科技部補助專題研究計畫成果報告
期末報告
漢語分類詞與量詞的分與合:探究其內在之認知機制與神經關
連性(第3年)
計 畫 類 別 : 個別型計畫 計 畫 編 號 : MOST 103-2410-H-004-136-MY3 執 行 期 間 : 105年08月01日至107年02月28日 執 行 單 位 : 國立政治大學語言學研究所 計 畫 主 持 人 : 何萬順 共 同 主 持 人 : 顏乃欣、吳嫻 計畫參與人員: 碩士級-專任助理:陳盈君 報 告 附 件 : 移地研究心得報告 出席國際學術會議心得報告中 華 民 國 107 年 03 月 31 日
中 文 摘 要 : 漢語是典型的分類詞語言,在數詞(Num)與名詞(N)之間需用分類詞 (C),例如「五本書」,或量詞(M),例如「五箱書」。許多語言學 家,尤其是形式句法學家,認為C/M 應統合為同一範疇;然而也有 許多學者堅稱兩者應分屬不同的類別。這個存在超過了半世紀的爭 議在Her (2012a)的數學解釋中找到了一個突破:C/M 的分與合乃歸 因於其數學功能上的分與合。(1) C/M 在數學上的分與合 (Her 2012a)[Num X N] = [[Num × X] N], where X = C iff X =1, otherwise X = M.將 [Num C/M]的關係解釋為乘法的關係可將C/M 統合為「被乘數」;其區分在於其質(value)的不同:C=1, M≠1。 Her (2012b) 進一步在一個形式語言學的架構下分析,C/M 之「合 」在於句法:二者為同一句法類別,二者之「分」在於語意:C 為 修飾語並非述詞,因此語意有穿透性,M 為述詞,因此語意無穿透 性。以上的看法解釋了為何在[Num C/M N]中C的訊息包含於N,因此 C 是可省略的,但是在[Num C/M N] 中M 的訊息並不包含於N,因此 M 是不可省略的。但是對於數量詞與分類詞是否與數詞的處理有相 同的神經基礎,從既有的實驗研究中並無法得到定論。在一個最新 的fMRI 實驗中,Cui et al (2013)發現分類詞的處理與工具名詞相 似,與點陣和數目不同。然而,這項研究中所謂的classifiers 其 實包含了大量的量詞,不僅未區分C 與M,也未區分出數值的M和非 數值的M。此外,他們也沒有排除掉分類詞的語義屬性影響,這樣的 混淆極可能導致實驗結果的失真。我們從數學的角度對於 C/M 的解 讀所得到的預測是:具有數值的C 與M1-2 應與數詞的處理類似,而 非一般名詞,例如工具名詞。因此本研究的目的有二:一、複製Cui et al (2013)的實驗派典,首先進行行為實驗,但在語料上區分數 值的C&M1-2 與非數值的M3-4,並將材料以最小對立體呈現,以控制 語義屬性。二、測試上述Her (2012a, 2012b)有關C/M 的數學理論 。針對目的二,我們原先設計計畫採用促發作業來探究C/M 分與合 的認知機制與其神經關連性,以點與文字二種表示數量的方式,首 先檢視C/M 是否的確含有數量的概念,再進一步檢視C 與M 的被乘 數角色。然而,多次促發作業實驗都無顯著效果,因此我們改變實 驗派典,改採numerical Stroop作業,受試者須判斷語意數量或字 型大小,透過檢驗C/M是否表現出典型數量處理時會出現的距離效果 和一致效果來驗證Her (2012a, 2012b)的理論。實驗結果顯著,支 持Her (2012a, 2012b)的理論:1.C/M 的確含有數量的概念、2.C與 M扮演被乘數的角色。 中 文 關 鍵 詞 : 分類詞、量詞、乘法、認知機制、fMRI
英 文 摘 要 : The element in between a numeral (Num) and a noun (N) in Chinese, a textbook example of classifier languages, is recognized to be either a numeral classifier (C) or measure word (M). Many linguists, largely formalists, consider C/M converge as a single category, while others, many of them functionalists, claim that C and M diverge and form
distinct categories. The stalemate lasted for more than half a century until a breakthrough in Her (2012a), which takes serious the mathematical interpretation of C/M and comes up with the most precise formulation for the C/M
distinction.(1) C/M Distinction in Mathematical Terms (Her 2012a:1679)[Num X N] = [[Num × X] N], where X = C iff X =1, otherwise X = M.This multiplication interpretation of [Num C/M] has C/M converge as the multiplicand and diverge in their respective value: C=1, M≠1. Her (2012b) further demonstrates within a formal linguistic framework that the C/M convergence is syntactically encoded as the two belong to the same syntactic category, but their divergence is semantic in nature: C is transparent in being a modifier and not a predicate, but M is opaque and thus a predicate. This view satisfactorily explains why C is redundant and can thus be omitted in the NP but M is not.However,
existing empirical studies produce conflicting results. Cui et al (2013) found that the processing of classifiers is similar to that of tool nouns, but not that of numbers and dot arrays. However, the so-called classifiers in the study included lots of Ms. The C/M distinction was not made, nor was the distinction between numerical Ms and non-numerical Ms. Furthermore, they did not control the potential
confound of semantic attributes of C/Ms. Such confusions can certainly distort the results of the experiments.The mathematical interpretation of C/M suggests that the numerical C and M1-2 should be similar to numbers in processing than to common nouns. The goal of this project is: 1) to determine whether C/M share the same neural basis with numbers in processing, by replicating the fMRI study in Cui et al (2013) but with better experimental control and selection of stimuli; 2) to further test the
mathematical interpretation of C/M in Her (2012a, 2012b). Originally, we planned to use a priming task to investigate the cognitive mechanism underlying C/Ms. However, we could not observe significant priming effect after trying several priming experiments. Consequently, we changed priming task into numerical stroop task, in which participants had to choose the C/M phrase that denotes a larger quantity or has a larger font size. By examining whether C/Ms reflect
distance effect and congruity effect as classic number processing, we would like to verify Her's (2012a, 2012b) theory. The distance effect is a phenomenon that comparing proximate digits is more difficult than comparing remote ones. The congruity effect emerges when congruent pairs lead to facilitation effect whereas incongruent pairs result in interference effect. Our results showed
significant distance and congruity effect, supporting Her's (2012a, 2012b) theory.
英 文 關 鍵 詞 : classifier, measure word, multiplication, cognitive mechanism, fMRI
科技部補助專題研究計畫成果報告
(□期中進度報告/■期末報告)
(計畫名稱)
計畫類別:■個別型計畫 □整合型計畫
計畫編號:MOST 103-2410-H-004-136-MY3
執行期間: 103 年 8 月 1 日至 107 年 2 月 28 日
執行機構及系所:國立政治大學語言學研究所
計畫主持人:何萬順教授
共同主持人:顏乃欣教授、吳嫻教授
計畫參與人員:專任研究助理陳盈君
本計畫除繳交成果報告外,另含下列出國報告,共 _5_ 份:
■執行國際合作與移地研究心得報告
■出席國際學術會議心得報告
□出國參訪及考察心得報告
中 華 民 國 107 年 3 月 23 日
研究計畫中文摘要
漢語是典型的分類詞語言,在數詞(Num)與名詞(N)之間需用分類詞(C, classifier),例如「五 本書」,或量詞(M, measure word),例如「五箱書」。許多語言學家,尤其是形式句法學家,認為 C/M 應統合為同一範疇;然而也有許多學者堅稱兩者應分屬不同的類別。這個存在超過了半世紀的爭 議在Her (2012a)的數學解釋中找到了一個突破:C/M 的分與合乃歸因於其數學功能上的分與合。 (1) C/M 在數學上的分與合 (Her 2012a:1679)[Num X N] = [[Num × X] N], where X = C iff X =1, otherwise X = M.
