具可信度的語意資訊服務網架構:認證理論 vs. 社會網路
(第 3 年)
研究成果報告(完整版)
計 畫 類 別 : 個別型
計 畫 編 號 : NSC 95-2221-E-004-010-MY3
執 行 期 間 : 97 年 08 月 01 日至 98 年 12 月 31 日
執 行 單 位 : 國立政治大學資訊科學系
計 畫 主 持 人 : 胡毓忠
計畫參與人員: 碩士班研究生-兼任助理人員:郭弘毅
碩士班研究生-兼任助理人員:吳建輝
碩士班研究生-兼任助理人員:林光德
碩士班研究生-兼任助理人員:黃宏傑
報 告 附 件 : 出席國際會議研究心得報告及發表論文
處 理 方 式 : 本計畫可公開查詢
中 華 民 國 99 年 02 月 24 日
行政院國家科學委員會補助專題研究計畫成果報告
具有可信度的語意資訊服務網架構:認證理論 vs. 社會網路
Trusted Semantic Web Services Infrastructure:
Certification Theory vs. Social Network
計畫類別:■ 個別型計畫 □ 整合型計畫
計畫編號:NSC 95-2221-E-004-010-MY3
執行期間:2006 年 08 月 01 日至 2009 年 12 月 31 日
計畫主持人:胡毓忠
計畫參與人員:余承遠、宋昆銘、張易修、雷嘉慶、吳政修、黃宏傑、
林光德、郭弘毅、吳建輝
成果報告類型(依經費核定清單規定繳交):□精簡報告 ■完整報告
本成果報告包括以下應繳交之附件:
□赴國外出差或研習心得報告一份
□赴大陸地區出差或研習心得報告一份
■出席國際學術會議心得報告及發表之論文各一份
□國際合作研究計畫國外研究報告書一份
處理方式:除產學合作研究計畫、提升產業技術及人才培育研究計畫、
列管計畫及下列情形者外,得立即公開查詢
■涉及專利或其他智慧財產權,□一年■二年後可公開查詢
執行單位:國立政治大學資訊科學系
中 華 民 國 99 年 02 月 02 日
關鍵字:資訊服務網運算、資訊服務網架構、語意資訊服務網、可信度、憑證理論、
社會網路
資訊服務網運算(Services Oriented Computing)及資訊服務網架構(Services Oriented
Architecture)在最近幾年廣為國際知名的資訊業界所積極的推動。研究語意網的學界也順
應這個風潮試圖要將語意網的核心技術如資料分類的本體論與程序本體論來和原生性的資
訊服務網的架構相結合並試圖找出其附加價值。目前初步的研究目的是以能夠達成一個自
動化完成資訊服務網的運算流程為主。雖然他們對於這些一般功能性(Functional)的資訊
服務網的操作機制及其加值方式已經有不少的研究成果,但是對於如可信度非功能性
(Non-Functional)的一些準則規範和執行方式研究則不多見。如此一來語意資訊服務網將
因為缺少安全可信度檢驗的服務功能讓系統的完整性和可用性受到很大挑戰。
本 3 年期的研究案試圖要在現有的歐美兩大流派的語意資訊服務網的架構:SWSF 及 WSMF
以共有服務的方式讓可信度的管理規範準則可以被彈性的選擇和加入以加強一般性語意資
訊服務流程的服務品質。我們的可信度管理的共有服務機制將利用上述語意資訊服務網的
語言,本體論架構與平台來加以標示及處理,因此我們將此可信度服務程序以一般性語意
資訊服務網的完整建構程序來加以描述、搜尋、比對、搓合、協商及整合,如此一來我們
所提出的可信度模組和未來主流語意資訊服務網架構的結合將沒有問題。我們將同時從憑
證理論及社會網路兩方面考量可信度該如何被引入到上述的語意資訊服務網的架構。我們
將找出有哪些可信度的概念及適用時機可以利用安全式規範來處理,而又有哪些是必須要
用社會人際網路的方式來加以達成。並同時找出兩者對於可信度規範的差異性、互斥性、
及互補性為何? 最後為了確認我們所提出可信度準則規範在語意資訊服務網架構的適用
性,我們將同時應用此項技術於兩種網路資訊傳播平台:部落格資訊服務網與政府公共資
訊公開服務網。我們也將在實際的全球資訊網的系統之上實作出上述的各項研究議題。
Key Words: Services Oriented Computing (SOC), Services Oriented
Architecture (SOA), Semantic Web Services, Trust,
Certification Theory, Social Network
For the past few years, both services oriented computing (SOC) and services
oriented architecture (SOA) were proposed and promoted eagerly by several
well-known information technology companies. People from academic research
areas were also trying to apply the core technologies of semantic web’s
data ontology and process ontology to the generic web services architecture
and find out what are the value-added incentives. At this moment, the
primary achievement of this study is to realize the concepts for automatic
semantic web service processes. Even there already have several significant
results for functional semantic web service overlay operations mechanisms.
But the non-functional service criteria, such as trust and secure issues
for semantic web services are not so significant. Thus we might face a
big challenge for people to accept our semantic web services for the lack
of trust and secure system integrity.
Based on two major semantic web service frameworks, i.e., SWSF and WSMF,
the objective of this 3 years period research project is to construct the
trust management system as common services and that will be flexibly added
on to enhance the QoS for the web service processes. Our trust management
common services will be defined and specified as semantic web service
processes using the language and ontology from these two frameworks so
that there will be no incompatible problem. The trusted common web services’
description, requesting, matching, negotiation, and composition
mechanisms are similar to ordinary web services. We are considering the
trust management of web services from both certification theory and social
network. Furthermore, we are going to explore the possibility of
introducing these technologies into SWSF or WSMF frameworks. We will
clarify which trust management criteria are feasible from certification
theory and which criteria are from social network. Incidentally, we will
confirm the differences, disparities, and complements between these two
trust management concepts. Finally we are going to apply our trust
management concepts to two usecase application domains: blog information
web services and information dissemination web services for public domain.
All of our research proposal issues will be implemented on the WWW.
