行政院國家科學委員會專題研究計畫 成果報告
子計畫三:MPEG 多媒體傳輸機制及通訊協定在嵌入式行動平
台上的分析設計(III)
計畫類別: 整合型計畫 計畫編號: NSC94-2219-E-009-009- 執行期間: 94 年 08 月 01 日至 95 年 07 月 31 日 執行單位: 國立交通大學資訊工程學系(所) 計畫主持人: 蔡淳仁 計畫參與人員: 何健鵬、高政汗、張文潔、蔡雅婷 報告類型: 完整報告 報告附件: 出席國際會議研究心得報告及發表論文 處理方式: 本計畫可公開查詢中 華 民 國 95 年 10 月 16 日
行政院國家科學委員會專題研究計畫成果報告
MPEG 多媒體傳輸機制及通訊協定
在嵌入式行動平台上的分析設計
Design and Analysis of MPEG Multimedia Transport
Mechanisms and Protocols for Embedded and Mobile
Environment
計畫編號:NSC 94-2219-E-009-009,
執行期限:94 年 8 月 1 日至 95 年 7 月 31 日
主持人:蔡淳仁 國立交通大學資訊工程系
參與人員:何健鵬、高政汗、張文潔、蔡雅婷
國立交通大學資訊工程系
中文摘要 在三年的整合計畫中,本子計畫除了配合總計畫團隊,協助 MPEG 標準 ISO/IEC 21000-12:Test Bed for MPEG-21 Resource Delivery 的制定之外,在過去三年共發展了以 下幾項在異質性網路及不同能力的終端設備間進行多媒體串流傳輸相關的技術。在第一 年的時候,除了開發 Test Bed,主要是研究現有的流量控制和容錯機制的設計。第二年 則改進了現有的碼率失真最佳化(rate-distortion optimized)可調式串流傳輸機制並整合 進計畫團隊開發的 MPEG Test Bed 標準測試環境中。另外,在第二年的計畫中,也針 對未來多媒體嵌入式系統的相當有潛力的多次內容調適(multiple adaptations)的應用,設 計出以 wavelet 為基礎之 scalable video codec 的流量控制機制。最後,在第三年的研究 中,我們更進一步提出了更好的碼率失真最佳化(rate-distortion optimized)可調式串流 傳輸機制。在此系統中,我們會根據封包內容的重要度進行不同的 Reed-Solomon 容錯 保護。在研究成果的產出方面,根據第二年和第三年的研究,我們分別寫了兩篇期刊論 文,目前正在審核中。 關鍵詞:MPEG-4、MPEG-21、多媒體串流傳輸、嵌入式行動多媒體系統、碼率失真最 佳化、多媒體傳輸流量控制、可調式視訊壓縮Abstract
There are several achievements in this project for the past three years. First of all, the project team participated in the MPEG standard activities and developed the International Standard, ISO/IEC 21000-12: Test Bed for MPEG-21 Resource Delivery. In addition, we have developed several technologies for multimedia streaming over heterogeneous networks and devices. In the first year of the project, in addition to participating in the development of the test bed, we have investigated existing rate control and error control mechanisms for video streaming. During the second year of the project, we have improved one of the existing rate-distortion optimized scalable streaming schemes and integrated it into the test bed. Furthermore, we have looked into the problem of multiple adaptations of scalable video streaming. Multiple adaptations have a lot of important applications for future heterogeneous environment, especially for embedded multimedia devices. Finally, for the third year of the project, we have designed a better rate-distortion optimized scalable streaming system. In this system, we have developed a content-adaptive Reed-Solomon error control mechanism with interleaving packetization to cope with packet losses over IP networks. Both the research results in the second and third years have been submitted to international journals and are currently under the review process.
Keywords: MPEG-4, MPEG-21, multimedia streaming, digital content transport, flow control,
目錄
Part I: 綜合討論 一、前言 ... 1 二、研究目的 ... 1 三、文獻探討 ... 1 四、結果與討論 ... 1 五、計劃成果自評 ... 2 六、與計畫相關之已發表文獻 ... 3 Part II: 研究成果詳細內容 研究成果一:Multiple Adaptation and Content-Adaptive FEC Using Parameterized R-D Model for Embedded Wavelet Video ………..……… 4研究成果二:Content-Adaptive Packetization and Streaming of Wavelet Video over IP Networks ……….. 18
一、前言 本報告是過去三年的整合計畫的完整 報告。在最後一年的計畫中,我們整合了 過去三年的研究,寫了兩篇尚未發表的期 刊論文,目前己交付國際期刊審查中。本 報告內容主要是以這兩篇論文為主,詳見 第頁開始的研究成果。 二、研究目的 過去的串流傳輸系統的設計重點是在 於同一時間內要能服務最多的客戶端為 主,而且多半假設所有連到伺服器的終端 機都是透過類似的網路以及具有相似的計 算 能 力 。 本 計 畫 的 主 要 目 的 在 於 配 合 MPEG-21 的理念,設計出一個具有實用性 系統,可以橫跨不同的網路架構和在不同 的客戶端設備上(PC、手機、PDA 等等) 提供高品質多媒體傳輸播放服務。因此, 這個傳輸系統必須能動態地根據不同的應 用環境調整資料包裝和傳輸的方式。簡言 之,一個數位多媒體傳輸系統的架構必需 包含流量控制和容錯機制。另外,依據客 戶端的能力來調整媒體資料流品質的能力 也是十分重要的。 為了在頻寬和封包掉失率隨時在改變 的環境下給使用者最好的串流傳輸品質, 許多人嘗試對傳輸的資料進行碼率失真最 佳化(Rate-Distortion)分析,然後根據分析 結果來傳輸視訊串流。過去所提出的碼率 失真最佳化的網路傳輸的流量控制機制 裏,最大的問題在於封包漏失所造成的失 真(distortion)沒有辦法量化。許多現有系 統的做法在封包漏失所造成的失真的估測 都十分不切實際(或完全忽略了)。我們 提出了一個較實際的方法,可以合理的把 封包失真量化。 要達到碼率失真最佳化的網路串流傳 輸,除了要根據網路頻寬和封包漏失率來 估測出最好的串流資料量,還必須能在算 出的串流資料量限制下,從 scalable video 的位元流中,抽出最好的子位元流。所以 我們針對這方面的需求,設計出了一個快 速 收 斂 的 小 波 轉 換 視 訊 壓 縮 法 (wavelet video coding)的流量控制機制,另外,更進 一步設計了可以有效進行多次碼率失真最 佳化的子位元流抽取(multiple adaptation) 的機制。 另外,多媒體串流資料傳輸之前,一 般的系統會進行 Forward Error Correction (FEC)或 Automatic Retransmission reQuest (ARQ)的保護。然而,在目前公開發表的系 統中,最多只是針對漸層式編碼可調式編 碼的的不同傳輸層做不同程度的 FEC 保 護。而我們則改進了這項缺點。在本計畫 第三年的成果中,我們提出了一套機制, 在碼率失真最佳化的原則下,能較精確地 對視訊內容依其重要性進行不同程度的 Reed-Solomon 編 碼 保 護 , 並 配 合 data interleaving 的封包包裝法來強化資料對封 包掉失的容錯度。 三、文獻探討 本計畫的總合成果主要有兩大方向, 首先是以適用於小波轉換視訊壓縮法的多 次 碼 率 失 真 最 佳 化 的 子 位 元 流 抽 取 (multiple adaptation)的機制,以及小波轉換 視訊串流傳輸的能自動隨視訊內容重要性 和即時封包掉失率來調整 FEC 保護強度的 機制。關於這兩個研究方向的文獻探討, 請參見綜合報告之後的成果報告一和二。 四、結果與討論 前面大致提到了本計畫在過去三年除 了參加 MPEG 標準制訂之外的三項主要研 究成果,首先是一個較實用的碼率失真最 佳化串流傳輸系統、其次是一個較適合嵌 入式系統使用的低複雜度可多次內容調適 的流量控制機制、最後則是一個根據 IP 封 包網路串流傳輸特性所設計的自動隨內容 重要性調整的(content-adaptive)FEC 保護 機制。 本節首先描述本計畫在碼率失真最佳 化串流傳輸系統方面的創新設計。目前在 這方面較知名的是由 P. A. Chou 等人所 發展的系統。這個系統有兩大缺點。首先 是他們使用封包掉失率來估測碼率失真最 佳化分析中的失真。這是很不實際的做 法。其次,該系統為了避開傳統 ARQ 對封 包回傳時間很敏感的問題,因此採用封包 預先重覆傳送的方法來降低失真,這也是