將 [Num C/M]的關係解釋為乘法的關係可將C/M 統合為「被乘數」;其區分在於其質(value) 的 不同:C=1, M≠1。Her (2012b) 進一步在一個形式語言學的架構下分析,C/M 之「合」在於句法: 二者為同一句法類別 (syntactic category),二者之「分」在於語意:C 為修飾語 (modifier) 並 非述詞 (predicate),因此語意有穿透性 (transparent),M 為述詞(predicate)因此語意無穿透性 (opaque)。 以上的看法解釋了為何在[Num C/M N]中C 的訊息包含於N,因此C 是可省略的,例如「五(張) 餅二(條)魚」,但是在[Num C/M N] 中M 的訊息並不包含於N,因此M 是不可省略的,例如「五*(籃) 餅二*(箱)魚」。 但是對於數量詞(quantifiers)與分類詞(classifiers)是否與數詞(numbers)的處理 (processing)有相同的神經基礎,從既有的實驗研究中並無法得到定論。而在一個最新的fMRI 實驗 中,Cui et al (2013)發現分類詞的處理與工具名詞(tool nouns)相似,與點陣(dot arrays)和數目 不同。然而,這項研究中所謂的classifiers 其實包含了大量的量詞(measure words),不僅未區分C 與M,也未區分出數值的M和非數值的M。此外,他們也沒有排除掉在實驗中受試者的判斷可能受到分 類詞的語義屬性影響,這樣的混淆極可能導致實驗結果的失真。 我們從數學的角度對於 C/M 的解讀所得到的預測是:具有數值的C 與M1-2 應與數詞的處理類似, 而非一般名詞,例如工具名詞。因此本研究的目的有二:一、複製Cui et al (2013)的實驗派典,首 先進行行為實驗,但是在語料上嚴格區分數值的C&M1-2 與非數值的M3-4,並且將材料以最小對立體 呈現,以控制語義屬性可能造成的影響;待行為實驗結果明確後,再執行fMRI實驗。二、測試上述Her (2012a, 2012b)有關C/M 的數學理論。 針對目的二,我們原先設計計畫採用促發作業來探究C/M 分與合的認知機制與其神經關連性,以 點與文字二種表示數量的方式,首先檢視C/M 是否的確含有數量的概念,再進一步檢視C 與M 在被乘 數的特性上,是否C 是可省略的,而M 是不可省略的。然而,在計畫執行過程中,我們發現促發作業 的效果雖有趨勢但是不達到統計上的顯著效果,且在修改實驗設計多次後,每次的結果均無法得到顯 著的促發效果。因此我們改變實驗派典,將促發作業改為numerical Stroop作業,受試者須判斷語意 數量或字型大小,透過檢驗C/M是否表現出典型數量處理時會出現的距離效果和一致效果來驗證Her (2012a, 2012b)的理論。距離效果是指,比較距離近的數字比起比較距離遠的數字困難,會有較低的 正確率與較長的反應時間;一致性效果則是指當語義數量和字型大小一致時,有促進效果;當兩者不 一致時,有干擾效果。實驗結果顯著,支持Her (2012a, 2012b)的理論:1.C/M 的確含有數量的概念、 2.C與M扮演被乘數的角色。 關鍵詞:分類詞、量詞、乘法、認知機制、fMRI
Abstract
The element in between a numeral (Num) and a noun (N) in Chinese, a textbook example of classifier languages, is recognized to be either a numeral classifier (C) or measure word (M). Many linguists, largely formalists, consider C/M converge as a single category, while others, many of them functionalists, claim that C and M diverge and form distinct categories. The stalemate lasted for more than half a century until a breakthrough in Her (2012a), which takes serious the mathematical interpretation of C/M and comes up with the most precise formulation for the C/M distinction.
(1) C/M Distinction in Mathematical Terms (Her 2012a:1679)
[Num X N] = [[Num × X] N], where X = C iff X =1, otherwise X = M.
This multiplication interpretation of [Num C/M] has C/M converge as the multiplicand and diverge in their respective value: C=1, M≠1. Her (2012b) further demonstrates within a formal linguistic
framework that the C/M convergence is syntactically encoded as the two belong to the same syntactic category, but their divergence is semantic in nature: C is transparent in being a modifier and not a predicate, but M is opaque and thus a predicate. This view satisfactorily explains why C is redundant and can thus be omitted in the NP but M is not.
However, existing empirical studies produce conflicting results. Cui et al (2013) found that the
processing of classifiers is similar to that of tool nouns, but not that of numbers and dot arrays. However, the so-called classifiers in the study included lots of Ms. The C/M distinction was not made, nor was the
distinction between numerical Ms and non-numerical Ms. Furthermore, they did not control the potential confound of semantic attributes of C/Ms. Such confusions can certainly distort the results of the
experiments.
The mathematical interpretation of C/M suggests that the numerical C and M1-2 should be similar to
numbers in processing than to common nouns. The goal of this project is: 1) to determine whether C/M share the same neural basis with numbers in processing, by replicating the fMRI study in Cui et al (2013) but with better experimental control and selection of stimuli; 2) to further test the mathematical
interpretation of C/M in Her (2012a, 2012b).
Originally, we planned to use a priming task to investigate the cognitive mechanism underlying C/Ms. However, we could not observe significant priming effect after trying several priming experiments.
Consequently, we changed priming task into numerical stroop task, in which participants had to choose the C/M phrase that denotes a larger quantity or has a larger font size. By examining whether C/Ms reflect distance effect and congruity effect as classic number processing, we would like to verify Her's (2012a, 2012b) theory. The distance effect is a phenomenon that comparing proximate digits is more difficult than comparing remote ones. The congruity effect emerges when congruent pairs lead to facilitation effect
whereas incongruent pairs result in interference effect. Our results showed significant distance and congruity effect, supporting Her's (2012a, 2012b) theory.
Key words: classifier, measure word, multiplication, cognitive mechanism, fMRI
目錄
Year 1‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧ p2
Introduction p2 Method p5 Results p9 Discussion p10Year 2‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧p15
Introduction p15 Method p19 Results p22 Discussion p27Year 3‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧p33
Introduction p33 Method p36 Results p40 Discussion p42Year 1
Mathematical Values in the Processing of Chinese Numeral Classifiers and Measure Words
Her, One-Soon; Chen, Ying-Chun; Yen, Nai-Shing 2017, PLOS ONE, Vol.12, No.9, pp.e0185047
Introduction
Chinese is a numeral classifier language, where an element known as numeral classifier that denotes a unit is essential when a noun (N) is quantified by a numeral (Num). Numeral classifiers come in two varieties, sortal classifer (C) and measural classifier (M), also known as ‘classifier’ and ‘measure word’, respectively. In Table 1,
ben and ke are classifiers (C); xiang (box) and da (dozen) are measure words (M). In
this paper, the category of numeral classifiers is referred to as C/M. (Insert Table 1 roughly here)
Table 1. Examples of Chinese numeral classifiers and measure words
Numeral Classifier (C) Measure Word (M)
五 本 雜誌 五 箱 雜誌
wu ben zazhi wu xiang zazhi
5 C magazine 5 M-box magazine
‘5 magazines’ ‘5 boxes of magazines’
十 顆 蘋果 十 打 蘋果
shi ke pingguo shi da pingguo
10 C apple 10 M-dozen apple
’10 apples’ ’10 dozens of apples’
C and M converge in that they appear in the same grammatical position and are mutually exclusive [1-3]. However, C and M diverge in that Cs qualify the noun but Ms quantify the noun [4-6]. To be more specific, Cs categorise nouns by highlighting certain salient or inherent properties of the noun, while Ms denote the quantity of the entity of the noun [5, 7]. For example, ben in Table 1 highlights the volume feature and can only be used for a bound copy of printed materials, such as a book or a magazine, whereas xiang means “a box of”, which carries new information indicating the quantity of the noun being quantified, since a box can contain different amounts of any object.
This convergence and divergence between C and M were reconciled by Her [8], where an innovative mathematical view was proposed to interpret the relation
between Num and C/M as multiplication. The distinction between C and M is
otherwise X = M. In other words, X being the element required between Num and N, X is C if its inherent mathematical value is 1; otherwise, X is M. For example, in shi
ke pingguo (ten C apple), shi (ten) and ke (C) form a multiplicative unit, i.e., (10×1);
likewise, in shi da pingguo (ten M-dozen apple), shi (ten) and da (M-dozen) also form a multiplicative unit, i.e., (10×12). Under this view, C and M thus converge as the multiplicand of Num, the multiplier. C and M occupy exactly the same syntactic position and thus belong to a single syntactic category. Yet, C and M diverge in terms of their respective inherent values: C = 1, M ≠ 1, and thus constitute two distinct subcategories.
Note that a multiplicand 1 is unique in that it is the only identity element, or neutral element, in multiplication; 1 is thus redundant in the multiplicative equation. A multiplicand with any other value, numerical or non-numerical, is not redundant. This unique property of multiplicand 1 can explain why Cs may behave differently from Ms, in spite of C/M as a single syntactic category [8].