以全球資訊網(WWW)為主的資訊網服務(web services)因為 Web 網路的方便性以及具有高度
彈性的 XML 旗標語法的大量使用,使得資訊網服務在開放式的網路環境也可以非常的容易
被表示、登錄、查詢和執行。雖然實務界的資訊網服務的推動已經有一段時間,但是學界
還是希望能夠運用過去所發展的一些語意網的理論和技術來提昇業界原生性資訊網服務的
能量。因此語意資訊網服務(semantic web services)的構想因而應運而生。但是語意資訊
網服務的研究範圍和面向非常的廣泛,不是我們一般小型研究團隊所能完全解決的。我們
希望能夠鎖定語意資訊網的一個特定議題,也就是可信度(trust)的問題來解決如何建置一
個具有高可信度的語意資訊網服務環境和架構。
基本上可信度語意式資訊網服務不論是透過認證理論或社會網路來檢驗和比較,整個研究
的重心將會是如何設計語意式可信度表達規範來檢驗其相關設定的準則,因此我們整個研
究的重點將會是如何來運用本體論與規則(Ontologies+Rules)兩大知識系統整合的學理基
礎來表示與執行可信度的規範和準則的檢驗。本研究的重心將會是找出最適合的本體論與
規則的結合來表示與落實規範與準則的表示與執行,並將此技術應用到語意式資訊網服務
最重要的兩大議題:數位著作權保護與隱私權保護的規範設計與執行,主要是因為這兩大
議題尤其是隱私權保護規範的設計和落實將導引語意資訊服務網是否可以被大眾所接受。
本計畫成果報告書在於說明國科會計畫 NSC 95-2221-E-004-010-MY3 執行三年研究的具
體成果,我們將對於建立具有可信度語意資訊服務網的架構的研究核心進展有所說明。其
中以本體論加規則為本研究的核心理論基礎。因此我們探索了現有 Ontologies+Rules 的
最新發展趨勢如 SWRL, AL-log, DL-log, DL+log等,並且選中幾個模式適合在我們研究
特定應用領域:著作權管理與隱私權保護資訊兩大系統來進行可信的語意示表達與執行。
基本上這項核心理論的發展是 W3C 在語意網研究上最為重要的一環,我們具體的掌握了這
項技術的發展趨勢並且將其應用到著作權管理與隱私權保護兩大重要領域之上。
二、
研究目的
我們希望能夠以三年的時間來完成一個可信度語意資訊服務網環境建置的目標。為了要解
決可信度資訊網服務的目的我們將同時選擇兩種方式來加以分析和處理即:憑證理論和社
會網路。不論是上述的任何一種處理方式我們都希望能夠以語意網的本體論語言和規則語
言來表示,因此我們要找出哪些可信度的條件可以用本體論語言來表示,又有哪些條件可
以用規則語言來表示。我們希望以分年度的方式來進行這兩項可信度準則建立與檢驗,並
希望在研究的過程中找出它們之間的優越點並且找出是否可能同時來融合上述兩項技術的
可能性。對於可信度的準則建立,我們將挑選適當的資訊網服務的應用範例如著作權管理
系統或隱私權保護的資訊網服務來展示我們所提出方法的可行性和優越性。
services)並且同時從 Web 2.0 的社會網路及 Web 3.0 語意網來研究其可信度建立方法
上的差異。我們在第一年是以 Web 2.0社會網路分析(Social Network Analysis, SNA)的
方法來論述其產生的程序。而在第二年則是以 Web 3.0 語意網來建置具有可信度的資訊揭
露和使用的方法。我們初步鎖定的研究目標是兩個重要的領域:數位著作權管理(Digital
Rights Management, DRM)與隱私權保護(Privacy Protection)。我們希望能夠找出具有語
意執行能力的數位著作權管理資訊系統與隱私權保護的資訊系統,並且能夠將這兩種資訊
使用、控管與揭露的資訊系統來和語意資訊服務網的架構來相結合,以達成一個具有可信
度語意資訊網服務的數位內容使用平台與個人資訊與隱私保護的系統使用環境。
一、
文獻探討
語意網(Semantic Web)的可信度和語意資訊服務網(Semantic Web Services)的可信度在概
念上是有所不同的。因為語意網強調的是網路上資訊產生和傳播擴散的自動化處理及語
意判斷而語意資訊服務網則是強調以語意網的核心技術來加值資訊服務的完整程序讓
自動化處理完整複合服務程序的目的可以達成。
可信語意網:原生性的可信語意網的研究主要是用來檢驗流通在語意網之上的訊息
內涵是否值得信任[5],我們同時也可以利用篩選(Filter)機制在網路上找出符合每種
可信度門檻的宣告訊息[9]。有很多的研究成果是以社會網路的方式來檢驗在語意
網上其傳播資訊的可信程度,因此語意網核心知識如本體論語言和規則語言在此所
扮演的角色將是提供資訊整合,可信度準則收集和檢驗的功能,他們並沒有具體的
以完整的本體論和策略規則兩種知識表達機制來表示可信度概念和所需遵循的條
件[22][23][26]。至於其它以規範語言來規範安全式可信度檢驗的系統如 KAoS, Rei,
Ponder 等,雖然有在可信度規則上著力但是他們對於可信度所要規範的目標還是
以代理者程式的安全及授權檢驗為主,因為未必有充分反應語意網資訊內涵的可信
度檢驗和判斷[31][32],同樣的情況也發生在以語意網規則為資源控管機制的研究
結果上[33]。
可信語意資訊服務網:至於可信度語意資訊服務網(Trusted Semantic Web Services)
的研究在現階段則更為欠缺,目前在兩大語意服務網的架構:
(美國)SWSF 及(歐
盟)WSMF,他們通常是把可信度或安全當作是一個非功能性(Non-Functional)的單
一檢驗準則,但是並未詳細說明這些準則的產生方法和具體的檢驗規範和確認機制
[1][7]。
我們的研究目標是不論語意網上資訊傳播的可信度規範管理或是語意資訊服務網上的
完整服務流程可信度的規範和確認都利用一個共有語意資訊服務網的服務機制讓需要
的資訊(或服務)的要求者及資訊(服務)的提供者可以彈性的來加以選擇和使用以達
成他們所期望的可信度條件。
經過這三年的研究我們首先從社會網路建立可信度的方式來進行,主要是因為以 Web 2.0
為主的社會網路(social web)研究在最近幾年為大家所樂於討論的主題。我們在這項國科
會的支助完成位碩士班學生的論文和口試其學生姓名和題目分別為:
余承遠 建構以語意社會網路為主的部落格入口網站,碩士論文(2007)
楊鈞筑 在對等式網路上建構創用 CC 之著作權控管系統,碩士論文(2007)
陳進棋 在網路上建構以 SWRL 為主的數位版權管理規範及應用,碩士論文(2007)
宋昆銘 在社會網路上透過 Tag-Thesaurus 模型達到有效的資源彙整,碩士論文(2008)
張易修 在點對點網路上以 BT 為基礎的數位媒體語意式搜尋系統,碩士論文(2008)
李家輝 企業間顧客隱私權的保護,碩士論文(2008)
雷嘉慶 網路論壇資訊的語意擷取,碩士論文(2008)
黃宏傑 建構具有語意隱私偏好保護平台,碩士論文(2009)
林光德 逼近合理使用的數位著作權管理規範語意執行,碩士論文(2009)
郭弘毅 使用本體論與規則來執行企業隱私保護規範,碩士論文(預計 2010 年 7 月畢業)
吳建輝 個人隱私揭露意願之推論行(預計 2010 年 7 月畢業)
其中余承遠同學的碩士論文經過修改之後經發表於到每兩年舉辦的第三屆 Communities
and Technologies (C&T) 2007 之下的一個 workshop: Between Ontologies and
Folksonomies (BOF), 網址:
https://ebusiness.tc.msu.edu/cct2007/page4b.html
,
論文題目為:Bridging Different Generation of Web via Exploiting Semantic Social
