應用類神經網路減少TFT-LCD產品測試項目之研究
65
0
0
全文
(2) 應用類神經網路減少TFT-LCD產品測試項目之研究 Reducing Test Items of TFT-LCD Product By Using Neural Networks 研究生 :孔祥竹. Student : Hsiang-Chu Kung. 指導教授:蘇朝墩、洪瑞雲博士. Advisor : Dr. Chao-Ton Su Dr. Ruey-Yun Horng. 國 立 交 通 大 學 管理學院(工業工程與管理學程)碩士班. 碩 士 論 文 A Thesis Submitted to Master Program of Industrial Engineering and Management College of Management National Chiao Tung University In Partial Fulfillment of the Requirements for the Degree of Master of Science in Industrial Engineering and Management October 2007 Hsin-Chu, Taiwan, Republic of China. 中華民國九十六年十月 i.
(3) 應用類神經網路減少TFT-LCD產品測試項目之研究 Reducing Test Items of TFT-LCD Product By Using Neural Networks 研究生:孔祥竹. 指導教授:蘇朝墩、洪瑞雲博士. 國立交通大學管理學院(工業工程與管理學程)碩士班 摘要 台灣是國際上 TFT-LCD (Thin-Film Transistor Liquid-Crystal Display),薄膜電晶體液 晶顯示器) 主要的製造和生產基地。由於 TFT-LCD 在生產設備和儀器的投資金額相當 龐大,因此如何降低製造的時間,維持一定的品質,縮短產品的生命週期和加速新產品 的開發,比競爭對手更早推出產品在市場上,是企業生存的必要條件。在 TFT-LCD 的 生產過程中,檢驗和測試是一個大瓶頸。 本研究透過運用類神經網路的方法減少 TFT-LCD 在生產製造上的測試項目,以期 能降低測試的時間和設備的投資,並希望當利用較減少測試項目之檢驗的結果和使用原 有測試項目所檢驗出的結果要非常近接近。此外,在減少測試項目所做的 TFT-LCD 面 板的品質分類結果,也希望能和原有測試項目所做的 TFT-LCD 面板的品質分類結果非 常近接近。本研究以一實際案例來說明所提類神經網路的方法的有效性,並與傳統的統 計迴歸方法進行比較。. 關鍵字:TFT-LCD,類神經網路,迴歸分析. i.
(4) Reducing Test Items of TFT LCD Product by Using Neural Networks Student:Hsiang-Chu Kung. Advisor:Dr. Chao-Ton Su Dr. Ruey-Yun Horng. A Thesis to Department of Industrial Engineering and Management College of Management National Chiao Tung University. Abstract Taiwan is the major TFT-LCD (Thin-Film Transistor Liquid-Crystal Display) manufacture and engineering base in the world. Owing to quite huge amount of expense in design and production facilities, the necessary survival criteria for this industry based on how to shorten the manufacturing time, maintain the high quality, cut the product lifecycle and expedite the newer model design on current market, have become critical issue. This research aims to deduct the TFT-LCD test items on manufacturing process via applying Neural Network approach. We expect to reduce the test time and the facility investment, and hopelly to get the same or less inaccuracy test results between reduced test items and original test items. Moreover, the TFT-LCD quality classified results by reduced test items are approximately the same as them by keeping the original test items. This research uses a real example to demonstrate the validity of Neural Network approach and also does the comparison to the traditional statistic regression analysis.. Key words:TFT-LCD, Neural Networks, Regression Analysis. ii.
(5) 誌. 謝. 我在交大求學這段期間,讓我覺得生活充實和驕傲,因為交大有著優良的學習環 境,有相當優秀的老師傳授我們知識,還有樂觀上進的學習夥伴們。在修課一年後,因 公司組織的變化讓我學習受阻,慶幸的是在一年期間我學分都修完,僅剩下論文;然而 這論文卻讓我差點無法在修業期間完成。隨著這篇論文即將付梓之際,內心對這一路走 來鼓勵我和鞭策我的師友,致上最大的謝意。 首先要深深的感謝的是恩師 蘇朝墩教授的指導和協助,在這坎坷的路上,可謂 不離不棄。 讓我能順利完成我的論文,在此深深的表達我最真誠的感謝。另外,也要 感謝另一位指導教授. 洪瑞雲教授,在我困難的時候伸出援手,對我論文寫作的方向和. 重點提供寶貴的建議,讓我得以最大的勇氣,繼續完成論文。還有口試教授 授的不吝指導,讓我得以順利完成我的研究。 最後,是可愛的小學妹. 陳穆臻教. 林依祈幫我分. 析整理最重要的資料到深夜,讓我有完整的結果呈現。 我要感謝給摯愛的老婆. 燕華,兒子 昱棠,以及最愛的女兒. 湘云的鼓勵與支. 持,尤其是老婆燕華的體貼,一路的協助和鼓勵,我才能走到現在克服種種挫折並完成 碩士學位。 最後,僅以此篇論文,獻給我的恩師們、朋友和最親愛的家人。並祈願他們身體 建康,萬事如意。. iii. 孔祥竹. 謹誌. 新竹風城. 交通大學. 中華民國. 九十六年十月.
(6) 目. 錄. 中文摘要 .....................................................................................................................................i 英文摘要 ....................................................................................................................................ii 誌. 謝 .......................................................................................................................................iii. 目. 錄 .......................................................................................................................................iv. 圖目錄 .......................................................................................................................................vi 表目錄 ......................................................................................................................................vii 第一章 緒論 ..............................................................................................................................1 1.1 研究背景與動機 ........................................................................................................................1 1.2 研究目的 ....................................................................................................................................2 1.3 研究方法與步驟 ........................................................................................................................2 1.4 研究範圍限制 ............................................................................................................................4 第二章 TFT-LCD製程簡介.....................................................................................................5 2.1 TFT-LCD工作原理及顯影 ........................................................................................................5 2.2 TFT-LCD的製程 ........................................................................................................................7 2.3 TFT-LCD測試項目 ..................................................................................................................10 第三章 類神經網路 ..............................................................................................................13 3.1 類神經網路之特性 ..................................................................................................................14 3.2 類神經網路之類型 ..................................................................................................................15 3.3 倒傳遞類神經網路 ..................................................................................................................16 3.4 類神經網路之應用 ..................................................................................................................20 第四章 研究方法 ....................................................................................................................22 4.1 資料的取得和處理 ..................................................................................................................22 4.2 類神經網路模式的建立 ..........................................................................................................23 第五章 案例說明 ....................................................................................................................27 5.1 個案公司簡介 ..........................................................................................................................27 5.2 資料的收集和說明 ..................................................................................................................28 iv.
(7) 5.3 資料的處理和類神經網路模型建構 ......................................................................................28 5.4 統計迴歸分析 ..........................................................................................................................43 5.5 比較與分析 ..............................................................................................................................49 第六章 結論 ............................................................................................................................53 參考文獻 ..................................................................................................................................55. v.
(8) 圖目錄 圖 1.1. 本研究流程圖 ..............................................................................................................3. 圖 1.2. 本研究測試項目的範圍 ..............................................................................................4. 圖 2.1 TFT元件的工作原理 ...................................................................................................5 圖 2.2 TFT-LCD 元件基本架構............................................................................................6 圖 2.3 TFT-LCD 的顯影原理................................................................................................6 圖 2.4 TFT-LCD 的製程........................................................................................................8 圖 2.4 TFT-LCD 的製程(續) .................................................................................................9 圖 2.5 TEG測試點位 ............................................................................................................11 圖 3.1. 多層前饋網路 ............................................................................................................14. 圖 3.2. 倒傳遞類神經網路架構 ............................................................................................17. 圖 3.3. 常用的非線性轉換函數 ............................................................................................18. 圖 4.1. 建立完整的倒傳遞類神經網路模型之流程 ............................................................24. 圖 4.2. 建立簡化的倒傳遞類神經網路模型之流程 ............................................................25. 圖 5.1. 訓練樣本之RMSE變化 (Full Model).......................................................................33. 圖 5.2. 訓練樣本之correlation變化 (Full Model) ................................................................33. 圖 5.3. 測試樣本之RMSE變化 (Full Model).......................................................................34. 圖 5.4. 測試樣本之correlation (Full Model) .........................................................................34. 圖 5.5. 目標值與輸出值標準化後之散佈圖 (Full Model)..................................................35. 圖 5.6. 根據資料順序各資料對應之輸出值與目標值(Full Model)....................................35. 圖 5.7. 殘差常態分佈圖 ........................................................................................................44. 圖 5.8. 殘差合適圖 ................................................................................................................44. 圖 5.9. 殘差對數據順序圖 ....................................................................................................44. vi.
(9) 表目錄 表 2.1. 測試項目 ....................................................................................................................11. 表 2.2. 線缺點檢驗項目 ........................................................................................................12. 表 5.1 TFT-LCD產品分類標準............................................................................................29 表 5.2. 可用屬性的測試項目表 ............................................................................................31. 表 5.3. 完整模型中η和α的對照表 ........................................................................................32. 表 5.4. 完整模型中不同隱藏層結點之對照表 ....................................................................32. 表 5.5. 各輸入結點的貢獻度 (Full Model)..........................................................................36. 表 5.6. 訓練樣本的分類結果(Full Model)............................................................................37. 表 5.7. 測試樣本的分類結果(Full Model)............................................................................37. 表 5.8. 不同隱藏層結點之訓練結果(Reduced Model-I) .....................................................38. 表 5.9. 訓練樣本的分類結果(Reduced Model-I) .................................................................38. 表 5.10. 測試樣本的分類結果(Reduced Model-I) ...............................................................38. 表 5.11. 工程知識判斷所穫得之重要變數(Reduced Model-II) ..........................................39. 表 5.12. 不同隱藏層結點之訓練結果(Reduced Model-II) ..................................................39. 表 5.13. 訓練樣本的分類結果(Reduced Model-II) ..............................................................39. 表 5.14. 測試樣本的分類結果(Reduced Model-II) ..............................................................40. 表 5.15. 不同隱藏層結點之訓練結果(Reduced Model-III).................................................40. 表 5.16. 訓練樣本的分類結果(Reduced Model-III).............................................................40. 表 5.17. 測試樣本的分類結果(Reduced Model-III).............................................................41. 表 5.18. 工程知識判斷所穫得之重要變數(Reduced Model-IV) ........................................41. 表 5.19. 不同隱藏層結點之訓練結果(Reduced Model-IV).................................................42. 表 5.20. 訓練樣本的分類結果(Reduce Model-IV) ..............................................................42. 表 5.21. 測試樣本的分類結果(Reduce Model-IV) ..............................................................42. 表 5.22. 變數係數表 ..............................................................................................................45 vii.