Her and Wu [9] further proposed a taxonomy of the magnitude values that C/Ms encode, along two dimensions: numerical vs. non-numerical and fixed vs. variable (See Table 2). While M1 and M2 both encode numerical values, the former has fixed
values and the latter does not. Likewise, M3 and M4 both encode non-numerical
values, but the former has fixed values and the latter does not. Thus, C, M1 and M3
encode fixed values, while M2 and M4 do not.
(Insert Table 2 roughly here) Table 2. Types of mathematical values denoted by C/Ms
Numerica l
Fixed n = 1 e.g., ben (本), ke (顆), tiao (條), zhi (隻) C
n = 2 e.g., duei (pair 對); n = 12 e.g., da (dozen 打) M1
Variable n > 1 e.g., pai (row 排), bang (gang 幫), die (stack 疊) M2
Non- numerical
Fixed e.g., gongjin (kilogram 公斤), gongli (kilometer 公里) M3
Variable e.g., di (drop 滴), dai (bag 袋), bei (cup 杯) M4
M2 and M4 are thus similar in that their values are vague and not fixed. The
difference is that the vague value of a M2 is numerical, while that of a M4 is not. For
example, the M2 cuo ‘small gang’ must take a count noun, e.g., yi cuo qiangdao ‘a
small gang of bandits’, and must have a numerical value larger than one. Likewise, the M2 bang ‘gang’ in yi bang qiangdao ‘a gang of bandits’ must also have a
numerical value larger than two. However, the typical number implied by bang ‘gang’ is larger than that implied by cuo ‘small gang’. In contrast to M2, the vague values
denoted by M4 are not numerical and may be length, area, weight, volume, time, etc.
For example, the M4 di ‘drop’, as in yi di shui ‘a drop of water’, refers to a vague volume of water in the shape of a teardrop. The M4 tan ‘puddle’, as in yi tan shui ‘a
puddle of water’, though likewise referring to a vague volume of water, but in a random shape, has an implied value much bigger than that implied by di ‘drop’. Note, crucially, that the English counterparts of M2 and M4 are clearly nouns in terms of
syntactic category. Yet, in Chinese, M2 and M4 are part of a distinctive syntactic
category C/M, or numeral classifiers [8]. It is controversial whether the processing of Chinese numeral classifiers involves magnitude. The aim of our study was to address this issue.
However, as attractive as this theory may be, empirical evidence of the mathematical function of C/Ms was lacking. Thus, the aim of this study was to conduct a psycholinguistic experiment to examine whether participants process C/Ms based on their mathematical values as this multiplicative theory of C/M predicted they would. More specifically, the theory predicted that the difference between C/Ms with fixed values, i.e., C, M1, and M3, and those with non-fixed vague values, i.e., M2 and
M4, would be more prominent than the difference between C/Ms with numerical
values, i.e., C, M1, and M2, and those with non-numerical values, i.e., M3 and M4, for
the simple reason that a M2/4 with a vague value cannot be coerced into having a rigid
fixed value without an appropriate and robust discourse context, while a M3/4 with an
inherent non-numerical value can be quite easily converted numerically to a smaller unit, e.g., one kilo into one thousand grams.
The most relevant previous study is Cui et al. [10], where a functional magnetic resonance imaging (fMRI) experiment compared the brain activities of processing classifiers with those of processing tool nouns, numbers, and dot arrays. Tool nouns are non-quantity words which refer to concrete objects used as tools, utensils, or instruments, e.g., liandao (sickle) and laba (trumpet). A semantic distance comparison task was used, where participants chose from two items the one that was semantically closer to the target item. For example, the target fuzi (axe) was presented on the top of the screen and participants had to judge whether liandao (sickle) or niezi (tweezers) which were displayed at the bottom of the screen was semantically closer to the target word fuzi (axe). Greater activation was found in the left middle frontal gyrus (MTG) and the left inferior frontal gyrus (IFG) instead of the right intraparietal sulcus (IPS) for processing classifiers and tool nouns than numbers and dot arrays. This result is rather unexpected under Her’s [8] theory, which predicts that brain activities of processing C/Ms should be more similar to those of processing numbers and dot arrays than to those of processing tool nouns. Given that some C/Ms (see Table 2), numbers, and dot arrays represent numerical magnitude, we expected that the processing of C/Ms, but not that of tool nouns, would elicit higher activations in the right IPS, which plays an important role in representation of numerical magnitude [11-12].
One possible critical reason why Cui et al. [10] did not find the IPS more activated for processing C/Ms than processing tool nouns is that their experimental materials of the so-called “classifiers” mixed up Cs and Ms and thus no distinction was made between Cs and Ms. Yet, as reviewed above, linguistic studies suggested that Cs differ significantly from Ms [e.g., 5-6]. Furthermore, the taxonomy proposed by Her and Wu [9] also categorizes the mathematical values of C/Ms along the
dimension of [fixed vs. variable]. Presumably, C/Ms with a fixed value may be related to exact representation of numbers, while C/Ms that encode a variable value may be associated with approximation. We hypothesized that participants would choose the C/M option that had the same or closer value as that of the target C/M, when the values in question were all fixed. However, it was unclear how participants would process C/Ms with variable values.
Note also that Cui et al. [10] did not use complete [Num X N] phrases, e.g. yi
zhang haibao (1 C-flat poster, one poster), as stimuli in the semantic distance
comparison task. Rather, they used [Num X] phrases, e.g. yi zhang (1 C- flat), in their
study. Thus, the semantic context was not strictly confined in their study. Therefore, we replicated the paradigm by Cui et al. [10] but used a more appropriate set of stimuli, i.e. [Num X N] phrases, e.g. yi zhang haibao (1 C- flat poster, one poster), to
examine whether C/Ms were processed based on mathematical values.
We hypothesized that, first, participants would compare the mathematical values the C/Ms encode and select the one with the same or closer value to the target C/M, and, second, the accuracy of C/Ms with fixed values to be higher than that of C/Ms with variable values.
Method
Participants
Twenty individuals (16 females, 4 males, ages 20-28, mean age = 22.6 ± 2.06) were recruited from National Chengchi University. Participants were right-handed, had normal or corrected-to-normal vision. Their first language is Mandarin. They gave written informed consent to the study approved by the Research Ethics Committee of National Taiwan University and received NT$100.
Stimuli and experimental design
We conducted a 2 × 2 within-subject design. The two independent variables were the numerical type (numerical: C, M1, and M2 vs. non-numerical:M3 and M4) and
mathematical value type (fixed value: C, M1, and M3 vs. variable value: M2 and M4).
as the target C/M. For each trial, another two C/Ms from the same condition were selected to be paired with the target C/M. When three C/Ms phrases were paired together for a trial, two experimenters produced a reasonable noun for this set of C/Ms to confine the semantic contexts. One experimenter created these [Num X N] phrases and the other experimenter checked if all phrases were clear and
understandable. For the phrases that were unclear, the two experimenter discussed and came up with another noun that better fit the set of C/Ms. The nouns were unrepeated throughout the experiment. Consequently, there were 104 sets of C/M phrases in total. Each condition included 26 trials. The target C/M phrases were composed of the number 1 and a C/M. The answer and distractor C/M phrases included the number 1, a C/M, and a noun. The answer and distractor C/M phrases differed in the C/M. The numeral enabled participants to process the C/M as a C/M, not a noun. By designing the answer/distractor phrase as a minimal pair, we strictly confined the semantic context for the C/M (Table 3). We recorded responses and reaction times (RT).
Table 3. Structure of the experimental stimuli with a sample set for each condition.
Stimuli type Value type Target C/M C/M Option 1 C/M Option 2
Numerical Fixed 一副 yi fu one set of (M1, n = 2) 一對耳環 yi dui erhuan
one pair of earrings (M1, n = 2) 一只耳環 yi zhi erhuan one earring (C, n = 1) Variable 一隊 yi dui one team of (M2, n > 1) 一群殺手 yi qun shashou
one group of killers (M2, n > 1)
一幫殺手
yi bang shashou
one gang of killers (M2, n > 1) Non-numerical Fixed 一公斤 yi gongjin one kilo of (M3) 一磅橡膠 yi bang xiangjiao
one pound of rubber (M3)
一噸橡膠
yi dun xiangjiao
one ton of rubber (M3) Variable 一杯 yi bei one cup of (M4) 一罐咖啡 yi guan kafei
one can of coffee (M4)
一瓶咖啡
yi ping kafei
one bottle of coffee (M4)
Table legend: There were 26 trials for each condition in the experiment. In each trial, there was a target C/M phrase, an answer C/M phrase, and a distractor C/M phrase. The target C/M phrases were composed of the number 1 and a C/M. The answer and distractor C/M phrases formed a minimal pair which included the number 1, a C/M, and a noun. The answer C/M phrases were indicated in bold in this table. Note that they were not presented in bold in the experiment.
