國 立 交 通 大 學
工業工程與管理學系
碩 士 論 文
規劃等候系統時各設計方案之效益評比
Performance evaluation for the designs of a
queuing system
研 究 生:林晏生
指導教授:劉復華 教授
i
規劃等候系統時各設計方案之效益評比
學生:林晏生 指導教授:劉復華 教授
國立交通大學工業工程與管理學系碩士班
摘 要
在一般等候系統中,管理者除了想知道不同的顧客到達速率及服務人員服務 速率所產生的顧客平均等候時間和系統平均的等候人數之外,更希望可以從顧客 等候的機會成本、等候空間的設置成本、服務員的人事成本進一步考量整個系統 應該如何規劃設計,運作起來才會有效率。本研究將資料包絡分析模型做一個事 前的應用,規劃設計一個具有雙重服務速率的 M/M/1 等候系統,並從所有設計 出來的可行方案中,選出較佳的方案,提供管理者參考。 關鍵字:資料包絡分析、等候理論、雙重服務速率、M/M/1ii
Performance evaluation for the designs of a
queuing system
Student: Yeng-Sheng LIN Advisor: Fuh-Hwa F. LIU, Ph.D.
Department of Industrial Engineering and Management
National Chiao Tung University
Hsin Chu City, Taiwan, Republic of China
Abstract
The set of problems is aimed to a M/M/1 queue system with bi-level changeable service rates. The design parameters for the system could have average waiting time, the expected number of customers in queuing, mean arrival rate and mean service rate, etc. In the general queuing system, managers design a system may also considering opportunity cost of customer waiting, set-up cost of waiting spaces, and attendants’ payoff. This research will use data envelopment analysis model as a prior application to design the queuing system, confer the weight of each parameter, and choose several suitable plans from the entire designed and workable plans.
iii
致 謝
本論文能夠能順利完成,最需要感謝的就是指導老師劉復華教授。這兩年老 師的付出以及指導,讓學生得以走入績效評量的領域,了解其中的深奧,老師在 研究的過程中,不時與學生討論、指點,讓學生可以走在正確的方向。此外,從 老師身上,學到的不僅僅是學術上的知識,老師對於做學問的嚴謹態度更是我輩 學習的典範,在這邊學生向老師致上最高的謝意。同時也感謝交大資管所林妙聰 教授、交大運管系姚銘忠教授擔任學生的口詴委員,在口詴時給予許多寶貴的意 見,有兩位老師的建議,讓本論文能夠更加的完整。 在新竹這兩年,很快就過去了,這期間得到許多貴人的幫助、許多朋友的扶 持。感謝實驗室學長、學姊和學弟妹,無論在課業上還是生活上都給我很多照顧。 在撰寫論文的過程中,感謝宗賢同學一起努力、奮鬥,讓我們能夠一起完成這重 大的任務。另外,感謝其他實驗室同學、朋友和這一路上曾經支持我、照顧我的 所有人,有了你們,讓我這兩年在新竹的生活更加多彩多姿。 最後要感謝的,就是我的父母和家人的大力支持,讓我沒有後顧之憂的完成 這個學位。這篇論文能完成,晏生覺得收穫很多且相當開心,願將這份喜悅獻給 我的雙親以及所有關心我愛護我的人一同分享。 林晏生 謹誌 于 交通大學工業工程與管理學系 民國九十九年七月iv
目錄
摘 要... i Abstract ... ii 致 謝... iii 圖目錄... v 表目錄... vi 符號表... vii 1. 簡介 ... 1 2. 文獻回顧 ... 4 2.1. 等候理論文獻... 4 2.2. 績效評量簡介... 6 2.2.1 生產力衡量與績效表現 ... 6 2.2.2 投入指標的望小性質與產出指標的望大性質 ... 6 2.2.3 效率前緣 ... 7 2.2.4 權重 ... 8 2.2.4 迴歸模型 ... 8 2.2.5 資料包絡分析模型 ... 9 3. 等候模型與規劃設計之方法 ... 16 3.1. 等候系統之參數與表現... 16 3.2. 等候系統設計方案之評選... 20 3.3. 顯著性與敏感度分析... 25 3.4. 管理最佳規劃與數學最佳規劃... 26 4. 數據分析 ... 28 4.1. 小規模等候系統數據分析... 28 4.1.1 規劃設計候選等候系統 ... 28 4.1.2 五步驟求解流程 ... 30 4.1.3 事後分析 ... 32 4.1.4 管理最佳規劃 ... 33 4.2. 大規模等候系統數據分析... 33 4.2.1 規劃設計候選等候系統 ... 34 4.2.2 五步驟求解流程 ... 35 4.2.3 事後分析 ... 37 4.2.4 管理最佳規劃 ... 38 5. 研究貢獻與未來研究機會 ... 40 參考文獻... 41v
圖目錄
圖 1 等候系統圖示... 4 圖 2 效率前緣圖示... 7 圖 3 具有雙重服務速率之等候系統... 16 圖 4 雙重服務速率等候系統流率圖... 17vi
表目錄
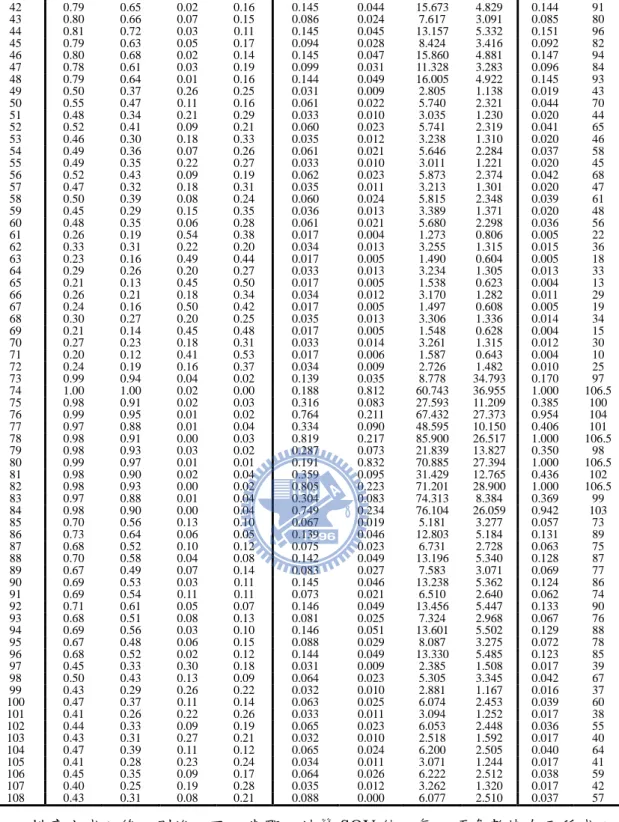
表 1 小規模候選等候系統參數值以及等候系統表現... 28
表 2 小規模候選等候系統相對績效值及其所對應之權重與排名... 30
表 3 包含 λ1 = 40 之 DMU 以及其排名(DMUo, ranko) ... 31
表 4 小規模等候系統各可行 λ 值之 SOV 值、顯著性和敏感度 ... 32 表 5 小規模數據管理可行方案等候系統參數值... 33 表 6 大規模候選等候系統參數值以及等候系統表現... 34 表 7 大規模候選等候系統相對績效值及其所對應之權重與排名... 36 表 8 大規模等候系統各可行 λ 值之 SOV 值、顯著性和敏感度 ... 37 表 9 大規模數據管理可行方案等候系統參數值... 38
vii
符號表
