行政院國家科學委員會補助專題研究計畫
□ 成 果 報 告
期中進度報告
支援 3-D 立體視訊的數位電視多媒體平台設計
計畫類別:□ 個別型計畫
整合型計畫
計畫編號:NSC
96-2220-E-009-038
執行期間:
96 年
11
月
1 日至
99
年 10
月
31
日
計畫主持人:蔡淳仁
共同主持人:
張添烜、范倫達、彭文孝
計畫參與人員:
孫域晨、蘇冠年、廖珮晴、黃建峰、白佳芸、曾宇晟、廖元歆、陳奕均、
洪瑩蓉、許博雄、陳宥辰、陳漪文、陳俊吉、楊復堯、許籐耀、林丞蔚、
謝佳育、董盈里
成果報告類型(依經費核定清單規定繳交):□精簡報告
完整報告
本成果報告包括以下應繳交之附件:
□赴國外出差或研習心得報告一份
□赴大陸地區出差或研習心得報告一份
出席國際學術會議心得報告及發表之論文各一份
□國際合作研究計畫國外研究報告書一份
處理方式:除產學合作研究計畫、提升產業技術及人才培育研究計畫、列
管計畫及下列情形者外,得立即公開查詢
□涉及專利或其他智慧財產權,□一年□二年後可公開查詢
執行單位:國立交通大學資訊工程系、電子工程系
中
華
民
國
98 年
08 月
28 日
摘要
本計畫的目標在設計一個能支援下一代立體視訊及 3-D 人機介
面的嵌入式系統多媒體應用程式平台。本平台的重點是它不是針對
任何一個殺手級應用而設計,而是依照一個開放式的 Java 執行環境
DVB-MHP 來進行設計。這個平台因為是架構在一個公開的國際標
準之下,所以可以由協力商(third party)發揮創意來擴充其上的應
用。這個平台的設計是透過中介軟體來包裝並整合底層的寬頻多媒
體應用所需要的元件(如影音解碼、繪圖、以及 3-D 視訊)的加速
功能。讓應用程式的開發者可以不用擔心底層的嵌入式系統所使用
的處理器、作業系統是什麼,就能發揮出系統最豐富的功能。在這
個計畫下,我們會開發出下列的關鍵元件:由 DVB-MHP 所擴充而
來的 3-D 人機介面中介軟體、一個專為支援 Java 執行環境而設計的
極小型 OS、3-D Video 加速器、3-D Graphics 加速器、Java 處理器、
和配合 3-D Video 的 MVC 多視角合成技術。
關鍵詞:中介軟體、Java 處理器、嵌入式作業系統、3-D Video、
視差估測加速器、3-D Graphics 加速器、Multi-view Video 編碼
Abstract
The goal of this project is to design an embedded platform to
support next generation stereo video and 3-D man-machine user
interfaces for multimedia applications. The key design focus of this
platform is that it is not designed for any particular killer applications.
Instead, it is designed based on an open multimedia application
middleware, namely DVB-MHP. Therefore, any third party designer can
develop innovative applications for this platform without having to
worry about the underlying architecture, such as the type of processor or
the type of OS used to create the platform. More importantly, the
middleware provides user application accesses to highly efficient
feature-rich multimedia components, including audio-video decoding,
graphics, and 3-D video. The key technologies that will be developed in
this project include: DVB-MHP middleware with extension for stereo
video and man-machine user interface, a deeply-embedded minimal OS
designed specifically for Java runtime support, 3-D video accelerator,
3-D graphics accelerator, Java processor, and multiview video coding
technology.
Keywords: Middleware, Java Processor, Embedded OS, 3-D Video,
Disparity Estimation Accelerator, 3-D Graphics Accelerator, Multiview
Video Coding
I、
計畫成果概述
本計畫預期目標是設計支援立體顯示的數位電視 DVB-MHP 標準的嵌入式平
台,其中關鍵模組為:視差估測模組(子計畫一)、3D 繪圖加速器模組(子計畫二)、
立體視訊顯像模組(子計畫三)以及嵌入式 JAVA 平台設計(子計畫四)。目前為止,
總計畫已經階段性整合子計畫研發之模組,設計出兩個嵌入式平台,分別為:整
合視差估測模組和立體視訊合成模組的立體視訊平台(符合 MPEG FTV 應用的嵌
入式平台)、整合 3D 繪圖加速器模組和嵌入式 JAVA 平台提出支援 3D 人機介面
的嵌入式 JAVA 平台。
以下將依序介紹總計劃的整合成果以及各子計畫關建模組成果:
總計畫整合成果
目前總計畫是分成兩階段進行整合,第一階段是先由子計畫一跟三進行局部整
合,還有子計畫二跟四進行局部整合。因此在這次的期中 demo,我們會有兩
個子系統的 demo。第一個子系統是由子計畫一跟三合作的立體視訊合成平
台。第二個子系統是由子計畫二跟四合作的支援 3D 人機介面的 JAVA 平台。
以下就針對這兩個整合的成果進行描述。
整合成果一、立體視訊合成平台
目前總計劃已在 ARM Versatile 平台整合子計畫一與子計畫三,成為可支援
立體電視的嵌入式系統設計,其架構如。在系統啟動前已將視訊影像和程式儲
存於 Data Flash 和 Flash。首先 ARM 處理器從 SD card 至 SDRAM 搬移視訊影
像,並以 Enable 訊號啟動視差估測。視差估測產生 Depth map 存於 SDRAM,
並以 Finish 訊號通知 ARM 處理器進行 view synthesis。
Image Depth map Instr Memory View Synthesis AHB Bus Flash SDRAM Disparity Estimation Display Buffer Screen FPGA SRAM ARM EJ926 Processor LCD Controller Data Data Flash JTAG
Multi ICE DebuggerAXD PC AXF files
Boot script
Enable Finish WTA/
Aggreggation WeightV WeightY CensusR CensusL WeightU Image Buffer Disparity FIFO Wrapper
圖1. 立體電視視訊顯示平台架構圖
圖2. 子計畫一於 AMBA 的架構
子計畫一整合視差估測於 AMBA AHB 的架構如圖 1。視差估測的核心外以
Disparity FIFO 及 Image Buffer 作為外部讀寫資料的暫存記憶體,並以 Wrapper
作為 AMBA AHB 的介面連接於 bus。 將視差估測演算法實現於 FPGA 上使用
資源如下表所示。
FPGA Virtex4-XC4VLX20
Clock rate 75M Hz
LUT (4-input) 85,843
Slices 45,993
Total Equivalent Gate Count 5,563,039
Dual Port RAM 7,740
16x1 RAMs 144
FPS 7
子計畫三執行流程如圖 3,若 disparity map 有壓縮則以 disparity refinement
處理後再進行 virtual view 的合成,最後再把合成影像轉為立體影像。由讀
Image 至合成影像並輸出螢幕上,其整體的效能如表 1。
表1. Software performance
Current Version (sec) CIF
Load Stereo Images ~0.04
HW- disparity Calculation(including overhead) ~0.93
Stereo-View Synthesis ~1.22
Write to VGA Buffer ~0.58
Total time ~2.77
圖 4 為子計畫一和子計畫三的成果展示:
圖3. Software flow chart
圖4. Virtual view synthesis
整合成果二、支援 3D 人機介面的 JAVA 平台
