國立臺中教育大學教育測驗統計研究所理學碩士論文
指 導 教 授:施慶麟 博士
指 導 教 授:楊志堅 博士
三種定錨題選題法於先定錨後檢核策略
之效果比較
─以概似比檢定法檢核多分
題差異試題功能為例
─
研 究 生:陳惠靖 撰
中 華 民 國 一00 年 六 月
致謝
今晚是月全食的夜晚,當我沉浸在回顧研究所這兩年生活點滴的同時,天 狗食月也靜悄悄的展開。回憶起剛入學的自己,是試題反應理論這塊領域的門 外漢,藉由指導教授施慶麟教授及楊志堅教授一點一滴、不厭其煩的教導,才 讓我對這迷人的領域有更深刻的理解,並且鑽研其中而不可自已。同時,教授 們也將對於學習應有的態度及待人處事的原則潛移默化於平時課堂教學,讓我 在這兩年獲益良多,除了學會「做學問」之外,更加學會了如何「做人」。 成功不是一蹴可幾的,論文亦不是一朝一夕可以完成。本論文的完成,除 了兩位教授的悉心指導之外,也要感謝國瑋學姐平時對我的照顧,當我在研究 上遇到困難時,學姐總是二話不說,立刻為我解答;當我遭遇挫折與難過時, 學姐也總是給我支持與鼓勵。璟慶對程式上的協助,我也銘記在心,若沒有他 耐心的教學,本研究將無法如期完成。如果可以,希望這些緣分可以一直持續 下去,然而天下無不散之筵席,除了致上最深的謝意,我也只能期許自己將這 份感謝延續下去,造福國家未來的幼苗。 一起為論文打拼的繼成、品緁、淑芬、國誠、媛如與雅婷都是不可或缺的 實驗室夥伴。在心情沮喪時,我們總是為彼此加油打氣;在研究順遂時,也為 彼此歡欣鼓舞。也許摩擦與誤會經常是無法避免的,但是也藉由一同經歷過的 種種,我們不僅成為學習上的好同伴,更是一輩子的好朋友。 最後,更要感謝的是我親愛的家人。如果沒有他們的大力支持與協助,相 信我將無法兼顧學業與工作。在我的認知中,家人們所提供的心靈支持,是我 內心中最原始的渴望,亦是無可取代的寶藏。也感謝我的朋友們,當我需要時 給予我陪伴及傾聽,讓我能順利的完成學位。僅以這篇論文獻給我最愛的家人 與朋友。 惠靖 100.6.16 凌晨摘要
鑑於以往有關差異試題功能(DIF)之研究發現,當測驗中 DIF 試題比例過 高時,則會導致大部份 DIF 檢核方法的型一誤差失控且檢核力下降。為改善上 述情況,Wang(2008)提出了先定錨後檢核策略,且發現若能正確選擇不具 DIF 的試題做為定錨題,將可控制檢核後所得之型一誤差,並增加檢核效能。為 使 先 定 錨 後 檢 核 策 略 能 有 效 運 用 在 DIF 檢 核 上 , Wang ( 2004 ) 及 Woods (2009)分別提出了迭代定題法及排序選題法,藉以能正確找出 DIF-free 試 題。另外,量尺淨化程序也時常被學者建議加入 DIF 檢核程序之中,故本研究 實驗也將運用量尺淨化程序來選擇定錨題。因此,本研究目的為在多分題情境 下,探討迭代定題法、排序選題法與量尺淨化法選取 DIF-free 試題的正確率及 比較以這三種選題法所選取之定錨題進行後續檢核所得之型一誤差及檢核力。 研究結果顯示當運用先定錨後檢核策略於各實驗情境時,量尺淨化法在大 部份情境中選取 DIF-free 試題的正確率皆較高。對於選取定錨題後進行的 DIF 檢核而言,絕多數的情境下以 4 道定錨題進行 DIF 檢核均可將型一誤差控制在 理想的範圍之內,且可得較高的檢核力,建議研究者在使用先定錨後檢核策略 時可使用量尺淨化法選擇 4 題 DIF-free 的定錨題,以控制型一誤差並且提升檢 核效能。 關鍵字:先定錨後檢核策略、迭代定題法、排序選題法、量尺淨化、概似比檢 定法
The DFTD Strategy with Likelihood Ratio Test
method in Assessing DIF for polytomous items
Abstract
It was found the Type I error rates of differential item functioning (DIF) assessment methods were inflated as the percentage of DIF items in the test increased. To deal with this problem, DIF-free-then-DIF (DFTD) strategy was recommended to implement in DIF assessment methods (Wang, 2008). It is important to develop reliable ways in selecting DIF-free items as anchor, and perform well on both Type I error rate control and power of DIF assessment. Wang (2004) and Woods (2009) proposed iterative constant item (ICI) method and rank-based method(RB) in order to identify the DIF-free items, respectively.In addition, the scale purification procedures have been strongly advocated and widely implemented in DIF detection methods, and can be taken as a candidate in selecting DIF-free items. Therefore, the purpose of this study was to select DIF-free items by ICI method, RB method and scale purification procedures, and then compare their performance in accuracy on selecting DIF-free items as anchor and Type I error rate and power of the subsequent DIF assessment with CI method for polytomous items.
The results showed only scale purification procedures can yield higher accuracy than other methods on selecting DIF-free items as anchor. Taking these items as anchor of DFTD strategy, the subsequent CI method performed well on both Type I error rates and power rates of DIF assessment.
Keywords: DIF-free-then-DIF Strategy, Iterative Constant Item Method, Rank-based
目錄
致謝 --- I 摘要 --- I Abstract --- III 目錄 --- IV 表目錄 --- V 圖目錄 --- VI 第一章 緒論 --- 1 第一節 研究背景與動機 --- 2 第二節 研究目的與問題 --- 3 第二章 文獻探討 --- 4 第一節 差異試題功能 --- 4 第二節 多分題的差異試題功能檢核方法 --- 6 第三節 先定錨後檢核策略及定錨題選題法 --- 10 第三章 研究方法與設計 --- 12 模擬研究一 三種選題法篩選 DIF-free 試題之正確率 --- 12 模擬研究二 三種選題法用於先定錨後檢核策略之型一誤差及檢核力 --- 17 第三節 軟體介紹 --- 20 第四章 研究結果與討論 --- 21 第一節 三種選題法篩選 DIF-free 試題之正確率 --- 21 第二節 三種選題法用於先定錨後檢核策略之型一誤差及檢核力 --- 28 第五章 結論與建議 --- 41 第一節 結論 --- 41 第二節 後續研究建議 --- 42 參考文獻 --- 44表目錄
表 1 模擬研究所使用之 GRM 試題參數值 --- 20 表 2 三種選題法篩選 2 道及 4 道定錨題之正確率(constant) --- 22 表 3 三種選題法篩選 2 道及 4 道定錨題之正確率(balanced) --- 24 表 4 選題正確率變異數分析結果 --- 27 表 5 進行 DFTD 策略之型一誤差及檢核力(constant、2 anchors) --- 29 表 6 進行 DFTD 策略之型一誤差及檢核力(balanced、2 anchors) --- 30表 7 混合性 DIF 試題進行 DFTD 策略之檢核力(constant、2 anchors) --- 30
表 8 混合性 DIF 試題進行 DFTD 策略之檢核力(balanced、2 anchors) --- 31
表 9 進行 DFTD 策略之型一誤差及檢核力(constant、 4 anchors) --- 32
表 10 進行 DFTD 策略之型一誤差及檢核力(balanced、4 anchors) --- 33
表 11 混合性 DIF 試題進行 DFTD 策略之檢核力(constant、4 anchors) --- 33
表 12 混合性 DIF 試題進行 DFTD 策略之檢核力(balanced、4 anchors) --- 34
表 13 型一誤差變異數分析結果 --- 38
圖目錄
