分布式数据库中间件
最佳实践
文档版本 01
发布日期 2022-02-10
版权所有 © 华为技术有限公司 2022。 保留一切权利。
非经本公司书面许可,任何单位和个人不得擅自摘抄、复制本文档内容的部分或全部,并不得以任何形式传 播。
商标声明
和其他华为商标均为华为技术有限公司的商标。
本文档提及的其他所有商标或注册商标,由各自的所有人拥有。
注意
您购买的产品、服务或特性等应受华为公司商业合同和条款的约束,本文档中描述的全部或部分产品、服务或 特性可能不在您的购买或使用范围之内。除非合同另有约定,华为公司对本文档内容不做任何明示或暗示的声 明或保证。
由于产品版本升级或其他原因,本文档内容会不定期进行更新。除非另有约定,本文档仅作为使用指导,本文 档中的所有陈述、信息和建议不构成任何明示或暗示的担保。
目 录
1 合理制定分片策略... 1
2 如何选择 DDM 逻辑库分片数... 4
3 广播表和单表的使用场景...6
4 DDM 事务模型... 8
5 DDM SQL 使用规范...10
6 如何将单 RDS 数据整库迁移至 DDM...14
7 如何将 Mycat 数据整库迁移至 DDM...17
8 通过 JDBC 连接池连接 DDM... 21
9 通过 Navicat 客户端连接 DDM 实例...24
最佳实践 目 录
1 合理制定分片策略
DDM创建逻辑表时,若逻辑表类型选择为拆分表,则需要制定分片策略,并选择拆分 键。
当数据表之间存在E-R关系时,可以制定相同的分片规则,各数据表分别选择有关联关 系的字段作为拆分键,这样各表中有关联关系的数据将会存储在一个分片上,避免数 据跨分片JOIN操作。如客户表、订单表与订单明细表,在创建拆分表时,建议都选取 客户ID作为拆分键。
表1-1 拆分键与拆分算法使用简介
拆分算法 hash类 range类
拆分键 表字段 表字段+日期
函数
表字段 表字段+日期 函数
详细说明 根据指定的表 字段将数据平 均拆分到各个 分片上。
根据指定的表 字段+日期函 数将数据平均 拆分到各个分 片上。
表字段必须是 日期类型(date、
datetime、
timestamp)
。
将数据表内的 记录按照算法 元数据定义的 规则将数据拆 分到指定的分 片上。
根据指定的表 字段+日期函 数将数据按照 算法元数据的 规则将数据拆 分到各个分片 上。
表字段必须是 日期类型(date、
datetime、
timestamp)
。
最佳实践 1 合理制定分片策略
适用场景 适用于需要将 数据均匀分布 的场景,例 如:银行类客 户业务应用,
业务逻辑主体 是客户,可使 用客户对应的 表字段(例如 客户号)作为 拆分键,详情 参见如下示 例。
需要按时间
(年、月、
日、周及其组 合)对数据进 行拆分的场 景,例如:游 戏类的应用,
可使用玩家对 应的表字段
(例如玩家注 册时间)作为 拆分键,按 日、月、年等 函数分片,方 便统计和查询 某日、月玩家 的操作数据,
帮助游戏厂家 做大数据分 析。
适合范围类操 作较多的场 景,例如:电 商类应用,如 果业务场景是 围绕商家做活 动进行,业务 逻辑主体是活 动日期,可使 用活动日期对 应的表字段
(例如活动名 称、日期范 围)作为拆分 键,方便统计 某周期内销量 等情况。
例如日志分析 场景,日志系 统中可能包含 各类复杂的信 息,这时您可 以选择时间字 段作为拆分 键,然后对拆 分键使用日期 函数拆分。
为了方便日志 清理和转储,
采用range拆 分算法,对时 间字段用日期 函数转换成 年,表示按年 存储到各个分 片上,详情参 见如下示例。
如何选择拆分算法
拆分算法即将逻辑表中数据拆分到多个数据库分片上的算法,DDM支持hash和range 两大类拆分算法。
● hash类
将数据均匀分布在各个分片。
适用于SQL查询条件使用“=”、“IN”之类运算符相对较多的场景。
● range类
将数据表内的记录按照算法元数据的取值范围进行分片存储。
适用于SQL查询条件使用“>”、“<”、“BETWEEN ... AND ...”之类运算符相 对较多的场景。
注意
如果分库算法是range类+日期函数,且拆分键字段又表示创建时间,在数据入库 时可能造成热点问题,无法充分利用多MySQL的优势。
拆分算法的使用,需要结合业务查询场景进行评估,以选择合适的拆分算法,提升 DDM效率。
如何选择拆分键
拆分键是在水平拆分逻辑表的过程中,用于生成路由结果的表字段,指定表字段后,
可以进一步选择日期函数,也可以手动输入“日期函数(字段名)”,数据表字段必须 是日期类型(date、datetime、timestamp),日期函数适用于需要按时间(年、
月、日、周及其组合)对数据进行拆分的场景。
最佳实践 1 合理制定分片策略
DDM根据拆分键与拆分算法计算路由结果,对拆分表的数据进行自动水平拆分,分发 到数据分片中。
选取拆分算法与拆分键一般遵循以下规则:
● 尽可能使数据均匀分布到各个分片上。
● 该拆分键是最频繁或者最重要的查询条件。
● 优选主键作为拆分键,因为主键作为查询条件时,查询速度最快。
有明确主体的业务场景
拆分表的数据量一般都达到千万级,因此选择合适的拆分算法和拆分键非常重要。如 果能找到业务主体,并且确定绝大部分的数据库操作都是围绕这个主体的数据进行 的,那么可以选择这个主体所对应的表字段作为拆分键,进行水平拆分。
业务逻辑主体与实际应用场景相关,下列场景都有明确的业务逻辑主体。