(10) 表 5.23. 迴歸模式中顯著的 7 個變數 ..................................................................................46. 表 5.24. 複迴歸模式ANOVA分析表....................................................................................46. 表 5.25. 訓練樣本的分類結果(複迴歸模式) .......................................................................46. 表 5.26. 測試樣本的分類結果(複迴歸模式) .......................................................................46. 表 5.27. 逐步迴歸模式ANOVA分析表................................................................................47. 表 5.28. 十三個自變數對依變數有顯著之影響 ..................................................................48. 表 5.29. 訓練樣本的分類結果(逐步迴歸模式) ...................................................................48. 表 5.30. 測試樣本的分類結果(逐步迴歸模式) ...................................................................48. 表 5.31. 分類正確率彙整表 ..................................................................................................49. 表 5.32. 訓練樣本之執行誤差 ..............................................................................................49. 表 5.33. 測試樣本之執行誤差 ..............................................................................................50. 表 5.34. 簡化模型II所刪減的測試項目 ...............................................................................51. viii.
(11) 第一章 緒論 1.1 研究背景與動機 TFT-LCD(Thin-Film Transistor Liquid-Crystal Display,薄膜電晶體液晶顯示器)產業 具資本密集、技術密集、產品生命週期短及生產線技術更換快速等特性,並且隨次世代 面板的持續開發生產設備不斷加碼[1]。在今日國內廠商紛紛投入更高世代 TFT-LCD 技 術生產之際,預期未來面板有供過於求的現象下,獲利空間愈來愈小。然而,消費者對 TFT-LCD 的功能要求愈來愈多,譬如希望有更高的解析度、更快的反應速度和更低的消 耗功率等等,這些功能的加入需要更進階的製程和更多的設計改善才能做到,也就是要 繼續投入更多的資本,然而產品的價格變化並不大。此外,產品的生命週期變短了,由 原先的一年降低到半年,因此需要加速新產品的推出時程,希望能搶先競爭對手,可以 及時上市新產品以獲得較高的利潤。 TFT-LCD 面板的製造主要分為三段製程,分別是陣列製程(Array)、組立製程(Cell)、 以及模組製程(Module)。在陣列製程中,首先將做為原材料的大片玻璃基板清洗乾淨, 之後反覆經過薄膜形成、光阻塗佈、曝光顯影、蝕刻與剝膜等手續五到七次,以形成所 需的電晶體。然而因為製造程序複雜、影響變數眾多,工程師往往無法從所收集的龐大 資料中,迅速有效地察覺可能導致製程異常的原因或是歸納造成產品品質不良的因素, 更遑論從資料中發現先前隱藏不知的重要訊息。當有更新的產品開發出來的同時,製程 往往需要加入更多的測試項目以驗證新的功能,而這些都要投入昂貴的測試設備和花更 多的測試時間才能做到。 TFT-LCD 產品在現今的製程上,產品不良率較低,所以,好與壞產品的資料呈現不 平衡(imbalanced)的情況,即壞產品佔總產量比較低。經常是有些檢測項目發現到的缺失 數很少,當進行資料分析時,這些少數不良品的資料會被誤認為離異值而被剔除,但是 它有可能是非常重要的檢測項目。因此如何透過所蒐集的大量製程資料加以統計、分 析,得到有意義的模型,以釐清缺陷產生與製程的關連性,並找到合理的測試項目,以 正確與迅速的檢測產品,來降低測試成本、縮短測試時間及縮短 TTM (Time To Market) 的時間,這對 TFT-LCD 產業而言是相當重要的。 1.
(12) 1.2 研究目的 本研究擬應用類神經網路(Neural Networks)探討 TFT-LCD 產品測試項目的合理 性,希望使用倒傳遞類神經網路的方法,去除貢獻性不高的測試項目。本研究期望當測 試項目被減少時,仍然擁有非常好的檢出準確性。此外,本研究以一實例來說明應用類 神經網路和傳統統計迴歸分析之後的差異性比較討論。. 1.3 研究方法與步驟 由於類神經網路具有自我學習及平行處理非線性問題的能力,使得它相較於傳統方 法,更能應用在充滿複雜,影響變因不確定的環境之下輔助分析問題。類神經網路對預 測及分類問題有好的表現[8][11],已有很多成功的實際應用例子。另外,迴歸分析是探 討一變數對另一變數的影響情況,它建構方程式較簡單而且快速,對分析測試方面的問 題很有幫助。因為產品的根本問題,可能只有少數幾個,但是不同的測試項目會反應這 些問題,所以迴歸分析也常被應用在分類問題的解決。 本研究進行的流程如圖 1.1 所示。首先,確認研究問題的目的之後,經由與測試單 位訪談,討論產品測試項目和良率的關係,然後進行數據的收集。接著,澄清分析這些 數據的適合性,選出重要變數(測試項目)來建立倒傳遞類神經的模式,稱之為完整的模 型 (Full Model)。接著,參考現有的經驗模式,刪除一些貢獻度低的測試項目後建立簡 化的倒傳遞類神經網路,稱之為簡化的模型 (Reduced Model)。此外,本研究也建立統 計迴歸的模型,做為比較的對象。最後,本研究針對上述模型的分類率和誤差做比較和 分析,期望能定義出有效的測試項目,並提出結論與建議。. 2.
(13) 圖 1.1. 本研究流程圖. 3.
(14) 1.4 研究範圍限制 本研究主要以 TFT-LCD 的產品為對象,收集了新產品 9 吋 LCD 測試項目和良率的 數據進行作研究。研究範圍是 TFT-LCD 的生產製程中 Array 製程的測試項目,如圖 1.2 所示。此外,本研究係以一家個案公司做實證研究,但由於個案公司有其企業營運的背 景,因此本研究僅針對類神經網路應用在縮減測試項目及其成效進行討論,並不對個案 公司導入此研究結果後,對其整體營運績效影響加以評論。. 圖 1.2. 本研究測試項目的範圍. 4.
(15) 第二章 TFT-LCD 製程簡介 本章主要分為二大部份;第一部份介紹 TFT-LCD 的工作及顯影原理,第二部份針 對製程和測試介紹。. 2.1. TFT-LCD 工作原理及顯影 TFT-LCD (Thin-Film Transistor Liquid-Crystal Display,薄膜電晶體液晶顯示器),是. 由許多的電晶體所組合而成,每一個電晶體有三個端點,分別是閘極(Gate)、源極(Source) 與吸極(Drain),外加保持電容(Cs);TFT元件可看成開關,當VGS>Vth則導通,當VGS<Vth 則關閉,其中Vth是臨界電壓,即為感應出載子所需最小電壓,如圖 2.1 所示[13]。. Ids 線性區. D. D. S. VGS〈Vth G. 飽和區 Vgd<Vth Vgs=Vth+8. S. Vgs=Vth+6 Vgs=Vth+4 Vgs=Vth+2. G. Vgs〈Vth. (1) Vgs<Vth:感應通道未形成 此時,Ids=0 (2) Vgs及Vgd>Vth:形成感應通道 此時,Ids=1/2unCox(W/L)[(Vgs-Vth)Vds-Vds2] (3) Vgs>Vth及Vgd<Vth:進入夾止區(在Drain側通道消失) 此時,Ids=1/2unCox(W/L)(Vgs-Vth)2. 影響Ids之重要參數 1. Vth 2. un:Mobility 3. Cox:Gate到Channel的電容 4. W/L. 符號的意義: Vgs :Gate到Source的電壓; Vgd :Gate到Drain的電壓 Vds : Drain到Source的電壓;Vth :臨界電壓 Ids :Drain到Source的電流;μn :電子移動率 Cox:Gate到Channel的電容;W/L :零件的寬度/長度. 圖 2.1 TFT 元件的工作原理. 5. VDS.
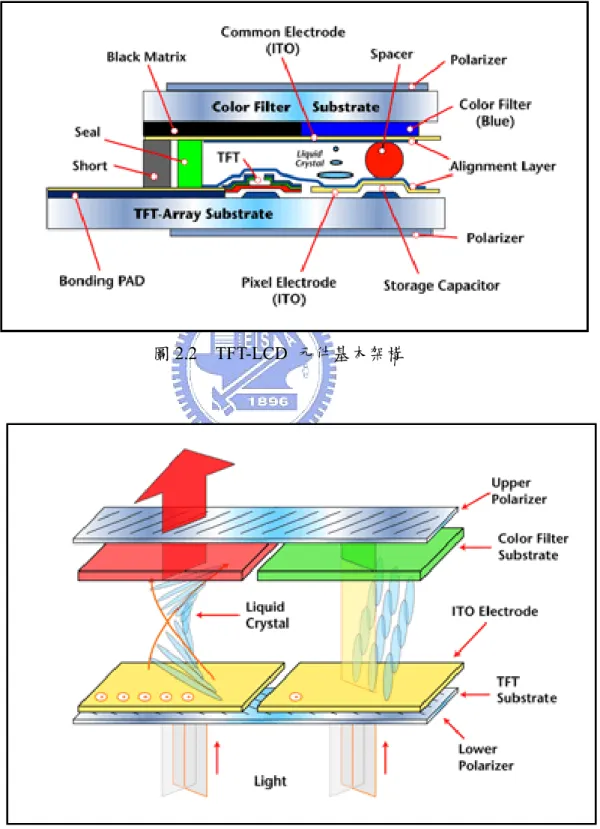
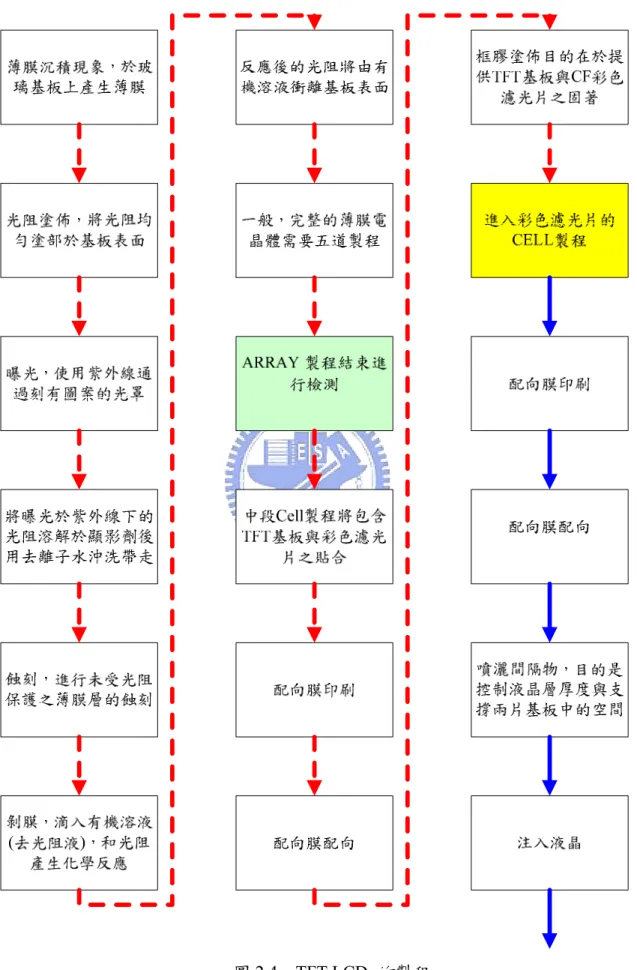
(16) TFT-LCD 當施電壓於電晶體時,液晶轉向,光線穿過液晶後在前端面板上產生一個 畫素,如圖 2.2 所示[13]。液晶站立角度愈大,則可以穿透的光線愈弱(TN mode)。不受 導引的光線會被上面的偏光片所吸收掉,只讓某一特定方向的光通過,如圖 2.3 所示[13]。. 圖 2.2 TFT-LCD 元件基本架構. 圖 2.3 TFT-LCD 的顯影原理. 6.
