行政院國家科學委員會專題研究計畫 成果報告
一個基於開放式網格服務架構的共用記憶體多處理器系統
(第 3 年)
研究成果報告(完整版)
計 畫 類 別 : 個別型 計 畫 編 號 : NSC 96-2221-E-151-018-MY3 執 行 期 間 : 98 年 08 月 01 日至 99 年 07 月 31 日 執 行 單 位 : 國立高雄應用科技大學電機工程系 計 畫 主 持 人 : 梁廷宇 共 同 主 持 人 : 張志標 計畫參與人員: 碩士班研究生-兼任助理人員:王柏森 碩士班研究生-兼任助理人員:羅博仁 碩士班研究生-兼任助理人員:黃進安 碩士班研究生-兼任助理人員:陳敏君 碩士班研究生-兼任助理人員:楊家豪 碩士班研究生-兼任助理人員:徐瑞興 博士班研究生-兼任助理人員:陳聖元 報 告 附 件 : 出席國際會議研究心得報告及發表論文 處 理 方 式 : 本計畫可公開查詢中 華 民 國 99 年 10 月 29 日
目錄
目錄 ...I
圖目錄 ...II
表目錄 ... III
中文摘要: ... IV
英文摘要: ... IV
1
研究目的... 1
2
文獻探討... 1
3
研究方法... 2
3.1
Workflow Editor... 3
3.2
Workflow Monitor ... 4
3.3
Reservation Scheduler ... 5
3.4
未來資源可用度預測 ... 7
3.5
Resource Broker、Agent Server 與 Reservation Server ... 10
4.
效能評估... 12
4.1
預測準確度的評比結果 ... 12
4.2
資源選擇效能的評估結果 ... 14
5.
結論與未來工作... 16
圖目錄
圖 3.1、Teamster-G 系統架構... 2
圖 3.2、Workflow Editor... 4
圖 3.3、Workflow Job 的工作需求資訊 ... 4
圖 3.4、Workflow Deadline 的設定 ... 4
圖 3.5、尚未完成的 Job 狀態 ... 4
圖 3.6、已經完成的 Job 狀態以及執行結果選項 ... 4
圖 3.7、找出所有路徑演算法 ... 6
圖 3.8、Job 的 deadline 設定演算法... 7
圖 3.9、資源可用度預測的軟體架構圖 ... 8
圖 3.10、CPU Workload chain-code... 8
圖 3.11、負載樣式 ... 8
圖 3.12、在設定時段的資源可用度預測 ... 8
圖 3.13、預測時間點的切割 ... 9
圖 3.14、請求 Reservation ID 時序圖... 11
圖 3.15、Reservation table ... 11
圖 3.16、預訂資源的判斷條件 ... 11
圖 3.17、Agent Server 軟體架構... 12
表目錄
表 3-1、sequential 工作需求表單 ... 9
表 3-2、資源在一小時的 40 分鐘內的可用度 ... 9
表 3-3、teamster-g 工作需求表單... 9
表 3-4、預測一小時各個資源 CPU 可用度級數... 10
表 3-5、預測一小時的所有配對組合(Load Balance)執行後的結果 ... 10
表 4-1、實驗環境規格表... 12
表 4-2、CPU 負載預測的 MSE 統計... 13
表 4-3、CPU N-Step 負載預測的 MSE 統計 ... 13
表 4-4、Bandwidth N-Step 負載預測的 MSE 統計 ... 14
表 4-5、模擬各個資源的效能... 14
表 4-6、工作需求表... 15
表 4-7、測量 CASE 的雜訊分配表 ... 15
表 4-8、CPU_0-BW_0、CPU_0-BW_10%、CPU_0-BW_20% ... 15
表 4-9、CPU_10-BW_0、CPU_10-BW_10%、CPU_10-BW_20% ... 16
表 4-10、CPU_20-BW_0、CPU_20-BW_10%、CPU_20-BW_20% ... 16
中文摘要:
本實驗室已經成功地為 Teamster-G 開發一個 Workflow 的管理系統,讓使用者可以容易地在 計算網格上管理與執行自己的 Workflow。然而 Teamster-G 過去並不支援 QoS。但是對服務導 向的系統,維護系統的 QoS 是一項重要的議 題。為此本計畫第三年的工作目的即是在解決 Teamster-G 的 QoS 問題。以往的相關研究經常 採用預訂資源保留的方法來維護系統的 QoS, 卻因其所提出的方法並沒有將資源未來的可用 度納入考量,而導致系統的工作服務品質不 佳。為此,我們設計了一套基於未來資源可用 度的資源預留方法,並實現於 Teamster-G 的 Workflow 管理系統中,以維護在 Teamster-G 上 執行 Workflow 的服務品質。本報告主要內容在 介紹完整的 Teamster-G 系統架構,以及為維護 QoS 所開發的相關機制與演算法。關鍵字:
Teamster-G、服務品質、預留排程器、 資源可用度英文摘要:
We have successfully developed a workflow management system on Teamster-G for users to manage and execute their workflow jobs. However, the problem of QoS on Teamster-G has not been resolved. Since it is very important issue for a service-oriented grid system, the goal of our work in the third year of this project is aimed at the problem of QoS problem in Teamster-G. Although there are many related studies proposed methods for the QoS problem of Grids, all of these methods do not take future resource availability into account. As a result, the QoS of user jobs was not effectively maintained due to dynamic resource availability. To overcome this drawback, we are aimed at design and implementation of a resource reservation scheme based on future resource availability for the workflow jobs in
Teamster-G. In this report, we will introduce the whole system framework of Teamster-G, and the resource reservation scheme and algorithm proposed for QoS of workflow jobs.
Keywords: Teamster-G、QoS、Reservation Scheduler、Resource availability
1 研究目的
本研究團隊(KUAS and NCKU-HPDS Labs) 在國科會的計畫經費補助下,成功開發一個基 於 OGSA 架 構 的 計 算 網 格 系 統 , 稱 為 Teamster-G[1][2]。此系統可讓使用者利用共用 記 憶 體 系 統 (Distributed Shared Memory System,DSM)[3][4][5][6]的程式介面 Pthread 和 OpenMP 開發平行的網格計算與應用,並且提供 資源選擇、配置與重組的服務,使得使用者的 程 式 獲 得 較 佳 的 執 行 效 能 。 然 而 卻 因 為 Teamster-G 並不適用於 Workflow 的工作模式, 使得使用者在提交工作時,必須自行控制工作 的分派順序,這對於 Workflow 工作模式的開發 與應用造成很大的不便。 為 了 解 決 這 個 問 題 , 本 實 驗 室 為 Teamster-G 設計與實現一套 Workflow 管理系統 [7]。透過此系統服務,使用者可以透過視窗介 面 上 自 訂 編 輯 Workflow 以 及 立 即 追 蹤 Workflow 執行的狀態。另一方面,Workflow Scheduler 會自動為 Workflow 的工作進行排 程,將工作提交給 Teamster-G 的 Broker 進行資 源的挑選與配置。此 Broker 會根據使用者自訂 的工作需求與資源未來可用度的預測來進行資 源配置,並將 Workflow 的工作分派至配置的資 源上執行。由此可知,Teamster-G 已經可以有 效地支援 Workflow 的工作。 為了使整個系統更加完善,本實驗室在第 三年研究目標將著重於系統的 QoS 維護。我們 在 Teamster-G 的 Workflow 管理系統上,設計 與實現一套基於資源未來可用度預測[8]的預先 資源保留(Advance Resource Reservation)機制, 讓 使 用 者 在 管 理 介 面 上 設 定 Workflow 的 Deadline 。 當 使 用 者 提 交 Workflow 後 , Reservation Scheduler 則會為此 Workflow 裡 的 每一個 Job 設定合適的 Deadline。其方法基本上 是根據 Job Path 的權重值與 Job 的工作需求量來 決定分配 Deadline 的優先權及大小,並將計算 出 來 Job Deadline 再 縮 短 20% 作 為 最 後 的 Deadline。其目的是為了讓 Workflow 即使在資 源 可 用 度 變 化 超 乎 預 期 時 , 仍 能 順 利 地 在 Deadline 之前完成。在完成 deadline 分配後,系 統會將整個 Workflow 提交給 Broker 來進行資 源的挑選與預訂保留,而 Broker 則會藉由一套 支 援 長 程 (long-termed) 資 源 可 用 度 預 測 的 機 制,來進行資源保留。此資源可用度預測的機 制能夠依照 Broker 提供的起始時間及 Deadline 長度,針對符合使用者需求的計算資源進行未 來可用度的預測。Broker 會根據預測的資源未 來可用度、Job 的 Deadline 和工作需求量來為每 一個 Job 預留最合適的計算資源。 本篇成果報告後續的內容將安排如下:第二 章相關研究。第三章研究方法。第四章效能評 估。第五章結論與未來研究。