Procedure
There were eight practice trials to ensure that participants fully understood the task. In each trial, participants saw three C/M phrases on the screen at the positions of the three end points of a triangle (Fig 1). They had to perform a semantic distance comparison task: which one of the two C/M phrases at the bottom was semantically closer to the target C/M phrase at the top. The positions of the answers and the distractors were randomized. Participants had up to 8 seconds (s) to respond. The inter-trial interval was 500 milliseconds (ms). There were 104 trials in total; each condition included 26 trials. The order of the trials was randomized. Right after the experiment, participants filled in a questionnaire to indicate their subjective
mathematical values of the M2 and M4 used in the experiment. The questionnaire
(one set of) for example, participants had to fill in the blank yue “ “ ge (around “ “ C) to indicate their subjective mathematical value. For non-numerical M3-4,
participants had to fill in the blank to indicate around how much centimeter (length), square meter (area), gram (weight), and milliliter (volume) they think the M3-4
represented for different types of M3-4 respectively. For example, when participants
saw yi bei (one cup of), they had to fill in the blank yue “ “ haosheng (around “ “ milliliter) to indicate their subjective mathematical value of yi bei (one cup of).
(Insert Figure 1 roughly here)
Fig 1. The experimental procedure. In each trial, participants saw three C/M phrases on the screen. They had to choose between the two C/M phrases at the bottom the one that was semantically closer to the target C/M phrase on the top. The C/M options were composed of minimal pairs which included an identical numeral, a classifier or a measure word, and an identical noun.
Data analysis
The responses and RT were analysed in a two-way (numerical/ non-numerical × fixed/ variable values) repeated measures ANOVA. IBM SPSS 20.0 was used for the statistical analysis with the α value set at .05. Post-hoc analyses of the simple main effects were made by means of t-tests applying Bonferroni’s correction for multiple comparisons. We calculated the accuracy of M2 and M4 based on the subjective
mathematical values reported by the participants individually (see S1 Table for the descriptive statistic reports). For each participant, we determined the correct answer of each trial according to the subjective mathematical values that they reported. Take the sample set of M2 in Table 3 for example, if a participant reported that his/her
subjective mathematical values of yi dui (one team of), yi qun (one group of), and yi
bang (one gang of) were 10, 20, and 30, respectively, the answer of this trial for this
participant would be yi qun shashou (one group of killers) instead of yi bang shashou (one gang of killers), as 20 is closer to 10 than 30 is.
Results
The mean (and standard deviation, SD) of accuracy and RT are shown in Table 4. (Insert Table 4 roughly here)
Table 4. The mean (and standard deviation) of accuracy and reaction times (RT) in Experiment
Accuracy
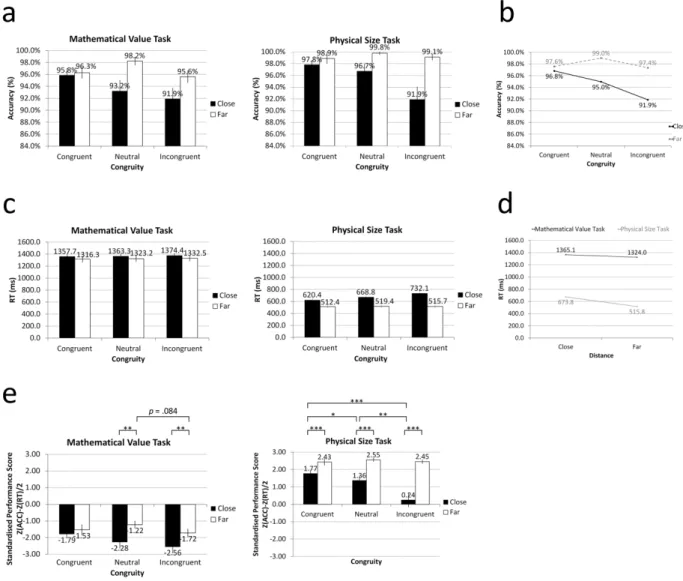
The significant main effect of the numerical types was not significant, F (1,19)
= .227, p = .639, such that the accuracy of the numerical C, M1, and M2 and that of the
non-numerical M3 and M4 were not significantly different. However, there was a
significant main effect of the mathematical value types, such that the accuracy of C/Ms with fixed values was significantly higher than those with variable values, F (1,19)
= 68.298, p < .001. The accuracy of C and M1 was significantly higher than that of M2
(p < .001), and the accuracy of M3 was significantly higher than that of M4 (p < .001).
There was no significant interaction effect between the numerical types and the mathematical value types, F (1,19) = .013, p = .91 (Table 4).
Reaction times
The significant main effect of the numerical types was not significant, F (1,19) =
2.098, p = .164, such that the RT of numerical C/M1-2 and that of non-numerical M3-4
were not significantly different. However, the mathematical value types displayed a significant main effect, F (1,19) = 37.726, p < .001, such that the participants responded
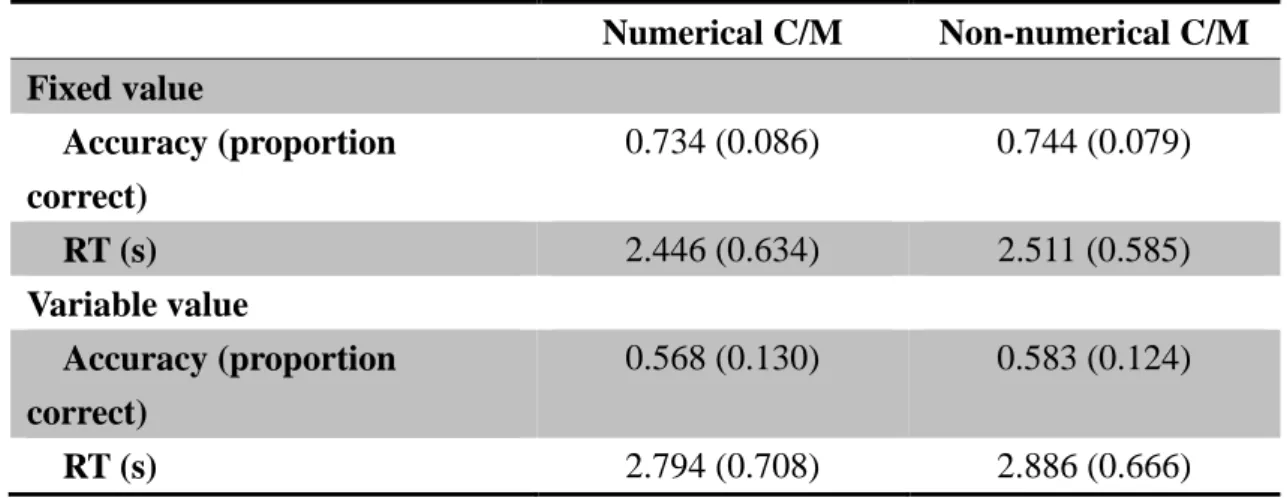
Numerical C/M Non-numerical C/M Fixed value Accuracy (proportion correct) 0.734 (0.086) 0.744 (0.079) RT (s) 2.446 (0.634) 2.511 (0.585) Variable value Accuracy (proportion correct) 0.568 (0.130) 0.583 (0.124) RT (s) 2.794 (0.708) 2.886 (0.666)
faster while processing the C/M with fixed values compared with the C/M with variable values. The RT of C/M1 was significantly shorter than M2 (p = .001), and the
RT of M3 was significantly shorter than M4 (p < .001). There was no interaction
between the numerical types and the mathematical value types, F (1,19) = .068, p = .797
(Table 4). In general, the pattern of reaction times under the four conditions was consistent with that of accuracy. The higher the accuracy, the shorter the RT.
Discussion
The results showed that participants made semantic judgments based on the mathematical values of C/Ms, numerical or not, when the values were fixed rather than variable. They responded faster in processing C/Ms with a fixed value than a variable value. The mean accuracy of M2 (0.568) and M4 (0.583) with variable values
was relatively low, even though the accuracy was calculated individually dependent on the subjective mathematical values reported by each participant. This was consistent with our prediction that C/Ms with fixed values are mathematically comparable, while C/Ms with variable values are too vague to be comparable. It is still possible that participants represented a rough value that M2 or M4
encode and tried to compare. However, because of the variability of the values they encode, participants may not be able to represent these variable values exactly the same way every time. In other words, the subjective mathematical values may have fluctuated between the time of performing the semantic distance comparison task and filling in the post-experimental questionnaire.To modify this limitation in the current study, we suggest future studies ask participants to report their subjective
mathematical values immediately after each trial.
