認知能力與一般化強化學習–凱因斯選美賽局實驗之實證分析 - 政大學術集成
69
0
0
全文
(2) 謝辭 當寫下這些字句時,表示我的學生生涯即將畫下一個句點,從兩年前入學至 今日完成論文取得碩士學位,這一路上要感謝的人真的太多太多,實在無法一一 道盡, 這二年的碩班生活,由衷地感謝政大經濟學系的栽培,首先要特別感謝 陳 樹衡老師,在學問方面給予我許多建議與指導,因為有您的指導, 我才有今天的 成果, 學生我以最誠摯的心感謝您,並且感謝口試委員 陳建福老師及 戴中擎老 師的建議,使我的論文能更加完臻;也謝謝 業榮學長在論文上的幫助,無論自. 政 治 大 鼓勵下才能走到今天這一步,真的萬分感謝,我想你是我這兩年最常與之相處的 立 己有多繁忙,仍常常跟我一起討論論文,在論文不斷卡關的情況下,也是有你的. ‧ 國. 學. 學長了吧。. 經研所的同學,雖然大家都很忙碌,但每一個人都很善良熱心,我要特別感. ‧. 謝同門的明昌及信璋,在完成論文的這一段期間,有你們的陪伴以及鼓勵,才能. sit. y. Nat. 走到今天這一步,真的非常感謝,也謝謝所有所上的同學,每當論文做到非常煩. n. al. 謝謝每一個曾經幫助過我的人,我都感激在心。. Ch. engchi. er. io. 悶時,都能聽到一些有趣的事情,還有一同出遊唱歌,使我的心情變得愉快,也. i Un. v. 最後,感謝我的父母,讓我在求學的路上無後顧之憂地完成學業,不斷地關 心我,給予我強大的力量,在此將這份喜悅與你們分享。. 民國一○一年七月 蔡明翰.
(3) 摘要 本文研究的主要目的為研究學習行為與智能的相關性,採經驗加權吸引模型 (Experience-Weighted Attraction)來描述受測者在選美競賽賽局(Beauty Contest Game)實驗下的決策及行為,不單只選擇強化學習或信念學習模型,其理由為經 驗加權吸引模型綜合了以上兩個學習的特點;在智能的部分,本文以實驗所得的 工作記憶能力(Working Memory Capacity)分數的高低,來代表智能高低。 從研究結果發現,智能高與低兩類受測者的初始吸引分配,皆與其在第一期. 政 治 大. 的選擇類似,而低智能的受測者在初始吸引部分,所估計的分配結果會與第一期. 立. 之後期間的分配較不相似,這可能代表著低智能的受測者對於類似賽局實驗以及. ‧ 國. 學. 此實驗的分析或想像較差;在ψ的參數估計上,由於低智能的初始吸引與最後一 期猜測的分配較不相似,以理論來說會遞減較快,也就是說會小於高智能所估計. ‧. 的結果,而真實的估計結果也顯示如此,此外,ψ的估計結果,也表示低智能受. y. Nat. io. sit. 測者,對於之前吸引遞減較快,遺忘地較快。本文在δ的部分,高智能的受測者. n. al. er. 明顯地大於低智能的受測者,這表示高智能的受測者,對於失去的報酬比較敏感,. Ch. i Un. v. 會較關心沒有選擇到的數字所能得到的報酬,本文認為此結果可能隱含高智能受. engchi. 測者的認知階層較高。在受測者對於吸引敏感度λ的參數部分,本研究發現,此 兩類受測者並無太大差異,也就是此兩類受測者對於吸引的變動,敏感度差距不 大,也就代表影響人們對於吸引敏感度的原因,可能不是來自於智商高低。由本 文的實證結果,可以發現學習行為與智能的相關性,因此本文建議在往後與學習 行為有關的研究上,也許可以納入智能為主要研究探討的核心。. 關鍵詞:選美競賽賽局、經驗加權吸引模型、工作記憶、智能.
(4) Abstract The purpose of this paper is to explore possible relationships between individual differences in working memory capacity (WMC) and behavioral heterogeneity revealed in a repeated beauty contest experiment. We use ‘experience-weighted attraction’ (EWA) learning, to describe the decision-making and learning behavior of subjects in the beauty contest game (BCG) experiment. In the intelligence section, the level of the experiment from the working memory capacity score, to represent the intelligence high or low.. 立. 政 治 大. We found high and low intelligent of the subject's initial attract allocated all its. ‧ 國. 學. similar to the first period choice. In parameter estimation of ψ, due to the initial attraction of low intelligence subject is less similar to the choice of the following. ‧. periods. According to theory,ψ of the low intelligence subjects will decrease faster,. y. Nat. io. sit. and the estimate of the results also show that. In addition, part of δ, high intelligence. n. al. er. subjects was larger than the low intelligent subjects, which means that subjects of. Ch. i Un. v. high intelligence, more sensitive to lost revenue. We think that may be implied the. engchi. higher intelligent subjects are higher cognitive hierarchy. The sensitivity of players to attractions λ, we found that these two types of intelligent is not much difference. This means that the impact of the sensitivity of players to attractions, may not be from the intelligent level. By the empirical results, we can find the relationship between behavioral heterogeneity and intelligence, so we suggests that it may be incorporated into the intelligent as the main research.. Key Words: Beauty Contest Game, Experience-Weighted Attraction, Working Memory Capacity, Intelligence.
(5) 目錄 目錄. I. 表目錄. III. 圖目錄. IV. 第一章、研究動機. 1. 1.1 研究動機與目的. 1. 政 治 大. 1.2 研究流程. 立. 6. 學. ‧ 國. 第二章、文獻回顧. 4. 2.1 選美競賽賽局與學習模型. ‧. 2.1.1 選美競賽賽局. 6 7. y. al. n. 2.3 總結. sit. io. 2.2 智能與策略行為. er. 2.1.3 小結. Nat. 2.1.2 選美競賽賽局實驗與學習模型. 6. Ch. n engchi U. 第三章、研究資料處理與模型. iv. 15 15 17 20. 3.1 研究資料. 20. 3.2 學習模型. 21. 3.3 資料處理. 25. 3.4 估計方法. 27. 第四章、實證結果. 29. 4.1 實證資料敘述性統計分析. 29. 4.2 經驗加權吸引模型估計結果. 34 I.
(6) 4.3 初始吸引. 37. 4.3.1 初始吸引設定參數估計結果. 37. 4.3.2 初始吸引設定的檢驗(LR test). 39. 4.4 智能與學習模型. 41. 4.4.1 智能分數分為三等份結果. 41. 4.4.2 參數差異的檢驗. 44. 4.4.3 智能分數分為四等份結果. 45. 第五章、結論. 47. 5.1 結論. 立. 參考文獻. 47 50. ‧. ‧ 國. 學. io. sit. y. Nat. n. al. er. 附錄. 政 治 大. Ch. engchi. II. i Un. v. 54.
(7) 表目錄 表 2.1:選美競賽賽局實驗相關文獻. 18. 表 2.2:較高智能對策略思考的影響. 19. 表 3.1:各群組工作記憶分數. 26. 表 4.1:每一期受測者的選擇. 30. 表 4.2:高智能分數受測者的每一期選擇. 31. 表 4.3:低智能分數受測者的每一期選擇. 32. 表 4.4:高低智能受測者的勝率. 32. 立. 政 治 大. ‧ 國. 學. 表 4.5:經驗加權吸引模型參數估計 表 4.6:各分配初始吸引數值. er. n. Ch. 表 4.11:高低智能估計參數結果. 40. sit. io. 表 4.9:LR test 檢定結果(模型二) 表 4.10:LR test 檢定結果(模型三). ‧. Nat. 表 4.8:LR test 檢定結果(模型一). 39. y. 38. 表 4.7:初始吸引設定參數估計結果. al. 36. engchi. i Un. v. 40 40 43. 表 4.12:LR test 檢定結果(以 N(0)取代). 44. 表 4.13:LR test 檢定結果(以ψ取代). 44. 表 4.14:LR test 檢定結果(以 ρ 取代). 45. 表 4.15:LR test 檢定結果(以 δ 取代). 45. 表 4.16:LR test 檢定結果(以 λ 取代). 45. 表 4.17、各個高低智能結果比較表. 46. III.
(8) 圖目錄 圖 1.1:研究流程圖. 5. 圖 3.1:所有人在τ-d 與 τ+d 之間所有選擇的強化. 25. 圖 3.2:贏家在 τ-d 與 τ+d 兩點選擇的強化(假設贏家所選數字為 τ+d). 25. 圖 3.3:輸家在 τ-d 與 τ+d 兩點選擇的強化. 26. 圖 4.1:第一期的選擇(右:高智能 左:低智能). 33. 圖 4.2:第四期的選擇(右:高智能 左:低智能). 33. 圖 4.3:第七期的選擇(右:高智能 左:低智能). 33. 圖 4.4:第十期的選擇(右:高智能 左:低智能). 33. 政 治 大. 立. 35. 圖 4.6:初始吸引設定圖. 37. ‧ 國. 學. 圖 4.5:本研究與 Camerer 的初始吸引參數值. 圖 4.7:高低智能與所有受測者的初始吸引參數值. 42. ‧. 圖 A.1:各個群組各個期間的目標數. sit. y. Nat. 圖 A.2:各個群組的工作記憶分數. io. er. 圖 A.3:所有受測者的選擇頻率. 圖 A.4:第一期的選擇(右:智能前三分之一 左:智能後三分之一). n. al. Ch. n engchi U. iv. 54 54 55 55. 圖 A.5:第二期的選擇(右:智能前三分之一 左:智能後三分之一). 55. 圖 A.6:第三期的選擇(右:智能前三分之一 左:智能後三分之一). 56. 圖 A.7:第四期的選擇(右:智能前三分之一 左:智能後三分之一). 56. 圖 A.8:第五期的選擇(右:智能前三分之一 左:智能後三分之一). 56. 圖 A.9:第六期的選擇(右:智能前三分之一 左:智能後三分之一). 56. 圖 A.10:第七期的選擇(右:智能前三分之一 左:智能後三分之一). 57. 圖 A.11:第八期的選擇(右:智能前三分之一 左:智能後三分之一). 57. 圖 A.13:第十期的選擇(右:智能前三分之一 左:智能後三分之一). 57. 圖 A.14:第一期的選擇(右:智能前四分之一 左:智能後四分之一). 58. 圖 A.15:第二期的選擇(右:智能前四分之一 左:智能後四分之一). 58. 圖 A.16:第三期的選擇(右:智能前四分之一 左:智能後四分之一). 58. IV.
