利用核平滑化自動選取參數於隨機子空間方法
摘 要
對於高維度資料的應用上,通常存在著樣本點數不足的問題,如何以有效的 方法來解決就成為研究高維度資料分類的研究方向之一。多重分類器是在樣式辨 識中,常使用的技巧之一,而隨機子空間方法是一種可以解決小樣本問題的多重 分類器,但是對於隨機子空間方法如何決定其子空間維度及其如何選取特徵的方 法仍具改善的空間。在本研究中,提出在高維度資料分類下,以加權隨機子空間 法來自動選取子空間維度的方法,而子空間維度的選擇是利用核平滑化法在進行 訓練時估計維度重要性的分配。此外亦提出以分類精確度及線性區別分析分離 度,兩種不同的特徵加權方法來改善原來隨機子空間方法的特徵選取方式。在分 類結果表現中,在大部份的情形中具有不錯的成效,故本文所提之方法可改良隨 機子空間方法,可解決維度選取的問題。 關鍵字:高維度資料、多重分類器、隨機子空間方法、核平滑化法Random Subspace Methods with Automatic Selecting Parameter
based on Kernel Smoothing
Abstract
In high dimensional data, how to solve small size problem is very important in many research domain. Random Subspace Method is a multiple classifier systems and has been shown that is a good approach to overcome small sample problems. In original Random Subspace Method, classifiers are constructed in the subspaces selected randomly from the original data space and the dimensionality of all subspaces is a fixed number. Then the decisions of base classifiers are usually combined by simple majority voting for the final decision. There is still not an effective way to estimate the best dimensionality of subspace, although it has a great impact on the classification result.
In this paper, a weighted random subspace method with automatic subspace dimensionality selection has been proposed for classifying high dimensional data. The dimensionality selection method is based on the importance distribution of
dimensionality estimated by kernel smoothing technique during the training process. Two feature weighting methods based on normalized re-substitution accuracy and Fisher’s linear discriminate analysis separability are introduced for improving the original subspace method. Experimental result shows that the proposed algorithm outperforms the original random subspace method.
Keyword : high dimensional data, multiple classifier systems, random subspace method, kernel smoothing.
目 錄
第一章 緒論...1
第一節 研究動機與目的
...
2
第二節 符號表
...
3
第二章 文獻探討...5
第一節 小樣本及高維度的問題...5
第二節 多重分類器...7
第三節 特徵選取與萃取...9
第四節 隨機子空間方法...11
第五節 核平滑化法...13
第六節 分類器...13
壹、高斯分類器...13
貳、k 最近鄰分類器...14
參、支撐向量分類器...15
第三章 改良的隨機子空間方法...17
第一節 RSM 演算法...18
第二節 WRSM_KS1 演算法
...
20
第三節 WRSM_KS2 演算法
...
22
第四章 研究設計...25
第一節 資料描述...25
壹、Washington DC Mall 資料集...25
貳、Indian Pine Site 資料集...25
參、教育測驗資料集...26
第二節 實驗描述...28
第五章 結果及討論...31
第六章 結論與建議...63
表目錄
表 3-1 本研究所提出新演算法列示...17
表 4-1 擴分、約分錯誤類型組別...17
表 4-2 Washington DC Mall 資料集實驗設計...29
表 4-3 Indian Pine Site 資料集實驗設計...29
表 4-4 教育測驗資料集實驗設計...30 表 4-5 本研究比較之演算法...30 表 5-1 Washington DC Mall 辨識正確率的平均及標準差(實驗 1)...33 表 5-2 Washington DC Mall 辨識正確率的平均及標準差(實驗 2)...35 表 5-3 Washington DC Mall 辨識正確率的平均及標準差(實驗 3)...37 表 5-4 Washington DC Mall 實驗平均訓練時間...39
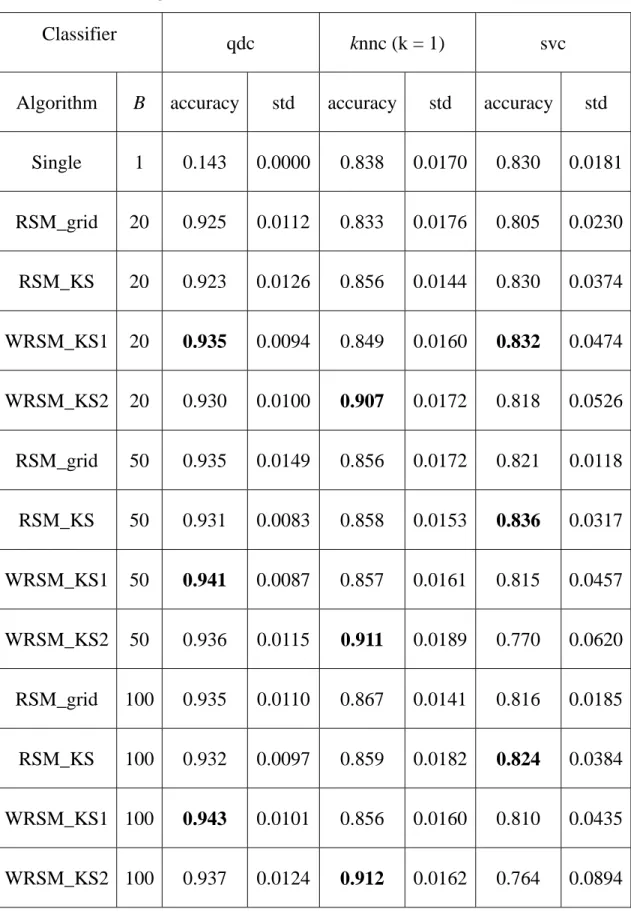
表 5-5 Indian Pine Site 辨識正確率的平均及標準差(實驗 4) ...41
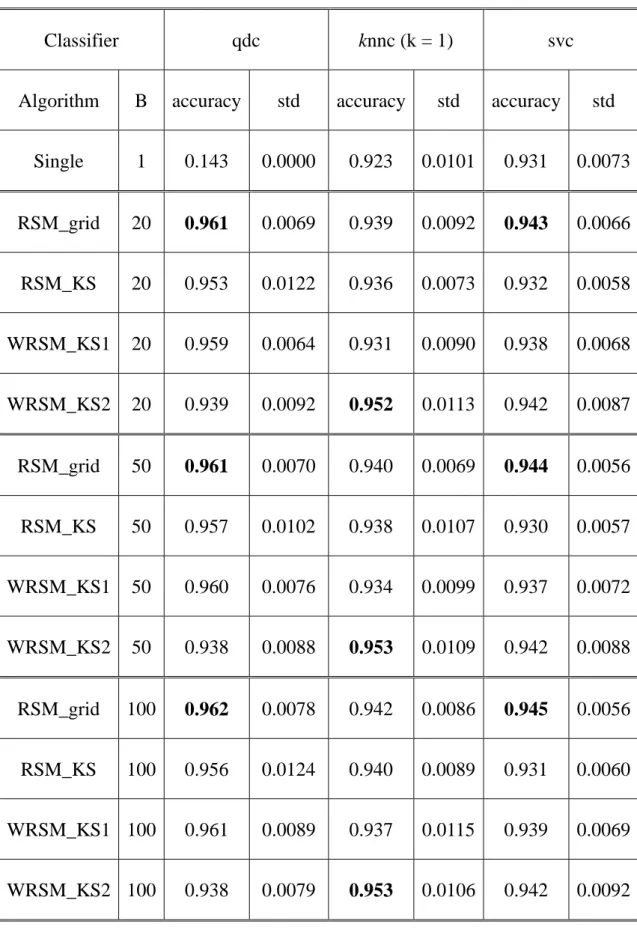
表 5-6 Indian Pine Site 辨識正確率的平均及標準差(實驗 5) ...43
表 5-7 Indian Pine Site 辨識正確率的平均及標準差(實驗 6) ...45
表 5-8 Indian Pine Site 實驗平均訓練時間...47
表 5-9 教育測驗資料辨識正確率的平均及標準差(實驗 7) ...49
表 5-10 教育測驗資料辨識正確率的平均及標準差(實驗 8) ...51
表 5-11 教育測驗資料實驗平均訓練時間...53
表 5-12 Washington DC Mall 網格法的最佳維度數...57
表 5-13 Indian Pine Site 網格法的最佳維度數...57
圖目錄
圖 2-1 維度詛咒...6 圖 2-2 高維度資料的分類器設計流程...7 圖 2-3 採用多重分類器的理由...8 圖 2-4 多重分類器的設計...9 圖 2-5 特徵的選取與萃取...10 圖 4-1 Washington DC 紅外線空拍圖...26圖 4-2 Indian Pine Site 紅外線空拍圖...26
圖 5-1 Washington DC Mall 辨識正確率比較圖(實驗 1, B=20)...34 圖 5-2 Washington DC Mall 辨識正確率比較圖(實驗 1, B=50)...34 圖 5-3 Washington DC Mall 辨識正確率比較圖(實驗 1, B=100)...34 圖 5-4 Washington DC Mall 辨識正確率比較圖(實驗 2, B=20)...36 圖 5-5 Washington DC Mall 辨識正確率比較圖(實驗 2, B=50)...36 圖 5-6 Washington DC Mall 辨識正確率比較圖(實驗 2, B=100)...36 圖 5-7 Washington DC Mall 辨識正確率比較圖(實驗 3, B=20)...38 圖 5-8 Washington DC Mall 辨識正確率比較圖(實驗 3, B=50)...38 圖 5-9 Washington DC Mall 辨識正確率比較圖(實驗 3, B=100)...38 圖 5-10 Washington DC Mall 訓練時間比較圖...40
圖 5-11 Indian Pine Site 辨識正確率的比較圖(實驗 4, B=20)...42
圖 5-12 Indian Pine Site 辨識正確率的比較圖(實驗 4, B=50)...42
圖 5-13 Indian Pine Site 辨識正確率的比較圖(實驗 4, B=100)...42
圖 5-14 Indian Pine Site 辨識正確率的比較圖(實驗 5, B=20)...44
圖 5-16 Indian Pine Site 辨識正確率的比較圖(實驗 5, B=100)...44
圖 5-17 Indian Pine Site 辨識正確率的比較圖(實驗 6, B=20)...46
圖 5-18 Indian Pine Site 辨識正確率的比較圖(實驗 6, B=50)...46
圖 5-19 Indian Pine Site 辨識正確率的比較圖(實驗 6, B=100)...46
圖 5-20 Indian Pine Site 訓練時間比較圖...48
