行政院國家科學委員會專題研究計畫 成果報告
總計畫(3/3)
計畫類別: 整合型計畫 計畫編號: NSC91-2219-E-009-033- 執行期間: 91 年 08 月 01 日至 92 年 07 月 31 日 執行單位: 國立交通大學電信工程學系 計畫主持人: 張仲儒 共同主持人: 楊啟瑞,張仲儒,陳伯寧,陳耀宗 計畫參與人員: 林立峰、黃鏗銘、黃慶喜、丁崇光、陳柏翰、鄭永宏、吳育葵、 顏寧佑、翁昭源、潘家斳、殷偉盛、花凱龍、林建光、王聖賢、 姚建、詹益禎、郭國承、張均瑋、何凱元、吳忠興、陳志偉、 田伯隆、施汝霖 報告類型: 完整報告 報告附件: 國際合作計畫研究心得報告 處理方式: 本計畫可公開查詢中 華 民 國 93 年 2 月 16 日
計畫中文摘要
由於網際網路的蓬勃發展,使得網際網路上的訊務量急遽增加,且跨網域 的比重也驟然提升甚多,除了最初且最基本的數據通訊之外,也加入了語音或影 像等即時性類型的服務。如此,訊務流量(traffic flow) 的增加、訊務特性的多樣 化與服務品質(QoS) 需求的大幅差異,使得原本只適合於非即時性數據(Data)傳 輸的網際網路之各項應用的服務品質不易獲得保障。為了確保目前和未來可能的 各項應用與服務能夠在網際網路上運作順暢甚或具有一定的品質,並維持網際網 路的永續發展,故其需要對新型態的訊務特性有所瞭解,並透過頻寬的提升、與 有效的QoS 運作架構與訊務控制機制來確保使用者的服務品質可以獲得保障。 本整合型計畫擬以三年來研究網際網路上之訊務特性與提供服務品質保證 的運作架構及訊務控制方式,並提出有效的解決方案,以完成網際網路端點對端 點之服務品質保證。子計畫一由張仲儒教授主持,主要研究網際網路中高速路由 選徑技術與提供服務品質保證之訊務控制法及其設計:直接針對路由器本身著 手,增加路由器路由選徑的處理速度,或利用第二層網路的高速交換(Switch) 來 取代第三層之路由選徑,以獲得等效於加快路由選徑速度之效果,並配合差別服 務,提出精確且有效的允諾控制與使用參數控制法;子計畫二由陳伯寧教授主 持,主要在探討網際網路中具有自我類似(Self-Similar) 性質的真實網路訊務,瞭 解其成因與特性並提出訊務模型以作為其它子計畫方法設計之依據;子計畫三由 陳耀宗教授主持,主要研究網際網路差異化服務的路由器中,多欄位分類器與負 責提供差別服務的排程器之設計,驗證並比較出最適合者,並利用各種軟硬體方 式以實現所完成之設計。 於計畫執行第二年度,新加入由楊啟瑞教授所主持的第四子計畫。子計畫 四主要著眼於個人行動通訊時代的來臨,通訊網路已經由有形的網路延伸至無線 的環境了,在最接近用戶的終端可以藉著可攜式多媒體通訊設備或電腦透過無線 行動通訊科技進行通訊,甚或進入網際網路中擷取資料或取得服務,然而多變的 無線環境也相對增加了各項訊務控制機制的複雜度。因而擬透過子計畫四探討如 何以無線設備進行具備 QoS 保證的寬頻網際網路的存取,設計一個持續穩定且有高效能並支援QoS 的無線媒體多重接取(Multiple Access) 競入技術,能夠使得
競入訊號能以極高效率進入系統,同時保持區域網路的最大效能,並進一步於其 上設計出一個動態頻寬分配機制。
Abstract
With the blooming of Internet application services, the Internet traffic flow increases dramatically and the traffic flow from inter-network transmission also increases rapidly. Not only the basic data transmission but also some multimedia services (such as: voice, real-time video services) are also carried on the Internet. Henceforth, to provide the QoS-provisioning services, the larger bandwidth capacity, effective QoS-provisioning service framework, and traffic control mechanisms are the primary requirements in the design of the Internet.
The three-year integrated project is intended to propose an effective solution to provide end-to-end QoS guaranteed Internet services and the corresponding research interestings are: the traffic characteristics of the Internet services, a QoS-provisioning service framework and the traffic control mechanisms. The subproject one is to study the high speed Internet routing techniques, the QoS-provisioning traffic control mechanisms and the network configuration. To speed up the Internet routing, 2 possible techniques will be proposed to improve the performance of the router: faster the routing path searching techniques and layer-2 high speed switching techniques for replacing the layer-3 routing techniques. A precise and effective control admission control (CAC) and usage parameter control (UPC) will be also proposed for providing differentiated services. The subproject two is to study the self-similarity of traffic characteristics of the real Internet services and propose an appropriate traffic model that will be the reference model for other subprojects. The subproject three is to study and design the multiple field classifier and scheduler for the routers that provide differentiated services. The subproject four is to propose a persistently stable, efficient multiple access scheme for wireless networks, capable of providing signaling traffic high performance while retaining maximal throughput for local wireless networks. Many possible configurations will be verified and the most appropriate one will be proposed and implemented by hardware and software.
Keywords: Routing, Multi-Protocol Label Switch (MPLS), DiffServ, Edge Router, Core Router, Multi-field Classifier, Scheduler, Traffic Control, Call Admission Control, Usage Parameter Control, Self-similar
目錄
一、 計畫緣由及目的... 1
二、 研究方法、成果與討論... 3
1. 高速的路由選徑機制... 3
1-1. 高速單一路由選徑(Unicast Routing)機制-階層式分群解析架構.... 3
1-2. 高速單一路由選徑(Unicast Routing)機制-TCAM-based 架構... 10
1-3. 高速群播路由選徑(Multicast Routing)機制.... 15
2. MPLS 網路之 VC-Merge 機制的效能分析... 17
3. MPLS 網路之路徑保護及快速回復(Path Recovery) 機制... 22
4. DiffServ 網路中精確的訊務監控調節(Traffic Contioner)機制.... 29
5. 高速 IP 封包分類(Packet Classification) 演算法... 37
6. 提供等比例封包延遲變異(jitter)之排程器(Scheduler)... 40
7. 具有自我類似性質之訊務特性研究與訊務源模型設計... 44
7-1. 馬可夫過程(Markovian Process) 的自我類似性質探討.... 44
7-2. 自我類似特性之網路封包的產生... 47
