國
立
交
通
大
學
電機與控制工程研究所
碩
士
論
文
利用深度資訊對複雜場景中的三維物體
進行分割與辨識
3D Object Segmentation and Recognition
in Cluttered Scene Based on Range Data
研 究 生:徐煜維
指導教授:林昇甫 教授
利用深度資訊對複雜場景中的三維物體進行分
割與辨識
3D Object Segmentation and Recognition
in Cluttered Scene Based on Range Data
研 究 生:徐煜維 Student:Yu-Wei Hsu
指導教授:林昇甫 Advisor:Sheng-Fuu Lin
國 立 交 通 大 學
電機與控制工程研究所
碩 士 論 文
A ThesisSubmitted to Institute of Electrical and Control Engineering College of Electrical Engineering
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Master
in
Electrical and Control Engineering
July 2009
Hsinchu, Taiwan, Republic of China
利用深度資訊對複雜場景中的三維物體
進行分割與辨識
學生:
徐煜維指導教授
:林昇甫 博士國立交通大學電機與控制工程學系 碩士班
摘要
本論文提出一個快速且有效的三維物體辨識系統,以辨識複雜場景下的三維物體。 此系統可解決深度資訊(range data)中,因為測量誤差所產生的雜訊,同時提高物體被遮 蔽時的辨識率,未來可將此系統應用在機器人視覺上,來進行辨識與引導動作。首先,本論文結合了適應性中值濾波器(adaptive median filter)與移動式最小平方法 (moving least square)來修復因測量誤差產生的三維雜訊,以獲得正確的物體部分表面, 並且提出了一個多重臨界值演算法(multilevel thresholding),使得複雜場景變成多個單一 場景,再利用深度影像中像素的連通性,來分離每個單一場景中的物體,以作為辨識之 輸入。
其次,為了使得目標物體在遮蔽環境下,也可以有效地被辨識出來,本論文使用了 邊緣圖像(edge map)的概念,使單一物體依照其表面變化,被分割成許多不同的封閉區 塊,以提高目標物體被遮蔽時的辨識率。首先,利用 Canny 邊緣偵測器(Canny edge detector)來偵測出深度影像中物體的步階邊緣,然後本論文提出了計算物體表面法向量 變化以形成梯度影像,再偵測出物體的屋脊邊緣(roof edge),就形成了邊緣影像(edge image),最後對邊緣影像使用形態學運算(morphological operator),使邊緣影像變成邊緣 圖像。 然後,對每個物體的邊緣圖像中的每個封閉區塊使用區域成長法(region growing)來抽 取出該區塊的特徵後,並使用多維直方圖(multidimensional histogram)統計整體特徵與區 塊特徵,形成了整體直方圖(unity histogram)與部分直方圖(partial histogram);其中,在 本論文中,使用曲率之形狀指標(shape index)及法向量分量之夾角,這兩個區域特徵來 表示三維物體部分表面之特徵。 最後使用 -divergence 計算直方圖相異程度,並且結合了幾個常用的直方圖比對方 法,以計算部分直方圖的相異程度,同時提出了兩階段的辨識系統來縮短辨識所需的時 間。 i
3D Object Segmentation and Recognition
in Cluttered Scene Based on Range Data
Student : Yu-Wei Hsu Advisor: Dr. Sheng-Fuu Lin
Institute of Electric and Control Engineering
National Chiao Tung University
ABSTRACT
In this thesis, a highly efficient 3D view-based object recognition system, which is to recognize 3D objects in cluttered scenes, is proposed. This system can handle the 3D noise in the range data because of measure error margin in the range finder, and increase the recognition accuracy when object is covered in cluttered scene. In the future, I hope that this recognition system will apply to the robotic vision.
First of all, in order to handle the 3D noise in the range data, an algorithm which combines adaptive median filter and moving least square (MLS) is proposed in the beginning of the recognition system. After that, a multilevel thresholding method is proposed which segments a cluttered scene into several monotonous scenes, and then separates each object in the scene by using the 8-connected component of pixels in range image. These objects will be the input of the recognition system.
More importantly, in order to recognize objects which are covered in cluttered scene, a concept of edge map is applied in this thesis. Then, extract the feature belongs to each closed region in the edge map by using region growing method, and calculate the features to create unity histogram and partial histogram by using multidimensional histogram; moreover, the local feature is presented as features of 3D object’s surface; however, in order to increase the speed during the recognition, a two-step recognition system is presented in this thesis.
iii
誌
謝
首先,我要感謝我的母親,提供給我衣食無缺的環境,讓我可以有機會在交 通大學就讀碩士班,其次我要感謝我的姐姐,讓我有了學習的榜樣,可以一同競 爭、一同進步,再來我要感謝我的指導教授林昇甫博士,在這兩年就讀研究所期 間,不只在研究上,也在做人處事上,給與我許多的啟蒙與啟發。 再來,我要感謝我的實驗室學長們,晉嘉、國育、士哲、弦澤、啟耀以及實 驗室的同學們、學弟們在研究上給我許多的指導與幫助,由於他們熱心的協助 我,並時常跟我討論研究內容,所以才有這篇論文的誕生,。 最後,我要感謝我身邊的所有人,由於他們的支持與鼓勵,才得以讓我順利 完成碩士學位,致上我最誠摯的感謝,。
目 錄
