科技部補助專題研究計畫成果報告
期末報告
文本史料資訊檢索與探勘工具之開發與實踐(第2年)
計 畫 類 別 : 整合型計畫 計 畫 編 號 : MOST 102-2420-H-004-052-MY2 執 行 期 間 : 103年08月01日至104年08月31日 執 行 單 位 : 國立政治大學資訊科學系 計 畫 主 持 人 : 蔡銘峰 計畫參與人員: 碩士班研究生-兼任助理人員:劉澤 碩士班研究生-兼任助理人員:林哲立 碩士班研究生-兼任助理人員:陳禔多 碩士班研究生-兼任助理人員:陳奕安 碩士班研究生-兼任助理人員:梁韶中 大專生-兼任助理人員:簡伯銓 報 告 附 件 : 出席國際會議研究心得報告及發表論文 處 理 方 式 : 1.公開資訊:本計畫涉及專利或其他智慧財產權,2年後可公開查詢 2.「本研究」是否已有嚴重損及公共利益之發現:否 3.「本報告」是否建議提供政府單位施政參考:否中 華 民 國 104 年 12 月 01 日
中 文 摘 要 : 隨著資訊科技的日新月異,數位資訊透過通訊以及網際網路的快速 發展,已經造成人文科學和社會科學與資訊科學之間在學科內涵、 規範、社會實踐等方面開始產生質變。在文學研究領域方面,資訊 科技改變了文學創作與文學研究之想像與模式。在傳播學領域方面 ,網際網路使得知識的傳播更加無遠弗屆。在歷史學領域方面,由 於資訊科技中資訊檢索(Information Retrieval)與資料探勘分析 (Data Mining and Analysis)等技術,得以幫忙史學家發現文本 史料中錯綜複雜的關係。有鑑於過去數位典藏技術已將許多傳統的 歷史書籍資料數位化,接下來該如何有效地處理這些數位文本史料 便成了一個重要的研究議題。為完成此目的,資訊檢索技術將是一 個必要的核心工具,因透過檢索系統的建立,其技術可以將非結構 化的文本資料變成半結構化的索引資料,以便系統有效地搜尋資料 ,如此將可讓後續的資料探勘分析技術得以順利進行。 由於在人文社會科學相關研究中,研究人員經常需要閱讀與檢索大 量文獻,而在資訊科學領域,檢索相關技術近年來已有相當的發展 ,而這些發展中蘊含於資訊檢索、自然語言處理(Natural Language Processing)等資訊領域裡進階的技術。本計畫採用這些 技術建立了一個有效率的文本史料資訊檢索系統,幫助史學家從大 量的史料中找尋相關的資訊、並協助進行文本分析,使得史學家可 以進行更深入的史學相關研究。在所開發的系統裡,我們利用了資 訊檢索和自然語言處理等技術,提供精準的搜尋結果。接下來我們 將介紹本計畫中所使用史料文本和開發技術,以及介紹此適合人文 社會科學研究導向的檢索工具平台。 在本次計畫中,我們所使用的史料文本為「自由中國文本集」,此 文本集由政治大學雷震研究中心薛化元教授團隊所提供。在此計畫 報告中,另外我們介紹了有關在處理史料文本時,會所遇到的一些 困難以及相關的解決方法,包括:史料本文前處理、中文斷詞工具 、以及資料儲存格式系統之選擇等。在此報告中,我們也針對計畫 所使用到的建立檢索平台技術進行介紹,其中包括資訊檢索平台 (Search Engine Platform)、網路開發框架(Web Framework)、 前端介面(Front-end Interface)及後端資料處理(Back-end Data Processing)等具體的實踐方案。 目前,我們已成功建立起「數位人文自由中國搜尋系統」平台讓使 用者進行檢索, 同時我們也使用分頁的方式呈現結果,並提供全文 顯示等功能,此外我們也提供了以下側邊後設資料欄位以便使用者 更進階的搜索需求。 中 文 關 鍵 詞 : 數位人文、自由中國文本集、資訊檢索、自然語言處理 英 文 摘 要 : With the advances of digital technology, digital
information through communication as well as the rapid development of the Internet has begun to impact people life, which therefore makes huge changes to the research of humanity and social science. For example, in the field of literature, digital technology has changed the imagination
and creation of literary works and literary studies; in the field of communication, with the Internet information can be spared faster and further; in the field of history, the data-mining techniques has been applied to discover
implicit information within historical materials; in the field of library science, digital libraries are becoming more and more popular than traditional ones. With such many digital-archived text materials, how to effectively handle the data has already become a challenging task. For
achieving the task, the techniques of information retrieval are becoming crucial because the techniques can help build an information retrieval system for users to adjust their way of searching data and customize their search
preferences.
The goal of this project is to develop an effective information retrieval system that can help historians conduct research on historical text collections. By means of the techniques of information retrieval and natural language processing, we aim to provide more accurate search results and advanced search functionalities for historical researchers; in addition, we also attempt to integrate the methods of data visualization to present search results, in order to assist historian researchers to better understand the relationship within the retrieved documents and
keywords.
In this project, we first indexed the historical text collections and building n retrieval system on the
collections; then, we developed some advanced meta-search functions. In addition, we also developed some useful and friendly user interfaces for the retrieval systems. We hope such a project can help historical researchers conduct historical related research more efficiently and
effectively.
英 文 關 鍵 詞 : Digital Humanities, Information Retrieval, Natural Language Processing
摘要
隨著資訊科技的日新月異,數位資訊透過通訊以及網際網路的快速發展,已 經造成人文科學和社會科學與資訊科學之間在學科內涵、規範、社會實踐等方面 開始產生質變。在文學研究領域方面,資訊科技改變了文學創作與文學研究之想 像與模式。在傳播學領域方面,網際網路使得知識的傳播更加無遠弗屆。在歷史 學領域方面,由於資訊科技中資訊檢索(Information Retrieval)與資料探勘分析 (Data Mining and Analysis)等技術,得以幫忙史學家發現文本史料中錯綜複雜 的關係。有鑑於過去數位典藏技術已將許多傳統的歷史書籍資料數位化,接下來 該如何有效地處理這些數位文本史料便成了一個重要的研究議題。為完成此目的, 資訊檢索技術將是一個必要的核心工具,因透過檢索系統的建立,其技術可以將 非結構化的文本資料變成半結構化的索引資料,以便系統有效地搜尋資料,如此 將可讓後續的資料探勘分析技術得以順利進行。 由於在人文社會科學相關研究中,研究人員經常需要閱讀與檢索大量文獻, 而在資訊科學領域,檢索相關技術近年來已有相當的發展,而這些發展中蘊含於 資訊檢索、自然語言處理(Natural Language Processing)等資訊領域裡進階的 技術。本計畫採用這些技術建立了一個有效率的文本史料資訊檢索系統,幫助史 學家從大量的史料中找尋相關的資訊、並協助進行文本分析,使得史學家可以進 行更深入的史學相關研究。在所開發的系統裡,我們利用了資訊檢索和自然語言 處理等技術,提供精準的搜尋結果。接下來我們將介紹本計畫中所使用史料文本 和開發技術,以及介紹此適合人文社會科學研究導向的檢索工具平台。 在本次計畫中,我們所使用的史料文本為「自由中國文本集」,此文本集由 政治大學雷震研究中心薛化元教授團隊所提供。在此計畫報告中,另外我們介紹 了有關在處理史料文本時,會所遇到的一些困難以及相關的解決方法,包括:史 料本文前處理、中文斷詞工具、以及資料儲存格式系統之選擇等。在此報告中, 我們也針對計畫所使用到的建立檢索平台技術進行介紹,其中包括資訊檢索平台(Search Engine Platform)、網路開發框架(Web Framework)、前端介面(Front-end
Interface)及後端資料處理(Back-end Data Processing)等具體的實踐方案。 目前,我們已成功建立起「數位人文自由中國搜尋系統」平台讓使用者進行 檢索, 同時我們也使用分頁的方式呈現結果,並提供全文顯示等功能,此外我 們也提供了以下側邊後設資料欄位以便使用者更進階的搜索需求。
Abstract
With the advances of digital technology, digital information through communication as well as the rapid development of the Internet has begun to impact people life, which therefore makes huge changes to the research of humanity and social science. For example, in the field of literature, digital technology has changed the imagination and creation of literary works and literary studies; in the field of communication, with the Internet information can be spared faster and further; in the field of history, the data-mining techniques has been applied to discover implicit information within historical materials; in the field of library science, digital libraries are becoming more and more popular than traditional ones. With such many digital-archived text materials, how to effectively handle the data has already become a challenging task. For achieving the task, the techniques of information retrieval are becoming crucial because the techniques can help build an information retrieval system for users to adjust their way of searching data and customize their search preferences.
