國立高雄大學資訊管理學系碩士班
碩士論文
運用文本探勘技術於基於人格特質之遊戲推薦之研究
Game Recommendation by Personality Traits Using Text
Mining on Game Reviews
國立高雄大學資訊管理學系碩士班
研究生:黃梓瑞 撰
指導教授:楊新章 博士
誌謝
本篇一開始的起頭當然只能先說,沒想到我這個蠕蛇竟然能死撐拖著我這瘸 子般的身軀來走到碩士里程碑的盡頭,自己都覺得難以置信。但在碩二下最後這 一階段的途中遇到實在是讓人不得不七竅生煙的事情,我想這種這麼荒謬的事情 大概是高大資管中有史以來第一個被我碰上的。至於是什麼可怕的事情會讓人生 氣又無助呢?當然就是某語言機構該死的無法判讀啥 Bird 機制,除了封殺小人 之外,連君子也一起封殺,不分清紅皂白的定罪生死狀實在是讓人難以啟齒。 雖然不能全把論文進度都歸咎在這件事情上面,但是這實在是會整個影響到 讓人全心全意去完成一件事情(論文)的動力與心情,我覺得我就是真的徹底的被 這件事情所影響!在此也奉勸若碰巧有在看小弟這篇抱怨文的各位學弟妹們,切 記,趕快先去把英文門檻先考到後再來煩惱論文吧!千萬別拖到碩二才來考,不 然可能除了要擔心分數未達系上門檻(主線關卡)之外,還可能會有分數無法判讀 (支線關卡、副本關卡)讓你需要累積更多經驗值才能升等。 抱怨文打完了,接下來就得來好好的闡述碩班生活中由始至終的點點滴滴了。 從碩一的菜鳥迎新活動起頭,那時候的我抱著既期待又害怕受傷害的心情進到了 高大資管碩士班。從迎新中已經跟部分的同學與學長姐們有了初步的談話,從一 開始學長姐的立德、柏翰、阿 C 還有同梯同學們的神父、Ray,從談話中也有了 初步的彼此認識。 迎新活動完後,接著就是系上招生活動的事情,那時候我不知道我為什麼會 自告奮勇的突然想自願去畫電子文宣招生海報這件事情,就是有一股聲音在呼喊 著我,叫我一定要去亂搞一下,哈哈!不過透過了這種額外的機會,我覺得的確 有讓我學到更多東西。招生這件事讓我最印像深刻的就是印海報文宣金費收據核 銷日期 deadline 的事情了 XD,還記得某一天我跟 Ray 一起飆車殺去高應大附近 拿招生海報加吃便當。比較悲慘的事情就是收據拿錯啦!好在之後被 Ray 處理 掉了,真的是辛苦你當了招生總召這個職位了,還有招生影片的剪輯 XD。 除了碩一的招生活動之外,還有特別有趣的研究所課程正如火如荼且並駕齊 驅的進行著,先從大俠的研究方法課程開始說起。從這堂課的進行中就不知不覺 就出現了許多有趣的綽號,像是院長、邪惡神父、義大利人、養鳥ㄏㄨㄟ、還有 我的抓頭臺北市市長,哈哈!從大俠的研方課程中除了該學的東西之外,大俠也 不時的將許多生活上實用的點子傳授給我們,至於比較羞愧的部分大概就是我研 方期中考分數實在很糟 XD,糟到連我自己都無法形容,實在是感謝大俠刀下留 人,不然我今天可能就離不開高大了。除此之外也非常感謝大俠在這兩年總是不 斷給我勉勵的話,不過我自身覺得我一直是滿身缺點的人,沒想到大俠您還是有 辦法在我身上找到可以讚美我的話 XD,真的是非常感謝您!也感謝您總是在背 後默默幫助著我,我已七孔流淚! 除了研究方法課程外,還有碩一時候最精彩的電子商務課程,謙虛昂貴的出 現果然不虛此行啊!雖然中途發生了實在是令人感到丟臉的事情,不過,從這堂課中最後終於給了我重新證明自己的機會。也非常感謝凱西在碩一這一年來給了 我非常深刻的回憶與震撼教育 XD,還有給了我許多課程與同學們之間的協助溝 通與幫忙。 接下來就是雄哥的天馬行空之資訊科技與競爭策略課程了,不過說真的,感 覺跟雄哥的接觸機會只有在碩一的時候,之後好像就都不見了 XD,這堂課雄哥 允許我們胡思亂想,來激發我們對於資訊相關的想法與點子。一開始比較可怕的 還是雄哥常常會拿著麥克風突然衝到自己面前來希望我們分享自己的想法 XD, 我想,這就是一種訓練,在進來研究所之後就發現這種機會是無時無刻都有的, 一開始雖然會害怕開口,不過真的越來越多次之後,真的就會變比較不會害怕開 口了,這部分在研究所真的我覺得是有改善的,不過在系上好像幾乎不常看不到 雄哥的蹤影,真的是來無影去無蹤的雄哥啊! 接下來就是我老闆的技術課程囉!修到自己老闆的課也同時為論文技術的 部分奠定了基礎,也非常感謝我老闆竟然能這麼肯定我的技術能力,我自己都有 點感到吃驚。除此之外,在論文題目雛型的部分,真的非常感謝我老闆在我快掉 入奈落深淵的時候拉了我一把,讓我順利找到了自己有興趣的論文題目。說到論 文,在最後程式與實驗還有結論的部分大約耗時 2 個月的時間來爆肝結束掉它。 在這兩個月的時間,已經跟學校的實驗室培養了非常良好的感情,看了無數 次的美好日出、與廁所該死的蟑螂共舞、還有廁所旁垃圾桶與肥大老鼠的邂逅, 最後終於到了口試完畢。這段日子雖然有點累,不過也累得很興奮,在這當中累 積了許多技術實作完成的成就感,也慶幸自己順利的完成了口試。實在是非常感 謝謝謝謝謝謝謝謝謝謝謝謝謝謝謝謝謝謝謝謝無數謝我的老闆新章對我這麼好, 還能盡快放我走 XD,也不好意思麻煩您非常忙碌的時後還得抽出時間來跟我開 會,老師,感謝您啊!當您的旗下門徒,真的是非常值得! 接下來要說到 James Wu 老師,曾經在我們碩一全英文的 MIS 中授課,非常 感謝您可以在我報告時候給予許多的觀念提示,讓我才有辦法在說英文冏掉的時 候能再硬是擠出一些英文來解釋報告的內容 XD。碩一的時候有您這位老師當我 們的班導真的感覺蠻有趣的,每次一出來聚餐您就是有辦法一開口跟我們聊到有 趣東西,雖然碩二的時候就比較沒辦法有機會遇見您,不過我想有碩一時候還有 拍畢業時的回憶,這對我來說真的就非常足夠了。 與班上同學相處的部分可以說的就更多了,我想在我求學的過程中,讓我感 到最快樂的時刻就是在這 2 年的碩班與你們相處的日子,每一點每一滴至今仍是 記憶猶新。從送舊、一起出遊、系友回娘家,累積了無數的美好回憶,接下來就 來好好的為班上同學一個一個來點評與給予離別送詞囉! 首先就是 Ray,從碩一到現在,我覺得應該真的可以跟你成為兄弟了吧!一 起經曾經共同歷過了不知道多少的考驗與奮鬥 XD,還有發瘋似的不停互揪打籃 球以及桌球的時刻。各種患難都曾經一起經歷度過,尤其是該死的多益。不過有
一起熬過來了,也祝你趕快順利改好論文拿到畢業證書離開這裡,未來一年後有 空再一起約出來啊!也期待你的民宿夢想能如其實現!我一定會去包宿的,哈 哈! 接下來就是順利第一個離開的宛儀了,這兩年與你相處的過程中,在許多的 課程與活動的小細節中都能發現到妳對一些事物的堅持與信念,很有自己的個性 以及想法,我想這部分也正是我有所欠缺必須更加學習的。在這兩年之中,也在 不少地方明明是不經意發生的小錯誤事情也能成為我的笑點 XD,對不起對我來 說真的很好笑,哈哈!也祝福您在自己的工作上能更順利的發展下去,適時調適 自己的心情奮鬥下去,希望 3 年後有機會在高雄一起撞見,哈哈! 亮蓁與家慧的部分我想還是要先祝福妳們能趕快順利口試完畢!亮臻這兩 年給我的感覺就是個一直在默默奮鬥低調型個性的人,雖然我好像跟妳比較少有 互動,但還是有辦法見到面就找到話題聊 XD,也祝妳未來能找到理想的工作與 發展順利!家慧的話,非常抱歉之前常常用 FB 一直亂貼一些東西給妳 XD,也 非常感謝妳沒有對我生氣,哈哈!這兩年中有時候也會從一些地方上發現你總是 在偷偷的竊笑,呵呵,不要以為我不知道,因為我也會偷偷的竊笑,也祝福妳未 來可以找到理想的工作,當然啦!找到的工作有跟鳥有關係是再好不過了,希望 找妳買鳥能給個折扣,哇哈哈! 接下來就是常常一起出去的餐友建廷,雖然你跟雄哥也是來無影去無蹤的一 個傢伙,哈哈!跟你碰面總是有無止盡的話題可以一直聊,不管是吃菜包還是吃 剉冰還是吃便當,吃什麼就是有話題可聊,這實在是讓我感到非常有趣,從這兩 年中觀察後也知道你是一位非常熱於助人的好好先生,但是該出現的時候還是希 望你要出現啊!也祝福你最後能順利離開高大!未來再約! 然後最後就是院長啦!大學跟妳是同校的沒想到研究所竟然變成同班了,呵 呵!碩一的時候好像都比較少跟妳有互動,似乎是碩二開始的時候才突然變多的。 碩一的時候妳好像沒有很調皮搗蛋,不過自從碩二的時候調皮搗蛋的情形似乎有 變頻繁了,結果到了現在真的是調皮搗蛋。不過還是要稱讚妳好的一面,從妳來 問我一些問題或是在面對重重關卡的時候妳總是打破砂鍋問到底這點精神以及 願意努力嘗試的決心真的很令我欽佩。有一段時間因為我在煩惱英文的事情,所 以心情可能不是很穩定,如有冒犯到請見諒,哈哈!除了這些以外的許多細節中 也能仔細觀察的出來妳的確是個好女孩,或許以前就是好女孩了,呵呵!也祝福 妳能趕快順利的到自己所理想的工作崗位上奮鬥,期待未來有緣再相見!對了, 還有我不吃牛,ㄎㄎ。 雖然並沒有所有人都全部提及,但沒有提及的人我也很非常的感謝在這兩年 與你們相處的時光,打了很多有點累了,接下來就是要正式出社會面對該面對的 職場生活了,也祝福自己希望能活著回來,I will be back!