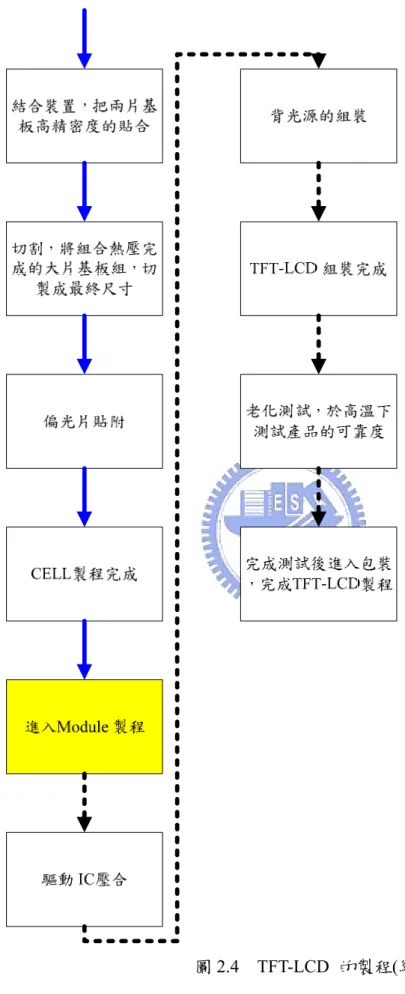
(17) 2.2. TFT-LCD 的製程 TFT-LCD 的製造過程中,液晶顯示器電測非常重要。因為 LCD 的電測判斷為不良. 品時,就需報廢整塊液晶玻璃,所以電測為實務切割前必需的步驟,目的在免於因瑕疵 品切割後耗費不必要的成本,因此比一般半導體元件更重視電測製程。 TFT-LCD 的製程,大致可區分為三階段;第一階段是 Array 製程,包括了薄膜、黃 光、蝕刻和剝膜,如圖 2.4 中粗虛線箭頭的流程。首先於玻璃基板上產生薄膜,之後將 光阻塗佈,光阻均勻塗部於基板表面,使用紫外線通過刻有圖案的光罩進行曝光,將曝 光於紫外線下的光阻溶解於顯影劑後用去離子水沖洗帶走,再進行未受光阻保護之薄膜 層的蝕刻,之後滴入有機溶液(去光阻液)和光阻產生化學反應,反應後的光阻將由有 機溶液衝離基板表面,如此重覆上述的程序,一般完整的薄膜電晶體需要五道製程。 Array 製程結束進行檢測,檢測的項目包括: z. TEG (Test Element Group)的檢查,包括了 TFT 特性,配線阻抗和接觸阻抗. z. Line Defect,包括了閘極(Gate)、源極(Source)、保持電容(Cs)通電是否達標準 和線欠陷的問題做檢測。. z. 目視檢查,包括點欠陷、連續欠陷、距離密度、縱 2 連續、橫 2 連續、LOW_VG、 IOFFLK、 GTLEAK、EXT_CHG、SITO_SH、SLFLEAK、R_GOOD 等。. 之後中段 Cell 製程將包含 TFT 基板與彩色濾光片之貼合、配向膜印刷與配向膜配向, 目的在於使印刷與基板表面的 PI 膜開出紋路,而使液晶一致性的排列。接下來是框膠 塗佈,目的是提供 TFT 基板與 CF 彩色濾光片之固著。 第二階段是進入彩色濾光片(CF)的 Cell 製程,如圖 2.4 中實線箭頭的流程。流程主 要步驟為配向膜印刷、配向膜配向、噴灑間隔物(目的是控制液晶厚度與支撐兩片基板 的中間) 、注入液晶、組合裝置(把二片基板高精密度的貼合) 、切割(將組合熱壓完成 的大片基板組)、切製成最終尺寸與貼偏光片即完成 Cell 製程。 第三階段是 Module 的製程,如圖 2.4 中細虛線箭頭的流程。首先壓合驅動 IC,接 著為印刷電路板的壓合、背光源的組裝,最後完成 TFT-LCD 的組裝,經抽樣做可靠度 7.
(18) 的驗證測試後,進入最後包裝完成 TFT-LCD 製程。. 圖 2.4 TFT-LCD 的製程 8.
(19) 圖 2.4 TFT-LCD 的製程(續). 9.
(20) 2.3. TFT-LCD 測試項目 當 Array 製程結束後進行需檢測的工作,而測試項目包括電器性能的測試、點和線. 造成的開路和短路、點和線的距離和密度的缺點數。其測試的數據包括了計量值(阻抗, 電壓,電流)和計數值(點和線相關缺點數)。以下分別對測試項目和其定義做說明。. 1. TEG (Test Element Group)的檢測: 目的是對螢幕內每一畫素 TFT 相關電器特性的測試,檢測出的值是計量值,包括電 流、電子遷移率、增益值等。每一測試項目都有相對應的測試規格,如果量測值超過規 格,該項測試判定為失效 (fail)。此類的檢測雖然是計量值的表現,但是最後判定的結 果是看有沒有符合規格,在規格內的計量值結果是 Pass,在規格外的計量值結果是 Fail。所以,這又是一種計數的表現。. z. 檢查的項目:TFT 特性--- Ion、Ioff、Vth、Ufe、gm 配線抵抗--- Rsl、Rgl、Rcl 接觸抵抗--- Rge1、Rge2、Rsd1、Rsd2. z. 測試方法:每個基板各測試約 38 個 TEG 元件(實際視機種而定),量測結果 送往 Server 計算,再經判定基準決定面板良否。. z. 需求資訊:TEG 座標、量測 TEG 種類. z. 提供資訊:Ion(Vg=20V),Ioff(Vg=-5V),Vth,ufe. z. 相關參數:TFT 之 W/L、介電層及半導體層厚度及介電係數等. z. TEG 測試點位:如圖 2.5 所示,一張(sheet)包括 6 個單元 (Cell). z. TEG 測試項目:如表 2-1 所示. 10.
(21) A: Rge2 , TFT , Rsd2 B: Rsl , Rsd1 , Rcl C: Rgl , TFT , Rge1. A1. B3. C3 B6. B2 C1. B1. C2B4. A3. A2. C4. 圖 2.5 TEG 測試點位 表 2.1. 測試項目. 項目. 單位. Ion. μA. Vd=20V、 Vg=20V時量測所得之 Id 值. Ioff. PA. Vd=20V、 Vg= -5V時量測所得之 Id 值. Vth. V. 臨界電壓 (由量測數據推算 ). μfe. cm /vs μA. 2. 電子遷移率 (由量測數據推算 ). Id1 gm. 說明. Vg=20V、 Vd=1時量測所得之 Id 值 增益值 (由量測數據推算 ). Rg1. KΩ. Gate配線抵抗. Rs1. KΩ. Source配線抵抗. Rc1. KΩ. Cs 配線抵抗. Rge1. Ω. PE/GE pattern M06接觸抵抗. Rge2. Ω. PE/GE pattern M32 接觸抵抗. Rsd1. Ω. PE/SD pattern M27 接觸抵抗. Rsd2. Ω. PE/SD pattern M08 接觸抵抗. Rank. TEG等級判定. 11.
(22) 2. Line Defect 的測試: 包括對閘極(Gate)、源極(Source)的短路、開路、保持電容(Cs)開路或不明線欠陷做 檢驗,因為其檢出值是不良數值,所以為計數值。其檢測的項目、單位和說明如 2.2 表 所示。 表 2.2. 線缺點檢驗項目. 項目. 單位. GO. Line. Gate Open. GG. Pair. Gate-Gate Short. SO. Line. Source Open. SS. Pair. Source-Source Short. GS. Line. Gate-Source Short. GC. Line. Gate-Cs Short. SC. Line. Source-Cs Short. GSR-Op. Line. Gate Short Ring Open. GSR-Sh. Line. Gate Short Ring Short. SSR-Op. Line. Source Short Ring Open. SSR-Sh. Line. Source Short Ring Short. G-POOR. Line. Gate通電不良 (未達 open 標準 ). S-POOR. Line. Source通電不良 (未達 open 標準 ). CS-OPE. Line. Cs Open. LINEUN. Line. 不明線欠陷. LDF Rank. 說明. 線欠陷規格判定. 3. 目視人工檢查: 包括檢驗點欠陷、連續欠陷、距離、密度、縱 2 連續、橫 2 連續、LOW_VG、IOFFLK、 GTLEAK、 EXT_CHG、SITO_SH、SLFLEAK、R_GOOD 等。檢出值是不良數值,所 以為計數值。. 12.
(23) 第三章 類神經網路 類神經網路(Artificial Neural Network)或譯為人工神經網路,最早在 1890 年被提 出,於 1943 年由 McCulloch 和 Pitts 提出運算元數學模型,1957 年由 Rosenblatt 提出感 知機(perceptron) ,使用反覆的權重調整進行學習,建模能力良好。第一次類神經網路被 使用的黃金時期是在 1957 年到 1969 年這段時期,後來因為其學習能力受限,類神經網 路沉寂一段時間,直到 1985 年類神經網路有新運算方法的突破,自此進入第二次類神 經網路被廣泛範應用的黃金時期[4][5][11]。 簡單說,類神經網路是一模仿生物神經網路的資訊處理系統。也就是說類神經網路 是一種計算系統,包括軟體與硬體,它使用大量簡單的相連人工神經元來模仿生物神經 網路的能力。人工神經元是生物神經元的簡單模擬,它從外界環境或者其它人工神經元 取得資訊,並加以非常簡單的運算,輸出其結果到外界環境或者其它人工神經元[10]。 從數學模型的角度來看,類神經網路是由許多人工神經細胞(artificial neuron) ,亦 即運算單元(processing element)所組成。每一個運算單元的輸出以扇狀送出,成為其 它許多運算單元的輸入。運算單元的輸出值與輸入值之關係式,一般可用輸入值的加權 乘積和之函數來表示[5]。以圖 3.1 為例,其中第 L 層結點 i 的輸出值為: n. y = ϕ i (∑ wij a j + bi ) j =1. 其中, a j 是 L -1 層上第 j 個結點的值。. wij 是權重,連結第 L 層的結點 i 到 L -1 層的結點 j 。 bi 是結點 i 的偏量。 ϕ i 是一個非線性的函數。 通常 ϕ i 在每一個結點是一樣的,所以我們通稱為 ϕ ; ϕ ( x) = 數)。. 13. 1 (稱之為運算函 1 + e−x.
