國
立
交
通
大
學
電信工程所
碩 士 論 文
多核心管狀視訊解碼運算
Multicore Pipeline Video Decoding
研 究 生:江志偉
指導教授:張文鐘 教授
多核心管狀視訊解碼運算
Multicore Pipeline Video Decoding
研 究 生:江志偉
Student:Chih-Wei Chiang
指導教授:張文鐘
Advisor:Wen-Thong Chang
國 立 交 通 大 學
電 信 工 程 所
碩 士 論 文
A ThesisSubmitted to Department of Communication Engineering College of Electrical and Computer Engineering
National Chiao Tung University in Partial Fulfillment of the Requirements
for the Degree of Master of Science
in
Communication Engineering
August 2009
Hsinchu, Taiwan, Republic of China
多核心管狀視訊解碼運算
學生:江志偉 指導教授 :張文鐘 博士
國立交通大學電信工程所碩士班
摘 要
本論文的目標是整合多核心架構以及視訊解碼演算法,因此我們建構了一顆主核心 與四顆副核心的多核心系統並在此系統架構下進行資料的平行處理,所以必須將運作於 單核心的解碼程式改寫成多核心程式,而多核心程式的撰寫著重在兩大重心,找出可平 行運算的解碼步驟、核心間的通訊機制與資料的傳輸。 首先從 MPEG-4 的完整解碼流程中找出可平行運算的解碼步驟,由於這些解碼步 驟位於不同的副核心上,所以在副核心上是選擇管狀解碼運算而不是平行解碼運算。通 訊機制方面,每個副核心有信號和信箱暫存區作為核心間的溝通管道,而暫存區均只有 32-bit 的大小,所以這些通訊機制主要是用來傳送資料的位址以及傳送工作運作時的狀 態。為了在四顆副核心上達到管狀解碼運算,我們便利用這些暫存區於核心之間設計一 個完整的溝通程序。資料的傳輸是透過 DMA 的方式取得資料,一旦知道資料位於記 憶體的位址後,不管是主核心或副核心均可以到該位址進行資料存取,除此之外,資料 傳輸會出現核心間資料覆蓋的問題,所以我們便利用多個資料暫存區來避免發生此錯 誤。 實作上,主核心利用信箱詢問副核心的工作進度,由此決定是否分配工作給副核心 協助解碼,由於副核心間是採用管狀解碼運算,所以主核心只需和第一顆副核心溝通而 不需等待其他副核心執行結束。Multicore Pipeline Video Decoding
Student:Chih-Wei Chiang Advisor:Wen-Thong Chang
Department of Communication Engineering
National Chiao Tung University
ABSTRACT
The goal of this thesis is to combine multi-core architecture with video decoding algorithm. We present a multi-core system with one main core and four secondary cores and compute data by parallel processing on this architecture. For this purpose, we must modify the single-core decoding program into multi-core decoding program. However, multi-core
programming focus on finding the parallel decoding step, communicating and data transferring between cores.
First of all, we find parallel decoding steps from MPEG-4 decoding flow. These decoding steps are on the different secondary core, so we use pipeline decoding instead of parallel decoding. In communication protocol, every secondary core can use signal and mailbox register to communicate with each other. These registers only have 32-bit capability, so we use it to send address of data and status of task. For achieving pipeline decoding on four secondary cores, we design a communication procedure between each core by these registers. We transfer data through DMA command. Once we know the memory address, we can read or write data to memory no matter on the main core or secondary cores. Besides, transferring these data will introduce data overwriting between cores, so we use multiple data buffer to solve this problem.
In implementation, main core use mailbox to check task status of secondary core and then decide when to assign task to secondary core. Because of pipeline decoding between each secondary core, main core only need to communicate with first secondary core and don’t have to wait for other secondary core.
誌謝
在此最最最感謝的就是我的指導教授 張文鐘博士,感謝他提供我完善的資源,和 一切所須的設備,讓我在兩年的碩士生涯中,不論在學業或是研究方面均無後顧之憂, 並在論文的盲點上,點出了許多可能的解決方向。同時也謝謝黃仲陵教授、何文楨教授 以及范國清教授在口試時的指導,老師們真是我研究過程中的一盞明燈,讓我順利完成 此論文。 接著要感謝實驗室裡的同學和學弟們,盛如、小瘋、夸克、弘達、秉謙、建民、怡 如、雅嵐、耀葦以及明穎,感謝他們陪我度過修課、報告、程式、寫論文的這兩年,沒 有他們在我失落或瓶頸時的支持和鼓勵,我可能沒辦法支持下去,因此感謝你們給我這 麼美好的回憶,期許我們一起成長前進。 感謝我的家人,父母親、大妹和小妹,他們是我的支柱,在研究所兩年中,提供我 一切生活所須,有如一股無形的力量支持著我,讓我可以心無旁騖地研究,順利地完成 論文。 最後感謝我的室友們,昆儒、國哲、士琪以及承曄,在兩年的共同扶持和幫助,也 感謝所有認識的知心好友、社團的朋友以及其他實驗室的朋友,謝謝你們陪我走過這段 時光。謝謝! 誌於 2008.08 風城 交大 志偉目錄
中文摘要.………...……….i 英文摘要..…………..………ii 誌謝 ... iii 目錄 ... iv 表目錄 ... vi 圖目錄 ... vii 第一章 緒論 ... 1 1.1 研究背景與動機 ... 1 1.2 論文架構 ... 2第二章 Cell Broadband Engine ... 3
2.1 多核心架構與系統說明 ... 3
2.2 SPE 程式的執行 ... 4
2.3 DMA 傳輸 (Direct Memory Access transfer) ... 5
2.3.1 主記憶體和 SPE 區域記憶體之間的資料傳輸 ... 6
2.3.2 SPE 區域記憶體之間的資料傳輸 ... 7
2.3.3 雙重緩衝技術 (Double Buffering) ... 8
2.3.4 匯流排錯誤 (Bus Error) ... 9
2.4 Mailboxs 和 Signal Notification Registers 之通訊機制 ... 11
2.4.1 Mailboxs ... 11
2.4.2 Signal Notification Registers ... 13
2.4.3 通訊機制的差異 ... 16
2.5 SPE 程式的嵌入 (Embedded SPE Program) ... 16
第三章 XVID CODEC ... 18
3.1 解碼資料流程 (Decoder Data Flow) ... 18
3.2 資料結構的分析 ... 19
3.3 Decode for I-Frame (Intra Frame) ... 22
3.3.1 get_mcbpc_intra() ... 23
3.3.2 get_cbpy() ... 25
3.3.3 decoder_mbintra() ... 26
3.4 Decoder for P-Frame (Predictive Frame) ... 35
3.4.1 get_mcbpc_inter() ... 35
3.4.2 get_cbpy() ... 35
3.4.3 get_motion_vector() ... 36
3.4.4 decoder_mbinter() ... 37
3.5 Decoder for B-Frame (Bidirectionally predictive Frame) ... 42
3.5.1 get_mbtype() ... 45
3.5.3 get_b_motion_vector() ... 45 3.5.4 decoder_bf_interpolate_mbinter() ... 45 第四章 MPEG-4 解碼的實現 ... 48 4.1 多核心程式的設計 ... 48 4.1.1 解碼元件的分配 ... 48 4.1.2 pipeline 的流程設計 ... 49 4.2 自訂資料結構及程式的撰寫 ... 51 4.2.1 自訂資料結構的分析 ... 52 4.2.2 PPE 端程式的修改 ... 54 4.2.3 SPE 端程式的修改 ... 60 4.3 問題與討論 ... 63 4.3.1 資料相依性 ... 63 4.3.2 記憶體不足 ... 64 第五章 實驗數據分析 ... 65 5.1 數據分析與比較 ... 65 5.2 解碼元件的問題論述 ... 68 第六章 結論與未來發展 ... 70 6.1 結論 ... 70 6.2 未來發展 ... 70 參考文獻 ... 72 附錄一:實驗環境的建立 ... 73 附錄二:Mplayer 的安裝 ... 75