黃梓瑞 謹致於 中華民國一零五年九月
運用文本探勘技術於基於人格特質之遊戲推薦之研究
指導教授:楊新章 博士 國立高雄大學資訊管理學系 學生:黃梓瑞 國立高雄大學資訊管理學系碩士班摘要
隨著社群網路服務的發展熱絡,進而形成了多元化的經營模式,人們透過不 同的社群網路服務來進行文章評論的發表,發表自己對於產品、任何事物的感受 或看法,經由時間的日積月累,如今已醞釀出了龐大的文字資料。在這些龐大的 文字資料中,至今還埋藏著許多有用的知識與價值。從這些文字資料發展出了許 多不同的應用,推薦系統就是其中一項資訊過濾的應用。 推薦系統目前已被廣泛的應用在不同領域,尤其是在商品推薦的領域應用上。 使用者不可能總是一直花費大量的金錢、時間去嘗試每一種商品。商品推薦系統 出現的主要目的,就是為了解決如何在有限的時間之中,幫助使用者找出哪些可 能是適合使用者的商品。 目前一般的推薦系統大多都是著重於依使用者的個人喜好、偏好之間的相似 度作為推薦依據。近期出現一種新的推薦方式,也就是依使用者的人格特質相似 度的方式來進行推薦,但目前所提方法仍有許多問題需要改進。 本研究將結合社群網路的評論文本資料與人格特質建立一套新的推薦技術。 本研究亦針對所提之人格特質探勘方法以及推薦技術進行評估,實驗結果顯示本 研究之基於人格特質之推薦方法具有不錯的成效。 關鍵字:人格特質、文本探勘、推薦系統、遊戲評論、巨量資料Game Recommendation by Personality Traits Using Text
Mining on Game Reviews
Advisor: Dr. Hsin-Chang Yang Department of Information Management
National University of Kaohsiung
Student: Zi-Rui Huang
Department of Information Management National University of Kaohsiung
ABSTRACT
Nowadays, common recommendation systems generally recommend resources according to users’ preference. Some approaches, however, adopted different aspects such as personality traits for recommendation. The general recommendation systems base on user's preference are changed to be the recommendation systems base on user's personality traits by some early studies. In this work, we proposed a novel method for resource recommendation based on personality traits using text mining technique on social comments. This study also assessed for personality traits mining methods, and recommended techniques mentioned. The results of this study show that it has good results. We hope this study can improve current personality-based recommendation systems.
Keyword:Personality Traits, Text Mining, Recommendation System, Game Review,
目錄
第一章 緒論... 1 1.1 研究背景... 1 1.2 研究動機... 3 1.3 研究目的... 5 第二章 文獻探討... 6 2.1 人格特質... 6 2.2 人格特質與遊戲之間的關係... 7 2.3 五大人格特質相關的應用與研究... 9 2.4 推薦系統... 10 2.4.1 基於內容(Content-Based)推薦方法 ... 10 2.4.2 協同過濾式(Collaborative Filtering)推薦方法 ... 10 2.5 小結... 10 第三章 研究方法... 11 3.1 研究架構... 11 3.2 遊戲資料的擷取... 12 3.2.1 利用網頁爬蟲進行資料擷取... 14 3.2.2 遊戲的評論擷取數量限制與過濾... 15 3.3 資料前置處理... 17 3.3.1 斷詞... 17 3.3.2 字詞淨化... 18 3.4 人格特質計算方法... 18 3.4.1 文本文件向量化... 19 3.4.2 LIWC 英文版字詞詞典 ... 19 3.4.3 Mairesse 人格特質計算方法 ... 19 3.4.4 TF-DF 人格特質計算方法 ... 23 3.4.5 本研究提出之人格特質計算方法... 24 3.5 遊戲人格特質計算... 24 3.5.1 遊戲人格特質向量空間模型... 26 3.6 使用者人格特質計算... 28 3.6.1 受測者文本資料... 29 3.6.2 LIWC 中文版本字詞詞典 ... 29 3.6.3 使用者人格特質向量空間模型... 29 3.7 遊戲人格特質總分計算結果之對映方法... 32 3.8 遊戲推薦... 364.1 研究資料之結構化搜集... 42 4.2 研究資料前置處理與字詞屬性種類選取... 44 4.3 資料向量化與研究方法分數計算... 45 4.4 實驗評估... 49 4.4.1 實驗流程第一階段... 50 4.4.2 實驗流程第二階段... 55 4.5 實驗結果評估... 56 第五章 結論與分析... 63 5.1 結論... 63 5.2 研究限制... 63 5.3 未來研究... 64 參考文獻... 66
圖目錄
圖 1-1: 2014 年第 3 季全球知名社群網站的使用率排名統計圖 ... 2 圖 1-2: 2015 年第 2 季財報 Facebook 官方月活躍使用者人數統計圖... 2 圖 1-3: 依使用者的偏好或喜好來進行推薦之實際案例 1 ... 3 圖 1-4: 依使用者的偏好或喜好來進行推薦之實際案例 2 ... 4 圖 2-1: 人格特質與遊戲偏好之相關係數分析圖表 ... 8 圖 3-1: 研究架構圖 ... 11 圖 3-2: 遊戲資料擷取概要圖 ... 12 圖 3-3: 一款遊戲所包含的屬性標籤實際範例 ... 13 圖 3-4: Steam 遊戲名稱與 ID 的 JSON 檔案輸出結果 ... 14 圖 3-5: 利用 import.io 平台進行 Steam 遊戲資料的批次查詢轉換 ... 15 圖 3-6: Steam 遊戲的玩家評論資料裡所有屬性內容結構化轉換結果 ... 15 圖 3-7: Steam 遊戲具有幫助性的評論過濾實際案例 ... 16 圖 3-8: 資料前置處理概要圖 ... 17 圖 3-9: CKIP 斷詞系統進行英文例句斷詞後結果之實際範例 ... 18 圖 3-10: 人格特質計算方法概要圖 ... 18 圖 3-11: 向量空間模型圖 ... 19 圖 3-12: LIWC 與五大人格特質之皮爾森相關係數第 1 部分資料圖 ... 21 圖 3-13: LIWC 與五大人格特質之皮爾森相關係數第 2 部分資料圖 ... 22圖 3-14: Personality Recognizer Tool 輸出分析後結果的實際範例 ... 22
圖 3-15: 遊戲人格特質計算詳細流程圖 ... 25 圖 3-16: 遊戲的部分屬性標籤實際範例 ... 26 圖 3-17: 遊戲內容之向量模型 ... 26 圖 3-18: 遊戲人格特質總分之向量模型 ... 27 圖 3-19: 遊戲人格特質總分搭配遊戲內容之向量模型 ... 27 圖 3-20: 遊戲人格特質所屬的人格特質總分向量模型 ... 27 圖 3-21: 使用者人格特質計算詳細流程圖 ... 28 圖 3-22: 使用者挑選的遊戲人格特質總分之向量模型 ... 29 圖 3-23: 受測者挑選的遊戲人格特質總分搭配遊戲內容之向量模型 ... 30 圖 3-24: 受測者所提供文本資料的人格特質總分向量空間模型 ... 30 圖 3-25: 使用者人格特質所屬的人格特質總分向量模型 ... 31 圖 3-26: 某款遊戲發表評論的玩家發表過的所有文章總數連結 ... 32 圖 3-27: 某款遊戲發表評論的玩家個人檔案 ... 33 圖 3-28: 某款遊戲發表評論的玩家發表過的所有文章瀏覽頁面 ... 33 圖 3-29: 對映方法 1 ... 34
