并记录其路径。
图1-1 在 MRS 上查看数据存储路径
步骤2 创建外表。 SERVER名字填写步骤10创建的外部服务器名称,foldername填写步骤1查 到的路径。
DROP FOREIGN TABLE IF EXISTS foreign_product_info;
CREATE FOREIGN TABLE foreign_product_info ( product_price integer , product_id char(30) , product_time date , product_level char(10) , product_name varchar(200) , product_type1 varchar(20) , product_type2 char(10) , product_monthly_sales_cnt integer , product_comment_time date , product_comment_num integer ,
product_comment_content varchar(200) ) SERVER hdfs_server_8f79ada0_d998_4026_9020_80d6de2692ca OPTIONS (
format 'orc', encoding 'utf8',
foldername '/user/hive/warehouse/demo.db/product_info_orc/' ) DISTRIBUTE BY ROUNDROBIN;
----结束
执行数据导入
步骤1 创建本地目标表。
DROP TABLE IF EXISTS product_info;
CREATE TABLE product_info
( product_price integer , product_id char(30) , product_time date , product_level char(10) , product_name varchar(200) , product_type1 varchar(20) , product_type2 char(10) , product_monthly_sales_cnt integer , product_comment_time date , product_comment_num integer ,
product_comment_content varchar(200) ) with (
orientation = column, compression=middle
) DISTRIBUTE BY HASH (product_id);
步骤2 从外表导入目标表。
INSERT INTO product_info SELECT * FROM foreign_product_info;
步骤3 查询导入结果。
SELECT * FROM product_info;
----结束
1.6 教程:导入远端 DWS 数据源
大数据融合分析场景下,支持同一区域内的多套GaussDB(DWS)集群之间的数据互通 互访,本实践将演示通过Foreign Table方式从远端DWS导入数据到本端DWS。
本实践演示过程为:以gsql作为数据库客户端,gsql安装在ECS,通过gsql连接DWS,
再通过外表方式导入远端DWS的数据。本实践预计时长40分钟,基本流程如下:
1. 准备工作
2. 创建ECS
3. 创建集群并下载工具包
4. 使用GDS导入数据源
5. 通过外表导入远端DWS数据
准备工作
已注册华为云账号,账号不能处于欠费或冻结状态。
创建 ECS
参见自定义购买弹性云服务器购买。购买后,参见登录Linux弹性云服务器进行登录。
须知
创建ECS过程中,注意选择与后续的DWS集群在同一个区域、可用区和同一个VPC子网 下,ECS的操作系统选择与下面的gsql客户端/GDS工具的操作系统一致(本例以 CentOS 7.6为例),并选择以密码方式登录。
创建集群并下载工具包
步骤1 登录华为云管理控制台。
步骤2 在“服务列表”中,选择“大数据 > 数据仓库服务”,单击右上角“购买数据仓库集 群”。
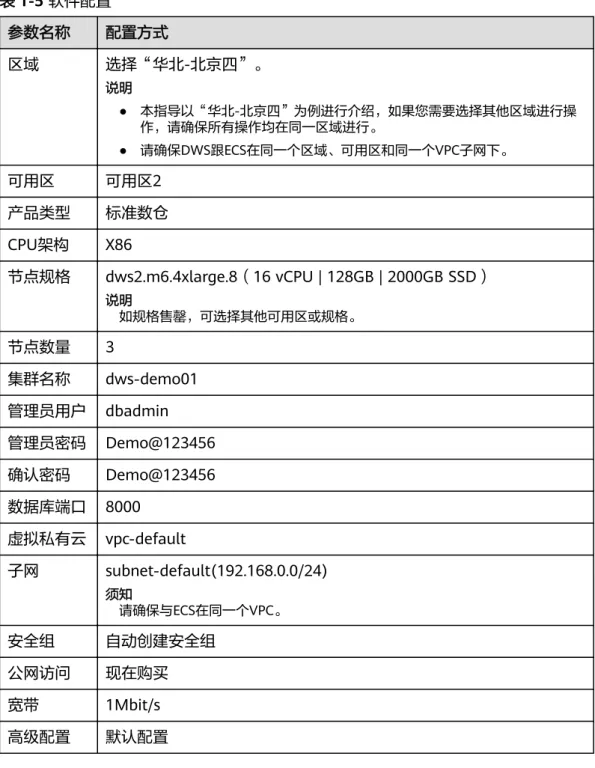
步骤3 参见表1-5进行参数配置。
表1-5 软件配置
参数名称 配置方式
区域 选择“华北-北京四”。
说明
● 本指导以“华北-北京四”为例进行介绍,如果您需要选择其他区域进行操 作,请确保所有操作均在同一区域进行。
● 请确保DWS跟ECS在同一个区域、可用区和同一个VPC子网下。
