最佳实践
文档版本 01
发布日期 2021-04-13
非经本公司书面许可,任何单位和个人不得擅自摘抄、复制本文档内容的部分或全部,并不得以任何形式传 播。
商标声明
和其他华为商标均为华为技术有限公司的商标。
本文档提及的其他所有商标或注册商标,由各自的所有人拥有。
注意
您购买的产品、服务或特性等应受华为公司商业合同和条款的约束,本文档中描述的全部或部分产品、服务或 特性可能不在您的购买或使用范围之内。除非合同另有约定,华为公司对本文档内容不做任何明示或暗示的声 明或保证。
由于产品版本升级或其他原因,本文档内容会不定期进行更新。除非另有约定,本文档仅作为使用指导,本文 档中的所有陈述、信息和建议不构成任何明示或暗示的担保。
目 录
1 数据分析...1
1.1 使用 Spark2x 实现车联网车主驾驶行为分析... 1
1.2 使用 Hive 加载 HDFS 数据并分析图书评分情况...9
1.3 使用 Hive 加载 OBS 数据并分析企业雇员信息... 15
2 数据迁移...24
2.1 数据迁移方案介绍... 24
2.1.1 准备工作... 24
2.1.2 元数据导出... 25
2.1.3 数据拷贝... 26
2.1.4 数据恢复... 26
2.2 数据迁移到 MRS 前信息收集... 27
2.3 数据迁移到 MRS 前网络准备... 32
2.4 Hadoop 数据迁移到华为云 MRS 服务... 34
2.5 HBase 数据迁移到华为云 MRS 服务... 37
2.6 Hive 数据迁移到华为云 MRS 服务... 43
2.7 数据迁移网络端口要求... 46
2.8 离线数据迁移-使用 BulkLoad 向 HBase 中批量导入数据... 47
2.9 MySQL 数据迁移到 MRS 集群 Hive 分区表... 53
2.10 MRS HDFS 数据迁移到 OBS...62
3 数据备份与恢复... 66
3.1 元数据备份恢复说明... 66
3.1.1 HDFS 数据... 66
3.1.2 Hive 元数据... 67
3.1.3 Hive 数据...68
3.1.4 HBase 数据... 68
3.1.5 Kafka 数据... 73
1 数据分析
1.1 使用 Spark2x 实现车联网车主驾驶行为分析
本手册基于华为云MapReduce服务实践所编写,用于指导您使用Spark实现车主驾驶 行为分析。
本实践基本内容如下所示:
1. 场景描述
2. 第一步:创建集群
3. 第二步:准备Spark样例程序和样例数据
4. 第三步:创建作业
5. 第四步:查看作业执行结果
场景描述
目的:
了解MRS的基本功能,利用MRS服务的Spark2x组件,对车主的驾驶行为进行分析统 计,得到用户驾驶行为的分析结果。
场景:
本次实战的原始数据为车主的驾驶行为信息,包括车主在日常的驾驶行为中,是否急 加速、急减速、空挡滑行、超速、疲劳驾驶等信息。通过Spark2x组件的强大的分析能 力,分析统计指定时间段内,车主急加速、急减速、空挡滑行、超速、疲劳驾驶等违 法行为的次数。
说明
本实践仅适用于MRS 3.x版本,请按照指导创建集群。
创建集群
步骤1 登录华为云管理控制台。
步骤3 单击页面右上角“购买集群”,进入购买集群页面。
图1-1 购买集群
步骤4 选择“自定义购买”。
参见表1-1配置集群软件信息。
表1-1 软件配置
参数名称 配置方式
区域 选择“华北-北京四”。
说明本指导以“华北-北京四”为例进行介绍,如果您需要选择其他区域进行操
作,请确保所有操作均在同一区域进行。
集群名称 mrs_demo 集群版本 选择MRS 3.x。
说明本实践仅适用于MRS 3.x版本,请选择对应版本集群。
集群类型 选择“分析集群”,用来做离线数据分析。
组件选择 勾选所有组件。
元数据 选择“本地元数据”。
图1-2 自定义购买-软件配置
步骤5 单击“下一步”配置硬件信息。
参见表1-2配置集群硬件信息。
表1-2 硬件配置
参数名称 配置方式
计费模式 按需计费
可用区 可用区2
虚拟私有云 选择需要创建集群的VPC,单击“查看虚拟私有云”进入VPC服务 查看已创建的VPC名称和ID。如果没有VPC,需要创建一个新的 VPC。
子网 选择需要创建集群的子网,可进入VPC服务查看VPC下已创建的子 网名称和ID。若VPC下未创建子网,请单击“创建子网”进行创
参数名称 配置方式
安全组 选择“自动创建”。
弹性公网IP 选择“暂不绑定”。
企业项目 选择“default”。
集群节点 保持默认值。
图1-3 自定义购买-硬件配置
步骤6 单击“下一步”,高级配置页签参考表1-3配置以下信息,其他选项保持默认值。
表1-3 高级配置 Kerberos认证
单击 来关闭Kerberos认证。
用户名 Manager管理员用户,目前默认为admin用户。
密码 配置Manager管理员用户的密码。
确认密码 再次输入Manager管理员用户的密码。
登录方式 选择“密码”。
用户名 用于登录弹性云服务器的用户,目前默认为root用户。
密码 配置登录ECS的用户密码。
确认密码 再次输入登录ECS的用户密码。
通信安全授权 勾选“确认授权”。
图1-4 自定义购买-高级配置
步骤7 单击“立即购买”,进入任务提交成功页面。
步骤8 单击“返回集群列表”,可以查看到集群创建的状态。
集群创建需要时间,所创集群的初始状态为“启动中”,创建成功后状态更新为“运 行中”,请您耐心等待。
----结束
准备 Spark2x 样例程序和样例数据
步骤1 创建OBS并行文件系统,用于存放Spark样例程序、样例数据、作业执行结果和日志。
1. 登录华为云管理控制台。
2. 在“服务列表”中,选择“存储 > 对象存储服务”。
3. 单击“并行文件系统 > 创建并行文件系统”,创建一个名称为obs-demo- analysis-hwt4的文件系统。策略等参数保持默认值。
图1-5 创建并行文件系统
步骤2 单击obs-demo-analysis-hwt4文件系统名称。选择左侧导航栏“文件”,在“文件”
页签下单击“新建文件夹”,分别新建program、input文件夹,如图1-6所示。
图1-6 新建文件夹
步骤3 从 https://mrs-obs-cn-north-4.obs.cn-north-4.myhuaweicloud.com/mrs- demon-samples/demon/driver_behavior.jar路径下载样例程序driver_behavior.jar 至本地。
步骤4 进入program文件夹,单击“上传文件”,选择本地存放的driver_behavior.jar样例程 序。
步骤5 单击“上传”,上传样例程序到OBS桶。
步骤6 从https://mrs-obs-cn-north-4.obs.cn-north-4.myhuaweicloud.com/mrs-demon- samples/demon/detail-records.zip获取Spark样例数据到本地。
步骤7 解压获取到的Spark样例数据。
步骤8 进入input文件夹,单击“上传文件”,选择本地存放的Spark样例数据。
步骤9 单击“上传”,上传样例数据到OBS文件系统。
----结束
创建作业
步骤1 在MRS控制台左侧导航栏选择“集群列表 > 现有集群”,单击名称为“mrs_demo”
的集群。
步骤2 在集群信息页面选择“作业管理”页签,单击“添加”,进入添加作业页面。
图1-7 添加作业
步骤3 按图1-8完成作业参数配置。
表1-4 配置作业信息
参数名称 配置方法
作业类型 选择“SparkSubmit”。
作业名称 输入“driver_behavior_task”。
执行程序路径 单击“OBS”,选择准备Spark2x样例程序和样例数据 中上传的名称为driver_behavior.jar的jar包。
运行程序参数 参数选择“--class”,值输入
“com.huawei.bigdata.spark.examples.DriverBehavior
”。
执行程序参数 输入“AK SK 1 输入路径 输出路径”。
● AK/SK请参考说明方式获取。
● 1为固定输入,用于指定作业执行时调用的程序函 数。
● 输入路径可通过单击“OBS”进行选择输入路径。
● 输出路径请手动输入一个不存在的目录,例如obs://
obs-demo-analysis-hwt4/output/。
说明AK/SK,请通过如下方式获取。
1. 登录华为云管理控制台。
2. 单击右上角的用户名,然后选择“我的凭证”。
3. 系统跳转至“我的凭证”页面,单击“访问密钥”。