(24) i. 圖 3.1 多層前饋網路. 3.1 類神經網路之特性 類神經網路因具有平行運算能力、學習式記憶力、歸納能力及強健性,近幾年來已 被廣泛地應用在各個不同的學術領域上,如非線性系統的模擬、股票市場的預測、圖形 影像的分類、辨識上...等等,其貢獻是很大的。類神經網路相對於數位電腦,它有 幾項特性與優點[10]:. 1. 高速運算: 類神經網路是一自然的巨量平行處理系統或架構,利用大量的運算單元與單元之 間的連結來同時處理資訊,單位時間內類神經網路比數位電腦快了近 1010 倍。. 2. 高容記憶能力: 類神經網路是個高度連結的網路,任何一種從 m 維空間到 n 維空間的映射,可用 一個具有三層的網路來完成,依此,類神經網路將有驚人的記憶容量。. 3. 聯想性記憶: 類神經網路可以根據過去的經驗,以自我學習的方式判斷找出相當接近真實的結 果。藉著自我學習,解決使用者在資料的描述及處理上所遇到一些缺乏答案的問 題。. 4. 容錯能力: 類神經網路因為運算元及連結鍵組成的架構,特別擅長處理錯誤、多餘、矛盾、. 14.
(25) 重複、殘缺的資料,也就是具模糊推論(fuzzy reasoning ) 能力。. 5. 具有處理非線性訊號的特質: 類神經網路可以從輸入及輸出資料中相互對應學習,在線性系統中為單一輸入和 輸出的變化且輸入值為單一的影響,但在非線性系統中各輸入值為相互關連,輸 入值彼此互相影響。在真實世界中許多問題往往是非線性的,類神經網路提供了 處理實際複雜非線性系統的功能。. 3.2 類神經網路之類型 類 神 經 網 路 大 致 分 為 四 類 : 監 督 式 學 習 (supervised learning) 、 非 監 督 式 學 習. (unsupervised learning) 、 聯 想 式 學 習 (Associative learning) 與 最 適 化 應 用 網 路 (Optimization application network) [10]。 1. 監督式學習(supervised learning) 從問題領域中取得訓練範例 (有輸入變數值,也有輸出變數),並從中學習輸入變 數與輸出變數的內在對映規則,以應用於新的案例。監督式學習網路例如:感知 機網路、倒傳遞網路、機率神經網路與學習向量量化網路等。. 2.非監督式學習(unsupervised learning) 從問題領域中取得訓練範例 ( 只有輸入變數值),並從中學習範例的內在聚類規 則,以應用於新的案例。非監督式學習網路例如:自組織映射圖網路與自適應共 振理論網路。. 3.聯想式學習(Associative learning) 從問題領域中取得訓練範例(狀態變數值),並從中學習範例的內在記憶規則,以 應用於新的案例。聯想式學習網路例如:霍普菲爾網路與雙向聯想記憶網路。. 4.最適化應用網路 (Optimization application network) 所設計的變數值,在條件限制下,使其達到最佳的狀態的一種學習應用,諸如排. 15.
(26) 程應用等可屬於最適化應用學習型的網路設計。最適化應用網路例如:霍普菲爾 網路─坦克網路與退火神經網路。 類神經網路在被應用實際問題前,我們必須對它進行必要之訓練,所謂網路的訓練 就是從應用的環境中選出具代表性的訓練範例樣本,持續的呈現給網路,再藉著學習法 則,不斷地調整網路的連接權重,重複訓練到期望的目標和網路輸出值之誤差在容許範 圍內。 在此研究上,我們使用最普遍的倒傳遞類神經網路 (Backpropagation Neural. Network)來作為訓練架構。. 3.3 倒傳遞類神經網路 倒傳遞類神經網路是目前類神經網路學習模式中應用最普遍、成功案例最多、最具 代表性的一種,它的優點有學習精度高、回想速度快...等。因屬於監督式學習,適 合應用於診斷、預測等 [4][8] 。倒傳遞類神經網路的基本原理是利用最陡坡降法(the. gradient steepest descent method)的觀念,找出誤差函數與輸入、輸出層權值之間的關係, 並藉著修正權值來使其誤差函數達到我們要求的最小值[5][6][7]。 倒傳遞類神經網路架構如圖 3.2 所示,包括:. 輸入層:接受自外界的訊號作為網路的輸入變數,其運算單元數目依問題需求而定。 因為輸入變數可為連續值,故使用線性轉換函數,即 f ( x) = x 。 隱藏層:用以表現輸入運算單元間交互影響,其運算單元數目往往需以多次試驗方式 決定其最佳數目。通常隱藏層使用非線性轉換函數,例如雙彎曲函數(Sigmoid 。通常倒傳遞網路使用一層隱藏層,至多二層,可以表現出最好的 Function) 收斂效果。一、二層隱藏層已足以反應輸入單元間交互作用,更多的隱藏層 反而使網路過度複雜,造成更多局部最小值,而無法收斂。一般問題可取一 層隱藏層,較複雜的問題則取二層隱藏層。當隱藏層設定為無隱藏層架構的 倒傳遞網路,其效果接近統計學上一些有「線性」假設的方法,例如線性迴 歸、區別分析。隱藏層運算單元不宜太多或太少。若太多,雖可達到更小的. 16.
(27) 誤差值,但因網路過於複雜,造成收歛越慢;而若太少,則不足以反映輸入 變數間的交互作用,因而有較大的誤差。在訓練的過程中為避免過度訓練. (overtraining),找出趨勢比找到最小的 RMSE 更為重要。 輸出層:表現網路的輸出變數,其運算單元數目依問題而定。使用非線性轉換函數。 轉換函數:最常用的非線性轉換函數為雙彎曲函數(Sigmoid Function) ,如圖 3.3 之(1), 其公式為 f ( x) =. 1 。這種函數當 x 值趨於正無窮大時,函數值 f (x) 趨 1 + e− x. 近於 1;當 x 值趨於負無窮大時,函數值 f (x) 趨近於 0,亦即其函數值域在 【0,1】之間。另一非線性轉換函數為雙彎曲線正切函數(Hyperbolic Tangent. Function),如圖 3.3 之(2),其公式為 f ( x) =. e x + e−x 。 e x + e−x. 輸出向量. 輸出層: 輸出變數. 隱藏層:處理單元間 的交互影響. 輸入層: 輸入變數. 輸入向量. 圖 3.2 倒傳遞類神經網路架構. 17.
(28) (2)雙曲線正切函. (1)雙彎曲. 圖 3.3 常用的非線性轉換函數. 以下說明倒傳導類神經網路的學習過程與回想過程[5]: 1.學習過程的訓練步驟: (1.)設定網路的學習參數,以隨機方式設定網路的初始權重。 (2.)開始輸入訓練範例 (3.)計算輸出值. net pi =. ∑w a. ij pj j∈ previous _ layer. + bi. 其中, a pj 是對 p 樣本 j 單元的輸出值: a pi =. 1 1+ e. − net pi. 。. wij 是由 j 到 i 單元的權重 bi 是 i 單元的偏量 (4.)計算誤差 E:根據坡降法或最小平方誤差函數,計算如下。. E = ∑ Ep , Ep = p. 1 t p − op 2. 2 2. 其中, E 是總誤差。. t p 是對 p 樣本,目標輸出值。 18.
(29) o p 是對 p 樣本,真實輸出值。 (5.)計算差距量 δ pi. (t pi − o pi ) f ' (net pi ) ,如果 i 單元是輸出結點。. δ pi = f ' (net pi )Σδ pk wki ,如果 i 單元是在隱藏層的輸出結點。 (6.)計算加權值修正量 ∆ p wij. ∆ p wij = ηδ pi a pj 其中, ∆ p wij 是 p 樣本中, wij 的改變量。 (7.)更新權重值 w ji 及偏量值 b ji q w new = w old ji ji + ∆w ji. 對 q 層, ∆w qji = ηδ iq O qj −1 ; 其中 O qji−1 是 q − 1 層的輸出值 q b new = b old ji ji + ∆b ji. 對 q 層, ∆b qji = ηδ iq (8.)重複步驟(2)至步驟(7) ,不斷的輸入訓練範例,直到收斂現象出現(也就是 誤差不再有明顯變化)。 2. 回想過程的步驟: (1.)輸入一個測試範例的輸入向量 X 至已訓練好的網路中。 (2.)計算輸出值。. net pi =. ∑w a. ij pj j∈ previous _ layer. + bi. 其中, a pj 是對 p 樣本 j 單元的輸出值: a pi =. 19. 1 1+ e. − net pi. 。.
(30) wij 是由 j 到 i 單元的權重 bi 是 i 單元的偏量. 3.4 類神經網路之應用 類神經網路在實務上的應用十分廣泛,可分為以下幾方面來說明[9]: 市場:可以運用在市場區隔,利用人工統計學( demographics )、社會經濟學 (socio-economic)等等,區分出會喜歡這個產品的顧客,在將銷售的目標 放在這些客戶身上,而不須要將時間或金錢花在本身就不喜歡這個產品的客 戶身上。 零售:運用類神經網路可以同時考慮多個變數的特性,成功的運用在產品的銷售預 測上,提供零售商在存貨水準、產品售價等決策上的支援。 金融財務:這方面的運用十分廣泛,如衍生性金融商品的買賣與套利、未來價格的 預估、股票及匯率的預估等等,而且成效十分卓越。在授信方面,則運用在 信用評等。同時在公司倒閉的預估方面,類神經網路也有非常成功的案例。 較新的方面,則是運用在建立公司財富累積與公司經營策略,短期財務狀況 及經營成效之間的關係。 保險:運用在投保人員的行為來分成不同的族群,以預估保費及要求保險索賠的頻 率及機會。 電信:包括客戶通信行為分析、預測客戶是否繼續使用,並提供客戶產品組合來留 住客戶。此外,類神經網路也被應用在電信網路架構及設計的最佳化上。 作業管理:從排程、計劃、品質管理到專案完成時程預估等複雜的最佳化問題,有 非常多運用的實例。 製造:運用在生產線上即時品質缺陷的識別,例如運用機率類神經網路來辨識並分 類生產線上陶瓷磚的表面缺陷。運用 Fuzzy ART 根據零件的加工道次來形成. 20.
(31) 機台族群,透過機台族群的設立,讓加工零件的距離能儘可能的減少。運用 類神經網路解決在物料需求計劃中經濟批量大小的問題並與其他近似解決 做比較,結果顯示類神經網路具有不錯的效果、可以提供合適的訂購批量大 小,來降低成本。 由最近幾十年來類神經網路的廣泛運用,可明顯的看出其實用性及接受度,而其不 必有分佈及統計的假設前提,也是優於傳統統計之處。透過學習而得到的輸入與輸出之 間的應對關係,更具有一般性,在實際運用上的效果,十分的顯著。. 21.