很沒有效率的容錯保護機制。因此這套方 法目前發表的成果以理論分析為主,在實 作上有很多細節並沒有提出解決方案,而 且在頻寬變化大的網路環境下,串流傳輸 最難達到的平滑播放要求也沒有考量。 在本計畫的碼率失真最佳化串流傳輸 系統中,我們把封包漏失所造成的失真, 轉化為不同程度的 FEC 保護所造成的失 真。舉例而言, 10-3 的封包漏失率造成的 失 真 , 就 相 當 於 10-3 的 FEC 的 error
protection 導致 data rate 降低所造成的失 真。整個系統可以分成兩大部份:媒體封 包相依性控制:媒體封包相依控制和碼率 失真最佳化傳輸控制。在提出的系統中, 碼率失真最佳化傳輸模組會根據資料內容 的移動量資訊,來調整流量控制時的最佳 化決定。簡單地說,一般的碼率失真最佳 化控制架構必需在資料單元群組之間利用 碼率及失真的 Lagrangian cost function 來 算出最小值的解來有效率的分配時間和頻 寬的網路資源。而本計畫提出的系統則會 同時利用 FEC 的編碼率和每一段視訊資料 所 含 的 移 動 量 大 小 來 校 正 傳 統 的 cost function 以求得更佳的效果。 在可調式位元串流傳輸中,影像資料 可以分成好幾次傳送,每次的傳送都可以 幫助解碼端得到更接近於原影像資料的重 建訊號,因此可調式位視訊編碼法必須必 須 能 支 援 多 樣 化 的 調 適 運 作 (adaptation operations)以針對不同應用產生有效可解 碼的位元流。前面所提到的系統設計,主 要是以 MPEG-4 FGS 的編碼法(從 2005 年起,FGS 已經不屬於 MPEG-4 標準的一 部份)為可調式編碼的核心。但在第一年 的研究過程中,我們發現 FGS 的諸多限 制,因此在第二年開始的研究中,就開始 轉向採用小波轉換視訊壓縮法。 小波轉換視訊壓縮法的流量控制機 制,一般系統(e.g. JPEG 2000 及 3-D ESCOT) 是利用在編碼階段所產生的碼率失真資料 表,配合二分搜尋法,來決定在某個頻寬 條件下最佳的視訊位元流子集合。在本計 畫中,我們設計了一個比碼率失真表更有 效的雙參數碼率失真模型來進行最佳的位 元流切割點的快速搜尋。也因為我們所提 出的視訊視訊資料模型比較精簡也更有效 率,我們可以把它隨著抽取出的位元流一 起傳輸到接收端以進行多次的碼率失真最 佳化子位元流切割。 在第三年的計畫中,我們開發了一個 能自動隨視訊內容重要性和即時封包掉失 率來調整 FEC 保護強度的機制。這部份的 設計主要是針對 IP 網路封包串流傳輸的應 用而開發的。目前所有的 IP 網路的串流傳 輸系統都會由 layer-2 以下的通訊協定處理 位元錯誤,而在 layer-3 以上往往只能看到 封包掉失的錯誤。現有系統多半以 ARQ 封 包重傳的方法或是用 Reed-Solomon 編碼配 合資料交錯安排(data interleaving)來逹到 修復掉失的封包的功能。前者往往不適用 封包回傳時間(round-trip time)較長的網 路,而後者則是很難逹到碼率失真最佳化 的原則。在本計畫提出的方法,則是利用 我們在第二年時所發展的雙參數碼率失真 模型,並根據小波轉換的視覺效應,定出 一個能夠隨視訊內容和即時網路封包掉失 率來調整 Reed-Solomon 保護強度的 FEC 封包編碼保護機制。 五、計劃成果自評 總合三年的成果,和原計畫提出的目 標相當吻合。在達成預期目標情況方面有 以下數點: 1. 配 合 總 計 畫 團 隊 , 成 功 地 制 訂 出 ISO/IEC TR 21000-12 : Test Bed for MPEG-21 Resource Delivery 的國際標 準。 2. 完成碼率失真最佳化串流傳輸系統的 開 發 , 並 將 其 整 合 到 總 計 畫 團 隊 為 MPEG 開發的所設計出的多媒體傳輸 共通測試平台上。 3. 完成小波轉換視訊壓縮法的可進行多 次碼率失真最佳化切割的流量控制機 制設計。這部份的設計特別適合異質性 點對點(p2p)的應用,如從桌上電腦傳到 PDA 再傳到手機的串流傳輸。或者是行 動裝置的省電機制。利如手機首先收到 適 合 較 大 的 內 螢 幕 播 放 的 視 訊 位 元 流,然後在需要省電時,可以從這個位 元流中以碼率失真最佳化的原則抽出 較小畫面的子位元流在外螢幕播放。 4. 設計了一套能自動隨視訊內容重要性
和即時封包掉失率來調整保謢強度的 FEC 保護強度的機制。這個設計可以提 供 IP 網路封包串流傳輸的應用更好的 效果。 5. 在人才培育方面本計畫三年來共有一 個博士生,七個碩士生參與。參與過的 學生畢業後分別加入聯詠、聯發科、 IBM、明碁、工研院等單位工作。 在論文發表方面,本計畫己發表一篇國際 期刊(IEEE Trans. On Multimedia)、一篇 國內期刊(CCL Technical Journal)、另外 投稿兩篇國際期刊論文正在審核中。除此 尚有四篇國際研討會論文。
六、與計畫相關之已發表文獻
[1] ISO/IEC 21000-12:2004(E), Information Technology – Multimedia Framework (MPEG-21) – Part 12: Test Bed for MPEG-21 Resource Delivery, 2004.
[2] C.-W. Tang, C.-H. Chen, Y.-H. Yu, and
C.-J. Tsai,“VisualSensitivity-Guided Bit Allocation forVideo Coding,”IEEE Trans. Multimedia, Vol. 8, No. 1, 2005, pp.
11-18.
[3] C.-P. Ho, C.-J. Tsai, and Y.-F. Hsu,
“MPEG-21 Digital Item Adaptation
Architecture for Fully Scalable Video Streaming,”CCL Technical Journal, Vol.
109, Sep. 2004, pp. 55- 64.
[4] C.-P. Ho , W.-C. Chang , K.-C. Lee , C.-J.
Tsai, "Rate-Distortion Optimized Video
Streaming with Smooth Quality
Constraint," Proc. IEEE Int. Symposium
on Circuit and System, Canada, May 2005,
pp.3271 - 3274.
[5] Y.-H. Yu and C.-J.Tsai,“A Model-based
Rate Allocation Mechanism for
Wavelet-based Embedded Image and
Video Coding,” Proc. IEEE Int.
Symposium on Circuit and System, Canada,
May 2005, pp.6066 - 6069.
[6] C.-W. Tang, C.-H. Chen, Y.-H. Yu, and
C.-J. Tsai, “A Novel Visual Distortion Sensitivity Analysis for Video Encoder Bit
Allocation,” Proc. IEEE Int. Conference
on Image Processing, Vol. 5, Singapore,
October 2004, pp. 3225-3228.
[7] C.-J. Tsai, C.-W. Tang, C.-H. Chen, and
Y.-H. Yu, “Adaptive Rate-Distortion
Optimization using Perceptual Hints,”
Proc. IEEE Int. Conference on Multimedia
and Expo, Vol. 1, Taipei, Taiwan, June
研究成果一
Multiple Adaptation and Content-Adaptive FEC Using Parameterized RD Model for Embedded Wavelet Video
1. Introduction
Data networks for multimedia communications are growing fast nowadays. The network technologies vary from dial-up connections, broadband cable/ADSL networks, to wireless/mobile networks. In addition, the terminal devices for multimedia distribution systems are different in many aspects, including storage capacity, computational power, and screen sizes, etc. For distribution and playback of a video content on various devices under different network conditions, scalable video coding schemes are usually used. A typical approach for scalable coding is to use a layered coding approach such as that of MPEG-4 Simple Scalable Profile [1] or FGS [2]. For layered coding approaches, the content quality is optimized for certain bitrate conditions. Adaptation of such content to a new target bitrate after encoding process usually results in sub-optimal bitstreams.