中文摘要 i 英文摘要 ii 銘謝 iii 目錄 iv 圖目錄 v 表目錄 vi 第一章 緒論 ... 1 1.1 三維辨識介紹 ... 1 1.2 研究動機與背景 ... 2 1.3 相關研究之探討 ... 3 1.3.1 深度影像分割 ... 4 1.3.2 三維物體辨識 ... 5 1.4 論文主體之貢獻 ... 7 第二章 相關技術原理 ... 9 2.1 深度資訊處理 ... 9 2.1.1 三維深度資訊 ... 9 2.1.2 法向量計算 ... 11 2.2 三維雜訊處理 ... 12 2.2.1 適應性中值濾波器 ... 12 2.2.2 移動式最小平方法 ... 14 iv2.3 複雜場景分割 ... 19 2.3.1 多重臨界值法 ... 19 2.3.2 連通量分析 ... 22 2.4 邊緣資訊處理 ... 23 2.4.1 邊緣偵測 ... 24 2.4.2 法向量之梯度變化 ... 27 2.4.3 形態學運算 ... 31 2.4.3 區域成長法 ... 33 2.5 區域特徵抽取 ... 35 2.5.1 表面之深度變化 ... 35 2.5.2 法向量分量之夾角 ... 36 2.5.3 曲率之形狀指標 ... 37 2.6 區域特徵比對 ... 42 2.6.1 多維度直方圖 ... 43 2.6.2 直方圖比對 ... 45 第三章 系統流程說明 ... 48 3.1 辨識系統架構 ... 48 3.2 三維雜訊處理 ... 49 3.2.1 雜訊前處理 ... 49 3.2.2 雜訊後處理 ... 50 3.3 深度影像切割 ... 52 3.3.1 場景分離 ... 53 3.3.2 物體分離 ... 55 3.4 封閉邊緣處理 ... 57 3.4.1 邊緣影像 ... 58 3.4.2 邊緣圖像 ... 60 iv
iv 3.5 三維特徵抽取 ... 61 3.5.1 整體特徵統計 ... 62 3.5.2 區塊特徵統計 ... 64 3.6 辨識系統介紹 ... 65 3.6.1 整體直方圖比對 ... 66 3.6.2 部分直方圖比對 ... 67 第四章 實驗結果與討論 ... 68 4.1 實驗設備與效能評估 ... 68 4.1.1 系統實驗設備 ... 68 4.1.2 系統效能評估 ... 94 4.2 實驗結果 ... 95 4.3 結果分析 ... 103 第五章 總結與未來方向 ... 106 參考文獻 ... 108
表目錄
表 4-1 資料庫中的物體 ... 69 表 4-2 已知物體旋轉角度與姿態對照表 ... 70 表 4-3 未知物體的角度範圍與姿態對照表 ... 71 表 4-4 未知物體的測試角度與該角度所對應的姿態 ... 88 表 4-5實驗組別與實驗變因之關係 ... 95 表 4-6 各方法與各種樣本區間個數列表 ... 96 表 4-7 輸入的測試資料為組別 1 之各種方法的辨識率比較 ... 97 表 4-8 輸入的測試資料為組別 2 之各種方法的辨識率比較 ... 97 表 4-9 輸入的測試資料為組別 3 之各種方法的辨識率比較 ... 97 表 4-10 輸入的測試資料為組別 4 之各種方法的辨識率比較 ... 97 vi圖目錄
圖2-1 強度影像與深度影像之差異 (a)強度影像 (b)深度影像 ... 10 圖2-2 深度資訊的擷取方式之示意圖 ... 11 圖2-3 深度資訊顯示於三維座標中之顯示圖 ... 11 圖2-4 3 3遮罩所對應的係數及點 (a) 所對應的係數 (b)所對應的點 ... 12 圖2-5 3 3遮罩所對應的係數及值(a) 遮罩係數 (b) 遮罩下所對應的值 ... 13 圖2-6 移動式最小平方法流程 某點集合之代表點 重新取樣的點集合之代表點 曲 之曲面 .... 16 .... ... 圖 投影點的區域座標 ... 圖 深度影像與深度統計後的直方圖 圖 不同區間個數的直方圖與臨界值位置 b 16 (b) b 32 (c) b 64 (d) b ... 20 圖2-11 深度影像之單一場景 (a)場景一(b)場景二(c)場景三(d)場景四 ... 22 圖2-12 不同的鄰接方式 (a) 鄰接 N P 8-鄰接 N P 圖 不同的連通方式 連通成份 連通成份 25 (a)數位影像 (b)使用 圖 藉由深度資訊所測量到物體之邊緣 深度影像 步階邊緣 (d) (a) (b) (c) 投影在原本曲面上之投影點 (d) P為近似原本 面 圖2-7 移動式最小平方法之原理 ... ... ... 16 2-8 18 2-9 (a)深度影像 (b)直方圖 ... 20 2-10 (a) 128 4- (b) ... 23 2-13 (a) 三個 4 (b) 兩個 8 ... 23 圖2-14 影像邊緣之灰階與一階導數之變化 (a)具明顯邊緣影像 (b)水平灰階變化 (c)一階導數變化 ... 24 圖2-15 Sobel 運算子 (a)計算 G (b)計算G ... 圖2-16 高斯濾波器遮罩 ... 26 圖2-17 數位影像使用不同邊緣偵測器之差異 Sobel 邊緣偵測器 (c)使用 Canny 邊緣偵測器 ... 27 2-18 (a)真實物體 (b) (c) 屋脊邊緣 ... 28 v圖2-19 3 3的遮罩內的係數與對應的法向量 (a)係數 (b)法向量 ... 29 圖2-20 不同的 圖 二值影像與結構元素 圖2-23 二值影像的膨脹過程與結果 (a)二值影像進行膨脹(b)膨脹後的二值影像 ... 32 的二值影像 ... 32 (b) n=50 ... 33 (a)係數 (b) 不同影像的直方圖 圖 強度影像的整體直方圖與部分直方圖關係 (a)強度影像 (b) 圖 ... 圖 ... 49 (a) (b)電腦 ... 圖 去除雜訊前的法向量之z 方向分量 圖3-5 去除雜訊後的法向量之 z 方向分量 (a)椅子 (b)電腦 ... 52 法向量的梯度變化 ... 30 圖2-21 γ值使得屋脊邊緣細節改變 (a)γ 0.5 (b)γ 2 (c)γ 10 ... 30 2-22 (a)原本二值影像 (b)結構元素 ... 31 圖2-24 二值影像的侵蝕過程與結果 (a)二值影像進行侵蝕 (b)侵蝕後 圖2-25 閉合後的二值影像 ... 33 圖2-26 收縮 n 次的二值影像 (a) n=20 圖2-27 不同視角下的深度影像 (a)原本的視角 (b)後來的視角 ... 36 圖2-28 法向量分量之夾角 ... 37 圖2-29 物體的區域特徵 (a) (b) θ ... 37 圖2-30 二維曲率的定義之示意圖 ... 38 圖2-31 馬鞍面的主曲率計算之示意圖 ... 39 圖2-32 3 3的遮罩內的係數與對應的點集合 點集合 ... 41 圖2-33 計算曲率方式之示意圖 (a)側面投影圖 (b)三維空間投影圖 ... 41 圖2-34 曲面形狀指標 ... 42 圖2-35 (a)強度影像的直方圖 (b)深度影像的直方圖 ... 43 2-36 整體直方圖為部分直方圖之總和 ... 45 3-1 實際拍攝深度資訊之整體系統架構 48 3-2 深度資訊之雜訊處理架構 圖3-3 深度影像 椅子 51 3-4 (a)椅子 (b)電腦 ... 52 v
圖3-6 影像切割架構 ... 53 圖3-7 T=6 時,由真實場景中所分離的物體 (a)真實場景 (b)物體 1 (c)物體 2 (d)物體 3 (e)物體 4 (f)物體 5 (g)物體 6 (h)物體 7 ... 54 圖3-8 Th=0.01 時,由真實場景中所分離的物體 (a)物體 1 (b)物體 2 (c)物體 3 (d)物體 4 (e)物體 5 (f)物體 6 (g)物體 7 (h)物體 8 (i)物體 9 (j)物體 10 ... 56 圖3-9 Th=0.05 時,由真實場景中所分離的物體 58 圖3-11 ... 59 圖3 圖3-23 辨識系統架構 ... 66 圖4-1 雷射測距儀 ... 69 圖4-3 CRT 電腦螢幕的強度影像與 39 張姿態的深度影像 度 圖4-4 玩具人偶的強度影像與 39 張姿態的深度影像 (a)物體 1 (b)物體 2 (c)物體 3 (d)物體 4 (e)物體 5 ... 57 圖3-10 邊緣處理架構 ... 物體的步階邊緣影像 (a)椅子 (b)電腦 ... 59 圖3-12 物體的屋脊邊緣影像 (a)椅子 (b)電腦 ... -13 物體的邊緣影像 (a)椅子 (b)電腦 ... 60 圖3-14 形態學閉合後的邊緣影像 (a)椅子 (b)電腦 ... 60 圖3-15 形態學收縮後的邊緣影像 (a)椅子 (b)電腦 ... 61 圖3-16 物體的邊緣圖像 (a)椅子 (b)電腦 ... 61 圖3-17 特徵抽取架構 ... 62 圖3-18 物體的整體區域特徵影像 (a)椅子 (b)電腦 ... 63 圖3-19 物體的整體區域特徵影像 (a)椅子 (b)電腦 ... 63 圖3-20 物體的整體區域特徵影像 (a)椅子 (b)電腦 ... 63 圖3-21 物體的整體區域特徵影像 (a)椅子 (b)電腦 ... 64 圖3-22 物體的區塊圖像 (a)椅子 (b)電腦 ... 64 圖4-2 資料庫中的八個物體 ... 71 (a)俯角 45 度,z 軸固定 (b)仰角 45 ,z 軸固定 (c)水平 0 度,z 軸固定 (d)水平 0 度,x 軸固定 (e)水平 0 度,y 軸固定 ... 73 v