圖 5-21 教育測驗資料辨識正確率的比較圖 (實驗 7, B=20) ...50 圖 5-22 教育測驗資料辨識正確率的比較圖 (實驗 7, B=50) ...50 圖 5-23 教育測驗資料辨識正確率的比較圖 (實驗 7, B=100) ...50 圖 5-24 教育測驗資料辨識正確率的比較圖 (實驗 8, B=20) ...52 圖 5-25 教育測驗資料辨識正確率的比較圖 (實驗 8, B=50) ...52 圖 5-26 教育測驗資料辨識正確率的比較圖 (實驗 8, B=100) ...52 圖 5-27 教育測驗資料訓練時間比較圖...54 圖 5-28 RSM_KS 在 W 為均勻分佈 U 下,qdc、knnc 及 svc 的 R 分佈...55 圖 5-29 WRSM_KS2 在 W 為 LDA 類別分離量下,qdc、knnc 及 svc 的 R 分佈...55 圖 5-30 WRSM_KS1 在 W 為辨識正確率下,qdc、knnc 及 svc 的 R 分佈...56 圖 5-31 Washington DC Mall 部份紅外線空照圖影像...59 圖 5-32 knnc 的分類結果...59 圖 5-33 svc 的分類結果...59 圖 5-34 RSM_KS 使用 qdc 的分類結果...60 圖 5-35 WRSM_KS1 使用 qdc 的分類結果...60 圖 5-36 WRSM_KS2 使用 qdc 的分類結果...60 圖 5-37 RSM_KS 使用 knnc 的分類結果...61 圖 5-38 WRSM_KS1 使用 knnc 的分類結果...61 圖 5-39 WRSM_KS2 使用 knnc 的分類結果...61 圖 5-40 RSM_KS 使用 svc 的分類結果...62
圖 5-41 WRSM_KS1 使用 svc 的分類結果...62 圖 5-42 WRSM_KS2 使用 svc 的分類結果...62
誌 謝
本篇論文得以完成,首先感謝指導教授郭伯臣博士,在研究方向的指 導,也感謝己畢業的學長,在研究上的提醒。在研究過程中,同學光佑及 峻豪在本論文的各階段的討論及協助,使論文得以逐步完成。在訂正論文 的工作上,特別感謝晉民助教及學弟們細心的校定。在口試階段感謝口試 委員,所長許天維教授、亞洲大學劉湘川教授、交通大學林進燈教授及中 央大學任玄教授在論文上的諸多指正與寶貴意見,以及慶麟肋教的協助。 在研究所的兩年多生涯中,對於父母、師長及同學們在這段期間的幫 助感謝萬分。感謝父母的支持,師長在求學期間的指導以及同學在研究上 的切磋與討論,都是我能完成論文的最大動力。第一章 緒論
近年來,在樣式辨識(pattern recognition )的應用領域上,出現越來越多屬於高 維度(high dimensional data)的資料,如遙測影像、微基因陣列、人臉影像及教學 診斷測驗資料等等,若以傳統的分類方法來解決問題,會因為樣本採集不易而造 成高維度且小樣本的問題,因為樣本少所以構建分類器(classifier)會因樣本的變動 或雜訊產生相當大的偏差(bias)。多重分類器(multiple classifier systems, MCS)中的 隨機子空間方法(random subspace method, RSM)為解決此一問題的方法之一,但 是在使用隨機子空間方法時,需要設定子空間的維度和組合的分類器個數,對於 子空間維度的選取目前並無一定的準則,常隨著資料以及分類器的不同而有所不 同。通常分類器個數設定越多,雖可提高效能,但訓練所需要花費的時間也越多。 故本研究為解決子空間維度的選取問題,假設子空間維度之選取是基於某分配, 在選取維度同時以核平滑化法(kernel smoothing)來估計並更新其分佈函數,此外 目前在隨機子空間方法中,假設每一個特徵(feature)都是同樣重要而以均勻分配 (uniform distribution)作為隨機選取特徴的分佈函數,這樣的假設並不適宜,因為 對於分類有幫助的特徵應有較高被選取的機會,故改以加權方式建構特徵重要程 度分佈函數來取代原隨機子空間方法的均勻分佈函數,另外亦研究不同分類器個 數對於分類器效能的影響。本研究將使用 Washington DC Mall、Indian Pine Site 及教育測驗資料 3 種不同的高維度資料,利用高斯分類器(quadratic gaussian density classifier, qdc)、k 最近鄰分類器(k nearest neighbors classifier, knnc)和支撐向 量分類器(support vector classifier, svc) 3 種分類器,結合本研究所改良的隨機子空 間方法,來驗證本研究所提方法的可用性,最後結果顯示在大部分的情形中,本 研究所提方法可以提供一個較佳選擇的子空間維度的選擇方案,並在 Washington DC Mall 資料中,可以提供更佳的分類效能表現,接下來將說明本研究旳動機與 目的。
第一節 研究動機與目的
在目前對於高維度資料的分類需求及領域不斷增加,如何針對此一現象提出 一個妥善的解決方法,己經成為現在研究分類器的主要研究目標之一。對此類型 資料的分類模式在傳統方法上,最常見的主要方法是先以特徵選取(feature selection)或特徵萃取(feature extraction)降低資料維度後,再以單一分類器來建構 資料的分類決策函數(decision function),然而以此模式建構的分類器仍然常發生 分類器效能不彰的情形。多重分類器是目前在改善傳統方法的一種分類器建構模 式方法,可提供更穩定具效能的分類器,而隨機子空間方法是一種可以解決小樣 本問題的多重分類器。本研究將說明要設計改良所使用多重分類器模式來改善原 本傳統方式的分類模式及原有的隨機子空間方法。 本研究將改良原有的隨機子空間方法,針對使用原方法的缺點及待解決的問 題,提出新的多重分類器方法,對於研究的主要目標如下所示: 1. 以核平滑化法來估計並更新子空間維度的分佈函數,並從此分佈函數來 選取所用的子空間維度來解決維度選取問題。 2. 原方法對於選取特徵,個別特徵以均等重要來看待,但是不同特徵對於 分類的效能,應有不同程度的重要,故本研究亦提出以各特徵的重要程 度來選取特徵改善原方法。 3. 研究不同分類器個數對於分類器效能的影響變化。 接下來第二章將說明探討建構方法所需的相關文獻。第二節 符號表
訓練樣本集:D={(xi,yi)|1≤i≤ N}, xi∈X ⊂S, yi∈{1,K,L}⊂C,i=1,KN i x :樣本點 i i y :樣本點 xi對應的類別標記 p S⊂ℜ :樣本的原始空間 p:維度(dimensionality)。 ) , , , (x1 x2 xN X = L :由 N 個樣本點組成的資料集 N:訓練樣本點數。 C:分類決策的解集合 L:類別數 i:訓練樣本點索引指標 h:分類器 r:固定子空間維度,也就是特徵數。 r F∈ℜ :特徴空間 Φ:轉換矩陣 j P :類別 j 的先驗機率 j:類別的索引指標 B:分類器個數 b:分類器個數的索引指標 Learner:分類器學習演算法 C S hfinal : → 最終決策,即分類器R:子空間維度重要程度分佈(importance distribution of subspace dimensionality) W:特徵重要程度分佈(importance distribution of features)
B :分類器個數
B0:初始階段用於估計R0的分類器個數
R0:R 之初始分佈
第二章 文獻探討
在本章中首先將探討應用高維度資料於小樣本資料分類時,所遭遇的問題, 及傳統上如何設計分類系統來解決此問題,和改善傳統單一分類器的多重分類器 系統的設計過程,及可以提升效能及穩定度的原因,再說明傳統上對於降低維度 的方法,通常是用特徵選取及特徵萃取方法。然後是說明運用降低維度的隨機子 空間方法,其為多重分類器方法適用於小樣本問題的技巧之一,最後說明用於估 計子空間維度的核平滑化法及所使用到的不同分類器。第一節 小樣本及高維度的問題
傳統的分類方法大多是假設在樣本數充足的情形下建構分類器,雖然資料維 度提高能提供越多訊息幫助資料的分類,但是需要採集更多的樣本來建構分類 器,否則反而會因為參數估計的不精確,造成辨識正確率下降,這就是所謂的維 度詛咒(curse of dimensionality)的問題(圖2-1)。圖中的縱軸代表辨識正確率,而橫 軸代表著資料的複雜度也就是維度,每一條線段表示在不同樣本數下的情形。從 圖中可以看出當維度越高,雖可提高辨識正確率,但想要維持卻需要更多的樣本 才能達到,也就是當維度增加時,可提高分類器的複雜度,但是訓練樣本數未增 加時,會造成分類器效能的減少。通常是因為應用領域的維度資料不斷增加,而 建構分類器所需樣本資料相對變小的情形,造成在面對此類問題時,因為小樣本 而高維度的資料常會遭遇過適訓練(overfitting)及估計有偏差的情形,需以針對小 樣本問題的分類方法來解決。m=2 5 10 20 50 100 200 1000 500 m 1 2 5 10 20 50 100 200 500 1000
MEASUREMENT COMPLEXITY n (Total Discrete Values) 0.50 0.55 0.60 0.65 0.70 0.75 M E A N A C C U R A C Y ( % ) 維度 R E C O G N IT IO N 辨 識 正 確 率 = ∞ 圖 2-1 維度詛咒(Hughes, 1968) 所以為了解決此問題,可以縮減維度來減少分類器設計時的複雜度,傳統上常使 用的是特徵選取或特徵萃取的方法。圖 2-2 為針對高維度資料的分類器設計來建 構分類器的流程圖,當使用高維度資料來進行分類器的設計時,通常會將資料維 度透過特徵選取或特徵萃取的方法來降低資料的維度,再將此縮減維度後的資料 用於訓練分類器,然後以測試資料來檢視所設計的分類器效能,通常我們會重覆 此流程直到找到適合的分類模型。以上是傳統單一分類器設計用來解決高維度資 料的方法,因為以單一分類器來建構分類系統,對於所使用的分類器的選擇就變 得更重要,但是有些分類器在樣本數小的情形中,以上述的系統來建構的分類器 會產生偏差和變異程度較高的分類器系統,可使用多重分類器的技術來改善此情 形。
高維度訓練資料 高維度測試資料 特徵萃取 特徵選取 分類器 分類效能評估 圖 2-2 高維度資料的分類器設計流程
第二節 多重分類器