符號 定義 單位時間顧客到達等候系統之平均人數 單位時間服務員平均服務人數 2 N 由低速率切換至高速率,系統人數閥界值 1 N 由高速率切換回低速率,系統人數閥界值 k 服務速率提升倍數 0 P 等候系統沒有顧客的穩態機率 F 使用高速率服務佔總時間的比例 L 等候系統平均顧客人數 Pq 等候系統有 q 位顧客的穩態機率 W 顧客在系統之平均等候時間 n 受評單位個數 m 望小指標個數 s 望大指標個數 j 第 j 項受評單位 i 第 i 項投入指標 r 第 r 項產出指標 o 目標決策單位 ij x 第 j 項受評單位,第 i 項投入指標 rj y 第 j 項受評單位,第 r 項產出指標 io v 第 o 項受評單位當主角時,第 i 項投入指標所對應的權重 ro u 第 o 項受評單位當主角時,第 r 項產出指標所對應的權重 j E 第 j 項受評單位,利用績效公式所算出的績效值viii o h 第 o 項受評單位當主角時,所求得 CCR 績效值 I i 第 i 項投入指標所對應的正阿基米德數 O r 第 r 項產出指標所對應的正阿基米德數 -i s 在 CCR 對偶模式中,第 i 項投入指標的差額變數 + r s 在 CCR 對偶模式中,第 r 項產出指標的差額變數 o 第 o 項受評單位當主角時,CCR 對偶模式所求得之效率值 j CCR 對偶模式中,第 j 個受評單位所賦予的權重 o g 第 o 項受評單位當主角時,CCR 產出導向之績效值 o 第 o 項受評單位當主角時,CCR 產出導向對偶模式所求得之績效值 io xˆ 第 o 項受評單位當主角時,投入指標改善之投影點 ro yˆ 第 o 項受評單位當主角時,產出指標改善之投影點 ij x~ 第 j 個候選方案,第 i 項望小等候表現之值 rj y ~ 第 j 個候選方案,第 r 項望大等候表現之值 b 因子有 b 種水準數 c c 種因子數 n 共有n種可行數值 n 共有n種可行數值 1 N n N1共有 1 N n 種可行數值 2 N n N2共有 2 N n 種可行數值 k n k 共有nk種可行數值 N 可行方案數 SOVbc 第 c 項因子第 b 個水準的 SOV 值
ix c I 第 c 項因子之影響力 c SA 第 c 項因子之敏感度 io L x B 第 i 項投入指標虛擬權重限制下界 io U x B 第 i 項投入指標虛擬權重限制上界 ro L y B 第 r 項產出指標虛擬權重限制下界 ro U y B 第 r 項產出指標虛擬權重限制上界 i 第 i 項投入指標所對應之迴歸係數 e 迴歸模型的誤差項
1
1. 簡介
量販店、大賣場中排隊顧客達一定數時,管理者會增派收銀服務員,當排隊 人數減少至一定數時,再減少服務員。如何設定排隊顧客的人數做為增減服務員 的切換點?需多少服務員?等候的空間成本,服務員的成本、顧客等候的機會成 本等多個事項均和這些人數控制事項具相關性。在設計大賣場空間時,需綜合考 慮顧客流量、服務速率以及上述各項管控的事項,始得最佳之規劃與管理方案。 許多事項頇列入考量,各事項的計量單位不同、兩兩事項間的因果互動關係不易 直接界定,在規劃設計時各事項該如何設置?在各種設計方案中,哪些方案較為 可行?如何評估各種規劃方案?類似如上述的等候系統在許多製造、組裝、以及 服務業的系統中均常常見到。本研究將重點放在設計規劃的階段,以資料包絡分 析模型解決上述規劃與管理的問題。 大多數等候理論的文獻,乃在已知顧客到達速率、服務員服務速率、服務員 個數、服務規則的情況下,利用數學推導或是電腦模擬技術求得平均等候人數、 平均等候時間、各種人數在系統內的穩態機率等結果,至於等候系統的規劃與設 計則較少去探討。 本研究針對一等候系統,假設顧客平均每小時到達人數有λ 人,且到達的間 隔時間服從指數(exponential)分配。而系統內僅有一位服務員服務,此服務員 有兩種服務速率,低速率(平均每小時服務μ 人)與高速率(平均每小時服務 kμ 人),且每小時服務的人數服從卜瓦松(Poisson)分配。一開始服務員使用低速 率服務,等到系統人數大於 N2人時,再切換速率改用高速進行服務,等候人數 下降至 N1(N1 < N2)時,則恢復成低速率服務。 若λ 值增加,會讓管理者的利潤增加,但在其它事項不變的情形下,相對需 要較多的等候空間,且會使得顧客等候的機會成本提升,造成資源以及成本的消 耗。而μ 值增加,會讓服務員服務效率提高,降低顧客等候的機會成本,但相對 的管理者就需要花費較高的人事成本,提供較快的服務速率。k 值的增加,會讓2 高速服務之速率增加,減少顧客等候的機會成本和等候空間的設置,但相對的也 需花費較多的人事支出,使提升的倍數增加。N2 值較大,代表等候系統累積的 人數較多才切換到高速率進行服務,雖然這樣會讓管理者花費較少的人事成本, 卻需要較多等候空間的設置,也代表著顧客的等候的機會成本會增加,造成顧客 的流失。N1 值大代表切換過於頻繁,需要花費較多的切換成本,且會造成使用 低速率服務的時間較長,提高顧客等候的機會成本。但若其值過小,又勢必會造 成人事成本的增加,增加管理者的負擔。由此可知,λ、μ、N2、N1、k 值的訂定 是很困難的。這些事項與等候空間的設置成本、顧客等候的機會成本、管理者的 人事成本、切換成本都有一定的關聯,但其互動關係又不易直接去界定。故本研 究提供一套有系統的方法,規劃設計此類型的等候系統。 管理者先根據自身的資源限制,分別給予這五個事項若干個可行的數值。若 假設有 3 種可行的 λ、3 種可行的 μ、3 種可行的 N2、2 種可行的 N1、2 種可行的 k 值,則共可以組成 108 組可行之方案。規劃設計出這 108 組可行方案之後,希 望可以從中選出對於管理者和顧客皆為有利的方案。本研究將五種可控制或決定 參數視為因子(factor),而各參數的可行數值則當成是水準(level),希望能從 中找出最佳的參數組合。 各種參數組合都會有預期反應結果(desired response),這邊利用四項等候表 現:顧客不用等待即可接受服務的機率(P0)、平均顧客使用面積(1/L)、使用 高速率服務佔總時間的比例(F)以及顧客平均等候時間(W),做為預期反應結 果。其中 L 為平均在系統內的顧客人數,在固定等候面積下,1/L 即為每人平均 可使用之面積。在這四項等候結果中,會希望顧客不用等候即可接受服務的機率 和平均顧客使用面積越大越好。若顧客不用等待即可接受服務,即可減少顧客等 候的機會成本,亦可減少等候空間的設置;顧客平均可以使用的面積越大,代表 顧客在等候系統內較不會擁擠,會使其滿意度增加。而使用高速率服務的比率與 系統顧客等候時間則希望越小越好,使用高速率服務佔總時間的比例過大會造成 耗費的成本較大,增加管理者的負擔;而顧客在等候線上等候的時間較短,會使