圖 1 一致性差異試題功能 --- 5 圖 2 非一致性差異試題功能 --- 6 圖 3 兩群體能力相等時 ASA 與正確率相關圖- 2 anchors --- 25 圖 4 兩群體能力不相等時 ASA 與正確率相關圖- 2 anchors --- 25 圖 5 兩群體能力相等時 ASA 與正確率相關圖- 4 anchors --- 25 圖 6 兩群體能力不等時 ASA 與正確率相關圖- 4 anchors --- 25 圖 7 兩群體能力相同、constant 型態 RB 法定錨題數比較 --- 35 圖 8 兩群體能力相同、constant 型態 SP 法定錨題數比較 --- 35 圖 9 兩群體能力相同、constant 型態 ICI 法定錨題數比較 --- 35 圖 10 兩群體能力不同、constant 型態 RB 法定錨題數比較 --- 35 圖 11 兩群體能力不同、constant 型態 SP 法定錨題數比較 --- 36 圖 12 兩群體能力不同、constant 型態 ICI 法定錨題數比較 --- 36 圖 13 兩群體能力相同、balanced 型態 RB 法定錨題數比較 --- 36 圖 14 兩群體能力相同、balanced 型態 SP 法定錨題數比較 --- 36 圖 15 兩群體能力相同、balanced 型態 ICI 法定錨題數比較 --- 36 圖 16 兩群體能力不同、balanced 型態 SP 法定錨題數比較 --- 36 圖 17 兩群體能力不同、balanced 型態 SP 法定錨題數比較 --- 37 圖 18 兩群體能力不同、balanced 型態 ICI 法定錨題數比較 --- 37第一章 緒論
自古以來,從科舉考試到現在的基測、大學指考,都是使用「測驗」來了 解受試者的學習成效、分辨受試者程度的優劣,不管是何種測驗,測驗的內容 都有一定的範圍,畢竟試題是由「人」所編寫的,難免在撰寫的試題內容上可 能會有所爭議,計分結果也可能會有所偏頗,故試題編製的內容是否能有效測 驗出受試者個人的能力,所得的測驗結果是否能使大眾信服,這些都是舉辦測 驗時相當重要、受到關注的議題。 近幾年來,國際間有許多團體對於學生學習評量進行整合性的研究,如: 國際數理趨勢研究(The Trends in International Mathematics and Science Study, TIMSS)或是國際學生評量(Programme for International Student Assessment, PISA ) 等 。 而 國 內 也 建 立 了 「 臺 灣 學 生 學 習 成 就 評 量 資 料 庫 」 ( Taiwan Assessment of Student Achievement, TASA),以客觀、縱貫性(longitudinal)的 角度來瞭解學生的學習表現及成長情形。當進行國際間跨國性學生學習評量的 研究時,若試題受到各國風土民情或是種族差異而影響了受試者的作答反應, 其測驗的公平性也會令人質疑,這份測驗亦將無法公平的評斷及比較各國受試 者的表現。而這類型的試題在試題反應理論(item response theory, IRT)的研究 中,稱之為具「差異試題功能」(differential item functioning, DIF)的試題。換 言之,「當隸屬於不同群體但能力相同的受試者對於同一道試題有不同的作答 反應」的現象,稱這樣的試題具有 DIF。 為了避免測驗中的試題對不同群體產生不公平的情形,故在編製測驗時, 許多研究學者建議除了檢驗其測驗信、效度之外,也應該進行加入 DIF 檢核的 程序。國內外學者對於 DIF 的研究已有相當的成果,亦提出了許多 DIF 檢核的 方式,但如何改善 DIF 檢核的效能是目前重要的議題之一,以下此章將分為 「研究背景與動機」以及「研究目的與問題」兩部份進行介紹及說明。第一節 研究背景與動機
測驗中即使只有少部份試題具有 DIF 現象,或多或少都會影響到受試者的 作答情形,而產生測驗結果不公平的情況。探究許多有關 DIF 文獻,可以知道 在 IRT 取向中,主要有二種方式可以檢核試題是否具有 DIF 現象,分別為試題 與差異功能檢測法(differential functioning of items and tests, DFIT; Raju, van der Linden, & Fleer, 1995)及概似比檢定法 (likelihood ratio test, LRT; Thissen, Steinberg, & Wainer, 1988)。雖然以上二種方法能找出具有 DIF 現象的試題,但 在以往的 DIF 研究也發現到,當測驗中含有較多 DIF 試題時,多數 DIF 檢核方 法的結果均容易產生型一誤差(Type I error)失控與檢核力(power)下降的情 況(Shih & Wang, 2009; Wang & Yeh, 2003)。而為解決此一狀況,許多研究學 者提出量尺淨化(scale purification)程序且建議在 DIF 檢核過程中加入此程 序,以期控制 DIF 檢核時的型一誤差(Candell & Drasgow, 1988; French & Maller, 2007; Holland & Thayer, 1988; Lord, 1980; Park & Lautenschlager, 1990; Wang, Shih, & Yang, 2009)。不過,Wang 等人(2009)發現測驗中 DIF 試題的比例高於 20 %時,即使在檢核過程中加入量尺淨化程序,多數的 DIF 檢核方法進行檢核後 所得之型一誤差仍然會發生膨脹而失控的情況,檢核力也隨之降低,因此,定 題法(constant item method ,CI; Thissen, Steinberg, & Wainer, 1988; Wang & Yeh, 2003)的概念被提出且運用於 DIF 檢核之中。定題法為研究者選擇一組定錨題 (anchor item)作為配對變項(matching variable),以檢核測驗中其他剩餘試 題是否具有 DIF,以期控制 DIF 檢核後所得之型一誤差失控的情形。依據文獻 指出,當所選擇的定錨題確實為 DIF-free,也就是定錨試題為不具有 DIF 情況 時,可有效控制檢核後之型一誤差並 且提升其檢核力(Stark, Chernyshenko, Oleksandr, & Drasgow, 2006; Wang, 2004; Wang & Yeh, 2003)。而經由定題法的 概念,Wang(2008)提出了「先定錨後檢核」(DIF-free-then-DIF, DFTD)策略
運用於 DIF 檢核方法上,以改善檢核效能。
第二節 研究目的與問題
近年來有幾位學者提出了不同的選擇定錨題的方式,並透過模擬研究驗證 其效果。Shih 與 Wang(2009)在 MIMIC 法的架構下,以迭代定題法(iterative constant item method, ICI method; Wang, 2004)選擇定錨題;Woods(2009)則是 在概似比檢定法下以排序選題(rank-based)法來選擇定錨題。然而,除了前述 兩種方法之外,量尺淨化程序也常被學者建議加入 DIF 檢核程序之中,故本研 究也將以量尺淨化程序來挑選出最不具有 DIF 的試題做為定錨題,並比較以這 三種選題法篩選出之定錨題來進行 DIF 檢核時的成效。
以往的研究結果顯示,當定錨題確實為 DIF-free 題目時,即便只有一題定 錨題,型一誤差依然可以控制合理的範圍之內(Stark et al., 2006; Wang, 2004; Wang & Yeh, 2003),倘若 DIF-free 的定錨題數增加時,其檢核力會比只有一道 DIF-free 定錨題的檢核力來得好(Wang, 2004; Wang & Yeh, 2003)。
關於上述研究,已有學者完成二元計分(dichotomous)資料下的探討。本 研究擬延伸至多元計分(polytomous)資料情境下,比較迭代定題法、量尺淨化 法、排序選題法在多分題情境下選取 DIF-free 試題的正確率,並比較利用此三 種選題法所選取之定錨題進行後續檢核後的型一誤差及檢核力。
第二章 文獻探討
第一節 差異試題功能
現今社會經常利用同一份測驗或是量表針對多群體進行能力的比較,如: 性別、種族或是國籍等不同的群體,然而不論測驗或是量表的目的為何,測驗 及量表的評量標準都應建立在共同量尺之上。以此為前提,群體間的比較才有 意義,但若以相同能力的兩位受試者而言,只因隸屬於不同群體或居住在不同 地區的關係,而造成兩人在問題的作答反應機率上有所差異,造成不公平的狀 況,換言之,當隸屬於兩個不同群體之間,但能力相同的兩個受試者作答某一 題的答對機率不同時,在試題反應理論中稱之為「差異試題功能」(differential item functioning, DIF)。典型的差異試題功能研究通常是由兩群體透過使用同一組試題來估計試題 參數。兩群體的受試者分別為參照群體(reference group)及焦點群體(focal group)。通常,參照群體為主要團體,焦點群體為次要團體,在利用兩群體進 行試題參數估計時,必頇在相同量尺之上才能夠進行有意義的比較。在多元計 分的 IRT 模式下,試題期望分數機率在參照群體與焦點群體之間為不相等時, 試題則會被認為具有 DIF 現象(Cohen, Kim, & Baker, 1993; Kim & Cohen, 1998)。而 Bolt(2002)提到依據不同的多元計分方法,多分題的 DIF 定義分 有兩種:一為受試者群體間在多分題任一得分類別的得分機率不同;二為受試 者群體間在待檢測試題(studied item)上的期望得分不同。當測驗中出現具有 DIF 現象的試題時,會影響到測驗的正確性及其功能。
在試題反應理論中,最基礎的架構為試題反應函數(item response function, IRF)。以二分題而言,IRF 為受試者潛在能力與正確作答反應機率之間的關 係;以多分題而言,IRF 為試題的期望分數與受試者潛在能力的關係。不管為 二元或是多元的 IRT 模式,試題具有 DIF 現象就是試題對兩群體受試者的功能