(a)俯角 45 度,z 軸 e 固定 (b)仰角 45 度,z 軸固定 (c)水平 0 度,z 軸固定 (d) 0 度,x 軸固定 圖 摺疊椅的強度影像與 (a)俯角 z 軸固定 (b)仰角 45 z 軸固定 (c)水平 度,z 軸固定 ... 77 0 度,z 軸固定 79 檯燈的強度影像與 張姿態的深度影像 )水平 0 度,z 軸固定 ... 81 電腦螢幕的強度影像與 0 度,z 軸固定 ... 83 旋轉椅的強度影像與 張姿態的深度影像 (c)水平 0 度,z 軸固定 ... 85 有抽屜 的強度影像與 0 度,z 軸固定 ... 87 圖 未遮蔽之場景 的強度影像 89 4-13 ... 圖 遮蔽之場景 的強度影像 ... 89 ... 89 水平 (e)水平 0 度,y 軸固定 ... 75 4-5 39 張姿態的深度影像 45 度, 度, 0 (d)水平 0 度,x 軸固定 (e)水平 0 度,y 軸固定 ... 圖4-6 桌子(無抽屜)的強度影像與 39 張姿態的深度影像 (a)俯角 45 度,z 軸固定 (b)仰角 45 度,z 軸固定 (c)水平 (d)水平 0 度,x 軸固定 (e)水平 0 度,y 軸固定 ... 圖4-7 39 (a)俯角 45 度,z 軸固定 (b)仰角 45 度,z 軸固定 (c (d)水平 0 度,x 軸固定 (e)水平 0 度,y 軸固定 ... 圖4-8 LCD 39 張姿態的深度影像 (a)俯角 45 度,z 軸固定 (b)仰角 45 度,z 軸固定 (c)水平 (d)水平 0 度,x 軸固定 (e)水平 0 度,y 軸固定 ... 圖4-9 39 (a)俯角 45 度,z 軸固定 (b)仰角 45 度,z 軸固定 (d)水平 0 度,x 軸固定 (e)水平 0 度,y 軸固定 ... 圖4-10 桌子( ) 39 張姿態的深度影像 (a)俯角 45 度,z 軸固定 (b)仰角 45 度,z 軸固定 (c)水平 (d)水平 0 度,x 軸固定 (e)水平 0 度,y 軸固定 ... 圖4-11 資料庫中的各別單一物體的深度資訊顯示 ... 88 4-12 1 ... 圖 未遮蔽之場景1 的強度影像 89 4-14 1 圖4-15 遮蔽之場景 1 的強度影像 ... 圖4-16 未遮蔽狀況下之場景 1 的不同姿態之深度影像 ... 90 圖4-17 未遮蔽狀況下之場景 2 的不同姿態之深度影像 ... 91 圖4-18 遮蔽狀況下之場景 1 的不同姿態之深度影像 ... 92 v
v 圖4-19 遮蔽狀況下之場景 2 的不同姿態之深度影像 ... 93 圖4-20 組別 1 與組別 2 的各種方法之物體辨識率比較 ... 98 圖4-21 組別 1 與組別 2 的各種方法之姿態辨識率比較 ... 98 圖4-22 組別 1 與組別 2 的各種方法之前三名物體辨識率比較 ... 98 圖4-23 組別 3 與組別 4 的各種方法之物體辨識率比較 ... 99 圖4-24 組別 3 與組別 4 的各種方法之姿態辨識率比較 ... 99 圖4-25 組別 3 與組別 4 的各種方法之前三名物體辨識率比較 ... 100 圖4-26 組別 1 與組別 3 的各種方法之物體辨識率比較 ... 101 圖4-27 組別 1 與組別 3 的各種方法之姿態辨識率比較 ... 101 圖4-28 組別 1 與組別 3 的各種方法之前三名物體辨識率比較 ... 101 圖4-29 組別 2 與組別 4 的各種方法之物體辨識率比較 ... 102 圖4-30 組別 2 與組別 4 的各種方法之姿態辨識率比較 ... 102 圖4-31 組別 2 與組別 4 的各種方法之前三名物體辨識率比較 ... 103 圖5-1 雷射測距儀所測得的大型複雜深度影像 ... 107
第一章 緒論
本章分成四節,將三維物體辨識這個領域作詳盡的介紹。首先,1.1節將介紹三維物 體辨識(3D object recognition)相對於以往二維影像辨識的優點,然後說明三維物體資料 的取得方式以及三維物體辨識的未來發展潛力;1.2節將介紹研究三維物體辨識動機,以 及如何將三維物體辨識應用到機器人視覺中;1.3節將說明在三維物體辨識中,切割複雜 場景中的三維物體之演算法以及抽取三維物體特徵之演算法;1.4節將說明本論文在三維 物體辨識的貢獻,提出一個三維物體切割與辨識系統以處理複雜場景的多物體辨識,並 且在不犧牲計算速度的前提下,提高物體的辨識率。1.1
三維辨識介紹
近十年以來,由於取像技術的發展是取得二維影像為主,例如:灰階影像或是彩色 影像,使得影像辨識大多是從二維資訊中抽取特徵並發展其辨識演算法,像是文字辨識、 人臉辨識、指紋辨識、車牌辨識、生物特徵辨識等方面,但限於二維影像提供的資訊會 因為光源照射角度的差異以及光源強度的不同,使得辨識的效果不好或是無法辨識出影 像中的目標物體;然而,近年來隨著擷取物體三維資訊的取像技術越來越快速及準確, 使得以物體表面的三維資訊為基礎來進行物體辨識,已經成為電腦視覺及圖形識別等領 域中,一個極具發展潛力的研究主題。 一般二維影像只能提供以真實世界投影在影像平面上的資訊,基於物體表面的反射 特性,來獲得物體的輪廓、邊界、紋理等特徵,但是以二維資訊為基礎的辨識演算法, 來辨識出實際的三維物體時,會產生許多問題,而大多的問題是因為缺乏資訊而產生的, 因為光源照射角度的差異以及光源強度的不同,以致於針對同一場景,會獲得不同的二 維資訊,使得影像辨識複雜場景的辨識率偏低;然而,相較之下,如果能夠直接取得場 景的三維資料來進行物體的辨識,相對於二維影像所提供的資訊,三維資訊更能準確地 描述複雜場景中每個物體的外觀,並且提供更多辨識用的資訊,也具有更佳處理複雜場 1景的辨識能力。
然而,要進行三維物體辨識(3D object recognition),首先要取得三維物體表面的資 訊。三維物體表面資訊的取得,根據許多研究取得資料的方式,大部分都經由雷射測距 儀(laser range finder)所取得的深度資訊(range data)為主[1][2][3]。雷射測距的技術廣泛地 被使用在許多不同的領域,像是距離測量、地形地貌的監測,建築物的測量、三維立體 物體的測量等。藉由三維雷射測距儀獲得的深度資訊,可以得知物體表面完整的三維空 間分布資訊,也可獲得物體的輪廓、邊界、紋理等;這些影像資訊可以廣泛地應用於機 器人視覺[4],地形變化的測量,機械精密定位以及生物立體影像的重建等;但是在過去 這些裝置不僅昂貴且體積過大以致於不易攜帶,所以取得三維立體影像技術十分不普及 化;然而,隨著近年來三維取像儀器的成本降低以及精確度大幅提高,故直接利用雷射 測距儀來獲得物體的三維資訊,快速且便利許多,相較於以往是利用立體視覺影像產生 的三維資訊,三維雷射測距儀的影像,不需要經過複雜的三維重建過程,而且獲得的量 測結果相當準確且快速。現今,由於三維雷射測距儀的越來越普及化,藉由三維雷射測 距儀獲得物體表面的三維資訊分布,並利用此資訊來提升三維影像識別技術的可能性大 幅提升。
1.2
研究動機與背景
在現實生活中,自動化辨識系統應用在居家保全、安全監控以及自動化設備等方面 的需求性日益增加;然而,目前的自動化辨識系統仍是以二維影像為基礎來進行辨識為 主,應用在人臉辨識、車牌辨識、指紋辨識、生物辨識等,而這些辨識系統應用單一物 體的辨識上,均有蠻高的辨識率,主要原因是因為這些辨識系統皆處在良好的環境下來 進行辨識,例如外來光源充足的環境中或是被辨識之物體沒被遮蔽的前提下,才可以有 這麼高的辨識率,但是這些以二維影像為基礎的辨識系統,若應用在機器人視覺中[4], 辨識率卻很低,主要原因是這些辨識系統無法處理場景中的物體彼此有互相遮蔽之情形 或是目標物體處於光源不足的環境中。 2機器人視覺是希望用計算機來模擬出跟人一樣的視覺系統,並且藉由儀器來取得真 實空間中的三維物體之資訊,進行資訊處理並且加以理解,最後可以用於機器人上。相 對於以往的計算機視覺,計算機視覺只要求辨識率高,準確度高,然後可以應用自動化 設備的機器上,速度並不是主要的考量,故計算機視覺大多是二維影像辨識系統為基礎, 再進一步地應用到其他方面;然而,在機器人視覺中,必須要求計算速度快且可辨識出 處於惡劣環境中的物體,因為機器人必須要視覺引導下立即作出判斷及動作,並且取代 人類於惡劣的環境下的工作,故執行速度與辨識能力是主要考量。 而人類的視覺系統就是將真實的三維世界中的場景投影到視網膜上,類似投影到一 個二維陣列中,陣列中所包含的資訊有真實空間中物體的相對位置,其類似由雷射測距 儀所獲得的深度資訊,以及因為外來光源的變化,物體所表現的顏色、輪廓等資訊,其 類似由相機所取得的 RGB 二維影像;而人類可以辨識出真實世界中的三維物體,除了 利用物體的二維資訊外,也需要利用物體的三維資訊,像是物體的表面形狀變化,才得 以辨識出該物體,在機器人視覺中就包括這兩個資訊的處理與辨識,但由於使用二維資 訊為基礎的辨識系統,已經有很高的辨識率,然而使用三維資訊進行三維物體辨識仍在 發展階段,故本論文希望設計出一個針對三維資訊進行辨識的辨識系統,並且改進以往 三維辨識系統的缺點,使得此辨識系統更為優良,並且未來進一步地應用在機器人視覺 上。 在本論文中,將設計出一個三維物體辨識系統,可以應用在機器人視覺上,針對一 個複雜場景,可以同時將一個複雜場景分割成很多單一場景,並從單一場景中分離不同 物體,然後平行進行不同物體之辨識。在只能取得物體之部分表面的情形下,並且考慮 當物體被遮蔽的情形發生,此辨識系統仍然有很高的辨識率;此外,即使因測量視角的 改變造成物體的姿態略為改變,此辨識系統依舊可以辨識出場景中的物體。
