國 立 交 通 大 學
電信工程研究所
博 士 論 文
多封包接收無線網路之上鏈媒體存取控制
協定設計
Medium Access Control Protocol Design
for Uplink in Wireless Networks with
Multipacket Reception Capability
研 究 生:楊 雯 芳
指導教授:李 大 嵩 博士
共同指導教授:吳 卓 諭 博士
多封包接收無線網路之上鏈媒體存取控制
協定設計
Medium Access Control Protocol Design
for Uplink in Wireless Networks with
Multipacket Reception Capability
研 究 生:楊雯芳
Student:
Wen-Fang
Yang
指導教授:李大嵩 博士 Advisor:
Dr.
Ta-Sung
Lee
共同指導教授:吳卓諭 博士
Co-Advisor: Dr. Jwo-Yuh Wu
國立交通大學
電信工程研究所
博士論文
A Dissertation
Submitted to Institute of Communication Engineering
College of Electrical and Computer Engineering
National Chiao Tung University
in Partial Fulfillment of the Requirements
for the Degree of Doctor of Philosophy
in
Communication Engineering
Hsinchu, Taiwan
January 2010
多封包接收無線網路之上鏈媒體存取控制協定設計
學生:楊雯芳 指導教授:李大嵩 博士
共同指導教授:吳卓諭 博士
國立交通大學電信工程研究所
摘要
本論文主要探討多封包接收(MPR)無線網路之上鏈媒體存取控制(MAC)協定設計, 藉由一個簡單的旗標位元機制,吾人提出適用於多封包接收無線網路之多群優先佇列 (MGPQ)媒體存取控制協定。多群優先佇列協定能夠克服現今多封包接收媒體存取控制協 定設計的兩大瓶頸。首先,此法避免使用複雜的使用者狀態估測演算法,而依據封包接收狀 況自動排序出使用者的可能活躍程度,進而大幅降低演算複雜度;其次,遷就使用者狀態估 測演算法所加諸於使用者的封包阻絕(blocking)限制也隨之解除。因此,多群優先佇列協定 不僅可以適用於異質使用者的環境,同時性能也優於現今的多封包接收媒體存取控制協定。 模擬數據顯示,相對於常見的動態佇列(DQ)媒體存取控制協定,多群優先佇列協定最多可 以提昇 40%的系統吞吐量,平均而言,也有 14%的改善。 本論文接著將同質(homogeneous)通道的假設推廣為異質(heterogeneous)通道環境。 協力式的媒體存取控制協定在多封包接收無線網路的設計上為一具挑戰性的議題,也尚未見 諸於文獻上;吾人提出協力式多群優先佇列(CMGP),以利用空間多樣性(diversity)來提 昇系統吞吐量,並利用使用者空閒(idle)的時間作封包的中繼傳輸,因此沒有一般中繼方式 造成部分使用者吞吐量下降的缺點。此外,吾人也以馬可夫鍊(Markov Chain)針對最差情 況作分析,推導出直接傳輸受到中繼傳輸干擾所引起的吞吐量損失上界,及中繼傳輸對失敗 傳輸所提供的吞吐量增益下界。藉由上述推導的封閉解,吾人將可以直接經由實體層的多封 包接收矩陣,計算協力式多群優先佇列的吞吐量性能。 無線通道不可避免地受到各種衰落(fading)而惡化,儘管吾人可利用以機率密度函數 為基礎的統計量,例如蜂巢邊緣可靠度、蜂巢區域可靠度等來量測其影響,但實際上由於傳 統的多封包接收媒體存取控制協定必須分配通道資源給每一使用者,因此單一個具有較差通 道狀況的使用者都可造成整個系統吞吐量的惡化。本論文最後從系統吞吐量最佳化的觀點, 提出基於流量的動態使用者集合(DUST)演算法,進一步改善整體系統吞吐量並已模擬加以 驗證。Medium Access Control Protocol Design
for Uplink in Wireless Networks with Multipacket
Reception Capability
Student: Wen-Fang Yang Advisor: Dr. Ta-Sung Lee
Co-Advisor: Dr. Jwo-Yuh Wu
Institute of Communication Engineering
National Chiao Tung University
Abstract
This dissertation focuses on the medium access control (MAC) protocol design for the uplink of wireless networks with multi-packet reception (MPR) capability. Relying on a simple flag-assisted mechanism, a multi-group priority queueing (MGPQ) MAC protocol is proposed. The proposed MGPQ scheme is capable of overcoming two major performance bottlenecks inherent in the existing MPR MAC protocols. First, the proposed solution can automatically produce the list of active users by observing the network traffic conditions, remove the need of active user estimation algorithm, and thus can largely reduce the algorithm complexity. Second, the packet blocking constraint imposed on the active users for keeping compliant with prediction is relaxed. As a result, the proposed MGPQ is not only applicable to both homogeneous and heterogeneous (in traffic) cases, but also outperforms the existing MPR MAC protocols. Simulation results show that the network throughput can be improved by 40% maximum and 14% average as compared with the well-known dynamic queue (DQ) MAC protocol.
Subsequently the homogeneous channel is generalized into heterogeneous channel. MAC protocol design for cooperative networks over MPR channels is a challenging topic, but has not been addressed in the literature yet. In this dissertation, we propose a cooperative multi-group priority (CMGP) based MAC protocol to exploit the cooperation diversity for throughput enhancement over MPR channels. The proposed approach can bypass the computationally-intensive active user identification process. Moreover, our method can efficiently utilize the idle periods for packet relaying, and can thus effectively limit the throughput loss resulting from the relay phase. By means of a Markov chain model, the worst-case throughput analysis is conducted. Specifically, we derive (i) a closed-form upper bound for the throughput penalty of the direct link that is caused by
the interference of concurrent packet relay transmission; (ii) a closed-form lower bound for the throughput gain that a user with packet transmission failure can benefit thanks to cooperative packet relaying. The results allow us to investigate the throughput performance of the proposed CMGP protocol directly in terms of the MPR channel coefficients. Simulation results confirm the system-wide throughput advantage achieved by the proposed scheme, and also validate the analytic results.
Wireless channel is inevitably degraded with many kinds of fading. Probability density function based statistics, e.g. cell edge reliability and cell area reliability, are used to measure the effect of shadowing. However, in practice even one user with poor link may severely degrade the system throughput, because the central controller (CC) needs to allocate channel resource for such an inefficient access. To overcome the above problem, we propose a dynamic user set based on traffic (DUST) algorithm aiming for uplink throughput optimization in wireless networks with multi-packet reception. Numerical results show significant improvement in the network throughput.
iv
Acknowledgement
I would never have been able to complete this dissertation without the help from many people. Foremost, I would like to express my deep gratitude to my advisors Prof. Ta-Sung Lee and Prof. Jwo-Yuh Wu, because they provided me with the platform to investigate the advanced wireless technology at National Chiao Tung University. I learned much from them to improve my research and working attitude, especially the insight into complicated issues. Special thanks went to Prof. Li-Chun Wang, who led me into the MAC field and encouraged me while facing difficulty and frustration. Of course, the valued comments from oral defense committee were highly appreciated.
I particularly appreciated my bosses, president Ming-I Wong and vice president Dr. Frank Hwang, in Tellus. They gave me maximal working flexibility to balance between company and school at the first two years.
I also want to thank all the members of Communication System Design and Signal Processing (CSDSP) Lab: Dr. Chih-Yuan Lin, Dr. Fang-Shuo Tseng, Kuang-Ming Lin, Wen-Chang Yu, Chester Huang, Wei-Sheng Lai, Hsien-Lee Pan, Shi-Yuan Liu, Wen-Chin Ouyang, and so on, for team work and sharing these years.