2 文獻探討
過去的研究中,曾對於 Advance Resource Reservation 排程議題提出一些方法。例如:澳洲 墨爾本大學 Rajkumar Buyya 與 Chen Khong Tham 提出一套配置 Workflow Deadline 的排程 方 法 稱 為 STS(Synchronization Task Scheduling)、BTS(Branch Task Scheduling)[9]以 及重新排程機制。此方法會尋找出 Workflow Task 的任務屬性,並將其歸類為 Synchronization Task 或 Simple Task。所謂的 STS 是針對其 Parent 或 Child 有兩個以上的 Task 進行 Deadline 配置。至於 BTS,則是一個 Branch 的 Deadline 排程。此 Branch 為兩個連續的 Simple Task。BTS 排程方法有較佳的 Deadline 調整空間,當 Job 的執行時間有可能超出 Deadline 時,可即時透 過重新排程機制調整其 Child Job 的 Deadline 長 度來避免影響整個 Workflow Deadline。雖然此 機制的考慮相當完善,但是其研究方法在排程 時並沒有考慮資源的動態性與未來可用度的變 化,導致必須依賴其後續動態的重新排程來彌 補資源動態性所造成的效能損失。即使他們透 過重新排程來改善效能損失,卻因為重新排程 也未考量資源本身的動態性負載變化,所以重 新排程方法所得的效益相當有限,甚至會引發連鎖的工作遷移而使整個 Workflow 的 Deadline 大幅度延遲。
日 本 東 京 的 Grid Technology Research Center 也 曾 提 出 的 一 套 支 援 Advance Reservation 的 Local Scheduling System 機制,稱 為 TORQUE[10][11]。它是基於 OpenPBS 而開 發 出 來 的 , 其 架 構 是 由 多 個 PBS 的 local Scheduler、PBS Server 以及 Scheduler Module 所組成。其 Scheduler 是一個簡單的 FIFO 排程, 並實作一套 Scheduler Module 與 PBS Server 之 間的溝通介面。此機制基於 GT4(Globus Toolkit 4)[12][13]的 container 實作了一個 Web Service 系統。整體架構都遵循著 WSRF[15]的標準規範 而增加其架構延展性,對於系統的擴展性幫助 甚大。
相較之下,本研究所實現的 Workflow 管理 系統提供了更完整的管理服務,包括 Workflow 編輯、Workflow 監視以及 Resource Reservation 的狀態訊息等功能,並基於 GT4 架構且遵循著 WSRF[14]的標準規範建構而成。更重要的是我 們所提出的 Advance Resource Reservation 排程 機制能夠有效的配置較適當的 Deadline 長度給 予 Workflow Job,並且基於資源未來可用度預 測的機制,而更有效地維護系統的工作服務品 質。
3 研究方法
在第一年的研究計畫中,本實驗室已經將 Teamster-G 演進成為符合 OGSA 架構的計算網 格系統,並且於第二年成功為 Teamster-G 系統 設 計 與 實 現 一 個 Workflow 管 理 系 統 。 此 Workflow 管理系統主要包含 Workflow Editor、 Workflow Monitor 與 Workflow Scheduler。使用 者須登入 Teamster-G 的 Web Portal 並利用 Workflow 編輯器來定義 Workflow 的各個 Job 參數。在執行期間,Workflow Scheduler 會自動 為使用者編輯的 Workflow 進行排程,並與 Teamster-G 的 Broker 合作將工作分派至遠端的 資源上執行。其執行期間,使用者可以透過Workflow Monitor 即時的追蹤其 Workflow 執行 狀態。為了讓使用者的 Workflow 獲得更好的工 作 服 務 品 質 , 本 實 驗 室 在 第 三 年 以 維 護 Workflow 工作的 QoS 為首要目標。為了達到這 個目的,我們採取本實驗室所開發的一套長時 程資源未來可用度預測機制作為選擇預留資源 的 依 據 。 圖 3.1 為 整 合 三 年 研 究 成 果 的 Teamster-G 系統架構圖。 圖 3.1、Teamster-G 系統架構
Teamster-G 是使用 Globus Toolkit 4 所開發 出來的網格系統。此系統基於 OGSA 概念,並 且遵循 WSRF 的標準規範。其中主要單元有 Workflow System、Resource Broker、資源可用 度預測、Reservation Server、Agent Server 與 Local Scheduler。而整個系統流程步驟可分為下 列項目:
1.1 使用者透過 Workflow 管理系統的 Portal 介 面進行申請專屬的帳號密碼。
2.1 使用專屬帳密登入後,利用 Workflow 管理 系統的 Workflow Edit 自行定義 Workflow Job 參數與設定 Workflow Deadline。
3. 將 編 輯 完 的 Workflow 提 交 給 Workflow System , 此 時 系 統 會 透 過 Reservation Scheduler 來為每個 Job 進行 Deadline 的配 置。此 Reservation 排程器會根據 Workflow Path 的權重值與 Job 的工作需求量來決定分 配 Deadline 的優先權及大小,並且將配置完 畢的 Workflow 提交至 Resource Broker。
4. Resource Broker 接收到 Workflow 系統的資 源預訂要求後,會立即向 Resource Monitor 詢問是否有適合的資源可用。
5. 此時 Resource Monitor 會根據 Job 的 CPU 與 Memory 需求來篩選符合的計算資源,並且 透過 Job 的起始時間與 Deadline 長度來進行 資源未來的可用度預測,然後將符合條件的 資源之未來可用度回覆給 Broker。 6. Broker 再依照這些資源可用度由低到高進 行資源預訂,此時 Broker 會根據 Job 的起始 時間與 Deadline 長度來詢問遠端的計算資 源,在未來此段時間是否可預訂保留。 7. 而 Reservation Server 會確認此段時間是否 為空閒時段。如果是,則為此 Job 配置 Reservation ID,並將此 ID 與所預定的時間 段紀錄於 Reservation 表單,同時將此 ID 回 覆給 Broker;如果否,則拒絕 Broker 的資源 預訂要求。 8. Broker 如果接收到預訂成功的訊息,則會將 Reservation ID 紀錄在 Workflow 表單,然後 繼續為下一個 Job 進行資源預訂。如果接收 到拒絕的訊息則從可用度表單中詢問下一 個計算資源是否可預訂。直到所有 Job 都預 訂 成 功 後 , 將 傳 回 完 成 預 定 的 訊 息 給 Workflow 系統;反之,將傳回預定失敗的訊 息。 9. Workflow 的資源預訂完成之後,系統會依照 Job 的起始時間將其提交至指定的計算資源 執行工作。若是 Workflow 資源預定失敗, 則會回覆預訂失敗的訊息給使用者。 10. 遠端的計算資源由 Agent Server 接收系統執 行工作的要求,此程序會先驗證 Job 的 Reservation ID,然後再命令 Local Scheduler 管理者將 Job 提交至機器上進行運算。在執 行過程中,Agent Server 會將 Job 的執行狀 態回覆給 Workflow 系統;直到此 Job 執行 完畢,則將執行結果傳回 Workflow 系統。 11. Workflow 系統則會將 Job 的執行狀態與執 行結果展示在 Workflow Monitor 介面上,而 使用者可以從此介面上得知整個 Workflow 運行的情況,亦可從此介面上獲得執行結 果。 以下我們將針對此 Teamster-G 系統架構的 主要單元,將其實作方法做詳細的介紹。而 Workflow System 又 可 細 分 為 Workflow Editor 、 Workflow Monitor 與 Reservation Scheduler。
3.1 Workflow Editor
Workflow Editor 是參考國家高速電腦與網 路中心的 Liferay Project 所設計的介面。Liferay Project 為高速計算與電子商務網站的開發平 台。此網站平台上,透過 Eclipse 軟體撰寫 JSP 語法與 Java Core 來完成此介面的實作。此 Workflow Editor 介面如圖 3.2 所示。每當新增完 一個 Job 後,按下介面上的 Add Button 按鈕來 進行此 Job 參數的儲存。系統會自動列出目前 完成編輯的所有 Job 參數資訊(如圖 3.3 所示), 並 且 讓 使 用 者 選 擇 繼 續 新 增 Job 或 者 進 行 Workflow Deadline 的設定(如圖 3.4 所示)。當使 用者想針對某個 Job 做修改時,則可以在 Job 資訊的欄位中按 Edit 鈕來進行此 Job 的參數修 改;或者選擇 Del 按鈕刪除此 Job。修改完畢後 則可以選擇 Save Button 將此 Job 的參數資訊更 新。以下為 Job 的參數設定說明:
