A Fuzzy Analysis Method for New-Product
Development
C-C
Lo*
and
P W a g +
Institute
of
Information
Management,
National Chiao Tung
Wniversiv,
Taiwan
K-M Chao,
DSM Research Group
School
of
MS,
Coventry Universiv,
UK
*[email protected].
edu. tw;
[email protected].
uk
.
‘ping.
wang88@msa, hinet. net
Abstract
This paper reports a new idea-screening method for new product development
(NPD)
with a group ofdecision makers having imprecise, inconsistent and uncertain preferences. The traditional NPD analysis method determines the solution using the membership function of ihefuz.r set which cannot treat the negative evidence. The advantage of vague sets with the capabilig of representing negative evidences supports the decision makers with abiliq of modeling uncertain objects. In this paper? we present a new method for new-product screening in the
NPD
process by relaxing a mmber of assumpiions so that imprecise, inconsistent and uncertain ratings can be considered In addition, anew simiiariiy measure of vague sets is introduced to proceed with the ratings aggregation for a group of decision makers. From numerical iIlustrations, the proposed model can outperform conventional jaq
methods. It is able to provide decision makers (DMs) with consistent information and to model the simation where vague and ill-defined informalion exist in the decision process.
Keywords: New Product Development, Idea Screening, Vague Sets, Similarity, MPDM
1.
Introduction
New-product development is one of the most critical tasks in business process. Every company develops new products to increase sales, profits, and competitiveness; however
NPD
isa
complex process and is linked to substantial risks. The objective of NPD is to search for possible products for the target markets. In NPD process, decision makers have to screen new-product ideas according to a number of criteria. Consequently, they recommend the ideas to R&D engineers, marketers, and sales managers in every stage of development. The decision makers’ preferences have a significant impact on the selection of new products and the outcomeof
decision-making. How to reach the consistent group preference on each new-product is an important issue and is notoriously difficult to achieve. in most cases,
NPD is risky due to lacking of sufficient information with consumers’ preferences for making decisions. The information is often imprecise, inconsistent and uncertain. Recent studies [la] report the failure rate of new consumer products at 95% in the United States and 90% in Europe. The failures lead to substantial monetary and non-monetary loses. For example, Ford lost $250 million on i t s Edsel; RCA lost $500 million on its videodisk player etc. Many reasons result in the faiture of new products. Some of important factors in high technology NPD can be summarized as folIows
[Z,
6,101:
1) In idea-screening phase, it is impossible to acquire precise and consistent information regarding customers’ preferences, but it is possible to obtain imprecise, inconsistent and uncertain information; 2) In concept development and testing phase, the criteria
for new-product screening are not always quantifiable or comparable;
3 ) In product development phase, the choice of enabling technologies for developing new products is a challenging issue as the technologies evolve rapidly. In addition, it is often the case that development costs are higher than ‘expected;
4) In commercialization phase, participating competitors will use tactics or other means to contend.
Many methods [2,5,6]and tools [l] are used to control NPD process in an attempt to assist product managers in making better screening decisions. For example, 3M, Hewlett-Packard, Lego, and other companies use the stage-gate system to manage the innovation process [5]. However, the traditional technique [5,6] is likely to use quantitative methods, such
as
optimal techniques, mathematical programming, and utility models etc, which neglect the human behavior and only can be applied to the case if the required data are sufficient. Since new-product screening process must involve the judgments of decision makers and the expression of human judgments often lacks precision. In addition, the confidence levels on the judgments contribute to various degrees of uncertainty. A human-consistent approach is likely to adopt imprecise linguistic terms instead of numerical values in the expression of preference. The issue is compounded when a decision-The 9th International Conference on Computer Supported Cooperative Work in Design Proceedings
making process involves a group of decision-makers who have inconsistent preferences over the ratings on new products,
This research sets out to tackle more human- consistent by adding the assumptions (i.e., "I am not sure") ofien prohibited by other existing approaches [2,4,8,9]. In this paper, we propose a new method, which extends the traditional NPD methods to a fuzzy environment, uses the simitarity measures of vague sets [3,13] to aggregate the ratings of all decision makers including the negative evidence, and supports the decision on the priority among alternatives through the use of fuzzy synthetic evaluation method [ 121.