This dissertation is dedicated to my family, my father, mother, elder sister, and wife, for their unwavering support and endless love. I am very grateful to my lovely wife Candy Liao for her understanding and cheering.
Finally, "Glory to God in the highest, and on earth peace to men on whom his favor rests." (Luke 2:14)
Contents
Chinese Abstract
i
English Abstract
ii
Acknowledgement iv
Contents v
List of Figures
viii
List of Tables
ix
List of Notations
x
List of Acronyms
xi
1 Introduction
1
1.1 Basics of MAC 1 1.2 Basics of MPR 21.3 Related Literature Review 3
1.4 Main Contributions 5
1.5 Organization of Dissertation 8
2 Multipacket Reception MAC Design in Homogeneous Channels
10
2.1 Overview 10
2.2 System Model 10
2.2.1 System Description 10
2.2.2 MPR Channel 11
2.3 Multi-Group Priority Queueing Protocol 12
2.3.1 An Illustrative Example 12
2.3.2 Proposed MGPQ Algorithm 14
2.3.3 Stability 15
2.4 Optimal Waiting Period Selection 17
2.4.1 Markov Chain 18
2.4.2 State Transition Probability 19
2.4.3 Computation of Mean Delay 20
2.4.4 Homogeneous Case 21
2.5 Numerical Results 21
2.5.1 Validation of Analytical Results 22
2.5.2 Comparison with Previous Work 24
2.5.3 General Case 26
2.6 Summary 28
3 Multipacket Reception MAC Design in Heterogeneous Channels
30
3.1 Overview 30
3.2 Preliminary 31
3.2.1 System Scenario 31
3.2.2 MPR Matrix 31
3.2.3 Highlight of the MGP Protocol 32
3.3 Cooperative Multi-Group Priority Protocol 34
3.3.1 Operation of the Proposed CMGP Protocol 34
3.3.2 An Illustrative Example 35
3.3.3 Algorithm Summary 37
3.4 Throughput Analysis 39
3.4.1 Upper Bound for Worst-Case Throughput Penalty 40
3.4.2 Lower Bound for Worst-Case Throughput Gain 43
3.5 Optimal Waiting Period Selection 44
3.5.1 Markov Chain 44
3.5.2 State Transition Probability 47
3.5.3 Computation of Mean Delay 47
3.6 Simulation Results 48
3.6.1 Throughput Enhancement due to Cooperation 49
3.6.2 Throughput Results for Near- and Far-End Users 50
3.6.3 Delay and Packet Blocking Performances 52
3.6.4 Throughput Results in a Dense Environment 53
3.7 Summary 54
4 Dynamic User Set Based Uplink Throughput Optimization for Wireless
Networks 55
4.1 Overview 55
4.2 Preliminary 56
4.2.1 Generalized MPR Channel 56
4.2.2 Capacity Bound 57
4.3 Proposed DUST Algorithm 59
4.3.2 DUST Equations 59
4.3.3 DUST+CMGP Algorithm 59
4.4 Numerical Results 60
4.5 Summary 60
5 Conclusions and Future Works
62
5.1 Summary of Dissertation 62
5.2 Future Works 63
Appendix 64
Bibliography 79
List of Figures
Fig. 1.1 Schematic diagram of uplink transmission 2
Fig. 1.2 Category of MAC 5
Fig. 2.1 An illustrative example of MGPQ with four users 12
Fig. 2.2 Mean throughput performance of the proposed MGPQ 23
Fig. 2.3 Mean delay performance of the proposed MGPQ 23
Fig. 2.4 Delay performance of individual users 24
Fig. 2.5 Throughput performance comparison between MGPQ and DQ 25
Fig. 2.6 Delay performance comparison between MGPQ and DQ 25
Fig. 2.7 Packet loss ratio performance comparison between MGPQ and DQ 26 Fig. 2.8 Throughput comparison between MGPQ, PMP, and DQ for different buffer size 27 Fig. 2.9 Throughput comparison between MGPQ, PMP, and DQ for different number of users 28
Fig. 3.1 Packet formats 33
Fig. 3.2 An illustrative example 36
Fig. 3.3 Flow chart of user acting as a relay 38
Fig. 3.4 Centrally controlled state transition diagram of an individual user 39 Fig. 3.5 Throughput performance for different number of users participating in cooperation 49
Fig. 3.6 Average throughput of near, far and all users 50
Fig. 3.7 Lower bound of throughput gain derived from Theorem 3.2 51 Fig. 3.8 Upper bound of throughput penalty derived from Theorem 3.1 51
Fig. 3.9 Average delay of near, far and all users 52
Fig. 3.10 Average packet blocking probability of near, far and all users 53
Fig. 3.11 Average throughput in a dense environment 53
Fig. 4.1 Schematic throughput curves for different user sets. 57
List of Tables
Table 2.1 Transition conditions among three different priority groups 14
List of Notations
⊗ matrix Kronecker product
[ ]
E y expected value of the random variable y
Pr{ } probability m n X × m n× matrix C matrix ⎣ ⎦ floor function ⎡ ⎤ ceiling function
List of Acronyms
AF Amplify-and-Forward
ALLIANCES ALLow Improved Access in the Network via Cooperation and Energy Savings AMC Adaptive Modulation and Coding
BMDQ Bit-Map assisted Dynamic Queue
CC Central Controller
CDMA Code-Division Multiple-Access CMA Cooperative Multiple Access
CMGP Cooperative Multi-Group Priority CoopMAC Cooperative MAC
DF Decode-and-Forward
DQ Dynamic Queue
DUST Dynamic User Set based on Traffic FCFS First-Come First-Served
FDMA Frequency-Division Multiple-Access
MAC Medium Access Control
MGP Multi-Group Priority
MGPQ Multi-Group Priority Queueing
MPR Multi-Packet Reception
MQSR Multi-Queue Service Room
OFDMA Orthogonal FDMA
PHY PHYsical
PLR Packet Loss Ratio
PMP Predictive Multicast Polling
PREM PRe-EMptive
TDMA Time-Division Multiple-Access
Chapter 1
Introduction
In this introductory chapter, some background materials about medium access control (MAC) in uplink/downlink transmissions, and multi-packet reception (MPR) are presented. What follow up are the literature survey, contributions and an overview of this dissertation.
1.1 Basics of MAC
Multiple access is a technique used to make best use of the transmission medium. In multiple access, multiple terminals or users share the bandwidth of the transmission medium. An efficient MAC mechanism is characterized by high throughput and low delay. A major concern in a MAC protocol is to decide which users are allowed to participate in each simultaneous transmission. Specifically, the MAC protocol may need to restrict the number of simultaneous transmissions in order to provide service to each user with acceptable quality.
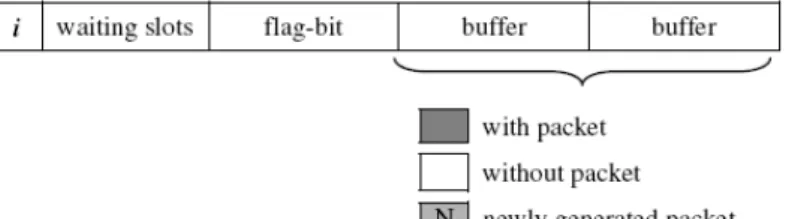
A centralized network typically involves two-side communications, namely, downlink and uplink. The former is the transmission from the central controller (CC) to users, and the latter is the transmission from users to the CC. As all the packets of downlink are stored at the buffer of the CC, MAC can easily exploit the MPR capability of physical (PHY) layer due to the full knowledge about the packet status for all users. Nevertheless, there must be some specially designed mechanism for scheduling the uplink transmission due to the lack of full knowledge about the status of users’ buffers in which the packets are stored as shown in Fig. 1.1. We will focus on the uplink in this dissertation.