(9) 圖 A.17:第四期的選擇(右:智能前四分之一 左:智能後四分之一). 58. 圖 A.18:第五期的選擇(右:智能前四分之一 左:智能後四分之一). 59. 圖 A.19:第六期的選擇(右:智能前四分之一 左:智能後四分之一). 59. 圖 A.20:第七期的選擇(右:智能前四分之一 左:智能後四分之一). 59. 圖 A.21:第八期的選擇(右:智能前四分之一 左:智能後四分之一). 59. 圖 A.22:第九期的選擇(右:智能前四分之一 左:智能後四分之一). 60. 圖 A.23:第十期的選擇(右:智能前四分之一 左:智能後四分之一). 60. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. V. i Un. v.
(10) 第一章、研究動機. 1.1 研究動機與目的 賽局理論研究的是個體在互相考慮對手策略環境中互動的結果,透過謀略推 估,為一種策略性思考,透過推估對手的行動,以擬訂尋求最大利益的策略,追 求尋求自己最大的勝算或利益。賽局理論用於研究人類的決策及行為,有助於了 解人們在互動過程,如何制訂策略。在一個賽局中,幾個重要的元素包括參與的. 政 治 大. 玩家(players),指賽局中選擇以自身利益最大化的決策主體 (可以是個人,也可. 立. 以是團體,如廠商或國家)、選擇的策略(strategies),以及不同策略組合(strategy. ‧ 國. 學. profile)下每個玩家的報酬(payoffs)。賽局理論可以用來預測人們的行為,如果賽 局理論能夠正確的假設,它不但能夠預測出人們最終的行為,也能夠解釋人們的. ‧. 行為,解釋為何會有如此決策。因此,賽局論應該可以預測,提供解釋,並且建. y. Nat. n. al. er. io. Keynes (1936, P.155-56)提出以下這段話:. sit. 議人們應該採取何種策略。. i Un. v. “professional investment may be likened to those newspaper. Ch. engchi. competitions in which the competitors have to pick out the six prettiest faces from a hundred photographs, the prize being awarded to the competitor whose choice most nearly corresponds to the average preferences of the competitors as a whole…It is not a case of choosing those which, to the best of one’s judgment, are really the prettiest, nor even those which average opinion genuinely thinks the prettiest. We have reached the third degree where we devote our intelligence to anticipating what average opinion expects the average opinion to be. And there are some, I believe, who practice the fourth, fifth, and higher degrees.” 1.
(11) Keynes以一個選美競賽,來形容的投資行為背後的策略思想。這段話說明投 資市場,就像是預測選美大賽的結果,不是要挑每個人各自認為最漂亮的臉蛋, 而是努力預測一般人心目中認為大家公認最漂亮的會是誰。這段話也使人開始思 考,是否人們的推論方式是否真的會如上述所說,推論的程度到達第四、第五或 更高的階層,還是有其他的推論方式,因此有許多研究開始尋找這問題的答案, 而他們在研究實驗中,最常使用選美競賽賽局(Beauty Contest Game)的架構。選 美競賽賽局架構,會因p值的不同,以及所乘上的數字,如所有人選擇的平均數、 中位數或最大值等不同,而有不同的結果,除此之外,實驗中還有許多調整的因 素,如將受測者分為有無實驗經驗或受測者的人數。接著,如果我們考慮以下選. 治 政 美競賽賽局的實驗,假設班上每位同學都從0到100選一個數字,然後算出所有人 大 立 數字的總平均,最接近總平均乘上三分之二的人為獲勝者,並贏得獎金。請問你 ‧ 國. 學. 會如何選擇?在傳統賽局理論中的均衡告訴我們,如果不斷地推論,並刪除不可. sit. y. Nat. 會如此?智能較高的同學會是最大的贏家嗎?. ‧. 能獲勝的策略之後,最後的奈許均衡解,應該為大家都會選擇0,但實際狀況真. io. er. 經濟學家們藉由實驗設計類似的賽局實驗(game experiment),探討賽局在理 論與實際間的差異,在過去的實證的結果中,可以發現大部分的受測者都不會選. al. n. iv n C 擇均衡,這也代表大部分的受測者都違反了傳統經濟學,給定理性預期的假設, hengchi U 為了解釋這種異常的現象,也開始從心理學的文獻中尋求幫助來解釋,而在經濟 的研究中,至少有兩種方向。其一為在原本傳統理性選擇的框架下,將非標準的 表 現 、信 念和 決 策納入 理 論預 測和 觀 察行為 , 另一 為根 據 杜恩 - 奎 因 理 論 (Duhem-Quine thesis) (Cross,1982),認為要將這些異常的現象歸因於特定的假設 理論錯誤是不可能的,這意味著堅持著之前的假設,將可能失去更好的機會去解 釋人類的行為,因此這也有利於開始思考經濟學與心理學之間關聯的可能性(Earl, 1990)。 本文建議將工作記憶能力(Working Memory Capacity)納入分析的核心,其理. 2.
(12) 由為以一般而言,人類的短期記憶(Short-term Memory),在於解釋許多思考和學 習的現象,為一個重要的行為表現(Simon,1990)。工作記憶能力也與一般智力 (Intelligence),有強烈的相關性(Conway et al., 2002; Engle et al., 1999; Kyllonen and Christal,1990),而且也被認為是主要的推論處理要素(Kyllonen, 1996)。有關 於學習,工作記憶能力不只支持透過心智表達所建構的新學習理論(Cantor and Engle,1993),而且也可能有關於自身已知能力的使用 (Daily et al., 2001;Hambrick and Engle,2002) 。學者對於智力的定義對常有不同的看法,而以下四類是較為 普遍所被接受的定義,分別認為智力是抽象思考和推理的能力、智力是學習的能 力、智力是環境適應的能力以及智力是問題解決的能力。根據智力的學習理論,. 治 政 智力代表一個人學習的能力,因此,可用學習法則來解釋智力的性質。Thorndike 大 立 認為學習是一種聯結形成的過程,個人所具之聯結形成能力即為智力,智力有神 ‧ 國. 學. 經生理學之基礎,但也受訓練和經驗影響(Thorndike,1913,引自張春興,1994)。. ‧. 在各種賽局的實驗下,經濟學家們提出許多學習模型(Learning Model)描述. sit. y. Nat. 參賽者的決策及行為,而本文將採用經驗加權吸引模型(Experience-Weighted. io. er. Attraction),來描述受測者在選美競賽賽局實驗下的決策及行為,不單純只選擇 強化學習模型或信念學習模型,其理由為在強化學習模型下,人們不會改變信念,. al. n. iv n C 但真人會改變,而在信念學習模型下,人們不會對實際報酬做出反應,但真人會 hengchi U. 對這些誘因產生反應,經驗加權吸引模型則綜合了以上兩個學習的特點,且在 Camerer and Ho(1999)的實證結果中,模型配適度也比較好。此外;本文也會將 所有參數進行估計,並討論各個參數值的意義,不像過去的實驗並沒有如此討論, 多數只純粹以模型描述策略行為。 綜合以上所述,本文將使用選美競賽賽局實驗的資料,採取學習模型估計, 以學習模型參數更準地來解釋學習行為,並且納入智能為實證研究的核心,觀察 各種不同高低的智能,在選美競賽實驗中的表現以及所估計出的模型參數值,來 探討智能對於學習行為上的差異。. 3.
(13) 1.2 研究流程 本文從實驗經濟出發,利用真人實驗獲得資料,以實證資料代入模型,而實 驗的方法,也參照過去文獻的介紹加以改良。此外,實驗的過程中,也包含認知 能力測驗,本研究在認知能力測驗所得到的工作記憶分數,將代表受測者智能的 高低,而在之後研究,也會使用智能的高低將資料做劃分,並將智能與學習模型 參數估計做結合。 本文研究的主要目的是將實驗中所獲得的資料,以經驗加權吸引模型進行分 析,並將受測者以工作記憶分數做分類,並以各種方法探討不同智能的受測者在. 治 政 經驗加權吸引模型裡的參數是否有明顯差異;此外,本研究也會討論有關初始吸 大 立 引的設定。 ‧ 國. 學. 在第二章,我們會先介紹有關選美競賽賽局實驗以及有關學習模型的文獻,. ‧. 接著會再介紹有關智能的文獻。第三章,本文會介紹研究資料的處理、估計採用. sit. y. Nat. 的模型以及實證所使用的方法,第四章,本文會先對實驗所得資料更進一步探討. io. er. 與分析,之後進行參數估計。在參數估計上,會先估計以經驗加權吸引模型的各 個參數,並與Camerer and Ho(1999)所做的實證結果做比較;此外,會額外再針. al. n. iv n C 對初始吸引的部分作探討;接著會將資料以智能的高低分為三類,將最高的一類 hengchi U. 與最低的一類,進行參數估計,分別比較各個參數之差異,以驗證智能是否對選 美競賽賽局的推論學習行為有所影響:最後,再將資料以智能高低分為四類,同 樣也是取用最高的一類與最低的一類的受測者資料,進行參數估計,並與劃分為 三類群體的參數作比較,以檢驗此結果是否會更強烈的支持智能對選美競賽賽局 推論行為的影響,亦或是違反此假設,並且觀察是否在更極端的受測者中有不同 的學習行為。. 4.
(14) 研究動機與目的. 文獻回顧. 研究資料處理與模型. 立. 政 治 大. ‧. ‧ 國. 學. EWA 模型參數估計. Nat. n. al. er. io. sit. y. 初始吸引設定分析. Ch. engchi. i Un. 不同智能下的 EWA 模型 參數估計. 實證結果與分析. 圖 1.1:研究流程圖 5. v.