It is worth noting that the mean subjective mathematical value of M2 ranged only
from 5 to 18 and the variance was rather small (see S1 Table). This may make choosing between the two options of C/Ms difficult and result in fifty percent of chance to choose one of the two options of C/Ms. Even if the participants represented M2 as a mathematical value, the closeness of the two options of C/Ms may be too
competitive to make a distinct difference. Furthermore, although the mean subjective mathematical value of M4 varied to a greater extent than M2 did, the variance was
large. This indicates that there was a large individual difference of the subjective mathematical values of M4s. Future studies are suggested to use a complete sentence
or story to confine the context to better control the semantic distance of C/Ms. Since behavioral responses could not answer whether participants processed C/Ms with variable values mathematically, future studies can further investigate the quantity processing of C/Ms that encode variable values using fMRI by examining the brain activations related to numerical representation such as the IPS [11-12].
One may argue that the quantification of a gang of might be different for killers and for hooligans and the quantification of a litter of might be different for mice than for cats. This indeed may be true for M2 and M4, which have non-fixed variable
values. Yet, this possible noun-contingency effect was not a factor in the experiment, as all minimal pairs of [one M2/4 N] have exactly the same N. One may also suspect
that the discriminability of these pairs might vary over nouns, e.g., the difference between a team of salespeople and a gang of salespeople might be different in not only magnitude but sign from the difference between a team of killers and a gang of
killers. Again, this possible effect was not a factor in the experiment as no such
cross-pair comparison was elicited and only within-pair comparison was required. Not surprisingly, there was no significant difference between numerical and non-numerical C/Ms. One of the reasons may be that we adopted the semantic
distance comparison task in this experiment. It is likely that participants converted the non-numerical C/M into the same unit to make a comparison. For example, when participants had to choose between yi bang (a pound) and yi gongjin (one kilo), they represented them as 453 grams and 1000 grams,whether exactly or approximately, to make the judgment. In other words, it was possible that due to the nature of the semantic distance comparison task which may require accurate quantity comparison, participants preferred representing C/Ms as a numerical value to perform the task in the current study. This may explain why we did not observe significant difference between numerical and non-numerical C/Ms. We suggest future studies use other tasks to further investigate whether the cognitive processing of numerical and
non-numerical C/Ms are similar in spite of experimental paradigms. Future study may also use neuroimaging techniques to examine whether numerical and non-numerical C/Ms engage in a similar neural network.
Partially consistent with our hypothesis that C/Ms encode mathematical values, we found that participants did represent and compared the mathematical values of C/Ms with fixed values. If participants did not process them based on their
mathematical values, the accuracy of numerical C/Ms would not have been above the chance level. However, it remains unclear how participants processed the C/Ms with variable values. Moreover, it is unknown whether participants processed
non-numerical C/Ms in a numerical form to perform the semantic distance
comparison task. Therefore, future studies are needed to further examine the cognitive processing of non-numerical C/Ms using other tasks. In general, our findings, in part, corroborated Her's [8] mathematical theory of C/M that C/Ms encode mathematical values by providing behavioral evidence of C/Ms with fixed mathematical values.
To our knowledge, this study was the first study providing evidence that showed Chinese C/Ms encode mathematical values. Participants represented and compared
fixed mathematical values of C/Ms to make a semantic judgment. This psychological finding laid an empirical foundation supporting Her's [8] mathematical theory, where C and M converge as the multiplicand of Num but diverge in terms of their respective value: C = 1, M ≠ 1. We verified the notion that Cs encode 1 and Ms encode certain other mathematical values by showing that participants chose the C/M that had the same or closer value to the target C/M when the mathematical values were fixed in the semantic distance comparison task. Future psycholinguistic and neurolinguistic studies should further investigate whether the mathematical relation between Num and C/M is multiplication. In sum, findings in the current study implied that the linguistic system of C/Ms might influence magnitude cognition.
Acknowledgements
We thank Denise H. Wu for suggesting this study, Kuan-Ju Chou for helping to create experimental stimuli, and Jie-Li Tsai, Marc Tang, and Ya-Ting Chuang for helpful comments on a previous version of the paper. Previous versions of the paper were presented at the 2016 Annual Meeting of Taiwan Society of Cognitive
Neuroscience, January 23, 2016, National Chengchi University, Taipei, Taiwan, and the 2016 Annual Meeting of the Cognitive Neuroscience Society, April 2-5, 2016, New York Hilton Midtown, New York. We thank the participants of the two conferences who commented on the work and gave constructive suggestions.
Funding
This work was supported by the Ministry of Science and Technology (MOST 103-2410-H-004-136-MY3).
Competing interests
We declare that there is not any actual or potential conflict of interest including any financial, personal or other relationships with other people or organizations within three years of beginning the submitted work that could inappropriately influence, or be perceived to influence, our work.
References
1. He J. Xiandai Hanyu Liangci Yanjiu [A Study of Measures in Modern Chinese]. Beijing: Beijing Language University Press; 2008.
2. Hsieh ML. The internal structure of noun phrases in Chinese. Crane Publishing Company; 2008.
3. Her OS. Structure of classifiers and measure words: A lexical functional Account. Language and Linguistics. 2012 Nov 1; 13(6): 1211.
4. Adams KL, Conklin NF. Toward a theory of natural classification. InAnnual Regional Meeting of the Chicago Linguistic Society 1973 Apr 13 (Vol. 9, pp. 1-10).
5. Her OS, Hsieh CT. On the semantic distinction between classifiers and measure words in Chinese. Language and linguistics. 2010 Mar 1; 11(3): 527-51. 6. Li X, Rothstein S. Measure readings of Mandarin classifier phrases and the
particle de. Language and Linguistics. 2012 Jul 1; 13(4): 693-741.
7. Tai J, Wang L. A Semantic Study of the Classifier Tiao. Journal of the Chinese Language Teachers Association. 1990; 25(1): 35-56.
8. Her OS. Distinguishing classifiers and measure words: A mathematical perspective and implications. Lingua. 2012 Nov 30; 122(14): 1668-91.
9. Her OS, Wu JS. Taxonomy of numeral classifiers and measure words: A formal semantic proposal. Under review with Journal of Chinese Linguistics. 2017. 10. Cui J, Yu X, Yang H, Chen C, Liang P, Zhou X. Neural correlates of quantity
processing of numeral classifiers. Neuropsychology. 2013 Sep; 27(5): 583-94. 11. Dehaene S, Piazza M, Pinel P, Cohen L. Three parietal circuits for number
processing. Cognitive neuropsychology. 2003 May 1; 20(3-6): 487-506. 12. Nieder A, Dehaene S. Representation of number in the brain. Annual review of
neuroscience. 2009 Jul 21; 32: 185-208.
13. Cheng CC, Huang CR, Lo FJ, Tsai MC, Huang YC, Chen XY, et al. Digital Resources Center for Global Chinese Language Teaching and Learning. 2005 [cited 22 May 2017]. Available from:
Supporting information
http://journals.plos.org/plosone/article?id=10.1371/journal.pone.0185047
#sec011
S1 Table. Stimuli used in the experiment. The word frequency was obtained from the Digital Resources Center for Global Chinese Language Teaching and Learning by Cheng et al. [13].
Year 2
Neural Correlates of Quantity Processing of Chinese Numeral Classifiers Her, One-Soon; Chen, Ying-Chun; Yen, Nai-Shing
2018, Language and Linguistics, Vol.18, No.1, pp.26-71
Introduction
In a classifier language like Chinese an additional element is essential when a noun (N) is quantified by a numeral (Num). This additional element is known as a numeral classifier. As shown in Table 1, numeral classifiers come in two varieties, sortal classifiers (C) and mensural classifiers (M). Note that there are a number of alternative names for the two, e.g., classifiers and measure words, classifiers and massifiers, count-classifiers and mass-classifiers, etc. Suffice to say that making the distinction within the category of numeral classifiers is far more important than the particular terms used. We will thus use the abbreviations C and M for this distinction and C/M for the category of numeral classifiers.