可用区 可用区2 产品类型 标准数仓 CPU架构 X86
节点规格 dws2.m6.4xlarge.8(16 vCPU | 128GB | 2000GB SSD)
说明
如规格售罄,可选择其他可用区或规格。
节点数量 3
集群名称 dws-demo01 管理员用户 dbadmin 管理员密码 Demo@123456 确认密码 Demo@123456 数据库端口 8000
虚拟私有云 vpc-default
子网 subnet-default(192.168.0.0/24) 须知请确保与ECS在同一个VPC。
安全组 自动创建安全组 公网访问 现在购买 宽带 1Mbit/s 高级配置 默认配置
步骤4 信息核对无误,单击“立即购买”,单击“提交”。
步骤5 等待约10分钟,待集群创建成功后,单击集群名称进入“基本信息”,选择“网络 >
安全组名称”,确认安全组规则已添加,以IP为192.168.0.x的客户端网段为例(本例
gsql所在ECS的内网IP为192.168.0.90),需要添加192.168.0.0/24,端口为8000的安 全组规则。
步骤6 返回到集群“基本信息”界面,记录下“内网IP”。
步骤7 返回到DWS控制台首页,左侧导航选择“连接管理”,选择ECS的操作系统(以 CentOS 7.6为例,则选择“Redhat x86_64”),单击“下载”将工具包保存到本地。
(工具包中包含gsql客户端和GDS工具)。
步骤8 重复执行步骤1~步骤6,创建第二套DWS集群,名称设置为dws-demo02。
----结束
准备源数据
步骤1 在本地PC指定目录下,创建以下3个.csv格式的文件,数据样例如下。
● 数据文件“product_info0.csv”
100,XHDK-A,2017-09-01,A,2017 Shirt Women,red,M,328,2017-09-04,715,good!
205,KDKE-B,2017-09-01,A,2017 T-shirt Women,pink,L,584,2017-09-05,40,very good!
300,JODL-X,2017-09-01,A,2017 T-shirt men,red,XL,15,2017-09-03,502,Bad.
310,QQPX-R,2017-09-02,B,2017 jacket women,red,L,411,2017-09-05,436,It's nice.
150,ABEF-C,2017-09-03,B,2017 Jeans Women,blue,M,123,2017-09-06,120,good.
● 数据文件“product_info1.csv”
200,BCQP-E,2017-09-04,B,2017 casual pants men,black,L,997,2017-09-10,301,good quality.
250,EABE-D,2017-09-10,A,2017 dress women,black,S,841,2017-09-15,299,This dress fits well.
108,CDXK-F,2017-09-11,A,2017 dress women,red,M,85,2017-09-14,22,It's really amazing to buy.
450,MMCE-H,2017-09-11,A,2017 jacket women,white,M,114,2017-09-14,22,very good.
260,OCDA-G,2017-09-12,B,2017 woolen coat women,red,L,2004,2017-09-15,826,Very comfortable.
● 数据文件“product_info2.csv”
980,"ZKDS-J",2017-09-13,"B","2017 Women's Cotton Clothing","red","M",112,,, 98,"FKQB-I",2017-09-15,"B","2017 new shoes men","red","M",4345,2017-09-18,5473
50,"DMQY-K",2017-09-21,"A","2017 pants men","red","37",28,2017-09-25,58,"good","good","good"
80,"GKLW-l",2017-09-22,"A","2017 Jeans Men","red","39",58,2017-09-25,72,"Very comfortable."