(15) 第二章、文獻回顧. 2.1 選美競賽賽局與學習模型 本文在以下的部分,由於內容包含賽局架構以及其相關文獻,內容繁多,所 以將會先介紹選美競賽賽局的基本架構,接著回顧一些相關的文獻,在最後的部 分並先做個小結。. 2.1.1 選美競賽賽局. 政 治 大 基本的選美競賽賽局說明如下:許多玩家同時選擇一個在 0 至 100 之間的數 立. ‧ 國. 學. 字,贏家為猜中最接近目標數的玩家,目標數的定義為 p 乘上所有玩家選擇數的 平均,例如 p=2/3,p 值為正,且所有玩家都知道,相同賽局被重覆數期,而且. ‧. 受測者會被告知每一期的結果,受測者們會互相關心別人推測的深度。在賽局理. sit. y. Nat. 論上,對於 p<1 的賽局符合唯一均衡解,所有人最後都會選擇0;而對於,p>1. n. al. er. io. 區間的最高上限則是均衡。對於 p<1 的每一期,所有玩家們應該都猜測數字為. i Un. v. 0,因此每個人都是贏家。 如果其他玩家都選擇 0,那麼猜測偏離 0 的數字,將. Ch. 產生零的報酬,這是顯而易見的。. engchi. 舉個例子,對於任何人數 n>2 且 p=2/3,一個理性玩家會消去所有大於 100‧(2/3)=66.667 的數,弱勢支配策略為 66.667。我們發現新的賽局區間為[0, 66.667],如果玩家們相信其他人也會消去大於 66.667 的數,則 66.667‧(2/3)= 100‧(2/3)2=44.444 會弱勢支配所有大於 44.444 的數,區間變為[0,44.444],之 後不斷地反覆刪除劣勢策略,直到均衡 0。也就是說,理性的玩家不會隨機選擇 數字或選擇較喜好的數字, 對於理性玩家來說,也不會選擇超過 100p 的數字, 因為那是劣勢策略。此外,如果某玩家相信其他玩家也是理性的,那他將不會選 超過 100p2 的數字,之後若他又相信其他人是理性,而其他人也如此認為,則所 6.
(16) 選數字將不會超過 100p3,然後依此類推。反覆支配的觀念,在賽局理論上是非 常重要的;而在研究被應用有多深度的推論層級時,選美競賽賽局是一個理想的 工具。 選美競賽賽局相對於其他賽局,如複動機(mixed-motive)賽局,選美競賽賽 局為一般的常數和(constant-sum)形式賽局,所以玩家可以預期一些非策略性觀點, 如公平性,將不會被用來解釋違反重覆支配的行為;因此,選美競賽賽局可以專 注於推論策略上的問題,額外的好處是選美競賽賽局不用複雜的賽局架構或改變 報酬的架構,就可以很容易地改變達到均衡時,劣勢策略所需要被反覆刪除的次 數,而選美競賽賽局的其他特色,如在第一期時的行為,經常遠離均衡點,且隨. 治 政 著時間經過,選擇會漸漸收斂至均衡(Nagel,1995)。一些學習模型,已經在選美 大 立 競賽賽局被嘗試用來解釋,隨著時間經過後的確切行為。如:反覆最佳回應模型 ‧ 國. 學. (Iterated Best Response Models),學習方向理論(Learning Direction Theory),簡單. ‧. 的 強 化 理 論 (Simple Reinforcement Model) , 基 本 規 則 強 化 模 型 (Rule-Based. sit. y. Nat. Reinforcement Model),經驗加權吸引 (Experienced-Weighted Attraction),而在大. io. er. 部分的文獻回顧發現, 隨著時間經過玩家會極少去學習更高層級的推論。在研 究學習行為上,選美競賽賽局是非常有用的,因為其不會立刻地收斂,可以使我. n. al. 們能夠研究觀察動態的過程。C h. engchi. i Un. v. 2.1.2 選美競賽賽局實驗與學習模型 首先,本文會先介紹每篇文獻的實驗想法與設計,接著敘述實驗觀察與結果, 最後描述各個作者為了解釋及描述這些結果,以及所提出的學習模型;此外,本 文將依照時間順序來介紹每篇文獻。 Nagel (1995)首先提出選美競賽賽局(p-Beauty Contest Game)實驗,每次的實 驗人數為 15 至 18 人。作者將實驗分為三種分別為 p 值為 1/2、2/3 及 4/3,在 p 值為 1/2、2/3 的實驗中,可以選擇的區間為 0 至 100,而在 p 值為 4/3 的實驗中,. 7.
(17) 可以選擇的區間為 100 至 200;依賽局理論而言,在 p 值為 1/2 及 2/3 的狀況下, 奈許均衡(Nash equilibrium)為 0;而 p 值為 4/3 時,奈許均衡(Nash Equilibrium) 為 200。Nagel 認為選美競賽賽局不用複雜的賽局架構或改變報酬架構,就可以容 易地改變達到均衡時,且選美競賽賽局為常數和(Constant-Sum)賽局,不像複動 機 (Mixed-Motive) 賽局,可以專注於有關推論策略的問題,且玩家在選美競賽 賽局第一期時的行為,經常遠離均衡點,隨著時間經過,選擇才會漸漸收斂至均 衡。 在實驗流程上,Nagel 在 1 至 3 回合採 p=1/2 模擬,4 至 7 回合採 p=2/3,而 8 至 10 回合採 p=4/3,贏家可以獲得大約 13 塊美金的獎勵,Nagel 在第一期發現,. 治 政 選擇劣勢策略的玩家(劣勢策略為 100p),在 p=1/2 大 的實驗下,約 6%選擇大於 50 立 及 8%選擇等於 50;而在 p=2/3 的實驗下,約 10%選擇大於 67,6%選擇等於 67。 ‧ 國. 學. Nagel 從實驗結果中分析,第一期時,玩家的行為會強烈地偏離奈許均衡(Nash. ‧. equilibrium),而且在不同 p 值下,在 0 至 100 的區間內,各個選擇的數字分配會. sit. y. Nat. 明顯不同;Nagel 在此也提出了一個說法,他認為一開始的反應點或起始點(此反. io. er. 應點或起始點為第一次猜測時以何種數字做為依據),不是 100 而是 50,也就是 說如果一開始玩家推論在第 1 階段時,則會猜測數字會在 50p 附近,若為第 2. al. n. iv n C 階段時,會在 50𝑝 附近,而在p=1/2 的實驗發現,大約 50%的人數選擇在 h e和n 2/3 gchi U 2. 第 1 和 2 階段,然而在所有不同p值的實驗中,推論在第 3 階段或更高階段的玩 家,只有 6%至 10%左右。隨後,Nagel 又分析了第二、三和四期的結果,這是 為了觀察行為會如何隨著時間的經過而改變,在 p=1/2 的實驗中,144 個觀察值(選 擇的數字)有 135 個會比前一期小,而在 p=2/3 中 201 個觀察值中會有 163 個小 於前一期,也就是在這兩種實驗下,玩家所選擇的數字,會越來越小;另外,在 p=4/3 的實驗中,153 個觀察值,有 133 個大於前一期所選擇的數字,也就是說 無論 p 值是如何,都會往各自的均衡去移動,並且 Nagel 認為移動的速度取決於 p 值;另外,Nagel 也試著分析推論的深度是否隨時間經過而改變,他發現實驗. 8.
(18) 者們一般會推論至第二階段左右,大部分都推論不超過第三階段。 Nagel 根據這些實驗結果,提出了學習方向理論(Learning -Direction Theory ), 這模型的調整參數是來自於經驗,而模型引用自 Selten 和 Stoecker (1986),相似 的研究是由 Camerer(1991)在協調賽局(Coordination Game)的實驗中提出,此模型 描述玩家調整其決策,使用的事後推論是依據之前期間的結果,如果實驗者的選 擇低於最適的數字,那麼他將增加他的調整要素;反之,當他選擇高於最適的數 字時,則會降低他的調整要素。 Duffy and Nagel(1997)依據選美競賽賽局架構,在實驗中新增兩種試驗,將 平均數替換為中位數及最大值,並與平均數的試驗做比較,所以共做了三種不同. 治 政 的實驗,每次實驗人數為 13 至 16 人,共 175 位受測者,猜測區間為 0 至 100, 大 立 而贏家為猜測數字最接近 p 乘上平均數、p 乘上中位數或 p 乘上最大值(依實驗設 ‧ 國. 學. 計),贏家可獲得 20 塊美金,若有多個贏家則平分,而每次實驗給予 5 塊美金,. ‧. 在每回合結束後,皆會公布平均數、中位數或最大值,以及 p 乘上平均數、p 乘. sit. y. Nat. 上中位數或 p 乘上最大值,在這些實驗中,p 值為 1/2。Duffy and Nagel 從實驗. io. er. 中發現,在中位數的實驗下,第四回合時,約有 90%的猜測小於 10,在平均數 的實驗下,第四回合時,約有 76%的猜測小於 10,而在最大值的實驗下,第四. al. n. iv n C 回合時,約有 13%的猜測小於 10;Duffy Nagel 也將實驗的觀察重點分為受 h e n g and chi U 測者在第一回合時的行為與受測者隨時間經過的行為,在第一期時,並沒有人選. 擇 0 這個數字,在中位數的實驗下,約有 5%的受測者選擇大於 50(劣勢策略), 在平均數的實驗下,約為 10%,而在最大值的實驗下,約為 15%;在之後的期 間,指出中位數的實驗下,各階層(level)的比例變動會顯著大於其他兩種實驗, 也就是中位數的實驗,推論深度會不斷增加,然而這在平均數和最大值的試驗下, 卻沒有發現。此外,Duffy and Nagel 也發現第一回合時,在最大值的實驗中的選 擇會顯著的大於在中位數及平均數的實驗。 此外 Duffy and Nagel(1997)也根據 Nagel(1995)所提出的學習方向理論. 9.