7-3. 自我類似特性之訊務流在資訊理論上的特徵.... 52
8. 支援 QoS 的無線媒體多重接取(Multiple Access)競入技術... 56
三、 參考文獻... 60
一、計畫緣由及目的
從1969 年發展至今的網際網路(Internet),已經由最初實驗性的研究成果, 在歷經幾次的變革之後普及至教育和商業環境;更由於其跨網路、跨地域(無遠 弗屆)、極富有彈性(Flexibility) 與可能性(Possibility) 的特點,吸引了愈來愈多 人投入此一新的網路世界,然而它的成功卻也加速顯現其發展的瓶頸。擁有超過 兩千萬個節點及上億使用者的 Internet,必須進行大幅度的改造,才能進一步像 電話一樣普及,事實上這些改造的研發工作也從未間斷。架構出網際網路的網際網路協定(IP Protocol) 原本只是適用於數據 (Data) 通訊的第三層網際網路協定,並藉著路由器連接不同的網路/網域形成一非連結 導向(Connectionless) 的廣域網路。然而在網際網路蓬勃發展之際,也使得許多 非單純數據傳輸的應用,例如語音或影像等具備即時 (Real-time) 傳輸要求的服 務也採用IP Protocol 進入網際網路中,再加上多媒體技術的突飛猛進與其服務的 普及,使得對頻寬與網路服務品質保證的需求也相對應地提升。所以有許多的改 革動作也應運而生,其中最主要的即是在高頻寬傳輸速度與服務品質保證上 (QoS guarantee)的研究。 為了解決寬頻的問題,提升路由器的處理速度成為必然的趨勢。目前在這 方面的研究可以分成兩大類:一是直接針對路由器本身著手,增加路由器路由選 徑 (Routing) 的處理速度,即是要發展出高速的路由選徑機制;另一方面則是藉 著改變架構,利用連結導向(Connection-oriented) 的第二層(電信)網路的高速 交換(Switch) 動作來取代第三層非連結導向(Connectionless) 的 IP 協定網路的路 由選徑動作,使可以獲得相當於在第三層上加快路由選徑動作速度的效果,我們 也可以將其視為一種虛擬的路由選徑(Virtual Routing)方式,如 IETF 所提出的 MPLS(Multi-Protocol Label Switch) 技術。
提供服務品質保證方面,目前IETF 已經針對這方面(服務品質保證)的需
求成立了相關的Working Group。其中的 DiffServ 並不針對 per-flow 的訊務提供 服務品質保證,而是將訊務分為幾種不同的等級種類(Class),再對每一種類提供 不同的服務品質。不同種類的訊務在路由器上會被封包分類器(Classifier) 分開 來,將相同種類的訊務再進行匯流整合(Aggregate) 視為一體的訊務流(flow),然 後只對此匯流整合的per-class 訊務進行 QoS 的處理(例如排程與佇列管理),而 不再對其中單一的 per-flow 訊務進行處理,如此便可以降低系統的複雜度與負 擔,增加網路規模的擴充性。分類的依據可以是多樣的,根據 IP 封包中不同的
欄位(例如:Source IP、Destination IP、Transport-layer Port、ToS/DSCP……等) 與其上記載的訊息,或單一欄位、或多欄位組合的條件方式進行訊務的分類。 DiffServ 在實際的運作方式上也必須引入連線導向(電信)網路中訊務控制的概 念,例如以呼叫允諾控制對新進的連線作系統資源的確認,再決定是否接受此連
線的訊務,以更進一步確保能提供各種類的訊務所要求的QoS。 此外,未來寬頻網際網路技術之走向,應是以解決目前與未來可能發生的 網路問題為主軸。而在此研究上,如網路節點的排程控制,或是網路規約整體設 計,多以傳統的波以松(Poisson)式的訊務為模擬基礎;而近年來的網路流量特性 之量測研究顯示,真實網路封包序列(Packet-Train) 流量與波以松式的訊務有著 極大的差距,甚至具有自我類似(Self-Similar) 的特性,因此要真正的了解乃至於 提出真實網路問題的解決方案,勢必要對真實網路訊務有深入的了解。 而著眼於個人行動通訊的時代的來臨,通訊網路已經由有形的網路延伸至 無線的環境了,在最接近用戶的終端可以藉著可攜式多媒體通訊設備或電腦都透 過無線行動通訊科技進行通訊,甚或進入網際網路中,擷取資料或取得服務。如 此大大增加了通訊的自由度與彈性,但也因為範圍涵蓋了較多變的無線環境,故 相對地增加了複雜度,其中主要的研究課題是探討如何以無線設備存取寬頻網際 網路。基本上,無線ATM 網路己被視為下一代無線區域網路中最有潛力的一個 可行方法,因為它具備了整合性多媒體高速服務,並能滿足各式不同 QoS 的需
求,如CBR、VBR 與 ABR。對 VBR 和 ABR 來說,它所要求的 QoS 分別為有
限的傳送延遲與保證擁有最小的傳輸速率。在無線ATM 網路上所面臨的主要挑
戰有二:首先,是如何來設計一個有效率且支援QoS 的無線媒體存取控制協定;
其次,是如何於前述之協定上設計出一個動態頻寬分配機制。過去我們已經提出
了一個無線ATM 網路上的智慧型多重存取控制系統 (IMACS),它是一個功能強
大並可動態調整頻寬分配的設計。IMACS 包含了三個部份:媒體存取控制器 (MACER)、訊務推估器 (TEP),與智慧型頻寬分配器 (IBA)。MACER 利用 TDMA 混合模型的架構,它的競入存取控制是基於動態樹狀分割 (DTS) 的碰撞解決演 算法,以最佳化的分割深度 (SD) 為其參數,而無線網路的存取與訊務控制都可 建立於此範例上。然而在此仍有三個相當富有挑戰性的問題等待我們去研究:第 一個問題是DTS 利用最佳化的 SD 可以不經任何額外的控制而達到 utilization 為 0.368。我們的第一個目標為設計出一套盡可能使用最少 feedback 的無線通訊方 法,可以將這utilization 昇高,使其接近理論上限 0.58。第二個問題是在 IMACS 中,需服務品質保證的即時性訊務 (如 CBR 與 VBR)和不需即時服務的訊務並不 在一起考慮;我們第二個目標為設計出一個能同時考慮即時和非即時訊務的機 制,且能滿足各自的QoS 要求,並能達到最高的 utilization;最後,我們第三個
目標為研讀長程(Long Range Dependent) 相關或自我相似性的論文,並設計以 Autocorrelation 函數為依據的一個智慧型訊務大小推估技術,以提供未來無線網 路訊務工程的開發能力。
伯寧主持)主要在探討網際網路中具有自我類似(Self-Similar) 特性的真實網路訊 務,瞭解其特性並可作為其它子計畫架構設計之依據;子計畫三(陳耀宗主持) 主要研究網際網路差異化服務的路由器中,多欄位分類器與負責提供差別服務的 排程器之設計。子計畫四(楊啟瑞主持)主要是針對區域無線網路而言,擬提出 了一個具有持續穩定且有高效能的多重接取(Multiple Access) 競入技術,能夠使 得競入訊號能以極高效率進入系統,並能同時保持區域網路的最大效能。 接下來我們將分別就本計畫在「高速頻寬傳輸」與「服務品質保證運作機 制」上的各項具體研究成果,進行方法說明與成果討論,
二、研究方法、成果與討論
1. 高速的路由選徑機制
這部分主要是發展適合硬體實現(Hardware-oriented) 的高速路由選徑方 法,期以硬體的運作方式加速路由選徑的運算速度,以滿足Gigabit 超高速網路 環境下以及未來更寬頻的網際網路應用的需求。1-1. 高速單一路由選徑(Unicast Routing) 機制-階層分群解析架構
經過歸納與研究分析的結果,適合硬體實現的路由選徑方法應具備有下列 的特性與概念:「固定資料長度」的資料運算動作,以及「規則化」的、「反覆運 作」的處理程序(Process),而「階層式分群解析」(或稱「多層次群組解析」)的 方法即具備有上述的末兩項特點,再配合上以階層式的多元完全展開樹(Trie) 來做為其將整個IP 位址進行多層次的 IP 位址區段分群的參考架構後,便具備有 「固定資料長度」的資料運算動作的條件,因而極適合於做為採用實際的硬體邏 輯&運算電路來實現的路由選徑機制。「階層式分群解析」的方式是:將整個IP 位址進行多個層次的 IP 位址區段分群-先進行第一層次的較粗略分群,再依據 實際路由表格中路由字首(Route Prefix) 的資訊,針對有需要做進一步細部分群 解析的群組(即包含一個以上,對應至更小範圍 IP 位址區段的路由字首)進行 下一層次更精細的分群展開,如此反覆運作至每一分群中沒有對應至更小範圍IP 位址區段的路由字首為止。接下來將每一層次的每一IP 位址區段分群與該 IP 位 址區段路由選徑的結果進行對應並以表格紀錄(「分群-路由結果」對應表格): 若為毋須再進行下一階段細部分群解析的群組,將必然可以對應至一個該 IP 位 址區段的(共同)路由選徑結果(即封包的輸出埠(output port));若為需要再進一 步細部分群解析的群組,則可以對應至一個「必須進行下一層次更細部分群解析」的指示,並且指向連結至該進一層次的「分群-路由結果」對應表格。進行實際 路由選徑的應用時,只要將所欲查詢的目的IP 位址(Destination IP Address) 與各 層次的IP 位址區段分群進行比對,尋找其所屬的最細的分群,待確定目的 IP 屬 於何層次的某一分群後,即可以由該層次的「分群-路由結果」對應表格直接查 表得知其路由結果輸出埠。而此「比對」動作是規則地、次第從第一層分群開始, 再視需要逐步往分群更精細的層次檢視、比對。由於是將路由選徑之搜尋演算動 作化為「規則」化的、「反覆運作」的多層次比對與查表動作,因此已具備適合 硬體實現的初步條件了。 因此我們將以「階層式分群解析」的方式為主,來發展適合硬體實現的高 速路由選徑方法。而我們所提出的作法,是以階層式的多元完全展開樹(Trie) 來做為「階層式分群解析」方法中,將整個IP 位址進行多層次的 IP 位址區段分 群的參考架構—也就是使每層次的IP 位址區段分群恰好為一 N-bit (1≤N<16) 的 完全展開樹(Trie),如此一分群的 IP 位址區段範圍皆可以用一個 IP 位址字首 圖 0: Trie-based 階層式分群解析路由方法 ∗ 001∗ 010∗ 011∗ 100∗ 101∗ 110∗ 111∗ 000∗ ∗(default Route) 0 ∗ 11 ∗ 1 2 3 4 Prefix Output Port