圖 3-32: 推薦方法一的雙方人格特質總分之間的相似度計算 ... 37 圖 3-33: 推薦方法二的雙方人格特質總分之間的相似度計算 ... 38 圖 3-34: 推薦方法三的雙方人格特質總分之間的相似度計算 ... 39 圖 3-35: 所用方法組合最後呈現出來的結果數目 ... 40 圖 3-36: 推薦結果的呈現 ... 41 圖 4-1: JSON 格式檔案匯出... 43 圖 4-2: 評論字詞過濾與斷詞後之結果 ... 45 圖 4-3: tf-idf 向量化字詞字典 ... 46 圖 4-4: tf-idf 評論向量化後計算結果 ... 47 圖 4-5: LIWC 五大人格分數維度向量字典 ... 48 圖 4-6: 每一款遊戲所對映的人格特質分數與屬性標籤 JSON 檔內容... 49 圖 4-7: 遊戲推薦受測系統註冊與登入畫面 ... 50 圖 4-8: 受測者挑選喜愛或有興趣遊戲之遊戲清單畫面圖 ... 51 圖 4-9: 遊戲檢索系統畫面圖 ... 51 圖 4-10: 選擇開始進行遊戲推薦畫面圖 ... 52 圖 4-11: 推薦結果畫面圖 ... 53 圖 4-12: 推薦結果評估畫面圖 ... 54 圖 4-13: 文字評論檔案上傳畫面圖 ... 55 圖 4-14: 各方法整體滿意度平均分數 ... 56 圖 4-15: 各方法整體推薦遊戲屬性偏好相似度平均(僅考慮到人格特質分數推薦) ... 58 圖 4-16:全部 18 種推薦結果滿意度分數趨勢 ... 59 圖 4-17:全部 18 種推薦結果遊戲屬性偏好趨勢 ... 60 圖 4-18: 實驗流程第一階段推薦結果滿意度分數趨勢 ... 60 圖 4-19: 實驗流程第一階段推薦結果遊戲屬性偏好趨勢 ... 61 圖 4-20: 實驗流程第二階段推薦結果滿意度分數趨勢 ... 61 圖 4-21: 實驗流程第二階段推薦結果遊戲屬性偏好趨勢 ... 62
表目錄
表 4-1: 資料集數量統計表 ... 43 表 4-2: 2050 款遊戲的前 20 名屬性分類標籤數量統計表 ... 43 表 4-3: LIWC 字詞屬性使用數量統計表 ... 44 表 4-4: 受測者數量統計表 ... 50 表 4-5: 人格分數對映方法一(以評論對映)滿意度平均分數統計表 ... 56 表 4-6: 人格分數對映方法二(以評論作者對映)滿意度平均分數統計表 ... 56 表 4-7: 推薦方法一(以遊戲總分)滿意度平均分數統計表 ... 57 表 4-8: 推薦方法二(以遊戲總分搭配屬性標籤)滿意度平均分數統計表 ... 57 表 4-9: 推薦方法三(以使用者文字評論回饋資訊)滿意度平均分數統計表 ... 57第一章 緒論
1.1 研究背景 近年來,社群網路服務發展的熱絡形成了多元化的經營模式。線上虛擬社群 的社會互動(Social Interaction)目前已處於相當活躍的狀態,人們透過分享與交換 訊息的方式來增進彼此的熟悉感與親密感。不同社群網路的服務公司透過獨特創 新的服務功能優勢吸引了大量使用者註冊使用,服務功能從基本的部落格文章發 表到與多媒體的結合,進而發展出了多元的多媒體社群網路服務。根據英國市場調查研究機構 Global Web Index (2015)發表的 2014 年第三季社 群網路研究報告 [1]指出了全球知名社群網站的使用率排名,如圖 1-1 所示;粉 紅色長條的部分代表為「一天之內登入次數超過一次以上」;紫色長條的部分代 表為「一天之內登入次數只有一次」;深藍色長條的部分代表為「一週之內登入 次數只有一次」;淺藍色長條的部分代表為「登入次數比一週之內登入次數只有
一次還要更少」。一天之內登入次數超過一次以上使用率的第一名為 Facebook(參
考網址: https://www.facebook.com),Twitter(參考網址: https://twitter.com)則緊接在 後,不僅如此,根據 Facebook (2015)年第二季財報統計 [2]指出了每月活躍之使 用人數最高已達 14 億,由此可知,Facebook 等社群網站已成為被大眾廣為使用 且深具影響力的社交媒介。 其中最著名應屬 Facebook。Facebook 為 2004 年所推出,發展至今已推出多 樣化的功能,人們可以利用 Facebook 的功能來針對一些議題發表評論或是心情 記事、到好友的塗鴉牆進行評論的發表、轉貼自己有興趣的文章連結到塗鴉牆上、 對文章點讚、上傳相片或影片、聊天室即時訊息的傳達、社團還有粉絲專頁的成 立與加入等等。 自從一般社交類性質社群服務網站的興起後,多媒體社群網路服務網站也如 雨 後 春 筍 般 的 出 現 , 像 是 以 影 片 串 流 服 務 為 主 的 YouTube( 參 考 網 址 : https://www.youtube.com),還有以單機遊戲電子商務為主遊戲類的 Steam(參考網 址: http://store.steampowered.com)這些多媒體社群網路服務網站。 社群網站的使用者們,經常透過社群網站的文章評論發表功能來發表自己對 於產品、任何事物的感受或看法,經由時間的日積月累,如今,已醞釀出了龐大 的文字資料,從這些文字資料中發展出了許多不同的應用,推薦系統就是其中的 一項應用。在這些龐大的文字資料中至今還埋藏著許多不為人知有用的知識與價 值正等待著人們透過不同的探勘技術方法去挖掘出來。
圖 1-1: 2014 年第 3 季全球知名社群網站的使用率排名統計圖 (資料來源: [1])
圖 1-2: 2015 年第 2 季財報 Facebook 官方月活躍使用者人數統計圖 (資料來源: [2])
1.2 研究動機 在這資訊爆炸的時代,人們透過資訊檢索系統來進行資訊過濾(Information Filtering)的輔助以快速取得正確所需的目標資訊。現在一般最常見的資訊過濾應 用系統就是所謂的推薦系統(Recommender System),推薦系統目前已被廣泛的應 用在不同領域,尤其是在商品推薦的領域應用上。商品推薦系統出現的主要目的, 就是為了解決如何在有限的時間之中,幫助使用者找出哪些可能是適合使用者的 商品這個問題,使用者不可能總是一直花費大量的金錢、時間去嘗試每一種商品。 商品就如同所謂的資訊一般,在茫茫大海的商品中,找出適合使用者的商品並推 薦給他們。 現在的推薦系統幾乎都是著重於依照使用者的個人喜好、偏好之間的相似度 作為推薦依據,以遊戲的推薦系統舉例來說可能有下列方式: (一) 遊戲玩家 A 曾經玩過以下三款遊戲,第一款為惡靈古堡、第二款為戰慄時 空、第三款為絕地要塞,而另一名遊戲玩家 B 玩過的三種遊戲第一款為惡 靈古堡、第二款為戰慄時空、第三款為俠盜獵車手。若依據這樣的情況來進 行推薦,系統會將遊戲玩家 A 沒玩過的俠盜獵車手遊戲推薦給遊戲玩家 A, 而遊戲玩家 B 則是會將其沒玩過的絕地要塞遊戲推薦給遊戲玩家 B。 (二) 遊戲玩家 A 常常玩動作類的遊戲,推薦系統會推薦其還沒玩過的其他動作
類的遊戲給遊戲玩家 A,而不會推薦其他類型的遊戲給遊戲玩家 A。在 Steam 系統中的實際推薦案例如圖 1-3 與圖 1-4 所示。
圖 1-3: 依使用者的偏好或喜好來進行推薦之實際案例 1 (資料來源: [3])
圖 1-4: 依使用者的偏好或喜好來進行推薦之實際案例 2 (資料來源: [3])
早期的研究有出現一種不同的推薦方式,就是將以往只著重於依使用者的個 人喜好、偏好之間的相似度作為推薦的方式改為依使用者的人格特質相似度的方 式來進行推薦。例如 Roshchina & Cardiff [4]便將 Mairesse et al. [5]提出的人格特 質文本探勘之方法與 KNN 相似度演算法作結合而產生了一種基於人格特質的推 薦方式,並且利用了旅遊評論平台 TripAdvisor 上的評論文本資料建構出了一套 基於人格特質飯店推薦系統的應用。 在人格特質的偵測研究上,目前已有研究提出了以文本探勘進行人格特質偵 測的方法[5] [6] [7] [8] [9]。這些研究進行人格特質分析的分類面向皆是採用目前 廣為接受的五大人格特質分類面向[10],即外向型、順從型、開放型、謹慎型、 與神經質型。 Mairesse et al. [5]提出的人格特質文本探勘之方法中,利用到了皮爾森相關 係數分析法(Pearson's Correlation Coefficient),分析出了不同種類的字詞類別與五
詞權重,然後再把所有類別每個字詞出現頻率的重要程度權重 TF-IDF(Term Frequency Inverse Document Frequency)一併考慮,將這兩者結合後算出人格特質 的總分再來進行推薦,並且再將推薦系統加入新的人格特質對應的方法與新的要 素。