The goal of this project is to develop an effective information retrieval system that can help historians conduct research on historical text collections. By means of the techniques of information retrieval and natural language processing, we aim to provide more accurate search results and advanced search functionalities for historical researchers; in addition, we also attempt to integrate the methods of data visualization to present search results, in order to assist historian researchers to better understand the relationship within the retrieved documents and keywords.
In this project, we first indexed the historical text collections and building n retrieval system on the collections; then, we developed some advanced meta-search functions. In addition, we also developed some useful and friendly user interfaces for the retrieval systems. We hope such a project can help historical researchers conduct historical related research more efficiently and effectively.
一、前言
透過數位典藏,許多傳統的書籍資料早已不在是單純的紙本形式,額外的影 音檔案則需要被另外紀錄於光碟片中。數位化的各種文獻、書籍資料將不會隨著 時間、以及其他外在因素而受到損壞的以電子資料形式被完整的儲存於電子設備 中,數位典藏。數位典藏可以透過網際網路讓數位學習成為大眾間智慧分享,個 人學習服務的管道。當資料已經被完整的保存時,下一個目標在於如何有效率的 處理,整合並進一步的應用這些資料,這一階段的進展,我們稱之為數位人文。 在數位人文的時代,不論古典與現代,人文相關內容皆可以輕易地被傳播、分析、 結合各種創意,產生許多的創新運用,而其中的首要工作,便是數位人文的資訊 檢索,我們可以利用現在已經融入我們每日生活中的搜尋引擎達成即時檢索資料, 即時存取數位人文內容。透過自行建立的搜尋引擎,我們將可以自行調整搜尋資 料的方式,並且彈性的加入搜尋偏好,以在此大量資料中有效率的做資訊檢索, 以供學習與研究。二、研究目的
此計畫的目標在於如何從大量的文史資料量中幫助人文歷史學家迅速的找 到有用的資訊。藉由資訊科學領域中的資訊檢索(Information Retrieval)技術與 自然語言處理(Natural language processing)的技術提供不同的搜尋建議、良好的搜尋結果,最後結合資料視覺化(Data Visualization)技術呈現查找資料間的 關係,可以是文件與文件間的關係,也可以是關鍵字與關鍵字並結合時間軸的多 重關係呈現等等。 第一年的目標著重在將資料檢索中文本索引的工作,以及利用自然語言處理 解決關鍵字剖析問題,例如:中文斷詞問題,此為搜尋中文資料的最小基本單位, 在中文內的一個字並不能完整代表一個意思。「詞」是最簡小有意義且可以自由 使用的語言單位,任何處理語言的系統都必須先能分辨資料中的詞才能做進一步 的處理,包括計畫目的中的搜尋資料。這些問題產生的原因來自於中文複雜的文 法使得中文斷詞相對困難,相較於英文中單純的以每個字詞中間空白作為分隔, 中文的斷詞難度則困難許多,目前並不存在任何一個詞典或是方法可以涵蓋所有 的中文詞,處理不同專業領域的文件時,相應領域中的專有名詞常常造成分詞系 統因為參考詞彙不足而造成在切詞時判斷上的錯誤,進而嚴重影響搜尋時的結果。 將此技術應用在不同時代的文本資料時,將會遇上更大的問題,首當其衝的是古
鍵詞擷取、關連詞分析、文件摘要、主題分類、相似詞等等。這些將是影響一個 搜尋系統表現關鍵的核心因素,是故第一年的目標著重於良好的搜尋基礎建立, 以銜接第二年計畫中進階搜索的應用。因此,第一年主要目標為完成以使用者為 導向之文本史料資訊檢索系統,為達成此目標,此年工作包括建置檢索系統中的 基礎元素、完成使用者介面、提供使用者測試環境、並檢驗搜尋結果效能等。 第二年的目標則著重在資訊檢索系統的效能改善以及進階搜索的功能,我們 將多加利用文本所擁有之後設資料進行進階搜索,例如:時間、作者…等等文章 相關資訊,使用者可以查詢某特定時間內的所有文章,藉以觀察一些現象,或者 針對不同作者的撰文內容來推測其立場,此外,在計畫的第二年我們也透過主題 模型等進階機器學習方法對文本進行更進一步的分析。
三、研究方法
本計畫將分成三個部分進行:分別是 1、選定文本集,對文本資料進行格式 分析、資料清理[1]及預處理等前置工作,目前選定之文本集為政治大學雷震研 究中心所提供之「自由中國」數位史料;2、對文本進行斷詞與索引的建立;3、 檢索系統之設計與實作。自由中國文本集
此文本集由政治大學雷震研究中心薛化元教授團隊所提供,我們在此文本集 中發現以下兩個問題: 1. 原始文本儲存於微軟 doc 格式之文件檔中,此格式為一封閉格式[2],較 難以使用自行開發之電腦程式進行分析。 2. 原始文本雖有訂定資料綱要,但由於僅僅透過人工方式登錄、驗證,我們 撰寫了一資料萃取與分析程式,發現約有兩百多筆資料不符綱要規則,並 且存在資料缺失、重複的問題,難以進行有效的分析。解決方案
我們與雷震研究中心的團隊都相當重視文本集之有效性及可分析性,經過幾 次討論,決定採人工方式,以Excel 軟體對文本集進行全面的重新登錄與綱要驗 證,雖然Excel 之檔案格式亦屬於封閉格式,但我們有能力將其轉換成 CSV、JSON 等開放格式。中文斷詞問題
在自然語言處理的領域裡,詞是最小的語言單位[3]。任何語言處理的系統都必須先能分辨文本中的詞才能進行進一步的處理。對於中文而言,句子由詞所 組成,詞由字組成,然而詞與詞之間不一定被標點符號所隔開,故對於一連續中 文字串而言,其中所包含的詞,可能有數種解讀(斷詞)方式,例如:「中文長 詞優先斷詞」,可以被解讀為「中文 長詞 優先 斷詞」、「中文長 詞優 先斷 詞」、 「中 文長 詞優 先斷詞」、「中文長詞優先斷詞」等等,對於中文文本分析而言, 如何對中文文本進行斷詞是個相當重要的基本課題。
斷詞工具
因為中文斷詞通常會根據詞庫的內容,進行斷詞的決策,故我們在尋找中文 斷詞工具時,將詞庫的自訂能力做為一必要條件,我們選擇使用「結巴中文分詞」 [4]做為中文斷詞工具,其為一使用 Python 程式語言開發之自由開源軟體,具備 自訂詞庫之能力,若有必要,亦能對其斷詞程式進行修改。權威詞字典建立
如上所述,自訂詞庫對於斷詞工具所產生之斷詞結果而言十分重要,因此在 計畫實施的兩年間,透過團隊間成員的相互合作,我們建立了《自由中國》文本 專有的人工關鍵詞、權威詞字典,包含人名、專有名詞、書報雜誌社名稱等等特 殊詞庫,以增進斷詞效果,讓後續的文本分析工作更加地準確。自動化詞性判讀
在文本分析的工作中,詞性標記也是一個重要的工作,除了提供斷詞及詞頻 統計結果,我們另外也利用斷詞工具所提供的詞性字典自動化產生詞性結果,提 供給團隊裡的歷史學者作為參考,利用這些資訊可以作為一種篩選機制,讓歷史 學者能夠專注於欲觀察的項目,省去人工標記詞性的繁瑣過程。TF-IDF 權重分析
文本經過斷詞過後我們進行了初步的詞頻統計,同時我們也利用 TF-IDF 的 統計方法來得到進一步的結果,TF-IDF(Term Frequency–Inverse Document Frequency)是應用於資訊檢索以及資料探勘常用的加權技術,它是一種統計的 方法評估詞彙對於一個語料庫的其中一篇文章的重要程度,其主要思想為:如果 某個詞或短語在一篇文章中出現的頻率 TF 高,並且在其他文章中很少出現,則 認為此詞或者短語具有很好的類別區分能力,亦即對於文章本身的重要性較高。LDA 主題分析