Web Blog Portal 本論文(詳見附錄一)已於 2007 年 6 月 27 日發表於研討會的舉辦地美
國密西根州立大學。我們另外也投稿另一篇有關於著作權管理規則的論文到第六屆國際語
意網知名的研討會 International Semantic Web Conference (ISWC) 2007,今年(2007)
11 月將於韓國的釜山同時和亞洲的第二屆 Asia Semantic Web Conference (ASWC)一起來
舉辦,研討會的網址:
http://iswc2007.semanticweb.org/
。論文發表的題目為(詳見附
件二)
:Semantic-Driven Enforcement of Rights Delegation Policy via Combining Rules
and Ontologies。另外一項研究成果則是和中央研究院的許聞廉教授一起推動台灣國內的
semantic computing 的研究,並且於 2008 年 6 月 12 日在台中舉辦一場小型的 IEEE
International Workshop on Ambient Semantic Computing (ASC2008), 我們也發表了一
篇論文(詳見附件三):Semantic Enforcement of Privacy Protection Policies via the
Combination of Ontologies and Rules。基於 2007 在韓國釜山 ISWC+ASWC 2007 的研討會,
我們結識了服務於加拿大 NRC-CNRC 的 Dr. Harold Boley 並且成為 2008 和 2009 兩屆 RuleML
國際研討會的主辦成員。我們也在 RuleML2009 研討會成為 Rule Challenges track 的主持
工作的 Co-Chair,並且同時發表另外一篇論文(詳見附件四):Challenges for Rule Systems
on the Web。計畫主持人也因為這項合作關係於 2009/02/01-2009/06/01 到 Dr. Harold
Boley 服務的加拿大國科會 NRC-CNRC 實驗室進行一項 4 個月短期的學術訪問和合作的研究
98-2918-I-004-003)才得以完成。
另外我們也因為社會網路分析(social network analysis)的研究和本校法律系的陳起行老
師進行資訊與與法律的跨領域研究,這個研究的主題是在一個資訊與社會(info-society)
的一個子議題來進行。目前積極的希望能夠透過國科會國合處來和歐盟執行 FP7 計畫的相
關單位來進行跨國合作,我們將以 eParticipation 之下的 Argumentation Theory for
Policy Formation 為研究的重點,未來則是希望能夠將此研究成果應用到數位著作權管理
及隱私權保護等相關資訊與法律議題。目前主要的合作對象是服務於德國 FOKUS Institute
for Open Communication Systems 的 Dr. Thomas F. Gordon。
三、
研究方法
我們的研究方法先從現有的語意網核心技術的發展來進入,我們瞭解到本體論語言如 OWL
和規則語言如 RuleML 在知識表達上的差異點,實際上這個議題一直是語意網 layer cake
的研究討論的重點。因為我們所需要建立可信度原則(policy)的表達和執行必須要藉助於
上述兩項本體論語言與規則語言的整合能力。現有的研究發現本體論語言以 description
logic 理論基礎的表示對於一般屬於集合論的關係建立和查詢有其優越性,而且 OWL 本體
論語言也因為是在開放式空間如 WWW 的查詢因此沒有規則語言的 CWA and Negation As
Failure (NAF)的特性,但是本體論語言在具體資料數學運算上有其限制。規則語言則對於
特性(predicate)從一個個體轉移到另一個個體上有其優越性,但是對於規則語言中其
predicate 的使用也是相當的嚴格。為了運算的可決定性(decidability)和降低複雜度等
因素必須規定 predicate 只能有單一或雙變數的限制,我們也不允許具有負面(negative or
falsity) 的 predicate 的存在以避免要進行 non-monotonic 的推論。另外規則語言因為在
過去專家系統的發展上有其較悠久歷史的經驗,因此在推論引擎上比較成熟。但是過去專
家系統的原理和架構卻不能直接轉換到以開放式空間資訊交換為主的 Web 環境之上,尤其
是以 Web 具有獨特性的 URI 定址方式,在原有專家系統的運作上有很大的發展空間。同樣
的以 description logic (DL)理論基礎為主的 OWL 本體論語言也已經從 OWL 1 演進到最新
在 W3C 通過的標準規範 OWL 2,其表達能力已經有很大的提升,而其 OWL 2 的語言本身也
分成三個子分項(profiles): OWL 2 EL, OWL 2 QL, and OWL 2 RL.
在語意網的階層架構(Layer Cake)之上可信度層(Trust Layer)的位階最高,透過底
層本體論語言和規則語言所表示的規範(Policy)可以利用 Logic Framework 的推論及檢
驗機制來完成。因此我們提出了一個具有規範互通格式的架構平台(如圖一之所示)
。
這個語意式規範互通的架構平台是以原有的語意網階層架構圖為藍本,並且在原有的整
合式邏輯(Unifying Logic)可驗證(Proof)之上加入了一個具有兩個模組即 Policy
Interchange Format (PIF), meta-PIF 的語意式規範交換層。如此一來不同的規範語言所表
示的可信度規範可以透過 PIF 和 meta-PIF 來達成規範互通和整合的目的。而 PIF 本身
圖一:具有可信度規範準則檢驗的語意式規範互通架構平台
也可以直接用來表示我們所需要檢驗的可信度規範。主要是因為我們的規範互通語言 PIF
和控管規範的 meta-PIF 本身是直接以本體論語言如 OWL 和規則語言如 RIF 來加以設計並且
選擇在不同的應用領域之上來建構出其可信度規範所需要的本體論和規則。
我們在第一年因為是從社會網路所建立可信度的環境來切入,因此我們花了很多的時間在
社會網路分析(social network analysis)的瞭解和探索,並且從中瞭解到社會網路和語意
網相結合的必要性和方向。因為我們知道社會網路分析的結果可以提供語意網查詢上提供
具有高人氣指數指標。而語意網的旗標語法可以讓我們在社會網路的分析上更加有效和快
速。這是我們在發展語意網部落格(semantic blog)入口網站時所發現的事實。至於以軟性
的社會網路分析所建立的可信度準則和檢驗將和傳統式以安全憑證等機制建立的黑白分明
的可信度檢驗有很大的不同。
本研究計畫案所用的方法是使用現有語意網正在發展的最核心技術,也就是本體論
(Ontologies)和規則(Rules)的結合(ontologies+rules)來表示上述的數位版權管理與隱
私權保護的概念與控管規範(Access Control Policies)
。從過去 SWRL (Semantic Web Rule
Language)來表示 ontologies+rules 的結合,可是這項結合方式除非所有的控管規則
(Rules)是遵守 DL-Safe 的條件否則有可能產生控管規範檢驗時不可決定性(Undecidable)
的不好結果。因此我們全面的探索所有已經被提出 ontologies+rules 的結合方式如