有許多推薦系統的研究所應用的領域都聚焦在電影或是音樂的推薦上,針對 遊戲領域之推薦系統的研究較少。事實上,Johnson et al. [11]及 Zammitto & Dipaola [12]的研究已經證明了遊戲跟人格特質之間是有關係的。所以本研究將運 用知名的遊戲社群平台 Steam 上的社群資料並依照人格特質間的相似度來進行 遊戲的推薦。 除了提出新的人格特質文本探勘的方法以外,本研究會再將所提之方法與另 外兩種既有方法分別實作成推薦系統,並且評估分別使用這三種人格特質文本探 勘方法進行推薦後的推薦可行性。 1.3 研究目的 綜合以上所述,本研究之主要目的如下: (一) 發展一遊戲領域之人格特質為依據之推薦方法。 (二) 提出一種新的人格特質文本探勘方法。 (三) 評估所提方法與既有方法之推薦可行性。 (四) 評估不同之人格特質特徵對映方法之可行性。
第二章 文獻探討
2.1 人格特質 本研究將會採用五大人格特質的面向來為文本資料進行分類,在此概略介紹 五大人格特質的發展由來。人格特質(Personality Traits)在心理學領域中的發展已 經行之有年,心理學家們透過不同的構面方法加以區分人格特質的種類。至今, 已經發展出了成熟的方法將人格特質加以定義區分。人格特質已被廣泛的應用在 不同領域上,其中一項就是職場上的應用。人格特質的人格量表是最常被用來作 為是甄選人才的一個檢測的工具,因為已有研究證明了人格特質與工作績效確實 是有關聯性存在的[13]。「人格」一詞的英文為「Personality」,1990 年 Hergenhahn 的著作一書(An Introduction To Theories Of Personality)中內文提到了「Personality」一詞最初起源
於拉丁文的「Persona」所被延伸出來的,「Persona」拉丁文一詞的意思指的是古 希臘戲劇演戲時候的演員所穿戴的臉譜面具,不同的演員扮演著劇本中不同的角 色,也戴著不同角色所代表的臉譜面具,透過不同的角色定位,表達出不同角色 所代表的特殊行為模式與其風格,因為這樣的緣故,所以當初對人格特質定義成 「每一個不同的人類,各自戴上不同角色定位的臉譜面具後,所產生的特殊角色 與行為模式」[14]。 從現實生活中的周遭環境來觀察的話,我們可以很輕易的聯想到,我們身旁 的朋友,每個人都擁有不同的人格,有些人是比較內向的;有些人是外向的;有 些人是情緒比較起伏不定的;有些人是比較隨性的,諸如此類,甚至可以聯想到, 有著某種屬性人格特質的人,在文字書寫與開口說話的用字遣詞表達上,就會帶 給別人某種人格特質風格的感受。每個人都戴著屬於自己獨一無二的角色面具一 般,有著不同的人格,更反映出了每個人不同的行為模式。 早期的心理學家利用了特質理論來對人格進行描述,2003 年 Saul 的著作一 書(Psychology)中內文提到了特質理論為研究人格的一個最主要的方法,主要的 目的在於測量「特質」。「特質」一詞被定義為行為、思想、情緒的所表達出的慣 性模式。特質以時間週期的角度來說是相對較穩定的,有些人是外向的;有些人 是內向的。個體與個體之間的特質是不同的,會影響其行為的表達結果。1993 年 Pervin 的著作一書(Personality:Theory And Research)中認為人格是由一系列的 人格特質所組成的,也就是說,特質為人格的基本組成單位,一個人類長期、持 久所表現出的不同行為特點就稱為「特質」[15]。
1963 年的心理學家 Norman 對人格特徵進行因素分析(Factor Analysis)後,進 而產生了所謂最具代表性的五大人格特質模型(The Big Five Model)。心理學家們 凝聚一致的共識以此模型為基底進行了多層面不同的研究,進而發展出了用來衡
的相關形容特徵詞描述[16] [17],經整理後如下所示:
(一) 外向型 (Extraversion):熱情的、活躍的、冒險的、樂觀的、健談的、喜愛 社交的、大膽的、社交的、果斷的、精力旺盛的。
(二) 神經質型 (Emotional Stability / Neuroticism):多愁的、猜疑的、易怒的、嫉 妒的、易受刺激的、焦慮的、敵對的、壓抑的、脆弱的。 (三) 順從型 (Agreeableness):信任的、直率的、利他人的、樂於合作、仁慈的、 依從的、謙虛的、有同情心的。 (四) 謹慎型 (Conscientiousness):有條理的、有組織能力、有效率的、謹慎的、 盡責的、自律的、成就的。 (五) 開放型 (Openness To Experience):有想像力的、有哲理的、情感豐富的、有 創造力的。 2.2 人格特質與遊戲之間的關係 本研究將依據人格特質來進行遊戲的推薦,在進行推薦以前,我們必須先思 考一個問題,那就是「人格特質到底跟遊戲之間是有關聯的嗎?」,我們要以人 格特質來進行遊戲的推薦,但是如果人格特質跟遊戲一點關係也沒有,那進行推 薦後的結果必然是會有問題的。因此,我們必須先確立這個問題的答案為何後, 才能再繼續往下一步邁進。目前已有研究驗證了人格特質與遊戲偏好之間是有關 聯性的[11] [12],此小節將概略的介紹這兩篇文獻的研究結果。 Johnson et al. [11]研究結果指出,屬外向型人格特質的人與團隊合作類、音 樂類、休閒類遊戲之間的相關性呈正相關;與角色扮演類、大型多人線上角色扮 演類、動作角色扮演類、策略類、即時戰略類遊戲之間的相關性呈負相關。屬謹 慎型人格特質的人與運動類、競速類、飛行模擬類、模擬類、格鬥類遊戲之間的 相關性呈正相關。屬開放型人格特質的人與動作冒險類、大型平台類遊戲之間的 相關性呈正相關。 除此之外,從 Johnson et al. [11]的研究結果可以反推出,比較喜歡玩團隊合 作類、音樂類、休閒類遊戲的人,人格特質可能會比較偏向外向型;比較喜歡玩 角色扮演類、大型多人線上角色扮演類、動作角色扮演類、策略類、即時戰略類 遊戲的人,人格特質可能會比較不偏向外向性;比較喜歡玩運動類、競速類、飛 行模擬類、模擬類、格鬥類遊戲的人,人格特質可能會比較偏向謹慎型;比較喜 歡玩動作冒險類、大型平台類遊戲的人,人格特質可能會比較偏向開放型。
Zammitto & Dipaola [12]研究結果指出,屬外向型人格特質的人與動作射擊
類、動作類、格鬥類、運動類、線上類遊戲之間的相關性呈正相關。屬謹慎型人 格特質的人與動作類、休閒類遊戲之間的相關性呈正相關;與卡車模擬類遊戲之 間的相關性呈負相關。屬開放型人格特質的人與 AI 模擬類、冒險類、休閒類遊 戲之間的相關性呈正相關;與動作射擊類、運動類、線上類遊戲之間的相關性呈 負相關。屬順從型人格特質的人與冒險類遊戲之間的相關性呈正相關;與動作射
擊類、動作、格鬥類、運動類、線上類遊戲之間的相關性呈負相關。屬神經質型 人格特質的人與動作射擊類、動作類、格鬥類、運動類遊戲之間的相關性呈正相 關。詳細分析圖表如圖 2-1 所示。
圖 2-1: 人格特質與遊戲偏好之相關係數分析圖表 (資料來源: [12])
2.3 五大人格特質相關的應用與研究
目前已經有許多的研究發展出了許多不同的人格特質的預測方法。Mairesse et al. [5]透過問卷的方式蒐集受測者真實五大人格特質的資料與手寫的文本資料, 並利用這些問卷、文本資料結合現成的字詞字典,透過統計的方法分析出了字典 中字詞類別與人格特質之間的相關係數。之後利用了 4 種預測方法,包括線性迴 歸(Linear Regression)、M5 模式樹(M5 Model Tree)、M5 迴歸樹(M5 Regression Tree)、支援向量機(Support Vector Machine Regression)等,針對文本資料來建立 人格特質分數的預測模型。
李永銘與張曉珍[6]自五大人格特質研究的相關文獻中蒐集與人格特質有關 的特徵字詞,除了蒐集到了這些特徵字詞後,還透過了語料庫加以擴充字詞數目, 依同義詞、上位詞、下位詞由 403 個擴充至 2731 個特徵詞,最後利用這些特徵 詞結合文本探勘 TF-IDF 方法來進行文本資料的人格特質分析與預測。
Celli[18] 有 研 究 從 Mairesse et al. [5] 所 分 析 的 五 大 人 格 特 質 與 LIWC(Linguistic Inquiry and Word Count Dictionary)之相關係數字詞分類表中挑 選了 12 個類別字詞來建立一套人格特質文本辨識工具,然後來進行 Twitter 上文 章轉推的行為與五大人格特質的關聯分析以及預測模型的建立。 Golbeck et al. [9]透過蒐集了社群網路上的社交資訊與問卷來進行人格特質 的關聯分析,分析出了在社群網路上的文本資訊中,不同人格特質的人都常用哪 些類別的字詞與不常用哪些類別的字詞,除此之外,還結合了社會網絡的資訊來 進行混搭,透過社群網路上的朋友數(Number of Friends)、自我中心網絡密度 (Egocentric Network Density)、參與活動數(Activities)、喜愛的書籍數(Favorite Books)、是否為單身(Relationship Status)、姓氏長度(Last Name),將這些社群網 路的特徵資訊結合起來與人格特質進行關聯度分析。