整合子計畫二與子計畫四的目的是希望利用可重組 3D 繪圖加速器(子計畫
二)與異質雙核心 Java 執行系統(子計畫四)來建立一個更豐富的嵌入式多媒體
平台。執行至今,開發團隊已經建構出全系統的雛形,並且能夠做一些應用程
式的展示。目前的整合系統實作在兩個不同的開發平台: Xilinx Spartan 3A DSP
與 Xilinx ML405。兩個平台中間採用 IIC 匯流排做為溝通的介面。完整的整合
系統架構圖如下圖所示:
Java 3D App. Java Language Class Lib. (based on CLDC) Java 2D Graphic Class Lib. MHP Widget Lib. Java Core Xilinx Standalone I/O Routines Interface to Graphics sub-system RISC Core (PPC 405)
IPC RISC Core (MicroBlaze) Xilinx Standalone 2-D/3-D Graphics Lib. In te rf a ce L o g ic (I IC ) 2-D/3-D Graphics C codes Geometry Engine Frame Buffer VGA Controller To Displa y Xilinx Spartan 3A DSP Xilinx ML405
圖5. 支援 3D 人機介面的 JAVA 嵌入式平台架構
在 Java 執行系統方面,雙指令的 Java 處理核心能夠有效地執行 Java 應用
程式,並且一些 3D 繪圖加速器的溝通介面會以 RISC 輔助程式的方式增加在
執行環境裡。程式執行過程中,如果需要做 3D 繪圖的動作,Java 處理核心會
利用快速的內部通訊機制將參數傳送給 RISC 核心。最後,輔助程式與 IIC 匯
流排傳送端程式會利用 IIC 匯流排將控制參數傳給 3D 繪圖加速器。
當 Spartan 3A DSP 上的 IIC 匯流排接收端程式收到參數時會將其儲存起
來,並且啟動 3D 繪圖加速器。在 3D 繪圖加速器執行過程中,前段的幾何轉
換子系統會先讀取頂點和顏色資料作運算,運算完成之後三角形資料將被傳遞
到後段的著色子系統做之後的繪圖動作。但是由於 FPGA 容量的問題,因此在
目前的開發平台上,3D 繪圖加速器前段的幾何轉換子系統採用硬體的實作,
而後段的著色子系統則是用軟體的方式執行。
兩個團隊的硬體架構的合成數據如表 2 與錯誤! 找不到參照來源。。圖
6 則是成果的展示。
FPGA Spartan3-XC3SD1800A Clock rate 87M Hz LUT (4-input) 15,751 47% Slices 11,271 67% RAM16s 67 79% DSP48s 40 47% IOBs 22 4% FPGA Virtex4-XC4VFX20 Clock rate 101M Hz LUT (4-input) 8,372 62% Slices 7,817 91% RAM16s 48 70% DSP48s 3 9% IOBs 93 29%表2. 子計畫二硬體架構的合成數據
表3. 子計畫四硬體架構的合成數據
圖6. 子計畫二、四整合成果展示
子計畫一成果:視差估測模組
一、前言
視差資料估測(disparity map estimation)的計算複雜度與記憶體頻寬需求相
當龐大,越是高正確度的視差資料估測,需求越高,可達一般用於視訊壓縮的
移動估測十倍至百倍以上的複雜度。子計畫一目的在於以硬體實現視差估測演
算法,並且輸出高準確度且即時處理速度的視差圖。計畫執行至今已發展
semi-global approach 的演算法與硬體設計,該硬體設計已達到本子計畫預定之
效能。此外,論文發表共 7 篇,培育畢業研究生共 3 位。未來,將進一步發展
可處理更大影像,且降低成本的硬體設計。
二、研究目的
子計畫一目的在發展適合硬體實現的視差估測演算法與其硬體實作。視差
估測模組可讀取已校正的兩視角影像,大小為 CIF(325x288),輸出高正確度的
視差資料,視差估測硬體處理速度達 5 fps 以上。配合總計劃的多媒體開放式
平台,視差資料估測運算元將依據 MHP 給予的指令而運作,並且將運算結果
交付給 3-D 繪圖合成運算元,進一步合成出 3-D 影像,最後經由 FPGA 平台
與晶片設計驗證本計畫成果。
三、結果與討論
子計畫一執行至今已發展出適合硬體實現的半全域視差估測演算法。此演
算法基於適應性權重計算(Adaptive Weight)演算法結合微型普查(Mini-Census)
的比對方式,以及量子化指數曼哈頓色彩距離(Quantized Manhattan Color
Distance)等技巧。演算法如圖 7 所示。
Mini-Census Transform & Matching Vertical Cost Aggregation Left Image Horizontal Cost AggregationWeight
Generation
Winner Takes-All Right Image Depth Winner Takes-All Winner Takes-All First Aggregation Initial Depth圖7. 視差估測演算法
首先,由 Mini-Census 計算兩像素的比對值(matching cost)可減少運算量,
從原始的一個方型視窗的運算量轉換為六個點的運算量。其運算如圖 8 所示。
Mini-Census 優點在於較原始演算法更能承受影像受光線影響的問題。
34 3 13 5 15 23 2 54 30 0 1 1 1 X 0 1 0 0 4 68 17 61 51 4 23 3 59 1 0 1 0 X 1 1 1 0bistream 1: 01110100
bistream 2: 10101110
Hamming Distance = 5Census
Census Template
Mini-Census Template
圖8. Mini-Census
接著,以 Weight Generation 以量子化指數曼哈頓色彩距離產生 Weight,此
Weight 用於加權相鄰像素 matching cost 的匯聚。Weight 在影像上的分布如圖
9 所示,Proximity 表示距中心越近的像素點比重越高,Color Similarity 表示與
中心顏色越接近得像素點比重越高。此兩項相乘成為 matching cot 匯聚的比重。
Proximity
Color Similarity
圖9. Cost Aggregation
為減少運算量,我們分析 Weight 有無 Proximity 在視差圖準確度上的變化。
圖 10 顯示對於有 Proximity 的視差圖而言,在 Mask size 大於 39 時較無改變。
並且,對於 Mask size 在 39 以內,無 Proximity 與有 Proximity 的視差準確度是
相同的。因此我們可以省略 Proximity 於 Weight 中,並設定 Mask size 於 39 以
內,即可達到相同於包含 Proximity 的效果。
0 5 10 15 20 25 30 35 40 3 15 27 39 51 63 75 87 99 11 1 12 3 13 5 14 7 15 9 17 1 nonocc all disc rank rms 0 5 10 15 20 25 30 35 40 3 15 27 39 51 63 75 87 99 11 1 12 3 13 5 14 7 15 9 17 1
Er
ro
rR
at
e
Er
ro
rR
at
e
Mask Size
Mask Size
With Proximity
Without Proximity
圖10. 比較有 Proximity 與無 Proximity 在視差圖準確度的差別
為提升 Weight Generation 的運算速度,我們在匯聚 matching cost 時分離原
始 運 算 成 垂 直 匯 聚 (Vertical Cost Aggregation) 與 水 平 匯 聚 (Horizontal Cost
Aggregation)兩步驟 。利用以上所提之方法, 可減少原始演算法運算量的
64.2%。另外,我們化簡 Color Similarity 的 exp 運算為 2 冪次的查表運算,各
種運算化簡的方式如圖 11 所示。最後我們選擇圖中 x64, Quantize P1-bit 的簡
化方式。
0 0.2 0.4 0.6 0.8 1 1.2 0 20 40 60 80Original
0 10 20 30 40 50 60 70 0 20 40 60 80x64, Quantized
-20 0 20 40 60 80 0 20 40 60 80x64, Quantized, P 2-bits
0 10 20 30 40 50 60 70 0 20 40 60 80x 64, Quantize, P 1-bits
圖11. 比較 Color Similarity 的運算化簡
總和以上改變演算法以利於硬體設計的技巧,在個人電腦運算時間與視差
圖準確度如下表所示。對於準確度約降低 1.2%以內,而運算時間大幅降低至
原始運算的 1.9%。如此的硬體導向演算法將有利於進一步的硬體架構設計。
Error Rate %
Method
TSUKUBA VENUS TEDDY CONES
Exec.
