I
國立交通大學
土木工程研究所
碩士論文
多目標基因演算法於鋼筋混凝土結構設計之應用
Application of Multi-Objective Genetic Algorithm in Reinforced
Concrete Structures Design
研究生:呂怡廷
指導教授:洪士林 博士
II
多目標基因演算法於鋼筋混凝土結構設計之應用
Application of Multi-Objective Genetic Algorithm in Reinforced
Concrete Structures Design
研 究 生:呂怡廷 Student : Yi-Ting Lu 指導教授:洪士林 博士 Advisor : Dr. Shih-Lin Hung
國立交通大學 土木工程研究所
碩士論文
A Thesis
Submitted to Department of Civil Engineering College of Engineering
National Chiao Tung University In Partial Fulfillment of the Requirements
for the Degree of Master of Science
in
Civil Engineering September 2008
HsinChu, Taiwan, Republic of China
i
多目標基因演算法於
鋼筋混凝土結構
設計之應用
學生:呂怡廷
指導教授:洪士林 博士
國立交通大學土木工程學系
摘要
結構設計過程是一種複雜程序且設計方案需滿足各方面需求,隨著社會需求的日益 嚴苛,根據需求將結構功能特性區分為五項,分別為安全性、耐久性、經濟性、環境性 與適用性,設計目標除了滿足這些需求外還必須進一步量化評估以迎合社會需求,故設 計結構時往往需同時考量到多方面的要求。因此本研究就其安全與經濟兩方面進行鋼筋 混凝土構件設計探討,在安全耐震部分依據美國 ATC-40 耐震性能評估法進行考量,其 中引入位移指標對結構的耐震性能進行控制概念。而安全與經濟又是處於衝突狀態,這 類問題稱為多目標問題,一般無法精確地定義出所謂的最佳解,而是必須透過 Pareto Front 有 關 非 支 配 解 的 搜 尋 , 尋 求 問 題 之 可 行 方 案 。 故 利 用 多 目 標 基 因 演 算 法 (Multiobjective Optimization Genetic Algorithm,MOGA)來尋求耐震性能設計與最適成 本,此方法為有效的全域搜尋技術,可以處理離散變數(discrete variables)的最佳化問 題及具有克服局部最小化的能力,並且找出適當 Pareto front。經由數值案例測試,證實 多目標基因演算法可以進行耐震設計並找出最適成本。ii
Application of Multi-Objective Genetic Algorithm in
Reinforced Concrete Structures Design
Student: Yi-Ting Lu
Advisor: Dr. Shih-Lin Hung
Department of Civil Engineering
College Engineering
National Chaio Tung University
Abstract
Design of structures that satisfy all kinds of requirements is a very complicated process. Requests of designed structure performances are categorized as five issues: safety, durability, economy, environment and comfort. Following, design objectives of structures’ performance are not only satisfying the aforementioned issues but also can be quantified and evaluated. Also, design of structures is considered as a multiobjective optimizatioal problem. This work aims to study design of reinforced concrete buildings with two objectives, safey and economy. Herein, safey is consided for seismic assessment of reinforced concrete buildings for ATC-40 regulation. It is based on displacement based design. These two objectives, safey and economy, are conflict explictly. In this work, a multiobjective optimization genetic algorithm (MOGA) is employed to solve the problem. Rather than unquie optimal solution for single objective optimization problem, a set of solution, called Pareto front, can be found and all are consided as feasible optimal solutions. Two cases, a two-story snd a seven-story RC buildings, are adapted to verify the performance of the porposed approach. The results of two cases reveal that MOGA can find a set of optimal solutions for reinforced concrete buildings satisfying safty and minimum cost.
iii
誌謝
研究所兩年即將結束,在交大的求學生涯也將劃下句點,其中最要感謝的人是我的 指導老師洪士林博士,在獨立思考與研究領域上,老師給予學生很大幫助與自由度,所 以我在研究所求學期間,學習到不少東西。最後本研究能夠順利完成,都要感謝我的老 師在旁細心叮嚀與協助,在此祝福老師身體健康、萬事順心。 此外,我還要感謝同研究室同學承禹、世賢一起熬夜趕論文、看棒球賽;與同屆土 木所資訊組沈秉廷同學一起唱談研究的辛酸血淚及學長詹君治、林子軒、陸勇奇、李忠 錦在研究上幫助;及大學社團朋友熙淵、廷凱、佩琪一同就讀交大一同努力畢業;及室 友伯聰、宏碁一起激勵與趕論文。感謝志銘、彥伶、智中學弟妹們,有了你們實驗室多 了歡笑。最後感謝家人在背後督促我,我能順利畢業,一切都要感謝大家陪伴。iv
目錄
中文摘要 ... iii 英文摘要 ... iii 誌謝 ... iii 目錄 ... iv 表目錄 ... viii 圖目錄 ... ix 第一章 緒論 ... 1 1-1 研究背景 ... 1 1-2 研究動機與目的 ... 3 1-3 研究步驟 ... 7 1-4 論文章節及架構 ... 8 第二章 文獻回顧 ... 9 2-1 結構分析與設計之發展狀況 ... 9 2-1-1 目前發展趨勢 ... 9 2-1-2 評估耐震能力相關研究 ... 12 2-2 基因演算法 ... 14 2-2-1 基因演算法之基本概念 ... 14 2-2-1 基因演算法之運作方式 ... 16v 2-2-2 基因演算法之應用 ... 19 2-3 多目標最佳化問題 ... 23 2-3-1 多目標最佳化問題之基本概述 ... 23 2-3-2 Pareto Optimality ... 27 2-3-3 多目標最佳化演算法 ... 30 2-4 類神經網路 ... 36 2-4-1 類神經網路之介紹 ... 36 2-4-1 倒傳遞類神經網路之架構 ... 39 2-4-3 類神經網路應用 ... 43 第三章 系統設計之理論與工具軟體 ... 45 3-1 多目標基因演算法 ... 45 3-1-1 NSGA-II ... 45 3-1-2 多目標基因演算法範例 ... 48 3-2 極限強度設計法 ... 56 3-2-1 混凝土材料之力學性質 ... 56 3-2-2 鋼筋材料之力學性質 ... 58 3-2-3 鋼筋混凝土梁之極限強度設計法 ... 59 3-2-4 鋼筋混凝土短柱之極限強度設計法 ... 61 3-3 非線性靜力分析容量震譜耐法震能力評估 ... 64 ... 64