Fig. 1.1 Schematic diagram of uplink transmission.
1.2 Basics of MPR
MAC is responsible for allocating communication bandwidth resources to multiple users. An essential requirement is the “separation” of users at the receiver in order to achieve effective multipoint-to-point communication. In practice, we want to allow users to transmit data simultaneously such that their transmissions can be separated at the receiver. However, such transmission simultaneity can be manifested in time, in space, in frequency, or in all of these domains. Which form of simultaneity is preferable depends on the cost and the application of the system. Different choices of transmission simultaneity lead to different user separation schemes (i.e., different methods to provide orthogonality). For example, in a frequency-division multiple-access (FDMA) system, users transmit data simultaneously from the time domain perspective but are
separated in the frequency domain. In a code-division multiple-access (CDMA) system, users transmit data simultaneously in both time and frequency domains, but are separated in the “code” domain. Traditionally, the design of MAC protocols is based on the so-called collision channel model, that is, a transmitted packet is successfully received only when no concurrent transmission occurs. Such a paradigm, however, ignores the MPR capability at the PHY layer, for example, FDMA, orthogonal FDMA (OFDMA), CDMA, and multiuser detection [18].
1.3 Related Literature Review
Recently MAC protocols with the MPR capability draw increasing attention. Several proposals have been reported in the literatures. An initial attempt to reflect the MPR facility is the channel model with capture effect characterized via the probability of successful reception [17]. The impact of capture effects on various existing MAC protocols such as slotted ALOHA, and FCFS has been addressed in [8][29][30]. However, the capture model overall remains a simplified representation of the actual channel characteristics and does not explicitly account for the MPR capability. This thus motivates the development of more realistic MPR channel model [7], based on which several MAC protocols have been proposed for realizing various system-wide performance requirements. The multiqueue service room (MQSR) protocol [27] is, to the best of our knowledge, the first proposal which relies on the MPR model [7] for user scheduling. It calls for active user prediction via an exhaustive search over all the available network-traffic and PHY layer channel capacity information up to the current slot. However, as the total number of users increases, the number of search states grows exponentially thereby incurring high-computational complexity. Moreover, the transmission of the newly generated packets of selected users is not allowed in order to maintain the active user prediction determined via the previous network traffic, inevitably resulting in throughput degradation. The dynamic queue (DQ) protocol introduced in [28] delivers a large portion of performance gain attained by MQSR solution but at reduced complexity. By viewing the traffic as a flow of transmission periods (TP), the DQ protocol otherwise aims for minimization of the expected
TP duration by exploiting the MPR property. To further reduce the idle period of users with empty buffer, a modification of DQ scheme that includes active user identification at the receiver is subsequently introduced in [15]. In [6], a predictive multicast polling (PMP) scheme was proposed for the general finite buffer size. This approach relies on active user prediction slot by slot, and can significantly improve system throughput since packet blocking is no longer necessary. However, the computational complexity is still a concern. The bit-map assisted dynamic queue (BMDQ) protocol [22], which is essentially a modified DQ scheme, inserts an extra time-division multiple-access (TDMA) slot at the head of each TP for channel access/reservation request. However, such an overhead will reduce the bandwidth efficiency, especially when the number of users is large. The two major performance bottlenecks inherent in the existing MPR MAC protocols are the computational complexity and the packet blocking constraints. In order to optimize the number of concurrent transmissions, the CC may rely on an exhaustive search to estimate the buffer status of each user, thus resulting in a high-computational load. Second, the newly generated packets are not allowed to enter the buffer (hence blocked) for maintaining a static buffer status during each processing round.
Cooperative MAC protocol design can exploit multi-user diversity for network-wide performance enhancement, and has attracted considerable attention in the recent years [5][12]. The cooperation diversity can be exploited to improve system performance in both PHY and MAC layers. In PHY layer, many variant technologies based on amplify-and-forward (AF) and decode-and-forward (DF) are proposed. As in MAC layer, the special cooperative MACs such as CMA [16], CoopMAC [13], and ALLIANCES [26] are proposed. As shown in Fig. 1.2, the packet reception capability and cooperation diversity are never jointed together to design the MAC protocol. On the one hand it is difficult to take MPR capability into cooperative single-packet reception (SPR) MAC unless certain assumption, such as separate channels in [26], is assumed. On the other the existing non-cooperative MPR MACs are too complicated to further include cooperation into analysis. Most of the existing works, however, are devised exclusively for the collision channel model and do not
Fig. 1.2 Category of MAC.
exploit the MPR capability at the PHY layer [7][8][17][19][20][29]. Toward more efficient solutions, one promising approach is thus to further take the MPR advantage into consideration so as to gain full benefits from the PHY-layer processing.
1.4 Main Contributions
The contributions of this dissertation are summarized as three parts: A. MPR MAC in homogeneous channels
1. A single flag-bit is appended on the tail of the transmitted packet for indicating the existence of the following packet in the buffer. This scheme provides the CC with the certain partial knowledge about the subsequent network traffic in a deterministic fashion. The flag-assisted information can greatly simplify the channel access which can be reserved directly for the users with packets ready to transmit. Note that the deterministic knowledge is only available for those users whose packets are successfully received by the base station. Although the
mechanism similar to the flag-bit may be available in the existing network protocol such as IEEE 802.11 [2], it is never exploited for facilitating the MPR MAC protocol design.
2. By exploiting the on-off flag signature, we propose to classify the users into three groups with different service priorities: the ACTIVE group consisting of the users with packets to send, the STANDBY group consisting of those with empty buffers, and the PRe-EMptive (PREM) group accommodating those who have stayed in the STANDBY or the ACTIVE group longer than certain waiting period. The users in the ACTIVE group are guaranteed to have packets waiting for transmission. However, those users in the STANDBY group are NOT guaranteed to have no packets waiting for transmission, because there may be packets generated after last successful transmission (note that the successful transmission is the only way for the users to convey the flag-bit information to the CC). The inclusion of the complementary PREM group is to avoid unfair scheduling that can occur in a binary grouping strategy. (If there are merely two groups, users in the STANDBY group would suffer an unlimited service delay since the channels could be constantly reserved for some ACTIVE links with heavy traffic.) With the trigroup user classification scheme, the priorities of service (from high to low, respectively) are PREM, ACTIVE, and STANDBY. The proposed method integrates the deterministic knowledge of those users in the ACTIVE group and the estimated states of those users in the STANDBY group to derive the optimal waiting period for the PREM group.
3. Through a Markov chain model of the proposed protocol and an associated analysis of the steady-state transition probabilities, we propose a method for determining the optimal waiting period, subject to the constraint that a uniform mean delay requirement among all users must be met.
4. In the proposed scheme, the number of users permitted for channel access is deterministically set to be that attaining the MPR channel capacity. This prevents the channel from being overloaded and hence avoids irrecoverable packet collision in a heavy traffic environment.
B. MPR MAC in heterogeneous channels
1. The proposed protocol is, to our best knowledge, the first cooperative MPR MAC scheme. It is free from any assumptions on the channel and is applicable to the general heterogeneous environment [26].
2. The number of users permitted for channel access is deterministically set to attain the MPR channel capacity. This prevents the channel from being over-loaded, thereby avoiding irrecoverable packet failure due to collisions.
3. Based on the Markov chain model, the throughput performance in the worst-case scenario is analytically characterized. Specifically, we derive 1) a closed-form upper bound for the throughput penalty of the direct-link user that is incurred by the interference of relay packet transmission; 2) a closed-form lower bound for throughput gain that a user with packet transmission failure can benefit thanks to cooperative packet relaying. The results allow us to investigate the throughput performance of the proposed cooperative multi-group priority (CMGP) protocol directly in terms of the MPR channel coefficients. Also, simulation study evidences that the proposed CMGP protocol results in a system-wide throughput advantage. 4. In the proposed CMGP protocol there is a threshold for the waiting time slots above which the
idle users are permitted for channel access. Again based on the Markov chain model of the proposed protocol and an associated analysis of the state transition probabilities, we propose a method for determining the optimal period threshold, subject to the requirement that a uniform average delay of all users must be met.