Time(sec)
Original
1.85
1.19
13.3
9.79
95.65
+MC+2P
3.47
0.91
14.3
11.2
4.75
+MC+2P+ Manhattan
3.08
0.59
14
10.1
3.12
+MC+2P+ Manhattan +Truc(64,2)
3.03
0.61
14
10.1
2.52
+MC+2P+ Manhattan+Truc(64,1)
3.06
0.66
13.9
10.1
1.84
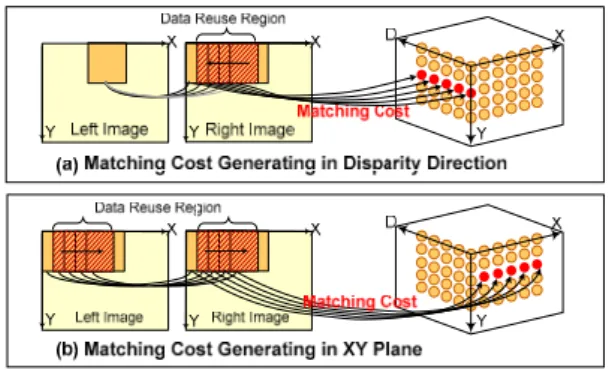
在硬體架構設計方面,我們針對 Mini-Census 及 Cost Aggregation 的運算分
析 各 種 資 料 對 記 憶 體 存 取 的 方 法 。 在 Mini-Census 有 視 差 優 先 再 利 用
(Disparity-Order Reuse)以及像素優先再利用(Pixel-Order Reuse)之方法。在 Cost
Aggregation 有列局部再利用(Partial Column Reuse)以及行垂直延伸再利用
(Vertically Expanded Row Reuse)。考慮運算量、記憶體用量以及頻寬用量,最
後採用 Disparity-Order Reuse、Pixel-Order Reuse 與 Vertically Expanded Row
Reuse 方法於硬體實現。硬體架構如圖 12 所示。此架構所有運算皆以握手機
制(Handshaking)讀寫資料,以達到各運算處理時間的彈性。
圖12. 視差估測架構圖
本硬體架構在聯華電子 90 奈米製程可工作於 100MHz 且 bus 寬度為
32-bit,可處理 CIF(352x288)影像大小且 64 視差範圍(disparity range)達到 42
fps。下表為合成的記憶體用量與組合電路的邏輯閘數量。總內部記憶體用量
約 21k 位元組,總組合電路用量約 562k 邏輯閘。如此硬體效能已達到子計畫
一的目標。
Performance under UMC 90nm Technology
Clock rate
100 MHz
External bus width 32 bit
Image size
352x288
Disparity level
64
Logic
562k equivalent gate counts
Internal memory
21k bytes
FPS
42
對於演算法之效能,以下比較本演算法與其他文獻視差圖的錯誤率以及運
算速度。我們的演算法可達高準確度且即時運算速度。
Ground truth
Proposed
TrellisDP
HBP
RealTimeBP
RealTimeGPU
ReliabilityDP
SepLaplacian
RealDP
ReliableGPU
CBiased
圖13. 視差圖比較
Design
Category
MDE/s
TSU
VEN
TED
CON
SAW
MAP
Proposed
Hardware
272.5
2.80
0.64
13.7
10.1
2.11
3.21
TrellisDP [1]
Hardware
294
2.63
3.44
-
-
1.88
0.91
HBP[2]
Hardware
73.7
2.85
1.92
-
-
6.25
6.45
EffectAggr [3]
CPU
18.9
2.96
3.53
10.7
4.92
-
-RealDP [4]
CPU
209
2.85
6.42
-
-
6.25
6.45
Cbiased [5]
CPU+GPU
605
4.77
10.2
-
-
0.82
0.65
SepLaplacian [6]
CPU+GPU
679
13.0
-
-
-
-
-RealTimeBP [7]
CPU+GPU
19.6
3.40
1.90
13.2
11.6
-
-RealTimeGPU [8]
CPU+GPU
19.6
4.22
2.98
14.4
13.7
-
-ReliableGPU [9]
CPU+GPU
-
1.36
1.09
-
-
2.35
0.55
GradientGuided[10]
CPU+GPU
117
2.48
3.91
-
-
1.63
0.73
四、計畫整體成果與自評
總合今年的成果,和原計畫提出的目標大致吻合,僅有部分目標稍有變更。完
成與修改之目標如下幾點所列:
1. Local approach 方面,以分析軟體演算法之效果並移植於 DSP 加速運算,可
達效能為 50fps@CIF 之速度。但因視差圖的準確度過差,故無將該演算法
時作為硬體設計。計畫研究直接轉為發展 semi-global approach。
2. Semi-global approach 方面的演算法發展,初期以 mean-shift 做為 color
segmentation 演算法與 semi-global approach 視差估測演算法結合。接著發展
color segmentation 演算法,但因所發展之演算法包含 recursive 運算,運算量
過大而不適合硬體設計。最後,我們所提出的 semi-global approach 可使視差
圖的準確度接近利用 mean-shift 演算法的效果。因此 color segmentation 演算
法的發展中止。
3. Semi-global approach 方面的硬體設計,已完成該演算法的硬體設計,並提前
達到子計畫一原定之運算效能。
4. Global approach 方面的演算法發展,已完成 belief propagation 的演算法及硬
體架構規劃,但因為該記憶體及匯流排頻寬需求量過大,並且此演算法的視
差 圖 準 確 度 僅 與 semi-global approach 相 當 。 故 轉 而 研 究 並 發 展 提 升
semi-global approach 的效能。
5. 已提前達到預定的處理速度且可產生高準確度的視差圖。
6. 人才培育方面,本計畫兩年來共有 1 位博士生及 2 位碩士生畢業。
7. 論文發表方面,本計畫共發表 5 篇國際研討會論文與 2 篇國內研討會論文。
子計畫一兩年來已提前達到預定的處理速度且可產生高準確度的視差圖,但目
前開發的視差估測硬體設計仍舊無法整合於總計畫成為單一平台,其原因在於
硬體設計面積過大。因此,子計畫一未來將著重於 semi-global approach 演算法
的發展,並且降低硬體設計成本,並且期許能夠開發出處裡更大像素的視差估
測硬體設計。
子計畫二成果:3D 繪圖加速器模組
一、前言
本子項目二之研究重點為可重組之3D繪圖加速器設計如圖14所示。因此
目前我們分別在前端幾何轉換子系統中的打光運算單元以及後端繪圖子系
統中的深度壓縮機制提出可重組式的演算法與對應的硬體架構,根據不同的
輸入規格重組不同的硬體架構,達到系統的最佳效能。同時也已完成前後兩
級的基本的硬體電路設計與FPGA模擬驗證平台。其他可重組/壓縮單元與整
個重組加速器系統將持續進行研究與設計。
圖
14. 重組式 3D 繪圖系統架構圖
二、研究目的
本計畫的 3D 繪圖技術與傳統 3D 視訊的不同點在於由於不同視角影像能
使用 3D 繪圖技術即時繪製出來以節省大量頻寬,另一個優點是全虛擬的 3D
模型能夠提供全視角影像而不限於只能由有限的視角觀看,這給予互動式或
虛擬實境的應用很大的自由度。在這個過程之中 3D 加速器扮演了相當重要
的角色,主要是因為 3D 圖形成像過程中包含了複雜且大量的運算,如座標
投影轉換的矩陣乘法,打光的內積、方根、倒數、次方等等,這些運算雖可
用軟體來完成但是在高解析度複雜場景的即時顯示的需求下,其獨立的嵌入
式 CPU 的架構與記憶體的頻寬並不能有效率地且即時地完成,若採高運算
能力嵌入式處理器來達到所需的效能,將導致昂貴的硬體花費與嵌入式處理
器使用率不高所造成的浪費。因此在兼顧效能與成本的考量下,需將這些運
算使用特定的硬體加速器完成且要大幅減少其頻寬的需求,利用其平行與管
線的硬體架構來提高 3D 繪圖的效能,使處理器僅需負責一般程式的執行、
介面與硬體控制上,降低處理器需求的規格之餘不但硬體成本得以有效減
少,效能也能提升,因此 3D 的相關應用在嵌入式系統比傳統桌上型電腦更