vi 3-3-2 地震設計反應譜 ... 65 3-3-3 塑鉸設定性質 ... 66 3-3-4 ATC-40 所建議結構耐震能力評估方式 ... 69 3-3-5 ADRS ... 72 3-3-6 功能點計算 ... 76 3-3-7 等效阻尼對需求譜折減 ... 80 3-2-8 側推分析方法的用途 3-4 類神經網路模擬容量震譜 ... 87 3-4-1 容量震譜模型 ... 87 3-4-2 類神經網路模擬系統 ... 91 3-5 系統架構 ... 93 第四章數值案例測試 ... 95 4-1 建立斷面資料庫 ... 95 4-2 兩層樓數值案例 ... 99 4-2-1 兩層樓數值案例多目標搜尋 ... 103 4-2-2 兩層樓數值案例分析結果 ... 105 4-3 七層樓數值案例 ... 107 4-3-1 七層樓數值案例多目標搜尋 ... 112 4-3-2 七層樓數值案例分析結果 ... 115
vii 4-4 分析結果討論 ... 117 第五章結論與建議 ... 118 5-1 結論 ... 118 5-2 建議 ... 118 參考文獻 ... 119 附錄一 斷面編碼說明 ... 122
viii
表目錄
表 2-1 多目標範例之部分解 ... 26
表 3-6 NSGA-II 範例族群 ... 48
表 3-7 NSGA-II the fitness assignment procedure ... 51
表 3-1 梁構件塑鉸建模參數表 ... 67
表 3-2 柱構件塑鉸建模參數表 ... 68
表 3-3 Structural Behavior Types ... 83
表 3-4 Values for Damping Modification Factor ... 83
表 3-5 Minimum Allowable SRA and SRV Values ... 85
表 4-1 柱斷面設定物理參數 ... 96 表 4-2 梁斷面設定物理參數 ... 97 表 4-3 類神經網路設定參數 ... 98 表 4-4 兩樓數值案例之類神經網路設定表 ... 100 表 4-5 訓練案例設定 ... 100 表 4-6 兩樓數值案例之多目標基因演算法參數設定表 ... 101 表 4-7 部分二層樓案例訓練案例資訊 ... 102 表 4-8 兩數值案例之Pareto front解 ... 104 表 4-9 七樓數值案例之類神經網路設定表 ... 108 表 4-10 七層樓數值訓練案例設定 ... 109 表 4-11 七樓數值案例之多目標基因演算法參數設定表 ... 110 表 4-12 部分七層樓訓練案例 ... 111 表 4-13 七數值案例之Pareto front解 ... 114 表 6-1 柱斷面編碼說明 ... 123 表 6-2 梁斷面編碼 ... 124
ix
圖目錄
圖 1-1 土木工程發展簡史 ... 1 圖 1-2 住宅設計目標五要素 ... 2 圖 1-3 極限強度設計法概念圖:梁彎矩強度為例 ... 3 圖 1-4 成本與設計軸力關係 ... 4 圖 1-5 結構耐震設計流程圖 ... 4 圖 1-6 Sa與成本關係圖 ... 5 圖 2-1 結構受地震動的作用 ... 10 圖 2-2 基因演算法操作流程 ... 18 圖 2-3 受一集中力懸臂梁與斷面圖 ... 23 圖 2-4 解空間與目標空間關係圖 ... 25 圖 2-5 多目標解集合示意圖 ... 26 圖 2-6 多目標最佳化的解之間的不受支配與受支配 ... 27 圖 2-7 多目標最佳化的解之間的不受支配與受支配 ... 28 圖 2-8 四種不同Pareto front情形,以兩目標函數為例 ... 29 圖 2-9 solution與simple objective映射關係 ... 30 圖 2-10 solution與multiple objective映射關係 ... 30 圖 2-11 典型之三層類神經網路架構圖 ... 39 圖 3-1 NSGA-II的外部暫存器更新示意圖 ... 46 圖 3-2 同等級解之疏密計算示意圖 ... 47 圖 3-3 NSGA-II範例之步驟一 ... 48 圖 3-4 NSGA-II範例之步驟二 ... 49 圖 3-5 NSGA-II範例之步驟三 ... 53 圖 3-6 NSGA-II範例之步驟四 ... 53x 圖 3-7 NSGA-II範例之步驟五 ... 54 圖 3-8 NSGA-II範例之步驟六 ... 55 圖 3-9 E. Hognestad混凝土應力應變關係 ... 56 圖 3-10 鋼筋之完全塑彈行模式 ... 58 圖 3-12 鋼筋之塑性行為模式 ... 58 圖 3-13 梁斷面之內力計算示意圖 ... 59 圖 3-14 柱斷面之軸力彎矩交互作用示意圖 ... 61 圖 3 15 柱斷面之內力計算示意圖 ... 62 圖 3-16 performance point評估過程 ... 64 圖 3-17 彈性地震設計反應譜示意圖 ... 65 圖 3-18 塑鉸定義 ... 66 圖 3-19 以樓層高分配側推力示意圖 ... 70 圖 3-20 以第一振態分配側推力示意圖 ... 70 圖 3-21(a)形成不穩定機制 (b)達到設定位移值 ... 71 圖 3-22 設計地震譜轉換至ADRS示意圖 ... 72 圖 3-23 側推分析之容量曲線示意圖 ... 73 圖 3-24 容量震譜模擬之單自由度系統 ... 75 圖 3-25 Type A ... 76 圖 3-26 Type A步驟一 ... 77 圖 3-27 Type A步驟二 ... 77 圖 3-28 Type A步驟三 ... 78 圖 3-29 Type A步驟四 ... 79 圖 3-30 Type A步驟五 ... 79 圖 3-31 容量震譜之雙線性模擬 ... 80 圖 3-32 阻尼於運動過程中之產生消能作用圖 ... 80
xi 圖 3-33 ED能量修散示意圖 ... 81 圖 3-34 折減反應譜之示意圖 ... 85 圖 3-35 容量震譜計算流程示意圖 ... 87 圖 3-36 容量震譜步驟一:斷面配置示意圖 ... 88 圖 3-37 容量震譜步驟二:塑鉸配置(左圖)與參數設定(右圖)-以梁為例 ... 88 圖 3-38 容量震譜步驟三:側推分析與容量曲線示意圖 ... 89 圖 3-39 容量震譜步驟四:容量曲線轉換示意圖 ... 89 圖 3-40 求取容量震譜數值模型系統示意圖 ... 90 圖 3-41 類神經網路模擬系統示意圖 ... 90 圖 3-42 輸入層參數設定示意圖 ... 91 圖 3-43 輸出層參數設定 ... 92 圖 3-44 系統主要架構圖 ... 93 圖 3-45 次系統-斷面資料庫建立示意圖 ... 93 圖 3-46 次系統-多目標基因演算法示意圖 ... 94 圖 3-47 次系統-功能點還原示意圖 ... 94 圖 4-1 兩層樓案例參數設定(左)與斷面配置(右)... 99 圖 4-2 兩層樓性能點設計目標前進方向 ... 103 圖 4-3 兩數值案例之Pareto front ... 104 圖 4-4 兩層樓分析結果之ADRS格式 ... 105 圖 4-5 兩層樓分析結果之平均值 ... 106 圖 4-6 兩層樓分析結果之成本與譜位移關係 ... 106 圖 4-7 七層樓案例參數設定(左)與斷面配置(右)... 107 圖 4-8 七層樓性能點設計目標前進方向 ... 112 圖 4-9 七數值案例之Pareto front ... 113 圖 4-10 七層樓分析結果之ADRS格式 ... 115
xii
圖 4-11 七層樓分析結果之平均值 ... 116 圖 4-12 七層樓分析結果之成本與譜位移關係 ... 116 圖 6-1 斷面編碼說明圖 ... 122
1
第一章 緒論
本章將闡述研究背景、研究動機、研究目的、研究方法及論文架構。簡單敘述過去 研究情形及本研究所要討論問題。1-1 研究背景
隨著時代在進步,建築提供服務也隨著增多。人類出現以來,為了滿足住和行以及 生產活動的需要,從構木為巢、掘土為穴的原始操作開始,到今天能建造摩天大廈、萬 米長橋,以至移山填海的宏偉工程,經歷了漫長的發展過程。土木工程的發展至今,它 同社會、經濟,特別是與科學、技術的發展有密切聯繫。土木工程內涵豐富,而就其本 身而言,主要是圍繞著材料、施工、理論三個方面的演變而不斷發展的,我們可以土木 工程發展史簡單劃分為古代土木工程、近代土木工程和現代土木工程三個時代。以 17 世紀工程結構開始有定量分析,作為近代土木工程時代的開端;把第二次世界大戰後科 學技術的突飛猛進,作為現代土木工程時代的起點[1, 2]。以上所描述發展過程簡化繪成 下圖所示: 圖 1-1 土木工程發展簡史(資料來源:[1, 2])2 第二次世界大戰後,現代科學技術飛速發展,土木工程也進入了一個新時代。現代 土木工程所經歷的時間儘管只有幾十年,但以電腦技術廣泛應用為代表的現代科學技術 的發展,使土木工程領域出現了嶄新的面貌。現代土木工程的新特徵是工程功能化、城 市立體化和交通高速化等。土木工程在材料、施工、理論三個方面也出現了新趨勢,即 材料輕質高強化、施工過程工業化和理論研究精密化。 若以結構設計角度觀察,結構設計定義為工程師所欲設計的結構物預估其可能發生 的載重,選擇適當的材料,決定結構元件的位置、大小,以設計能符合其當初預期需求 的結構物。這些因素大致上可分為五項,如下圖所示: 圖 1-2 住宅設計目標五要素(資料來源:[3]) 二十世紀以前,身為一位結構工程師,設計結構時,結構安全性為最高原則,在滿 足這原則下,還必須同時考慮其適用性與經濟性。經濟性可以認知為如何利用最少資源 達到最大效能或不可有任何無謂的資源浪費,而適用性的因素例如:因變形過大,或振動 過大等問題而導致影響結構之正常使用,或讓使用者感到不便都不是一個正確或良好的 設計。 但在經過國內外發生的強震經驗後。發現到過去耐震設計規範之建築物雖然滿足了 保障「生命安全」的目標,但是仍許多建築物受到不同輕重的損害,其修復費用和時間 出乎意料的高,造成很大的財產損失。因此對結構要求也就更多了,現在工程師在進行 結構設計時,除了生命安全與成本外,更必須進一步去考量結構耐震能力。