C. Throughput Optimization
1. A theoretical channel capacity bound for a user set is derived, which reveals the importance of selection on user set.
2. A dynamic user set based on traffic (DUST) algorithm is proposed to optimize the system performance from throughput viewpoint.
1.5 Organization of Dissertation
The remaining of this thesis is organized as follows.
In Chapter 2, relying on a simple flag-assisted mechanism, a multi-group priority queueing (MGPQ) MAC protocol is proposed for the wireless networks with MPR. The proposed MGPQ scheme is capable of overcoming two major performance bottlenecks inherent in the existing MPR MAC protocols. First, the proposed solution can automatically produce the list of active users by observing the network traffic conditions, remove the need of active user estimation algorithm, and thus can largely reduce the algorithm complexity. Second, the packet blocking constraint imposed on the active users for keeping compliant with prediction is relaxed. As a result, the proposed MGPQ is not only applicable to both homogeneous and heterogeneous (in packet generating probabilities) cases, but also outperforms the existing MPR MAC protocols. Simulation results show that the network throughput can be improved by 40% maximum and 14% average as compared with the well-known DQ MAC protocol.
Chapter 3 generalizes the homogeneous channel into heterogeneous channel. MAC protocol design for cooperative networks over MPR channels is a challenging topic, but has not been addressed in the literature yet. In this chapter, we propose a CMGP based MAC protocol to exploit the cooperation diversity for throughput enhancement over MPR channels. The proposed approach can bypass the computationally-intensive active user identification process. Moreover, our method can efficiently utilize the idle periods for packet relaying, and can thus effectively limit the throughput loss resulting from the relay phase. By means of a Markov chain model, the worst-case throughput analysis is conducted. Specifically, we derive 1) a closed-form upper bound for the throughput penalty of the direct link that is caused by the interference of concurrent packet relay
transmission; 2) a closed-form lower bound for the throughput gain that a user with packet transmission failure can benefit thanks to cooperative packet relaying. The results allow us to investigate the throughput performance of the proposed CMGP protocol directly in terms of the MPR channel coefficients. Simulation results confirm the system-wide throughput advantage achieved by the proposed scheme, and also validate the analytic results.
In Chapter 4, a pre-processing algorithm is proposed to further improve the system throughput. As we know that wireless channel is degraded with three major factors: quasi-deterministic attenuation, shadow fading, and multipath fading. Probability density function based statistics, e.g. cell edge reliability and cell area reliability, are used to measure the effect of shadowing. However, in practice even one user with poor link may severely degrade the system throughput, because the CC needs to allocate channel resource for such an inefficient access. To overcome the above problem, we propose a DUST algorithm aiming for uplink throughput optimization in wireless networks with MPR. Numerical results show significant improvement in the network throughput.
Chapter 2
Multipacket Reception MAC Design in Homogeneous
Channels
2.1 Overview
In this chapter, we propose a new approach to design the MAC protocol for wireless networks with MPR capability. The proposed approach relies on the flag-bit assisted knowledge about the presence of buffered packets as well as a priority user grouping strategy. The distinctive advantage of the proposed method is three-fold: 1) it is applicable to both the homogeneous and heterogeneous environments (in traffic), whereas almost all existing protocols developed for the MPR channel are exclusively tailored for the former case; 2) the insertion of a single bit facilitates the acquisition of network traffic condition with minimal bandwidth expansion; 3) the adopted user grouping policy avoids computationally-intensive search for the active user set as required in the existing protocols. To prevent an infinitely long service delay the waiting period of those yet-to-be-served users can be determined subject to a specified delay requirement. Simulation results show that, compared with the DQ protocol, the proposed scheme yields improved throughput, reduces the average delay penalty when the traffic condition is light, and yields a smaller packet loss ratio (PLR).
2.2 System Model
2.2.1 System Description
In the proposed system model, all accesses to the common wireless channel are controlled by the CC. At the beginning of each slot, the CC broadcasts an access set to inform the users who are allowed to access the channel in the current slot. Upon reception, the CC acknowledges the users
whose packets are successfully received. Users who transmit packets but do not receive the acknowledgments assume their packets are lost, and will retransmit whenever they are enabled. At the end of this slot, the CC updates the access set by the proposed multi-priority grouping strategy. In this dissertation, it is assumed that feedback acknowledgement channel (from the CC to the users) is error free and the incurred time delay is negligible. As in [28], we assume that each user has a buffer of size two. We propose to append one flag-bit on the tail of the transmitted packet for indicating if there is a following packet in the buffer. The extra flag-bit has the advantage to provide explicit information about the incoming traffic condition, as discussed next.
2.2.2 MPR Channel
Following [28], the MPR channel matrix for M users is described as
C 1,0 1,1 2,0 2,1 2,2 ,0 ,1 ,2 , M M M M M C C C C C C C C C ⎡ ⎤ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ = ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎣ ⎦ , (2.1) where
C =Pr{k packets correctly received |n packets transmitted}, n k, (2.2)
for 1≤ ≤n M and 0≤ ≤ . Denote k n ,
1 n n n k k C kC =
=
∑
the expected number of the correctly received packets when n packets are concurrently transmitted. The capacity of an MPR channel is defined as1maxn MCn
η
≤ ≤
= . Note that the numbers of simultaneously transmitted packets to achieve the channel capacity may not be unique. Let
{
}
0 min arg max1 n M n
n C
≤ ≤
Fig. 2.1 An illustrative example of MGPQ with four users.
be the minimum amount of capacity-achieving packets. Hence the maximal number of users permitted to access the channel should be n , since there will be no further improvement in system 0 capacity if more than n users are simultaneously served. Note that the MPR matrix (1) can be 0
determined via the physical layer performance metric such as bit error rate; an illustrative example based on CDMA communication can be found in [28].
2.3 Multi-Group Priority Queueing Protocol
2.3.1 An Illustrative Example
Fig. 2.1 shows an illustrative example for the proposed MGPQ protocol, where the total number of users is M = 4 and n = 2 users are selected to simultaneously access the channel. In MGPQ, all 0
users are classified into three different priority groups (PREM, ACTIVE, and STANDBY). The condition of the user i is summarized in a tag as shown in Fig. 2.1(a), in which the first field represents user ID, second field is the count of waiting slots, third field marks the on/off status of
the flag-bit, fourth and fifth fields represent the contents of the buffer. Fig. 2.1(b) depicts the operation of the proposed protocol during three consecutive time slots. At the end phase of slot
1 −
t , there is no user in the PREM group, user 1 with two packets and user 2 with one packet are in the ACTIVE group, and user 3 with one packet and user 4 with two packets are in the STANDBY group. The detailed operations of the proposed MGPQ are described as follows.
1) At the start phase of slot t , with empty PREM group, users 1 and 2 in the ACTIVE group are selected for transmitting packets.
2) At the end phase of slot t ,
(i) upon successful packet reception, user 1 with flag-bit on in the start phase is retained in the ACTIVE group; the flag-bit is then switched off since there is no packet in the second buffer. User 2 is moved to the tail of the STANDBY group since the flag-bit is off; (ii) the waiting slots of both users 1 and 2 are reset to 1, and the waiting slots of the
yet-to-be-served users 3 and 4 are increased to 2;
(iii) user 3 has a newly generated packet in the second buffer, and the associated flag-bit is switched on.
3) At the start phase of slot t +1, there is no user in the PREM group and there is only one user in the ACTIVE group, so users 1 and 3 are selected.
