Developer's Guide
Software Release 2.3 June 2017
Two-Second Advantage®
Important Information
SOME TIBCO SOFTWARE EMBEDS OR BUNDLES OTHER TIBCO SOFTWARE. USE OF SUCH EMBEDDED OR BUNDLED TIBCO SOFTWARE IS SOLELY TO ENABLE THE FUNCTIONALITY (OR PROVIDE LIMITED ADD-ON FUNCTIONALITY) OF THE LICENSED TIBCO SOFTWARE. THE EMBEDDED OR BUNDLED SOFTWARE IS NOT LICENSED TO BE USED OR ACCESSED BY ANY OTHER TIBCO SOFTWARE OR FOR ANY OTHER PURPOSE.
USE OF TIBCO SOFTWARE AND THIS DOCUMENT IS SUBJECT TO THE TERMS AND CONDITIONS OF A LICENSE AGREEMENT FOUND IN EITHER A SEPARATELY EXECUTED SOFTWARE LICENSE AGREEMENT, OR, IF THERE IS NO SUCH SEPARATE AGREEMENT, THE CLICKWRAP END USER LICENSE AGREEMENT WHICH IS DISPLAYED DURING DOWNLOAD OR INSTALLATION OF THE SOFTWARE (AND WHICH IS DUPLICATED IN THE LICENSE FILE) OR IF THERE IS NO SUCH SOFTWARE LICENSE AGREEMENT OR CLICKWRAP END USER LICENSE AGREEMENT, THE LICENSE(S) LOCATED IN THE “LICENSE” FILE(S) OF THE
SOFTWARE. USE OF THIS DOCUMENT IS SUBJECT TO THOSE TERMS AND CONDITIONS, AND YOUR USE HEREOF SHALL CONSTITUTE ACCEPTANCE OF AND AN AGREEMENT TO BE BOUND BY THE SAME.
This document contains confidential information that is subject to U.S. and international copyright laws and treaties. No part of this document may be reproduced in any form without the written
authorization of TIBCO Software Inc.
TIBCO, Two-Second Advantage, The Power of Now, TIB, Information Bus, Rendezvous, TIBCO Rendezvous, and Messaging Appliance are either registered trademarks or trademarks of TIBCO Software Inc. in the United States and/or other countries.
Enterprise Java Beans (EJB), Java Platform Enterprise Edition (Java EE), Java 2 Platform Enterprise Edition (J2EE), and all Java-based trademarks and logos are trademarks or registered trademarks of Oracle Corporation in the U.S. and other countries.
All other product and company names and marks mentioned in this document are the property of their respective owners and are mentioned for identification purposes only.
THIS SOFTWARE MAY BE AVAILABLE ON MULTIPLE OPERATING SYSTEMS. HOWEVER, NOT ALL OPERATING SYSTEM PLATFORMS FOR A SPECIFIC SOFTWARE VERSION ARE RELEASED AT THE SAME TIME. SEE THE README FILE FOR THE AVAILABILITY OF THIS SOFTWARE VERSION ON A SPECIFIC OPERATING SYSTEM PLATFORM.
THIS DOCUMENT IS PROVIDED “AS IS” WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, OR NON-INFRINGEMENT.
THIS DOCUMENT COULD INCLUDE TECHNICAL INACCURACIES OR TYPOGRAPHICAL ERRORS. CHANGES ARE PERIODICALLY ADDED TO THE INFORMATION HEREIN; THESE CHANGES WILL BE INCORPORATED IN NEW EDITIONS OF THIS DOCUMENT. TIBCO SOFTWARE INC. MAY MAKE IMPROVEMENTS AND/OR CHANGES IN THE PRODUCT(S) AND/OR THE PROGRAM(S) DESCRIBED IN THIS DOCUMENT AT ANY TIME.
THE CONTENTS OF THIS DOCUMENT MAY BE MODIFIED AND/OR QUALIFIED, DIRECTLY OR INDIRECTLY, BY OTHER DOCUMENTATION WHICH ACCOMPANIES THIS SOFTWARE,
INCLUDING BUT NOT LIMITED TO ANY RELEASE NOTES AND "READ ME" FILES.
Copyright © 1997 - 2017 TIBCO Software Inc. ALL RIGHTS RESERVED.
TIBCO Software Inc. Confidential Information
Contents
Figures . . . 11
TIBCO Documentation and Support Services. . . . 12
TIBCO ActiveSpaces Overview. . . .13
Benefits of TIBCO ActiveSpaces. . . .13
TIBCO ActiveSpaces Features. . . .13
Usage Profiles. . . 14
In-Memory Operational Data Store. . . .14
Space-Based Architecture. . . .14
Grid Computing. . . .15
Deployment Models. . . .15
Distributed Data Cache. . . .15
TIBCO ActiveSpaces Concepts. . . .16
Introduction to TIBCO ActiveSpaces Applications. . . .16
Basic ActiveSpaces Terms. . . .16
Metaspace. . . .17
Metaspace Connection. . . .17
Metaspace Life Cycle. . . .18
Space. . . .18
Space Contents. . . .18
Differences Between ActiveSpaces and a Distributed Cache. . . .19
Tuples and Fields. . . .19
Field Type Conversion. . . 19
Guidelines to Define Key Fields. . . .20
Indexes. . . .20
Basic Operations on Tuples. . . .21
Batch Versions of Tuple Operations. . . .22
The Put Operation Storing Data into a Space. . . 22
The Update Operation to Update Existing Data In a Space. . . .22
Batch Versus Blocking Operations. . . .22
Space Data Retrieval Methods. . . .22
The Take Operation Consuming or Removing Data from a Space. . . .23
Space Members and Member Roles. . . .24
Characteristics of Seeders versus Leeches. . . .24
The as-agent Process. . . .24
The as-agent as a Seeder for Remote Clients. . . .24
About Joining the Space as a Seeder or a Leech. . . .24
Space Definition. . . .25
Overview of Space Attributes and Policies. . . .25
Field Definitions. . . .26
Distribution. . . .26
Replication. . . .28
Degrees of Replication. . . .28
Phase Count and Phase Ratio Tuning Redistribution and Replication. . . .29
Synchronous and Asynchronous Replication. . . 29
Host-Aware Replication. . . .30
Space Storage Options and Persistence. . . .30
RAM Storage. . . .30
Persistence Concepts. . . .31
Persistence Policy and Implementation. . . .32
Terms and Concepts for Persistence. . . .32
TIBCO ActiveSpaces Cluster Startup with Persistence. . . .33
Space Recovery with Persistence. . . .33
Space Resume with Shared-All Persistence. . . .34
Space Life Cycle and Persistence. . . .34
Persistence and Space Life Cycle. . . .34
Write-Behind Caching. . . .35
Expiration Time to Live and Tuple Locking. . . .36
Concurrent Data Update in a Space. . . 37
Data Lock in a Space. . . .37
Results. . . .38
Browsers. . . .38
Scopes of a Space Browser. . . .39
Listeners. . . .40
Filters. . . .41
Remote Invocation of Code over a Space. . . .44
Transactions. . . .45
Deployment. . . .45
Networking Considerations. . . .46
Special Considerations for Joining a Space or Metaspace. . . .46
The as-agent Utility as a Seeder. . . .47
Remote Clients. . . .47
Remote Client Communication. . . .47
ActiveSpaces Routing. . . .48