(32) 第四章 研究方法 4.1 資料的取得和處理 TFT-LCD 測試區接收自製造區來的成批(每一批稱一 Recipe)的玻璃,直接以機械手 臂移至測試機櫃(Cassette)中。測試開始前,測試工程師需將準備好的邏輯模具組送到測 試機台上,測試機台再依指示送要求訊息給機械手臂。機械手臂依訊息自機櫃移出待測 液晶玻璃至探測機台(Probe)後,Probe 向測試機台送出 ready 的訊息,經測試機台及探 測機台彼此協調(handshaking)完成 Setup 的動作後,測試首先執行自我測試(Self-Test), 然後開始一連串的測試[2]。 本研究的範圍是 TFT-LCD 的生產製程中 Array 製程的測試項目,包括電器性能的 測試、點和線造成的開路和短路、點和線的距離和密度的缺點數。其測試的數據包括了 計量值(阻抗、電壓、電流)和計數值(點和線相關缺點數)。 在測試區的製程中多數是複雜繁瑣的,愈有製程經驗的工程師愈能掌握產品測試的 精準性,而且多半在液晶玻璃切割前的電測外,另外有切割後經組合後的實際成品測試 過程,廠方會將二者的測試結果,作一比較看是否有誤判率過高的情況,如果誤判率過 高會要求工程師調加測試項目或是調整允收範圍...等方式。然而,下列所述二個問 題,一般沒有使用一套有效的系統來全面審查所增加的測試項目和時間是否能同時符合 經濟性和測試有效性[3]。. (1.) 加上驗證新功能的測試項在原有一般的測試項目上,對於新的測試項目是否已能 取代原有一些的測試項目,沒有進行整體的審查,因此增加很多測試項目和時間。. (2.) 當製程日漸成熟後,一些測試項目是否可以精簡?但是希望精簡後仍能對於測試 的結果和不良品的檢出能力與原有的結果必需要很接近。. 22.
(33) 所搜集到的檢測資料需要經過處理才能做進一步的分析,其處理的步驟如下:. 1.確定資料的屬性和類別 (1.) 資料筆數:儘可能取得 100 筆以上(含計數值和計量值)資料,並希望是在 不同的批量中獲得,其中要記錄批號、投入和產出時間。. (2.) 檢測項目(x):測試項目包括電器測試和目視檢驗項目。 (3.) 輸出結果(y):測試良率。 2.資料處理 (1.) 去除離群值和屬性有問題的筆數。 (2.) 去除敏感度不高或對輸出結果沒任何影響的項目。 (3.) 選擇可用屬性的量測項目。 3.資料分類 測試良率的分類:不同等級產品都經過相同的測試流程,雖然等級不同但是測 試成本卻是相同的,然而售價有差別。因此,可將數據區分為若干等級,例如 等級 A、B 與 C。. 4.2 類神經網路模式的建立 本 研 究 建 議 使 用 所 有 的 檢 測 項 目 應 用 倒 傳 遞類 神 經 網 路 建 立 完 整 模 型 ( Full. Model),流程如圖 4.1 所示。首先決定類神經網路的參數,然後進行訓練學習。檢驗, 建構需選擇較低的 RMSE 較高的 Correlation 以決定η (Learning rate 學習率 ) ,α. (Momentum 慣性)和隱藏層的結點數,建立後這個模型就是一個參考的標準,包括訓練 和測試樣本的正確分類率和訓練和測試樣本的平均數和標準差。. 建立簡化的倒傳遞類神經網路模型: 將輸入變數的貢獻度做一排序,加上工程專業的判斷,修剪輸入結點數(即測試項 目),之後再建構一個倒傳遞的類神經網路,這個模型要和完整模型一樣有高的訓練和 測試樣本的正確分類率和較低的誤差平均數。 如果這個簡化模型有跟完整模型一樣的 23.
(34) 分類率,且有較低的平均誤差,那麼我們就有信心採用這個模型。流程如圖 4.2 所示, 詳細的步驟如以下說明。 輸入變數的貢獻度的計算步驟如下[5]: 步驟一:對每一輸入結點計算權重值的總和,加總 W1(輸入層-隱藏層) x W2 (隱藏層輸出層)。 步驟二:對步驟一的值做由大至小的排序,並刪除極小值的項目。 步驟三:由步驟二找到重要的輸入結點,當輸入的結點變少,再由這些輸入結點重新 訓練一個類神經的網路模型。如果新模型的成效可以被接受,則停止。否則, 應該重新考慮步驟二的演算。. 圖 4.1 建立完整的倒傳遞類神經網路模型之流程. 24.
(35) 圖 4.2 建立簡化的倒傳遞類神經網路模型之流程 當測試資料處理完畢之後,我們要先決定構建倒傳遞類神網路模型的相關參數. (1.) 已知參數:輸入層結點的個數與輸出層結點的個數。 (2.) 自訂參數:隱藏層的層數與結點個數,以及 Epoch 數。 (3.) 學習參數:使用試誤法學習決定 Learning rate(η)與 Momentum(α)。 本研究建議訓練樣本對測試樣本的比例為 75%:25%,以這樣的比例去建構類神經 網路模型。測試樣本由原始數據的 A,B,C 等級內取訓練和測試筆數,這樣測試完整 性較好。經過訓練和學習後可以找到倒傳遞類神網路模型的合理參數,包括隱藏層的層 數,學習率(η)和 Momentum(α)。 在應用倒傳遞類神網路時,較大的學習率(η)會有較大的權重改變,然而大的學 習率會引起振盪和不穩定的結果,以下的方程式可以提供一個方法去變動學習率而不會. 25.
(36) 導致振盪的現象。 ∆wij (n + 1) = ηδ pi a pi + α∆wij (n) ,其中, n 是指重覆的次數,α是一個 固定值(momentum 係數) 它決定舊的權重在現有權重改變的效果,η和α由倒傳遞類神 網路的使用者決定。根據經驗,η值剛開始可以被設定為較低的值,慢慢的增加η的值, 我們可以找到一個較合適的學習率(η) ;此外,α剛開始可以被設定成較高的值,慢慢 的減少α的值,我們可以找到一個較合適的 Momentum(α)。 網路輸出值與目標值的誤差可以被拿來當做訓練網路的指標,如果誤差達到一個穩 定的值(或是低於一個標準值)的時後,我們就可以停止訓練。接著檢查訓練結果,包括 重複訓練樣本的 MSE(Mean Squared Error)和相關性、重複測試樣本的 MSE 和相關性、 目標值與輸出值標準化後的散佈圖,檢視其是否符合常態分佈的型態。 根據各個輸入結點(測試項目)相對輸出值(即測試良率 AT2)的貢獻度,做一排序, 如此可以了解那些測試項目重要的程度。根據上述的貢獻度和工程專業的判斷去刪除相 對不重要的測試項目,最後,觀察這些測試項目對輸出結果的正確性。. 26.
(37) 第五章 案例說明 5.1 個案公司簡介 本研究主要針對國內某著名光電大廠(A 公司)的薄膜電晶體液晶顯示器(TFT-LCD) 之測試問題做探討分析。A 公司是在台成立的公司,具有設計、研發、製造和銷售全方 位能力的公司,同時為全球第一家於美國紐約證券交易所(NYSE)上市之 TFT-LCD 製造 公司。A 公司之產品線齊全,涵蓋了 1.5 至 65 吋 TFT-LCD 面板,應用領域包含桌上型 顯示器、筆記型電腦、液晶電視、車用顯示器、工業用電腦、數位相機、數位攝錄機、 手持 DVD、掌上遊戲機、手機等全系列應用,亦是全球少數供應大、中、小完整尺寸 產品線之廠商,客戶涵蓋電腦資訊與消費性產品之全球知名品牌。 A 公司之大尺寸液 晶面板出貨量全球領先,市佔率達 20.5%。除全球市場行銷成績斐然,A 公司更深耕於 技術與研發,是國內最大之光電研發中心,研發技術包括 TFT-LCD 與 LTPS (Low. Temperature Poly-Silicon,低溫多矽晶)等顯示技術。A 公司投入研究發展之經費居國內 光電之首,2002-2006 年專利申請數量連續蟬連國內平面顯示器產業之冠。此外,A 公 司也率先生產反射式 TFT-LCD 面板並應用在無線以及低耗電量需求之小尺寸應用產 品,其第 3.5 代、4 代、5 代、6 代及 7.5 代廠皆於國內率先量產。. A 公司所提供的產品線雖然涵蓋很廣的產品線,在製程高度自動化和零組件技術的 改進下提高了效率和增加產能,也減低人為疏失。但是,檢驗和測試的項目因為品質的 要求和良率需不斷提升的壓力以及新功能的增加下,發展出更多的測試項目,如 TEG. (Test Element Group)、Line Defect 和 Auto Plot 及目視檢查等項目。目前 A 公司並沒有 整體的去分析這些測試項目的合理性。然而,當前市場競爭嚴重,產品生命週期愈來愈 短,價格和利潤愈來愈低的情勢下,除了不斷的研發和創新產品之外,合理的簡化測試 項目以降低測試成本和時間,並提升產品的產出速度,才能使 A 公司在市場上更具有競 爭力。. 27.
(38) 5.2 資料的收集和說明 本研究的對象是 A 公司在 9 吋 TFT LCD 的新產品,該產品應用於車用顯示器和一 般 的 小 型 電 視 , 資 料 來 源 是 在 Array 製 程 中 採 用 近 2 個 月 (2007-02-01. 07:30:00~2007-03-27 07:30:00)的良率數據,其中包括電器功能的檢測和個別缺點的檢 測,一共有 123 筆資料。每一筆資料記載了每批的代碼、投入和產出的時間、批量的數 量大小、測試良率 AT1 和 AT2 和測試項目包括點和線的缺點檢測和電器功能的測驗, 共 102 個測試項目。. 1.批(LOT)和測試數量的關係: 每一批有 25 片裝在一車,每一片有 24 個面板(panel),因此一批有 600 個面板. (panel),本研究所謂測量的數量是指面板的數量。. 2.測試良率 AT1 和 AT2 的關係:. AT1 是一連串的電器測試後的良率值,每一片每一個面板都經過這項測試,每一項 測試都有規格,不在規格內的就算一個缺點,這些面板是沒有經過雷射修補的。AT2 是 這批最後的良率值,它是 AT1 乘以β。β是一個係數,定義成一連串的點線缺點檢測的 良率係數, e. −. γ η. (其中 γ 是點線檢測缺點數的總和,η是總產出數)。點線檢測是由每一. 車,25 片內做抽樣檢測。. 3.本研究採用 Array 製程中最後良率值 AT2 做分析。. 5.3 資料的處理和類神經網路模型建構 在 LCD- TFT 的產品中,會將最終的產品區分為不同的等級,將測試品質和良率高 的產品劃歸為 A 級品,其次為 B 級品和 C 級品。A 公司的策略是品質高的賣較高的價 格,品質較低的賣較低的價格,這樣所有的產品都可以依據客戶在經濟和功能上需求, 賣出所有的產品,不致因小瑕疵而報費。分類的規則如表 5.1 所示。 28.