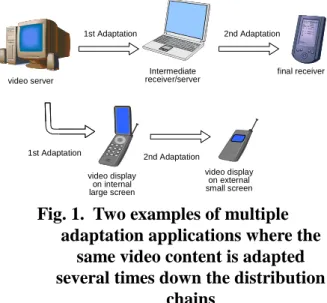
A different approach from the layered coding schemes is to design a scalable codec that produces embedded scalable bitstreams without inherent layered structures. The wavelets-based video codecs belongs to this category [3][4][5]. Although it is not necessary for an embedded wavelet video bitstream to assume a layered structure, video parameters such as resolution, frame rate, and bitrate of the bitstream can still be dynamically adapted with fine granularity after the encoding procedure. If the R-D tradeoff information is also embedded in the bitstream, the dynamic bitstream adaptation process can produce an R-D optimal bitstream at run-time for the target application. One of the advantages of embedded wavelet bitstreams is for multiple adaptation applications. For example, in Fig. 1, the video server transmits dynamically adapted scalable bitstreams to two different devices, namely the notebook and the cellular
phone. Upon reception of the embedded bitstreams, the notebook plays the high quality bitstream on its screen. In addition, it truncates (adapts) the received bitstream further and send it to another device with tighter channel and device constraints (the PDA). For the other distribution chain in Fig. 1, the cellular phone received a good quality bitstream and plays it on its internal large screen. Later, when the user decides to watch the video on the small external screen to conserve power, the video decoder can decode only part of the received bitstream and display a smaller video.
video server 1st Adaptation 2nd Adaptation Intermediate receiver/server 1st Adaptation 2nd Adaptation video display on internal large screen video display on external small screen final receiver
Fig. 1. Two examples of multiple adaptation applications where the
same video content is adapted several times down the distribution
chains
Although multiple adaptations can be achieved using layer-structured embedded bitstreams as well, it is not desirable because each layer of such bitstreams is pre-optimized for certain target bitrate by the encoder. For the same example in Fig. 1, in order to adapt the bitstream for the PDA, the notebook extracts the embedded layers which do not exceed the channel and device constraints of the PDA’s. This approach is quite simple but the bitstream can not achieve the best quality possible since the run-time constraints may not meets the pre-optimized layers of the scalable bitstream. On the other hand, with a fully embedded bitstream where both R-D information and the wavelet video data are transmitted to the
notebook, the notebook can extract an R-D optimized bitstream according to the run-time constraints of the target device. This approach achieves better quality than the layer-structured scheme, but the side information, namely the R-D information, is required and the complexity of the bitstream adaptor is higher. The issue is especially true for resource critical systems, like PDA’sor cellular phones. Therefore, a low complexity bitstream adaptation mechanism which can extract embedded R-D optimized bitstream is very important.
Many rate adaptation schemes have been proposed for embedded image/video codecs [6]–[8]. The basic idea behind these rate control techniques is similar. In general, the rate control scheme for embedded coders is composed of two parts. The first part is to model the rate-distortion characteristics of a group of input image/video data, and the second part is the bit allocation mechanism that assigns proper number of bits to various parts of the input data according to their importance. For wavelet video codecs, the most popular rate adaptation scheme is the 3D-ESCOT proposed by Xu et al. [4]. In this approach, R-D information are computed from real data points and encoded into the bitstream for later adaptation. Bisection search is applied at run-time to determine the optimal truncation point. Although the adapted bitstream achieves optimality given certain rate constraint, the size of the side information and the complexity of the adaptation are not trivial for small devices.
In addition to multiple adaptations, R-D side information is also very useful for video streaming applications. Several frameworks for wavelet based video streaming have been proposed in the literature recently. Chu and Xiong [9] introduced a packetization scheme for combined wavelet video coding and FEC for video streaming and multicasting. The packetized wavelet video coder marks the truncation points of the bitstream at the nearest packet boundaries (instead of the end of each fractional bit-plane). In the FEC-based error protection scheme, it applies Reed-Solomon (RS) coding to produce parity
packets. The scheme broadcasts all source packets to one multicast group and parity packets to different multicast groups. Hence, for each client, the optimal number of layers and error protection to subscribe to can be determined by the packet loss ratio and the available channel bandwidth. However, data-interleaving is not used in this work, which makes the system less robust to burst errors. Dong and Zheng [10] proposed a content-based retransmission framework for wavelet video streaming. The compression module adopt dynamical grouping and bounded coding scheme for improving compression efficiency and removing unnecessary dependency to each coefficient subband. In the transmission module, a video packet includes one or more subbands, and a content-based retransmission is used to provide robustness against transmission errors. The content-based retransmission scheme is based on the importance of packet content which is computed by the square-sum of coefficients for each wavelet subband. Nevertheless, retransmission-based error control requires longer jitter buffer and may consume too much extra bandwidth in high error rate channels [11]. On the other hand, fixed level of FEC protection consumes considerable overhead which are wasted if there is not channel error. If the R-D side information is available to the streaming server, it can estimate the importance of subband data more accurately. Hence, it is possible to design a content-adaptive FEC protection scheme that has lower channel distortion with lower FEC overhead.
In this paper, a parameterized R-D model-based approach for multiple adaptation applications and for content-adaptive FEC protection for streaming video is proposed. For multiple adaptations, the goal is to reduce both the size of the R-D side information embedded in the bitstreams and the computational complexity of the run-time rate adaptor. For content-adaptive FEC protection applications, the goal is to improve the accuracy of importance estimation of various subband data. The organization of the paper is as
follows. Section 2 introduces some previous work of the rate adaptation scheme for embedded codecs and discusses their strengths and weaknesses. Section 3 discusses a parameterized rate-distortion model for wavelet video. The proposed multiple adaptation scheme and content adaptive FEC protection scheme based on the parameterized R-D model are presented in section 4. The experimental results will be shown in section 5. Finally, the conclusion and discussions will be given in section 6.
2. Rate Adaptation Problem of Wavelet
Video Coding
A general framework for wavelet-based embedded video coding [3][4] is shown in Fig. 2. The input YCBCR frame data is first
transformed into frequency domain via temporal and spatial subband decompositions. The transform process is followed by the quantization and the entropy coding processes with rate allocation mechanism. Popular wavelet-based image and video coders typically use Discrete Wavelet Transform (DWT) for spatial subband decomposition and Motion-Compensated Temporal Filtering (MCTF) for temporal subband decomposition. Context-adaptive arithmetic coding is used for entropy coding. Finally, the rate allocation procedure is used to explore bitrate (quality) scalability of the embedded bitstreams. Note that, in addition to being an encoder module, the rate allocation module can be used in a video server as a standalone module with an entropy-coded embedded bitstream as the input and its subset bitstream as the output.
Temporal MCTF Spatial DWT Quantizer Context Modeling Arithmetic Coding Rate Allocation Output Embedded Bitstream Original YCBCRdata
Fig. 2. General wavelet coding framework
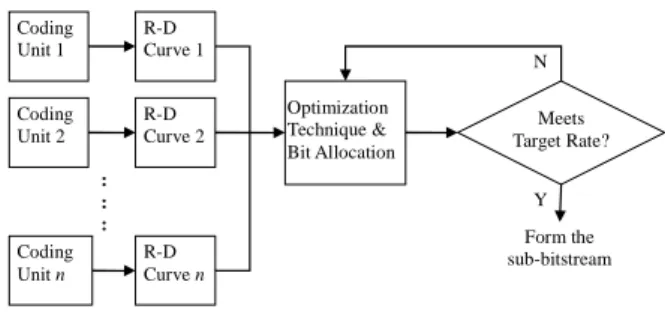
Coding Unit 1 Coding Unit 2 Coding Unit n Optimization Technique & Bit Allocation R-D Curve 1 R-D Curve 2 R-D Curve n Meets Target Rate? Form the sub-bitstream N Y : : :
Fig. 3. Basic rate allocation scheme
For wavelet-based codecs, video data is partitioned into coding units, which could be a frame, a frequency band, or a coding block. A basic scheme of the rate allocation module is shown in Fig. 3. The function of rate allocation is to extract a smaller sub-bitstream from a compressed bitstream that meets some application constraints. During the rate allocation process, the frame rate, resolution, and bitrate can all be changed to form the target bitstreams. This is called full-dimensional scalability. Many rate control schemes have been proposed for embedded image/video codecs. In general, the rate control scheme for embedded codecs is composed of two parts. The first part is to model the R-D characteristics of a group of input image/video data, and the second part is the bit allocation mechanism that assigns proper number of bits to various parts of the input data according to their importance.
2.1. R-D Model Construction
Several R-D models have been proposed to establish the tradeoff between rate and distortion for each coding unit [4][8][12]. An R-D model represents the degree of degradation of a coding unit when the size of the compressed data is constrained by the available bandwidth. The R-D models of the coding units can be used by the bit allocation algorithm to sort out the priority of the coding units. There are two typical ways to build the R-D characteristics model. The first method computes discrete R-D relationship data points from the real image data for model construction. The other method is to use a parameterized close-form model.