30,"HWEC-L",2017-09-23,"A","2017 shoes women","red","M",403,2017-09-26,607,"good!"
40,"IQPD-M",2017-09-24,"B","2017 new pants Women","red","M",35,2017-09-27,52,"very good."
50,"LPEC-N",2017-09-25,"B","2017 dress Women","red","M",29,2017-09-28,47,"not good at all."
60,"NQAB-O",2017-09-26,"B","2017 jacket women","red","S",69,2017-09-29,70,"It's beautiful."
70,"HWNB-P",2017-09-27,"B","2017 jacket women","red","L",30,2017-09-30,55,"I like it so much"
80,"JKHU-Q",2017-09-29,"C","2017 T-shirt","red","M",90,2017-10-02,82,"very good."
步骤2 使用root帐户登录已创建好的ECS,执行以下命令创建数据源文件目录。
mkdir -p /input_data
步骤3 使用文件传输工具,将以上数据文档上传到ECS的/input_data目录下。
----结束
使用 GDS 导入数据源
步骤1 使用root帐户登录ECS,使用文件传输工具将步骤7下载好的工具包上传到/opt目录 下。
步骤2 在/opt目录下解压工具包。
cd /opt
unzip dws_client_8.1.x_redhat_x64.zip
步骤3 创建GDS用户,并修改数据源目录和GDS目录的属主。
groupadd gdsgrp
useradd -g gdsgrp gds_user
chown -R gds_user:gdsgrp /opt/gds chown -R gds_user:gdsgrp /input_data 步骤4 切换到gds_user用户。
su - gds_user 步骤5 导入GDS环境变量。
说明
仅8.1.x及以上版本需要执行,老版本请跳过。
cd /opt/gds/bin source gds_env 步骤6 启动GDS。
/opt/gds/bin/gds -d /input_data/ -p 192.168.0.90:5000 -H 192.168.0.0/24 - l /opt/gds/gds_log.txt -D
● -d dir:保存有待导入数据的数据文件所在目录。本教程中为“/input_data/”。
● -p ip:port:GDS监听IP和监听端口。配置为GDS所在的ECS的内网IP,可与DWS通 讯,本例为192.168.0.90:5000。
● -H address_string:允许哪些主机连接和使用GDS服务。参数需为CIDR格式。本 例设置为DWS的内网IP所在的网段即可。
● -l log_file:存放GDS的日志文件路径及文件名。本教程为“/opt/gds/
gds_log.txt”。
● -D:后台运行GDS。
步骤7 使用gsql连接第一套DWS集群。
1. 执行exit切换root用户,进入ECS的/opt目录,导入gsql的环境变量。
exit cd /opt
source gsql_env.sh
2. 进入/opt/bin目录,使用gsql连接第一套DWS集群。
cd /opt/bin
gsql -d gaussdb -h 192.168.0.8 -p 8000 -U dbadmin -W Demo@123456 -r – -d: 连接的数据库名,本例为默认数据库gaussdb。
– -h:连接的DWS内网IP,即步骤6查询到的内网IP,本例为192.168.0.8 – -p:DWS端口,固定为8000。
– -U:数据库管理员用户,默认为dbadmin。
– -W:管理员用户的密码,为步骤3创建集群时设置的密码,本例为 Demo@123456。
步骤8 创建普通用户leo,并赋予创建外表的权限。
CREATE USER leo WITH PASSWORD "Bigdata@123";
ALTER USER leo USEFT;
步骤9 切换到leo用户,创建GDS外表。
说明
以下LOCATION参数请填写为步骤6的GDS的监听IP和端口,后面加上/*,例如:gsfs://
192.168.0.90:5000/*
SET ROLE leo PASSWORD "Bigdata@123";
DROP FOREIGN TABLE IF EXISTS product_info_ext;