目前多重分類器越來越受到研究樣式辨識研究者的重視,因為當單一分類器 不穩定時,多重分類器可以比使用單一分類器所得的效能更佳。在本研究所應用 的領域為小樣本高維度的情形,會造成所訓練的單一分類器易有估計偏誤及不穩 定,以多重分類器來取代原有的單一分類器方法,可以提高分類器的性能及穩定 性。在近年的研究提出組合多個分類器來完成原先單一分類器的工作,通常多重 分類器是希望能透過分類器的組合來得到更正確的分類決策,而如何去組合不同 的分類器是影響多重分類器效能的主要議題( Skurichina & Duin, 2002)。多重分類 器較單一分類器佳的原因,可從統計上、計算上及表徵上來解析其原理如圖 2-3。 統計上的原因,主要是因為在統計上如果沒有足夠的訓練樣本來訓練分類器,對 於分類器的建構會不穩定,而造成分類器有偏差,然組合這些分類器可以解決此 問題如圖 2-3(a)。最外圍的區域內為分類器的解空間 H,內圈的區域為分類器模 式的假設空間,h1、h2、h3 及 h4 為不同的單一分類器,f 是平均各分類器消除偏 誤情形的較佳解。在計算上的理由,各個分類器從解空間 H 的邊界開始搜尋求解,會因為訓練起始點的不同而得到不同的解,但是常發生無法選取適當初始值 或是不良的搜尋方式,而陷於區域解,組合不同起始點的分類器可以找到較佳的 解如圖 2-3(b),例如以多重分類器解決類神經網路的初始值問題。最後是表徵上 的理由,因為有些分類器模式的假設會比在解空間 H 中的分類器更適宜,如圖 2-3(c)。 (a) (b) (c) 圖 2-3 採用多重分類器的理由(Dietterich, 2000) 在單一分類器設計的常用方法是確定一組合理的分類器模式,再選出最好效 能的分類器,但是在沒有那一個分類器是明顯最好的情形時,就可以考慮利用多 重分類器來改善多重分類器設計流程如圖 2-4。首先產生多個分類器,這些分類 器可能是不同的分類器模式、樣本或特徵空間等等,依照不同的技術來產生相異 的分類器,接著是選擇適合的分類器,然後是設計組合不同分類器的方法,最後
評估效能選擇適當的多重分類器設計。
分類器的產生
分類器的選擇
組合分類器的設計
效能的估計
圖 2-4 多重分類器的設計(Bunke & Kandel, 2002)
第三節 特徵選取與萃取
解決高維度的問題,常常使用減低資料維度的方法來克服因為維度過高而無 法估計建構分類器的問題。基本上資料可以利用兩種不同的方法來減少維度,通 常有特徵選取方法及特徵萃取方法。特徵選取是選擇對分類貢獻大的特徵,在分 類問題上,可以忽略那些對分類幫助不大的特徵,可從原始 p 個維度中選出 r 個 特徵(也就是 r 維度,其中 r 遠小於 p),如圖 2-5(a)為特徵選取視為可見的,可直 接看出從原始空間選取那些特徵。特徵萃取方法是從原始 p 維度的原空間轉換到 更低維度 r 的特徵空間,如圖 2-5(b)為特徵萃取視為一黑箱,無法得知所得的特 徵是如何組成,轉換可以是原始空間的線性或非線性組合,主要是找到可使類別 更容易分類的特徵。p r p r (b) 特徵萃取 (a) 特徵選取 圖 2-5 特徵的選取與萃取 本研究的所採用的特徵選取方式是以隨機方式選取,或是建構特徵重要程度分佈 函數,再從此函數中選擇特徵。現行建構的函數是以辨識正確率及線性區別分析 (linear discriminant analysis, lda)的類別分離量(class separability)作為特徵重要程 度的權值。而線性區別分析的定義如下: 假設現有訓練樣本集D:x∈X每個樣本有一對應的類別標記 ,而線 性區別分析的目的是找到一個轉置矩陣 } , , 1 { L y∈ L Φ,能夠用矩陣將原始資料從 S 空間投影 到類別分離度較大的特徵空間 F,通常 F 的維度遠小於 S,由下列式子表示: F=ΦTS (2-1)
線性區別分析在統計上是估計組間分散矩陣(between-class scatter matrix) 、組
內 分 散 矩 陣 (within-class scatter matrix) 及 混 合 分 散 矩 陣 (mixture scatter matrix)( ,組內分散矩陣表示為(Fukunaga, 1990): b S w S b w S S )−1
∑
∑
(2-2) = = ∑ = − − = L j j j L j j T j j j w PE X M X M C P S 1 1 } | ) )( {(在此Pj是指類別 j 的先驗機率(prior probability),Mj是 j 類別的平均向量而Σj是 j 類別共變異數矩陣,L 為類別數,組間分散矩陣可表示如下:
∑
= − − = L j T j j j b P M M M M S 1 0 0)( ) ( (2-3)∑
= = = L j j jM P X E M 1 0 { } 在此 是指全部資料的平均向量,而線性區別分析演算法的最佳化目標函數為 ,主要是希望取組內資料分散程度越小而組間越大,由此矩陣 可找到m個特徵值最大的特徵向量,在本研究以單一維度的線性區別分析類別分 離量來當做特徵選取的條件。 0 M trace((Sw) 1Sb) J = −第四節 隨機子空間法
為了解決在高維度下,訓練樣本不足的情形所造成的問題,由Ho (1998)提出 的隨機子空間方法是一種可以克服小樣本問題的方法。隨機子空間方法是一種可 提高分類器效能及穩定性的多重分類器技巧,組合多個不同特徵的分類器來增加 辨識資訊的互補性,再透過組合的策略,能有效提高效能(Skurichina & Duin, 2001)。隨機子空間方法使用的第一步驟為設定固定的子空間的維度r,也就是隨 機選定r個維度的特徵空間,再設定所組合的分類器個數B。此外,隨機子空間方 法中,以均勻分佈來隨機選取特徵。 本研究根據 Ho (1998)所提的隨機子空間演算法為基準,其定義如下: [RSM 演算法] 輸入:訓練集 , 在此 N i C L y X x N i y x D i p i i i, )|1 }, , {1,K, } , 1,K {( ≤ ≤ ∈ ⊂ℜ ∈ ⊂ = =yi 是 xi的類別。L 是類別數,C 為分類決策解集合。而 N 是訓練樣 本點數。 分類器學習演算法 Learner 固定子空間維度 r < p 分類器個數 B 輸出: 最終決策 hfinal :Χ→C 由 B 個分類器組合所得 BEGIN for b = 1 to B ) , ( _selection D r Subspace Db = ) ( b b Learner D h = end
hfinal(x)=argmaxy∈Ccard(B|hb(x)=y)
End D 為 p 維的訓練樣本集且 xi 是一個 p 維向量 xi=[xi1,..,xip]T ,子空間選擇是以 Subspace_selection 從原空間{1,2,…,p}隨機抽取 r 個特徵子集合 A={d1,d2,…,dr}, 每個子空間都是定義一個映射Φ r,在此 為特徵空間 的 映 射 。 由 Subspace_selection 函 數 可 得 新 的 訓 練 樣 本 集 , b 為分類器個數的索引指標。新訓練樣本集依學習 分類器算法 Learner 得到決策分類器 h p A:ℜ →ℜ T id id i A(x)=[x 1,K,x r] Φ } 1 | ) ), ( {( x y i N Db = ΦA i i ≤ ≤ final b,重覆 B 次過程,利用簡單的投票法來組 合分類器得到最終決策h ,在此 B 是分類器個數。card(S)是指 S 集合中每一分 類器對類別判定類別的個數,每個測試樣本點的類別由最多者決定。隨機子空間 方法具備多重分類器及特徵選取減少維度的優點,特別適用於小樣本的情形。
第五節 核平滑化法
核平滑化法可以利用已知的數據,選用適合的核函數(kernel function)及帶寬 (bandwidth)估計分佈函數。本研究採用核平滑化方法來估計維度重要程度分佈函 數 R,並從此函數中抽取每次建構分類器所需的維度,也利用此法更新函數的權 重值。首先假設有 x1,…, xN 個隨機樣本點,和單變數密度函數 f,其核平滑化估 計函數定義如下:∑
= = N i i N K x x N x x x f 1 1 ( | , ) 1 ) , , | ( σ σ σ K (2-4) 而核函數是使用高斯函數 ) 2 ) ( exp( 2 1 ) , | ( 2 2 σ πσ σ i i x x x x K = − − ,而σ是帶寬。 (2-5)第六節 分類器
在樣式辨識領域中,最主要的部份就是選擇一個應用領域適用的分類器。分 類器主要是用來分隔不同的類別,每種分類器具有不同特性,通常需要依資料的 特性來決定。不過在資料過於複雜的情形時,就不一定可以得到適合的分類器, 往往需要一連串試驗才能得知。在本研究採用的分類器,主要以常用且廣為人所 熟知的高斯分類器、k 最近鄰分類器及支撐向量分類器簡介如下:壹、高斯分類器
高斯分類器是一種參數型分類器其平均向量和共變異數矩陣,假設為常態高 斯分佈,其定義如下(Fukunaga, 1990): )} ( 2 1 exp{ | | ) 2 ( 1 ) | ( 2 2 1 2 x d y x P p − Σ = π j (2-6)) ( ) ( ) ( 1 2 j j T j x M M x x d = − Σ − − (2-7) 在此 y 為類別,j 是類別索引,而 Mj和Σj為 j 類別常態的平均向量及共變異數矩 陣,公式(2-6)為一個常態分佈下,距離函數(2-7)的指數函數。對於類別的決定主 要是由下列的決策函數決定: ) | ( max arg ) (x j1,..,LP x yj D = = (2-8) 在此yj是指為某類別,L 是指類別數。
貳、k 最近鄰分類器
最近鄰分類器是一個在樣式辨識中的簡單方法。首先是找尋最鄰近一個測試 樣本鄰近的 k 個訓練樣本點。並且將此測試樣本點判定為最多鄰近點的類別。 k 最近鄰法是一種無參數型的分類器。主要是利用測試樣本的區域,直到找到 k 個最近點。利用 k 最近鄰法估計樣本的機率密度分佈其定義如下 (Fukunaga, 1990) ) ( 1 ) ( x v N k C x P j j − = (2-9) 在此 k 是在 x 周圍的樣本點,v(x)是 x 所佔的容量及 Nj是類別 j 的樣本點數。在 此的決策函數和(2-8)的決策函數相同。參、支撐向量分類器
支撐向量分類器是新的分類工具,是近年來受注目的研究主題。支撐向量分 類器的理論是基於結構風險最小化(structural risk minimization)的概念,在許多應 用中,支撐向量分類器比傳統學習機制有更好的辨識結果,在解決分類問題上己 經是強力的工具之一。支撐向量分類器將輸入資料映射至高維度特徵空間且尋找 可分離 2 個類別的空間中,具有最大邊界(margin)的可分離超平面(hyperplane), 最大化邊界是二次規劃(quadratic programming, qp)問題,能經由 Lagrangian 乘數 轉變成對偶格式的問題來解決。支撐向量分類器尋找最佳平面是利用特徵空間中 函數的點積稱為 kernel,最佳平面是由少數的輸入點組合而成,稱為支撐向量, 其原始定義如下: N i x w y to subject w w i i i T i N i i T , , 1 . 0 , 1 ) ) ( ( 2 1 min 1 L = ≥ − ≥ + ⋅ + ⋅
∑