In wavelet-based embedded codecs, bitrate scalability is achieved by fractional bit plane coding. As the available bandwidth of
the target applications goes from low to high, more and more fractional bit planes could be included into the target bitstreams according to their significance. In other words, an embedded bitstream is composed of fractional bit planes. The more fractional bit planes the bitstream contains, the higher quality it would be. Therefore, inclusion of an additional fractional bit plane in a coding unit contributes to both increment of bits (rate) and reduction of quality loss (distortion). Recording of the rate and distortion data point of each fractional bit plane provides a precise yet discrete R-D model of the embedded bitstream [4]. By using real data points to represent the R-D model, the tradeoff between rate and distortion at each truncation point can be precisely determined. However, storing all the discrete R-D values for each fractional bit plane in each coding unit during the bit allocation procedure requires a lot of memory space. Even worse, for multiple adaptations, this R-D information must be embedded in the bitstream throughout the distribution chain. Furthermore, in order to find the best truncation point which matches the rate constraint, some search techniques (possibly time-consuming) must be applied while doing bit allocation.
Different from the discrete R-D model approach, some literatures [8][12] use close-form models to describe the R-D characteristic of the video data. This approach first applies information theory on a simplified source model and a codec model to calculate the relationship between coding rate and distortion. In the closed form R-D equation, content-dependent information is summarized in a few parameters. With the parameterized R-D model, the R-D characteristic of each coding unit will be estimated at runtime by solving the content-dependent parameters. In general, the parameters can be estimated from the content statistics and/or by curve fitting of sparse data points. By using a closed-form R-D model, memory consumption of the rate control process can be substantially reduced, but the accuracy of bit allocation may
decrease, depending on the accuracy of the R-D model.
2.2. Bit Allocation
The goal of the bit allocation procedure is to achieve maximal quality for a given bitrate or minimal bitrate for a given distortion. Giving the R-D characteristics models for each coding unit, nonlinear optimization techniques can be applied to distribute the coding bits among all coding unit in an optimal way. A popular approach is to use the Lagrange multiplier to transform constrained optimization problem into unconstrained optimization problem [4][8][12]. During this process, some truncation points will be deleted from the candidates of optimal solutions since they do not fall on the convex hull of R-D curves.
After establishing the R-D characteristic model and the optimization process using Lagrange multiplier, each optimal truncation point contains three attributes including rate, distortion, and the Lagrange multiplier value (refer to as the value hereafter). The next step is to form an optimal target bitstream given a rate or distortion constraint. Some literatures use iterative search method to achieve this goal [4][8][12]. Among the optimal truncation point attributes, the values represent the trade off parameters between rate and distortion at those truncation points. By applying a specificc to
all coding units, the collective set of all truncation points with their values closest to c builds an optimal bitstream with the
given constraint. An iterative search method, such as bisection search, can be used to iteratively selecting different c until the
composed bitstream meets the target constraint. The weakness of the iterative search method is that the convergence rate may be slow. Further improvement can be achieved if the search process takes advantage of the R-D characteristics of the content.
Besides the iterative search method, some studies [13][14] designed special data structure to record R-D tradeoff points of all
coding units. For example, a heap-based structure has been proposed to process rate allocation for embedded image coding in [13]. The heap structure which contains all possible truncation points is built internally during encoding process and some heap manipulations, such as “shiftdown” and “update root,” are conducted according to R-D property of each truncation point. The heap manipulation operations stop when the heap tree is balanced and the root of the tree meets the target bitrate constraint. At this point, the final bitstream is composed. Another approach that uses quadtree merge-based algorithm is proposed in [14]. Similar to the heap-based proposal, this method tries to achieve fast R-D optimization by applying simple operations to manipulate the data structure during the bit allocation process. One major disadvantage of fast search algorithm with well-designed data structure is that the memory required may be extremely large in order to build the complete data structure to store all coding unit information, especially for video coding.
3. Parameterized R-D Models for
Wavelet Video
The concept of rate distortion function is first published by Shannon [15]. Based upon the idea of Shannon, several literatures [16][17][18] pointed out that rate and distortion have the relationship shown in (1), where R() is the source rate, E(b) represents the entropy of the signal source b, and D is the distortion measured by square error.
) 2 ( log 2 1 ) ( ) (D E b 2 eD R (1)
From (1), let RL(D) = E(b) –
log2(2eD)/2, one can infer the general form
of the Rate vs. Square-Error-Distortion function as shown by (2):
The parameter, ω, in (2) is related to the probability density function of the source signal. Take Gaussian distribution for example, assume the probability density function of the source is p(x) with mean μ and variance σ2, the entropy of the source signal is: 2 22 log 2 1 ) (p e E . (3) Therefore, 2 , and D D RL 2 2 log 2 1 ) ( . (4)
Note that in (4), when 2 < D, RL(D)
becomes negative. If this is not desirable, (4) can be rewritten as follows:
2 2 2 2 2 2 , 0 0 , log 2 1 ) 0 , log 2 1 max( ) ( D D D D D RL . (5)
In this section, the general rate distortion relationship is established. The rate distortion model can be extended by using different distortion measures or content probability density functions. Some literatures apply the function to embedded wavelet coder [8][14] and make a little empirical adjustment on the parameters. The revised relationship with an additional parameter, χ, is in (6): D D R log2 2 1 ) ( , e b E 2 22 ( ) . (6)
The parameter χ characterizes the exponentially decaying rate. Base on the analysis of the experimental results in [8][14], the parameter is shown to be related to the distribution of the source. The general R-D function for embedded wavelet coder with square-error measure is shown in (7):
D D
R( )ln, (7)
where = (log2e)/2 is the scaling factor for changing the base of the log function.
We conducted an experiment using a wavelet video codec [5] to examine the
D D e D R Eb L 2 2 ) ( 2 2 log 2 1 ) 2 ( log 2 1 2 log 2 1 ) ( , e b E 2 22 ( ) . (2)
precision of the rate distortion relationship in (7). The test sequence is STEFAN in CIF resolution. The partial results for two coding blocks are shown in Fig. 4. Each point in the figure represents an available truncated point in a coding block, and each curve represents the characteristic model for a coding block. The models are calculated by solving the parameter γ and ω in (7) using least-squares-error curve fitting method. Due to different local source distributions, these two coding blocks have different values of the parameters. D(R) = 3739.1 e–0.0120R for coding block one and D(R) = 19794 e–0.0137R for coding block 2. The experiment shows the precision and the reliability of the rate distortion function when applying to coding blocks with different characteristics.
So far, we have introduced the theoretical background of scalable rate control algorithms. However, there are still some gap between the theory and actual implementations. For example, the determination of the Lagrange multiplier value is difficult in practice, and the overall bit allocation procedure should be restructured in order to achieve computational efficiency. Solutions to these issues will be developed in the proposed scheme in the next section.
0 100 200 300 400 0 0.5 1 1.5 2 2.5 3x 10 4 Rate(bit) D is to rt io n (M S E )
RD function for coding blocks
Coding Block 1 Coding Block 2
Fig. 4. R-D models for coding blocks in a wavelet video codec
4. The Proposed Multiple Adaptations
and Context-Adaptive FEC schemes
In this section, we presents the proposed multiple adaptation scheme and content-adaptive FEC protection for
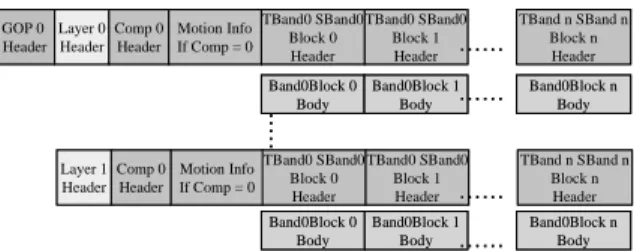
streaming applications for wavelet codec using the parameterized R-D model introduced in section 3. The implementation is based on the Microsoft Research Asia (MSRA) wavelet codec [5]. A bitstream encoded using the MSRA codec is organized in the format shown in Fig. 5. A bitstream parser extracts the information for the truncated candidates from the headers. After all the required data are collected, the bitstream truncation procedure begins without entropy decoding involved. The truncation module decides the truncation point in order to meet the resolution, frame rate, and bit rate criterions. The bitstream is then composed again with new header information and truncated body bits. The new bitstream should conform to the usage scenario and can be transmitted over the network to the target receiver.