z Job ID : Job 的執行辨識碼 z Job name : Job 的執行檔案名稱
z CPU Count : 執行此 Job 所需要的 CPU 個數
z Job Parent : Job 的 Parent Job,必須填寫 Parent Job 的 Job ID
z Job Childset : Job 的 Child Job,必須填寫 Child Job 的 Job ID
z Memory Size : 執行此 Job 所需要的記憶 體需求量
z CPU Size : 執行此 Job 所需要的 CPU 核 心頻率
z Job Size : 此 Job 的工作需求量
z Job Type : 此 Job 的工作類別,可為 Sequence 或 Parallel 程式
圖 3.2、Workflow Editor 圖 3.3、Workflow Job 的工作需求資訊 圖 3.4、Workflow Deadline 的設定
3.2 Workflow Monitor
當使用者編輯完 Workflow 後,便可以由此 介面來追蹤 Workflow 的執行情況。此 Workflow Monitor 可透過 Search 與 Select 按鈕來挑選過去 曾經執行過的 Workflow 或目前正在執行的 Workflow,然後從介面上觀看所有 Job 的狀態 與執行結果,如圖 3.5 所示。當使用者想要更新 資訊時,便可選擇 Refresh 按鈕將 Workflow 資 訊更新為目前當下的 Workflow 情況。另外,使 用者如果想查看 Job 的執行結果,選擇 Output 按鈕即可,如圖 3.6。此 OutPut 按鈕只能在 Job 狀態為 Finish 時才會列出,並且會開啟新視窗 秀出 Job 執行結果。 圖 3.5、尚未完成的 Job 狀態 圖 3.6、已經完成的 Job 狀態以及執行結果選項3.3 Reservation Scheduler
資源預留排程器是基於貪婪演算法(Greedy algorithm)所發展出來的,並且使用 Java Core 撰 寫其程式碼。首先,此排程器會找出此 Workflow 所有可能的路徑,然後再針對 Workflow 裡面的 所有 Job Path 權重值來決定 Job Deadline 配置的 順序。最後,再根據 Workflow Deadline 來為每 條 Workflow Path 上的 Job 配置適當的 Job Deadline。因為優先權較高的 Workflow Path 上 的 Job 可能會再度出現於優先權較低的路徑 上 , 所 以 排 程 器 在 為 此 路 徑 上 的 Job 配 置 Deadline 時,必須檢查其 Parent Job 與 Child Job 是否已經配置過。如果其 Parent 或 Child 已經完 成 Deadline 配置,則此 Job 的起始時間會取決 於 Parent 的 End Time,而此 Job 的 End Time 則 取 Child 的起始時間為其值。如果此 Job 有多個 Parent 和 Child 已經完成 deadline 配置,則排程 器會從 Parent 當中挑選出最晚的 End Time 為 此 Job 的 Start Time。同理,如果多個 Child 已 經完成 deadline 配置,則從 Child 當中挑選出最 早的 Start Time 為此 Job 的 End Time。 為了使 排程器更有效率地執行,我們利用資料結構的 概念來撰寫演算法,並且證明由 50 個 Job 組成 的 Workflow 找出所有可能的路徑總數約 1 千 3 百多組左右,在系統為 Ubuntu-8.0.4、Core2 核 心以及 2Gb 的 DDR2 記憶體測試下,找出所有 路徑以及為所有 Job 配置 Deadline 所花費的時 間大約 280~320 毫秒。此排程演算法的詳細流 程如下圖所示,我們可以將整個演算法分成找 出所有可能的路徑、設定 Job Deadline 以及資源 可用度預留的保護措施。 A. 找出 Workflow 所有可能的路徑演算法 以下是尋找所有路徑演算法的參數說明 1. WT:_存放 Workflow 所有 Job 資訊的容器
2. Jid:_Job 的 ID,每個 Job 都以此 ID 當作辨
識碼 3. InDegree:_Job 的 Parent 數量 4. OutDegree:_Job 的 Child 數量 5. Q:_FIFO 的佇列,用來存放 InDegree 為零 的 Job 6. e:_為索引值,代表 Job 的位子
7. Js:_Job 的工作需求量,意即 Job Size
8. path:_索引值,其值取決於 p 的 size 9. p:_記錄所有路徑的 Vector 10. s:_記錄每個路徑的工作需求量,為一個 Vector 11. Jp:_記錄所有會出現此 Job 的路徑,為索引 值 12. Jc:_此 Job 所有的 child 找出所有路徑演算法是根據貪婪演算法再 加以修改,如下圖 3.7 所示。它必須在開始之前 做些預備的工作,如程式第 1-5 行所示,讀取 Workflow 表的 Job 資訊,然後依照其 Job id 順 序置入 Vector 存放,並且計算所有 Job 的 InDegree 與 OutDegree,意即 Job 的 parent 與 child 數量。最後再將 InDegree 值為零的 Job 置入 Q, 而 Q 為 FIFO 特性的佇列,它存放的值為 Job 資訊存放於 Vector 的位子(意即索引值,演算法 裡面都根據索引值找出其相對映的位子)。以下 的程式碼則是開始進行所有路徑的生成。首 先,我們必須先確定佇列 Q 不為空才繼續尋找 路徑,否則停止尋找路徑。從 Q 裡頭拿出第一 個值之後,藉由此值從 Vector 容器尋找相對映 位子的 Job 是否為 entry job(意即沒有 parent job)。圖 3.7 的 9-13 行則為 entry job 時的該執行 的動作,它會去取得此 entry job 的 Job id 和 Job size(工作需求量),然後建立一組新的生成路徑 記錄於 vector p。而 p 會根據此 vector 目前的 size 來當作最新生成路徑的索引值。例如:假設目前 vector p 的容器大小為 2,則記錄路徑的索引值 有 0 與 1(意即 p[0]、p[1]兩條路徑)。如果現在 必須建立一組新的路徑,則程式會取 vector p 目前的 size=>2 當作是新生成的路徑 p[2],最後 將此 entry job 的 Job id 記錄在此生成的路徑 p[2] 內。另外,我們也依照 vector p 的索引值位置對 映至 vector s 來累加每條路徑的工作需求量。而 且每一個 Job 的資訊裡會記錄所有出現該 Job
的路徑(例如:p[0]=>1/2/4、p[1]=>1/3/4,p[0]這 條路徑有 Job1、Job2、Job3,p[1]則有 Job1、Job3、 Job4,在 Job1 的資訊裡就會記錄路徑的索引值 0 以及 1,Job2 則會記錄索引值 0,而 Job3 會記 錄索引值 1)。 接著從 Q 佇列取出的索引值 e,對映至 Jp[e]記 錄出現過該 Job 的路徑(其儲存的值為 vector p 的索引值)。我們以 pathIndex 來暫時存放 Jp[e] 的值,並且以迴圈方式針對 pathIndex 裡每一個 索引值來繼續路徑的生成。如圖 3.7 的第 14-31 行。各別為取出迴圈 pathIndex 的一個路徑索引 值 path、得知此 Job 的所有 child 以及此路徑的 工作需求量 s[path]。之後我們再將每個 child 加 入此路徑,並且同時將 child 的工作需求量累加 至記錄路徑工作需求量大小的 vector s。每當一 個 child 加入至路徑之後,必須將此 child 的 InDegree 值減 1,直到為零則將此 child 放入 Q 佇列(表示此 child 的所有 parent 生成的路徑都已 經加入 child 了)。另外,程式碼也會判斷是否在 此 Job 之 後 , 會 變 成 分 叉 路 徑 。 我 們 藉 由 OutDegree 值來判斷此 Job 的路徑之後,是否必 須生成另一條路徑(OutDegree 表示此 Job 的 child。如果 OutDegree 值為 2 以上,則表示此 Job 之後有兩條路徑),直到所有 child 做完路徑 生成以及 Q 佇列為空,則表示所有可能路徑已 經全部生成。 圖 3.7、找出所有路徑演算法 B. 為每一個 Job 設定 Deadline 演算法 以下是 deadline 配置演算法的參數說明 1. T:_Workflow 的 Deadline 2. heap:_Binary Heap 的排序器 3. S:_路徑的工作需求量,為一個 Vector 4. P:_所有路徑組合的 Vector 5. PathSize:_從 Heap 取出的最大工作需求 量 6. Path:_從 Heap 取出最大的工作需求量 路徑,其記錄的索引值位子
7. Out:_存放 OutDegree 的 Vector 8. jobEndTime:_記錄 Job 的截止時間 9. jobFirstTime:_記錄 Job 的起始時間 10. foremost:_ 在 此 Job 所 有 已 經 完 成 deadline 配置的 child 中,起始時間最 早 的 first time 11. aftermost:_ 在 此 Job 所 有 已 經 完 成 deadline 配置的 parent 中,截止時間最 晚的 end time