需要 3D 繪圖加速器的輔助。
又因 3D 立體視訊的應用面非常廣泛且需求面與功能面非常多元,其硬體
設計必須有能力根據不同解析度與不同 3D 圖形品質要求下提供具有不同壓
縮能力(也就是提供不同頻寬的能力)、不同打光能力與滿足即時的需求,所
以此設計必須具備可重組性(Reconfgurability),故子項目二之重點為可重組
之 3D 繪圖加速器設計,本子項目二負責進行包括 3D 繪圖軟體平台開發、
程式庫與介面開發、具重組暨低頻寬需求之 3D 繪圖加速器 Soft IP/單晶片的
設計與其嵌入式平台整合。
因此子項目二目的為研發具有可重組式與低頻寬需求特性之硬體與軟體
環境,讓開發者在合理硬體成本下能針對所繪製的場景與模型特型選擇適當
的硬體組態來達成繪圖品質來滿足效能的要求。
三、結果與討論
本子計畫我們將各子區塊的實作情形以及目前進度分項列出,主要分為打
光器的設計與硬體實現、深度緩衝區壓縮的演算法設計與硬體實現以及前後
兩段幾何子系統與著色子系統的設計與硬體實現等,最後總結整個子計畫目
前的實作進度與預期目標。
1. Approximating Phong Shading
本子計畫在打光器設計上主要有三項突破點以及實現結果,分別是:三角
型切割之演算法與其硬體設計與實現、頂點變數共用機制、邊函數修正機
制。以下分別討論之。
甲、
三角形切割演算法
圖 15 和圖 16 分別是兩種主流打光演算法及 Subdivision Based
Shading 的結果,由這三張圖得比較後可知 Subdivision Based Shading
與 Phong Shading 的繪圖結果相當接近,而兩者間運算量得比較可參考
圖 17,圖中黑色的部分表示須作打光運算的像素,由圖可知在打光效
果相近的情形下,切割式渲染演算法大約可以省下近 50%的打光運算。
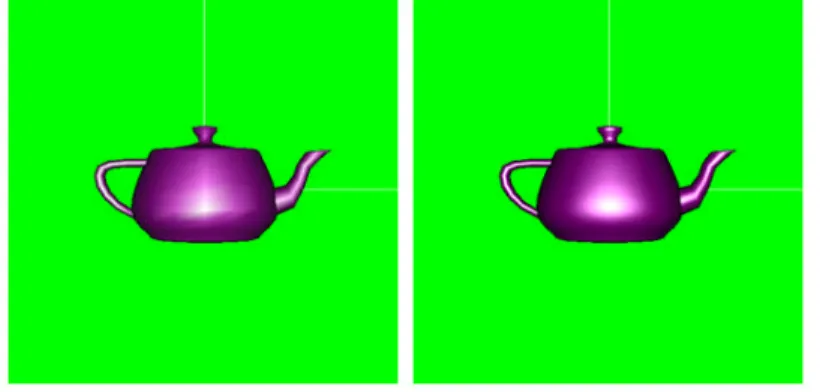
圖16. Subdivision Based Shading 的茶壺打光
圖17. Phong shading 和 Subdivision Based Shading 運算次數比較
切割器是切割式渲染法的核心,而切割器不適合在軟體中實作的其中
一個原因是切割時會產生新的頂點,若切割的動作是在處理器中完成,
則切割出來的新頂點需要花費額外的頻寬將它們送到繪圖硬體上;反之
若切割的動作是在繪圖硬體上完成則新頂點就不需要在匯流排上傳送,
如此就可省下許多的頻寬而使繪圖效能提升。傳統的切割演算法使用遞
迴的方式,但遞迴演算法不適合在硬體上實作,主要的原因在於堆疊的
支援與切割出頂點的管理。由於遞迴式演算法會在共用邊上切割出相同
的頂點,管理這些頂點所需的資料結構在硬體上實現相當複雜。但如果
不使用管理頂點的機制而直接將產生的任何頂點直接送到打光單元中,
就會對相同的頂點重複打光。打光的運算是相當耗時的,所以我們希望
盡量避免重複的打光動作,為了兼顧硬體複雜度與效能我們使用了漸增
式(Incremental)切割的方式來實作切割器。圖 18 說明漸進式切割的概
念,要將一個三角形切成四個小三角形需要計算出在各邊上中點的頂
點,而 dy 與 dx 可以事先計算,透過這種逐一加上一個向量的方式就可
以循序地產生所有的頂點。由於頂點是依序被產生因此可以直接送到打
光單元進行打光而不需要擔心重覆頂點的問題,因此也不需要額外的頂
點管理機制。漸增式切割可以很容易的進行任意數量的切割運算,如圖
19 所示,只要計算出需要的 dx 與 dy 向量並透過漸增的方式即可產生所
有需要的頂點。
圖18. 漸增式切割演算法
圖19. 任意數量的漸增式切割
乙、
頂點變數共用機制
而經由切割器切割後產生的許多小三角形無疑的會對效能造成衝
擊,頂點數量增加意味著需要更多的幾何轉換,三角形的數量增加也代
表三角形準備的運算和後端著色子系統所有的效能負擔的增加,因此前
後端如何互相配合才能不影響系統效能也成為我們的研究重點。在後端
我們透過了係數共用的機制便可以減少一半以上的三角形準備運算,如
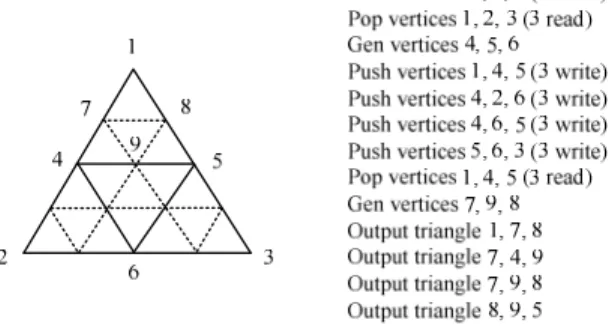
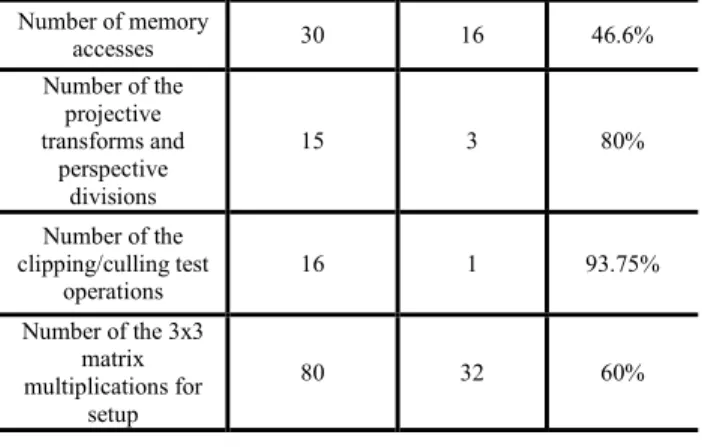
圖 20 所示,共用的係數一旦被計算出來便可以提供給所有切割出來的
三角形使用而不需要重新計算這些係數。表 4 整理了變數共用機制前後
的運算量比較,可以看出使用這套方法確實能有效的降低運算複雜度進
而減少切割式渲染演算法對系統效能的影響。
圖20. 係數共用機制圖
表4. 變數共用機制前後運算量之比較表
Conventional subdivision algorithm Proposed subdivision algorithm Complexity reduction in percent Number of the lighting operations 24 15 37.5% Number of the 4x4 matrix multiplications for perspective transformation 24 3 87.5%Number of the clipping/culling test operations 16 1 93.75% Number of the 3x3 matrix multiplications for setup operation for rasterization 80 27 66.25% Rasterization anomalies Sometimes occur Completely eliminated
丙、
邊函數修正機制
第二個問題來自於切割過程中產生的誤差,如圖 21 所示,原本在共
用邊上的頂點應該要在相同的位置上,但是切割時的誤差使得最後的位
置產生落差,因而造成像素化異常的現象,如圖 22 之左所示,我們在
畫面上可以看到物體上因為像素化異常而產生破洞。為了處理這個問
題,我們也提出以原本三角型的頂點取代部分切割後的頂點的方法,成
功的解決了這個問題,如圖 22 之右所示所有的破洞已經完全消失。
(a) Before subdivision (b) After subdivision
(c) Rasterization result (a) (d) Rasterization result (b)
圖22. 消除破洞模擬結果
2. 可重組深度緩衝區壓縮器
目前此子項的硬體設計所提供使用者的壓縮演算法共有 Modified HA,
Modi
f
i
e
d
DDPCM,
Ge
ner
a
l
DDPCM,
one
/
t
wo
pl
ane
mode
…等等數種主流的
壓縮法,並可自動判斷輸入的 3D 場景適合何種壓縮法。經由模擬的驗證已
經確定我們所提出的演算法能夠有效提升平均壓縮率,並改善約 38.7%至
76.9%,目前已經進入硬體驗證階段。而圖 23a)藍色曲線為適應性壓縮演算
法的壓縮比,紅色曲線則為目前被廣泛運用之 DDPCM 深度壓縮演算法之壓
縮比;b)同樣場景下適應性壓縮演算法(藍色)和另一種廣泛運用之 HA 深度
壓縮演算法之壓縮比比較。三種演算法(proposed:DDPCM:HA)壓縮比比
較為 1.91:1.37:1.09。
圖23. 常用演算法和 proposed 演算法之壓縮比之比較
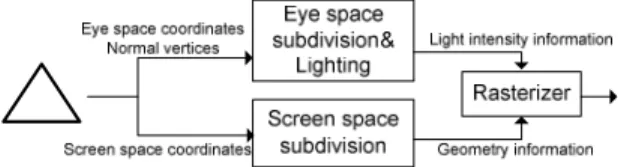
3. Rasterizer Subsystem
在後端 Rasterizer Subsystem 部分,其系統流程圖如圖 24,總共可以區分
成 三 塊 主 要 子 系 統 , 包 含 Triangle Setup Engine 負 責 將 前 級 系 統 的
Triangle-level 轉換成後級的 Pixel-level;Depth Testing Unit 負責測試每個像
素(pixel)的深度值,決定該像素是否需要顯示在螢幕上;Texture Mapping Unit
負責替每個像素套上該場景下的色彩。接下來會分別深入探討三個子系統的
實際設計理念。
另外為了提高後級著色子系統的效能以配合前級三角型切割所造成的額
外負擔,我們在計算材質貼圖的模型精確度(LOD)參數時,採取漸進式的演
算法,利用多邊形和其相對應的貼圖材質模型間固定的長寬比關係,在第一