GOP 0 Header Layer 0 Header Comp 0 Header Motion Info If Comp = 0 TBand0 SBand0 Block 0 Header Band0Block 0 Body Band0Block 1 Body Band0Block n Body Band0Block 0 Body Band0Block 1 Body Band0Block n Body …… … … TBand0 SBand0 Block 1 Header TBand n SBand n Block n Header …… Layer 1 Header Comp 0 Header Motion Info If Comp = 0 TBand0 SBand0 Block 0 Header TBand0 SBand0 Block 1 Header TBand n SBand n Block n Header …… …… GOP 0 Header Layer 0 Header Comp 0 Header Motion Info If Comp = 0 TBand0 SBand0 Block 0 Header Band0Block 0 Body Band0Block 1 Body Band0Block n Body Band0Block 0 Body Band0Block 1 Body Band0Block n Body …… … … TBand0 SBand0 Block 1 Header TBand n SBand n Block n Header …… Layer 1 Header Comp 0 Header Motion Info If Comp = 0 TBand0 SBand0 Block 0 Header TBand0 SBand0 Block 1 Header TBand n SBand n Block n Header …… ……
Fig. 5. MSRA Wavelet Bitstream Format 4.1. Proposed Rate Allocation Algorithm
for Multiple Adaptation Applications
On a PC platform, the truncation process account for 72% of the bitstream adaptation time. The proposed framework (Fig. 6) tries to build a closed-form R- relationship for each coding block and each GOP. The rate of each coding block corresponds to the truncation point, and the rate of each GOP corresponds to the target bit rate. These two values are related to each others by the value. Therefore, the truncated point for each coding block can be selected given the target bit rate.
Rblock(λ) Rate Distortion Characteristics Model Bit Allocation Mechanism Entropy Coded Bitstream Layer-Structured / Fully-Embedded Bitstream Proposed Rate Control Kernel
coding block level
Rate (truncation point) Lambda Rate (target bitrate)
λ(RGOP)
GOP level
Fig. 6. The framework proposed rate control extractor
4.1.1. R-Lambda Model Analysis
The proposed R- model for each coding block is established by combining the parameterized R-D model mentioned in section 3 and the Lagrange multiplier optimization technique. Recall that in (7) the parameter γdepends on the distribution of the source, and the parameter ωis related to the signal variance. For a given value λ, the minimization of the Lagrange cost function
J(R) = D + R can be obtained when dJ(R)/dR = 0, that is,
dR R dD . (8)Taking the inverse of (7), we have
R e R D ) ( D(R) = e–R/. Substitute
D(R) into (8), we obtain the relationship
between the Lagrange multiplier and the bitrate:
e
R
1
. (9)As a result, the R– model in coding block level can be written as in (10), where the parameters αand βare source dependent:
R
e
. (10)For each coding block, a parameter pair of (α, β) will be estimated by curve-fitting to real R- data points. Fig. 7 shows an example of a coding block of the FOOTBALL sequence using the MSRA codec. Each point in the figure is the R-D point of a possible truncation point. Therefore, the R-D information of the whole coding block can be represented using simply two parameters, instead of 11 data points as in in Fig. 7.
The GOP level R- model can be extended from the coding block model. First, by adopting the R-D form of 錯誤! 找不到
參照來源。, we have max(1 ln ,0) R
be a nonnegative R-D model. For > 0 and < 0, the R- model at GOP level is derived as follows: ). ln 1 ( ln ) 1 ( } { , ln 1 ) 0 , ln 1 max(
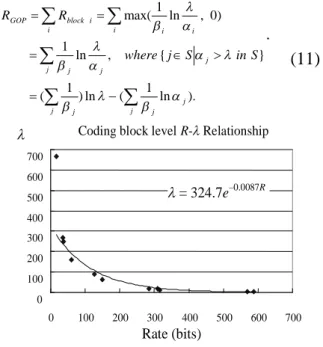
j j j j j j j j j i i i i i block GOP S in S j where R R . (11)Coding block level R-Relationship
0 100 200 300 400 500 600 700 0 100 200 300 400 500 600 700 Rate (bits) = 324.7e–0.0087R
Fig. 7. Example of coding block level R–
relationship
It is straightforward that the rate of a GOP is the sum of the rates of a group of coding blocks; and the size of the group is related to the value. We define the two summation terms in (11) as follows:
j j GOP p 1 and j j j GOP q ln 1
. (12)In order to keep the model simple, we assume that these two summations can be modeled by polynomials as shown in (13):
n n n GOP a a a P 2 2 1 1(ln()) (ln()) and n n n GOP b b b q 2 2 1 1(ln()) (ln()) . (13)
Finally, the relationship of the GOP level R- model is established in (14):
1 1 2 1(ln ) (ln ) ln n n n GOP GOP GOP p q R . (14)
The graph in Fig. 8 illustrates the accuracy of the proposed R- model in the GOP level. The order of the function is determined empirically. In general, a cubic
GOP level R-Relationship 0 100000 200000 300000 400000 500000 600000 700000 800000 900000 4 5 6 7 8 9 10 11 Rate y = –3957x3+128678x2–106x–5106
Fig. 8. Example of GOP level R- model
function can be used to fit the data points well for a wide range of rate.
4.1.2. Embedded Rate-Distortion Information Generation
In order to allow for multiple adaptation applications, we must embedded the R-D information into the bitstream so that a terminal receive the bitstream can perform another adaptation with R-D optimality. In addition, we must minimize the size of the R-D information so that it will not consume too much bandwidth. In the following discussions, we assume that the input to the R-D information embedding algorithm is the original full wavelet bitstreams generated by the MSRA encoder. That is, all the R- data points for all the fractional bitplane coding pass truncation points are embedded in the bitstream. Although it is not necessary for an embedded wavelet bitstream to assume a layer structure, it is a common practice for the MSRA codec to generate bitstreams with pre-optimized quality layers (one for each potential target bitrate). Note that this structure is only for application convenience and is not a necessary feature of wavelet-based scalable video. However, we still preserve this structure through the proposed algorithm.
The coding block level model (10) is used as an adaptive model since the source dependent parameters αand βare estimated based on the input data. Given n pairs of numerical data (λi, Ri), i = 0, … n–1, the
parameter α and β can be calculated as follows. First, (10) can be rewritten as lnλ= lnα+ βR. Therefore, for n > 2 we have an
over-determined system of equations 錯誤!
找不到參照來源。, ln 1 1 1 1 ln ln ln 1 1 0 1 1 0 n n R R R . (15)
The system can be solved using least-squares estimation. Once the parameters
α and β are determined, the relationship
between the Lagrange multiplier and rate is directly established. In a similar manner, the GOP level R- model (see (14)) is adaptively built by the least-squares curve fitting method. For certain GOP, assume that
1 ) (ln ) (ln 1 ) (ln ) (ln 1 2 2 1 1 1 n n n n A , : 2 1 GOP GOP R R Y , and 1 2 1 n X . (16)
The parameters γ1, γ2, …, γ3 can be
solved by computing the pseudo inverse
X = (ATA)–1ATY. As the whole GOP level
R- model is established, the R- value can
be solved using closed form solutions for n < 5 (typical n is 3).
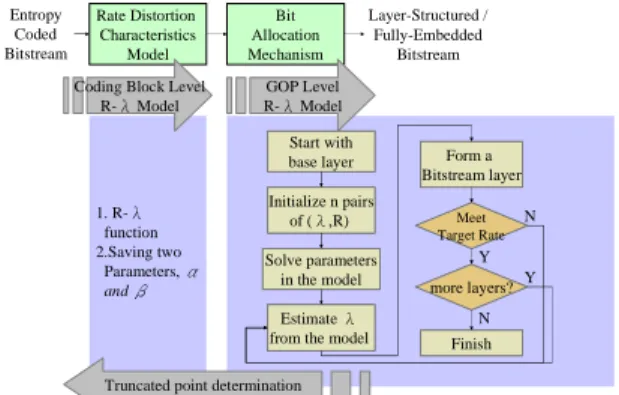
The overall proposed algorithm which adopts the R- model is illustrated in Fig. 9. In the bit allocation mechanism, the R- model is used to search the lambda value in the GOP level, and in the rate distortion optimization procedure, the R- function is used to represent the rate distortion properties in the coding block level.
Rate Distortion Characteristics Model Bit Allocation Mechanism Entropy Coded Bitstream Layer-Structured / Fully-Embedded Bitstream 1. R-λ function 2.Saving two Parameters, α and β Start with base layer Initialize n pairs of (λ,R) Solve parameters in the model Estimate λ from the model
Form a Bitstream layer Meet Target Rate more layers? Finish N Y Y N Coding Block Level
R-λ Model
GOP Level R-λ Model
Truncated point determination
Fig. 9. Overall framework of the proposed rate adaptation mechanism
The algorithm used to embed R-D information into a MSRA encoded bitstream are summarized as follows (note that the original discrete R-D information will be removed):
1. Search for the optimal Lagrange multiplier at GOP level:
a) Find the first n pairs of (λ, R) in a quality layer of the input wavelet bitstream (encoded by the original MSRA encoder), and n is typically 4 if cubic model is used in GOP level. b) Solve for the parameter (γ1,
γ2,…,γ3).
c) Given the target bitrate, solve the R–λmodel for λ. Use the estimated λ to form a bitstream quality layer and obtain another (λ, R) data point.
d) Add the new (λ, R) pair to the data set.
e) Iteratively doing the (b)-(d) steps until the R value is close enough to the target bitrate within a tolerable error range
TR.
f) Repeat the procedure for another quality layers.