1. 银行类客户业务应用,业务逻辑主体是客户,可使用客户对应的表字段(例如客 户号)作为拆分键。部分业务系统的业务场景为围绕银行卡/账号的,可以选取卡/
账号作为拆分键。
2. 电商类应用,如果业务场景是围绕商品进行操作,业务逻辑主体是商品,可使用 商品对应的表字段(例如商品编码)作为拆分键。
3. 游戏类的应用,主要围绕玩家数据进行操作,业务逻辑主体是玩家,可使用玩家 对应的表字段(例如玩家id)作为拆分键。
以银行类客户业务为例,建表SQL语句如下:
CREATE TABLE PERSONALACCOUNT (
ACCOUNT VARCHAR(20) NOT NULL PRIMARY KEY, NAME VARCHAR(60) NOT NULL,
TYPE VARCHAR(10) NOT NULL,
AVAILABLEBALANCE DECIMAL(18,2) NOT NULL, STATUS CHAR(1) NOT NULL,
CARDNO VARCHAR(24) NOT NULL, CUSTOMID VARCHAR(15) NOT NULL ) ENGINE=INNODB DEFAULT CHARSET=UTF8;
无明确主体的业务场景
如果业务场景中找不到合适的主体,也可以选择那些数据分布较为均匀的属性所对应 的表字段作为拆分键。
例如日志分析场景,日志系统中可能包含各类复杂的信息,这时您可以选择时间字段 作为拆分键。
选择时间字段作为拆分键时,支持对拆分键使用日期函数拆分。
为了方便清理和转储,采用range拆分算法,对时间字段用日期函数转换成年,表示按 年存储到各个分片上。
建表SQL语句:
CREATE TABLE LOG (
LOGTIME DATETIME NOT NULL, LOGSOURCESYSTEM VARCHAR(100), LOGDETAIL VARCHAR(10000) );
最佳实践 1 合理制定分片策略
2 如何选择 DDM 逻辑库分片数
在DDM实例创建逻辑库时,对需要水平拆分的表,选择合适的MySQL实例数量,通过 预估拆分表的数据量,规划出逻辑库分片数量,可以避免各个分片的上单张表数据容 量过高。一个分片即为MySQL实例的一个数据库,逻辑库的总分片数等于所关联的 MySQL分片数总和。
● 逻辑库选择“非拆分”模式时,一个逻辑库仅对应一个MySQL实例,在该实例上 仅创建1个分片。
● 逻辑库选择“拆分”模式时,一个逻辑库可对应多个MySQL实例,在每个实例 上,可创建1-64个分片。
分片平移到新实例:将逻辑库部分分片(分库)平移到新增的实例上,数据不会进行 重分布。
图2-1 分片平移示意图
分片个数变更:逻辑库对应的物理库分片可以根据用户需要自定义添加,单数据节点 上的物理分片数不超过64个。DDM会尽量将分片均匀分配到数据节点上,只要总分片 数有变化,数据都会进行重分布。
最佳实践 2 如何选择 DDM 逻辑库分片数
图2-2 分片变更示意图
最佳实践 2 如何选择 DDM 逻辑库分片数
3 广播表和单表的使用场景
单表指数据只存储在其中一个默认分片上的表;广播表指在所有分片上都存储全量数 据,提升JOIN效率。
单表
DDM管理控制台不提供单表创建操作,用户可以通过MySQL客户端或应用程序连接到 DDM实例后自行创建。
如果一张表的数据,数据量预估在1000万条以下,且没有与其他拆分表进行关联查询 的需求,建议将其设置为单表类型,存储在默认分片中。
单表样例,不做任何拆分:
CREATE TABLE single(
id int NOT NULL AUTO_INCREMENT COMMENT '主键id', name varchar(128),
PRIMARY KEY(id) );
广播表
在业务数据库中,存在一些数据量不大,更新频度低,但常常需要用来做关联查询的 表。
为了支持这类表与拆分表进行JOIN操作,DDM设计了一类“广播表”,具有以下特 点:
● 广播表在各分片中数据一致。数据插入、更新与删除会实时在每一个分片中执行 一次。
● 对广播表的查询,仅在一个分片中执行。
● 任何表都可以与广播表进行JOIN操作。
● 使用广播hint的前提是需要确保表的存在性。
例如:
电商企业的订单管理系统,需要查询统计广东地区的订单数据。假如涉及到省份地区 表与订单流水表进行JOIN查询,由于订单数据量庞大,订单流水表需要分片存储,因 此可以考虑将省份地区表设计为“广播表”,避免跨库JOIN操作。
广播表创建样例:
最佳实践 3 广播表和单表的使用场景
CREATE TABLE broadcast_tbl (
id int NOT NULL AUTO_INCREMENT COMMENT '主键id', name varchar(128),
PRIMARY KEY(id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci BROADCAST;
说明
广播表操作 、不带分片条件的SQL语句等全表扫描类语句,并发不要太高(或者选择在业务低 峰时进行),否则可能报“后端rds连接数可能不够用”的错误。
最佳实践 3 广播表和单表的使用场景
4 DDM 事务模型
因为DDM中的表一般都做了分库分表,使得这些表中的数据可能分布在很多个RDS实 例上的不同数据库分片内。在DDM中一个事务中对各个逻辑表的增删改查很有可能实 际发生在多个RDS实例上的不同数据库分片上,每个RDS实例上同一数据库分片内所发 生的对分片内数据表的一系列操作相当于一个本地事务,这样DDM层面的事务就相当 于由多个RDS实例上的本地事务所组成的分布式事务,这些本地事务要么全部成功,