CREATE FOREIGN TABLE product_info_ext ( product_price integer not null, product_id char(30) not null, product_time date , product_level char(10) , product_name varchar(200) , product_type1 varchar(20) , product_type2 char(10) , product_monthly_sales_cnt integer , product_comment_time date , product_comment_num integer ,
product_comment_content varchar(200) ) SERVER gsmpp_server
OPTIONS(
LOCATION 'gsfs://192.168.0.90:5000/*', FORMAT 'CSV' ,
DELIMITER ',', ENCODING 'utf8', HEADER 'false',
FILL_MISSING_FIELDS 'true', IGNORE_EXTRA_DATA 'true' )READ ONLY
LOG INTO product_info_err PER NODE REJECT LIMIT 'unlimited';
步骤10 创建本地表。
DROP TABLE IF EXISTS product_info;
CREATE TABLE product_info
( product_price integer not null, product_id char(30) not null, product_time date , product_level char(10) , product_name varchar(200) , product_type1 varchar(20) , product_type2 char(10) , product_monthly_sales_cnt integer ,
product_comment_time date , product_comment_num integer ,
product_comment_content varchar(200) ) WITH (
orientation = column, compression=middle
) DISTRIBUTE BY hash (product_id);
步骤11 从GDS外表导入数据,并查询,数据导入成功。
INSERT INTO product_info SELECT * FROM product_info_ext ; SELECT count(*) FROM product_info;
----结束
通过外表导入远端 DWS 数据
步骤1 参见步骤7在ECS上连接第二套集群,其中连接地址改为第二套集群的地址,本例为 192.168.0.86。
步骤2 创建普通用户jim,并赋予创建外表和server的权限。FOREIGN DATA WRAPPER固定 为gc_fdws
CREATE USER jim WITH PASSWORD "Bigdata@123";
ALTER USER jim USEFT;
GRANT ALL ON FOREIGN DATA WRAPPER gc_fdw TO jim;
步骤3 切换到jim用户,创建server。
SET ROLE jim PASSWORD "Bigdata@123";
CREATE SERVER server_remote FOREIGN DATA WRAPPER GC_FDW OPTIONS (address '192.168.0.8:8000,192.168.0.158:8000' ,
dbname 'gaussdb', username 'leo', password 'Bigdata@123' );
● address:第一套集群的两个内网IP和端口,参见步骤6获取,本例为 192.168.0.8:8000,192.168.0.158:8000。
● dbname:连接的第一套集群的数据库名,本例为gaussdb。
● username:连接的第一套集群的用户名,本例为leo。
● password:用户名密码,本例为Bigdata@123。
步骤4 创建外表。
须知
外表的字段和约束,必须与待访问表的字段和约束保持一致。
CREATE FOREIGN TABLE region ( product_price integer , product_id char(30) , product_time date , product_level char(10) , product_name varchar(200) , product_type1 varchar(20) , product_type2 char(10) , product_monthly_sales_cnt integer , product_comment_time date , product_comment_num integer ,