4. 单击“新增访问密钥”申请新密钥,按照提示输入密码与 验证码之后,浏览器自动下载一个“credentials.csv”文 件,文件为csv格式,以英文逗号分隔,中间的为AK,最后 一个为SK。
服务配置参数 保持默认不配置。
图1-8 添加作业
步骤4 单击“确定”,开始提交作业,执行程序。
----结束
查看作业执行结果
步骤1 进入“作业管理”页面,查看作业执行状态。
图1-9 作业执行状态
步骤2 等待1~2分钟,登录OBS控制台,进入obs-demo-analysis-hwt4文件系统的output目 录中,查看执行结果,在生成的csv文件所在行的“操作”列单击“下载”按钮将该文 件下载到本地。
图1-10 下载作业执行结果
步骤3 在本地将下载后的csv文件使用Excel文本打开,按照样例程序中定义的字段为每列数据 进行分类,得到如下图所示作业执行结果。
图1-11 执行结果
----结束
1.2 使用 Hive 加载 HDFS 数据并分析图书评分情况
MRS离线处理集群,可对海量数据进行分析和处理,形成结果数据,供下一步数据应 用使用。
离线处理对处理时间要求不高,但是所处理数据量较大,占用计算存储资源较多,通 常通过Hive/SparkSQL引擎或者MapReduce/Spark2x实现。
本实践基于华为云MapReduce服务,用于指导您创建MRS集群后,使用Hive对原始数 据进行导入、分析等操作,展示了如何构建弹性、低成本的离线大数据分析。
基本内容如下所示:
1. 创建MRS离线查询集群。
2. 将本地数据导入到HDFS中。
3. 创建Hive表。
4. 将原始数据导入Hive并进行分析。
场景描述
Hive是建立在Hadoop上的数据仓库框架,提供大数据平台批处理计算能力,能够对结 构化/半结构化数据进行批量分析汇总完成数据计算。提供类似SQL的Hive Query Language语言操作结构化数据,其基本原理是将HQL语言自动转换成MapReduce任 务,从而完成对Hadoop集群中存储的海量数据进行查询和分析。
Hive主要特点如下:
● 海量结构化数据分析汇总。
● 将复杂的MapReduce编写任务简化为SQL语句。
● 灵活的数据存储格式,支持JSON,CSV,TEXTFILE,RCFILE,SEQUENCEFILE,
ORC(Optimized Row Columnar)这几种存储格式。
本实践以某图书网站后台用户的点评数据为原始数据,导入Hive表后通过SQL命令筛 选出最受欢迎的畅销图书。
创建 MRS 离线查询集群
1. 登录华为云控制台,选择“大数据 > MapReduce服务”,单击“购买集群”,选 择“快速购买”,填写软件配置参数,单击“下一步”。
表1-5 软件配置(以下参数仅供参考,可根据实际情况调整)
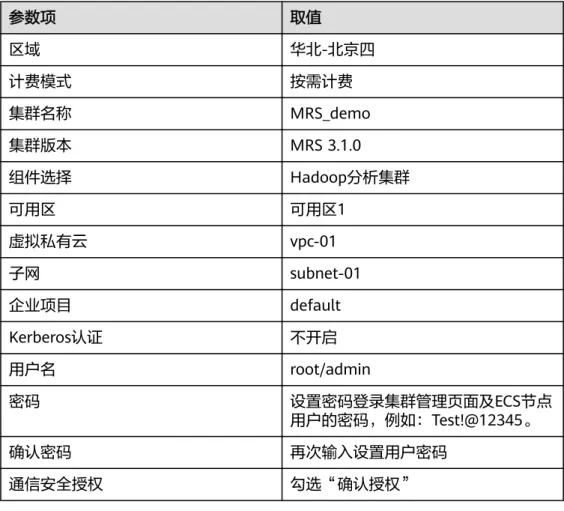
参数项 取值
区域 华北-北京四
计费模式 按需计费
集群名称 MRS_demo
集群版本 MRS 3.1.0
组件选择 Hadoop分析集群
可用区 可用区1
虚拟私有云 vpc-01
子网 subnet-01
企业项目 default
Kerberos认证 不开启
用户名 root/admin
密码 设置密码登录集群管理页面及ECS节点
用户的密码,例如:Test!@12345。
确认密码 再次输入设置用户密码
通信安全授权 勾选“确认授权”
2. 单击“立即购买”,等待约15分钟,MRS集群创建成功。
将本地数据导入到 HDFS 中
1. 在本地已获取某图书网站后台图书点评记录的原始数据文件“book_score.txt”,
例如内容如下。
字段信息依次为:用户ID、图书ID、图书评分、备注信息 例如部分数据节选如下:
202001,242,3,Good!
202002,302,3,Test.
202003,377,1,Bad!
220204,51,2,Bad!
202005,346,1,aaa 202006,474,4,None 202007,265,2,Bad!
202008,465,5,Good!
202009,451,3,Bad!
202010,86,3,Bad!
202011,257,2,Bad!
202012,465,4,Good!
202013,465,4,Good!
202014,465,4,Good!
202015,302,5,Good!
202016,302,3,Good!
...
2. 登录对象存储服务OBS控制台,单击“创建桶”,填写以下参数,单击“立即创 建”。
表1-6 桶参数
参数项 取值
区域 华北-北京四
数据冗余存储策略 单AZ存储
桶名称 mrs-hive
默认存储类别 标准存储
桶策略 私有
默认加密 关闭
归档数据直读 关闭
企业项目 default
标签 -
等待桶创建好,单击桶名称,选择“对象 > 上传对象”,将数据文件上传至OBS 桶内。
3. 切换回MRS控制台,单击创建好的MRS集群名称,进入“概览”,单击“IAM用 户同步”所在行的“同步”,等待约5分钟同步完成。
4. 将数据文件上传HDFS。
a. 在“文件管理”页签,选择“HDFS文件列表”,进入数据存储目录,如
“/tmp/test”。
“/tmp/test”目录仅为示例,可以是界面上的任何目录,也可以通过“新 建”创建新的文件夹。
b. 单击“导入数据”。
▪
OBS路径:选择上面创建好的OBS桶名,找到“book_score.txt”文件,单击“是”。
▪
HDFS路径:选择“/tmp/test”,单击“是”。c. 单击“确定”,等待数据导入成功,此时数据文件已上传至MRS集群的HDFS 文件系统内。
创建 Hive 表
1. 下载并安装集群全量客户端,例如在主Master节点上安装,客户端安装目录为
“/opt/client”,相关操作可参考安装客户端。
也可直接使用Master节点中自带的集群客户端,安装目录为“/opt/Bigdata/
client”。
2. 为主Master节点绑定一个弹性IP并在安全组中放通22端口,然后使用root用户登
cd /opt/client source bigdata_env
3. 执行beeline -n 'hdfs'命令进入Hive Beeline命令行界面。
执行以下命令创建一个与原始数据字段匹配的Hive表:
create table bookscore (userid int,bookid int,score int,remarks string) row format delimited fields terminated by ','stored as textfile;
4. 查看表是否创建成功:
show tables;
+---+
| tab_name | +---+
| bookscore | +---+
将原始数据导入 Hive 并进行分析
1. 继续在Hive Beeline命令行中执行以下命令,将已导入HDFS的原始数据导入Hive 表中。
load data inpath '/tmp/test/book_score.txt' into table bookscore;
2. 数据导入完成后,执行如下命令,查看Hive表内容。
select * from bookscore;
+---+---+---+---+
| bookscore.userid | bookscore.bookid | bookscore.score | bookscore.remarks | +---+---+---+---+
| 202001 | 242 | 3 | Good! |
| 202002 | 302 | 3 | Test. |
| 202003 | 377 | 1 | Bad! |
| 220204 | 51 | 2 | Bad! |
| 202005 | 346 | 1 | aaa |
| 202006 | 474 | 4 | None |
| 202007 | 265 | 2 | Bad! |
| 202008 | 465 | 5 | Good! |
| 202009 | 451 | 3 | Bad! |
| 202010 | 86 | 3 | Bad! |
| 202011 | 257 | 2 | Bad! |
| 202012 | 465 | 4 | Good! |
| 202013 | 465 | 4 | Good! |
| 202014 | 465 | 4 | Good! |
| 202015 | 302 | 5 | Good! |
| 202016 | 302 | 3 | Good! | ...