除了傳統文本分析方法,我們也將使用目前整理好的文本資料,利用 Latent Dirichlet Allocation (LDA) 或稱為 Topic Model 之機器學習方法進行資料的分析。 LDA 是一種主題模型[17],其能夠將文檔集中每篇文檔的主題按照機率分布的形 式給出。同時它是一種無監督學習演算法[18],故訓練時不需要手工標註的訓練 集,僅僅需要文檔集以及指定主題的數量 k 即可。除此之外的另一個優點則是, 對於每一個主題均可找出一些詞語來描述它,但很多時候這些詞語是非常的片段, 我們希望透過團隊史學家對於文本的熟捻程度進而解釋這些詞語所代表的意義, 可以更正確的描述該分類主題,進而得知總體文本主題分佈並幫助其分析這些現 象。 LDA 是一種典型的詞袋模型1(bag of words model),它將每一篇文檔視為 一組詞構成的一個集合,而詞與詞之間並沒有先後順序的關係。一篇文檔可以包 含多個主題,文檔中每一個詞都由其中的一個主題生成。 圖一:LDA貝葉斯網路結構 另外,正如 Beta 分布是二項式分布的共軛先驗機率分布,Dirichlet 分布作為 多項式分布的共軛先驗機率分布。因此正如 LDA 貝葉斯網路結構中所描述的, 在 LDA 模型中一篇文檔生成的方式如下: • 從狄利克雷分布 α 中取樣生成文檔 i 的主題分布 θi • 從主題的多項式分布 θi中取樣生成文檔 i 第 j 個詞的主題 zi, j 1詞袋模型(bag of words model)是資訊檢索領域中,文件表示法的一種。其將文件中出現的詞 彙,想像是放在袋子裡零散而獨立的物件,如此一個袋子代表一篇文件。引用自國家教育研究院 圖書館學與資訊科學大辭典,參見網址:http://terms.naer.edu.tw/detail/1679006/,瀏覽時間:2015 年 10 月 25 日• 從狄利克雷分布 β 中取樣生成主題 zi, j的詞語分布φzi, j • 從詞語的多項式分布 zi, j中採樣最終生成詞語 wi, j 因此整個模型中所有可見變數以及隱藏變數的聯合分布是 最終一篇文檔的單詞分布的最大似然估計可以通過將上式的θi以及Φ 進行 積分和對 zi進行求和得到 根據 p(wi |α, β)的最大似然估計,最終可以通過吉布斯採樣等方法估計出模型中 的參數。 最後,每一篇文章將可以得到 K 種主題的機率分佈,而每個主題又可以得到 N 個詞語的機率分佈,史學家即可對最高機率的幾種主題以及詞語進行解釋,再經 由文本的後設資料(如年份、作者)的綜合結果進行文章脈絡的分析。
資料庫系統
資料庫系統為存放資料集合的軟體系統,相對於檔案系統而言,資料庫系統 能提供更完善的資料存取與管理能力,有利於電腦程式對資料進行分析。由於本 計劃之目的為開發一資訊檢索系統及文本分析,對於後者而言,可能會產生許多 事先未知、無法定義的中介資料,因為傳統關聯式資料庫系統必須事先定義好資 料綱要,較不適合管理文本分析導向的資料,故我們選用現今流行的「文件導向 資料庫系統」CouchDB 進行資料的儲存。CouchDB 是 Apache 基金會所管理之開源軟體專案,它的理念為「完全擁抱 web
的資料庫(a database that completely embraces the web)」[5],使用 JSON[6]儲存資
料、JavaScript[7]做為查詢語言,並採用 MapReduce[8]架構,且提供基於 HTTP[9]
的API[10]。
排序」三個階段,典型的檢索查詢指令為以空格為分隔,對查詢字串進行交集查 詢,取得符合條件之相關文件後,再根據文件相關度進行結果排序。故我們選用 的資訊檢索引擎,必須至少要能提供上述三樣功能,並且可以被進行二次開發, 以利更進一步的演算法開發或參數之調校。
我們選用自由開源軟體Whoosh 做為資訊檢索引擎,它是一套 Python 程式
語言的程式庫,由Matt Chaput 所開發與維護,它原先是 Side Effects Software 公
司為了業務需要而開發的資訊檢索引擎,現已開源[11]。 Whoosh 除了可以滿足前面提及之三樣需求,也提供先進的文件結果排序演 算法實作,亦能自由抽換演算法及參數,相當符合計畫的需求。
Web 伺服器
Web 伺服器是一種透過 HTTP 將內容傳送至使用者瀏覽器的軟體,其必須 要能解釋、處理使用者的任意查詢需求,並將結果返回給使用者,是接收使用者 查詢需求的第一道門戶。由於此計畫所預計實作之資訊檢索系統是為了服務歷史 研究人員,客製化需求的程度較高,必須要能提供自訂程式碼的機制,故我們選擇使用Bottle 做為 web 伺服器的開發框架,Bottle 為一 Python 程式語言所開發
而成的自由開源web 開發框架,其特色為 RESTful 導向、輕量、易開發[12]。
前端介面
由於計畫所預計實作之資訊檢索系統使用網站形式的方式提供服務,有鑑於 市面上盛行多款流行的網頁瀏覽器,不同瀏覽器對於網頁的視覺詮釋都略有不同, 為了提供較具一致性、視覺上更專業、更好的使用者經驗的操作介面,我們選擇
使用Bootstrap 做為前端介面的開發框架,Bootstrap 由 Twitter 公司所開發,是當
今最流行的自由開源前端介面,乃經由專業使用者介面與經驗設計師所設計,並 具備大量使用者之實證[13]。
主要程式語言
此計畫大量地使用了 Python 程式語言進行系統開發之任務,這是因為在自 然語言處理、機器學習、資訊檢索、科學計算等領域裡,因為已經有許多相關工 具皆是以 Python 開發而成、以 Python 做為操作平台,故 Python 幾已成為這些
四、計畫整合
圖二:史料文本探索平台總資料流程圖 有鑑於豐碩的學術研究成果之醞釀,往往出自於眾多來自不同領域的傑出研 究人才的共同合作與互相配合,本計劃已與政大資訊科學系劉吉軒教授團隊、政 大雷震研究中心薛化元教授團隊的相關計畫進行整合成一史料文本探索平台,由 薛化元教授團隊提供文本資料、史學觀點,我們並以資訊檢索系統做為回饋,另 一方面,本計劃所產出之分析資料將提供予劉吉軒教授團隊,以進行更進一步的 關聯式社會網路分析,探索其中人、事、物的關係型態、個體模型的塑造、個體 之間的關係、以及探索個體匯集成為的群體、再觀察群體與群體之間的關係類型。 圖二為史料文本探索平台總資料流程圖。五、結果與討論
此一部份將分成兩個主要工作:分別為透過機器學習與自然語言處理方法進 行文本分析之結果,以及經過斷詞與索引建立後,資訊檢索系統之呈現,而後則 有成果自評及未來展望等相關討論。文本分析
在計畫的兩年之間,我們完成了資料清理及預處理等前置工作,並且循序漸 進的利用詞頻統計、TFIDF、主題模型分析等統計與機器學習方法進行文本分析, 以下為相關結果之呈現: 表 1: 斷詞結果 首先,我們將既有文本重新整理,並使用結巴分詞進行斷詞的工作,表 1 為 2 至 4 字詞的前十大斷詞結果,或可從中觀察到《自由中國》文本的一些特性。 表 2: 詞性判讀結果 2 字詞 數量 3 字詞 數量 4 字詞 數量 自由 24755 一九五 3370 民主自由 729 政府 19611 百分之 2504 另一方面 703 政治 15517 一方面 2345 反共抗俄 597 民主 14637 一九四 2116 自由民主 574 可以 13982 立法院 2060 外交政策 564 人民 13762 行政院 1731 北大西洋 458 不能 13327 艾森豪 1227 最高法院 438 不是 10872 不得不 1213 南斯拉夫 421 世界 9745 莫斯科 1175 一九四八 381 所以 9258 不能不 1166 第二次世 312 單詞 詞性 單詞 詞性 單詞 詞性 證券 x 國民黨 x 法律 n 人權 x 日本 ns 憲法 x 交易所 nt 美國 x 中東 x 蔡先生 nr 儲蓄 n 南共 j除了提供斷詞過後的詞頻統計結果,我們更利用斷詞工具自動產生出字詞的 詞性,提供給團隊裡的歷史學者作為參考,結果如表 2,其中 x 為字符串、j 為 簡稱、n 為名詞、nt 為機構團體名、nr 為人名、ns 為地名、vn 為名動詞2。 表 3: TF-IDF 權重分析結果 斷詞後的詞頻統計結果可說是針對全文架構進行初步的分析,接著我們分別 以文章、年份、作者、卷、期為單位,透過 TF-IDF 權重分析,更進一步的觀察 每年度(卷期、作者)的詞彙重要性, 表 3 為以卷為單位(擷取卷 6、卷 11、 卷 15)的統計結果,或可從中發現《自由中國》文本各卷期收錄文章所著重的 議題。 2 此處詞性標記之解釋來源自開源分詞系統 ICTPOS3.0 詞性標記集、ICTCLAS 漢語詞性標註集, 參見網址:https://gist.github.com/luw2007/6016931,瀏覽時間:2015 年 10 月 29 日 投資 x 觀念 n 學校 n 市場 n 先生 n 湖州 ns 宣言 nr 權利 n 宇弩 nr 教育 vn 公司 n 世界 n 學生 n 革命 vn 蘇州 ns 臺灣 x 中共 b 僑務 x 卷 6 卷 11 卷 15 單詞 權重 單詞 權重 單詞 權重 日本 779.062 孟氏 680.126 貨幣 907.811 美國 614.439 法國 654.153 蘇俄 820.333 蘇聯 575.308 英國 615.122 銀行 703.979 阿刺伯 486.752 右翼 610.909 埃及 670.762 誹謗 485.231 越南 607.749 本邦 615.862 價值 476.433 銀行 583.435 流通 553.942 傑弗遜 475.158 歐洲 527.517 華僑 549.168 蘇俄 473.696 共和黨 504.447 共產黨 494.544 臺灣 463.069 美國 488.400 教育 486.809 共黨 441.552 國會 453.281 佛洛伊德 486.435