3 其滿意度上升,故希望這兩個等候系統表現其值越小越好。 田口方法是挑選最佳組合常見的方法,該法顧及到成本、時間和設備等不同 的因素,不需將所有組合都做一次實驗,僅需挑選其中幾組特定的組合做實驗, 即可判斷出最佳之配方。但本研究所有資料皆可順利取得,另外,使用資料包絡 分析時,考慮的組合越多,評量結果越有參考價值。因此將所有組合窮舉同時接 受評量。把望大的等候系統表現視為產出,望小的等候系統表現視為投入,各種 不同的組合視為決策單位,利用資料包絡分析模型進行評量,接著再利用評量的 結果計算出總和排序值 SOV(sum of ordinal value),藉此選出最佳組合。
管理者本身的資源,在一開始規劃設計等候系統時,會與真實運作起來產生 些許的誤差,因此,選出良好的可行方案後,再進行事後分析,判斷各參數的顯 著性與其敏感度。希望所規劃設計出來的等候系統,不要因為某些事項無法達到 預期的目標,就使整個系統運作起來缺乏效率。 本研究在第二章,先回顧一些有關於等候理論的文獻,介紹等候理論一些重 要的議題。接著就績效評量做一個簡介,該領域的重要工具:資料包絡分析模型 的文獻更是所要回顧的重點。第三章則先介紹具有雙重服務速率的 M/M/1 等候 系統,並說明管理者如何規劃設計出可行方案。接著介紹本研究如何利用資料包 絡分析模型選出最佳等候系統,最後利用事後分析判斷各參數的顯著性以及敏感 度。第四章則舉兩個例子進行數據分析,說明本研究方法應該如何使用。第五章 則對本研究的貢獻以及未來的研究機會做一個總結。
4
2. 文獻回顧
本章首先詳細的回顧與本研究有關的幾篇等候理論文獻,接著簡介何謂績效 評量,績效評量領域的重要工具:資料包絡分析模型,更是所要回顧的重點。這 些文獻即是本研究的背景所在。2.1. 等候理論文獻
在大多數的等候模型中,其基本過程如下(Hillier & Lieberman, 2008):由輸 入源(input source)隨時間產生需要被服務的顧客,這些顧客隨後進入等候系統 並加入我們所謂的等候線(queue),在某一特定時間點,等候線上的一個成員依 照其特定的服務規則(queue discipline)被選取,然後再依照服務機制(service mechanism)被服務,服務完畢之後,顧客隨即離開等候系統。這就是最基本的 等候過程。我們可以將這過程用下面的圖表示: 圖 1 等候系統圖示 輸入源第一個重要因素就是它規模的大小,即潛在的顧客總數,可以為無限 或是有限的潛在顧客總數。另一個需要考慮的因素即為隨時間產生顧客的統計分 配形式,不同的分配會產生不同的結果。等候線即為顧客等待的地方,在分析時 需考慮等候線可容納的顧客數,一般來說可分為無限等候線和有限等候線。等候 規則為等候線上顧客被選擇來服務的順序,可能是先到先服務或是具有一特定的 優先順序,若不特別說明,即假設為先到先服務。服務機制即包含了服務設施的 設立、服務員個數和服務員服務時間的統計分配…等,服務設施可以為單一亦可 為多個串聯或平行設置。服務員在一般情況下都為有限個,但也可以顧客到達等
5 候系統後自己為自己服務。服務員服務時間分配的不同也會使分析的結果不同, 在大多數情況都假設所有服務員的服務時間分配相等。 (Teghem, 1986)提出四個影響等候系統的主要控制因素: 1. 服務者個數:每個服務員在某個時間點是否需要服務,依照當時等候系統的 狀態而定,管理者決定各種不同的狀態下,分別有幾個服務員在服務。 2. 服務速率:此因素有別於上個因素,上個因素主要是在探討不同狀態下有幾 個服務員在服務,而這裡在探討不同情況下服務員的服務速率應該設為多少。 3. 顧客是否進入:顧客的到達速率往往可以被調整或甚至拒絕顧客的要求,在 一些等候模型中,顧客也可以自己決定是否進入等候系統。 4. 服務規則:這類因素在探討服務員是否比較關心特定的顧客群,或是該如何 分配顧客到不同的服務員去接受服務。 而本研究主要是在探討第二類因素的控制政策,將討論具有雙重服務速率的 M/M/1 等候模型,該如何設定切換速率的系統人數,且應該如何決定服務員在系 統人數少和系統人數多時候的服務速率。
(Crabill, Gross, & Magazine, 1977)也曾經對等候系統的設計和控制分成幾類 去探討。確定型等候系統的設計、動態型等候系統的控制、等候系統中服務規則 的控制、其它一些特殊等候模型的控制。確定性的等候系統中,所有的參數都不 隨時間改變,所以這類的問題被稱為是等候系統設計的問題。動態型的等候系統 中,有些參數會隨著系統的時間或是狀態的不同而有所改變。這類問題常常被分 成兩大類:顧客到達過程的控制和服務員服務過程的控制。而關於服務規則的控 制,則是探討各種不同顧客被選取的規則,會對等候系統造成什麼影響。其它不 屬於上述三種分類的等候系統控制,就被歸類為特殊等候系統的控制當中。 本篇研究主要是針對動態型的等候系統去做討論。把等候系統的人數視為狀 態,服務員根據不同的狀態而有不同的服務速率,進而去探討服務速率以及切換 狀態的設定,如何規劃設計才能使具有雙重服務速率的 M/M/1 等候系統有良好 的運作。
6
2.2. 績效評量簡介
本節將介紹何謂績效評量,從單一投入與產出指標的績效值開始,一步步進 到多個指標的績效值該如何去評量,本研究所用到的資料包絡分析模型,更是所 要回顧的重點工具。 2.2.1 生產力衡量與績效表現 「績效評量」目的就是為了評量一個單位的績效表現。此種單位的定義很廣, 大到可以是一個跨國企業、一個城市甚至是一個國家,小也可以是一間雜貨店、 一間公司甚至只是一個人。然而不同單位的表現,也需要不同的方法、指標或是 計算方式來評量,舉例來說:工廠會希望每個工人一天所能生產的產品越多越好; 一個城市可能會期望其居民幸福指數越大越好;一個國家會期待其國民平均所得 越高越好。但總括來說,績效的評估,即是衡量一個單位其生產力的表現,在同 樣投入的情況下,如何發揮最大效率將其轉換為產出,轉換的效率即為各單位所 要注意的最大關鍵。 生產力的評估即為績效評量的源頭的概念。生產力的定義為產出和投入的比 值。這裡所指的投入與產出僅是一個廣義的定義,對於不同的單位來說,產出與 投入可能是不同的東西。投入可以是員工、資金、廠房;產出可以是產品、顧客 滿意度等不同的項目。利用生產力,不僅僅可以評量獨單一個單位的績效,更可 以利用其評量同一單位不同週期的績效表現、同一週期多個性質相近單位的績效 表現甚至是多個性質相近單位在多個週期的績效表現。由此可知,績效的表現可 以從橫斷面、縱斷面和時間面等多個不同的角度切入去評量。 2.2.2 投入指標的望小性質與產出指標的望大性質 若僅有單一個投入指標與產出指標的情況下,定義績效值的符號為 E、投入 為 x1、產出為 y1,則可以將生產力定義如(E1)所表示: 1 1 y E x (E1) 從(E1)可以發現,各單位會希望每一個單位投入所能產生的產出越多越7 好,因此會希望分子的 y1值越大越好,也代表 y1是一個望大項,其值越大會讓 績效的表現越佳。而放在分母項的 x1值,則會希望其值越小越好,其值越小反 而會讓績效值的表現變好,因此投入 x1則為一個望小項。 在廣義的績效評量中,所謂的產出指標,並不一定是真實的產出項,而是一 個望大的指標;同樣的,投入指標也不一定是真實的投入項,而是一個望小指標。 產品檢驗的不良率往往是生產過後的結果,理應視其為產出指標,但卻不希望其 值是很大的,因此在績效評量的過程中,應該將不良率列為望小的指標才是。反 之,若以產品檢驗的良率做為指標,則應該將其列為望大指標。 因此在做績效評量時,應該先了解所選取的指標對於管理者而言,是一個望 大指標還是望小指標,而不是單從所觀察得知該項指標是一產出項還是投入項來 判斷其應該為何種指標。 2.2.3 效率前緣 效率前緣(efficient frontier)即為所有績效表現良好的單位所構成的一個面, 稱為包絡面(envelopment),包絡面將其它受評單位覆蓋在其下方,換句話說,不 在包絡面上的點,就要想以包絡面上的點做為標竿,視為參考對象,向包絡面做 改善,提升自身的績效值。 以兩項投入指標 x1、x2和一項產出指標為例,假設所有單位(A~G)產出量皆 為 1,將效率前緣畫出如圖 2 所表示: 圖 2 效率前緣圖示