3
1-2 研究動機與目的
如何用最少資源達到最好成果,一直是人們所追求目標,特別是在有限資源情況下。 因此這幾年來結構設計在符合「生命安全」下,也同時在追求另一目標「最小成本」, 在這樣需求下,借助計算機來幫助我們來處理這類問題,而在處理這樣的問題或過程可 被稱為「最佳化問題」或「最佳化設計」。因此發展許多數值方法來解決這樣問題;例 如利用基因演算法來對結構最小成本設計[4, 5];或者改良基因演算法處理結構設計的效 率[6, 7]。 而從上節可以了解到結構設計考量因素越來越多。考量安全因素,以其設計過程大 致程序為分析使用載重來決定材料斷面[8],如下圖 1-3 所示: 圖 1-3 極限強度設計法概念圖:梁彎矩強度為例4 以鋼筋混凝土柱斷面為例,鋼筋比範圍,而安全與成本關係如下圖所示: 圖 1-4 成本與設計軸力關係 若以耐震因素考量,其設計過程變為先選擇一斷面配置,進行結構分析評估耐震能 力,不滿足要求則再重新選擇一組新斷面一直到滿足要求為止,如下圖所示; 決定 斷面配置 分析 使用載重 評估 耐震能力 檢核規範條件 YES 完成設計 NO
5 以七層樓動力分析反應譜加速度(Spectral acceleration,Sa)與成本關係又如下圖所示: 圖 1-6 Sa 與成本關係圖 可以觀察到安全與成本及耐震與成本大致上都成正比關係,但是小區間內卻是有許 多不同變化。這樣數學關係有時會令工程師在進行結構設計時感到煩雜。 如何滿足結構設計各個目標,將是未來所要面對問題。從上段可以觀察幾件狀況; 首先,建築物在進行耐震設計過程,工程師必須嘗試各種斷面配置並對之進行耐震能力 評估,才能知道該斷面配置是否滿足耐震需求。這樣過程往往是乏味冗長程序,其設計 工作效率取決於工程師是否有經驗,有經驗的工程師知道怎樣的斷面配置進行分析時會 往設計目前進,沒有經驗的工程師則反之。接著觀察到另一個情形,從上兩圖觀察到兩 者並無明顯直接關係,這對設計者而言,是件滿困擾的問題。當我們在追逐其中一個目 標最佳值時,卻發現另一個目標值無法明確知道該落點,甚至發生無法滿足要求的情形, 其設計過程也是用試誤法或經驗法則來處理。 在過去鋼筋混凝土結構設計目標為承載力需求、最低成本,這一類問題稱為單目標 問題搜尋演算法;若再增加另一目標「韌性需求」則改稱作多目標問題搜尋演算法。在 多目標問題當中,由於各個目標之間往往是相互衝突的,若只是一味求其中單一目標的 最佳目標,經常會造成違背其他目標。因此如何在多個具有衝突的目標之間,找到一個
6 平衡點,來達到整體的最佳目標,使整體的目標能夠符合決策者的要求,確實是一個相 當困難的問題。 本研究之目的即採用最佳化理論之基因演算法進行結構多目標設計,利用基因演算 法快速搜尋及計算簡單特性來幫助我們尋找可能解,而基因演算法相關研究在第二章簡 述。而「韌性需求」的發展與設計流程也將會在第二章、第三章敘述。 本文擬以一兩層及七層樓鋼筋混凝土構架為本論文將討論案例,為簡化此一設計問 題的分析程式並基於一般化的設計考量,將會設定一些合理簡化假設條件。並對該案例 進行最低成本、最適合斷面選擇的分析與探討。
7
1-3 研究步驟
本研究在探討多目標基因演算法應用於鋼筋混凝結構設計,研究的步驟簡述如下: 1. 資料蒐集 首先蒐集多目標問題與結構耐震評估相關的論文和研究報告,藉此了解學術界 對此問題的研究情形和成果。 2. 建立前處理架構 鋼筋混凝土結構設計的過程主要針對斷面尺寸進行調整,但同時考慮多種限制 條件時,處理的步驟及流程成為控制效能及結果的關鍵,因此需要由基礎的力學觀 念為依據搭配經驗法則建立出適合計算機演算的多目標基因演算法前處理架構。 3. 多目標基因演算法的建構 確認多目標基因演算法的輸入參數和細部情形,並配合前處理架構建立基因演 算法的搜尋空間及初始代。 4. 數值案例測試及程式修正 透過最佳化設計案例,對撰寫好的程式進行測試,驗證程式的可行性。 5. 撰寫論文 彙整本研究之相關理論、成果及結論撰寫成論文。8
1-4 論文章節及架構
本研究論文之架構分為五個章節: 第一章為緒論,說明本研究的背景、研究的動機、目的及方法。 第二章為文獻回顧,簡要的介紹結構設計趨勢、多目標問題、基因演算法、類神經 網路。 第三章為系統設計之理論與工具軟體,說明多目標基因演算法、結構極限強度設計、 結構耐震能力評估法、類神經網路、整體系統架構。 第四章為數值案例測試,用來討論多目標基因演算法應用於鋼筋混凝土結構設計。 第五章為結論與建議,本章節對多目標基因演算法應用於結構設計的研究提出結論 及未來的展望。9
第二章 文獻回顧
本章將簡單介紹近年來與本研究有關之相關研究成果。主要分兩部份:首先是結構物 設計發展狀況;另一部份是數值搜尋理論。在結構物設計發展狀況中會說明目前設計趨 勢與所面對的問題;在數值搜尋理論中,則是介紹「多目標問題」、「基因演算法」及 「類神經網路」。2-1 結構分析與設計之發展狀況
本節將介紹結構分析趨勢以及目前國內外相關研究情形。在分析趨勢這方面主要針 對結構耐震的分析研究;接著說明國外對評估結構物耐震能力所發展出來的理論介紹 結構設計規範主要日標在於保障住戶之生命安全。任何結構構件最主要的性能就是 它的實際強度,該強度必須大到足以抵抗在結構使用期限內所有可能作用的預期載重, 而不致於造成破壞或其他損壞。根據此原則,我們設計出結構構件的目標為使得該構件 具有足夠的強度以抵抗根據假設的超載狀態所引起內力。此種設計觀念稱為極限強度設 計法。 對於鋼筋混凝土結構,當載重接近和達到破壞時,鋼筋和混凝土材料中的一種或兩 種不可避免地進入其非線性非彈性階段。亦即,結構構件中的混凝土在應力與應變遠超 出正比的初始彈性範圍後,達到其最大強度後隨即發生破壞。同理,當構件接近和達到 破壞時,鋼筋的應力通常超出彈性範圍,進入甚至超過降伏範圍。因此,構件的標稱強 度必須根據材料的非彈性行為進行計算。10 但從近年來國內外歷史經驗可以發現,當結構物遭受到強震而倒塌,常常會造成人 員傷亡與設備損毀。由國外經驗可得知,1976 年中國大陸唐山大地震、1985 年墨西哥 8.1 級地震與 1989 年美國舊金山 7.1 級,以及 1995 年日本 7.2 級阪神地震,造成許多 鐵路與公路損壞及橋梁破壞,造成 5 千多人死亡,其中更有 85% 因結構物倒塌喪生。 除了強震會造成結構倒塌之外,亦可能因為施工或設計的失誤、火災和颱風、煤氣爆炸、 炸彈爆炸、飛機撞擊等偶然荷載作用所引起。例如 1968 年 5 月 16 日發生於英國倫敦 Ronan Point 公寓因為第 18 層樓廚房內煤氣爆炸將外牆推倒,引起上部樓板墜落導致下 部結構破壞造成倒塌事件,也引起人們對高樓建築因部份結構或構件破壞而導致整體結 構破壞的問題受到各界廣泛注意。美國在 2001 年 911 恐怖攻擊事件,因為飛機撞擊大 樓爆炸使得大樓結構系統中之構件受高溫燃燒,最後使得結構系統破壞造成世貿大樓倒 塌,及喪失上千人之生命。[9] 圖 2-1 結構受地震動的作用 由上段所描述近年來國內外發生的強震經驗,依照目前規範設計之建築物雖然滿足 了保障「生命安全」的目標,但是仍許多建築物受到不同輕重的損害,其修復費用和時 間出乎意料的高,造成很大的財產損失,一方面是現代社會日趨複雜,往往建築物結構 體造價僅為全部造價的一小部分,而建築內容之損失可能遠大於結構體之損失。因此, 提高耐震設計的水準以降低地震災害的風險成為另一選擇。為了適應此社會需求的改變, 耐震設計的理念亦需作大幅度的修改。
11 以往的耐震規範主要目標在於設計強烈地震之下不至於倒塌而傷害到人命安全的 結構物,並未考慮在各種地震下結構物的性能績效甚至不同外力作用下如何避免結構物 倒塌,已逐步引起國際間之重視,更是今後國內外工程與學術界之重要研究課題。 若能有效評估結構物耐震能力及瞭解結構物受力倒塌機制,將可以改善目前以承載 力設計不足之地方。以承載力設計的基本概念是結構實際強度要大於預期使用載重狀態, 甚至在考慮結構物在地震行為下也是用相同概念下去設計。這樣設計下往往會使得結構 承受大部份地震能量,因此在規範中會加入一些限制條件來確保構件韌性。但這僅僅保 證最小韌性,對於結構物所能提供耐震能力並不瞭解,這將造成成本浪費或震後建築物 補強評估上的困難。