1.3
相關研究之探討
在本論文中,將對複雜場景的深度影像進行分割,分割成許多不同深度範圍的單一 3場景,然後再從個別單一場景分離出單一物體;然而,為了使每個單一物體在被遮蔽的 情況下,可以有效地被辨識出來,將會對每個單一物體進行分割,使得單一物體可以分 割成許多封閉的區塊;如此一來即使物體有部分的面積被遮蔽,仍可有效地辨識出該物 體,故本論文將會在 1.3.1 節介紹關於深度影像切割的相關研究。 在本論文中,要辨識出複雜場景中的未知物體對應資料庫中哪個物體時,將比對兩 物體表面的特徵是否相符,然而,依照抽取物體表面特徵的方式,可以將特徵分為全域 特徵(global structural feature)、區域特徵(local feature)以及半區域特徵(semi-local feature) 三類,依照不同的表面特徵抽取方式,會發展出不同的三維物體辨識演算法。故本論文 將會在 1.3.2 節介紹關於利用深度資訊來抽取特徵以進行三維物體辨識的相關研究。
1.3.1
深度影像分割
深度影像分割的主要目的,是將複雜場景中的多個物體各自獨立分割出來,作為三 維物體辨識系統的輸入。在深度影像的分割演算法的研究中,深度影像分割可依照分割 方法的不同[5],分成兩類:以區域為基礎的分割演算法(region-based)與以邊緣為基礎的 分割演算法(edge-based)。區域基礎的深度影像切割演算法都是以深度影像中的像素的相 似性來進行分割,主要根據應用影像分割之原理於深度影像中,例如:區域成長法(region growing)[5]、臨界值法(thresholding)、區域合併與分裂(merge and spilt)[6]、分群法 (clustering)[5][7][8][9],然而以區域為基礎的分割演算法中,若是預先設定好的幾何曲面 特性有無來分割深度影像,則可分為兩類:參數模型基礎(parametric model-based)[10] 以及區域成長基礎(region-growing based)[5][6]。以參數模型為基礎的分割演算法,主要 是在分割深度影像前,設定好一連串的參數化的曲面模型,像是平面、雙二次曲面、圓 柱面等,然後將深度資訊中的點開始進行區域成長,其中這些點將視為曲面上的點來進 行成長,最後這些點可以成長為一個原本設定的曲面,缺點是在於需要假設好未知物體 可能形狀的曲面模型;此外,當物體可能是有許多複雜曲面所組成的,要決定像素屬於 哪種曲面,是一個比較大的問題;而以區域成長為基礎的分割演算法,主要是根據預定 4的準則或是策略,使得影像可以被分割不同的區域,缺點是分割區域的過程是以區域為 基本單位,故分割出來的區域邊界往往有可能跟原本物體的邊界不能重疊;此外,當遇 到不同的分割問題時,就需設定不同的準則來分割影像。 以邊緣基礎的深度影像切割演算法,主要利用深度影像深度值變化的不連續或是深 度資訊中取每點曲率變化的不連續性,來分割深度影像,主要的方法為邊緣偵測(edge detection)[11],將原本影像處理中的偵測強度影像邊緣的方法,應用到深度影像或是深 度資訊上,像是利用梯度運算子、灰階矩量搜尋法、鏈狀輪廓追蹤法、空間矩量次像素 搜尋法等去找尋深度影像中深度值為不連續的點,而以找尋邊緣為基礎的切割演算法的 優點是計算速度快並且在不同的區域交界處可產生明確的邊界,缺點是對於曲面的邊界 處較為連續時,會無法偵測出其邊界,以及不一定會產生出封閉的邊界以隔離不同的區 域。 本論文希望設計出一個強健性的三維物體分割系統應用到機器人視覺上,可以有效 且快速分割場景與物體,所以將使用尋找邊緣為基礎的切割演算法來分割深度影像,並 且改良切割演算法,使得針對連續變化的曲面,也可偵測出其邊緣所在。
1.3.2
三維物體辨識
三維物體辨識的主要目的,是以物體的三維資訊為基礎來進行辨識,將複雜場景中 的未知物體,與資料庫中的已知物體進行比對,進而辨識出該未知物體。主要的比對方 式是根據物體表面的特徵是否相符,以決定兩物體是否相同。首先,將由雷射測距儀測 量到一堆空間點資料作為輸入,這些點資料來表示複雜場景中的未知物體在某姿態下之 表面,然後利用演算法找出屬於該物體的點,並且抽取出該物體的表面特徵,作為代表 此三維物體的主要特徵。在許多三維物體辨識演算法的研究中,主要可依照表示特徵方 式的不同,將特徵分為全域特徵(global feature)、區域特徵(local feature)以及半區域特徵 (semi-local feature)三類。以全域結構特徵作為特徵表示的辨識演算法,像是M. Kazhdan、F. Stein等人所提出
全 域 化 球 諧 波 特 徵 (global spherical harmonic feature)[12][13] , 主 要 以 球 諧 波 函 數 (spherical harmonic function)為基礎,不考慮物體表面上的點與鄰近點之相對關係,只考 慮整體形狀,將物體的表面上的點用體素(voxel)堆積方式來表示。之後利用類似傅利葉 轉換法(Fourier transform),用一組正交函數去近似每個有著固定半徑的球面其所涵蓋的 體素數量。這樣表示法的優點是考慮到物體部分表面的整體形狀,但是會因為測量視角 的些微差異,使得物體的部分表面的整體形狀會有很大的差異,會受到物體姿態變化的 影響很大。 以半區域特徵作為特徵表示方式的辨識演算法,像是A. E. Johnson等人提出的旋轉 影像(spin image)[14][17],相對於以全域特徵的特徵表示法,半區域特徵在特徵的描述 上更具有彈性。因為只要物體表面上的點與鄰近點之間相對位置沒有改變,即使對於不 同尺寸的同樣物體,也會具有相同的特徵。有不少辨識法與應用[15][16],採用半區域 特徵抽取法作為描述物體表面的基礎。其中以旋轉影像來描述三維物體,是最具代表性 的方法。旋轉影像是由Johnson等人所提出,是一種與目標物體姿態無關的特徵表示法。 利用許多方向點(oriented point)作為基準點,來計算物體整體的表面特徵。由於旋轉影像 是使用局部座標,對該物體表面上的所有點來進行編碼,因此取得的特徵,不會因為物 體在三維空間中姿態的不同而改變。也就是說,旋轉影像的特徵是與姿態無關的特徵; 但是,由於旋轉影像是針對物體表面上每個頂點都做特徵描述,最後每個點都對應一張 旋轉影像,故資料量相對地十分龐大,也造成計算上龐大負擔,大多應用在電腦視覺中 的三維物體檢索;此外,深度資訊只能獲得物體部分表面資訊,即物體在某視角下的表 面,因此半區域特徵不太適合應用基於深度資訊的三維物體辨識上;此外,使用旋轉影 像作為物體部分表面的特徵描述,有許多的限制與參數,故本論文不使用半區域特徵作 為三維物體辨識的特徵。
以區域特徵作為特徵表示方式的辨識演算法,例如:C. Dorai、R. Jarvis以及 J. Thirion 所提出的shape index[18][19][20],是以物體表面變化作為抽取特徵的基礎(shape-based), 將一個三維物體之組成採用以自由曲面(free form)的方式來描述,能真實的描述物體的 表面組成,然後抽取出物體表面的幾何特徵,作為特徵比對用,例如:物體表面之曲率。
此幾何特徵跟因為物體的大小無關,以及受到物體姿態變化的影響較小,故即使測量視 角些微改變,但是仍測量到物體相同表面時,代表此物體的表面特徵並不會有太大改變; 然而,此演算法只能針對單一物體的辨識有很好的效果,對於處於在雜亂場景中的目標 物體或是物體的表面以非連續方式來組成,就無法提供良好的辨識能力。 本論文將使用區域特徵作為三維物體辨識系統中的特徵比對基礎,區域特徵相較於 全域特徵,比較不受到測量視角些微變化的影響,即物體姿態些微變化的影響,相較於 半區域特徵,特徵比對的計算量卻小非常多,故將採用區域特徵作三維物體辨適用之特 徵。
1.4
論文主體與貢獻