表 4: LDA 主題聚類結果 除了以上傳統文本分析方法,我們更利用了機器學習裡的主題模型(Topic Model)技術進行更進一步的分析,表 4 為 Latent Dirichlet allocation (LDA) 所群 聚出的主題詞彙結果,希望能夠透過機器自動產生的詞彙與歷史學家既有知識作 結合,從中找出其他可能的研究議題。
檢索系統
另一方面,資訊檢索系統的開發與建置工作已經完成,並且於政治大學校內 上線,網址為http://clip.csie.org/DHP/ 圖二至圖八為網站成果縮圖。 圖二:搜尋網站主頁面 教育/救國團 總統三連任問題/修憲/國大 其他基本權問題 教育 學術 憲法 修改憲法 人權 逮捕 學校 教育部 代表 問題 人民 宣言 學生 標準 國民大會 立法院 機關 臺灣 青年 先生 總統 先生 政府 規定 大學 考試 修憲 國民黨 自由 警察 科學 問題 連任 臨時條 國家 賠償 課程 中學 修改 可以 保障 法院 研究 教授 蔣總統 解釋 法律 思想 校長 救國團 規定 法律 權利 司法 臺灣 社會 國大代表 總額 憲法 拘禁我們將檢索首頁設計為入口網站的形式,使用者將欲查詢的檢索詞(query)填入中 央欄位,按下「搜尋」按鈕即可進行檢索。 圖三:查詢「人權」 圖四:文本總數、標題、後設資料 在檢索介面中,為了讓使用者能快速找到關鍵資訊,我們將檢索詞以黃底粗 字標示(如圖三所示),並提供其上下文,方便瀏覽,這種作法稱之為命中凸顯 (hit highlighting)。檢索結果可以檢視檢索到的文本總數,並置頂於檢索頁面之正 上方,各篇文章顯示日期、卷、期、作者、專欄等後設資料,網頁左側欄位則是 提供了文本所提供之後設資料的快速檢索欄位,增進使用者體驗。
圖五:側邊後設資料欄位 此四個欄位可以讓使用者了解此檢索系統可以有哪些進階搜尋選項,包括年 代、日期區間、作者、專欄等,使用者可以直接點選這些欄位以及填入日期區間, 系統會自動增加檢索條件,方便檢索文本之後設資料。 圖六:查詢「人權」並選取後設資料「作者:殷海光」
圖七:檢視檢索全文 除前後文外,我們也提供檢視全文的功能,此功能為按鈕觸發後才將文字從 後端資料庫傳出,而非連結至全新頁面,如此可以讓使用者看到通篇文章的脈絡, 也可以保護原始資料,不能被輕易複製。
圖八:檢索結果分頁 有些字詞之檢索結果可能會有上百或上千筆結果,為了瀏覽的方便性,我們 於每頁顯示十筆資料,並增加換頁按鈕,避免大量文章的顯示影響系統效能,使 檢索結果在數秒內顯示。
成果自評
此計畫之執行結果與當初規劃相符,惟在經過一番琢磨後,我們使用了與原 先規劃不太一樣的工具、架構,揚棄了原本所預計使用的重量級檢索引擎 Apache Lucene [15],改用比較容易操作、擴充的 Whoosh,以期能夠進行更寬廣的發展。 在資料庫的部份,我們嘗試了以文本為導向的 CouchDB,傳統資料分析通常 是自行產生中繼的資料檔,將檔案系統做為資料庫使用,這些中繼資料檔會隨著 資料分析的工作成果與日俱增,使得中繼資料檔的管理工作成為一個問題,使用 文本導向的資料庫來儲存與管理這些原始資料、分析中繼資料,是較現代的解決 方式。 由於文本集的先天品質問題,難以直接進行分析,我們額外做了資料清理的 工作,使得「自由中國」文本集得以結構化,這使得此文本集在日後能有更大的 運用空間。 對於專業領域的資訊檢索系統而言,往往需要較高的檢索求全率(Recall Rate),以避免遺漏重要資訊,然而較高的求全率往往意味著大量的回傳資料,當回傳資料量大到電腦難以瞬間處理、顯示時,使用者便會感受到系統效能問題, 而在我們的努力之下,也成功的利用分頁瀏覽、以及全文預覽的方式改善了先前 系統運行效能較差,查詢反應稍微緩慢的問題,不過對於使用者介面的設計(如 美觀、易用性),由於目前檢索系統使用者較少,我們較難獲得使用者經驗的反 饋。 在文本分析的工作當中,我們也嘗試了多種機器學習與統計的方法,並且得 到不錯的結果,在與子團隊間的合作與討論之中,也逐漸了解我們所使用之文本 架構以及歷史學家們可能關注的議題。
未來展望
在未來,我們希望可以將此檢索系統更加地延伸,開放所有擁有數位文本資 料的使用者來使用,使其可以成為一個開放式的文本平台,讓使用者自行上傳文 本,自由的檢索文本,另外,我們也希望能夠將我們使用的文本分析技術開發成 線上版本,並逐步的開放,讓其他使用者也可以透過這些工具來輔助分析自己的 文本,創造更多數位典藏的價值。而藉由此開放平台,我們也能較容易地收集使 用者體驗的反饋,進一步的改善介面或者檢索系統及分析工具的效能。 另一方面,近年來由谷歌公司所發表的利用巨量資料處理自然語言相關理論 與工具,我們也能將其應用到此文本集上,又或者將現有的理論以及分析工具進 行改良,期許能找出對於歷史研究而言,更有研究意義的資訊。六、參考資料
[1] Data cleansing http://en.wikipedia.org/wiki/Data_cleansing [2] 好公民不助長非法拷貝 -- 請停止散佈 .doc 檔
http://user.frdm.info/ckhung/a/c041.php
[3] Introduction to Natural Language Processing
http://www.mind.ilstu.edu/curriculum/protothinker/natural_language_processing.php
[4] 結巴中文分詞https://github.com/fxsjy/jieba
[5] Apache CouchDB http://couchdb.apache.org/
[6] JSON http://zh.wikipedia.org/wiki/JSON
[7] JavaScript http://zh.wikipedia.org/wiki/Javascript
[8] MapReduce http://zh.wikipedia.org/wiki/MapReduce
[9] Hypertext Transfer Protocol
http://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol
[10] Application programming interface
http://en.wikipedia.org/wiki/Application_programming_interface
[11] Whoosh https://bitbucket.org/mchaput/whoosh/wiki/Home
[12] Bottle: Python Web Framework http://bottlepy.org/docs/dev/index.html
[13] Bootstrap http://getbootstrap.com/
[14] Python http://en.wikipedia.org/wiki/Python_(programming_language) [15] Apache Lucene http://lucene.apache.org/
[16] word2vec https://code.google.com/p/word2vec/
[17] Blei, David M.; Ng, Andrew Y.; Jordan, Michael I. Latent Dirichlet allocation. (編) Lafferty, John. Journal of Machine Learning Research. 2003-01, 3 (4–5): pp. 993–1022.