4) At the end phase of slot t+1,
(i) upon successful packet reception, user 1 is moved to the tail of the STANDBY group (flag-bit off). User 3 is moved into the ACTIVE group, and then flag-bit is switched off; (ii) both the waiting slots of users 1 and 3 are reset to 1, and the waiting slots of the
yet-to-be-served users 2 and 4 are increased to 2 and 3 respectively;
(iii) because user 4 has stayed in the STANDBY group for a certain waiting period S = 3 (to be specified later), it is moved into the PREM group.
5) At the start phase of slot t+2, there is one user in the PREM group and one user in the ACTIVE group, so users 4 and 3 will be selected.
Table 2.1 Transition conditions among three different priority groups.
2.3.2 Proposed MGPQ Algorithm
The proposed MGPQ protocol is now stated as follows, and the resulting state transition conditions are summarized in Table 2.1.
(I) Put all users into the PREM group.
(II) Select first n users (by the order of PREM, ACTIVE, and then STANDBY group) to 0 access the channel.
(a) If the packet of a certain user is received successfully, then put the user to the tail of the ACTIVE (if the flag-bit is on) or STANDBY group (if the flag-bit is off). And reset its count of waiting slots to zero.
(b) If, for a certain user, the buffer is empty (no packet sent) or there is packet transmitted but not successfully received, and then put the user back to the tail of the STANDBY or ACTIVE group in which the user originally stayed.
(III) Increase waiting slots of all users by one.
(V) Repeat steps (II) to (IV).
We note that, in the initial step, all users should be put in the PREM group rather than the STANDBY group. The rationale behind this choice is to avoid unfair scheduling when the packet generating probability is high. Indeed, if the protocol starts with all users in the STANDBY group, the first-selected n users are likely to stay ACTIVE for a long time. The channel will thus be 0 reserved for such ACTIVE users (with higher service priority), and those in the STANDBY group will then suffer a long delay.
2.3.3 Stability
System stability in the MAC design is extremely important since it guarantees all users with acceptable delays. A fixed packet arrival rate vector is stable if a transmission probability vector can be found to make all the queues in the corresponding system are stable [3]. However, it is difficult to derive the stability region for MPR protocols due to the complicated interactive queue behavior. Another approach to characterize the stability in the systems with finite buffer size is the absence of deadlock [4], or equivalently, all packets will be successfully received with finite delay. In this section, instead of finding the stability region, we will prove that the MGPQ MAC protocol is stable in terms of the finite delay criterion. According to the proposed protocol, the worst case occurs when a certain user is assigned with the lowest service priority in the STANDBY group while having two packets in the buffer. In this case, the second buffered packet will experience the longest service delay dmax. To prove that the average of dmax is finite, we need the following two lemmas (the detailed proofs can be found in Appendices A and B, respectively).
Lemma 2.1 Let p be the minimal probability that a packet can be successfully received. Then ms
ms
p is bounded away from zero. That is, there exists δ>0 such that pms ≥ >δ 0.
Lemma 2.2 Let t be the total time slots elapsed after k rounds of channel access (k k ≥1), and
max ≤ k t kt , (2.4) where , if , if 0 0 max 0 1 ⎧⎡ ⎤ ⎪⎪⎢ ⎥ ≤ ≤ ⎪⎪⎢ ⎥ ⎪⎪⎢ ⎥ = ⎨ ⎪⎪ < < ∞ ⎪⎪ ⎪⎪⎩ M M S n n t M S S n , (2.5)
and S is the waiting period.
Based on the above two lemmas, the following theorem can be sustained.
Theorem 2.1 The mean worst-case delay E d
[
max]
satisfies[
]
1 1 max max 0 − − ≤ +M < ∞ E d t n δ δ . (2.6) Proof: The mean worst-case delay can be expressed as E d[
max]
=E d[ ]
1 +E d , where[ ]
2 E d[ ]
1and E d are the averaged delays upon which the first and the second packets associated with the
[ ]
2last-to-be-served user are successfully received, respectively. We first observe that
[ ]
{ }{ }
(
)
(
)
{
}
(
)
Pr 1st packet successfully received in the th round Pr 1st packet successfully received in the th round
1 1 max 1 2 max 1 max 1 1 max 2 1 3 1 1 . ∞ = ∞ = ∞ − = − = ≤ ≤ + − + − + = − =
∑
∑
∑
k k k ms ms ms ms ms k ms ms k ms E d t k t k k t p p p p p t kp p t p (2.7)We note that the considered user will be moved to the ACTIVE group when the first packet is successfully received. In the worst-case, d will incur when all the M users are in the ACTIVE 2 group. Therefore, the CC will assign users to access the channel in a round-robin way, and the average time slots elapsed per service round is thus
0
M
[ ]
(
)
(
)
(
)
2 2 0 0 0 1 1 0 1 0 2 1 3 1 1 . ∞ − = − ⎛ ⎞⎟ ⎛ ⎞⎟ ⎛ ⎞⎟ ⎜ ⎟ ⎜ ⎟ ⎜ ⎟ ≤⎜⎜⎜ ⎟⎟ + ⎜⎜⎜ ⎟⎟ − + ⎜⎜⎜ ⎟⎟ − + ⎝ ⎠ ⎝ ⎠ ⎝ ⎠ = − =∑
ms ms ms ms ms k ms ms k ms M M M E d p p p p p n n n M kp p n M p n (2.8)Combining (2.7) and (2.8), we obtain
[
max]
[ ]
1[ ]
2 1 1 max 0 1 1 max 0 . − − − − = + ≤ + ≤ + < ∞ ms ms E d E d E d M t p p n M t n δ δ (2.9) Note that for those protocols with more than n users allowed to access the channel 0simultaneously, deadlock may occur if Cn0+i,0 =1 for i≥1. With the benefit from the fixed n 0
accesses, MGPQ is more robust in such a channel environment.
2.4 Optimal Waiting Period Selection
In the proposed protocol, the number of users permitted for channel access is fixed to be n , 0
namely, the one attaining the MPR channel capacity. A natural criterion for determining the waiting period S is to maximize the probability that each of the selected n users has a packet to send. 0
We first note the probability of the user i (selected from PREM) with a packet to transmit after waiting a period of S is at least [14]
(
)
: 1= − −1 S
i i
p p , i∈{1,2, ,M , (2.10) }
waiting period S , the more likely the users in the PREM group have packets to send. As a result, S should be kept as large as possible. However, the unlimited increase in S may incur severe delay penalty. Particularly if S → ∞, the transition from STANDBY to PREM is prevented and the proposed trigroup priority queuing protocol degenerates into a bigroup scheme. To determine an S for striking a balance between large p and small delay, we propose to seek the optimal i S opt
with which the following set of constraints on the mean delay per user is satisfied: ( ) ≤
i r
D S D , 1 ≤ ≤i M , (2.11)
where D S stands for the mean delay of the user i and i( ) D is a uniform delay requirement. r
To find the desired S from (2.11), one crucial step is to determine an explicit expression of ( )
i
D S in terms of S . Toward this end, we shall determine all the possible transitions of states (an exact definition of a “state” will be specified later) in the proposed protocol. This can be solved by applying Markov chain analysis shown below.