执行以下命令统计表行数:
select count(*) from bookscore;
+---+
| _c0 | +---+
| 32 | +---+
3. 执行以下命令,等待MapReduce任务完成后,筛选原始数据中累计评分最高的图 书top3。
select bookid,sum(score) as summarize from bookscore group by bookid order by summarize desc limit 3;
例如最终显示内容如下:
...INFO : 2021-10-14 19:53:42,427 Stage-2 map = 0%, reduce = 0%
INFO : 2021-10-14 19:53:49,572 Stage-2 map = 100%, reduce = 0%, Cumulative CPU 2.15 sec INFO : 2021-10-14 19:53:56,713 Stage-2 map = 100%, reduce = 100%, Cumulative CPU 4.19 sec INFO : MapReduce Total cumulative CPU time: 4 seconds 190 msec
INFO : Ended Job = job_1634197207682_0025 INFO : MapReduce Jobs Launched:
INFO : Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 4.24 sec HDFS Read: 7872 HDFS Write:
322 SUCCESS
INFO : Stage-Stage-2: Map: 1 Reduce: 1 Cumulative CPU: 4.19 sec HDFS Read: 5965 HDFS Write:
143 SUCCESS
INFO : Total MapReduce CPU Time Spent: 8 seconds 430 msec INFO : Completed executing
command(queryId=omm_20211014195310_cf669633-5b58-4bd5-9837-73286ea83409); Time taken:
47.388 seconds INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager +---+---+
| bookid | summarize | +---+---+
| 465 | 170 |
| 302 | 110 |
| 474 | 88 | +---+---+
3 rows selected (47.469 seconds)
以上内容表示,ID为456、302、474的3本书籍,为累计评分最高的Top3图书。
1.3 使用 Hive 加载 OBS 数据并分析企业雇员信息
MRS Hadoop分析集群,提供Hive、Spark离线大规模分布式数据存储和计算,进行海 量数据分析与查询。
本实践基于华为云MapReduce服务,用于指导您创建MRS集群后,使用Hive对OBS中 存储的原始数据进行导入、分析等操作,展示了如何构建弹性、低成本的存算分离大 数据分析。
基本内容如下所示:
1. 创建MRS离线查询集群。
2. 创建OBS委托并绑定至MRS集群。
3. 创建Hive表并加载OBS中数据。
4. 基于HQL对数据进行分析。
场景描述
Hive是建立在Hadoop上的数据仓库框架,提供大数据平台批处理计算能力,能够对结 构化/半结构化数据进行批量分析汇总完成数据计算。提供类似SQL的Hive Query Language语言操作结构化数据,其基本原理是将HQL语言自动转换成MapReduce任 务,从而完成对Hadoop集群中存储的海量数据进行查询和分析。
Hive主要特点如下:
● 海量结构化数据分析汇总。
● 将复杂的MapReduce编写任务简化为SQL语句。
● 灵活的数据存储格式,支持JSON,CSV,TEXTFILE,RCFILE,SEQUENCEFILE,
ORC(Optimized Row Columnar)这几种存储格式。
本实践以用户开发一个Hive数据分析应用为例,通过客户端连接Hive后,执行HQL语 句访问OBS中的Hive数据。进行企业雇员信息的管理、查询。如果需要基于MRS服务
本实践中,雇员信息的原始数据包含以下两张表:
表1-7 表 1 雇员信息数据 编
号
姓名 支付 薪水 币种
薪水 金额
纳税税种 工作地 入职时间
1 Wa
ng R 800
0.01 personal income
tax&0.05 China:Shenzhen 2014 3 Tom D 120
00.02
personal income
tax&0.09 America:NewYor
k 2014
4 Jack D 240 00.03
personal income
tax&0.09 America:Manhat
tan 2015
6 Lind
a D 360 00.04
personal income
tax&0.09 America:NewYor
k 2014
8 Zha
ng R 900
0.05 personal income
tax&0.05 China:Shanghai 2014
表1-8 雇员联络信息数据
编号 电话 邮箱
1 135 XXXX XXXX [email protected] 3 159 XXXX XXXX [email protected] 4 186 XXXX XXXX [email protected] 6 189 XXXX XXXX [email protected] 8 134 XXXX XXXX [email protected]
通过数据应用,进行以下分析:
● 查看薪水支付币种为美元的雇员联系方式。
● 查询入职时间为2014年的雇员编号、姓名等字段,并将查询结果加载到新表中。
● 统计雇员信息共有多少条记录。
● 查询使用以“cn”结尾的邮箱的员工信息。
创建 MRS 离线查询集群
1. 登录华为云控制台,选择“大数据 > MapReduce服务”,单击“购买集群”,选 择“快速购买”,填写软件配置参数,单击“下一步”。
表1-9 软件配置(以下参数仅供参考,可根据实际情况调整)
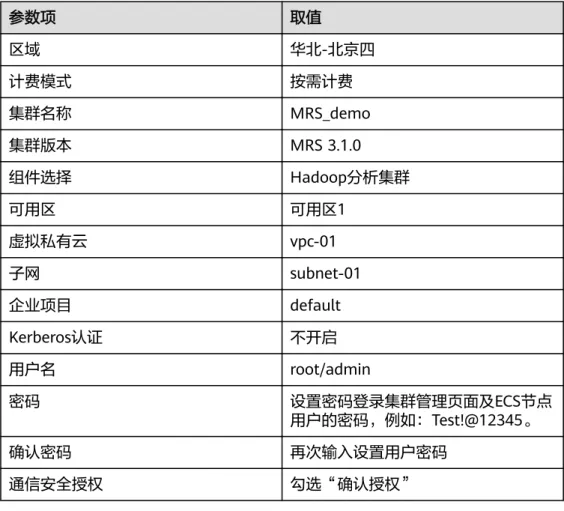
参数项 取值
区域 华北-北京四
计费模式 按需计费
集群名称 MRS_demo
集群版本 MRS 3.1.0
组件选择 Hadoop分析集群
可用区 可用区1
虚拟私有云 vpc-01
子网 subnet-01
企业项目 default
Kerberos认证 不开启
用户名 root/admin
密码 设置密码登录集群管理页面及ECS节点
用户的密码,例如:Test!@12345。
确认密码 再次输入设置用户密码
通信安全授权 勾选“确认授权”
2. 单击“立即购买”,等待约15分钟,MRS集群创建成功。
创建 OBS 委托并绑定至 MRS 集群
说明
● MRS在IAM的委托列表中预置了MRS_ECS_DEFAULT_AGENCY委托,可在创建自定义过程 中可以直接选择该委托,该委托拥有对象存储服务的OBSOperateAccess权限和在集群所在 区域拥有CESFullAccess(对开启细粒度策略的用户)、CES Administrator和KMS
Administrator权限。
● 如需使用自定义委托,请参考如下步骤进行创建委托(创建或修改委托需要用户具有 Security Administrator权限)。
1. 登录华为云管理控制台。
2. 在服务列表中选择“管理与监管 > 统一身份认证服务 IAM”。
3. 选择“委托 > 创建委托”。
4. 设置“委托名称”,“委托类型”选择“云服务”,在“云服务”中选择“弹性 云服务器ECS 裸金属服务器BMS”,授权ECS或BMS调用OBS服务。
5. “持续时间”选择“永久”并单击“下一步”。
图1-12 创建委托
6. 在弹出授权页面的搜索框内,搜索“OBS OperateAccess”策略,勾选“OBS OperateAccess”策略。
图1-13 配置权限
7. 单击“下一步”,选择权限范围方案,默认选择“所有资源”,单击“展开其他 方案”,选择“全局服务资源”。
8. 在弹出的提示框中单击“知道了”,开始授权。界面提示“授权成功。”,单击
“完成”,委托成功创建。
9. 返回MRS控制台,在集群列表中,单击已创建好的MRS集群名称,在集群的“概 览”页面中,单击“管理委托”,选择创建好的OBS委托后单击“确定”。
创建 Hive 表并加载 OBS 中数据
1. 在服务列表中选择“存储 > 对象存储服务 OBS”,登录OBS控制台,单击“并行 文件系统 > 创建并行文件系统”,填写以下参数,单击“立即创建”。
表1-10 并行文件系统参数
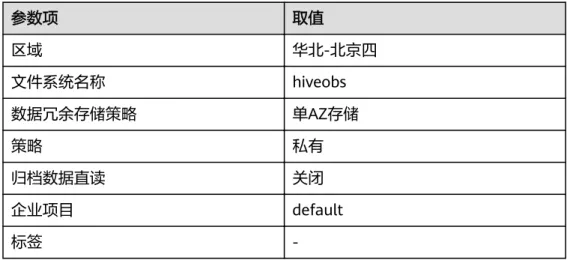
参数项 取值
区域 华北-北京四
文件系统名称 hiveobs
数据冗余存储策略 单AZ存储
策略 私有
归档数据直读 关闭
企业项目 default
标签 -
等待并行文件系统创建成功,单击并行文件系统名称,选择“文件 > 上传文 件”,将数据文件上传至OBS桶内。
2. 下载并安装MRS集群客户端,例如在主Master节点上安装,客户端安装目录为
“/opt/client”,相关操作可参考安装客户端。
也可直接使用Master节点中自带的集群客户端,安装目录为“/opt/Bigdata/
client”。
3. 为主Master节点绑定一个弹性IP并在安全组中放通22端口,然后使用root用户登 录主Master节点,进入客户端所在目录并加载变量。