以往在電腦圖學以及圖形識別這兩個領域,在國外已經有許多文獻提出物體的三維 物體辨識法則,其中包括使用基因演算法、類神經網路、模糊系統以及基於樣版模式的 三維物體辨識系統,但是這些法則都未考慮在使用雷射測距儀測量物體時,外在環境或 式儀器本身等因素之影響,導致所測量到的物體表面是凹凸不平的,例如:物體的表面 材質為透明或是反光,導致無法測量到物體表面上的點,或是儀器本身的誤差,導致使 用雷射測距儀所獲得的深度資訊會有誤差。以上兩個原因導致深度資訊中的物體之表面 凹凸不平,在本論文中稱這種現象為三維雜訊,所以在進行三維資訊辨識前,必須對於 獲得的三維資訊進行前處理,以消除三維雜訊並獲得近似於原本物體之表面。本論文貢 獻一:利用兩階段的雜訊處理,使得測量時所獲得物體的表面資訊更可以回復成原本物 體的表面資訊,以取得正確的物體表面特徵,並且提高物體在雜訊影響嚴重下之辨識 率。 當未知物體在複雜場景中,先將物體個別分離出來,然後可以平行地進行下一步的 辨識,以加快辨識速度。本論文貢獻二: 提出一個切割複雜場景的架構,利用深度變 化將一個複雜場景分割成幾個不同的單一場景,然後有效地將每個物體從個別單一場景 個別分離出來,作為接下來辨識系統的輸入。 7當未知物體在複雜場景中,可能會有被其他物體遮蔽的情形發生,為了要解決物體 在被遮蔽的環境下,也可以有效地辨識出該物體。本論文貢獻三: 利用邊緣圖像(edge map)的概念,將物體切割成許多不同的區塊,利用偵測物體的步階邊緣(step edge)以及 屋脊邊緣(roof edge)之演算法,並且使用形態學運算將物體的所有邊緣變成連結成封閉 邊緣,形成該物體的邊緣圖像,之後可以針對邊緣圖像中每個區塊抽取特徵,然後針對 未知物體的每個區塊特徵作辨識,即使該物體的某區塊被遮蔽住了,也可以有效地辨識 出來該未知物體。 為了同時提高辨識三維物體辨識系統的辨識率以及不犧牲其辨識速度的前提下,本 論文使用了兩階段辨識系統,將原本的一階段辨識系統,該系統只比對未知物體的整體 特徵 [32],後方加入了辨識物體區塊的辨識系統,形成了二階段辨識系統,在第一階段 辨識系統完後,列出可能是該未知物體的候選清單,之後再經由第二階段辨識系統仔細 比對未知物體與後選清單上的物體,兩者的所有區塊特徵,進而辨識出該未知物體。 8
第二章 相關技術原理
本章分成六節,依照本論文第三章所提出的三維物體分割與辨識系統中的每個步驟 之演算法,依其順序分成六小節討論,每節依序介紹演算法的原理及流程。2.1 節將介 紹深度資訊的取得與表示方式,以及如何計算深度資訊中每一點的法向量;2.2 節將介 紹在取得深度資訊時會受到測量誤差的影響,藉此提出雜訊模型來模擬深度資訊中的測 量誤差,並且介紹處理雜訊的方法;2.3 節介紹分割所量測到的深度影像之演算法,並 適用於測量的場景為一個複雜場景時;2.4 節介紹如何偵測三維物體的邊緣,並且使邊 緣形成封閉的邊界;2.5 節將介紹如何抽取出三維物體的區域特徵;2.6 節將介紹將區域 特徵統計成多維度直方圖,然後如何其比對其直方圖。2.1
深度資訊處理
本節將介紹由雷射測距儀取得一個場景的深度資訊,其深度資訊為多維度之陣列, 每個二維維度陣列中的值,為所量測的點投影到卡氏座標系中三個正交向量上的值,若 是只取投影在雷射測距儀之切平面上的陣列,即為深度影像,其中 2.1.1 節將說明深度 資訊的取像原理與表示方式;2.1.2 節將說明如何由深度資訊計算出深度資訊中每點的法 向量,並形成一個多維度的法向量陣列。2.1.1
三維深度資訊
強度影像(intensity image)跟深度影像(range image)的差別是:強度影像的像素值表 示的是物體表面經由光反射後的強度資訊,即經由取像儀器所接收的亮度值(gray level) 而強度影像如圖 2-1(a)所示;深度影像的像素值表示的是物體表面與取像儀器的所在切 平面之距離,即經由取像儀器所接收的深度值(depth),深度影像如圖 2-1(b)所示。
(a) (b) 圖 2-1 強度影像與深度影像之差異 (a)強度影像 (b)深度影像 一般的二維強度影像可用下式表示: a a a a , 2.1 其中1 m, 1 n,上式也可表示為: 1,1 1, n m, 1 m, n , 2.2 其中1 m , 1 n,每個像素值 a 或是 , 代表的是物體上該點在影像中 的亮度值,然而在深度資訊(range data)表示中,也可用下式來表示: , 2.3 其中 x, y, z T , 1 m , 1 n,將屬於物體部分表面上的點,對於一個平 面陣列作投影,示意圖如圖 2-2 所示,以獲得該物體或是該場景的三維資訊,每個物體 部分表面上的點對應其陣列中的像素,但像素在陣列中的相對位置,並非是物體上的點 在空間中真正的相對位置,每個陣列的元素 表示的是物體上該點在空間中的位置, 立體圖如圖 2-3 所示, 若只取得深度資訊在 z 方向投影的影像,就形成了深度影像(range image),而深度影像會因為測量視角的不同,擷取到物體不同的姿態。 10
圖 2-2 深度資訊的擷取方式之示意圖 圖 2-3 深度資訊顯示於三維座標中之顯示圖
2.1.1
法向量計算
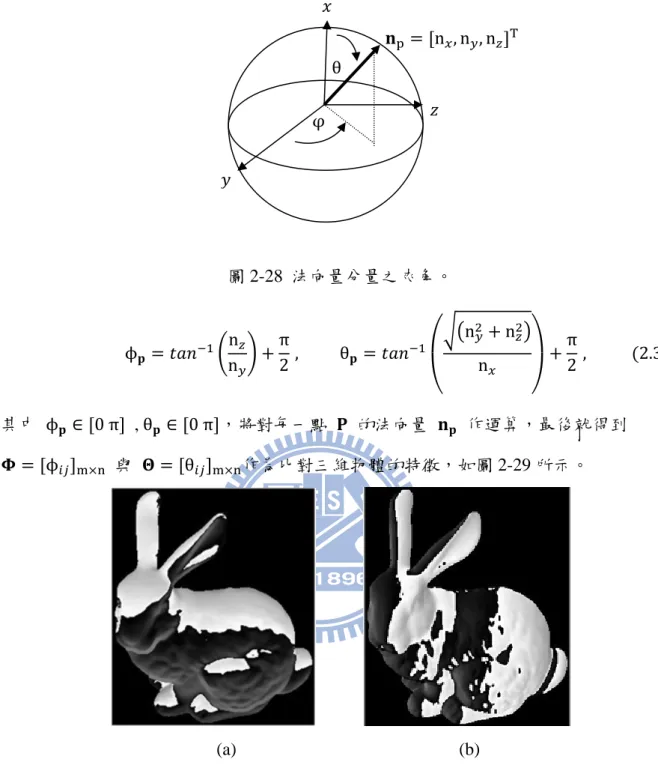
深度資訊可以描述出物體表面輪廓的資訊,同時也可以計算出該點在空間中的法向 量,深度資訊中法向量的計算是利用 Hoffman [21]所提出的方法來計算某點 的法向 量 。首先,要定義出一個遮罩(mask) S ,遮罩大小為 S S,遮罩中的係數為 w ,然 後移動遮罩於深度資訊陣列中,去計算遮罩下所對應的點集合 P , ,··· , ,··· , SS 所形成曲面的法向量 ,其中遮罩中心所對應的點為 ,也是此點集合的代 表點。以 3 3為例,其中 ,如圖 2-4 所示。 11w w w w w w w w w ( 圖 2-4 3 3遮罩所對應的係數及點 (a) 所對應的係數 (b)所對應的點 a) (b) 目的希望取得下列 D 的最小值, 下 所 :如 式 示 D w T , , 2.4 其中,令協方差矩陣 ,如下式所示: w T , , 2.5 則可以得到D ,由於 是法向量,所以令 為單位法向量,即 T 1,若欲使 D 最小值,使用拉格朗日乘子法可得下式: ∂ ∂ D λ 1 T 0, 2.6 由此可得 λ ,代入(2.6)式後,可得下式: D T λ λ T λ, 2.7 由上式可知,所以要使 D 有 D ,恰好為所對應的是協方差矩陣的最小特徵值 λ λ ,而對應到特徵向量就是該點 的單位法向量 n , n , n T。
2.2
三維雜訊處理
本節將介紹之後用於處理三維雜訊的演算法,進而有效地消除三維雜訊。2.2.1 將介 紹應用適應性中值濾波器;2.2.2 將介紹移動式最小平方法。2.2.1
適應性中值濾波器
12適應性中值濾波器(adaptive median filter)是中值濾波器(median filter)的改良,是一個 非線性的濾波器,原本中值濾波器對於某些特定隨機雜訊的類型,像是脈衝雜訊,提供 了絕佳抗雜訊的能力,並且對於同樣遮罩大小的線性平滑濾波器所產生的模糊少了許多 然而,適應性中值濾波器相對於原本的中值濾波器,在雜訊的處理上也可有跟中值濾波 器一樣的效果;但是相對於中值濾波器處理後的影像,卻更可以保留影像內物體的邊緣 與細節,降低物體的失真與模糊。 根據 Gonzalez 與 Woods[22]所定義的,主要是利用一個濾波器遮罩 S ,大小為 S S,其中 S 可以允許的最大值為S ,w 為遮罩所對應的係數,其中 w 1, , 為遮罩S 下所對應的值,1 , S ,以3 3 的遮罩為例,如圖 2-5 所示 w w w w w w w w w 1,1 1,2 1,3 2,1 2,2 1,1 3,1 3,2 3,3 (a) (b) 圖 2-5 3 3遮罩所對應的係數及值 (a) 遮罩係數 (b) 遮罩下所對應的值 此遮罩的大小會因為濾波器區域內影像的統計特性而改變其遮罩大小,此演算法有 主要三個目的:(1) 移除脈衝雜訊 (2) 提供其他可能不是脈衝雜訊的平滑化 (3) 減少物 體邊界過度細小化與增厚化等失真。 其演算法如下: 符號表示 : z , S w , z , S w , z w , 13
z w g s , t , 其中(s , t) 為該遮罩S 之中心位置 適應性中值濾波器,依照下列二步驟來運作。 步驟一: A z z ,A z z 假如 A 0 並且 A 0 , 跳到步驟三 否則增加 S 的大小 假如 S S ,重複步驟二,否則輸出 z 步驟二: B z z , B z z 假如 B 0 並且 B 0 , 輸出 z 否則輸出 z
2.2.2
移動式最小平方法
由 Lancaster 與 Salkauskas[23]所提出的移動式最小平方法(moving least square),
是將原本加權最小平方法(weighted least square),如下式所示:
min ∏ , 2.8 作改良,最後如下式所示: , min ∏ , 2.9 主要用於使多維資料中的點分布較為平滑,是將原本作為輸入的任意固定點 , ,改成此固定點 可移動於整個參數域 中,利用多個區域函數 去近似一 個全域函數 ,其中 是一個加權函數(weighted function)。 移動式最小平方法也被應用在電腦圖學領域中,Marc Alexa[24]等人應用移動式最 14