8 從生產力也就是績效值的角度來說,在產出等量的情況之下,會希望兩項投 入值越少越好,這樣即會讓績效的表現是良好的。但由於有兩個投入項,所以無 法直觀的做出判斷。圖 2 兩條線連結 D、B 兩點與 B、E 兩點,形成一效率前緣, 在效率前緣上的三個點 D、B 和 E,無法比較其優劣好壞,因為在這效率前緣上 移動時,會有其中一項投入指標其值減少,但另一項投入指標其值又會增加,因 此無法判斷在效率前緣上的點其優劣到底為何。 2.2.4 權重 為了解決效率前緣上無法判斷優劣的問題,因此必頇引進權重的概念,以兩 個投入和兩個產出指標為例,重新將生產力也就是效率定義如(E2)所表示: 1 1 2 2 1 1 2 2 y u y u E x v x v (E2) 就如同單項投入與單項產出的情況一樣,績效評量的產出項即是一望大的指 標,故將其放在分子項;而投入項即為一望小的指標,所以放置於分母項。(E2) 中,兩項產出指標的相對重要性可利用 u1和 u2兩個權重來做決定;而投入指標 的相對重要性,就利用 v1和 v2兩個權重來做決定,若能適當的決定權重,即能 將落在效率前緣上各受評單位之績效值,做一個排序,但權重的決定往往是最困 難的部分,沒有辦法很輕易的決定。一般而言,若為多個投入指標與單一產出指 標的問題,權重可以使用迴歸模型來做決定;遇到多個投入指標與多個產出指標 的問題,則可以使用資料包絡分析模型做解析。 2.2.4 迴歸模型 遇到多個投入指標和單一產出指標問題時,可以利用迴歸模型判斷其權重。 最常見之迴歸模型為簡單迴歸模型。簡單迴歸模型目的在找出一條直線,使得所 有點與該條直線的總差距最小。n 項投入的迴歸方程式如(E3)所表示: 0 1 1 2 2 F( )x y x x nxne (E3) 在(E3)當中,e 即為該點於直線的差距,簡單迴歸模型目的就是希望所有 點距離迴歸直線的總差距最小化。而 0, 1, n即為各項投入指標所對應之權重。
9 本研究之所以不採用迴歸模型原因在於無法顯示投入項的望小性質與產出項的 望大性質。 0, 1, n的值可正可負,若為正數,代表投入與產出為正相關;反 之,若為負數,即表示兩者為負相關,因此迴歸模型雖能看出各指標之權重和投 入與產出指標的相關性,但卻無法凸顯各項指標望大望小的性質。 此外,在實務上,僅僅只有一個產出項的績效評量亦不常見,受評單位大多 具有多個投入指標與多個產出指標,這時只能使用多指標績效評量中最常見的工 具—資料包絡分析模型進行解析。 2.2.5 資料包絡分析模型
(Charnes, Cooper, & Rhodes, 1978)提出傳統的資料包絡分析模型,簡稱 CCR 模型。CCR 模型為一固定報酬的模型,其主要是用來評量 n 個性質類似的決策 單位(Decision-Making Units, DMU),各決策單位分別有 m 個望小的投入指標和
s 個望大的產出指標。其主要評量方式為各受評單位輪流當被評量之主角,分別 給予(s+m)項指標一組權重,使它的績效值最佳。 CCR 模式在進行多指標的績效評量時,引進了權重的概念,認為效率即為 產出指標的加權組合和投入指標的加權組合之比值。合理的訂出每項指標的權重 才能真正解決效率計算的問題,可是在許多的組織當中,不論權重怎樣制定都無 法達到令大家滿意的結果。因此 CCR 模型權重所選取的方式為各受評單位輪流 當被評量之主角,各選出一組對主角最有利的權重進行評量,藉此算出各受評單 位間的相對績效,區辨出高效受評單位與非高效的受評單位。 假設現在有決策單位(DMUj),即可利用下列的績效公式(E4)算出此決策 單位的績效值: 1 1 2 2 1 1 2 2 j j s sj j j j m mj u y u y u y E v x v x v x (E4) 績效公式中所用到的符號,定義如下: xij:DMUj第 i 項投入指標值,為一已知的值 yrj:DMUj第 r 項產出指標值,為一已知的值
10 vi:第 i 項投入指標所對應的權重,為一決策變數 ur:第 r 項產出指標所對應的權重,為一決策變數 從這個績效公式,也可以看出投入和產出指標的望小和望大特性。放在分子 的產出指標,其值越大績效值 Ej 就越大,故為望大指標。而放在分母的投入指 標,其值越小反而會使績效值 Ej越大,所以為望小的指標。 在投入導向的 CCR 模型中,其觀點是在目前的產出水準之下,應消耗多少 的投入量才是有效率的。接著讓每個 DMU 輪流當被評量之主角(以 DMUo表示 之),視 vio和 uro為決策變數,在對 DMUo最有利的情況下,給予其投入的相對 權重 vio(i = 1,…, m)與產出的相對權重 uro(r = 1,…, s),求解下列模式(P1), 使它的綜合績效值 ho最高。 (P1)
m i io io s r ro ro o v x u y Max h 1 1 * (1.0) 1 1 . . 1, 1, , , s rj ro r m ij io i y u s t j n x v
(1.1) 0, 1, , , O ro r u r s (1.2) 0, 1, , . I io i v i m (1.3) 目標式(1.0)即為資料包絡分析領域中的績效公式,將投入指標與其相對 應的權重相乘做加總放在分母,產出指標與其所對應的權重相乘做加總放在分子, 兩者的比值 * o h 就代表 DMUo的績效值。但 DMUo在選取權重時,其限制式不能 讓任一 DMUj的績效值超過 1,如式(1.1)所示。而各投入與產出指標所對應之 權重,皆要大於一個正的阿基米德常數 I i 和 O r ,如式(1.2)及(1.3)所示。每 個 DMU 輪流當一次主角,因此模型頇進行計算 n 次。11 (P1)模型是一個分式模型,頇轉為線性始能求解。因此限制(1.0)之 1 1 m i o io i x v
, 並將式(1.1)同乘 1 m ij io i x v
做移項,可以將上述的分式模型轉為線性模型(P2)。 此模型也稱為乘數型(multiplier form)的 CCR 模型。 (P2)
s r ro ro o Max y u h 1 * (2.0) 1 . . 1, m io io i s t x v