(39) 表 5.1 TFT-LCD 產品分類標準 類別. AT2 良率. A. ≥95.50%. 31. 15. B. 90.00% ≤ AT2 < 95.50%. 44. 13. 12. 2. 87. 30. C. 訓練樣本數. < 90.00% 合計. 測試樣本數. 1.完整模式之建立 由原始的資料中做篩選並去除一些離異值,保留可用筆數和可用屬性來建構完整的 類神經網路模型。在訓練和測試的樣本時必需選取在原始資料中良率分類為 A、B、C 的類別內資料以避免所建構模型的偏差。 以下說明詳細的步驟和訓練結果。 原始資料: z. 資料筆數:123 筆. z. 屬性(x):102 項(包含同一欄位所有資料皆為 0 的 49 項). z. 輸出結果(y):1 項(測試良率 AT2,單位%). 資料處理: z. 可用筆數:117 筆(No.1,15,42,75,115 五筆離群值、No.20”Rgl”屬性有問題). z. 可用屬性:53 項(去除皆為 0 的屬性),可用屬性如表 5.2 所示。. 資料分類 z. 訓練樣本:測試樣本=87:30(約為 75%:25%). z. 測試樣本選取法則:由於資料是依照時間順序得到之檢測結果,因此從 117 筆資料中選取後面的 30 筆作為測試樣本。(No.93-No.123). 模型參數 z. 輸入層結點個數:53. z. 輸出層結點個數:1. z. 隱藏層數:1. z. Epoch 數:100(iteration=11,700) 29.
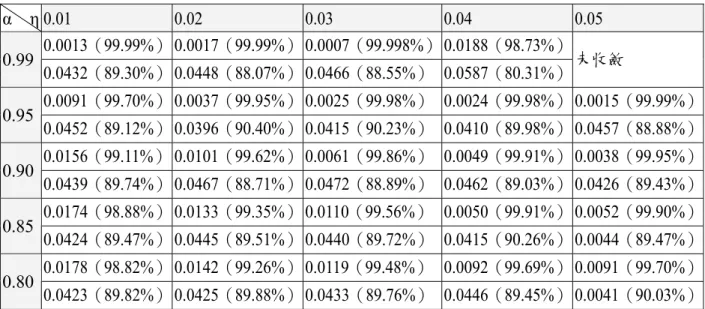
(40) z. 決定 Learning rate(η) 、Momentum(α): 一般隱藏層的結點個數無法確定,採用 try-and-error 找出最佳個數,而通常 隱藏層結點個數會介在「輸入層結點數和輸出層個數之和的一半」與「兩倍 輸入層結點個數」之間。因此在此採用 53-27-1 之模型,其結果如表 5.3。 由表 5.3 可發現 α 值越高,其訓練樣本之 RMSE 會隨之降低且相關性會隨之增 加。但當 α 值設定為 0.99 時,雖然 RMSE 值更低,但會發生過度訓練或是震 盪的狀況發生,因此將 α 設為 0.95。 η 值在[0.01,0.05],隨著 η 值越高,訓練 樣本之 RMSE 會隨之降低且其相關性會隨之漸增。然而,當設定 α = 0.95 且 η=. 0.05 時,雖然訓練樣本之 RMSE 降低,但測試樣本之 RMSE 卻提高,因此將 η 設定為 0.04 即可。. z. 決定隱藏層結點個數: 在 α = 0.95、η = 0.04 下,決定隱藏層結個數,其結果如表 5.4 所示。 由表中 可發現隱藏層結點個數在 5-30 之間結果皆差不多,個數在 3 的時候訓練樣本 和測試樣本的 RMSE 皆較高,個數在 35 時會有過度訓練的問題發生,因此不 與考慮。 若依經驗,一般建議隱藏層結的最小個數為 27 個,因此在結果差不 多的情況下,選用 53-27-1 之模式來做分析。. 訓練結果 本研究使用軟體 Q-net v.2000 trail 進行分析,採用 53-27-1、α = 0.95、η = 0.04、重 複 100 個 epoch 來建立模式。訓練與測試結果的 RMSE 與 Correlation 如圖 5.1 至圖 5.4 所示。此外,目標值與輸出值則如圖 5.5 所示,圖 5.6 則根據資料順序描繪各資料對應 之輸出值與目標值。從這些圖看出,訓練樣本之輸出值與目標值幾乎完全吻合,而測試 樣本雖然無完全吻合,但基本上趨勢有呈現出來。各輸入結點的貢獻度如表 5.6 所示。 若以產品的分類等級來看,訓練標本之正確分類率為 100%,而測試樣本之正確分類率 為 83.33%,分別如表 5.6 與 5.7 所示。. 30.
(41) 表 5.2 可用屬性的測試項目表 輸入結點的編號. 名稱. 輸入結點的編號. 名稱. 1. GG_SHORT. 28. LOW_VG. 2. S_OPEN. 29. IOFFLK. 3. SS_SHORT. 30. GTLEAK. 4. SG_SHORT. 31. EXT_CHG. 5. 32. 6. GC_SHORT Charge 量. 33. OTHERS 不明. 7. 點欠陷(重)(X). 34. LOW_VG(>0). 8. 點欠陷(重)(>0). 35. IOFFLK(>0). 9. 點欠陷(輕)(>0). 36. GTLEAK(>0). 10. 點欠陷(合計)(>0). 37. EXT_CHG(>0). 11. 2 連續(重)(>0). 38. 12. 2 連續(輕)(>0). 39. OTHERS(>0) 不明(>0). 13. 2 連續(合計)(>0). 40. Ion. 14. 多連續(重)(>0). 41. Ioff. 15. 多連續(輕)(>0). 42. Imin. 16. 多連續(合計)(>0). 43. Vth. 17. 距離 NG(輕)(>0). 44. ufe. 18. 距離 NG(合計)(>0). 45. Id1. 19. 密度 NG(重)(>0). 46. gm. 20. 密度 NG(輕)(>0). 47. Rgl. 21. 密度 NG(合計)(>0). 48. Rsl. 22. 縱 2 連續(重)(>0). 49. Rcl. 23. 縱 2 連續(輕)(>0). 50. Rge1. 24. 縱 2 連續(合計)(>0). 51. Rge2. 25. 橫 2 連續(重)(>0). 52. Rsd1. 26. 橫 2 連續(輕)(>0). 53. Rsd2. 27. 橫 2 連續(合計)(>0). 31.
(42) 表 5.3 完整模型中η和α的對照表 0.02 0.03 0.04 0.05 α η 0.01 0.0013(99.99%) 0.0017(99.99%) 0.0007(99.998%) 0.0188(98.73%) 未收斂 0.99 0.0432(89.30%) 0.0448(88.07%) 0.0466(88.55%) 0.0587(80.31%). 0.95 0.90 0.85 0.80. 0.0091(99.70%) 0.0037(99.95%) 0.0025(99.98%) 0.0024(99.98%) 0.0015(99.99%) 0.0452(89.12%) 0.0396(90.40%) 0.0415(90.23%) 0.0410(89.98%) 0.0457(88.88%) 0.0156(99.11%) 0.0101(99.62%) 0.0061(99.86%) 0.0049(99.91%) 0.0038(99.95%) 0.0439(89.74%) 0.0467(88.71%) 0.0472(88.89%) 0.0462(89.03%) 0.0426(89.43%) 0.0174(98.88%) 0.0133(99.35%) 0.0110(99.56%) 0.0050(99.91%) 0.0052(99.90%) 0.0424(89.47%) 0.0445(89.51%) 0.0440(89.72%) 0.0415(90.26%) 0.0044(89.47%) 0.0178(98.82%) 0.0142(99.26%) 0.0119(99.48%) 0.0092(99.69%) 0.0091(99.70%) 0.0423(89.82%) 0.0425(89.88%) 0.0433(89.76%) 0.0446(89.45%) 0.0041(90.03%). (每一格上格代表訓練樣本的RMSE,下格代表測試樣本的RMSE;括號內的數值為其相 關性。). 表 5.4 完整模型中不同隱藏層結點之對照表. 隱藏層結點個數. 訓練樣本. 測試樣本. RMSE. correlation. RMSE. correlation. 35. 0.0008. 99.997%. 0.0433. 88.21%. 30. 0.0023. 99.98%. 0.0406. 90.54%. 27. 0.0018. 99.99%. 0.0406. 90.54%. 25. 0.0024. 99.98%. 0.0377. 91.51%. 20. 0.0028. 99.97%. 0.0385. 90.71%. 15. 0.0029. 99.97%. 0.0375. 91.62%. 10. 0.0029. 99.97%. 0.0374. 91.21%. 5. 0.0021. 99.98%. 0.0372. 91.45%. 3. 0.0185. 98.74%. 0.0538. 82.67%. 32.
(43) 圖 5.1 訓練樣本之 RMSE 變化 (Full Model). 圖 5.2 訓練樣本之 correlation 變化 (Full Model). 33.
(44) 圖 5.3 測試樣本之 RMSE 變化 (Full Model). 圖 5.4 測試樣本之 correlation (Full Model). 34.
(45) 圖 5.5 目標值與輸出值標準化後之散佈圖 (Full Model). 圖 5.6 根據資料順序各資料對應之輸出值與目標值(Full Model). 35.
(46) 表 5.5 各輸入結點的貢獻度 (Full Model) 輸入結點編號. 貢獻度. 所佔百分比. 累積百分比. 53. 10.6897. 3.2118%. 3.2118%. 48. 10.4765. 3.1478%. 6.3596%. 25. 9.9588. 2.9923%. 9.3519%. 20. 9.8392. 2.9563%. 12.3082%. 9. 9.5615. 2.8729%. 15.1811%. 35. 9.3894. 2.8212%. 18.0022%. 18. 8.8870. 2.6702%. 20.6724%. 47. 8.8200. 2.6501%. 23.3225%. 8. 8.4672. 2.5441%. 25.8666%. 13. 8.4660. 2.5437%. 28.4103%. 5. 8.4653. 2.5435%. 30.9538%. 1. 8.2005. 2.4639%. 33.4177%. 43. 7.7368. 2.3246%. 35.7423%. 24. 7.6969. 2.3126%. 38.0550%. 32. 7.5887. 2.2801%. 40.3351%. 41. 7.3803. 2.2175%. 42.5526%. 6. 7.3520. 2.2090%. 44.7616%. 28. 7.0843. 2.1286%. 46.8902%. 19. 6.9500. 2.0882%. 48.9784%. 7. 6.9432. 2.0862%. 51.0646%. 40. 6.7068. 2.0151%. 53.0797%. 51. 6.4311. 1.9323%. 55.0120%. 31. 6.3791. 1.9167%. 56.9287%. 46. 6.3452. 1.9065%. 58.8352%. 2. 6.0940. 1.8310%. 60.6662%. 38. 6.0426. 1.8156%. 62.4818%. 27. 5.9415. 1.7852%. 64.2670%. 11. 5.8402. 1.7548%. 66.0217%. 3. 5.8197. 1.7486%. 67.7703%. 15. 5.8081. 1.7451%. 69.5154%. 45. 5.7647. 1.7321%. 71.2475%. 42. 5.6822. 1.7073%. 72.9548%. 30. 5.4431. 1.6355%. 74.5903%. 16. 5.2527. 1.5782%. 76.1685%. 36.