Implementing ActiveSpaces Routing. . . .48
Enabling Routing in the Space Definition. . . .48
Creating the Router Object. . . .48
Declaring a Callback Function. . . .49
Setting the Router Object on the Space. . . .49
Freeing a Router. . . .50
Performance Monitoring. . . .50
The ASCommon Object. . . .50
The tibasMetaspace_Connect Method. . . .50
Discovery Attribute. . . .51
PGM (Pragmatic General Multicast) URL Format. . . .51
TCP Discovery URL Format. . . .52
Discovery URL Format for Remote Clients for Connecting as a Remote Client. . . .52
Listen Attribute. . . .53
MemberName Attribute. . . .53
The close Method. . . .53
Metaspace Membership. . . .54
The getSelfMember method. . . .54
The getUserSpaceNames Method. . . .54
File Logging. . . .54
The defineSpace Method. . . .56
Space Definition Through the Admin CLI. . . .56
Space Definition Through the API. . . .56
The getSpaceDef Method. . . 56
The dropSpace Method. . . .57
Distribution Policy Methods. . . .57
Define Capacity. . . .57
Host-Aware Replication. . . .57
LockTTL Methods. . . .58
Methods to Define Fields. . . .59
Types of Field Definitions. . . .59
Key Fields. . . .60
Key Fields for Distribution (Affinity). . . .60
Adding Fields to a Previously Defined Space. . . .61
The getSpace Method. . . .61
The close Method. . . .62
Persistence. . . 62
API Operations for Setting up Persistence. . . .63
Shared-Nothing Persistence Concepts. . . 64
Shared All Persistence. . . .64
Recovery with Persistence. . . .65
Tuple. . . .66
The getName and getSpaceDef Methods. . . .68
Context Tuples. . . .68
An Example of a Context Tuple. . . .68
Context Tuple APIs. . . .69
The Read and Write in a Space. . . .69
Getting or Taking a Single Tuple from the Space. . . .69
Put Operation for Storing a Tuple in a Space. . . .70
Operations on a Tuple in a Space. . . .71
Lock and Unlock Methods. . . .71
Use of Transactions. . . .72
Transaction Methods. . . .72
Space Operation Options. . . .72
Batch Operations. . . .72
Listeners. . . .73
SpaceEvent Objects. . . .74
Space Browser Methods. . . .75
ASEventBrowser. . . .76
Performance Monitoring. . . .76
Remote Space Invocation. . . 77
Space as a Cache. . . .77
Working with Remote Clients. . . .78
Connecting a Remote Client. . . 78
Starting as-agent to Listen for a Remote Client. . . .78
Connecting to the Seeder from the Remote Client. . . .79
Implementing ActiveSpaces Security. . . .80
Overview of ActiveSpaces Security. . . .80
ActiveSpaces Security Architecture. . . .81
Applying Security to a Metaspace. . . .82
Security Domain Controllers. . . .82
Setting Up a Node as a Security Domain Controller. . . .83
Security Policy Files. . . .83
Creating a Security Policy File. . . .84
Security Domain Settings. . . .84
Validating a Security Policy File. . . 85
Security Policy File Keys and Certificates. . . .85
Security Domain Requestors. . . .85
Connecting to a Metaspace Without Using a Security Token File. . . .85
Security Token Files. . . .86
Creating a Security Token File. . . .86
Limiting Metaspace Access. . . .86
Validating a Security Token File. . . .86
Security Token File Keys and Certificates. . . .87
Metaspace Access List. . . .87
Transport Security. . . .88
Restricting Transport Access. . . .88
Data Encryption. . . .89
Security Tracing and File Logging. . . .90
User Authentication. . . .90
Operating System User Authentication. . . .91
LDAP User Authentication. . . .91
LDAP Certificate Authentication. . . .92
Authentication Callback. . . .93
User Access Control. . . .93
Enabling User Access Control. . . .94
Access Control Groups. . . 95
Access Control Permissions. . . .95
Permissions Precedence. . . .95
ActiveSpaces Examples. . . .97
The Examples Directory. . . .97
Building the ActiveSpaces Examples. . . .97
Building the Java API Examples. . . .97
Building the .NET API Examples. . . .98
Building the .NET Examples from the Windows Command Line. . . .98
Building the .NET Examples from MS Visual Studio. . . .98
Building Other .NET Examples in MS Visual Studio . . . .99
Building the C API Examples . . . .99
Building the C Examples on Windows. . . .100
Building the C Examples on Non-Windows Platforms. . . .100
Running the Examples. . . .100
Running the Java API Examples. . . .100
Running the C API Examples on Windows. . . .101
Running the C API Examples on UNIX Linux AIX HP UX. . . .101
Running the .NET API Examples. . . .102
Command Line Arguments. . . .102
Command Line Help. . . .102
Metaspace Command Line Arguments. . . .102
SpaceMemberDef Command Line Arguments. . . .103
SpaceDef Command Line Arguments. . . .103
Default Metaspace Name. . . .103
Default Discovery URL. . . .103
Default Space Fields. . . .103
Security. . . .104
Example Security Policy File. . . .104
Example Security Token File . . . .105
ASOperations. . . .106
Starting ASOperations. . . .106
Starting ASOperations With Security. . . .107
ASOperations Parameters. . . .107
ASBatchOperations. . . .108
Starting ASBatchOperations. . . .108
Starting ASBatchOperations With Security. . . .109
ASBatchOperations Parameters. . . .109
ASChat. . . .110
Starting ASChat. . . .110
Starting ASChat With Security. . . .111
Using ASChat. . . .111
ASPaint (Java and .NET Only). . . .111
Starting ASPaint. . . .112
Using ASPaint. . . .112
ASQuery (Java Only). . . .113
Starting ASQuery. . . .113
Starting ASQuery with Security. . . .113
ASPersistence. . . .113
Starting ASPersistence. . . .114
Starting ASPersistence with Security. . . .115
Using ASPersistence with a Database. . . .115
Shared-Nothing Persistence. . . .116
Starting ASOperations for Shared-Nothing Persistence. . . .116
Starting as-agents for Shared-Nothing Persistence. . . .117
Starting ASOperations for Shared-Nothing Persistence With Security. . . .117
Using Shared-Nothing Persistence. . . .118