小平方法來處理三維空間的資料點,是專門針對三維物體之曲面表示(representation)或 是三維場景之重建(reconstruction)等問題,這個方法也可以解決在使用雷射測距儀或是 其他儀器去取得物體表面的點資料時,出現取樣不均(up-sampling or down-sampling)或是 測量距離誤差的問題,利用移動式最小平方法去對這些三維資料點重新取樣以改變原本 三維資料點的位置,可計算出近似原本物體曲面上的點;此外,也應用在處理電腦中三 維模型,改變曲面的平滑程度,使物體表面更為平滑且連續,這些問題在電腦圖學領域 中是個重要的議題。在本論文中,將使用移動式最小平方法使三維資料點所建立的曲面 平滑化,以達成消除雜訊的效果。 Marc Alexa 等人所提出的概念如下所示: 假設某區域曲面 P 是物體表面 的一部分,在使用雷射測距儀取得物體表面上 的所有點資料集合 P 時,因為測量誤差的關係,導致所量測到之每一個區域曲面上的 點集合 P 可能不在曲面SP上,其中 為代表此集合 P 的點, 如圖 2-6(a)所示, 為了要獲得一個區域曲面 P 以近似原本曲面 P,首先,將此空間點集合 P 重 新取樣,找出一群更能代表曲面 P 的點集合 R ,其中 為代表此集合 R 的 點,如圖 2-6(b)所示,再利用加權最小平方法去求出點集合 R 的近似區域曲面 P (MLS surface),以近似真正的曲面 P,最後再將 投影至近似區域曲面 P 上,以獲得投 影點 ,重複此步驟使得 P 中的所有點都進行更新,如圖 2-6(c) 所示,這樣被稱為 移動式最小平方法,這個方法可以確保近似的區域曲面 P 與原本的區域曲面 P 的誤 差會達到最小,如圖 2-6(d)所示。 15
f (a) (b) (c) (d) 圖2-6 移動式最小平方法流程 (a)某點集合之代表點 (b)重新取樣的點集合之代表點 (c) 投影在原本曲面上之投影點 (d) P為近似原本曲面之曲面 將移動式最小平方法中所提的部分點集合 P 移動於整體點集合 P 之中,去 求得每個近似區域曲面 P 後,然後更新每個點集合的代表點,就完成了去除雜訊的動 作了,其中移動式最小平方法的演算法步驟如下,如圖 2-7 所示。 圖 2-7 移動式最小平方法之原理 步驟一:求得點 的單位法向量 定義一群空間點之集合 P ,然後對此空間點集合重新取樣以獲得 R , 使得 R 相對於 P 更能描述原來物體的表面 P,並計算出代表其中此集合 R 的點 。 首先,為了要計算出 此點的單位法向量 ,用 2.1.2 節的方法來計算法向量,先計 P P P P P H P 16
算該群空間點集合中的每點 與 的距離 ,然後加上加權函數 w , 最後形成的協方差矩陣 ,如下式所示: w T, 2.10 計算 的最小特徵值所對應的特徵向量,即單位法向量 。 步驟二:求得 投影至切平面 的投影點 如圖 2-7 所示,切平面 會滿足下式: | T D 0, P P , 2.11 其中D 是常數, 是 投影在切平面 上的點,可以使得下式有最小值: min T D , 2.12 令 ( e ,是一個高斯函數,也是一個加權函數,其中h是一個固定的 參數,然後設 t 代入式(2.12),並對(2.12)式進行偏微分,可獲得下式: 2 ∑ t T 1 T e , 2.13 其中t 0, t , ,求得 t 以得到 。 步驟三:求 至切平面 之距離 f 與 投影至切平面上之投影點 由圖 2-7 可得知f ,如下式所示: f T , 2.14 並設立局部座標系統(local coordinate system)於切平面 上, u , v 為該座標系統的 座標值,在此局部座標下,令 H 為該局部座標系統之原點,即 H 0, 0 ,其中 和
H 在三維空間中是同一點,只是 是相對於世界座標系統(global coordinate system)的
點, H 是相對於局部座標系統的點,接下來要計算其他點 相對於此局部座標系統
下的點 H。
首先,令任意兩向量 , H 且 , 為此局部座標之兩正交單位向量,其中
且 T 1,欲求出投影點 ,如圖 2-8 所示。 圖 2-8 投影點的區域座標 由圖 2-8 可得 H,如下式所示: H u , v T , T . 2.15 步驟四:求得近似區域曲面 P 在此局部座標系統,令一個最高次為 n 次多項式來表示此近似區域曲面 P,如下式 所示: P g u , v c u v , c u c , u v ··· c , 2.16 由(2.15)式將計算出來的投影點集合QH H 代入(2.16)式中,並計算出該區域曲面 P 的多項式係數 c c , ··· c c T,其中係數的總個數為 。 因為 g u , v 要使此加權最小平方法誤差為最小,要滿足下式: g u , v – f , 2.17 其中,g u , v 為投影點 H 跟區域曲面 P 的距離。 步驟五:最後求得 投影至區域曲面 P 的投影點 定義 在區域曲面 P 的投影點 ,如下式所示: g 0,0 , 2.18 其中,g(0,0)是 跟區域曲面 P 的垂直距離,即區域曲面 P 之多項式的常數係數 c , 再將原本 沿著法向量方向移動長度 g 0,0 ,即可得到區域曲面 P上的近似投影點 , 再 將 之 前 設 t 代 入 (2.18) 式 , 最 後 可 得 , 如 下 式 所 示 : 18
t c . 2.19
2.3
複雜場景分割
本節將介紹分割複雜場景的演算法及概念,並介紹如何分割深度影像,使之成為多 個單一場景,並且從多個單一場景中分離來多個單一物體出來。2.3.1 節將介紹多重臨界 值法,使得複雜場景變成許多單一場景;2.3.2 節將介紹深度影像中像素之間的連通性, 以分離出每個物體。2.3.1
多重臨界值法
在影像處理中,常利用臨界值法(thresholding)[22]來分割影像,找出適當的臨界值 將影像分割成目標物體與背景兩部分,而臨界值法中,最常使用直方圖來統計影像中的 灰階值,可表示成(2.20)式,其中灰階值的區間範圍為 0, G ,灰階值區間個數(bin size) 為b,區間大小Δ G , r 是在整體區間 0, G 中的第 個區間的區間位準,其中 r Δ ,而 h 是該區間 r , r 內灰階值個數, h h h h h r , 2.20 然後,可根據不同的分割問題來找出直方圖中的適當臨界值去分割影像,使影像成為兩 個 區 域 ; 然 而 , 若 尋 找 的 臨 界 值 數 目 不 只 一 個 , 則 稱 之 多 重 臨 界 值 法 (multilevel thresholding)。 在本論文中,將設計出一個多重臨界值演算法,是以雷射測距儀測量場景所獲得的 深度影像為基礎,然後根據深度影像中像素的深度值變化,對複雜場景進行分割,最後 可複雜場景分割成前景、中景、後景 等單一場景。分割的目的是為了提高三維物體辨 識的速度。在進行物體辨識的時候,可以同步進行辨識且找出物體所在的正確位置。 一個深度影像,如圖 2-9(a)所示,利用直方圖對深度距離做統計,可得到圖 2-9(b)。 19分割的場景區塊 (a) (b) 圖 2-9 深度影像與深度統計後的直方圖 (a)深度影像 (b)直方圖 一般而言,根據經驗會將深度影像分割成前景、中景、與後景等,臨界值的個數不 超過 5 為主,然後由圖 2-9(a)可以用看的出來,深度影像中物體的深度變化幾乎連續的, 所以只需要找出深度變化不連續的部分,就可以有效的分割深度影像,如圖 2-9(b)所示, 可將圖 2-9(a)的深度影像分割成四個場景,而每個場景的邊界範圍所在,就是直方圖中 局部最小值(local minimum)。多重臨界值的數目以及大小,會隨著直方圖橫軸的深度值 區間數目增加而增加;但是,可以發現初始局部最小值的位置大約不變,如箭頭所示, 依然是後來的局部最小值,如圖 2-10 所示。 1 1.5 2 2.5 0 500 1000 1500 2000 2500 1 1.5 2 2.5 0 500 1000 1500 2000 2500 3000 3500 4000 4500 (a) (b) 1 1.5 2 2.5 0 200 400 600 800 1000 1200 1400 1600 1800 1 1.5 2 2.5 0 100 200 300 400 500 600 700 800 900 1000 (c) (d) 圖 2-10 不同區間個數的直方圖與臨界值位置 a b 16 (b) b 32 (c) b 64 (d) b 128 20