= ξ ξ θ φ ξ λ (2-10) 在此θ 是偏誤,訓練樣本點 經由函數xi φ 映射至一個較高維度空間的空間,此空 間可最大化邊界。w 是可分離超平面向量,ξi是分類錯誤的容許量,λ是代表錯誤 的調節參數,而λ是常數,參數λ可看成是正規化參數,此參數是支撐向量分類 器唯一可以調整的,變動此參數能平衡邊界大小及允許分類錯誤。找尋最佳超平 面的(2-10),可將問題以 Lagrangian 來解決且將原問題轉成對偶形式 N i y to subject x x y y W i N i i i j N i N j i j i j i N i i , , 1 , 0 0 ) ( ) ( 2 1 ) ( max 1 1 1 1 K = ≤ ≤ = − =∑
∑∑
∑
= = = = λ α α φ φ α α α α (2-11) 在此α =(α1,K,αN)是非負 Lagrange 乘數的向量。Kuhn-Tucker 定理在支撐向量分 類器的理論中扮演重要的角色,根據此理論要解決(2-11)的問題,則α 的問題需 滿足N i x w yi( ( i) ) 1 i) 0, 1, , ( ⋅φ +θ − +ξ = = K α (2-12) N i i i) 0, 1, , (λ−α ξ = = K (2-13) i α 是滿足條作的最佳值,從這些等式可知只有在(2-12)非零值的α 是滿足限制式i 且正負相等。資料點 對應 i i T i w x y ( ⋅φ( )+θ)≥1−ξ xi αi >0被稱為支撐向量,可是支 撐向量在不可分離的情形時,有兩種不同的類型。在0<αi <λ對應的支撐向量 滿足等式 i x 1 )= ) ( ( ⋅φ i +θ i w x y 且ξi =0,在αi =λ的情形下則ξ 不是空的且對應的支i 撐向量 不滿足限制式 ,此類的支撐向量為錯誤。當資料 點 對應 i x i x i ≥ 1 i x φ ⋅ ( ) T w + )θ i y ( −ξ 0 = i α 表示分類正確且能明確的在決策邊界分隔,建構最佳化超平面 θ φ + ⋅ (xi) w 是以
∑
= = N i i i iy x w 1 ) ( φ α (2-14) 且純量θ 是由(2-12)的 Kuhn-Tucker 條件來決定。在各最值佳決定後,其決策函 數就是 ) ) ( ) ( ( ) ) ( ( ) ( 1∑
= + ⋅ = + ⋅ = N i i i i i sign y x x x w sign x f φ θ α φ φ θ (2-15)第三章 改良的隨機子空間方法
隨機子空間方法的分類效能是根據分類器、訓練樣本點數及子空間維度三個 因素來決定,當分類器與訓練樣本點數固定時,辨識正確率是按照隨機子空間的 子空間維度r決定,本研究中所研究的維度r是相當重要的。此外在原本的隨機子 空間方法中,每次分類器所選擇的特徵,對於分類的貢獻是同等重要的,但是每 個特徵應該是具不同的重要性,較重要的特徵應提高被選取的機會。在本章中, 將提出3種不同的隨機子空間方法,這3種方法的自動選擇維度方法是在訓練期 間,依照核平滑化法所估計的子空間維度重要程度分佈R來選取,而其中加權隨 機子空間方法(weighted random subspace method, WRSM)則是依照特徵的重要程 度的不同所建構重要程度分佈W。其如表3-1所示:表 3-1 本研究所提出演算法列示
全名 縮寫 說明
random subspace method based on kernel smoothing RSM_KS 原隨機子空間方法由核平滑 化法所估計的子空間維度分 佈 R 來自動選取子空間維度 r。
weighted random subspace method based on kernel smoothing 1
WRSM_KS1
RSM_KS 使用訓練樣本辨識 正確率,作為特徵重要程度 分佈 W 的加權。
weighted random subspace method based on kernel smoothing 2
WRSM_KS2
RSM_KS 使用線性區別分析 類別分離量,作為特徵重要 程度分佈 W 的加權。
第一節 RSM_KS 演算法
RSM_KS 方法主要是為解決子空間維度的選取問題,提出以核平滑化法來建 構子空間維度的重要程度分佈函數,每次從此分配決定子空間維度產生分類器, 再以分類器的辨識正確率作為加權,以核平滑化法來更新分配。 [RSM_KS 演算法] 輸入:D ={(xi,yi)|1≤i ≤ N}, xi∈X ⊂ℜp, yi ∈{1,K,L}⊂C,i=1,KN 在此 yi 是 xi的類別。L 是類別數,C 為分類決策解集合。而 N 是訓練樣本點數。 分類器學習演算法 Learner 分類器個數 B 估計R0的分類器個數 B0 子空間維度重要分佈 R R 的初始分佈 R0 計算訓練樣本的辨識正確率 ACC 均勻分配 U 輸出: 最終決策 hfinal :Χ→C 由 B 個分類器組合所得 BEGIN for k = 1 to B0
min ( )/ 0
* ) 1 ( 1 k N B rk = + − j∈C j ) , , ( _selection D r U Subspace Dk = k ) ( k k Learner D h = 計算正規化的ACC(hk)作為 R 分佈的初始分佈 R0,在此 ACC(hk)是使 用訓練樣本資料於 hk的辨識正確率。end for b = B0 to B ) ( _ −1 = b b Dimension selection r R Db =Subspace_selection(D,rb,U) ) ( b b Learn D h = 及計算 ACC(hb) )) ( , , ( _ b 1 b b
b =Kernel smooth R − r ACC h R end ) ) ( | ( max arg ) (x card B h x y hfinal = y∈C b = END 在本方法中,第一個迴圈是用 B0個分類器來估計 R 的初始分佈 R0。第二個迴圈 先從 R 中選擇維度 rb , Subspace_selection 和原先的隨機子空間方法相同,以均 勻分佈 U 隨機選取特徵,U 是範圍由 1 至 p 的離散均勻分配,由 Subspace_selection 從原空間{1,2,…,p}隨機抽取 rb個子空間集合Ab ={d1,K,drb},但是在此的維度不 再是固定的 r,而是由 R 分佈決定每次建構分類器的維度 rb,所以在此子空間是 定義一個特徵空間的映射 其 ,透過映 射可得到新的資料集 b b r p A
ℜ
→
ℜ
Φ :
1 | ) ), ( {(PAb xi yi T id b rx
]
,
,
K
id i Ab(
x
)
=
[
x
1Φ
} N i Db = ≤ ≤ 。新資料集 Db其維度 rb可經由 Subspace_selection 獲得,每個資料集輸入經分類器學習演算法 Learner 可得分類 器 hb ,再以 hb的訓練樣本辨識正確率作為權值,以核平滑化來更新 R。這程序 會重覆 B 次,再經由簡單的投票法來組合分類器得到最後決策。有關初始的分佈 R0 , 是 由 B0 個 初 始 點 計 算 其 點 的 分 佈 , 範 圍 是 從
min ( )/ 0
, ,(B0−1)
minj∈C(Nj)/B0
, 1 j∈C Nj B L 來決定。在本研究中,B0 是設定為 5, 在初始化後,子空間維度重要程度分佈 R 是經由核平滑化函數來更新,其公式定 義如下:( ) ( ), ) ( 1 ) ,..., ), ( | ( 0 1 0
∑
∑
= = − = = b B m m m p i m m r r K h ACC h ACC b B m h ACC r f σ σ (16) ) 2 ) ( exp( 2 1 ) ( 2 2 2 σ πσ σ m m r r r r K − = − − ,而 σ 是帶寬。 (17)第二節 WRSM_KS1 演算法
WRSM_KS1 的方法主要是更改隨機子空間方法的特徵選取方法,由訓練樣本 辨識正確率來為個別特徵加權,建構特徵重要程度分佈函數 W,而在選取維度的 方法則和 RSM_KS 相同。 [WRSM_KS1 演算法] 輸入:D x y i N x X yi L C i N p i i i, )|1 }, , {1,K, } , 1,K {( ≤ ≤ ∈ ⊂ℜ ∈ ⊂ = = 在此 yi 是 xi的類別。L 是類別數,C 為分類決策解集合。而 N 是訓練樣本點數。 分類器學習演算法 Learner 分類器個數 B 估計R0的分類器個數 B0 子空間維度重要分佈 R R 的初始分佈 R0 計算訓練樣本的辨識正確率 ACC 特徵重要程度分佈 W 輸出: 最終決策 hfinal :Χ→C 由 B 個分類器組合所得 BEGIN for q = 1 to p}) ,.. 1 | ) ({(x ,y i N learn hq = iq i = Wq= ACC(hq) 計算每個特徵的重要程度,以ACC(hq)作為 W 分佈權值,在此 ACC(hq) 是使用訓練樣本資料於 hq的辨識正確率。 正規化 W 的權值於[0,1]範圍 end for k = 1 to B0
min ( )/ 0
* ) 1 ( 1 k N B rk = + − j∈C j ) , , ( _selection D r W Subspace Dk = k ) ( k k LearnD h = 計算正規化的ACC(hk)作為 R 分佈的初始分佈 R0 。其中 ACC(hk)為 訓練樣本資料於 hk的辨識正確率。 end for b = B0 to B ) ( _ −1 = b b Dimension selection r R Db =Subspace_selection(D,rb,W) ) ( b b Learn D h = 及計算 ACC(hb) )) ( , , ( _ b 1 b bb =Kernel smooth R − r ACC h R end ) ) ( | ( max arg ) (x card B h x y hfinal = y∈C b = END 在本方法中,第一個迴圈是估計特徵重要程度分佈 W,其代表每個特徵的重要 性,以個別特徵的訓練樣本辨識正確率做為特徵重要的權值。而 Wq為 W 的分量, 代表在 q 特徵的權重值,計算全部特徵的重要權值後,將 W 正規化成為介於 0 至 1 之間的機率分配函數,Subspace_selection 將根據 W 從原空間{1,2,…,p}隨機 抽取 rb個子空間集合Ab ={d1,K,drb},之後的程序同 RSM_KS 方法。