(19) (Learning Direction Theory)檢視受測者們的行為,隨著時間經過是否會根據此理 論的描述, Duffy and Nagel 發現在前四期時,三種不同變數的實驗下,受測者 主要的行為皆與學習方向理論(Learning Direction Theory)的預測相似,但在最大 值實驗中,對於之後回合受測者的行為預測會失敗,而在平均數的實驗中準確度 也會有些減少。 Ho,Camerer and Weigelt(1998)將選美競賽賽局的實驗進一步地延伸,實驗中 總共有 55 個群組,總共 277 個受測者,實驗人數分為 3 或 7 人,有 27 組為 3 人,28 組為 7 人,會如此分類是由於實驗人數多寡是 Ho, Camerer and Weigelt 實驗觀察的其中一個方向;依理論而言,在實驗人數較少時,每位玩家對平均數. 治 政 會有較大的影響,反之則較少,實驗將 p 值設為 0.7、0.9、1.1 及 1.3;除此之外, 大 立 Ho,Camerer and Weigelt 也將玩家分為有無經驗,以檢視經驗對結果的影響;如 ‧ 國. 學. 果 p 值設為 0.7 及 0.9 時,則選擇的區間設在 0 至 100 間,為一個反覆支配次數. ‧. 為無限的賽局,我們將它稱之為無限門檻(infinite-threshold)賽局,而 p 值設為 1.1. sit. y. Nat. 及 1.3,則選擇的區間設在 100 至 200 間,為一個反覆支配次數為有限的賽局,. io. er. 我們將它稱之為有限門檻(finite-threshold)賽局;依賽局理論而言,在 p 值為 0.7 及 0.9 的狀況下,奈許均衡(Nash equilibrium)為 0;而 p 值為 1.1 及 1.3 時,奈許. n. al. Ch 均衡(Nash Equilibrium)為 200。. engchi. i Un. v. Ho, Camerer and Weigelt 的實驗結果有以下顯著幾點,第一點為受測者們第 一期時的選擇,分部會較為寬廣,且離均衡點較遠,而在之後的期間,受測者們 的選擇會隨時間慢慢收斂至均衡點,尤其是在有限門檻(finite-threshold)賽局下, 而且就算實驗對象為較老練的玩家,如經濟學家、教授或公司主管,也有如此特 點(Camerer ,1997),第二點為約 70%的受測者們,在第一期之後,會以之前的目 標數作加權平均來選擇數字,最後一點為 P 值、受測者人數多寡及是否有無接觸 過類似賽局經驗,對受測者的選擇會有極大影響;受測者在有限門檻 (finite-threshold)賽局選擇會比無限門檻(infinite-threshold)賽局更接近均衡,且 p. 10.
(20) 值越遠離 1,其選擇也會更接近,以及受測者群體越大(人數為 7)相對於小群體(人 數為 3)選擇會更接近均衡,除此之外,在玩家是否有無接受此類實驗的經驗上, 第一期時並沒有辦法看出其差異,但在之後的期間,有經驗的玩家群會較快收斂 至均衡。 Ho, Camerer and Weigelt 根據實驗結果應用了兩種理論解釋,其一為反覆支 配模型(Iterated Dominance Model),另一個為反覆最適回應模型(Iterated Best Response Model),分別描述玩家學習行為在第一期及之後期間的動態過程。Ho, Camerer and Weigelt 最後也提到如果要將學習模型描述得更好,應該要包含老練 以及會依經驗做簡單回應的兩種類型玩家;除此之外,Ho, Camerer and Weigelt. 治 政 認為只考慮上一期的庫諾最適回應動態(Cournot Best-Response Dynamics )及虛 大 立 擬對策 (Fictitious Play),是無法適用的。 ‧ 國. 學. Nagel(1998)又介紹了幾個新的處理方法,Nagel 改變了報酬的架構,像是贏. ‧. 家的報酬不再是固定,而是依照贏家選擇的數字給予報酬,例如果贏家選擇的數. sit. y. Nat. 字 為 5, 他會 得到 5 塊美金 ,而 不是固 定報酬, 這導 致賽局 變成複動 機. io. er. (Mixed-Motive)賽局形式,而不是常數和(Constant-Sum)賽局,其他選美競賽賽局 的性質,則皆不調整。這跟固定報酬的賽局比較起來,收斂至均衡的速度會變得. al. n. iv n C 較慢。在變動報酬與固定報酬的實驗結果上,玩家的行為隨著時間經過會顯示出 hengchi U. 其差異性,Nagel 在此列出第三期與第四期時,選擇的變動情形,在變動報酬實 驗中,會有較多的玩家的選擇變大,而在固定報酬下則較少;Nagel 也提到收斂 速度會取決於基本的四個要素,p 值、玩家的人數(玩家對目標數字的相對影響)、 贏家獲得報酬的方式,以及有無任何關於選美競賽賽局的相關經驗。 在此篇文章中,Nagel 也介紹了許多解釋玩家推論行為的理論,將之分別為 靜態推論模型(Static Reasoning Models)以及適應性學習模型 (Adaptive Learning Models),實際上,這兩種類型的模型,是非常相關的,靜態模型關注於玩家在 第一期實的行為,提出反覆支配層級(Levels of Iterated Dominance)、反覆最佳回. 11.
(21) 覆模型(Iterated Best-Reply model)、貝氏模型(Bayesian Model),而適應性學習模 型,則關注於玩家隨時間經過的行為,Nagel 介紹了反覆最適回應模型(Iterated Best Response Model)、學習方向理論(Learning Direction Theory)及經驗加權吸引 模型(Experienced-Weighted Attractionl)。Nagel(2008)又更進一步,將選美競賽賽 局實驗整理介紹,並提出幾個問題,他認為目前還沒辦法藉由學習模型的描述, 解釋參與者選擇的數目如何影響隨著時間經過的收斂過程;此外,仍然無法解釋 在變動報酬試驗裡,選擇為何會突然增加。 在前面的描述中,我們知道有關選美競賽賽局的實驗設計以及結果(將之整 理為表 2.1),並且作者們,也提出許多理論解釋實驗的結果,但這些研究並沒有. 治 政 真正得使用有關學習的模型,去估計參數,並分析實驗結果。因此,本文將再介 大 立 紹幾篇有關個人的學習行為,以學習模型估計的文獻。 ‧ 國. 學. Cheung and Friedman(1995)提出了有關於個人學習行為的估計方法,雖然作. ‧. 者並非採用選美競賽賽局,但已提供了許多估計學習模型的方法,因此我們在此. sit. y. Nat. 提出並說明。在文章中 Cheung and Friedman 建構了包含一個參數的學習規則,. io. er. 包含虛擬對策(Fictitious Play)及庫諾最佳反應(Cournot Best Response)形式,將玩 家的學習行為分類,其中虛擬對策假設玩家擁有長期記憶,且會對之前所有的觀. al. n. iv n C 察做考慮,而庫諾最佳反應則假設玩家在考慮策略上,會專注於最近期的觀察, hengchi U 更勝於之前的觀察,另一方面也建構了包含兩個參數的決策規則,所以整個模型 共有三個參數;在實驗上,使用了四種賽局架構,分別為鷹鴿賽局(Hawk-Dove Game)、協調賽局(Coodination Game)、買家-賣家賽局(Buyer-Seller Game)和兩性 戰爭賽局(Battle of the Sexes Game),這是為了能適當的估計出學習模型裡的參數, 每一次的實驗,在 60 至 200 期之間,共有 6 至 24 位受測者,整個資料包含共三 十次的實驗。Cheung and Friedman 在實驗中發現玩家們有的行為相當的異質性, 因此在估計中應該要允許每個人所估計的參數有所不同,且 Cheung and Friedman 認為在不同報酬函數下,玩家們採取虛擬對策、適應性(adaptive)(介於虛擬對策. 12.
(22) 和庫諾最佳反應對策的行為)和庫諾最佳反應的分配,應該不會改變,而 Cheung and Friedman 的資料結果也與此論點一致,但 Cheung and Friedman 也提到,雖 然在其文章上,許多的估計都是非常成功,但他並不認為簡單的三個參數模型, 就可以捕捉到在賽局裡,所有學習的重要面相。 Camerer and Ho(1999)也提出了有關於個人學習行為的估計,建構了一個包 含信念學習模型(Belief learning model)與強化學習模型(Reinforcement Learning) 性質的經驗加權吸引模型(Experience-Weighted Attraction);經驗加權吸引模型, 在信念學習模型的部分,假定玩家會追蹤其他玩家之前的策略,且依據過去觀察 形成一些有關其他玩家,在未來會採取何種採取策略的信念;而強化學習模型部. 治 政 分,則假設策略會藉由強化之前所獲得的報酬,且傾向依據被強化的程度,來選 大 立 擇其策略。Camerer and Ho 在實驗中,使用了有單一混合策略均衡的常數和賽局 ‧ 國. 學. (Constant-Sum Games)( 其 有 一 個 弱 劣 勢 策 略 ) ; 有 協 調 多 重 柏 拉 圖 等 級. ‧. (Pareto-Ranked)均衡的中位數-行為(Median-Action);和有單一均衡的選美競賽賽. sit. y. Nat. 局(p-Beauty Contest Game),Camerer and Ho 認為根據大部分的研究報導指出,. io. 有新的挑戰。. er. 會偏好強化學習或者信念學習模型其中之一,使用的這些賽局,對於這些模型會. al. n. iv n C 在參數的估計上,Camerer and h eHon還將模型劃分一部門(one-segment)及兩部 gchi U. 門(two-segment)。由於經驗加權吸引模型相對於其他特殊模型總是更一般化,對 於資料的配適將會更好,所以可能會有過度配適的危險。為了防止此種狀況, Camerer and Ho 校準然後並驗證模型,使用每一個樣本前 70%的觀察使用最大概 似估計法(Maximum Likelihood Estimator)估計,然後使用這些估計去預測其餘 30%樣本資料的策略途徑;為了評估模型的精確度在校準方面,Camerer and Ho 報告四個準則分別為對數概似估計量(Log Likelihoods),Akaike 訊息準則(AIC) 和 Bayesian 訊息準則(BIC)和 pseudo-𝑅 2,對於在驗證樣本,除了使用對數概似估 計量外,也計算平均平方差(MSD),越小的平均平方差,代表模型預測能力越好;. 13.
