國 立 交 通 大 學
資訊管理研究所
碩 士 論 文
一個以賽局理論為基礎的網頁主題區塊擷取演算法
A Game-Theory-Based Algorithm
for Extracting Theme-Block from A Web Page
研 究 生:陳 昌 民
指導教授:羅 濟 群 博士
一個以賽局理論為基礎的網頁主題區塊擷取演算法
A Game-Theory-Based Algorithm
for Extracting Theme-Block from A Web Page
研 究 生:陳 昌 民 Student: Chang-Min Chen
指導教授:羅 濟 群 Advisor: Chi-Chun Lo
國立交通大學 資訊管理研究所
碩士論文
A Thesis
Submitted to Institute of Information Management College of Management
National Chiao Tung University in Partial Fulfillment of the Requirements
for the Degree of Master of Science
in
Information Management June 2009
Hsinchu, Taiwan, the Republic of China
一個以賽局理論為基礎的網頁主題區塊擷取演算法
研究生:陳昌民 指導教授:羅濟群 博士
國立交通大學
資訊管理研究所
摘要
隨著資訊與網路科技的快速蓬勃發展,網際網路已成為目前最龐大的資料 體,由於科技的進步以及使用者人數爆增,每天有數以萬計的網頁產生。而網際 網路也成為使用者最大的資訊來源。資訊爆炸的現代,要在這麼龐大的資料當中 找尋特定主題的相關資料,變成是一件相當重要的研究課題。 因此,本論文提出一個以賽局理論為基礎的網頁主題區塊擷取演算法(a Game-theoRy-based Algorithm for extracting theme-Block from a web page, GRAB),能夠自動地將使用者有興趣的主題區塊自動地辨識出來,並轉換成易 於儲存、檢索與分析的結構化資料,提供不同平台(e.g.手機、PDA)應用的方便性。 本論文針對提出的 GRAB 演算法設計一雛型系統,並設計了兩個實驗,以 實際網頁資料測試驗證演算法的效能。實驗一的結果證明 GRAB 演算法在 10 種 主題的 HTML 網頁具有 70%到 90%的效能,對於新聞網頁的效果特別好。實驗 二從實驗一挑選效能最好的 3 種主題做為資料集,並與現有三種網頁區塊擷取法 比較。實驗結果證明 GRAB 的整體效能優於三種現有方法,其中處理結構化網 頁的效能雖與現有方法差不多,但對於新聞網頁的效能仍優於現有方法;在處理 非結構化網頁則具有 87%到 95%的效能,都優於現有的三種網頁區塊擷取方法。 關鍵字:網頁擷取、資料擷取、主題區塊、賽局理論A Game Theory-based algorithm
for extracting Theme Block from web pages
Student:Chang-Min Chen Advisor:DR. Chi-Chun Lo
Nation Chiao Tung University
Institute of Information Management
Abstract
Because of the rapid development of Information and network technology, Internet has become the largest body of information. The progress of technology and the explosion in the number of users, so there are produced tens of thousands pages every day. Internet has become the largest source of information. In the information explosion times, searching specific topic data in such a huge data is becoming an important topic.
For this reason, this paper presents a Game-theoRy-based Algorithm for extracting theme-Block from a web page(GRAB). It can automatically identify user interested topic blocks, and then converted to easy storage, retrieval and analysis of structured data for providing different platforms (eg. mobile phone, PDA) to facilitate the application.
This paper provides a prototype system based on GRAB algorithm. I design two experiments, and verify the effectiveness of algorithms through the actual web page data. The first experiment results prove that GRAB algorithm in ten topics of HTML web page can achieve 70% to 90% accuracy rate, especially in news web page. The second experiment selects the best three topics from the first experiment results for data sets, and compare with three existing web blocks retrieving methods. The results prove GRAB overall performance is better than three existing methods. Although processing structured web performance is similar to existing methods, but news web performance is better than existing methods. Processing unstructured web performance is can achieve 87% to 95% accuracy rate, and all is better than three existing web blocks retrieving methods
誌謝
首先我要感謝指導教授羅老師在研究所兩年內的細心指導,羅老師做事方法 與態度影響我很多,讓我要求自己做事要更講求效率、具有正確邏輯。老師開放 而不放縱的個性,讓我能自由選擇有興趣的題目,開會時也提供鞭辟入理的建 議,使本論文更加嚴謹。 感謝實驗室的同學、學長姐與學弟妹,特別是要感謝鼎元學長與同儕志華, 給我學術研究上眾多的支持與建議。大蓉、湘婷每次出現總是能帶來歡笑,讓實 驗室氣氛和樂許多。學弟們寫程式認真的態度,也點醒我不少。雖然只相處短短 的時間,大家卻像是一家人。 感謝我的女朋友-韋君,在我心情低落的時候能給我勇氣,在我開心的時候 能與我共享,在我煩悶的時候能逗我開心。全世界就屬妳最瞭解我,妳以後也會 是我的好老婆,我會一直把妳留在身邊。 最後我要感謝一位生命中最重要的人-我的父親。在撰寫論文最後的時刻, 父親因重病住院,因此那陣子時常兩地來回跑,假日就到醫院照顧父親。沒想到 父親還是沒能撐過去,在五月的時候去世了。也因為如此,這篇論文有一部份是 在醫院陪父親的時候寫的,也有一部份是半夜守靈的時候寫的。父親走得突然, 對我的打擊很大,但也同時讓我成熟許多,對人生有更多體悟。 能從交大畢業,是我父親、母親最大的期待與驕傲。我終於沒有辜負您們的 期待,將從這個殿堂離開,到未來另一個殿堂打拼。目錄
摘要... I ABSTRACT...II 誌謝... III 第一章 緒論...1 1.1 研究背景與動機 ...1 1.2 研究目的 ...3 1.3 章節規劃 ...5 第二章 文獻探討...6 2.1DOMTREE架構 ...6 2.2 現有網頁區塊擷取方法 ...72.2.1 Machine Learning(Wrapper Induction)擷取方法 ...7
2.2.2 Automatic Extraction 擷取方法...8 2.2.3 Rule-based Extraction 擷取方法 ... 11 第三章 一個以賽局理論為基礎的網頁主題區塊擷取演算法 ...13 3.1 問題定義 ...13 3.2GRAB 演算法 ...13 3.2.1 GRAB 演算法步驟 1:轉換(Transformation) ...15 3.2.2 GRAB 演算法步驟 2:篩選(Selection) ...18 3.2.3 GRAB 演算法步驟 3:精煉(refinement)...46 第四章 系統實作與分析...50 4.1 系統實作 ...50 4.1.1 DOM Tree 轉換模組 ...51 4.1.2 主題區塊樹轉換模組...52 4.1.3 資訊含量計算模組...53 4.1.4 賽局決策模組...53 4.1.5 主題區塊樹調整模組...54 4.1.6 主題區塊樹擷取模組...55 4.2 實驗結果與討論 ...56 4.2.1 實驗環境與限制...56 4.2.2 實驗設定...57 4.2.3 實驗評估方式...57 4.2.4 針對各領域的效能(實驗一)...58 4.2.5 與現有擷取方法比較(實驗二)...60 4.2.6 總結...64 第五章 結論與未來研究...65 參考文獻...66