cd /opt/client source bigdata_env
4. 执行beeline命令进入Hive Beeline命令行界面。
执行以下命令创建一个与原始数据字段匹配的雇员信息数据表
“employees_info”:
create external table if not exists employees_info (
id INT,
name STRING, usd_flag STRING, salary DOUBLE,
deductions MAP<STRING, DOUBLE>, address STRING,
entrytime STRING
)
row format delimited fields terminated by ',' map keys terminated by '&' stored as textfile
location 'obs://hiveobs/employees_info';
执行以下命令创建一个与原始数据字段匹配的雇员联系信息数据表
“employees_contact”:
create external table if not exists employees_contact (
id INT,
phone STRING, email STRING )
row format delimited fields terminated by ',' stored as textfile
location 'obs://hiveobs/employees_contact';
5. 查看表是否创建成功:
show tables;
+---+
| tab_name | +---+
| employees_contact |
| employees_info | +---+
6. 将数据导入OBS对应表目录下。
Hive内部表会默认在指定的存储空间中建立对应文件夹,只要把文件放入,表就 可以读取到数据(需要和表结构匹配)。
登录OBS控制台,在已创建的文件系统的“文件”页面,将本地的原始数据分别 上传至生成的“employees_info”、“employees_contact”文件夹下。
例如原始数据格式如下:
info.txt:
1,Wang,R,8000.01,personal income tax&0.05,China:Shenzhen,2014 3,Tom,D,12000.02,personal income tax&0.09,America:NewYork,2014 4,Jack,D,24000.03,personal income tax&0.09,America:Manhattan,2015
contact.txt:
1,135 XXXX XXXX,[email protected] 3,159 XXXX XXXX,[email protected] 4,189 XXXX XXXX,[email protected] 6,189 XXXX XXXX,[email protected] 8,134 XXXX XXXX,[email protected]
7. 在Hive Beeline客户端中,执行以下命令,查询源数据是否被正确加载。
select * from employees_info;
+---+---+---+--- +---+---+---+
| employees_info.id | employees_info.name | employees_info.usd_flag | employees_info.salary | employees_info.deductions | employees_info.address | employees_info.entrytime |
+---+---+---+--- +---+---+---+
| 1 | Wang | R | 8000.01 | {"personal income tax":
0.05} | China:Shenzhen | 2014 |
| 3 | Tom | D | 12000.02 | {"personal income tax":
0.09} | America:NewYork | 2014 |
| 4 | Jack | D | 24000.03 | {"personal income tax":0.09}
| America:Manhattan | 2015 |
| 6 | Linda | D | 36000.04 | {"personal income tax":
0.09} | America:NewYork | 2014 |
| 8 | Zhang | R | 9000.05 | {"personal income tax":
0.05} | China:Shanghai | 2014 |
+---+---+---+--- +---+---+---+
select * from employees_contact;
+---+---+---+
| employees_contact.id | employees_contact.phone | employees_contact.email | +---+---+---+
| 1 | 135 XXXX XXXX | [email protected] |
| 3 | 159 XXXX XXXX | [email protected] |
| 4 | 186 XXXX XXXX | [email protected] |
| 6 | 189 XXXX XXXX | [email protected] |
| 8 | 134 XXXX XXXX | [email protected] | +---+---+---+
基于 HQL 对数据进行分析
在Hive Beeline客户端中,执行HQL语句,对原始数据进行分析。
1. 查看薪水支付币种为美元的雇员联系方式。
创建新数据表进行数据清洗。
create table employees_info_v2 as select id, name,
regexp_replace(usd_flag, '\s+','') as usd_flag, salary, deductions, address, entrytime from employees_info;
等待Map任务完成后,执行以下命令
select a.* from employees_info_v2 a inner join employees_contact b on a.id = b.id where a.usd_flag='D';
INFO : MapReduce Jobs Launched:
INFO : Stage-Stage-3: Map: 1 Cumulative CPU: 2.95 sec HDFS Read: 8483 HDFS Write: 317 SUCCESS
INFO : Total MapReduce CPU Time Spent: 2 seconds 950 msec
INFO : Completed executing command(queryId=omm_20211022162303_c26d4f1b- a577-4d6c-919c-6cb96095b24b); Time taken: 26.259 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+---+---+---+---+---+---+---+
| a.id | a.name | a.usd_flag | a.salary | a.deductions | a.address | a.entrytime | +---+---+---+---+---+---+---+
| 3 | Tom | D | 12000.02 | {"personal income tax":0.09} | America:NewYork | 2014 |
| 4 | Jack | D | 24000.03 | {"personal income tax":0.09} | America:Manhattan | 2015 |
| 6 | Linda | D | 36000.04 | {"personal income tax":0.09} | America:NewYork | 2014 | +---+---+---+---+---+---+---+
3 rows selected (26.439 seconds)
2. 查询入职时间为2014年的雇员编号、姓名等字段,并将查询结果加载进表 employees_info_extended中的入职时间为2014的分区中。
创建一个表:
create table if not exists employees_info_extended (id int, name string, usd_flag string, salary double, deductions map<string, double>, address string) partitioned by (entrytime string) stored as textfile;
insert into employees_info_extended partition(entrytime='2014') select id,name,usd_flag,salary,deductions,address from employees_info_v2 where entrytime = '2014';
数据抽取成功后,查询表数据。
select * from employees_info_extended;