[18] Jordan, Michael I.; Bishop, Christopher M. (2004). "Neural Networks". In Allen B. Tucker. Computer Science Handbook, Second Edition (Section VII: Intelligent Systems). Boca Raton, FL: Chapman & Hall/CRC Press LLC. ISBN 1-58488-360-X.
2015 07 10
ACM
Web Science
2015
6 28
7
1
Oxford e-Research Centre
and Keble College
ACM Web Science
2015
6
29
poster
“Social Influencer Analysis with Factorization
Machines” poster session
MOST 102-2420-H-004-052-MY2
--2
2015
6
28
2015
7
1
(
)
(
)
The 2015 ACM Web Science Conference (WebSci'15)
(
)
(
)
Social Influencer Analysis with Factorization
Machines
poster session
PHD
Prof. Tat Seng Chua
Prof.
Tsai
1)
2)
5/8/15, 3:30 PM Welcome to ACM Web Science 2015 — ACM Web Science 2015
Welcome to ACM Web Science 2015
Web Science is the emergent study of the people and technologies, applications, processes and practices that shape and are shaped by the World Wide Web. Web Science aims to draw together theories, methods and findings from across academic disciplines, and to collaborate with industry, business, government and civil society, to develop our knowledge and understanding of the Web: the largest socio-technical infrastructure in human history.
We look forward to seeing you in Oxford for the 2015 ACM Web Science
conference #WebSci15. The conference is running from Sunday 28 June to Wednesday 1 July,
and is the seventh in the conference series organised by the Web Science Trust, following events in Athens, Raleigh, Koblenz, Evanston, Paris, and Indiana.
Keynote Speakers
Confirmed keynote speakers include:
Professor Mia Consalvo, Professor and Canada Research Chair in Game Studies and Design at Concordia University in Montreal Professor Rachel Gibson, Professor of Political Science, University of Manchester
Conference Organisation
WebSci'15 is hosted in the University of Oxford by the Oxford e-Research Centre.
Conference Chair
David De Roure, Professor of e-Research, University of Oxford, UK
Programme Chairs
Christine L. Borgman, Professor and Presidential Chair in Information Studies, UCLA Pete Burnap, School of Computer Science and Informatics, Cardiff University, UK
Susan Halford, Professor of Sociology, Web Science Institute, University of Southampton, UK
Executive Chair
Tat Seng Chua, Professor at the School of Computing, National University of Singapore
Programme Committee
William Allen, University of Oxford
Fabricio Benevenuto, Federal University of Minas Gerais (UFMG) Mark Bernstein, Eastgate Systems, Inc
Paolo Boldi, Università degli Studi di Milano Niels Brügger,
Carlos Castillo, Qatar Computing Research Institute Lu Chen, Kno.e.sis Center, Wright State University Pasquale De Meo, VU University, Amsterdam Pnina Fichman, IU
Matteo Gagliolo, Université libre de Bruxelles (ULB) Bruno Gonçalves, Aix-Marseille Université
Bernhard Haslhofer, AIT-Austrian Institute of Technology Geert-Jan Houben, TU Delft
Jeremy Hunsinger, Wilfrid Laurier University Ajita John, Avaya Labs
Robert Jäschke, L3S Research Center Renaud Lambiotte, University of Namur Matthieu Latapy, CNRS
Silvio Lattanzi, Google
Vili Lehdonvirta, University of Oxford
Sune Lehmann, Technical University of Denmark Kristina Lerman, University of Southern California David Liben-Nowell, Carleton College
Massimo Marchiori, UNIPD and UTILABS Luca Maria Aiello, Yahoo Labs
Dan McQuillan,
5/8/15, 3:30 PM Welcome to ACM Web Science 2015 — ACM Web Science 2015
Catherine Pope, University of Southampton Alison Powell, London School of Economics Daniel Romero, University of Michigan Matthew Rowe, Lancaster University Giancarlo Ruffo, Universita' di Torino Derek Ruths, McGill University
Ralph Schroeder, Oxford Internet Institute Xiaolin Shi, Microsoft Corporation Elena Simperl, University of Southampton Philipp Singer, Knowledge Management Institute Marc Smith, Connected Action Consulting Group Steffen Staab, University of Koblenz-Landau Mark Weal, University of Southampton
Ingmar Weber, Qatar Computing Research Institute Matthew Weber, Rutgers University
Lilian Weng, Indiana University
Christopher Wienberg, Institute for Creative Technologies, University of Southern California
Event management
Clementine Harris, University of Oxford, UK
Communications
Adi Himpson, University of Oxford, UK
Join the WebSci15 mailing list
Fill in the form below to be added to our mailing list for notifications about the call, registration, etc.
Your name
First Name Last Name
Your e-mail address ex: [email protected]
Submit
5/8/15, 3:27 PM Gmail - WebSci 2015 notification for paper 109
Chuan-Ju Wang <[email protected]>
WebSci 2015 notification for paper 109
WebSci 2015 <[email protected]> Fri, May 8, 2015 at 2:35 AM
To: Chuan-Ju Wang <[email protected]> Dear Chuan-Ju
We are delighted to inform you that your paper Social Influencer Analysis with Factorization Machines has been accepted at #WebSci15.
The conference was very competitive this year with 164 submissions, around 20 have been accepted as full papers and 10 as short papers.
Please find reviewer comments below and try to address these when preparing the camera ready version. The deadline for camera ready papers is 22nd May. Instructions on how to submit will follow shortly.
Kind Regards Pete Burnap Susan Halford Christine Borgman Programme Chairs -- REVIEW 1 ---PAPER: 109
TITLE: Social Influencer Analysis with Factorization Machines AUTHORS: Ming-Feng Tsai, Chuan-Ju Wang and Zhe-Li Lin REVIEW
---This work uses common collaborative filtering techniques in order to evaluate the influence of an individual in a community, where each individual is involved in many collaborative works. In particular, the method is proposed in bibliometrics, and experimented with a fragment of the DBLP dataset.
The idea is interesting and fresh, and the paper is in general well presented.
The (hidden) assumption in the transformation function F is that an author may have an influence on all works done by its co-authors. After being processed by factorization machines, it results in a matrix where the influence of author i on work j is estimated according to this latent form of collaboration.
The experimental part is promising, though exploratory. In particular, the ground truth should be briefly explained. In fact, authors employ the order returned by Microsoft Academic Research, but what this order represents should be made clear. Are individuals ranked by some standard bibliometric measure? Or is this order human-picked? Moreover, if the ground truth ranking is not based on a standard academic index, then including a non-naive baseline of this kind (for example h-index) in the experimental comparison could be very informative.