2.4.1 Markov Chain
Associated with the user i ( 1 ≤ ≤i M ), we define x t , i( ) y t , and i( ) z t to be the i( )
assumed value of the waiting slots, the indication of the flag, and the number of packets in the buffer at the t th time slot, respectively. Hence we have x ti( )∈{1,2, ,S , } y ti( )∈{ }0,1 , and
( )∈{0,1,2}
i
z t . (The waiting period
0
⎡ ⎤ ⎢ ⎥ ≥ ⎢ ⎥⎢M⎥
S
n and the buffer of size two are assumed hereafter if
not specified otherwise.) Let us further collect x t , i( ) y t , and i( ) z t for all users to form i( ) ( )=
(
1( ), 2( ), , M ( ))
X t x t x t x t , Y t( )=
(
y t y t1( ), 2( ), ,yM( )t)
, and( )=
(
1( ), 2( ), , M ( ))
Z t z t z t z t . The proposed protocol can be modeled by a Markov chain with
( ) ( ) ( ( ) ( ) ( ))
{
,}
: , , 1
Ω = E t E t = X t Y t Z t t ≥ . (2.12)
We note that the number of states is at most ( ⋅ ⋅2 3)M
S . However, since in each time slot, exact
0
n users can simultaneously access the channel, it follows that (i) the number of “1” in X t ( )
must be equal to n ; (ii) no more than 0 n entries in 0 X t will assume the same value. Taking ( )
the above constraints into account and using the permutation and combination theory, the number of distinct outcomes of X t is (see Appendix C for proof) ( )
(
)
( )(
)
(
)
( ) 0 0 0 0 0 0 0 ! 1 ! ! ! ! ! ! = = − − = ⋅ ⋅ −∑
∏
∏
i i n n C m m i i i M n S M N n M n m i , (2.13)where the integers m ’s are found as the solutions to the following equations: i
0 0 0 0 0 1 = = ⎧⎪⎪ ⋅ = − ⎪⎪⎪ ⎨⎪ ⎪ = − ⎪⎪ ⎪⎩
∑
∑
n i i n i i i m M n m S . (2.14)With (2.13) and the constraint that there must be packet(s) in the buffer for the users in the ACTIVE group (i.e.,
(
y zi, i)
≠(1, 0)), the total number of possible states in the system can be reduced to5
= ⋅ M
S C
N N . (2.15)
If there exists some p = 0 or 1, the total number of states will be further reduced. i
2.4.2 State Transition Probability
We proceed to compute the state transition probabilities as follows. Assuming that the events of packet generation among users are independent, we have
( )
(
)
( ) ( ){
}
(
) (
) (
)
Pr 1 1 , , , , , = + = = =∏
M x i y i z i i E t X Y Z E t X Y Z P x P y P z (2.16) where X −X =(
x1, x2, , xM)
, Y −X =(
y1, y2, , yM)
, and(
1, 2, ,)
− = MZ Z z z z ; Px
(
xi)
, Py(
yi)
, and Pz(
zi)
are the probabilities of the increment of state components given (X Y Z (see Appendix D for details). Based on the state , , ) transition probabilities (2.16), we can immediately construct the transition matrix TNS×NS , with which the steady-state probability π , 1 ≤ ≤j j N can be readily obtained by S1 2 1 2 1 2 lim →∞ ⎡ ⎤ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ = ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎣ ⎦ S S S N N t t N π π π π π π π π π T . (2.17)
In this dissertation, we assume that the above limit exists, and the assumption is justified by numerical results. The mean delay D S can be then determined as follows. i( )
2.4.3 Computation of Mean Delay
According to Little’s law [11], we have
( ) ( ) ( ) = i i i N S D S S λ , (2.18)
where N S is the average number of packets in the buffer of the user i , and ( )i( ) λi S is the
packet departure rate (i.e., throughput) of the user i . Let z be the number of buffered packets of i j,
( ) , 1 = =
∑
S N i j i j j N S πz . (2.19)Also, denoted by pB i, ( )S the packet blocking probability of user i , therefore
( )
(
)
, ' , ' , ' ' 1 ' , 2, 1 ' , 2, 1 ≤ ≤ = ∉ ≤ ≤ = ∈ =∑
+∑
− S i j S i j B i j j S j N z i A j N z i A p S π π P , (2.20)where access set A and success probability P are defined in Appendix D. Then it follows that S
( )=
(
1− , ( ))
i S pi pB i S
λ . (2.21)
Substituting (2.19) and (2.21) into (2.18), we can obtain a functional relation of D S in terms of i( ) S . The solution to (2.11) can then be computed via numerical search.
2.4.4 Homogeneous Case
In the homogeneous environment, that is, the packet generating probabilities of all users are identical; it can be shown that the mean delay in (2.18) is independent of waiting period S (the detailed proof is referred to Appendix E). An intuitive explanation of this phenomenon is that, when subject to the same packet generating probability, all users tend to share the same service priority, and hence experience the same average service delay irrespective of the choice of S .
2.4.5 Extension to Finite Buffer Case
Although the previous derivation is obtained under the assumption that each user has a buffer of size two, it can be easily extended to the case with finite buffer size B by allowing
( )∈{0,1,2, , }
i
z t B . The N in (2.15) must also be increased to S (2 +1) M C
N B accordingly.
This case will be simulated and compared with other MPR MACs in the next section.
In this section, simulations are carried out by Matlab and we first compare the results with the theoretical analysis for a simple scenario to validate the derivation in Section 2.4. In this dissertation, throughput is defined as the average of successful packet transmissions per slot; delay is defined as the average elapsed time slots for a packet to be successfully received by CC; PLR is defined as the average ratio of the number of blocked packets to the number of generated packets. Then in the heterogeneous case, the individual delay curves with increasing S are plotted to show the effect of S on system performance. In the homogeneous case, throughput, delay, and PLR of MGPQ are further compared with those of DQ. Finally, the throughput performance with more users and finite buffer size of MGPQ, PMP [6], and DQ [28] are compared to verify their scalability.
2.5.1 Validation of Analytical Results
This simulation aims at validating the analytical performance results in Section 2.4. The test system is a CDMA network with random spreading; the packet length, spreading gain, number of correctable errors in a packet, and noise variance are, respectively, 200, 6, 2, and 10 dB as adopted in [28]. The capacity of such an MPR channel in this scenario is 1.7925, which is attained by
0 =2
n concurrent transmissions in each time slot. The total number of users is set to be M =3. We note that the incurred overhead due to the insertion of a flag-bit is 1/201 < 0.005, which is rather small and is thus neglected in the performance evaluation. Figures 2.2 and 2.3, respectively, show the mean throughput and mean delay curves for the two scenarios: (i) the heterogeneous case with packet generating probabilities
[
p p p1, ,2 3]
=[0.1, 0.1, 0.9], and (ii) the homogeneous case with an equal packet generating probability p1 =p2 =p3 =0.5. As we can see from the figures, inboth cases the theoretical results well predict the corresponding simulated outcomes. It can also be seen that, in the homogeneous environment, the mean throughput and mean delays remain unchanged as the waiting period increases: this confirms the assertion in Section 2.4.4. For the heterogeneous case, we impose the mean delay requirement of each user to be less than 4 time slots;
Fig. 2.2 Mean throughput performance of the proposed MGPQ.
Fig. 2.4 Delay performance of individual users.
by using the results in Section 2.4.3, the optimal waiting period is computed to be Sopt =7. Fig. 2.4 depicts the mean delay of each user. It can be seen that the delays of all the three users are indeed kept below 4 when S =Sopt =7. We also note from Fig. 2.4 that users with large (or small, respectively) packet generating probabilities p experience less (or more) delay. This is not i unexpected since, if p is large, the flag-bit will be on with a high probability and the user will be i
allowed for accessing the channel more frequently.