如 DL-Safeness 滿足則可以獲得可決定性(Decidable)的計算結果。我們都知
道上述的 Ontologies 和 Rules 是現有語意網知識表達的兩大主軸,Ontologies 是來自
於 Description Logic (DL)的理論基礎,而 Rules 則是來自於 Logic Program (DL) 的
理論基礎,雖然這兩種知識的表達上有部分交集之處,但是整體而言他們在背景假設條件
上的假設還是有幾項是不同的如 Ontologies 是以 Open World Assumption (OWA)以及非
Unique Name Assumption 來 建 立 背 景 的 預 設 值 , 而 Rules 則 是 以 Closed World
Assumption 以及 Unique Name Assumption 來建立其背景預設值。因此要完全無接縫
(Seamless)的方式似乎有其困難度,因此我們選擇的則是用 Hybrid Integration的方法來
進行ontologies+rules的結合。
而這也是現有最新 W3C Semantic Web well-known layer cake 所採取RDF(S), OWL 和 RIF
並排結合方式的趨勢是一樣的。因此我們對於 ontologies+rules 的選擇大致上說來和現
有語意網最新的發展趨勢是相吻合的。 除此之外為了要能夠實現語意表達與執行現有著作
權管理系統與隱私權保護系統的目的,我們參考了現有相關以 XML-based 為基礎的一些標
準規範如 ODRL, XrML(這兩者是 DRM 規範),EPAL(企業平台隱私權保護規範)
,XACML(同
時應用到 DRM 與 Privacy Protection 保護),並且將上述 ontologies+rules 語意表達
與執行的機制以 overlaid 的方式建置在這些 XML-based 的標準規範之上來加以確認其
語意在表達契約合同(License Agreement),控管規範(Access Control Policies)的可行
性。基本上來說我們是以現有的這些 Rights Expression Languages (RELs)如 ODRL, XrML,
EPAL, XACML 當作基石來在其上建置一個具有語意表達與執行能力的 Semantic RELs 並且
將這個 Semantic RELs 用來表示上述的 DRM 與 Privacy Protection 的電子化契約與控
管規範,以達到機器這些電子化契約與控管規範的目的。當然我們已深入和其它現有已經
被提出的Semantic DRM and Semantic Privacy Protection 來加以深入的比較並且提出我
們的優勢之處。
四、
計畫成果自評
第一年的研究因為 Web 2.0 網路的風行,我們原來要先進行安全式可信度準則建置的目
標將移到第二年來進行,因此我們第一年是也社會網路可信度的建立為主要發展的方
向。也就是我們希望利用社會網路的分析方式來達成社會網路服務(social network
services)的可信度建立。我們初步是以社群網站如 blog 為主要的平台,並從中找到可
信度可以發揮的空間。至於 Web 2.0 的主要研究議題如 tagging system, mash-up 其可
信度的建立也是我們研究的重點。我們在上述的眾多 Web 2.0 社會網路環境中找出其可
信度準則建立的元素和必要性。在社會網路中的資訊網服務(web services)將不會是只
有單純的查詢服務而它將會是一個完整的組合式服務,否則就無法將我們的可信度準則
標示於其上。傳統式的資訊網服務主要是在交易式(transaction)導向的私有商業服
非常多樣化。因為在網路社群中如何反應並且找出大眾化的意見,來引導後來的使用者
可以瞭解到大眾化意見的變化趨勢並且讓他們可以快速且有效的找到所需要的資訊將
會是一個重要的議題。而在這些眾人意見的形成步驟中我們也不希望被有心人士所誤
導,因此可信度準則的建立將會同時包含有口碑建立出來推薦系統的正確性和公平性等
特質。另外為了確保個人的隱私權,我們往往是以匿名的方式來進行個人資訊的表達,
因此在人脈社會網路上的建立和發現將會面臨更大的挑戰。這些議題我們透過這個計畫
讓他們可以一一的獲得具體的釐清和解決。
雖然透過本計畫陸陸續續有研究的成果,包含有碩士學生的畢業論文,國際研討會的論文
發表、和政大法學院、社會科學院等跨領域合作,及和國際歐盟的跨國合作。但是離我們
原先要建立完整的具可信度語意資訊服務網的目標還有一段距離。主要是因為語意資訊網
服務的技術涵蓋面非常的廣泛,我們在不重覆國外已經達成的研究議題的目標下,必須要
找出自己非常獨特的研究方向,所以在整體的進展上並不是非常的快速。另外對於可信度
的研究我們雖然過去幾年來也已經有不錯的研究成果,但是研究的面向主要還是以安全式
憑證理論(certification theory)為基礎的代理者可信度研究。對於具可信度的組合式資
訊網服務方面有加強和改進的空間。對於社會網路分析之下的資訊網服務,目前還是停留
在單純的搜尋和排序的典型資訊導引服務,我們希望可以在完整的組合式社會網路資訊服
務上有所新發現來加強 Web 2.0 的新服務架構運作。我們也希望以語意為主的著作權管理
系統可以加入語意資訊網服務的元素讓數位內容的使用和傳播更可以更符合原有數位內容
擁有者的期待及公平使用(fair use)的原則(目前這一項議題已完成初步論文並且在進行
修訂和期刊投稿之中)
,而彈性授權與資訊流通的目標也希望可以一併加以實現。最後對於
電子化政府(electronic government or digital government)的公領域資訊網服務和現有
私領域的資訊網服務的整合也是未來需要解決的重點,如何讓公領域的電子化政府和私領
域的商業資訊網服務可以在語法上和語意上達成互通的目的並且提供一個完整且具有高可
信度的語意資訊網服務平台將會是我們往後要努力的重點。這一部份的研究議題我們希望
在新一期的國科會計畫案可以持續的來進行,其主要的方向是利用現有以 RDF(S)為基礎的
Linked Open Data (LOD)來達成開放式政府(Open Government)資訊公開的研究議題我們希
望能夠應用這個計畫案所使用的 ontologies+rules 的結合理論基礎來實踐新申請計畫
案:提供資料共享與保護的語意規範於雲端環境中的研究目標。
1.
Battle, Steve, et al., Semantic Web Services Framework (SWSF) Overview, 2005,
http://www.daml.org/services/swsf/1.0/
.
2.
Berners-Lee, James Hendler, and Ora Lassila, The Semantic Web, Scientific American,
May 2001.
3.
Burstein, M. et al., A Semantic Web Services Architecture, IEEE Internet Computing,
Sep.-Oct., 2005.
4.
Carroll, J., et al., The Semantic Web Trust Layer, Developers Day, WWW 2004, New
York, 2004.
5.
Carroll, J. Jeremy, et al., Named Graphs, Provenance and Trust, WWW 2005, 2005.
6.
Creative Commons (CC),
http://creativecommons.org/
7.