要么全部失败。
DDM 的分布式事务实现
DDM中的分布式事务模块基于MySQL XA协议实现,XA协议是对2PC(Two Phase Commit)事务模型的一种实现,2PC是一种经典的分布式事务实现方案。
在分布式系统里,每个参与者都可以知晓自己操作的成功或者失败,却无法知道其他 节点操作的成功或失败。当一个事务跨多个节点时,为了保持事务的原子性与一致 性,需要引入一个协调者(Coordinator)来统一掌控所有参与者(Participant)的操 作结果,并指示它们是否要把操作结果进行真正的提交(commit)或者回滚
(rollback)。DDM节点在这个分布式事务中扮演协调者的角色,RDS实例则是参与 者。
2PC顾名思义分为两个阶段,其实施思路可概括为:
1. 准备阶段(prepare phase):参与者将操作结果通知协调者,参与者如果给出了 已准备的回应,则应保证在协调者做出决定之前需要将本次决议所需资源进行预 留。
2. 提交阶段(commit phase):收到参与者的通知后,协调者再向参与者发出通 知,根据反馈情况决定各参与者是否要提交还是回滚。
举例说明:
甲乙丙丁四人要聚餐,需要确定时间,不妨设甲是协调者,乙丙丁是参与者。
准备阶段:
1. 甲发短信给乙丙丁,周二中午十二点聚餐是否有时间。
2. 丁回复有时间。
3. 乙回复有时间。
4. 丙迟迟不回复,此时对于这个活动,甲乙丙丁均处于阻塞状态,算法无法继续进 行。
最佳实践 4 DDM 事务模型
5. 丙回复有时间(或者没有时间)。
提交阶段:
1. 协调者甲将收集到的结果(周二中午聚餐或者不聚餐)反馈给乙丙丁(什么时候 反馈,以及反馈结果如何,在此例中取决与丙的时间与决定)。
2. 乙收到。
3. 丙收到。
4. 丁收到。
5. 如果有人没有收到,则甲后续不断重新进行通知,直到通知成功。
2PC 具体实现
DDM对事务的2阶段提交进行了透明化封装。应用侧使用DDM事务的时候不需要关心 底层是否为分布式事务,只需像使用普通事务一样执行BEGIN/COMMIT指令进行事务 操作。DDM会自动处理分布式事务的两阶段提交逻辑。如果事务只涉及一个数据分 片,那么DDM还可以自动将事务降级为一阶段提交的本地事务。一阶段提交的细节本 文不详细展开。
图4-1 分布式事务执行流程
其中XID由节点内事务序号、节点ID和时间戳组成,代表了一个全局维度的分布式事务 唯一编号,该编号再加上对应分库名构成实际在物理库上开启分布式事务分支的 XA_ID 。
DDM 事务使用建议
● 虽然DDM支持分布式事务,但如果能够使事务内所有SQL都带上同一个拆分键,
DDM可以把事务优化为单分片事务从而获得更极致的性能。
● DDM事务模型采取2PC分布式事务模型,RDS自身的死锁检测无法避免跨RDS的 分布式事务死锁,如遇到lock wait超时则提示可能存在跨分片死锁,请检查业务 模型是否存在这方面问题。
最佳实践 4 DDM 事务模型
5 DDM SQL 使用规范
insert 操作
● insert写法规范
– 不建议逐条insert,推荐使用insert into values (),()..();语法。
– MySQL的JDBC连接的url中要加rewriteBatchedStatements参数,并保证 5.1.13以上版本的驱动,才能实现批量插入。MySQL JDBC驱动在默认情况下 会无视executeBatch()语句,把预计批量执行的一组sql语句拆散,一条一条 地发给MySQL数据库,批量插入实际上是单条插入,直接造成较低的性能。
只有把rewriteBatchedStatements参数置为true, 驱动才会批量执行SQL。另 外这个选项对INSERT/UPDATE/DELETE操作都有效。
– 拆分字段的值:不建议使用函数、表达式、子查询等,推荐使用常量值。
– 普通字段的值:不建议使用子查询,推荐使用常量、函数、表达式。
● 大批量数据导入
推荐使用loaddata local infile来实现大批量数据导入。
注意
这个地方只需要开一个session窗口导入即可,DDM内部会自动进行并行导入。
● 数据迁移场景
建议使用mysqldump导出sql文件,再使用mysql source命令导入。具体操作请参 考数据从DDM实例导出。
● auto_increment字段
– DDM使用Sequence来实现auto_increment语义,并保证全局唯一。
– 赋值:若使用auto_increment字段,建议不要在values子句中赋值,否则容 易造成主键冲突。如果在values中赋了值,建议使用alter sequence语句更 改,具体操作请参考全局序列。
– 步长:auto_increment字段步长建议不要设置成1,会导致性能低下。默认设 置成1000。
update 与 delete 操作
● 普通更新
最佳实践 5 DDM SQL 使用规范
– 进行update/delete操作时,where条件建议带上拆分字段;
– 无法带上拆分字段的场景,建议控制并发度,控制更新/删除涉及的数据条 数。建议先用select查出相应的数据,double check确保数据范围无误后再实 行update/delete操作。
● 拆分字段更新
– 条数限制:DDM拆分字段更新有数据量限制,一般不能超过10000条数据,
数据量越少越好。若超过10000条数据,建议用改重建表的方式来做,或者 是拆分成多次update操作来等价实现。