+---+---+--- +---+---+--- +---+
| employees_info_extended.id | employees_info_extended.name | employees_info_extended.usd_flag | employees_info_extended.salary | employees_info_extended.deductions |
employees_info_extended.address | employees_info_extended.entrytime |
+---+---+--- +---+---+--- +---+
| 1 | Wang | R | 8000.01 | {"personal income tax":0.05} | China:Shenzhen | 2014 |
| 3 | Tom | D | 12000.02 | {"personal income tax":0.09} | America:NewYork | 2014 |
| 6 | Linda | D | 36000.04 | {"personal income tax":0.09} | America:NewYork | 2014 |
| 8 | Zhang | R | 9000.05 | {"personal income tax":0.05} | China:Shanghai | 2014 | +---+---+--- +---+---+--- +---+
3. 统计雇员信息有多少条记录。
select count(1) from employees_info_v2;
+---+
| _c0 | +---+
| 5 | +---+
4. 查询使用以“cn”结尾的邮箱的员工信息。
select a.*, b.email from employees_info_v2 a inner join employees_contact b on a.id = b.id where b.email rlike '.*cn$';
+---+---+---+---+---+---+--- +---+
| a.id | a.name | a.usd_flag | a.salary | a.deductions | a.address | a.entrytime | b.email |
+---+---+---+---+---+---+--- +---+
| 3 | Tom | D | 12000.02 | {"personal income tax":0.09} | America:NewYork | 2014 | [email protected] |
| 6 | Linda | D | 36000.04 | {"personal income tax":0.09} | America:NewYork | 2014 | [email protected] |
| 8 | Zhang | R | 9000.05 | {"personal income tax":0.05} | China:Shanghai | 2014 | [email protected] |
2 数据迁移
2.1 数据迁移方案介绍
2.1.1 准备工作
本迁移指导将指导适用于多种不同场景下的HDFS、HBase、Hive数据向MRS集群的迁 移工作。由于数据迁移过程中可能存在数据覆盖、丢失、损坏等风险,因此本指导只 作为参考,具体的数据迁移方案的制定及实施请华为云支持人员协同完成。
数据迁移前源集群的准备工作,目的是防止在数据迁移过程中源集群产生新数据,导 致源集群与迁移后的目标集群数据不一致。在数据迁移完成之前,目标集群应处于初 始状态,期间不能运行除数据迁移作业外的其它任何业务。
停止集群业务及相关服务
● 如果您的集群涉及到Kafka业务,请先停止所有向Kafka中生产数据的作业,等待 Kafka的消费作业消费完Kafka中的存量数据后,再执行下一步操作。
● 停止所有与HDFS、HBase、Hive相关的业务和作业,然后停止HBase、Hive服 务。
打通数据传输通道
● 当源集群与目标集群部署在同一区域的不同VPC时,请创建两个VPC之间的网络连 接,打通网络层面的数据传输通道。请参见VPC对等连接。
● 当源集群与目标集群部署在同一VPC但属于不同安全组时,在VPC管理控制台,为 每个安全组分别添加安全组规则。规则的“协议”为“ANY”,“方向”为“入 方向”,“源地址”为“安全组”且是对端集群的安全组。
– 为源集群的安全组添加入方向规则,源地址选择目标集群的安全组。
– 为目标集群的安全组添加入方向规则,源地址选择源集群的安全组。
● 当源集群与目标集群部署在同一VPC同一安全组且两个集群都开启了Kerberos认 证,需要为两个集群配置互信。
2.1.2 元数据导出
为了保持迁移后数据的属性及权限等信息在目标集群上与源集群一致,需要将源集群 的元数据信息导出,以便在完成数据迁移后进行必要的元数据恢复。需要导出的元数 据包括HDFS文件属主/组及权限信息、Hive表描述信息。
HDFS 元数据导出
HDFS数据需要导出的元数据信息包括文件及文件夹的权限和属主/组信息。可通过如 下HDFS客户端命令导出。
$HADOOP_HOME/bin/hdfs dfs –ls –R <migrating_path> > /tmp/hdfs_meta.txt
其中,各参数的含义如下。
● $HADOOP_HOME:源集群Hadoop客户端安装目录
● <migrating_path>:HDFS上待迁移的数据目录
● /tmp/hdfs_meta.txt:导出的元数据信息保存在本地的路径。
说明
如果源集群与目标集群网络互通,且以超级管理员身份运行hadoop distcp命令进行数据拷贝,
可以添加参数“-p”让distcp在拷贝数据的同时在目标集群上分别恢复相应文件的元数据信息。
因此在这种场景下可直接跳过本步骤。
Hive 元数据导出
Hive表数据存储在HDFS上,表数据及表数据的元数据由HDFS统一按数据目录进行迁 移。而Hive表的元数据根据集群的不同配置,可以存储在不同类型的关系型数据库中
(如MySQL,PostgreSQL,Oracle等)。本指导导出的Hive表元数据即存储在关系型 数据库中的Hive表的描述信息。
业界主流大数据发行版均支持Sqoop的安装,如果是自建的社区版大数据集群,可下 载社区版Sqoop进行安装。借助Sqoop来解耦导出的元数据与关系型数据库的强依赖,
将Hive元数据导出到HDFS上,与表数据一同迁移后进行恢复。步骤如下:
步骤1 在源集群上下载并安装Sqoop工具。请参见http://sqoop.apache.org/。
步骤2 下载相应关系型数据库的jdbc驱动放置到${Sqoop_Home}/lib目录。
步骤3 执行如下命令导出所有Hive元数据表。所有导出数据保存在HDFS上的/user/
<user_name>/<table_name>目录。
$Sqoop_Home/bin/sqoop import --connect jdbc:<driver_type>://<ip>:<port>/<database> --table
<table_name> --username <user> -password <passwd> -m 1
其中,各参数的含义如下。
● $Sqoop_Home:Sqoop的安装目录
● <driver_type>:数据库类型
● <ip>:源集群数据库的IP地址
● <port>:源集群数据库的端口号
● <table_name>:待导出的表名称
● <passwd>:用户密码 ----结束
2.1.3 数据拷贝
根据源集群与目标集群分别所处的区域及网络连通性,可分为以下几种数据拷贝场 景:
同 Region
当源集群与目标集群处于同一Region时,根据打通数据传输通道进行网络配置,打通 网络传输通道。使用Distcp工具执行如下命令将源集群的HDFS、HBase、Hive数据文 件以及Hive元数据备份文件拷贝至目的集群。
$HADOOP_HOME/bin/hadoop distcp <src> <dist> -p
其中,各参数的含义如下。
● $HADOOP_HOME:目的集群Hadoop客户端安装目录
● <src>:源集群HDFS目录
● <dist>:目的集群HDFS目录
不同 Region
当源集群与目标集群处于不同Region时,用Distcp工具将源集群数据拷贝到OBS,借 助OBS跨区域复制功能(请参见跨区域复制)将数据复制到对应目的集群所在Region 的OBS,然后通过Distcp工具将OBS数据拷贝到目的集群的HDFS上。由于执行Distcp 无法为OBS上的文件设置权限、属主/组等信息,因此当前场景在进行数据导出时也需 要将HDFS的元数据信息进行导出并拷贝,以防HDFS文件属性信息丢失。
线下集群向云迁移
线下集群可以通过如下两种方式将数据迁移至云:
● 云专线(DC)
为源集群与目标集群之间建立云专线,打通线下集群出口网关与线上VPC之间的 网络,然后参考同Region执行Distcp进行拷贝。
● 数据快递服务(DES)
对于TB或PB级数据上云的场景,华为云提供数据快递服务 DES。将线下集群数据 及已导出的元数据拷贝到DES盒子,快递服务将数据递送到华为云机房,然后通 过云数据迁移 CDM将DES盒子数据拷贝到HDFS。
2.1.4 数据恢复
HDFS 文件属性恢复
根据导出的权限信息在目的集群的后台使用HDFS命令对文件的权限及属主/组信息进 行恢复。
$HADOOP_HOME/bin/hdfs dfs –chmod <MODE> <path>
$HADOOP_HOME/bin/hdfs dfs –chown <OWNER> <path>