2. Represent R-D property of a coding block:
In procedure d), a bitstream layer is formed given a Lagrange multiplier value. The truncation point of each coding block is determined at the fractional bitplane pass with the nearest Lagrange multiplier value. To achieve the typical coding block level rate allocation, the Lagrange multiplier value of each fractional bitplane pass in all coding blocks should be stored during tier 1 of entropy coding. In order to reduce the memory usage of the information and distribute the rate among all coding blocks based on information theory, the coding block level R-lambda model is applied to describe the property of each coding block. Therefore, only
theparametersα and β should be stored for a single coding block, and the coding block level rate allocation can be easily done by adopting the inverse R-lambda model with a given Lagrange multiplier. In the proposed method, the truncation point would be the fractional bitplane pass with the nearest rate.
4.1.3. Rate Adaptation Procedure
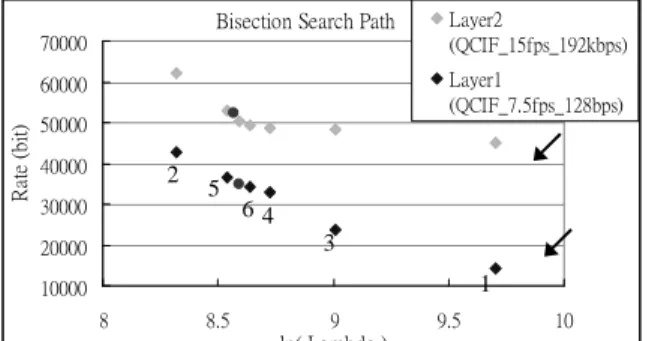
Once the bitstream is formed, run-time adaptation to a target bitrate becomes a question of searching for a value that marks all the truncation points to form a target bitstream that following the rate constraint. For discrete R-D information used by the original MSRA codec, bisection search is used for determining the value. The search process starts from the initial maximum and minimum value estimates. By half-eliminating the search range at each iterative step, the search results converge and the value which meets the target bitrate is obtained at the end. Fig. 10 shows an example of such process. In Fig. 10, the MSRA bitstream extractor is used to adapt the full FOOTBALL bitstream to two quality layers. The first layer is QCIF resolution, 7.5 frames per second, bitrate 128 kbps. The second layer is QCIF resolution, 15 frames per second, bitrate 192 kbps.
For the proposed algorithm, the value is estimated in a different way. Because the GOP level model is a cubic function, the procedure begins with four evenly spaced initial guesses. These guesses are marked with arrows in Fig. 11. Then the model is fitted to these data points. The closed-form model is then solved to determine the value. If this value results in a bitstream that meets the target rate, the process stops, otherwise, the process will be repeated with the new (R, ) pair replacing the first data point. Usually, the estimation process can meet the target bitrate in two steps.
Bisection Search Path 10000 20000 30000 40000 50000 60000 70000 8 8.5 9 9.5 10 ln( Lambda ) R at e (b it ) Layer2 (QCIF_15fps_192kbps) Layer1 (QCIF_7.5fps_128bps) 1 2 3 4 5 6
Fig. 10. Example search path for the MSRA method
(numbers are the iteration number)
Model-based Search Path
0 10000 20000 30000 40000 50000 60000 70000 80000 90000 7 7.5 8 8.5 9 9.5 10 ln( Lambda ) R at e (b it ) Layer2 (QCIF_15fps_192kbps) Layer1 (QCIF_7.5fps_128bps)
Fig. 11. Example search path for the proposed method
(both searches stop in one step) 4.2. Proposed Context-Adaptive
Streaming Framework
Another proposed application for the
R- model is for content-adaptive FEC protection of the embedded bitstream. For video streaming FEC protection video packets is sometimes preferred over retransmission since the round trip time of a congested network may be too long for effective retransmission of missing packets. However, FEC protection of video data imposes noticeable overhead that unequal error protection should be used to achieve the best rate-distortion tradeoff.
For example, for each group of video bitstream data, an (n, k) Reed-Solomon (RS) code can be applied to add resiliency to the data. For (n, k) RS code, n is the codeword length, k is the number of video data symbols (for example, a symbol is composed of 8 bits of bitstream data). The number of parity symbols is 2s, where 2s = n –k. This means that if burst errors occur during transmission the RS decoder can correct up to s errors and detect up to 2s errors per codeword.
Therefore, in order to perform content-adaptive FEC protection, the degree of protection level s should be based on the importance of the video data.
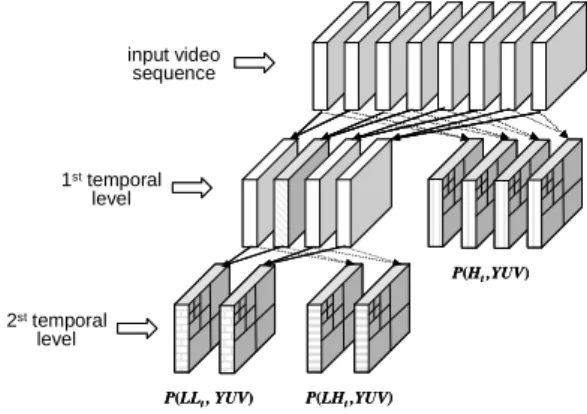
In the generic wavelet coding framework (Fig. 2), video frames are first temporally decomposed into several levels of low- and high-frequency subbands, and then 2D spatial decomposition is applied to each temporal subband for spatial subband decomposition of the signals. After temporal and spatial subband decomposition, all the spatio-temporal subband data are encoded by the 3D-ESCOT entropy coder. Typically, low frequency band data are more important than high frequency band data. In addition, the importance of the coefficients within a coding block in a particular subband can be ranked based on the R-D model of the coding block.
After wavelet decomposition, the subbands can be arranged and indexed from low to high frequencies. The smaller the index is, the lower the frequency is. Therefore, each coding block in subband i has a temporal subband index ωiand a spatial
subband index τi. The proposed
content-adaptive protection mechanism determines the level of FEC protection for different subband coefficients based on their subband index and the R-D model of their coding block. To compute the level of FEC protection, we first compute the subband factor Wi based on the subband indices as in
(17):
i i i S C T W 1 T 1 exp 1 , (17) where T is the maximum temporal level index, S is the maximum spatial subband index, and C1 is a weighting factor.The level of FEC protection is defined by the value s, the number of correctable symbols. Without loss of generality, assume that the bitstream of a coding block i is divided into m codeword. The protection level s of different portions of coding block i is computed by
o n W R C s i pl x j j i i i x i
exp 0 , , , odd is if 0 even is if 1 , , x i x i s s o , (18)wherex = 0,1,…,m-1, the parameters αiand βi are the close-form R- model (10) parameters for the coding block i, Ri,x is the length of the xth RS codeword in coding block i, C is a weighting factor, npl denotes the estimated number of packet losses per second, and ω is a scale factor determined empirically. Equation (18) is designed so that si,0 ≥ si,1 ≥…≥ si,m-1, that is, the level of protection decreases following fractional bitplane coding pass order. Note that the operation stands for “taking the largest integerlessthen.”
5. Experimental Results
In this section, some experiments on the proposed algorithm are conducted using the MSRA scalable video codec, with the MPEG test sequences, STEFAN, FOREMAN, MOBILE and FOOTBALL in CIF resolution. The coding parameters used in the experiments are as follows. The GOP size is 64 frames, and the frame rate is 30 fps. The parameter n in the GOP level model is set to 3, and the bitrate error threshold TR is set to 3% of the target bitrate.
5.1. Computational Cost Reduction for Bitstream Adaptation
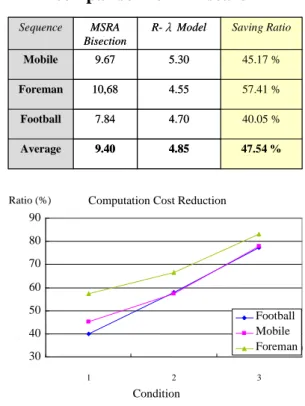
The number of iterations required before the solution converges for the proposed method and the bisection search used in the MSRA codec is shown in TABLE I. The average computation cost saving is about 47% when the resolution and the frame rate settings for each layer are all different. When the number of layers for each resolution and frame rate setting increases, the search procedure can converges even faster by taking advantage of the R- model from the previous layer. According to our experiments, the saving ratio is about 60% when the layer
number is 5, and up to 80% when the layer number is 12 (Fig. 12).