A minor flaw in the presentation is that the textual information -- proven useful by the experiments -- is introduced vaguely. A very short explanation about how the bag-of-words representation is used to estimate social influence should be added.
There is a typo in the second paragraph of Section 3: the word "column" should probably be replaced by "row". -- REVIEW 2
---5/8/15, 3:27 PM Gmail - WebSci 2015 notification for paper 109
TITLE: Social Influencer Analysis with Factorization Machines AUTHORS: Ming-Feng Tsai, Chuan-Ju Wang and Zhe-Li Lin REVIEW
---The authors propose a method measure the latent social influence among individuals, analyzing their pattern of collaborations. They use the Factorization Machine technique and run experiments on a dataset of scientific papers, comparing the results with the ranking of Microsoft Research (ground truth).
They state that the original contribute is adding textual information to the features used to model the latent social influence, but then in the paper it is not so clear how they consider this feature (while the rest of the process is very well explained). In particular they state that incorporate textual info, i.e. title words of the papers, improve the performance. I suggest that, in this case, it could be interesting considering the keywords of the paper. I think that some other validations on different datasets are needed.
Errors:
1) in Introduction, third sentence: "the aim […] is to infer the latent social inference.." , I think you mean influence and not inference.
Social Influencer Analysis with Factorization Machines
Ming-Feng Tsai
Department of Computer Science & Program in Digital
Content and Technology National Chengchi University
Taipei 116, Taiwan [email protected] Chuan-Ju Wang Department of Computer Science University of Taipei Taipei 100, Taiwan [email protected] Zhe-Li Lin Department of Computer Science
National Chengchi University Taipei 116, Taiwan
[email protected] ABSTRACT
How will the reputations of individuals in a social network be influenced by their communities in a quantitative way? This work attempts to observe the collaborative events oc-curring at individuals involved in a social network to obtain such crucial knowledge. We propose a Factorization Ma-chine approach to find out the latent social influence among the individuals based on their collaborations. Experiments conducted on a real-world DBLP dataset verify that the proposed approach can discover the latent social influence among individuals and provide a better predictive model than several baselines.
Keywords
Social Influence Analysis, Collaborative Filtering, Factoriza-tion Machines
1. INTRODUCTION
How will the reputations of individuals in a social network be influenced by their neighbors? Such important knowledge is unfortunately not obtainable nowadays, and we attempt to observe its manifestation in the form of collaborative events occurring at the individuals involved in a social network to understand the problem. Therefore, the aim of this paper is to infer the latent social influence among individuals based on their patterns of collaborations. In order to tackle the problem, we use the idea of Collaborative Filtering (CF) to discover the latent social influence among individuals [4]. Considering that Factorization Machines (FM), which is one of the state-of-the-art CF techniques, provide some advan-tages over other existing CF approaches [3], we apply the FM method to model the latent social influence. Specifi-cally, we first present an influence transformation function to build up the influence matrix of individuals based on their patterns of collaborations. Then, the social influence of each individual is obtained via FM with the influence matrix; furthermore, some auxiliary information is utilized
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than ACM must be honored. Abstracting with credit is permitted. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from [email protected].
WebSci ’15, June 28 - July 01, 2015, Oxford, United Kingdom
c 2015 ACM. ISBN 978-1-4503-3672-7/15/06 ...$15.00 DOI: http://dx.doi.org/10.1145/2786451.2786490.
to help the latent influence discovery. Experiments, which are conducted on a real-world DBLP dataset including 3,662 authors and 5,122 papers, attest the proposed method can discover the latent social influence among individuals and produce a better predictive model than several baselines.
2. METHODOLOGY
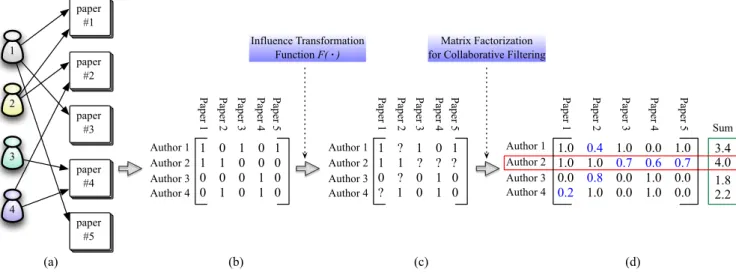
Fig. 1 gives an illustrative example to introduce the core idea of the modeling process for the latent social influence. Fig. 1(a) depicts the relationships between the authors and their papers. These relationships can be transformed to the matrix representation in Fig. 1(b), in which each element xai,pj equals to 1 if aiis the author paper pj and otherwise
that equals to 0. We then define an influence transformation function F (·) to build up the influence matrix (see Fig. 1(c)); this is a key step to transform the relationships in Fig. 1(a) to the input of a standard CF algorithm. The transformation function F (·) can be designed variously; in this paper, F (·) is defined as F (xai,pj) = 8 < : 1, if ai is the author of pj,
? if9 ak2 Cai and ak is the author of pj,
0, otherwise,
(1) where Cai is the set of the authors who have coauthored
with ai. After the transformation, we can obtain the resulting matrix in Fig. 1(d) via any CF algorithms.1
In Fig. 1(d), each number in blue color can be explained as the estimated latent social influence; the numbers in the green box are the sum of the influence scores of each author on all papers. As shown in the figure, we can observe that although author 2 has only written 2 papers, his/her social influence score (i.e., 4) is larger than that of author 1 (i.e., 3.4), who has written the most papers among the 4 authors. Even though author 2 is not the author of papers 3, 4, and 5, we consider that author 2 should still have (latent) influence on these three papers and the influence can be modeled with the patterns of collaborations among the authors.
FM provides an advantage over other existing CF ap-proaches, which make it possible to incorporate with any auxiliary information that can be encoded as a real-valued feature vector. Thus, via using FM, this paper integrates with other supplementary information to model latent social influence, and we use textual information as the supplemen-tary information in our experiments.
1Here the standard matrix factorization is adopted to calcu-late the resulting matrix.
1 2 3 4 paper #2 paper #3 paper #5 paper #4 paper #1 Influence Transformation Function F( · ) 1 0 1 0 1 1 1 0 0 0 0 0 0 1 0 0 1 0 1 0 Author 1 Author 2 Author 3 Author 4 P ape r 1 P ape r 2 P ape r 3 P ape r 4 P ape r 5 1 ? 1 0 1 1 1 ? ? ? 0 ? 0 1 0 ? 1 0 1 0 Author 1 Author 2 Author 3 Author 4 P ape r 1 P ape r 2 P ape r 3 P ape r 4 P ape r 5 Matrix Factorization for Collaborative Filtering
1.0 0.4 1.0 0.0 1.0 1.0 1.0 0.7 0.6 0.7 0.0 0.8 0.0 1.0 0.0 0.2 1.0 0.0 1.0 0.0 Author 1 Author 2 Author 3 Author 4 P ape r 1 P ape r 2 P ape r 3 P ape r 4 P ape r 5 Sum 3.4 1.8 2.2 4.0 (a) (b) (c) (d)
Figure 1: The Modeling Process for the Latent Social Influence with CF.
Spearman’s Rho Kendall’s Tau #coauthor (baseline) 0.233 0.179
#paper (baseline) 0.388 0.284 #citation (baseline) 0.469 0.347 FM without texts 0.478⇤†‡ 0.349⇤† FM with texts 0.556⇤†‡ 0.409⇤†‡
Table 1: The Experimental Results. The notations⇤, †, and ‡ in Table 1 denote the result is significant better than the three baselines #coauthor, #paper, and #citation, respectively, with p < 0.05.
3. EXPERIMENTS
The experimental dataset is built for a certain research community from the DBLP data set,2 which contains the information of papers and the coauthors of each paper. We first collect the top 20 authors in the field of data mining from Microsoft Academic Search. Then, these 20 authors, their coauthors, and all of the papers of the 20 authors, are constructed as our experimental dataset, which consists of 3,662 authors and 5,122 papers. Note that the ranking of these 20 authors from Microsoft Academic Research is also considered as the ground truth of the experiments. Two rank correlation metrics are used to evaluate the performance in our experiments: Spearman’s Rho [2] and Kendall’s Tau [1]. The FM library, libFM [3], is adopted to conduct the experi-ments.