Fensel D. and C. Bussler, The Web Service Modeling Framework (WSMF), 2005,
http://www.wsmo.org/
.
8.
Gavriloaie, R. et al., No Registration Needed: How to Use Declarative Policies and
Negotiation to Access Sensitive Resources on the Semantic Web, ESWS 2004, 2004.
9.
Golbeck, J. and B. Parsia, Trust Network-Based Filtering of Aggregated Claims,
International Journal of Metadata, Semantics and Ontologies (IJMSO), 2005.
10. Grandison, T. and M. Solman, A Survey of Trust in Internet Applications, IEEE
Communications Surveys, Fourth Quarter, 2000.
11. Grosof, N. B., et al., Description Logic Program: Combining Logic Programs with
Description Logic. WWW 2003, May 20-24, 2003, Budapest, Hungary.
12. Gruninger, M and C. Menzel, The Process Specification Language (PSL) Theory and
Applications, AI Magazine, Fall 2003.
13. Horrocks, I., et al., SWRL: A Semantic Web Rule Language Combining OWL and
RuleML, Apr., 2004,
http://www.daml.org/2003/11/swrl/
14. Hu, Y. J., Combining Ontology and Rules as Service Constraint Policy for P2P Systems.
Web Service Semantics
:Towards Dynamic Business Integration Workshop at
WWW2005
(position statements)
, 2005.
15. Hu, Y. J. and C. W. Tang, Agent-Oriented Public Key Infrastructure for Multi-Agent
E-Service. Seventh International Conference on Knowledge-Based Intelligent
Information & Engineering Systems
(KES'2003)
, University of Oxford, UK
16. 胡毓忠,如何在對等式資訊系統下合法且公平的共享及使用數位內容:科技創新和
版權保護的均衡點,
資訊時代之公共領域與資訊取得研究先導計畫學術研究研討
會,
中研院法律研究所,2005 年 10 月 14 日
17. Hu, Y. J., Trusted Agent-Mediated E-Commerce Transaction Services via Digitial
Certificates Management. Electronic Commerce Research Journal
(ECR Journal)
Vol. 3,
Issues 3-4, July-October, 2003, pp. 221-243.
18. Hu, Y. J., Some Thoughts on Agent Trust and Delegation. The Fifth International
Conference on Autonomous Agents
(AA'01)
, May 28-June 1, 2001, Montreal, Canada.
19. Kagal, L., et al., A Policy Based Approach to Security for the Semantic Web, ISWC 2003,
http://www.ninebynine.org/SWAD-E/Security-formats.html
21. Malone, W. T. et al. Editors, Organizing Business Knowledge: The MIT Process
Handbook, The MIT Press, 2003.
22. Nejdl, W., et al., Ontology-Based Policy Specification and Management, ESWC 2005,
2005.
23. O’Hara, K. et al., Trust Strategies for the Semantic Web, ISWC 2004, 2004.
24. Papazoglou, M., Service-Oriented Computing: Concepts, Characteristics and Directions,
WISE’03, 2003.
25. Payne, T. and Ora Lassila, Semantic Web Services, IEEE Intelligent Systems, 2004.
26. Richardson, M., et al., Trust Management for the Semantic Web, ISWC 2003, 2003.
27. Ruohomaa, S. and L. Kutvonen, Trust Management Survey, iTrust 2005, LNCS3477,
2005.
28. Sabater, J. and C. Sierra, Review on Computational Trust and Reputation Models,
Artificial Intelligence Review, 2005.
29. Sycara, K. et al., Automated Discovery, Interaction and Composition of Semantic Web
Services, Journal of Web Semantics,. Volume 1, Issue 1, December 2003.
30. Thompson, R. M., et al., Certificate-Based Authorization Policy in a PKI Environment,
ACM Transactions on Information and System Security, Vol. 6, No. 4, Nov. 2003.
31. Tonti. G., et al., Semantic Web Languages for Policy Representation and Reasoning: A
Comparison of KAoS, Rei, and Ponder, ISWC 2003, 2003.
32. Uszok, A. et al., Applying KAoS Services to Ensure Policy Compliance for Semantic
Web Services Workflow Composition and Enactment, ISWC 2004, 2004.
33. Weitzner, J. D., et al., Creating a Policy-Aware Web: Discretionary, Rule-based Access
for the World Wide Web, Web and Information Security, Idea Group, 2006.
34. S. N. Dorogovstsev and J. F. F. Mendes, Evolution of Networks: From Biological Nets to
the Internet and WWW, Oxford 2003.
35. Web Services Trust Language (WS-Trust), Feb. 2005,
http://specs.xmlsoap.org/ws/2005/02/trust/WS-Trust.pdf
.
36. The Semantic E-Business Vision, Comm. Of ACM, Vol. 48, No. 12, Dec. 2005.
[碩士學生畢業論文部分]
余承遠 建構以語意社會網路為主的部落格入口網站,碩士論文(2007)
楊鈞筑 在對等式網路上建構創用 CC 之著作權控管系統,碩士論文(2007)
陳進棋 在網路上建構以 SWRL 為主的數位版權管理規範及應用,碩士論文(2007)
宋昆銘 在社會網路上透過 Tag-Thesaurus 模型達到有效的資源彙整,碩士論文(2008)
張易修 在點對點網路上以 BT 為基礎的數位媒體語意式搜尋系統,碩士論文(2008)
李家輝 企業間顧客隱私權的保護,碩士論文(2008)
雷嘉慶 網路論壇資訊的語意擷取,碩士論文(2008)
黃宏傑 建構具有語意隱私偏好保護平臺,碩士論文(2009)
林光德 逼近合理使用的數位著作權管理規範語意執行,碩士論文(2009)
郭弘毅 使用本體論與規則來執行企業隱私保護規範,碩士論文(預計 2010 年 7 月)
吳建輝 個人隱私揭露意願之推論行(預計 2010 年 7 月)
[研究論文發表部分]
[Hu10]Hu, Y. J., G. D. Lin, H. Y. Guo, “Semantics-enabled Policies for a Fair Use
Decision (In revision for publishing).
[Hu09]Hu, Y. J., C. L. Yeh, and W. Laun, "Challenges for Rule Systems on the
Web", The International RuleML Symposium on Rule Interchange and
Applications (RuleML 2009), Las Vegas, Neveda, USA, Nov. 5-7, 2009,
Springer-Verlag,
LNCS 5858
.
[Hu08]Hu, Y. J., Hong-Yi Guo, and Guang-De Lin, "Semantic Enforcement of Privacy
Protection Policies via the Combination of Ontologies and Rules", IEEE
International Workshop on Ambient Semantic Computing (ASC2008)
In
conjunction with
IEEE International Conference on Sensor Networks,
Ubiquitous, and Trustworthy Computing (SUTC2008), Taichung, Taiwan, June 12,
2008
[Hu07a]Hu, Y. J.,"Semantic-Driven Enforcement of Rights Delegation Policies via
the Combination of Rules and Ontologies", Workshop on Privacy Enforcement
and Accountability with Semantics
,
ISWC+ASWC 2007, Busan Korea,
2007,
CEUR-WS Vol-320 Proceedings
.