第三節 WRSM2_KS2 演算法
WRSM_KS2 也是更改隨機子空間方法的特徵選取方法,由線性區別分析 的最佳化目標函數,來建構特徵重要程度分佈函數 W,而在選取維度的方法也是 和 RSM_KS 相同。 [WRSM_KS2 演算法] 輸入:D ={(xi,yi)|1≤i ≤ N}, xi∈X ⊂ℜp, yi ∈{1,K,L}⊂C,i=1,KN 在此 yi 是 xi的類別。L 是類別數,C 為分類決策解集合。而 N 是訓練樣本點數。 分類器學習演算法 Learner 分類器個數 B 估計R0的分類器個數 B0 子空間維度重要分佈 R R 的初始分佈 R0 計算訓練樣本的辨識正確率 ACC 特徵重要程度分佈 W 線性區別分析類別分離量條件 J 輸出: 最終決策 hfinal :Χ→C 由 B 個分類器組合所得 BEGIN for q = 1 to p Wq= J((xiq,yi)|i=1,..N}) 計算每個特徵的類別分離量。計算方法如(18),可得各個特徵的類別 分離量作為權重值。正規化 W 的權值於[0,1]範圍 end for k = 1 to B0
min ( )/ 0
* ) 1 ( 1 k N B rk = + − j∈C j ) , , ( _selection D r W Subspace Dk = k ) ( k k Learner D h = 計算正規化的ACC(hk)作為 R 分佈的初始分佈 R0,其中 ACC(hk)為訓 練樣本資料於 hk的辨識正確率。 end for b = B0 to B ) ( _ −1 = b b Dimension selection r R Db =Subspace_selection(D,rb,W) ) ( b b Learn D h = 及計算 ACC(hb) )) ( , , ( _ b 1 b bb =Kernel smooth R − r ACC h R end ) ) ( | ( max arg ) (x card B h x y hfinal = y∈C b = END 本方法中,第一個迴圈是估計維度的特徵重要程度分佈 W,權值估計的方法是按 類別分離量最佳化公式 J 來計算,其單一維度的計算方式定義如下: = W
∑
, , = p i i q q J J 1 / Jq trace(Swq1Sbq) − = , , (3-1)∑
= ∑ = L j jq j wq P S 1∑
= − − = L j T q jq q jq j bq P M M M M S 1 0 0 )( ) (∑
= = L j jq j q PM M 1 0 在此Pj是指類別 j 的先驗機率,Mjq 和 ∑jq是其分別是第 q 個維度,其第 j 類別 的平均向量與變異數。Swq及 Sbq則分別是第 q 個維度的組內分散矩陣與組間分散 矩陣,以單一特徵訓練樣本的類別分離量做為重要的權值,計算全部特徵的單一 重要權值後,將 W 正規化成為介於 0 至 1 之間的機率分配函數。Subspace_selection將根據 W 從原空間{1,2,…,p}隨機抽取 rb個子空間集合Ab ={d1,K,drb},之後的程
第四章 研究設計
在本章的實驗設計中,首先要驗證提出的演算法,是否能解決原先的隨機子 空間方法的維度選取問題,再來對於特徵選取的方式,以提出的加權方式在效能 上能否改善,接著探討組合的分類器個數對於分類效能及效率的影響,然後是不 同分類器是否對於子空間維度的具偏好性。本研究將以二種高光譜的遙測影像真 實資料及教育測驗資料來驗證提出方法的可行性。第一節 資料描述
壹、Washington DC Mall 資料集
Washington DC Mall 都市地區的高光譜影像資料,如圖 4-1 所示是感測器從 0.4 到 2.4 µm 取 210 個波段,包含可視光區域及內紅外線光譜,資料大小大概 為 150 Megabytes,因為去除水所造成的雜訊,故在本實驗只使用 191 波段,共 有 7 個類別,分別是建築物(Roofs)、路面(Road)、小路(Trail)、草地(Grass)、樹林 (Trees)、水(Water)及陰影(Shadow)。貳、Indian Pine Site 資料集
Indian Pine Site 為森林和農作物地區是 1992 年 6 月所收集的資料,取 Indiana 州西北 100 平方公里區域如圖 4-2,共 9 個類別,分別為玉米田己耕地 Corn-clean till)、玉米田未耕地(Corn-no till)、玉米略耕地(Corn-min till)、牧草地
(Grass/Pasture)、林地(Woods)、乾草地(Hay-windrowed)、大豆未耕地(Soybean no till)、大豆略耕地(Soybean-min till)和大豆己耕地(Soybean-clean till)
圖 4-2 Indian Pine Site 紅外線空拍圖 圖 4-1 Washington DC 紅外線空拍圖
參、教育測驗資料集
利用樣式辨識技術建立針對測驗資料之分類系統,作為補救教學分類之用, 有利補救教學的分群,可因材施教,縮短補救教學時間,而教學診斷的應用為小 樣本高維度的問題。採用擴分、約分教材是九十二學年國小六年級數學教材使用 的版本,依照民國 82 年新課程綱要編輯而成,配合施測學校使用的情形施測後, 進行試卷批閱及成績登錄,將學生作答情形根據「擴分、約分」單元教材專家知識結構進行補救教學類型的分類。本研究「擴分、約分」單元紙筆測驗計有 27 題,有效樣本點數 1192 個,用以進行實驗,測試所得之學生側面圖,各錯誤類 型組別的學生人數,如表 4-1。 表 4-1 擴分、約分錯誤類型組別 組別 人數 需進行補救教學之概念 1 89 「兩異分母比較大小」 2 31 「兩異分母比較大小」、「通分」 3 186 「最簡分數」 4 154 「最簡分數」、「兩異分母比較大小」 5 62 「最簡分數」、「兩異分母比較大小」、「通分」 6 41 「約分」 7 80 「最簡分數」、「約分」、「兩異分母比較大小」 8 59 「最簡分數」、「約分」、「兩異分母比較大小」、「通分」 9 63 「最簡分數」、「約分」、「公因數」、「等值分數」、「兩異分 母比較」、「通分」 10 59 需重新學習「最簡分數」、「約分」、「公因數」、「等值分數」、 「兩異分母比較」、「兩同分母比較」、「公倍數」 11 79 「最簡分數」、「約分」、「兩異分母比較」、「通分」、「兩同 分母比較 12 77 「最簡分數」、「約分」、「兩異分母比較」、「兩同分母比 較」、「公倍數」、「擴分」 13 35 「最簡分數」、「約分」、「公因數」、「等值分數」、「兩異分 母比較」、「兩同分母比較」、「公倍數」、「擴分」 14 150 所以概念都需重新學習 15 27 加強練習(粗心犯錯) 合計 1192
第二節 實驗描述
在實驗中為了解不同訓練樣本點數的影響,從 2 種高維度資料中,抽取不同 數目的訓練樣本點數作為實驗資料集。在 Washington DC Mall 資料中,訓練樣本 點數分為每個類別各 20、40 及 100,分為實驗 1、實驗 2 及實驗 3,實驗抽取每 個類別各 100 個測試樣本點數,而在 Indian Pine Site 資料,抽取訓練樣本點數分 為每個類別各 20、40 及 100,分為實驗 4、實驗 5 及實驗 6,實驗抽取每個類別 各 200 個測試樣本點數。在教育測驗資料中,訓練樣本點數分為每個類別各 10 及 20,分為實驗 7 及實驗 8,測試樣本為除訓練樣本點數外的全部樣本。本研究 隨機選取 10 組訓練及測試樣本集進行實驗,Washington DC Mall 資料集的實驗樣 本點數如表 4-2,Indian Pine Site 資料集的實驗樣本點數如表 4-3,教育測驗資料 集的實驗樣本點數如表 4-4,而各實驗中所使用的 3 種分類器的設定、實驗的比 較基準和改良的演算法,列在表 4-5。在每一個實驗中的參數設定部份詳述如下。
本研究的核平滑化帶寬σ 設定為 5,為探討分類器個數 B 的影響,在 3 個實
驗中,針對 B 值為 20、50 和 100 的情形進行比較。高斯分類器、k 最近鄰法和支 撐向量分類器,各分類器的參數設定為,支撐向量分類器是使用 rbf(radial basis function) kernel,並以 5-fold cross-validation 法來選取參數,k 最近鄰法的 k 值設 為 1。在比較基準方面,本研究所提出的 3 種演算法將與使用單一基準分類器及 使用網格法的隨機子空間方法進行比較。網格法的範圍是由第 5 維閞始,每 5 維 建構原隨機子空間方法至每 1 類別的最大訓練樣本點數為止。
表 4-2 Washington DC Mall 資料集實驗設計 維度 191 類別數 7 實驗 實驗 1 實驗 2 實驗 3 訓練樣本點數 (個別類別) 20 40 100 總訓練樣本 140 280 700 測試樣本點數 (個別類別) 100 總測試樣本 700
表 4-3 Indian Pine Site 資料集實驗設計
維度 220 類別數 9 實驗 實驗 4 實驗 5 實驗 6 訓練樣本點數 (個別類別) 20 40 100 總訓練樣本 180 360 900 測試樣本點數 (個別類別) 200 總測試樣本 1800
表 4-4 教育測驗資料集實驗設計 維度 27 類別數 15 實驗 實驗 7 實驗 8 訓練樣本點數 (個別類別) 10 20 總訓練樣本 150 300 總測試樣本 1042 892 表 4-5 本研究比較之演算法 縮寫 說明 Single 高斯分類器(qdc)、k 最近鄰分類器(knnc, k=1)及支撐 向量分類器使用 rbf kernel(svc,用 5-fold 法取參數)。 RSM_grid 原隨機子空間方法使用網格法來找尋最佳辨識正確 率,Washington DC Mall 資料的實驗 1 至 3 中,維度 網格分別設為[5, 10, 15, 20]、[5, 10, ..., 40]及[5, 10, …, 100]。Indian Pine Site 的實驗 4 至 6 中,維度網格分 別設為[5, 10, 15, 20]、[5, 10, ..., 40]及[5, 10, …, 100]。教育測驗資料在實驗 7 維度網格為[5,10],在 實驗 8,為[5,10,...,20]。 RSM_KS 原隨機子空間方法由核平滑化法所估計的重要分佈 來自動選取維度。 WRSM_KS1 RSM_KS 用訓練樣本辨識正確率作為特徵加權。 WRSM_KS2 RSM_KS 用線性區別分析類別分離量作為特徵加權。