(2.1) 1 1 0, 1, , , s m rj ro ij io r i y u x v j n
(2.2) , 1, , , O ro r u r s (2.3) , 1, , . I io i v i m (2.4) 所有的線性規劃問題都存在一對偶問題,兩者除了最佳解的目標函數值相同 外,亦有許多性質,如:對偶差額互補定理…等可做後續分析。若假設 O I r i 並以 σo、j、sr和si分別做為(P2)中四條限制式之對偶變數,即可將線性模型(P2)轉為下列的對偶模型(P3) (Hillier & Lieberman, 2008),(P3)即為投 入 導 向 的 CCR 對 偶 模 型 。 此 模 型 亦 稱 為 包 絡 型 的 CCR 的 包 絡 型 模 型 (envelopment form)。 (P3)
s r r m i i o o Min s s 1 1 * (3.0) , , 1 , . . 1 s r s y y t s n j r ro j rj
(3.1) , , 1 , 1 m i s x x n j i io o j ij
(3.2) , sign in free o (3.3)12 j 0, j1, , ,n (3.4) si 0, i 1, , ,m (3.5) sr 0, r 1, , .s (3.6) 在(P3)中si 和 s r+分別代表第 i 項投入指標超額的投入和第 r 項產出指標所 短缺的產出,而j則代表在評量主角 DMUo時,DMUj的權重。式(3.1)與(3.2) 等號左側即為各受評單位所構成的包絡面,等號右側即為其所調整之方向。由於 ε 為一極小之常數,故將(P3)以兩階段進行求解,可免去決定 ε 值所產生之誤 差,階段一如(P4)所表示。 o o Min * (4.0) , , 1 , . . 1 s r y y t s n j ro j rj
(4.1) , , 1 , 1 m i x x n j io o j ij
(4.2) , sign in free o (4.3) j 0, j1, , ,n (4.4) 在此階段中決定各投入指標的值 xio減少的比例o*,以提高績效值。但由於 (4.1)和(4.2)中,有些限制式在最佳解時”可能”仍是不等式,此時需進行階 段二(P5),求出各項指標的差量。
s r r m i i s s Max 1 1 (5.0) , , 1 , . . 1 s r s y y t s n j r ro j rj
(5.1) , , 1 , 1 m i x x n j io o j ij
(5.2) j 0, j1, , ,n (5.3)13 si 0, i 1, , ,m (5.4) sr 0, r 1, , .s (5.5) 以(P5)模型所求得的最佳解,各變數的最佳值以右上角加“*”表示之。 則受評單位中各指標的改善目標值為: * * ˆ * , ˆ r ro ro i o io io x s y y s x ,xio和 yro即 為 xio和 yro的改善後的量。若(P4)的目標函數值為o* 1,且各不等式的限制 式均以達成等式,代表此 DMUo為高效;反之,若o* 1,則代表此 DMUo為非 高效。若(P4)的最佳解顯示 * 1 o ,但仍有不等式存在,則需執行(P5)求解 * i s 及 * r s 。此 DMUo稱之為假高效。 投入導向的 CCR 模型,主要的訴求是求出各投入項同時折減的比例 * o 。若 是換個角度,想要求出產出項同時增長的比例,就變為產出導向的 CCR 模型。 其分析方法與投入導向相似,模型如下面(P6)所表示: (P6)
s r ro ro m i io io o u y v x Min g 1 1 * (6.0) 1 1 . . 1, 1, , , m ij io i s rj ro r x v s t j n y u
(6.1) 0, 1, , , O ro r u r s (6.2) 0, 1, , . I io i v i m (6.3) (P6)僅做為求解策略的表示,因此可以參考投入導向的處理方式將(P6) 轉換成線性的乘數型模型(P7),始能求解: (P7)14
m i io io o Min x v g 1 * (7.0) 1 . . 1, s ro ro r s t y u
(7.1) 1 1 0, 1, , , m s ij io rj ro i r x v y u j n
(7.2) , 1, , , O ro r u r s (7.3) , 1, , . I io i v i m (7.4) 如同投入導向的模式,假設 O I r i 並令ηo、j、sr和si為限制式(7.1) 至(7.4)的對偶變數,即可將線性模型(P7)轉換為對偶模型(P8)。此模型即 為 CCR 產出導向的包絡型模型。 (P8)
s r r m i i o o Max s s 1 1 (8.0) , , 1 , . . 1 s r s y y t s n j r o ro j rj
(8.1) 1 , 1, , , n ij j io i j x x s i m
(8.2) , sign in free o (8.3) j 0, j1, , ,n (8.4) , 0 r s (8.5) . 0 i s (8.6) (P8)也需如同(P3)、(P4)及(P5)採取兩階段求解。 產出導向的 CCR 包絡模型,如同投入導向的包絡模型。可以從中觀察出評 量出來為高效的受評單位,到底是真高效還是假高效。並可計算出非高效受評單 位改善之投影點,及調整方向。 產出導向的績效值 * o 即為投入導向績效值 * o 的倒數。換句話說,投入導向15
以及產出導向即為一體的兩面,只是評量的角度不同。資料包絡分析模型在 CCR 模式之後亦發展了其它多種資料包絡分析模型,(Cook & Seiford, 2009)對於其它 多模型詳加做過文獻之回顧。
16
3. 等候模型與規劃設計之方法
本章首先介紹管理者所能控制或是決定的參數:顧客單位時間平均到達速率、 服務員單位時間平均服務速率、切換到高速率系統的人數、切換回低速率系統的 人數、切換倍數。這五項參數也是影響具有雙重服務速率的 M/M/1 等候系統表 現的最重要因素,並說明在規劃設計此種等候系統時,所應該注意的事項。接著 將介紹等候系統表現:等候系統沒有顧客的機率、平均顧客使用面積、使用高速 率服務的機率和平均顧客等候時間,將這四項結果當成是資料包絡分析模型的投 入與產出指標,利用模型進行評量,選出最佳之設計方案。挑選出最佳可行方案 之後,進行事後分析,探討各參數的顯著性以及敏感度,提供管理者在規劃時有 一個適當的依據,應該將重點擺在哪些參數上面。最後再提出一管理最佳規劃, 使設計規劃出的結果,更具參考性。3.1. 等候系統之參數與表現