表目錄
表 1. DECODER 的結構成員 ... 19
表 2. IMAGE 和 VECTOR 的結構成員 ... 20
表 3. MACROBLOCK 的結構成員 ... 21
表 4. VLC table for mcbpc ... 24
表 5. VLC table for cbpy ... 26
表 6. QP Ù dc_scaler 轉換表 ... 28 表 7. EVENT 和 REVERSE_EVENT 的結構成員 ... 31 表 8. B-Frame 預測方式之 mode 對照表 ... 42 表 9. B-Frame mb_type 的解碼 ... 45 表 10. parm_context 的結構成員 ... 52 表 11. parm_addr 的結構成員 ... 54 表 12. 位址的設定 ... 56 表 13. 解 150 張畫面的平均解碼時間 ... 65 表 14. 測試傳輸時間 ... 69
圖目錄
圖 1. 多核心架構圖 ... 3 圖 2. SPE 程式的執行 ... 5 圖 3. 執行 SPE 程式的片段程式碼 ... 5 圖 4. 記憶體空間示意圖 ... 6 圖 5. DMA 傳輸 ... 7 圖 6. SPE 端 DMA 傳輸的片段程式碼 ... 7 圖 7. DMA 流程圖 ... 9 圖 8. 匯流排錯誤 (16-byte) ... 10圖 9. 匯流排錯誤 (less than 16-byte) ... 10
圖 10. Mailboxs ... 11
圖 11. Mailbox 錯誤的解決方法 ... 12
圖 12. 傳送 PPE 端資料位址的片段程式 ... 13
圖 13. Signal Notification Registers ... 13
圖 14. PPE 端計算 SNR2 位址之程式碼以及示意圖 ... 14
圖 15. 對照圖 13.的片段程式碼 ... 14
圖 16. 覆寫模式和邏輯 OR 模式 ... 16
圖 17. 編譯程序 ... 17
圖 18. Video Stream 結構圖 ... 18
圖 19. Decoder Data Flow ... 19
圖 20. cbp 的位元資訊 ... 22 圖 21. decoder_iframe() 流程圖 ... 22 圖 22. decoder_iframe() 片段程式碼 ... 23 圖 23. 001-xxx 對照 mcbpc 之範例 ... 24 圖 24. get_mcbpc_intra 程式碼 ... 25 圖 25. mcbpc_intra_table ... 25 圖 26. get_cbpy 程式碼 ... 25 圖 27. decoder_mbintra() 片段程式碼 ... 27 圖 28. decoder_mbintra() 流程圖 ... 27 圖 29. 相鄰 block 的示意圖 ... 28 圖 30. predict_acdc() 片段程式碼 ... 29 圖 31. DC、AC 係數的預測 ... 29 圖 32. 係數掃描方式 ... 30 圖 33. coeff_tab 部分陣列元素 ... 31 圖 34. 建立 DCT3D 陣列的部分程式碼 ... 32 圖 35. 反量化的 pseudo code ... 33 圖 36. FDCT 示意圖 ... 34 圖 37. decoder_pframe() 流程圖 ... 35
圖 38. decoder_pframe() 片段程式碼 ... 36 圖 39. motion vector 示意圖 ... 37 圖 40. decoder_mbinter() 流程圖 ... 38 圖 41. 模式為 inter + 4mv 的部分程式碼 ... 38 圖 42. interpolate16x16_switch 部分程式碼 ... 39 圖 43. half-pixel 內插示意圖 ... 39 圖 44. interpolate8x8_switch 程式碼 ... 40 圖 45. decoder_mb_decode() 部分程式碼 ... 40 圖 46. decoder_mb_decode() 流程圖 ... 41
圖 47. 反移動補償 (Inverse Motion Compensation : IMC) 示意圖 ... 42
圖 48. decoder_bframe() 流程圖 ... 43
圖 49. 預測 B-Frame 之 block 的部分程式碼 ... 44
圖 50. MODE_DIRECT 範例以及相關的 pseudo code ... 44
圖 51. decoder_bf_interpolate_mbinter 流程圖 ... 46 圖 52. interpolate8x8_add_switch 程式碼 ... 47 圖 53. SPE 所執行的解碼元件示意圖 ... 49 圖 54. 利用通訊機制實現 pipeline 之示意圖 ... 50 圖 55. 利用多個暫存區解決資料覆蓋之示意圖 ... 51 圖 56. PPE 端的完整解碼程式流程 ... 52 圖 57. 於 PPE 端的程式碼 ... 53 圖 58. interlaced ... 53 圖 59. Cell BE 執行緒示意圖 ... 54 圖 60. 建立執行緒的部分程式碼 (於 PPE 端) ... 55 圖 61. 利用傳入參數取的 parm_addr 的結構資料 ... 56
圖 62. SPE2 ~ SPE4 取得位址之部份程式碼 (以 SPE1 和 SPE2 為例) ... 57
圖 63. decoder_mbintra() 修改後的部份程式碼 ... 58 圖 64. decoder_mb_decode() 修改後的部份程式碼 ... 59 圖 65. IQ 的部份程式碼 (於 SPE1 端) ... 60 圖 66. IDCT_1 的部份程式碼 (於 SPE2 端) ... 61 圖 67. 更新解碼畫面的部份程式碼 (於 SPE4 端) ... 62 圖 68. 存放係數資料與位址對齊之示意圖 ... 63 圖 69. Y、U、V 畫面位於記憶體中的儲存方式 ... 66
圖 70. SPE 運作在 I-Frame 之 YUV 示意圖 ... 67
第一章 緒論
1.1 研究背景與動機 隨著科技的演進,處理器已由單核心漸漸走向多核心架構,原因在於多核心處理器 較為省電,且具有指令平行化的功用。 多核心處理器之所以能夠節省電量,原因在於處理器脈衝頻率的限制,當頻率加快 到一定速率之後,為了繼續增加成效而加快速率時,成效與所消耗的電量不成比例,此 時,若改用兩個處理器,耗電量相當,可是運算效能卻可以多出更多。而指令平行化的 優點在於,軟體同時執行多項作業時,各個核心處理器可以獨立執行一項作業,因此多 核心將提供較大的計算量,為了讓軟體具有更多可平行運算的指令,就必須讓現有程式 中,找出可平行運算的指令。 若要使多核心處理器達到高效能的運算,就必須將單核心用的原程式重新撰寫,故 須對原程式有一定的了解,並妥善分配運算的工作量,解決資料同步等複雜性的問題。 另一方面,隨著影片畫質越來越好,檔案大小相對的也越來越大,為了降低檔案大 小,並保持影片畫質與原本的一樣好,便有了影像壓縮技術的出現,視訊壓縮為一種高 複雜度的編解碼演算法,藉由運算時間換取檔案的資料空間,所以需要的計算量相當 大,因此,透過研究 Xvid 開發團隊所提供的 Open Source,深入探討 MPEG-4 解碼 技術,目的為了解如何使用軟體實現演算法,以及視訊壓縮演算法是如何達到資料壓縮 的目的,並從中找出可透過平行運算的解碼元件,將原本作用於單核心的 Xvid Codec 程式碼,修改成可在多核心處理器上運作,經由視訊壓縮演算法的平行化,降低影像解 碼的時間。 目前較為普及的視訊壓縮技術為 MPEG-4 和 H.264,H.264 可說是 MPEG-4 下一 代的影音壓縮標準,但是,現階段MPEG-4 比 H.264 較被廣泛使用著,因此先從MPEG-4 的視訊壓縮技術開始著手,多核心處理器方面,則是使用 Sony Cell Broadband Engine (PS3),它包含一顆主核心以及八顆副核心,並在 Linux 環境下進行實驗。
1.2 論文架構
本論文的目標是整合 Cell Engine 多核心架構以及視訊壓縮演算法,將其編解碼指 令平行化,以達到高效率的運算結果,因此,分成幾個章節來做詳細的闡述。第二章先
介紹多核心處理器的軟體與硬體架構,以及porting 部分程式至副核心時,必須用到的
API 之使用方法;第三章藉由探討 XVID CODEC 的解碼流程,找出可平行運算的指令,
主要著重在I、P、B-Frame 的解碼;第四章討論主題為結合二、三章之後,重新撰寫了
哪些程式、如何在 SPE 端實現 pipeline 運作流程以及討論 porting 過程中所遭遇到的 問題;第五章是實驗的部份,藉由數據的分析,討論 DMA 傳輸的問題以及改善的解 碼時間;第六章則是本論文的結論以及未來發展。
第二章 Cell Broadband Engine
本論文以 Cell Broadband Engine (PS3) 為實驗的週邊設備,因此,此章對於多核心 處理器做細部的分析與討論。2.1 節簡單介紹 PS3 的硬體以及系統架構;2.2 節說明 SPE 程式運作時,整個詳細的硬體與軟體流程;2.3 節將深入討論核心之間資料傳輸的 各種問題;程式運作時,為了解決同步問題,核心間的通訊方式必須非常清楚,2.4 節 則是針對通訊機制來做詳細的說明;2.5 節透過程式編譯的流程了解核心間的關係。
2.1 多核心架構與系統說明
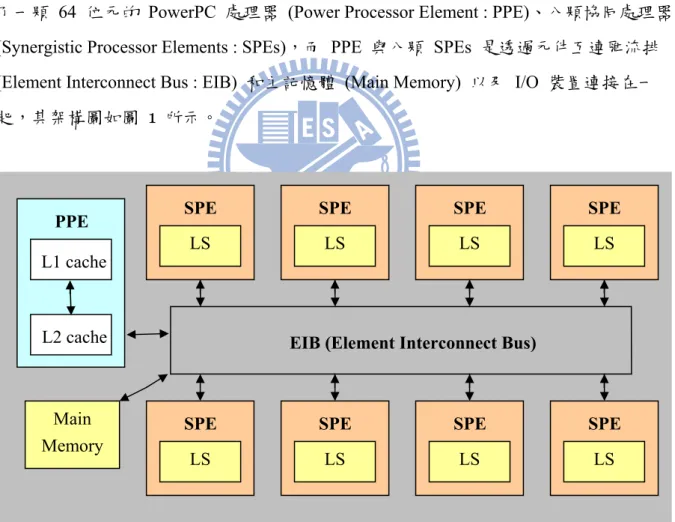
PS3 是一個多核心處理器 (Cell Broadband Engine : Cell/B.E.),Cell/B.E. 本身包含 了一顆 64 位元的 PowerPC 處理器 (Power Processor Element : PPE)、八顆協同處理器 (Synergistic Processor Elements : SPEs),而 PPE 與八顆 SPEs 是透過元件互連匯流排 (Element Interconnect Bus : EIB) 和主記憶體 (Main Memory) 以及 I/O 裝置連接在一
起,其架構圖如圖 1 所示。
圖 1. 多核心架構圖