ASRequestReplyServer and ASRequestReplyClient. . . .118
Starting ASRequestReplyServer. . . .119
Starting ASRequestReplyClient. . . .119
Starting ASRequestReplyServer and ASRequestReplyClient with Security. . . .120
Remote Space Invocation InvokeClient. . . .120
Starting InvokeClient. . . .120
Starting InvokeClient with Security. . . .120
Using InvokeClient. . . .121
Overview of ASBrowser ASEventBrowser and ASListener. . . .121
ASBrowser. . . .122
Starting ASBrowser. . . .122
Starting ASBrowser with Security. . . .122
Using ASBrowser. . . .123
ASEventBrowser. . . .123
Starting ASEventBrowser. . . .123
Starting ASEventBrowser with Security. . . .123
Using ASEventBrowser. . . .124
ASListener. . . .124
Starting ASListener. . . .124
Starting ASListener with Security. . . .124
Using ASListener. . . .125
MetaspaceMemberMonitor. . . .125
Starting MetaspaceMemberMonitor. . . .125
Starting MetaspaceMemberMonitor with Security. . . .125
Using MetaspaceMemberMonitor. . . .126
SpaceDefMonitor. . . .126
Starting SpaceDefMonitor. . . .126
Starting SpaceDefMonitor with Security. . . .126
Using SpaceDefMonitor. . . .127
SpaceStateMonitor. . . .127
Starting SpaceStateMonitor. . . .127
Starting SpaceStateMonitor with Security. . . .127
Using SpaceStateMonitor. . . .128
SpaceMemberMonitor. . . .128
Starting SpaceMemberMonitor. . . .128
Starting SpaceMemberMonitor with Security. . . .128
Using SpaceMemberMonitor. . . .129
ASDomainController. . . .129
Starting ASDomainController. . . .129
ASDomainController Options. . . .129
Enabling User Authentication. . . .130
Running an Example with User Authentication. . . .130
ASUserAuthenticator. . . .130
Starting ASUserAuthenticator. . . .131
Using ASUserAuthenticator. . . .131
Enabling User Access Control Example. . . .131
Running ASOperations with Security. . . .132
ASPerf. . . .132
Starting the ASPerf Master. . . .133
Starting the ASPerf Slave. . . .134
Starting the ASPerf Agent. . . .134
Result and Status Codes. . . .134
Figures
Field Definition . . . .19 Distribution of Entries in a Space . . . .27 TIBCO ActiveSpaces Security Architecture . . . .81
TIBCO Documentation and Support Services
Documentation for this and other TIBCO products is available on the TIBCO Documentation site. This site is updated more frequently than any documentation that might be included with the product. To ensure that you are accessing the latest available help topics, visit:
https://docs.tibco.com
Product-Specific Documentation
Documentation for TIBCO products is not bundled with the software. Instead, it is available on the TIBCO Documentation site. To directly access documentation for this product, double-click the following file:
TIBCO_HOME/release_notes/TIB_activespaces_version_docinfo.html where TIBCO_HOME is the top-level directory in which TIBCO products are installed. On Windows, the default TIBCO_HOME is C:\tibco. On UNIX systems, the default TIBCO_HOME is /opt/tibco.
The following documents for this product can be found on the TIBCO Documentation site:
● TIBCO ActiveSpaces® Installation
● TIBCO ActiveSpaces® Administration
● TIBCO ActiveSpaces® Monitoring and Management Console Guide
● TIBCO ActiveSpaces® Developer's Guide
● TIBCO ActiveSpaces® C API Reference
● TIBCO ActiveSpaces® Java API Reference
● TIBCO ActiveSpaces® .NET API Reference
● TIBCO ActiveSpaces® Release Notes How to Contact TIBCO Support
For comments or problems with this manual or the software it addresses, contact TIBCO Support:
● For an overview of TIBCO Support, and information about getting started with TIBCO Support, visit this site:
http://www.tibco.com/services/support
● If you already have a valid maintenance or support contract, visit this site:
https://support.tibco.com
Entry to this site requires a user name and password. If you do not have a user name, you can request one.
How to Join TIBCO Community
TIBCO Community is an online destination for TIBCO customers, partners, and resident experts. It is a place to share and access the collective experience of the TIBCO community. TIBCO Community offers forums, blogs, and access to a variety of resources. To register, go to the following web address:
https://community.tibco.com
TIBCO ActiveSpaces Overview
TIBCO ActiveSpaces® is a peer-to-peer distributed in-memory data grid—a form of virtual shared memory that is replicated on distributed devices and applications.
ActiveSpaces provides an application programming interface (API) that allows developers to store and retrieve data and implement database and messaging functionality. ActiveSpaces also provides an administrative CLI tool and an administrative GUI that you use to create and administer the data grid.
This makes it easy to create distributed applications that exchange and modify data shared between processes and across a network.
Benefits of TIBCO ActiveSpaces
ActiveSpaces provides coherent, in-memory, data storage and retrieval. It supports several network data transport options, including TCP and TIBCO SmartPGM. ActiveSpaces also provides an API that can be used to develop custom applications which use the features of ActiveSpaces. An API is available for the Java, C, and .NET programming languages.
ActiveSpaces facilitates and speeds up storage and retrieval of data in a distributed manner so that you can concentrate on writing business logic. You do not have to worry about where to store new data, where current data is stored, or if it is out-of-date.
In addition, ActiveSpaces provides the following benefits:
● Combines database features with a simple, easy to use middleware management system.
● Supports many hardware and software platforms, so programs running on many different kinds of computers on a network can communicate seamlessly.