Table 1
Examples of sortal and mensural classifiers
Sortal Classifiers (C) Mensural Classifiers (M)
三 本 雜誌 三 箱 雜誌
san ben zazhi san xiang zazhi
3 C magazine 3 M-box magazine
‘3 magazines’ ‘3 boxes of magazines’
三 個 蘋果 三 公斤 蘋果
san ge pingguo san gongjin pingguo
3 C apple 3 M-kilo apple
‘3 apples’ ‘3 kilos of apples’
Though it has been controversial whether C and M belong to the same
grammatical category, C and M clearly converge syntactically as they always appear in the same grammatical position and are mutually exclusive (1-3), but C and M
diverge semantically in the sense that Cs qualify the noun but Ms quantify the noun (4, 5). Her (6) indicated that in the nominal phrase [Num C/M N], C is semantically redundant but M is semantically substantive, and proposed an innovative
interpretation in terms of the mathematical relation between Num and C/M. The precise formulation he offered is: [Num X N] = [[Num × X] N], where X = C if and only if X = 1, otherwise X = M (6). Given the multiplicative function between Num and C/M, i.e., [Num × C/M], C and M converge as multiplicands but diverge in terms of their respective values, i.e., C = 1, M ≠ 1.
types of mathematical values they encode (Table 2). While M1 and M2 both encode
numerical values, the former has fixed values and the latter does not. Likewise, M3
and M4 both encode non-numerical values, but the former has fixed values and the
latter does not. Thus, C, M1 and M3 encode fixed values, while M2 and M4 do not.
Table 2
Types of mathematical values denoted by C/Ms
Numerical Fixed
n=1 e.g., ben (本), ke (顆), tiao (條), zhi (隻) C
n=2 e.g., duei (pair 對); n=12 e.g., da (dozen 打) M1
Variable n>1 e.g., pai (row 排), zu (group 組), die (stack 疊) M2
Non- numerical
Fixed e.g., gongjin (kilogram 公斤), gongli (kilometer 公里) M3
Variable e.g.,chi (spoon 匙), dai (bag 袋), bei (cup 杯) M4
While Her's (6) multiplicative theory of C/M is based on the premise that numerals and C/Ms are closely related, it is still controversial whether language and mathematics belong to two independent domains or are related in some aspects. While the two seem to involve distinct cognitive abilities, both represent concepts by
symbols (e.g., number words, Arabic numbers, and arithmetic operations, etc.). Psychologists have thus investigated whether the form of neural representation of number is notation-independent (8, 9) or notation-specific (10).
Neuropsychological studies (11-13) and neuroimaging studies (14, 15 ) tapped into this question by examining the neural basis in processing number words, quantifiers, classifiers, and numbers. In Butterworth et al. (11), a semantic dementia patient, who had left temporal lobe atrophy, encountered severe impairment in linguistic abilities and general knowledge while preserving intact mathematical abilities. This patient performed remarkably well at reading and spelling number words, whereas he was unable to read or spell non-number words. Cappelletti et al. (12) also described a semantic dementia patient who selectively possessed intact understanding of quantifiers (e.g., many, a few) only. Likewise, this patient showed the ability in the comprehension of numerical knowledge but not linguistic concepts. These results suggested that the semantic processing of numerical knowledge is functionally and neuroanatomically distinct from non-numerical knowledge and is notation-independent.
Nevertheless, inconsistent results are found in other studies, e.g., Cipolotti et al. (13) and Wei et al. (15). Cipolotti et al. (13) reported an acalculic patient who was able to read letters, words, and number words but not Arabic numbers, suggesting that number processing is notation-dependent. Notably, Cipolotti et al. (13) also found that the patient’s knowledge of cardinal value of Arabic numbers was intact in magnitude comparison tasks. This suggested that although the number processing is
notation-dependent, the processing of semantic quantity may not be
notation-dependent. Wei et al. (15) compared the brain activations of semantic
processing of quantifiers (e.g., frequency adverbs and quantity pronouns), words (e.g., animal names), Arabic numbers, and dot arrays with functional magnetic resonance imaging (fMRI). They found that processing of numbers and dot arrays activated more in the right intraparietal sulcus (IPS), which plays an important role in
representation of numerical magnitude (16, 17), whereas the processing of quantifiers elicited greater activations in the left middle temporal gyrus (MTG) and the left inferior frontal gyrus (IFG) that are usually associated with general semantic processing (18).
Similar results were obtained from the very first fMRI study on quantity processing of Chinese numeral classifiers by Cui et al. (14).1 They compared the processing of classifiers with those of tool nouns, numbers, and dot arrays in a semantic distance comparison task, where participants had to judge which one of the two items was semantically closer to the target item. They reported that classifiers, tool nouns, numbers, and dot arrays commonly activated in the right IFG, right angular gyrus, right supplementary motor area, right precentral gyrus, left insula, left cerebellum, and bilateral lenticular nucleus. They found that classifiers and tool nouns elicited greater activation in the left IFG and the left MTG than numbers and dot arrays. They did not find that classifiers elicited more activations than tool nouns in the IPS, which plays an important role in processing and representation of numerical magnitude (16, 17). The aim of our study is thus to reexamine the neural correlates of quantity processing of Chinese numeral classifiers.
One possible critical reason why Cui et al. (2013) did not find the IPS more activated for processing classifiers than tool nouns may be that they did not make the crucial distinction between C and M. Nor did they make the distinction between numerical and non-numerical C/Ms. The term "classifier" they used referred to both C and M in their study. As reviewed above, linguistic studies suggest that Cs differ significantly from Ms and Ms can be further classified, according to Her and Wu (7), into four categories along two dimensions: numerical vs. non-numerical and fixed vs. variable (Table 2). The processing of numerical and non-numerical C/Ms may vary significantly.
1 While non-classifier languages have no syntactic category of C/M, the semantic concept of Ms exists
cross-linguistically. English, and other non-classifier languages, may thus have words of measure such as pair, group, and kilo that are nouns syntactically. Numerals, on the other hand, are available in nearly all languages, and are considered part of quantifiers, e.g., a lot, many, and few. However, grammatical number markers, e.g., the suffix /-s/ in English, and sortal classifiers, or Cs, are largely mutually exclusive in a noun phrase, in the few languages that employ both. This fact has led to a controversial view that C and grammatical number belong to the same syntactic category. Relevant to our study is the fact that C/Ms, numerals, quantifiers, and plural markers all carry quantity information.
Also, Cui et al. (14) did not explain how they selected and arranged the stimuli for each trial in the semantic distance comparison task. Thus, they may not have controlled the potential confounding effect of the semantic attributes of C/Ms, which may have been another reason why they did not find the IPS more activated for processing C/Ms than processing tool nouns. To be more specific, Chinese Cs are based on a range of semantic attributes such as human, animacy, shape, function, etc. Cs thus function as a profiler in highlighting an inherent semantic feature of the noun (6, 19). For example, there are at least three different Cs that are compatible with the noun yu (fish): zhi emphasizes the feature of animacy, tiao highlights the long shape, and wei profiles the tail (6). Accordingly, it is possible that, aside from the
mathematical values of C/Ms, the semantic attributes of C/Ms play a role in
processing C/Ms. Thus, that the confounding factor of C/M’s semantic attributes was not controlled in the fMRI study by Cui et al. (14) may also explain the higher activation in brain regions that are related with general semantic processing such as the left IFG and the left MTG.
The purpose of our study was to replicate the fMRI experiment by Cui et al. (14), but with a modified paradigm which controlled the confounding factors. We expected to see that C/Ms and numbers induce more activation in the IPS compared with tool nouns.
Prior to the fMRI experiment, we conducted two behavioral experiments with semantic distance comparison tasks to clarify how the variables mentioned above influenced the processing of C/Ms. In the first experiment, we examined how semantic attributes of C/Ms influenced processing. Participants had to decide which one of the two C/M phrases at the bottom of the screen was semantically closer to the target C/M phrase on top. Results showed that participants preferred the one with comparable semantic attributes over the one with a closer mathematical value. This suggested that a C/M’s semantic attributes affected processing, and this thus was likely a confounding factor not controlled in the fMRI study by Cui et al. (14).