12. jobDeadline:_記錄每個 Job 的 deadline 時間長度 13. unFinishJob:_尚未完成 deadline 配置的 job 數量 在進行 deadline 配置之前,程式會先執行 所有路徑的工作需求量排序工作,如圖 3.8 第 2-4 行所示。我們採用 Binary Heap 的排序方式, 亦即使用 binary tree 方式來進行排序的堆積資 料結構。藉由此排序法可以更加快速地從大量 的路徑組合中,挑選工作需求量最大的路徑。 每次挑選出最大工作需求量的路徑時,此排序 器便會進行調整,並且將目前排序器的最大工 作 需 求 量 的 路 徑 放 至 排 序 器 的 頂 端 ( 意 即 root),讓每次進行路徑組合取出時都會是目前 排序器當中工作需求量最大的路徑。挑選出路 徑組合之後,我們必須為這組路徑的 deadline 以及 path size 進行調整。其調整方式是確認在 此路徑組合中已經完成 deadline 配置的 job,將 其 job deadline 以及 job size 的部分扣除掉,然 後用路徑剩餘的 deadline 總數配合 path size 與
job size 的比例來分配 deadline 給其餘的 job,如 圖 3.8 的 5-23 行所示。對於 job 截止時間的設置 方式,取決於此 job 所有已經完成 deadline 配置 的 child 當中,以最早執行的 child 的起始時間 為此 job 的截止時間,而此 job 的起始時間,則 由截止時間扣除掉 job deadline 為預設的起始時 間。但預設的起始時間必須與此 job 所有已經完 成 deadline 配置的 parent 之最遲的 end time 相比 較。若前者較遲,則取決於前者;反之,則取 決於後者。如圖 3.8 的 15-20 行所示。 圖 3.8、Job 的 deadline 設定演算法 C. 過度資源可用度預留的保護措施 為了避免資源可用度預測的誤差,而造成 整體 Workflow 工作的完成時間超過 Deadline, 我們採用過度資源可用度預留的措施,意即選 擇預留的計算資源,必須比工作實際需求還要 多 20%,才會被成為資源預留的對象。此措施 之用意,是為了當計算資源可用度的變化突然 超出我們的預測時,只要資源可用度的誤差不 要太大,工作仍能在原先設定 Deadline 之前完 成 。 所 以 在 Reservation Scheduler 完 成 Job Deadline 的設定之後,會對每一個 Job Deadline 進行資源可用度預留的保護措施,將其 Deadline 縮短 20%。而 Resource Broker 會根據此 Deadline 為預測資源可用度時所需要的條件參數,向 Resource Monitor 詢問符合 Job 需求條件的資 源,然後從這些滿足 Job 需求條件的資源進行 篩選。之後 Resource Broker 會依照的 Start Time 以及 End Time 的時間去詢問篩選到的資源是否 在這段時間可以預訂保留。值得一提的是在 Workflow table 當中每個 Job 都有 Deadline,排 程器只會資源預留時將 Job Deadline 提早 20% 作為資源挑選的條件,但是 Job 的 Start Time 和 End Time 並沒有改變。
3.4 未來資源可用度預測
Workflow 系統在進行計算資源配置以前, 會先使用 Resource Monitor 系統去預測在未來 某段時間計算資源的可用度。其預測資源可用 度所需要的條件參數則是由 Resource Broker 傳 送給 Resource Monitor(如圖 3.9),而此條件內容 為 Job 需求的 Start time、Deadline、CPU 核心頻 率、Memory Size、CPU 核心數、執行的回合數 以及每回合的網路傳輸量,然後再由 Resource Monitor 啟動 Predictor 服務預測資源可用度。 Predictor 會查詢由 Probe 與 Data Miner 所收集且 探勘過後的資源工作負載資訊,然後根據 Job 的 需 求 條 件 預 測 資 源 未 來 可 用 度 , 並 且 由 Resource Monitor 將這些資源的可用度回傳給 Resource Broker,由 Broker 來篩選資源且進行 預訂。Resource Broker 會將這些資源由高的可 用度到低來排序,並且會優先挑選可用度最低 的資源進行與 Job 的工作需求量比較與預訂。 而被挑選的資源必須能夠滿足 Job 的工作需求 量(job size),Broker 才會視其為合適此 Job 的資 源,並且詢問此資源是否在未來的某段時間可 預訂保留。而資源必須滿足以上所述的兩個條 件(滿足 job size 以及資源在 Job 指定的那段時間為 free),此 Job 才算是完成 resource reservation。 反之,只要兩者其中一個條件不成立,則 Broker 會挑選可用度次低的資源進行兩個條件比對。 如果在這個資源可用度排列中並無同時滿足兩 者條件的資源,則系統會拒絕使用者的資源預 訂請求,且由 Broker 回覆資源預訂失敗訊息給 Workflow 管理系統。 圖 3.9、資源可用度預測的軟體架構圖 以下我們將介紹此機制的預測方式並且舉例說 明。此機制會根據每天收集的資源 load 狀態, 將此 Load 狀態轉換成 Workload chain-code,如 圖 3.10 所示。
圖 3.10、CPU Workload chain-code
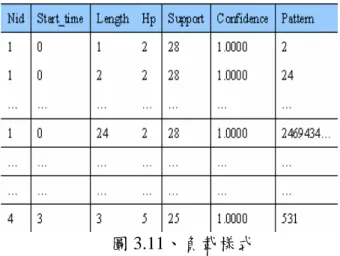
然後由 chain-code 表找出每一個時段在過去的 load 紀錄中,出現次數最多的 pattern,如圖 3.11
所示。
圖 3.11、負載樣式
我們必須藉由 Resource Broker 的請求,從 Job 起始時間至截止時間之間的時間長度以每小時 為單位切割成片段。然後再針對每一個片段中 的執行時段所佔的部份,從負載樣式中尋找相 符合的 load pattern。再利用下圖所示(圖 3.12) 的紅色公式算出此計算資源在這小時所能提供 的可用度,直到累加完每個片段可提供的可用 度為止。 圖 3.12、在設定時段的資源可用度預測 以下我們舉個例子說明,假設目前時間為 12:00 且 Job 的 Start time 為 12:10,而 deadline length 為 40 分鐘。依照假設條件,我們可將切 割為一個時間片段(以小時為單位),如圖 3.13 所示。Deadline length 佔一小時的 2/3(40 分鐘/60 分鐘)。另外,假設其第一小時的 load pattern 為
2。則計算可用度為下列公式:
z 總 可 用 度 =confidence*(free-level)*Cmax* 一 小 時的秒數*(Deadline 權重值)
¾ confidence=>load pattern 出現的機率(此 load pattern 出現次數最多)
¾ free-level=>可用度的單位為 0-9(load 為 2,則
free 為 9-2=7)
¾ Cmax=>此 CPU 的最大計算量(即 CPU 為 idle
的時候)
¾ Deadline 權重值=>deadline length 在這小時所
佔的比例(40 分鐘/60 分鐘)
圖 3.13、預測時間點的切割
以下我們將介紹 Resource Monitor 預測系 統針對 sequential type 與 Teamster-G type 的資源 可用度預測以及 Resource Broker 的資源配置。
A. Sequential Type
假設目前時間為 12:00,而 sequential type 的 Job 工作需求表如表 3-1:S-T 表示為 Start Time。D-L 表示為 Deadline Length。E-T 表示為 End Time。 N-S 表示為 Node Sum。 表 3-1、sequential 工作需求表單 Start Time 12:10 Deadline Length 40 分鐘 End Time 13:00 Node Sum 1 CPU Request 1.4GHz Memory Size 512MB Job Size 1300MIPS
那我們的 Resource Monitor 系統的 Predictor 會 將滿足 Job 工作需求的資源(滿足 CPU speed、 Memory size 的使用量需求),評估其未來一小時 的可用度(start time 加上 Deadline Length 為 50 分鐘,以一小時為最小單位,所以取一小時為 評估的時間長度。)。Broker 由可用度最低至最 高的資源開始進行 Job 工作需求量比對與資源 預訂,直到有資源能滿足這兩個條件,否則 Broker 就回覆預訂保留失敗的訊息給使用者得 知。 表 3-2、資源在一小時的 40 分鐘內的可用度 Site ID CPU Speed CA(可用度)
1 1.8GHz 7400MI
2 1.6GHz 6200MI
Site2 的 Node 可用度 CA 為 6200>Job Size 為 1300,則 Broker 會詢問 Site2 的這個資源在 12:10-13:00 是否為 free 狀態。如果是 free 的話, 則可以預訂資源這段時間的使用權;反之,則選 擇次低可用度的資源並且比對上述兩個條件。 假設這些資源都無法滿足上述兩個條件,Broker 會發出 reject 的訊息給 Workflow Server 給使用 者得知。
B. Parallel Type
假設目前時間為 12:00,而 Parallel type 的 Job 工 作 需 求 表 如 表 3-3:D-L 表 示 為 Deadline Length。 表 3-3、teamster-g 工作需求表單 Start Time 12:10 Deadline Length 40 分鐘 End Time 13:00 Node Sum 3 CPU Request 1.5GHz Memory Size 1024MB