2.5.2 Comparison with Previous Work [28]
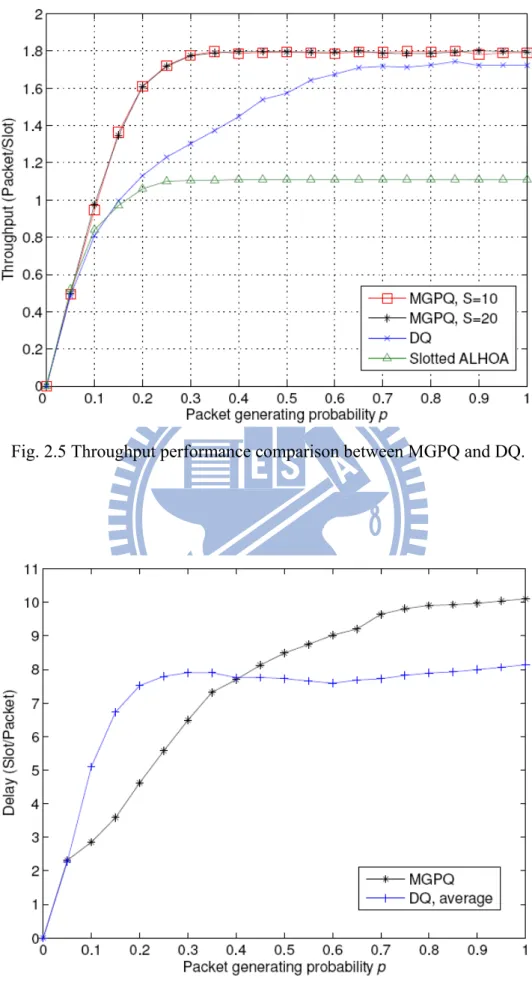
This simulation further compares the proposed MGPQ scheme with the DQ protocol [28]. We will consider the homogeneous case since the DQ protocol is exclusively tailored for this scenario. The respective throughput curves, including the slotted ALOHA with optimal retransmission probability [28], are plotted in Fig. 2.5. As we can see, the proposed solution can outperform the
Fig. 2.5 Throughput performance comparison between MGPQ and DQ.
Fig. 2.7 Packet loss ratio performance comparison between MGPQ and DQ.
DQ protocol over a wide range of the packet generating probabilities. The maximal achievable throughput improvement is about 40% for p = 0.25. Also, the proposed approach almost achieves the channel capacity 1.7925 whenever p≥0.3, whereas the DQ protocol can attain at most 96% of the capacity for p ≥0.8. Fig. 2.6 shows the delay performances (measured via time slots per packet) of the two schemes. As shown, the proposed method yields a smaller mean delay with light traffic (p ≤0.4). This is because the MGPQ method tends to reserve the channel access for those who are more likely to have packets to send, thus avoiding the time latency incurred by the procedure of network-wide active user prediction. In a heavy-traffic environment, the DQ protocol will block the incoming packets, thereby reduce the mean delay. However, this comes at the expense of a larger PLR, as evidenced in Fig. 2.7.
2.5.3 General Case
Fig. 2.8 Throughput comparison between MGPQ, PMP, and DQ for different buffer size.
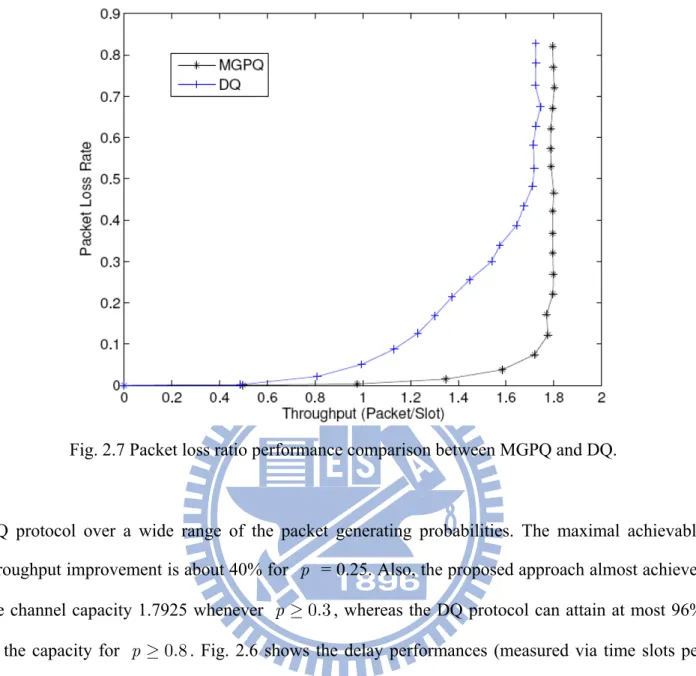
performance with the DQ [28] and PMP [6] methods (the latter is specifically devised for the case with finite buffer size).We consider the system setup as in [6] which is described in terms of the MPR matrix as 0 1 0 0 1 1 0 0 1 0 0 0 ⎡ ⎤ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ = ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎣ ⎦ C , (2.22)
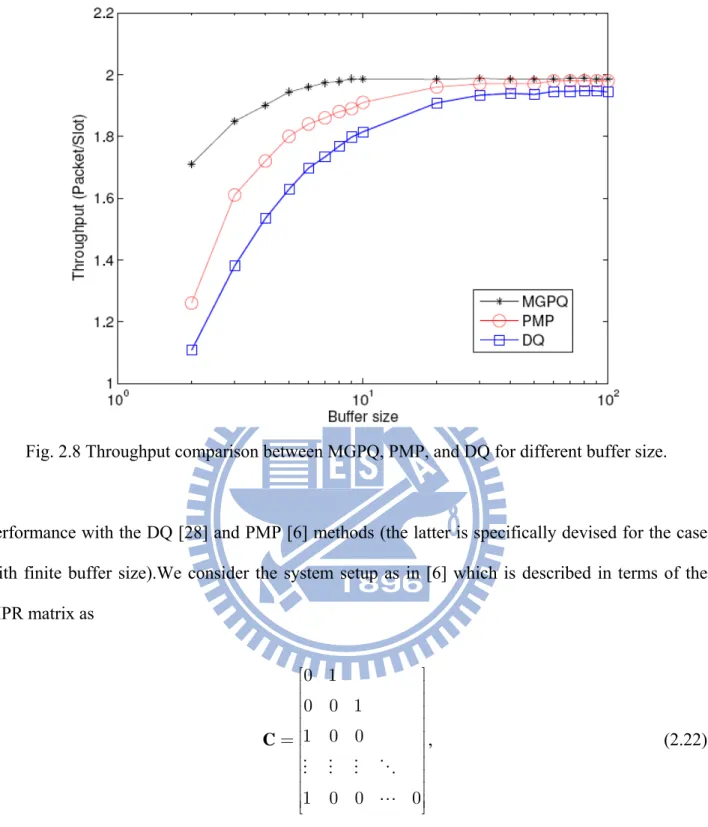
thus with n0 =2, η =2, and set the total traffic load to be the same with channel capacity. Fig. 2.8 shows the throughput curves of the three methods as the buffer size increases from 2 to 100. It is seen that the DQ scheme results in the lowest throughput, mainly due to the packet blocking constraint. The proposed MGPQ protocol outperforms the PMP solution, thanks to the benefits from the priority mechanism which can reduce the blocking rate especially when the buffer size is
Fig. 2.9 Throughput comparison between MGPQ, PMP, and DQ for different number of users.
small. Fig. 2.9 further depicts the respective throughput performance as the number of user increases from 2 to 100. The result shows that the DQ protocol degrades the performance severely when there are more than two users. This is mainly because in the DQ protocol all users, no matter with packet or not, will be served continually until their packets are received successfully or empty slot occurs. With more than n users in the system, the probability of serving idle users is 0
definitely increased.