Hive 元数据恢复
在目的集群中安装并使用Sqoop命令将导出的Hive元数据导入MRS集群dbservice。
$Sqoop_Home/bin/sqoop export --connect jdbc:postgresql://<ip>:20051/hivemeta --table <table_name> -- username hive -password <passwd> --export-dir <export_from>
其中,各参数的含义如下。
● $Sqoop_Home:目的集群上Sqoop的安装目录
● <ip>:目的集群上数据库的IP地址
● <table_name>:待恢复的表名称
● <passwd>:hive用户的密码
● <export_from>:元数据在目的集群的HDFS地址。
HBase 表重建
重启目的集群的HBase服务,使数据迁移生效。在启动过程中,HBase会加载当前 HDFS上的数据并重新生成元数据。启动完成后,在Master节点客户端执行如下命令加 载HBase表数据。
$HBase_Home/bin/hbase hbck -fixMeta -fixAssignments
命令执行完成后,重复执行如下命令查看HBase集群健康状态直至正常。
hbase hbck
2.2 数据迁移到 MRS 前信息收集
由于离线大数据搬迁有一定的灵活性,迁移前需要掌握现有集群的详细信息,能够更 好的进行迁移决策。
业务信息调研
1. 大数据平台及业务的架构图。
2. 大数据平台和业务的数据流图(包括:峰值和均值流量),识别平台数据接入 源。大数据平台数据流入方式(实时数据上报、批量数据抽取),分析平台数据 流向。数据在平台内各个组件间的流向。比如使用什么组件采集数据,采集完数 据后数据如何流向下一层组件,使用什么组件存储数据,数据处理过程中的工作 流等。
3. 业务作业类型:hive sql, spark sql, spark python等,是否需要使用MRS的第三方 包,参考MRS应用开发样例。
4. 调度系统:需要考虑调度系统对接MRS集群。
5. 迁移后,业务割接允许中断时长,识别平台业务优先级。识别在迁移过程中不能 中断的业务,可短时中断的业务,整体业务迁移可接受的迁移时长,梳理业务迁 移顺序。
6. 客户端部署要求。
7. 业务执行时间段和高峰时间段。
8. 大数据集群的数量和大数据集群功能划分,分析平台业务模型。各个集群或各个 组件分别负责什么业务,处理什么类型的数据。比如实时/离线数据分别使用什么
集群基本信息收集
表2-1 集群基本信息
参数 取值 说明
集群名称 - -
集群版本 - MRS、CDM、FI等集群的版本。
节点数及规格 - 必填项,调研现有集群节点数和节点规
格。
如果集群硬件异构,请填写多种规格和 对应节点数。请参见表2-2。
例如:
2台 32U64G机器部署NameNode + ResourceManager
2台 32U64G机器部署Hiveserver 20台 16U32G 机器部署DataNode和 NodeManager
是否开启Kerberos
认证 - 必填项: 是或否
权限控制及说明 - 必填项,调研各个开启ACL权限控制的组 件和配置。
涉及: Yarn 、Hive、 Impala、 HBase 组件。
使用ranger、sentry或组件开源的权限能 力进行权限控制。
所在region/AZ - 云上资源填写项
虚拟私有云 - 云上资源填写项
子网 - 云上资源填写项
安全组 - 云上资源填写项
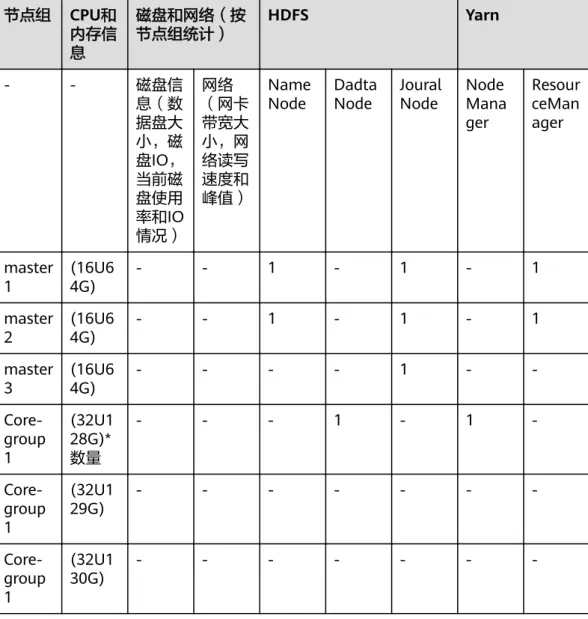
表2-2 硬件信息调研表 节点组 CPU和
内存信 息
磁盘和网络(按 节点组统计)
HDFS Yarn
- - 磁盘信
息(数 据盘大 小,磁盘IO,
当前磁 盘使用率和IO 情况)
网络
(网卡 带宽大 小,网 络读写 速度和 峰值)
NameNode Dadta
Node Joural
Node Node Manager
Resour ceMan ager
master
1 (16U6
4G) - - 1 - 1 - 1
master
2 (16U6
4G) - - 1 - 1 - 1
master
3 (16U6
4G) - - - - 1 - -
Core- group 1
(32U1 28G)*
数量
- - - 1 - 1 -
Core- group 1
(32U1
29G) - - - -
Core- group 1
(32U1
30G) - - - -
大数据组件信息
使用的大数据组件信息和规划的新版本大数据集群版本信息比较,主要识别版本差异 可能对迁移过程的影响,以及对迁移后业务兼容性的影响。
表2-3 大数据组件信息
大数据组件 源端集群版本 目的端集群版本
(以MRS 1.9.2为 例)
说明
HDFS/OBS(或其
他文件存储系统) Hadoop 2.8.3 Hadoop 2.8.3 -
Hive 1.2.1 2.3.3 存储元数据的数据
大数据组件 源端集群版本 目的端集群版本
(以MRS 1.9.2为 例)
说明
HBase 1.3.1 1.3.1 -
Spark 2.2.2 2.2.2 -
Kafka 1.1.0 1.1.0 -
Oozie 2.x 自建 -
mysql 5.7.1 RDS -
Flink 1.7 1.7 -
... ... ... -
待迁移的存量数据及数据量统计
如果使用HDFS作为文件存储系统,可以使用` hadoop fs -du -h /user/test`命令统计 路径下的文件大小。
表2-4 现有数据量统计
大数据组件 待迁移数据的路径 数据量大小 文件个数或表个数 HDFS/OBS(或其
他文件存储系统) /user/helloworld xx 总共:xxxx个文件 小于2M的文件数 量:xxx个 Hive /user/hive/
warehouse/ xx 表个数:xxx
HBase /hbase xx 表个数:xx
Region个数:xx
每天新增数据量统计
每天新增数据量主要评估数据增长速度(可以按天/小时等周期维度)。在第一次全量 迁移数据后,后续可以定期搬迁老集群新增数据,直到业务完成最终割接。
表2-5 新增数据量统计
大数据组件 待迁移的数据路径 新增数据量大小
HDFS/OBS(或其他文件
存储系统) /user/helloworld xx Hive /user/hive/warehouse/ xx
大数据组件 待迁移的数据路径 新增数据量大小
HBase /hbase xx
网络出口带宽能力
● 迁移数据可以使用的最大网络带宽和专线带宽(是否可调)
● 迁移数据作业每天可以运行的时间段
流式 Kafka 集群信息收集
表2-6 流式 Kafka 集群信息
收集信息项 描述
kafka的topics数量和名称 - kafka的本地数据暂存时间,如果每个 topic配置不一样,按topic粒度收集 - 每个topic的副本数和partition数量。
(默认为2,副本数越多数据越可靠,也 会消耗磁盘空间),如果每个topic配置 不一样,按topic粒度收集
-
Kafka生产和消费的流量大小,细化到
topic级别 -
kafka客户端ACK配置acks -
数据迁移模型样例
● 一个离线分析平台的客户业务系统框图,由spark streaming消费kafka数据存入 HDFS上,HDFS上进行小文件合并后由Hive load加载到Hive表中,运营可以通过 presto进行hive数据查询。
图2-1 源集群业务图
● 针对大数据离线平台包括HDFS和Hive数据需要迁移,Kafka、 spark streaming、
图2-2 迁移示意图
2.3 数据迁移到 MRS 前网络准备
进行大数据迁移时,需要保证源端集群和目的端集群之间的网络互通,例如用Hadoop distcp命令跨集群拷贝数据时候需要所有DataNode是网络互通。根据不同的迁移场景 需要使用不通的方式先打通两套集群之间网络连接。
● 客户线下数据中心迁移数据到华为云MRS集群,通过云专线服务为用户搭建本地 数据中心与云上VPC之间的专属连接通道。可以创建华为云的云专线服务或使用 第三方的云专线服务来连通华为云网络。
图2-3 线下数据中心迁移
● 客户在华为云上自建大数据集群(或老版本的MRS集群)需要迁移到华为云MRS 集群,且在同一个region区域和VPC子网,可以使自建集群和MRS集群使用相同安 全组、VPC、子网网络,从而保证网络连通。
图2-4 线上同 region 同 VPC 迁移
● 客户在华为云上自建大数据集群(或老版本的MRS集群)需要迁移到华为云MRS 集群,且在同一个region区域,但是使用不同VPC子网。需要使用VPC对等连接方 式配置网络连通。
图2-5 线上同 region 不同 VPC 迁移
● 客户在华为云上自建大数据集群(或老版本的MRS集群)需要迁移到华为云MRS 集权,但在不同region区域,可以通过使用云连接构建跨区域VPC的网络连接。
图2-6 线上不同 region 迁移
2.4 Hadoop 数据迁移到华为云 MRS 服务
场景介绍
本章节适用于将线下IDC机房或者公有云Hadoop集群中的数据(支持数据量在几十TB 级别或以下的数据量级)迁移到华为云MRS服务。本章节以通过华为云CDM服务进行 数据迁移为例介绍。
图2-7 Hadoop 数据迁移示意
方案优势
● 简单易用:免编程,向导式任务开发界面,通过简单配置几分钟即可完成迁移任 务开发
● 迁移效率高: 基于分布式计算框架进行数据任务执行和数据传输优化,并针对特 定数据源写入做了专项优化,迁移效率高
● 实时监控:迁移过程中可以执行自动实时监控、告警和通知操作
操作步骤
步骤1 登录CDM管理控制台。