圖目錄
圖 1、由眾多主題區塊所組成的網頁...3 圖 2、結構化網頁...4 圖 3、非結構化網頁...5 圖 4、HTML 語法範例與對應的 DOMTREE結構 ...6 圖 5、DELA資訊擷取系統的架構圖 ...9 圖 6、一般化節點與資料區域...10 圖 7、DEPTA 系統架構 ...10 圖 8、網頁轉換成 DOMTREE架構 ...15 圖 9、原始網頁與 HTML/XHTML 格式之對應...17 圖 10、資訊含量不同之主題區塊...18 圖 11、瀏覽新聞網頁的眼球移動模式 圖 12、網頁區塊位置之優先順序 ..19 圖 13、各個頂點的座標...20 圖 14、位置區塊座標範圍...21 圖 15、落在不同座標範圍的元件...22 圖 24、套用不同 INLINE NODE的效果...31 圖 25、判斷要獨立成為主題區塊...36 圖 26、較理想的判斷結果...37 圖 27、主題區塊之判斷考量...37 圖 28、PLAYER I與-I...38 圖 29、PLAYER I與-I選擇策略的四種情況 ...40 圖 30、玩家I與玩家-I的資訊含量...40 圖 31、玩家I與玩家-I的納許均衡...43 圖 32、玩家I與玩家-I進行賽局後的決策結果...43 圖 33、玩家I與玩家-I無均衡點...43 圖 34、計算報酬平均最大值...44 圖 35、依優先選擇來決策...44 圖 36、以 DFS 進行搜尋的順序 ...45圖 37、DOM TREE與 THEME-BASED TREE及原始網頁之對應...45
圖 38、STM 演算法 ...48 圖 39、不同資訊含量的相似主題區塊...48 圖 40、整併過的主題區塊樹對應到網頁...49 圖 41、系統主畫面功能...50 圖 42、擷取出來的 HTML 內容 ...51 圖 43、系統架構圖...51 圖 44、DOMTREE轉換模組流程 ...52 圖 45、主題區塊樹轉換模組流程...52 圖 46、資訊含量計算模組流程...53 圖 47、賽局決策模組流程...54 圖 48、主題區塊樹調整模組流程...55 圖 49、主題區塊樹擷取模組流程...55
圖 51、主題區塊正確性實驗數據圖(實驗一)...60 圖 52、與現有三類方法 PRECISION比較圖(實驗二) ...61 圖 53、與現有三類方法 RECALL比較圖(實驗二) ...61 圖 54、與現有三類方法 F-MEASURE比較圖(實驗二)...62 圖 55、處理結構化網頁的 F-MEASURE比較圖(實驗二)...63 圖 56、處理非結構化網頁的 F-MEASURE比較圖(實驗二)...63
表目錄
表 1、文獻探討整理與比較...12
表 2、網頁位置權重...20
表 3、優先順序權重公式對應表...21
表 4、INSIGNIFICANT NODE節點值 ...30
表 5、INLINE NODE節點值...31
表 6、VISIBLE NODE節點值...33 表 7、FORMAT NODE節點值 ...34 表 8、區塊組成內容權重的判斷表...34 表 9、主題區塊的豐富程度...36 表 10、GAME THEORY與主題區塊擷取的關係 ...38 表 11、依圖 30 為範例的報酬計算結果...42 表 12、實驗網頁資料集...56 表 13、主題區塊效能實驗數據(實驗一)...59 表 14、與現有三類方法 PRECISION比較(實驗二) ...61 表 15、與現有三類方法 RECALL比較(實驗二) ...62 表 16、與現有三類方法 F-MEASURE比較(實驗二)...62 表 17、處理結構化網頁的 F-MEASURE比較(實驗二)...63 表 18、處理非結構化網頁的 F-MEASURE比較(實驗二)...64
第一章 緒論
1.1 研究背景與動機
網際網路是目前最龐大的資料環境,科技的進步加上使用者人數爆增,每天有數以 萬計的網頁產生,而網際網路也成為使用者最大的資訊來源。資訊爆炸的現代,要在這 麼龐大的資料當中找尋特定主題的相關資料,是相當不方便的。因此,近年來網頁資料 擷取技術的研究變得相當熱門。 目前的網頁資料擷取技術主要有三種 [26]:(1) Web Context Mining
從網路頁的內容中擷取出有用的資訊,然後將資料傳送給使用者,內容包含文字、 圖片、影音資訊等。
(2) Web Structure Mining
用來發現網頁間結構的資訊,或以超連結(Hyperlinks)的方式連結兩個相關的網頁之 間的關係。
(3) Web Usage Mining
是以 Data Mining 的技術從網頁中去發現使用者對網頁的使用行為,進而了解與提 升所需提供的網頁服務內容。 一般網頁資料探勘技術(Web Mining),主要探勘的資料皆是以 HTML 的網頁內容為 主。但是以 HTML 建構的網頁內容大多都是缺乏組織且結構鬆散,也因此提升了網頁 資料擷取的難度。網頁資料擷取的相關研究包括資訊檢索、資料擷取、資料探勘、資訊 整合等。這些技術皆是要從大量資料中,擷取出有用的資訊,並可進一步用來決策推論。 人類在閱讀網頁時,會透過許多視覺化線索(visual cues),例如背景顏色、文字大小、 表格排版等線索,來辨認網頁中不同的區域[10]。而且網頁的設計者在建置網頁時,為 了使版面更容易閱讀,通常會把一些相關的內容放在一起,形成一個區域,不同區域之
間就用視覺化分隔(visual separators)來區隔。例如用水平線、空白、框線、對比顏色來 做區隔。這些區域就稱為網頁區塊(block)[9]。
網頁是由多個區塊所構成,一個網頁可以切割成許多個區塊。每個區塊是由特定主 題以及內容所組合成[13, 14],若該區塊可以提供使用者有用的資訊(useful),且對讀者是 有意義的(relevant),那麼就稱之為資訊內容區塊(Informative Content Block)[21, 24]。
以圖 1 為例,方框中的區塊是主題是“頭條新聞",區塊中每一個元件都是在表達 同一個新聞事件,包括新聞圖片、新聞標題、新聞摘要、新聞全文、相關新聞連結等。 從使用者的觀點來看,在瀏覽一個網站時,是以區塊為單位,先找到要閱讀的主要區塊 後,再進一步進行詳讀。以圖 1 的頭條新聞區塊為例,使用者在閱讀時,心中想著要瀏 覽『頭條新聞』的區域,因此網頁一呈現出來之後,目光會先掃描『頭條新聞』,然後 在心中形成大致的範圍,如圖 1 框起來的部份[10]。接著使用者才認知到這個區塊,是 由頭條新聞標題、新聞圖片、新聞標題、新聞摘要、及相關新聞等元件所組成的[9]。 由此可知,每個網頁是由多個不同主題的資訊內容區塊所組成,這些區塊所包含的 元件皆有一定的相關性、都是在講同一件事、且具有較緊密的排版關係。綜合相關文獻, 本研究將這些具有特定主題的資訊內容區塊,定義為主題區塊(Theme Block)。 從網頁中擷取出主題區塊(Theme Block),具有下列三個好處: 第一、解決資訊過載問題 網頁是由許多不同主題的區塊組成,若能夠自動地將這些區塊辨識出來,使用者就 可以只閱讀感興趣的主題區塊。 第二,應用在各種平台 將主題區塊轉換成易於儲存、檢索與分析的結構化資料,例如 XHTML,就可以把 各個區塊應用於手機或 PDA 等視窗較小的智慧型手持設備,只顯示出使用者需要的那 一塊資訊。 第三,個人化網頁 應用於使用者個人化自訂網頁,即使用者可以從各個網頁中取出他需要的區塊,將 所有區塊整合在一起,組成一個對使用者最有資訊價值的個人化網頁。
圖 1、由眾多主題區塊所組成的網頁 來源:www.cnn.com
1.2 研究目的
本論文提出一個以賽局為基礎的網頁主題區塊擷取方法,以『主題區塊』為首要考 量,來處理各種網頁,包括結構化與非結構化網頁,以及含有一筆到多筆記錄的單一網 頁,使得擷取出來的每個『主題區塊』都在描述同一件事,並且是已經將同網頁中相同 主題的區塊做過整合。 本論文之目的有三點:(1)處理結構化及非結構化網頁、(2)處理含有一到多筆記錄 的單一網頁、以及(3)整合內容相似的區塊。這三個研究目的說明如下: (1) 處理結構化及非結構化網頁 目前現有的網頁資料擷取方法,皆是針對結構化網頁[26]來做處理。所謂結構化網 頁,是指網頁內容係由網頁伺服器在後端抓取資料庫的記錄之後,依照固定的樣板格 式,再透過動態網頁技術顯示在頁面上,如圖 2 所示,網頁中每一筆書籍資料的記錄都 是由程式動態產生,因此每筆記錄的樣版格式是相同的。而裡面的圖片與資料則是從後 端資料庫抓取出來。 結構化網頁有兩個特性:(1)具有相同的樣式(pattern)、(2)區塊間彼此相鄰。目前的 網頁區塊擷取技術,大多皆是針對結構化的網頁[26]。如圖 2 中每筆書籍記錄的部分,就是網頁區塊。由此可知,結構化的網頁區塊具有固定的資料型態與架構,擷取結構化 區塊的技術,是先把網頁轉成 DOM Tree 架構[33],再從 DOM Tree 架構中找出多筆相 似的子樹(sub-tree),經由計算子樹間的相似度之後,就可以推斷出哪幾棵子樹是具有相 同樣版格式(pattern),而這些子樹就是網頁中重複出現的重要區塊了。因此現有方法對 於結構化區塊的處理正確率都很高。 圖 2、結構化網頁 來源:http://www.amazon.com/ 然而,只針對結構化網頁的擷取技術,並無法完全適用於真實情況。如圖 3 所示, 網頁工程師通常會為了排版好看、容易閱讀等理由,依照使用者的觀感,自行設計各種 大小不一的樣版格式,而分成各種樣版格式不同的區塊,因此目前仍有許多網頁是非結 構化,而現有的研究在處理非結構化網頁的效能並不高。 (2) 處理含有一到多筆記錄的單一網頁 現有網頁擷取方法,如[17,7],是經由計算網頁裡每筆記錄的相似度,找出共同的 樣式,再建構成要擷取的網頁區塊。這樣的方法在含有多筆記錄的單一網頁有顯著的效 果,但是若遇到只含有一筆或極少記錄的網頁,由於無法跟其他記錄做比較,因此就很 難準確的擷取出區塊。