TABLE I. Number of iterations comparison for search
47.54 % 4.85 9.40 Average 40.05 % 4.70 7.84 Football 57.41 % 4.55 10,68 Foreman 45.17 % 5.30 9.67 Mobile Saving Ratio R-λ Model MSRA Bisection Sequence 47.54 % 4.85 9.40 Average 40.05 % 4.70 7.84 Football 57.41 % 4.55 10,68 Foreman 45.17 % 5.30 9.67 Mobile Saving Ratio R-λ Model MSRA Bisection Sequence
Computation Cost Reduction
30 40 50 60 70 80 90 1 2 3 Condition Ratio (%) Football Mobile Foreman
Fig. 12. Computation reduction ratio of the proposed method
Since the proposed mechanism allocates rate for each coding block differently from that of the MSRA codec’s, the rate distribution (and quality) in a GOP is different from that of the MSRA codec’s.The coding efficiency is shown in Fig. 13, Fig. 14, and Fig. 15. The test sequences are STEFAN, FOOTBALL, and FOREMAN in CIF resolution and are truncated at frame rate 30 and 15. The figures show that the proposed rate adaptation mechanism achieves similar PSNR performance in comparison with that of the MSRA codec’s at any rates. The average PSNR degradation is only 0.25dB.
Stefan, CIF, Frame rate 30
25 27 29 31 33 35 37 39 41 0 500 1000 1500 2000 2500 3000 3500 PSNR MSRA Codec Proposed Method Rate(kbps)
Stefan, CIF, Frame rate 15 25 27 29 31 33 35 37 39 41 0 500 1000 1500 2000 Rate(kbps) PSNR MSRA Codec Proposed Method
Fig. 13. PSNR performance comparison of STEFAN
Football, CIF, Frame rate 30
25 27 29 31 33 35 37 39 41 0 500 1000 1500 2000 Rate(kbps) PSNR MSRA Codec Proposed Method
Football, CIF, Frame rate 15
25 27 29 31 33 35 37 39 41 0 500 1000 1500 2000 PSNR MSRA Codec Proposed Method Rate(kbps)
Fig. 14. PSNR performance comparison of FOOTBALL
Foreman, CIF, Frame rate 30
25 27 29 31 33 35 37 39 41 0 500 1000 1500 2000 2500 3000 3500 Rate(kbps) PSNR MSRA Codec Proposed Method
Foreman, CIF, Frame rate 15
25 27 29 31 33 35 37 39 0 500 1000 1500 2000 Rate(kbps) PSNR MSRA Codec Proposed Method
Fig. 15. PSNR performance comparison of FOREMAN
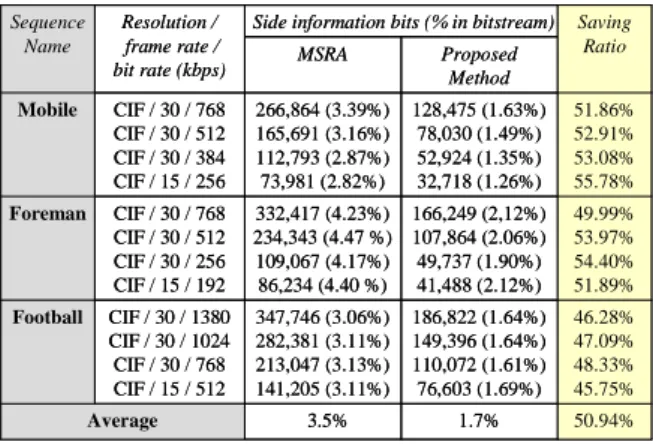
5.2. Side Information Saving for Multiple Adaptation Scheme
The experimental result in the Table 2 shows the saving ratio in different resolutions and framerates for different sequences in a multiple-adaptation scenario. The average saving ratio of the side information is about 50%, and the side information percentage in the bitstream is reduced from 3.5% to 1.7%.
TABLE II. Side information saving ratio
46.28% 47.09% 48.33% 45.75% 186,822 (1.64%) 149,396 (1.64%) 110,072 (1.61%) 76,603 (1.69%) 347,746 (3.06%) 282,381 (3.11%) 213,047 (3.13%) 141,205 (3.11%) CIF / 30 / 1380 CIF / 30 / 1024 CIF / 30 / 768 CIF / 15 / 512 Football
Side information bits (% in bitstream)
CIF / 30 / 768 CIF / 30 / 512 CIF / 30 / 256 CIF / 15 / 192 CIF / 30 / 768 CIF / 30 / 512 CIF / 30 / 384 CIF / 15 / 256 Resolution / frame rate / bit rate (kbps) 50.94% 1.7% 3.5% Average 49.99% 53.97% 54.40% 51.89% 166,249 (2,12%) 107,864 (2.06%) 49,737 (1.90%) 41,488 (2.12%) 332,417 (4.23%) 234,343 (4.47 %) 109,067 (4.17%) 86,234 (4.40 %) Foreman 51.86% 52.91% 53.08% 55.78% 128,475 (1.63%) 78,030 (1.49%) 52,924 (1.35%) 32,718 (1.26%) 266,864 (3.39%) 165,691 (3.16%) 112,793 (2.87%) 73,981 (2.82%) Mobile Saving Ratio Proposed Method MSRA Sequence Name 46.28% 47.09% 48.33% 45.75% 186,822 (1.64%) 149,396 (1.64%) 110,072 (1.61%) 76,603 (1.69%) 347,746 (3.06%) 282,381 (3.11%) 213,047 (3.13%) 141,205 (3.11%) CIF / 30 / 1380 CIF / 30 / 1024 CIF / 30 / 768 CIF / 15 / 512 Football
Side information bits (% in bitstream)
CIF / 30 / 768 CIF / 30 / 512 CIF / 30 / 256 CIF / 15 / 192 CIF / 30 / 768 CIF / 30 / 512 CIF / 30 / 384 CIF / 15 / 256 Resolution / frame rate / bit rate (kbps) 50.94% 1.7% 3.5% Average 49.99% 53.97% 54.40% 51.89% 166,249 (2,12%) 107,864 (2.06%) 49,737 (1.90%) 41,488 (2.12%) 332,417 (4.23%) 234,343 (4.47 %) 109,067 (4.17%) 86,234 (4.40 %) Foreman 51.86% 52.91% 53.08% 55.78% 128,475 (1.63%) 78,030 (1.49%) 52,924 (1.35%) 32,718 (1.26%) 266,864 (3.39%) 165,691 (3.16%) 112,793 (2.87%) 73,981 (2.82%) Mobile Saving Ratio Proposed Method MSRA Sequence Name
5.3. Content-Adaptive FEC Protection Experiments
For the evaluation of the performance of the content-adaptive FEC protection, the CIF version of the standard MPEG test sequences STEFAN and MOBILE are used. Those sequences are encoded using the MSRA codec at 15 frames per second and the GOP size of 64 frames. Four levels of 5/3 MCTF temporal decomposition and three levels of 9/7 wavelet spatial decomposition are used for subband decomposition. The number of luma coding blocks is 1024 and the number of chroma coding blocks is 608.
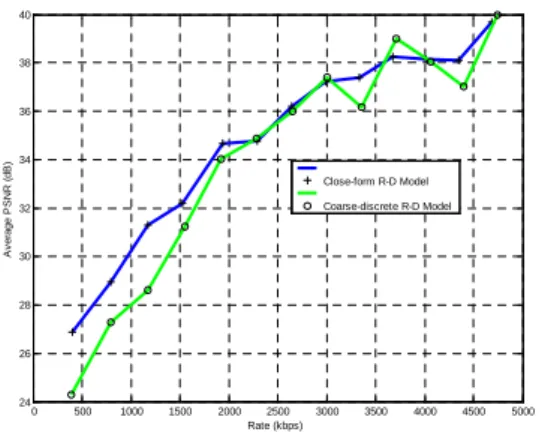
Based on the reports in [19][20][21], we have applied 5% packet loss rate to the IP packets in order to evaluate the performance of the proposed content-adaptive FEC protection system. The close-form R- model (10) is compared against a coarse discrete R- model where the first in the coding block is used to determine the importance of all the coefficients in the block [22]. The PSNR of the luma channel of the reconstructed video sequences are shown in Fig. 15 and Fig. 16. In either case, the maximal packet loss protection level can only recover up to 4% packet losses on average.
As one can see from the figures, the close-form R-D model has higher performance than the coarse R-D model, especially in the low bitrate cases. At low bitrate, accurate R-D models are crucial for both rate control and FEC protection decisions for video servers.