Sarkar et al. [19]透過了 Youtube 的人格特質語意資料集(YouTube personality data)使用邏輯迴歸分析(Logistic regression)的方式來建立人格特質的預測模型。
Bachrach et al. [20]透過了 Facebook 社群網路上的社群特徵資訊與問卷來進 行人格特質的關聯度分析。社群特徵資訊有包含了朋友數(number of Facebook friends)、社團數(number of associations with groups)、按讚數(number of Facebook "likes")、上傳的照片數(number of photos uploaded by user)、發文數(number of status updates by user)、在照片中被別人標記的次數與時間頻率(number of times others “tagged” user in photos)等資訊。
Nunes[21]將人格特質的問卷結合到了推薦系統上而變成基於人格特質的推 薦系統。透過人格特質問卷蒐集多位使用者的人格特質屬性及偏好,之後透過人 格特質的相似度,來將偏好決策推薦給使用者,舉例來說,有很多神經質的人都 買哈利波特這本書,那如果你測出來的人格特質也屬於神經質的話,那就會將哈 利波特這本書推薦給你。此研究還透過了人格特質特徵屬性的多面向分類結合蒐
集不同人格特質的理想總統候選人問卷來分析及根據人格特質來預測使用者在 總統選舉可能會投哪一位候選人為總統。
Roshchina & Cardiff [4]將人格特質文本探勘的方法與推薦系統進行結合,利 用 Mairesse et al. [5]提出的人格特質文本探勘方法之工具結合 KNN 法,建置針 對 TripAdvisor 評論基於人格特質的飯店推薦系統,產生了有別於一般推薦系統 的不同推薦方式。
Ferwerda & Schedl [22]則提出了或許可以試著嘗試透過結合人格特質的因 子來加強音樂推薦的成效。 2.4 推薦系統 現在一般常見推薦系統的推薦技術方法主要可以被區分為兩種,第一種為基 於內容之推薦;第二種為協同過濾式推薦。針對新進使用者的部分,由於使用者 的偏好輪廓(Preference Profile)是空的,所以推薦系統大多都伴隨著有冷啟始 (Cold Start)的問題,通常都是利用隨機進行推薦的方式來解決這項問題。 2.4.1 基於內容(Content-Based)推薦方法 透過商品的文字內容描述資訊與使用者歷史購買記錄、搜尋商品紀錄、個人 檔案等資訊,來分析尚未被使用者購買過商品彼此之間的關聯屬性及預測出使用 者的偏好,再將適合的商品推薦給使用者,主要是以資料內容為導向來進行推薦 [23]。 2.4.2 協同過濾式(Collaborative Filtering)推薦方法 透過不同使用者之間給予商品評價分數的回饋機制,來將相似使用者進行最 近鄰居法(Nearest Neighbor)的分群預測,最後再將使用者未購買過的商品依據結 果推薦給使用者。 由於是倚賴使用者給與評價分數的回饋機制,所以當如果出現商品項目都沒 有使用者來進行分數評價或是使用者給予分數評價的數量不多的話,會造成稀疏 矩陣的問題,這個問題將會造成推薦的效果不彰[23]。 2.5 小結 推薦系統的發展已經行之有年,已經有相當多的研究提出了許多不同的方法 來改進推薦系統的推薦成效,由於一般的推薦系統多著重於偏好相似度上的推薦, 若可以試著嘗試把偏好改成其他屬性或是搭配其他屬性的話,就可能演變發展成 新的推薦方法。
第三章 研究方法
3.1 研究架構 本研究將會運用到 Steam 遊戲社群上的社群資料以及受測者所提供的資料 進行基於人格特質之遊戲推薦。Steam 平台所提供的遊戲種類與數量充足而且為 目前頗受歡迎的遊戲社群平台。根據 Steam 遊戲社群 2015 年官方的統計資料指 出[24],同時在線上的玩家人數已經達到史上最高的 1348 萬人。因此,本研究 選擇使用此平台作為資料的獲取來源。本研究所需的資料內容主要包含了遊戲評 論的資料、遊戲屬性的詳細資料、受測者提供的文本資料。由於本研究所需的文 本資料量龐大,不同文本資料間的內容結構程度相對的也參差不齊,所以必須先 對資料進行結構化的前置處理,前置處理完後,接著再以不同人格特質文本探勘 的方法來進行相似度的推薦。最後針對這幾種方法分別推薦出來後的結果進行評 估,以驗證本研究所提出的人格特質文本探勘方法之成效。本研究的研究架構圖 如圖 3-1 所示,以下將會詳述本研究整個研究的主要方法以及流程步驟。 圖 3-1: 研究架構圖以下首先會介紹本研究如何從 Steam 上擷取所需遊戲資料;其次再介紹如何 將擷取出來的文字資料進行前置處理;之後再詳述遊戲推薦方法及結果呈現方式; 最後成果評估方式。 3.2 遊戲資料的擷取 圖 3-2: 遊戲資料擷取概要圖 本研究將擷取目前最受歡迎的社群遊戲平台 Steam 上的遊戲資料,遊戲資料 擷取步驟的概要圖如圖 3-2 所示,所要擷取的遊戲資訊詳細清單主要包含如下: (一)遊戲名稱與 ID。 (二)遊戲的屬性標籤。(如圖 3-3 所示) (三)遊戲評論內容。 (四)評論玩家帳號 ID。
圖 3-3: 一款遊戲所包含的屬性標籤實際範例 (資料來源: [3]) 截至 2016 年 5 月,Steam 平台上總共包含了 14928 款的遊戲,每款遊戲也 涵蓋了大量的評論與屬性資料。除此之外,由於使用者遍佈全世界,Steam 上混 著不同語言的評論資料與遊戲屬性,但主要還是以英文資料佔多數。所以,本研 究主要聚焦的資料語言以英文為主。 由於所需的資料量龐大,必須想出可自動化處理的方法,以節省時間。所以, 擷取這些資料前,我們必須得先確認提供這些資料的網頁平台是否有提供針對程 式開發者需求的 API(Application Programming Interface)指令功能服務,藉此可直 接透過提供資料的網頁平台更快的將所需的資料直接進行結構化的自動處理。經 由服務平台處理後,輸出成機器可讀(Machine Readable)的資料格式檔案供使用 者下載,這樣可以節省很多前置處理所耗費掉的時間。
本研究查閱 Steam 官方的網頁開發者文件之後,發現 Steam 官方只提供了遊 戲名稱與 ID 清單輸出成 JSON(JavaScript Object Notation)開放資料格式檔案的 API 指令功能服務,API 連結指令下達後,輸出結果如圖 3-4 所示,輸出後便可 直接進行 JSON 檔案的存檔。
圖 3-4: Steam 遊戲名稱與 ID 的 JSON 檔案輸出結果 (資料來源: [3]) 由於 Steam 提供的 API 指令功能服務有限,所以針對遊戲的屬性標籤、遊 戲評論內容、評論玩家帳號 ID,這些無法直接透過 API 獲取的資料部分,本研 究將透過網頁資料抽取(Web Scraper)線上服務並結合撰寫輔助程式的方式來進 行自動化的擷取,這樣可以節省許多撈取資料所耗費的時間成本。 3.2.1 利用網頁爬蟲進行資料擷取 近年來,網路上已經發展出許多針對擷取網頁資料的客製化服務平台,也就 是所謂的網頁資料抽取(Web Scraper)的線上服務,使用者只需先了解要抓取目標 網頁資料傳遞的指令結構參數網址,例如網頁連結參數的傳遞 Get 以及 Post 知 道目標網頁下達批次的資料連結指令後回傳所需資料,即可透過此服務來快速的 結構化抓取回傳的資料,最後,輸出成開放格式檔案供使用者下載。下達 Steam 資料連結查詢指令後,Steam 的伺服器進行查詢結果的資料回傳,然後,網頁資 料抽取服務平台會進行回傳資料的轉換,批次查詢與轉換結果如圖 3-5 與圖 3-6 所示。
圖 3-5: 利用 import.io 平台進行 Steam 遊戲資料的批次查詢轉換 圖 3-6: Steam 遊戲的玩家評論資料裡所有屬性內容結構化轉換結果 本研究所選擇的網頁資料抽取線上服務平台為 import.io 平台,除了透過此 平台的輔助外,部分的搭配以 Java 函式庫套件 Jsoup 撰寫的網頁標籤自動化處理 程式來進行資料的擷取,然後存成純文字檔文件完成資料之擷取。 3.2.2 遊戲的評論擷取數量限制與過濾 Steam 每款遊戲的評論數量分佈不均,許多款遊戲的評論數量甚至多達上萬 筆。為求一致性,所以本研究制設定了每一款遊戲要擷取的評論數量統一為 200 筆評論,玩家的部分則鎖定為這 200 筆評論的作者玩家所曾經發過的所有評論, 若評論數量未達到 200 筆的遊戲將會被直接剔除掉。 Steam 本身有一套過濾機制能針對評論進行篩選與排序,本研究以評論之幫 助性(Helpful)進行排序後再進行評論的撈取。Steam 社群上玩家可針對某一款遊 戲的某一筆評論是否提供助益進行評分,實際案例如圖 3-7 所示。透過這樣的過 濾方式,能一開始就為我們排除掉評論內容品質較差的評論。
圖 3-7: Steam 遊戲具有幫助性的評論過濾實際案例 (資料來源: [3])