第五章 結果及討論
本章將討論有關於所提出演算法的實驗結果,從 Washington DC Mall 資料集經 由實驗 1 至 3 所得的平均辨識正確率和標準差,列於表 5-1、5-2 及 5-3,執行時 間的結果於表 5-4。圖 5-1、5-2 及 5-3 顯示表 5-1 的比較圖表,圖 5-4、5-5 及 5-6 則是表 5-2,表 5-3 的比較則是顯示在圖 5-7、5-8 和 5-9,表 5-4 時間上的比較於 圖 5-10。Indian Pine Site 資料集的實驗 4 至 6 結果,在表 5-5、5-6 及 5-7 為平均 辨識正確率和標準差的結果,執行時間結果於表 5-8。實驗 4 的表 5-5 的比較結 果顯示於圖 5-11、5-12 及 5-13,實驗 5 的表 5-5 的結果則列示於圖 5-14、5-15 和 5-16,實驗 6 的比較結果則列於圖 5-17、5-18 及 5-19,而訓練時間的比較則是於 圖 5-20。教育測驗資料集的實驗 7 和實驗 8 的結果,在表 5-9 及 5-10 為平均辨識 正確率和標準差的結果,執行時間結果於表 5-11。實驗 7 的表 5-9 的比較結果顯 示於圖 5-21、5-22 及 5-23,實驗 8 的表 5-10 的結果則列示於圖 5-24、5-25 和 5-26, 而訓練時間的比較則是於圖 5-27。另外為顯示不同分類器具不同的維度偏好,以 Washington DC Mall 在實驗 3 且分類器個數為 100 (B=100) 情形下,使用 RSM_KS、WRSM_KS1 及 WRSM_KS2 的 qdc、knnc 及 svc 的 R 分佈與 W 分佈 於圖 5-28、圖 5-30 及圖 5-29 的圖形,看出分類器具不同的維度偏好情形。在表 5-12、5-13 與 5-14 則是隨機子空間方法使用網格法可得的最佳維度,此外圖 5-31 是 Washington DC Mall 的部份紅外線空照圖影像,可用來作為測試所提出之演算 法的運作效能,所用的分類器是實驗 3 且分類器個數為 100 (B=100)的分類器,所 得結果。圖 5-32 和 5-33 是 knnc 和 svc 單一分類器的分類結果圖用來與本研究所 提方法比較,圖 5-34、5-35 和 5-36 是分別是使用 RSM_KS、WRSM_KS1 及 WRSM_KS2 的 qdc 分類後結果分類結果圖。而圖 5-37、5-38 及 5-38 則是對應的 分類器換成 knnc 的分類結果分類結果圖。最後是圖 5-39、5-40 與 5-41 則是 svc 的分類結果分類結果圖。本研究發現如下所示:
1. 大部份的實驗結果顯示所提出的自動維度選取方法能解決子空間維度選 擇問題。
2. 在 Washington DC Mall 資 料 集 中 , 大 部 份 實 驗 的 WRSM_KS1 及 WRSM_KS2 表現得比單一分類器及 RSM_grid 法好。
3. 在 Indian Pine Site 資料集中,各方法的實驗表現和 RSM_grid 大致相同。
4. 當訓練樣本點數小時(實驗 1 及實驗 4),分類器個數 B 參數需較大才能得 到較好的結果。在實験 2、實驗 3、實驗 5 及實驗 6 時,使用較小的分類 器個數 B 值就能得到滿意的結果,訓練樣本點數越多的實驗,所需要的分 類器個數就越少。 5. 在時間的花費上,所提出的演算法在實驗 1 至實驗 6 中,與網格法比較, 所需的時間較少,如圖 5-10 及 5-20。 6. 顯示 Washington DC Mall 的實驗 3 且分類器個數為 100 的情形下,圖 5-28 至圖 5-30 為維度重要分佈 R 及特徵重要分佈 W,可看出每個分類器有不 同的子維度偏好,qdc 使用較低維度,knnc 和 svc 則是需要比較高的維度。 7. 由 Washington DC Mall 的部份空照圖上來看,圖 5-34 至圖 5-41 以本研究 所提出的方法分類後的結果,和圖 5-32 及 5-33 的單一分類器分類結果相 比,顯示改善分類的效果。
表 5-1 Washington DC Mall辨識正確率的平均及標準差(實驗 1)
Classifier qdc knnc (k = 1) svc
Algorithm B accuracy std accuracy std accuracy std
Single 1 0.143 0.0000 0.838 0.0170 0.830 0.0181 RSM_grid 20 0.925 0.0112 0.833 0.0176 0.805 0.0230 RSM_KS 20 0.923 0.0126 0.856 0.0144 0.830 0.0374 WRSM_KS1 20 0.935 0.0094 0.849 0.0160 0.832 0.0474 WRSM_KS2 20 0.930 0.0100 0.907 0.0172 0.818 0.0526 RSM_grid 50 0.935 0.0149 0.856 0.0172 0.821 0.0118 RSM_KS 50 0.931 0.0083 0.858 0.0153 0.836 0.0317 WRSM_KS1 50 0.941 0.0087 0.857 0.0161 0.815 0.0457 WRSM_KS2 50 0.936 0.0115 0.911 0.0189 0.770 0.0620 RSM_grid 100 0.935 0.0110 0.867 0.0141 0.816 0.0185 RSM_KS 100 0.932 0.0097 0.859 0.0182 0.824 0.0384 WRSM_KS1 100 0.943 0.0101 0.856 0.0160 0.810 0.0435 WRSM_KS2 100 0.937 0.0124 0.912 0.0162 0.764 0.0894
0.70 0.80 0.85 0.90 0.95 1.00 qdc knnc svc Single RSM_grid RSM_KS WRSM_KS1 WRSM_KS2 0.75 平 均 辨 識 正 確 率 (% ) 分類器 圖 5-1 Washington DC Mall辨識正確率比較圖(實驗 1, B=20) 0.70 0.75 0.80 0.85 0.90 0.95 1.00 qdc knnc svc Single RSM_grid RSM_KS WRSM_KS1 WRSM_KS2 平 均 辨 識 正 確 率 (% ) 分類器 圖 5-2 Washington DC Mall辨識正確率比較圖 (實驗 1, B=50) 平 均 辨 識 正 確 率 (% ) 0 0.70 0.75 .80 0.85 0.90 0.95 1.00 qdc knnc svc Single RSM_grid RSM_KS WRSM_KS1 WRSM_KS2 分類器 圖 5-3 Washington DC Mall辨識正確率比較圖 (實驗 1, B=100)
表 5-2 Washington DC Mall辨識正確率的平均及標準差(實驗 2) Classifier
qdc knnc (k=1) svc
Algorithm B accuracy std accuracy std accuracy std
Single 1 0.143 0.0000 0.880 0.0194 0.873 0.0116 RSM_grid 20 0.950 0.0088 0.886 0.0174 0.869 0.0203 RSM_KS 20 0.945 0.0105 0.893 0.0193 0.878 0.0130 WRSM_KS1 20 0.952 0.0099 0.887 0.0192 0.893 0.0127 WRSM_KS2 20 0.938 0.0100 0.934 0.0147 0.914 0.0070 RSM_grid 50 0.952 0.0118 0.897 0.0161 0.867 0.0227 RSM_KS 50 0.948 0.0100 0.897 0.0193 0.878 0.0152 WRSM_KS1 50 0.955 0.0109 0.894 0.0178 0.896 0.0122 WRSM_KS2 50 0.942 0.0113 0.935 0.0152 0.914 0.0113 RSM_grid 100 0.955 0.0110 0.902 0.0155 0.938 0.0089 RSM_KS 100 0.951 0.0123 0.897 0.0210 0.880 0.0133 WRSM_KS1 100 0.957 0.0106 0.896 0.0171 0.895 0.0127 WRSM_KS2 100 0.943 0.0120 0.934 0.0155 0.913 0.0119
0.70 0.80 0.85 0.90 0.95 1.00 qdc knnc svc Single RSM_grid RSM_KS WRSM_KS1 WRSM_KS2 0.75 平 均 辨 識 正 確 率 (% ) 分類器 圖 5-4 Washington DC Mall辨識正確率比較圖 (實驗 2, B=20) 0.70 75 0.80 0.85 0.90 0.95 1.00 qdc knnc svc Single RSM_grid RSM_KS WRSM_KS1 WRSM_KS2 0. 平 均 辨 識 正 確 率 (% ) 分類器 0.70 0.75 0.80 0.85 0.90 0.95 1.00 qdc knnc svc Single RSM_grid RSM_KS WRSM_KS1 WRSM_KS2 圖 5-5 Washington DC Mall辨識正確率比較圖 (實驗 2, B=50) 平 均 辨 識 正 確 率 (% ) 分類器 圖 5-6 Washington DC Mall辨識正確率比較圖 (實驗 2, B=100)
表 5-3 Washington DC Mall辨識正確率的平均及標準差(實驗 3)
Classifier qdc knnc (k = 1) svc
Algorithm B accuracy std accuracy std accuracy std