2. Preliminary Description of Vague Set
Theory
The Vague Set (VS), which
is
a generalization of the concept of afuzzy
set, has been introduced by Gau and Buehrer [ 131 as follows:A vague set
A ' ( x )
inX,
x={x,,x,,...,
x,,}, is characterized by the truth-membership 6, and a fafse- membership functionf,
of the elementxk
E X
toA ' ( x )
EX
,
(k=1,2,...,
n); t,:X+Ql] and f, :X+[0,1], where the functions t,(x,)andf , ( x , )
areconstrainedby OIt,(x,)+ f A ( x k ) I 1 , (1) where t , ( x k ) is a lower bound on the grade of membership of the evidence for X t , f , ( x k ) is a lower bound on the negation of xk derived from the evidence against xk . The grade of membership of X k in the vague set A' is bounded to a subinterval [ f A ( x k ) , l
-
f , ( x , ) ]
of [0,1]. In other words, the exact grade of membership [ f A ( x k ) , l -f A ( x k ) ]
ofxk may
be unknown, but it is bounded byFig 1. shows a vague set in the universe of discourse t"(Jc&) 5
WJ
l-fA(%).X .
Fig. 1. A vague set
When Xis continuous, a vague set
A'
(X) can be written as&)= hIf.(x).X'-fi(Jc.c)l~.~, Xk
EX.
(2)4 x 1 = C [ f A ( X t ) , 1 - j A G k ) I / X k , X k E
x.
(3) When X is discrete, a vagueset
A ' ( x )
can be writtenas
"
&=l
The vague value is simply defined as unique element of a vague set. For example, we assume that
x
={1,2,...
J O ] ,a
vague value "Beuuryl' o fX
may be defined by &@~=[0,5,0.4]/5 . It implies the positive preference is 0.5 and the negative preference is 0.6 (i.e.,In the sequel, we wilI redefine
A'
(x)
is a vague set,A'
is a vague value, and omit the argumentxk
off A (x,) and
f ,
(xk)
throughout unless they are needed for cIarity.Definition 1. The intersection of two vague sets
A ' ( x )
and
B'(x)
is a vague set C'(x), written asd(x)
=A(X)Ad(X), truth-membership function and false-membership function aret ,
andfc
,
respectively, wheret ,
=Min(f,,
le), and1 - f ,
=Minll-f,,l-S,).Thatis, 1-0.4).rw
-f,i
= [ f A,I
- A I
,,
[ t , ~
-f,
I
=WW,,
t,1,
Mi41
-
f"
,I-f,
11.
(4) Definition 2. The union of vague setA'(x)
andB'(x)
is a vague set ~ ' ( x ),
written asC'(x) =
A'
( x ) vB'(x),
where truth-membership function and false-membership function aret,
andfc
, respectively, where t ,= M c c E ( ~ ~ , ~ ~ ) ~
and 1- f , = M m ( l - f , , l - f , > . That is, Pc 9 1-
sc1
=
[ t A J-
f,
1
vP,
7 1
-
f,
1
=
I M 4 , , t , ) , M W - f,,l-f,>l- (5) Further, let us define the similarity measures between two vague values in order to represent the preference agreement between experts' ratings as follows: [3] Let A' = [ t A ( x L ) , l
-
f , ( x , )] be a vague value, wherer,4 b k
1
E[OJl,
fA (x,1
E[OJI
I and0 5 t A ( X L ) f f " ( X , ) S I .
Definition 3. Let
A'
be a v a g u e v a i u e i nX,
x=&,
...,xn}
,
A' = [ f A ( x k ) , 1 - f A ( x k ) ].
The median valueofA'
is [6]2
Definition 4. For two vague values
A'and
B'
inX,
X
= { . ] I ~ , . , . , X , ) , S ( A ' , B ' ) is the degree of similarity betweenA'
and B'which preserves the properties (P1)-(P4).
cpl) 0 I S ( A ' , B ' )
s
1;(E)
s ( A ' , B ' ) = ~
ifA ' = B * ;
(7)
(p3) S( A ' , B ' ) = S(B', A ' ) .