001 1∗ 5 001 10 10∗ 6 101 01 ∗ 7 001 ∗ ∗(default Route) 0 ∗ 11 ∗ 1 2 3 4 Prefix Output Port
001 1∗ 5 001 10 10∗ 6 101 01 ∗ 7 001 ∗ 2 N1 2 2 1 N2 3 3 4 4 N3 5 1 7 1 1 5 5 6 5 01 01 100 (MSB) (LSB) 000 001 010 011 100 10 1 110 11 1 00 01 10 10 00 01 10 10 00 01 10 10 Routing Table (路由表格)
Data Structure of the Corresponding Memory Usage Destination IP Addr. of incoming IP Header (if necessary) Compare Compare Compare
Full Expansion of IP(v4) Address
0.0.0.0 28.28.28.28 01 01 100 (MSB) (LSB) 01 01 100 (MSB) (LSB) Address Decoder (定址電路) (MSB) (LSB) (MSB) (LSB) 11 11 11
群展開(以上的敘述可以參見圖 0 所示)。每一層次皆對應至一組表格,紀錄此 層次中各分群IP 位址區段(Segment) 及其所對應的路由選徑結果,或是必須進行 下一層次更細部分群解析的指示。而針對有需要才進一步細部分群解析的方式也 比起純粹的(階層式)多元完全展開樹方法大大減少所需的記憶體容量。實際應 用於進行路由選徑查詢動作時,即是將所欲查詢封包的目的 IP 位址(Destination IP Address) 與各層次的分群進行比對:由第一層次分群開始,直至其所屬的分 群不再有進一步的分群解析為止,此時只要查詢該層次的「分群-路由結果」對 應表格即可得到該封包的路由輸出埠。而由於我們是以階層式的多元完全展開樹 (Trie),來做為其將整個 IP 位址區段進行多層次分群的參考架構,每層次的 IP 位址區段分群恰好為一N-bit (1≤N<16) 完全展開樹(Trie),因此可以如同圖 0 右 半部份所示,進一步將目的IP 位址在各層次的「分群比對」動作,轉換為 N-bit 固定長度的「定址」動作,而所定址到的記憶體內容即儲存該階層中該 IP 位址
群組(Segment) 的路由選徑結果(output port),或是指向儲存著下一層次分群解析
的路由選徑結果的 Pointer,如此也相當於將原本分群比對之後的「分群-路由結 果」表格的查詢動作也一併整合進來了。也就是說,只要透過反覆的(固定資料 長度的)定址動作,即可以得到路由選徑的結果。至此,我們已將傳統路由選徑 之搜尋演算動作,轉化為一套系統化的階層式路由資料結構,與一「規則」化的、 「反覆運作」的多層次「定址」動作,而這些都可以採用實際的硬體邏輯&運算 電路來加以實現並獲得加速的效果,例如其中的定址動作便能夠採用定址電路來 達成。此時Routing 的速度則完全取決於「記憶體定址」的「存取次數」與「定 址電路運作速度」。 為了決定實際運作時,所使用的實際階層分群(參數)的設定,包含階層 數目與每一階層中的分群大小(因為每一階層是為一個N-bit 的多元展開樹,所 以這裡也相當於是在決定每一階層的N 值大小,亦即多元展開樹的大小),以及 所需要的記憶體容量大小,因此我們進一步探討 Routing Table 的特性,並再深 入瞭解所設計方法的特點,以及兩者之間的關係。對於每一種路由選徑方法而 言,不同的 Routing Table 資料皆會因為其中路由字首數據的不同,諸如路由字 首數量多寡、分佈的型態/趨勢、分佈的量值大小差異,造成其不同的運作記憶 體容量需求。在觀察我們所設計的路由選徑方法之後發現,對於一筆 Routing Table 資料而言,不同的階層分群方式會影響儲存路由結果的資料結構所需要的 記憶體容量,這也表示我們可以藉由適當地設定階層分群方式,來獲得最小記憶 體容量。透過初步的檢驗程序發現,增加分群階層數可以使每一階層的完全展開 樹規模較小,相對上每一分群範圍較廣,因此可以較有效率地針對有需要再進一 步分群解析的 Subnet 才進行下一階層的展開,所以可以相當有效地減少記憶體 需求,然而卻有平均記憶體存取次數隨之遞增的缺點,因而我們必須在分群階層 數與記憶體存取次數之間權衡一最佳點。此外觀察也發現,記憶體容量需求也並 非隨著階層數的增加而永遠呈等速率地減少,而是會趨向一飽和值。因此在綜合 考量階層數變化對於記憶體容量以及存取次數的效應之後,我們決定採用5 層次
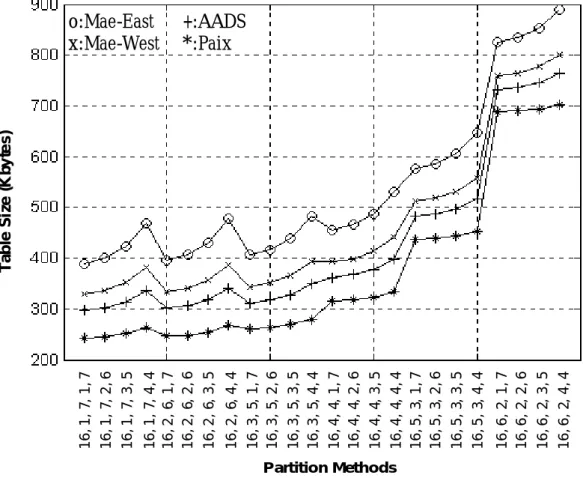
的分群解析架構。 最後我們更進一步地分析實際Routing Table 中路由字首的分佈狀況,作為 階層式多元完全展開樹各層次中分群的依據,期望能以對應路由字首分佈特性來 最佳化的分群設計,獲得更有效率的記憶體使用。圖 0 為一般 Routing Table 中 普遍的路由字首分佈狀態統計圖,從圖上可見大多數的路由字首長度集中在 16 bits 至 24 bits 之間,因此若是在此長度之間有一個階層分界展開點,便可以在此 階層的展開中完成大多數的路由選徑查詢動作(如果實際的 IP 封包標頭的目的 IP 位址不特別集中在長度超過 24 bits 的路由字首的話)。而根據之前分群階層數 考量與決策過程的經驗來看,如果在 1 至 15 bit 的字首長度之間定有分層展開 點,則應該可以有較小的記憶體容量需求,然而卻也會因而增加平均記憶體存取 圖 0: Routing Table 中路由字首的分佈狀態圖 (本圖數據參考自MaeEast 2000/07/18 的統計資料[4])
層分群方式為「16-1-7-1-7」,因為此方式可以得到最佳的表現:平均記憶體存取 次數較小,以及最小的記憶體需求。
最後,我們採用一簡單的位元圖(Bit Map) 壓縮法(Compression Bit Map, CBM) 將儲存路由結果的資料結構做壓縮,以進一步減少所需的儲存記憶體空 間。而我們所設計的階層式分群解析法原本在運作架構特性上就相當適合模組化 的運作,可以將每一個階層的分群解析路由查詢動作都視為一獨立而完整的運作 模組,因此透過適當的電路規劃與安排,可以達成硬體上超管線式(Pipeline) 平 行多工架構的運作方式及其優點,當有 IP 路由選徑查詢進入第二階層後,便可 以馬上接受下一 IP 路由查詢的要求,維持高度的路由查詢 Throughput,使每個 封包路由選徑動作所要存取記憶體的平均次數減少至極致,可達到相當於在一次 的記憶體存取動作與時間,便可以完成一筆IP 路由選徑查詢的動作,此時 Routing 的速度將幾乎完全取決於記憶體存取定址的硬體定址電路運作速度。 圖 0: 不同的 IP 位址 (32-bit IPv4) 階層分群方式及其所需之記憶體容量
(對不同ISP/NSP 的 Routing Table 而言)
1 6 , 1 , 7 , 1 , 7 1 6 , 1 , 7 , 2 , 6 1 6 , 1 , 7 , 3 , 5 1 6 , 1 , 7 , 4 , 4 1 6 , 2 , 6 , 1 , 7 1 6 , 2 , 6 , 2 , 6 1 6 , 2 , 6 , 3 , 5 1 6 , 2 , 6 , 4 , 4 1 6 , 3 , 5 , 1 , 7 1 6 , 3 , 5 , 2 , 6 1 6 , 3 , 5 , 3 , 5 1 6 , 3 , 5 , 4 , 4 1 6 , 4 , 4 , 1 , 7 1 6 , 4 , 4 , 2 , 6 1 6 , 4 , 4 , 3 , 5 1 6 , 4 , 4 , 4 , 4 1 6 , 5 , 3 , 1 , 7 1 6 , 5 , 3 , 2 , 6 1 6 , 5 , 3 , 3 , 5 1 6 , 5 , 3 , 4 , 4 1 6 , 6 , 2 , 1 , 7 1 6 , 6 , 2 , 2 , 6 1 6 , 6 , 2 , 3 , 5 1 6 , 6 , 2 , 4 , 4 Partition Methods Ta b le S iz e ( K b y te s ) o:Mae-East +:AADS x:Mae-West *:Paix
圖 0 所示即為我們所設計的快速路由選徑機制的硬體邏輯架構。從表 0 的 模擬結果看來,目前我們所設計適合於IPv4 Unicast 的高速路由選徑方法相較於 其他類似概念的方法 [3],僅需要不到 400 Kbytes 的記憶體空間,而且透過硬體 上Pipeline 平行多工的方式,可達到每個封包在平均一次記憶體定址存取的動作 即可以獲得路由選徑結果。未來我們將考量實際商用化系統環境與規格(速度與 圖 0: 快速路由選徑機制的硬體邏輯架構