● Allows programmers to easily implement distributed processing of the data stored in ActiveSpaces while leveraging “data locality” using remote invocation functionality.
● Scales linearly and transparently when machines/peers are added. An increase in the number of peers in a space produces a corresponding increase in the memory and processing power available to the space.
● Allows your application to continue to function smoothly without code modification or restarts.
● Allows you to implement shared-all persistence or shared-nothing persistence to persist space data on local storage media.
● Ensures that any change in data is reflected on all nodes as it happens and that no node will deliver stale data when reading or querying data from any node.
From the programmer’s perspective, the ActiveSpaces software suite provides the following benefits:
● Is distributed for speed, resiliency, and scalability
● Simplifies distributed system development
● Provides location transparency: there is no need to worry about where or how to store or find data
● Decouples producers and consumers of data
● Allows applications to be notified automatically as soon as data is modified
TIBCO ActiveSpaces Features
ActiveSpaces combines some of the important features of a database and a messaging system in a single integrated interface.
ActiveSpaces provides the following features that are similar to a database:
● Has a data definition language.
● Has SQL-like where clause filters.
● Can be made fault-tolerant using data.
● Implements a form of horizontal partitioning.
● Has locks for concurrent access control.
● Has full ACID properties and includes support for transactions.
● Supports Create, Read, Update, Delete (CRUD) operations.
● If you have purchased and installed the TIBCO ActiveSpaces Remote Client version, allows you to connect to TIBCO ActiveSpaces from remote clients.
ActiveSpaces provides the following features that are similar to a messaging system:
● Listeners give applications the ability to subscribe to changes in the data.
● One or multiple recipients.
● Changes to the data are immediately distributed to all intended recipients at the same time.
● Browsers let applications use a space as a queue.
Additional features:
Beyond the simplicity and convenience of having a single unified interface for both data storage features and messaging features, ActiveSpaces provides the ability to:
● Receive initial values when creating a listener.
● Run continuously updated queries in real-time.
● Trigger code execution transparently on the processes storing the data, either in parallel or using the distribution algorithm to direct a query directly to one of the nodes.
Usage Profiles
The ActiveSpaces data grid can solve a variety of application problems.
The nature of the problem determines the best ActiveSpaces configuration. For an effective ActiveSpaces configuration, consider the following:
● Size of the data
● Frequency of data updates versus reads
● Relative importance of update speed versus absolute consistency of data between members of the grid
The optimal architecture for your application also depends on whether the application is being built from scratch as a space-based application, or is being augmented for scalability, or is space-enabled.
In-Memory Operational Data Store
A real-time data store aggregates data from multiple sources to speed processing.
Real-time data stores are often used to integrate real-time feeds such as market data, airline reservation data, or other business data, making the data instantly available for efficient processing. The data must be highly available, and the system must process large data sets and transient, volatile data.
Space-Based Architecture
When designing a new system from scratch, a space-based approach provides several advantages.
● Space-based architectures use a grid approach for both data storage and processing.
● Data storage and access is virtualized.
● The space takes care of both data communication and process coordination
● Processing units are loosely coupled, and run in parallel.
● Processes are coordinated through data and events.
Grid Computing
Grid computing refers to using multiple machines or nodes to solve a large computing problem. A complex problem is decomposed into smaller pieces that can be executed across many machines in parallel.
ActiveSpaces can improve analytical processing of large data sets because it allows you to co-locate and invoke processing of the data directly on the nodes that store the data. Because ActiveSpaces stores the data in a distributed manner over many machines, processing is naturally and transparently
distributed.
Deployment Models
ActiveSpaces provides the peer-to-peer and remote client deployment modes.
Peer-to-Peer Deployment Mode
You can deploy ActiveSpaces-enabled applications in a true peer-to-peer configuration where all processes are direct peers to each other and there are no “servers” or “clients,” but rather seeders (contributing nodes) and leeches (non-contributing nodes).
This deployment mode yields the highest performance level, but requires all processes to establish bidirectional TCP connections with each other. In peer-to-peer mode, it is also recommended (although not absolutely required) that all the peers be physically interconnected by LANs (Local Area Networks) or MANs (Metropolitan Area Networks) rather than by WANs (Wide Area Networks).
You cannot use peer-to-peer deployment mode if there is network address translation between any of the peer machines.
Remote Client Deployment Mode
In this deployment mode, seeder processes (which can be seen as “servers”) are full peers to each other and fully interconnected by TCP connections. Any number of applications can access the seeders as remote clients by making a single TCP connection to one of the ActiveSpaces agent processes, which act as proxies for the remote clients. Remote clients can connect to their ActiveSpaces agent proxies over any network topology that supports TCP connections, including WANs.
You can use this deployment mode even if there is a one-way firewall or network address translation between the remote client and the full peer proxi(es).
Distributed Data Cache
You can use ActiveSpaces as a distributed data cache to store copies of data that is too expensive to fetch or compute.
Data is distributed across multiple machines, so that cache size is limited only by the aggregate memory of all peers participating in the space. A distributed database cache aside architecture reduces database hits by caching database reads. Database updates invalidate the cache.
ActiveSpaces keeps the cache synchronized across any number of hosts, eliminating the costly operation of going to a disk. Data is fetched quickly from an in-memory data cache across a local network. The space handles coherency and locking.
TIBCO ActiveSpaces Concepts
An ActiveSpaces distributed application system is a set of ActiveSpaces programs that cooperate to fulfill a mission (either using the administrative CLI tool or the ActiveSpaces API calls). Tuples are distributed, rather than “partitioned” across seeders (members that are configured to contribute memory and processing resources to a space).
Introduction to TIBCO ActiveSpaces Applications
ActiveSpaces applications are programs that use ActiveSpaces software to work collaboratively over a shared data grid. The data grid comprises one or more tuple spaces.
ActiveSpaces automatically redistributes tuples when seeders join and leave the space. Unlike a horizontally partitioned database, where the allocation of items to nodes is fixed, and can only be changed through manual reconfiguration, ActiveSpaces data is automatically updated on all devices on the data grid and rebalanced transparently by using a minimal redistribution algorithm.
ActiveSpaces allows the distribution of data replicates on different peers for fault tolerance. The data access optimization feature of ActiveSpaces uses a replicate if one is locally available. If a seeder suddenly fails, the replicate is immediately promoted to seeder, and the new seeder creates new replicates. This optimizes system performance.