– 操作的时机:建议选择在业务低谷期做。
● 关联操作
不建议进行表关联更新、表关联删除操作,即不建议进行多张表同时进行update/
delete操作。
● 子查询及limit操作
不建议update/delete语句中含有子查询。不建议update/delete语句中含有limit或 order by limit语句。
select 操作
● Order by 及 Limit函数
– "order by limit offset, count"场景,禁止给offset赋大数值,即禁止深度翻 页。
– 如遇到临时表超限(Temp table limit exceeded)报错,说明排序中间数据 产生了临时表且超限,考虑联系DDM值班进行SQL调优。
● Group by函数
– 不建议select_list部分含有非group by列。
– 不支持不可下推的group_concat聚合函数内含有order by子句。
– 不建议distinct、group by字段多于3项。
– 不建议join、或者子查询操作之后含有group by操作 – 不建议使用count(distinct ),sum(distinct )操作。
– 如遇到临时表超限(Temp table limit exceeded)报错,说明聚合操作中间 数据产生了临时表且超限,考虑联系DDM值班进行SQL调优。
● Join函数
– select场景,建议join条件是每个表的拆分字段或使用广播表,或者是驱动表 是一个小表(inner/left join驱动表是左表,right join驱动表是右表)。
– 不建议两个大表直接进行join操作。
– 不建议join on condition中含有非等值操作。
– 如遇到临时表超限(Temp table limit exceeded)报错,说明JOIN中间数据 产生了临时表且超限,考虑联系DDM值班进行SQL调优。
– 不建议5张表以上进行join操作。
– join查询操作建议不要开启事务。
– 不建议在事务中进行join查询,开启事务会影响DDM对join算法的选择,无法 使用最高效的算法。
最佳实践 5 DDM SQL 使用规范
注意
这里的大表和小表的意思不是指原始表的规模,指的是经过where条件过滤 之后的数据规模。
● 子查询
– 不建议子查询包含在OR表达式中,或者是子查询的关联条件包含在OR表达 式中
– 不建议使用含有limit的标量子查询,如 select (select x from t2 where t2.id=
t.id limit 1),a,b from t。
– 如果子查询和主表都路由到同一分片,建议在SQL前加/*+db=xxx*/来精准路 由。
– 不建议子查询内部含有join语句。
– 不建议写嵌套子查询。
– 不建议ROW表达式跟子查询做比较操作,如 select * from t where (a,b,c)=(select x,y,z from t2 where …)。
– 不建议select_list里面含有超过2个以上的子查询 。
DDL
● DDL执行时机
对已有表进行DDL操作时建议放在业务低峰期进行。
● 分片数
创建新拆分表时建议结合实际数据量进行合理预估,总分片数满足需求即可。不 建议使用超出实际需求的分片数,拆分表分片数并非越多越好
● 高危DDL
进行高危DDL时请仔细校验SQL后谨慎操作,如DROP TABLE, TRUNCATE TABLE 等操作。
● DDL失败修复
DDL命令如遇报错,可以使用"check table 表名"命令对各个分片表结构进行校 验,识别出失败的分片进行针对性修复。如ALTER TABLE命令遭遇失败可以在命 令前添加/*+allow_alter_rerun=true/,开启ALTER语句的幂等可重入执行后重 试,直到check table 命令提示各个分片表结构达到一致则可认为执行成功。
● MDL锁导致执行DDL报错
– 背景:为保证DDL的可用性,DDM内部在执行DDL前会检查底层RDS相关表 是否存在MDL锁。 若存在MDL锁,,则DDL会提前报错退出。
metadata lock exists, one of MDL is [%s],DDL operation can not proceed, please use 'show metadata lock' to check current mdl, and use 'kill physical threadId@host:port' to clean it
– 可能出现的问题:若系统中存在慢SQL,执行时间为几分钟不等,那么可能 被MDL锁所阻拦,无法执行DDL。
– 解决方案1:在DDM控制台提高参数“ddl_precheck_mdl_threshold_time”
的大小, 如提高到30分钟(1800秒)。
说明
“ddl_precheck_mdl_threshold_time”表示DDL允许MDL锁持有的最大时长。持有 超过这个时间长度的MDL锁,DDL才会报错,默认值为120秒。
– 解决方案2:执行show metadata lock查看是否因为持有慢事务的MDL锁阻 塞了DDL的执行。若存在阻塞, 可以使用kill physical threadId@host:port 来
最佳实践 5 DDM SQL 使用规范
关闭底层慢事务。配合/*+allow_alter_rerun=true*/的hint, 以及check table 来查看和执行,直到DDL彻底执行完。