12
13
ATC 於 1995 年發表的 ATC-34 報告和 1996 年發表 ATC-40 報告中包括 PBSD 方法。 1996 年 Federal Emergency Management Agency (FEMA)發表的 FEMA273 和 FEMA274 報告中也包括 PBSD 內容。Structural Engineers Association of California(SEAOC) Vision 2000 同樣包括 PBSD 內容。SEAOC Vision 2000 對 PBSD 的定義是“性能設計應該是選 擇一定的設計推測,恰當的結構形式、合理的規劃和結構比例,保證建築物的結構與非 結構構件的細部構造設計,控制建造質量和長期維護水平,使得建築物在遭受一定水準 地震作用下,結構的損傷或破壞不超過某一特定的極限狀態”。SEAOC Vision 2000 致 力於建立設計未來不同水準地震下能達到預期性能水準且能實現多級性能目標建築的 一般架構。SEAOC Vision 2000 闡述了結構和非結構構件的性能水準,而且基於位移建 議了五級性能水準,建議用性能設計原理分析彈塑性結構的地震反應。基於性能的設計 是從結構抗震性能的預先估計出發,人為的形成合理的抗震體,實現結構的多層次抗震 設防。 ATC-40 對 PBSD 的定義為“基於性能的抗震設計是指結構的設計準則由一系列可以 實現的結構性能目標來表示,主要針對鋼筋混凝土結構並且建議採用基於能力譜的設計 原理”。顯然,ATC-40 建議使用能力譜方法對鋼筋混凝土結構進行抗震設計。 FEMA273 和 FEMA274 對 PBSD 的定義為:“基於不同程度地震作用,達到不同的 性能目標。在分析和設計中採用彈性擬靜力分析和彈塑性時程分析來實現一系列的性能 水準,並且建議採用建築物頂點位移來定義結構和非結構構件的性能水準,不同的結構 形式採用不同的性能水準”。而且,FEMA273 利用隨機地震動概念提出了許多種性能目 標,適合於多級性能水準結構的分析與設計方法(從彈性分析延伸到彈塑性時程分析)。 綜合上述,不同的研究機構或個人對 PBSD 的定義可能不完全相同,但都有一個共 同的理念,即在設計使用期內,建築遭受不同水準地震的作用時,應該達到相應的性能 水準,該方法又稱為容量譜法。至於還有其他評估方法如[14]:位移係數法、容量譜法、 歷時法,本論文將以容量譜法做為結構耐震評估方法。
14
2-2 基因演算法
2-2-1 基因演算法之基本概念
達爾文(Charles Darwin)在經過了多年的觀察與研究之後,於 1859 年在他的著作「物 種原始(On the Origin of Species by Means of Nature Section)」提出「物競天擇,適者生存, 不適者淘汰」的生物演化規則。到了 1960 年密西根大學的 John Holland 和他的同事爲 了發展人工智慧系統參考達爾文的演化理論提出基因演算法的概念,但是直到 1975 年 John Holland 才在他的著作"Adaptation in Nature and Artificial System"提出基因演算 法的基本架構,並由他的學生 David Goldberg 在 1989 年發表著作"Genetic Algorithms in Search, Optimization and Machine Learning"中詳細說明基因演算法的理論和應用,而且 發展出一套基因演算法的電腦程式 SGA(Simple Genetic Algorithms),奠定了日後基因演 算法發展的基礎。
基因演算法(genetic algorithms,GAs)與「演化策略」(evolution strategies,ESs)、 「演化程式」(evolutionary programming,EP)並稱為「演化演算法」(evolutionary
algorithms,EAs)的三個主要分支研究,但近年來以基因演算法最受研究者所重視[15]。
早於 1960 年代生物學家 Fraser A. S.便提出人為交換染色體 DNA 以刺激生物演化
的方法,此便成為發展基因演算法之靈感來源[15]。成熟的基因演算法概念則首次出現
於 1975 年 John H. Holland 大作 Adaptation in Natural and Artificial Systems[16]。Holland 由自然界生物基因中 DNA 編碼與繁殖的原理中得到靈感,提出了基因演算的方法,用 以模擬自然環境與人造環境中的一些現象。Holland 認為,無論自然或人造環境,可以
15
將事物依其屬性進行如基因 DNA 一樣的編碼(coding and representation),並在物群之 間藉由編碼的運算繁衍出「下一代」。透過函數設計可以遴選適合環境的「下一代」繼 續參與繁衍,以此獲得較適合環境的物種。 Holland 在該書中認為,除了自然界生物基因學研究之外,經濟學、遊戲理論、模 式辨識(Pattern-Recognition)、控制與函數最佳化(Optimization)等等領域當中,均 有近似基因工程之現象。換言之,無論自然環境或人造環境,均可以運用基因演算法描 述一些現象,或甚至預測某些未知現象之發生。Holland 在該書所提示領域,幾乎指引 出後來基因演算法所應用的範疇。
16
17
爲了演化出更為優良的後代,需經過擇優的程序每次選出一對優良的染色體進行複 製,讓原有族群中適應值較高的個體有較大的機會被複製,而淘汰適應值較差的個體。 一般較常用的擇優方法有輪盤法(Roulette wheel selection)、比較選取法(Tournament selection)及排序選取法(Rank selection)…等。
5. 基因操作(Genetic operations)
交配:將上步驟獲選的染色體組進行交配(crossover)。每次經過擇優與複製後會 有一對染色體成為親代,接著進行交配的程序,將兩個染色體中某些位元字串互相交換, 以達到產生新子代的效果。一般交配的方式有單點交配(One-point crossover)、雙點交配 (Two-point crossover)與均勻交配(Uniform crossover)…等。本研究採用均勻交配法則而是 否要進行交配的程序則由「交配率」決定。 突變:不以編碼互換的方式繁衍,而是以隨機方式抽取染色體中的若干編碼進行改 變,便可產生突變(mutation)。在基因演算法中若缺乏突變的機制,經過數代的演化 之後,整個族群會很快的趨於一致性,不再有新的搜尋空間。突變時會將染色體中的某 一個位元由 1 變為 0 或由 0 變為 1。但是突變發生的機率不適合設定的太高,因為太高 的突變率會破壞原有的優良個體使得整個搜尋難以收斂。 5. 操作配比設定( operationalrates settings):調配基因進行「交配」或「突變」 的配比。倘若「交配」比例較多,則基因重組的情形較多,但有可能好的染色體保留的 成分較少;反之,若「突變」比例較多,則基因重組機會較少,但也相對地使繁殖結果 趨近隨機的狀態。 6. 替換: 以演化結果( offsprings ) 替換(replacement)原來的染色體。替換可 以將原來的染色體全部或局部替換,或者全數保留原來的染色體而加入新染色體。替換 的比例可以根據原染色體與新染色體的適應值來決定,選擇提升整體系統適應力的方式 行之。
18 以上所敘述操作程序可以繪製成流程如下圖 2-2 物群界定 染色體編碼 替換 評估 目標函數 適應函數 選擇 基因操作 交配 突變 產生結果 染色體編碼 操作 配比設定 圖 2-2 基因演算法操作流程
19
20 3. 管理學領域之應用研究 因為具備局部重組、測試能力,基因演算法在管理領域中普遍應用於「排程」問題 (scheduling),或解得最佳路徑、最短路徑等旅行推銷員問題。如吳兆凱的研究便是 以基因演算法應用於「生產週期前」的製造流程排序計畫、以及「生產過程中」面臨各 種突發狀況時的排序調整(吳兆凱,2002);林建智的研究則以基因演算法為主,以類 神經網路法為輔,有效率地解答訂單排程問題(林建智,2002)。同樣應用基因演算法 在解決排序問題上的長處,基因演算法在營建管理研究上亦有所嘗試。如柯義峰便是以 基因演算法就「單位成本或生產力」為目標函數建立「GA-COST」營建作業電腦模擬 程式(柯義峰,2001);而劉昱江的研究則是應用基因演算法對重複性工程的管理及規 劃進行「時間-成本權衡」分析(劉昱江,2001);謝叔暖的研究是以基因演算法處理 工地的空間排程管理。該研究視工地空間為有限之資源,導入動態工地配置之觀念,使 工地配置不再侷限於單次、靜態之配置,使工地配置隨工程進度而變更,提高營建工地 管理的效率(謝叔暖,2000)。 4. 模式辨識之應用研究 基因演算法的評量比對、局部保留、重組的功能具有逐步修正接近解答的能力,極 適宜進行圖形模式、語音模式、聲紋模式等方面的比對工作。或是在模式比對的過程中 去除「雜質」(noise),以產生較為純粹的模式。在音響聲紋鑑別的研究技術大量應用 在機械工程領域所進行音響設計研究之中。如吳文生的研究便是以雙音圈喇叭的「表面 速度感知器」測得「感知器參數」(可視為染色體編碼),做為基因演算法計算的輸入 值,使「表面速度感知器」成為鑑別雙音圈喇叭的可靠工具(吳文生,2002);又如劉 博文的研究是以基因演算法求得平面喇叭系統的音響效果(目標函數)中,喇叭致動器 的位置和信號的延遲是最佳化的「設計變數」(設計關鍵)(劉博文,2002)。