Basic ActiveSpaces Terms
This section defines basic terms for ActiveSpaces, which are used in the discussion of ActiveSpaces concepts.
ActiveSpaces Terms
Term Definition
Metaspace A logical group of spaces—a cluster of hosts and processes that share the same metaspace name and set of discovery transport attributes. The hosts and processes in a metaspace work together by joining the same spaces.
Space A shared, virtual entity that functions as a container for a collection of entries consisting of a tuple and associated metadata. Applications become members of a space in order to execute operations on the space. Spaces are contained in a metaspace.
Tuple A sequence of named elements called fields (similar to the columns in a database table) that contain values of a specific type.
Seeder A space member that can execute operations on spaces that it is connected to and which also plays an active role in maintaining the space by providing CPU and RAM. The service of storing the data contained in a space and handling requests to read and write this data is implemented in a distributed peer-to-peer manner by one or more seeders.
Leech A space member that can execute operations on spaces that it is connected to but which does not contribute memory or CPU time to maintenance of the space.
Replication An ActiveSpaces process that backs up data from one seeder to one or more additional seeders, to enable fault tolerance.
Term Definition
Persistence An ActiveSpaces feature that allows you to persist data to disk storage and recover data if data loss occurs or there is a problem with cluster startup.
ActiveSpaces allows the distribution of data replicates on different peers for fault tolerance. If a seeder suddenly fails, the replicate is immediately promoted to seeder, and the new seeder creates new replicates. This optimizes system performance
Browser A mechanism to iterate through a series of tuples retrieved from a space using filters. Unlike a traditional iterator that works only on a snapshot of the data to be iterated through, the space browser is continuously updated according to the changes in the data contained in the space being browsed.
Listener A mechanism that allows an application to monitor events that represent changes to the tuples stored in a space through a callback routines that are automatically called when specific events occur in a space.
Metaspace
A metaspace is a logical group of spaces—a cluster of hosts and processes that share the same metaspace name and set of discovery transport attributes.
A metaspace:
● Is a virtual entity that contains spaces, which store the data used by applications.
● Is an administrative container for the spaces. A metaspace can contain:
— System spaces—Spaces defined by ActiveSpaces.
— User spaces—User-defined spaces.
● Consists of a cluster of application processes.
The processes are usually deployed on multiple hosts interconnected by a network where ActiveSpaces is installed. ActiveSpaces applications can also be installed on a standalone host.
The hosts and processes in the cluster work together by joining the same spaces.
You can deploy multiple independent metaspaces over a single network, each with a different set of members and spaces, and each identified by a name and a set of network transport attributes.
Each metaspace should have a unique name, because an application cannot connect to two different metaspaces using the same metaspace name.
Space access is based on the combination of metaspace name and space name. Therefore, changes to a space called clients in a metaspace named Dev have no impact on a space named clients in a metaspace named Prod.
Metaspace Connection
To use ActiveSpaces, your application must first connect to a metaspace.
For detailed information on connecting to a metaspace, see The tibasMetaspace_Connect Method.
When your application is connected to a metaspace, you can perform the following tasks:
● Define and make use of any number of spaces.
● Connect to additional metaspaces; however, your application can only have a single connection for each metaspace.
When your application no longer needs access to a metaspace, you should disconnect from the metaspace.
For information on disconnecting from a metaspace, see The close Method.
Metaspace Life Cycle
A metaspace is created when the first process connects to it, and disappears when the last process disconnects from it. The metaspace grows or shrinks automatically as members connect to it and disconnect from it.
Initially, a metaspace contains only system spaces. As users create spaces in the metaspace, the definition of those spaces (along with other administrative data) is stored in system spaces.
If you implement the ActiveSpaces data persistence feature, you can persist data to local storage.
However, space and field definitions are not persisted in existing spaces after the last metaspace disconnects from it.
Space
Spaces are the main feature offered by ActiveSpaces. Together with metaspaces, spaces provide a distributed data grid.
A space:
● Is a virtual entity that provides shared virtual storage for data.
● Is a container for a collection of entries that consist of a tuple and associated metadata.
● Is used concurrently by applications distributed over a network to store, retrieve, and consume data.
Each application has the same view of the data contained in the space.
After connecting to a metaspace, your application can define, drop, join, and leave spaces, and also get an existing space’s definition and list of members.
For information on joining and leaving a space, see The getSpace Method.
To enable the data grid, spaces:
● Distribute and synchronize data in a platform independent manner.
● Proactively notify applications of changes in the data contained in the space as changes happen (push model), and can therefore be used as a coordination mechanism for building distributed systems.
A space is distributed and implemented collaboratively by a group of processes located on multiple hosts and communicating over the network.
ActiveSpaces handles changes in the set of processes automatically: processes may join or leave the group at any time without requiring any user intervention. A space automatically scales up as the number of processes in the group increases, and scales down when processes suddenly disappear from the group or network. There is no negative impact on the data contained in the space when processes leave the space.
Space Contents
A space contains tuples and associated metadata.
● A tuple is a container for a collection of fields. A tuple is equivalent to a row in a database.
● Each field in the tuple has a name, a type and a value.
For more information on tuples and fields, see Tuples and Fields.
Differences Between ActiveSpaces and a Distributed Cache
ActiveSpaces is a distributed data grid that implements a distributed in-memory tuple space.
There are important differences between the ActiveSpaces distributed data grid and a distributed cache.
● A cache can evict entries at any time if it needs to make room for new entries, but a tuple space data grid does not evict entries Therefore, a distributed cache (like all caches) can only be used in a cache- aside architecture to cache a system of record, and, unlike a data grid, can never be used as a system of record itself.
Although it is possible to use ActiveSpaces as a distributed cache (in a cache-aside or in a cache- through architecture), the reverse is not true: a distributed cache cannot be used as a system of record.
● A distributed cache does not have a notification mechanism to proactively inform applications of changes in the data stored in the cache. Unlike ActiveSpaces, a distributed cache cannot be used for distributed process coordination.
Tuples and Fields
ActiveSpaces spaces store data in tuples.
A tuple:
● Is a container for a sequence of field.
● Is equivalent to a row in a database.
● Represents a set of related data.
A field is similar to a column in a database table. Each field has a specific name, type and value, as shown in the following figure.
Tuples and fields function like rows and columns in a traditional database.
Field Definition
A tuple can be seen as a kind of map in which fields can be put or removed. A tuple can also be seen as a self-describing message. Tuples are platform independent, and can be serialized and deserialized.