3.3 資料前置處理 由於文本資料是由一大串文字所構成,所以,內容可能還存在著冗餘字詞與 雜訊。為了利於萃取資料關鍵的特徵內容,必須進行資料的前置處理,藉此達到 資料淨化以去除不需要的字詞以及無效的遊戲評論,資料前置處理步驟的概要圖 如圖 3-8 所示。 圖 3-8: 資料前置處理概要圖 3.3.1 斷詞 本研究使用的文字斷詞系統為中央研究院的 CKIP 斷詞系統,透過此系統能 將文本資料的每個字詞進行斷詞分隔並給予詞類的標記,以利於我們進行文本資 料內容關鍵字詞的計算,斷詞實際範例如圖 3-9 所示。
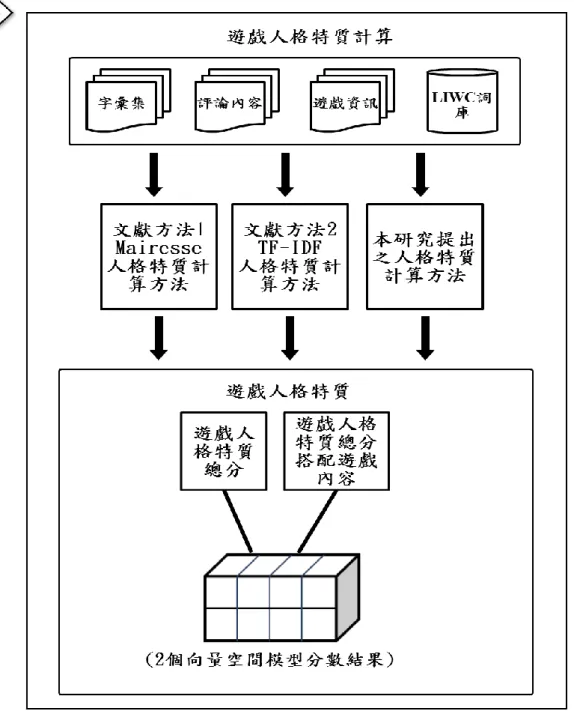
圖 3-9: CKIP 斷詞系統進行英文例句斷詞後結果之實際範例 3.3.2 字詞淨化 經由斷詞處理過後,每筆遊戲評論文件已經可以被字詞的集合所代表表示, 由於字詞的集合之中可能還會存在著像是特殊符號、數字、日期或是一些對本研 究沒有顯著相關意義的字詞,若保留這些無意義的字詞,將會變成本研究在進行 人格特質計算上的累贅。所以,此步驟會將字詞進行篩選處理,將沒用的字詞去 除後而成為關鍵的字詞集合。 篩選處理過後,接著,再把所有遊戲評論文件的字詞集合彙整構成字彙集, 有了字彙集(Vocabulary Set)之後,就可以利於我們進行每筆遊戲評論文件所含有 的字詞比對計算,計算出每個字詞在不同遊戲評論文件出現的次數。 3.4 人格特質計算方法 人格特質計算方法概要圖如圖 3-10 所示,本研究會將從遊戲評論算出來的 人格特質分數視為是遊戲的人格特質分數,也就是說,如果從評論上最後計算出 來的五大人格特質總分數為神經質這個人格特質最高的話,那我們就會把這款遊 戲視為是屬於神經質這類人格特質的人都會玩的遊戲。 本研究一共利用了三種人格特質文本探勘方法來針對遊戲評論進行計算,第 一種為 Mairesse et al. [5]提出的方法;第二種為李永銘與張曉珍 [6]提出的方法; 第三種為本研究所提出的新方法,在此小節會解釋這三種計算方法的內容。 圖 3-10: 人格特質計算方法概要圖
3.4.1 文本文件向量化
計算文本字詞的次數必須將其計算後的結果轉換為向量空間模型 VSM (Vector Space Model),此模型在 1975 年被提出[25],為目前被許多研究最普遍接 受使用的模型。向量空間模型是由字詞與所對映文件所組成的關係矩陣,利於機 器方便進行閱讀處理。如圖 3-11 所示,矩陣是由 i 個字詞與 j 份文件所組成, Wij則為字詞 i 在 j 中的權重值。 𝐴 = [ 𝑡𝑒𝑟𝑚1 𝑡𝑒𝑟𝑚2 ⋯ 𝑡𝑒𝑟𝑚𝑖 𝑑𝑜𝑐1 𝑊11 𝑊21 ⋯ 𝑊𝑖1 𝑑𝑜𝑐2 𝑊12 𝑊22 ⋯ 𝑊𝑖2 ⋮ ⋮ ⋮ ⋱ ⋮ 𝑑𝑜𝑐𝑗 𝑊1𝑗 𝑊2𝑗 ⋯ 𝑊𝑖𝑗 ] 圖 3-11: 向量空間模型圖 (資料來源: [25]) 3.4.2 LIWC 英文版字詞詞典 前人研究中提到了「日常生活語言的使用,包括書寫與口語,反映了個人內 在的心理狀態、思考型態甚至人格特質。它為心理學研究提供了一扇探索心靈的 窗口。Francis & Pennebaker (1993)針對了人們平常書寫的文本資料進行了文本分 析,透過編寫程式進行字詞的計算之後,再將字詞分類,接著再進行字詞字典的 編制,因此產生了語文探索與字詞計算詞典(Linguistic Inquiry and Word Count Dictionary),簡稱 LIWC 字詞字典。」[26]。由此可知,我們可以了解到,一個 人所表達出來的用字遣詞多少是可以間接的反應出一個人的心理狀態的。
隨著字詞與種類的擴充,Pennebaker et al. [27]又更進一步的發展出了擴充的 LIWC2001、Pennebaker et al. [28]擴充的 LIWC2007、以及目前最新的 LIWC2015 版本,目前已可用來分析多種字詞類別,具有相當好的信、效度。
本研究在英文文本資料的分析將使用 LIWC2001 的版本,此因 Mairesse et al. [5]分析所搭配使用的就是 LIWC2001 的版本字典。基於一致性,本研究英文文 本資料的分析上一律採用 LIWC2001 英文版字詞詞典來進行分析。 3.4.3 Mairesse 人格特質計算方法 Mairesse et al. [5]透過了問卷的方式蒐集受測者真實五大人格特質的資料與 手寫的文本資料,並利用這些問卷資料透過統計的方法分析了 Pennebaker et al. [27]所制定的語文探索與字詞英文版本的計算詞典 LIWC 中的字詞類別與五大人 格特質之間的皮爾森相關係數,如圖 3-12 與圖 3-13 所示,之後利用了 4 種預 測方法針對文本資料來建立人格特質分數的預測模型。 此 預 測 方法 已 經 被原 作 者 寫成 一 套 分析 軟 體 工具 , 名 稱為 Personality Recognizer Tool,此軟體是基於著名的開源資料探勘軟體(Weka)所開發撰寫的, 透過此軟體工具,我們可以快速的直接將文本資料的文字檔批次分析後,再透過
Weka 將分析結果直接轉成 CSV 的資料格式,然後再透過程式處理進行轉換即 可。
此軟體工具的 四 種預測方法可供使用者選擇, 分別 為 線性迴歸 (Linear Regression)、M5 模式樹(M5 Model Tree)、M5 迴歸樹(M5 Regression Tree)、與支 援向量機(Support Vector Machine Regression)。Roshchina & Cardiff [4]指出,若要 針對文字評論使用這個軟體工具來進行人格特質的分析的話,使用 M5 迴歸樹這 個方法的預測效果比較好,因此本研究將使用 M5 迴歸樹來對遊戲評論進行計算, 計算結果實際範例如圖 3-14 所示。分析一款遊戲的兩百篇評論後,輸出結果會 呈現出每一篇評論的五大人格特質的五個分數比重。 利用 Mairesse et al. [5]提出的人格特質預測方法來分析一款遊戲所代表的人 格特質分數之計算公式如下: 𝐺𝑎𝑚𝑒𝑀𝑎𝑖𝑟𝑒𝑠𝑠𝑒 𝑃𝑒𝑟𝑠𝑜𝑛𝑎𝑙𝑖𝑡𝑦 𝑆𝑐𝑜𝑟𝑒(𝑔𝑎𝑚𝑒𝑎) = ∑𝑗𝑘=1𝐷𝑜𝑐𝑘(𝐸𝑥,𝐸𝑚,𝐴𝑔,𝐶𝑜,𝑂𝑝) 𝑗 (1) 其中𝐷𝑜𝑐𝑘(𝐸𝑥, 𝐸𝑚, 𝐴𝑔, 𝐶𝑜, 𝑂𝑝)代表的是第 k 篇評論的五大人格特質的五個分數
比重,Ex 為外向型的人格特質分數、Em 為神經質型的人格特質分數、Ag 為順 從型的人格特質分數、Co 為謹慎型的人格特質分數、Op 為開放型的人格特質分 數。將一款遊戲的所有評論的五大人格特質分數計算出來後,再全部加總後進行 平均即為這款遊戲的人格特質分數。j 代表為評論的總數,在此為 200。
圖 3-12: LIWC 與五大人格特質之皮爾森相關係數第 1 部分資料圖 (資料來源: [5])
圖 3-13: LIWC 與五大人格特質之皮爾森相關係數第 2 部分資料圖 (資料來源: [5])
3.4.4 TF-DF 人格特質計算方法
李 永 銘 與 張 曉 珍 [6] 所 提 出 的 方 法 為 TF-IDF(Term Frequency Inverse Document Frequency)分數加總的方法,他們自行整理了與五大人格特質有關的 403 個特徵字詞,並將其擴充成 2731 個。先計算出文件中的每個字詞的 TF-IDF 值,然後再判定這 2731 個特徵字詞是否有出現在文件中,最後再計算與這 2731 個特徵字詞有關的每個字詞 TF-IDF 值的加總分數,再利用加總分數最高的特徵 字詞的人格特質類別來判定寫某篇文章的作者的人格特質可能是屬於哪一類。基 於一致性的緣故,本研究並不會採用其所整理的 2731 個特徵詞來進行遊戲人格 特質的分析計算,而是採用語文探索與字詞英文版本的計算詞典 LIWC(Linguistic Inquiry And Word Count)中的字詞來進行計算。此方法會將 Mairesse et al. [5]所分 析的如圖 3-12 與圖 3-13 所示的皮爾森相關係數(Pearson's Correlation Coefficient) 結果裡面與字詞種類呈顯著正相關以及顯著負相關的人格特質考慮進來。 TF、IDF、TF-IDF 以及一款遊戲所代表的人格特質分數計算公式分別如下: 𝑡𝑓𝑖,𝑗 = 𝑛𝑖,𝑗 ∑ 𝑛𝑘 𝑘,𝑗 (2) 式(2)使用了一般傳統計算字詞權重的方式來衡量字詞的重要性,傳統字詞 權重的計算方式是利用了字詞出現頻率 TF(Term Frequency)來衡量字詞的重要性, 然後計算出其權重值。此算式的分子指的是某字詞𝑡𝑒𝑟𝑚𝑖在文件𝑑𝑜𝑐𝑗中出現的次 數,而分母則為文件𝑑𝑜𝑐𝑗中所有字詞出現過的次數總和。 𝑖𝑑𝑓𝑖 = 𝑙𝑜𝑔|{𝑗:𝑡|𝐷| 𝑖∈𝑑𝑗}| (3)
式(3)定義逆向文件頻率 IDF (Inverse Document Frequency)指的是某字詞有 出現在多少篇文件過的數量,若某字詞算出的 IDF 值越大,則代表此字詞具有
很好的類別區分能力。分子 D 指的文件的總數,而分母則為某字詞𝑡𝑖有在某些文
件出現過的文件數目。