(P4)
S(A',C')<S(A',B') and $(A'$') 5 S(E',C') ifA'
~3
cc,
C'is
avague set inX3. The'Proposed Method
In NPD process, decision makers including marketers, customers, managers, and
R&D
members, have to form a new-product committee. Each decision maker has to evaluate and screen new-products according to fie well- defined criteria, and then assign performance ratings to the alternatives for each criterion individually. The decision-makers allocate ratings based on their own preferences and subjective judgments. The explicit representation of their preference and judgment with precise numerical values may not be simple, whereas the use of linguistic terms is more natural to human decision makers. This formulation is imprecise, ambiguous and often leads to an increase in the complexity of the decision making process. To simplify the evaluation process of group decision-making, the evaluation criteria are pre-defined here. Hence the new-product screening activity of NPD can be regardedas
a
fuzzy
MPDM problem. A fuzzy MPDM problem [4,S], however, can be formulated as a generic decision making matrix.3.1 Problem Formulation
Suppose that a decision group contains g decision makers who have to give linguistic ratings on m
alternatives according to n evaluation criteria, then a
hzzy MPDM problem can be expressed concisely in preference-agreement matrix [ 121 as follows: Suppose that a decision group has m decision makers who have to give linguistic ratings on n evaluated targets,
I
m
~ = [ q y
...
w.1, m d X w i= I ,
where D is a decision matrix of the group,
d , E { d , , d z ,
...,
d , } are a set of decision makers, and t , ~ ( f l , f 2 ,...,
t , ) are a finite set of possible targets(i.e., new-products) from which decision makers have to select, X Y (iQ=l, ..., m) is the Iinguistic rating on,=I
*
target
t,
by di,
andw,
is the importance weights of4
.
These linguistic terms can be transformed into a vague value
A ' ,
A
= [ t A ( x ~ ) , 1 - f A ( x ~ > l / x , ~ ~ E X .In the following, we use the similarity measure of vague sets to aggregate linguistic ratings of a group's preferences in order to obtain their preferences on each new-product.
(9)
3.2. SimiIarity Measure
We present a new similarity measure
between
two
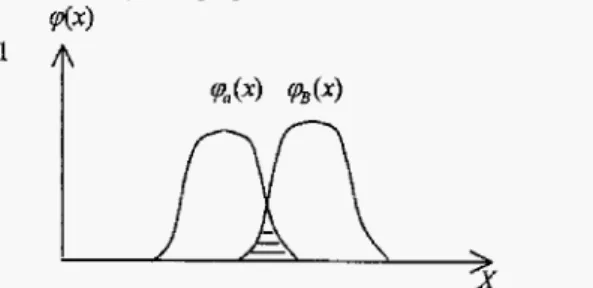
vague sets which may be continuous or discrete form. We give corresponding proofs of these similarity measures as follows.According to Def. 3, we use the median value of A'and B' to represent the mean of truth-membership and false-membership function. The preference agreement between two experts can be represented by the proportion of the consistent area to the total area, as shown in Figure 2 [ll].
$44
%(4
PBWFig. 2. Preference agreement between two DMs'
linguistic ratings expressed by median of vague sets
Definition 5. Using median of vague value, S " ( A ' , B ' ) is defined
as
the similarity measure between two vague values3.3 Preferences Aggregation
We calculate the preference-agreement degree of two experts' ratings expressed
by
Eq.(9)and
denote
S"(1,i) as
aii'
,
i,i' = 1,...,
m,
where two vague setsI , and I' represents the linguistic rating of decision maker di,di . The preference-agreement matrix A for evaluated targets tl
..
1, isThe 9th International Conference on Computer Supported Cooperative Work in Design Proceedings
Remark. For ai; = S m ( I , I ' ) if
I#i
,
and =i ifI=i;
It means that if two decision makers fully agree toan
evaluated target,and
they have ari' = I ; it implies:t,(X)=t,(x),
l - ~ ( x ) = l - f B ( x ) .