具有雙重服務速率的 M/M/1 等候模型,即顧客平均到達間隔時間和服務員 平均服務間隔時間都服從指數分配,且僅有一個服務員。其服務速率與系統人數 的關係可以用圖 3 表示: 圖 3 具有雙重服務速率之等候系統 系統一開始服務速率為μ,當系統人數過多到達 N2個人時,即從 A 點升至 B 點,服務員平均服務速率從原本的 μ 提升到 kμ,即從 B 點跳至 C 點。等到系 統人數減少到 N1(N1 < N2)時,即由 C 點降至 D 點,服務員服務速率再切換回 原本的服務速率 μ,即從 D 點跳回 A 點。而在這過程中,顧客單位時間平均到17
達間速率一直維持在λ。
關於具有雙重服務速率的 M/M/1 等候系統,包含(Gebhard, 1967)、(Lee, Park, Kim, Yoon, Ahn, & Park, 1998)和(Liu & Tseng, 1999)都曾經對此種模型或是其變 化型做過探討。不管是基本型還是有成批到達的變化型,推導手法皆是使用生死 過程(birth-death process),我們將此種等候系統的流率圖繪製如圖 4: 圖 4 雙重服務速率等候系統流率圖 圖 4 中每個節點代表此等候系統各種可能的狀態,括號中第一個數字代表系 統中的人數,第二個數字則表示現在狀態所使用的服務速率,其中 1 代表使用低 速率服務而 2 代表使用高速率服務。而具有方向性的弧線,上方符號則表示兩個 狀態(結點)間轉換的速率。接著將所有狀態分成四個部分討論:第一部分為系 統人數少於或等於 N1時,服務員服速率皆為 μ。第二部分為系統人數大於或等 於 N2時,服務員服務速率皆為 kμ。第三以及第四部分,則是系統人數大於 N1 小於 N2時,分成服務速率為μ 和 kμ 探討。在這四個部分,其顧客到達速率皆為 λ。分成這四個部份之後,即可利用生死過程來推導。計算出下列四項等候系統 的表現: L:平均等候系統人數 Pq:等候系統有 q 個人的穩態機率 F:使用高速率服務時間佔總時間機率 W:顧客平均等候時間
18 首先先介紹五項參數所代表的意義,並說明其值大小對整個等候系統表現的 表現和資源消耗的影響。 參數一:λ(人/小時),顧客單位時間平均到達速率。從收入的角度來看, 管理者會希望單位時間到達的平均顧客越多越好,顧客越多自然收入也會越多。 但相對的,若要越多顧客進入等候系統,就勢必得花費更多的錢就做廣告或是舉 辦各種不同的促銷手段來吸引顧客。除此之外,若在其它參數不變下,僅僅只有 λ 值增加,也必頇要夠多的等候空間來容納這些顧客,這些空間的設置,也是資 源的耗費。因此λ 值到底大好還是小好,沒有辦法很直接的就做出判斷,應該用 一套有系統的方法來分析。 參數二:μ(人/小時),系統人數少,服務員單位時間平均服務速率。在服 務業的等候系統中,管理者會希望服務員平均服務一個顧客的時間越短越好,這 樣不但可以加快等候系統流轉的速度,也可以縮短顧客被服務的時間,使其滿意 度增加。服務速率越大,所需要的等候空間也越小,可以節省這方面資源的消耗。 但是若要服務速率提升,就需要花費比較多的人事成本來聘請具有比較高速服務 速率的服務人員。由此可知,μ 值到底要大或要小也無法明確的直觀決定,需有 一套有效的方法來訂定。 參數三:N2(人),由低速率切到高速率系統人數的閥界值。在雙重服務速 率的 M/M/1 等候系統中,必頇設置一個切換的臨界點。這個臨界點就是系統人 數達到 N2人時,服務速率即由低速率切換至高速率。當然 N2的選擇不能太大, 否則系統內會累積過多的人,除了降低系統的流動速率外,亦需要準備比較多的 等候空間,造成資源的消耗。但若 N2太小,又會造成使用高速率服務的時間過 長,人事成本也隨之提高。因此,N2 究竟是要大還是要小,也要有一合理的方 法來做衡量。 參數四:N1(人),由高速率切換回低速率系統人數的閥界值。在切換為高 速率之後,必頇設置另外一個臨界點,也就是由高速率切換回低速率時的系統人 數 N1。N1為一個小於 N2的值,若 N1選擇的值過大,代表越接近 N2,會造成過
19 度頻繁的切換。每一次的切換都是成本的花費,因此過度頻繁的切換會使的管理 者的負擔加重。但 N1的值太小,又會造成使用高速率服務的時間過長,使得成 本花費過大。因此 N1也無法直接判斷要大還是要小,要用一適當的方法來決定。 參數五:k(倍),提升速率之倍數。在具有雙重服務速率的等候系統中,當 系統人數過多達到一特定的數量時,即會加快服務速率從原本每單位時間平均服 務μ 人提升到服務 kμ 人。但若一次倍數提的過高,會造成過高的轉換成本,對 管理者而言是過大的負荷。但若 k 提升的倍數不夠,則會造成等候系統運作不夠 有效率,且需要較多的等候空間供顧客等候。所以說 k 的制訂也需要一個系統化 有依據的方法,不能任意訂定。 利用這些指標,就可以計算管理者有興趣的等候系統表現。接下來就介紹這 些表現所代表的意義,以及如何利用五項參數計算出這些結果(Gebhard, 1967) 和(Liu & Tseng, 1999)。
等候表現一:P0,系統中顧客數為 0 之機率。顧客進入等候系統有 P0的機 率不需等待即可接受服務。一進入等候系統即可接受服務,除了可以省去顧客在 隊伍的等候時間,提升滿意度以外;對管理者而言,相對也可以不用設置這麼多 的等候空間,因此希望 P0越大越好。其計算方式如(E5)所示: 1 N 1 +1 0 1 ( +1) ( ) 1 1 = P 1- (1- )(1- ) p p p (E5) 其中pN2N11, , 1 k 。等算出 0 1 P 之後,再將其倒數即可得 P0。 等候表現二:1/L,平均顧客使用面積。管理者會希望每單位時間顧客到達 人數越多越好,卻又不希望系統內累積過多的人,這樣會使等候線上的顧客活動 空間過小,造成擁擠的情況。所以希望 1/L 越大越好,才不會讓等候線上的顧客 產生過大的壓力。其計算方式如(E6)所表示: 1 N 1 1 1 0 2 1 1 1 ( 1) ( ) (2N ) (1 ) L P (1 ) (1 )(1 ) 2 (1 )(1 ) p p p p (E6)
20 計算出 L 之後,再將其倒數即可得到平均顧客使用面積。 等候表現三:F,使用高速率服務的機率。在具有雙重服務速率的 M/M/1 等 候系統中,使用高速服務之成本比使用低速服務來得高。因此就管理者的角度來 說,當然會希望比較多的時間是使用低速率服務,減少成本的支出,以降低本身 的負擔。故希望 F 的值越小越好。其計算方式如(E7)所示: 1 N 1 0 1 1 ( 1) (1 )P F (1 )(1 ) p p p (E7) 等候表現四:W(小時)平均顧客等候時間。在等候理論的研究中,平均顧 客等候時間(W)也是常常被拿來討論的。顧客在等候線上等候的時間,往往都 希望越短越好,等候時間變長,相對的機會成本也會跟著增加,因此管理者會希 望 W 越小越好。根據 Little 的公式(Little’s formula),W 和 L 兩者的關係為( L= W