For information on defining tuple fields, see FieldDef Methods.
Field Type Conversion
When a tuple is stored into a space, the fields that it contains must match the names and types of the fields described in the space definition. If there is a type mismatch between a field contained in the tuple and the type of the field defined in the space field definition, then, if possible, ActiveSpaces performs an automated field conversion. If the conversion is not possible, the operation fails.
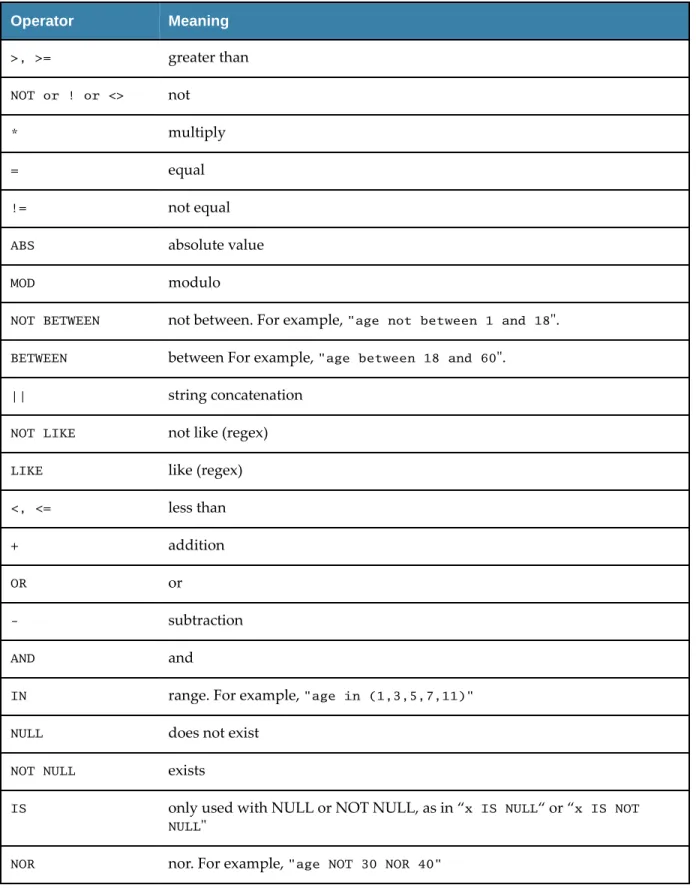
The following table shows which type conversions are supported. The letters in the table have the following meanings:
● x: Conversion is supported with no loss of precision.
● l: Conversion is supported, but with loss of precision.
● N Conversion is not supported.
Field Type Conversions
Boolea n
Shor t
Intege r
Lo
ng Float
Doubl e
Blo b
Strin
g DateTime
Boolean x x x x x x N N N
Short l x x x x x N N N
Integer l l x x l x N N N
Long l l l x l l N N N
Float l l l l x x N N N
Double l l l l l x N N N
Blob N N N N N N x N N
String N N N N N N x x N
DateTime N N N N N N N N x
There is a Get and Put method for each type of field. In Java, an overloaded Put method is also provided for convenience.
For general information on operations applied to tuples, see The getName and getSpaceDef Methods.
Guidelines to Define Key Fields
You must define at least one of the fields in the space definition as a key field. ActiveSpaces uses key fields to build a key-value index for the space.
In the Java API, you can specify a set of fields to be used as key fields by using the SpaceDef's setKey method and passing it a number of strings containing the space names.
For detailed information on defining key fields, see Key Fields.
Indexes
ActiveSpaces automatically builds a distributed, in-memory index of the tuples in the space when a space is created or loaded. Because indexes are stored in memory, queries locate matching records more quickly because the queries do not have to iterate through every record.
Using indexes, ActiveSpaces also allows you to query for any field of the records contained in the space, and the queries can be serviced faster if indexes are built on the fields used by the query filter statement.
Indexes can be either hash indexes (the default) or tree type indexes, and can contain one or more fields.
● A hash index is more efficient if the set of values to be stored is randomly distributed or the query is selecting for specific values rather than ranges of values.
● A tree index is more efficient when the query is selecting ordered ranges of values.
ActiveSpaces allows you to define as many indexes as you want on a space, as required, depending on the types of queries that will be run over the space. Indexes are part of the space's definition and are built on one or more of the fields that are defined for the space. You can build indexes on any of the fields defined for the space. Indexes have a type, which can be either “HASH” or “TREE.” Hash indexes speed up queries where the filter is an exact match ('=' operator) of a value to the field, e.g.: “field =
value”. Tree indexes speed up queries where the filter is a range match ('>', '<', '>=', '<=' operators) of a value to the field, e.g. “field > value.”
If your query filter uses only one field, then you can speed it up by defining an index just on the field that it uses. If your query filter uses more than one field, then you can speed it up by creating a 'composite index' on the fields used in the filter. In this case the order of the fields when the index is defined matters when the TREE index type is used and the query filter contains both equality and range operators separated by 'AND': for example if the query is “field1 = value1 and field2 = value2 and field3
> value3” then in order to benefit from the index, it should be defined on fields “field1”,”field2,”field3”
in that order (and only in that order).
A particular field can be used in more than one index, for example if two query filters such as “field = value” and “field > value” are to be used, then you could define two indexes on the field in question:
one of type 'HASH' and the other one of type 'TREE,' and the ActiveSpaces query optimizer will automatically use the appropriate index depending on the query being issued.
There is always an index automatically created on the key fields of the space, this index is of type HASH by default (but can be changed to a TREE type if needed).
Basic Operations on Tuples
You can perform basic operations on tuples such as, Put, Get, Take, Lock, and Update.
Put
Stores a tuple into a space.
Get
Retrieves the complete entry associated with provided key field(s).
Take
Performs an atomic “get and remove” action on the entry for provided key field(s).
A take is a “consume” operation; therefore if two takes are initiated at the same time on the same entry, only one succeeds.
Lock
Performs an atomic “get and lock” action on the entry for provided key fields(). Can also lock a specific entry directly.
Update
Performs an atomic “compare and set” operation on the entry for provided key field(s). When used on a locked entry, also automatically unlocks it.
UpdateField(s)
Updates the values for the specified fields without having to pass all the fields to the space.
Get, Put, Take, Lock, and Update are single entry operations. Two additional combination atomic operations are provided:
For information on performing puts, gets, and takes, see The Read and Write in a Space.