𝑡𝑓𝑖𝑑𝑓𝑖,𝑗 = 𝑡𝑓𝑖,𝑗× 𝑖𝑑𝑓𝑖 (4) TF-IDF(Term Frequency Inverse Document Frequency)是一種常用的技術加權 機制,常被應用在資訊檢索及本文探勘上。其概念為如果某個字詞在某篇文章中 出現的頻率高,且在其他篇文章中較少出現時,則代表此字詞具有很好的類別區 分能力,較適合被用來做分類,可用來計算某個字詞在文件中的相對重要程度, 這樣可以防止某個字詞的影響力過強。
遊戲所代表的人格特質分數計算公式如下式所示: 𝐺𝑎𝑚𝑒𝐽ℎ𝑎𝑛𝑔 & 𝐿𝑖 𝑃𝑒𝑟𝑠𝑜𝑛𝑎𝑙𝑖𝑡𝑦 𝑆𝑐𝑜𝑟𝑒(𝑔𝑎𝑚𝑒𝑎) = ∑𝑗𝑘=1𝐷𝑜𝑐𝑘(∑𝑛𝑖=1𝑇𝐹𝐼𝐷𝐹(𝑋𝑐𝑖)) 𝑗 (5) {𝑋𝑐𝑖~𝑋𝑐𝑛} ∈ 𝐼 ∩ 𝑉𝑐 其中 j 代表為評論的總數、𝐷𝑜𝑐𝑘代表為某一篇的遊戲評論、Vc 為 LIWC 某個與 人格特質有關的特徵字詞、I 為某篇遊戲評論使用過的字詞、𝑇𝐹𝐼𝐷𝐹(𝑋𝑐𝑖)為各類 別人格特質特徵字詞之 TF-IDF 值、n 為字詞數。 3.4.5 本研究提出之人格特質計算方法
本研究使用 Web Scraper 擷取 Steam 遊戲社群上的社群資料以及受測者所提 供的文本資料,進行資料的前置處理以去除不需要的字詞以及無效的遊戲評論, 結合 Mairesse et al. [5]的皮爾森相關係數法,以及李永銘與張曉珍 [6]所提出的 TF-IDF 分數加總法,提出以皮爾森相關係數當權重,乘上已經算出來後字詞的 TF-IDF 值之人格特質計算方法,這套新的計算方法如下: 𝐺𝑎𝑚𝑒𝑁𝑒𝑤 𝑃𝑒𝑟𝑠𝑜𝑛𝑎𝑙𝑖𝑡𝑦 𝑆𝑐𝑜𝑟𝑒(𝑔𝑎𝑚𝑒𝑎) = ∑𝑗𝑘=1𝐷𝑜𝑐𝑘(∑𝑛𝑖=1𝑃(𝑌𝑐,𝑖) × 𝑇𝐹𝐼𝐷𝐹(𝑋𝑐,𝑖)) 𝑗 (6) {𝑋𝑐𝑖~𝑋𝑐𝑛, 𝑌𝑐𝑖~𝑌𝑐𝑛} ∈ 𝐼 ∩ 𝑉𝑐 其中 j 代表為評論的總數、𝐷𝑜𝑐𝑘代表為某一篇的遊戲評論、Vc 為 LIWC 某個與 人格特質有關的特徵字詞、I 為某篇遊戲評論使用過的字詞、𝑇𝐹𝐼𝐷𝐹(𝑋𝑐, 𝑖)為各 類別人格特質特徵字詞之 TF-IDF 值、𝑃(𝑌𝑐, 𝑖)為各類別人格特質特徵字詞之 P 值、 i 為字詞數,由 1 至 n 個。 3.5 遊戲人格特質計算 此小節的詳細流程圖如圖 3-15 所示,會使用 3.4 節所描述的三種人格特質 計算方法計算所有遊戲代表的五大人格特質總分,使用的三種人格特質計算方法 最後都會各自輸出成兩種結果的向量空間模型。
3.5.1 遊戲人格特質向量空間模型 本研究會將每款遊戲所對映的屬性類別標籤以及遊戲人格特質計算後的總 分結果分別建構成向量空間模型,如圖 3-17 至圖 3-19 所示,分別為遊戲內容、 遊戲人格特質總分、遊戲人格特質總分搭配遊戲內容的向量空間模型。遊戲內容 指的就是在 Steam 上的每款遊戲已經被社群玩家貼上了許多屬性分類的類別標 籤,部分的屬性類別標籤如圖 3-16 所示。圖 3-17 與圖 3-18 為遊戲人格特質計算 輸出後的兩個向量空模型分數結果。總分向量模型建立完成後,如圖 3-20 所示, 接下來我們就可以進行遊戲與使用者之間關聯度的計算。 圖 3-16: 遊戲的部分屬性標籤實際範例 (資料來源: [3]) 圖 3-17: 遊戲內容之向量模型
圖 3-18: 遊戲人格特質總分之向量模型
圖 3-19: 遊戲人格特質總分搭配遊戲內容之向量模型
3.6 使用者人格特質計算 此小節的詳細流程圖如圖 3-21 所示,會牽涉到受測者的參與,一開始會先 請受測者挑選自己有感興趣的遊戲,挑選的數量限制在至少一款,最多不得超過 十款。受測者挑選完遊戲後,會使用 3.4 節所描述的三種人格特質計算方法計算 受測者所挑的遊戲的五大人格特質總分,使用的三種人格特質計算方法最後都會 各自輸出成三種結果的向量空間模型。
3.6.1 受測者文本資料 受測者文本資料的部分會請受測者提供親筆寫的文本資料,例如:任何網路 社群上所發過的自己打的文章、心得報告、聊天訊息內容,只要是文字的資料即 可,提供的文章限制在至少要五篇以上且兩百字以上,本研究會撰寫一個平台讓 受測者上傳文字檔。透過提供的文本資料來計算出受測者的人格特質分數。 3.6.2 LIWC 中文版本字詞詞典 由於本研究的受測者目前只限制在台灣地區,所以提供的受測文本資料基本 上為中文,若要直接將 LIWC 英文詞典進行直接翻譯相對上會有所限制。所幸台 灣心理語言學相關研究的團隊黃金蘭等人[26]發展出了 LIWC 中文版本字詞詞典, 透過統計分析進行英文與中文字詞的轉換與對映,此詞典對於常用的語詞,具有 相當不錯的偵測率,所以本研究針對中文的文本資料將採用黃金蘭等人[26]所編 制的 LIWC 中文版本字詞詞典來進行分析。 3.6.3 使用者人格特質向量空間模型 此小節建構向量空間模型的部分會將受測者所挑選的所有遊戲以及提供的 文本資料的五大人格特質計算後的總分結果分別建構成使用者所代表的人格特 質分數向量空間模型,如圖 3-22 至圖 3-24 所示,分別為受測者挑選的遊戲人格 特質總分、受測者挑選的遊戲人格特質總分搭配遊戲內容、受測者所提供文本資 料的人格特質總分向量空間模型,n 為受測者挑選的遊戲數量之文本資料篇數。 總分向量模型建立完成後,如圖 3-25 所示,接下來我們就可以進行遊戲與使用 者之間關聯度的計算。 圖 3-22: 使用者挑選的遊戲人格特質總分之向量模型
圖 3-23: 受測者挑選的遊戲人格特質總分搭配遊戲內容之向量模型
3.7 遊戲人格特質總分計算結果之對映方法
本研究一共使用了兩種遊戲人格特質表達方法,分別依據遊戲本身與發表遊 戲評論的玩家來計算,本小節將解釋這兩種人格特質表達方法之差異性。
圖 3-26: 某款遊戲發表評論的玩家發表過的所有文章總數連結 (資料來源: [3])
圖 3-27: 某款遊戲發表評論的玩家個人檔案 (資料來源: [3])
圖 3-28: 某款遊戲發表評論的玩家發表過的所有文章瀏覽頁面 (資料來源: [3])
第一種表達方法以遊戲本身所獲得之評論作為其人格特質之依據,圖 3-29 為此 方法之概念圖。其概念為一遊戲之人格特質可由玩家針對此遊戲所發表之評論內 容表達。若不同的玩家針對同一款遊戲發了一篇評論,則兩百位玩家總共針對此 遊戲發表了二百篇評論。本方法直接將這兩百篇評論之人格特質向量進行平均即 視為是此遊戲的人格特質分數。圖 3-31 顯示其詳細計算流程。 第二種表達方法如圖 3-30,為依據使用者人格特質來表達遊戲人格特質。 其概念為會玩同一種遊戲的玩家應具有同一人格特質。本方法透過對某一款遊戲 發表評論的玩家之個人檔案資訊,連結到此玩家於其他遊戲所發表之評論,其範 例如圖 3-26 至圖 3-28 所示。根據這些評論我們可以算出其人格特質向量。亦 即,假如一個玩家在十款遊戲各發過一篇評論,那就代表此玩家總共發過十篇遊 戲評論,我們將這十篇評論經由人格特質文本計算方法分別計算出總分後再除以 總篇數算出平均,然後這個平均分數即代表這個玩家的人格特質分數。若一款遊 戲有兩百位玩家發表評論,本方法先算出每位玩家的人格特質分數,接著再將這 兩百位玩家的人格特質分數進行平均即代表為此款遊戲的人格特質分數。圖 3-31 顯示其詳細計算流程。 圖 3-29: 對映方法 1 圖 3-30: 對映方法 2
3.8 遊戲推薦 本研究在人格特質相似度的計算將採用餘弦相似度(Cosine Similarity)為主 要的計算方法。餘弦相似度為最常被用來計算文本相似度的計算方法,用來比較 兩份文本向量之間的相似程度,餘弦相似度的計算公式如下: 𝐶𝑜𝑠(𝑢𝑠𝑒𝑟 , 𝑔𝑎𝑚𝑒) = | 𝐴⃑⃑⃑⃑⃑ |×| 𝐵 𝐴⃑⃑⃑⃑⃑ ∙ 𝐵⃑⃑⃑⃑⃑ ⃑⃑⃑⃑⃑ | = ∑𝑛𝑖=1𝐴𝑖×𝐵𝑖 √∑𝑛𝑖=1(𝐴𝑖)2×√∑𝑛𝑖=1(𝐵𝑖)2 (7) 其中𝑢𝑠𝑒𝑟代表的是一位受測者;𝑔𝑎𝑚𝑒代表的是一款遊戲, 𝐴⃑⃑⃑⃑ 為使用 3.6 節所述 使用者人格特質計算方式所得到之人格特質總分向量; 𝐵⃑⃑⃑⃑⃑ 為使用 3.5 節遊戲人格 特質計算流程計算方式所得到的人格特質總分向量。 推薦時首先將受測者所代表的人格特質總分向量與遊戲所代表的人格特質 總分向量進行相似度的計算,計算出有哪些遊戲的人格特質跟受測者的人格特質 是最相似的,而後便可將最相似的遊戲推薦給受測者。本研究設計下列三種推薦 方法: 推薦方法一、基於遊戲總分之推薦方法:推薦流程示意圖如圖 3-32 所示, 推薦步驟流程如下: 1. 使用者人格特質計算:將受測者所挑選遊戲之向量平均作為受測者之人 格特質向量。 2. 遊戲人格特質計算:遊戲之人格特質向量。 3. 將受測者人格特質向量與遊戲人格特質總分向量進行相似度的計算,依 關聯度高低進行推薦。 推薦方法二、基於遊戲總分搭配遊戲內容推薦方法:推薦流程示意圖如圖 3-33 所示,推薦步驟流程如下: 1. 使用者人格特質計算:將受測者所挑選遊戲之人格特質向量與屬性類別 標籤向量合併後進行平均後作為受測者之人格特質向量。 2. 遊戲人格特質計算:合併遊戲之人格特質向量與屬性類別標籤向量。 3. 將受測者人格特質向量與遊戲人格特質總分向量進行相似度的計算,依 關聯度高低進行推薦。 推薦方法三、基於受測者文本資訊推薦方法,推薦流程示意圖如圖 3-34 所 示,推薦步驟流程如下: 1. 使用者人格特質計算:將受測者所提供的文本資料計算出來後的人格特 質總分平均向量作為受測者之人格特質向量。 2. 遊戲人格特質計算:遊戲之人格特質向量。