(23) 除此之外,在模型配適方面,也與所有策略在每一期被選擇機率皆相同的隨機選 擇模型做比較。Camerer and Ho 為了確認在經驗加權吸引模型所加入的變數,皆 分別擁有解釋力,也對參數間的相關性估計。 實驗估計的結果方面,分別從常數和賽局、中位數-行為以及選美競賽賽局 描述,在常數和賽局在驗證面向上,強化模型表現較差。在某些賽局上(四種策 略),信念模型比經驗加權吸引模型好,但在某些賽局上(六種策略),信念模型比 經驗加權吸引模型差,然而這些差異並不大;在中位數-行為上,從明顯的數據 以及預測誤差圖裡,可看出經驗加權吸引模型配適得比強化模型和信念模型好; 在選美競賽賽局上,Camerer and Ho 為了實行經驗加權吸引模型,Camerer and Ho. 治 政 假設所有人都知道贏家所選的數字(ω),然後定義 大 d 為目標數(target number;τ) 立 與贏家所選數字的差距,在經驗加權吸引模型中的強化模型部分,所有玩家皆會 ‧ 國. 學. 以 δ 乘上總報酬,強化 τ-d 與 τ+d 之間所有的選擇(不包括 τ-d 與 τ+d 兩點),在 τ-d. ‧. 與 τ+d 兩點的部分,贏家會以所獲得的報酬(總報酬/贏家人數)強化其所獲得的選. y. Nat. 擇(τ-d 與 τ+d,其中一點為贏家所選數字),而另一點,則以 δ 乘上所獲得的報酬. er. io. sit. (總報酬/贏家人數)強化,輸家則會以 δ 乘上報酬(總報酬/(1+贏家人數))強化此兩 點;在經驗加權吸引模型中的信念模型部分,只會以總報酬強化 τ-d 與 τ+d 之間. al. n. iv n C 所有的選擇(不包括 τ-d 與 τ+d 兩點)。結果顯示,兩部門的經驗加權吸引模型在 hengchi U 校對和驗證上皆比一部門的經驗加權吸引模型好,但在信念學習模型與強化學習 模型,一部門或二部門並沒有太大提升,但 Camerer and Ho 認為在選美競賽賽 局上,這三種模型(無論一或二部門),皆沒有辦法將資料解釋得較完美;整體來 說,經驗加權吸引模型在三種類型的賽局(共六個賽局),配適得比信念學習模型 與強化學習模型好,信念學習模型在常數和賽局比強化學習模型好,在中位數行為,信念學習模型則比強化學習模型差,在選美競賽賽局上,則各有優劣(校 對上強化學習模型較好;驗證上信念學習模型較好)。在參數間的相關性估計上, 除了 ρ 和 φ 有較大相關之外,其餘參數間,皆有適中(或較低)的相關性。. 14.
(24) 在 Camerer and Ho(1999)的這篇文章中,可以清楚的知道,經驗加權吸引模 型在常數和賽局、中位數-行為以及選美競賽賽局,皆配適得比信念學習模型與 強化學習模型好,因此我們的研究在實證分析中,將只採用經驗加權吸引模型, 來進行實證分析。. 2.1.3 小結 在以上幾篇文獻中,本研究發現在探討推論行為的過程中,作者們紛紛提出 各種理論與假說,來解釋受測者在選美競賽賽局裡的學習行為,但並未納入與工 作記憶有關的分析,而本研究也將在下一節,介紹有關學習行為與智能的相關文. 治 政 獻,來解釋為何本研究在探討推論行為的過程中,會納入有關智能的分析。 大 立 ‧ 國. 學. 2.2 智能與策略行為. ‧. 選美競賽賽局的實驗的結果已經顯示出與賽局理論的預測有所偏離(Nagel,. sit. y. Nat. 1998, 2008),這也引起了一些有關認知經濟的研究,如 Crawford 提出的層級 k. io. er. 推論(Level-k Reasoning)和 Camerer 提出的認知層級(Cognitive Hierarchies)。 Crawford 提出的層級 k 推論假設不同的層級會導致非準則信念,而非不理性,認. al. n. iv n C 知層級模型假設認知上的層級,可能是由於受測者不能夠理解其他較高層級的受 hengchi U 測者,而這可能的原因為來自於大腦的限制,像是工作記憶的限制(Camerer, Ho and Chong, 2004),但儘管如此,仍有許多待解的問題,因此擁有較高智能的人 是否在選美競賽賽局中比較有優勢,成為了一個受關注的議題。以下本文將探討 智能與策略行為的相關文獻作介紹。 Camerer (1997)提出有關受測者在選美競賽賽局下的行為與智力並無關聯的 假設;他發現 SAT 數學分數較高的學生相對於平均分數的學生,並不會選擇比 較靠近奈許均衡的數字。Coricelli and Nagel(2009)使用功能性磁振造影(fMRI)測 量受測者在進行選美競賽賽局時,大腦的活動過程,以調查人類的心理程序。作. 15.
(25) 者使用認知層級模型,根據策略推論的層級,將受測者的選擇做分類,使作者可 以確定不同策略層次的神經基質(Neural Substrates)。作者對於為什麼人們會有不 同且有限的推論層級,提出了兩個解釋,其中一個理由為玩家因為認知能力的限 制,可能無法使用較高層次的推論,另一個理由為或許受測者也相信其他受測者 如同他一樣,不會使用太高的推論層級。實驗的結果顯示人們使用有限理性的策 略 或 認 知 層 級 (Cognitive Hierarchies) , 會 反 應 在 在 特 定 的 神 經 基 質 (Neural Substrates),較高的推論層級和推論 IQ 與在內側前額葉皮層的神經活動有關,這 裡所指的推論 IQ 為正確猜中的能力;此外,實驗結果顯示數學上的表現與推論 IQ 無關,這與 Camerer (1997)的結果相似。. 治 政 雖然上述兩篇文獻都認為數學上的表現與推論大 IQ 無關,但以下幾篇文獻卻 立 有不一樣的觀點,Burnham et al. (2009)為第一篇試圖尋找選美競賽賽局的策略行 ‧ 國. 學. 為與認知能力相關性的文獻,作者在研究中使用了一些標準認知能力的心理測驗,. ‧. 來檢視受測者的能力;不像之前的研究,此文獻的結果顯示策略行為與智能是相. sit. y. Nat. 關聯的,例如:較高認知能力的受測者,在第一期時,所猜測的數字會較低,並. io. er. 且這些較高認知能力的受測者,所猜測數字的平均,也會較接近目標數。Rydval、 Ortmann 和 Ostatnicky( 2009) 為了解在對稱的優勢可解(dominance-solvable)賽局. al. n. iv n C 中,違反優勢策略的性質,採取了選美競賽賽局實驗,作者們研究受測者的推論 hengchi U 程序、選擇、信念、認知能力和個人特質,在智能的測量上採用運算廣度作業 ( Operation span task),作者在實驗中,將受測者分為三類,分別為推論錯誤的受 測者、推論策略為優勢策略,但無法解釋的受測者,以及推論策略為優勢策略, 也能清楚的解釋的受測者。作者在實驗中發現將近三分之二受測者的推論與優勢 策略不相符,而作者認為會發生推論錯誤的原因,較有可能是因為受測者事前較 低的工作記憶(working memory)以及預設態度(有可能是由於較低的意願或者不 願仔細地思考)所造成,此文獻說明了當不理性的競爭者被排除或被忽略時,短 暫記憶(short term memony)和工作記憶在策略的思考上,扮演了重要的角色。. 16.
(26) Schnusenberg and Gallo (2011)在文獻中,也提出認知能力與策略行為的相關性, 此文獻的結果與 Burnham et al. (2009)的結果相當類似。作者在智能的測量上採用 認知反應測驗(cognitive reflection test),研究發現在第一期時,較高認知能力的人, 所猜測的數字會較低,且這類受測者的猜測數字會較集中,雖然這現象只在第一 期時發生,並沒有在之後的期間發生,但仍說明了認知能力對於策略行為是有相 關的。 其他有關智能對策略思考,但非採用選美競賽賽局實驗的文獻,如 Devetag and Warglien (2003),在實驗中,建構了三個賽局,以檢視短暫記憶(short term memony)對策略行為的影響,此三種賽局分別有具反覆支配解的賽局、污臉賽局. 治 政 (Dirty Faces Game)及序貫賽局(Sequential Game),結果顯示短暫記憶(short term 大 立 memony)與行為者的策略推論有關。我們在表 2.2 將這些有關智能對策略思考的 ‧ 國. 學. 影響的文獻作些簡單的整理。. ‧. 2.3 總結. sit. y. Nat. io. er. 從上述可知,智能與受測者在選美競賽賽局的行為策略的相關性,是一個常 被關注的議題,但過去的研究,一直都是直接觀察實際猜測推論行為與智能表現. al. n. iv n C 之間的關係,缺少了有關模型的架構,無法準確描述之間的差異,也就是未直接 hengchi U 關注於學型模型,以學習模型參數估計值上的差異,更準確地來解釋智能表現對 於學習行為策略的相關性,因此本研究將會著重於此部分的實證研究,並使用學 行模型參數的意義,來解釋智能差異對於學習行為的影響。. 17.
(27) 表 2.1:選美競賽賽局實驗相關文獻. (1997). 4. 贏家:$20 輸家:$0 參加費:$5. 立. p= 1/2. [0,100] ; 整數. 4 或 10. 贏家:$20 參加費:$5. 10. 贏家:$3.5;如果 n=7 贏家:$1.5;如果 n=3 輸家:$0. 4. 贏家:$X X 為選擇的數字 參加費:$5. 政 治 大. p x 最大值. ‧. 3或7人 (共 277 人). p x 平均數. p x 中位數 p x 平均數. p=1/2,2/3,4/3. [0,100] 整數. p=0.7,0.9 p=1.1,1.3. Nat. p x 平均數. io. Ho, Camerer and Weigelt (1998). 13 至 16 人 (共 175 人). 報酬. al. n. Nagel (1998). 12 至 17 人 (共 59 人). 學. Duffy and Nagel. 實驗期數. p x 平均數. [0,100] if p<1 ; [100,200] if p>1. y. 15 至 18 人 (共 166 人). 選擇範圍. 參數(p). sit. Nagel (1995). 贏家定義. er. 受測者(n). ‧ 國. 作者. Ch. ep=2/3 ngchi. 18. i n U. v. [0,100] 整數.
(28) 表 2.2:較高智能對策略思考的影響 作者. 採用賽局. 智能測量. 相關性. Camerer(1997). 選美競賽賽局. SAT(Scholastic Assessment Tests). 無. Devetag and Warglian (2003). 反覆支配解的一般 賽局;污臉賽局;序 貫賽局;. Burnham et al.(2009). 選美競賽賽局. Coricelli and Nagel(2009). 選美競賽賽局. 立. 表現較好. 標準化一般智能的 心理測驗. 猜測數字降低 表現較好. 數學計算作業. 無. 政 治 大. ‧ 國. 運算廣度作業. ( Operation span task). 採取優勢策略 較頻繁. y. ‧. 簡化的選美競賽賽 局. Nat. sit. 認知反應測驗. 選美競賽賽局. n. al. (Cognitive reflection test). er. io. Schnusenberg and Gallo (2011). (Wechsler digit span). 學. Rydval, Ortmann and Ostatnicky (2009). 魏氏記憶廣度. Ch. engchi. 19. i Un. v. 猜測數字降低 群集越密.