架構上,PPE 有一對 32KB 的一級快取記憶體 (L1 cache),分別是指令快取記憶 體 (instruction cache) 和數據快取記憶體 (data cache),以及一個 512KB 的二級快取記
L1 cache LS
L2 cache EIB (Element Interconnect Bus)
PPE SPE SPE
SPE SPE SPE SPE SPE SPE LS LS LS LS LS LS LS Main Memory
憶體 (L2 cache),周圍的八顆 SPE 裡面都有一個 256KB 的區域記憶體 (Local Store : LS) 可供存取,至於 EIB 的功用,在於接收 PPE 或 SPE 發出直接記憶體存取 (Direct Memory Access : DMA) 的指令,以讀寫主記憶體上的資料。
系統上,PPE 主要是用來運行操作系統,而 SPE 則是負責執行 PPE 所分配的計 算任務,PPE 會先將資料放置主記憶體上的某個暫存區,再由 SPE 從主記憶體搬運資 料回區域記憶體,等 SPE 拿到資料並計算好之後,再將位於區域記憶體的結果由 EIB 寫回主記憶體。因此在實作上,我們便在 PS3 上安裝 Yellow Dog Linux 6.0 作業系統, 並藉由 IBM 提供的 SDK (Software Development Kit) 函式庫來達到 SPE 和 PPE 之 間系統上的實際操作。
2.2 SPE 程式的執行
當一個系統程式在執行時,大致上可分為主程式和子程式,系統程式又可分為在單
一核心及多核心上運作。以PS3 此多核心架構為例,當主程式和子程式同時運作於 PPE
時,就稱為單核心運作。若主程式在PPE 上,而其他子程式則是在 SPE 上,此稱為多
核心運作。但是要在 PPE 主程式中執行 SPE 子程式,需要調用一些必要的 API (Application Programming Interface) 函數,詳細的硬體及軟體架構流程如圖2 所示。 一開始,需先將各個撰寫好的 SPE 原始碼透過 Compiler 編譯成可執行檔,此時 的可執行檔位於硬碟中,接著使用以下的 API 函數。
1. 先使用 spe_image_open() 函數開啟位於硬碟中的 SPE 執行檔至主記憶體,此 函數回傳指向該 SPE 程式的指標。
2. 接著,PPE 主程式需要執行 SPE 程式時,使用 spe_context_create() 函數建立 一個 SPE 內容 (context),此函數回傳該 SPE 內容的 handle,此 handle 可以當作此 SPE 內容的 ID,以提供使用者辨別、控制 SPEs。
3. 得到 SPE 內容之後,使用 spe_program_load() 函數,將程式從主記憶體載 入至 SPE 內容中的區域記憶體,換句話說,256 KB 大小的區域記憶體,不只是儲存 待處理的資料,還包含了程式碼的大小。
4. 此時 PPE 就透過已建立好的 SPE 程式內容,利用 spe_context_run() 函數去 執行該程式,等 SPE 執行結束後,會回傳終止訊息給 PPE。
5. 當子程式 SPE 不再需要被用到時,使用 spe_context_destroy() 函數將 SPE 內容銷毀掉,此時原本的 SPE 內容就可再一次等待被建立及使用。
6. 最後,還要使用 spe_image_close() 函數將存在於主記憶體的 SPE 程式的指標
關閉,以等待下一次 SPE 程式的開啟,程式碼的實現如圖 3 所示。
圖 2. SPE 程式的執行
圖 3. 執行 SPE 程式的片段程式碼
2.3 DMA 傳輸 (Direct Memory Access transfer)
DMA 是一種特殊的硬體結構,它允許系統直接讀寫記憶體,而不必透過 CPU,這 種直接由特殊硬體完成資料傳輸的方法,節省了許多程式的執行時間。這邊所指的 DMA 傳輸,是以主記憶體與 SPE 上的區域記憶體以及 SPE 區域記憶體之間的資料傳 輸為討論主軸,此外,後面還特別介紹雙重緩衝技術的應用以及 DMA 傳輸最常發生 的錯誤 -- 匯流排錯誤 (Bus Error)。 主記憶體以及 SPE 區域記憶體是位於相同的記憶體空間上,如圖 4 所示,因此, 只要取得位於記憶體空間的絕對位址,就可以知道資料位於 PPE 端或 SPE 端上的確 PPE SPE ID Disk Storage SPE Program LS SPE Program Execute Termination 1. 2. EIB 5. spe_image_open() spe_program_load() 4. 6. spe_context_run() Main Memory 3. spe_image_close() SPE Program spe_program_handle_t *program; spe_context_ptr_t speid;
uint32_t entry = SPE_DEFAULT_ENTRY;
program = spe_image_open( “ spe ” );
speid = spe_context_create( 0 , NULL );
spe_program_load( speid , program );
spe_context_run( speid , &entry , 0 , NULL , NULL , NULL );
spe_context_destroy( speid );
spe_image_close( program ); 傳入參數 spe_context_destroy()
ppe.c
切位置,但是,PPE 端的絕對位址和 SPE 端區域記憶體上的絕對位址有些不同,每個 SPE 的區域記憶體可以想成是記憶體空間的某段記憶體,所以要得到區域記憶體上的絕 對位址,必須知道該段記憶體的起始位址,以及相對於起始位址之位址偏移 (offset), 有了起始位址和位址偏移,便可以計算出區域記憶體上的絕對位址,有了絕對位址,不 論是 PPE 與 SPE 之間或是 SPE 之間的資料傳輸,均可以用 DMA 傳輸到絕對位址 作存取的動作。 圖 4. 記憶體空間示意圖 2.3.1 主記憶體和 SPE 區域記憶體之間的資料傳輸 每個 SPE 都有 256KB 大小的區域記憶體,同時也是唯一 SPE 有權限進行讀寫 的記憶體,因此,如果想和 PPE 共享位於主記憶體的資料時,必須先知道資料位於主 記憶體的哪一個位置,並將資料從主記憶體搬運至自己的區域記憶體中,所以得到 PPE 端的資料位址為首要步驟。 得到 PPE 端的資料位址的方法有兩種:一、儲存在啟動 SPE 程式時的傳入參數, 但只能在執行的一開始傳送一次,如圖 3 圈起來的部分,二、 SPE 程式執行期間,可 透過 Mailbox 來傳送絕對位址的資訊,Mailbox 的詳細說明將會在 2.4.1 提到。 當取得絕對位址之後,便可利用 API 函數並透過 DMA 命令,將資料從主記憶體 讀入至區域記憶體,或是從區域記憶體寫出至主記憶體中。詳細的硬體及軟體架構流程 如圖 5 所示,流程以讀取主記憶體上的資料為例子。 1. 已知位址資料之後,需先在 SPE 程式內,宣告一個資料結構,其大小、型態 要和主記憶體欲傳送過來的資料完全相同,接著,使用 mfc_get() 函數,告知函數要從 主記憶體的哪個位址,傳多少資料到 SPE 的區域記憶體內,此函數會發出 DMA 指 令,通過 channel 到 MFC (Memory Flow Controller) 裡的 DMA controller 下達指令。
2. 下完 DMA 指令之後,MFC 便會開始執行主記憶體和區域記憶體之間資料的 調動,然後便開始接收 PPE 端送來的資料至 SPE 端已建立好的資料結構中。 Reserved
. . . .
SPE1 Main Memory Memory Map SPE2 起始位址 位址偏移 絕對位址3. 最後,使用 mfc_write_tag_mask() 和 mfc_read_tag_status_all() 函數等待資料 傳送完成,圖6 為程式的實現。 圖 5. DMA 傳輸 圖 6. SPE 端 DMA 傳輸的片段程式碼 2.3.2 SPE 區域記憶體之間的資料傳輸 SPE 之間的資料傳輸,相當於 SPE 的區域記憶體之間的記憶存取,舉例來說,當 SPE1 需要取得位於 SPE2 的區域記憶體上的資料時,SPE1 必須先知道資料位於 SPE2 區域記憶體的哪一個位置,但是,要取得 SPE2 區域記憶體上的資料之絕對位 址,需要取得兩個位址參數,第一個位址參數為 SPE2 的區域記憶體之起始位址,第二 個位址參數是資料相對於起始位址的位址偏移 (offset),將這兩個位址參數相加之後才 是真正 SPE2 區域記憶體的資料位址,也就是說,當要跟某人拿東西時,你要知道要到 spe.c uint32_t tag_id ; ctx_t ctx __attribute__ ((aligned(128))) ; // 任意的一個資料結構變數 tag_id = mfc_tag_reserve();
mfc_get( &ctx , addr , sizeof(ctx) , tag_id , 0 , 0 );
mfc_write_tag_mask( 1<<tag_id ); mfc_read_tag_status_all(); 位於 PPE 端上的資料之絕對位址 main memory SPE Data mfc_write_tag_mask() mfc_read_tag_status_all() EIB SPU LS
SPE Program Data
MFC
DMA controller
1. mfc_get() , mfc_put() 2.
channel
哪一層樓的哪一間房間,樓層就相當於起始位址,房間號碼就相當於偏移,而整棟樓就 相當於整個記憶體空間。 SPE1 要取得 SPE2 的區域記憶體上的資料之絕對位址,所需的位址參數之取得流 程如下: 1. 起始位址: SPE2 的區域記憶體之起始位址是由 PPE 利用系統函數獲得,接著 透過 Mailbox 將起始位址傳送給 SPE1。 2. 資料的相對位址偏移:先由 SPE2 本身透過 Mailbox 方式將資料的相對位址偏
移送回 PPE ,再從 PPE 端利用 Mailbox 傳送給 SPE1。
3. 最終位址:將 1. 得到的起始位址,加上 2. 的相對偏移, SPE1 就得到了 SPE2 資料位於區域記憶體上的絕對位址,利用計算出來的位址,就可使用 DMA 傳輸資料。 2.3.3 雙重緩衝技術 (Double Buffering) SPE 程式運作中,當需要讀取大量的資料,並對部分資料進行運算的動作時,若使 用雙重緩衝技術,將會大幅提升 SPE 程式運作的效能,因此,這邊將對雙重緩衝技術 作詳細的說明,以及為何能達到提升效能的原因。以下為雙重緩衝的必要過程,其中輸 出和輸入的緩衝區均有兩個,input_1、input_2 代表輸入的緩衝區,而 output_1、 output_2 則代表輸出的緩衝區。