2.6 Summary
In this chapter, we proposed a new approach to design the MAC protocol for wireless networks with MPR capability. The proposed approach relies on the flag-bit-assisted knowledge about the presence of buffered packets as well as a multi-priority user grouping strategy. The advantages of the proposed method are three folds: 1) it is applicable to both the heterogeneous and homogeneous environments, whereas almost all existing protocols developed for the MPR channel are exclusively
tailored for the latter case; 2) the insertion of a single bit facilitates the acquisition of network traffic condition with minimal bandwidth expansion; 3) the adopted user grouping policy avoids computationally intensive search for the active users as required in the existing protocols. To prevent an infinitely long service delay in the heterogeneous environment, the waiting period of those yet-to-be-served users can be determined subject to a specified delay requirement. Simulation results show that, compared with the DQ protocol, the proposed scheme achieves higher throughput, reduces the mean delay penalty in light traffic condition, and yields a smaller PLR. Also, the proposed MGPQ protocol outperforms the PMP protocol for the general case with finite buffer size. Next chapter will focus on generalizing the result in this chapter to the more realistic generalized MPR channel model [1].
Chapter 3
Multipacket Reception MAC Design in Heterogeneous
Channels
3.1 Overview
Cooperative MAC protocol design aimed for MPR channels is typically subject to the following challenges. Firstly, the CC may require the knowledge of the MPR channels of all links, as well as the traffic conditions of all users, to determine the access set. However, this will call for extra communication overheads, and will degrade the system-wide throughput, especially in a large-scale mobile network. Secondly, when packet reception failure occurs due to collisions, a certain portion of the users may have to serve as the relay for data retransmission. Without properly designed MAC protocols for cooperative user scheduling, there would be a large throughput penalty incurred by the latent of packet relaying phase. To the farthest of our knowledge, cooperative MAC protocol designs for MPR channels have not been found in the literature yet.
MGPQ scheme proposed in Chapter 2 has several distinctive features that make it a potential candidate for cooperative MPR MAC protocol designs. Firstly, in the MGPQ scheme the users are allowed to access the channel according to some prescribed service priority. There is no need for active user selection through exhaustive search over the channel knowledge and local traffic conditions. This will thus considerably reduce the communication overheads in dense cooperative networks. Secondly, the flag-bit can provide the CC with the knowledge of each user’s buffer status. Combined with the multi-group service priority, the channel access can then be reserved for both direct data transmission and packet relaying in a more balanced fashion. Hence, in a high collision environment, the throughput penalty incurred by the relay phase can be largely reduced. To realize the aforesaid advantages, in this chapter we subsequently extend the MGPQ scheme and propose a
cooperative MAC protocol for MPR channels.
3.2 Preliminary
3.2.1 System Scenario
We consider the uplink transmission of a centralized cooperative wireless network, in which the CC and the user terminals are equipped with the MPR capability. We assume that the transmission is slotted, and the CC controls the user’s access to a common wireless channel. At the beginning of each time slot the CC determines an access set according to some user scheduling rule to be specified later, and broadcasts this message to initialize data transmission. Due to the broadcast nature of the wireless medium, the CC and all the inactive users can receive the transmitted packets at the end of the data transmission phase. Depending on whether or not the packet of a particular user is successfully received at the CC, an associated ACK or NAK is sent by the CC over the wireless channel and will be received by all users. When the packet reception failure occurs, one of the inactive users who successfully decode the packet may serve as the relay during some future channel access period.
3.2.2 MPR Matrix
This section reviews the MPR channel model matrix [28] which specifies the MPR capability at the receiver. Assume that the total number of users is M. Let U be a permutation of the index set
{
1, 2, ,M}
that represents a particular order of the user service schedule. Then the MPR matrixassociated with U is described as
( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) 1,0 1,1 2,0 2,1 2,2 ,0 ,1 ,2 , M M M M M C U C U C U C U C U U C U C U C U C U ⎡ ⎤ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎣ ⎦ C , (3.1)
where Cn k,
( )
U =Pr{k packets are correctly received | n packets from first n users in U aretransmitted} for 1 n≤ ≤M and 0 k≤ ≤ . We note that, according to the setting (3.1), different n permutation index sets U in general result in different MPR matrices. Let
( )
,( )
1 n n n k k C U kC U =∑
(3.2)be the expected number of correctly received packets when n packets are concurrently transmitted. The capacity of an MPR channel for the particular service sequence U is defined as
( )
( )
1, , max n n M U C U η = . (3.3)Note that the numbers of simultaneously transmitted packets for achieving the channel capacity may not be unique. Let
( )
{
( )
}
0 min arg maxn 1, ,M n
n U C U
= (3.4)
be the minimum amount of capacity-achieving packets. Hence the maximal number of users permitted to access the channel should be n U0
( )
, since there will be no further improvement insystem capacity if more than n U0
( )
users are simultaneously served. Note that the MPR matrix(3.1) can be determined via the PHY layer performance metric such as bit error rate; an illustrative example based on CDMA communication can be found in [28].
3.2.3 Highlight of the MGP Protocol [24]
The proposed cooperative MPR MAC scheme is based on the MGP method [24], which is highlighted below. As in [28] it is assumed that each user has a buffer of size two for storing two
Fig. 3.1 Packet formats.
data packets. The central idea behind the MGP scheme is to append a flag-bit at the tail of the transmitted packet to inform the CC about the next buffer status (see Fig. 3.1 for a schematic description). The flag will be set ON if there is a packet in the next buffer, and is set OFF when otherwise. By exploiting such an on-off flag signature, the MGP scheme classifies the users into three groups with different service priorities: the ACTIVE group consisting of the users with flag-bit ON, the STANDBY group consisting of those with flag-bit OFF, and the PREM group accommodating those who have stayed in the STANDBY or the ACTIVE group for longer than a certain waiting period S . The inclusion of the complementary PREM group is to avoid unfair service scheduling that can occur in a binary grouping strategy: Without the PREM mechanism, users in the STANDBY group would suffer an unlimited service delay since the channels could be constantly reserved for some ACTIVE links with heavy traffic. Based on the tri-group user classification scheme, the channel access priority (from high to low, respectively) is PREM, ACTIVE, and STANDBY. According to such a service strategy, at the beginning of each time slot a total number of n U0
( )
users (for some U ) are selected for data transmission, where n U0( )
isthe minimal number of users that achieves the capacity of the MPR channel. In case that the CC successfully receives the packet sent from, say, user i, the service priority of this user is determined by the decoded flag information from the current packet. If, instead, packet reception failure occurs,
Data
Buffer 2 Buffer 1
the CC schedules the service priority of user i according to the previous flag record. We shall note the followings:
a) In the MGP scheme the number of users permitted for channel access is deterministically set to attain the MPR channel capacity. This prevents the channel from being overloaded, thereby avoiding irrecoverable packet reception failure due to collisions.
b) Under light traffic environments, a significant portion of the users could be in the idle phase (i.e., no data packets to send). If packet reception failure occurs, the idle periods can then be exploited for packet relaying to reduce the possible throughput loss. This can be effectively accomplished via a natural extension of the MGP protocol, as discussed next.
3.3 Cooperative Multi-Group Priority Protocol
The flag-bit is the instrumental mechanism for facilitating the multi-group priority based user service in the MGP protocol. The central idea of the proposed CMGP scheme is to exploit the flag-bit message for distinguishing the direct links from the relay ones. By assigning different service priority to different types of links, the throughput degradation due to the packet relaying overheads can be limited, and an increase in the network-wide throughput can be achieved.
3.3.1 Operation of the Proposed CMGP Protocol
If user i is permitted to access the channel, as in the MGP scheme a flag-bit b is appended at i the tail of the packet upon transmission. The flag signature is ON (b = ) only if the second buffer i 1 is non-empty and contains a data packet also of user i. The flag signature is instead OFF (b = ) i 0 when either one of the following cases is true: i) the second buffer is empty, ii) the second buffer is nonempty but the packet therein is received from some other user j
( )
≠i . Upon successful packetreception, the CC decodes the flag-bit message and then schedules the user access according to the MGP protocol. If packet reception failure occurs at the CC and user k, who is not in the access set