Therefore, we conducted a second experiment and controlled the semantic attributes of C/M by using minimal pairs as stimuli (20). An example of a minimal pair is yi qun shashou (one group of killers) and yi bang shashou (one gang of killers), where the identical human noun shashou (killer) confines the semantic attributes of the two Ms in the two nominal phrases, which thus differ minimally only in terms of the mathematical values the two Ms encode.Consequently, the judgment whether yi
qun shashou (one group of killers, n > 1) or yi bang shashou (one gang of killers, n >
1) is semantically closer to yi dui shashou (one team of killers, n > 1) must be based on this variable alone. For example, if a participant reported that his/her subjective mathematical values of yi dui (one team of), yi qun (one group of), and yi bang (one
gang of) were 10, 20, and 30, respectively, the correct answer of this trial for this participant would be yi qun shashou (one group of killers) instead of yi bang
shashou (one gang of killers), as 20 is closer to 10 than 30 is. Results showed that participants performed better for C/Ms with fixed values than those with variable values (20).
Therefore, in order to better examine the neural correlates of C/Ms in the fMRI study, we developed a modified paradigm based on these behavioral findings and used minimal pairs of phrases with C/Ms of fixed values. Given previous findings that the IPS represented number independent of notations (8, 16), we expected to find greater activations in the IPS for processing C/Ms than tool nouns by adopting our modified paradigm.
Method
Participants
Twenty-six native speakers of Mandarin (14 males, mean age = 23.23 ± 2.35 years) were recruited from National Chengchi University. All participants were right-handed. They had normal or corrected-to-normal vision and had no history of neurological or psychiatric disorders or contraindications to MRI. Before the
experiment started, they gave written informed consent to the study approved by the Research Ethics Committee of National Taiwan University.
Stimuli and Materials
We conducted a within-subject design and manipulated two variables. The two independent variables were comparison (C/Ms vs. tool noun) and C/M type
(numerical vs. non-numerical). The four main experimental conditions were C/M comparison with numerical stimuli, C/M comparison with non-numerical stimuli, tool noun comparison with numerical stimuli, and tool noun comparison with
non-numerical stimuli (see Figure 1 gray part). The nominal phrases consisted of a numeral (the number “one”), a C or M, and a tool noun. Including the numeral in the phrase enabled participants to process the C/M in the phrase correctly as C/M instead of other meanings.
There were five other conditions: baseline, numbers, dots, number words, and tool nouns. We modified the baseline condition in Cui et al. (14), which was the rest (fixation). In this study, the baseline condition contained three identical nominal phrases for each trial. In this case, participants still had to process the stimuli that were visually as complicated as the ones in the main four experimental conditions (see Appendix A for all experimental stimuli). Consequently, we could examine the
brain activations involved in processing C/M or tool nouns by contrasting the four main experimental conditions against the baseline condition. Following the paradigm by Cui et al. (14), we further included conditions of numbers, dots, number words, and tool nouns to investigate the neural correlates that commonly activated during number processing (C/M comparison, numbers, dots, number words) and semantic processing (tool noun comparison and tool nouns).
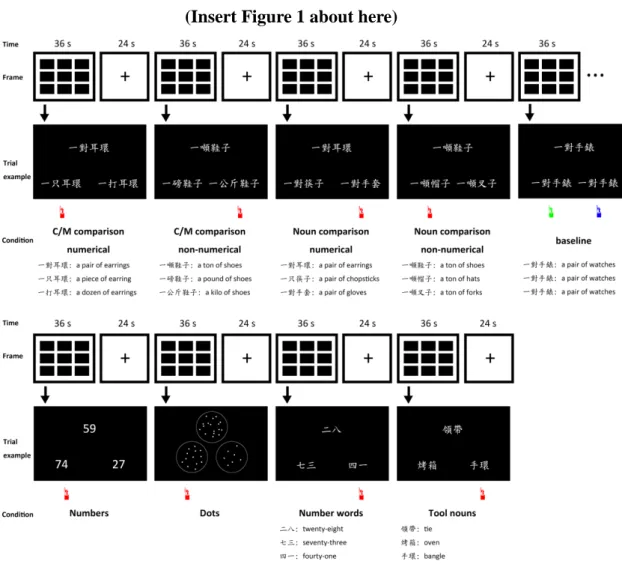
(Insert Figure 1 about here)
Figure 1. The experimental procedure and sample trials of each condition in this study.
The four main experimental conditions, varying in comparison (C/Ms vs. tool nouns) and C/M type (numerical vs. non-numerical), were shown in the gray part. The other five conditions were baseline, numbers, dots, number words, and tool nouns. There were 3 runs in total; each run had 9 blocks. Each block was 36 s followed by a 24-s rest. Each condition had 9 trials per block. For each trial, participants had to judge which one of the two items at the bottom was semantically closer to the target item. For the conditions of numbers, dots, or number words, participants were asked to judge which one of the bottom items had a closer quantity with the target item. The answer item was indicated with the hand icon. For the baseline condition, in which the three phrases were identical, half of the participants were told to press button 1 (left)
and the other half were told to press button 2 (right) to show that they remain concentrated in the scanner.
The number of strokes, frequency of C/Ms, and frequency of nouns were carefully matched among the four main experimental conditions and the baseline condition (Appendix B). The word frequency was obtained from the Digital Resources Center for Global Chinese Language Teaching and Learning (21).
For the conditions of C/M comparison, numbers, dots, and number words, the number of the target item was larger or equal to the answer for one third of the trials; the number of the target item was in the middle of the answer and the distractor for one third of the trials; the number of the target item was smaller or equal to the
answer for the rest one third of trials. For the conditions of numbers, dots, and number words, the number of the stimuli ranged from 7 to 99.
For the conditions of tool noun comparison and tool nouns, the answer was an item that fell into the same category as the target item. Tool nouns were selected from a set of tool nouns that were categorized into seven categories: constructional material, stationery, clothing and accessories, kitchenware and utensils, weapons, sporting goods, and daily essentials. The conditions of noun comparison and the tool noun condition were composed of two different sets.
Procedure
We conducted a block design. There were 3 runs in total; each run had 9 blocks. Each block was 36 s followed by a 24-s rest. Each condition had 9 trials per block. In each trial, stimuli displayed for 3.5 s with a 0.5 s inter-trial interval. The order of blocks and trials were randomized. Before scanning, participants completed 18 practice trials and made sure that they were clear about the procedure.
In each trial, participants saw three items on the screen and were asked to judge which one of the two items at the bottom was semantically closer to the target item at the top. Accuracy and speed were both emphasized. If they saw numbers, dots, or number words, they were asked to judge which one of the bottom items had a closer quantity with the target item. They pressed button 1 or 2 to choose the stimuli on the left or right, respectively. They were also told that in order to ensure that they remain focused in the scanner, sometimes they might see three identical items. In this case, i.e. the baseline condition, half of the participants were told to press button 1, whereas the other half were told to press button 2 (Figure 1).
fMRI Data Acquisition
MRI images were collected using a 32-channel head coil in a 3T scanner (Skyra, Siemens Medical Solutions, Erlangen, Germany). A T2*-weighted gradient-echo echo
planar imaging (EPI) sequence was used for fMRI scanning, with a 4 mm slice thickness, 200 × 200 mm2 field of view (FOV), 90° flip angle, 32 axial slices, 2000 ms repetition time (TR), and 30 ms echo time (TE). The anatomical, T1-weighted high-resolution image (1 × 1 × 1 mm3) was acquired using a standard MPRAGE sequence, with a 7° flip angle, 2530 ms TR, 3.3 ms TE and 1,100 ms inversion time (TI).
Statistical Analysis of the fMRI Data
Preprocessing and statistical analysis of brain images were performed using a statistical parametric mapping 8 (SPM8; Wellcome Trust Center for Neuroimaging, London, UK) software package. The functional images of each participant were corrected for slice timing and head motion and then co-registered to the participant’s segmented gray matter image. Next, the images were normalized to the standard Montreal Neurological Institute (MNI) standard space and spatially smoothed by convolution using an 8 mm full width at half maximum Gaussian kernel.
We conducted two random-effect whole-brain analyses. One was a full factorial 2 (C/M vs. noun comparison) by 2 (numerical vs. non-numerical CM) ANOVA with images from the individual-level fixed-effect analysis modelling each condition in contrast to the baseline. Then, we conducted contrast analyses for the four main conditions. The other was a one-way ANOVA with images of 9 conditions relative to rest. Consequently, we ran three conjunction analyses to examine the brain regions that co-activate for the four main conditions, five conditions of number processing, and three conditions of semantic processing. The threshold of the statistical maps was at a whole brain voxel-wise intensity of p FWE-corr < .05 (Family-wise error correction).
The resulting regions of activation were characterized in terms of their peak voxels in the MNI coordinate space and specified with the automated anatomical labeling.