1. 首先,對 input_1 和 input_2 同時下達 DMA get 指令。
2. 等待 input_1 接收完成,對此資料進行運算,完成後存至 output_1,並下達 DMA put 指令將 output_1 寫出,同時,再次對 input_1 下達 DMA get 指令 (因為 input_1, 已經完成運算的動作,所以可以再次接收新的一筆資料,等待下一次的運算)。
3. 此時切換到 input_2,等待接收完成 => 進行運算並存至 output_2 => 下達 DMA put 指令將 output_2 寫出 => 再次對 input_2 下達 DMA get 指令。
4. 再一次切換回 input_1,這時,要注意的是,除了等待 input_1 接收完成,還須
多等待output_1 寫出結束,才可進行運算,否則會覆蓋到未寫完的資料,而造成結果
錯誤,後面的步驟就跟 2. 一樣,進行運算並存至 output_1 => 下達 DMA put 指令將 output_1 寫出 => 再次對 input_1 下達 DMA get 指令。
5. 將 4. 的所有步驟切換成緩衝區 2。 6. 重複切換 4. 和 5.。
使用雙重緩衝技術之所以能夠提高效率,是因為DMA 在進行資料傳輸時,不用透 過CPU,藉由此種特殊的硬體特性,可以在等待 DMA 傳輸完成的時間內,插入程序運 算的步驟。最簡單的DMA 流程如圖7 所示,這種方法浪費大量時間等待 DMA 傳輸完 成,因此,為了達到運算與傳輸同步進行,就需要分配兩個緩衝區,之所以輸出及輸入 均須使用兩個緩衝區,原因在於等待DMA 傳輸以及程式運算作用在不同的緩衝區,以 達到資料間不會造成覆寫的情況。 圖 7. DMA 流程圖 2.3.4 匯流排錯誤 (Bus Error) 匯流排錯誤是撰寫 SPE 程式的 DMA 傳輸中,最常見、也是最麻煩的問題,當 SPE 的區域記憶體要讀取主記憶體上的資料,取得資料的位址為首要步驟,但是,若讀 取的主記憶體位址和存放的區域記憶體位址,沒有同時達到位址的對齊 (alignment),此 時就會發生匯流排錯誤,圖8 為 16-byte 對齊與沒有對齊的例子。DMA 傳輸時,除了 位址對齊的問題之外,還須考慮 DMA 傳輸大小,因此接下來將針對這兩大問題作詳 細的討論與說明。 1. DMA 傳輸大小 每次的 DMA 傳輸資料大小必須為 1、2、4、8 或 16 的倍數,且每次的傳輸上限 為16 K,單位為 byte 數。
圖8. 匯流排錯誤 (16-byte) 2. 位址對齊 傳輸資料大小為16 的倍數時,只須注意位址是否對齊在 16 位元組的邊界上 (byte boundary),若小於 16 位元組時,傳送端和接收端要同時符合兩個限制條件,才可以避 免造成匯流排錯誤,圖9 是以傳輸大小為 4-bytes 的錯誤與正確範例。 (1) 限制一:傳輸大小與位址對齊大小相符,換句話說,當傳輸大小為 2-bytes 時,
位址就要在 2-byte boundary 上,圖中的 Error_1 就是不符合此限制條件。
(2) 限制二:以16-byte boundary 為基準點,傳送端與接收端位址之相對位置也要
完全相同,如圖中的Error_2,雖然有達到傳輸大小和位址對齊限制相符,但相對
位置卻不相同。
圖 9. 匯流排錯誤 (less than 16-byte) Main Memory 16 bytes 16 byte boundary Local Store Error_1 OK Error_2 Main Memory 16 bytes 16 byte boundary Local Store Error O K
2.4 Mailboxs 和 Signal Notification Registers 之通訊機制
在多核心系統的架構下,因為 SPE 的區域記憶體並不是共享的,因此須透過通訊 機制來達到交換資料、同步等問題,除了上一節的 DMA 傳輸之外,還有 Mailboxs 和 Signal Notification Registers 這兩種通訊機制,這三種基本的通訊機制都是由 SPE 的 MFC 所控制,所以本節將對 Mailboxs 以及 Signal Notification Registers 來做詳細的說 明。
2.4.1 Mailboxs
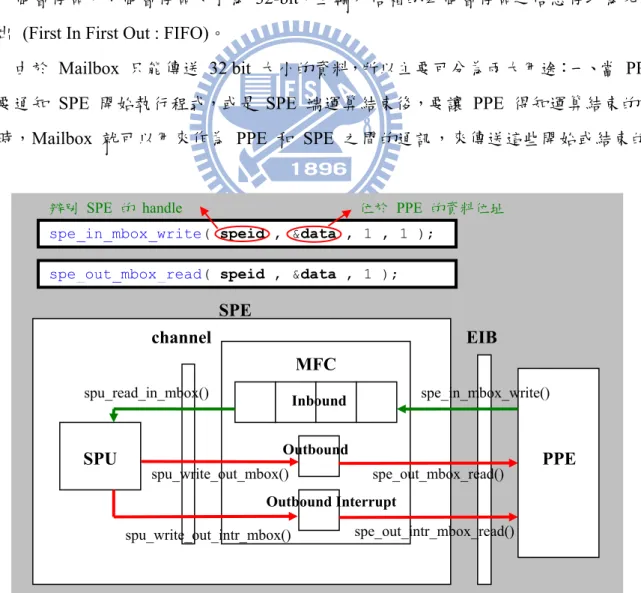
每個 SPE 均有三種不同功能的 Mailboxs,分別是輸出信箱 (Outbound Mailbox)、 輸出中斷信箱 (Outbound Interrupt Mailbox) 以及輸入信箱 (Inbound Mailbox),詳細的硬
體及軟體架構流程如圖 10 所示,其中輸入信箱有四個暫存區,輸出及輸出中斷信箱各
有一個暫存區,每個暫存區大小為 32-bit,且輸入信箱的四個暫存區之信息存取為先進 先出 (First In First Out : FIFO)。
由於 Mailbox 只能傳送 32 bit 大小的資料,所以主要可分為兩大用途:一、當 PPE 端要通知 SPE 開始執行程式,或是 SPE 端運算結束後,要讓 PPE 得知運算結束的訊 息時,Mailbox 就可以用來作為 PPE 和 SPE 之間的通訊,來傳送這些開始或結束的
圖 10. Mailboxs SPE EIB SPU MFC channel spe_in_mbox_write() Inbound Outbound Outbound Interrupt PPE spu_read_in_mbox() spe_out_mbox_read() spu_write_out_mbox() spe_out_intr_mbox_read() spu_write_out_intr_mbox()
spe_in_mbox_write( speid , &data , 1 , 1 );
辨別 SPE 的 handle 位於 PPE 的資料位址
狀態報告。二、當 SPE 程式的運作過程中,需要到主記憶體或其他 SPE 端的區域記 憶體抓取資料時,必須有那些資料的所在位址,這時,就可透過 Mailbox 來傳送位址 給其他 SPE,或是接收其它 SPE 的所在位址。
輸出信箱和輸入信箱的使用上,最主要的不同在於,SPE 不論是讀取輸入信箱、寫
入輸出信箱,均是阻塞式的 (BLOCKING),而 PPE 則為非阻塞式的。以 SPE 讀取輸
入信箱為例,當輸入信箱為空時,SPE 將會一直處於阻塞狀態,直到 PPE 或其他 SPE
寫入資料至輸入信箱。
而對於非阻塞式的 PPE 信箱操作來說,可能會發生兩種錯誤,一、當 PPE 在 SPE 程式讀取輸入信箱之前,PPE 已經連續寫入五次,此時第五次的資料將會遺失,二、當 PPE 讀取輸出信箱時,其實 SPE 還未寫入信息,此時 PPE 將會讀到錯誤的值。因此, 為了解決以上兩種問題,必須使用特殊的 API 函數,來了解信箱內的狀態。 1. 錯誤一 當 PPE 要寫入信息到輸入信箱之前,都要先利用 spe_in_mbox_status() 函數,取得輸入信箱中,尚可寫入幾個信息,當狀態為零時,代表是滿的,此時就要等 待狀態不為零,才可以再寫入信息。 2. 錯誤二 當 PPE 要從輸出信箱讀取出信息之前,先使用 spe_out_mbox_status() 函數,取 得輸出信箱中,尚有幾個信息未讀出,當狀態為零時,代表輸出信箱是空的,因此要等 狀態不為零,即表示有資料進來了,此時才可去讀取信息,圖 11 分別為解決錯誤一、 二的片段程式碼。 圖 11. Mailbox 錯誤的解決方法 錯誤一
while( spe_in_mbox_status(speid)==0 ); // 0 代表滿的,就停住
spe_in_mbox_write( speid , &data , 1 , 1 );
錯誤二
while( spe_out_mbox_status(speid)==0 ); // 0 代表空的,就停住
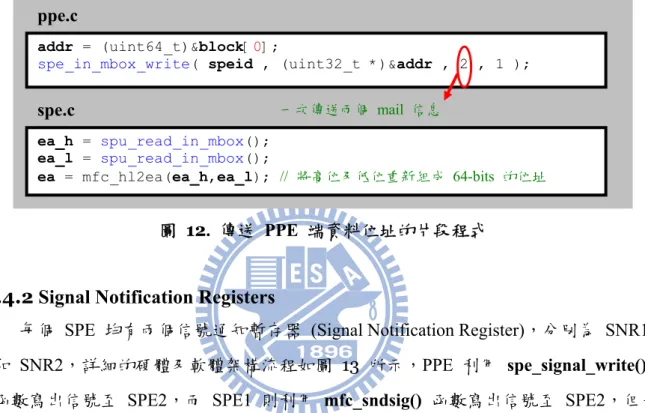
之前有提到 SPE 程式執行期間,可以透過 Mailbox 取得主記憶體上的資料之位址,
圖 12 為片段程式碼內容,目的是將 PPE 端陣列的起始位址傳送給 SPE 端,由於 PPE
端的位址大小是 64-bits,但 Mailbox 一次只能傳送 32-bits 的信息,所以須分兩次傳 送,第一次先傳送位址之較高位元的 32-bits 資料,第二次再傳送較低位元的 32-bit資 料。
圖 12. 傳送 PPE 端資料位址的片段程式
2.4.2 Signal Notification Registers
每個 SPE 均有兩個信號通知暫存器 (Signal Notification Register),分別為 SNR1 和 SNR2,詳細的硬體及軟體架構流程如圖 13 所示,PPE 利用 spe_signal_write() 函數寫出信號至 SPE2,而 SPE1 則利用 mfc_sndsig() 函數寫出信號至 SPE2,但是
圖 13. Signal Notification Registers
,要讓 SPE1 傳送信號到 SPE2 的 SNR2 時,必須讓 SPE1 知道 SPE2 的 SNR2 之 位址,因此,要先在 PPE 端取得 SPE2 的 SNR2 之絕對位址,而取得步驟如下:一、 SPE2 SPU channel spe_signal_write() Signal – Notification Register 1 PPE spu_read_signal1() mfc_sndsig() spu_read_signal2() Signal – Notification Register 2 SPE1 ppe.c addr = (uint64_t)&block[0];
spe_in_mbox_write( speid , (uint32_t *)&addr , 2 , 1 );
spe.c
ea_h = spu_read_in_mbox();
ea_l = spu_read_in_mbox();
ea = mfc_hl2ea(ea_h,ea_l); // 將高位及低位重新組成 64-bits 的位址 一次傳送兩個 mail 信息
先使用系統函數 spe_ps_area_get() 取得 SNR2 的起始位址,二、從起始位址位移 12-byte 之後即為 SNR2 的確切位址,再將此確切位址利用 Mailbox 傳送給 SPE1,接
著,SPE1 就可以利用此位址傳送信號給 SPE2。圖 14 為計算 SPE2 的 SNR2 之絕對
位址的程式碼以及記憶體的示意圖。 圖 14. PPE 端計算 SNR2 位址之程式碼以及示意圖 圖 15 為圖 13 的程式實現,由上述可知,信號通知暫存器是 12-byte 位址對齊, 所以 SPE 之間的信號傳輸要如圖 14 中 spe1.c 方塊框起來的程式寫法,才能正確傳送 信號,而不會造成匯流排錯誤。 圖 15. 對照圖 13.的片段程式碼