根據以上所描述深度影像的直方圖之局部最小值的特性,可依照下列的演算法來有 效的分割深度影像: 步驟一:決定初始的樣本區間個數,並找出局部最小值 令直方圖的樣本區間個數為 2 的次方,即 b 2 , N ,然後決定初始的 值, 即 ,然後找出直方圖中的局部最小值的位置及數值,若局部最小值的個數少於 T 個, 則增加 ,直到局部最小值的個數超過 T 個,不再增加 ,則 bT 2 。而局部最 小值之集合 D T,如下式所示: D T d , d , , dT h , h h h . 2.21 步驟二:增加深度值取樣區間個數,以獲得更準確的臨界值 增加深度值區間個數 b 2 其中, b bT ,隨著 增加,所以原本獲得之局部最 小值集合 D T 中的元素 d 也會是後來局部最小值之集合 D 中的元素 dℓ 的附近, 可由圖 2-10 看的出來,隨著深度值區間個數是 2 的次方,隨著次方的增加,後來的部 分局部最小值dℓ 會滿足下式: d D T dℓ D dℓ D , dℓ d 1 2 之後再用後來的局部最小值更新去原來的局部最小值,即令 dℓ d ,直到更新的局部 最小值與經由步驟一計算所得的局部最小值,兩者的誤差小於某個值 T 時,也就是最 後的局部臨界值不再變化,就可以停止增加深度值區間個數,其中T 的大小是根據深度 影像中所有相鄰兩點像素的深度值之差的平均值所決定的。 Δ , 2.22 最後,利用多重臨界值法找出的局部臨界值,可用來分割深度影像圖 2-9,可計算 出 3 個局部最小值將影像分割成四個單一場景,分割後的影像以二值影像表示,白色區 域表示分割後的影像,如圖 2-11 所示。 21
(a) (b) (c) (d) 圖 2-11 深度影像之單一場景 (a)場景一(b)場景二(c)場景三(d)場景四
2.3.2
連通量分析
像素之間的連結性可以決定影像當中的區域或是邊界。首先,要確定兩個像素是否 相鄰,必須要先定義出鄰接的方式,再依照這些鄰接的像素是否滿足某些特定的相似準 則,來判斷這些像素是否為相鄰的像素。 首先,N P 表示與 P 點相鄰的像素之集合。像素之間鄰接的方式[22][25],常用的 有 4-鄰接(4-neighbors),以N P 表示,如圖 2-12(a),8-鄰接(8-neighbors),以N P 表示, 如圖 2-12(b)。下圖中的灰色區塊表示 P 點相鄰之像素的位置,虛線表示其連通路徑, 若對於任意像素 P 而言,其餘的像素 S (S 代表影像中像素的子集合)滿足上面的鄰接方 式,並且存在著一條全部由 S 中的像素所組合的連通路徑,可以稱之 P 的連通成份 (connected component),依據不同的連接方式,會有不同的連通方式,如圖 2-13 所示。 22(a) (b) 圖 2-12 不同的鄰接方式 (a) 4-鄰接 N P (b) 8-鄰接 N P (a) (b) 圖 2-13 不同的連通方式 (a) 三個 4 連通成份 (b) 兩個 8 連通成份 圖 2-13(a)是以 4-鄰接為鄰接方式來形成 4 連通(4-connected),故二值影像可以被標 記為三個 4 連通成份(4-connected component);圖 2-13(b)是以 8-鄰接為鄰接方式來形成 8 連通(8-connected),故二值影像可以被標記為兩個 8 連通成份 (8-connected component); 依照不同的鄰接定義,會有不同連通路徑,使得同樣的影像形成不同區域大小及個數。
2.4
邊緣資訊處理
本節將介紹如何找出物體的所有邊緣,並且使物體的邊緣成為封閉邊界,最後物體 將根據此邊界而被分割成許多區塊。2.4.1 節介紹一個有效的邊緣偵測演算法:Canny 邊 緣偵測器,用來尋找物體深度資訊中的邊緣,即步階邊緣;2.4.2 節將介紹如何利用法向 量的變化,稱之法向量的梯度變化,進而找出物體曲面變化較大的邊緣,即屋脊邊緣; 2.4.3 節將介紹影像處理中的形態學運算,目的是使物體的邊緣成為封閉邊界;2.4.4 節 0 0 0 1 0 1 1 0 1 0 1 1 0 0 1 1 1 0 1 1 0 0 0 0 0 0 0 0 1 0 1 1 0 1 0 1 1 0 0 1 1 1 0 1 1 0 0 0 0 0P
P
23將介紹區域成長法,用於取得物體每個區塊中的特徵。
2.4.1
邊緣偵測
在影像分割的方法中,主要是利用影像強度值的兩個基本特性來進行影像的分割: 不連續性與相似性;其中邊緣偵測就是一種最常見的方法,是利用影像中強度值不連續 的特性來分割影像的方法。 在影像當中的邊緣往往是介於兩個區域之間且有著不同灰階強度的邊界,兩個各別 的區域可能是物體與背景或是物體與物體,使得邊緣處的灰階值變化較為劇烈,如圖 2-17 所示。 (a) (b) (c) 圖 2-14 影像邊緣之灰階與一階導數之變化 (a) 具明顯邊緣影像 (b)水平灰階變化 (c)一階導數變化 由圖 2-14(c)可以觀察一階導數的極值所在,往往是影像中邊緣出現的區域,故找出 區域導數的極值所在,即可找出區域邊緣。在數位影像中常利用梯度運算子去找出其區 域導數極值的所在,進而尋找出邊緣點,除此之外,還有灰階矩量搜尋法、鏈狀輪廓追 蹤法、空間矩量次像素搜尋法等,以下將介紹如何使用梯度運算子來搜尋邊緣的所在。 影像 上的某一點像素值 , 在 , 處的梯度向量如下式所示: x, y GG ∂ ∂ ∂ ∂ , 2.23 24 此向量的大小為 ,也是個在邊緣偵測上一個重要的量,如下式所示:, mag G G , 2.24 此梯度向量 的方向指向 , 在座標 , 改變最大率的方向上,而該點 , 梯度最大改變率之角度,如下式所示: , G G . 2.25 由於數位影像上的像素值為非連續的性質,所以在偵測數位影像的邊緣時,最常使 用的方法是使用一個空間遮罩S ,其大小是3 3,去通過數位影像 的每一點像素 x, ,去計算遮罩 S 內像素 , 的線性響應R,下式所示: R w , S , 2.26 以上列之方式來近似一階導數 G 及 G ,其中又以 Sobel 邊緣偵測器[22][26]最常 被使用,其遮罩中的係數如圖 2-15 所示。 (a) (b) 圖 2-15 Sobel 運算子 (a)計算 G (b)計算G 經由上圖所列之係數,可獲得G 及 G ,如下式所示: G 3,1 2 3,2 3,3 1,1 2 1,2 1,3 2.27 G 1,3 2 2,3 3,3 1,1 2 2,1 3,1 2.28 Sobel 邊緣偵測器計算簡單,所以常被使用在數位影像中,但是對於較弱的邊緣卻 沒辦法偵測出來,所以接下來將介紹 Canny 邊緣偵測器 [22][27],相對於 Sobel 或是其 他線性或非線性的邊緣偵測器,是一個強而有力的邊緣偵測器,可同時找出主要的邊緣 並降低不相干的細節。 -1 -2 -1 -1 0 1 0 0 0 -2 0 2 1 2 1 -1 0 1 25
Canny 邊緣偵測器的演算法說明如下: 步驟一:設定一個高斯遮罩 影像先經過一個特定標準差σ的高斯濾波器來使影響平滑且降低雜訊。高斯濾波器 為一個空間遮罩S ,大小為S S,其遮罩內的係數由中心開始往外分布為高斯函數分 布,係數由下式中的σ來決定: w e , 2.29 其中 s , t 為該遮罩S 之中心位置,而高斯函數之分布的平均值為 0,w 取整數且 ∑ , S w 1,最後該遮罩的響應R可由(2.26)式計算,其遮罩中的係數如下圖 2-16 所 示,為一個5 5高斯濾波器的遮罩,其中σ 1。 1 4 7 4 1 4 16 26 16 4 1 273 7 26 41 26 7 4 16 26 16 4 1 4 7 4 1 圖 2-16 高斯濾波器遮罩 步驟二:計算每點梯度大小 由(2.23)(2.24)式之定義計算每點之局部梯度大小,即 , ,並可用 Sobel 運算子 (2.27)式、(2.28)式算出 G 及 G 或是其他運算子算出G 及 G 並且由(2.25)式算出該 點之邊緣方向 , 。一個邊緣點 , 被定義為該梯度方向有局部最大強度的點。 步驟三:形成山脊來劃分強弱邊界 將步驟二所求得的這些邊緣點,在梯度大小影像上造成山脊,接著沿著這些山脊上 方追蹤,並將沒有真正在山脊頂點的所有點像素值為零,以便輸出中得到一條細長的線, 26
這個程序稱為非最大值的抑制(non-maximal suppression)。這些山脊像素將用兩個臨界值 T 及 T 來分界,其中T T 。若是其山脊像素的值大於 T ,會被稱為強邊界像素, 若是其山脊像素的值介於 T 與 T 之間,會被稱為弱邊界像素。
步驟四:利用連通性分析
最後利用 8 連通 (8-connected)路徑 將強邊緣像素與弱邊緣像素進行邊緣連接。 如圖 2-17 所示,分別使用 Sobel 邊緣偵測器與 Canny 邊緣偵測器於圖 2-17(a),
(a)
(b) (c) 圖 2-17 數位影像使用不同邊緣偵測器之差異
(a) 數位影像 (b)使用 Sobel 邊緣偵測器 (c)使用 Canny 邊緣偵測器
其中,可以看的出圖 2-17(c)中的邊緣,不論是弱邊緣或是強邊緣,都可以有效的找出來。 故本論文中,將使用 Canny 邊緣偵測器來偵測出深度影像中物體與物體或是物體與背景 的邊緣。
2.4.2
法向量的梯度變化