綜合上述的內容來看,我們在高速路由選徑法之研究設計方面,藉由適當 的查詢架構與路由表格結構的設計,快速而硬體架構導向的路由查詢演算法得以 實現,配合上實際硬體化操作與超管線(Pipeline) 平行多工運作架構的設計,使 得路由選徑查詢得以達到平均約一次記憶體存取動作即可完成的高通透率 (Throughput),可以向上支援至超高速乙太網路(Gigabit Ethernet) 甚或更高速網 際網路頻寬的需求。根據階層式分群解析概念,配合壓縮化完全展開樹以及 Compression Bit Map 壓縮法而發展出來的路由選徑方法,確實能使路由選徑機制 運作所需的記憶體容量降低許多,相對於平面展開式的壓縮方式,更小的記憶體 容量亦更有利於硬體架構的設計與運作,甚至可以將記憶體與周邊相關的邏輯電 路整合入同一單晶片中,成為一獨立的硬體路由選徑搜尋引擎,除了可以更大幅 提升速度之外,也符合系統化晶片(System on Chip, SoC) 的發展潮流與趨勢。另
外,我們也將所設計的方法針對Routing Table 中,大量的路由字首長度大於 24
的此種特殊路由字首分佈情況做進一步的檢驗與分析,發現其所造成的記憶體容 量需求成長的幅度相當低,並未隨之成比例地大量增加,從此結果也可見我們的 方法還具有相當的空間擴展性的優勢。藉由對單一路由(Unicast Routing) 之選徑 技術研究,我們可以很快進入多點群播路由(Multicast Routing) 及下一代網際網
路IPv6 之相關路由選徑技術的研究,甚至是封包分類器(Packet Classifier) 中複
雜度更高、查詢參照資訊(欄位)更多的查表搜尋演算機制的設計。 表 0: 路由選徑方法所需記憶體容量之比較
NAP (Number of Route Prefixes )
Enhanced Forwarding Table Size (Kbytes)
with (16, 1, 7, 1, 7) Forwarding Table Size (Kbytes) in [3] Mae-East (57,701) 388 464 Mae-west (34,319) 350 438 AADS (30,705) 337 431 Paix (16,274) 270 357
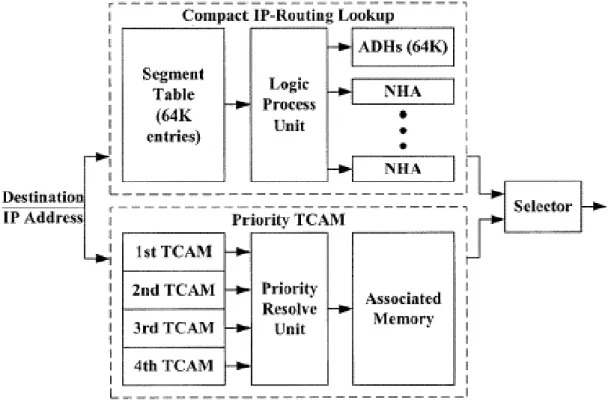
1-2. 高速單一路由選徑(Unicast Routing) 機制-TCAM-based 架構
除了上述根據階層式分群解析概念,配合壓縮化完全展開樹而發展出來的 硬體架構導向的路由選徑方法之外,另一類硬體化操作的路由選徑機制,即是著 眼於因半導體製程技術的進步而開發出來的TCAM (Ternary Content Addressable Memory) 記憶體特性,而採用其為基礎的路由選徑方法,可稱之為「直接 TCAM 路由比對方法 (Direct TCAM Match)」。因此在本計畫中,我們也提出一套採用 TCAM 記憶體特性的硬體化操作路由選徑機制。相較而言,如上一節中採取階 層式分群解析概念,或以完全展開樹為基礎的這一類方法 [2, 3, 6],相當於是 將原本路由選徑所需要的查詢演算方式進行轉換,成為一些單純、規律的邏輯電 路運作和記憶體存取動作的操作程序,之後只要將IP 封包標頭的 Destination IP 位址輸入,透過此規則化的操作程序即可以獲得路由選徑的結果。由於並不是直 接透過一般 IP 路由選徑搜尋演算方法的過程,而是間接地透過轉換後的規則化 操作程序即可獲得等效於路由選徑搜尋演算法的結果,因此也被歸類稱為「間接 路由查詢方法(Indirect Lookup)」。 隨著半導體技術的進步,記憶體的種類與功能也不斷推陳出新,除了運作 速度與記憶容量之單位面積密度的提升與價格的下降之外,也從最初單純的資料 儲存目的發展至以專屬應用為主的功能性記憶體,「內容定址記憶體(Content Addressable Memory, CAM)」即是做為「資料搜尋」用途的專門記憶體。其應用 的方式為:記憶體中的每一個儲存單位存入的為某一應用的一筆候選內容資料以 及該內容的相關聯數據資料,待該應用需要進行內容搜尋的時候,僅需將該內容 輸入記憶體做為定址用途,CAM 記憶體自動會將內容比對吻合的該儲存單位的 內容相關聯數據資料輸出。省去在傳統記憶體架構的操作程序中,必須自行將記 憶體中的候選內容資料一一定址取出並分別比對,再將內容吻合項目的相關聯數 據資料另外定址讀出所必須花費的時間。而具三元資料比對能力的 TCAM
(Ternary CAM) 記憶體的提出,更是讓 CAM 記憶體的資料搜尋能力因為具備更
彈性的應用方式而進一步提升:儲存的內容可以包含 don’t care 萬用字元(*), 因此可做到多對一的模糊化搜尋方式,也就是一筆候選內容可以包含多個可能 性,輸入資料時不再需要完全吻合候選內容才會得到輸出,只要與候選內容近 似,在其包含的可能性範圍內,就可以得到相對應的關聯數據輸出。這樣的資料 搜尋應用方式與IP 路由選徑有著相近似的運作方式(Routing Table 中每一筆路 由字首資料皆可視為是以萬用字元對應至一IP 位址區段,也就是多個 IP 位址, 而同一IP 位址可能會被多個路由字首所對應的 IP 位址區段範圍所涵蓋。當欲查
以TCAM 為基礎的 IP 路由選徑方法即是一個硬體化操作的路由選徑方式, 具備有多方面的優點:由於屬於硬體的運作架構,所以運作的速度相當快;也因 為其本身的操作特性即相當符合 IP 路由選徑搜尋演算模式,所以僅需要搭配相 當簡單的周邊邏輯電路便能夠進行路由選徑查詢的應用,而運作所需要的資料結 構的建立與更新速度也很簡單、迅速,可以直接使用 Routing Table 的路由字首 資料而不需做任何轉換或處理的動作,所需要額外的記憶體容量也很小。然而其 目前唯一、也屬重大的缺點是,價格仍然過高,使得其雖然具備執行路由選徑機 制最佳且優秀的能力條件,但是真正商用化的路由器仍未見有採用其做為路由選 徑機制的應用。在本研究中,我們提出了一個整合直接 TCAM 路由比對和間接 路由查詢方法的路由選徑演算法,而設計的主要動機與概念便是:充分利用 TCAM 的特性並兼顧其價格缺點,整合間接路由查詢方法,並採用兩者平行處 理、分工合作的概念,截長補短—以間接路由查詢方法彌補 TCAM 因價格高而 數量不足,無法完全負擔路由選徑搜尋應用需求的缺點;利用少量的 TCAM 搭 配Priority 處理邏輯單元,來負擔部分(路由字首長度較長的)路由資訊的路由 選徑應用,減少間接路由查詢方法所需負責的路由資訊數量,因而降低其記憶體 需求。而此新的複合式路由選徑方法,最多只需要2 次的記憶體查詢時間,便可 以得到路由選徑的結果,而且也一併減少路由搜尋資料表的更新時間。其較細部 的設計與運作程序如下面的內容所述。 令li和hi表示路由器 (Router) 路由表格中第 pi筆路由字首的長度及其對應 的路由器輸出埠。我們所設計採用 TCAM 記憶體特性的硬體化操作路由選徑方 法的架構圖如圖 0 所示:上半部是為一個既有的間接路由查詢方法,處理 li小 於或等於24 的路由字首 pi,下半部即是直接TCAM 路由比對方法,處理 li大於 24 的路由字首 pi。此兩部份在實際的操作中是為平行處理的運作方式,對於一 筆輸入欲進行路由選徑查詢的 IP 位址,會同時被輸入至兩部份。若只有上半部
分的Indirect Lookup 有輸出,則 Selector 單元會將此結果直接做為自己的輸出,
成為該待查 IP 路由選徑的最終結果;若上下兩部份都分別得到路由選徑的結
果,則Selector 單元將會因為 Longest Prefix Match 的路由選徑原則,而以下半部
分Direct TCAM Lookup 的結果做為自己的輸出,同時也表示是該待查 IP 路由選
徑的最終結果。上半部的Segment Table 是存放以 IP 位址的前 16 位元為第一分
群解析階層展開後的每一分群IP Segment 所對應的路由結果 Pointer;而邏輯處
理單元(Logic Process Unit) 則是根據 Segment Table 所輸出的路由結果 Pointer, 進一步指向ADH (Associated Default Hop) 取得對應的路由選徑結果(也就是路
由輸出埠),或是指向儲存著下一層次分群解析的路由選徑結果的 NHA (Next
Hop Array)。而下半部的 1st、2nd、3rd 和 4th TCAM 表示 4 群 TCAMs 硬體單元, 分別儲存並處理Routing Table 中字首長度為 25 至 26 bits、27 至 28 bits、29 至 30 bits 和 31 至 32 bits 的路由字首,並依序具有由小至大的輸出優先權;Priority Resolve Unit 單元則如同一個 Filter,依 1st、2nd、3rd 和 4th TCAM 的實際輸出
TCAM 皆無有效輸出,則 Priority Resolve Unit 便以一個預設輸出代替; Associated Memory 存放四個 TCAM 中所有(長度大於 24 bits 的)路由字首所對
應的路由選徑結果(也就是路由輸出埠),並會根據Priority Resolve Unit 的結果,
輸出所對應的路由選徑結果;若Priority Resolve Unit 的輸出是為預設輸出,則
Associated Memory 將不會有輸出。
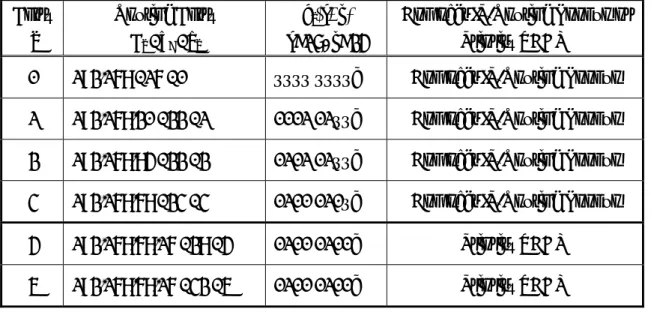
令pi (x, y)表示 pi 的 x 位元至 y 位元。表 0 顯示 IP segment 192.168 的對應
路由表。因為192.168 IP segment 的最大長度 li為32 bits。因此若利用傳統上單
純的間接路由查詢方式Huang’s scheme [3] 來查詢的話,此 192.168 IP segment
需要 2(32-16) 個對應的 NHA 路由器輸出埠 entry。利用我們提出的複合式路由選
徑查詢方法(如表 0 的最後一個欄位所示):我們把li大於24 bits 的路由字首 pi,
用直接TCAM 路由比對方法來處理;把 li小於或等於24 bits 的路由字首 pi,才由
間接路由查詢方法來處理。因此在間接路由查詢方法這部分只需要2(23-16)個(因