By contrast, if they have completely different estimates, then we get-
a..,
= 0,After all the preference-agreement degrees between two decision makers are measured, we then aggregate those pairs of vectors using the average aggregation rule to obtain the preference of the
group
on each new- product.By applying simple additive aggregation rule, we have the group preference of all the decision makers on an evaluated target as
' i = l ,
3.4 Group preference on New-Product
In order to synthesize the preference degree of group, a general compensation operator proposed by Zimmermann and Zysno (1983) is adopted as the group-preference operator in this paper [7]. This index synthesizes confidence level of preference of all experts on an evaluated target r j , A global measure of
preference on each evaluated targets ( t l , ..., t , ) is obtained as
As
the compensation parameter y varied &om 0 to 1, the operator describes the aggregation properties of "AND" and "OR", that is,max ( r j ) 2 F(t,,
...,
t B ) 2 min ( t , ) .]=I, ..., n j = l , ..., n
where F is an aggregation b c t i o n of Eq.( 15).
The compensation parameter y indicates the confidence level of preference of decision maker. A small y implies the higher degree of confidence. Finally, the moderator can estimate the degree of confidence and decide whether the group preference has been reached throught the use of C(t) and y. If the group consensus
has
not been reached,then
the decisionmakers
have to modify their ratings according to the Delphi iterative procedures.3.5 Fuzzy Synthetic Evaluation Method
Once the group preference for all decision makers on each new-product has reached, the fuzzy synthetic evaluation method is employed to attain the priorities of new products. The
fuzzy
simple weighting additive rule is adopted to derive the synthetic evaluations of alternatives by multiplying the importance weight o feach decision maker ( W , ) with fizzy rating of
alternatives ( x y ). The formulation of synthetic
evaluations of new products which is shown as follows.
v=[v,]
= @x,,
i=1,2,. ;.,m,j=1,2,;..,.
(15)However, the aggregation results V are still vague values, which cannot be applied directly to decisian- making. The use of
fkzzy
ranking methodand
a -cuts of fuzzy number is torank
the orderof
alternativesand
to transform them into numerical values, according to the synthetic evaluation results.
Based on Def.3, the synthetic evaluation values can be represented as
-
-
"
-
J=1
-
= -f
lf,
( X tFinally, the fizzy ranking method proposed by Yager(l981) is adopted to determine the ranking of results of synthetic evaluation as follows [ 121:
-
SA
( x k11
=2
P A ( x k1.
(16),=1 X t k = l
Given a fi~zzy number
,
Yager's index is defined asF ( Y )
=
c-
X , ( f , ) d a ,(17)
where amax = SUP U - and
i(f,)
represents theaverage value of the elements having at least
a
degree of membership.r v
4.
Numerical Example: New-products
ScreeningIn this section an example
for
aLCD
TV development is used as a demonstration of the application of the proposed method in a realisticscenario, as well as a validation of the effectiveness of the method.
The evaluation
processof products
screening is specified as Figure 3,4 M . * m I m *r@=.1 I I&. F m L I -
1
5- -m 7 &I h r r + A d 4 qFig. 3. The evaluation process of LCD-TV products
screening.
Suppose that there i s a new-product committee consisting of six decision makers, {R&D manager, marketer, sales manager, sales, accounting manager, customer] and a set of four different models with various choices such as colors, shapes, and prices, which must be selected through product-screening process. The resulting selection will be sent to product
LOO a88 a93 aoo a83 a87
a88 1.00 Q82 a00 a94 a77
4‘1)-
aoo aoo aoo 1.00 000 ama87 a77 a93 aoo a72 1.00
a00 e80 a87 0.83 1.00 Q88
1
QOO a72 0.77 a94 aas 1.00 a93 ~ 8 2 too a00a n
a93083 Q94 a78 000 100 a72
1.00 0.00 aoo 0.00 0.00 0.06
a00 1.00 0.92 067 0.80 0.72
QOO a92 1.00 a72 Q87 CL77
I
44)-
aoo a67 a n 1.00 Q83 0.94 A f 4 ) =development and market testing. The committee has to perform the screening process and select the best target from the four candidates according to the defied criteria.
The proposed method is applied to solve this problem according to the following computational procedure:
and possible targets t = { t , , t 2 , f , , t 4 ) , In the following, we have the priori information to determine the weighting vectors of each decision maker by hidher relative importance,
-
,Pw,
,
that is,Step 1: Form a working W U p d ={dl,d2,d3,d,,d~.ds}.