21 影像模式資料處理方面可以吳憲珠的研究為代表。吳憲珠將影像檔視為染色體編碼, 利用基因演算操作的「套選法」原理將原 JPEG 檔案編碼混入一組紀錄著作權編碼 (mask),可以在呈現影像時同時呈現著作權圖形,在圖檔存取過程中順利進行浮水印 的嵌入和擷取動作,可以成功保障影像著作人之權益(吳憲珠,2002)。 5. 國防研究上之應用研究 基因演算法在國防上的應用則是 Holland 始料未及的應用領域。國防方面的應用包 含戰術戰略的選定與武器系統的研發兩方面。在戰術與戰略的研究方面的應用研究,如 李仕銘採用基因演算法引入路徑效能及序列效能的概念,在集中化序列攻擊策略的架構 中進行多目標攻擊推進模式之合理策略選擇(李仕銘,2002);在武器系統之研發方面 的應用研究,如王允成的研究則以灰色系統理論配合基因演算法進行 M42 火砲之底火 膛壓曲線之研究(王允成,2002)。 6. 設計與規劃上之應用研究 設計與規劃也是 Holland 未提及的應用領域。基因演算法在解答設計問題的應用多 半偏重於工程(engineering)設計問題,對於空間、環境設計問題的著墨較少。如機械 工程領域便常以基因演算法進行風扇葉片(黃福居,2001)、飛行器之雙旋轉翼(黃明 德,2002)設計等; 或者與建築的關係較緊密的研究可以舉劉志雄的研究為例。該研 究是以基因演算法計算出最佳化鋼構斜張橋。該研究以最小重量為目標參數,以橋之纜 索、主桁、橋塔之橫斷面為設計參數,並且再經過「滿載應力設計法」(Fully Stress Design) 的修正獲得最佳解答(劉志雄,1997)。 在工業設計方面的應用可以辛宜芳與游麗娟為例。辛宜芳的研究著重在以基因演算 法來對平面形體做最適當的安排,以建立最佳化排版機制,可節省印刷或裁切等製版費 用(辛宜芳,2002);游麗娟的研究乃著重在立體形的排列,使得形體排列可以達到某 種要求。此研究可實際應用於工業塑膠押出模具之上,可以應用基因演算法求得最節省 原料、空間的模具排列方式(游麗娟,2000)。
22 在空間設計上的應用,有結合基因演算法與管理概念所進行配置規劃工作,近似前 述工地管理之問題。例如陳宏坤對倉儲量販賣場設施佈置研究,以部門間的關連性及標 準化流量做為佈置評量的依據(目標參數),應用基因演算法與田口方法(Taguchi Method) 來找出賣場佈置的最佳參數組合(陳宏坤,2000)。 在都市規劃方面應用,有林楨家的研究為例。林楨家的博士論文企圖以基因演算法 構建都市規劃者的分析工具。該工具以調查所得之民眾感受做為目標參數,以基因演算 法逐次逼進的方式獲得最佳替選方案(林楨家,1999)。
23
2-3 多目標最佳化問題
多目標優化問題對於科學家和工程師來說無疑是一個非常重要的研究課題,因為現 實問題大多具備多目標的特徵,通常難以處理。過去在運籌學、決策學和計算機科學等 學科湧現過很多種確定型或者隨機化方法,專門用於求解多個指標的優化問題。現代計 算設備的能力急劇提高,需要高計算速度和大內存的隨機化搜索算法越來越受到青睞。 本節將說明多目標最佳化問題、Pareto optimality 及相關研究發展。2-3-1 多目標最佳化問題之基本概述
圖 2-3 受一集中力懸臂梁與斷面圖24 此懸臂梁材料性質如下: 密度ρ=7800kg/m3 集中力 P=1kN 彈性模數 E=207GPa 降伏應力σy=300MPa 容許桿端位移δmax=5mm 懸臂梁限制條件: 1.10<d<50 (mm) 2.200<L<1000 (mm) 3. σy>σmax=32PL/πd3 4. δ<δmax 懸臂梁限制條件目標函數: 目標一、Min 重量 F1(d,L)=ρπ d 2L 4 (kg) 目標二、Min 位移 F2(d,L)=64PL 3 3Eπd4 (mm) 在上述條件下,例如:載重、材料性質、容許最大位移等,當勁度越高懸臂梁的重量 也越重,控制懸臂梁長度與斷面直徑所計算自由端位移與重量關係如下圖 2-4 所示。
25 圖 2-4 解空間與目標空間關係圖 Note:上為梁長與斷面關係,下為自由端位移與對應重量關係 由此例子觀察得知,勁度越高的懸臂梁會有較小的位移,勁度與懸臂梁長度及斷面 直徑有關係,懸臂梁重量是由懸臂梁長度及斷面直徑所求得。因此很難得到位移小且重 量輕的懸臂梁。由此可知這兩個目標是明顯衝突的,而且會互相拉扯。因此,當問題本 身包含兩個或兩個以上的目標,又必須同時找出它們的最佳化解,這類問題就稱為多目 標最佳化問題 (multi-objective optimization problem, MOP)。
26
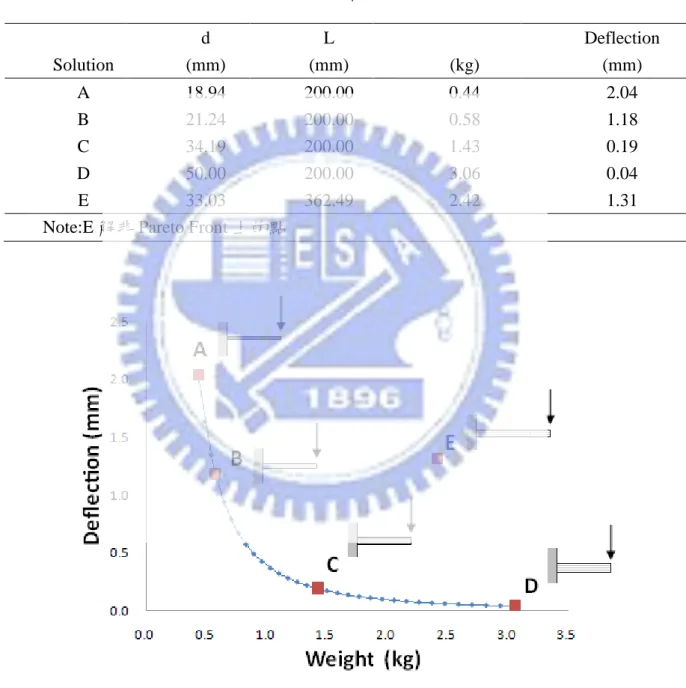
我們希望在多目標最佳化問題得到的是一組最佳的解,通常稱之為 Pareto 最佳解 (Pareto best solutions),這些解所形成的曲面,就稱之為 Pareto Front 。從上個例子我們
列出一部分解如下表所示,並將之繪出 Pareto Front 如下圖 2-5 所示。 表 2-1 多目標範例之部分解 d L Deflection Solution (mm) (mm) (kg) (mm) A 18.94 200.00 0.44 2.04 B 21.24 200.00 0.58 1.18 C 34.19 200.00 1.43 0.19 D 50.00 200.00 3.06 0.04 E 33.03 362.49 2.42 1.31
Note:E 解非 Pareto Front 上的點
27
2-3-2 Pareto Optimality
Pareto optimality 或 Pareto efficiency 是經濟學中的重要概念,並且在博弈論、 工程 學和社會科學中有著廣泛的應用。Pareto Optimality 是以提出這個概念的義大利經濟學 家 Vilfredo Pareto (1848-1923)的名字命名的,Vilfredo Pareto 在他關於經濟效率和收入分 配的研究中使用了這個概念。 Pareto Optimality 是指資源分配的一種理想狀態。假定固有的一群人和可分配的資 源,如果從一種分配狀態到另一種狀態的變化中,在沒有使任何人境況變壞的前提下, 使得至少一個人變得更好。Pareto Optimality 的狀態就是不可能再有更多的帕累托改善 的狀態;換句話說,不可能再改善某些人的境況,而不使任何其他人受損。 換句話說。Pareto Optimality 只是各種理想態標準中的「最低標準」。一種狀態如 果尚未達到 Pareto Optimality,那麼它一定是不理想的,因為還存在改進的餘地,可以 在不損害任何人的前提下使某一些人的福利得到提高。但是一種達到了 Pareto Optimality 的狀態並不一定真的很「理想」。
Pareto Optimality 是由一群互相不支配的解(non-dominated solutions) 所組成的集合, 如下圖示
28
以數學理論可以描述為:若有 n 個目標,而 fi(x) ∀ i{1,2,3,...,n}表示為各目標的目標
函數,若在最小值的多目標問題(minimization)中有 a 及 b 二個向量解,若對所有的 i ∈ {1,2,3,...,n},出現 fi(a)≤fi(b)且存在 j ∈{1,2,3,...,n}使 fj(a)<fj(b),則稱 a 支配(dominate)b,
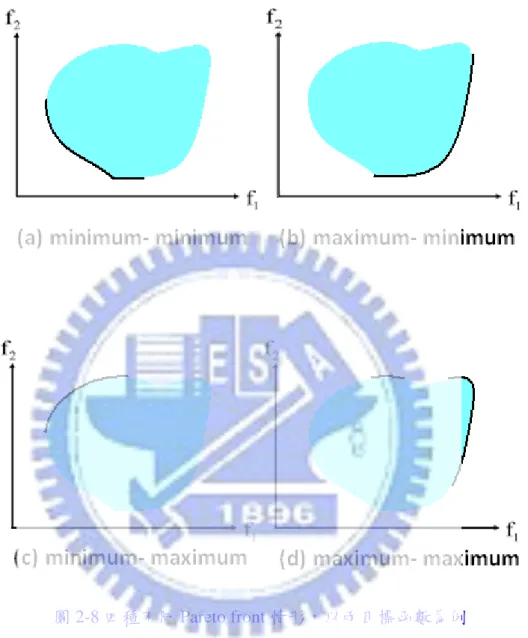
並以符號 a≺b 記之,此時 a 為一個不受支配的解。以圖所示的例子說明: 圖 2-7 多目標最佳化的解之間的不受支配與受支配 若 A、B 及 C 三點為在兩個目標(F1、F2)最佳化問題的解,A、B 這兩個解,互相 至少有一個目標比對方好,但是並沒有全部的目標 都比對方好,所以無法判定這兩個解 之間的優劣,因此這兩個解呈現互相不受支配 (non-dominated)的情況,但是 C 解與 A 及 B 兩個解比較,在兩個目標上皆比較差,因此 C 為可被 A 及 B 支配的解 (dominated solution)。而所有不受支配解所成曲面又稱為「Pareto front」。 由於每個函數的最佳化目標可能式求極大值也可能是求極小值,所以在兩個目標函 數的案例,可以在問題搜尋空間描繪出四種不同目標組合的 Pareto Optimality 集合的連 續曲線;圖 2-8(a)為同時針對兩個目標皆為最小值地解組合(solution set),黑色的實線即 為 Pareto front;若在同一個搜尋空間求 f1的極大值且求 f2的極小值,則其 Pareto front 將會如圖 2-8(b)分布的 曲線。同理,圖 2-8(c)表示 f1的極小值且求 f2的極大值,圖 2-8(d) 則為同時求 f1與 f2的極大值的 Pareto front 的分布情形。