Job Size 1500MIPS
Iteration 50 BW 80Mb
我們舉例子來說明 Parallel Type Job 的資源 配 置 方 式 , 假 設 目 前 有 一 個 工 作 需 要 3 個 Node、CPU 頻率為 1.5 GHz、總共需執行 50 回 合以完成此工作。而在每一回合的計算時間與 通訊時間將設定分別為 40(sec)與 30(sec),以實 際標準的網路傳輸率 50Mbps 為基準。依照此工 作的需求,套入式 3-1 與式 3-2 的公式,即可計 算出此工作的計算需求量(CP)和通訊需求量 (CM)。 其中 CPU 頻率為 1.5GHz=1500MHz,假設 CPI 值為1時,表示一個指令執行完成需要1個 脈波(clock),由此可知 1500MHz=1500MIPS。 則 計 算 結 果 以 工 作 一 回 合 的 需 求 為 CP=180000(MI)、CM=3000(Mb)。 CP(MI)=CPU 計算能力*所需資源數量*總回合 數*每回合的計算時間…[式 3-1] CP(Mb)=網路傳輸率*總回合數*每回合通訊時 間…[式 3-2] CP=1500(MIPS)*3(node sum)*50(iteration)*40( sec)=9000000(MI) CM=100Mbps*50(iteration)*30(sec)=150000(Mb) 以表 3-4 所示為目前所提供的資源 CPU 可 用度級數,主要表示預測的那個小時各個資源 CPU 效能的可用度級數,然後從每一個 site 中 挑選出可用度最高的 3 個 node 資源為一組合, 並將每一個 site 的組合排序,如表 3-5。 表 3-4、預測一小時各個資源 CPU 可用度級數 首先,計算出每一個組合的工作計算量與 網路傳輸量,並且將最高可用度的組合回傳給 Resource Broker,由 Broker 將可用度與工作需 求量比較是否滿足。 表 3-5、預測一小時的所有配對組合(Load Balance)執行後的結果 我們可以算出這個例子最低可用度的資源組 合,其計算量與通訊量如下: Site1: 計 算 量 =>0.8*[(6+5+4)×1600]÷9×3600 ( sec ) =7680000 (MI) 通訊量=>1*100Mbps×3600= 360000(Mb) 因 為 7680000(MI)<Job 的 工 作 需 求 量 9000000(MI),所以繼續挑選次高可用度的 Site2 組合。 Site2: 計 算 量 =>1*[(9+9+6)×1800]÷9×3600 ( sec ) =17280000 (MI) 通訊量=>1*100Mbps×3600= 360000(Mb) 由 於 17280000(MI)>Job 的 工 作 需 求 量 9000000(MI),因此若 Site2 的 Node1、Node5、 Node7 資源在 12:10-13:00 為 free,則資源預訂 成功。
3.5 Resource Broker 、 Agent Server 與
Reservation Server
在 此 , 我 們 將 介 紹 Resource Broker 、 Reservation Server 以及 Agent Server 之間的關 係,如圖 3.14 所示。系統會將 Reservation ID 以 及 預 訂 的 資 源 名 稱 位 置 透 過 Broker 回 傳 給 Workflow Server,然後 Workflow Server 將 Job
提交至指定的計算資源上的 Agent Server。而計 算 資 源 會 由 Agent Server 來 驗 證 此 Job 的 Reservation ID 是否合格,合格則啟動底層服務 來進行 Job 的執行以及管控。反之,則拒絕 Job 的請求服務。
圖 3.14、請求 Reservation ID 時序圖 至於資源提供端的資源與工作管理方面,則由 Reservation Server 與 Agent Server 分別負責。為 了實作預訂資源保留,紀錄計算資源各時段的 預約時間將成為不可或缺的程序。為此我們採 用 MySQL 為紀錄預約時間的表單資料庫,而 Reservation Server 即是此 Reservation table 的管 理者。Reservation table 的內容如圖 3.15 所示。 Job ID 為 Job 在 Workflow 的辨識碼,而 Start Time 與 End Time 分別是預訂的起始時間以及 截止時間。Reservation ID 則是整個系統用來辨 別 Job 預定資源的根據。往後欲執行 Job 時,必 須根據此 Reservation ID 來決定是否可使用此資 源服務,其 ID 是由 Start Time 與 End Time 組 成,所以必定是唯一的。 圖 3.15、Reservation table 另外,在預訂之前我們必須先透過以下的 判斷步驟來決定此 Job 的預訂請求是否可行, 方可達成資源預訂而建立 Reservation ID。圖 3.16 為 Reservation Server 判斷是否可預訂資源 的流程圖。其判斷式可分為以下五個步驟: 1. 欲將執行預訂資源的 Job,其起始時間不在 資料庫內任何一組已經達成預訂的時間段 範圍內。條件成立則繼續步驟 2,不成立則 跳至步驟 5。 2. 欲將執行預訂資源的 Job,其終點時間不在 資料庫內任何一組已經達成預訂的時間段 範圍內。條件成立則繼續步驟 3,不成立則 跳至步驟 5。 3. 在資料庫內任何一組已經達成預訂的時間 段不在即將預訂的起始至終點的時間段範 圍內。條件成立則繼續步驟 4,不成立則跳 至步驟 5。 4. 建 立 專 屬 於 此 Job 的 唯 一 識 別 碼 Reservation ID 於 Reservation 表單內,並且 將此 Reservation ID 告知 Broker,而往後計 算資源根據此 Reservation ID 來認定此 Job 是否有權使用本地端的運算資源。 5. 拒絕 Broker 的資源預訂要求。 圖 3.16、預訂資源的判斷條件 在多個運算資源分擔執行同一工作時,如 何依照 Job 需求的資源數量來切割其工作量給 各個運算資源執行,以及將各個運算資源所執 行完的結果合併回傳是必須解決的問題。所幸 地,Teamster-G 可自動為 Job 工作量分散至運 算叢集下的計算資源執行,並且能將各個資源 運算所得的結果合併回傳。為了能夠管理 Job 的工作情況,如錯誤處理或狀態回報等,以及 適應各種不同 Local Scheduler 的考量下,我們 利用 GT4 的 GRAM(Globus Resource Allocation Manager)機制來作為 Workflow Server 與 Local
Scheduler 之間的溝通管道。GRAM 是網格環境 中任務執行的中心,其負責遠端資源需求的處 理、任務的分配、排程以及管理。它使用自己 的 資 源 定 義 語 言 (Resource Specification Language-RSL)與本地的 Local Scheduler 以及計 算資源進行聯繫溝通。
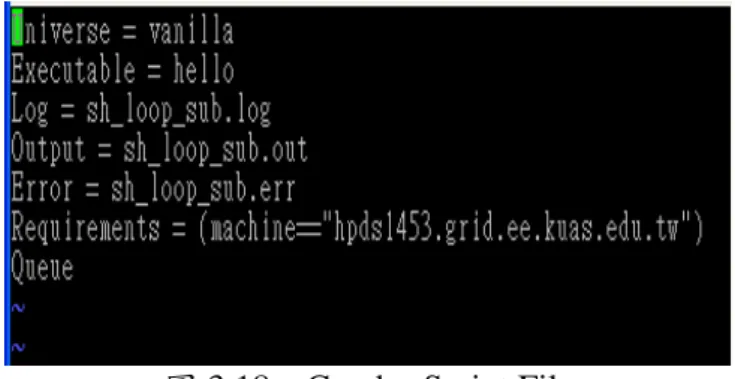
在 Teamster-G 的架構下,Agent server 的工 作主要再於啟動工作的執行並將執行狀態回報 給 Workflow Monitor。其過程如圖 3.17 所示, Agents Server 會 透 過 Globus 的 High-Level Services and Tools 階層的 GlobusRun 程序來啟 動 Core Services 階層的 GRAM 服務,並藉由此 服務與 Local Services 階層的 Local Scheduler 進 行聯繫溝通,將任務提交給 Local Scheduler 執 行與管理。在此,我們可以透過 GRAM 來挑選 欲使用的 Local Scheduler,並且將任務轉置成 Local Schulder 的專屬語法,如圖 3.18 的 Condor script file。在此 Condor script file 語法會描述 Job 的路徑、欲提交至指定的 Node 資源、Output file、Error file、Log file 的存放路徑。
Condor script file 指令說明: Universe:適用的版本 Executable:執行檔的路徑 Log:產生 Log file 的存放目錄 Output:執行結果的存放目錄 Error:錯誤訊息的存放目錄 Requirements:指定計算資源名稱
圖 3.17、Agent Server 軟體架構
圖 3.18、Condor Script File
4. 效能評估
在 整 個 Teamster-G 系 統 架 構 上 , 整 個 Workflow 執行效能的優劣,其關鍵取決於預測 方式的準確度。表 4-1 為效能評估所執行的機器 環境以及軟硬體配備的規格如下: 表 4-1、實驗環境規格表 中央處理器(CPU) Intel Xeon 3.2GHz 快取記憶體(L2 Cache) 1024K Byte 實際記憶體(Memory) 4 GB作業系統(OS.) Windows XP Service Pack 2 軟體(Software) Visual C++ 6.0
4.1 預測準確度的評比結果
為了模擬環境更符合網格特性,本實驗室 去觀測資源在運作時 CPU 的負載走向、網路頻 寬。CPU 負載波形記錄是以本校園多資源為觀 察對象。而網路傳輸則以 NWS 監控軟體來監控 國立高雄應用科技大學至國立成功大學之間的 網路傳輸。我們將收集 30 天的資源負載波形轉 換成 chain-code,再對前兩週的資料進行負載樣 式探勘,而後兩週的負載資料作為預測比對的 樣本。最後再透過平均方誤差值(MSE)作為預測 準確度的標準。平均方誤差(Mean square error) 的方程式如下:∑
=−
=
N i i i fW
W
N
t
MSE
0 2)
ˆ
(
1
)
(
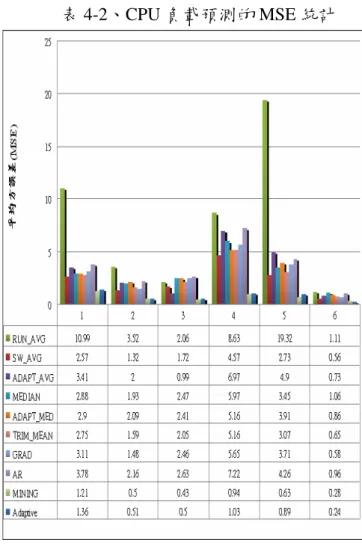