Signal 和 Mailbox 相同的是,暫存器大小都是 32-bit,不同的是,Signal 對於
spe_sig_notify_2_area_t *ea_area2; uint64_t ea_sig2;
ea_area2 = (spe_sig_notify_2_area_t*)
spe_ps_area_get( speid , SPE_SIG_NOTIFY_2_AREA);
ea_sig2 = (uint32_t)&(ea_area2->SPU_Sig_Notify_2); SPE2 的 handle ppe.c SPE_SIG_NOTIFY_2_AREA ea_area2 ea_sig2 SPE2 SNR2 ppe.c
spe_signal_write( speid , SPE_SIG_NOTIFY_REG_1 , data );
spe1.c
uint32_t signal[4] __attribute__ ((aligned(16)));
signal[3] = data;
mfc_sndsig( &signal[3] , ea_sig2 , tag_id , 0 , 0 );
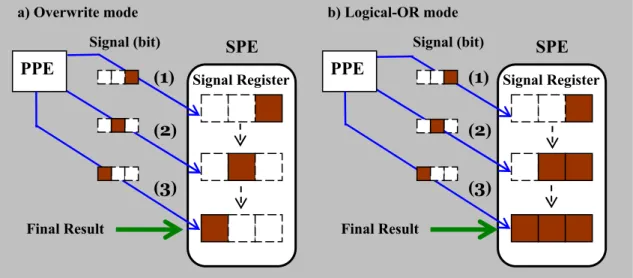
Register 的寫入模式可設定成覆寫模式 (Overwrite mode) 或是邏輯 OR 模式 (logical-OR mode),且 Register 每被讀取一次,內部所有位元資料將全被清為零。
1. 覆蓋模式
此模式的功能和 Mailbox 的輸入信箱大致上相同,只是由四個暫存區變成一個暫存 區,而且對於 PPE 來說,信號的寫入也是屬於非阻塞式的,所以也會發生如 Mailboxs 提到的錯誤一,但是 Signal 和 Mailbox 產生的錯誤卻有些不同。當 SPE 程式讀取信 號通知暫存器之前,PPE 已經寫入兩次以上時,不像 Mailbox 的輸入信箱,遺失的資 料不是最後一次寫入的資料,而是前一次的資料會被後一次的寫入所覆蓋,換言之,就 是只留下最後一次寫入的資料,因此,該模式比較像是一對一的信號通知。
2. OR 模式
此寫入模式算是多對一的一種,因為它可針對每個 bit 作個別寫入的動作,換句話 說,如果 SPE1 和 SPE2 分別傳送 4 和 8 的 Signal 信號 (相當於第三和第四個 bit 為一的信號) 給 SPE3 時,其接收到的 Signal 信號結果將會變成 12 (=> 4 + 8),但是, 在 SPE3 讀取信號之前, SPE1 和 SPE2 必須已經完成寫入 Signal 信號的動作,否則 就只會取得 SPE1 或 SPE2 的信號。 從圖 16 的示意圖可以看出這兩種模式的差異,而這差異在於位元處理的方式,因 此,我們可以利用 OR 模式這種特別的通訊原理,來進行資料運算之間的同步作業, 舉例來說:當 SPE1 和 SPE2 為兩個不同運算步驟的程式,每個程式均要處理六筆資 料,且每筆資料要先等待 SPE1 運算完之後,才可由 SPE2 接著下一步驟的運算作業, 因此,在 SPE1 端,每計算完一筆資料,就傳送代表著該筆資料的 bit 代號,換句話說, 當 SPE1 的第一筆資料運算結束後,就向 SPE2 發出 000001 的信號,第二筆資料運 算結束後,發出 000010 的信號,而最後一筆運算結束後,則是發出 100000 的信號, 然而,在 SPE2 端,則不定時的去讀取信號通知暫存器,如果讀取到的信號為 000111, 則代表目前 SPE1 已經運算完前三筆資料,此時 SPE2 就會先對這三筆資料作下一步 驟的運算,運算結束之後,再次去查看信號通知暫存器,直到六筆資料都處理完成。
圖 16. 覆寫模式和邏輯 OR 模式
2.4.3 通訊機制的差異
Signal 和 Mailbox 的通訊機制最大差異在於 PPE 端與 SPE 端之間的通訊, Signal 屬於單向的溝通,而 Mailbox 是雙向的。對 Signal 來說,它只能從 SPE 端接 收 PPE 端的信號,而不能傳送信號給 PPE 端,但是, Mailbox 還能讓 SPE 端寫入 信息到輸出信箱,讓 PPE 端來讀取,因此,若考慮 SPE 和 PPE 之間的通訊問題,使 用 Mailbox 較為恰當。
2.5 SPE 程式的嵌入 (Embedded SPE Program)
PPE 程式執行 SPE 程式時,是讀取編譯好的 SPE 程式之 ELF (Executable and Linkable Format) 可執行檔,其詳細流程已在之前已提過了,但是,一般大型程式的建 立,最後的 ELF 可執行檔,均是由許多個不同的子程式編譯 (Compiler) 成各個 object 檔,最後再將這些物件檔結合 (Link) 起來形成 ELF 執行檔,因此,除了直接讀取 SPE
程式之ELF 執行檔之外,SPE 程式還可以直接嵌入到 PPE 程式之 ELF 可執行檔中。
簡單來說,就是透過一些特別的 API 函數來將 SPE 執行檔轉換成 PPE 的 object
檔,圖17 為編譯時的整個程序,藉由了解其詳細過程,可以對於 PPE 和 SPE 程式之 間的關係有更加深入的了解。 Signal (bit) Signal Register Final Result PPE (3) (1) (2) Signal Register Final Result SPE SPE
a) Overwrite mode b) Logical-OR mode Signal (bit)
(1) PPE
(2) (3)
圖 17. 編譯程序
1. 先透過 spu-gcc 指令將 SPE 原始碼編譯成 object 檔。 2. 連結 object 檔形成 ELF 可執行檔。
3. 接著利用 ppu-embedspu 指令將 SPE 程式之 ELF 執行檔轉換成 CESOF (CBEA Embedded SPE Object Format) object 檔,此 object 檔為特殊的 PPE object 檔。 4. 再使用 gcc 指令將 PPE 原始碼編譯成 object 檔。
5. 最後將 3. 產生的特殊 PPE object 檔一併連結成 PPE 程式之 ELF 執行檔。 SPE Source
(ex: spe.c)
SPE Compiler
spu-gcc SPE Object
(ex: spe.o)
SPE Linker SPE Program
(.elf) PPE Source (ex: ppe.c) PPE Compiler gcc PPE Object
(ex: ppe.o) PPE Linker
PPE Program (.elf) CESOF Objects
(ex: embed.o) ppu-embedspu
Convert to PPE Object
1.
3. 2.
4.
第三章 XVID CODEC
由於最後實驗的軸心是將 Xvid Codec 部分程式碼 porting 到 SPE 上運作,所以 此章為細部討論影像解碼時,各個解碼元件的程式分析,並透過程式的分析,從中探討 MPEG-4 如何實現影像的壓縮技術。因此,3.1 節為簡單介紹整個解碼流程,以幫助對 於程式的分析有初步的了解;對於 MPEG-4 編碼之後的資料來說,畫面之間會有相依 性,因此,每解出一張畫面,便須將畫面以及一些必要的資訊儲存在資料結構中,3.2 節將針對這些資料結構做詳細的分析;3.3 至 3.5 節討論 I-Frame、P-Frame 以及 B-Frame 的程式解碼流程,並分析程式的架構。
3.1 解碼資料流程 (Decoder Data Flow)
藉由研究 Xvid Codec 的原始碼 (Open Source),深入了解影像解碼的部分,因此,
必須先對影片的結構有一定的了解。一段未壓縮的影片經過Xvid Codec 編碼之後的影
片結構如圖 18 所示,每個 Video Bitstream 是由許多 Sequence 構成的,每個 Sequence
圖18. Video Stream 結構圖
又是由一堆 Frame 所組成,通常是一個 I-Frame 以及多個 P-Frame 和 B-Frame,每張 Frame 是由許多 MacroBlocks (MBs) 所組成,最後每個 MB 是 4y1u1v 六個 blocks
所組成,而標準的 I-Frame 或 P-Frame 的 MB 解碼資料流程如圖 19 所示: 1. 首先,對於壓縮影像的位元流進行變動長度解碼 (VLD),內容包括計算所有 MB 的係數、移動向量以及相關的標頭。 2. 接著將解好的係數經過一些適當的重新排列,並進行反量化 (IQ)、反離散餘弦 轉換 (IDCT) 等運算得到資料 D,若目前是進行 I-Frame 的解碼,D 即為結果 (稱為 intra MB)。 Video Bitstream … Sequence Group of Frames Frame Macro Block Block
圖 19. Decoder Data Flow 3. 若目前是進行 P-Frame 的解碼,得到 D 之後,複製參考畫面中之移動向量所 對應的預測區塊 P (也稱為 reference MB),此步驟稱為移動補償 (MC),然後將 P 加上 D (這邊的 D 是 residual MB,因為是儲存係數間的差值),就得到資料 Fn,而 Fn 即 為 P-Frame 解碼的最後結果 (稱為 inter MB)。 3.2 資料結構的分析 由於畫面間具有相依性,因此,解碼之後的部分影像資料必須保留,而儲存這些資 料的結構為 DECODER,表 1 列出較為重要的結構成員,而表 2 為儲存整張畫面的
IMAGE 以及儲存 motion vector 的 VECTOR 結構內容,IMAGE 中的 *y、*u 以及 *v 分別為指向記憶體中存放 Y、U、V 畫面的起始位址。
表 1. DECODER 的結構成員 --- 變數宣告為 *dec
type Name description
uint32_t mb_width 寬度有幾個MBs uin32_t mb_height 高度有幾個MBs int quarterpel 是否使用 1/4 畫素的旗標 int interlacing 是否使用交錯式處理的旗標 int time_bp 目前 B 畫面和先前參考畫面撥出時間差 int time_pp 未來參考畫面和先前參考畫面撥出時間差 VECTOR p_fmv 順向移動向量之預測值 VECTOR p_bmv 逆向移動向量之預測值 IMAGE cur 目前畫面 IMAGE refn[2] 參考畫面 MACROBLOCK *mbs 畫面中全部 MBs 的必要資訊 MACROBLOCK *last_mbs 未來畫面中全部 MBs 的必要資訊
表 2. IMAGE 和 VECTOR 的結構成員
資料結構名稱 type name 資料結構名稱 type name