(3) 整合內容相似的區塊 網頁的眾多主題區塊當中,可能有幾個包含相同主題,若使用者要瀏覽同主題的區 塊,就會希望把同主題的區塊整合在一起。例如一個網站的上方有體育相關的主題區 塊,在下方亦有一個體育相關的主題區塊,這兩個區塊具有相似的主題,但卻是位在相 隔甚遠的兩個地方,可能造成瀏覽者在閱讀時的不方便。因此本論文透過計算區塊間的 相似度,將在 HTML 上不連續、在視覺線索上不相鄰,但區塊內容相似的區塊整合在 一起。 圖 3、非結構化網頁 來源:www.cnn.com
1.3 章節規劃
本論文的章節規劃如下:第一章緒論闡述研究背景、動機、目的,並概括描述研究 的整體架構。第二章文獻探討,概述 DOM Tree 及現有研究對於網頁處理的方法,包括 網頁區塊化、網頁資料擷取,針對各方法之優劣進行比較。第三章為本論文所提出的 GRAB 演算法,可分成(1)建構 DOM Tree、(2)建構主題區塊樹(Theme-based Tree)、(3)主題區塊樹之整併及分割等三大步驟。第四章為系統實作與分析,概述雛形系統之架 構、程序運作流程、及實際畫面。接著設計了兩個實驗來驗證 GRAB 擷取主題區塊出來 的效果,並說明實驗結果與討論。第五章為本論文做總結,進一步描述未來尚可研究的 方向。
第二章 文獻探討
本章首先介紹了 DOM Tree 架構,再介紹現有三大類的網頁資料擷取技術,包括: 經由人工或自動學習的 Machine Learning 方法、找尋重複記錄的 Automatic Extraction、 以及自行定義擷取規則的 Rule-based Extraction。
2.1 DOM Tree 架構
近年來已有許多對於網頁資料處理與擷取方面的研究,絕大多數研究都採用 DOM Tree 架構來表示一個網頁的結構。DOM 的全名是 Document Object Model,由 W3C[33]
所定義的一種規範,將網頁的標籤結構以樹狀資料結構來表示,目的在於表現單一網頁 的結構性。使用 DOM Tree 架構可表現網頁的初步結構,且能夠清楚辨識出標籤之間的 階層關係,在處理標籤、追遡標籤、或搜尋標籤上都極為方便。圖 4 是一個簡單的 HTML 語法範例,以及其對應的 DOM Tree 架構。
圖 4、HTML 語法範例與對應的 DOM Tree 結構 透過樹狀的表示方式,能清楚看出網頁結構中的上下層次關係,以及節點的歸屬關 係。DOM Tree 的基本概念如下[29]:
(1)被 Non-empty Tag(例如 :<html>、</html>、<table></table>等)所涵蓋的內容,都
以樹狀結構中的子節點來表示,並置於 Non-empty Tag(父節點)之下。
(2)Empty Tag(例如:<br>、<hr>、<p>等)部份與其它位於同一個 Non-empty 下的標
2.2 現有網頁區塊擷取方法
網頁資料擷取的方法,可歸納為三大類: (1)Machine Learning、(2)Automatic Extraction、(3)Rule-based Extraction。
2.2.1 Machine Learning(Wrapper Induction)擷取方法
此方法又稱為 wrapper induction。Line Eikvil[15]對 Wrapper 的定義為:由一組擷取 規則,加上應用這些規則來進行擷取動作的程式碼所構成的。所以 Wrapper[28]是一種 自動化的資訊擷取程式,能自動的將文件包含的資訊擷取出來,並透過單一格式顯示出 來。Wrapper induction 則是透過監督式機器學習的方法,讓系統能夠自動根據使用者所 標記的擷取部份來產生擷取規則,再進行內容的擷取,如 SoftMealy[7,8]和 STALKER[12] 的系統。 產生擷取規則的方式可歸納為兩種方式:(1)透過學習、(2)手動直接建立規則。採 取學習的機制來訓練擷取程式,稱為學習法(Learning Rules),事先為系統設計一套學習 演算法,讓程式自動從網頁中學習,進而產生規則,讓系統依循規則進行擷取工作。另 一種方式則稱為建立擷取規則法(Building Rules),是透過定義擷取規則來指示擷取程式 所要進行擷取工作的內容,只要設定好擷取規則,擷取程式就可以工作。
WIEN(WRAPPER Induction ENvironment)系統是由 Kushmerick[18,19]等人提出,能
透過學習方式產生擷取規則。WIEN 由六種模組所組成,模組之間能互相搭配,判斷標 籤的結構,分別處理不同的標籤樣式,產出擷取規則。這六種模組分別是判斷標籤及左 右 兩 方 標 籤 的 LR-Wrapper(Left-Right) 模 組 、 擷 取 標 籤 前 後 左 右 資 訊 的 HLRT-Wrapper(Head-Left-Right-Tail) 模 組 、 以 資 訊 的 前 後 界 定 標 籤 來 做 判 別 的
OCLR-Wrapper(Open-Close-Left-Right)模組、結合 HLRT 與 OCLR 的 HOCLRT-Wraper
模組、以及能處理巢狀網頁的 N-HLRT Wrapper 模組。
Chidlovskii[1]等人提出人 CRR,一開始需要以手工方式來標記要擷取的部份,以便
讓擷取程式做學習,之後再讓程式透過歸納法來產生擷取規則。但無論是經由學習方式 還是手動方式,Wrapper Induction 的效果皆取決於產生出來擷取規則的正確性,若訓練
資料選得不好,或手動標記有誤,皆會影響規則正確性。再者,透過餵養訓練資料(training data)來學習,或者經由手動標記來學習,都非常耗費時間,效率不彰。 2.2.2 Automatic Extraction 擷取方法 此方法則是屬於不須標註(Non-Labeling)的方法,藉由找尋相似或重複資料樣式,自 動找出應該要擷取的部份。其中又可概分成兩類:(1)在同一個網頁內互相比較,比較同 一個網頁內所有資料記錄是否具有相同樣式。(2)在新舊網頁之間比較,例如新網頁與三 天前的舊網頁比較,若有某些記錄的資料有更新或異動,那麼這些記錄就可能是重要的 資訊[30]。
IEPAD[6]、DeLa[15]、MDR[2]、DEPTA[3,4]等系統,皆是屬於 automatic extraction
第一類的方法。其做法是認為所謂重要的資料區塊,是指多筆重複相似的資料記錄(Data Records),因此主要目標,就是設法找出這些重複資料記錄[32]。
IEPAD[6]是 2001 年由張嘉惠博士等人所開發的系統,係以自動化的方式產生
Wrapper 藉以擷取資料。IEPAD 認為每一個網頁中皆含有多筆重複出現的資料,具有相
同的 pattern,若能找到網頁中重複出現的記錄中具有相同的 Prefix 的字串,即是所謂的 Repetitive Pattern。下一步再從這些 Repetitive Pattern 中找到一個滿足使用者所給的
Maximal Repeat 條件,接著計算每個 Pattern 的變異性與密度來決定此 Pattern 是否為真
實的資料記錄,並從剩餘的 Pattern 推導出擷取規則。此方法對於多筆記錄的網頁擷取 能力相當好,但對於網頁中只有單一筆記錄的網頁,則無法進行擷取。
DeLa[15]是在 2003 年由 Wang 等人所發表的系統,主要包含兩大功能:資料擷取與
資料標識。Wang 認為網頁中的資料記錄大多是連續且重複的,若能將網頁中所有標籤 建立出一棵 Suffix-tree 來找出連續重複的樣式(C-Repeated Patterns)。有了連續重複的樣 式,就可以用來產生 Wrapper。圖 5 為 DeLa 系統的架構圖。
圖 5、DeLa 資訊擷取系統的架構圖
來源:Data Extraction and Label Assignment for Web Databases [15]
MDR[2]為 Liu 等人在 2003 年所發表的系統,Liu 提出兩個概念:一般化節點
(Generalized Nodes)和資料區域(Data Region)。一般化節點用來表示包含多個節點的集
合,此集合裡所有的節點皆具有相同父節點,且所有節點皆左右相鄰;資料區域表示一 個或多個一般化節點之集合,如圖 6 中,灰色網底的節點即為一般化節點,其中節點 5、 6 較相似,同屬於資料區域 1;節點 8、9、10 同屬於資料區域 2;節點 14、15 的一般化 節點,跟節點 16、17 的一般化節點,同屬於資料區域 3。 DEPTA[3]是 Liu 等人在 2005 年所發表的系統,它改善了 MDR 的擷取功能,利用 MDR 所找出來的資料記錄中,透過 Tree Alignment 的方法,將資料轉換成結構化的格
式,能夠存入資料庫中。為了更進一步改善計算 Tree node 相似度的 STM (Simple Tree Matching)演算法,Liu 等人在 2006 提出 ESTM (Enhanced Simple Tree Matching)演算法
[4],在計算兩棵樹的最大符合(maximum matching)的時候,把節點的內容也一併加入考
點的內容皆不同,其權重也應該有所不同。Y.Kim 等人藉由節點值(Node value)的計算, 改善原本的 STM 方法。圖 7 為整個 DEPTA 系統之架構與流程
圖 6、一般化節點與資料區域
來源:Mining Data Records in Web Pages [2]
圖 7、DEPTA 系統架構