[Hu07b]Hu, Y. J. and Yu, Cheng-Yuan, "Bridging Different Generation of Web via
Exploiting Semantic Social Web Blog Portal",
Between Ontologies and
Folksonomies (
BOF
) workshop at
Communities & Technologies
(C&T)
2007,
Michigan State University, USA,
CEUR-WS Vol-312 Proceedings
.
[Hu05]胡毓忠,如何在對等式資訊系統下合法且公平的共享及使用數位內容:科技創新和
著作權保護的均衡點,
資訊時代之公共領域與資訊取得研究先導計畫學術研究研討
會,
中研院法律研究所,2005 年 10 月 14 日.
透過本計畫的執行和國際研討會論文發表的經費補助,主持人分別在 2007 年參與了兩次的
國際研討會論文發表地點和論文發表的題目如下:
Hu, Y. J. and Yu, C. Y., “Bridging Different Generation of Web via Exploiting
Semantic Social Web Blog Portal", Between Ontologies and Folksonomies (BOF)
Workshop at Communities & Technologies (C&T) 2007, Michigan State University,
CEUR-WS Vol-312.
Hu, Y. J., “Semantic-Driven Enforcement of Rights Delegation Policies via the
Combination of Rules and Ontologies", Workshop on Privacy Enforcement and
Accountability with Semantics, ISWC+ASWC 2007, Busan, Korea, 2007, CEUR-WS,
Vol-320.
基本上來說這兩個研討會差異性很大。C&T 2007 的研討會參與者主要是社會門的研究學
者,其研究的理論主要是以統計學和社會學為導向來研究在 2007 年竄紅的 Web 2.0 社會網
路如 Facebook, MySpace 等的研究。雖然部分的參與者是電腦與資訊科技為導向的研究人
員,但是整體來說研討會的主導者還是社會學門的國際大老。
至於 ISWC+ASWC 2007 則是語意網的第一線研討會,這是首次亞洲的 ASWC 語意網研討會和
國際的 ISWC 語意網研討會合辦,主辦者刻意的在歐洲的 ESWC 之外,在亞洲成立一個語意
網的研討會,後續的 ASWC 2008 和 ASWC 2009 則分別選在泰國曼谷和中國上海獨立的來舉
辦第二屆和第三屆的 ASWC 研討會。在 ISWC+ASWC 2007 研討會因為論文的發表也認識了不
少知名的研究語意網的國際學者,因此收穫良多。
在 2008 年主持人除了在 TAAI 的 AI Forum 介紹了語意網的最新發展趨勢之外,也和中研院
的許聞廉教授共同舉辦了一個小型的 semantic computing workshop,並且發表論文如下:
Hu, Y. J., H. Y. Guo, and G. D. Lin, “Semantic Enforcement of Privacy Protection
Polocies via the Combination of Ontologies and Rules," IEEE International
Workshop on Ambient Semantic Computing (ASC2008), Taichung, Taiwan, June 12,
2008..
腦運算的領域都希望可以涵蓋進來,因此和現有的 semantic web 以 W3C Tim Berners-Lee
所要推動的研究議題有很大的落差。因此主持人也沒有參與後續的合作事宜。
在 2008 和 2009 主持人同時參與了 RuleML 2008, 2009 國際研討會的主辦工作,主要是因
為這個研討會的主旨和本計畫的研究核心有很大的重疊之處。因此也花費了很多的心力和
RuleML 的其他國家的學者有所互動,這些學者主要是要推動標準規則語言(RIF),並且希
望這個 RIF 標準規範語言可以為 W3C 所接受並且可以完美的和本體論語言 OWL 相結合。我
們 也 在 RuleML 2009 主 辦 了 Rule Challenges 並 且 將 參 賽 者 的 論 文 整 理 成 為 CEUR
Proceedings, 從中瞭解到如何進行一個完整國際研討會的主辦事物如 CFP 的發送,論文的
收集和分配給審稿人,意見和評分的彙整,及最後的論文發表的議程進行等。主持人也在
RuleML 2009 主研討會發表論文如下:
Hu, Y. J., C. L. Yeh, and W. Laun, “Challenges for Rule Systems on the Web",
The International RuleML Symposium on Rule Interchange and Applications
(RuleML 2009), Las Vegas, Neveda, USA, Nov. 5-7, 2009, Springer-Verlag, LNCS
5858.
Exploiting Semantic Social Web Blog Portal", Between Ontologies and Folksonomies
(BOF) Workshop at Communities & Technologies (C&T) 2007, Michigan State University,
CEUR-WS Vol-312.
via Exploiting Semantic Social Web Blog
Portal
Yuh-Jong Hu and Cheng-Yuan Yu
Emerging Network Technology (ENT) Lab. Dept. of Computer Science
National Chengchi University, Taipei, Taiwan, 11605, (hu, g9302)@cs.nccu.edu.tw Summary. The goal of this research is to analyze one of the Web 2.0 platforms, e.g., weblog (or blog) and to justify whether it is possible to bridge Web 2.0 ↔ Web 3.0 (or the semantic web) via exploiting semantic social web blog portal. Compared with semantic annotation system using web mining techniques to extract keywords from the WWW, our semantic social web annotation system is based on ontologies derived from folksonomy tagging system to truly reflect the intentions of people on the classification of resources. The blogsphere will be our first experimental example to validate the ontology+folksonomy mashup model. We hope this idea can be applied to the other Web 2.0 platforms, such as wiki, web services. We have built a semantic social web blog portal from the Taiwan’s biggest blog service provider (BSP). From this semantic social web blog portal, users are allowed to execute a variety of online semantic social web queries that can not be achieved from other Web 2.0 blog search engines, such as Blogpulse or Technorati. The incentives of having semantic social web annotation for blogsphere were justified and this might shed some light on bridging Web 2.0 ↔ Web 3.0.
1 Introduction
The principles on how to identify one application as “Web 1.0” and another as “Web 2.0” were previously clarified by Tim O’Reilly [21]. The Web x.0 in-dicates how the x.0 Web generation platform copes with their contents writer and reader’s experiences. The bridging of Web generation is defined as the contents created in previous generation of Web can be extracted or accessed in next generation (or vice versa). The bridging of Web 1.0 ↔ Web 2.0 is an ongoing process while the bridging of Web 2.0 ↔ Web 3.0 is not well under-stood yet. To bridge different Web generation does not necessarily mean the old generation Web will be completely phased out. On the contrary, different Web generation still might be happily live together. Ever since the New York Times reporter John Markoff coined the semantic web as Web 3.0 [16], we were curious whether there existed a feasible bridging mechanism for Web 2.0
The folksonomy of tagging system for blogs is an example to enable so-cial web services in the Web 2.0. On the other hand, ontologies with their machine understandable metadata aim at achieving Web 3.0 vision. If we can (semi-)automatically mash up the ontology data and query model with the folksonomy tagging system services, then we are in a very good shape toward this paradigm shift. Eventually, this might realize Tim Berners-Lee’s seman-tic web vision for an extension of the current web (Web 1.0 or 2.0) in which information is given well-defined meaning and better enabling computers and people to work in cooperation [2].