Results
Participants’ exclusion for data analyses
Among the 26 participants, two participants were excluded from data analysis because of data loss and three participants were excluded due to excessive head movement (i.e., whose overall motion was more than 3 mm across the runs or more than 1.5 mm motion between adjacent functional volumes).
Contrast analyses
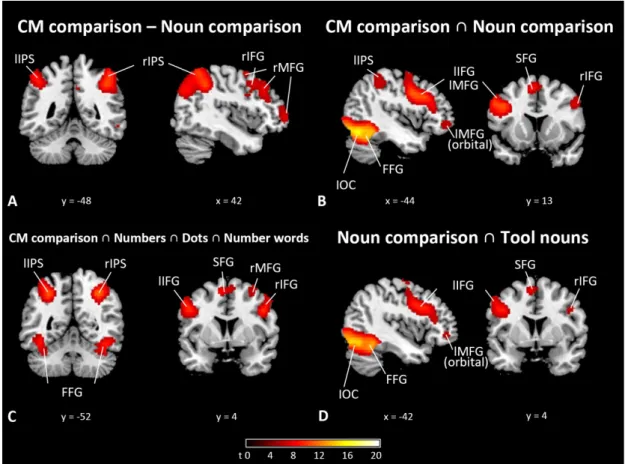
Figure 2A and Table 3 show the results from contrast analyses. First, C/M comparison elicited higher activation than noun comparison in the bilateral inferior
parietal lobule (IPL) including the IPS, right superior frontal gyrus (SFG), bilateral middle frontal gyrus (MFG), right medial frontal gyrus (mFG), right middle temporal gyrus (MTG), and left lingual gyrus. However, on the other hand, noun comparison did not elicit significantly higher activation than C/M comparison. In addition, the contrast analyses between numerical C+M1 and non-numerical M3 did not reveal any
significant activation.
(Insert Figure 2 about here)
Table 3
Brain activation for contrast analysis between four main conditions, relative to baseline. (pFWE-corr < .05; BA, Brodmann’s area)
Conjunction analyses
Conjunction analysis of the four main conditions (processing C/M or tool nouns in classifier phrases with either a numerical C+M1 or a non-numerical M3) showed
activation in the bilateral inferior occipital cortex (IOC) including the fusiform gyrus (FFG), bilateral inferior frontal gyrus (IFG, especially in the left hemisphere), left SFG, left MFG (orbital part), and left insula (see Figure 2B and Table 4).
Conjunction analysis of the five conditions involved in number processing (C/M comparison of numerical C+M1, C/M comparison of non-numerical M3, numbers,
dots, and number words) showed activation in the IOC including the FFG, bilateral superior parietal lobule (SPL), bilateral inferior parietal lobule, bilateral IFG, right MFG, bilateral SFG, and bilateral insula (see Figure 2C and Table 4).
Conjunction analysis of the three conditions involved in semantic processing (two noun comparison conditions and the tool noun condition) showed activation in the bilateral occipital cortex including the FFG, bilateral superior parietal lobule, bilateral IFG (mostly in the left hemisphere), left SFG, and bilateral MFG (see Figure 2D and Table 4).
Hemisphere Brain regions Peak MNI
x y z t-Value
Cluster size CM comparison – Tool noun comparison
Right Inferior parietal lobule (BA 40) 42 -48 44 9.71 3928
Left Inferior parietal lobule (BA 40) -44 -52 50 8.69 1343
Right Superior frontal gyrus (BA 6) 34 4 66 8.64 2544
Left Lingual gyrus -18 -88 -12 7.01 122
Right Middle frontal gyrus (BA 10) 44 54 0 6.78 404
Right Medial frontal gyrus (BA 8) 4 30 46 5.90 73
Left Middle frontal gyrus (BA 10) -40 56 10 5.85 98
Right Middle temporal gyrus 56 -50 -12 5.65 21
Tool noun comparison – CM comparison None
Numerical C+M1 – Non-numerical M3
None
Non-numerical M3 – Numerical C+M1
Table 4
Common brain activation for different types of conditions, relative to rest. (pFWE-corr
< .05; BA, Brodmann’s area)
Hemisphere Brain regions Peak MNI
x y z t-Value
Cluster size CM comparison ∩ Tool noun comparison
Left Inferior occipital cortex -18 -94 -12 20.68 17196
Left Precentral gyrus
(Inferior frontal gyrus, BA 9) -44 4 34 10.33 3107
Left Supplementary motor area
(Superior frontal gyrus, BA6) -6 6 58 8.65 533
Right Precentral gyrus
(Inferior frontal gyrus, BA 9) 48 8 34 7.54 509
Left Middle frontal gyrus, orbital part -44 46 -4 5.58 116
Left Insula -30 20 4 5.53 31
CM comparison ∩ Numbers ∩ Dots ∩ Number words
Right Inferior occipital cortex 34 -80 -12 14.51
18086
Right Superior parietal lobule (BA 7) 30 -62 52 12.26
Left Superior parietal lobule (BA 7) -24 -62 54 12.05
Left Inferior parietal lobule (BA 7, 40) -30 -52 46 10.04
Right Precentral gyrus
(Inferior frontal gyrus, BA 9) 50 8 34 9.75 1033
Left Precentral gyrus
(Inferior frontal gyrus, BA 9) -48 2 36 9.04 1576
Left Supplementary motor area
(Superior frontal gyrus, BA 6) -6 6 58 8.39 604
Right Superior frontal gyrus
(Middle frontal gyrus, BA 6) 32 -2 62 6.57 302
Right Insula (BA 45) 32 24 6 5.93 80
Left Insula (BA 45) -30 24 6 5.83 64
Tool noun comparison ∩ Tool nouns
Left Inferior occipital cortex -34 -86 -8 16.07
14504
Left Superior parietal lobule -28 -64 48 9.93
Right Angular gyrus
(superior parietal lobule, BA 7) 30 -60 50 7.57
Left Precentral gyrus
(Inferior frontal gyrus, BA 6, 9) -42 4 34 8.69 2319
(Superior frontal gyrus)
Right Precentral gyrus
(Inferior frontal gyrus, BA 9) 46 8 34 6.40 194
Left Middle frontal gyrus, orbital part -44 46 -4 5.58 92
Discussion
We adopted a modified paradigm that included minimal pairs of C/M with fixed mathematical values to investigate the number processing of C/M with fMRI in this study. We found that processing C/M in a semantic distance task elicited higher activations in the bilateral IPL including the IPS, right SFG, bilateral MFG, right mFG, and right MTG than processing tool nouns. As we predicted, the IPS, which has been shown to frequently engage in numerical representation, was more activated for the contrast of C/M comparison versus tool noun comparison (16, 17). Moreover, the brain activations in the IPL, SFG, and mFG largely overlapped with the brain regions that were reported in a very recent meta-analysis study of number processing (22). Sokolowski et al. (22) revealed that not only the parietal lobule but also the frontal regions play an important role in number processing. Specifically, the SFG was repeatedly activated for symbolic magnitude processing while the right mFG and cingulate gyrus were activated for non-symbolic magnitude processing. Moreover, the right SFG consistently activated during symbolic and non-symbolic number
processing. Taken together, processing C/M than tool nouns engaged in frontal and parietal regions that have been suggested to associate with processing numerical information. This finding was consistent with the mathematical theory of C/M which proposed that C/M represents mathematical values (6). Although the number of strokes, frequency of C/Ms, and frequency of nouns were carefully matched among the four main experimental conditions and the baseline condition, participants still made more errors while processing C/M compared to processing tool nouns, t(20) =
-3.281, p = .004. One may argue that the activation in the IPS for processing C/M than tool nouns reflected higher task demand rather than magnitude representation in this study. However, it is worth noting that the bilateral IPL was found activated during number proceesing in both active and passive tasks (22). This suggests that the activation was related to magnitude processing rather than task demands. However, the function of the bilateral MFG and the rMTG for processing C/M than tool nouns remains unclear and needs further research as these regions were not typical regions that were found to be involved in number processing in the literature.
This finding was different from the finding in the study by Cui et al. (14), in which the contrast analyses between classifiers and tool nouns resulted in no
significant activations. The critical reason why we observed different neural activities of processing classifiers may lie on the nature of classifiers. Chinese classifiers not only have a mathematical function but also function as a profiler. That is, Chinese classifiers not only encode the mathematical values but also highlight the inherent semantic attributes of the noun. However, Cui et al. (14) overlooked the potential