不僅如此,我們還進一步提出一個「同值位元整合壓縮法(Common Bit Integration)」,來改善間接路由查詢方法的(NHA)記憶體需求。以表 0 中 entry 1 至 entry 3(li小於或等24 bits 的路由字首)為例,其第 17、19、21 和 22 位元 是相同的,因此我們只需紀錄第18、20 和 23 位元的 3-bit 的 pattern 即可,因此 對應的NHA 路由器輸出埠 entry 可進一步由原來的 2(23-16)減少至2(23-16-4) = 23, 更進一步減低所需要的記憶體大小。 圖 0 表示 TCAM 硬體單元的架構圖。TCAM 硬體單元由路由字首 pi暫存
器,對應的pi mask bit pattern、32 個 3 位元比較器,和 1 個 32 位元的 AND 邏輯
運算單元所構成。由於 TCAM 硬體單元完全是由硬體構成,因此以其為基礎的
路由選徑方法比起同為硬體操作架構的間接路由查詢方法而言,仍是具有較快的 運作速度。
以網際網路上運作的實際IP 路由表為例,表 0 列出三個大型 ISP 處的實際
Routing Table 的資料,以及兩種具代表性的間接路由查詢方法(Huang’s scheme
及 Chen’s scheme)與我們提出的複合式路由選徑查詢方法對記憶體需求的比
較。由表中可見,增加少量的 TCAM 硬體單元,所需的記憶體可大幅降低,不
僅使 IP 路由輸出埠的查詢時間降低在 2 次的記憶體讀取的時間內,亦可降低更
新搜尋的資料表的時間。
表 0: Routing prefixes of the 192.168 segment Entry i Routing Entry Pi / l I / hi pi(x, y) x=17, y=24
Compact IP-Routing Lookup or Priority TCAM
0 192.168 / 16 / 0 xxxx xxxxb Compact IP-Routing Lookup 1 192.168.20 / 22 / 1 0001 01xxb Compact IP-Routing Lookup 2 192.168.84 / 22 / 2 0101 01xxb Compact IP-Routing Lookup 3 192.168.68 / 23 / 3 0100 010xb Compact IP-Routing Lookup 4 192.168.68.16 / 28 / 4 0100 0100b Priority TCAM 5 192.168.68.16 / 32 / 5 0100 0100b Priority TCAM
1-3. 高速群播路由選徑(Multicast Routing) 機制
群播路由選徑(Multicast Routing) 與一般單一路由選徑(Unicast Routing) 的 不同點在於:一個Multicast IP 即代表著一個唯一的 Multicast Group,其包含(對 應到)多個分佈在不同區域的主機(Host),並非如其他(一般的)Unicast IP 多半 是以一個連續的區段(Segment) 為單位,來指派、對應到某一區域的單一主機。 所以, 在路由表格中,Multicast 的 Routing entry 是以(單一)完整長度的路由
字首來呈現,與一般Unicast 的 Routing entry 是以不完全長度的字首來代表一個
連續 IP 位址區段的形式有所不同; 同時,其路由選徑結果也不再只是對應到
單一的輸出埠,而可能是一「組」的多個輸出埠; 另外一個與Unicast Routing
形式上較大的不同是,為了讓 Multicast 的運作更有彈性,可以自由地根據不同
的資料發送端來設定不同的資料群播遞送的方式,Multicast Routing 採取多(雙)
欄位資料搜尋比對的路由選徑動作,除了Multicast 的 Destination IP 之外,也必
須同時根據Source IP 位址來決定路由結果輸出埠為何。因此,Multicast Routing
的關鍵技術是為一個高速的多欄位資料完全相符(Exactly Match) 的比對搜尋機 制,並且能同時迅速地解析出所需要進行封包轉送的多個路由輸出埠。從高速單 一路由選徑方法的設計經驗得知,內容定址記憶體 CAM 和 TCAM 本身即可視 為一個簡單而易於實現的硬體架構的資料比對搜尋裝置,而CAM 的運作方式即 相當於一個資料完全相符(Exactly Match) 的比對搜尋機制,因此相當適合應用在 表 0: 各種路由選徑方法所需記憶體容量之比較
AADS Mae-West PAIX
Prefixes 33,931 37,523 18,569 Segments 5,813 6,126 3,571 Length>24 431 433 443 Huang’s [3] 599K 610K 507K Chen’s [6] 659K 781K 543K Priority TCAM IP-Routing Lookup 423K +431 TCAM 463K +433 TCAM 377K +443 TCAM
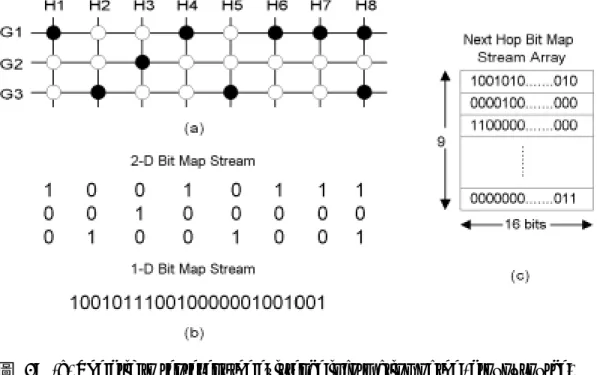
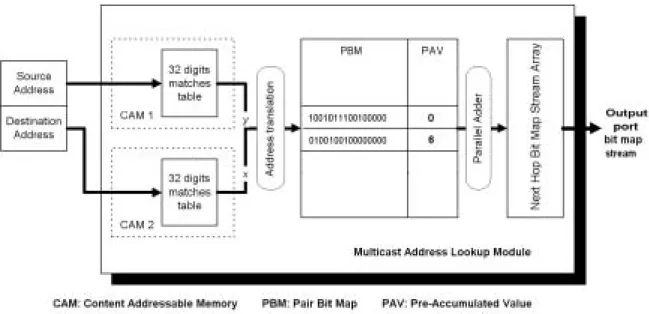
高速硬體化操作的 Multicast Routing 路由選徑機制的設計中;此外,有鑑於 Compression Bit Map (CBM) 的概念對於單一路由選徑機制運作所需的資料結構 記憶體空間上的壓縮有很大的幫助,因此我們同樣將此概念應用在群播路由 (Multicast Routing) 的選徑機制設計上,以有效降低、控制路由表格的大小。綜 合上述的考量,我們提出一套以CAM 為基礎,並採用 CBM 技術為輔的高速硬 體化操作的Multicast Routing 路由選徑方法。此方法的群播路由查詢速度可以相 當快,一次群播路由查詢只需要三次的記憶體存取次數(Memory Accesses),再加 上管線式(Pipeline) 運作架構的可行性,也同樣能使得平均查詢次數降至一次的 記憶體存取次數。其細部的設計與運作如下面的內容所述。 整個群播路由表格的組成基本上包含來源位址(Source Address)、目的位址 (Destination Address) 以及由此兩個位址所決定出唯一的一組輸出埠號碼(Output Port Numbers)。根據群播路由查詢法則,當路由器收到一個封包,發現其目的位 址為群播網際網路位址(Multicast IP Address) 後,接著必需檢查其來源位址,確 定這是此群播組(Multicast Group) 裡的成員,以及是哪一位成員所發出的封包, 由這兩個位址便可決定出一組輸出埠號碼;每一個號碼表示路由器必須要複製一 份此封包往這個輸出埠送。基本上,我們以底下所示的方式表示一個群播組和其 所包括的成員: Group G1: Sources H1, H4, H6, H7, H8. Group G2: Sources H3. Group G3: Sources H2, H5, H8. Gx 表示目的位址,Hx 表示來源位址。根據這個法則,我們把路由器上經 由路由協定(Routing Protocol) 所獲知的來源位址和目的位址(這裡特別是針對對 應至Multicast Group 的 Multicast IP 位址)作成一個二維空間的棋盤狀對應表, 此表格的縱軸表示來源位址,橫軸表示目地位址,而兩軸的交叉點基本上有一個 圓圈,黑色圓圈表示這是一個有效的群播組和組員的關係,(群播組(Multicast
Group), 組員(Membership Source)),白色圓圈則表示是一個無效的群播組和組員
的關係,如圖 0(a) 所示。將這些圖形資訊做一個二進位數字編碼,黑色圓圈為 1,白色圓圈為 0,便可形成如圖 0(b) 的一串二進位數字串列。接著我們將此種 Bit Map 的資訊編碼方式也同樣運用在路由輸出埠組上,我們將每一個有效的 (Multicast Group, Membership Source)關係所對應的輸出埠號碼組作以 Next Hop Bit Map Stream 的形式來表示,每一筆 Next Hop Bit Map Stream 的每個位元 依序對應到一個輸出埠,而以其位元值表示是否要複製一份封包往這個輸出埠
進行Multicast Routing 路由選徑查詢時,先要根據封包標頭的(Source IP, Destination IP)資訊在這個二維空間棋盤狀對應表中尋找其對應的圓圈的幾何位
置,接著再從棋盤最左上邊的第一個交會點開始計算到此對應位置前位元值為1
的個數是多少,此數目即代表從棋盤狀對應表左上角第一個交會點算起有效的 (Multicast Group, Membership Source)關係組數,將這個數目對應到存有輸出
埠資訊的Next Hop Bit Map Stream Array 陣列中的位置,如此便可快速取得所需
要的路由資訊。為使路由速度更快,在查詢由來源位址和目的位址所組成的幾何 位置資訊上,採用「內容定址記憶體Content Addressable Memory (CAM)」的方 式來實作,並將原本圖 0(b) 的二進位數字串列作一個簡單切割以利實作上匯流 排的資料寬度需求,形成如圖 0 的系統架構圖;這個架構適用於管線運作方式, 因此也可大幅提高整體路由查詢的資料輸出率(Throughput)。
圖 0: (a) The grid to represent the existence information of the (group, source) pairs, (b) The pair bit map streams, (c) The next hop bit map stream array.