IMAGE uint8_t *y VECTOR int x
uint8_t *u int y
uint8_t *v
mb_width、mb_height
為了解出一張完整的 Frame,我們總共需要解出 mb_height × mb_width 個 MB, mb_height 代表 y 方向有幾個 MB,而 mb_width 則代表 x 方向。 quarterpel 在作移動補償時,一般的移動向量均落在整數畫素上,為了使移動補償達到更好的 壓縮率,有時移動向量會落在 1/2 畫素或 1/4 畫素上。整數畫素之間的中間點即稱為 1/2 畫素,所以 1/2 畫素之間的中間點即為 1/4 畫素。 interlacing 當畫面使用交錯式處理時,代表著該畫面的奇數橫列和偶數橫列,分別儲存著不同 時間點的影像資料,使用交錯式處理與否,將影響解碼時,該如何將正確影像資料還原 回來。 time_bp、time_pp
解 B-Frame 時,如果為直接模式 (direct mode),順向、逆向移動向量均是從參考 向量運算出來,而參考的移動向量為未來畫面中位於相同的 MB 所在位置上之向量。 欲運算出向量,除了需要上述的參考向量,還需要 time_bp 和 time_pp 參數,而 time_bp 為目前 B 畫面的撥出時間減去先前參考畫面的撥出時間,相對的,time_pp 為 未來參考畫面的撥出時間減去先前參考畫面的撥出時間,至於更完整的運算過程,會在 3.5 節中做說明。 p_fmv、p_bmv 移動向量的取得為向量差值加上向量預測值,因此,解 B-Frame 時,若不為直接 模式,p_fmv、p_bmv 為儲存順向、逆向移動向量之預測值的參數。 cur、refn[0]、refn[1] cur 為存放目前解碼後的整張畫面之結構變數,而 refn[0] 則是存放未來參考畫面 之結構變數、refn[1] 為先前參考畫面之結構變數。
*mbs
解碼過程中,不只是畫面之間資料有相依性,同一個畫面中相鄰的 MBs 之間也具 有相依性,因此,每個 MB 運算完之後,均要將相關的資料留下,讓下一個 MB 利用
這些資料進行運算。*mbs 為指向整張畫面的所有 MBs 相關資料的起始位址指標。MB
相關的資料結構為 MACROBLOCK,較為重要的結構成員如表 3 所示,且儲存所有
MBs 相關資料的記憶體大小為 sizeof (MACROBLOCK)
×
mb_width × mb_height。 *last_mbs進行 B-Frame 的解碼,且為直接模式時,運算向量需要儲存未來畫面中的參考向 量,而參考向量就儲存在 last_mbs->mvs[4] 中,其中,*last_mbs 為指向未來參考畫面 之 MBs 相關資料的起始位址指標。
表 3. MACROBLOCK 的結構成員
type name description
short int pred_values[6][15] 係數的預測值
int acpred_directions[6] AC 係數的預測方向
int mode 此 MB 的模式 (0 ~ 4)
int quant 量化參數
int cbp 4y1u1v 六個 block 的位元資訊
VECTOR mvs[4] Y 的四個 block 之移動向量 VECTOR b_mvs[4] Y 的四個 block 之逆向移動向量
pred_values[6][15]、acpred_direction[6]
因為相鄰的intra-coded 8× 8 blocks 通常都是有相關性的,所以,與其儲存整個係數
值,倒不如儲存相鄰blocks 係數之間的差值,以達到資料壓縮的目的,而這些差值稱為
係數的預測值 (coefficient prediction)。因此,要計算一塊未解碼的 block 時,可從相鄰 的 (左、上及左上) block 來計算出 DC 係數及 AC 係數的第一列或第一欄的預測值 (因
此預測暫存區總共為15 個),加上每個 MB 由六個 blocks 所組成,所以每個 MB 的
所有係數之預測值,便儲存在dec->mbs[mb_width × mb_height].pred_values[6][15] 的 參數中。
當決定好 AC 係數是由相鄰 block 的第一列或第一欄取得後,便存下預測方向在 acpred_direction[6] 參數中,在 3.3.3 節有針對 Intra prediction 作更詳細的說明。
mode
對於 MB 的情況,一般可以分為五種,0 為 inter、1 為 inter + Q (Q 表示量化參 數須作變動性的調整)、2 為 inter + 4mv、3 為 intra、4 為 intra + Q。
quant
還原係數時,須乘上該量化參數以取得原始的係數值,量化參數的範圍為 1 ~ 31。 cbp
此變數的位元資訊如圖 20 所示 (最右邊為最低位元),且 cbp 又可以分成 cbpc
和 cbpy,cbpc 為 U、V 的部分,而 cbpy 則是 Y。進行 intra block 解碼時,此資訊 決定是否運作 Run-level Coded 係數的解碼,而進行 inter block 解碼時,此資訊決定是 否運作 residual block 的解碼。
圖 20. cbp 的位元資訊 mvs[4]、b_mvs[4]
當 mode 為 inter + 4mv 時,mvs[0] ~ mvs[3] 代表著 Y 的四個 motion vector,若 mode 不為 inter + 4mv 時,Y 只需儲存一個 motion vector,所以只使用 mvs[0],而 b_mvs 為 B-Frame 解碼時,儲存逆向移動向量之參數。
3.3 Decode for I-Frame (Intra Frame)
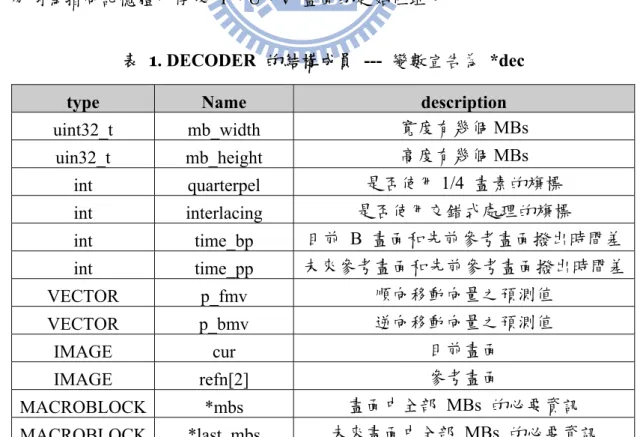
I-Frame 的解碼,位於 Xvid Codec 原始碼的 decoder_iframe(),圖21 為程式的流
程圖,圖22 為實現 I-Frame 解碼的部分程式碼,接下來將詳細說明子程式的運作流程。
圖 22. decoder_iframe() 片段程式碼
3.3.1 get_mcbpc_intra()
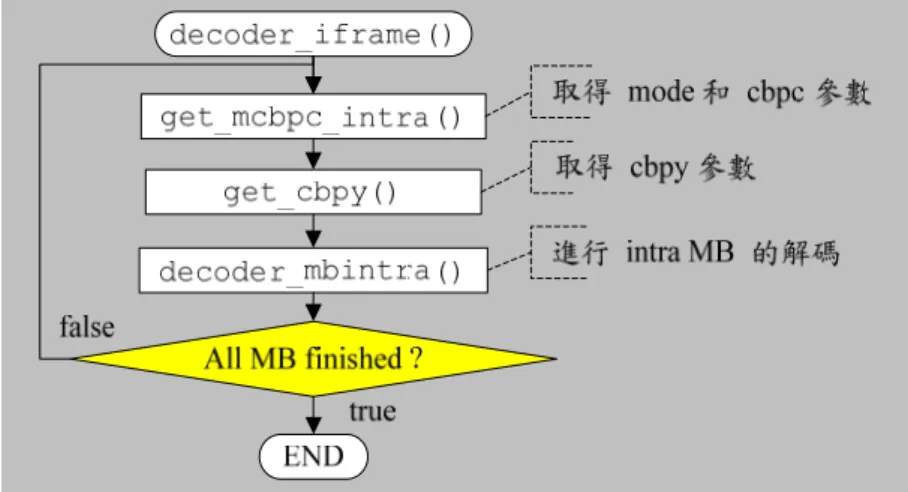
此函數是從位元流中取得 mcbpc (mode and coded block pattern for chrominance) 參 數值,mcbpc 代表二個資訊,第一個資訊為 MB 的 mode,而第二個資訊為 cbpc。由於 目前是 intra mode,所以 mode 只會有 3 和 4 兩種可能,配合 cbpc 有四種情況 (00、01、 10、11) ,將 mode 和 cbpc 組合之後,共有八種結果,其中 mode 資訊儲存在 mcbpc
值的右邊四位元,cbpc 資訊則是儲存在右邊數過來的第五、六位元,如表4 所示。
一般常用的編碼技術為變動長度編碼 (Variable Length Coding : VLC),而解碼時, 我們可以利用 Huffman tree 或是查表的方式來進行解碼,這邊選用查表的方式解出 Huffman Code 所對應到的資訊,接下來,將以 intra mode 為例,分析如何透過 table 達 到 Huffman Code 的編解碼。
void decoder_iframe(DECODER *dec , Bitstream *bs ,int quant) {
for( y = 0 ; y < mb_height; y++) { for (x = 0; x < mb_width; x++) {
mcbpc = get_mcbpc_intra(bs);
mb->mode = mcbpc & 7; // 只取 mcbpc 的最右邊 3 bits
cbpc = (mcbpc >> 4);
// 是否採用 prediction 來取得 ac 係數的旗標
acpred_flag = BitstreamGetBit(bs);
cbpy = get_cbpy(bs, 1); // 1 表 intra , 0 表 inter
cbp = (cbpy << 2) | cbpc;
if ( mb->mode == MODE_INTRA_Q ) {
quant += dquant_table[ BitstreamGetBits(bs, 2) ]; if (quant > 31)
quant = 31; else if (quant < 1)
quant = 1; }
mb->quant = quant; // 取得量化參數(quantizer parameter) if (dec->interlacing) // 是否採用交錯式處理
mb->field_dct = BitstreamGetBit(bs);
decoder_mbintra(dec, mb, acpred_flag, cbp, bs, quant); }
} }
表4. VLC table for mcbpc Huffman Code cbpc (56) mbtype mcbpc (cbpc-mode) Integer for mcbpc 1 00 3 00-0011 3 001 01 3 01-0011 19 010 10 3 10-0011 35 011 11 3 11-0011 51 0001 00 4 00-0100 4 000001 01 4 01-0100 20 000010 10 4 10-0100 36 000011 11 4 11-0100 52 以編碼的角度來看,當 mcbpc 為 01-0011 (cbpc-mode) 時,對照表4 可以得知 Huffman Code = 001,因為這八種 Huffman Code 長度最長為 6,欲使用查表就必須將長 度均固定為6,於是將 001 後面添加 3-bits 的資訊,而 Huffman Code + 添加的 bits 即為
陣列位置,如001-xxx,而且 xxx 不論資訊為何,均會對應到相同的 mcbpc,如圖23 所
示,圖中的 {19 , 3},分別表示 mcbpc 和 Huffman Code Length,下一段將以解碼的角 度來解釋如何利用 {mcbpc , Huffman Code Length} 達到解碼。
圖 23. 001-xxx 對照 mcbpc之範例
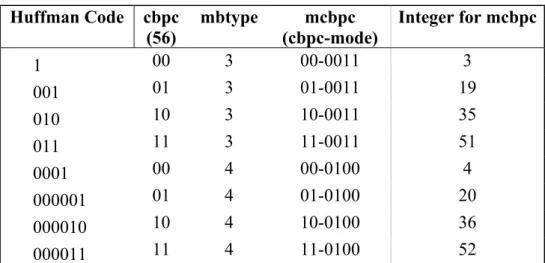
以解碼的角度來看,由圖24 的程式碼得知,先從位元流中取出 6-bits 換算成陣列
位置 index,以 index = 59 (位元表示為 111011) 為例,對照圖25 的表後,得到 mcbpc_intra_table [59] = { 3 , 1 },又 111011 屬於 1- xxxxx 的情況,所以 Huffman Code = 1、Huffman Code length = 1,因此,元素 {3, 1}中的第一個資料 3 是待回傳的 mcbpc 值, 第二個資料1 為 Huffman Code length,是用來從位元流中取出 Huffman Code 資訊。