说明
threadId为物理层RDS的线程id,host和port分别为物理层RDS的ip和端口。
● DDL长时间卡死
在业务低峰期执行DDL时如果遇到长时间卡死情况,请另开会话执行xa recover命 令查看是否有慢事务存在,如存在慢事务挂起请及时联系值班人员解决。
最佳实践 5 DDM SQL 使用规范
6 如何将单 RDS 数据整库迁移至 DDM
操作场景
本章节主要介绍将单RDS(非拆分,以下简称旧RDS)库中的数据整库迁移到DDM实 例非拆分库中,仅使用DDM做读写分离场景。
说明
● 迁移过程中可能会出现业务中断情况,中断时长与迁移数据量大小、网络情况相关。
● 数据迁移是一项比较复杂的操作,建议在业务量较低时进行。本实践仅供参考,您需要根据 自己业务场景、数据量、停机时间要求等情况,设计合适的迁移方案。
● 对于数据量较大的场景,建议通过工单或售后服务联系DDM技术支持人员进行支撑,在正式 数据迁移前进行充分的迁移演练测试。
迁移前准备
● 准备可以访问旧RDS实例、目标DDM实例和目标DDM实例关联的RDS实例的 ECS。
a. 确保旧RDS实例、目标DDM实例和目标DDM实例关联的RDS实例都在同一个 VPC下,保证网络互通。
b. 旧RDS实例、目标DDM实例和目标DDM实例关联的RDS实例的安全组建议配 置相同,如果不同则需要放开对应端口访问。
c. ECS已安装MySQL官方客户端,MySQL客户端版本建议为5.6或5.7。
▪
Redhat系列Linux安装命令:yum install mysql mysql-devel▪
Debian系列Linux安装命令:apt install mysql-client-5.7 mysql- client-core-5.7d. ECS磁盘空间足够存放临时转储文件;ECS内存空间足够,可以用来比较转储 文件。
● 准备已关联RDS实例的DDM实例,并配置DDM账号、DDM逻辑库等相关信息。
● 如果目标DDM实例逻辑库为拆分库,则需要在迁移前,在DDM控制台先创建与旧 RDS数据表结构相同的逻辑表。
约束限制
● 为了保持数据完整性,需要先停止旧RDS业务后再进行数据迁移。
最佳实践 6 如何将单 RDS 数据整库迁移至 DDM
● 该场景不支持通过DDM关联旧RDS实例进行数据关联,需要将旧RDS实例数据导 出后再导入到DDM实例完成数据迁移。
● 目标DDM关联的RDS版本与旧RDS的MySQL版本需要保持一致。
从旧 RDS 导出数据
步骤1 登录ECS。
步骤2 执行如下命令导出结构数据,其中斜体参数需根据实际情况配置,详细参数说明如表 6-1所示。
mysqldump -h
{DB_ADDRESS}
-P{DB_PORT}
-u{DB_USER}
-p --skip-lock-tables --add- locks=false --set-gtid-purged=OFF --no-data{DB_NAME}
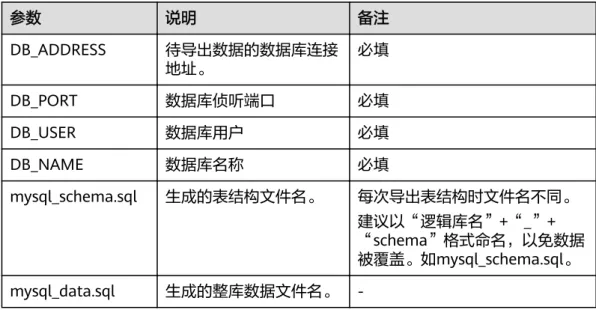
> {mysql_schema.sql}表6-1 参数解释
参数 说明 备注
DB_ADDRESS 待导出数据的数据库连接 地址。
必填
DB_PORT 数据库侦听端口 必填
DB_USER 数据库用户 必填
DB_NAME 数据库名称 必填
mysql_schema.sql 生成的表结构文件名。 每次导出表结构时文件名不同。
建议以“逻辑库名”+“_”+
“schema”格式命名,以免数据 被覆盖。如mysql_schema.sql。
mysql_data.sql 生成的整库数据文件名。 -
步骤3 执行如下命令导出整库数据,其中斜体参数需根据实际情况配置,详细参数说明如表 6-1所示。
mysqldump -h
{DB_ADDRESS}
-P{DB_PORT}
-u{DB_USER}
-p --hex-blob --complete-insert -- skip-lock-tables --skip-tz-utc --skip-add-locks --set-gtid-purged=OFF --no-create-info{DB_NAME}
>{mysql_data.sql}
步骤4 导出完成后,在ECS上执行如下可查看步骤2和步骤3导出的.sql文件。
ls -l ----结束
将数据导入至 DDM 实例
步骤1 在ECS上执行如下命令,将结构文件导入DDM。
mysql -f -h
{DDM_ADDRESS} -P {DDM_PORT} -u {DDM_USER} -p {DB_NAME} <
{mysql_schema.sql}
Enter password: **********
最佳实践 6 如何将单 RDS 数据整库迁移至 DDM
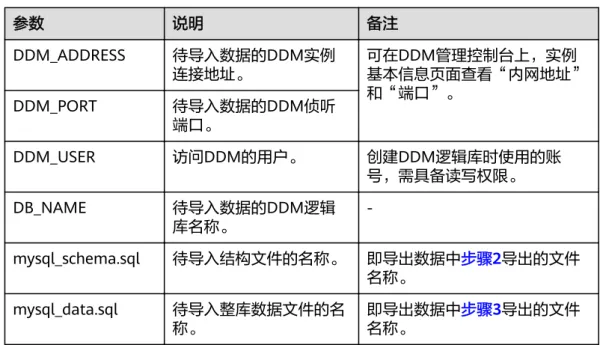
表6-2 参数解释
参数 说明 备注
DDM_ADDRESS 待导入数据的DDM实例
连接地址。 可在DDM管理控制台上,实例 基本信息页面查看“内网地址”
和“端口”。
DDM_PORT 待导入数据的DDM侦听 端口。
DDM_USER 访问DDM的用户。 创建DDM逻辑库时使用的账 号,需具备读写权限。
DB_NAME 待导入数据的DDM逻辑
库名称。 -
mysql_schema.sql 待导入结构文件的名称。 即导出数据中步骤2导出的文件 名称。
mysql_data.sql 待导入整库数据文件的名