Single 1 0.143 0.0000 0.923 0.0101 0.931 0.0073 RSM_grid 20 0.961 0.0069 0.939 0.0092 0.943 0.0066 RSM_KS 20 0.953 0.0122 0.936 0.0073 0.932 0.0058 WRSM_KS1 20 0.959 0.0064 0.931 0.0090 0.938 0.0068 WRSM_KS2 20 0.939 0.0092 0.952 0.0113 0.942 0.0087 RSM_grid 50 0.961 0.0070 0.940 0.0069 0.944 0.0056 RSM_KS 50 0.957 0.0102 0.938 0.0107 0.930 0.0057 WRSM_KS1 50 0.960 0.0076 0.934 0.0099 0.937 0.0072 WRSM_KS2 50 0.938 0.0088 0.953 0.0109 0.942 0.0088 RSM_grid 100 0.962 0.0078 0.942 0.0086 0.945 0.0056 RSM_KS 100 0.956 0.0124 0.940 0.0089 0.931 0.0060 WRSM_KS1 100 0.961 0.0089 0.937 0.0115 0.939 0.0069 WRSM_KS2 100 0.938 0.0079 0.953 0.0106 0.942 0.0092
0.70 0.80 0.85 0.90 0.95 1.00 qdc knnc svc Single RSM_grid RSM_KS WRSM_KS1 WRSM_KS2 0.75 平 均 辨 識 正 確 率 (% ) 分類器 0.70 75 0.80 0.85 0.90 0.95 1.00 qdc knnc svc Single RSM_grid RSM_KS WRSM_KS1 WRSM_KS2 圖 5-7 Washington DC Mall辨識正確率比較圖 (實驗 3, B=20) 0. 平 均 辨 識 正 確 率 (% ) 0.70 0.80 0.85 0.90 0.95 1.00 qdc knnc svc Single RSM_grid RSM_KS WRSM_KS1 WRSM_KS2 圖 5-8 Washington DC Mall辨識正確率比較圖(實驗 3, B=50) 分類器 0.75 平 均 辨 識 正 確 率 (% ) 分類器 圖 5-9 Washington DC Mall辨識正確率比較圖(實驗 3, B=100)
表 5-4 Washington DC Mall實驗平均訓練時間 實驗 1 實驗 2 實驗 3 Algorithm B qdc knnc svc qdc knnc svc qdc knnc svc Single 1 9.5 0.8 0.2 8.9 2.2 0.4 8.7 25.3 0.9 RSM_grid 20 6.8 16.6 2.6 15.8 78.7 12.2 86.3 1139.1 110.2 RSM_KS 20 1.4 4.4 2.7 1.7 10.7 5.4 3.1 54.0 13.0 WRSM_KS1 20 1.3 5.1 2.7 1.6 12.7 5.0 2.9 48.7 10.7 WRSM_KS2 20 1.5 4.2 3.5 1.9 10.1 7.1 5.0 45.2 14.0 RSM_grid 50 15.7 41.7 6.2 45.1 220.1 32.5 221.2 2698.3 280.7 RSM_KS 50 3.7 11.4 6.6 4.7 27.2 13.2 9.3 130.8 30.2 WRSM_KS1 50 3.7 12.3 6.6 4.7 34.1 12.4 8.6 120.2 26.5 WRSM_KS2 50 4.2 10.8 8.3 5.3 26.0 15.0 12.1 111.5 32.3 RSM_grid 100 98.2 199.9 16.9 252.2 959.6 74.3 1333.5 4872.7 843.3 RSM_KS 100 6.4 22.1 12.8 7.9 55.2 27.1 18.4 260.1 59.0 WRSM_KS1 100 6.3 24.4 12.9 8.9 66.8 25.7 17.4 240.4 54.2 WRSM_KS2 100 7.4 21.1 16.0 10.6 50.1 28.6 22.4 224.2 63.6 注記:時間單位為秒(s)
1 訓 練 時 間 (lo g 1 0 /s ) 訓 練 時 間 (lo g 1 0 /s ) (i) 實驗 3(svc) 分類器個數(B) 3 4 -1 0 2 3 4 20 50 100 1 訓 練 時 間 (lo g 1 0 /s ) 分類器個數(B) (g) 實驗 1(svc) -1 0 2 3 4 20 50 100 (f) 實驗 3(knnc) -1 0 1 2 3 4 20 50 100 分類器個數(B) (e) 實驗 2(knnc) 100 -1 0 2 3 4 20 50 分類器個數(B) (c) 實驗 3(qdc) -1 2 3 4 20 50 100 (a) 實驗 1(qdc) -1 0 1 2 3 4 20 50 100 分類器個數(B) (d) 實驗 1(knnc) -1 2 3 4 20 50 100 -1 0 2 3 4 20 50 100 分類器個數(B) (b) 實驗 2(qdc) 1 訓 練 時 間 (lo g 1 0/s ) 分類器個數(B) 0 1 訓 練 時 間 (lo g 1 0 /s ) 訓 練 時 間 (lo g 1 0/s ) 分類器個數(B) 0 1 訓 練 時 間 (lo g 1 0 /s ) (h) 實驗 2(svc) 分類器個數(B) 1 訓 練 時 間 (lo g 1 0/s ) -1 2 20 50 100 0 1 訓 練 時 間 (lo g 1 0 /s ) Single RSM_KS RSM_grid WRSM_KS1 WRSM_KS2WRSM_KS2 圖 5-10 Washington DC Mall 訓練時間比較圖
表 5-5 Indian Pine Site 辨識正確率的平均及標準差(實驗 4)
Classifier qdc knnc (k = 1) svc
Algorithm B accuracy std accuracy std accuracy std
Single 1 0.111 0.0000 0.692 0.0127 0.789 0.0130 RSM_grid 20 0.787 0.0177 0.692 0.0141 0.739 0.0186 RSM_KS 20 0.753 0.0195 0.693 0.0129 0.796 0.0147 WRSM_KS1 20 0.763 0.0209 0.694 0.0126 0.803 0.0144 WRSM_KS2 20 0.717 0.0305 0.693 0.0147 0.798 0.0149 RSM_grid 50 0.810 0.0167 0.697 0.0170 0.748 0.0219 RSM_KS 50 0.782 0.0175 0.695 0.0146 0.799 0.0142 WRSM_KS1 50 0.793 0.0219 0.694 0.0142 0.806 0.0129 WRSM_KS2 50 0.752 0.0282 0.695 0.0160 0.804 0.0170 RSM_grid 100 0.817 0.0180 0.699 0.0147 0.748 0.0231 RSM_KS 100 0.803 0.0154 0.696 0.0143 0.801 0.0122 WRSM_KS1 100 0.812 0.0157 0.694 0.0127 0.808 0.0117 WRSM_KS2 100 0.780 0.0232 0.696 0.0172 0.806 0.0164
0.60 0.65 0.75 0.80 0.85 0.90 0.95 1.00 qdc knnc svc Single RSM_grid RSM_KS WRSM_KS1 WRSM_KS2 0.70 平 均 辨 識 正 確 率 (% ) 分類器
圖 5-11Indian Pine Site 辨識正確率的比較圖 (實驗 4, B=20)
0.60 0.65 0.75 0.80 0.85 0.90 0.95 1.00 qdc knnc svc Single RSM_grid RSM_KS WRSM_KS1 WRSM_KS2 0.70 平 均 辨 識 正 確 率 (% ) 分類器 0.60 0.75 0.80 0.85 0.90 0.95 1.00 qdc knnc svc Single RSM_grid RSM_KS WRSM_KS1 WRSM_KS2
圖 5-12Indian Pine Site 辨識正確率的比較圖 (實驗 4, B=50)
0.65 0.70 平 均 辨 識 正 確 率 (% ) 分類器
表 5-6 Indian Pine Site 辨識正確率的平均及標準差(實驗 5)
Classifier qdc knnc (k = 1) svc
Algorithm B accuracy std accuracy std accuracy std
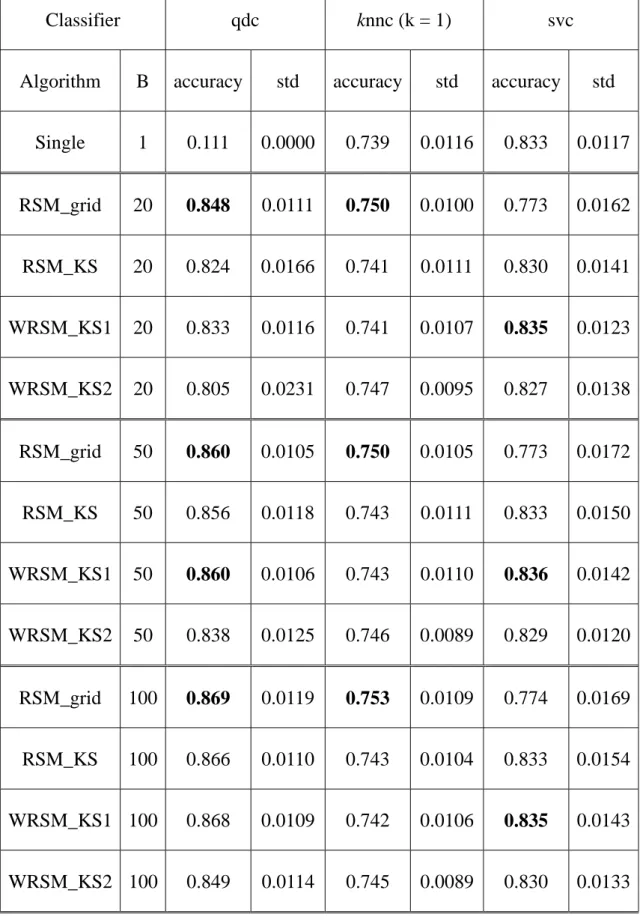
Single 1 0.111 0.0000 0.739 0.0116 0.833 0.0117 RSM_grid 20 0.848 0.0111 0.750 0.0100 0.773 0.0162 RSM_KS 20 0.824 0.0166 0.741 0.0111 0.830 0.0141 WRSM_KS1 20 0.833 0.0116 0.741 0.0107 0.835 0.0123 WRSM_KS2 20 0.805 0.0231 0.747 0.0095 0.827 0.0138 RSM_grid 50 0.860 0.0105 0.750 0.0105 0.773 0.0172 RSM_KS 50 0.856 0.0118 0.743 0.0111 0.833 0.0150 WRSM_KS1 50 0.860 0.0106 0.743 0.0110 0.836 0.0142 WRSM_KS2 50 0.838 0.0125 0.746 0.0089 0.829 0.0120 RSM_grid 100 0.869 0.0119 0.753 0.0109 0.774 0.0169 RSM_KS 100 0.866 0.0110 0.743 0.0104 0.833 0.0154 WRSM_KS1 100 0.868 0.0109 0.742 0.0106 0.835 0.0143 WRSM_KS2 100 0.849 0.0114 0.745 0.0089 0.830 0.0133