001-000 8 001-001 9 001-010 轉成整數 10 001-011 11 001-100 12 001-101 13 001-110 14 001-111 15 mcbpc_intra_table [ 8 ] = { 19 , 3 } mcbpc_intra_table [ 9 ] = { 19 , 3 } mcbpc_intra_table [10] = { 19 , 3 } mcbpc_intra_table [11] = { 19 , 3 } mcbpc_intra_table [12] = { 19 , 3 } mcbpc_intra_table [13] = { 19 , 3 } mcbpc_intra_table [14] = { 19 , 3 } mcbpc_intra_table[15] = { 19 , 3 } index (陣列位置) 產生 table 001-xxx
圖 24. get_mcbpc_intra 程式碼
圖 25. mcbpc_intra_table
得到回傳值mcbpc = 3 後,換算成位元為 00-0011 (cbpc - mode),即得到 mode = 3 且cbpc = 00 的資訊,然後就結束了 Huffman Code 的解碼。
3.3.2 get_cbpy()
由圖26 的程式碼得知,先從位元流中讀出 6-bits 換算成陣列位置 index,透過 index 查表取出cbpy 參數,cbpy 參數是儲存亮度 y0 ~ y3之 block 是否為 1 的資訊,因此,
圖 26. get_cbpy 程式碼
get_cbpy(Bitstream * bs, int intra){
int cbpy;
uint32_t index = BitstreamShowBits(bs, 6);
BitstreamSkip(bs, cbpy_table[index].len); // 取出 Huffman Code
cbpy = cbpy_table[index].code;
if (!intra) cbpy = 15 - cbpy; // inter 和 intra 剛好相反 return cbpy; } VLC const mcbpc_intra_table [64] = { {-1, 0},{20, 6},{36, 6},{52, 6},{4, 4}, {4, 4}, {4, 4}, {4, 4}, {19, 3},{19, 3},{19, 3},{19, 3},{19, 3},{19, 3},{19, 3},{19, 3}, {35, 3},{35, 3},{35, 3},{35, 3},{35, 3},{35, 3},{35, 3},{35, 3}, {51, 3},{51, 3},{51, 3},{51, 3},{51, 3},{51, 3},{51, 3},{51, 3}, {3, 1}, {3, 1}, {3, 1}, {3, 1}, {3, 1}, {3, 1}, {3, 1},{3, 1}, {3, 1}, {3, 1}, {3, 1}, {3, 1}, {3, 1}, {3, 1}, {3, 1},{3, 1}, {3, 1}, {3, 1}, {3, 1}, {3, 1}, {3, 1}, {3, 1}, {3, 1},{3, 1}, {3, 1}, {3, 1}, {3, 1}, {3, 1}, {3, 1}, {3, 1}, {3, 1},{3, 1} } ; index 代表陣列位置 index = 59 get_mcbpc_intra(Bitstream * bs){ uint32_t index; index = BitstreamShowBits(bs, 6);
BitstreamSkip(bs,mcbpc_intra_table[index].len); // 取出 Huffman Code return mcbpc_intra_table[index].code; // 回傳 mcbpc 值 }
cbpy = 0 ~ 15,cbpy = 1111 代表全部為 1,詳細的編解碼技術和取得 mode 和 cbpc 的 函數 (get_mcbpc_intra) 相同,且從表5 得知,intra 和 inter 的 cbpy 剛好相反,例如:
當Huffman Code = 11,對 intra 來說,此時 cbpy = 1111,而 inter 時,cbpy = 0000。
表5. VLC table for cbpy Huffman Code cbpy(intra-MB)
(1234) cbpy(inter-MB) (1234) 0011 0000 1111 00101 0001 1110 00100 0010 1101 1001 0011 1100 00011 0100 1011 0111 0101 1010 000010 0110 1001 1011 0111 1000 00010 1000 0111 000011 1001 0110 0101 1010 0101 1010 1011 0100 0100 1100 0011 1000 1101 0010 0110 1110 0001 11 1111 0000
取得 cbpy 參數後,將 cbpy 和 cbpc 作 OR 運算合併成 cbp,接著會查看 mode
是否為 intra + Q,如果是,將對量化參數作些微的調整,如圖22 框起來的地方,而這
些調整大小為 {-2 , -1 , 1 , 2},且量化參數的最小值為 1、最大值為 31。
3.3.3 decoder_mbintra()
此程式為解出 intra block 的核心函數,圖27 為 decoder_mbintra() 的部分程式碼,
而圖28 為程式的流程圖,從流程圖可以看出,先前得到的 cbp 參數,是用來決定是否
圖 27. decoder_mbintra() 片段程式碼
圖 28. decoder_mbintra() 流程圖
static void decoder_mbintra(dec, pMB, acpred_flag, cbp, bs,quant) {
for (i = 0; i < 6; i++) {
uint32_t iDcScaler = get_dc_scaler(quant, i<4); int16_t predictors[8]; // 係數預測值的暫存區
predict_acdc( .., predictors ,.. );
if (!acpred_flag) pMB->acpred_directions[i] = 0; if (cbp & (1 << (5 - i)))
get_intra_block(bs,&data[i*64],direction, .. );
add_acdc( .., &data[i*64], iDcScaler, predictors, .. );
dequant_h263_intra(.,&data[i*64],quant,iDcScaler,.);
idct((short * const)&data[i*64]); }
transfer_16to8copy(pY_Cur , &data[0*64] , stride);
transfer_16to8copy(pY_Cur + 8 , &data[1*64] , stride);
transfer_16to8copy(pY_Cur + next_block , &data[2*64] , stride);
transfer_16to8copy(pY_Cur + next_block + 8 , &data[3*64] , stride);
transfer_16to8copy(pU_Cur , &data[4*64] , stride2);
transfer_16to8copy(pV_Cur , &data[5*64] , stride2); }
1.get_dc_scaler()
傳入值 quant 為量化參數 (Quantizer scale parameter : QP),而 i = 0 ~ 3 時,為 Luminance,i = 4 ~ 5 時,為 Chrominance,接著由表6 取得所對應的 DC 係數之量化參 數iDcScaler。 表 6. QP Ù dc_scaler 轉換表 Block type QP ≤ 4 5 ≤ QP ≤ 8 9 ≤ QP ≤ 24 25 ≤ QP Luma 8 2× QP QP + 8 (2× QP)-16 Chroma 8 (QP + 13)/2 (QP + 13)/2 QP-6 2. predict_acdc() 此函數用來計算DC 係數以及部分 AC 係數之預測值。首先,先針對左、上及左上 區塊的係數預測值做初始化,其默認值 (default values) 為 DC 係數 1024,其餘的 14 個 AC 係數設為 0,然後開始判斷左、上及左上的 block 此時是否位於邊界上,若位於邊界, 其相鄰block 的係數預測值則使用默認值,若不在邊界上,則使用相鄰 block 的係數預
測值,由於亮度 (Luma) 是由四個 block 所組成,所以選擇的相鄰 block 之係數預測值,
特別要經過一些指標上的偏移,以圖29 為例,當想要取得 Y2的相鄰block 之係數預測
值時,左邊block 的係數預測值位於 left MB 的 Y3位置,上面block 的係數預測值則為
圖 29. 相鄰 block 的示意圖
current MB 的 Y0位置,而程式碼的實現如圖30 的 case2 所示,而 case 5 的程式碼,為
取得V 的相鄰 block 之係數預測值。若想取得 current V 的相鄰 block 之係數預測值時, 由於V 只有一個 block,且每一個 MB 的係數預測值是依照 Y0、Y1、Y2、Y3、U、V 的
Y0 Y2 Y1 Y3 diag top left current D2 L2 MBPRED_SIZE = 15
圖 30. predict_acdc() 片段程式碼
順序所排列,因此從程式碼可以看出,均是固定跳過五個block 的指標偏移來取得 V 的
相鄰block 之係數預測值。
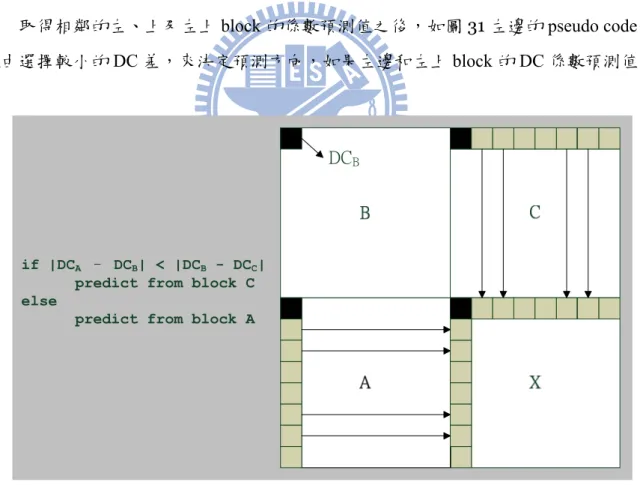
取得相鄰的左、上及左上 block 的係數預測值之後,如圖31 左邊的 pseudo code,
經由選擇較小的DC 差,來決定預測方向,如果左邊和左上 block 的 DC 係數預測值相
DCB
if |DCA DCB| < |DCB - DCC|
predict from block C else
predict from block A
圖 31. DC、AC 係數的預測