次計算 LOD 參數時額外計算一次該模型位置長寬和 LOD 參數間的差值關
係,之後即可用簡單的加減法運算取代整套複雜的連續乘加運算,以加快系
統速度與節省功率消耗。
圖
24. 著色子系統的細部流程圖
甲、
Triangle Setup Engine (TSE)
主要工作在於將前級的 Triangle-level 轉變成後級的 Pixel-level。首先
TSE 會接收來自前級傳送過來的三角形三個頂點(Vertex)資訊及控制訊
號,然後透過 Triangle PCU 和 Block PCU 算出後端各級漸進式演算法
的初始值,使之後的各級管線省下一連串複雜的初始乘除法運算,而可
以用較容易的加減法運算代替,之後經由 Block Generator 產生一連串
該三角形內所包含的 8x8 block,最後再經由 Edge Test 檢測各 block 與
該三角形間的幾何關係以剔除 ghost block,以減少後半部元件多餘的資
料量,整個流程結束後,會將每個像素資料傳給深度測試元件(Depth
Testing Unit)。另外,TSE 中的 SKIP #1 與 SKIP#2 是分別將太小的三角
形清除與空的 Block 清除。
乙、
Depth Testing Unit
此元件的主要功能為減少 Texture Mapping Unit 的運算資料量,由於
3D 模型轉換到 2D 座標系統時,許多物件的像素有可能對應到相同座
標,但其中只有一個像素需要顯示在座標系統上,於是透過比較深度值
的方式,決定哪個像素的 Z 值最小,表示最接近人的眼睛、及需要顯
示在螢幕上,並清除其他像素的資料,進一步減少後端貼圖運算單元的
運算量。
丙、
Texture Mapping Unit
Texture Mapping Unit 就是傳統的 Pixel Process,主要在於計算每個像
素的色彩資訊,其中包含了透視角校正機制(Correction Unit)、像素產生
器(Pixel Generator)、材質讀取元件(Texture Access Unit)和色彩混和器
(Color Blending Unit)。透視角校正機制接收來自 TSE 的資料,進行貼
圖座標的透視角校正,而像素產生器則接收來自深度測試元件的資料,
產生相對應的像素資料,之後透過材質讀取元件從記憶體讀取貼圖資
訊,最後再利用色彩混和器將之前的色彩與記憶體讀取的色彩做混和的
動作,並把結果傳送到 Frame Buffer。
4. FPGA 驗證平台
下表 5 為 3D 管線前後兩個子系統在 Xilinx Spartan 3A DSP 開發板所使用
的 FPGA 資源,由此表看來無論是 FPGA 的 Slice 使用量或是特殊運算單元
DSP48A 的使用量都算是十分吃緊,因此在之後本子計畫與整合平台將會移
到 Xilinx ML507 開發板。
表5. 各子區塊所占 FPGA(Spartan 3A DSP 1800)資源統計表
Module
name
slices
Slices Flip
Flops
4 input LUT
DSP48A
Geometry
Engine
4069
3605
6168
35
Raster
Engine
4220
4776
7776
44
Total
8289
8381
13944
79
%
24%
50%
42%
94%
目前整合在 Xilinx Spartan 3A DSP 開發平台上的硬體系統架構如圖 25。
由 FPGA 中的 MicroBlaze processor 啟動 FPGA 的中幾何轉換子系統,而幾
何轉換子系統抓取記憶體中的頂點和顏色資料運算完後,會把處理後的三角
形資料傳回 MicroBlaze 做之後的繪圖動作,最後 MicroBlaze 把處理後的像
素資料寫入畫面緩衝區。
圖25. FPGA 驗證平台之系統架構
本子計畫在 Xilinx ML507 開發板所使用的 FPGA 資源如表 6 所示,目前
所使用資源不到百分之五十,故整合平台與其他子計畫能夠一起整合在此開
發板中。而由於後端著色子系統中有使用到多週期路徑(multicycle path),因
此系統顯示的最快時脈只有 40MHz,實際上系統可乘載的周期能夠和前端
幾何子系統配合,約在 100MHz 左右。
表6. 各子區塊所占 FPGA(ML507)資源統計表
Device : Vertex-5 5vfx70t ff1136 -1
Geometry Engine
Raster Engine
Total
Slice Logic Utilization
Slices Register
7361(16%)
14074(31%)
47%
Slices LUTs
5823
8844
31%
Number used as Logic
5644
8844
31%
IO Utilization
Number of IOs
902
1601
-Number of bonded IOBs
0
0
-Specific Feature Utilization
Number of DSP48E
35
28
49%
Maximum Frequency
153.86 MHz
40.912 MHz
四、計畫整體成果與自評
本子計畫在本年度執行到目前,各項預期進度均依據計畫的執行步驟進
行,無論是理論面、實作面或是應用面都有良好的成果展現。設計實現方面,
部分研究重點的子方塊也已經進入硬體驗證階段,呈現前端幾何轉換子系
統、後端繪圖子系統以及 FPGA 開發板相關流程三大主軸平行進行,本子計
畫除了在演算法方面提出可重組式的架構,另外也進行基本管線的實作與
FPGA 驗證,同時研究成果也陸續發表在 IEEE 的期刊與國際研討會上,例
如 IEEE Trans. Computers,2009 年的 ISCAS、2008 年的 ICME、MUE。
目前本子計畫已在 Xilinx Spartan 3A DSP 開發板上與子計畫四部分整合
完成,其系統展示圖如圖 26(左),畫面中央綠色背景的視窗中即為本子計畫
3D 繪圖引擎中前段幾何轉換子系統在 FPGA 中即時運算模擬的結果。另外
由於 Spartan 系列 FPGA 容量不足以支援本子計畫完整設計的整合驗證,因
此計畫轉移展示平台到 Xilinx ML507 的開發板,其開發中的畫面如圖
26(右)。未來將會繼續以 ML507 為主要驗證平台,完成整體 3D 電腦繪圖引
擎的設計與驗證。
圖26. 左)Spartan 3A DSP Demo 展示平台 右)ML507 Demo 展示平台
過去學界雖不乏有類似本子計畫的 3D 電腦繪圖加速晶片研究或設計,但
均以獨立高效能晶片為主軸;而本子計畫採取的是以可以應用在各種不同領
域的平台、提供可重組高能源效率的加速電路,以提供更有彈性的加速功能
與更優質的 3D 立體畫面及人機介面。
子計畫三成果:立體視訊顯像模組
一、 前言
本文簡述子計畫三前兩年的研究成果。本子計畫的研究目標,在於深度圖
因視訊壓縮所造成之量化效應(Quantization Effect)下,利用參照影像間隱
藏之深度資訊,修補失真之深度圖。本子計畫提出了一個檢測單一像素之合
成誤差的模型(Per-pixel Synthesis Distortion Model),透過此模型,可
分析各種造成影像失真的原因;此外,基於此分析模型,發展出合成品質導
向之深度圖修補演算法,此演算法可有效偵測出有問題的深度值,並進行修
正。此演算法相較於現行的 MPEG FTV 標準架構下,平均多 1.2 dB,且在主觀
視覺上也較接近於原始影像。
二、 研究目的
深度圖(Depth map)經過現行視訊壓縮標準的編解碼後,將造成解碼重建
後深度圖有不同程度的失真。這些失真可能會影響到最終虛擬影像的合成品
質,例如在物體邊界的深度值發生錯誤時,可能明顯地造成主、客觀影像品質
評量上的降低。因此,本子計畫針對重建後的深度圖對虛擬影像合成的影響,
提出一個單一像素之合成誤差的檢測模型。透過此模型之分析,可有效預測出
每個像素可能造成的合成誤差。利用不同參照視角(Reference Views)畫面之
間 對 應 點 關 係 , 找 出 隱 藏 的 深 度 資 訊 , 並 依 此 修 正 不 可 靠 的 深 度 像 素