S.J. Lim 與 Y.K. Ng 提出 CDA(Change Detection Algorithm),是屬於 automatic extraction 第二類方法[20],將新網頁與舊網頁的網頁結構轉換成分支(Branch),每個分 支分別給予權重值,接著針對分支兩兩進行比較,計算新舊分支的差異度。差異度最大 的分支,就代表新網頁跟舊網頁不同之處。此方法的優點是能將網頁結構轉成易儲存的 表格形式,能節省網頁儲存空間;而缺點是僅能比對出新舊網頁結構化表格的變動,對 於非結構化的異動則無法處理。 2.2.3 Rule-based Extraction 擷取方法 以規則為基礎的擷取方法是最直覺方式。其做法是先定義一組規則,然後以深度為 優先搜尋(Depth First Search, DFS)針對每個節點去做 IF-THEN 的判斷,若判斷之後認為 該節點及其底下的所有子節點可以獨立成為一個主題區塊,則以該節點為樹根,擷取出 整棵子樹,所得到的一棵子樹就是一個主題區塊[10,25]。 Jobbot[32]是范綱岷等人在 2001 年發表的系統,透過樹狀結構來表示網頁的結構, 然後由使用者決定網頁中所要擷取的資訊位置,在樹中建立一條路徑,做為規則來源。 當系統要進行擷取的時候,就會依照先前產生的規則來執行,將指定路徑上的資料擷取 回來,並能透過資訊融合的規則進行資訊整合。
VIPS (Vision-based Page Segmentation)演算法[10,23],是 Yu、Ma 等人在 2003 年提
出,其概念是先把整個網頁以 DOM Tree 架構表示,DOM Tree 中的每個節點,都代表 一個虛擬區塊(Visual Block)。但因為有些區塊太大,必須進一步做切割,分成更小的區 塊。切割的方法是以背景顏色、文字數目、區塊大小等視覺上的線索來做依據,若一個 區塊內的這些特徵差異性太大,就必須將區塊切割成更小。切割出許多虛擬區塊之後, 接下來偵測這些區塊之間的分隔線,依照其權重值來判斷該分隔線是不是重要的。決定 出分隔線之後,所有在分隔線同一邊的區塊都將合併成一個區塊,再針對這個區塊計算 顆粒值(Granularity),又稱為 DoC。若區塊的 DoC 小於某個門檻值,就重複進行切割, 直到所有區塊都滿足門檻值為止。
改規則,只需要修改規則庫即可,核心的擷取程式不必重新撰寫。 然而這樣的方式的缺點是太過於主觀,容易因為規則不足或例外情況等因素,造成 誤判,且網頁結構往往相當複雜,難以制定通用的規則。 這三大類網頁擷取方法共通的優點,是在處理結構化網頁的效能都很高。因為結構 化網頁具有重複的 Pattern,要針對結構化網頁定義規則或從中學習擷取規則,也比較 容易。但這三種方法仍有可以改善的空間,分別整理如表 1 所示: 表 1、文獻探討整理與比較 網頁擷取方法 現有研究 方法概述 改善空間 Machine Learning (Wrapper Induction) SoftMealy STALKER WIEN CRR 透過手動或自動方式,讓系 統能夠自動學習,產生擷取 規則,再進行內容擷取 (1) 若 訓 練 資 料 選 得 不 好,或手動標記有誤都會 影響正確性 (2) 非常耗費時間,效率 不彰 Automatic Extraction IEPAD Dela MDR DEPTA 認為網頁中的資料記錄大多 是連續且重複的,若從中找 出重複的 Pattern,就可以用 來產生 Wrapper (1)對於網頁中只有單一 筆記錄的網頁,則無法進 行擷取 (2)對於非結構化或較複 雜的網頁,計算出來的樹 相似度可能效果不彰 Rule-based Extraction Jobbot VIPS 事先定前一組規則,或在使 用者操作時建立規則,等到 要進行擷取時再逐一做判斷 (1)可能因規則不足或例 外情況等因素,造成誤判 (2)網頁結構往往相當複 雜,難以制定通用的規則
第三章
一個以賽局理論為基礎的網頁主題區塊擷取演算法
這一章首先定義本論文要解決的問題,並說明 GRAB 演算法為何能解決這些問題。 接著再介紹 GRAB 演算法的每一個步驟,以及各步驟的計算方法。3.1 問題定義
從一棵 DOM Tree 之中判別出哪些節點可以直接擷取出來,形成一個主題區塊,是 最核心也最重要的部份。在第二章 2.2 節的部份,整理了現有的三大類網頁區塊擷取方 法,以及它們各自的缺點: 採用手動標記的方式,非常耗費時間,效率不彰 非結構化網頁或只含一筆記錄的網頁,難以找出重複相似的資料記錄 定義擷取規則,可能因規則不足而有誤判或例外情況出現 因此,本論文提出一個以賽局為基礎的網頁主題區塊擷取方法(GRAB),透過計算 資訊含量的方式來判斷是否要擷取。資訊含量的計算方式,是站在貼近使用者的觀點, 同時考慮了網頁元件所在的視覺位置,也考慮了不同網頁元件的特性,給予不同權重 值,因此不須要人工建立標記、進行學習、或自行定義規則,也可以針對非結構化網頁, 計算出每個網頁元件的資訊含量,進而判斷是否要組成主題區塊。除了能避免上述三種 方法的缺點外,更利用賽局理論求取最適策略的概念,考慮節點與其他節點的關係,以 及做決策時彼此的影響,讓每個節點做出最適的決策。3.2 GRAB 演算法
本論文所提出的 GRAB 演算法可分成三個步驟(Step): Step 1 轉換(Transformation) 此步驟的目的是將原始網頁轉換成 DOM Tree 的樹狀架構,概略的表現整個網頁結 構及階層性,並且對於網頁也有初步的區隔。Input:HTML 網頁
(1) 利用 Tidy 套件,清除不必要的 Tag
(2) 修復有錯的 Tag
(3) 轉換成 XHTML 格式,即代表一棵 DOM Tree 的架構
Output:XHTML 檔案(DOM Tree)
Step 2 篩選(Selection)
此步驟的目的,是在 Step 1 產生的 DOM Tree 中,逐一計算 DOM Tree 裡面每一個 節點的資訊含量,再透過正規式的賽局(Normal Form Game)的方式,判斷該節點是否可 以自己獨立成為一個主題區塊。在此步驟適合獨立成為主題區塊的節點,將逐一加入主 題區塊樹(Theme-based Tree),漸漸形成一棵樹。步驟 2 又可細分成兩個小步驟:
Step 2.1 挑選主題區塊
Input:DOM Tree
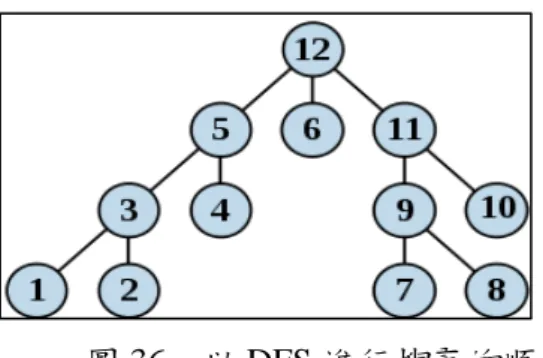
透過以深度為優先搜尋(DFS)方式,遞迴的處理每個節點
(1) 計算節點的資訊含量(Information Content, IC)
(1-1)計算所在位置權重(Position Weight, PW) (1-2)計算元件權重(Component Weight, CW) (1-3)經由 PW、CW、以及子節點資訊含量的和,算出自己的資訊含量 (2) 節點進行賽局決策 (2-1)自己節點的報酬和下面所有子節點的報酬進行賽局 (2-2)找出雙方均衡點,決定要獨立成主題區塊的節點,就暫存起來 Output:所有決定要獨立的主題區塊 Step 2.2 建立主題區塊樹 Input:所有決定要獨立的主題區塊 (1) 從最後要獨立的主題區塊開始,逐一建構成一棵樹 Output:主題區塊樹(Theme-based Tree)
Step 3 精煉(Refinement) 此步驟的目的,是調整上個步驟所產生的主題區塊樹,同主題的區塊進行合併,主 題性不足的區塊,也就是小於門檻值的節點,將放入步驟二,繼續分割。最後,會得到 一棵調整過後的主題區塊樹,其中的每一個樹葉節點,就是一個主題區塊。 Input:Theme-based Tree 逐一處理 Theme-based Tree 的每個節點 (1) 若資訊含量大於門檻值 H,代表主題性已足夠,不須要再精煉 (2) 若資訊含量小於門檻值 L,代表主題性不夠,要放入 Step 2 再處理一次 (3) 若資訊含量介於 H 與 L 之間,則先標記起來。 (4) 所有已標記的節點,用 TSTM 演算法計算相似度,相似的節點合併成一 個一般化節點(Generalized Node) Output:Refined Theme-based Tree
以下就用三個小節來詳細說明 GRAB 演算法的三個步驟。 3.2.1 GRAB 演算法步驟 1:轉換(Transformation)
一般的 HTML 網頁,可以先經由轉成 XML 格式之 XHTML,處理掉 HTML Tag 的 缺漏問題,再清除不必要的 tag,例如 JavaScript、註解等資訊後,轉換成 DOM Tree 的 樹狀架構。如圖 8 所示:
圖 8、網頁轉換成 DOM Tree 架構
DOM Tree 架構就代表網頁的階層架構,其中每一個節點都是一個 HTML Tag。但
有意義的網頁區塊資訊。如圖 8 所示,若只取出<TD>這一個節點的內容,並無其他意 義;若是取出包含<TD>之下的整棵子樹,亦即取出<TD> <A …> <A …> <A …> <A …> <A …> </TD>就相當於擷取出這個表格的一個儲存格的內容,這就有意義了。因此在本
論文中,要取出某個節點的內容,指的就是擷取出該節點之下的整棵子樹。 在 W3C 的 HTML 規格書中,HTML DOM node 可分成三種:
(1)Insignificant node
無法在瀏覽器上顯示出來的節點。此類的節點包括只含有空白的節點、換段符號、 等等,例如註解文字、隱藏的 tag(例如<INPUT type=hidden>)等等。值得注意的
是<BR>並不是 Insignificant node,它是屬於 line-break node。 (2)Inline node 會影響文字顯示外觀的 html tag,包括:<A>、<ACRONYM>、<ABBR>、<B>、 <BIG>、<CITE>、<CODE>、<DEL>、<DFN>、<EM>、<FONT>、<I>、<INPUT>、<INS>、 <NOBR>、<KBD>、<Q>、<SAMP>、<SMALL>、<STRONG>、<SUP>、<SUB>、<TT>、 <U>、<VAR>等。 (3)Line-break node