2. MPLS 網路之 VC-Merge 機制的效能分析
在此,我們主要是設計一套有效的系統效能分析演算方法,針對VC-merge
的ATM-LSR 所需的緩衝器和 cell blocking 機率之間的關係進行分析,試著去探
討具有VC-merge 能力的 ATM-LSR 交換機需要比傳統的 ATM 交換機具備多少緩
衝器資源,這其中包含了Frame-level Interleaving 機制所需要的 ATM cell 重組緩 衝器以及ATM-LSR 原本既有的輸出緩衝器(Output Buffer, OB)。
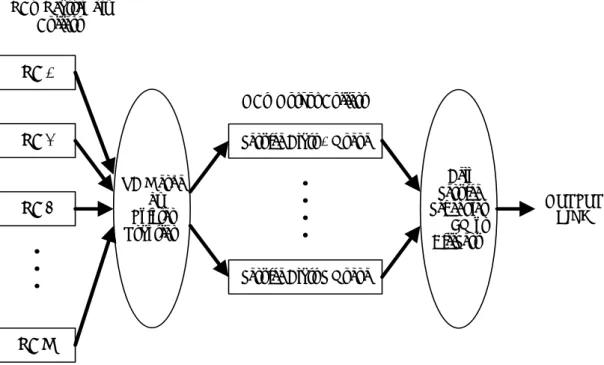
圖 0 顯示一個具有 VC-merge 能力的 ATM-LSR 交換器架構;包含了 N 個輸 入/N 個輸出的 ATM cell 交換單元及 N 個輸出模組(Output Module) 單元。圖 0
進一步顯示輸出模組的架構,包含了 M 個重組緩衝器(Reassembly Buffer)、具
VC-merge 功能方塊、S 個依服務等級不同的輸出緩衝器(Output Buffer) 及 ATM cell 服務的輸出排序等。
圖 0: Block diagram of a VC-merging capable ATM-LSR
Input Ports Output Module Output Module Output Module Output Module 1 2 3 N
Switch Fabric Output Ports
1
2
3
圖 0(d) 為傳統不具 VC-merge 能力的 ATM-LSR 交換機形式,即便是欲前
往相同目的網路或節點的IP Route,其相對應的 ATM cell 在交換後仍是採用不同
的 VPI/VCI 以區隔出其為分屬不同 IP Route 的訊務流,如此即便是對應至不同
IP Route 中 IP 封包的 ATM cell 有任意交錯傳輸的現象也沒有關係;圖 0(a)、(b) 及(c) 顯示三種不同型態的 VC-merge 形式:(a)是為 Full VC-merge,對於欲傳輸
至相同目的網路或節點的 IP Route,將其所屬的 ATM cell 皆轉換成一致的
VPI/VCI 進行傳輸,(b)和(c)則為在進行 VC-merge 時,除了一致的目的網路或節
點之外,額外考慮IP Route 不同的服務品質或其他屬性,將欲前往相同目的網路
或節點而且屬性相同的IP Route,其所屬的 ATM cell 才會在交換後轉換成一致的
VPI/VCI 進行傳輸,此種 VC-merge 方式則稱為 Partial VC-merge。在此種 VC-merge 方式中,VC-merge 後不同 VPI/VCI 的 ATM cell 可以任意交錯傳輸沒 關係,但是相同VPI/VCI 的 ATM cell 仍是必須要遵循 Frame-level interleaving 機
制,不可與對應至不同IP Route 中某一 IP 封包的 ATM cell 交錯。圖 0 中的縮小
數字表示起始的VCI,底線代表 ATM EOM (End of Message) cell。例如 52代表
EOM cell,原先 VCI=2 經過 ATM-LSR 交換機後轉成 VCI=5。 圖 0: Block diagram of the output module RB 1 RB 2 RB 3 RB M VC Merge (by Pointer Transfer)
OBs (Output Buffers) RBs (Reassembly
Buffers)
Service Class 1 Queue
Service Class S Queue
Cell Service Scheduler (WFQ or DiffServ) OUTPUT LINK
我們所設計的分析方法主要是參考論文[7]的方法並加以改進:在我們提出 的系統中,放寬[4]的 Input Model,可允許 Cell-interleaving 的 Input Pattern,並且
允許Partial VC-merge 的運作方式。我們建立一個排隊理論數學模式 D-BMAP/D/1
來分析輸出模組的機率分佈。D-BMAP/D/1 的排隊理論模式為:
M 個 IP Stream 可模擬成 M 個 ON-OFF sources,ON 的時間和 OFF 的時間為 幾何分佈(Geometrical Distribution);
在 ON 的時段裡,IP Stream 會產生 1 個 ATM cell 的機率為 r。在 OFF 的時段 裡,IP Stream 不會產生任何一個 1 個 ATM cell。參數(1/r)代表 ATM cell interleaving 的程度;
輸出服務模式為每個 ATM time slot 處理完 1 個 ATM cell。
研究結果顯示,相較於論文[7] D-BMAP (Discrete – Batch Markovian Arrival
Process)/D/1 的排隊理論模式,我們所設計的分析方法其計算複雜度可由 O(M4)
減少為O(M2),其中 M 為所模擬的 ON-OFF Source 的個數,並且更進一步多引
進了一個參數 r,來描述 IP 封包的 interleaving 程度,使得數學模型更接近實際
圖 0: Three types of VC-merging and one type of non-VC-merging
1 1 1 4 4 4 2 2 3 3 1 2 3 4 5 5 5 5 Input Cell Stream to a Specific Port In Out VCI Table Output Cell Stream of a Specific Port 1 1 1 4 4 4 2 2 3 3 1 2 3 4 6 5 6 5 Input Cell Stream to a Specific Port In Out VCI Table Output Cell Stream of a Specific Port 61 54 61 54 61 63 52 52 63 54
(a) Full VC-merge
(c) Partial VC-merge with multiple output buffers
54 54 51 51 51 53 53 52 52 54 81 81 63 54 72 54 63 72 81 54 54 54 61 61 61 63 63 52 52 54 1 1 1 4 4 4 2 2 3 3 1 2 3 4 8 7 6 5 Input Cell Stream to a Specific In Out VCI Table Output Cell Stream of a Specific Port 1 1 1 4 4 4 2 2 3 3 1 2 3 4 6 5 6 5 Input Cell Stream to a Specific Port In Out VCI Table Output Cell Stream of a Specific Port
(b) Partial VC-merge with Single output buffer
的情況,所得的分析結果也較為接近實際。複雜度較低的結果,使得對較大的 Buffer Size 分析也能夠得到較高的 Cell Loss Prob.的準確度(尤其 Cell Loss Prob. 通常低於10-6以下)。我們也利用了Moment-Generation Function 的理論方法來近
似 D-BMAP/D/1 的排隊理論模式,求得一個精確度蠻高的、接近前述所設計的
分析方法結果的輸出緩衝器(Output Buffer) 中 ATM cell 數量分佈的數學近似方
程式,可更快速計算Cell Loss Prob.。分析及模擬結果顯示 ATM-LSR 交換機需
要具備比傳統ATM 交換機多 50-70%的緩衝器資源來支援 ATM cell 重新組合使
用,以及避免VC-merge 後無法在目的網路或節點處分離出不同 IP Route 訊務的
問題。
圖 0 顯示透過數學分析及電腦模擬一個支援 VC-merge 功能的 ATM-LSR 其
總緩衝器 overflow 機率分佈的結果。可以發現,我們的數學分析結果和電腦模
擬結果相當一致。由圖 0 我們可得到以下結論:
1. 具有 VC-merge 能力的 ATM-LSR 交換機較傳統 ATM 交換機需要較大的緩衝
器資源。如圖 0 中顯示在 overflow 機率為 10-5次方的假設下,傳統ATM 交
換機需要約390 個 ATM cell 緩衝器;ATM-LSR 交換機需要至少 520 個 ATM cell 緩衝器。
2. 在細胞交錯 cell-interleaving 愈嚴重的情況下(r 參數愈小),需要更多的重組緩
衝器來重組IP 封包,因此需要更多的緩衝器資源。在一般的 cell-interleaving
圖 0: Overflow probability of the total buffer versus buffer threshold 0 100 200 300 400 500 600 700 10-5 10-4 10-3 10-2 10-1 Buffer Thresholds T B O ve rf low P rob ab ili ty (256,1/16) (16,1) (M,r)=(16,1), (32,1/2), (64,1/4) (M,r)=(128,1/8), (256,1/16) Simulation Non-VC-merging
3. MPLS 網 路 之 路 徑 保 護 (Protection)及 快 速 回 復 (Path
Recovery) 機制
這部分的研究主要在於提出一套有效的 MPLS 網路之路徑保護/回復機 制,以便於MPLS 網路傳輸路徑發生錯誤或損壞時還能夠維持部分基本的通訊, 並可以快速而正確地地恢復既有的通訊,降低 MPLS 網路上傳輸路徑錯誤或損 壞所帶來的影響,減少封包遺失率,並期望能夠進一步達到動態負載平衡的附加 效益,使系統資源做最佳的利用,如此便可有效的提高網路的資料輸出率 (throughput)。 一個完整的路徑保護/回復機制應包含有幾個要素:單一或多條的工作路 徑(Working path) 與備援路徑(Backup path)、路徑狀態監控/錯誤偵測和警告通知機制、以及路徑回復程序啟動時,切換到Backup path 的機制。IETF 提出了兩
種 路 徑 保 護 / 回 復 機 制 的 運 作 模 型(Model) [12, 9] , 也 可 做 為 許 多 Path Protection/Recovery 方法的兩大分類依據,其主要是根據 Backup path 建立的時間 點做為區隔:如表 0 所示,在路徑發生錯誤之前即預先規劃並建立好 Backup path
表 0: 兩種 Path Protection/Recovery Model 之比較
Recovery
Model Backup Path Type