其中 ith 為負載的時間點。 Wˆ i 為預測負載等級的情況。Wi 為實際負載等級的情況。 在本實驗中,除了本研究提出的預測方法, 也同時評估 NWS 所有預測方式的 MSE 值。由 於 NWS 的所有預測方式都只能預測下一個時 間片段的負載效能,故我們也同樣運用循序樣 式探勘的預測方式去預測下一個時間片段的負 載效能,並比較兩者的準確度差異。 表 4-2 所示為 CPU 的預測準確度所評估的結 果,在表中可以很明顯的看到我們的預測方式 的 MSE 比其它 NWS 的預測方式的 MSE 還要小 很多,證明了我們的預測方式的準確性是較高 的。其原因是我們的預測方式運用了資料探勘 的 觀 念 , 去 搜 索 過 去 經 常 出 現 的 負 載 樣 式 (Pattern),而 NWS 的預測方式是沒有使用這 樣觀念,大多只能往前看幾個時間片段的效能 負載來做統計,並使用了 NWS 所提出的預測方 來去預測下一個時段的負載,這樣對未來的效 能預測其實是不足的。 表 4-2、CPU 負載預測的 MSE 統計 從表 4-2 中可觀察到 RUN_AVG 預測方式是最 差,其主要原因它是考慮從過去到現在的負載 平均做為預測基準。但是在過去的歷史資訊的 負載情況往往都是過時的,對於在預測上勢必 會造成較大的誤差。故之後為了解決此問題也 提出了 SW_AVG 預測方式做修正,依照滑動視 窗的方式往前看幾個 Step,以最近的負載資訊 做為預測基準以提升預測準確性。另外一面, 所觀察到 AR 預測方式也是較差的,其原因在 於 AR 的特性較適合預測負載波形是持續上升 或下降的情況,倘若負載波形的幅度變化趨向 較大時,AR 是無法及時做調整。而在 GRAD 預測方式可以改善此問題,依照負載波形趨向 來做適當的調整,以降低在預測時的誤差。目 前所觀察的六台資源中,在 Node_3 與 Node_4 所量測的 MSE 是最高的,原因在負載波形趨向 變化幅度較大並且較無規律性,因此對於各個 預測方式的所預測的結果誤差度相對也較大。 另外,Mining 的預測方式不僅能預測未一下 個時段的負載狀態,也能預測資源於未來一段 長時間(好幾個小時)內的連續負載樣式,如 表 4-3、4-4 所示。在實測負載樣本的 Chain-code 上,以隨機的方式找一個起始點的位址,然後 根據起始點分別去預測 3、5、10、20 小時內的 負載狀態,將預測出來的波形與實際的波形比 較統計出它們的 MSE。我們重複同樣的動作執 行了一百回合,然後將一百回合的 MSE 做加總 做平均。其結果顯示我們的方法所預測的結果 和實際的負載樣本誤差依然很小。故可以顯示 我們的方法確實可以比較準確地預測長時間的 資源負載樣式。
表 4-3、CPU N-Step 負載預測的 MSE 統計 Mining 3-Step 5-Step 10-Step 20-Step
Node_1 0.35 1.45 2.13 2.23 Node_2 0.026 0.032 0.028 0.03 Node_3 0.32 3.33 2.92 8.74 Node_4 2.58 4.36 7.23 12.38 Node_5 0.11 0.18 0.36 0.37 Node_6 0.67 1.30 3.43 6.32
表 4-4、Bandwidth N-Step 負載預測的 MSE 統計 MINING 電機 電子 模具 機械 土木 成大 3-Step 0.22 0.23 0.1 0.21 0.26 0.18 5-Step 0.35 0.41 0.18 0.28 0.37 0.34 10-Step 0.43 0.48 0.35 0.58 0.38 0.51 20-Step 0.55 0.65 0.41 0.78 0.44 0.58
4.2
資源選擇效能的評估結果
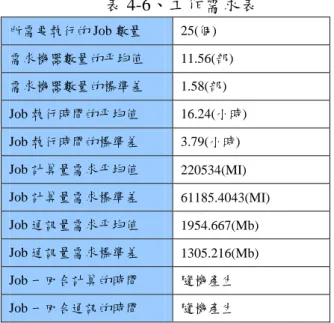
在實際的環境中取得大量的計算資源並不 容易,所以本實驗使用工作排程的模擬程式來 進行。表 4-5 所示為本實驗中模擬所使用的資源 個數,主要分為九個 Site。每一個 Site 分配不同 的資源數量,總共為 500 台資源。為了產生各 個資源所需要的 CPU 負載波形,我們以實際觀 測本校園幾台資源的 CPU 負載量變化,並歸納 所觀測到的負載變化趨向。其所得到的結論是 在某一段時間內,負載波形上下起伏相距不遠 並且會連續持續幾個小時。藉此,由模擬程式 為各個資源製造出三十天的 chain-code,然後經 由資料探勘發掘出每一個資源的經常性負載樣 式,並分別產生負載樣式表單,以作為資源選 擇的依據。目前,模擬程式在進行資源選擇時 只有考慮到未來 CPU 可用度與各個 site 之間的 網路頻寬。 表 4-5、模擬各個資源的效能 Site ID 資 源 數 量 計 算 能 力 (MIPS) 通 訊 能 力 (Mbps) S1 50 1700 100 S2 60 1800 100 S3 60 1600 100 S4 50 1800 100 S5 55 1600 100 S6 65 1800 100 S7 60 1700 100 S8 50 1800 100 S9 50 1700 100 在模擬程式的資源選擇方式,我們採用 Mining 進行資源可用度的預測方式,然後與當 下資源負載為下一個 Step 負載的預測方式做比 較,觀測 Mining 的預測方式的改善幅度。再根 據 NWS 預測方式與當下資源負載為下一個 Step 負載的預測方式比較過後的改善幅度做統 整,最後將全部的改善幅度進行比較。而測試 模式所設定的參數為此工作“所需的 CPU 能 力”、“所需的資源數量”、“總共需執行的回合 數”,以及每一回合所需的計算時間與通訊時 間。根據以上參數帶入我們所導出的公式,如 式 5-1 與式 5-2 所示以計算此工作“需求計算量 (CP)”與“需求通訊量(CM)”。 CP(MI)=CPU 計算能力*所需資源數量*總回合 數*每回合的計算時間 CP(Mb)=網路傳輸率*總回合數*每回合通訊時 間 在效能評估的模擬實驗中,參照表 4-5 所定義 的內容,將資源分成為九組 Site,共總計 500 台的資源以及 81 組的網路通訊組合。首先,將 之前所訓練的出來的 CPU 與網路傳輸率負載樣 式表格讀取至記憶體做為預測時參考的依據。 此後在讀取自行定義的工作表單,依照表單內 各個工作所需的條件以進行資源配置,表 4-6 為工作需求表單。模擬程式會執行 25 個工作, 其工作性質主要是以計算能力需求較高的模式 進行測試,然後設定各個工作所扺達的時間, 而各個工作會以先進先做的模式依序執行。以 表示工作會在不同的時間點扺達。倘若有一工 作在此時間點無法找尋到符合工作條件的資 源,那麼就會先把此工作擱置下來,直到下次 某個時間點能符合工作條件的資源,Broker 才 會從中挑選一組適合的資源配置給予此工作來 執行。而當工作執行完成後所分配的資源,將 會被釋放出來以支援其它工作的需求。
表 4-6、工作需求表 所需要執行的 Job 數量 25(個) 需求機器數量的平均值 11.56(部) 需求機器數量的標準差 1.58(部) Job 執行時間的平均值 16.24(小時) Job 執行時間的標準差 3.79(小時) Job 計算量需求平均值 220534(MI) Job 計算量需求標準差 61185.4043(MI) Job 通訊量需求平均值 1954.667(Mb) Job 通訊量需求標準差 1305.216(Mb) Job 一回合計算的時間 隨機產生 Job 一回合通訊的時間 隨機產生 在表中一回合計算與通訊時間是以隨機方式產 生,而計算一回合時間必需乘以(一分鐘)為 基準,例如:0.6×60(sec)代表一回合需 36(sec)。 然後 Broker 會透過預測各個資源在每一小時所 能提供的計算量[CP]與通訊量[CM]能夠為工作 完成多少個回合數,根據此評估的結果去配置 一組最快能完成工作全部回合數的資源組合給 予工作使用。我們會以九種 CASE(以表 4-7 所 示)在各個資源具備規律性的負載波形中,以隨 機方式改變波形某時間點的負載,並且測試預 測資源可用度對資源的負載影響以及將工作抵 達資源開始執行的間隔時間點也加入考量因 素。其加入的雜訊分別為 10%與 20%,然後取 原先 30 天的 chain-code,以隨機挑選方式變更 chain-code,總共為 30x24x10%=72 個不同時間 點,最後以亂數方式產生不同等級負載量加入 至 chain-code。 表 4-7、測量 CASE 的雜訊分配表 CASE CPU 與 BW 負載雜訊百分比 工作扺達時間 1 CPU_noise0%、BW_noise0% 1、3、5 2 CPU_noise0%、BW_noise10% 1、3、5 3 CPU_noise0%、BW_noise20% 1、3、5 4 CPU_noise10%、BW_noise0% 1、3、5 5 CPU_noise10%、BW_noise10% 1、3、5 6 CPU_noise10%、BW_noise20% 1、3、5 7 CPU_noise20%、BW_noise0% 1、3、5 8 CPU_noise20%、BW_noise10% 1、3、5 9 CPU_noise20%、BW_noise20% 1、3、5 其在 CPU 與 BW 負載波中加入雜訊,主要 原因是為了在模擬時,以改變負載波形原先的 規律性以及可用度級數,進而使得在資源的選 擇上會有不同的配對組合。以觀察是否在加入 不同雜訊之後,對於工作執行時所改善效率幅 度是否有很大的影響,然後再與 last 的預測方 式進行比較,並且觀測 Miming 預測方式與各個 的改善幅度。 我們可以從表 4-8(case1、case2、case3)所 示,工作抵達資源的間隔距離越長,其三種預 測方式的改善幅度都有明顯上升趨向,當中又 以我們的預測方式 Mining 最顯著。其主要原因 是將每一個工作所投入的時間錯開,當 B 工作 在等待被執行時,而 A 工作在過程中或許己執 行完成,此時就能把資源釋放出來給予正在等 待的 B 工作使用。 表 4-8、CPU_0-BW_0、CPU_0-BW_10%、 CPU_0-BW_20% -10.00% 0.00% 10.00% 20.00% 30.00% 40.00% 50.00% 60.00% 70.00% 改善幅度 (% ) CPU_0_BW_0 -1.93% 9.07% 33.21% 15.37% 25.20% 44.12% 18.71% 25.45% 49.44% CPU_0_BW_10 -1.93% 9.07% 33.21% 15.37% 25.20% 44.12% 26.97% 35.76% 63.00% CPU_0_BW_20 -1.93% 9.07% 33.21% 15.37% 25.20% 44.12% 18.71% 25.45% 49.44% SW GRAD Mining SW GRAD Mining SW GRAD Mining