Table 1 tabulates the preliminary experimental results, in which we compare the results of three baselines and those of the proposed FM approach. The three baselines are the ranking via the numbers of coauthors, papers, and citations per author from Microsoft Academic Search. In addition, the fourth (fifth) row denotes the results of our proposed FM method without (with) the textual information, which is described by a bag-of-words model with term frequency. Note that only title words of the papers are used as the text information; the resulting vocabulary size is 4,057. Due to
2The data is available at http://dblp.uni-trier.de/xml/.
the randomization of the algorithms implemented in libFM, the values in the fourth and fifth rows are the averages of the 20 times experiments. As shown in Table 1, the performance of both FMs without and with texts reach significantly bet-ter results than the baseline methods. In addition, we can observe that incorporating the supplementary textual infor-mation did greatly improve the performance, which confirms that the textual information is beneficial to the latent social influence discovery.
4. CONCLUSIONS AND FUTURE WORK
This study attempts to model the latent social influence among individuals based on their patterns of collaborations in a social network via the FM approach. Preliminary ex-perimental results on the small DBLP dataset for the data mining community show that the proposed approach provides a better predictive model than several baselines. In future work, we will conduct experiments on larger data sets with various fields of research communities. In addition, other auxiliary information, such as the temporal information of the publications [5], will be included and analyzed in our further experiments.
5. REFERENCES
[1] M. Kendall. A new measure of rank correlation. Biometrika, 30:81–93, 1938.
[2] J. L. Myers, A. Well, and R. F. Lorch. Research Design and Statistical Analysis. Routledge, 2010.
[3] S. Rendle. Factorization machines with libfm. ACM Transactions on Intelligent Systems and Technology (TIST), 3(3):57, 2012.
[4] L. Terveen and W. Hill. Beyond recommender systems: Helping people help each other. HCI in the New Millennium, 1:487–509, 2001.
[5] K. Zhou, H. Zha, and L. Song. Learning social infectivity in sparse low-rank networks using
multi-dimensional hawkes processes. In Proceedings of the Sixteenth International Conference on Artificial Intelligence and Statistics, pages 641–649, 2013.
2015 08 30
ACM
KDD
2015
8 10
8
13
Hilton
ACM KDD
Data Mining
KDD CUP 2015
Workshop
“ A Linear Ensemble of Classification Models with Novel
Backward Cumulative Features for MOOC Dropout Prediction”
Workshop
Prof.
MOST 102-2420-H-004-052-MY2
--2
2015
8
10
2015
8
13
(
)
(
)
The 21th ACM SIGKDD Conference on Knowledge
Discovery and Data Mining
(
)
(
)
A Linear Ensemble of Classification Models with
Novel Backward Cumulative Features for MOOC Dropout
Prediction
Oral
poster session
poster session
Matlab
1)
2)
12/1/15, 12:03 AM KDD CUP 2015
Login Sign up
XuetangX $20,000 821 Teams
KDD Cup 2015 - Predicting dropouts in MOOC
Ready End End Information Introduction Evaluation Timeline Prizes Organizers Q&A Submission Data Rules Make a Submission My Submission Social Rank Private Winners 1 Intercontinental Ensemble 2 FEG&NSSOL@DataVeraci 3 CLMS 4 Data Sapiens 5 FirstTimeEver
If you have any questions or comments, please send an email to [email protected].
Update, August 4 :
Here is the Schedule of KDD Cup 2015 Workshop
KDD Cup 2015 Workshop Schedule
9:00 – 9:30 Opening: Information about the competition and our Sponsor, XuetangX.
9:30 – 10:30 Invited Talk: Jacob Spoelstra, Hang Zhang (Microsoft) Solving the KDD Cup 2015 Challenge Using Azure ML. 10:30 – 11:00 Coffee Break
12/1/15, 12:03 AM KDD CUP 2015
Models with Novel Backward Cumulative Features for MOOC Dropout Prediction.
11:50 – 12:15 7th Prize: Nguyen Minh Luan Combining Intention and Engagement Features with Ensemble of Models for MOOC Dropout Prediction. 12:15 – 13:45 Lunch (on your own)
13:45 – 14:10 6th Prize: Aakansh Gupta, Nuo Zhang, Kei Yonekawa, Kazunori Matsumoto, Shigeki Muramatsu, Rui Kimura, Nobuyuki Maita, Yujin Tang, Keiichi Kuroyanagi, Takafumi Watanabe, Akihiro Kobayashi, and Takuya Akiyama Approach to Generate a Vast Variety of Features for Predicting Dropouts in MOOC.
14:10 – 14:35 5th Prize: Jingming Liu A Time Series Feature Extractor for Predicting Dropouts in MOOC.
14:35 – 15:00 4th Prize: Ming-Lun Cai, Chih-Wei Chang, Liang-Wei Chen, Si-An Chen, Hsien-Chun Chiu, Hong-Min Chu, Yu-Jheng Fang, Yi Huang, Kuan-Hao Huang, Chih-Te Lai, Yi-An Lin, Chieh-En Tsai, Yeh-Wen Tsao, Yu-Lin Tsou, Wei-Cheng Wang, Yu-Ping Wu, Yao-Yuan Yang, Sheng-Chi You, Sz-Han Yu, Hsuan-Tien Lin, and Shou-De Lin
NearUniform Aggregation of Gradient Boosting Machines for KDD Cup 2015.
15:00 – 15:15 Coffee Break
15:15 – 15:40 3rd Prize: Kenny Chua, Xavier Conort, Sergey Yurgenson, and Owen Zhang Featurizing Sequential Data - our Solution with XGboost.
15:40 – 16:05 2nd Prize: Yuichi Sugiyama, Kei Harada, Sayaka Yabu, Kazuki Onodera, Yuta Hino, Ryotaro Sano, Natsumi Kokubo, Daisuke Nishikawa, Sampei Nakabayashi, Masaaki Takada, Yasushi Iwata, Shinya Yazawa, Ryo Kato, and Tomomitsu Motohashi Feature Extraction for Predicting Dropouts and Feature Merging Experience with Data
Veraci.
16:05 – 16:30 1st Prize: Jeong-Yoon Lee, Andreas Toescher, Michael Jahrer, Kohei Ozaki, Mert Bay, Peng Yan, Song Chen, Tam T. Nguyen, and Xiaocong Zhou Three-Stage
Ensemble and Feature Engineering for MOOC Dropout Prediction.
16:30-17:30 The Serial Winner Panel (stay tuned!)
Update, July 19:
10 winners are listed here, one of the KDD Cup chairs will contact you soon.
Update, July 14:
The scores on the private leaderboard is now correct.
Update, July 13:
The rank of private leaderboard is correct, but the scores have some errors. We are fixing it.
Top 11 players are as follows. The final result is nearly same with the private rank. We will annouce the final winners today. Rank Team private score
1 Intercontinental Ensemble 0.9074429656630387 2 FEG&NSSOL@DataVeraci 0.9071299191403106 3 DataRobot.com 0.9068038441658484 4 CLMS 0.906652903315283 5 ttllbb 0.9060343458177709 6 KDDILABS&Keiku 0.9059718605039866 7 FirstTimeEver 0.9058898193220947 8 xiaochuan 0.9055778412303954 9 Donquote 0.9052017384333861 10 NCCU 0.9050289277229964
11 kyazuki&DT@Keio univ. Ohmori Lab 0.9047145809931961
12/1/15, 12:03 AM KDD CUP 2015
The submission is closed. The final results with private scores will be published in several hours.
Update, July 11:
The submission will be closed at 11:59PM, July 12, 2015 (UTC).
Updates:
1) Many people have asked the definition of "dropout". To better explain the definition, we extracted some information from the log file into a new file named "date.csv". However, all information regarding the data used for this competition has not been changed. So you do not need to change your existing code of algorithms. You can find the details of the file on "data" web page: https://kddcup2015.com/submission-data.html .