(47) 21. 5.1984. 1.5619%. 77.7304%. 36. 5.1836. 1.5575%. 79.2879%. 49. 5.0651. 1.5219%. 80.8098%. 33. 5.0614. 1.5208%. 82.3305%. 22. 4.9702. 1.4934%. 83.8239%. 50. 4.7108. 1.4154%. 85.2393%. 37. 4.6985. 1.4117%. 86.6510%. 10. 4.5723. 1.3738%. 88.0248%. 23. 4.4362. 1.3329%. 89.3577%. 12. 4.2936. 1.2901%. 90.6478%. 29. 4.1421. 1.2446%. 91.8924%. 26. 4.1194. 1.2377%. 93.1301%. 14. 3.7973. 1.1409%. 94.2710%. 34. 3.6352. 1.0922%. 95.3633%. 17. 3.5251. 1.0592%. 96.4224%. 4. 3.4819. 1.0462%. 97.4686%. 44. 3.1448. 0.9449%. 98.4135%. 39. 2.9366. 0.8824%. 99.2959%. 52. 2.3436. 0.7041%. 100.0000%. 表 5.6 訓練樣本的分類結果(Full Model). 目標類別. 輸出類別. A. B. C. A. 31. 0. 0. B. 0. 44. 0. C. 0. 0. 12. 表 5.7 測試樣本的分類結果(Full Model). 目標類別. 輸出類別. A. B. C. A. 14. 1. 0. B. 2. 10. 1. C. 0. 1. 1. 37.
(48) 2.簡化模式Ι之建立 本研究使用前述完整模式中貢獻度較大的前 27 個變數(即表 5.5 之前 1/2 變數)來 建立簡化的模式。使用與前面相同的方法,選用 η =0.15,α=0.95,執行結果如表 5.8 所示。由表中可發現,當隱藏層結點個數在 12 和 14 個的時候,其測試樣本之 RMSE 明 顯較小且 correlation 百分比較高,但隱藏層結點在 12 個時會發生震盪,因此選用 27-14-1 之模式。從產品分類等級來看,訓練標本之正確分類率為 100%如表 5.9,而測試標本之 正確分類率為 80%如表 5.10。 表 5.8 不同隱藏層結點之訓練結果(Reduced Model-I) 隱藏層結點個數. 訓練樣本 RMSE. 12(會震盪) 0.0029. 測試樣本. correlation. RMSE. correlation. 99.97%. 0.0372. 93.31%. 13. 0.0009. 99.997%. 0.4911. 89.10%. 14. 0.0020. 99.99%. 0.0369. 92.31%. 15. 0.0013. 99.99%. 0.0455. 89.01%. 16. 0.0481. 88.39%. 17. 0.0009 99.997% 不收斂. X. X. 18. 不收斂. X. X. 表 5.9 訓練樣本的分類結果(Reduced Model-I). 目標類別. 輸出類別. A. B. C. A. 31. 0. 0. B. 0. 44. 0. C. 0. 0. 12. 表 5.10 測試樣本的分類結果(Reduced Model-I). 目標類別. 輸出類別. A. B. C. A. 13. 2. 0. B. 3. 9. 1. C. 0. 0. 2. 38.
(49) 3.簡化模式Ⅱ之建立 本研究進一步使用上述模式Ι之 27 個輸入變數,另再依工程知識判斷,多加考慮 5 個較重要的變數(如表 5.11 所示)來建立簡化模式Ⅱ。使用與前面相同的方法,選用η. =0.10,α=0.85,執行結果如表 5.12 所示。由表中可發現,當隱藏層結點個數在 17 的 時候,其測試樣本之 RMSE 明顯較小且 correlation 百分比較高,因此選用 32-17-1 之模 式。從產品分類等級來看,訓練標本之正確分類率為 94.25%如表 5.13,而測試標本之 正確分類率為 83.33%如表 5.14。 表 5.11 工程知識判斷所穫得之重要變數(Reduced Model-II) 完整模型的輸入結點編號. 名稱. 3. SS_SHORT. 4 11. SG_SHORT 2 連續(重)(>0). 45. Id1. 49. Rcl. 表 5.12 不同隱藏層結點之訓練結果(Reduced Model-II). 隱藏層結點個數. 訓練樣本. 測試樣本. RMSE correlation RMSE correlation. 15(會震盪) 0.0050. 99.91%. 0.0461. 89.84%. 16. 0.0045. 99.92%. 0.0442. 90.72%. 17. 0.0088. 99.72%. 0.0386. 92.16%. 18 0.0056 19(會震盪) 0.0047 20(不收斂) X. 99.89%. 0.0405. 91.91%. 99.92%. 0.0491. 90.08%. X. X. X. 表 5.13 訓練樣本的分類結果(Reduced Model-II). 目標類別. 輸出類別. A. B. C. A. 30. 1. 0. B. 3. 41. 0. C. 0. 1. 11. 39.
(50) 表 5.14 測試樣本的分類結果(Reduced Model-II). 目標類別. 輸出類別. A. B. C. A. 14. 1. 0. B. 3. 9. 1. C. 0. 0. 2. 4.簡化模式Ⅲ之建立 本研究使用前述完整模式中貢獻度較大的前 17 個輸入變數(即表 5.5 之前 1/3 變數) 來建立簡化的模式。使用與前面相同的方法,選用η=0.005,α=0.85,執行結果如表. 5.15 所示。由表中可發現,當隱藏層結點個數設定多少,其測試樣本之 RMSE 值皆差不 多,因此選用一般建議隱藏層結點的最小個數「輸入層結點數和輸出層個數之和的一半」 (9 個) 。所以採用 17-9-1 之模式。從產品分類等級來看,訓練標本之正確分類率為 82.76% 如表 5.16,而測試標本之正確分類率為 83.33%如表 5.17。 表 5.15 不同隱藏層結點之訓練結果(Reduced Model-III) 隱藏層結點個數. 訓練樣本. 測試樣本. RMSE. correlation. RMSE. correlation. 5. 0.0362. 95.08%. 0.0475. 87.40%. 9. 0.0358. 95.18%. 0.0471. 87.42%. 12. 0.0359. 95.15%. 0.0478. 87.21%. 15. 0.0361. 95.10%. 0.0472. 87.21%. 18. 0.0362. 95.07%. 0.0470. 87.14%. 21. 0.0358. 95.17%. 0.0473. 87.27%. 25. 0.0358. 95.17%. 0.0473. 87.26%. 表 5.16 訓練樣本的分類結果(Reduced Model-III). 目標類別. 輸出類別. A. B. C. A. 25. 6. 0. B. 4. 39. 1. C. 0. 4. 8. 40.
(51) 表 5.17 測試樣本的分類結果(Reduced Model-III). 目標類別. 輸出類別. A. B. C. A. 14. 1. 0. B. 2. 10. 1. C. 0. 1. 1. 5.簡化模式Ⅳ之建立 本研究進一步使用上述模式 III 之 17 個輸入變數,另再依工程知識判斷,多加考慮. 6 個較重要的變數(如表 5.18 所示)來建立簡化模式Ⅳ。使用與前面相同的方法,選用 η=0.001,α=0.9,執行結果如表 5.19 所示。由表中可發現,當隱藏層結點個數設定為. 30 時,其測試樣本之 RMSE 值最低且 correlation 值最高。因此採用 23-30-1 之模式。從 產品分類等級來看,訓練標本之正確分類率為 85.06%如表 5.20,而測試標本之正確分 類率為 86.67%如表 5.21。 表 5.18 工程知識判斷所穫得之重要變數(Reduced Model-IV) 完整模型的輸入結點編號. 名稱. 3. SS_SHORT. 4 11. SG_SHORT 2 連續(重)(>0). 28. LOW_VG. 45. Id1. 49. Rcl. 41.
(52) 表 5.19 不同隱藏層結點之訓練結果(Reduced Model-IV) 訓練樣本. 隱藏層結點個數. 測試樣本. RMSE. correlation. RMSE. correlation. 10. 0.0307. 96.48%. 0.0470. 87.48%. 12. 0.0299. 96.66%. 0.0460. 87.83%. 15. 0.0311. 96.39%. 0.0471. 87.24%. 18. 0.0301. 96.61%. 0.0462. 87.63%. 21. 0.0307. 96.47%. 0.0467. 87.20%. 24. 0.0304. 96.55%. 0.0460. 87.43%. 27. 0.0306. 96.51%. 0.0454. 87.69%. 30. 0.0303. 96.56%. 0.0446. 87.88%. 35. 0.0302. 96.60%. 0.0459. 87.36%. 40. 0.0305. 96.52%. 0.0461. 86.97%. 表 5.20 訓練樣本的分類結果(Reduce Model-IV). 目標類別. 輸出類別. A. B. C. A. 25. 6. 0. B. 3. 40. 1. C. 0. 3. 9. 表 5.21 測試樣本的分類結果(Reduce Model-IV). 目標類別. 輸出類別. A. B. C. A. 15. 0. 0. B. 2. 10. 1. C. 0. 1. 1. 42.
(53) 5.4 統計迴歸分析 1. 複迴歸分析 本研究使用表 5.2 的 53 個測試項目為輸入變數,以 AT2 為輸出變數,利用 Minitab 進行複迴歸分析,獲得方程式如下: 測試良率(AT2) = 0.881 - 0.00864 1_GG_SHORT - 0.00459 2_S_OPEN. - 0.00387 3_SS_SHORT + 0.107 4_SG_SHORT - 0.00433 5_GC_SHORT - 0.0149 6_Charge 量 - 0.00326 7_點欠陷(重)(X) + 0.00085 9_點欠陷(輕)(>0) - 0.00399 10_點欠陷(合計)(>0) - 0.00375 11_2 連續(重)(>0) - 0.0174 12_2 連續(輕)(>0) + 0.0377 13_2 連續(合計)(>0) + 0.0006 14_多連續(重)(>0) - 0.0159 15_多連續(輕)(>0) + 0.0018 16_多連續(合計)(>0) - 0.00070 17_距離 NG(輕)(>0) - 0.00341 18_距離 NG(合計)(>0) + 0.00244 22_縱 2 連續(重)(>0) + 0.0039 23_縱 2 連續(輕)(>0) - 0.0420 24_縱 2 連續(合計)(>0) - 0.0394 27_橫 2 連續(合計)(>0) - 0.00170 28_LOW_VG + 0.00013 29_IOFFLK + 0.0167 30_GTLEAK + 0.00179 31_EXT_CHG - 0.00004 32_OTHERS - 0.0037 33_不明 - 0.00140 34_LOW_VG(>0) - 0.00445 35_IOFFLK(>0) - 0.00775 37_EXT_CHG(>0) - 0.00239 38_OTHERS(>0) + 0.0058 40_Ion + 0.00250 41_Ioff - 0.00082 42_Imin + 0.0029 43_Vth + 0.618 44_ufe - 0.009 45_Id1 - 0.00224 46_gm + 0.0610 47_Rgl + 0.00419 48_Rsl - 0.0192 49_Rcl +0.000024 50_Rge1 -0.000391 51_Rge2 -0.000041 52_Rsd1 -0.000544 53_Rsd2 常態性假設檢定如圖 5.7,殘差分析如圖 5.8 和 5.9,分析結果,此統計模式具有妥 善性[12]。各輸入變數係數表如表 5.22,各個輸入變數係數的關係利用訓練樣本之 Full. model 約可解釋 94%之 AT2 良率的變異。由此找出 p < 0.10,表示這些變數在迴歸模式 中較為顯著,其 7 個變數如表 5.23 所示。 整個簡化模式之 ANOVA 分析如表 5.24,整個模式之 F-test 統計量為 31.07(p 值=. 0.000),表示此迴歸模式非常顯著。從產品分類等級來看,訓練標本之正確分類率為 88.51%如表 5.25,而測試標本之正確分類率為 73.33%如表 5.26。. 43.