Arrive1 Arrive3 Arrive5
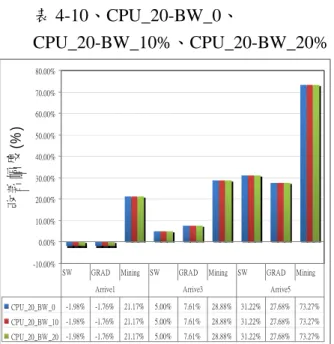
表 4-9 的 Arrive3 和 Arrive5 的 CPU_10-BW_10% 以及 CPU_10-BW_20% case 呈現出改善幅度略 遜於 CPU_10-BW_0 的 case。可能的原因為 CPU 雜訊為 10%的 case 系列,其 Job 的網路傳輸需 求要大於其它 CPU 雜訊的 case 系列。最後的表 4-10 所示的結果,更是證明出 Mining 的預測方 式在負載變化越大的情況下,改善幅度更優於 其 他 兩 者 。 意 即 說 明 本 實 驗 室 的 預 測 方 式 (Mining)在資源負載的動態環境下,是比較能夠 準確地預測出資源未來可用度。
表 4-9、CPU_10-BW_0、CPU_10-BW_10%、 CPU_10-BW_20% -10.00% 0.00% 10.00% 20.00% 30.00% 40.00% 50.00% 60.00% 改 善幅度 (% ) CPU_10_BW_0 -3.01% 3.48% 27.57% 9.58% 17.97% 33.22% 20.09% 25.17% 52.34% CPU_10_BW_10 1.20% 5.67% 29.86% 7.03% 12.73% 38.84% 4.55% 19.32% 46.84% CPU_10_BW_20 1.20% 5.67% 29.86% 7.03% 12.73% 38.84% 4.55% 19.32% 46.84% SW GRAD Mining SW GRAD Mining SW GRAD Mining
Arrive1 Arrive3 Arrive5
表 4-10、CPU_20-BW_0、 CPU_20-BW_10%、CPU_20-BW_20% -10.00% 0.00% 10.00% 20.00% 30.00% 40.00% 50.00% 60.00% 70.00% 80.00% 改善 幅度 (% ) CPU_20_BW_0 -1.98% -1.76% 21.17% 5.00% 7.61% 28.88% 31.22% 27.68% 73.27% CPU_20_BW_10 -1.98% -1.76% 21.17% 5.00% 7.61% 28.88% 31.22% 27.68% 73.27% CPU_20_BW_20 -1.98% -1.76% 21.17% 5.00% 7.61% 28.88% 31.22% 27.68% 73.27% SW GRAD Mining SW GRAD Mining SW GRAD Mining
Arrive1 Arrive3 Arrive5
5.
結論與未來工作
對服務導向架構(SOA)的計算網格而言,透 過 Advance Resource Reservation 來維護系統的 QoS,其最重要的關鍵為如何準確地預測資源未 來可用度。為解決此問題,本實驗室成功開發 一 套 基 於 可 長 時 程 預 測 資 源 未 來 可 用 度 的 Advance Resource Reservation 以 及 設 定 一 個 deadline 的保護值,讓系統可以透過此方式來維 持服務工作的品質,並且提高在 Deadline 之前 完成工作的機率。另外,本實驗室也已經驗證 未來資源預測方式的準確度是較優於 NWS 的 預測方式,而且從效能評估的結果可以得知將 此預測方式應用在資源選擇上確實能改善工作 執行效能。這對於 Resource Broker 進行資源配 置時,比較能夠為 Job 挑選更合適的計算資源, 而且我們所設計的 Reservation Scheduler 方式也 確實能以少量的時間對大規模的 Workflow 進 行 deadline 的設定與資源預留。 基於未來資源可用度預測上使用 Advance Resource Reservation 機制來維護系統工作品質 的方案,雖然可以有效地避免無資源可用的情 況以及降低 deadline delay 發生的機率。但是在 Grid 環境使用資源難免會出現無法預知的結果 而造成工作延遲。為了讓系統能夠更完善的處 理這些突發狀況,如何妥善解決 deadline delay 的問題是一個很重要的議題。過去相關的研究 方法會使用 Reschedule 的方式來彌補 deadline delay 所造成的損失。然而,將工作重新配置資 源所能彌補的幅度實在有限,因為這些相關研 究所開發的 Reschedule 機制通常都是將 Delay 的 Job 其後代所有 Child Job 重新配置資源。但 是重新配置的結果依然會受 Grid 環境的資源負 載動態性影響,而無法真正有效地解決 deadline delay 的問題。為此,我們可以設計一套基於長 時程資源未來可用度預測機制,實作一套 job rescheduling 的演算法 ,將目前的工作進度遷移 至其他資源上繼續執行工作,以更佳的方式彌 補 deadline delay 造成的損失。
參考文獻
[1] Tyng-Yeu Liang, Chun-Yi Wu, Jyh-Biau
Chang, Ce-Kuen Shieh, “Teamster-G : A Grid-enabled Software DSM System”, In of
the Proceeding of The 2005 International Workshop on Distributed Shared Memory on Clusters at the IEEE International Symposium on Cluster Computing and the Grid (CCGrid 2005), Cardiff, UK, May 9-12, 2005.
[2] J. B. Chang, Ce-Kuen Shieh, Tyng-Yeu Liang,
“A Transparent Distributed Shared memory for Clustered Symmetric Multiprocessors”,
Journal of Supercomputing, vol. 37, issue 2,
pp.145-160, August 2006.
Honghui L., Ramakrishnan R., Weimin Y., Willy Z., “TreadMarks: Shared Memory Computing on Networks of Workstations”,
IEEE Computer, pp. 18-28, 1996.
[4] Speight E. and Bennett J.K., “Brazos: A third
generation DSM system”, Proceedings of the
1997 USENIX Windows/NT Workshop, pp.
95-106, 1997.
[5] IVY K Li,“A shared virtual memory system
for parallel computing”, In Proceedings of the
1988 International Conference on Parallel Processing (ICPP'88), pp. 94-101, 1988.
[6] Carter J.B., Bennett J.K. and Zwaenepoel W.,
“Implementation and Performance of Munin”,
In Proceedings of 13th ACM Symposium on Operating System Principles, pp. 152-164,
1991.
[7] Tyng-Yeu Liang, We-Chen Li, Jin An Huang,
“Developing A Workflow Management System for Teamster-G”, Proceedings of
National Computer Symposium, pp.7-16, Nov.
27-28, 2009.
[8] Tyng-Yeu Liang., I-Han W., Sheng-Yuan C.,
“A Long-term Resource Availability Predictor Using Frequent Workload Patterns”, The 5th
Workshop on Grid Technologies and Applications (WoGTA’08), pp. 125-130, 2008.
[9] Jia Yu, Rajkumar Buyya and Chen Khong
Tham, “Cost-based Scheduling of Scientific Workflow Applications on Utility Grids”,The
First International Conference on e-Science and Grid Computing, pp.-147, 1-1 July 2005.
[10] TORQUE Resource Manager.
http://www.-clusterresources.com/pages/produ cts/torque-resourcemanager.php.