(29) 第三章、研究資料處理與模型 為分析在選美競賽賽局下,人們的學習行為,本文將以真人實驗資料,並採 取經驗加權吸引模型,使用最大概似估計法,估計學習行為的參數,作為實證上 的驗證。本章節將介紹本文所使用的研究資料、學習模型、資料處理方法及估計 方法。. 3.1 研究資料. 政 治 大. 本文資料是取自於 Chen, Du and Yang(2012),實驗中總共包括6個群組,每. 立. 個群組共有15至20位受測者,每位受測者皆會進行選美競賽賽局的實驗以及工作. ‧ 國. 學. 記憶的測試,所有受測者皆會獲得125元的報酬,而實驗在政治大學實驗經濟研 究室舉行。每一期,受測者們會同時選擇一個在0到100之間的數字,而贏家為猜. ‧. 中最接近目標數的受測者,在此的目標數為p乘上所有玩家選擇數的平均,此實. y. Nat. io. sit. 驗的p值設為2/3,相同賽局實驗將會被重覆十期,總實驗時間將近60分鐘。在每. n. al. er. 一期結束時,受測者將會被告知目標數、所選擇數字、獲得的報酬以及總累積報. Ch. i Un. v. 酬,贏家在實驗中將可額外獲得100元的獎勵,若贏家超過一人的話,則將平分. engchi. 此獎勵,本文將各個群體在各個期間的目標數繪於圖A.1(於附錄中)。 工 作 記 憶 測 驗 部 分 , 總 共 有 五 個 實 驗 為 逆 序 記 憶 廣 度 作 業 (Backward Digit-Span Task)、空間短期記憶測驗(Spatial Short-Term Memory Test)、記憶更新 作業(Mmory Updating Task)、語句判斷作業(Sentence-Span Task)以及運算廣度作 業(Operation-Span Task),所有實驗共90分鐘,並在實驗後支付200元新台幣給受 測者。在這五個實驗中所得到的分數將被標準常態化,其標準化的平均數與標準 差來自實驗受測者資料庫(Experimental Subject Database),這資料庫共包含740位 相關實驗受測者的資料,並非只來自此次實驗所獲得的平均數與標準差;在其之 後,將這五個被標準常態化的實驗分數平均,以得到本研究所使用的工作記憶測 20.
(30) 量分數,而此工作記憶測量的分數,本研究將之代表為受測者的智能高低,在往 後的研究中,所提到的智能高低,也就代表工作記憶分數的高低,本文將6個群 組的工作記憶繪製成盒鬚圖於圖A.2(於附錄中)。. 3.2 學習模型 本研究所採用的模型為經驗加權吸引模型(Experience-Weighted Attraction),而 此模型包含了強化學習模型以及信念學習模型的特色,因此,在說明經驗加權吸 引模型時,本文會先介紹強化學習模型(Reinforcement Learning Model)以及信念 學習模型(Belief Learning Model)。. 治 政 一、強化學習模型 (Roth and Erve,1995): 大 立 此模型的主要思想源自於心理學家Thorndike, E.L.,其所提出的效果定律 ‧ 國. 學. (Law of Effect),此法則認為如果所做出的選擇如果會得到較好的結果,則更有. ‧. 可能,再次做出相同的決定;反之,則會減少再次做出相同的決定;在這之後,. sit. y. Nat. 在經濟學的領域上,一直無人提起相關的理論及模型,直到二十世紀,才有經濟. io. er. 學家去使用此模型(Cross,1983),將強化學習應用在經濟決策上,不過於此之後, 又再也沒看到類似文獻,直到過後近十年,才漸漸有學者從新使用此模型,如. al. n. iv n C Roth and Erev(1995)等。此模型認為我們的決定是基於我們過去的記憶,這記憶 hengchi U 可以減少,也能夠更新,其最基本模型的架構如下:. qik (t ) (t ) q (t 1) k qi (t ) k i. 如果在t期策略為k. (3.1). 如果在t期策略不為k. 其中 為過去吸引的影響程度, (t ) 為在第t期時,選擇k策略時。所能獲得 的報酬。 玩家在下一期的策略,會如式(3.1)的規則去更新,稱之為更新規則,qik (t 1) 為策略k對於玩家i的吸引,若此值越大,代表越會傾向去選擇k策略,可以注意 21.
(31) 到(3.1)式,在下一期選擇k的機率只會增加不會減少,而增加幅度是依據上一回 合的報酬而定,當選擇k策略時,所得到的報酬越高,其吸引就會增加越多,在 下一期選擇k的機率就會變得相對較高,如果選擇k得到的報酬很低,對於下一次 選擇k的吸引就增加的相對較少。 二、信念學習模型 信念學習模型給定玩家的行為會察覺到對手的存在,且會注意對手過去的策 略,可能長期也可能只有短期;他們會去預測對手在下一期的作法並根據這規則 去反應,但他們所能從對手那學到的,只是非常表面,他們只能簡單地去計算或 重複地計算對手採取策略的頻率,無法深思熟慮地去推論對手過去曾做過的所有. 治 政 選擇。本文在以下列出其較基本的形式: 大 立 ‧ 國. N ki (t 1) I ( ski , si (t )). j. ( N k i. k i. 學. B (t ) k i. (3.2). (t 1) I ( s , si (t )) k i. ‧. 其中 N ki (t ) 為其他對手過去的經驗,而 為之前經驗影響的權重。. sit. y. Nat. 或者如以下形式:. N (t 1) Bki (t 1) I (ski , svi (t )) a (t ) l C h N (t 1) 1U n i engchi. n. B. er. io k i. (3.3). 其中 I ( sij , si (t )) 為一個指標函數,當 sij si (t ),則 I ( sij , si (t )) =1;而當 sij si (t ) , 則 I ( sij , si (t )) =0。 當 =1時,此模型就會化為虛擬對策(Fictitious Play)的形式,而當 =0則會 化簡為庫諾最佳反應(Cournot Best Response),在信念學習模型中的期望報酬,則 單調地相對於吸引,期望報酬的形式如下: J. Ei (t ) Bki (t ) ( sij , ski ) j. k 1. 22. (3.4).
(32) 也可以化為如下形式:. N (t 1) Ei j (t 1) ( sij , si (t )) Ei (t ) N (t 1) 1 j. (3.5). 三、經驗加權吸引模型(Cramer and Ho, 1999) 此模型的特性同時包含了強化學習模型以及信念學習模型,為此兩種模型的 一般型式,在強化學習模型中,被選擇到的策略會依據所得的報酬來強化,而沒 被選擇到的策略,則完全不會被加強,但在加權經驗吸引模型裡,則會被加強;. 治 政 在強化學習模型中,吸引會不斷地增加,這隱含可能急遽地收斂。(這意味著選 大 立 擇機率會分別走向 0 和 1),在信念學習模型,吸引為預期報酬,總是限制於報酬 ‧ 國. 學. 的範圍,經驗加權吸引模型對於過去經驗,能藉由使用ψ和 ρ,允許吸引的增加. y. . sit. Nat. . ‧. 率,在這兩個限制上有所不同。其模型形式如下:. n. al. er. io. j N (t 1) Ai j (t 1) ((1 ) I ( sij , si (t )) ( sij , si (t )) A ( t ) i N (t ) N (t ) N (t 1) 1 ,t 1 . Ch. engchi. i Un. v. (3.6). 當 sij si (t ) ,則 I ( sij , si (t )) =1;而當 sij si (t ) ,則 I ( sij , si (t )) =0。 其中ψ為過去吸引的影響程度,δ為未被選擇到策略的報酬權重,ρ為之前 經驗影響的程度,而 N(t)為過去的經驗權重。 吸引的更新規則如下:. Ai j (1) . N (0) Ai j (0) ((1 ) I ( sij , si (1))π ( sij , si (1)) N (0) 1. 23. (3.7).
(33) Ai j (2) . 2 N 0) Ai j (0) ((1 ) I ( sij , si (1)) ( sij , si (1)) 2 N (0) 1. ((1 ) I (s , s (2)) (s , s j. j. i. i. 2 N (0) 1. i. i. (3.8). (2)). . Ai j (k ) . k N (0) Ai j (0) k 1 ((1 ) I ( sij , si (1)) ( sij , si (1)) k N (0) k 1 1 (3.9). ((1 ) I (s , s (k )) (s , s j. j. i i i i ( k ) k k 1 N (0) 1. 政 治 大. 初始的吸引由 Ai j (0)所描繪,初始的吸引可能來自賽局的分析,由類似賽局. 立. ‧ 國. 學. 中成功的策略所推導出。在信念學習模型中,強烈地限制 Ai j (0),是因為在信念 學習模型中,初始的吸引是由之前信念所推導出,但這在經驗加權吸引模型中,. ‧. 使其更加彈性。我們可以從(3.6)式發現當 0, 0, N (0) 1,就會如同強化學. sit. y. Nat. 習模型(Reinforcement Learning),而 1, ,則會如同信念學習模型. n. al. er. io. (Belief Learning Model),因此我們又將之稱為學習模型的一般式;而學習模型裡. i Un. v. 的吸引轉換成選擇機率的規則,則如以下羅吉斯(logit)的形式:. Ch. engchi. Pi (t 1) . e Ai. j. 10. j. e k 1. 24. (t ) Aik ( t ). (3.10).