称。 即导出数据中步骤3导出的文件
名称。
步骤2 执行如下命令,将数据文件导入DDM。
mysql -f -h
{DDM_ADDRESS}
-P{DDM_PORT}
-u{DDM_USER}
-p{DB_NAME}
<{mysql_schema.sql}
Enter password: **********
----结束
最佳实践 6 如何将单 RDS 数据整库迁移至 DDM
7 如何将 Mycat 数据整库迁移至 DDM
操作场景
本章节主要介绍将Mycat中的数据整库迁移到DDM中。
说明
● 迁移过程中可能会出现业务中断情况,中断时长与迁移数据量大小、网络情况相关。
● 数据迁移是一项比较复杂的操作,建议在业务量较低时进行。本实践仅供参考,您需要根据 自己业务场景、数据量、停机时间要求等情况,设计合适的迁移方案。
● 由于DDM仅支持通过弹性云服务器(ECS)访问,因此需要先将数据库导出为文件到ECS,
然后从ECS将文件中的数据导入到DDM。
迁移前准备
● 准备可以访问Mycat、目标DDM实例和目标DDM实例关联的RDS实例的ECS。
a. 确保Mycat、目标DDM实例和目标DDM实例关联的RDS实例都在同一个VPC 下,保证网络互通。
b. 部署Mycat的ECS、目标DDM实例和目标DDM实例关联的RDS实例的安全组 建议配置相同,如果不同则需要放开对应端口访问。
c. ECS已安装MySQL官方客户端,MySQL客户端版本建议为5.6或5.7。
▪
Redhat系列Linux安装命令:yum install mysql mysql-devel▪
Debian系列Linux安装命令:apt install mysql-client-5.7 mysql- client-core-5.7d. ECS磁盘空间足够存放临时转储文件;ECS内存空间足够,可以用来比较转储 文件。
● 准备已关联RDS实例的DDM实例,并配置DDM账号、DDM逻辑库等相关信息。
● 本章节以Mycat 1.6版本进行迁移为例。
迁移策略
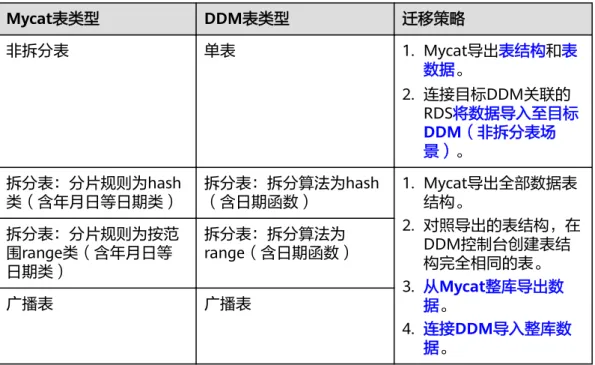
Mycat与DDM数据表类型不同,迁移策略也有所差异,详情如表7-1所示。
最佳实践 7 如何将 Mycat 数据整库迁移至 DDM
表7-1 迁移策略
Mycat表类型 DDM表类型 迁移策略
非拆分表 单表 1. Mycat导出表结构和表
数据。
2. 连接目标DDM关联的 RDS将数据导入至目标 DDM(非拆分表场 景)。
拆分表:分片规则为hash
类(含年月日等日期类) 拆分表:拆分算法为hash
(含日期函数) 1. Mycat导出全部数据表 结构。
2. 对照导出的表结构,在 DDM控制台创建表结 构完全相同的表。
3. 从Mycat整库导出数 据。
4. 连接DDM导入整库数 据。
拆分表:分片规则为按范 围range类(含年月日等 日期类)
拆分表:拆分算法为 range(含日期函数)
广播表 广播表
约束限制
● 为了保持数据完整性,需要先停止Mycat业务后再进行数据迁移。
● 该场景不支持通过DDM关联Mycat关联的RDS进行数据关联,需要将Mycat数据 导出后再导入到DDM完成数据迁移。
● 目标DDM关联的RDS版本与Mycat关联数据库的版本需要保持一致。
从 Mycat 导出数据表结构
步骤1 登录ECS。
步骤2 执行如下命令导出Mycat数据中的表结构数据,其中斜体变量参数需根据实际情况配 置,详细参数说明如表7-2所示。
mysqldump -h
{DB_ADDRESS}
-P{DB_PORT}
-u{DB_USER}
-p --skip-lock-tables --add- locks=false --set-gtid-purged=OFF --no-data --order-by-primary{DB_NAME}
>{mysql_schema.sql}
Enter password: **********
表7-2 参数解释
参数 说明 备注
DB_ADDRESS 待导出数据的数据库连接 地址。
必填
DB_PORT 数据库侦听端口 必填
DB_USER 数据库用户 必填
DB_NAME 数据库名称 必填
最佳实践 7 如何将 Mycat 数据整库迁移至 DDM
参数 说明 备注
mysql_schema.sql 生成的表结构文件名。 每次导出表结构时文件名不同。
建议以“逻辑库名”+“_”+
“schema”格式命名,以免数据 被覆盖。如mysql_schema.sql。
mysql_data.sql 生成的整库数据文件名。 -
----结束
从 Mycat 整库导出数据
步骤1 登录ECS。
步骤2 执行如下命令导出Mycat整库数据,其中斜体变量参数需根据实际情况配置,详细参数 说明如表7-2所示。
mysqldump -h {DB_ADDRESS} -P
{DB_PORT}
-u{DB_USER}
-p --hex-blob --complete-insert --skip-lock-tables --add-locks=false --set-gtid-purged=OFF --quick --no-create-info --order- by-primary{DB_NAME}
>{mysql_data.sql}
Enter password: **********
步骤3 导出完成后,在ECS上执行如下命令可查看导出的.sql文件。
ls -l ----结束