步骤2 创建CDM集群,该CDM集群的安全组、虚拟私有云、子网需要和迁移目的端集群保持
一致,保证CDM集群和MRS集群之间网络互通。
步骤3 在“集群管理”页面单击待操作集群对应“操作”列的“作业管理”。
步骤4 在“连接管理”页签,单击“新建连接”。
步骤5 参考CDM服务的新建连接页面,分别添加到迁移源端集群和迁移目的端集群的两个 HDFS连接。
连接类型根据实际集群来选择,如果是MRS集群,连接器类型可以选择“MRS HDFS”,如果是自建集群可以选择“Apache HDFS”。
图2-8 Hadoop 连接
步骤6 在“表/文件迁移” 页签,单击“新建作业”。
步骤7 选择源连接、目的连接:
● 作业名称:用户自定义任务名称,名称由英文字母、下划线或者数字组成,长度 必须在1到256个字符之间。
● 源连接名称:选择迁移源端集群的HDFS连接,作业运行时将从此端复制导出数 据。
● 目的连接名称:选择迁移目的端集群的HDFS连接,作业运行时会将数据导入此 端。
步骤8 请参见配置HDFS源端参数配置源端连接的作业参数,需要迁移的文件夹可通过“路径 过滤器”和“文件过滤器”参数设置符合规则的目录和文件进行迁移。例如“路径过 滤器”选择test*,迁移匹配/user/test*的文件夹下文件。该场景下“文件格式”固定为
“二进制格式”。
图2-9 配置作业参数
步骤9 请参见配置HDFS目的端参数配置目的端连接的作业参数。
步骤10 单击“下一步”进入任务配置页面。
● 如需定期将新增数据迁移至目的端集群,可在该页面进行配置,也可在任务执行 后再参考步骤14配置定时任务。
● 如无新增数据需要后续定期迁移,则跳过该页面配置直接单击“保存”回到作业 管理界面。
图2-10 任务配置
步骤11 选择“作业管理”的“表/文件迁移”页签,在待运行作业的“操作”列单击“运 行”,即可开始HDFS文件数据迁移,并等待作业运行完成。
步骤12 登录迁移目的端集群主管理节点。
步骤13 执行hdfs dfs -ls -h /user/命令查看迁移目的端集群中已迁移的文件。
步骤14 (可选)如果源端集群中有新增数据需要定期将新增数据迁移至目的端集群,则配置 定期任务增量迁移数据,直到所有业务迁移至目的端集群。
1. 在CDM集群中选择“作业管理”的“表/文件迁移”页签。
2. 在迁移作业的“操作”列选择“更多 > 配置定时任务”。
3. 开启定时执行功能,根据具体业务需求设置重复周期,并设置有效期的结束时间 为所有业务割接到新集群之后的时间。
图2-11 配置定时任务
----结束
2.5 HBase 数据迁移到华为云 MRS 服务
场景介绍
本章节适用于将线下IDC机房或者公有云HBase集群中的数据(支持数据量在几十TB级 别或以下的数据量级)迁移到华为云MRS服务。本章节以通过华为云CDM服务进行数 据迁移为例介绍。
图2-12 HBase 数据迁移示意
Hbase会把数据存储在HDFS上,主要包括Hfile文件和WAL文件,由配置项
hbase.rootdir指定在HDFS上的路径,华为云MRS的默认存储位置是/hbase文件夹下。
HBase自带的一些机制和工具命令也可以实现数据搬迁,例如:通过导出Snapshots快 照,Export/Import,CopyTable方式等,可以参考Apache官网。
本文主要介绍通过华为云CDM云迁移服务进行HBase数据搬迁。
方案优势
场景化迁移通过迁移快照数据然后再恢复表数据的方法,能大大提升迁移效率。
全量数据迁移
步骤1 登录CDM管理控制台。
步骤2 创建CDM集群,该CDM集群的安全组、虚拟私有云、子网需要和迁移目的端集群保持
一致,保证CDM集群和MRS集群之间网络互通。
步骤3 在“集群管理”页面单击待操作集群对应“操作”列的“作业管理”。
步骤4 在“连接管理”页签,单击“新建连接”,连接器类型选择“Hadoop发行版”。
步骤5 参考CDM服务的新建连接页面,添加到迁移源端集群的连接,其中Hadoop类型选择
“Apache Hadoop”。
说明
(可选)HBase迁移建议使用高权限用户,例如: 单击“显示高级属性”,新增迁移所需用户
“hadoop.user.name = 用户名(如omm用户)”。
图2-13 到迁移源端集群的连接
步骤6 在“连接管理”页签,单击“新建连接”,连接器类型选择“Hadoop发行版”。
步骤7 参考CDM服务的新建连接页面,添加到迁移目的端集群的连接,其中Hadoop类型选 择“MRS”。
说明
(可选)HBase迁移建议使用高权限用户,例如: 单击“显示高级属性”,新增迁移所需用户
“hadoop.user.name = 用户名(如omm用户)”。
图2-14 到迁移目的端集群的连接
步骤8 选择“作业管理”的“场景迁移”页签,单击“新建作业”。
说明
“场景迁移”仅2.9.0版本之前的CDM集群支持,若当前环境中无此页签,也可以创建表/文件迁 移作业或者整库迁移作业进行迁移,请参考创建CDM作业。
步骤9 进入作业参数配置界面。配置作业名称并选择迁移场景为“HBase快速迁移”。
步骤10 配置源端作业和目的端作业参数,并单击“下一步”。
图2-15 HBase 作业配置
步骤11 选择要迁移的数据表, 并单击“下一步”。
步骤12 进入任务配置页面,不做修改,直接单击“保存”。
步骤13 选择“作业管理”的“场景迁移”页签,在待运行作业的“操作”列单击“运行”,
即可开始HBase数据迁移。
步骤14 迁移完成后,可以在目的端集群和源端集群,通过同样的查询语句,对比查询结果进 行验证。
例如:
● 在目的端集群和源端集群上通过查询BTable表的记录数来确认数据条数是否一 致,添加--endtime参数主要排除迁移期间源端集群上有数据更新的影响。
Hbase org.apache.hadoop.hbase.mapreduce.RowCounter BTable -- endtime=1587973835000
图2-16 查询 BTable 表的记录数
● 通过HBase shell的scan ' BTable ', {TIMERANGE=>[1587973235000, 1587973835000]} 查询指定时间段内的数据进行对比。
----结束
增量数据迁移
在业务割接前,如果源端集群上有新增数据,需要定期将新增数据搬迁到目的端集 群。一般每天更新的数据量在GB级别可以使用CDM的“整库迁移”指定时间段的方式 每天进行HBase新增数据迁移。
当前使用CDM的“整库迁移”功能时的限制:如果源HBase集群中被删除操作的数据
场景迁移的HBase连接器不能与“整库迁移”共用,因此需要单独配置“HBase”连接 器。
步骤1 参考全量数据迁移的步骤1~步骤7步骤新增两个“HBase”连接器,选择连接器类型时 分别为源端集群和目的端集群选择“MRS HBase”和“Apache HBase”。
图2-17 HBase 增量迁移连接
步骤2 选择“作业管理”的“整库迁移”页签,单击“新建作业”。
步骤3 进入作业参数配置界面,作业相关信息配置完成后单击“下一步”。
● 作业名称:用户自定义作业名称,例如hbase-increase。
● 源端作业配置:源连接名称请选择步骤1中创建的到源端集群的连接名称,并展开 高级属性配置迁移数据的时间段。
● 目的端作业配置:目的连接名称请选择步骤1中创建的到目的端集群的连接名称,
其他不填写。
图2-18 HBase 增量迁移作业配置
步骤4 选择要迁移的数据表, 并单击“保存”。
步骤5 选择“作业管理”的“整库迁移”页签,在待运行作业的“操作”列单击“运行”,
即可开始HBase数据增量迁移。
----结束
2.6 Hive 数据迁移到华为云 MRS 服务
场景介绍
本章节适用于将线下IDC机房或者公有云Hive集群中的数据(支持数据量在几十TB级 别或以下的数据量级)迁移到华为云MRS服务。本章节以通过华为云CDM服务进行数 据迁移为例介绍。
Hive数据迁移分两部分内容:
● Hive的元数据信息,存储在mysql等数据库中。MRS Hive集群的元数据会默认存 储到MRS DBService(华为的Gaussdb数据库),也可以选择RDS(mysql)作为 外置元数据库。
● Hive的业务数据,存储在HDFS文件系统或OBS对象存储中。
使用华为云CDM服务“场景迁移功能”可以一键式便捷地完成Hive数据的迁移。
图2-19 Hive 数据迁移示意
方案优势
场景化迁移通过迁移快照数据然后再恢复表数据的方法,能大大提升迁移效率。
操作步骤
步骤1 登录CDM管理控制台。
步骤2 创建CDM集群,该CDM集群的安全组、虚拟私有云、子网需要和迁移目的端集群保持
一致,保证CDM集群和MRS集群之间网络互通。
步骤3 在“集群管理”页面单击待操作集群对应“操作”列的“作业管理”。
步骤4 在“连接管理”页签,单击“新建连接”。
步骤5 参考CDM服务的新建连接页面,分别添加到迁移源端集群和迁移目的端集群的连接,
其中连接器类型选择“Hadoop发行版”。
连接类型根据实际集群来选择,如果是MRS集群,Hadoop类型可以选择“MRS”,如 果是自建集群可以选择“Apache Hadoop”。
图2-20 Hive 连接
步骤6 在迁移目的端集群中创建数据迁移后的存储数据库。
步骤7 选择“作业管理”的“场景迁移”页签,单击“新建作业”。
说明
“场景迁移”仅2.9.0版本之前的CDM集群支持,若当前环境中无此页签,也可以创建表/文件迁 移作业或者整库迁移作业进行迁移,请参考创建CDM作业。
步骤8 进入作业参数配置界面。配置作业名称并选择迁移场景为“Hive快速迁移”,并单击
“下一步”。
步骤9 分别为源连接和目的连接选择步骤5中创建的对应数据连接并选择要迁移的数据库,并 单击“下一步”。