29
30
2-3-3 多目標最佳化演算法
多目標最佳化最困難的地方,莫過於如何在多個目標之間取捨,以取得最佳的平衡 點。最佳化問題的目的,是從解空間找出符合問題需求與邊界限定的最佳解。在處 理單 目標最佳化問題時,如下圖所示,著眼於如何找到最好且合理的解,或是一個最接近最 佳解的解。31 多目標問題與單目標問題最顯著的差異是目標空間(objective space)的維度的目標 空間。在多目標問題的解空間中,n 維的解向量將透過個目標函數的映射,轉換為一個 M 維的目標向量,例如上圖可以簡單標是一個三維地解空間與二維目標空間的映射關 係。 單目標最佳化問題是針對一個目標函數找出它的唯一的最佳解,但是在多目標最佳 化問題,最佳解非唯一而是一組。因此,必須先描述多目標問題的一般形式。所位多目 標最佳化的問題,這就是這個問題擁有多個目標函數,並且需要針對這些目標函數之需 求不同的目標最大化或最小化,同時也必須滿足下式(2-1)所示的條件限制。 x 為一個 n 維度的變數向量,表示為 x = (x1, x2, … , xn)T; g(x)為不等式條件限制函數(inequality constraint functions); h(x)為等式條件限制函數(equality constraint functions); x(L)為變數的下邊界; x(U)為變數的上邊界; M 為需要被最佳化的目標函數總數; J 為不等式限制函數的數量; K 為等式條件限制函數的數量; n 為變數的維度數量;
32
多目標最佳化問題無法像單目標最佳化問題獲得單一最佳解,僅能由解空間獲得一 組最佳的解,這些解形成 Pareto front。
然而在早期解決多目標最佳化的問題時,大多將多目標的目標函 數簡化為一單目標 的函數,再使用基因演算法來求解。第一個多目標演化式演算法(multi-objective
optimization evolutionary algorithm, MOEA)是 1985 年 David Schaffer 提出向量估測式的 基因演算法(Vector Evaluated Genetic Algorithm, VEGA) [19]。
VEGA 以一個向量的許多元素來表示多個需要最佳化的目標,若現在有 M 個目標 要進行最佳化,VEGA 的方法即為將族群分為 M 個子族群,每個子族群代表一個目標 函數,並計算各別的適應值 (fitness value)找出最佳解。它的優點為簡單、 不複雜而且容 易完成,只要由簡單的 GA 再加上一點的變動即可完成。在 VEGA 的執行過程中,假 設藉由選擇可以選出最靠近個別目標的解,經由交配的過程將這些選擇出 來的最佳解找 出來並且 Schaffer 也提出一些成功的結果,但 VEGA 似乎只能找到在 Pareto Front 端點
上的極值,而不能找到整個 Pareto Front。[20]
Murata[20]在其文獻中,在每個目標函數乘上一個加權因子(Weighting Factor),再將
其加總起來,如此一來,即可將多個目標函數轉化成單一目標函數,其加權因子的權重 (Weight)在每一代之間皆以亂數產生,進而達成在目標空間中廣泛地搜尋 Pareto 最佳解 (Pareto Solution)。劉東官[21]則針對 SISO 及 MIMO 系統作控制器參數設計,並採用多
目標最佳化基因演算法來達成系統多目標需求。Kurpati[22]則提出了多目標基因演算法
四個改善技巧,運用適合函數和約束條件的設計,來處理減速機重量和應力兩個目標的 最佳化問題。
Kim[23]則提出了適應型的權重,並導入了在目標空間中,用區域搜尋的概念來搜
尋出不足的 Pareto 解,以改善 Pareto front 的完整性。由上述可看出,多目標基因演算 法在機械領域的使用是相當廣泛的。
33
在 VEGA 之後,Hajela 和 Lin 在 1993 年提出以權重為基礎的基因演算法
(Weight-based Genetic Algorithm, WBGA) [19],把每個目標函數乘一個權值,並將它們 相加當作這個解的適應值。這個方法也是簡單 不複雜,可以由簡單的GA 來轉換完成, 且其複雜度較其他多目標演化式演算法低,但是面對最佳解為非凸面 (non-convex) Pareto front 時,WBGA 表現的結果卻是不太理想。
同年,Fonseca 和 Fleming 提出多目標基因演算法(Multi-objective GA, MOGA) [24], 使用 GA 的族群來分類所搜尋到的不受支配解,並給予排名 (rank) 來加強搜尋不受支 配解的能力及同時保持解的差異性,但是無法確定當一個較差排名的解總是有辦法對映 到較差的適應值,這將會造成有時演算法收斂較慢甚至不穩定的狀況。
為了改善這個問題,1994 年由 Srinivas 和 Deb 提出以不受支配解排序的基因演算 法(Non-Dominated Sorting Genetic Algorithm, NSGA)[25],NSGA 一開始就對族群依據不 受支配的特性做排序,並給予較好的不受支配解有系統的擁有較高的適應值,並可在 NSGA 的執行過程中,迫使解朝向 Pareto-optimal Front 移動。
Horn 等人亦於 1994 年提出計算利基的 Pareto 基因演算法(Niched Pareto Genetic
Algorithm, NPGA) [26],與前述的 VEGA、WBGA 及 NSGA 在選擇的機制有明顯的不
同,NPGA 採用一種二元競賽式的選擇 (binary tournament selection) 而不需再給定一個 精確的適應值,它本身也是第一個提出使用競賽式選擇的多目標演化式最佳化演算法。 但是競賽式選擇的空間選擇會影響本身的效能及計算效率,對於較多目標的最佳化問題, NPGA 會出現計算效率的問題。
此後,更有些架構在這些演算法的研究,加入其他有效的機制,例如菁英策略 (Elitism) 及外部儲存 (External Memory or Archive)的方法,如 Zitzler 和 Thiele 所提出 來的強化式 Pareto 遺傳演算法(Strength Pareto Evolutionary Algorithm, SPEA) [27]。
SPEA 利用明確的保留菁英策略,額外儲存一組族群,此族群內所儲存的解即為不 受支配解的群組。在每一個世代中,新找到的 不受支配解將和外部儲存的不受支配解比 較,並將較好的保留下來。
34
在 SPEA 之後更進而提出強化式 Pareto 遺傳演算法 2(Strength Pareto Evolutionary Algorithm 2,SPEA2) [28]。SPEA2 為進階的 SPEA 演算法,增加 了改進SPEA 的給定適 應值的架構,包含將被支配及支配的解都納入計算,並加入計算附近解的密度,使得在 尋找解的過程中可以有更多的精確引導。SPEA2 承繼 SPEA 的優點,當找到一個新的 落在 Pareto-optimal front 上的解就儲存在外部的族群中,在過程中的聚集方法可以使外 部儲存的解有更好的延展性。但是,如同 MOGA 所擁有的問題一般,擁有相同排序的 不受支配解,並不會擁有同等的地位。
學者 Joshua D.Knowles 等人提出 Pareto 空間演化策略(Pareto Archive
EvolutionStrategy, PAES) [29],PAES 採用演化策略 Evolution Strategy,ES),並擁有一組 固定大小的外部儲存空間存取目前為止找到的不受支配解。在演化的過程中,將搜尋空 間切割為許多區塊,藉由同一區塊中鄰近解的數量,決定子代是否在下世代取代原先的 母代,以保持解的差異性。因此,如何決定外部儲存空間的大小及區塊切割的大小是 PAES 面臨的困難點;當目標函數增加時切割空間將呈現指數的成長,更加難以保持解 的較佳延展性。 學者 Deb 提出 NSGA 演算法的改良,不受支配解排序的基因演算法
2(Nondominated Sorting Genetic Algorithm II, NSGA-II) [18]。NSGA-II 為一個同時擁有 菁英保留及明確的保持差異性機制的演算法,在產生大小為 N 的子代後,與原本大小 為 N 的母代合併為 2N,並做 不受支配解的排序,將較好的 N 個個體留下來,以確保母 代及子代之間最佳的不受支配解能夠被保留下來,另外也加入 Crowded Tournament Selection 來確保解之間的差異性。但是,也因此若第一次搜尋時,不受支配解的數量與 整體族群比較起來呈現較少的情況時,除了接近 Pareto front 的解被保留至下一代外, 另有一些非真正接近 Pareto front 的解也被保留,如此將會影響了演算法的收斂性。
35 NSGA-II 優點:
非支配解之間利用擁擠距離值(crowding distance values)來進行競爭(tournament)來 顯示非支配解之間的差異。完成這些解之間分布狀態並不需要額外函數計算。NSGA 雖 然須要求取在目標空間中目標值之間擁擠距離值,但此步驟可以完全獨立在另一參數空