● PutAndLock - Puts a tuple into a space and automatically locks it.
● UpdateAndLock - Performs an atomic compare and set operation on a tuple and automatically locks it.
Batch Versions of Tuple Operations
The ActiveSpaces API provides batch versions of the basic tuple operations, which operate on a collection of tuples instead of on than just one tuple. Using the batch forms of the operations increases throughput by parallelizing the operations (including operations over the network).
For example, the Java API includes a single entry Space.take method that operates on a single tuple, and also a Space.takeAll method that operates on a collection of tuples. And the C API set includes a
tibasSpace_Put() function that puts a single tuple into a space and also a tibasSpace_TakeAll
operation that puts a collection of tuples into a space.
The Put Operation Storing Data into a Space
Your application can store data into a space by using the space’s put method and passing it a tuple as its argument.
Once the tuple is in the space, it can be accessed by any other application using that space. Existing entries are replaced with new ones, which means that if there was already a tuple with the same key field values stored in the space, it is overwritten by the new tuple.
For information on performing a Put, see Put Operation for Storing a Tuple in a Space.
When a tuple is stored into a space, it is validated against the space definition.
● Field names and types are checked against the fields defined for the space.
If a tuple's field does not match the space's definition, ActiveSpaces attempts to automatically convert the field’s value to the desired type as long as the field type is numerical (no lexical casting).
● Fields marked as nullable need not be present in the tuple, but if they are present, their type must match or be able to be upcasted.
● Fields present in the tuple that are not defined in the space's definition are not stored in the space
The Update Operation to Update Existing Data In a Space
Use the update() method to modify existing data.
Your application can update fields in a tuple that is stored in the space by using the update() method.
This method takes two parameters - a key tuple and another tuple that contains the values for the fields to be updated. The new value for the field or fields in the passed tuple can be a dynamic expression that evaluates to a valid value at runtime.
Batch Versus Blocking Operations
By default, spaces are distributed, which means that the servicing of requests and storage of entries for the space is implemented in a distributed manner by all of the space's seeders.
If seeders are distributed over a network, then some operations require at least one network round-trip to complete. Therefore, using the parallelized batch versions of the operations (or distributing space operations over multiple threads) rather than invoking the same blocking operation in a loop is the best way to achieve a high throughput of operations.
Space Data Retrieval Methods
You can retrieve (or consume) data from a space in three ways: Get Method, Callback Query Method, and Space Browser Method. The method you use to retreive data from a space depends on the application logic of your code.
● Get Method - A tuple space implements the associative memory paradigm and allows the application to get a complete copy of the tuple associated with specific values of it's key fields.
This is done by using the spaces’s get method and passing a tuple containing appropriate key field values for that space. If a tuple with matching values for its key fields is currently stored in the space, the value of the status in the result object returned by the get method is equal to OK. If no tuple in the space has matching values for the key fields, the value of the status in the result object is NULL.
● Callback Query Method - You can create listeners on a space that invoke a user query callback function as filtered initial data and new data are pushed from the space to the listeners. For more information on listeners, see Listeners.
● Space Browser Query Method - You can also create space browsers on the space that let users retrieve filtered data initially stored in the space and retrieve new data tuple by tuple and on demand. For more information on space browsers, see Browsers.
The method used to retrieve data from a space depends on the application logic of your code.
● To retrieve a single tuple using an exact key match, use the get function.
● To retrieve and monitor either all or a filtered subset of the data contained in the space, both listeners and space browsers offer the same functionality. The choice of which method to use depends on whether your application needs a multi-threaded event-driven callback-oriented approach, or needs to iterate through the tuples at its own pace (i.e., on demand, using the space browser’s next method).
The Take Operation Consuming or Removing Data from a Space
You can remove tuples from a space by using the space’s take method and passing a tuple containing the appropriate key fields for that space.
The take method behaves exactly like an atomic get-and-remove: If a tuple with matching values for its key fields is currently stored in the space, you can infer the following:
● The status value of the result passed to the take operation is be equal to OK.
● The complete tuple is contained in the result, and at the same time removed from the space.
Otherwise (if there is no tuple with matching values for its key fields currently stored in the space), there is nothing retrieved by the Take operation, and the result's status is equal to NULL. Since ActiveSpaces provides immediate consistency, you have a guarantee that if two separate applications issue a take for the same entry at the same time, only one of them will see its take operation succeed;
the other one will see its result's status be equal to NULL.
Unlike a simple delete operation that succeeds even if there is nothing to delete, you can use the take operation to effectively “consume” data from a space (for example, using a space browser), and your application can easily distribute workload using ActiveSpaces.
You can also perform a take operation on all or a filtered subset of the tuples contained in a space by using a space browser. For more information on space browsers, see Browsers.
Specifying a filter for the Take Operation
If you want the operation to succeed only if a particular filter is matched, then specify the filter in the corresponding option, such as TakeOptions.setFilter(String). If the tuple does not match the filter condition, then an error is displayed.
This is true for the following operations:
● Take
● Put
● Lock
● Get
Space Members and Member Roles
Applications that need access to a space join the space and become space members.
Your application can play two distribution roles when it joins a space.
● Seeder - Plays an active role in maintaining the space by providing CPU and RAM resources.
● Leech - Plays a passive role. Has access to space data but provides no resources.
For detailed information on joining a space, see The getSpace Method.
Seeders
A seeder application participates in the storing of data in the space and can read and write data. When seeder applications join or leave the space, ActiveSpaces redistributes the data in the space as necessary to maintain even data distribution.
Leeches
A leech application participates passively in the space and does not read and write data or cause redistribution of space data when it joins or leaves the space.
Characteristics of Seeders versus Leeches
You can consider seeders to be “servers” for the space, and leeches to be “clients.”
However, because applications can join a space as seeders, effectively embedding ActiveSpaces inside the application process, an application joining a space as a seeder is both a server and a client. The role played by an application is on a per space basis: a single application might be a seeder on one space and a leech on another space.
The as-agent Process
ActiveSpaces includes a utility called as-agent, which can join a space and function as a seeder.
The as-agent process provides the following:
● Scalability to a space, by automatically joining distributed spaces as a seeder and leveraging the resources of the machine where the agent is running.
● An access point to the metaspace for the remote clients.
The as-agent as a Seeder for Remote Clients
A connection to a metaspace through a seeder or a leech is a direct connection to the metaspace. For applications running on hosts that are remote from the metaspace, or separated from it by a firewall, you can connect as a remote client.