不同,也就是無法對兩群體中相同能力的受試者測驗出同樣的潛在變項。 差異試題功能可依據其自身特性分為「一致性差異試題功能」(uniform DIF)和「非一致性差異試題功能」(nonuniform DIF)兩種類型(Mellenberg, 1982)。當兩群體作答同一道待檢測試題時,都是同一群體具有較高的答對機 率,換言之,唯有參照群體全體或是焦點群體全體的答對機率比另一群體的答 對機率均為較高,則該試題只針對某一群體具有一致性優勢的情況,稱之為 「一致性差異試題功能」。圖 1 為兩群體作答同一道待檢測試題的試題特徵曲 線(item characteristic curves, ICCs),顯示此道試題具有只對單一群體具有優 勢的情況,為一致性差異試題功能。 圖 1 一致性差異試題功能 若同一道待檢測試題的作答反應,對於參照群體某個能力區間的受試者具 有優勢的情況,但對於焦點群體另一個能力區間的受試者也具有有利的情況, 反之亦然。此時,該試題對於不同群體的不同區間受試者具有不一致有利的情 況,則稱之為「非一致性差異試題功能」。圖 2 為兩群體作答同一道待檢測試
題的 ICC 曲線,表現同一道試題對不同群體不同能力區間的受試者有不一致性 有利的情況,為非一致性差異試題功能。 圖 2 非一致性差異試題功能
第二節 多分題的差異試題功能檢核方法
試題反應理論的 DIF 研究中,不同群體的受試者必頇放置在相同量尺之上 來進行比較,才有其意義,換言之,在兩群體間必頇建立起配對變項做為相同 量尺,並且對隸屬於不同群體但能力相同的受試者進行潛在變項的比較。目前 有許多專家學者均對 DIF 檢核提出相當多的方法,而不管在二分題或是多分 題,DIF 檢核方法均可依其特性區分為非 IRT 取向及 IRT 取向。因本研究只針 對多分題進行探討,故以下只介紹多分題 DIF 檢核的方法,非 IRT 取向的 DIF 檢核方法是以受試者的原始測驗總分做為配對變項,有 Mantel 法(Mantel, 1963)、Generalized Mantel-Haenszel 法(GMH; Mantel & Haenszel, 1959)、Poly-SIBTEST 法(Shealy & Stout, 1993)及羅吉斯區辨函數分析法(logistic discriminant function analysis, LDFA; Miller & Spray, 1993)。IRT 取向的 DIF 檢 核方法則為先進行試題參數及能力參數的估計,並以受試者的能力參數估計值 做為配對變項,有概似比檢定法(likelihood ratio test, LRT; Thissen, Steinbreg, & Wainer, 1988)及試題與測驗差異功能檢測法(differential functioning of items and tests, DFIT;Raju, van der Linden, & Fleer, 1995)。
根據之前多數的 DIF 研究均發現將概似比檢定法運用於等級反應模式 (Graded Response Model, GRM; Samejima, 1969)資料的 DIF 檢核時,型一誤差 部份控制良好而且檢核力也較高(Cohen, Kim, & Baker, 1993; Kim & Cohen, 1998; Ankenmann, Witt, & Dunbar, 1999; Bolt, 2002; Wang, 2004; Wang & Yeh 2003; Woods, 2009),故本研究採用了 Thissen 等人在 1988 年所提出的概似比檢定法 來進行 DIF 檢核。
其 實 , 概 似 比 檢 定 法 一 開 始 並 非 使 用 在 IRT 理 論中, 是 由 Thissen 、 Steinberg 與 Gerrand(1986)以及 Thissen、Steinberg 與 Wainer (1988, 1993) 將其應用來進行 DIF 檢核(孫國瑋,2010; Kim & Cohen, 1998)。此方法均可使 用於二分題及多分題的資料,且此方法可以使用電腦測驗軟體,以方便將兩群 體的參數放置在同一量尺上比較,除了可使用 MULTILOG(Thissen, 1991)進 行 檢 核 之 外 , 也 可 使 用 IRTLRDIF ( Thissen, 2001 ) 進 行 DIF 檢 核 。 由 於 IRTLRDIF 在使用上比較方便、執行速度上較快速,加上其為免費的軟體,方便 使用者自行下載使用,因此本研究將採用 IRTLRDIF 進行 DIF 分析,復以該軟 體在多分題時僅能適用 GRM 模式,因此在模式操弄上,本研究設定資料均服從 GRM 模式。 概似比檢定法的 DIF 檢核,要先將欲檢核 DIF 的試題當作是待檢測試題, 針對每一待檢測試題,皆要進行以下三個步驟:第一步驟為先選擇與資料較適 配的 IRT 模式進行分析,並限定兩群體受試者在測驗中所有的試題參數均相
同,也包含待檢測試題,即假設所有的試題皆不具 DIF 現象。不管是否為待檢 測試題,將所有試題參數限定為相同的模式,概似比檢定法將此模式定義為縮 減模式(compact model),計算其 likelihood deviance(= -2 × log-likelihood),
以 2 C G 表示。 第二步驟則為將待檢測試題,從第一步驟中所限定兩群體試題參數均相同 當中移除,也就是假設待檢測試題可能為具 DIF 現象的試題,並且對於兩群體 分開估計該試題的試題參數。只將待檢測試題對兩群體分開估計試題參數,其 餘試題依舊為限定為相同試題參數的模式,概似比檢定法將此模式定義為擴充 模 式 ( augmented model ) , 並 以 與 第 一 步 驟 的 相 同 公 式 計 算 其 likelihood deviance,以GA2表示。 第三步驟為將上述兩模式的 likelihood deviance 相減,即為 2 2 2 G G GC A ,也 就是縮減模式與擴充模式的差異 2 G 值。此時,G 值將服從卡方分配,其自由度2 為兩模式間所估計參數之個數差,若G2值大於對應之卡方值,則可稱該待檢測 試題具 DIF 現象。 藉由以上的步驟,即可將待檢測試題檢核出是否具有 DIF 現象,以一份具 有 20 道試題且與 GRM 模式較適配的測驗為例,欲檢核第 1 題在階難度參數上 是否具有 DIF 現象時,必頇依循以下步驟:一為設定縮減模式,設定這份測驗 中的 20 道試題皆為不具有 DIF 的試題,將兩群體受試者所測驗的 20 道試題的 階難度參數以及鑑別度參數皆設定為相同,並計算其GC2。二為設定擴充模式, 假設兩群體受試者的第 1 題的階難度參數不同,但鑑別度參數仍相同,其餘題 數之兩試題參數設定均與第一步驟相同,並計算其GA2。三則為若兩個模式只相 差一個階難度參數,即為第 1 題第一階的階難度參數不同,將GC2減去 2 A G 所得之
2 G 將服從自由度為 1 的卡方分配,此時決斷值為 2 3.84 ) 1 ( ,若G2小於 3.84,則 顯示第 1 題第一階不具有 DIF 現象,反之則有 DIF 現象;若兩模式相差兩個階 難度參數,即為第 1 題第二、三階的階難度不同,將GC2減去 2 A G 所得之 2 G 將服 從自由度為 2 的卡方分配,此時決斷值為(22) 5.99,若G2小於 5.99,則顯示第 1 題第二、三階不具有 DIF 現象,反之則有 DIF 現象,依此類推,若兩個模式 相差四個階難度參數,即第 1 題一~四階的階難度均不同,則將GC2減去 2 A G 所得 之G2將服從自由度為 4 的卡方分配,此時決斷值為 2 9.48 ) 4 ( ,若G2小於 9.48, 則顯示第 1 題一~四階均不具有 DIF 現象,反之則有 DIF 現象。 而概似比檢定法可進行以下兩種 DIF 檢核策略,第一種為餘題法(all-other- item method, Wang & Yeh, 2003),其方法為假定除了待檢測之試題外,測 驗中其餘試題均未具有 DIF 現象,即以其餘試題當作定錨題來對待檢測試題進 行 DIF 檢核,如一份測驗 20 道試題,將以第 1 題作為待檢測試題進行 DIF 檢核 時,假設測驗中的剩餘題目為 DIF-free 定錨題來進行檢核,若以第 2 題做為待 檢測試題時,則假設第 1 題、第 3 題至最後一題均為 DIF-free 的定錨題來進行 後續檢核,此即概似比檢定法的標準檢核程序。
第二種則為定題法(constant item method, Thissen et al., 1988; Wang & Yeh, 2003),此方法的程序為在進行 DIF 檢核前,則不管概似比檢定法的三個步驟 為何,只設定一組固定不變試題當作定錨題,用來作為後續 DIF 檢核時,檢測 其餘試題是否具有 DIF 時的基準,如一份測驗 20 道試題,從中選取出某 4 道試 題設定為 DIF-free 定錨題,以檢核測驗中其餘試題,此步驟則為定題法的主要 內容。
第三節 先定錨後檢核策略及定錨題選題法
在本文的第一章提到 Wang(2008)為了要改善 DIF 檢核方法容易受到測驗 中 DIF 試題數量的影響,而導致型一誤差膨脹且檢核力下降的情形,提出了先 定錨後檢核策略。所謂先定錨後檢核策略,是透過一般的 DIF 檢核方法進行測 驗檢核的程序時,從中篩選出最不具 DIF 的一組試題,也就是測驗當中最可能 為 DIF-free 的試題做為定錨題,再利用所篩選出的定錨題使用於定題法對測驗 中其他試題進行 DIF 檢核。 在進行先定錨後檢核策略時,選題方法要必頇盡可能選擇確實為 DIF-free 的 定錨題,而不同的選題方法是否會影響先定錨後檢核策略的表現,則是本研究 所要探討的主題。以往文獻中有關於選擇定錨題的方法主要有 2 種,一為排序 選題法(rank-based, Woods, 2009),另一種則是迭代定題法(iterative constant item method, ICI; Wang, 2004)。由於排序選題法實際上就是概似比檢定法的標 準程序,既然標準程序可以用來選題,上一章提過的量尺淨化程序,可以提升 DIF 檢核的效能,自然也可以用來篩選 DIF-free 試題,而所謂量尺淨化程序是 將試題先進行一次 DIF 檢核後,將疑似 DIF 試題從配對變項中排除,排除後再 進行第二次 DIF 檢核,之後再分別加入各道疑似 DIF 試題進行 DIF 檢核,一直 重複此步驟直到檢測出相同 DIF 試題時才算檢核完成,而量尺淨化法也就是先 使用量尺淨化程序淨化一次之後,再從中選題。以下分別介紹各選題法的選題 程序。壹、排序選題法