product_comment_content varchar(200) ) SERVER
server_remote OPTIONS
( schema_name 'leo', table_name 'product_info', encoding 'utf8'
);
● SERVER:上一步创建的server的名称,本例为server_remote。
● schema_name:待访问的第一套集群的schema名称,本例为leo。
● table_name:待访问的第一套集群的表名,参见步骤10获取,本例为 product_info。
● encoding:保持与第一套集群的数据库编码一致,参见步骤9获取,本例为utf8。
步骤5 查看创建的server和外表。
\des+ server_remote
\d+ region
步骤6 创建本地表。
须知
表的字段和约束,必须与待访问表的字段和约束保持一致。
CREATE TABLE local_region
( product_price integer not null, product_id char(30) not null, product_time date , product_level char(10) , product_name varchar(200) , product_type1 varchar(20) , product_type2 char(10) , product_monthly_sales_cnt integer , product_comment_time date , product_comment_num integer , product_comment_content varchar(200) )
WITH (
orientation = column, compression=middle
) DISTRIBUTE BY hash (product_id);
步骤7 通过外表导入数据到本地表。
INSERT INTO local_region SELECT * FROM region;
SELECT * FROM local_region;
步骤8 您也可以直接查询外表而无需将数据导入。
SELECT * FROM region;
----结束
2 开发设计
2.1 表设计最佳实践
2.1.1 学习“教程:调优表设计”
进行数据库设计时,表设计上的一些关键项将严重影响后续整库的查询性能。表设计 对数据存储也有影响:好的表设计能够减少I/O操作及最小化内存使用,进而提升查询 性能。
教程指引指导您逐步完成选择排序键、分配方式和压缩编码的过程,并介绍如何比较 优化前后的系统性能。
下面各节总结最重要的表设计关键考虑点并给出优秀的实践建议。
2.1.2 选择存储模型
进行数据库设计时,表设计上的一些关键项将严重影响后续整库的查询性能。表设计 对数据存储也有影响:好的表设计能够减少I/O操作及最小化内存使用,进而提升查询 性能。
表的存储模型选择是表定义的第一步。业务属性是表的存储模型的决定性因素,依据 下面表格选择适合当前业务的存储模型。
存储模型 适用场景
行存 点查询(返回记录少,基于索引的简单查询)。
增删改比较多的场景。
列存 统计分析类查询 (group , join多的场景)。
2.1.3 选择分布方式
复制表(Replication)方式将表中的全量数据在集群的每一个DN实例上保留一份。主 要适用于记录集较小的表。这种存储方式的优点是每个DN上都有此表的全量数据,在 join操作中可以避免数据重分布操作,从而减小网络开销,同时减少了plan
segment(每个plan segment都会起对应的线程);缺点是每个DN都保留了表的完整数 据,造成数据的冗余。一般情况下只有较小的维度表才会定义为Replication表。
哈希(Hash)表将表中某一个或几个字段进行hash运算后,生成对应的hash值,根据 DN实例与哈希值的映射关系获得该元组的目标存储位置。对于Hash分布表,在读/写 数据时可以利用各个节点的IO资源,大大提升表的读/写速度。一般情况下大表定义为 Hash表。
策略 描述 适用场景
Hash 表数据通过hash方式散列到集群中的所
有DN实例上。 数据量较大的事实表。
Replication 集群中每一个DN实例上都有一份全量表 数据。
小表、维度表。
如图2-1所示,复制表如图中的表T1,哈希表如图中的表T2。
图2-1 复制表和哈希表
2.1.4 选择分布列
Hash分布表的分布列选取至关重要,需要满足以下原则:
1. 列值应比较离散,以便数据能够均匀分布到各个DN。例如,考虑选择表的主键为 分布列,如在人员信息表中选择身份证号码为分布列。
2. 在满足第一条原则的情况下尽量不要选取存在常量filter的列。例如,表dwcjk相 关的部分查询中出现dwcjk的列zqdh存在常量的约束(例如zqdh=’000001’),那 么就应当尽量不用zqdh做分布列。