将数据导入至目标 DDM(非拆分表场景)
在ECS上采用MySQL客户端直连目标DDM关联的RDS,直接执行以下命令导入表结构 文本文件和数据文件。
如果是单表或普通表,
mysql -f -h
{RDS_ADDRESS}
-P{RDS_PORT}
-u{RDS_USER}
-p{DB_NAME}
<{mysql_table_schema.sql}
Enter password: **********
mysql -f -h
{RDS_ADDRESS}
-P{RDS_PORT}
-u{RDS_USER}
-p{DB_NAME}
<{mysq_table_data.sql}
Enter password: **********
● RDS_ADDRESS为待导入数据的RDS的地址。
● RDS_PORT为RDS实例的端口。
● RDS_USER为RDS实例的用户名。
● DB_NAME为RDS数据库名称,如果导入的是单表,DB_NAME为RDS第一个分片 的物理数据库。
● mysql_table_schema.sql为待导入的表结构文件名。
● mysq_table_data.sql为待导入的表数据文件名。
将数据导入至目标 DDM(拆分表、广播表场景)
在ECS上采用MySQL客户端连接DDM执行如下命令,将整库数据文件导入DDM。
mysql -f -h
{DDM_ADDRESS}
-P{DDM_PORT}
-u{DDM_USER}
-p{DB_NAME}
<{mysql_data.sql}
Enter password: **********
最佳实践 7 如何将 Mycat 数据整库迁移至 DDM
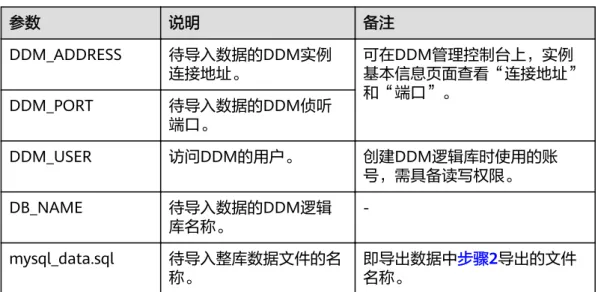
表7-3 参数解释
参数 说明 备注
DDM_ADDRESS 待导入数据的DDM实例
连接地址。 可在DDM管理控制台上,实例 基本信息页面查看“连接地址”
和“端口”。
DDM_PORT 待导入数据的DDM侦听 端口。
DDM_USER 访问DDM的用户。 创建DDM逻辑库时使用的账 号,需具备读写权限。
DB_NAME 待导入数据的DDM逻辑
库名称。 -
mysql_data.sql 待导入整库数据文件的名
称。 即导出数据中步骤2导出的文件
名称。
最佳实践 7 如何将 Mycat 数据整库迁移至 DDM
8 通过 JDBC 连接池连接 DDM
操作场景
连接池实现原理:在系统初始化的时候,将数据库连接作为对象存储在内存中,当用 户需要访问数据库时,发出请求,直接从连接池中取出一个已建立的空闲连接对象。
使用完毕后,再将连接放回连接池中,供下一个请求访问使用。连接的建立、断开都 由连接池自身来管理。同时,还可以通过设置连接池的参数来控制连接池中的初始连 接数、连接的上下限数以及每个连接的最大使用次数、最大空闲时间等等。也可以通 过系统自身的管理机制来监视数据库连接的数量、使用情况等。
本章节主要介绍了如何通过JDBC连接池与DDM对接,实现数据操作。如果是Java程 序,建议您使用HikariCP。
● Java 8:建议使用3.3.1版本。
● Java 7:建议使用2.4.13版本。
● JDBC连接DDM不支持开启用户游标提取(useCursorFetch)参数。
操作步骤
步骤1 配置Maven。
● Java 8:
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>3.3.1</version>
</dependency>
● Java 7:
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP-java7</artifactId>
<version>2.4.13</version>
</dependency>
步骤2 创建表。
最佳实践 8 通过 JDBC 连接池连接 DDM
表8-1 创建表。
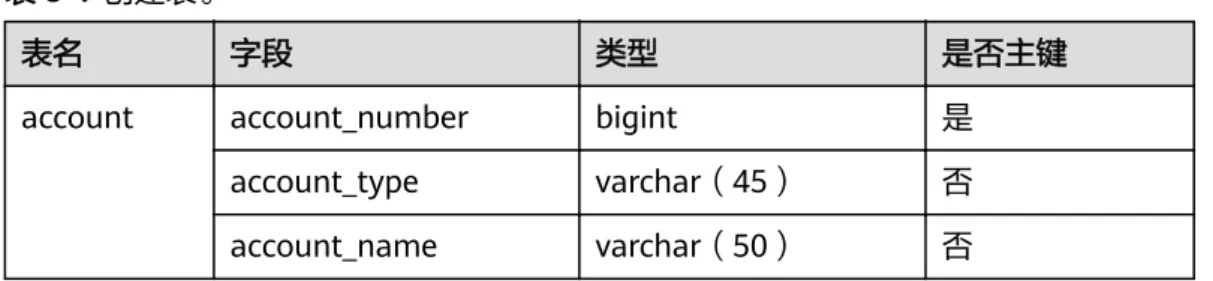
表名 字段 类型 是否主键
account account_number bigint 是 account_type varchar(45) 否 account_name varchar(50) 否
步骤3 连接DDM实例。
1. 配置连接数:JdbcUrl连接串中的参数和HikariCP参数。
2. 插入数据。
示例:package com.huawei.ddm.examples;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import javax.sql.DataSource;
import com.zaxxer.hikari.HikariConfig;
import com.zaxxer.hikari.HikariDataSource;
public class HikariCPDemo {
private static DataSource datasource;
private static DataSource getDataSource() { if (datasource == null) {
HikariConfig config = new HikariConfig();
// 配置JdbcUrl连接串中的参数
config.setJdbcUrl("jdbc:mysql:loadbalance://192.168.0.10:5066,192.168.0.11:5066/db_name?