既不屬於 Insignificant node,也不屬於 Inline node 的節點,就歸類為 Line-break node。 在本論文中,為了更明確地分辨節點的屬性及階層關係,因此將 W3C 定義的 Line-break node 擴充為以下兩種節點:
(1)Visible node:可以直接在瀏覽器上看到的節點,其下沒有子節點。包括以下幾個:
Text node:僅包含文字內容的節點
Url node:具有超連結功能的節點,如:<a href=”…”>
Image node:其內容為圖片、或 Flash 等能夠直接在瀏覽器上看見的物件 separate node:HTML tag 本身就具有分隔效果,如:<hr>
Free format node:包含多個 Visible node,且 Visible node 之間不相似。例 如同時包含圖片和文字的節點。
Area format node:本身具有區隔性,能將內容做表格式的呈現,如: <table>、<div>、<span>、<form>等
List format node:包含多個 Visible node 或 Format node ,且是以相似格式 重複出現
Combined format node:包含多個 Visible node 或 Format node
圖 9 描述了將網頁元件處理成 XHTML 的過程。首先,一個網頁會包含著各種元件, 其中註解、JavaScript、CSS 樣式等非必要的資訊,要先在這個步驟中拿掉,僅留下 HTML Tag。接下來,將 HTML 轉換成符合 XML 規範的 XHTML 格式。本論文是利用 Tidy 套 件來處理,Tidy 可在各種語言上執行,能夠自動判斷及修復容易寫錯的 HTML 標籤, 不論是標籤的順序,或是標籤是否有結尾等等,接著可以透過標準的轉譯方式,將合法 的 HTML 轉換成為 XML 格式的檔案。 此階段產出的合法 XHTML 檔,就是一個 DOM Tree 的架構。一個合法的 XHTML 檔,會有一個唯一的根節點,其下有數個子節點,每個子節點之下還有其他子節點。相 對於一棵 DOM Tree,就如同樹根、子樹節點、樹葉節點等概念。
在轉換成 XHTML 的過程中會為每個節點加入兩個屬性:ccmID(Check Content for Mark Identify)及 nodeType。ccmID 的值從 1 開始遞增,並且是從<BODY>標籤開始寫入,
因此所有 DOM Tree 的根節點都是<BODY>。而 nodeType 則是記錄該節點的型態是上述 HTML DOM node 的哪一種。
(a) (b) (c)
3.2.2 GRAB 演算法步驟 2:篩選(Selection)
演算法的第二步驟,是從 DOM Tree 中挑選出適合的主題區塊,並建構成一棵主題 區塊樹(Theme-based Tree)。DOM Tree 架構就代表網頁的階層架構,取出來的一棵子樹, 就相當於擷取出網頁當中的某塊內容。每一個 DOM Tree 節點都要去判斷:它是不是具 有足夠主題性的節點?若不是,是否要繼續往下找?
(1) 挑選主題區塊 (GRAB Step 2.1)
計算資訊含量(Information Content, IC)
學者 R.Song 等人在[16]提出了 Block Importance Model,並在研究中指出,在一個 網頁當中,依照區塊的位置、區域大小、內容量的不同,區塊所擁有的重要性也有所不 同。本論文採取計算資訊含量的方式來判斷 DOM node 是否可以獨立成為主題區塊,所 謂資訊含量,是指每個主題區塊有包含足夠豐富的元件。以圖 10 為例,主題區塊(a)包 含了標題文字、新聞圖片、新聞摘要等資訊,其資訊含量就比較高;而主題區塊(b)只包 含了一張圖片,其資訊含量相對而言就比較低。 當一個節點要判斷自己是否要獨立擷取成為主題區塊時,首先要計算自己節點本身 的資訊含量,若高於門檻值,代表這個區塊的內容夠豐富了,就將這個節點擷取出來。 圖 10、資訊含量不同之主題區塊 來源:www.cnn.com
(a)
(b)
計算資訊含量的方法,是以每個網頁元件的特性來做判斷,網頁設計者在放置這些 元件時,必然有他的目的及考量,事先決定好在這一塊要顯示出哪些資訊內容。因此本 方法更能客觀地貼近使用者的觀點,擷取出對使用者有意義的主題區塊。 資訊含量的採用遞迴計算方式,首先計算每個區塊的所在位置權重(Position Weight, PW)、區塊元件權重(Component Weight, CW)之後,再乘上所有子節點資訊含量的和, 所得到的結果;但若要得知子節點的資訊含量,就要繼續遞迴往下做,直到傳回樹葉節 點的資訊含量。 區塊所在位置權重(Position Weight, PW) 使用者在瀏覽網頁時,眼睛注視網頁位置順序,決定了網頁區塊所在位置的權重。 學者 George[5]針對網頁設計是否影響其使用性進行調查,發現使用者閱讀網頁的順序 是由上到下,由左到右,並且期待在頁面上方找到常用連結,如功能表單、網頁地圖等。 美國 Poynter[22]新聞研究院於 2004 年公佈「第三次眼球追蹤」研究報告,經由實 驗發現了一般使用者在瀏覽新聞網頁時的眼球移動模式也是由上到下,由左至右。如圖 11 所示,使用者在瀏覽新聞網頁時,眼球首先會停留在頁面左上角,然後在左上角附近 稍微瀏覽之後,接下來目光在右邊及左邊來回瀏覽之後,最後才移到右邊及右上角。 圖 11、瀏覽新聞網頁的眼球移動模式 圖 12、網頁區塊位置之優先順序 來源:The Best of Eyetrack III [22]
因此,可以將網頁劃分成4× 的區域,如圖 12 所示,最左上四塊的優先順序最高,4 其次是中間的部份六塊區域,再來是下面及右上角的六塊區域,接著再依照其優先順序 給定不同的權重ρ,如表 2 所示。 表 2、網頁位置權重 優先順序 優先順序權重公式ρ( ) 8 . 0 ) 1 _ (priority = ρ 5 . 0 ) 2 _ (priority = ρ 3 . 0 ) 3 _ (priority = ρ 將整個網頁的高(h)與寬(w)平均分成四等分,則可以計算出每個位置區塊(Position Block)所佔的座標範圍,如圖 13 所示。 圖 13、各個頂點的座標 接下來,每一個位置區塊利用左上及右下座標來定義其範圍,並以 B(i,j)表示,其 中i, j∈{0,1,2,3},B(i,j)代表第 i 行第 j 列的位置區塊座標範圍。因此 16 個位置區塊座標 範圍如圖 14 所示。 ) 0 , 0 ( ,0) 4 (w ,0) 2 (w ,0) 4 3 ( w (w,0) ) 4 , 0 ( h ) 2 , 0 ( h ) 4 3 , 0 ( h ) , 0 ( h ) 4 , 4 (w h ) 2 , 4 (w h ) 4 3 , 4 (w h ) , 4 (w h ) 4 , 2 (w h ) 2 , 2 (w h ) 4 3 , 2 (w h ) , 2 (w h ) 4 , 4 3 ( w h ) 2 , 4 3 ( w h ) 4 3 , 4 3 ( w h ) , 4 3 ( w h ) 4 , (w h ) 2 , (w h ) 4 3 , (w h ) , (w h
圖 14、位置區塊座標範圍 圖 14 列出了 16 個位置區塊的座標範圍,可以看出每一個位置區塊的長與寬都佔網 頁長與寬的 4 1 。因此可推導出下列位置區塊座標公式(B),而每個座標所對應到的優先順 序則如表 3 所示。 表 3、優先順序權重公式對應表 優先順序權重公式ρ( ) 對應到的優先順序 優先順序權重值
(
B(0,0))
ρ 、ρ(
B(1,0))
、ρ(
B(0,1))
、ρ(
B(1,1))
priority_1 0.8(
B(0,2))
ρ 、ρ(
B(1,2))
、ρ(
B(2,2))
、ρ(
B(2,0))
、(
B(2,1))
ρ 、ρ(
B(3,1))
2 _ priority 0.5(
B(0,3))
ρ 、ρ(
B(1,3))
、ρ(
B(2,3))
、ρ(
B(3,3))
、(
B(3,2))
ρ 、ρ(
B(3,0))
3 _ priority 0.3 ⎭ ⎬ ⎫ ⎩ ⎨ ⎧ = ) 4 , 4 ( ), 0 , 0 ( ) 0 , 0 ( h w B ⎭ ⎬ ⎫ ⎩ ⎨ ⎧ = ) 4 , 2 ( ), 0 , 4 ( ) 0 , 1 ( h w w B ⎭ ⎬ ⎫ ⎩ ⎨ ⎧ = ) 4 , 4 3 ( ), 0 , 2 ( ) 0 , 2 ( h w w B ⎭ ⎬ ⎫ ⎩ ⎨ ⎧ = ) 4 , ( ), 0 , 4 3 ( ) 0 , 3 ( h w w B ⎭ ⎬ ⎫ ⎩ ⎨ ⎧ = ) 2 , 4 ( ), 4 , 0 ( ) 1 , 0 ( h w h B ⎭ ⎬ ⎫ ⎩ ⎨ ⎧ = ) 2 , 2 ( ), 4 , 4 ( ) 1 , 1 ( h w h w B ⎭ ⎬ ⎫ ⎩ ⎨ ⎧ = ) 2 , 4 3 ( ), 4 , 2 ( ) 1 , 2 ( h w h w B ⎭ ⎬ ⎫ ⎩ ⎨ ⎧ = ) 2 , ( ), 4 , 4 3 ( ) 1 , 3 ( h w h w B ⎭ ⎬ ⎫ ⎩ ⎨ ⎧ = ) 4 3 , 4 ( ), 2 , 0 ( ) 2 , 0 ( h w h B ⎭ ⎬ ⎫ ⎩ ⎨ ⎧ = ) 4 3 , 2 ( ), 2 , 4 ( ) 2 , 1 ( h w h w B ⎭ ⎬ ⎫ ⎩ ⎨ ⎧ = ) 4 3 , 4 3 ( ), 2 , 2 ( ) 2 , 2 ( h w h w B ⎭ ⎬ ⎫ ⎩ ⎨ ⎧ = ) 4 3 , ( ), 2 , 4 3 ( ) 2 , 3 ( h w h w B ⎭ ⎬ ⎫ ⎩ ⎨ ⎧ = , ) 4 ( ), 4 3 , 0 ( ) 3 , 0 ( h w h B ⎭ ⎬ ⎫ ⎩ ⎨ ⎧ = , ) 2 ( ), 4 3 , 4 ( ) 3 , 1 ( h w h w B ⎭ ⎬ ⎫ ⎩ ⎨ ⎧ = , ) 4 3 ( ), 4 3 , 2 ( ) 3 , 2 ( h w h w B ⎭ ⎬ ⎫ ⎩ ⎨ ⎧ = ),( , ) 4 3 , 4 3 ( ) 3 , 3 ( h w h w B 0 1 2 3 0 1 2 3 } 3 , 2 , 1 , 0 { , , 4 ) 1 ( , 4 ) 1 ( ), 4 , 4 ( ) , ( ∈ ⎭ ⎬ ⎫ ⎩ ⎨ ⎧ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + + = iw jh i w j h where i j j i B由於網頁每個元件的大小不一,可能落在其中一塊座標範圍內,也可能落在好幾塊 座標範圍內。