3.9 滿意度評估 相似度計算完畢後,接著就是推薦結果關聯度的呈現,本研究將會依照相似 度高到低的順序列出前十名的遊戲。由於本研究在人格特質計算共有三種方法; 在向量表達的部分有兩種方法;在推薦的部分有三種方法,故全部組合後共有十 八種結果呈現,如圖 3-35 所示。 在受測的時候,本研究並不會告知受測者是用了什麼方法來進行推薦,以避 免出現偏誤的影響。本研究將透過受測者所決定的滿意度結果來評估這些方法, 推薦結果的呈現範例圖如圖 3-36 所示。 圖 3-35: 所用方法組合最後呈現出來的結果數目
圖 3-36: 推薦結果的呈現
在研究方法驗證方面,本研究將所提出的方法與 Mairesse et al. [5]以及李永 銘、張曉珍[6]所提的兩種方法進行比較。透過 3 種遊戲推薦法所呈現出的 18 種 推薦結果,進行滿意度評估來驗證研究方法的可行性。
第四章 研究資料與實驗評估
4.1 研究資料之結構化搜集 由於本研究當初設定的資料取得量過於龐大,所以花費了相當多的時間在資 料的取得以及處理上。除此之外,在本研究中需要使用到一些所引用到的前人文 獻中所提供的文本分析軟體上也碰上了不可預期的問題。以下將說明本研究蒐集 資料流程及其困難以供後續研究參考。 首先 Steam 遊戲平台官方並未提供可一次性撈取大量遊戲評論文字資料的 API,本研究發現 Steam 只允許使用者一次讀取 10 至 25 筆左右之評論文字資料 呈現在網頁上,也就是所謂的網頁瀑布式的讀取法。本研究初期使用程式的方式 一直重複下 Request 指令 Post 一次固定數量命令請求至 Steam 伺服器,然而回傳 結果為亂數跳動而非固定值,導致在要抓取固定數量評論的前題難以滿足。本研 究所設定的門檻為至少每款遊戲要達 200 篇的評論,為了預防這 200 篇之中評論 的雜訊過多,所以保險起見,提高到了 250 篇。為解決前述問題,本研究採用了 Selenium 的 Java 套件將 Steam 遊戲社群商 城上所提供的所有遊戲產品 Appid 之 JSON 檔清單來進行自動化的爬蟲撈取。但 在這個清單之中也發現了很多雜訊參雜在裡頭,像是 DLC(遊戲下載內容)、商用 軟體、遊戲原聲帶、遊戲影片、遊戲名稱不一樣但卻是同一樣重複的遊戲,與遊 戲比較無關的產品混雜在一起。清單中的總產品數高達 25715 筆,本研究分了三 個階段並搭配使用 Selenium 將本研究真正需要的遊戲清單處理完成。 遊戲清單清理的第一階段就是將非遊戲產品的 Appid 與 Name 清除掉。第一 階段處理後,總清單數目由 25715 筆刪減到至 8000 餘筆。第二階段則是刪除未 達本研究所設定的 250 筆評論門檻之遊戲,處理後剩餘 2050 筆遊戲。 最後在第三階段本研究繼續抓取所有遊戲之評論作者所發過的其他評論作 為後續人格特質分數計算方法之用。本研究使用了 Jsoup 的 Java 套件來撈取評論 作者的帳號資訊裡所顯示之所有評論之清單中之遊戲與評論,與該遊戲的屬性文 字標籤。 本研究所需的資料在全部撈取後皆會利用程式處理並以 JSON 格式的檔案 匯出,如圖 4-1 所示,以利機器程式批次自動化讀取。同時未來若有其他相關研 究需要,可增加後續發展之再利用性。本研究最後從 Steam 遊戲社群平台上所擷 取到的各個資料集統計總數量如表 4-1 所示。屬性標籤的部分,由於分類數量多 達 313 種,所以僅在此列出 2050 款遊戲中,佔了前 20 名最多的屬性標籤,如表 4-2 所示。
圖 4-1: JSON 格式檔案匯出
資料名稱 過濾前遊戲 過濾後遊戲 評論 評論作者 屬性標籤
數量 25715 2050 3048375 328972 313(種)
表 4-1: 資料集數量統計表
排名 屬性名稱 數量 排名 屬性名稱 數量
1 Singleplayer 1563 11 Open World 518
2 Action 1390 12 Casual 502 3 Adventure 1197 13 Simulation 501 4 Indie 1158 14 First-Person 476 5 Multiplayer 988 15 Shooter 474 6 Strategy 652 16 2D 424 7 RPG 618 17 Sci-fi 414 8 Great Soundtrack 614 18 FPS 406
9 Co-op 588 19 Story Rich 383
10 Atmospheric 578 20 Funny 364
![圖 1-2: 2015 年第 2 季財報 Facebook 官方月活躍使用者人數統計圖 (資料來源: [2])](https://thumb-ap.123doks.com/thumbv2/9libinfo/7412811.104060/14.892.162.731.137.874/圖12215年第2季財報Facebook官方月活躍使用者人數統計圖資料來源.webp)
![圖 1-4: 依使用者的偏好或喜好來進行推薦之實際案例 2 (資料來源: [3])](https://thumb-ap.123doks.com/thumbv2/9libinfo/7412811.104060/16.892.280.650.133.667/圖14依使用者的偏好或喜好來進行推薦之實際案例2資料來源3.webp)
![圖 2-1: 人格特質與遊戲偏好之相關係數分析圖表 (資料來源: [12])](https://thumb-ap.123doks.com/thumbv2/9libinfo/7412811.104060/20.892.186.796.332.633/圖21人格特質與遊戲偏好之相關係數分析圖表資料來源12.webp)
![圖 3-3: 一款遊戲所包含的屬性標籤實際範例 (資料來源: [3]) 截至 2016 年 5 月,Steam 平台上總共包含了 14928 款的遊戲,每款遊戲也 涵蓋了大量的評論與屬性資料。除此之外,由於使用者遍佈全世界,Steam 上混 著不同語言的評論資料與遊戲屬性,但主要還是以英文資料佔多數。所以,本研 究主要聚焦的資料語言以英文為主。 由於所需的資料量龐大,必須想出可自動化處理的方法,以節省時間。所以, 擷取這些資料前,我們必須得先確認提供這些資料的網頁平台是否有提供針對程 式開發者需求](https://thumb-ap.123doks.com/thumbv2/9libinfo/7412811.104060/25.892.203.689.105.710/一款遊戲所要聚以英文為主由於所需資料量龐大必省時間式開發需求.webp)
![圖 3-4: Steam 遊戲名稱與 ID 的 JSON 檔案輸出結果 (資料來源: [3]) 由於 Steam 提供的 API 指令功能服務有限,所以針對遊戲的屬性標籤、遊 戲評論內容、評論玩家帳號 ID,這些無法直接透過 API 獲取的資料部分,本研 究將透過網頁資料抽取(Web Scraper)線上服務並結合撰寫輔助程式的方式來進 行自動化的擷取,這樣可以節省許多撈取資料所耗費的時間成本。 3.2.1 利用網頁爬蟲進行資料擷取 近年來,網路上已經發展出許多針對擷取網頁資料的客製化服務平](https://thumb-ap.123doks.com/thumbv2/9libinfo/7412811.104060/26.892.133.753.118.758/合撰寫輔助程式的方式來進行自動化擷取這樣可以節省撈取服務平.webp)
![圖 3-7: Steam 遊戲具有幫助性的評論過濾實際案例 (資料來源: [3])](https://thumb-ap.123doks.com/thumbv2/9libinfo/7412811.104060/28.892.246.650.108.551/圖37Steam遊戲具有幫助性的評論過濾實際案例資料來源3.webp)

![圖 3-12: LIWC 與五大人格特質之皮爾森相關係數第 1 部分資料圖 (資料來源: [5])](https://thumb-ap.123doks.com/thumbv2/9libinfo/7412811.104060/33.892.158.803.132.1045/圖32LIWC與五大人格特質之皮爾森相關係數第1部分資料圖資料來源.webp)
![圖 3-13: LIWC 與五大人格特質之皮爾森相關係數第 2 部分資料圖 (資料來源: [5])](https://thumb-ap.123doks.com/thumbv2/9libinfo/7412811.104060/34.892.140.774.122.759/圖33LIWC與五大人格特質之皮爾森相關係數第2部分資料圖資料來源.webp)