I - 1
i=l
W
= [w, J = {O.l5,0.2,0.25,0.15,0.15,0.1}.Step 2: Let
a
vague setA’
inX=
{VL, L, M, H, VH) presents linguistic variables of sales price a~ Table 2. For example, “High” may be represented asA ’ = (0.7,0.2) / 4,
where tA(4) = 0.7, f A ( 4 ) = 0.8.
Table 2. Linguistic variables far the rating of new-product
Very low/ Very Poor [ t A ( . r ) , l - f A ( x ) ] / l Lowt Poor ( x ) d - f A ( x ) 1 ’ 2
Medium
r ~ A ( x > J - - f R ( x ) l / 3
High! Good
[~,tx)~-f,(x)il4
Vely high/ Very Good it, (x)J - fA (x)]/ 5
1.00 aoo 0.8s 0.69 0.75 as9
0.00 LOO 0.00 0.00 0.00 aoo
0.69 aoo 0.79 1.00 a92 0.61
0.89 aoo 0.78 a61 a67 LOO
088 a00 1.00 0.79 Q86 a78
Q75 000 a66 a92 LOO 067
1.00 0.92 0.86 0.67 0.71 0.86 0.92 1.00 0.93 0.72 0.77 0.93 0.86 0.93 1.00 0.78 0.82 0.87 0.71 0.77 0.82 0.94 1.00 o a2 0.86 0.93 as7 0.78 o.sz l a q 0.67 0.72 0.78 1.00 0.94 0.78 We use the linguistic variables, shown in Table 2, to assess the ratings of new products using vague value as Table3.
Step 3: For -evaluated target
t, ,
we calculate the preference agreement vectors between d , , d , using Eq.(8)as
matrixes are also constructed.
Step 5: Aggregate the preference-agreement vectors to obtain the group preference of each new product using Eq.(12) as
11 (2
t,
t 4c(t,)
0.564
0.715 0.5750.676
Step 6: Calculate the group-preference index
on
aII targets for y 4, 7 4 . 5 , 7 =1, respectivelyr=O
r=0.5 r = lc(r)
0.157 0.393 0.983Step 7: The new-product manager averages new-product with three different levels of confidences: low, moderate, and high, C(t) = 0.5 11 to judge that group preferences have been reached due to the fact
c(r)
= 0.51 1 2 0.5. Step 8: If a group has been reached a consensus over the preferences, then go to step 9. If not, it goesback
to step1. Step 9:
1.The weighted fuzzy rating is obtained using Eq.(15) and synthetic results for
four
target is obtained by integratingi(ca)
at a =0.05,0.10,0.15-1 through Eqs.(16)+17)’ For example, the median form of
rating on
t ,
evaluated bydl
) isi(1.1)
= 0.1112 + 01213 + 0 1 ~ 4.
The variousa
level sets are for ?(i,l) (i.e.,~ , = ( 4 , 3 , 2 ) , O < n ~ 0 . 0 5 ; Y.a(4,3,2},0.05<aS0.1;
Y, ={O}, O . I O i a < O . l S :
From this set of
im
,
wecan
computei(;*)
as .k(?‘.)~(4+3+2)/3=3, 0.00<U50.05;Xv.)
_ _
-(4+3+2)/3 = 3, 0.05 < a 5 0.kx@.)
= 0, 0.10 < a 5 0.15;k(i.)=
0, 0.15 < a<
1-00;Since the synthetic evaluation is a discrete form,
F(Y)
index is computed by
F ( Y ) = jX(G,)dcr = 9as3d@+f~503da=0,30.
Similarly, we can obtain the other elements for all decision makers, We, then, average the rating derived from six decision makers with respect t o t ,
,
t,, t,
andt ,
are4
t 2 t 3 1 4V ( r , ) 0.455 0.592 0.620 0.524
2. The order of the preferences of the decision makers
on
four models can be stated
as
t,+
t,
+
t,
+
f,.
3. The new-product manager makes the decision according to new-product screening rule
of
company asf ,
t,
(3 I, Decision kill go go kill ,The 9th International Conference on Computer Supported Cooperative Work in Design Proceedings
5.
Discussion
Without any comparison of the proposed method with other well-established methods, the resuiting decision may be questionable. In this section, we will compare the new-product ranking procedures, developed by Lin and Chen’s approach
[Z],
to treat thesame
problem.From Eq.(l8), the synthetic evaluation o f traditional fuzzy approach can be obtained when it is true that t{x)=I-f(x) for vague sets (i.e., ignore uncertainty) as Table 3.