Woods 所提出的排序選題法為先利用餘題法(all-other-item method, AOI; Wang & Yeh, 2003)對測驗進行 DIF 檢核,再從結果得出每一試題的 LR 統計量 比率並依此比率大小排列試題,當 LR 統計量比率越小時,表示該試題為 DIF-free 的機率越高,再從其中找出有著最小比率的題目當作定錨題。事實上,這
個方法就是標準的概似比檢定法。
貳、迭代定題法
Wang 所提出的迭代定題法為先利用定題法依序設定每一道試題為定錨題, 並對測驗中其餘試題進行 DIF 檢核,直到測驗中最後一題為止,再將上述檢核 過程中所得到之各題 LR 統計量比率進行加總,加總數值愈不具有 DIF 者,表 示該試題為 DIF-free 的機率愈高,再從其中找出 LR 統計量比率加總數值最低的 題目前幾道試題當作定錨題。參、量尺淨化法
量尺淨化法為先利用量尺淨化程序對測驗進行 DIF 檢核,在量尺淨化程序 完成後,可得到每一道試題的 LR 統計量比率,再從結果得出每一試題的 LR 統 計量比率並依此比率大小排列試題,當 LR 統計量比率越小時,表示該試題為 DIF-free 的機率越高,再從其中找出有著最小比率的題目當作定錨題。 基於 Woods(2009)所提出之排序選題法具有不錯的檢核效能,本研究認 為在其方法之上加入量尺淨化程序來進行選題,即為本研究所謂之量尺淨化 法,應該會是個更佳的方法,因此希望利用不同的情境來探討在多分題下不同 選題法篩選 DIF-free 試題的正確率,也希望找出理想的選題法與 DFTD 策略配 合,以期能更增加 DFTD 策略的效能。第三章 研究方法與設計
本研究主要目的為探究三種定錨題選題法於 IRT 取向中的概似比檢定法在 多分題等級反應模式下使用先定錨後檢核策略的效果為何,研究中將利用兩階 段的模擬研究探討三種篩選 DIF-free 試題的方法及其檢核效能。本章節中,將 以「三種選題法篩選 DIF-free 試題之正確率」及「三種選題法用於先定錨後檢 核策略之型一誤差及檢核力」兩節介紹兩階段的模擬研究設計,並在第三節 「軟體介紹」中介紹本研究使用的免費軟體 IRTLRDIF。模擬研究一 三種選題法篩選 DIF-free 試題之正確率
在文獻探討中,已探究過先定錨後檢核策略在以往研究中的表現效能,倘 若能在測驗中找到確實為 DIF-free 的定錨題,便可達到控制型一誤差的效果。 因此,本階段研究中擬探討三種選題法篩選確實為 DIF-free 試題之選題正確 率。壹、研究方法
由於以往研究中探討概似比檢定法進行 DIF 檢測時,常使用等級反應模 式,因此本階段研究是利用 GRM 模式的資料來探討三種篩選 DIF-free 試題方法 之選題正確率。GRM 模式適合用來分析順序變數的資料,如李克特式量表,且 其為二參數模式的延伸,亦即容許測驗中各試題的鑑別度參數有所不同,復因 估計受試者在各選項的得分機率需要兩步驟的過程,因此是一種「間接的」 (indirect)IRT 模式(Embretson & Reise, 2000)。GRM 模式的試題題型中,試題不需要有相同的反應類別,每一個量尺試題 即 有 一 個 鑑 別 度 ( slope parameter ) 和 反 應 選 項 減 1 的 階 難 度 ( category “threshold” parameter),如:有五個反應選項,就會有四個階難度。以下介紹
如何在 GRM 模式下計算每個選項的得分機率。 第一步估計 GRM 反應機率為: (1) 其中 x=j=1,….,mi,mi為階難度個數,i 為題數。公式 1 是用以計算出受試 者在第 i 題得到 x 分以上的機率。接下來是利用公式 2 計算出各個選項的得分機 率。 (2) 在五元計分的題型中,則Pi*0()1且 ( ) 0 * 5 i P 。由於 IRTLRDIF 可用來分析 GRM 模式,因此,本模擬研究將採用 IRTLRDIF 進行 LRT 法的相關參數估計, 並利用排序選題法、量尺淨化法以及迭代定題法,分別篩選 2 道及 4 道 DIF-free 試題做為模擬研究二的定錨題,且探討三種不同選題法對於篩選 DIF-free 試題 之選題正確率。
貳、研究設計
依據以往的研究,將兩群體分別定義為參照群體(reference group,簡稱為 R)以及焦點群體(focal group,簡稱為 F)常常用來分別代表優勢以及弱勢團 體。本研究設定兩群體人數分別為參照群體 1000 人,焦點群體 500 人。試題參 數部份則參考 Wang 與 Yeh(2003)之研究中的部份參數,使用參數列於表 1。 模擬資料由作者自行撰寫 Matlab 程式產生,將產生 GRM 模式的模擬資料分別 以 IRTLRDIF 進行三種選題法篩選試題過後,計算所選取到的試題為 DIF-free 試題的比例,即為三種選題法所篩選出確實為 DIF-free 定錨題之選題正確率。 以選取 4 道定錨題為例說明選題正確率的計算方式,當三種選題法個別篩選出 的 4 道定錨題中,4 道皆為 DIF-free 試題時,選題正確率為 100%,若只有 3 題 為 DIF-free 試題,另一題為 DIF 試題時,選題正確率則為 75%,依此類推,若 )] ( exp[ 1 )] ( exp[ ) ( * ij i ij i ix P ) ( ) ( ) ( ix* i*(x1) ix P P P所篩選出的 4 道試題皆為 DIF 試題時,則選題正確率為 0%。
以下將介紹本模擬實驗所操弄的四個獨立變項,觀察這些變項與選題正確 率個別的關聯與其影響。本研究中共操弄四個獨立變項,分別為受試者的能力 分配(ability difference)、DIF 型態(DIF pattern)、測驗中 DIF 試題的百分比 (DIF percentage)及定錨題數(anchor items)。
一、受試者的能力分配 本研究於此階段操弄兩群體之能力為相等與不相等兩種情形,參照群體的 受試者能力均設定為平均數為 0 且標準差為 1 的標準常態分配,而焦點群體的 受試者能力則分為兩種,第一是與參照群體相同的標準常態分配,代表兩群體 平均能力相等,第二則為平均數為-1 且標準差為 1 的常態分配,代表兩群體之 平均能力相差一個標準差。兩群體受試者平均能力相等,在現實情況中即為能 力相近,而兩群體受試者具有能力上的差異,在現實情況中有可能是因為種族 或是其他因素影響而導致有差異,研究者藉由操弄此變項來探討能力差異對不 同選題法篩選 DIF-free 試題正確率之影響。 二、DIF 型態 在真實的情況下,DIF 試題不一定只對某一群體有利或是完全不利,故而 本階段研究中,將操弄兩種 DIF 型態:完全傾向(constant)以及平衡傾向 (balanced)。constant 型態表示測驗中所有的 DIF 試題均對同一群體有利,通 常是針對參照群體,以本模擬研究設計為例,一份測驗 20 道試題中,設定 20% 的試題為 DIF 試題,意即在此份測驗中有 4 道試題被設定為是對參照群體有 利,而 balanced 型態則為測驗中具有 DIF 試題時,其中一半的 DIF 試題是有利 於參照群體,而另一半的 DIF 試題則是有利於焦點群體,同樣以 20 道試題為 例,設定 20%的試題為 DIF 試題,則測驗中將有 2 道試題是有利於參照群體、 另 2 道試題則是對焦點群體為有利的現象。以這兩個型態而言,若整份測驗的 DIF 型態為 balanced,此時對於兩個群體來說是相對公平的情況,亦即 balanced
型態為兩群體間 DIF 現象最不顯著的情況,而 constant 型態則是 DIF 現象最嚴 重的情況,而通常在真實的情境中,兩群體間的 DIF 現象介於這兩種情況之 間,因此,本研究中欲觀察在此兩種型態下三種選題法在篩選 DIF-free 試題的 結果,是否會影響選擇 DIF-free 試題之正確率。 三、測驗中 DIF 試題的百分比 當測驗中 DIF 試題增加,IRT 模式的檢核法在參數估計上將受到影響,概 似比檢定法也不例外,然而這類的情況很有可能影響篩選 DIF-free 試題之正確 率,於是本階段研究將操弄在測驗中不同比例的 DIF 試題,分別為 10%、 20%、30%以及 40%,以了解測驗中佔不同比例的 DIF 試題對於篩選 DIF-free 試 題之正確率有何影響。 四、定錨題數 當從測驗中找出的定錨題確實為 DIF-free 試題時,即便只有一題定錨題, 型一誤差皆能獲得良好的控制(Stark et al., 2006; Wang, 2004; Wang & Yeh, 2003)。若定錨題的題數增加,則檢核力也將隨之提高(Wang, 2004; Wang & Yeh, 2003),故考量 DIF 檢核的效能以及實務上要同時找到許多確實為 DIF-free 的定錨題並不容易,因此 4 道定錨題可能為較理想的選擇(Shih & Wang, 2009)。然因本研究為多分題,測驗長度為 20 道試題,為短測驗,且測驗中含 有高 DIF 百分比時,篩選 4 道定錨題是否合適值得探究。故本研究階段將觀察 選擇 2 道定錨題(測驗長度的 10%)及 4 道定錨題對於篩選 DIF-free 試題之正 確率有何影響。 在其他實驗設計部份,本研究模擬資料設定為 GRM 模式的資料且由於同 一試題的選項可能對於不同的受試者會產生不同的 DIF 現象,且不一定只有單 一選項具有 DIF,可能同一試題的多個選項都具有 DIF 現象,故本研究模擬資 料產生為 GRM 模式混合型 DIF 選項試題,也就是說在預設的 DIF 試題中,每 一道試題可能有不同個選項存在 DIF 現象。以本研究題長 20 題為例,DIF 百分