[11] Hidemoto Nakada, Atsuko Takefusa,
Katsuhiko Ookubo, Makoto Kishimoto Tomohiro Kudoh, Yoshio Tanaka, Satoshi Sekiguchi, “Design and Implementation of a Local Scheduling System with Advance Reservation for Co-allocation on the Grid”,
The Sixth International Conference on Computer and Information Technology at IEEE. pp. 65-65, Sept 2006.
[12] Globus project. http://www.globus.org.
[13] I. Foster. Globus toolkit version 4: Software
for serviceoriented systems. In IFIP International Conference on Network and Parallel Computing, Springer-Verlag LNCS 3779, pp. 2–13, 2005.
[14] WSRF.http://www.oasis-open.org/committees/
出席國際學術會議心得報告
計畫編號
NSC 96-2221-E-151-018-MY3
計畫名稱
一個基於開放式網格服務架構的共用記憶體多處理
器系統(第3年)
出 國 人 員 姓 名
服 務 機 關 及 職
稱
梁廷宇副教授 高雄應用科技大學電機系
會議時間地點
Dec. 8~11 2009, Shenzhen, China會議名稱
The Fifteenth International Conference on Parallel andDistributed Systems (ICPADS'09)
發表論文題目
A User-Level Remote Paging System for Grid Computing一、參加會議經過
本次參加 ICPADS 2009 會議行程共五天。第一天、高雄出發經香港轉深圳。第 二天發表論文。第三~四天參加會議議程與討論。第五天返回國門。二、與會心得
本次參加的 ICPADS 2009 國際會議,為平行與分散式系統研究領域中最受到重 視的學術研討會。此會議的論文集被 IEEE 訂為 EI 的等級,所以在學術上非常受到 重視。今年很榮幸有機會參與次盛會,藉此與世界一流的學者交流,實在是非常難 得的學習經驗。本次在會議上所發表的論文題目為『A User-Level Remote Paging System for Grid Computing』,其目的是為網格計算開發一個使用階層的遠端分頁機制 稱為 Grid Remote Pager (GRP),藉以解決記憶體不足的問題。此篇論文主要的特色 在此機制可以隨著資源擁有者本身的記憶體使用情形來調整使用者可利用的記憶體 數量,以避免資源競爭的發生並提高記憶體的使用量。另一方面,此機制還支援記 憶體資源的保留功能,以保障程式的執行效能。在論文發表中,很多人對於我們的 研究成果感到興趣,其中包括中國大陸國防大學的學者,他們也是發表 Petaflops 超 級電腦:天河一號的學者。他們給了我們一些寶貴的建議。例如,分析程式的資料 存取行為,藉以改善 page replacement 的演算法,提高記憶體分頁命中的機會,進而 減少遠端分頁置換的次數。未來我們將會在最短的時間內,根據會議中所獲得的建 議,來對我們所發表的機制進行改善。相信經由後續的加強後,本篇論文將會成為 一篇不錯的期刊論文。另一方面,我們在本次的會議中,亦參與多個其他 session 的 研討。例如:Multicore、Parallel Computing with GPU 與 Cluster and Cloud computing 等,得到有很多其他人的研究經驗,收穫頗為豐富。在此次的會議,有一個重要的論壇『When Petaflops meet the Cloud』,其議題在 討論:雲端計算(Cloud Computing)是否可以提供高效能計算的服務。在此論壇上,
發表看法的學者包括:天河一號的作者:Kai Lu、Ohio State University 的 Xaiodong Zhang、香港大學的 Lionel M. NI、以及 Dawning、Lenovo 與 IBM 的代表等。在此論 壇上,雖然持正反意見的學者專家都有。持反對意見的有 Zhang 和 Lu 教授。其原因 是需要高效能計算往往是為特定的科學領域,而雲端運算面對是普羅大眾,因此在 系統的設計與管理、乃至使用者介面都有很大的差異。相反地,持正面意見的學者 都為各個電腦公司的代表,他們認為這是一個商業的策略問題而不是一個技術問 題,意即是要不要提供而不是能不能的問題。雖然正反意見都有,但是他們都有一 個共同的看法,即是這兩個領域將來經由瞭解彼此的需求與特性而越來越緊密的結 合。 除了雲端計算外,另一值得注意的趨勢,即是 GPU 的崛起。此次會議,有很多 研究是利用 GPU 來作為平行運算的平台。由於 GPU 具有比 CPU 更多的運算核心, 而且有較低的 EPI 值,所以能夠以較少的能源獲得更高的運算效能。更重要的是, GPU 的普遍性讓它越來越廣泛地運算在 HPC 的領域。但是目前受限於硬體的設計, GPU 尚無法完全取代 CPU。例如:對於分支指令密集的程式執行效能不佳,程式介 面與 CPU 不相容、host_to_device 的資料傳輸頻寬不夠等,因此混合 CPU 與 GPU 的 系統架構最近被提出來,意即把 CPU 當成 control nodes,而 GPU 當成 computation nodes,然後一起共同解決同一問題。目前大陸的天河一號已經採用此一混合式的系 統架構,並成功地獲得 Petaflop 的運算效能,進而擠進 TOP500 的前十名內。相信這 將會是未來學術與產業發展的趨勢。 在參與此次的會議中,大陸讓我有些深刻的感受。例如:他們計劃 2010 年花費 數十億人民幣在深圳建置完成一個可以提供 10Petaflop 的 Supercomputing 中心,而 所有的硬體設備都是他們研發自製。由此可以感受他們那份的強烈企圖心。另一方 面,則是他們對於產業的發展往往有通盤的計畫,並且有很強的執行力去達到設定 的目標。例如:在雲端產業的發展上,他們準備在上海與深圳各誕生一朵雲,以作 為發展雲端產業的中心。目前不論是政策、資金、技術都已經準備到位,加上大陸 為數眾多的人才以及拼勁,相信很快就會達成預定的目標。相對地,雖然我們政府 也宣布要編列一百億的經費來獎勵民間發展雲端產業,但其計畫似乎不是很具體, 而且執行的效率似乎也需要加強。面對大陸的快速發展,我們真的必需要更加積極 地迎頭趕上才行。
96 年度專題研究計畫研究成果彙整表
計畫主持人:梁廷宇 計畫編號:96-2221-E-151-018-MY3 計畫名稱:一個基於開放式網格服務架構的共用記憶體多處理器系統 量化 成果項目 實際已達成 數(被接受 或已發表) 預期總達成 數(含實際已 達成數) 本計畫實 際貢獻百 分比 單位 備 註 ( 質 化 說 明:如 數 個 計 畫 共 同 成 果、成 果 列 為 該 期 刊 之 封 面 故 事 ... 等) 期刊論文 0 0 100% 研究報告/技術報告 0 0 100% 研討會論文 3 3 100% 篇 論文著作 專書 1 0 100% 申請中件數 0 0 100% 專利 已獲得件數 0 0 100% 件 件數 0 0 100% 件 技術移轉 權利金 0 0 100% 千元 碩士生 7 7 100% 博士生 0 0 100% 博士後研究員 0 0 100% 國內 參與計畫人力 (本國籍) 專任助理 0 0 100% 人次 期刊論文 3 3 100% 研究報告/技術報告 3 3 100% 研討會論文 9 9 100% 篇 論文著作 專書 1 0 100% 章/本 申請中件數 0 0 100% 專利 已獲得件數 0 0 100% 件 件數 0 0 100% 件 技術移轉 權利金 0 0 100% 千元 碩士生 0 0 100% 博士生 0 0 100% 博士後研究員 0 0 100% 國外 參與計畫人力 (外國籍) 專任助理 0 0 100% 人次其他成果
(
無法以量化表達之成 果如辦理學術活動、獲 得獎項、重要國際合 作、研究成果國際影響 力及其他協助產業技 術發展之具體效益事 項等,請以文字敘述填 列。) 獲得 2009 年全國計算機會議,『優秀論文』獎。 成果項目 量化 名稱或內容性質簡述 測驗工具(含質性與量性) 0 課程/模組 0 電腦及網路系統或工具 0 教材 0 舉辦之活動/競賽 0 研討會/工作坊 0 電子報、網站 0 科 教 處 計 畫 加 填 項 目 計畫成果推廣之參與(閱聽)人數 0國科會補助專題研究計畫成果報告自評表
請就研究內容與原計畫相符程度、達成預期目標情況、研究成果之學術或應用價
值(簡要敘述成果所代表之意義、價值、影響或進一步發展之可能性)
、是否適
合在學術期刊發表或申請專利、主要發現或其他有關價值等,作一綜合評估。
1. 請就研究內容與原計畫相符程度、達成預期目標情況作一綜合評估
■達成目標
□未達成目標(請說明,以 100 字為限)
□實驗失敗
□因故實驗中斷
□其他原因
說明:
2. 研究成果在學術期刊發表或申請專利等情形:
論文:■已發表 □未發表之文稿 □撰寫中 □無
專利:□已獲得 □申請中 ■無
技轉:□已技轉 □洽談中 ■無
其他:(以 100 字為限)
本實驗室總共發表了 3 篇 SCI 期刊論文、12 篇國際會議論文、1 篇 Book Chapter。此外, 還獲得 2009 年全國計算機會議的優秀論文獎,並獲邀在『國科會工程科技通訊』第 100 期中 刊出研究成果。