(54) Normal Probability Plot of the Residuals (response is 測試良率). 3. Normal Score. 2 1 0 -1 -2 -3. -0.03. -0.02. -0.01. 0.00. 0.01. Residual. 圖 5.7 殘差常態分佈圖. Residuals Versus the Fitted Values (response is 測試良率). 0.01. Residual. 0.00. -0.01. -0.02. -0.03. 0.8. 0.9. 1.0. Fitted Value. 圖 5.8 殘差合適圖. Residuals Versus the Order of the Data (response is 測試良率). 0.01. Residual. 0.00. -0.01. -0.02. -0.03. 10. 20. 30. 40. 50. 60. 70. Observation Order. 圖 5.9 殘差對數據順序圖. 44. 80.
(55) 表 5.22 變數係數表 Predictor Constant 1_GG_SHO 2_S_OPEN 3_SS_SHO 4_SG_SHO 5_GC_SHO 6_Charge 7_點欠陷 9_點欠陷 10_點欠? 11_2 連續 12_2 連續 13_2 連續 14_多連? 15_多連? 16_多連? 17_距離 N 18_距離 N 22_縱 2 連 23_縱 2 連 24_縱 2 連 27_橫 2 連 28_LOW_V 29_IOFFL 30_GTLEA 31_EXT_C 32_OTHER 33_不明 34_LOW_V 35_IOFFL 37_EXT_C 38_OTHER 40_Ion 41_Ioff 42_Imin 43_Vth 44_ufe 45_Id1 46_gm 47_Rgl 48_Rsl 49_Rcl 50_Rge1 51_Rge2 52_Rsd1 53_Rsd2. Coef SE Coef 0.8806 0.1064 -0.008638 0.005550 -0.004588 0.002656 -0.003865 0.002717 0.1067 0.1531 -0.004327 0.001957 -0.01485 0.02745 -0.003259 0.005834 0.000850 0.005533 -0.003987 0.006378 -0.003752 0.007088 -0.01743 0.01239 0.03773 0.01250 0.00056 0.01298 -0.01590 0.01642 0.00184 0.01141 -0.000702 0.004941 -0.003411 0.002305 0.002440 0.007566 0.00387 0.01461 -0.04198 0.01258 -0.03944 0.01388 -0.001700 0.001222 0.000131 0.002370 0.01673 0.01793 0.001785 0.003328 -0.000037 0.002102 -0.00368 0.01275 -0.001404 0.003361 -0.004451 0.004526 -0.007748 0.006142 -0.002388 0.003707 0.00577 0.01906 0.002495 0.003349 -0.000818 0.003763 0.00287 0.02192 0.6183 0.6770 -0.0095 0.1895 -0.002244 0.004260 0.06101 0.02651 0.004194 0.005214 -0.01922 0.01766 0.00002378 0.00001832 -0.0003909 0.0005883 -0.00004094 0.00006844 -0.0005440 0.0002260. S = 0.008994. R-Sq = 97.2%. T 8.28 -1.56 -1.73 -1.42 0.70 -2.21 -0.54 -0.56 0.15 -0.63 -0.53 -1.41 3.02 0.04 -0.97 0.16 -0.14 -1.48 0.32 0.26 -3.34 -2.84 -1.39 0.06 0.93 0.54 -0.02 -0.29 -0.42 -0.98 -1.26 -0.64 0.30 0.75 -0.22 0.13 0.91 -0.05 -0.53 2.30 0.80 -1.09 1.30 -0.66 -0.60 -2.41. P 0.000 0.127 0.092 0.162 0.490 0.033 0.591 0.579 0.879 0.535 0.599 0.167 0.004 0.966 0.339 0.872 0.888 0.147 0.749 0.793 0.002 0.007 0.172 0.956 0.356 0.595 0.986 0.774 0.678 0.331 0.214 0.523 0.764 0.460 0.829 0.896 0.366 0.960 0.601 0.027 0.426 0.283 0.201 0.510 0.553 0.021. R-Sq(adj) = 94.0%. 45.
(56) 表 5.23 迴歸模式中顯著的 7 個變數 輸入結點編號編號. 名稱. 2. S_open. 5 13. GC_SHORT 2 連續(合計)(>0). 24. 縱 2 連續(合計)(>0). 27. 橫 2 連續(合計)(>0). 47. Rg1. 53. Rsd2. 表 5.24 複迴歸模式 ANOVA 分析表 Source. DF. SS. MS. F. P. Regression. 45. 0.1130833. 0.0025130. 31.07. 0.000. Residual Error. 41. 0.0033166. 0.0000809. Total. 86. 0.1164000. 表 5.25 訓練樣本的分類結果(複迴歸模式). 目標類別. 輸出類別. A. B. C. A. 28. 3. 0. B. 4. 40. 0. C. 0. 3. 9. 表 5.26 測試樣本的分類結果(複迴歸模式). 目標類別. 輸出類別. A. B. C. A. 11. 4. 0. B. 3. 10. 0. C. 0. 1. 1. 46.
(57) 2. 逐步迴歸分析 本研究進一步採用逐步排除法進行分析,一般建議之型一誤差之機率設定為 0.15, 自由度為(1,n-(k+1)) = (1,87-54) = (1,33),其中 n 為樣本數,k 為自變數個數;因此,可 得知 F0.15(1,33) = 2.1722 ,所以 F to enter 值與 F to remove 值為 2.1722。 總共執行了 15 個步驟,選出 13 個變數,利用 Statistica 6.0 執行,其結果如表 5.27。 經 ANOVA 分析,整個模式之 F-test 統計量為 102.45(p 值= 0.000) ,表示此迴歸模式非 。該模型可解釋 93.88%之 AT2 常顯著,該 13 個自變數對依變數有顯著之影響(表 5.28) 良率的變異。從產品分類等級來看,訓練標本之正確分類率為 87.36%如表 5.29,而測 試標本之正確分類率為 83.33%如表 5.30。. 最適之迴歸模式如下: 測試良率(AT2) = 1.039817 -0.007314 * 5_GC_SHORT-0.002974 *8_點欠陷(重)(>0). -0.007727 * 10_點欠陷(合計)(>0) -0.013715*12_2 連續(輕)(>0) -0.01632*15_多連續(輕)(>0) -0.004696*18_距離 NG(合計)(>0) -0.008969*24_縱 2 連續(合計)(>0) -0.005097*25_橫 2 連續(重)(>0) -0.008425*26_橫 2 連續(輕)(>0) -0.001096*28_LOW_VG -0.000284*51_Rge2+0.000026*52_Rsd1-0.000328*53_Rsd2 表 5.27 逐步迴歸模式 ANOVA 分析表 Sums of Squares. df. Mean Squares. F. Regress.. 0.110352. 13. 0.008489 102.4528. Residual. 0.006048. 73. 0.000083. Total. 0.116400. p-level 0.000000. Regression Summary for Dependent Variable: 測試良率(AT2) (model.sta) R= .97367269 R2= .94803851 Adjusted R2= .93878509 F(13,73)=102.45 p<0.0000 Std.Error of estimate: .00910. 47.
(58) 表 5.28 十三個自變數對依變數有顯著之影響 Beta. Std.Err. of Beta. Intercept. B. Std.Err. of B. t(73). p-level. 1.039817. 0.014067. 73.92014. 0. 5_GC_SHORT -0.141575. 0.027763. -0.007314. 0.001434. -5.09944. 0.000003. 8_點欠陷(重)(>0) -0.17268. 0.086916. -0.002974. 0.001497. -1.98674. 0.050705. 10_點欠陷(合計)(>0) -0.513632. 0.083914. -0.007727. 0.001262. -6.12097. 0. 12_2 連續(輕)(>0) -0.116766. 0.062216. -0.013715. 0.007308. -1.87677. 0.064545. 15_多連續(輕)(>0) -0.103843. 0.034564. -0.01632. 0.005432. -3.00441. 0.003644. 18_距離 NG(合計)(>0) -0.120836. 0.035503. -0.004696. 0.00138. -3.4035. 0.001083. 24_縱 2 連續(合計)(>0) -0.104322. 0.031807. -0.008969. 0.002735. -3.27981. 0.001594. 25_橫 2 連續(重)(>0) -0.122657. 0.038024. -0.005097. 0.00158. -3.22576. 0.001881. 26_橫 2 連續(輕)(>0) -0.042025. 0.048711. -0.008425. 0.009765. -0.86275. 0.391101. 28_LOW_VG -0.146887. 0.060731. -0.001096. 0.000453. -2.41864. 0.018073. 51_Rge2 -0.210092. 0.074335. -0.000284. 0.0001. -2.82629. 0.006071. 52_Rsd1 0.128557. 0.108589. 0.000026. 0.000022. 1.18388. 53_Rsd2 -0.173369. 0.078502. -0.000328. 0.000148. -2.20848. 表 5.29 訓練樣本的分類結果(逐步迴歸模式). 目標類別. 輸出類別. A. B. C. A. 26. 5. 0. B. 2. 41. 1. C. 0. 3. 9. 表 5.30 測試樣本的分類結果(逐步迴歸模式). 目標類別. 輸出類別. A. B. C. A. 13. 2. 0. B. 2. 11. 0. C. 0. 1. 1. 48. 0.2403 0.030351.
數據

+7





Outline
相關文件
[r]
國立臺北教育大學教育經營與管理學系設有文教法律碩士班及原住民文
國立高雄師範大學數學教育研究所碩士論文。全國博碩士論文資訊網 全國博碩士論文資訊網 全國博碩士論文資訊網,
營建工程系 不限系科 工業工程與管理系 不限系科 應用化學系 不限系科 環境工程與管理系 不限系科 工業設計系 不限系科. 景觀及都市設計系
管理學院 50,914 理工學院 58,189 設計學院 58,189 人文暨社會學院 50,914 資訊學院 58,189..
1.本招生以參與「工業工程與設備管理產學攜手專班」之國立霧峰農工 104 學年度日間部機 械科、國立秀水高工 104
木工程/都市設計與規劃/建築設備) 全日制,兼讀制 先進科技及管理學理學碩士 全日制,兼讀制 金融與精算數學理學碩士 全日制,兼讀制
電機工程學系暨研究所( EE ) 光電工程學研究所(GIPO) 電信工程學研究所(GICE) 電子工程學研究所(GIEE) 資訊工程學系暨研究所(CS IE )