以圖 15 為例,右下角的廣告區塊就同時落在 4 個座標範圍(a、b、c、d) 之內。由此可知,每個網頁元件可能只會落在 1 格內、可能落在同一列內、可能落在同 一行內、也可能落在多行與多列的範圍內。 圖 15、落在不同座標範圍的元件 來源:www.yahoo.com 以下分別概述這四種情況:(1)元件落在同一格內、(2)元件落在同一列內、(3)元件 落在同一行內、(4)元件落在多行及多列之內,並用較粗的藍色方框表示網頁元件,較細 的紅色方框代表位置座標範圍,分別推導元件落在位置區塊的面積權重計算方法。計算 的概念是要設法找出網頁元件落在 16 個位置區塊中的哪幾個?面積有多少?再各自乘上 優先順序權重,就可以算出區塊所在位置權重(PW)。 假設網頁元件的長為 m,寬為 n,左上角座標為(x, y),右上角座標為(x+m, y),左下 角 座 標 為 (x, y+n) , 右 下 角 座 標 為 (x+m, y+n) , 且 (x, y) 是 落 在 ⎭ ⎬ ⎫ ⎩ ⎨ ⎧ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + + = 4 ) 1 ( , 4 ) 1 ( ), 4 , 4 ( ) , (i j iw jh i w j h B 座標範圍內,則:
a
b
c
d
(情況一)元件落在同一格內: 若元件僅落在同一格內,如圖 16,其計算方式就非常簡單,只要算出元件面積,再乘上 所在位置權重即可。 ¾ 公式推導: 元件落在位置區塊的面積權重(PW) = 元件面積×所在權重 =
(
(m.n)×ρ(
B(i, j))
)
(情況二)元件落在同一列內: 元件落在同一列,可能會橫跨好幾條直軸線。假設元件橫跨了 k 條直軸線(k≧1): ¾ 若元件只橫跨 1 條直軸線(k=1),如圖 17,則只需要計算以 4 ) 1 (i w X = + 為直軸 線所劃分出來的左右兩段面積即可。 ) 4 , 4 (iw jh ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + + 4 ) 1 ( , 4 ) 1 (i w j h 4 ) 1 (i w X= + n m ) , (x y m n ) 4 , 4 (iw jh ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + + 4 ) 1 ( , 4 ) 1 (i w j h ) , (x y 圖 16、落在同一格的元件 圖 17、橫跨 1 條直軸線的元件¾ 若元件橫跨 2 條以上直軸線(k≧2),如圖 18,就要計算 3 段面積: (1) 4 ) 1 (i w X = + 直軸線以左的 1 塊面積 (2) 4 ) 1 (i w X = + 直軸線到 4 ) (i k w X = + 直軸線之間,共有(k-1)塊面積 (3) 4 ) (i k w X = + 直軸線以右的 1 塊面積 ¾ 公式推導: 元 件 上 邊 線 與 直 軸 線 相 交 於 ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + y w g i , 4 ) ( 點 , 元 件 下 邊 線 與 直 軸 線 相 交 於 ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + + ) ( , 4 ) ( n y w g i ,g∈[1,2,..,k],則: 元件落在位置區塊的面積權重(PW) = (元件左段面積×所在權重)+ (元件中段面積×所在權重) +(元件右段面積×所在權重)
(
)
(
)
(
)
⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ × × + ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + − + + ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ × × + + ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ × × ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + − =∑
− = ) , ( 4 ) ( ) ( ) , ( 4 ) , ( 4 ) 1 ( 1 1 j k i B n w k i m x j g i B n w j i B n x w i k g ρ ρ ρ ) 4 , 4 (iw jh ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + + 4 ) 1 ( , 4 ) 1 (i w j h 4 ) 1 (i w X = + 4 ) (i k w X = + n m ) , (x y 圖 18、橫跨 k 條直軸線的元件 (情況三)元件落在同一行內: 元件落在同一行,則可能會直跨好幾條橫軸線。假設元件直跨了 t 條橫軸線(t≧1): ¾ 若元件只直跨 1 條橫軸線(t=1),如圖 19,則只需要計算以 4 ) 1 (j h Y = + 為橫軸 線所劃分的上下兩段面積即可。 ¾ 若元件直跨 2 條以上橫軸線(t≧2),如圖 20,就要計算 3 段面積: 4 ) 1 (j h Y = + 橫軸線以上的 1 塊面積 4 ) 1 (j h Y = + 橫軸線到 4 ) (j t h Y = + 橫軸線之間,共(t-1)塊面積 4 ) (j t h Y = + 橫軸線以下的 1 塊面積 4 ) 1 (j h Y= + ) 4 , 4 (iw jh ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + + 4 ) 1 ( , 4 ) 1 (i w j h ) , (x y m n ) 4 , 4 (iw jh ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + + 4 ) 1 ( , 4 ) 1 (i w j h ) , (x y n m 4 ) 1 (j h Y = + 4 ) (j t h Y = + 圖 19、直跨 1 條橫軸線的元件 圖 20、直跨 t 條橫軸線的元件
¾ 公式推導: 元 件 左 邊 線 與 橫 軸 線 相 交 於 ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + 4 ) ( , j q h x 點 , 元 件 右 邊 線 與 橫 軸 線 相 交 於 ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + + 4 ) ( ), (x m j q h ,q∈[1,2,..,t],則: 元件落在位置區塊的面積權重(PW) = (元件上段面積×所在權重)+ (元件中段面積×所在權重) +(元件下段面積×所在權重)
(
)
(
)
(
)
⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ + × × ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + − + + ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ × × + + ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ × × ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + − =∑