Backup Path Establish Point Switch -over Processing Recovery Time Resource Utilization/ Optimization Establish-On-Demand (Simple-Dynamic,
Shortest-Dynamic) Slowest High
Re- Routing Pre-Qualified After Fault Local Medium Medium 1+1 (Haskin Algorithm,
Makam Algorithm) Fast Lowest
Protection Switch 1:1, 1:n, m:n* Before Fault Head-end Fast Low
用,造成系統資源的使用效率最低,因為需要預先保留做為備援專用的相當數量
的資源在一般時候是閒置的。也由於必須耗費較多系統資源,因此 Backup path
多半僅在靠近通訊兩方的頭端(Head-end) 網路節點建立。「Re-Routing Model」的
傳統方式(如Simple-Dynamic 和 Shortest-Dynamic)是當路徑錯誤時才開始搜尋
並建立適當的Backup path,因此路徑回復(切換至 Backup path)的速度較慢,
但也因為不事先保留資源所以可以讓系統資源做最有效的利用,而且可以在距離 路徑錯誤當地(Local) 的最近或較近的節點(LSR)即進行路徑回復,不需要再 回到頭端節點才來進行,對路徑錯誤的反應速度較快且靈活度佳。其在路徑錯誤
的Local 節點建立至通訊終端的 Backup path 的方式,也對於路徑回復後因路徑
錯誤影響而需要重送的資料量減少。而分類上仍歸屬於「Re-Routing Model」的 Pre-Qualified 方式則其實是介於兩類方法間的機制,兼具兩者的優點,其關鍵在 於:以Re-Routing Model 為主,但是引用 Protection Switch Model 預先建立 Backup path 的觀念,在路徑錯誤發生之前先搜尋、規劃好可作為備援 Backup path 的數 個候選路徑,一旦路徑錯誤發生時即能夠透過簡單的資源保留與設定的動作,便
可迅速地建立Backup path 並恢復原有的通訊。由於並未在事先建立 Backup path
並保留資源,僅是預先搜尋、規劃候選Backup path 而已,因此資源仍可做充分
的利用而不浪費,並且也可以預先在Working path 沿線的各個 LSR 節點上分別
搜尋、規劃至通訊終端節點的Backup path,保有 Re-Routing Model 中在路徑錯
誤的最近幾個 LSR 處即可以快速反應的優點。如此再配合上前述當錯誤發生時
可節省搜尋時間並快速建立Backup path 的優點,更加使 Path Recovery 的速度獲
得更大幅度的提升。
著眼於兩種Path Protection/Recovery Model 各有其優缺點,因此我們嘗試結 合兩邊的優點,以屬性介於兩者之間的Re-Routing Model 作法中 Pre-Qualified 類 型的網路路徑錯誤復原演算法為主,提出一套高速而最佳的路徑保護/回復機制
的方法。然而在實際的操作上,由於Pre-Qualified 方法對於 Backup path 的形式
與數量並沒有明確的定義或限制,因此我們可以,也有必要根據Pre-Qualified 方
法的原則,設計、定義出一套適當並有效率的實際運作方式。如同之前內容所提,
除了在通訊的起迄的兩終端LSR 節點之間於通訊開始之前預先規劃 Backup path
之外,我們也在Working path 沿線的各個 LSR 節點上分別搜尋至通訊終端節點
的Backup path,然而此種 Backup path 的搜尋動作並不需要在通訊開始之前就進
行完畢,可以在通訊開始之後才進行,以避免過多通訊前的程序延遲了通訊開始
的時間,而且也不要求每一個沿線LSR 節點都必須要找到 Backup path。若發生
路徑錯誤時其最近一LSR 節點無法或尚未搜尋到 Backup path,便可通知其上游
(Up-stream) LSR 節點進行 Backup path 的建立與通訊的恢復;若此上游 LSR 節點
亦尚未搜尋到適當的Backup path,便可以再往其上游的 LSR 節點進行通知,直
到有上游LSR 已經找到 Backup path,或是到最上游的通訊終端 LSR 節點處為止
(這裡必定有Backup path,是通訊開始前即預先搜尋、規劃好的)。由於在搜尋
而又必須確保當路徑錯誤發生時Backup path 的「可用性(Availability)」—路徑連
線正常且仍有足夠資源可立即建立 Backup path,因此必須要有一套有效的
Backup path 可用性的監控、維護方法。最簡單的方式即是以一套週期性的信令 (Signaling) 方式,對於預先選擇、規劃好的 Backup path 的通訊路徑連線狀況以
及剩餘資源情形進行持續的監控,一旦可用資源不足建立Backup path 的需求,
或在此路徑上亦同樣發生路徑錯誤,便重新搜尋可用的其他路徑作為 Backup
path,以保持 Backup path 在 Working path 路徑錯誤時的可即時使用性。此外也 可以進一步對於Backup path 所需的資源先進行軟性保留(Soft Reservation),亦即
對 Backup path 所需要的網路資源有進行預先保留的動作,然而與 Protection
Switch Model 不同的是,此保留的資源在 Backup path 尚未真正建立使用時,仍
可允許被其它的通訊利用而不因此造成資源的浪費(特別是在有 traffic priority
的網路中,priority 等級低於目前連線的通訊而言),只有當 Working path 路徑發
生錯誤而必須啟用Backup path 時,便以優先使用權的身份將此預先軟性保留的
資源收回,以快速而順利地建立Backup path。在此方式中,Backup path 狀態監
控機制僅需針對其路徑連線狀況進行偵測即可,省去可用資源方面的監控,如此 可降低監控機制的複雜度與系統資源負擔(overhead),也使所選定的 Backup path
穩定度增加,較不容易時常需要進行重新搜尋、更換(路徑),而 Backup path
也僅需要一個簡單的通知性(Notification) 信令經過 Backup path 上的所有 LSR 之 後即可以馬上建立使用,有助於備援切換速度的提升。而唯一的代價是,當 Backup path 建立並進行切換時,對於原來位於 Backup path 上其他通訊的影響較 大,尤其是Traffic priority 等級低於此連線的通訊。另外,Backup path 的可用性
監控、維護方法還可以根據單一節點所建立的 Backup path 數目發展出多種變
形,例如:一開始即選定多個候選Backup path,並對所有的候選 Backup path 都
進行監控,確保有需要時至少有一個Backup path 能立即使用;或是仍僅對其中
一個進行監控,若剩餘資源不足或路徑錯誤再換另一個,如此只是節省重新搜尋
的時間而已。一般來說,對於比較重要的 Backup path(例如如通訊開始之前,
在兩通訊終端 LSR 節點之間必須預先規劃的 Backup path),可以採用軟性資源
保留的方式,以較穩定的Backup path 條件確保其立即可用性;而其餘的 Backup
path 便 可 以 採 用 最 簡 單 的 監 控 方 式 , 即 時 可 用 性 雖 然 會 較 Soft Resource Reservation 方式稍差,也會有較多的監控資源負擔(overhead),但是當路徑錯誤
發生時,對於Backup path 上其他通訊的影響則是最小的。
在確定 Backup path 的實際運作方式之後,我們設計採用網路第三層中之
OSPF 繞徑協定做為搜尋適當 Working path 與 Backup path 的基礎 [15, 16],並利
balancing) 機制 [17],充份利用 Working path 資源,提升網路資料輸出率 (Throughput)。
我們所設計的路徑保護/回復機制的運作步驟摘要如下:首先在通訊之
前,先透過第三層網路的OSPF 繞徑協定,配合我們對於通訊路徑品質(例如:
頻寬、傳輸延遲、封包遺失率等)的需求,進行自通訊起始 LSR 節點處至通訊
終端LSR 節點處的 Working path 與 Backup path 的選擇。原則上我們是以 N(N ≥ 1)條 Working path 與 M(M ≥ 1)條 Backup path 做為通訊的基礎。接下來,便 需要在所選擇的M 條 Working path 上進行 Load balancing 的規劃:根據各 Working path 的 (Bottleneck) BW 與 Delay 來適當地分配其上傳輸的 Traffic 的比例,以確
保能夠獲得最佳的通訊品質與Throughput。
當規劃好Load balancing 之後,便可以開始進行通訊資料的傳輸動作。而在
通訊開始進行的同時,除了通訊起迄兩終端LSR 節點之間 Backup path 的監控機
制之外,位於通訊路徑(Working path)上各 LSR 處至通訊終端 LSR 節點處 Backup path 的搜尋與監控機制也開始運作:原則上我們會在 Working path 沿線的各 LSR
同樣以 OSPF 繞徑協定配合我們對於通訊路徑品質的需求,來找尋一條最佳的
Backup path,若能順利找到此 Backup path,便將該路徑資料存在 LSR 的 Database
之中,接下來則以監控機制確保其可用性,透過現有 MPLS 本身的 E-RSVP
Signaling Protocol 以 Monitoring 的方法來代替實際上的資源保留與佔用,根據 RFC2205 的定義, E-RSVP 每隔 30 秒會重新檢查每個 LSR 節點與鏈路(Link) 的 State 狀況 [21, 22],包含是否有 Node 或是 Link 被增加、移除或發生錯誤,以
及其頻寬的使用與相關的 QoS 參數條件是否滿足需求等等。如此便可決定此
Backup path 是否可以繼續保留或需要重新搜尋,如結果為後者,則將再回到以 OSPF 搜尋 Backup path 的步驟。而當 Working path 發生路徑錯誤時,系統即在 最近一個且Database 具有 Backup path 紀錄的上游 LSR 處,進行 Backup path 的 建立與訊務的切換。
我 們 採 用 NS-2 這 一 套 網 路 模 擬 軟 體 平 台 , 來 對 所 設 計 的 Path Protection/Recovery 方法進行系統模擬與效能評估、驗證的工作,並與其他方法 進行比較。模擬驗證時所採取的網路架構如圖 0 所示:通訊的起迄終端節點分
別為LSR0 與 LSR20,其中每個節點間的鏈路(Link) 頻寬為 10Mbps,並且在通
訊的啟始節點LSR0 處產生 5Mbps 的 CBR/UDP Traffic 進入網路中。圖 0(a) 是