減較小,預測方向為垂直方向 (dec->mbs[x + y * mb_width].acpred_directions[i] = 1, 其中i 代表 4y1u1v 的 block 旗標) ,此時 block X 將選擇 block C 為預測目標,表示
case 2: 若左邊是邊界,此時 left 是 NULL if(left){
pLeft = left + 3 * MBPRED_SIZE; // 如圖 28 的 L2
pDiag = left + MBPRED_SIZE; // 如圖 28 的 D2
} pTop = current; top_quant = current_quant; break; . . . case 5:
if(left) pLeft = left + 5 * MBPRED_SIZE; // 跳過五個 block if(top) pTop = top + 5 * MBPRED_SIZE;
if(diag) pDiag = diag + 5 * MBPRED_SIZE;
block X 的 DC 以及 AC 的第一橫列之係數預測值將由 block C 取得,反之,當預測方向 為水平方向時 (dec->mbs[x + y * mb_width].acpred_direction[i] = 2),block X 的 DC 以及 AC 的第一直欄之係數預測值則是從 block A 取得,因此,此函數的目的,是取得八個 係數預測值 (一個 DC、七個 AC)。 3. get_intra_block() 經由查看 cbp 參數之後,決定是否要做 Run-level Decode (RLD),解碼的一開始, 會先決定存放 block 係數的掃描順序,選擇掃描方式的依據在於何種方式可以達到較佳 的壓縮效率,而掃描方式這邊分為三種,Z 字形 (Zig-Zag)、交錯式水平 (Alternate- Horizontal) 及交錯式垂直 (Alternate-Vertical) 掃描,一般都是選用 Z 字形掃描 (dec->mbs[x + y * mb_width].acpred_directions[i] = 0),因為 DCT 之後的係數大小會按 照頻率的高低來作排列,而且,越是高頻訊號,值為零的機率越高,因此,並可以利用 此特性配合Z 字形掃描使得出現零值的訊號連續出現,接著使用變動長度編碼 (Variable-Length Coding : VLC) 來達到最高的壓縮率,但是,如果在計算預測值的函數 中 (predict_acdc),預測方向為水平時 (dec->mbs[x + y * mb_width].acpred_directions[i]
= 1),此時的掃描方式就為交錯式垂直掃描,圖32 為不同掃描方式的示意圖。 圖 32. 係數掃描方式 決定好掃描方式之後,便開始從位元流中取出 RLD 所需要的參數,係數的解碼利 用查表來實現,其相關的表為 DCT3D [ 2 ] [ 4096 ],且表所儲存的資料結構為 REVERSE_EVENT,其結構成員如表 7,從結構成員可以看出,有四個最主要的參數, last 代表是否為最後一個不為零的係數,0 代表不是、1 代表是,run 的值代表該係數的
前面有幾個零,level 就是此係數真正的值,而 len 值代表該 VLC 的 Huffman Code 碼 長,len 的用途在於更新位元流的位置,藉由這四個參數就可以解出整個 block 的所有 係數值。DCT3D陣列前面的2 代表 intra 或 inter,後面的 4096 儲存了 0 ~ 212 - 1 的所有 值,因為最長的 VLC 長度為 12-bits,所以最長的 VLC 為最大限制,且每個 VLC 均外 加1-bit 儲存正負號。 表 7. EVENT 和 REVERSE_EVENT 的結構成員
資料結構名稱 type name 資料結構名稱 type name
EVENT uint8_t last REVERSE_EVENT uint8_t len
uint8_t run EVENT event
int8_t level
和係數相關的 (run , level , last) 共有 102 種組合,這些組合儲存在 coeff_tab 陣列
中,圖33 為 coeff_tab 的部分陣列元素,因此,DCT3D 透過這 102 種組合對陣列作初
圖 33. coeff_tab 部分陣列元素
始化,初始化的程式碼如圖34 所示,下一段將詳細說明如何利用 102 種組合來建立
DCT3D 陣列的所有元素,而DCT3D為 RLD 解碼所需要的 VLC table。
VLC_TABLE const coeff_tab[2][102] = { // intra = 0
VLC EVENT typedef struct {
code len last run level VLC vlc; { { { 2, 2}, { 0, 0, 1} }, EVENT event;
{ {15, 4}, { 0, 0, 2} }, } VLC_TABLE; { {21, 6}, { 0, 0, 3} }, . . },
// intra = 1 typedef struct { { { { 2, 2}, { 0, 0, 1} }, uint32_t code;
{ {15, 4}, { 0, 0, 3} }, uint8_t len; { {21, 6}, { 0, 0, 6} }, . . }, } VLC;
以圖33 圈起來的部分為例,此時 intra = 0,code = 2 (即 Huffman Code = 10),len = 2 (Huffman Code length) 時,已知最長的 Huffman Code 碼長為 12,但是目前碼長為 2, 因此剩下的 10-bits 便可任意存放 0 或 1,轉換成整數即為 0 ~ 210-1,因此,DCT3D [0] [index] .len = 2 且 DCT3D [0] [index] .event = {0 , 0 , 1},其中 index = 10xxxxxxxxxx, 換成整數為 2048 + (0 ~ 210-1),程式實現部分如圖34。 圖 34. 建立DCT3D 陣列的部分程式碼 DCT3D陣列建立好之後,解 RLD 的步驟,如同先前解 mcbpc (get_mcbpc_intra) 函 數提到的查表法,例如:當目前為 intra,且從位元流中取出的 12-bits 位元資訊為 010101-xxxxxx 時 (xxxxxx 中的 x 表示任意填入 0 或 1),將 12-bits 轉成陣列位置 index, 透過DCT3D 查表得到 DCT3D [1][index].len = 6,DCT3D [1][index].event={ 0, 0, 6 },其 中 index = 010101xxxxxx,接著,就可以透過這些參數來進行解碼。 4. add_acdc() 將先前計算出來的係數預測值 predictors [8],加上 RLD 之後的第一行或第一欄的 係數,並且將加完之後的DC 係數乘上 iDcScaler 參數,然後把 DC 係數以及 AC 係數 的第一行和第一欄 (總共 15 個值),儲存在 blocks 的 dec->mbs.pred_values[6][15] 結構 中,以提供給接下來未解碼的block,計算係數預測值之用。 5. dequant_h263_intra()
此函數為進行反量化 (Inverse Quantization : IQ) 運算的部份,至於反量化的原理是 將各個原始係數除上量化參數後,取最接近的整數,而此量化後的整數就是我們需要傳
for(intra = 0 ; intra < 2 ; intra++){ for(i = 0 ; i < 102 ; i++){
for(j = 0 ; j < (1<<(12- coeff_tab[intra][i].vlc.len)) ; j++){
DCT3D[intra][(coeff_tab[intra][i].vlc.code <<
(12-coeff_tab[intra][i].vlc.len))| j ].len = coeff_tab[intra][i].vlc.len;
DCT3D[intra][(coeff_tab[intra][i].vlc.code <<
(12-coeff_tab[intra][i].vlc.len)) | j ].event = coeff_tab[intra][i].event;
} } }
送的資料,而量化的目的是希望透過量化這個步驟,在影像品質能夠接受的情況下,將
不重要的訊號大小降低,由於DC 係數的值遠比 AC 係數大上許多,因此量化時所使用
的QP 也就不同,所以反量化時,DC 係數使用 iDcScaler 參數,而 AC 係數則使用 quant
參數,而詳細的程式實現如圖35 的 pseudo code 所示,此解碼步驟將 porting 到副核心
SPE 上運作。
圖 35. 反量化的 pseudo code
6. idct()
最後的一個解碼步驟就是反 DCT (Inverse Discrete Cosine Transform) 轉換,而 2-D DCT 的原理為,64 個係數經過 DCT 轉換之後,會將空間域數位影像資料轉換成頻率 域,而DCT 以及 IDCT 的轉換公式如下: otherwise n C m C and n m for n C m C where N n y M m x n m F n C m C MN y x f IDCT N n y M m x y x f n C m C MN n m F DCT M m N n M x N y 1 ) ( ), ( , 0 , 2 1 ) ( ), ( (2) 2 ) 1 2 ( cos 2 ) 1 2 ( cos ) , ( ) ( ) ( 2 ) , ( : (1) 2 ) 1 2 ( cos 2 ) 1 2 ( cos ) , ( ) ( ) ( 2 ) , ( : 1 0 1 0 1 0 1 0 = = = + + = + + =
∑∑
∑∑
− = − = − = − =π
π
π
π
由於 DCT 具有可分離的 (separable) 特性,意思就是說它可以先執行一維離散餘 弦轉換的列運算,再執行一維離散餘弦轉換的欄運算,此時的計算架構具有以乘累加的 DC = DCQ * iDcScalerif ( quant is odd and ACQ !=0 ) |AC| = quant * (2*|ACQ| + 1 ) else if ( quant is even and ACQ !=0 )
|AC| = quant * (2*|ACQ| + 1 )-1 else
AC = 0
if ( coefficient > 2047 ) coefficient = 2047 else if ( coefficient < -2048 ) coefficient = - 2048