− = ) , ( 4 ) ( ) ( ) , ( 4 ) , ( 4 ) 1 ( 1 1 t j i B m h t j n y q j i B m h j i B m y h j t q ρ ρ ρ (情況四)元件落在多行及多列之內: 元件落在多行及多列之內,則可能會同時跨過好幾條軸線。假設元件橫跨了 k 條直軸線, 同時直跨了 t 條橫軸線(k,t≧1): ¾ 若 元 件 只 橫 跨 1 條 直 軸 線 與 1 條 橫 軸 線 , 如 圖 21 , 則 只 需 要 計 算 以 4 ) 1 (i w X = + , 4 ) 1 (j h Y = + 兩條軸線所劃分的四塊面積即可。 ) 4 , 4 (iw jh ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + + 4 ) 1 ( , 4 ) 1 (i w j h 4 ) 1 (i w X = + n m ) , (x y 4 ) 1 (j h Y = + 圖 21、分別跨過 1 條直軸線及橫軸線的元件¾ 若元件橫的、直的皆跨過 2 條以上,就要計算九塊面積,如圖 22 所示: (1) 4 ) 1 (i w X = + 之左, 4 ) 1 (j h Y = + 之上,共 1 塊面積 (2) 4 ) 1 (i w X = + 到 4 ) (i+k w 之間, 4 ) 1 (j h Y = + 之上,共(k-1)塊面積 (3) 4 ) (i k w X = + 之右, 4 ) 1 (j h Y = + 之上,共 1 塊面積 (4) 4 ) 1 (i w X = + 之左, 4 ) 1 (j h Y = + 到 4 ) (j+t h 之間,共(t-1)塊面積 (5) 4 ) 1 (i w X = + 到 4 ) (i+k w 之間, 4 ) 1 (j h Y = + 到 4 ) (j+t h 之間,共(k-1)(t-1)塊面積 (6) 4 ) (i k w X = + 之右, 4 ) 1 (j h Y = + 到 4 ) (j+t h 之間,共(t-1)塊面積 (7) 4 ) 1 (i w X = + 之左, 4 ) (j t h Y = + 之下,共 1 塊面積 (8) 4 ) 1 (i w X = + 到 4 ) (i+k w 之間, 4 ) (j t h Y = + 之下,共(k-1)塊面積 (9) 4 ) (i k w X = + 之右, 4 ) (j t h Y = + 之下,共 1 塊面積
)
1
(
(
2
)
(
3
)
)
4
(
(
5
)
(
6
)
)
7
(
(
8
)
(
9
)
圖 22、跨過多條直軸線及橫軸線的九塊面積¾ 公式推導: 如圖 23,元件上邊線與直軸線相交於 ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + y w g i , 4 ) ( 點,元件下邊線與直軸線相交於 ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + + ) ( , 4 ) ( n y w g i ,g∈[1,2,..,k],元件左邊線與橫軸線相交於 ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + 4 ) ( , j q h x 點,元件右 邊線與橫軸線相交於 ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + + 4 ) ( ), (x m j q h ,q∈[1,2,..,t],則: 元件落在位置區塊的面積權重(PW) = (元件左上面積×所在權重) + (元件中上面積×所在權重) +(元件右上面積×所在權重) + (元件左中面積×所在權重) + (元件中間面積×所在權重) +(元件右中面積×所在權重) + (元件左下面積×所在權重) + (元件中下面積×所在權重) +(元件右下面積×所在權重) ) 4 , 4 (iw jh ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + + 4 ) 1 ( , 4 ) 1 (i w j h 4 ) 1 (i w X = + 4 ) (i k w X = + n m ) , (x y 4 ) 1 (j h Y= + 4 ) (j t h Y = + 圖 23、分別跨過多條直軸線及橫軸線的元件
=
(
)
⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ × ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + − × ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + − ) , ( 4 ) 1 ( 4 ) 1 ( j i B y h j x w i ρ +(
)
⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ × + ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + − ×∑
− = 1 1 ) , ( 4 ) 1 ( 4 k g j g i B y h j w ρ +(
)
⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ + × ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + − × ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + − + ) , ( 4 ) 1 ( 4 ) ( ) (x m i k w j h y ρ B i k j +(
)
⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ × + ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + − ×∑
− = 1 1 ) , ( 4 ) 1 ( 4 t q q j i B x w i h ρ +(
)
⎟⎟ ⎠ ⎞ ⎜ ⎜ ⎝ ⎛ ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ × × + +∑ ∑
− = − = 1 1 1 1 ) , ( 4 4 t q k g q j g i B h w ρ +(
)
⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ × + + ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + − + ×∑
− = 1 1 ) , ( 4 ) ( ) ( 4 t q q j k i B w k i m x h ρ +(
)
⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ + × ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + − + × ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + − ) , ( 4 ) ( ) ( 4 ) 1 ( t j i B h t j n y x w i ρ +(
)
⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ × + + ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + − + ×∑
− = 1 1 ) , ( 4 ) ( ) ( 4 k g t j g i B h t j n y w ρ +(
)
⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ + + × ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + − + × ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + − + ) , ( 4 ) ( ) ( 4 ) ( ) (x m i k w y n j t h ρ B i k j t 區塊元件權重(Component Weight, CW) 學者 George [5]研究指出,讀者在閱讀網頁時,若遇到有加底線、粗體的文字,因 為具有明顯區隔作用,因此讀者的注意力會被吸引過去。網頁中的水平分隔線,也同樣 具有區隔效果,能暫時阻斷讀著繼續閱讀後面的相關內容,因而把注意力集中過去。此 外,粗體框線、表格、不同底色等效果,也具有區隔作用。 這些引人注目的區域,又稱為「熱點區域」,例如聳動的標題、大張的圖片、特殊 文字等,能讓讀者一進入網頁,目光就馬上被吸引過去。一張210×230像素大小的圖片, 就能獲得超過一半受試者的注意,且圖片愈大愈能引起注意[5]。廣告能否吸引到目光,取決於它的位置及大小。研究發現置於首頁上方和左邊的廣 告,最能引人注目,而右邊及下方的廣告則較不引人注意[5]。 依據[5],本論文在 W3C 的 HTML 規格書中定義的三種 HTML DOM 節點,以及本 論文擴充兩類 DOM 節點中,把具有熱點區域效果的區塊元件,給予不同 DOM 節點值 (node value)。 其中在計算面積或元件數目的比例時,會先取自然對數 ln,理由是因為雖然算出來 的比例越大其權重就越高,但不應取線性正比,故取自然對數可以得到較為合理的結果。 (1) Insignificant Node 屬於 Insignificant Node 的 HTML 標籤,如表 4 所列,是瀏覽器上無法顯示出來的 節點。其主要功能是用在網頁的標頭宣告、空白換行、引述文字、註解文字、或做為其 他特定功能的隱藏控制項。這些標籤原則上都不會影響到網頁的呈現,也與網頁上的內 容無關。因此 node value 值皆設為 1。 表 4、Insignificant Node 節點值 作用 HTML 標籤 給定依據 node value 宣告文件 <!DOCTYPE>、<HTML> 、<HEAD>、<BODY>、 <BGSOUND>、<META> 、<STYLE>、<SCRIPT> 1 空白或換段換行符號  、空白內容、<BR> 、<P>、<WBR>、<NOBR> 1 引述文字、段落標籤 <BLOCKQUOTE> 1 註解文字 <!-- --> 1 隱藏的控制項 <INPUT type=hidden> 與內容無關 1 (2) Inline Node 屬於 Inline Node 的 HTML 標籤,如表 5 所示,是會影響網頁上文字顯示外觀的節 點,換句話說,若在一段相同的文字,套上不同的 Inline Node,就會產生不一樣的效果。