) 僅僅差一個參數 (Little, 1961),因此利用(E6)算出 L 之後,再將其除以 λ,即 可求出 W 之值。 了解這些參數與等候系統表現的意義與關係之後,即要規劃設計若干組可行 的候選等候系統。管理者先根據自身的資源限制,針對五個參數λ、μ、N2、N1、 與 k 給予可設計的層級共n、n、 2 N n 、 1 N n 和nk,則共可組成 2 1 N N k nnn n n 個候選等候系統。但這些參數在組合時,N2需要大於 N1,否則會造成切換規則 失效無法運作。另外,在所有候選等候系統中, k 需小於 1,否則會造成系統 人數無上限的增加,不會達到穩態。此外設計時,也必頇與實際的情況相符合, 舉例來說,N2N1必頇有一定的差距,若兩者差距太小,切換速率即失去其應 該有的效益;k 值在實務上也不可能過大,服務速率很難在短時間之內就瞬間提 高很多倍。這些因素都是管理者一開始規劃設計時,所必頇考量的。3.2. 等候系統設計方案之評選
如前述共有 2 1 N N k nnn n n N個可行方案可供選擇,本研究曾詴圖以21 田口方法(Taguchi method)先擇取一部分的方案,分別計算出每個方案的 P0、1/L、 F 和 W 的值,再來評選綜合表現較佳的方案。但顧及兩個現象,放棄了此方法。 一為計算各方案的 P0、1/L、F 和 W 的數值,所需的計算工作量在 Excel 詴算表 上所需的時間不多。二為在評比各方案的過程中,加入的方案數越多,對於使用 資料包絡分析模型的結果越有利,因此本研究採用窮舉法,亦即將全部 N 個方 案都列入評比。 以資料包絡分析模型做為評比的方法,各方案稱之為 DMU1、DMU2、…、
DMUN。以 DMUj為例,將λj、μj、N2j、N1j和 kj的值利用(E5)、(E6)和(E7)
即可得到 P0j和 1/Lj的值,分別以符號~y1j和~y2j表示之,亦可得到 Fj和 Wj的值, 分別以符號~x1j和~x2j表示之。同時 P0j和 1/Lj會希望其越大越好,而 Fj和 Wj則希 望其越小越好。接著詳細介紹本研究所提出規劃設計之方法。 第一步驟:將計算得到的~y1j、~y2j、x~1j和~x2j以下列(E8)和(E9)兩式進 行標準化: . 2 , 1 , ,..., 1 , ~ min ~ max ~ min ~ j N r y y y y y rj j rj j rj j rj rj (E8) . 2 , 1 , ,..., 1 , ~ min ~ max ~ min ~ j N i x x x x x ij j ij j ij j ij ij (E9) (E8)與(E9)的分母項,為該指標最大之值減掉最小之值。而分子項則 是該指標減去最小之值。標準化之後,所有資料皆會介於 0 和 1 之間,可以解決 各項指標間規模差距與單位不一的問題,增加各資料間數值的一致性。 第二步驟:利用資料包絡分析模型計算相對績效值。把各 DMU 標準化後的 數值帶入下列的模型(P9)進行相對績效值的計算。 (P9)
22
2 1 2 1 * i io io r ro ro v x u y Max h o (9.0) , ,..., 1 , 1 . . 2 1 2 1 N j v x u y t s i io ij r ro rj
(9.1) , 2 , 1 , 2 2 1 1 B r u y u y u y B Uy o o o o ro ro L yro ro (9.2) , 2 , 1 , 2 2 1 1 B i v x v x v x B Ux o o o o io io L xio io (9.3) , 2 , 1 , 0 r uro rO (9.4) . 2 , 1 , 0 i vio iI (9.5) 每個候選等候系統輪流當主角 DMUo,用(P9)進行評量,選取對 DMUo 最為有利的權重,讓 DMUo的相對績效值最大。其中式(9.0)、(9.1)、(9.4)和 (9.5)為傳統資料包絡分析模型的 CCR 投入導向模型,在加上(9.2)和(9.3) 更可以符合管理實務的需求。(9.2)是針對產出指標做虛擬權重限制。希望各項 虛擬產出佔總和虛擬產出的比例介在下界 ro L y B 和上屆B 之間。Uyro (9.3)則是針對 投入指標做虛擬權重限制,希望各項虛擬投入佔總和虛擬投入的比例介在下界 io L x B 和上界 io U x B 之間。管理者若不想對權重做特殊的限制,可將(9.2)和(9.3) 去掉即可。 (P9)為一非線性模型,頇轉為線性模型(P10)始能求解。 (P10)
2 1 * r ro rou y Max h o (10.0) 1 . . 2 1
i io iov x t s (10.1) , ,..., 1 , 0 2 1 2 1 N j v x u y r i io ij ro rj
(10.2)23 , 2 , 1 , 0 -) (y1u1 y2 u2 y u r B o o o o ro ro L yro (10.3) , 2 , 1 , 0 ) ( 1 1 2 2 B y u y u r u y o o o o U y ro ro ro (10.4) , 2 , 1 , 0 -) (x1 v1 x2 v2 x v i B o o o o io io L xio (10.5) , 2 , 1 , 0 ) ( 1 1 2 2 B x v x v i v x o o o o U x io io io (10.6) , 2 , 1 , uro rO r (10.7) . 2 , 1 , vio iI i (10.8) ro L y B 、B 、Uyro B 和xLio B 皆為管理者給定已知的數值,因此(P10)模型xUio 即為一個線性模型。(P10)中有u1o、u2o、v1o和v2o四個決策變數,共有 N + 8 條限制式。若 N 過大即限制式過多,容易產生多重解的情況。因此依序令o、j、 r 、r、i、i、si和sr為限制式之對偶變數,並假設 O I r i 將模型轉成 (P11)之對偶模型,始可利用 Excel 內建的規劃求解(solver)進行績效值的計算。 (P11)
2 1 2 1 * r r i i o o Min s s (11.0) , 2 , 1 , . . 2 1 2 1 1
x x x B B s i t s i i i i i U x i i L x io io o N j j ij io io (11.1) , 2 , 1 , 2 1 2 1 1
y y y B B r r sr r r U y r r L y ro ro N j j rj ro ro (11.2) , sign in free o (11.3) , 2 , 1 , 0 , , r sr r r (11.4) , 2 , 1 , 0 , , i si i i (11.5) (P11)為了避免 ε 設定的問題,仍然需要兩階段求解。階段一(P12)先求24 解各項投入指標的縮減比例 * o 。 (P12) o Min (12.0) , 2 , 1 , . . 2 1 2 1 1
i B B x x x t s i i i i U x i i L x io io o N j j ij io io (12.1) , 2 , 1 , 2 1 2 1 1