In Web 2.0, people interact with each other and address their opinions vol-untarily. The challenge of this social web services depends on whether we can collect these huge amount of unstructured public opinions and discover the patterns among them. For the past few years, research issues for the develop-ment of annotation system on bridging Web 1.0 ↔ Web 3.0 were intensively investigated. People were trying to figure it out whether it is possibly to bridge existing Web 1.0 with the future semantic web (or Web 3.0) [7][8][14]. Unfor-tunately, the progress of this study seems to be very slow because it is a grand challenge to have (semi)-automatic semantic annotation system to cre-ate ontology-based semantic annotations from huge amount of unstructured WWW contents.
The social web annotation of bridging Web 2.0 ↔ Web 3.0 seems to provide another window to deal with this problem. In social web annotation system, people use free tags (or vocabularies) to address their opinions or prefer-ences on the Internet resources, such as bookmarks, videos, blogs, and web pages, without relying on controlled vocabularies. This resolves a hard design problem for the construction of agreeable monolithic heavyweight ontologies. Because it is more explicit and direct on the categorization of resources via free tags from folksonomy than keywords mining from the Web’s contents [4]. Tagging systems are still not well studied and have the research potential for further improvement [17]. Are there any other incentives to use free tags social web annotation rather than to use conventional keywords-based annotation? This will be the issue we are interested to investigate further.
Ontologies are top-down approach with hierarchical classification of infor-mation sharing and manipulation mechanism while folksonomy is a bottom-up approach using flat indexing to organize and search information through user feedback. When we regard users’ free tags as social web annotations, we still might need ontologies to classify these free tags into different taxonomy. Fur-thermore, ontologies can provide well-defined structure schema to bind entity semantic association together and that was impossible to be realized by the tagging system alone. These entity relationship semantics might exist among tagger, tags, and resources declared implicitly by entity themselves. We pro-pose a blog ontology and a topic ontology to harbor all of these free tags to describe the semantics of entity relationships in the blogspace. We allow users to explicitly enable semantic social web query for tags with their entity semantic relationships to get what they are really interested.
In order to exploit the incentives of bridging different Web generation, we have built a semantic social web blog portal from the biggest blog service provider (BSP) WRETCH in Taiwan1. We have implemented blog crawlers to
collect all of necessary context and content information from this BSP. Three kinds of information sources were collected for this study: semi-structured HTML blog pages, structured XML-based RSS, and users’ annotation free tags. The content and context information from these sources were extracted, analyzed, and stored to satisfy user’s later semantic query services. Further-more, we also analyzed the blog information diffusion flow using social network analysis (SNA) to examine the possible patterns in the WRTECH BSP [24]. Therefore users are allowed to enable semantic social web query services using a variety of SNA measures in our semantic social web blog portal.
2 Related Work
Several important elements are required to exploit the bridging problem of Web 2.0 ↔ Web 3.0 to have semantic social web search services. They are annotation, ontology, blog, folksonomy, and SNA. Unfortunately, most of the related studies shown as the followings did not have these comprehensive considerations so they can not have the service capabilities as ours:
• Semantic annotation for ontology+web: The semantic annotation (or
bridging) of Web 1.0 ↔ Web 3.0 were extensively investigated before to support the indexing and retrieval of well-defined semantic information for agents [14][19][22]. The goals of these studies were too ambitious to have any significant progress.
• Semantic tag for ontology+folksonomy: Gruber proposed the mashup of
ontology and folksonomy to enable social web ecology on the Internet [10]. The tagOntology was a very primitive study for identifying and formalizing a conceptualization of the activity of tagging.
• Semantic blog for ontology+blog: Semantic blog systems were built to
leverage the power of ontology data model so that people can extract all of the implicit semantics from blogs [3][5][13]. But they did not really work for lacking enough amount of real dataset to experiment the system’s feasibility.
• Tagging blog for tags+blog: Brooks et al. analyzed the top 350 tags from
the Technorati blog search engine and they demonstrated that tags are useful for grouping articles into broad categories but less effective in indi-cating the particular content of an article [4]. This study did not aim at solving the bridging problem of Web 2.0 ↔ Web 3.0 either.
• Semantic Web (or Web) as social network: In a semantic social network,
a number of electronic information sources including web pages, emails,
FOAF profiles, are extracted and analyzed to acquire their semantic rela-tionships [9][19]. The purposes of these studies were to apply SNA tech-niques to analyze the ontology-based context information for the semantic web research community.
• Blog as social network: Gruhl et al. studied the dynamics of
informa-tion propagainforma-tion through blogspace [11]. Furthermore, the blogspace can be shown as community using SNA model to express its entity social rela-tionships through links, comments, and trackbacks, etc [1][6][15]. But they only addressed pure blog ecosystems.
3 Research Goal
The goal of this research is to construct a semantic social web portal and to exploit the incentives of bridging Web 2.0 ↔ Web 3.0. The incentives will be justified when we can search information through this semantic social web portal compared with other systems that only provide simple tags (or keywords) search on Web 2.0 or ontology query on Web 3.0. Unless we can extend tags to have corresponding semantic context, the expressive power of tags is limited. In this study, we found that coherent taxonomies of blog articles can emerge from users tagging so relevant customized ontologies can be constructed.
3.1 Social Network Analysis
Social network analysis (SNA) is the quantity study of the relationships be-tween individuals or organization. By quantifying social network structures, we can determine where are the most important nodes in the network [24]. The implications of SNA usage are quite different when we apply SNA to different generation of Web.
• SNA for Web 1.0: The information on Web 1.0 is rather static so people
only apply SNA on paper citation network or person relationship network to discover their stable relationships [18].
• SNA for Web 2.0: The nature of information flow on Web 2.0 is dynamic
and user oriented. All of the tags, resources, and tagger’s profiles on Web 2.0 are dynamically created so the challenge to apply SNA for this platform is how can we timely extract the relationships between taggers with an-notated tags and their respective resources to enable effective information search [12].
• SNA for Web 3.0: We are aiming at bridging of Web 2.0 ↔ Web 3.0. The
issues we consider including Web 2.0, Web 3.0, and SNA, are different from pure semantic social network approach shown in [19].
3.2 Blogs as Social Network
Applying SNA model to the blogsphere has revealed interesting findings about how individuals share information and interact socially online. Social relation-ships can be expressed online as different forms of blogs ties: blogroll links, citation links, and comment links [1]. We observed the WRETCH blog com-munities in terms of important SNA measures, such as indegree/outdegree, closeness/betweenness, and k-cores, to interpret their social implications. The basic idea is that blog article written by important blogger also becomes im-portant itself so we can reinforce the semantic search service capabilities for users to satisfy their interested from this perspective idea.