图2-21 Hive 作业配置
步骤10 选择要迁移的数据表, 并单击“下一步”。
步骤11 进入任务配置页面,不做修改,直接单击“保存”。
步骤12 选择“作业管理”的“场景迁移”页签,在待运行作业的“操作”列单击“运行”,
即可开始Hive数据迁移。
步骤13 迁移完成后,可以在目的端集群和源端集群,通过同样的查询语句,对比查询结果进 行验证。
例如:在目的端集群和源端集群上通过查询catalog_sales表的记录数来确认数据条数 是否一致
select count(*) from catalog_sales;
图2-22 源端集群数据记录
图2-23 目的端集群数据记录
步骤14 (可选)如果源端集群中有新增数据需要定期将新增数据迁移至目的端集群,则根据 数据新增方式进行不同方式的迁移。配置定期任务增量迁移数据,直到所有业务迁移 至目的端集群。
● Hive表数据修改,未新增删除表,未修改已有表的数据结构:此时Hive表已经创 建好,仅需迁移Hive存储在HDFS或OBS上的文件即可,请参考Hadoop数据迁移 到华为云MRS服务页面新增数据迁移方式进行数据迁移。
● Hive表有新增:请选择“作业管理”的“场景迁移”页签,在Hive迁移作业的
“操作”列单击“编辑”,选择新增的数据表进行数据迁移。
● Hive表有删除或已有表的数据结构有修改:请在目的端集群中手动删除对应表或 手动更新变更的表结构。
----结束
2.7 数据迁移网络端口要求
HDFS 组件端口
表2-7 HDFS 组件端口
配置参数 默认端口(Hadoop 2.x和
Hadoop 3.x版本) 端口说明
dfs.namenode.rpc.port 9820 迁移过程中,需要访问 namenode获取文件列 表。
dfs.datanode.port 25009 迁移过程中,需要访问 datanode读取具体文件数 据。
ZooKeeper 组件端口
表2-8 ZooKeeper 组件端口
配置参数 默认端口 端口说明
clientPort 2181 ZooKeeper客户端连接 ZooKeeper服务器。
Kerberos 组件端口
表2-9 Kerberos 组件端口
配置参数 默认端口 端口说明
kdc_ports 21732 Kerberos服务认证,非 Kerberos集群不涉及。
Hive 组件端口
表2-10 Hive 组件端口
配置参数 默认端口(Hive 2.x和
Hive3.x版本) 端口说明
hive.metastore.port 9083 MetaStore 提供Thrift 服 务的端口。迁移过程中,
需要访问该端口查询表元 数据信息。
HBase 组件端口
表2-11 HBase 组件端口
配置参数 默认端口(HBase1.x和
HBase 2.x版本) 端口说明
hbase.master.port 16000 HMaster RPC端口。该端 口用于HBase客户端连接 到HMaster。
hbase.regionserver.port 16020 RS (RegoinServer) RPC端 口。该端口用于HBase客 户端连接到
RegionServer。
Manager 组件端口
表2-12 Manager 组件端口
配置参数 默认端口 端口说明
NA 28443 FusionInsight/MRS Manager页面端口。CDM 迁移时候访问该地址获取 集群配置。
NA 20009 FusionInsight/MRS Manager CAS协议端口,
用于登录认证。
2.8 离线数据迁移-使用 BulkLoad 向 HBase 中批量导入数据
我们经常面临向HBase中导入大量数据的情景,向HBase中批量加载数据的方式有很多
的方式从HDFS上加载数据。但是这两种方式效率都不是很高,因为HBase频繁进行 flush、compact、split操作需要消耗较大的CPU和网络资源,并且RegionServer压力 也比较大。
本实践基于华为云MapReduce服务,用于指导您创建MRS集群后,使用BulkLoad方式 向HBase中批量导入本地数据,在首次数据加载时,能极大的提高写入效率,并降低 对Region Server节点的写入压力。
基本内容如下所示:
1. 创建MRS离线查询集群。
2. 将本地数据导入到HDFS中。
3. 创建HBase表。
4. 生成HFile文件并导入HBase。
场景描述
BulkLoad方式调用MapReduce的job直接将数据输出成HBase table内部的存储格式的 文件HFile,然后将生成的StoreFiles加载到集群的相应节点。这种方式无需进行 flush、compact、split等过程,不占用Region资源,不会产生巨量的写入I/O,所以需 要较少的 CPU 和网络资源。
BulkLoad适合的场景:
● 大量数据一次性加载到HBase。
● 对数据加载到HBase可靠性要求不高,不需要生成WAL文件。
● 使用put加载大量数据到HBase速度变慢,且查询速度变慢时。
● 加载到HBase新生成的单个HFile文件大小接近HDFS block大小。
创建 MRS 离线查询集群
1. 登录华为云控制台,选择“大数据 > MapReduce服务”,单击“购买集群”,选 择“快速购买”,填写软件配置参数,单击“下一步”。
表2-13 表 1 软件配置
参数项 取值
区域 华北-北京四
计费模式 按需计费
集群名称 MRS_hbase
集群版本 MRS 3.1.0
组件选择 HBase查询集群
可用区 可用区1
虚拟私有云 vpc-01
子网 subnet-01
企业项目 default
参数项 取值
用户名 root/admin
密码 设置密码登录集群管理页面及ECS节点
用户的密码,例如:Test!@12345。
确认密码 再次输入设置用户密码
通信安全授权 勾选“确认授权”
2. 单击“立即购买”,等待约15分钟,MRS集群创建成功。
将本地数据导入到 HDFS 中
1. 在本地准备一个学生信息文件“info.txt”,例如内容如下。
字段信息依次为:学号、姓名、生日、性别、住址
20200101245,张晓明,20150324,男,龙岗区 20200101246,李敏林,20150202,男,宝安区 20200101247,杨小刚,20151101,女,龙岗区 20200101248,陈嘉玲,20150218,男,宝安区 20200101249,李明耀,20150801,女,龙岗区 20200101250,王艳艳,20150315,男,南山区 20200101251,李荣中,20151201,男,福田区 20200101252,孙世伟,20150916,女,龙华区 20200101253,林维嘉,20150303,男,福田区
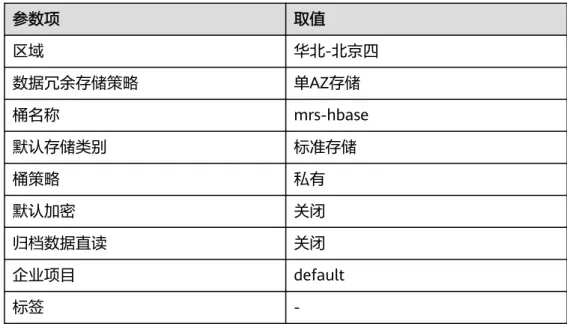
2. 登录对象存储服务OBS控制台,单击“创建桶”,填写以下参数,单击“立即创 建”。
表2-14 桶参数
参数项 取值
区域 华北-北京四
数据冗余存储策略 单AZ存储
桶名称 mrs-hbase
默认存储类别 标准存储
桶策略 私有
默认加密 关闭
归档数据直读 关闭
企业项目 default
标签 -
等待桶创建好,单击桶名称,选择“对象 > 上传对象”,将数据文件上传至OBS 桶内。
3. 切换回MRS控制台,单击创建好的MRS集群名称,进入“概览”,单击“IAM用 户同步”所在行的“单击同步”,等待约5分钟同步完成。
4. 将数据文件上传HDFS。
a. 在“文件管理”页签,选择“HDFS文件列表”,进入数据存储目录,如
“/tmp/test”。
“/tmp/test”目录仅为示例,可以是界面上的任何目录,也可以通过“新 建”创建新的文件夹。
b. 单击“导入数据”。
▪
OBS路径:选择上面创建好的OBS桶名,找到info.txt文件,单击“是”。
▪
HDFS路径:创建并选择“/tmp/test”,单击“是”。c. 单击“确定”,等待导入成功,此时数据文件已上传至HDFS。
创建 HBase 表
1. 登录集群的FusionInsight Manager页面(如果没有弹性IP,需提前购买弹性 IP),新建一个用户hbasetest,绑定用户组supergroup,绑定角色
System_administrator。
2. 下载并安装集群全量客户端,例如在主Master节点上安装,客户端安装目录为
“/opt/client”,相关操作可参考安装客户端。
也可直接使用Master节点中自带的集群客户端,安装目录为“/opt/Bigdata/
client”。
3. 为主Master节点绑定一个弹性IP,然后使用root用户登录主Master节点,并进入 客户端所在目录并认证用户。
cd /opt/client source bigdata_env kinit hbasetest
4. 执行hbase shell进入HBase Shell命令行界面。
需要根据导入数据,规划HBase数据表的表名、rowkey、列族、列,考虑好row key分配在创建表时进行预分割。
执行以下命令创建表“student_info”。
create 'student_info', {NAME => 'base',COMPRESSION => 'SNAPPY', DATA_BLOCK_ENCODING => 'FAST_DIFF'},SPLITS =>
['1','2','3','4','5','6','7','8']
– NAME => 'base':HBase表列族名称。
– COMPRESSION:压缩方式
– DATA_BLOCK_ENCODING:编码算法 – SPLITS:预分region
5. 查看表是否创建成功,然后退出HBase Shell命令行界面。