比若佔題長的 20%,即為 4 道試題存在 DIF 現象,這四道試題的試題選項分別 為試題中只有一個 DIF 選項、試題中有二個 DIF 選項、試題中有三個 DIF 選項 及試題中有四個 DIF 選項。而一般測驗中常見的 DIF 類型大部份為一致性 DIF,因此,本研究的 DIF 試題選項均預設為一致性 DIF,即在試題難度上存有 DIF 現象。為了使模擬資料更符合真實情境中,各試題選項的 DIF 效果量不一 定相同,本研究預設兩群體在 DIF 試題選項的難度差異皆服從平均數為 0.3 及標 準差為 0.05 的常態分配,代表各 DIF 試題選項具有中等程度的 DIF 現象,並且 為了避免抽樣時的誤差,所有情境下的資料都將重複模擬 100 次,共計進行模 擬實驗 9600 次。 本研究在前文中提到在一份測驗中並非所有的 DIF 試題皆對優勢團體有利 ,也有可能某些 DIF 試題對於弱勢團體有利,類似這類的狀況會造成同一份測 驗裡 DIF 試題對兩群體的影響是相等的,而在這種狀況下,測驗中 DIF 試題百 分比可能不是影響 DIF 檢核效能的關鍵指標,故 Wang 與 Yeh(2003)提出 average signed area(ASA)的概念,ASA 與 Raju 的面積測量法(Raju, 1988) 中之 signed area 有關,是計算參照群體與焦點群體兩群體的試題特徵曲線間的 平均面積。以下先介紹 signed area(SA)的公式如下: SAi
1ci
biF biR
(3) i c 為第 i 題的猜測度參數,biF及biR分別為焦點群體與參照群體在第 i 題上 的難度參數。ASA 則為 SA 平均值,若在 GRM 模式且測驗長度為 I 時,ASA 公式如下:
I i I i i Mi k ikR ikF b M b ASA 1 1 1 1 ) 1 ( / ) ( (4) i M 為第 i 題的反應選項數量,bikF及bikR分別為焦點團體及參照團體的第 i 題的第 k 個選項的難度參數。此公式是指在 GRM 模式下,ASA 為兩群體總平均難度的差異。當 ASA 為正值時,表示 DIF 試題對參照群體有利;當 ASA 為 負值時,表示 DIF 試題對焦點群體有利,則當 ASA 的數值恰巧為 0 時,表示 DIF 試題對兩群體皆無產生有利的現象,在 Wang(2001)比較餘題法及定題法 的研究中指出,使用餘題法進行 DIF 檢核,設定測驗中 DIF 試題均為 20%的情 境、ASA 為 0.09 時,型一誤差仍控制得不錯,但將之提升至 0.18 時,則會導致 型一誤差膨脹而失控;若設定 ASA 為 0 時,即使測驗中 DIF 試題百分比從 20% 提高至 50%,型一誤差仍舊有良好的控制且也有高檢核力,DIF 檢核會受到 ASA 的影響。故本階段研究也將計算不同情境下之 ASA,將於研究結果中探討 ASA 對於三種選題法篩選 DIF-free 試題正確率的影響。
模擬研究二 三種選題法用於先定錨後檢核策略之
型一誤差及檢核力
為研究 DIF-free 試題在 DIF 檢核方法中的效能,在本階段模擬研究將使用 模擬研究一中三種選題法所篩選出的 DIF-free 試題做為定錨題,利用這些定錨 題來進行後續定題法的 DIF 檢核,比較此三種選題法所篩選出的定錨題應用於 定題法 DIF 檢核,也就是運用 DFTD 策略後所得之型一誤差及檢核力。壹、研究方法
本階段研究方法為利用上一階段所使用的排序選題法、量尺淨化法及迭代 定題法三種篩選 DIF-free 試題的選題法所篩選出的 2 道及 4 道 DIF-free 試題做 為本模擬研究的定錨題,對測驗中其他試題進行後續的定題法 DIF 檢核,觀察 及比較進行先定錨後檢核策略後所獲得之型一誤差及檢核力。貳、研究設計
本階段研究之模擬資料延續使用上述階段的實驗設計,同樣是由作者使用 Wang 與 Yeh(2003)之研究中的部份參數撰寫 Matlab 程式,產生題長 20 題GRM 模式資料及受試者為參照群體 1000 人、焦點群體 500 人的模擬資料並利 用三種選題法所選取出的定錨題以 IRTLRDIF 進行定題法的 DIF 檢核。本研究 參考以往的文獻找出四個獨立變項,藉由模擬研究二來觀察這四個變項在進行 先定錨後檢核策略時,會如何影響所得之型一誤差及檢核力。而所謂型一誤差 即為「DIF 檢核方法將沒有存在 DIF 現象的試題誤判為具有 DIF 的試題」之機 率,而檢核力則是「檢核方法能正確的檢測出具有 DIF 現象的試題」的機率, 而本研究實驗預設每次模擬實驗可接受的型一誤差之機率為 0.05,顯著水準即 為 0.05,經由二項分配計算後,在 100 次的重複模擬中可容許 0.0073 至 0.0927 的機率被誤判具有 DIF 現象,此為型一誤差可接受之範圍,而型一誤差與檢核 力為一體兩面,若型一誤差膨脹且失控於此範圍之外,所得的檢核力不論是高 或低已沒有意義。 本 模 擬 研 究 共 操 弄 四 個 獨 立 變 項 , 分 別 為 受 試 者 的 能 力 分 配 ( ability difference ) 、 DIF 型 態 ( DIF pattern ) 、 測 驗 中 DIF 試 題 的 百 分 比 ( DIF percentage)以及定錨題數(anchor items)。 一、受試者的能力分配 根據以往的研究,即便測驗中含有 DIF 試題的百分比為 0,兩群體平均能力 差異為一個標準差時,依舊無法良好的控制型一誤差(孫國瑋,2010; Wang & Su, 2004),在本階段研究中同樣也操弄兩群體平均能力為相等與不相等的情 況。參照群體的受試者能力為平均數為 0,標準差為 1 的標準常態分配,而焦點 群體的受試者能力則分為兩種情況,一為標準常態分配,代表兩群體的平均能 力相等,二則為平均數為-1,標準差為 1 的常態分配,代表兩群體平均能力差了 一個標準差,即為能力不相等的情境。利用操弄兩群體平均能力的差異,以了 解受試者能力分配對進行 DFTD 策略後所得之型一誤差及檢核力有何影響。 二、DIF 型態 為了解 DIF 檢核效能的在真實情境下的表現範圍,在研究資料中將利用真
實情境中最輕微及最嚴重的兩種 DIF 型態,分別為完全傾向(constant)型態以 及平衡傾向(balanced)型態,來觀察進行 DFTD 策略後所得之型一誤差及檢核 力與 DIF 型態有何相關。
三、測驗中 DIF 試題的百分比
以往的研究發現當測驗中 DIF 試題增加時,DIF 檢核方法的型一誤差會發 生膨脹且失控的現象,進而影響到檢核力(Finch, 2005; Wang & Yeh, 2003), 因此,本研究操弄測驗中含有不同比例的 DIF 試題,分別為 0%、10%、20%、 30%以及 40%,以觀察測驗中 DIF 試題所佔的百分比對於進行 DFTD 策略後所 得之型一誤差及檢核力有何影響。
四、定錨題數
當從測驗中找出的定錨題確實為 DIF-free 試題時,即便只有一題定錨題, 型一誤差皆能獲得良好的控制(Stark et al., 2006; Wang, 2004; Wang & Yeh, 2003),隨著定錨題的題數增加,檢核力也將隨之增加(Wang, 2004; Wang & Yeh, 2003)。基於本測驗為 20 道試題的短測驗,要在測驗中高 DIF 百分比中找 出 4 道定錨題,篩選 4 道定錨題是否合適值得探究,故本階段研究將以 2 道及 4 道定錨題分別進行 DFTD 策略,並將觀察 2 道定錨題及 4 道定錨題對於進行 DFTD 策略後所得之型一誤差及檢核力是否有影響。
在其他實驗設計部份,如同前階段研究,本研究模擬測驗為 GRM 模式混合 型 DIF 選項試題,DIF 類型為一致性 DIF,DIF 試題選項的難度差異皆服從平均 數為 0.3 及標準差為 0.05 的常態分配,為避免抽樣時有偏誤,所有情境下的模 擬資料皆重複 100 次,共計進行模擬實驗 12000 次。
在本階段研究也將計算不同情境下之 ASA,於研究結果中探討 ASA 對於進 行 DFTD 策略後所得之型一誤差以及檢核力的影響。
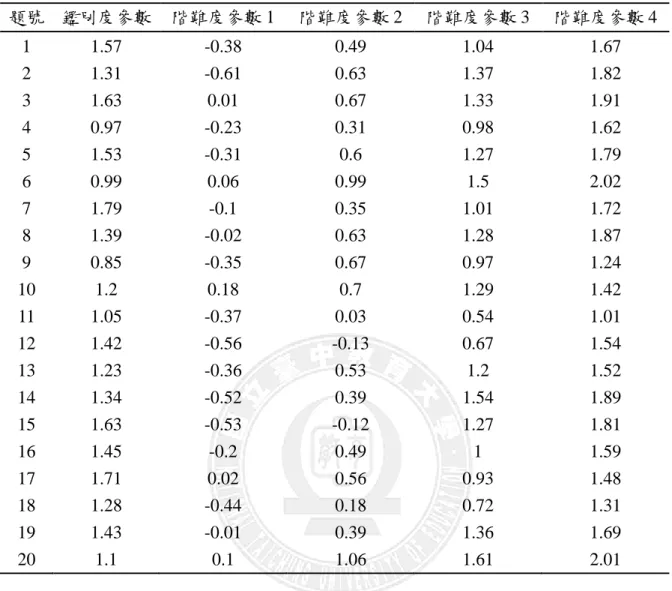
表 1 模擬研究所使用之 GRM 試題參數值 題號 鑑別度參數 階難度參數 1 階難度參數 2 階難度參數 3 階難度參數 4 1 1.57 -0.38 0.49 1.04 1.67 2 1.31 -0.61 0.63 1.37 1.82 3 1.63 0.01 0.67 1.33 1.91 4 0.97 -0.23 0.31 0.98 1.62 5 1.53 -0.31 0.6 1.27 1.79 6 0.99 0.06 0.99 1.5 2.02 7 1.79 -0.1 0.35 1.01 1.72 8 1.39 -0.02 0.63 1.28 1.87 9 0.85 -0.35 0.67 0.97 1.24 10 1.2 0.18 0.7 1.29 1.42 11 1.05 -0.37 0.03 0.54 1.01 12 1.42 -0.56 -0.13 0.67 1.54 13 1.23 -0.36 0.53 1.2 1.52 14 1.34 -0.52 0.39 1.54 1.89 15 1.63 -0.53 -0.12 1.27 1.81 16 1.45 -0.2 0.49 1 1.59 17 1.71 0.02 0.56 0.93 1.48 18 1.28 -0.44 0.18 0.72 1.31 19 1.43 -0.01 0.39 1.36 1.69 20 1.1 0.1 1.06 1.61 2.01
第三節 軟體介紹
在本研究中皆使用免費軟體 IRTLFDIF 進行概似比檢定法的 DIF 檢核,它 是以概似比檢定法為理論基礎,由美國北卡羅來納大學(University of North Carolina at Chapel Hill)的 David Thissen 教授在 2001 年所撰寫的 DOS 版本軟 體,此軟體預設檢核時採用餘題法,可檢核一致性 DIF 及非一致性 DIF,使用 者亦可選擇在該軟體中使用定題法做為 DIF 檢核的策略。第四章 研究結果與討論
第一節 三種選題法篩選 DIF-free 試題之正確率
本模擬研究一之數據結果列於表 2 及表 3 各別為利用三種選題方法篩選 2 道 及 4 道定錨題為 DIF-free 試題之平均正確率,以下將針對數據結果以兩種 DIF 型態進行說明。壹、DIF 型態為 constant