(Unreliable Depth Pixel),使其在虛擬影像合成上可得到較好的品質。採用
現行最新的視訊壓縮標準對原始深度圖(圖 27) 進行壓縮後,並再解碼重建深
度圖 (圖 28)。主觀視覺比較上,可在圖 27 與圖 28 看見明顯的落差,例如圖
28 中,人背上的深度影像產生明顯的區塊效應(Block Effect)。
目前 MPEG 標準制定小組已出現兩篇於接收端修正深度圖的演算法:第一
篇由 Tanimoto 提出,其利用合成相鄰參照視角時的合成誤差,以 Linear
Prediction 的方式,推測出虛擬視角可能的合成誤差,最後將此預測出來的
合成誤差補回虛擬視角之合成影像;第二篇由 Sung 提出,其利用合成虛擬視
角時,來自不同參照畫面的亮度值與深度值的差值,若此差值越過某個門檻
值,則判定此深度值需要被修正;其次,此方法為每個 Connected Component
找出一個最佳的深度值偏量,使得合成誤差可以降到最低。然而,上述方法未
考慮深度值壓縮的情況,兩者皆無法根據不同的壓縮品質進行調整,造成修改
的效能嚴重受到壓縮之品質所影響。
為解決上述問題,子計畫三設計一個單一像素之合成誤差的檢測模型,於
理 論 上 分 析 虛 擬 影 像 合 成 時 , 所 有 可 能 影 像 合 成 品 質 的 因 素 。 根 據
Depth-Image-Based Rendering(DIBR)描述參照視角和虛擬視角的對應點關
係,如公式(1):
11
:
1
1
1
Z
p
p
p
p
A RA
A T
(1)
其中
p
和
p
分別為參照視角和虛擬視角的對應點座標,R 和 T 為虛擬相機的旋
轉矩陣與位移向量,
A
和
A
分別為參照相機和虛擬相機的相機內部參數,本
文以
p
( ;
Z
p)
簡化表示公式(1)之運算子。在深度圖沒有失真的情況下,可確
保
p
( ;
p
Z
p)
,且亮度值相同
I
T( )
p
I
R( )
p ;若深度圖有失真(
Z
p加上雜訊,
p p pZ
Z
n
),以
q
( ;
p
Z
p)
表示,則合成誤差
可由泰勒展開式逼近:
p
2 2 2 2( )
( )
(
( )
( ))
( )
( )
( ) (
)
( ) (
)
p R T R R R R R RI
I
I
I
I
I
I
I
p
q
p
q
p
p
p
q p
p
q p
(2)
其中
1
;
Z
q
q
q
,
p 為
I
R( )
p
的 Gradient。利用
p
、
q
和
q
三點的關係
Z
q
Z
p
n
p
q;
p;
q'
,可將
(
q p
)
可表示為公式(3):
圖27. 原始深度圖.
圖28. 解碼後之深度圖.
(
)
p q p pn
Z
Z
n
q p
c
(3)
其中
1 2 2 1
c
I
0
AR T 。將
(
q p
)
帶入公式(2),並導出下式:
2 p p R q p pn
I
Z
Z
n
p c
(4)
在 MPEG FTV 的水平相機設置的限定下,位移矩陣只含水平方向之分量,因此
可將公式(4)簡化為下式:
2 2 2 p p x q p pn
g
c
Z
Z
n
p
(5)
其中
2
xg
p 為
p 的水平分量。因此,假設有真實(Ground-truth)深度資
I
R
訊的情況下,計算出合成影像誤差的條件期望值:
2 (2) 2 2 3 4 (2) 2 2 2 3 4 2 4 6 (2) 2 2 2 3 4 2 (2) 2 2 2|
,
|
,
1
2
3
1
9
75
1
p p q p p q g q p p p p p g q p p p n n n g q p p p n g q pE
Z
Z
n
E
Z
Z
m
c
Z
Z
n
E n
E n
E n
m
c
Z
Z
Z
Z
m
c
Z
Z
Z
Z
m
c
Z
Z
p
p
p
p
p
p
p
p
(6)
其中
(2)
2
g xm
p
E g
p
,
2
n p 為
n
p之變異數,並假設
n
p之數值呈現常態分布
2
~
0,
p nn
N
p
。透過公式(6)的推導結果得知,單一像素之合成品質係由四
個因素共同影響:Depth-error Variance、Intensity Variation、Ground-truth
Depth Value、Virtual Camera Location。本文給定公式(6)各種不同的參數設
定,並將結果描繪於圖 29 中,並提出四項詳細之觀察:
(1) 當
(2)
gm
p 越大,則 Depth-error Sensitivity(
Z
p/
p )越高,可歸納出
n
物體邊界或複雜的圖像內容,這些區域之深度值較不可靠。
(2) 比較圖(a)(c)(e)與(b)(d)(f),當景深越深,其造成之合成誤差相對越小。
(3) 比較圖(e)與(a)(c) (或是圖(f)與(b)(d)),若
Z
q
Z
p,其 Depth-error
Sensitivity 會比
Z
q
Z
p來的小。由圖 30 得知,當
Z
q1
Z
p
Z
p
Z
q2,
p
相對於
q 為一個背景的點,使用背景的點覆蓋前景的點,將產生較嚴重的
2合成誤差;反之,
p
相對於
q 為一個前景的點,此覆蓋情形較不會出現明顯的
1合成誤差。
(4) 由公式(6)的
2 2 n pZ
p
和
2c
可知,若虛擬視角與參照視角的距離越遠,其
Depth-error sensitivity 也會越高。
Expected Synthesis Distortion 0 5 10 15 20 25 30 35 40 D e p th -e rr o r S e n s it iv it y 0 50 100 150 200 250 300 350 400 450 500 mg (2) (p)=36 mg (2) (p)=64 333.0 249.7 Zp=30, Zq=0.5Zp
Expected Synthesis Distortion 0 5 10 15 20 25 30 35 40 D e p th -e rr o r S e n s it iv it y 0 50 100 150 200 250 300 350 400 450 500 mg (2) (p)=36 mg (2) (p)=64 166.5 124.8 Zp=60, Zq=0.5Zp
(a)
(b)
Expected Synthesis Distortion 0 5 10 15 20 25 30 35 40 D e p th -e rr o r S e n s it iv it y 0 50 100 150 200 250 300 350 400 450 500 mg (2) (p)=36 mg (2) (p)=64 166.5 124.8 Zp=30, Zq=Zp
Expected Synthesis Distortion 0 5 10 15 20 25 30 35 40 D e p th -e rr o r S e n s it iv it y 0 50 100 150 200 250 300 350 400 450 500 mg (2) (p)=36 mg (2) (p)=64 83.2 62.4 Zp=60, Zq=Zp
(c)
(d)
Expected Synthesis Distortion 0 5 10 15 20 25 30 35 40 D e p th -e rr o r S e n s it iv it y 0 50 100 150 200 250 300 350 400 450 500 mg (2) (p)=36 mg (2) (p)=64 111.0 83.2 Zp=30, Zq=1.5Zp
Expected Synthesis Distortion 0 5 10 15 20 25 30 35 40 D e p th -e rr o r S e n s it iv it y 0 50 100 150 200 250 300 350 400 450 500 mg (2) (p)=36 mg (2) (p)=64 55.5 41.6 Zp=60, Zq=1.5Zp
(e)
(f)
圖29. Measuring the depth-error sensitivity under various settings of
p
Z
,
Z
qand
p
2
x
g
.