(34) 3.3 資料處理 本文在資料處理上,每場遊戲實驗的贏家人數為 n,假設所有人都知道贏家 所選的數字(ω),然後定義 d 為目標數(target number;τ)與贏家所選數字的差距, 在經驗加權吸引(EWA)模型中,如圖 3.1 所示,所有玩家皆會以 δ 乘上總報酬, 去強化 τ-d 與 τ+d 之間所有的選擇,但並不包括 τ-d 與 τ+d 兩點,之所以會再乘 上 δ,是因為其為沒有選擇,而放棄(沒獲得)的報酬,對玩家會有所影響;而在 τ-d 與 τ+d 兩點的部分,贏家與輸家會有些差異,如圖 3.2 所示(假設 τ+d 為贏家 所選的數字),贏家會以所獲得的報酬(總報酬/n)強化其所選擇的數字(ω),也就是. 治 政 τ-d 或 τ+d(其中一點贏家所選數字,在圖 3.2 本文假設贏家所選數字為τ+d),而 大 立 另一點,則以 δ 乘上所獲得的報酬(總報酬/n)強化,會再乘上 δ 的理由與上述相 ‧ 國. 學. 同,在輸家的部分,如圖 3.3 所示,輸家則會以 δ 乘上報酬(總報酬/(1+n))強化此. 𝜹∗𝝅. n. al. er. io. 𝟎. sit. y. Nat. 兩點的話,則會成為贏家,而與其他贏家一起平分報酬。. ‧. 兩點,在報酬部分會設定總報酬除以(1+n),是因為輸家會假設自己若也猜到此. 𝝉−𝒅. Ch. engchi 𝝉. i Un. v. 𝝉+𝒅. 𝟏𝟎𝟎. 圖 3.1:所有人在 τ-d 與 τ+d 之間所有選擇的強化. 𝝅/n 𝝅/ 𝒏. 𝜹 ∗ (𝝅/n). 𝟎. 𝝉−𝒅. 𝝉. 𝝉+𝒅. 𝟏𝟎𝟎. 圖 3.2:贏家在 τ-d 與 τ+d 兩點選擇的強化(假設贏家所選數字為τ+d). 25.
(35) 𝜹 ∗ (𝝅/n+1) (𝝅. 𝟎. 𝝉−𝒅. 𝜹 ∗ (𝝅/n+1) (𝝅. 𝝉. 𝝉+𝒅. 𝟏𝟎𝟎. 圖 3.3:輸家在 τ-d 與 τ+d 兩點選擇的強化. 在工作記憶分數資料的處理上,本研究將受測者依工作記憶分數的高低,劃 分為三個群體,分別為高工作記憶分數(工作記憶分數前三分之一)、中工作記憶 分數及低工作記憶分數(工作記憶分數後三分之一),在實證上將只採取高工作記. 治 政 憶分數部分與低工作記憶分數部分,而將中間的部分剔除,其理由為在中間部分 大 立 的受測者,有可能在策略上的行為不夠明確,有可能會偏向工作記憶較高的一方, ‧ 國. 學. 也有可能偏向較低的一方,這將可能導致估計結果不夠明確。此外,在實證上,. ‧. 還會再額外劃分成四等分,留下工作記憶分數前四分之一與工作記憶分數後四分. sit. y. Nat. 之一的資料與劃分成三等分資料的參數估計作比較。表 3.1,將各群組資料作簡. io. er. 單地敘述統計,從表中發現前四分之一高工作記憶分數的群體,最高分數 0.9940, 最低為 0.5478;從表中發現前三分之一高工作記憶分數的群體,最高分數 0.9940,. al. n. iv n C 最低為 0.3645;從表中發現後三分之一高工作記憶分數的群體 ,最高分數-0.2790, hengchi U 最低為-2.9658;從表中發現後四分之一高工作記憶分數的群體,最高分數--0.5151, 最低為-2.9658;此外,高工作記憶分數的群體所得的分數標準差比較小。 表 3.1:各群組工作記憶分數 工作記憶分數. 平均. 標準差. 最高. 最低. 前四分之一. 0.7622. 0.1403. 0.9940. 0.5478. 前三分之一. 0.6690. 0.1865. 0.9940. 0.3645. 後三分之一. -0.9946. 0.7481. -0.2790. -2.9658. 後四分之一. -1.2494. 0.7695. -0.5151. -2.9658. 26.
(36) 3.4 估計方法 在參數估計上,本研究將採最大概似估計法(Maximum-Likelihood Estimate), 以數值方法,每次估計皆為一千次,吸引更新的規則如經驗加權吸引模型(EWA) 設定;估計上將初始吸引(initial attraction)分為 10 個等分,分別為 0-10、11-20、...、 91-100,共 10 個區間,所以在估計上,共有 10 個初始吸引參數需要估計,其他 需要估計的參數還有 N(0)、ψ、ρ、δ 及 λ,所以整個估計上,共有 15 個參數需 要估計,在參數限制上分別為ψ和λ必須大於 0,且 0≤δ,ρ≤1,以及 0≤ N(0)≤1/(1-ρ)。 最大概似估計式如下; 10. N. 10. 立. 政 治 大. LL ln ( I ( sij , si (t )) Pi j (t )) N. ln ( I ( si , si (t )) t 1 i 1. eAi (t ) j. 10. j. j 1. 10. e. Aik ( t ). (3.11). ). ‧. ‧ 國. 10. j 1. 學. t 1 i 1. sit. y. Nat. k 1. io. al. er. 在初始吸引設定的實證部分,本文試著去設定一些初始吸引的分配1,分別 如均勻分配 Uni(0,1)、及兩個貝他分配 Beta(2,2)和 Beta(2,5),來比較不同的初始. n. iv n C 吸引,是否對其他參數的估計會有影響。本研究在此部分,將採用概似比檢定 hengchi U. (Likelihood Ratio Test),去檢驗限制住初始吸引(各設定為三種分配)與沒有限制住 初始吸引(估計)的模型配適度。此外,在實證第四節,驗證高智能模型以及低智 能模型,估計參數有無差異,本研究也將採類似概似比檢定的方法,將低智能模 型所估計的參數值替換掉高智能模型參數值,檢驗兩模型參數,有無明顯差異。 概似比檢定的原理是將一個有參數限制的模型拿來和另一個沒有參數限制 的模型比較比較,判斷沒有參數限制的模型,在詮釋一組特定的統計資料時,是. 1. 初始吸引的分配:10 個初始吸引所構成的型態,有如分配的機率分布圖形,此處並無機率概 念,也就是所給定的 10 個初始吸引點的連線會構成類似如圖 4.6 的左邊三個分配的圖形,只是 一個簡單的概念。 27.
(37) 否比有參數限制的模型更合適。在理論上,沒有參數限制的模型,可以得到和真 實情況更高的配適度,但是當一個沒有參數限制的模型與有參數限制的模型相比 時,配適度沒有顯著地提高,此時就代表著,沒有參數限制的模型,並不一定能 提供更好的解釋能力。檢定的式子如下:. LR 2( LLR LLU ) ~ 2 (m). (3.12). LLU :未受限制模型最大對數概似值. LLR :受限制模型最大對數概似值. m :受限制條件個數. 立. 政 治 大. 概似比檢定用來檢定出各個模型之間,哪一個模型的設定較好,用於挑選適. ‧ 國. 學. 當的模型,若檢定結果 LR 顯著地異於 0,表示拒絕虛無假設,其未受限制的模 型設定會較為適當。. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. 28. i Un. v.
(38) 第四章、實證結果 上一章,本文介紹了有關資料的基本特性與處理方式,本章節將介紹實證 資料的分析,包括參數估計的結果分析以及納入認知能力分析的結果。首先,本 文根據上一章節資料處理的方式,進行參數估計,並將結果與 Camerer and Ho(1999)所做的實證結果做比較;在此之後,還會進行一些有關初始吸引方面的 設定,檢視其估計的改變;最後將資料依照工作記憶分數分組,比較其所估計的 參數差異。. 政 治 大. 4.1 實證資料敘述性統計分析. 立. ‧ 國. 學. 受測者選擇資料的敘述如表 4.1,在第一期時,所有人選擇的平均約為 39, 第二期時,所有人選擇的平均降低約為 26,到了第三期時,所有人選擇的平均. ‧. 降低為 17,到了第五期之後,所有人選擇的平均已經降低至 10 以下,尤其是到. sit. y. Nat. 了最後一期,所有人選擇的平均收斂至小於 4,由此可見,所有人選擇的平均會. n. al. er. io. 越來越靠近均衡 0;此外,從最後一期的標準差中,也可以發現所有人選擇會變. i Un. v. 得越密集。接著由資料中觀察選擇數字 0 的人數,在第一期時選擇數字 0 的人數. Ch. engchi. 有兩人,第二期時,無人選擇,從第三期之後,選擇數字 0 的人數一直增加,從 1 人,一直上升到第八期的 13 人,但最後一期選擇數字 0 的人數僅有 3 人。此 外,本文將資料以每 10 個數字為區間,劃分為 10 個等分(第一個區間多包含數 字 0,共 11 個數字),並以圖 A.3 表示(所有受測者在各期的選擇圖,本文將收錄 於附錄中),從圖中可以發現一開始最多人選擇的選擇區間,落在 31-40 這個區 間,41-50 區間次之,到了第二期,最多人選擇的區間落在 11-20,21-30 區間次 之,第三期時,最多人選擇的區間越來越接近均衡,從第四期之後,所有最多人 選擇的區間,均落在 0-10 內,尤其是最後一期,只有一個選擇落在 11-20 間,其 餘的選擇,皆落至 0-10 內。 29.
(39) 表 4.1:每一期受測者的選擇 期數. 平均. 標準差. 第一期. 38.9167. 19.9097. 第二期. 26.3704. 12.1375. 第三期. 17.0556. 15.6748. 第四期. 11.8241. 15.3677. 第五期. 6.7315. 8.8599. 第六期. 7.1204. 17.9082. 第七期 第八期. 立. 第九期. 9.2963 政 治 大 9.5463. ‧ 國. 第十期. 3.8704. 14.8219. 學. 6.1389. 20.3172. 5.2800 2.4114. ‧. 本研究將資料依照智能分數高低劃分,各個群體共 36 位受測者,從表 4.2. sit. y. Nat. 及表 4.3 中可以觀察出,高智能受測者在每一期選擇的平均,皆比低智能受測者. er. io. 低,這代表高智能受測者的猜測會較接近均衡,且除了第二期及第四期外,猜測. al. iv n C hengchi U 智能分數受測者與低智能分數受測者,在行為猜測上,有些許差異。此外,從表 n. 的分布相對於低智能受測者較密集,純粹從各群體的選擇資料中,就能觀察出高. 4.4 中,也可以看出高智能受測者在初期時對於低智能受測者的勝率差距並不大, 但到了最後一期時,高低智能分數受測者之間的差距卻相當明顯,這可能意味著, 高智能受測者比起低智能受測者,隨著每次實驗的學習,越來越能掌握目標數。 雖然在第二至第九期之間,高智能分數受測者的勝率,並沒有完全勝過低智能分 數受測者(在第二、四、五及七期,低智能分數受測者勝率較高),但本文認為是 因為受測者在二至第九期之間,猜測數字所受到的影響太多,例如受測者可能會 使用一些策略來影響之後期間的獲勝機率,可能會故意猜測較高,影響猜測的平 均數,使其他受測者,在下期猜測時,會受到影響。 30.