The sole purpose of creating this new file is to help you understand the definition of dropout. In brief, the timespan of each course is varied, thus the timespan for calculating dropouts depends on the course. We provide the timespan data of each course in date.csv. In addition, the timespan for calculating each course dropout is 10 days after the last day of that course. Please refer to the description of date.csv for more information about dropouts.
2) Because of this, we made a decision to extend the deadline of the competition to July 12, so everyone can refer to date.csv. Accordingly, we also shorten the time between the competition end date and the date of announcement, which is also July 12 now.
3) Microsoft generously provides their Azure Machine Learning services for KDD Cup participants. Please find the blog here on “Solving the KDD Cup 2015 Challenge Using Azure ML” . This blog provides detailed instruction on how to solve the KDD Cup challenge using Azure ML and achieve an accuracy of 0.87 AUC. This will help participants with a starting point for competing for the KDD Cup and help build even more accurate solutions on top.
For participants who are new to Azure ML, it is a cloud platform for developing machine learning based predictive solutions . It provides a rich UI and battle tested algorithms from Bing and Microsoft Research along with support for R & Python. It also allows users to quickly operationalize their solutions as a webservice.
Background:
Students' high dropout rate on MOOC platforms has been heavily criticized, and predicting their likelihood of dropout would be useful for maintaining and encouraging students' learning activities. Therefore, in KDD Cup 2015, we will predict dropout on XuetangX, one of the largest MOOC platforms in China.
Description
The competition participants need to predict whether a user will drop a course within next 10 days based on his or her prior activities. If a user C leaves no records for course C in the log during the next 10 days, we define it as dropout from course C For more details about log, please refer to the Data Descriptions.
About XuetangX:
XuetangX, a Chinese MOOC learning platform initiated by Tsinghua University, was officially launched online on Oct 10th, 2013. In April 2014, XuetangX signed a contract with edX, one of the biggest global MOOC learning platform co-founded by Harvard University and MIT, to acquire the exclusive authorization of edX’s high-quality international courses. In December 2014, XuetangX signed the Memorandum of Cooperation with FUN, the national MOOC platform in France, to make bilateral effort in course construction, platform development and other aspects. So far, there are more than 100 Chinese courses and over 260 international courses available on XuetangX.
1432709453426543.png
About Contact
Login Email
12/1/15, 12:03 AM KDD CUP 2015 Remember me Login forget/change my password Sign up
Each individual may only have one single account
Displayed Name
Your Unique Identity *
Real Name
Your Real / Legal Name *
Your real name won't be displayed. However, you must type in your real name to participate the competition.
E-mail Address
To Retrive Passwords *
You can use your email to login.
My Password Your password * Confirm Password Comfirm password * Verification code Verification code Sign me up
12/1/15, 12:03 AM KDD CUP 2015
科技部補助計畫衍生研發成果推廣資料表
日期:2015/11/30科技部補助計畫
計畫名稱: 文本史料資訊檢索與探勘工具之開發與實踐 計畫主持人: 蔡銘峰 計畫編號: 102-2420-H-004-052-MY2 學門領域: 數位人文無研發成果推廣資料
102年度專題研究計畫研究成果彙整表
計畫主持人:蔡銘峰 計畫編號:102-2420-H-004-052-MY2 計畫名稱:文本史料資訊檢索與探勘工具之開發與實踐 成果項目 量化 單位 備註(質化說明 :如數個計畫共 同成果、成果列 為該期刊之封面 故事...等) 實際已達成 數(被接受 或已發表) 預期總達成 數(含實際 已達成數) 本計畫實 際貢獻百 分比 國內 論文著作 期刊論文 0 0 100% 篇 研究報告/技術報告 0 0 100% 研討會論文 3 3 100% 1. 江子揚、薛 化元、劉吉軒、 蔡銘峰、黃文全 、甯格致。數位 人文脈絡下的史 學應用研究--「 自由中國」內涵 之檢證與詮釋。 第五屆數位典藏 與數位 人文國 際研討會 ,2014。 2. 甯格致、劉 吉軒、薛化元、 蔡銘峰。關聯式 文本探勘資訊探 索實驗平台設計 --以「二二八事 件臺灣本地新聞 史料彙編」為例 。第五屆數位典 藏與數位人文國 際研討會 ,2014。 3. 甯格致、劉 吉軒、薛化元、 蔡銘峰。以概念 場域相似度為基 礎之論述輪廓與 情感分析-– 以 「二二八事件臺 灣本地新聞史料 」為例。第六屆 數位典藏與數位 人文國際研討會 ,2015。專利 申請中件數 0 0 100% 件 已獲得件數 0 0 100% 技術移轉 件數 0 0 100% 件 權利金 0 0 100% 千元 參與計畫人力 (本國籍) 碩士生 5 5 100% 人次 博士生 0 0 100% 博士後研究員 0 0 100% 專任助理 0 0 100% 國外 論文著作 期刊論文 3 3 30% 篇 1. Ming-Feng Tsai, Chih-Wei Tzeng, Zhe-Li Lin, and Arbee L.P. Chen. Discovering Leaders from Social Network by Action Cascade. Social Network Analysis and Mining, 4(1): 165, 2014. 2. Yu-Xun Ruan, Hsuan-Tien Lin, and Ming-Feng Tsai. Improving Ranking Performance with Cost-sensitive Ordinal Classification via Regression. Information Retrieval, 17(1): 1-20, 2014. 3. Chieh-Jen Wang, Yung-Wei Lin, Ming-Feng Tsai, and Hsin-Hsi Chen. Mining
Different Aspects for Diversifying Search Results. Information Retrieval, 16(4): 452-483, 2013. 研究報告/技術報告 0 0 100% 研討會論文 6 6 30% 1. Ming-Feng Tsai and Chuan-Ju Wang. Financial Keyword Expansion via Continuous Word Vector Representation s. Proceedings of the 2014 International Conference on Empirical Methods in Natural Language Processing (EMNLP '14), 2014. 2. Chih-Ming Chen, Hsin-Ping Chen, Ming-Feng Tsai, and Yi-Hsuan Yang. Leverage Item Popularity and Recommendation Quality via Cost-sensitive Factorization Machines. Proceedings of the 2014 IEEE International Conference on Data Mining (ICDM '14),
3. Shu-Hao Yeh, Chuan-Ju Wang, and Ming-Feng Tsai. Corporate Default Prediction via Deep Learning. Proceedings of the 34th International Symposium on Forecasting (ISF '14), 2014. 4. Chih-Ming Chen, Ming-Feng Tsai, Jen-Yu Liu, and Yi-Hsuan Yang. Music Recommendation Based on Multiple Contextual Similarity Information. Proceedings of the 2013 IEEE/WIC/ACM International Joint Conferences on Web Intelligence and Intelligent Agent Technology (WI-IAT '13), 2013. 5. Chuan-Ju Wang, Ming-Feng Tsai, Tse Liu, and Chin-Ting Chang. Financial Sentiment
Risk Prediction. Proceedings of the 6th International Joint Conference on Natural Language Processing (IJCNLP '13), 2013. 6. Chih-Ming Chen, Ming-Feng Tsai, Jen-Yu Liu, and Yi-Hsuan Yang. Using Emotional Context from Article for Contextual Music Recommendation . Proceedings of the 21th ACM international conference on Multimedia (MM '13), 2013. 專書 0 0 100% 章/本 專利 申請中件數 0 0 100% 件 已獲得件數 0 0 100% 技術移轉 件數 0 0 100% 件 權利金 0 0 100% 千元 參與計畫人力 (外國籍) 碩士生 0 0 100% 人次 博士生 0 0 100% 博士後研究員 0 0 100% 專任助理 0 0 100% 其他成果 (無法以量化表達之 成果如辦理學術活動 、獲得獎項、重要國 際合作、研究成果國 際影響力及其他協助 無
字敘述填列。) 成果項目 量化 名稱或內容性質簡述 科 教 處 計 畫 加 填 項 目 測驗工具(含質性與量性) 0 課程/模組 0 電腦及網路系統或工具 0 教材 0 舉辦之活動/競賽 0 研討會/工作坊 0 電子報、網站 0 計畫成果推廣之參與(閱聽)人數 0