圖30. A geometrical interpretation of the effect of
Z
qon depth-error
sensitivity.
三、 結果與討論
基於 MPEG-FTV 的架構,圖 31 提供子計畫三研究之深度圖修正演算法的
系統架構圖,其中圖中虛線方塊處為本計畫提供的模組。影像和深度圖從傳
送端被壓縮後,傳至接收端重建影像和深度圖並合成影像。深度圖經過壓縮
後會造成許多的幾何誤差,進而可能產生影像合成上的錯誤。因此,本子計
畫針對重建後的深度圖對虛擬影像合成的影響,提出一個單一像素之合成誤
差的檢測模型(Per-pixel Synthesis Distortion Model)。透過此模型之分
析,可有效預測出每個像素可能造成的合成誤差,並在傳送端計算修改深度
圖後可能的合成誤差,使其在接收端之虛擬影像合成上,可得到主客觀視覺
品質的提升。
圖31. System Block Diagram.
子計畫三所提出來的深度圖修正演算法有下列特點。首先,在不改變
MPEG-FTV 架構的前提下,對深度圖進行修正。第二,在傳送端作分析,利用
不同參照視角之間的對應點關係,若對應點的 Intensity 差異超過門檻值,
則此深度值可能有問題,並將 Intensity 差值稱 Synthesis Error。此外,
對應點關係隱含了深度資訊在其中,本計畫以此為修正解壓縮後的深度圖之基
礎。其三,分析重建後深度圖對於虛擬影像合成的影響,並在傳送端模擬虛擬
視訊合成後所產生的誤差,此誤差包括原始與重建後的深度圖之間的差異、分
析並產生參數供接收端使用,我們需判斷哪些深度值可能有問題與深度值搜尋
範圍,接收端就可以根據這些參數修正解壓縮後的深度圖。
由圖 32 可以得知子計畫三提出的演算法和 Tanimoto、Sung 的演算法相較
於 MPEG-FTV 的 PSNR 還高,其原因是此三者演算法都有對深度圖和合成影像
進行修補;不過當深度圖失真越大時,子計畫三的演算法會比 Tanimoto 和 Sung
來的好,原因是這兩者演算法並沒有考慮到深度圖壓縮的問題,因為壓縮後的
深度圖已經遭到嚴重的破壞,若再使用它的話,合成品質會非常糟糕。從主觀
視覺圖 33)來看,也可以發現子計畫三的演算法相較於其他三者,也有更好的
觀看品質。
DepthQP 22 24 26 28 30 32 34 36 38 40 42 44 P S N R 29 30 31 32 33 34 35 36 37 MPEG FTV Tanimoto [7] Sung [8] Proposed DepthQP 22 24 26 28 30 32 34 36 38 40 42 44 P S N R 29 30 31 32 33 34 35 36 37 MPEG FTV Tanimoto [7] Sung [8] Proposed(a)
(b)
DepthQP 22 24 26 28 30 32 34 36 38 40 42 44 P S N R 26 27 28 29 30 31 MPEG FTV Tanimoto [7] Sung [8] Proposed DepthQP 22 24 26 28 30 32 34 36 38 40 42 44 P S N R 26 27 28 29 30 31 MPEG FTV Tanimoto [7] Sung [8] Proposed(c)
(d)
圖32. PSNR of synthesized images as a function of the depth and reference
QP.
The reference view images are coded with QP=22 (a)(b) and QP=31
(a)
(b)
(c)
(d)
圖33. Subjective quality comparison of synthesized images: (a) MPEG
FTV(without depth refinement), (b) Tanimoto, (c) Sung, (d) the
proposed scheme.
The depth QP is set to 44.
四、 計畫整體結果與自評
子計畫三進度和原本的研究目標不盡相同,我們做了以下的解釋:
(1) MVC (Multi-view Video Coding) 標準已經在今年 (2009) 三月結束
制定的工作。在所有 MVC 的參照軟體 JMVC 所接受的多視角視訊壓縮工具
中,尤以視角間預估 (Inter-View Prediction)、亮度補償 (Illumination
Compensation) 與運動向量省略模式 (Motion_Skip Mode) 等技術引起最多
與會者的討論。對比於 H.264/AVC 壓縮標準,JMVC 可以帶來平均約 20% 的
位元率 (Bit-Rate) 的節省,但仍舊未達當初 MVC 在 Coding Efficiency 上
制定的目標。在考慮不同工具在壓縮上所需要付出額外的複雜度,與其所能
帶來於 Coding Efficiency 的改善,因此 MVC 僅採用在 Anchor View 上進
行視角間預估。因 MVC 標準不接受 Macro-block Level 以下之 Syntax 的
改變,只接受視角間預估為標準當中的壓縮工具,有鑑於此,我們把研究發
展發向改為與 MVC 並行的 FTV 標準。
(2) MPEG-FTV 計畫主要目標在標準化以下三個子項:深度圖估測演算
法、虛擬視訊合成演算法與多視角影像與深度圖壓縮標準。其中壓縮標準目
前考慮使用 MVC,壓縮對象包含多視角視訊與其對應的深度圖。FTV 與 MVC
分別為 MPEG 與 JVT 並行的計畫,MVC 已於今年結束制定的工作;而 FTV 目
前專注在深度圖估測知正確性與虛擬視訊合成品質上的提升。FTV 為基於多
視角 DIBR (Depth-Image-Based Rendering) 的虛擬視訊合成技術,由子計
畫的研究發現,現行壓縮標準在壓縮深度圖上,對合成視訊的品質造成許多
影響,特別是影像上高對比的區域與深度值較小的區域,合成品質較容易受
到深度圖壓縮的影響。深度圖壓縮是下個階段 FTV 所要專注的重點目標,同
時也是許多國內外學者提供解決方案的重點項目,因此本子項轉向提出深度
圖對合成影響之模型,藉此模型幫助深度圖壓縮的設計。目前本子計畫已建
立壓縮深度圖對合成影像影響之模型,藉由此模型偵測壓縮後受影響的深度
像素,進而修正此像素後縮小合成之誤差。初步研究上,平均合成效能於 PSNR
表現上,相較於 FTV 標準已經產生 0.56dB 的提升,在低位元率的深度圖表
現上,更有 0.45-3.2dB (平均 1.2dB) 的改善,主觀視覺更可以有效消除影
像高頻區段的合成誤差,提升視覺上的品質。
(3) 基於 MPEG-FTV 的架構下,本子項已完成視角合成演算法的開發,目
前在順利移植到 ARM 嵌入式平台。於此平台上,在 CIF 與 QCIF 的解析度上
已經可以達到 0.54 與 1.56 fps,即時運算則是本子項下一步發展的目標。
因此,總合今年的成果,子計畫三完成下列幾點:
(1) 完成深度圖壓縮品質對合成影像影響的文獻研究。
(2) 完成檢測合成影像失真的模型。
(3) 完成修補壓縮後深度圖的演算法。
(4) 在 FPGA 上完成立體影像視訊軟體。
(5) 在人才培育方面,本計畫兩年來共有 1 個博士生、2 個碩士生參與。
(6) 在論文方面,本計畫完成了一篇期刊論文(審察中)。
子計畫四成果:嵌入式 JAVA 平台設計
五、前言
本報告將簡述本計畫前兩年之研究成果。子計畫四的研究目的是在開發一
套雙核心 Java 處理器以及最佳化的系統軟體,以提供一個高效能的 Java 執行
環境。在過去兩年,子計畫四除了完成異質雙核心的 Java 應用處理器的開
發,並完成了支援圖形介面應用程式的系統軟體開發,以用來在 FPGA 平台上
驗證我們所開發的 Java 處理器。目前我們所得到的系統執行效能大約是
Google Android 參考平台的四倍,Sun CVM 參考平台的五~八倍。而我們也
把研究的成果撰寫了一篇期刊論文(審查中)
,以及發表了三篇研討會論文。
六、研究目的
隨著嵌入式系統的發展,嵌入式 Java 執行環境已經變得越來越重要了。
經過一些調查,我們發現新一代的嵌入式多媒體平台有漸漸地往 Java 執行環
境收斂的趨勢。例如在 3GPP 手機上的 CLDC/MIDP 平台,Google 手機的