(40) 此外,本文分別列出第一期、第四期、第七期及第十期時高智能與低智能受 測者選擇的分配圖(從圖 4.1 至圖 4.4),從第一期可以看出高智能受測者的猜測會 比低智能受測者更靠近均衡,在往後的期間,兩類受測者的猜測,也會越來越接 近均衡,並且可以看出高智能受測者的猜測收斂至均衡的速度比低智能受測者來 得更快(由於篇幅關係,在此只列出第一期、第四期、第七期及第十期時的結果, 其他所有結果將收錄在附錄圖 A. 4 至 A.13);接著,本文將資料更近一步以記憶 分數劃分為四等分(所有結果在附錄圖 A.14 至 A.23),取前四分之一及後四分之 一,並將之與以記憶分數劃分為三等分的選擇分配作比較,可以發現前四分之一 與後四分之一的受測者,與之前有相同的結果,如高智能受測者的猜測收斂至均. 治 政 衡的速度比低智能受測者來得更快,而且前四分之一比前三分之一受測者的猜測, 大 立 更快速收斂,尤其在第七期之後,這也代表著以智能將資料劃分,對於觀察受測 ‧ 國. 學. 者行為是有幫助的,之後的參數估計,也將納入智能,以更驗證在此部分的結論。. 標準差. 24.5000. Ch. e13.9167 ngchi U. sit. y. al. n. 第三期. io. 第二期. 35.2778. er. 第一期. 平均. Nat. 期數. ‧. 表 4.2:高智能分數受測者的每一期選擇. v ni. 19.2749 13.1356 7.0442. 第四期. 10.5278. 16.3628. 第五期. 5.1944. 2.7756. 第六期. 2.9444. 2.1639. 第七期. 4.8889. 8.4305. 第八期. 10.2500. 17.7657. 第九期. 5.3056. 3.6318. 第十期. 3.6944. 2.4002. 31.
(41) 表 4.3:低智能分數受測者的每一期選擇 期數. 平均. 標準差. 第一期. 41.4167. 22.4339. 第二期. 31.0278. 10.9557. 第三期. 23.7222. 21.5322. 第四期. 14.9167. 13.5444. 第五期. 6.9444. 4.4333. 第六期. 8.2778. 18.5096. 第七期 第八期. 立. 第九期. 8.9722 政 治 大 11.3056. 第三期. al. Ch. 0.055556. e0.166667 ngchi U. sit er. 0.083333. y. 高智能. n. 第二期. io. 第一期. 表 4.4:高低智能受測者的勝率. Nat. 期數. 4.3056. 5.9348 2.6707. ‧. ‧ 國. 第十期. 18.0188. 學. 6.7500. 18.9759. v ni. 低智能 0.027778 0.083333 0.138889. 第四期. 0.027778. 0.111111. 第五期. 0.166667. 0.277778. 第六期. 0.277778. 0.111111. 第七期. 0.111111. 0.194444. 第八期. 0.166667. 0.111111. 第九期. 0.333333. 0.277778. 第十期. 0.333333. 0.083333. 32.
(42) 10 11 12 0. 1. 2. 3. 4. 5. 6. 頻率. 7. 8. 9. 10 11 12 9 8 7 6. 頻率. 5 4 3 2 1 0 0. 10. 20. 30. 40. 50. 60. 70. 80. 90. 100. 0. 10. 20. 30. 40. 選擇. 50. 60. 70. 80. 90. 100. 60. 70. 80. 90. 100. 60. 70. 80. 90. 100. 60. 70. 80. 90. 100. 選擇. 10 11 12 9 8 6 4. 4. 5. 6. 頻率. 7. 8 7. 政 治 大. 5. 頻率. 9. 10 11 12. 圖 4.1:第一期的選擇(右:高智能 左:低智能). 3 2 1 0. 10. 20. 30. 40. 50. 60. 70. 80. 90. 100. 0. 10. 20. 學. 0. ‧ 國. 0. 1. 2. 3. 立. 30. 選擇. 40. 50. 選擇. y. 10 11 12. sit. 9 8 7. er. 6. 頻率. 3 2. engchi. i Un. v. 0. 1. 3 2. Ch. 0. 1. 4. n. al. 5. 9 8 7 6 5. 頻率. io. 4. ‧. Nat. 10 11 12. 圖 4.2:第四期的選擇(右:高智能 左:低智能). 0. 10. 20. 30. 40. 50. 60. 70. 80. 90. 100. 0. 10. 20. 30. 40. 選擇. 50. 選擇. 10 11 12 9 8 7 6. 頻率. 0. 1. 2. 3. 4. 5. 6 5 4 3 2 1 0. 頻率. 7. 8. 9. 10 11 12. 圖 4.3:第七期的選擇(右:高智能 左:低智能). 0. 10. 20. 30. 40. 50. 60. 70. 80. 90. 100. 0. 選擇. 10. 20. 30. 40. 50. 選擇. 圖 4.4:第十期的選擇(右:高智能 左:低智能) 33.
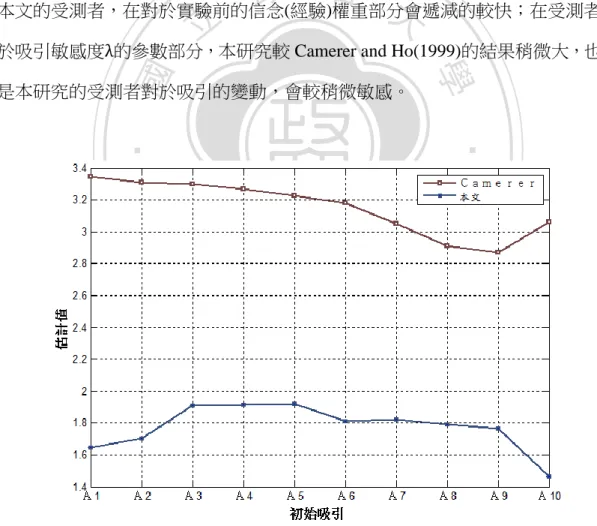
(43) 4.2 經驗加權吸引模型估計結果 在第二章,本文曾經介紹過經驗加權吸引模型(EWA),整個模型總共有 15 個待估參數,分別為𝐴1 (0)至𝐴10 (0)、N(0)、ψ、ρ、δ 及 λ,本文在估計上依據 Camerer and Ho(1999),將初始吸引(Initial Attraction)分為 10 個等分,分別為 0-10、 10-20、...、90-100,總共 10 個區間,所以在估計方面,就會如同上述𝐴1 (0)至 𝐴10 (0),共 10 個初始吸引參數需要估計,在參數方面本文也做了一些限制,本 文參照 Camerer and Ho(1999)的設定,在ψ和 λ 的估計上,限制ψ和λ必須大於 0, 在 δ 和 ρ 的估計上,限制 0≤δ,ρ≤1,以及限制 0≤N(0)≤1/(1-ρ),表 4.5 是本研究. 治 政 使用最大概似估計法,所估計的結果(中間欄位為本研究的估計結果,右側欄位 大 立 則為 Camerer and Ho(1999)的估計結果)。 ‧ 國. 學. 從最大概似估計值比較中,本文的資料在模型的配適度上,很顯然地優於. ‧. Camerer and Ho(1999)的結果,這代表著本文所採用的實驗樣本,更能使用經驗. sit. y. Nat. 加權吸引模型來描述受測者的行為,也可能是在實驗的設計或者樣本資料的處理. io. er. 上,使用了更精確的方法;本文的初始吸引相對於 Camerer and Ho(1999)的結果 比較低,但初始吸引若純粹以數值大小作比較並不適當,所以本文並不單純地使. al. n. iv n C 用數值的大小作比較,而需要以相對大小來觀察,因此本文將初始吸引以圖 4.5 hengchi U 的方式,將 10 個區間的分配描述出來,我們從圖 4.5 可以看出,本文的估計結. 果,從𝐴1 (0)開始遞增直到𝐴5 (0),之後不斷遞減直到𝐴10 (0),而𝐴10 (0)也是整個 分配的最低點;而 Camerer and Ho(1999)的估計結果,從𝐴1 (0)開始往下遞減至 𝐴9 (0),在𝐴10 (0)時又突然往上升,從這些結果可以看出這兩種結果有著極大差 異(兩種結果的初始吸引估計分配表置於圖 4.5),本文在初始吸引部分,所估計 的分配結果會與之後期間的分配較不相似(實驗數據顯示猜測會越來越集中在較 低數字),而 Camerer and Ho(1999)分配差異則較小,這可能代表著本研究的受測 者,較沒有接觸過類似賽局實驗的經驗或對於類似賽局的分析較差;以理論來說,. 34.
數據
相關文件
• e‐Learning Series: Effective Use of Multimodal Materials in Language Arts to Enhance the Learning and Teaching of English at the Junior Secondary Level. Language across
• To enhance teachers’ knowledge and understanding about the learning and teaching of grammar in context through the use of various e-learning resources in the primary
In the course of QA inspection, assessment of the quality of the learning and teaching of individual subjects
Making use of the Learning Progression Framework (LPF) for Reading in the design of post- reading activities to help students develop reading skills and strategies that support their
The Seed project, REEL to REAL (R2R): Learning English and Developing 21st Century Skills through Film-making in Key Stage 2, aims to explore ways to use film-making as a means
2-1 化學實驗操作程序的認識 探究能力-問題解決 計劃與執行 2-2 化學實驗數據的解釋 探究能力-問題解決 分析與發現 2-3 化學實驗結果的推論與分析
DVDs, Podcasts, language teaching software, video games, and even foreign- language music and music videos can provide positive and fun associations with the language for
Incorporating effective learning and teaching strategies to cater for students’ diverse learning needs and styles?. Integrating textbook materials with e-learning and authentic