間。在缺乏「擁擠距離值」操作下,該演算法找出 Pareto front set 之收斂情形也比 Rudolph’s
演算法好,但是在計算世代中族群大小會逐漸變大。而該演算法尋找菁英機制會刪去已 存在 Pareto front solution。
NSGA-II 缺點:
「擁擠距離值」操作通常會限制族群大小,這會使演算法失去收斂特性。例如第一 代非支配集合小於族群大小,該演算法會將之全部納入計算;這會使得較新世代中,則 會出現多於 N 數目其中包含在複合母代與子代中第一世代非支配解集合,當中會有過多 相同 Pareto-optimal solution 將會佔去分支配排序空間而非 non-Pareto-optimal solution。 這樣狀況會使得演算法收斂時無法得到很好 Pareto front 分佈。因此在早期,非支配解排 序需要族群數目 2N 運算,而其他演算法則只需要 N 數目足以運算。
36
2-4 類神經網路
2-4-1 類神經網路之介紹
類神經網路之相關研究已有近五十年的歷史,最近二十年逐漸發展成熟並應用在許 多的領域之中。Rosenblatt(1957)提出第一種神經網路模式-感知機(Perceptron)模式, 它由二元值神經元組成,以此模仿生物的大腦及視覺系統,主要用於理論研究與樣本識 別。Widrow 和 Hoff(1960)提出自適應線性元件(Adaptive Linear Element)模式,它 是一種連續值的線性網路。Rumelhart 等人(1985)提出著名的倒傳遞類神經網路模式 (Back-Propagation Network, BPN),此網路模式之基本原理是利用最陡坡降法(Gradient Steepest Descent Method)的觀念,將誤差函數予以最小化。Kohonen(1980)提出組織 映射圖(Self-Organizing Map)模式,並且在 1988 從該模式衍生出學習向量量化網路 (Learning Vector Quantization Network)。Hinton 和 Miller(1988)對霍普菲爾-坦克神 經網路在解決最佳化問題時,其收斂最小值和參數設定等問題加以改善。Barnard(1992) 探討訓練類神經,網路值目標函數最佳化之各種方法,並提出一個以隨機的觀念所建立 的序列演算法。Hagan 和 Menhaj(1994)根據 Kollias 和 Anastassiouh 所建議的概念, 提出改良式倒傳遞演算法,此法是將應用與非線性最小平方法的 Levenberg-Marquardt 演算法,配合傳統倒傳遞演算法來訓練前向式類神經網路。37
Flood 和 Kartam(1994)提出將類神經網路應用於土木工程上的明瞭性、使用性以 及實用性方面的論述,並利用倒傳遞前向式網路訓練,來解決結構分析問題。Narendra 和 Parthasarathg(1990)曾驗證類神經網路能有效地使用至非線性動力系統識別中。
Wu 等人[30]以一系列三層樓鋼構架之數值模擬資料,利用倒傳遞神經網路
(Back-Propagation Neural Network, BPN)來描述該結構的破壞狀態。該研究以加速度
反應富氏譜以及桿件勁度,分別作為其 BPN 之輸入及輸出變數。而 Elkordy 等人[31]
則以模態作為其 BPN 之輸入變數,以偵測模擬的結構破壞。
Szewczyk 與 Hajela [32]則應用反傳遞神經網路(Counter-Propagation Neural
Network, CPN),以剛架之靜定位移來估算桿件勁度的折減情形。Pandey 與 Barai [33]
應用多層感知器(Multilayer Perceptron),以數值模擬資料偵測桁架橋之破壞。Zhao 等 人[34]以靜定位移、自然頻率、以及模態,應用 CPN 來分別偵測梁和剛架的破壞位置。 Masri 等人[35]根據非線性系統識別,建立了一套破壞偵測的方法。其方法裡採用了實 驗中所量測到的位移、速度、加速度反應,以及輸入外力等資料,作為網路訓練之用。 傳統的類神經網路多為一非參數系統識別之方法,而本文則是利用 ARX 來模擬結構系 統的運動方程式,建立出參數系統識別之方法,而推出結構的系統參數。 類神經網路依照學習模式可以區分成兩大類: 1.監督式學習(Supervised learning) 監督式學習是以迭代方式不斷修正神經網路中的權值(Weight),在修正的過程中我 們希望輸出(Output)結果符合期待(Desired)的結果。在每一個訓練例子,給於神經網路一 個輸入值和期望輸出值,這個期望輸出值便扮演老師的角色,不斷監督神經網路去修正 權值,在整個訓練過程中不段修正權值,來修正神經網路輸入值與期望輸出值之間的誤 差,直到誤差小於一定的臨界值或權值不再改變才會停止訓練。
38 2.非監督式學習(Unsupervised learning) 非監督式學習僅需要提供輸入資料,不需要期望輸出資料,也就是說它不需要誤差 訊息去改善神經網路的輸出,僅需要依照輸入資料便可以判斷其類別。 所以,我們知道非堅督式學習神經網路通常是利用在分類的問題上面。而監督式神 經網路則是用在模型訓練。
39
2-4-1 倒傳遞類神經網路之架構
類神經網路是由生物神經網路得到靈感所發展出的一種系統;它由一些相互連結在 一起的簡單處理單元(結點)所組成,連結的權值(weights)代表儲存在系統的資訊並 用來表示連結的強度,這些權值掌握了使類神經網路產生功能的關鍵。在各種不同的類 神經網路模式中,使用誤差倒傳遞演算法之向前饋入、多層、監督式的神經網路,即所 謂的倒傳遞網路(Back-Propagation Network, BPN)[36],由於它的簡單性,是目前應用 最普遍的類神經網路學習模式。一個類神經網路在可以應用之前,必須先從一筆存在有 一對輸入值及輸出值的案例或資料庫來訓練。 圖 2-11 典型之三層類神經網路架構圖 如圖上所示,BPN 的網路架構包含了一層的輸入層、一或多層的隱藏層以及一層的 輸出層。而每一層之節點皆與其鄰層的節點相連接。40 通常隱藏層之結點數目越多收斂越慢,但可達到更小的系統誤差值,當超過一定數 目後,再增加則對降低系統誤差幾乎沒有幫助,只是徒然增加執行之時間。另外值得一 提的是,Hecht-Nielsen [37]在其研究中證明,一層的隱藏層已足夠解決大部分實際應用 上的問題。因此,於本報告中之各個神經網路將只使用一層的隱藏層。在一類神經網路 能夠使用之前,它必須先經過訓練的過程。利用 BP 學習演算法的訓練過程,一般包含 了三個階段。第一階段稱之為資料向前饋入(data feedforward)。輸出層中第 i 個節點 的計算輸出值 yi 定義如下,上圖 2-11: 其中 wij 為隱藏層及輸出層節點之間的連接權植;vjk 為輸入層及隱藏層節點之間 的連接權值;
θ
wi與θ
vj 其中 P 為學習的案例數。Y=( y y1 2 yi y )No ;Y=(y y1 2 yi y )No ,y
i為輸 出節點 i 之期望值,而 11 12 1 2 11 12(
h i h jk N N N ijv v
v
v
θ θ
ν νθ
νw w
w
=
W
1 )2 o h o N N w w wN w θ θ θ 。41
訓練的最後階段為權值的修正。標準 BP 演算法係基於最陡梯度法(gradient descent method)並使用固定的搜尋步幅(step length)或學習速率(learning ratio) 來訓練網路。 其權值的修正如下: η為學習率,一般介於 0~1 之間。上標(k)表示迭代第 k 次,亦即網路經過 k 次 的學習。BP 演算法中最小化搜尋方向是由負的誤差函數梯度決定,這種搜尋方向上的 搜尋步幅由固定的學習速率決定,因此常常導致學習之系統誤差不穩定以及學習速度緩 慢之困擾。 類神經網路訓練的目的,就是讓類神經網路的輸出越接近目標值。亦即,相同的輸 入進入到系統與類神經網路,得到的輸出值亦要相同。類神經網路未訓練前,其輸出是 凌亂的,隨著訓練次數的增加,類神經網路的鍵結值會逐漸的被調整,使得目標值與神 經網路的輸出兩者誤差越來越小。當兩者的誤差幾乎不再變化時,我們稱此類神經網路 已收斂(convergence),此時類神經網路便訓練完成。通常我們會定義一個價值函數(cost function)作為神經網路收斂的指標,價值函數將會隨著網路的訓練次數越變越小最後 幾乎不再變化。 學習率(learning rate),在類神經網路的訓練過程中是一個非常重要的參數。學習 率影響著類神經網路收斂的速度,若學習率選擇較大則類神經網路收斂的速度將變得較 快,反之,較小的學習率會使得類神經網路的收斂速度變慢。選擇太大或太小的學習率 對類神經網路的訓練都有不良的影響。 當類神經網路經由訓練樣本訓練完成後,雖然神經網路的輸出已經與我們所要求的 數值接近,但對於不是由訓練樣本所產生的輸入,我們並不知道會得到何種輸出。