Android 平台,或是歐規數位電視標準的 DVB-MHP 平台都是一些實際的例子。
通常一個能夠支援複雜的使用者圖形介面的 Java 執行環境往往需要一個全功
能的作業系統。在嵌入系統的環境中,這通常是 Embedded Linux。以往在 Java
系統的設計上,大部份的研究都集中在 Java bytecode interpreter (或稱作
Bytecode Execution Engine)的效能改進。很少有研究是針對整個 Java 執行環境
的最佳化設計進行討論。
通常在設計 Java 執行環境時,為了能讓 Java 執行環境有較高的效能,會
把許多 Java 執行環境所需要的功能直接對應到低層的作業系統和硬體平台所
提供的功能。不過這樣設計的缺點有下面兩大缺點。首先,如果 Java 執行環
境是儘量利用作業系統的功能來提昇效能,那麼這個設計的移植性就不高。現
今嵌入式系統的作業系統並沒有統一的趨勢,因此在設計 Java 平台時,如果
只針對某一套作業系統最佳化,它的應用就會受到限制。第二個問題是,Java
執行環境本身就等同一套虛擬的作業系統,如果所有的應用程式都是用 Java
開發,那麼,整個系統就只會用到底下的實體作業系統的一小部份。從系設計
的角度來看,這是一個相當浪費資源的設計。一個典型的例子就是 Android。
雖然 Android 的 Java 執行環境是架構在 Linux Kernel 2.6.25 之上,但是它只利
用 Linux Kernel 提供以下幾項主要功能:
Hardware abstraction layer
Process management
Shared library dynamic loading management
事實上,一個簡化的 OS Kernel 就能提供以上三項功能。所以單從 Java 執行
環境的支援來看,並沒有理由採用 Linux。不夠 Android 並不是一個傳統的 Java
執行環境。整個 Android 系統有相當大的系功能是透過 native code 完成的,
所以 Google 選擇了在 Android 系統內嵌一個 Linux 作業系統核心。
子計畫四的研究是在開發一套雙核心 Java 處理器以及最佳化的系統軟
體,以提供一個高效能的 Java 執行環境。一般而言,為了要提升嵌入式 Java
執行環境的效能,目前系統在實作上有兩種主要作法。一個方法是採用
Just-In-Time (JIT)編譯器,另一個方法是利用 Java 協同處理器
(co-processor)
來加速 Java 執行環境。透過一些相關的研究,我們發現上述兩種方法在嵌入
式系統的應用上各有一些問題,比方法說:
a. 當使用者啟動了一個 Java 應用程式之後,JIT 編譯器會即時把部份
Java 程式碼編譯成實體處理器可執行的機器碼,因此在一開時會造成
應用程式啟動的延遲。為了要降低延遲的時間,系統需要採用一個效
能較好的處理器。但這往往會提高成本,或是增加功耗。
b. JIT 編譯器在執行時會使用到大量額外的記憶體,而且也會大幅增加
應用程式碼的大小。例如在 Intel x86 處理器上,執行 JIT 編譯之後所
產生的程式碼與原來的程式碼相比之下,程式碼的大小增加了四倍;
而在 Sun SPARC 處理器上,則是大約增加了八倍。這樣的結果對資
源有限的嵌入式系統而言,會造成相當大的負擔。
c. 如果只是單純根據 Java stack machine 的架構設計處理器(例如 JOP
計畫)
,那麼在處理通訊及多媒體的工作時,效率又往往不好。
d. Java 協同處理器雖然可以解決上述各種問題,但又會受限於特定的
架構。例如 ARM Jazelle 是最有名的 Java 協同處理器,但只能限於採
用 ARM 架構的系統,這對於一些想要支援 Java 環境的其它處理器開
發團隊而言並不適用。
就嵌入式系統的應用而言,利用 Java 處理器來加速應用程式的執行仍然
是比較好的做法。因此,子計畫四目的是開發適合用在嵌入式多媒體平台上的
異質雙核心 Java 應用處理器,以及支援圖型介面的 Java 執行環境。
七、結果與討論
為了能設計出一個高效能,有彈性,能跟不同的 general-purpose 處理器
和作業系統做整合的 Java 執行環境,在子計畫四,我們所開發的關鍵技術有
以下幾項:
Java 處理器核心
把 Java 處理器核心和任意 general-purpose 處理器整合成一個異質
雙核心的 Java 應用處理器所需的介面電路設計
Java 執行環境的系統軟體設計
符 合 CDC/PBP 及 DVB-MHP 規 格 的 系 統 中 介 軟 體 ( 包 含 Java
classes library 及 native code library)
我們會採用異質雙核心架構的理由是,一方面可以透過 Java 核心有效率地執行
Java 程式,而且也能夠利用 RISC 核心來處理 I/O 的動作。以下,我們就針對上
述的關鍵技術的開發成果做一個大概的介紹:
machine 的架構,每一個 clock cycle 會執行兩個 bytecode。Java 核
心是設計成一個獨立的 IP,可以和任何 general-purpose 處理器整合,
形成一個異質多核心系統。跟目前業界常用的 ARM Jazella 的 Java
核心不一樣的是,ARM 的 Jazella 是透過 ARM 的 co-processor
interface 和主處理器溝通,所以一定要和 ARM 處理器合用。而我們
的 Java 處理器核心則沒有這個限制。目前我們已經成功地分別和
PowerPC 405 處理器核心以及 Microblaze 處理器核心進行整合測
試。
在異質雙核心的介面電路設計方面,因為我們的 Java 處理核心是設
計成一個獨立有 master interface 的 IP,所以可以透過標準的 shared
memory 和 interrupt-driven 機制和主處理器進行 IPC。另外,我們也
針對 Java 語言的特性設計了特別的 IPC 機制,可以快速的進行
Java-to-C 的呼叫。
在 Java 執行環境的系統軟體設計方面,我們的系統不需要依賴一個
功能完整的作業系統(e.g. Linux)就可以執行圖形介面的應用程式。並
且整個系統軟體的部分可以輕易的移植到任何能做中斷程序管理的
系統內核(kernel)之中。因此不管將來目標平台是採用何種作業系
統,都可以輕易和我們的 Java 環境進行整合。目前我們己經驗證測
試過和 Linux 的整合,以及無作業系統的獨立運作驗證。
在系統中介軟體的設計方面,最關鍵的核心中介軟體如 Java 的基本
class library (如 CDC Foundation classes、Java AWT classes、Java TV
classes ) 以及 native code 的軟體(如 2D graphics library、JMF media
accelerator interface)我們會重新開發出能支援 DVB-MHP UI 介面的
一個子集合,而不是單純地把 Sun 的 reference implementation 移植
到我們的目標平台。而上層的 DVB-MHP 圖形介面中介軟體則是會
由公開程式碼的 OpenMHP 計畫修改而來。目前已完成 DVB-MHP
的中介軟體層,至於其它部份則仍在開發中。
執行至今,子計畫四已經發展出第一代的 Java 軟硬體系統,也利用 Xilinx
Vertex-5 的 FPGA 平台完成驗證。雖然目前在系統軟體方面尚不符合標準 Java
執行環境的規範,但是從初步的全系效驗證可以看出我們所開發的異質雙核心
Java 處理器效能相當地好。我們所設計出來的雙核心 Java 執行環境架構如下
圖 34 所示,而圖 35 則是雙指令 Java 處理器的硬體架構設計。
System Software
System Hardware
Event-driven thin OS kernel GC, Floating Point, Media routines
Java core
Class Loader And VerifierRISC Processor Core
IPCData Comm. routines, Etc. Java Application Classes Method Area C la s s lo a d in g L o g ic System Classes (Java Language and
GUI support)