r B B y y y r r r U y r r L y ro ro N j j rj ro ro (12.2) , sign in free o (12.3) , 2 , 1 , 0 , r r r (12.4) , 2 , 1 , 0 , i i i (12.5) 若o* 1且限制式(12.1)和(12.2)均達成等式,則此 DMUo為高效。若 若o* 1但限制式(12.1)和(12.2)未全部達成等式,則必頇利用(P13)進行 差額的求解。若*o 1,則代表此 DMUo為非高效。 (P13)
2 1 2 1 r r i i s s Max (13.0) , 2 , 1 , . . 2 1 2 1 1
x x x B B s i t s i i i i i U x i i L x io io o N j j ij io io (13.1) , 2 , 1 , 2 1 2 1 1
y y y B B r r sr r r U y r r L y ro ro N j j rj ro ro (13.2) , sign in free o (13.3) , 2 , 1 , 0 , , r sr r r (13.4) , 2 , 1 , 0 , , i si i i (13.5) 第三步驟:將 DMU 依 * o 由小到大排名。若出現績效值相同的情況,利用25
無母數檢定(如:Wilcoxon Signed-Rank Test、Kruskal-Wallis Test)的方法處理, 將其對應的排名取平均,視為個別的排名。例如五個 DMU 之績效值為 0.7、0.8、 0.9、0.9、1,其排名由原有的 1、2、3、4、5 調整為 1、2、3.5、3.5、5,其中 3.5 為 3 和 4 的平均。因為績效值同為 0.9 的 DMU 應並列第 3.5 名,而並非第 3 和第 4 名。
第四步驟:計算總和排序值 SOV(sum of ordinal value)。管理者可以控制的
參數λ、μ、N2、N1、與 k 中,皆有若干個可行數值,每個數值都對應一個 SOV
值。以第一個參數λ 為例,有1,2,,n 共 nλ個可行數值。共有 N/nλ個方案採 用λ2。N/nλ個方案所對應排序加總即為λ 設定為 λ2時之 SOV 值,以 SOV21表示
之。同樣的,λ 設定為1,3,.,n均可求得其 SOV 值。因此共有 nλ個 SOV 值 以 SOV11,SOV31,…,SOVn1表示之。再分別以第二、三、四和五的參數表示 μ、
N2、N1、與 k 四的因子,各可計算出n,nN2,nN1,nk個 SOV 值,以 SOVbc表示第 c 個 參 數 、 第 b 個 可 行 數 值 的 SOV 值 。 因 此 在 本 研 究 中 , 總 共 會 有 2 1 N N k n nn n n 個 SOV 值。 第五步驟:挑選最佳等候系統。五項參數中,所有可行數值皆有對應的 SOV 值,SOV 值越大,代表績效表現越好。因此,在各個參數中,挑出具有最大 SOV
值的可行數值,即為該參數最適合的設定值。以λ 為例,在 SOV11,SOV21,…, SOV
1 n 共 nλ個 SOV 值當中,挑選擁其中最大的,即為 λ 之最佳設定值。各參數最適 合的值挑選出來,所構成的最佳組合,即為運作起來最有效率的等候系統,也是 管理者在自身資源限制下所規劃設計的最佳等候系統。 管理者利用上面五個步驟,即可依照自身的資源限制,針對具有雙重服務速 率的 M/M/1 等候系統,規劃設計出良好方案,使其運作起來是有效率的。
3.3. 顯著性與敏感度分析
26
由於設計等候系統涉及 λ、μ、N2、N1和 k 五項參數,經評量選擇出的方案
我們進一步分析此五項參數的顯著性與敏感度,顯著性高的參數,在設計時就頇 格外小心,才不會影響整個等候系統的績效表現。而敏感度高的參數,若其目前 的數值在實際運作時產生小幅度的變化,即會讓整個系統的績效值降低很多。
本研究利用上一節所介紹的 SOV 值進行敏感度分析。參考 (Liao & Chen, 2002),定義各參數 c 的影響力 Ic。
bc
b bc b cI maxSOV min SOV (E10)
在(E10)中,其意義就是該參數下,最大的 SOV 值與最小 SOV 值的差距。
若 Ic值越大,代表該參數對於等候系統表現的影響越顯著,管理者在規劃設計該 參數的數值時,更需要多加考量。Ic較小,代表該參數影響較小,對於整個等候 系統的表現來說,是一個較不重要的參數。 判斷出各參數的顯著性之後,接著就想從中判斷各參數的敏感度。這裡定義 各參數敏感度 SAc如(E11)所表示。
bc
b bc b bc b cSA maxSOV maxSOV \maxSOV (E11)
(E11)即表示參數 c 下,所有最大的 SOV 值(
bc
b SOV max )減掉次大的 SOV 值(
bc
b bcb SOV \maxSOV
max )。若SAc越大,代表參數 c 兩個可行數值的設置,會 讓等候系統表現有較大的差異,也代表參數 c 是一個敏感參數,一點點數值的變 化,即會使整個系統運作起來產生極大之變化,因此會希望此參數在實際運作時 要與一開始規劃設計時不要差距太大,因為一點點些微的差距,即會讓整個等候 系統的運作改變。相反的,若 SAc其值較小,意謂著該參數中,會有兩個數值的 表現差不多,皆會使等候系統運作起來有不錯的表現,也代表此參數較不敏感, 可允許該數值有些許的寬放,較不會對等候系統表現有重大的影響。
3.4. 最佳管理設計與最佳數學規劃
第 3.2 與 3.3 節所選出的等候系統,即為利用數學方法所選出的最佳方案,27 即稱為最佳數學規劃。但對於管理者而言,僅利用數學方法所選出單一的設計方 案,或許過於武斷,且僅挑選最大的 SOV 值組合即視最佳之等候系統,考慮也 不夠周延,因此這裡提出一最佳管理設計,對於管理者而言,最佳管理設計是一 個比較好的方案。 管理者將 3.2 節資料包絡分析模型(P12)所求出的結果 * j 依序做個排名, 將排名較高的若干個方案挑出,觀察其各個參數的值,若發現排名較高的候選方 案某項參數都為一特定的值,就代表參數的設定只要為該特定值,皆能使等候系 統有不錯的績效表現;反之,若參數在排名較前面的候選等候系統中,其值都不 一樣,意謂著此參數的設置對於等候系統的績效表現影響較小,設計時也不一定 要堅持為某特定的數值。 最佳管理設計相對於數學最佳規劃而言,不僅僅從單一最大的 SOV 值考慮, 而是從考慮若干個表現較佳的候選等候系統去做考慮。單從最大的去考慮,似乎 過於武斷,且忽略了其它績效表現也不錯的設計方案,也有失公允。 當然最佳數學規劃還是有其參考之處,除了可以找出單一最佳方案之外,亦 可從 SOV 值判斷其顯著性與敏感度。顯著性可讓管理者在規劃設計等候系統時 有一適當的依據,該特別注意哪些影響顯著的參數。而敏感度則可以讓管理者了 解在規劃設計出等候系統之後,實際運作時要密切監測哪些參數,才不會使等候 系統運作起來整個績效值變差。
28