從Working path 上幾處鏈路損壞(Link Failure)所導致的路徑錯誤狀況中,來比較
各Path Protection/Recovery 方法在封包遺失率上的表現。從圖上可以可明顯的看
出,我們所設計的方法-E-Algorithm-在 Packet Loss 上的確比其他的方法有較
好的結果。因為我們以預先規劃的、離路徑錯誤處最近節點的Backup path 資料
庫的存取來取代重新搜尋 Backup path 的時間,因此 Packet Loss 便少很多;而
Makam 的方法則是必須透過 Signaling 方式告知頭端網路節點 LSR1 網路錯誤的
狀況並進行Backup path 的切換,因此一旦錯誤發生點離入口處的 LSR 愈遠,則
通知的時間愈長,丟掉的 Packet 便愈多。Re-Routing Model 中的兩種方法
(Simple-Dynamic 和 Shortest-Dynamic)因為是在路徑錯誤之後才搜尋 Backup path,因此 Packet Loss 數量普遍較前兩者為高。Simple-Dynamic 則是因為在 Local
處尋找直接至目的地端的其他路徑做為 Backup path,因此路徑錯誤發生點離目
的地端愈近,丟掉的封包數便愈少。在Shortest-Dynamic 的方面則是因為利用 IP
層繞徑(Routing) 的方式將資料 Bypass 地繞過錯誤發生點至下一個 LSR 繼續傳 輸,所以基本上與錯誤發生點沒有太大的關係,但是若路徑錯誤發生點離目的地 端 愈 近 , 丟 掉 的 封 包 數 也 是 會 減 少 。 在 圖 0(b) 我 們 可 以 發 現 , 只 有
圖 0: Network configuration for NS-2 simulation
0 1 3 5 7 9 2 4 6 8 20 10 11 12 13 14 15 16 17 18 19
圖 0(a) 顯示的是當 Working path 上 LSR5 與 LSR7 之間的 Link6 發生 Link Failure 前後,位於通訊終端處所見到的 Throughput 的「(時間)暫態圖」。由此 圖可以看到,Link Failure 發生在 0.8 秒的時候,而我們的機制在 Link Failure 導
致的Throughput 衰減量比起其他的方法都小許多,並不會使 Throughput 降到零,
衰減速度也因為 Multipath 多重路徑的特性而較其他方法為緩,在錯誤發生到回
復機制的運行過程中,我們依舊可以維持High Throughput 的狀態,因而能在最
短時間內即恢復正常的傳送資料輸出率。反觀其他的方法衰減速度較快,加上又
都沒辦法很快完成接替備援的工作,導致Throghput 皆會在某段時間內降到 0。
因此在圖 0(b) 的平均 Throughput 比較圖看來,無論 Link Failure 發生於 Working path 的何處,我們的方法都可以獲得最高的 Throughput 值,而且這些值皆可維
持在一個相當好而穩定的水準;相較之下,其他的方法則會因為Link Failure 發
生地點的不同而使Throughput 的值有所差異。
圖 0: Performance comparison on (a) Packet loss and (b) Packet disorder
0 50 100 150 200 250 300 2 4 6 8
Link where the fault happened
N u m b er o f P a ck et L o s s E-Algorithm Makam Shortest Simple 0 10 20 30 40 50 60 70 2 4 6 8
Link where the fault happened
Nu m b er o f Un o rd er P ac k et E-Algorithm Makam Shortest Simple (a) (b)
綜合上述的內容來看,我們在Path Protection/Recovery 機制的設計上,利用
每個LSR 上預先規劃的 Backup path 的 Database 來幫助我們達成快速路徑回復的
目的,取代了以往錯誤發生後才開始搜尋Backup path 或是錯誤發生前先保留資
源建立 Backup path 的缺點:藉由 Re-Routing Model 方法的使用,不但排除了
Protection Switch Model 此類作法中預先建立 Backup path 並保留資源而造成資源 浪費的缺點,引入Protection Switch Model 預先規劃 Backup path 的概念,加速了 既有Re-Routing Model 作法的 Recovery time,而且仍保有 Re-Routing Model 中 在最近路徑錯誤的節點馬上進行切換的優點,因而能夠快速且有效地降低網路錯
誤發生時之影響時間與所需付出的代價。然而此種Path Protection/Recovery 機制
需要一套有效的Backup path 監控機制來確保 Backup path 可立即使用的特性,因
此我們也配合MPLS 網路既有的 E-RSVP Signaling Protocol 來進行 Backup path
狀態的監控。此外,同時選擇多條Working path 進行資料傳輸,不僅享有多路徑
傳送下Path protection 的優點,即使有其中一條 Working path 發生問題,也不會 在瞬間完全中斷資料的傳輸,維持通訊的可靠性與降低路徑錯誤的影響;同時可
藉由適當的 Load balancing 機制的設計,獲得 Throughput 與傳輸品質提升的優
點。最後,我們的方法可以讓ISP 業者很自由而彈性地根據其服務品質的需求與
使用者付費原則,評估採用不同複雜度的運作形式,在成本與演算法完整性之間 權衡一平衡點。
圖 0: Overflow probability of the total buffer versus buffer threshold
0 1 2 3 4 5 6 0.7 0.8 0.9 1 1.1 1.2 Time (s) Mbps E-Algorithm Makam Simple Shortest 4.5 4.6 4.7 4.8 4.9 5 2 4 6 8
Link where the fault happened Mbps E-Algorithm Makam Shortest Simple (a) (b)
4. DiffServ 網路中精確的訊務監控調節(Traffic Conditioner)
機制
這部分的研究主要在於提出一兼具訊務監控精確度與網路資源使用效率, 並進一步達成 micro-flow 微訊務流之 Cell Dropping Precedence 標記公平性 (Fairness) 的訊務監控調節機制(Traffic Conditioner, TC):在確保訊務特性符合 Traffic Profile 的規範下,精確地讓系統資源獲得充分且最佳的利用,並進一步保
障其中各 micro-flow 連線所實際獲得的 QoS,如此才能夠提升 DiffServ 此網際
網路QoS 架構的可行性與使用效益,並做為其他 QoS 訊務控制機制(例如:CAC
連線允諾控制機制、Scheduling 排程控制、流量控制、壅塞控制等 Per-Hop Behavior)運作的基礎。IETF 在所建議的 DiffServ 網路 QoS 架構中,也如同 ITU-T
於ATM 網路定義了 GCRA 的 UPC 訊務監控調節機制的參考模型一般,建議了
三種訊務監控調節機制模型,分別是Single Rate Three Color Marker (SRTCM) [34]、Two Rate Three Color Marker (TRTCM) [35] 與 Time Sliding Window Three Color Marker (TSWTCM) [36]。在初步的研究分析並參考過去我們在 ATM 網路
上的發展經驗後,我們選擇以TRTCM 方式的訊務監控調節機制做為基礎模型, 來進行更高效能的DiffServ 網際網路之訊務監控調節機制的發展與設計。 如圖 0 所示,TRTCM 是藉由兩級的 Token Bucket 造成多階的訊務封包的 合法性等級(Conforming Degree)(有別於傳統僅有合法與否的兩級判斷),將進 來的每一種服務等級(Service Class)的訊務封包皆根據其運作機制再區分並標記 成DiffServ 所定義的三種等級:綠色(Green)、黃色(Yellow)、紅色(Red)的封包出 圖 0: TRTCM 之系統架構圖與運作邏輯表 Token Token PIR CIR CBS PBS IP Packet Tp Tc (none) Red --Red (none) Red --Tnum_p< Psize Tnum_p Yellow --Tnum_p≥ Psize Yello w (none) Red --Tnum_p< Psize Tnum_p Yellow Tnum_c< Psize Tnum_p≥ Psize Tnum_p, Tnum_c Green Tnum_c≥ Psize Tnum_p≥ Psize Green Tnum_c Tnum_p Token consumptio n Output Bucket Condition/State Input (none) Red --Red (none) Red --Tnum_p< Psize Tnum_p Yellow --Tnum_p≥ Psize Yello w (none) Red --Tnum_p< Psize Tnum_p Yellow Tnum_c< Psize Tnum_p≥ Psize Tnum_p, Tnum_c Green Tnum_c≥ Psize Tnum_p≥ Psize Green Tnum_c Tnum_p Token consumptio n Output Bucket Condition/State Input
PIR: Peak Information Rate CIR: Committed Information Rate
PBS: Peak Burst Size CBS: Committed Burst Size
Demotion
Demotion
![圖 0 所示即為我們所設計的快速路由選徑機制的硬體邏輯架構。從表 0 的 模擬結果看來,目前我們所設計適合於 IPv4 Unicast 的高速路由選徑方法相較於 其他類似概念的方法 [3],僅需要不到 400 Kbytes 的記憶體空間,而且透過硬體 上 Pipeline 平行多工的方式,可達到每個封包在平均一次記憶體定址存取的動作 即可以獲得路由選徑結果。未來我們將考量實際商用化系統環境與規格(速度與圖 0: 快速路由選徑機制的硬體邏輯架構](https://thumb-ap.123doks.com/thumbv2/9libinfo/8422429.180607/12.892.120.760.145.776/多工方式可達到每個封包在平均一次記憶體定址存取的動作以獲架構.webp)