42 因此,我們必須使用另一組類神經網路從未見過樣本進入到類神經網路中,測試其 推廣性(generalization),看看是否與所要求的值接近,而此樣本則稱之為測試樣本 (testing pattern)。推廣性亦是類神經網路中的一項優點,當類神經網路訓練完成後, 對於與訓練樣本相近的輸入,類神經網路亦能給予一個合理的輸出,但是如果測試樣本 與訓練樣本的差異過大,類神經網路仍是無法給予正確的數值。
43
44 類神經網路優點: 類神經網路可以建構非線性的模型。 類神經網路有良好的推廣性,對於未知的輸入亦可得到正確的輸出。 類神經網路可以接受不同種類的變數作為輸入,適應性強。 類神經網路可應用的領域相當廣泛。 類神經網路優點: 類神經網路以迭代方式更新鍵結值與閥值,計算量大,相當耗費電腦資源。 類神經網路的解有無限多組,無法得知哪一組的解為最佳解。 類神經網路訓練的過程中無法得知需要多少神經元個數,太多或太少的神經元均會 影響系統的準確性,因此往往需以試誤的方式得到適當的神經元個數。
45
第三章 系統設計之理論與工具軟體
本章將介紹本論文所用理論及系統架構。首先介紹多目標基因演算法、極限強度設 計法、耐震能力評估、類神經網路輔助及最後整個系統架構。3-1 多目標基因演算法
本論文採用 Deb 所建議 NSGA-II 來處理多目標求解問題。 NSGA-II 的主要步驟如下: 首先隨機產生一群起始解,並將這群起始解區分成不同等級的非凌駕水準,每個解 都會被指定一個與非凌駕水準相同的最適值(Fitness Value),其中 1 表示最好的水準; 1.接著利用交配與突變等方法產生新的一代,而且每個水準的凌駕解個數不能大於 母體數(Population Size),如果有多餘的非凌駕解就利用 Crowded Tournament Selection Operator 此時必須決定去留:1.利用 Crowded Tournament Selection Operator 比較過程分兩階段: 首先比較非凌駕水準,留下非凌駕水準小的;
當兩個解的非凌駕水準相同時,就會利用 Crowding Distance Metric 分別計算與相 鄰兩個解的距離,公式如下: d Ijm = dIjm+ fm�Ij+1 m � −fm�Ij−1 m � fmmax−fmmin (3-1) 求出的解愈大表示與相鄰的解愈遠,即出現在非凌駕解較少的地方、比較不擁擠, 因此這樣的解比較具代表性,就會選擇讓它留下。
46 2.反覆實驗直到達到停止準則。 運用 Crowding Distance 決定新的非凌駕解是否去留的優點,包括使用者事先不需 要定義任何的參數來維持非凌駕解集合多元化;不用進行全面性的比較來決定新的非凌 駕解的去留,需要計算與相鄰兩個解的距離徹底簡化了比較過程所需的計算時間。 NSGA-II[38]是 K. Deb 在 2002 年提出來的一種多目標最佳化演算法,除了用到固定 大小的外部暫存器(external repository)及改良過的菁英政策(elitism policy)外,演化過程 與一般 GA 完全一樣。NSGA-II 提出的篩選或保留外部暫存器內成員的方法,是將演化 出來的解與外部暫存器解的結合,並依被支配的程度分級,若某個解被較少的其他解支 配,則此解的等級越高,反之則越低。
47 圖 3-2 同等級解之疏密計算示意圖 上圖 3-35所示為 NSGA-II 的外部暫存器更新示意圖。Pt與 Qt分別為外部暫存器內 的解與新一代演化搜尋出來的解,結合之後依被支配的程度從高到低分為 F1、F2、F3…, 並依等級將解填入外部暫存器。若 F3 內部的成員過多,無法將其全體填入外部暫存器。 若 F3 內部成員過多,無法將其全體填入外部暫存器。因此,NAGA-II 提出一種依解分 佈的疏密程度來判斷同等級解之優劣的方法。如上圖 3-36所示,若(i-1、i、i+1…)為同 等級的解,每一個同等級地解都有一個疏密度參數表示其優劣程度,解 i 的疏密程度參 數值是其與前一個解 i-1 的距離再加上與後一個解 i+1 的距離的平均值,若此參數越大 即表示此解出現在越稀有的位置,亦即此解在同一等級的解有較高的優先權被填入外部 暫存器中。
48
3-1-2 多目標基因演算法範例
以下用一簡單案例來說明 NSGA-II 運作過程[18]
圖 3-3 NSGA-II 範例之步驟一
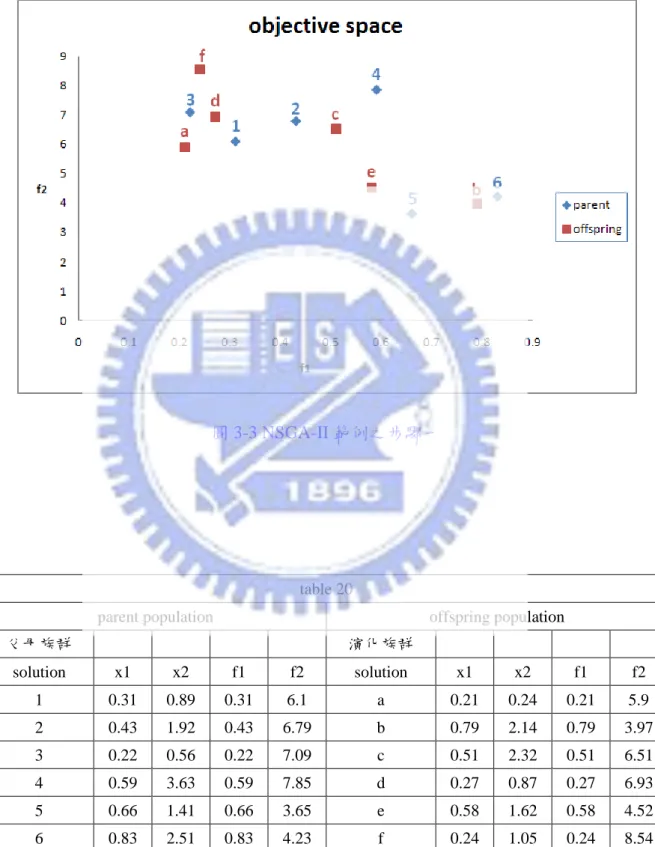
table 20
parent population offspring population
父母族群 演化族群 solution x1 x2 f1 f2 solution x1 x2 f1 f2 1 0.31 0.89 0.31 6.1 a 0.21 0.24 0.21 5.9 2 0.43 1.92 0.43 6.79 b 0.79 2.14 0.79 3.97 3 0.22 0.56 0.22 7.09 c 0.51 2.32 0.51 6.51 4 0.59 3.63 0.59 7.85 d 0.27 0.87 0.27 6.93 5 0.66 1.41 0.66 3.65 e 0.58 1.62 0.58 4.52 6 0.83 2.51 0.83 4.23 f 0.24 1.05 0.24 8.54
49 Step 1 我們先從族群 Rt={1,2,3,4,5,6,a,b,c,d,e,f}組合 Pt和 Qt族群, 接著,我們計算 Rt中非支配排序值。 我們可得到以下非支配曲面: front1=F1 = {5,a,e} front2=F2 = {1,3,b,d} front3=F3 = {2,6,c,f} front4=F4 = [19] 如下圖所示 圖 3-4 NSGA-II 範例之步驟二
50 Step 2 我們令 Pt+1=0,i=1。 接著,我們計算得�Pt+1� + �F1� = 0 + 3 = 3 大小值為 3。 當上式小於族群大小值 N(=6)時,我們可以將 F1 族群放入 Pt+1族群內。 所以現在 Pt+1 = {5,a,e}。 我們現在還需要超過三個解來填滿這新的母族群。 填入 F2 曲面,該大小值為�Pt+1� + �F2� = 3 + 4 = 7 當該值大於 6 時,我們則停止填入任何曲面到該族群。 注意如果 F1 和 F4 之前未被分類,我們則需保存了這些計算值。 Step 3 接著,我們只要考慮 F2 的解及觀察三或四個解必須選出來填滿在新族群中剩下排 序位置。 而以上動作必須根據下面敘述: 我們先排序這副族群(1,3,b,d)藉由≺C 操作(定義在[18]中 6.2.1 節)。 我們使用 step-by-step 過程來計算這些曲面解的擁擠距離值。≺C 操作步驟如下: Step C1 我們令 L=4 及 d1=d3=db=dd=0。
我們同時令f1max = 1,f1min = 0,f2max= 60,f2min = 60 Step C2
51
table 21 the fitness assignment procedure under NSGA-II
front 1 sorting in distance
solution x1 x2 f1 f2 f1 f2
5 0.66 1.41 0.66 3.65 third first ∞
a 0.21 0.24 0.21 5.9 first third ∞
e 0.58 1.62 0.58 4.52 second second 0.54
front 1 sorting in distance
solution x1 x2 f1 f2 f1 f2
1 0.31 0.89 0.31 6.1 third second 0.63
3 0.22 0.56 0.22 7.09 first fourth ∞
b 0.79 2.14 0.79 3.97 fourth first ∞
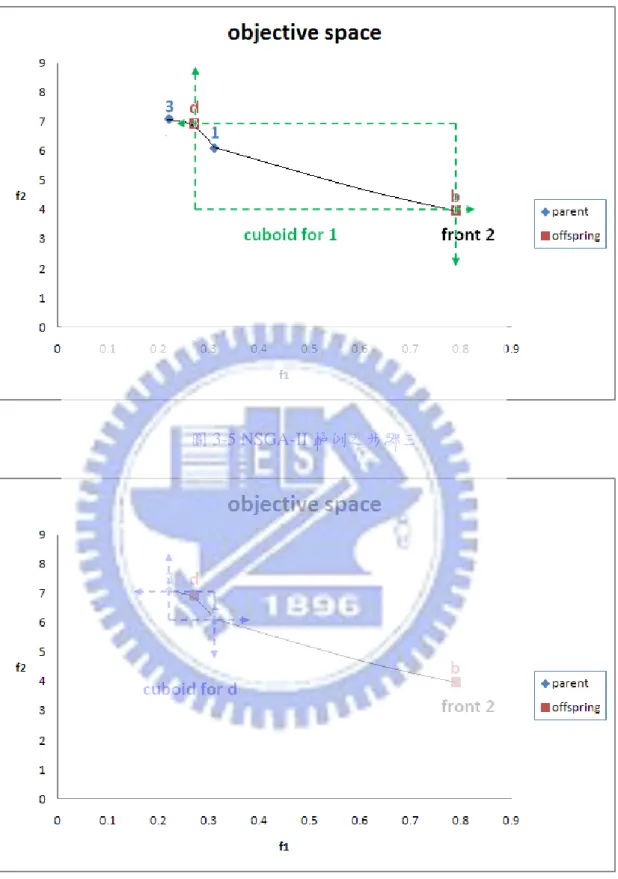
52 Step C3 3 與 b 依據 f1 排序為邊界,所以我們設定 d3=db=∞。 而其它兩個則 dd = 0 + f1 �1� − f1�3� f1max− f1min = 0 + 0.31 − 0.22 1 − 0.1 = 0.10 d1 = 0 + f1 (b) − f1(d) f1max− f1min = 0 + 0.79 − 0.27 1 − 0.1 = 0.58 接著,換 f2 排序計算,I2={b,1,d,3}。 設定邊界 b,3 其 db=d3=∞。 其他兩個則 d1 = d1+ f2 (d) − f2(b) f2max− f2min = 0.58 + 6.93 − 3.97 60 − 0 = 0.63 dd = dd+ f2 �3� − f2�1� f2max− f2min = 0.10 + 7.09 − 6.10 60 − 0 = 0.12 因此四個解的疊加擁擠距離值為 d1=0.63, d3=∞, db=∞, dd=0.12。 這些解的交集如圖 3-39、圖 3-40 與圖 3-41 所示
53
54
圖 3-7 NSGA-II 範例之步驟五
從上圖觀察得知在 F2 曲面中 d 解的 cuboid 範圍最小 接著回到主程式。
Step 3
依據擁擠距離值(crowding distance values)降冪排序得{3,b,1,d}。 我們選擇一到三解。