loadBalanceAutoCommitStatementThreshold=5&loadBalanceHostRemovalGracePeriod=15000&loadBal anceBlacklistTimeout=60000&loadBalancePingTimeout=5000&retriesAllDown=10&connectTimeout=10 000&socketTimeout=60000");
/*
// 配置JdbcUrl连接串中的参数也可以通过以下方法进行:
config.addDataSourceProperty("loadBalanceAutoCommitStatementThreshold",5);
config.addDataSourceProperty("loadBalanceHostRemovalGracePeriod", 15000);
config.addDataSourceProperty("loadBalanceBlacklistTimeout", 60000);
config.addDataSourceProperty("loadBalancePingTimeout", 5000);
config.addDataSourceProperty("retriesAllDown", 10);
config.addDataSourceProperty("connectTimeout", 10000);
*/
config.setUsername("username");
config.setPassword("password");
config.setMaximumPoolSize(10);
config.setAutoCommit(true);
// 配置HikariCP参数
config.addDataSourceProperty("cachePrepStmts", true);
config.addDataSourceProperty("prepStmtCacheSize", 250);
config.addDataSourceProperty("prepStmtCacheSqlLimit", 2048);
config.addDataSourceProperty("minimumIdle", 5);
config.addDataSourceProperty("maximumPoolSize", 10);
config.addDataSourceProperty("idleTimeout", 30000);
datasource = new HikariDataSource(config);
}
return datasource;
}
public static void main(String[] args) { Connection connection = null;
PreparedStatement pstmt = null;
最佳实践 8 通过 JDBC 连接池连接 DDM
ResultSet resultSet = null;
try {
DataSource dataSource = getDataSource();
connection = dataSource.getConnection();
System.out.println("The Connection Object is of Class: " + connection.getClass());
// 插入测试数据
String insertSql = "insert into account(account_number, account_type, account_name) values(?, ?, ?);";
PreparedStatement insertStmt = connection.prepareStatement(insertSql);
insertStmt.setLong (1, 1L);
insertStmt.setString (2, "manager");
insertStmt.setString (3, "demotest01");
insertStmt.executeUpdate();
connection.commit ();
// 查询数据
pstmt = connection.prepareStatement("SELECT * FROM account");
resultSet = pstmt.executeQuery();
while (resultSet.next()) {
String accountNumber = resultSet.getString("account_number");
String accountType = resultSet.getString("account_type");
String accountName = resultSet.getString("account_name");
System.out.println(accountNumber + "," + accountType + "," + accountName);
}
} catch (Exception e) { try {
if (null != connection) { connection.rollback();
}
} catch (SQLException e1) { e1.printStackTrace();
}
e.printStackTrace();
} } }
----结束
最佳实践 8 通过 JDBC 连接池连接 DDM
9 通过 Navicat 客户端连接 DDM 实例
操作场景
本文将介绍如何获取弹性公网的IP地址,并通过Navicat客户端连接DDM实例。
Navicat 客户端连接 DDM 实例
步骤1 登录分布式数据库中间件服务,单击需要连接的DDM实例名称,进入实例基本信息页 面。
步骤2 在“实例信息”模块的弹性公网IP单击“绑定”。选择任意地址进行绑定。
步骤3 在DDM管理控制台左侧选择虚拟私有云图标。单击“访问控制>安全组”
步骤4 在安全组界面,单击操作列的“配置规则”,进入安全组详情界面。在安全组详情界 面,单击“添加规则”,弹出添加规则窗口。根据界面提示配置安全组规则,设置完 成后单击“确定”即可。
说明
● 绑定弹性公网IP后,建议您在内网安全组中设置严格的出入规则,以加强数据库安全性。
步骤5 打开Navicat客户端,单击“连接”。在新建连接窗口中填写主机IP地址(弹性公网IP 地址)、用户名和密码(DDM帐号、密码)。
步骤6 单击“连接测试”,若显示连接成功,单击“确定”,等待1-2分钟即可连接成功。连 接失败会直接弹出失败原因,请修改后重试。
----结束 说明
通过其他可视化的MySQL工具(例如 Workbench)连接DDM实例的操作与此章基本一致,不 做详细描述。
最佳实践 9 通过 Navicat 客户端连接 DDM 实例