0.60 0.65 0 0.75 0.80 0.85 0.90 0.95 1.00 qdc knnc svc Single RSM_grid RSM_KS WRSM_KS1 WRSM_KS2 0.7 平 均 辨 識 正 確 率 (% ) 分類器 0.60 0.65 0.75 0.80 0.85 0.90 0.95 1.00 qdc knnc svc Single RSM_grid RSM_KS WRSM_KS1 WRSM_KS2
圖 5-13 Indian Pine Site 辨識正確率的比較圖 (實驗 5, B=20)
0.70 平 均 辨 識 正 確 率 (% ) 分類器
圖 5-14Indian Pine Site 辨識正確率的比較圖 (實驗 5, B=50)
0.60 0.65 0.75 0.80 0.85 0.90 0.95 1.00 qdc knnc svc Single RSM_grid RSM_KS WRSM_KS1 WRSM_KS2 0.70 平 均 辨 識 正 確 率 (% ) 分類器
表 5-7Indian Pine Site 辨識正確率的平均及標準差(實驗 6)
Classifier qdc knnc (k = 1) svc
Algorithm B accuracy std accuracy std accuracy std
Single 1 0.111 0.0000 0.794 0.0097 0.880 0.0121 RSM_grid 20 0.887 0.0133 0.807 0.0091 0.887 0.0102 RSM_KS 20 0.870 0.0071 0.799 0.0112 0.872 0.0168 WRSM_KS1 20 0.874 0.0079 0.801 0.0105 0.873 0.0130 WRSM_KS2 20 0.850 0.0082 0.803 0.0103 0.866 0.0217 RSM_grid 50 0.898 0.0079 0.811 0.0100 0.890 0.0103 RSM_KS 50 0.888 0.0070 0.802 0.0105 0.872 0.0155 WRSM_KS1 50 0.891 0.0078 0.801 0.0109 0.875 0.0123 WRSM_KS2 50 0.865 0.0083 0.806 0.0105 0.865 0.0209 RSM_grid 100 0.899 0.0108 0.811 0.0101 0.890 0.0104 RSM_KS 100 0.897 0.0070 0.802 0.0108 0.872 0.0160 WRSM_KS1 100 0.896 0.0080 0.801 0.0096 0.874 0.0133 WRSM_KS2 100 0.872 0.0086 0.807 0.0102 0.866 0.0197
0.60 0.75 0.80 0.85 0.90 0.95 1.00 qdc knnc svc Single RSM_grid RSM_KS WRSM_KS1 WRSM_KS2 0.65 0.70 平 均 辨 識 正 確 率 (% ) 分類器 0.60 0.65 0.75 0.80 0.85 0.90 0.95 1.00 qdc knnc svc Single RSM_grid RSM_KS WRSM_KS1 WRSM_KS2
圖 5-16Indian Pine Site 辨識正確率的比較圖 (實驗 6, B=20)
0.70 平 均 辨 識 正 確 率 (% ) 分類器
圖 5-17Indian Pine Site 辨識正確率的比較圖 (實驗 6, B=50)
0.60 0.65 70 0.75 0.80 0.85 0.90 0.95 1.00 qdc knnc svc Single RSM_grid RSM_KS WRSM_KS1 WRSM_KS2 0. 平 均 辨 識 正 確 率 (% ) 分類器
表 5-8Indian Pine Site 實驗平均訓練時間 實驗 4 實驗 5 實驗 6 Algorithm B qdc knnc svc qdc knnc svc qdc knnc svc Single 1 22.0 3.1 0.5 20.3 7.8 0.8 20.9 55.1 2.0 RSM_grid 20 10.5 49.0 6.7 39.7 308.7 46.3 238.7 3731.8 445.9 RSM_KS 20 3.0 13.9 6.0 3.4 32.1 10.8 8.6 135.4 28.1 WRSM_KS1 20 2.6 13.8 5.2 3.3 32.3 8.5 6.4 129.0 19.2 WRSM_KS2 20 2.7 13.7 4.7 3.3 32.2 8.2 6.9 131.8 22.5 RSM_grid 50 27.6 126.8 16.1 74.1 600.2 76.2 388.2 6784.1 388.2 RSM_KS 50 6.6 34.1 13.6 8.3 79.8 24.4 18.0 335.7 66.2 WRSM_KS1 50 6.4 34.0 12.3 8.2 81.1 21.0 15.6 323.6 47.8 WRSM_KS2 50 6.5 34.0 12.2 8.3 81.4 21.3 16.2 330.2 53.9 RSM_grid 100 167.6 576.4 43.0 440.6 2864.0 169.5 1000.5 14836.7 1606.5 RSM_KS 100 12.9 68.4 26.8 16.8 159.7 46.8 33.7 671.7 128.8 WRSM_KS1 100 12.6 68.0 24.9 16.4 163.5 41.6 30.8 646.9 96.2 WRSM_KS2 100 12.8 68.2 24.6 16.7 163.9 42.8 31.3 660.6 104.7 注記:時間單位為秒(s)
1 訓 練 時 間 (lo g 1 0 /s ) 訓 練 時 間 (lo g 1 0 /s )
圖 5-19Indian Pine Site 訓練時間比較圖 -1 2 3 4 20 50 100 分類器個數(B) (j)實驗 6(svc) -1 2 3 4 20 50 100 分類器個數(B) 0 1 訓 練 時 間 (lo g 1 0/s ) -1 2 3 4 20 50 100 (g)實驗 4(svc) 分類器個數(B) -1 0 3 4 20 50 100 分類器個數(B) (d)實驗 4(knnc) (f)實驗 6(knnc) 1 2 訓 練 時 間 (lo g 1 0/s ) -1 0 1 2 3 4 20 50 100 (e)實驗 5(knnc) 分類器個數(B) -1 2 3 4 20 50 100 分類器個數(B) 0 1 訓 練 時 間 (lo g 1 0 /s ) -1 2 3 4 20 50 100 分類器個數(B) (c)實驗 6(qdc) -1 0 2 3 4 20 50 100 分類器個數(B) (b) 實驗 5(qdc) 1 訓 練 時 間 (lo g 1 0/s ) -1 0 2 3 4 20 50 100 分類器個數(B) (a) 實驗 4(qdc) 0 1 訓 練 時 間 (lo g 1 0 /s ) 0 1 訓 練 時 間 (lo g 1 0 /s ) 0 1 訓 練 時 間 (lo g 1 0 /s ) (h)實驗 5(svc) Single RSM_KS RSM_grid WRSM_KS1 WRSM_KS2WRSM_KS2
表 5-9 教育測驗資料辨識正確率的平均及標準差(實驗 7)
Classifier qdc knnc (k = 1) svc
Algorithm B accuracy std accuracy std accuracy std
Single 1 0.076 0 0.481 0.0215 0.667 0.0305 RSM_grid 20 0.079 0.0361 0.249 0.0389 0.485 0.0425 RSM_KS 20 0.094 0.0388 0.146 0.0237 0.332 0.0654 WRSM_KS1 20 0.098 0.0550 0.153 0.0258 0.362 0.0644 WRSM_KS2 20 0.079 0.0354 0.191 0.0934 0.364 0.1184 RSM_grid 50 0.095 0.0390 0.257 0.0187 0.527 0.0390 RSM_KS 50 0.091 0.0333 0.140 0.0143 0.387 0.0729 WRSM_KS1 50 0.095 0.0478 0.162 0.0267 0.400 0.0941 WRSM_KS2 50 0.079 0.0367 0.181 0.0723 0.401 0.1293 RSM_grid 100 0.095 0.0391 0.257 0.0150 0.553 0.0193 RSM_KS 100 0.096 0.0348 0.142 0.0132 0.408 0.0726 WRSM_KS1 100 0.101 0.0408 0.153 0.0149 0.416 0.0722 WRSM_KS2 100 0.069 0.0187 0.190 0.0677 0.387 0.1109
0.00 0.40 0.60 0.80 1.00 qdc knnc svc Single RSM_grid RSM_KS WRSM_KS1 WRSM_KS2 0.20 平 均 辨 識 正 確 率 (% ) 分類器 0.00 0.20 0 0.60 0.80 1.00 qdc knnc svc Single RSM_grid RSM_KS WRSM_KS1 WRSM_KS2 圖 5-21 教育測驗資料辨識正確率的比較圖 (實驗 7, B=20) 0.4 平 均 辨 識 正 確 率 (% ) 0.00 .20 0.40 0.60 0.80 1.00 qdc knnc svc Single RSM_grid RSM_KS WRSM_KS1 WRSM_KS2 圖 5-22 教育測驗資料辨識正確率的比較圖 (實驗 7, B=50) 分類器 0 平 均 辨 識 正 確 率 (% ) 分類器 圖 5-23 教育測驗資料辨識正確率的比較圖 (實驗 7, B=100)