3. 在满足前两条原则的情况,考虑选择查询中的连接条件为分布列,以便Join任务能 够下推到DN中执行,且减少DN之间的通信数据量。
对于Hash分表策略,如果分布列选择不当,可能导致数据倾斜,查询时出现部分 DN的I/O短板,从而影响整体查询性能。因此在采用Hash分表策略之后需对表的 数据进行数据倾斜性检查,以确保数据在各个DN上是均匀分布的。可以使用以下 SQL检查数据倾斜性
select
xc_node_id, count(1) from tablename group by xc_node_id order by xc_node_id desc;
其中xc_node_id对应DN,一般来说,不同DN的数据量相差5%以上即可视为倾 斜,如果相差10%以上就必须要调整分布列。
4. 一般不建议用户新增一列专门用作分布列,尤其不建议用户新增一列,然后用 SEQUENCE的值来填充做为分布列。因为SEQUENCE可能会带来性能瓶颈和不必 要的维护成本。
GaussDB(DWS)支持多分布列特性,可以更好地满足数据分布的均匀性要求。
2.1.5 使用分区表
分区表是把逻辑上的一张表根据某种方案分成几张物理块进行存储。这张逻辑上的表 称之为分区表,物理块称之为分区。分区表是一张逻辑表,不存储数据,数据实际是 存储在分区上的。分区表和普通表相比具有以下优点:
1. 改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索效率。
2. 增强可用性:如果分区表的某个分区出现故障,表在其他分区的数据仍然可用。
3. 方便维护:如果分区表的某个分区出现故障,需要修复数据,只修复该分区即 可。
GaussDB(DWS)支持的分区表为范围分区表。
范围分区表:将数据基于范围映射到每一个分区。这个范围是由创建分区表时指定的 分区键决定的。分区键经常采用日期,例如将销售数据按照月份进行分区。
2.1.6 使用局部聚簇
局部聚簇(Partial Cluster Key)是列存下的一种技术。这种技术可以通过min/max稀 疏索引较快的实现基表扫描的filter过滤。Partial Cluster Key可以指定多列,但是一般 不建议超过2列。Partial Cluster Key的选取原则:
1. 受基表中的简单表达式约束。这种约束一般形如col op const,其中col为列名,
op为操作符 =、>、>=、<=、<,const为常量值。
2. 尽量采用选择度比较高(过滤掉更多数据)的简单表达式中的列。
3. 尽量把选择度比较低的约束col放在Partial Cluster Key中的前面。
4. 尽量把枚举类型的列放在Partial Cluster Key中的前面。
2.1.7 选择数据类型
高效数据类型,主要包括以下三方面:
1. 尽量使用执行效率比较高的数据类型
一般来说整型数据运算(包括=、>、<、≧、≦、≠等常规的比较运算,以及 group by)的效率比字符串、浮点数要高。比如某客户场景中对列存表进行点查 询,filter条件在一个numeric列上,执行时间为10+s;修改numeric为int类型之 后,执行时间缩短为1.8s左右。
2. 尽量使用短字段的数据类型
长度较短的数据类型不仅可以减小数据文件的大小,提升IO性能;同时也可以减 小相关计算时的内存消耗,提升计算性能。比如对于整型数据,如果可以用 smallint就尽量不用int,如果可以用int就尽量不用bigint。
3. 使用一致的数据类型
表关联列尽量使用相同的数据类型。如果表关联列数据类型不同,数据库必须动 态地转化为相同的数据类型进行比较,这种转换会带来一定的性能开销。
2.2 教程:调优表设计
2.2.1 教程指引
在本教程中,您将学习如何优化表的设计。您首先不指定存储方式,分布键、分布方 式和压缩方式创建表,然后为这些表加载测试数据并测试系统性能。接下来,您将应 用优秀实践以使用新的存储方式、分布键、分布方式和压缩方式重新创建这些表,并 再次为这些表加载测试数据和测试系统性能,以便比较不同的设计对表的加载性能、
存储空间和查询性能的影响。
估计时间:60 分钟。
2.2.2 本教程所用表模型
在设计数据仓库模型的时候,最常见的有两种:星型模型与雪花模型。选择哪一种模 型需要根据业务需求以及性能的多重考量来定。
● 星型模型由包含数据库核心数据的中央事实数据表和为事实数据表提供描述性属 性信息的多个维度表组成。维度表通过主键关联事实表中的外键。如图2-2。
– 所有的事实都必须保持同一个粒度。
– 不同的维度之间没有任何关联。
图2-2 星型模型
● 雪花模型是在基于星型模型之上拓展来的,每一个维度可以再扩散出更多的维 度,根据维度的层级拆分成颗粒度不同的多张表。如图2-3。
– 优点是减少维度表的数据量,在进行join查询时有效提升查询速度。
– 缺点是需要额外维护维度表的数量。
图2-3 雪花模型