由表 2 的實驗數據可知,兩群體能力相等時,DIF 試題高百分比會使選題 正確率會有較低的趨勢。在篩選 2 道定錨題時,RB 法在 DIF 試題百分比為 30% 以內,正確率可達 100%,當 DIF 試題百分比在 40%時,正確率些微下降至 99%;SP 法即使在 DIF 試題百分比遞增,高達 40%時,選題正確率仍可達 100%,而 ICI 法在 DIF 試題百分比 20%以內時,正確率可高達 100%,DIF 試題 百分比增加到 30%以上,正確率皆達到 97%以上。當選擇 4 道定錨題時,RB 法 在 DIF 百分比 20%以內,正確率可達 100%;DIF 試題百分比為 30%以上時,正 確率有些微下降到 99%。SP 法即使 DIF 試題百分比高達 40%,選題正確率都可 達 100%,而 ICI 法在 DIF 試題百分比遞增的情況下,正確率也隨之遞減,但皆 可達 95%以上。 當兩群體能力為不相等且 DIF 試題百分比高時,選題正確率有些微降低的 現象。在篩選 2 道定錨題時,RB 法在 DIF 試題百分比 40%時,正確率會有些微 降低,但正確率仍然有 98%;SP 法在 DIF 試題百分比 40%時,正確率也略為下 降,但正確率依然有 98%;ICI 法在 DIF 試題百分比為 10%時,正確率為 100%,DIF 試題百分比在 20%以上,正確率隨著測驗中 DIF 試題百分比遞增而 有些微遞減,但可達 91%以上。在篩選 4 道定錨題時,RB 法在 DIF 試題百分比 40%時,正確率有下降的趨勢,但正確率仍可達 97%;SP 法在 DIF 試題百分比為 10%時,正確率為 100%,DIF 試題百分比在 20%以上,正確率有些微下降, 但仍可達 96%以上;ICI 法在 DIF 試題百分比在 10%時,正確率達 100%,在 DIF 試題百分比 20%以上,正確率隨著測驗中的 DIF 試題百分比遞增而也有些 微下降的趨勢,但仍有 86%以上的正確率。 由上述的數據結果可知,在 DIF 型態為 constant 的情境下,當兩群體能力 為不相等時,三種選題法的選題正確率會比兩群體能力相同時平均來得低一 些。而當 DIF 試題百分比遞增時,ICI 法的正確率明顯產生遞減的狀況,在 DIF 試題高百分比時,選題正確率通常為最低,由於本研究中的 ASA 數值與 DIF 試 題百分比呈現同向的情況,故而在 constant 情境下可發現篩選定錨題的正確率受 到 ASA 與 DIF 試題百分比的影響,隨著 ASA 增加,正確率隨之下降。
表 2 三種選題法篩選 2 道及 4 道定錨題之正確率(constant)
ability
difference DIF% ASA
2 anchors 4 anchors
RB SP ICI RB SP ICI
mean std mean std mean std mean std mean std mean std
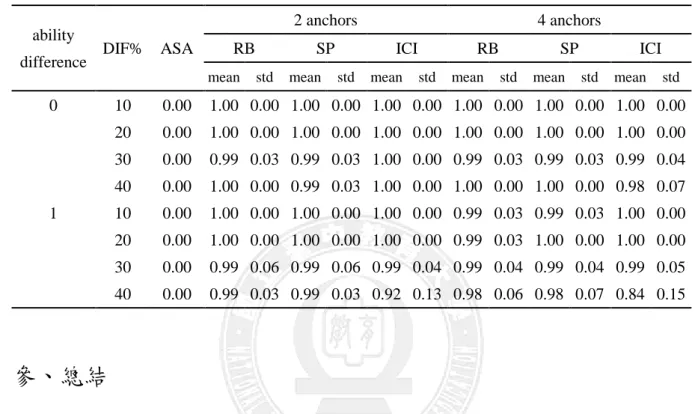
0 10 0.05 1.00 0.00 1.00 0.00 1.00 0.00 1.00 0.00 1.00 0.00 1.00 0.00 20 0.15 1.00 0.00 1.00 0.00 1.00 0.00 1.00 0.00 1.00 0.00 0.99 0.06 30 0.19 1.00 0.00 1.00 0.00 0.99 0.05 0.99 0.03 1.00 0.00 0.98 0.07 40 0.30 0.99 0.03 1.00 0.00 0.97 0.07 0.99 0.05 1.00 0.00 0.95 0.11 1 10 0.05 0.99 0.03 0.99 0.03 1.00 0.00 0.99 0.03 1.00 0.00 1.00 0.00 20 0.15 0.99 0.08 0.99 0.05 0.97 0.08 0.99 0.04 0.98 0.10 0.92 0.12 30 0.19 0.99 0.13 0.99 0.13 0.96 0.09 0.99 0.06 0.98 0.14 0.92 0.12 40 0.30 0.98 0.18 0.98 0.18 0.91 0.14 0.97 0.09 0.96 0.19 0.86 0.15
貳、DIF 型態為 balanced
由表 3 結果可知,當兩群體能力相等,雖然 DIF 試題百分比遞增,但選題 正確率幾乎可達 100%。在篩選 2 道定錨題時,RB 法在 DIF 試題百分比遞增的 情況下,正確率可達 99%以上;SP 法在 DIF 試題百分比為 20%以內,正確率都可達 100%,但在高 DIF 試題百分比,正確率有些微下降至 99%,而 ICI 法在所 有 DIF 試題百分比情境時,正確率皆可達 100%。而當選擇 4 道定錨題時,RB 法即使在 DIF 試題百分比遞增的情況下,正確率可達 99%以上; SP 法也在 DIF 試題百分比遞增的情況下,正確率可達 99%以上,而 ICI 法在 DIF 試題百 分比為 20%以內時,正確率可達 100%,之後隨著 DIF 試題百分比增加而遞減, 但依然可達 98%以上。 當兩群體能力為不相等時,雖然 DIF 試題百分比遞增,選題正確率幾乎都 能達 84%以上。在篩選 2 道定錨題時,RB 法在 DIF 試題百分比為 20%以內的情 況下,正確率可達 100%,在高 DIF 試題百分比時,正確率有些微降低,仍可達 99%;SP 法在 DIF 試題百分比為 20%以內,正確率都可達 100%,在高 DIF 試 題百分比,選題正確率有些微下降,也可達 99%,而 ICI 法在 DIF 試題百分比 為 20%以內,正確率都可達 100%,但在高 DIF 試題百分比,選題正確率略 降, 但也可達 92%。而當選擇 4 道定錨題時,RB 法在高 DIF 試題百分比的情 況下,正確率也會些微下降,但可達 98%以上; SP 法也在 DIF 試題百分比遞 增的情況下,正確率可達 98%以上,而 ICI 法在 DIF 試題百分比為 20%以內 時,正確率可達 100%,之後隨著 DIF 試題百分比增加而遞減。 由上述的實驗數據結果可知,在 DIF 型態為 balanced 的情境下,當兩群體 能力不相等時,三種選題法的選題正確率會受到影響,相較於兩群體能力相等 時,正確率略微下降。而當 DIF 試題百分比遞增時,正確率仍會受到 DIF 試題 百分比的影響,在高 DIF 試題百分比時,選題正確率還是會比低 DIF 試題百分 比時來得低一些。而本研究在 balanced 的情境下,ASA 數值為 0,且當兩群體 能力相等時,三種方法篩選 DIF-free 試題的正確率並無太大差異,正確率至少 皆在 98%以上,若當兩群體能力有差異時,在高 DIF 試題百分比時 RB 法以及 SP 法的正確率仍會受到些微影響至 98%,則 ICI 法的正確率皆顯著受到 DIF 試 題百分比遞增的影響,當 DIF 試題比例為 40%時,正確率隨之下降至 84%,可
見當兩群體能力分配不同的情況下,即便當 ASA 為 0,試題中 DIF 試題所佔的 百分比在選題正確率上仍產生影響。
表 3 三種選題法篩選 2 道及 4 道定錨題之正確率(balanced)
ability
difference DIF% ASA
2 anchors 4 anchors
RB SP ICI RB SP ICI
mean std mean std mean std mean std mean std mean std
0 10 0.00 1.00 0.00 1.00 0.00 1.00 0.00 1.00 0.00 1.00 0.00 1.00 0.00 20 0.00 1.00 0.00 1.00 0.00 1.00 0.00 1.00 0.00 1.00 0.00 1.00 0.00 30 0.00 0.99 0.03 0.99 0.03 1.00 0.00 0.99 0.03 0.99 0.03 0.99 0.04 40 0.00 1.00 0.00 0.99 0.03 1.00 0.00 1.00 0.00 1.00 0.00 0.98 0.07 1 10 0.00 1.00 0.00 1.00 0.00 1.00 0.00 0.99 0.03 0.99 0.03 1.00 0.00 20 0.00 1.00 0.00 1.00 0.00 1.00 0.00 0.99 0.03 1.00 0.00 1.00 0.00 30 0.00 0.99 0.06 0.99 0.06 0.99 0.04 0.99 0.04 0.99 0.04 0.99 0.05 40 0.00 0.99 0.03 0.99 0.03 0.92 0.13 0.98 0.06 0.98 0.07 0.84 0.15
參、總結
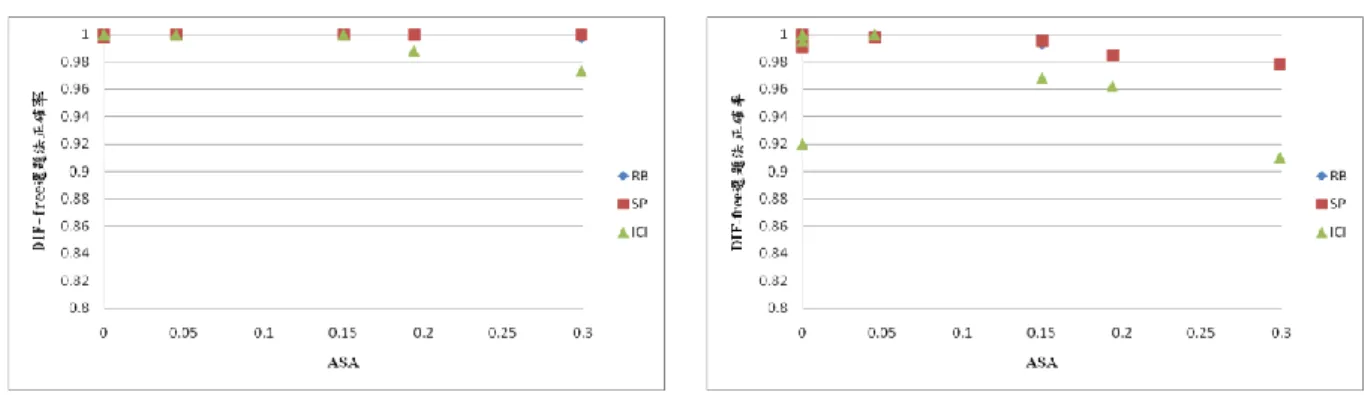
不論兩群體的能力是否相等,DIF 型態為 balanced 時,SP 法與 RB 法篩選 DIF-free 試題的表現相差不大,正確率幾乎都能達 98%以上,均為理想;DIF 型 態為 constant 時,SP 法篩選 DIF-free 試題之正確率幾乎都較 RB 選題法來得高 一些,而在兩種 DIF 型態中,ICI 法在某些情境下,正確率表現皆理想,但在高 DIF 試題百分比時,ICI 法的選題正確率就較其他兩種方法來得低一些。故經由 以上的討論結果可知,SP 法在本研究各實驗情境下為三種選題法篩選 DIF-free 試題表現最穩定也為最佳的一個方法。 接下來,以 ASA 數值與選題正確率來進行探討。圖 3 及圖 4 為兩群體能力 相等及不相等的情境下,ASA 與 2 道定錨題之正確率的相關圖。由圖 3 可觀察 到在兩群體能力相等時,ICI 法受到 ASA 的影響,隨著 ASA 遞增,ICI 法之選 題正確率也隨之遞減,SP 法及 RB 法則無太大影響。圖 4 可知當兩群體能力不同時,ASA 遞增,三種選題法都隨之下降,不過,也可發現當 ASA 為 0 時,三 種選題法之正確率會比兩群體能力相同時來得低一些。