由深度資訊中可以獲得物體表面上之點所包含的資訊,藉由這些資訊可以計算該點 27之法向量、曲率或是其他資訊,來作為三維物體曲面之特徵,而這些特徵可以作為影像 分割或物體辨識時的依據,其中在影像分割的領域中,一般的二維影像分割所需的資訊 是影像像素的強度值變化作為影像分割時的依據,主要是依照像素間強度的不連續性或 是相似性來進行影像的分割,如 2.4.1 節所探討的;但是,相對於二維影像中因像素強 度值變化所造成的邊緣,在三維深度資訊中所定義的邊緣或是真實三維空間中人類肉眼 看到的物體邊緣,是因為空間中點的位置變化,即空間中曲面的法向量變化過大所造成 的,所以在三維的深度資訊中,一個物體與其他物體或是物體上本身的邊緣可分為兩種, 步階邊緣(step edge)與屋脊邊緣[21][28][29]。 因為曲面上每點深度(即距離)的不連續所造成的邊緣,稱之步階邊緣 ,如圖 2-18(c) 所示,還有因為曲面變化劇烈所造成的邊緣,即曲面上每點法向量的不連續所造成的邊 緣,稱之屋脊邊緣,如圖 2-18(d)所示。 (a) (b) (c) (d) 圖 2-18 藉由深度資訊所測量到物體之邊緣 (a) 真實物體 (b)深度影像 (c)步階邊緣 (d) 屋脊邊緣 28
然而,要獲得三維物體的步階邊緣,只要將深度影像中的深度值替換成原來二維影 像中的強度值,再用 2.4.1 節中的 Canny 邊緣偵測來尋找深度影像中物體的邊緣;然而, 本論文提出一個有效且抗雜訊的偵測屋脊邊緣之方法;首先,要偵測到三維物體的屋脊 邊緣,如圖 2-18(d)所示,首先必須要取得深度資訊中每點的法向量,再利用每點與鄰近 點法向量的變化,計算出每點所對應的梯度大小,以獲得梯度影像。 首先,由 2.1.1 節可獲得深度影像所對應的法向量陣列,如下式所示: 2.30 其中 為深度資訊中每個點 對應的法向量,對法向量陣列使用一個空間遮罩 S ,其中遮罩下所對應的中心為 ,其大小S S,以 3 3的遮罩為例,如圖 2-19 所示。 ( 圖 2-19 3 3的遮罩內的係數與對應的法向量 (a)係數 (b)法向量 a) (b) 利用下式來計算每一點 的梯度值為 G G 1 S 1 , S T , γ 0 , 2.31 若 G 越接近 1 表示S 所對應之區域,越有可能是兩平面的交接處,反之若 G 越接 近 0,則表示S 所對應之區域是一個平面。 將遮罩 S 對法向量陣列中的每一點使用(2.31)式,就形成了梯度影像 (gradient image) G ,將法向量之梯度影像顯示在三維座標,可由圖 2-20 可看出屋脊邊 1 1 1 1 1 1 1 1 1 29
緣所在,即梯度變化大的點所形成之邊緣。 圖 2-20 法向量的梯度變化 (2.31)式主要計算遮罩中的每一點之法向量 與中心的法向量 ,兩者的內積 的絕對值再乘上 γ 次方,然後再計算此值與內積最大值 1 的差距,即1 | T | , 如果 1 T 很小,表示此兩點幾乎在同一平面上,如果很大,表示這兩點在 不同平面上。對 T 取絕對值,一方面是為了避免 T 小於 0 時,使得此數 列 1 T , S 分布在 0 的兩側時,之後再取平均值,其平均值可能很接近 0, 使得遮罩中心可能與其他點在不同的曲面,但最後該點的法向量之梯度值卻很接近 0, 導致做邊緣偵測時無法偵測到此點。此外,當 γ 很大時,梯度影像中的梯度值變化劇 烈的點數目會變多,使得在偵測屋脊邊緣時,邊緣的點數目也會變多,使得物體的屋脊 邊緣細節過多,由圖 2-21 所示,故一般而言,選擇 γ 1, 2 即可。 (a) (b) (c) 圖 2-21 不同的γ值使得屋脊邊緣細節改變 (a)γ 0.5 (b)γ 2 (c)γ 10 30
2.4.3
形態學運算
形態學運算(morphological operator) [22][25][30]在二值影像(binary image)中的主要 應用在於抽取對於適合描述形狀有用的影像成份,例如:抽取出其邊界、連通成份、凸 形封包以及區域骨架的形態,也應用於影像的前級與後級處理,例如:形態學濾波、細 線化以及剪除,而形態學運算除了用來處理二值影像,也可處理灰階強度影像。本論文 將會使用形態學處理其二值影像,故只介紹二值影像之形態學運算。
形態學是一種從二值影像 中的抽取出物體成分的工具,是由結構元素
(structuring element)來進行運算,如圖 2-22 所示,其中膨脹(dilation)與侵蝕(erosion)是形 態學運算中的兩個最基本的運算,許多形態學演算法都是建立在這兩個原始的運算上, 故首先介紹膨脹與侵蝕。 (a) (b) 圖 2-22 二值影像與結構元素 (a)原本二值影像 (b)結構元素 膨脹是一種使二值影像 中的物體增大或是變厚,就是使物體向外擴充,在數學 上是以集合運算的方式來定義, 藉由 膨脹記為 ,如下式: , 2.32 用圖 2-23 來說明其過程,結構元素 的中心在整個二值影像內平移,若結構元素內的 點於物體上的部分點重疊,將會使物體上的點向物體外部膨脹,虛線是膨脹後的邊界。 31
(a) (b) 圖 2-23 二值影像的膨脹過程與結果 (a)二值影像進行膨脹 (b) 膨脹後的二值影像 侵蝕是一種使二值影像 中的物體收縮或是變薄,使物體向內收縮,收縮的方式 也是由結構元素 所控制,在數學上也是以集合運算的方式來定義, 藉由 侵蝕 記為 ,如下式所示: 2.33 用圖 2-24 來說明,結構元素 的中心在整個二值影像內平移,若結構元素內的點於物 體上的所有點重疊,將會使物體上的點向物體內部收縮,虛線是侵蝕後的邊界。 (a) (b) 圖 2-24 二值影像的侵蝕過程與結果 (a)二值影像進行侵蝕 (b)侵蝕後的二值影像 在影像處理中,應用膨脹與侵蝕這兩個基本形態運算子的組合,形成其他的形態學 演算法,本論文將會使用形態學上的閉合(morphological closing)以及形態學上的收縮 (morphological shrinking),來處理邊界資訊。 形態學上的閉合,是將二值影像 先以結構元素 進行膨脹再進行侵蝕,如下 式所示 32
2.34 可以使物體的輪廓平滑,使窄的中段部分連接起來,填補細常缺口等功能,如圖 2-25 所示。 圖 2-25 閉合後的二值影像 形態學上的收縮[30],主要的概念就是將二值影像中,沒有洞的物體收縮成點,有 洞的物體收縮成環狀;此外,物體經過形態學的收縮處理後,依舊滿足尤拉數(Euler number)公式,例如:將圖 2-22 的二值影像,經過 n 次的收縮處理後,最後結果如圖 2-26 所示。 (a) (b) 圖 2-26 收縮 n 次的二值影像 (a) n=20 (b) n=50
2.4.4
區域成長法
區域成長(region growing)[22]是單一像素或是子區域根據預先定義的準則,然後成 長成更大區域的過程。基本的方法是從一組種子點出發,把每個種子點具有相同性質的 鄰近點像素添加進來一起進行區域成長。 33 假設一個影像區域 可以根據某種準則分割成 N 個不同的子區域 , 為第個子區 ,域 使得 , , , , , N ,會滿足下列式子: (a) N 。 (b) 是連通的區域, 1,2, , N。 (c) , 。 (d) True, 是屬性,表示子區域 都具有相同的屬性。 (e) False , 。 本論文將會基於 2.4.3 節所提過的形態學運算以及 2.3.2 節連通性分析等概念,使用 形態學重建(reconstruct)來進行區域成長的動作,並以像素之間的 8 連通作為準則,將二 值影像中的區域 分割成 N 個不同的子區域,並且取出這些子區域來計算其對應的 三維特徵,以進行三維物體辨識。 形態學重建必須使用兩張影像以及一個結構元素 ,其中一張影像作為標記 (marker)使用,以 表示之,另外一張原始影像 作為遮罩使用,以 表示之, 其重建步驟如下: 將初始種子點以隨機的方式撒在影像區域中,並標記初始種子點的位置,使其成為 初始標記影像 ,令初始遮罩為原始影像,即 ;此外產生一個結構元素 。 然後進行下列步驟,從 1開始。 步驟一:將影像種子點的位置變成標記影像 ,從 1開始 隨機撒一個種子於遮罩影像 中,對該種子點進行標記其遮罩影像中的位置,產 生其標記影像 。 步驟二:形成下一張標記影像,以取代原本的標記影像 首先,利用結構元素對標記影像進行形態學膨脹,滿足下式: , 2.35 持續重覆步驟二,直到滿足 ,其中最後的標記影像滿足 ̂ ,即完成該 子區域 的區域成長。 步驟三:重新進行區域成長 於 區 34 法 其他 域 重新定義其遮罩影像 ̂,即後來的遮罩影像 是原來的遮罩影
像 跟標記影像 ̂ 的差集,然後再重覆步驟一,並且 1,直到最後所有的 標記影像的聯集為一開始的原始影像,當區域成長完畢時,會滿足下式: ̂ N , 2.36 其中,為了重建快速,本論文採用了 Vincent [31]提出的快速混合重建法為基礎,來進 行上列演算法的步驟二,以加快重建區域的速度。