如圖 24 所示,在文字上套用<H1>的效果,該段文字就會放大並以粗體顯示;而套用<H6> 的效果,則是會縮小顯示。 圖 24、套用不同 Inline Node 的效果 因此 Inline Node 權重比例的算法,是根據顯示出來的字型樣式、以及字型大小,用 ) ( )
(text size text
B × 表示之。若實際顯示出來是粗體、斜體、刪除線體、上標字、下標字
等有變化的字型樣式,則 B 設為 2,若顯示出來沒有特殊變化,則 B 設為 1。size 則是 實際在網頁上看到的字型大小,若無設定的話預設值是 3。除了依照<FONT>的 size 屬 性來判斷外,其他標籤也換算成相對應的 font size 大小。例如<H2>TEXT</H2>的效果, 就等於<FONT size=5> <B> TEXT </B> </FONT>。
表 5、Inline Node 節點值 作用 HTML 標籤 給定依據 Node value= ) ( )
(text size text
B × 設定字體字型、顏 色、大小之標籤 <FONT> 字體愈大,權 重愈高 B=1 size 依照其<FONT>標籤內 size 屬性而定,預設是 3 設定標題文字之 標籤 <H1> 、 <H2> 、 <H3> 、 <H4> 、 <H5>、<H6> <H1>至<H6> 權重由大至小 B=2 <Hn>的 size 為:7-n 置中對齊之標籤 <CENTER> B=2,size=3 粗體文字標籤 <B>、<STRONG> B=2,size=3 斜體文字標籤 <ADDRESS> 、 <CITE> 、<DFN> 、<EM>、<I> 設定的內容愈 多,權重愈大 B=2,size=3 <H1>Test1</H1> <H6>Test2</H6>
加線文字標籤 <S> 、 <STRIKE> 、<U> B=2,size=3 固定字寬字體標 籤 <CODE>、<KBD> 、 <LISTING> 、 <SAMP> 、 <TT> 、<VAR>、<XMP> B=1,size=3 放大與縮小字型 <SMALL> 、 <BIG> B=1,<SMALL>的 size=2 <BIG>的 size=4 上標字與下標字 <SUP> 、 <SUB> 、 <ACRONYM> 、 <ABBR> 、 <DEL>、<INS>、 <Q> B=2,size=2 (3) Visible Node 屬於 Visible Node 的 HTML 標籤,是可以實際在瀏覽器上看到,且其下沒有包含子 節點。如表 6 所示,Visible Node 包括文字、超連結、圖片、分隔線等。Node value 的 算法,就依照該 Visible Node 與整個網頁所佔的比重。例如 Text node 就是計算該段文字 與整個網頁的文字之比例。
值得注意的是,超連結的計算方式有考慮內部連結所佔的比例。若網頁中的超連結 是連到同一部 Web Server 或同一個 domain name,就屬於內部連結,可能是選單目錄之 類;反之若是連到外部的 Web Server 或 domain name,就屬於外部連結,可能是廣告或 相關網站。因此內部連結愈多,則權重值就愈高。
水平分隔線(Separate node)本身就具有分隔效果,但它的資訊量並不多,因此 Node value 設為 0.5。
表 6、Visible Node 節點值
作用 HTML 標
籤 給定依據
Node value
Text node #TEXT
字數愈多,權重 愈大 ) ln( ) ln( tCount WebPageTex TextCount 其中 TextCount 為節點字數, WebPageTextCount 為網頁所有字數
Url node <A>
字數愈多,權重 愈大;內部連結 權重大於外部 連結 et urlT nt URLTextCou × arg URLTextCount 為超連結字數 若為內部連結,則 urlTarget=2 若為外部連結,則 urlTarget=1 Image node <IMG> 、 <MAP> 、 <AREA> 、 <MARQU EE> 、 <EMBED> 長、寬愈大,權 重愈大 ) ln( ) ln( PageHeight PageWidth height width × × width 與 height 為圖片的寬與高 PageWidth 與 PageHeight 為網頁的寬與高 Separate node <HR> 比相鄰節點大 0.5 (4) Format Node 屬於 Format Node 的 HTML 標籤,其下包含多個子節點,並用特定格式在網頁上呈 現,如表格、表單等,如表 7 所示。因此 Node value 計算方式,是考慮該節點包含了哪 些元件,再計算該節點在網頁上所佔的面積或數目比例。 節點所包含的元件,可分成文字、圖片及互動元件(如文字方框、按鈕…等)三種類 別,[31]定義了元件組成內容的權重判斷表,其權重可參照表 8 進行設定。
表 7、Format Node 節點值 作用 HTML 標籤 給定權重依據 Node value Area format node <TABLE> 、 <TBODY>、<TR>、 <TD> 、 <TH> 、 <CAPTION> 、 <DIV> 、<SPAN> 、 <IFRAME> 長寬愈大,包含 子節點愈多,權 重愈大 Combined format node <FORM> 、 <FIELDSET> 、 <EGEND> 、 <INPUT> 、 <TEXTAREA> 、 <SELECT> 、 <OPTION> 、 <LABEL> 設定的內容愈 多,權重愈大 ) ln( ) ln( a WebPageAre nodeArea × θ nodeArea 為元件所佔面積 WebPageArea 為網頁面積 List format node <OL>、<LI>、<UL> 、 <DL> 、 <DT> 、 <DD> 設定的內容愈 多,權重愈大 ) ln( ) ln( ntCount AllCompone listCount × θ
listCount 為 List format node 數目
AllComponentCount 為網頁所有 元件數目 表 8、區塊組成內容權重的判斷表 區塊組成內容 權重θ 說明 文字 0.75 應是內文 圖片 0.5 只有圖片 文字+圖片 1 內文 只有互動元件 0 沒有內容 文字+互動元件 0.1 可能為登入或搜尋區塊 圖+互動元件 0.1 可能為登入或搜尋區塊 文字+圖+互動元件 0.25 可能為登入或搜尋區塊,但考慮其多樣 性,權重稍高
算出 Node Value 之後,就可進一步計算區塊元件權重(Component Weight, CW),其 算法是本身節點的 Node value 與所有兄弟節點的 Node value 總和之比率:
∑
==
i ns j j i in
NodeValue
n
NodeValue
n
CW
1(
)
)
(
)
(
主題區塊資訊含量(Information Content, IC)
若只單純計算資訊含量,則節點 i 的資訊含量就等於其下所有子節點的資訊含量總 和,乘上獨立節點比率之後,再加上節點 i 的區塊位置權重、節點 i 的區塊元件權重, 最後再乘上區塊階層權重,公式如下所示:
ε
×
⎟
⎠
⎞
⎜
⎝
⎛
+
+
+
×
=
∑
=)
(
)
(
)
1
)
(
(
(
)
(
1m
PW
N
CW
N
n
k
child
IC
N
IC
m kvel
NumberOfLe
level
×
1
=
ε
其中 IC(N)為節點 N 的資訊含量;IC(child(k))為節點 N 底下第 k 個子節點的資訊含 量;m 為節點 N 底下所有子節點的個數;n 為節點 N 底下選擇要獨立的子節點個數,其 中 n≦m。 要考慮獨立節點權重( 1 + m n ),是因為如果節點 N 底下要獨立的子節點愈多,就代表 N 節點底下擁有愈多重要的子節點,因此節點 N 的資訊含量就相對變大。分母 m+1 的 用意是因為樹葉節點的子節點數目為 0,要避免分母為 0 的情況。 資訊含量的計算方法,是考慮其下所有子節點資訊含量的和以及要獨立子節點比 率,再乘上自己的區塊位置權重、區塊元件權重。為了不讓根節點的資訊含量愈算愈大, 所以要計算區塊所在的階層權重ε
。level 為該節點所在的階層,NumberOfLevel 是整棵 樹的層級數。例如一棵樹有五層,則第二層的階層權重為: 0.4 5 1 2× = 用賽局進行決策 當任一節點算出資訊含量後,就要進行決策: ¾ 若資訊含量大於或等於門檻值,就選擇獨立成為一個主題區塊 ¾ 若資訊含量小於門檻值,就選擇不獨立。 以圖 25 為例,圖 25(a)的 TR 經過計算資訊含量後,決定要獨立成為主題區塊(TB1); 而 TR 下面的兩個 TD 子節點(以 TDs 表示)經過計算資訊含量後,也決定要獨立成為主 題區塊(TB1-1 與 TB1-2),如圖 25(b)。那麼就會形成圖 25(c)的情況,一個區塊內包含了 兩個子區塊,而這兩個子區塊的內容各是一張圖片及一段文字。 圖 25、判斷要獨立成為主題區塊 但這種結果並非最好,因為它使用不必要的區塊來包含不夠豐富的子區塊。由表 9 可以看出,主題區塊 TB1 裡面就包含了較完整的一段 HTML 碼,而 TB1-1 與 TB1-2 包 含著不完整的 HTML 碼。較好的情況應該是如圖 26 所示,TR 獨立成為主題區塊 TB1, 而 TDs 不獨立,那麼 TR 獨立之後的區塊,就包含了底下 TDs 的內容,代表 TR 合併了 TDs。如此一來,只用了一個區塊,且這個區塊的內容就夠豐富,相當於一筆資料列。 表 9、主題區塊的豐富程度 Themeal block(TB) HTML code
TB1 <tr> <td><img …></td> <td>#TEXT</td> </tr> TB1-1 <td><img …></td> TB1-2 <td>#TEXT</td> (a) (b) (c)