圖 3 兩群體能力相等時 ASA 與正確率相關圖- 2 anchors 圖 4 兩群體能力不相等時 ASA 與正確率相關圖- 2 anchors
圖 5 及圖 6 為兩群體能力相等及不相等的情境下,ASA 與 4 道定錨題之正 確率的相關圖。由圖 5 兩群體能力相等與 ASA 的相關圖來看,可發現 RB 法與 ICI 法會受到 ASA 增加而影響到選題正確率,也就是當 ASA 遞增時,選題正確 率下降,但 SP 法則無。圖 6 可觀察到當兩群體能力不等時,三種選題法均受到 ASA 遞增的情況,因而選題正確率遞減,也可觀察到當 ASA 為 0 時,ICI 法依 然有一個情境的選題正確率較低,故由此四個相關圖來看,可發現 SP 法與 RB 法之選題正確率相差不大,兩者所得之選題正確率幾乎均優於 ICI 法,尤其是當 兩群體能力不等時, ICI 法所得之選題正確率明顯較其他兩種選題法來得低, 總而言之,在大部份的情境下 SP 法比 RB 法及 ICI 法可得較高的正確率,表現 也較穩定。
由上述的實驗結果可以發現選題正確率會隨著不同的選題方法而有些微的 差異,為更知悉本研究各獨變項對於選題正確率的影響,將針對不同選題方法 對進行各獨變項的變異數分析(Analysis of Variance)。在變異數分析上,可知 F 值易受到樣本數數量的關係而達到顯著,當 F 值已達到顯著水準但淨相關 η 2 係數太小時,在統計上已有其意義,但本研究欲找出高度關聯性的獨變項,也 就是當淨η 2 係數大於 0.14(Cohen, 1988),故結果分析只列出淨 η 2 係數在大 於 0.14 數值的獨立變項,顯示此獨立變項對於其依變項的差異不但具有統計意 義,也可顯示對其依變項的相關性。除使用變異數分析針對各獨立變項進行分 析之外,另外使用 Scheffe 法進行事後比較,以進一步了解各獨立變項間的關聯 性。 由表 4 選題正確率變異數分析結果可知,主要影響選題正確率之獨立變項 依序為測驗中 DIF 試題的百分比(F(3,63)=23.712、淨 η 2=0.530)、定錨題選題 法(F(2,63)=29.114、淨 η 2 =0.480)、受試者的能力分配(F(1,63)=43.171、淨 η 2=0.407)及 DIF 型態(F(1,63)=12.394、淨 η 2=0.164)。表 4 也可觀察到有達顯 著 的 交 互 作 用 影 響 依 序 為 測 驗 中 DIF 試 題 的 百 分 比 與 定 錨 題 選 題 法 (F(6,63)=10.906、淨 η 2=0.509)、受試者的能力分配與測驗中 DIF 試題的百分 比 ( F(3,63)=10.924 、 淨 η 2 =0.342 ) 及 受 試 者 的 能 力 分 配 與 定 錨 題 選 題 法 (F(2,63)=10.785、淨 η 2=0.255)。 使用 Scheffe 法進行選題正確率的獨立變項之事後比較,可以發現在受試者 的能力分配上,兩群體能力相等對於選題正確率的影響力大於兩群體能力不相 等;在 DIF 型態上,balanced 型態對選題正確率影響較大;測驗中 DIF 試題的 百分比為 10%對正確率的影響力分別大於 30%及 40%,20%大於 40%,30%則 大於 40%。在定錨題選題法上,則為 RB 法及 SP 對於正確率的影響均大於 ICI 法。
DIF 百分比時,選題正確率會些微下降,也會受到三種選題法的篩選步驟影響, 篩選出 DIF-free 的正確率會有所差異,當受試者的能力分配有差異且 DIF 型態 為 constant 時,也可發現選題正確率會較其它情境來得低。 表 4 選題正確率變異數分析結果 來源 df 平均 平方和 F 值 顯著性 淨η 2 事後比較 Ability difference 1 .008 43.171 <.001 .407 相等>不等
DIF pattern 1 .002 12.394 .001 .164 balanced>constant
DIF percentage 3 .004 23.712 <.001 .530 10%>30%,10%>40%
20%>40%,30%>40%
Anchors 1 .002 9.771 .003 .134
Methods 2 .005 29.114 <.001 .480 RB>ICI, SP>ICI
Ability difference * DIF pattern 1 .001 3.714 .058 .056
Ability difference * DIF percentage 3 .002 10.924 <.001 .342
Ability difference * Anchors 1 .001 3.371 .071 .051
Ability difference * Methods 2 .002 10.785 <.001 .255
DIF pattern * DIFpercentage 3 <.001 1.369 .260 .061
DIF pattern * Anchors 1 <.001 .722 .399 .011
DIF pattern * Methods 2 .001 2.895 .063 .084
DIF percentage *Anchors 3 .000 2.744 .050 .116
DIF percentage * Methods 6 .002 10.906 <.001 .509
Anchors * Methods 2 .001 4.063 .022 .114
誤差 63 <.001
總和 96
第二節 三種選題法用於先定錨後檢核策略之型一
誤差及檢核力
在前一節研究篩選 DIF-free 試題之正確率結果中,SP 法較 RB 法與 ICI 法 在各情境下篩選 DIF-free 試題之正確率較高且穩定。接下來,本章節將接續模 擬研究一所篩選出的 DIF-free 試題進行定題法 DIF 檢核,以測試各選題法所篩 選出 DIF-free 試題的檢核效能。本階段研究結果之數據結果分列於表 5 至表 12。表 5 及表 6 分別呈現三種選題法於不同 DIF 型態篩選 2 道定錨題進行先定 錨後檢核策略後所得之型一誤差及檢核力,表 9 及表 10 分別呈現三種選題法於 不同 DIF 型態篩選 4 道定錨題進行先定錨後檢核策略後所得之型一誤差及檢核 力。 表 7、表 8、表 11 及表 12 則分別呈現本研究混合性 DIF 選項試題於利用 2 道定錨題及 4 道定錨題進行先定錨後檢核策略後各題 DIF 選項數不同所得之檢 核力。表格中所呈現的 Type I error 數據為試題在 100 次的模擬實驗中進行 DIF 檢核後,檢核方法將非 DIF 試題判定為 DIF 試題的平均機率,而表格中所呈現 的檢核力則為試題在 100 次的模擬實驗中進行 DIF 檢核後,檢核方法能正確檢 測出 DIF 試題的平均機率,以下內容將結果數據以兩種定錨題數進行說明。壹、定錨題數為 2 題
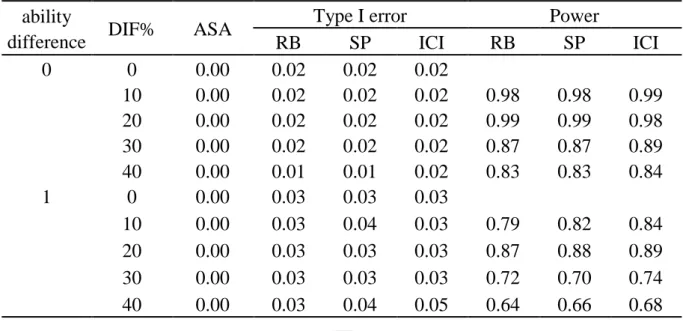
由表 5 數據結果顯示,以 DIF 型態為 constant 而言,不管兩群體平均能力 相等或是平均能力有差異時,以三種選題法所篩選出 2 道定錨題進行 DFTD 策 略時,所得之型一誤差皆在所能接受的合理範圍之內,約在 0.02~0.05 之間, 發現兩群體平均能力有差異時,所得之型一誤差相較兩群體平均能力相同時較 高,也可發現當即使 DIF 百分比高達 40%且 ASA 為 0.30 時,型一誤差也都控 制得相當良好。檢核力的部分,可發現兩群體能力有差異時,所得檢核力也會相較於兩群 體能力相同時略低一些。由表 5 可發現不管能力是否相同,測驗中 DIF 百分比 為 10%時,檢核力較佳,可達 90%以上。
表 5 進行 DFTD 策略之型一誤差及檢核力(constant、2 anchors) ability
difference DIF% ASA
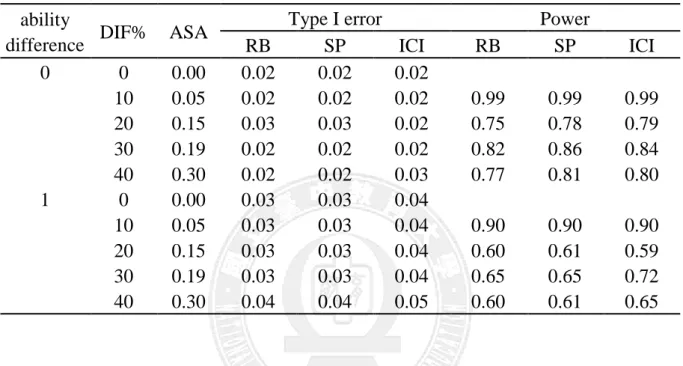
Type I error Power
RB SP ICI RB SP ICI 0 0 0.00 0.02 0.02 0.02 10 0.05 0.02 0.02 0.02 0.99 0.99 0.99 20 0.15 0.03 0.03 0.02 0.75 0.78 0.79 30 0.19 0.02 0.02 0.02 0.82 0.86 0.84 40 0.30 0.02 0.02 0.03 0.77 0.81 0.80 1 0 0.00 0.03 0.03 0.04 10 0.05 0.03 0.03 0.04 0.90 0.90 0.90 20 0.15 0.03 0.03 0.04 0.60 0.61 0.59 30 0.19 0.03 0.03 0.04 0.65 0.65 0.72 40 0.30 0.04 0.04 0.05 0.60 0.61 0.65 由表 6 可知,以 DIF 型態為 balanced 而言,兩群體能力有差異時,所得型 一誤差較兩群體能力相同時有些微的差距,但皆在合理誤差範圍之內,約在 0.01~0.05 之間,而檢核力也因兩群體能力的差異而略低一些。以 DIF 試題百分 比為例,可以發現 DIF 試題百分比高低對於型一誤差沒有明顯的影響,但對檢 核力較有明顯的影響,當兩群體能力相同且 DIF 百分比為 10%及 20%時,所得 到的檢核力較佳,可達 0.98 以上,而也發現 ASA 數值為 0 時,可以發現檢核力 還是會受到試題中 DIF 試題百分比的影響,DIF 試題百分比高時,所得之檢核 力較低。
表 6 進行 DFTD 策略之型一誤差及檢核力(balanced、2 anchors) ability
difference DIF% ASA
Type I error Power