You set up a remote client by running an as-agent that provides proxy access to the metaspace for remote clients. The as-agent, in effect, functions as a seeder for the remote client. The command line argument for the as-agent process specifies a “remote listen” URL that the agent uses to listen for data.
As-agents can also implement shared-nothing persistence.
For more information about as-agent, see The as-agent Utility as a Seeder.
About Joining the Space as a Seeder or a Leech
There are some factors that determine when your application must join a space as a seeder or a leech.
Consider the following points before deciding on the role played by your application:
● Even though ActiveSpaces has a true peer-to-peer architecture, rather than a client-server
architecture, you can deploy applications as leeches (effectively, as clients of the space service) with as-agents acting as a server cluster.
● For some operations, an application that joins a space as a seeder experiences better performance than it would as a leech, but this comes at the expense of higher RAM and CPU usage.
● The entries in the space are stored randomly using a hash of the value(s) of the key field(s) (in practice as good as random), but are stored evenly between all of the seeders of the space. Seeders do not necessarily seed what they put in the space.
● The distribution role (seeder or leech) is only a level of participation—not a limitation on use.
Leeches have access to the same set of space operations as seeders.
● You can also use the as-agent process to “keep the data alive” when all of the instances of an application have disconnected from the metaspace.
● When a seeder joins or leaves a space, there might be a temporary impact on space performance while redistribution is performed. On the other hand, leeches do not incur any impact when joining or leaving a space.
The choice of distribution role must be made on a per space basis: the best solution may be to join some spaces as a seeder and others as a leech.
Space Definition
You must define a space in the metaspace before it can be joined by applications and agents. The space is created when a member of the metaspace joins it and becomes the first member of the space.
Conversely, the space is destroyed when the last member leaves it (and there are no more members of the space).
The space remains defined after all members have left, and can be reactivated if needed.
A space definition comprises two parts:
● A set of space attributes and policies that define the space’s behavior and mode of deployment.
● A set of field definitions that describe the format of the data that will be stored in the space.
The space definition is contained in a SpaceDef object that is defined in the ActiveSpaces API set. The SpaceDef object is either created from scratch by invoking the SpaceDef’s create() method, or returned by the metaspace or space’s getSpaceDef methods.
After a SpaceDef object has been created, you can set values for space attributes by specifying values for elements in the SpaceDef object.
Overview of Space Attributes and Policies
The attributes of a space define the space’s behavior an mode of deployment.
By calling the SpaceDef functions or methods provided in the ActiveSpaces API, you can specify:
Space Distribution
Specifies whether a space is distributed.
For information on space distribution, see Distribution.
Space Capacity
Specifies the maximum number of entries per seeder.
Eviction Policy
(If a space capacity setting is specified, must be specified to set an eviction policy that is followed when the space capacity limit is reached.
Replication Count
Specifies whether replication is enabled, and if replication is enabled, specifies the number of seeders that are used to replicate data.
For information on replication, see Replication.
Replication Type
If replication is enabled, specifies whether replication is synchronous or asynchronous.
For information on synchronous and asynchronous replication, see Synchronous and Asynchronous Replication.
Persistence
Specifies whether space data is persisted to permanent storage, and if so, what type of persistence is used.
For information on persistence, seeSpace Storage Options and Persistence.
Routing
Specifies whether the space is routed.
For information on implementing routing for a space, see ActiveSpaces Routing Entry TTL
Controls how long a tuple can remain unmodifed before it is evicted from the space.
For information on time to live and lock wait, see Expiration Time to Live and Tuple Locking.
Lock TTL
controls how long a tuple remains locked after an application has locked it.
For information on time to live and lock wait, see Expiration Time to Live and Tuple Locking.
Lock Wait
How long an operation attempting to modify a locked tuple can block while waiting for a tuple lock to clear.
For information on time to live and lock wait, see Expiration Time to Live and Tuple Locking.
Field Definitions
You create field definitions in two steps:
● By creating field definitions and specifying the data type for each field.
● By associating the fields with a space definition.
Distribution
A space may be either distributed or non-distributed.
Distributed Spaces
With distributed spaces, management of the space data is shared among the seeders that have joined the space. Responsibility for storing the tuples is distributed evenly among all the seeders joined to the space.
Non-Distributed Spaces
With non-distributed spaces, a single seeder is responsible for all the tuples in the space (the responsibility for storing tuples in the space is assigned to one of the seeders joined to the space).
However, other seeders may still store the tuples in the space, depending on the replication degree specified for the space. degree). (other seeders joined to the space may also replicate these tuples if a degree of replication is specified)
Distributed Space
By default, spaces are distributed. In a distributed space, management of the space’s entries is distributed among the seeders that are members of the space, and the ActiveSpaces distribution algorithm ensures that entries are distributed evenly in the space.
Figure 2, Distribution of Entries in a Space shows how the entries for a space are distributed between seeders in the space. Each seeder has approximately the same number of entries.
Distribution of Entries in a Space
To ensure the best possible (most even) distribution of entries in a space regardless of the number of entries, the granularity of the ActiveSpaces distribution algorithm is a single key field’s value. This means that an individual distribution decision is made for every entry stored in the space.
In a distributed space, management of the space’s entries is distributed among the seeders that are members of the space:
● An efficient distributed hashing algorithm is used to ensure an even distribution of the entries among the seeders.
● The scalability of the space is limited to the number of entries that all the seeder nodes can manage.
● The ActiveSpaces coherence protocol ensures global ordering of the operations performed on values associated with a single key in a distributed space, and ensures that those changes are propagated as they happen. ActiveSpaces guarantees that every member of the space sees changes to the values associated with a particular key in the exact same order, regardless of the member’s physical location or level of participation in the space.
Non-Distributed Space
A non-distributed space is entirely managed by a single member. The main reason for using non- distributed spaces is to get absolute view synchrony, so that changes are seen in the same order (as opposed to seeing changes in the same key in the same order).
At any time, one member of the space—the seeder, is in charge of managing the entries for the space.
The scalability of the space is limited to the number of entries that the single seeder can manage.
Minimum Number of Seeders
It is possible to define a minimum number of seeders for a space. If this attribute is defined, the space is not usable until the required number of seeders have joined it. Since it is not possible to service any operation on a space until there is at least one seeder for it, there is always an implied default value of 1 for this setting.