Then, the average value of rating alI decision makers
is given
by- 1 ” -
-
v, = - C [ v ; @ v ; @
...
@.;;I n in1have attained. In addition, the synthetic evaluation is neither flexible nor can it illustrate the degree of confidence level of the decision makers. We can conclude that the proposed method is more effective than the traditional fuzzy method on
NPD
process.6.
Conclusion
This paper presents a new fuzzy approach to solve NPD screening problems. The proposed method allows the decision makers to express their preferences
in
linguistic terms and explicitly represent their uncertainty of their judgments using vague sets. The experimental results indicate that our approach can not only effectively reveal the uncertainty of decision makers’ subjective judgments, but also is applicable toNPD screening problems. From a numerical illustration, the usefulness
and
effectiveness of the proposed .modelhas
been demonstrated. TReferences
[I] A.D. Henriben and A.J. .Traynor, “A practical
R&D
project-selection scoring tool,” IEEE Trans. Engineering
Munugement, vol. 46, pp.158-169, May 1999.
[2] C.T., Lin, C.T.,Chen, “New product goho-go evaluation
at the ffont end: a fizzy linguistic approach”, IEEE Tram. Engineering Munogemeni, vol. 5 1, pp. 197-207, May 2004.
[3] D. H., Hong, and C. Kim, A note on similarity measures between vague sets and between elements, Fupv Sets undSystems, vol. 115, 1999, pp.83 -96.
[4] F. Herrera, et a], “A Rational Consensus Modef in Group
Decision Making Using Linmistic Assessments”, Fuzzy set In the following, the left-and-right
fuzzy
rankingmethod is applied to synthesize the fuzzy ratings [I21
YR
= SUP [U - ( X ) A U, (X)],vr.
= SUP [U - (XI*
U,,, ( X I ] ,(20) (21)
x “ I
r v i
The synthetic evaluation on each target is given by
The synthetic value on
each
targetis
calculatedusing
Eqs.(19)-(22) or geometric graphics described as [13]tl I, 13 t 4 .
Y ( t , )
0.47 0.51 0.55 0.49Obviously, the target 3 is the best choice and
the
ranking order is
t3
+
t,
+
t4r
tr.
The solution of Lin and Chen’s method concludes the same result as our proposed model.From Table 3 and Eq. (22), the traditional fuzzy method on
NFD
process is not able to dynamically analyze the group preferences of decision makers and does not specify whether the group consensus on targetsandsystems, vor 88, G.3 1-49, 1997.
[SI G.R. Copper, “Winning at New Product: Accelerating the
Process From Idea to Lunch,” Reading. MA: Addison- Wesley, 1993.
[6j G.R. Copper and E.J. Kleinschmidit, “An investigation
into the new product process: Steps, deficiencies, and impact,” 1 Prod Innav. Manuge, ~01.3, pp.71-85, 1986. [7] H.J. Zimermann, P. Zysno, “Decision and evaluations by
hierarchical aggregation of information”, F vSets and
Systems, vol. 10, 1983, pp.243-260.
[SI
J. Kacprzyk and M. Fedriui, “A human-consistence degree of consensus based on fuzzy Iogic with linguisticquantifiers,” Mathematical Sociul Sciences, vol. 18, pp.275-
290, 1989.
[9] L.L. Machacha and P. Bhaftachqa, “A fuzzy logic-based approach to projection selection,” IEEE Trans. Engineering Management, vol. 47, pp.65-73, Feb 2000.
[lo] P. Kotler, “Marketing Management”, Prentice Hall, 2003. 1111 R. Zwick, E. Carlstein and D.V. Budescy “Measures of similarity among fuzzy concepts: A comparative analysis”, Internat. J. Approximate Reusoning, vol. 1, pp.221-242,
1987.
1121
S-H.
Chen andC.E.
Hwang, “Fuzzy Multiple Attribute Decision Making Methods and Applications,“ Springer- Verlag, Berlin, Heidelberg, New York,1992, pp. 247-25 1[I31 W.L. Gau, D.j. Buehrer, “Vague sets,” IEEE Trans.
and pp.259-264.