0 500 1000 1500 2000 2500 3000 3500 4000 24 26 28 30 32 34 36 38 40 Rate (kbps) A v e ra g e P S N R (d B ) Close-form R-D Model Coarse-discrete R-D Model
Fig. 16. Content-adaptive FEC test for the STEFAN sequence (5% losses)
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000 24 26 28 30 32 34 36 38 40 Rate (kbps) A v e ra g e P S N R (d B ) Close-form R-D Model Coarse-discrete R-D Model
Fig. 17. Content-adaptive FEC test for the MOBILE sequence (5% losses)
6. Conclusions and Future Work
In this paper, we have proposed a framework for wavelet video multiple adaptations and content-adaptive FEC protection. The proposed framework use a closed-form R- model to reduce the size of R-D side information embedded in the coded bitstream while maintaining the accuracy of the rate-distortion information of the video data. In addition, the proposed technique can reduces the computational complexity of wavelet video adaptation by 50%. Although the existing model achieves good performance, there are till rooms for improvement in the future. For example, at high resolution and high bitrate, the motion vector information is quite large and is not covered by existing R-D model. There have been some efforts on scalable motion vector coding. Similar ideas can be applied to the construction of an R-D model for motion vector bits to increase the performance further.
7. References
[1] ISO/IEC JTC 1/SC 29/WG 11, 14496-2:2002 Information Technology –Coding of Audio-Visual Objects –Part 2: Visual 3rd Edition, Mar. 2003.
[2] W. Li, “Overview ofFineGranularity Scalability in MPEG-4 Video Standard,” IEEE Trans. on Circuits
and Systems for Video Technology, Vol.
11, No. 3, Mar. 2001, pp.301-317.
[3] S.J. Choi and J.W. Woods, "Motion-Compensated 3-D Subband Coding of Video," IEEE Transactions
on Image Processing, vol. 8, Feb. 1999,
pp. 155-167.
[4] J. Xu, Z. Xiong, S. Li, and Y.-Q. Zhang, “Three-dimensional Embedded Subband Coding with Optimized Truncation (3-D ESCOT),” Applied
and Computational Harmonic Analysis, Special Issue on Wavelet App., vol. 10,
pp. 290-315, 2001.
[5] ISO/IEC MPEG Video Group, “Wavelet Codec Reference Document and Software Manual V1.0,” MPEG
Document N7573, July, 2005.
[6] A. Said and W. Pearlman, “A New, Fast and Efficient Image Codec Based on Set Partitioning in Hierarchical Trees,” IEEE Trans. on Circuit and
System Video Technology, vol. 6, June
1996, pp. 243-250.
[7] D. Taubman, “High performance
scalable image compression with EBCOT,” IEEE Trans. on Image
Processing, vol. 9, July 2000, pp.
1158-1170.
[8] Po-Yuen Cheng, Jin Li, and C.-C. Jay Kuo, “Rate Control for Embedded WaveletVideo Coder,”IEEE Trans. on Circuit and System Video Technology,
vol. 7, NO. 4, Aug. 1997.
[9] T. Chu and Z. Xiong, “Combined Wavelet Video Coding and Error Control for Internet Streaming and Multicast,” EURASIP Journal on Applied Signal Processing: Special Issue on Multimedia Systems, pp. 66-80,
Jan. 2003.
[10] J. Dong and Y. F. Zheng, “Content-based Retransmission for 3-D Wavelet Video Streaming on the Internet," in Proceedings IEEE Int.
Conf. on Information Technology,
Coding and Computing, pp. 452-457,
April 2002.
[11] W. Tan and A. Zakhor, “Real-time Internet Video Using Error Resilient Scalable Compression and TCP-friendly Transport Protocol,”
IEEE Transactions on Multimedia,
1(2):172-186, May 1999.
[12] A.Aminlou and O.Fatemi,“Very Fast
Bit Allocation Algorithm, Based on Simplified R-D CurveModeling,”Proc.
of 10th IEEE International
Conferences on Electronics, Circuits, and Systems, Dec. 2003, pp. 112-115.
[13] WeiYu,“Integrated RateControlAnd
Entropy Coding ForJPEG 2000,”IEEE
Proc. of the Data Compression
Conference, 2004.
[14] Jin Li and C.-C.Jay Kuo,“Embedded Wavelet Packet Image Coder With Fast Rate- Distortion Optimized Decomposition,” Proc. SPIE: Visual
Communications and Image
Processing’97, Vol. 3024, 1997, pp.
1077-1088.
[15] C. E. Shannon, “A Mathematical
Theory ofCommunication,”Bell Syst. Tech. J., vol.27, 1948, pp.379-423 and
623-656.
[16] T. Berger, Rate Distortion Theory, Englewood Cliffs, NJ: Prentice Hall, 1971.
[17] A. N. Netravali and B. G. Haskell,
Digital Pictures: Representation and Compression, New York, NY: Plenum,
1988.
[18] Hsueh-Ming Hang and Jiann-Jone Chen, “Source Model for Transform Video Coder And Its Application –Part I: Fundamental Theory,” IEEE Trans.
on Circuit and System for Video Technology, vol. 7, No. 2, April. 1997. [19] J. M. Boyce and R. D. Gaglianello,
“Packet loss effects on MPEG video sentoverthepublicInternet,”Proc. of
ACM Multimedia, pp. 181-190,
September 1998.
[20] K. Lai, M. Roussopoulos, D. Tang, X. Zhao,and M.Baker,“Experienceswith aMobileTestbed,”Proc. of the Second Intern. Conf. on Worldwide Computing
and its Applications (WWCA'98),
March 1998.
[21] R. Rosa, C. -P. Angel, D. -F. Manuel, O. Luis, and G. Antonio, “On the Traffic Disruption Time and Packet Lost Rate during the Handover Mechanisms in Wireless Networks,”
Proceedings AINA, 2004, pp.351-354.
[22] C.-P. Ho and C.-J. Tsai, “Content-Adaptive Packetization and Streaming of Wavelet Video over IP Networks,” Submitted to Journal of Image and Video Processing, Aug. 2006.
研究成果二:
Content-Adaptive Packetization and Streaming of Wavelet Video over IP Networks
1. Introduction
There is a growing demand for video transmission over heterogeneous networks for communication and entertainment applications. Scalable video coding (SVC) techniques are often proposed for such systems since, ideally, a video sequence can be encoded once and adapted on-the-fly to different frame rate, bitrate, and resolution for different applications. Although scalable video is an interesting concept, it takes complete end-to-end system design to show the advantage of SVC over single-layer coding techniques. With single-layer coding, techniques like bitstream switching and simulcasting can be used to achieve video adaptations. However, it is easier to achieve good rate versus source-and-channel distortion tradeoff with scalable coding techniques.
The mainstream video compression techniques are based on hybrid motion compensated transform coding approach, where the transform algorithms are typically either Discrete Cosine Transform (DCT) or 3-D wavelet transform [1]. So far, DCT-based SVC approaches have demonstrated better coding efficiency than wavelet-based SVC techniques [2], especially for low bitrate applications. However, a wavelet-based SVC framework can provide fine-granularity bitrate (i.e. SNR) scalability with less system complexity than that of an FGS-based DCT framework. In addition, many on-going efforts show that wavelet-based SVC approaches still have room for improvement [3]. Therefore, in this paper, wavelet-based SVC is used as the core codec for the development of a scalable video streaming framework.
The most challenging problem for scalable video streaming over IP networks is about how to optimally adapt source data rate and degree of packet loss protection to real-time network conditions. Video packet
packetization and scheduling algorithms are mostly responsible for mitigating the effects of bandwidth variation and packet losses in the network. The packetization and scheduling algorithms are mainly based on resource-versus-distortion optimization [5][6][7][8], where resource can be available computation power, rate, delay, etc. A general resource allocation treatment for streaming systems is presented in [6]. Some researches tries to apply the rate-distortion optimization (RDO) principle [4] of source coding theories to video streaming over lossy networks [5]. For a streaming system, the distortion is a result from both source coding and channel losses. A key issue in an RDO-based streaming system is that the distortion due to packet losses is much more difficult to quantify than the distortion due to lossy source coding.
Several frameworks for 3-D wavelet based video streaming system have been proposed in the literature recently. Chu and Xiong [9] introduced a combined packetized wavelet video coding and FEC approach for video streaming and multicast. The packetized wavelet video coder marks the truncation points of the bitstream at the nearest packet boundaries (instead of the end of each fractional bit-plane). In the FEC-based error protection scheme, it applies Reed-Solomon (RS) coding to produce parity packets. And then the scheme broadcast all source packets to one multicast group and parity packets to different multicast groups. Hence, for each client, the optimal number of layers and error protection to subscribe to can be determined by the packet loss ratio and the available channel bandwidth. However, data-interleaving is not used in this work, which makes the system less robust to burst errors. Dong and Zheng [10] proposed a content-based retransmission framework for wavelet video streaming. The compression module adopt dynamical grouping and bounded coding scheme for improving