RB SP ICI RB SP ICI 0 0 0.00 0.02 0.02 0.02 10 0.00 0.02 0.02 0.02 0.98 0.98 0.99 20 0.00 0.02 0.02 0.02 0.99 0.99 0.98 30 0.00 0.02 0.02 0.02 0.87 0.87 0.89 40 0.00 0.01 0.01 0.02 0.83 0.83 0.84 1 0 0.00 0.03 0.03 0.03 10 0.00 0.03 0.04 0.03 0.79 0.82 0.84 20 0.00 0.03 0.03 0.03 0.87 0.88 0.89 30 0.00 0.03 0.03 0.03 0.72 0.70 0.74 40 0.00 0.03 0.04 0.05 0.64 0.66 0.68 以表 7 的數據結果顯示,在三種選題法篩選 2 道定錨題,DIF 型態為 constant 且兩群體能力相等,發現僅一階發生 DIF 所得之檢核力比其他二個階以 上發生 DIF 之情形的檢核力來得高,而試題若四個階都發生 DIF 之情形時,所 得之檢核力為最低的;兩群體能力有差異時,也有相似的情況,但兩群體能力 有差異與能力相同相較時,則發現兩群體能力有差異的情境所得之檢核力會較 兩群體能力相同時略低一些,類似結果也發生在不同階數的 DIF 型態中。
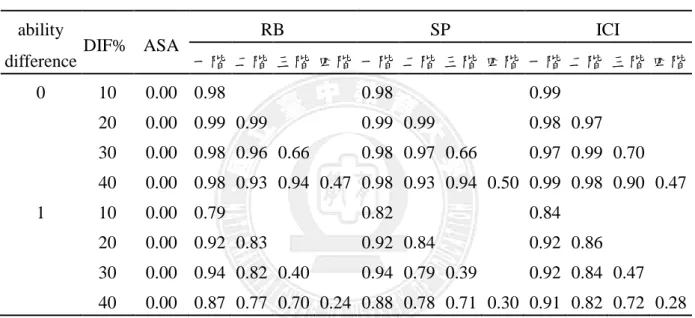
表 7 混合性 DIF 試題進行 DFTD 策略之檢核力(constant、2 anchors)
ability
DIF% ASA RB SP ICI
difference 一階 二階 三階 四階 一階 二階 三階 四階 一階 二階 三階 四階 0 10 0.05 0.99 0.98 0.99 0.98 0.99 0.97 20 0.15 0.99 1.00 0.77 0.24 0.99 1.00 0.83 0.28 1.00 0.96 0.90 0.30 30 0.19 0.98 0.92 0.78 0.33 0.99 0.94 0.86 0.45 0.97 0.96 0.85 0.32 40 0.30 0.99 0.94 0.82 0.34 0.99 0.94 0.86 0.45 0.99 0.95 0.88 0.39 1 10 0.05 0.96 0.84 0.96 0.84 0.93 0.86 20 0.15 0.92 0.83 0.51 0.14 0.93 0.84 0.54 0.13 0.90 0.71 0.49 0.24 30 0.19 0.83 0.77 0.59 0.09 0.83 0.78 0.57 0.14 0.91 0.81 0.66 0.21 40 0.30 0.83 0.76 0.66 0.16 0.83 0.77 0.68 0.18 0.86 0.79 0.74 0.24
由表 8 可知,當 DIF 型態為 balanced 且兩群體能力相等時,也可發現僅一 階發生 DIF 所得的檢核力比其他二個階以上發生 DIF 之情形的檢核力來得高, 而試題若四個階都發生 DIF 之情形時,所得檢核力是最低的;兩群體能力有差 異時,也有類似的狀況,但兩群體能力有差異與能力相等相較時,也可觀察到 以整份試題而言,不同階數發生 DIF 情形時,兩群體能力有差異的情境所得之 檢核力會較兩群體能力相等時些微較低。
表 8 混合性 DIF 試題進行 DFTD 策略之檢核力(balanced、2 anchors)
ability
DIF% ASA RB SP ICI
difference 一階 二階 三階 四階 一階 二階 三階 四階 一階 二階 三階 四階 0 10 0.00 0.98 0.98 0.99 20 0.00 0.99 0.99 0.99 0.99 0.98 0.97 30 0.00 0.98 0.96 0.66 0.98 0.97 0.66 0.97 0.99 0.70 40 0.00 0.98 0.93 0.94 0.47 0.98 0.93 0.94 0.50 0.99 0.98 0.90 0.47 1 10 0.00 0.79 0.82 0.84 20 0.00 0.92 0.83 0.92 0.84 0.92 0.86 30 0.00 0.94 0.82 0.40 0.94 0.79 0.39 0.92 0.84 0.47 40 0.00 0.87 0.77 0.70 0.24 0.88 0.78 0.71 0.30 0.91 0.82 0.72 0.28
貳、定錨題數為 4 題
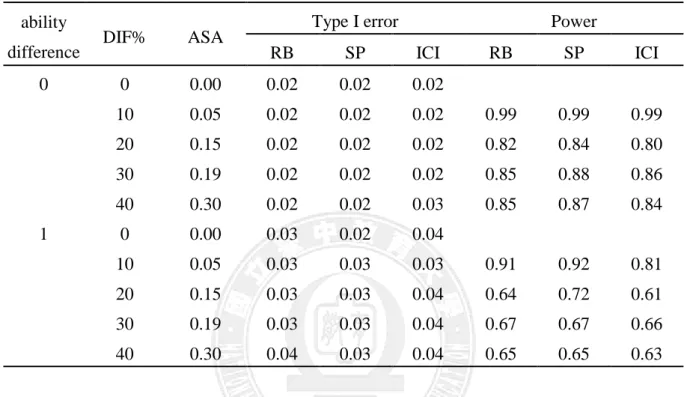
由表 9 的實驗數據結果來看,在 DIF 型態為 constant 時,無論兩群體平均 能力相等或是平均能力有差異時,以三種選題法所篩選出 4 道定錨題進行 DFTD 策略時,所得之型一誤差皆在理想的合理範圍之內,約 0.02~0.04,不過 也可發現當兩群體平均能力有差異時,所得之型一誤差相較兩群體平均能力相 同時較高,也可發現當即使 DIF 百分比高達 40%且 ASA 為 0.30 時,型一誤差 也都控制得相當良好。 就檢核力的部分,當兩群體能力有差異時,檢核力也會相較於能力相同時些來得低。而在測驗中 DIF 百分比為 10%且兩群體能力相等時,檢核力可達 99%,其餘的情境中檢核力較不佳。
表 9 進行 DFTD 策略之型一誤差及檢核力(constant、 4 anchors)
ability
difference DIF% ASA
Type I error Power
RB SP ICI RB SP ICI 0 0 0.00 0.02 0.02 0.02 10 0.05 0.02 0.02 0.02 0.99 0.99 0.99 20 0.15 0.02 0.02 0.02 0.82 0.84 0.80 30 0.19 0.02 0.02 0.02 0.85 0.88 0.86 40 0.30 0.02 0.02 0.03 0.85 0.87 0.84 1 0 0.00 0.03 0.02 0.04 10 0.05 0.03 0.03 0.03 0.91 0.92 0.81 20 0.15 0.03 0.03 0.04 0.64 0.72 0.61 30 0.19 0.03 0.03 0.04 0.67 0.67 0.66 40 0.30 0.04 0.03 0.04 0.65 0.65 0.63 由表 10 可觀察到,以 DIF 型態為 balanced 而言,當兩群體能力有差異與能 力相同時,所得之型一誤差也皆在合理誤差範圍之內,約在 0.02~0.04,但以相 同的情境比較,兩群體能力差異較能力相同時的型一誤差有些微的下降,而檢 核力也會因兩群體能力的差異而來得低一些。可以發現 DIF 試題百分比的高低 程度對於型一誤差沒有顯著的影響,但對檢核力卻有較明顯的影響,可以觀察 到當兩群體能力相等且測驗中 DIF 百分比在 30%以內,所得之檢核力都相當不 錯,可達 90%以上,當 DIF 百分比為 40%時,所得之檢核力比 DIF 試題百分比 低時來得些微下降, 即使 ASA 值為 0 時,可發現檢核力受到試題中 DIF 試題 百分比的影響
表 10 進行 DFTD 策略之型一誤差及檢核力(balanced、4 anchors)
ability
difference DIF% ASA
Type I error Power
RB SP ICI RB SP ICI 0 0 0.00 0.02 0.02 0.02 10 0.00 0.02 0.02 0.02 0.99 0.99 0.99 20 0.00 0.02 0.02 0.02 0.98 0.98 0.98 30 0.00 0.02 0.02 0.02 0.91 0.90 0.90 40 0.00 0.02 0.03 0.03 0.89 0.89 0.86 1 0 0.00 0.03 0.04 0.04 10 0.00 0.03 0.03 0.03 0.85 0.84 0.85 20 0.00 0.03 0.03 0.03 0.88 0.90 0.88 30 0.00 0.03 0.03 0.03 0.75 0.80 0.80 40 0.00 0.03 0.03 0.03 0.71 0.70 0.72 表 11 顯示,三種選題法篩選 4 道定錨題時,當 DIF 型態為 constant 且兩群 體能力相等,不同階數發生 DIF 情形時,發現當一階發生 DIF 之情形所得檢核 力比二個階以上發生 DIF 的檢核力較高,而當四個階均發生 DIF 之情形時,其 所得檢核力為最差的;兩群體能力有差異時,也可觀察到同樣狀況,但以整份 試題而言,不同階數發生 DIF 之情形時,兩群體能力有差異的情境所得檢核力 會較兩群體能力相等時些微較低,類似結果也發生在不同階數的 DIF 型態中。
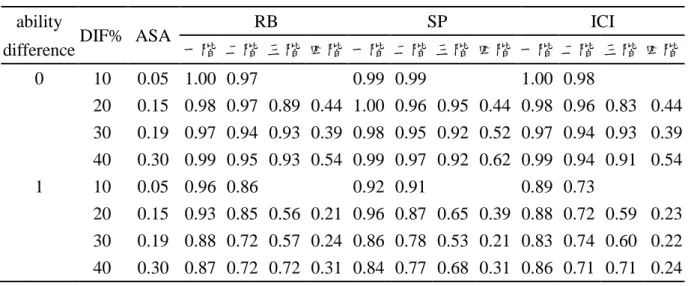
表 11 混合性 DIF 試題進行 DFTD 策略之檢核力(constant、4 anchors)
ability
DIF% ASA RB SP ICI
difference 一階 二階 三階 四階 一階 二階 三階 四階 一階 二階 三階 四階 0 10 0.05 1.00 0.97 0.99 0.99 1.00 0.98 20 0.15 0.98 0.97 0.89 0.44 1.00 0.96 0.95 0.44 0.98 0.96 0.83 0.44 30 0.19 0.97 0.94 0.93 0.39 0.98 0.95 0.92 0.52 0.97 0.94 0.93 0.39 40 0.30 0.99 0.95 0.93 0.54 0.99 0.97 0.92 0.62 0.99 0.94 0.91 0.54 1 10 0.05 0.96 0.86 0.92 0.91 0.89 0.73 20 0.15 0.93 0.85 0.56 0.21 0.96 0.87 0.65 0.39 0.88 0.72 0.59 0.23 30 0.19 0.88 0.72 0.57 0.24 0.86 0.78 0.53 0.21 0.83 0.74 0.60 0.22 40 0.30 0.87 0.72 0.72 0.31 0.84 0.77 0.68 0.31 0.86 0.71 0.71 0.24