• Indegree and Outdegree: The higher indegree measure indicates the higher
spread of blogger (or article) influence in the blogsphere. The indegree measures of the top 300 bloggers in the WRETCH BSP were shown as power law distribution. Contrarily, outdegree measure did not indicate any importance of a blogger in the community and its pattern did not appear as power law distribution either.
• Closeness and Betweenness: The higher closeness (or betweenness) of a
blogger means it is in the social network center (or pivoting bridge) so the spread of influences of this blogger is significant in the community. We found that closeness (or betweenness) is similar to indegree but it incurs high computation overhead so we avoid computing this measure in our online information access.
• K-Cores: A k-core is a maximal subgroup in which each blogger (or
ar-ticle) has at least degree k within the subgroup. Thus k-cores measure is effectively to demonstrate a particular subgroup cohesive relationship. The common interests of a community derived from k-cores are important for topic-specific semantic social web query services to discover similar resources from this high cohesion level subgroup.
3.3 Semantic Social Web Query Services
We provide different level of semantic query services in our semantic social web portal: basic semantic query services, advanced semantic query services, and semantic social web query services:
• Basic semantic query services: The initial contribution of this article is to
combine the tagging system’s folksonomy with ontology to achieve basic semantic query services. This service provides people or agents to effec-tively access clustering of blog information through tags and related tags.
• Advanced semantic query services via ontology+tags: In this service, user
enables conceptual semantic query services with relevant tags. The con-ceptual semantics can be defined as a channel declared from ontology with relevant tags in the tags cloud. In other words, the search space for this
service is classified and focused so the search time is reduced and accuracy is also improved.
• Semantic social web query services via SNA+ontology+tags: In a blog
ontology, we define properties to describe the relationships between blog-gers, tags, and articles. Additionally, the important SNA measurement attributes are also declared in a blog ontology. Therefore, we can leverage the power of SNA measures from dynamically generated relations through blogger’s daily activity events to enhance this service. We propose two possible scenarios for this service that could justify our hypothesis2:
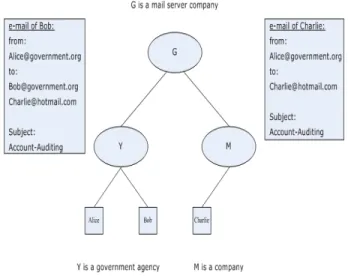
1. Scenario One: I would like to search authors and their blog articles with “cuisine” tag paired with “restaurant” keyword in the associated title or content of the article collected from the entire blog community. Furthermore, please present these authors’ names and their associated titles of article in a decreasing order of authors’ indegree measures:
prefix blog: <http://blog.nccucs.org/blog.owl#>
prefix rdf: <http://www.w3.org/19999/02/22-rdf-syntax-ns#>
SELECT DISTINCT ?Author ?Article WHERE
{?Article rdf:type blog:Article
?Article blog:has_articleTag blog:cuisine ?Article blog:has_author ?Person
?Person blog:person_ID ?Author
?Person blog:person_indegree ?Popularity FILTER {regex(?TitleOfArticle, "restaurant") || regex(?ContentOfArticle, "restaurant"))}
}
ORDER BY DESC (?Popularity)
2. Scenario Two: I would like to search blogger names and their articles from the cuisine channel for those of whom are known by authors pre-sented in scenario one. Furthermore, please present these blogger names and their associated titles of article in a decreasing order of authors’ indegree measures:
prefix blog: <http://blog.nccucs.org/blog.owl#>
prefix rdf: <http://www.w3.org/19999/02/22-rdf-syntax-ns#>
SELECT DISTINCT ?Author ?Friend ?TitleOfFriendArticle WHERE
{...
Codes Same As Scenario One ...
?Person blog:has_knows ?friend ?friend blog:person_ID ?Friend
2 The embedded codes are shown as SPARQL query language but users do not
require to have knowledge of SPARQL syntax in order to execute semantic social web query services.
?FriendArticle blog:has_author ?friend
?FriendArticle blog:has_channel blog:CuisineChannel ?FriendArticle blog:article_title ?TitleOfFriendArticle
?FriendArticle blog:article_description ?ContentOfFriendArticle FILTER {regex(?TitleOfFriendArticle, "restaurant") ||
regex(?ContentOfFriendArticle, "restaurant"))} }
ORDER BY DESC (?Popularity)
Compared with Technorati3, it only provides limited independent search
services for user from his input blog posts, tags or directory where user can not have semantic (social web) query services for any possible relevant outputs using his previous search results. So user can not search the most influential blogger friend’s articles or he can not search high similarity articles from those bloggers with certain higher level of SNA indegree measures.
4 Semantic Social Web Blog Portal
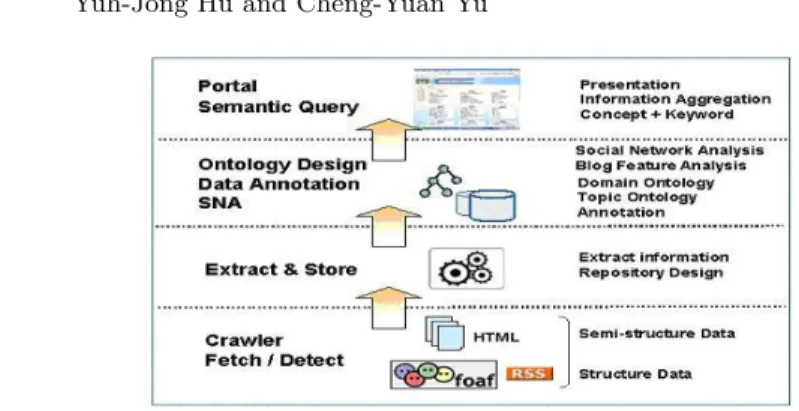
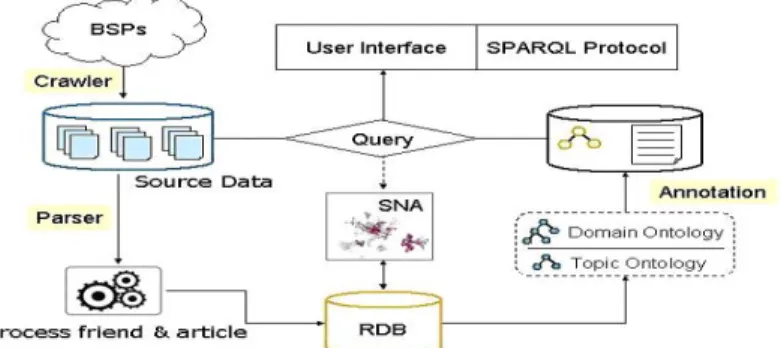
In this research, a semantic social web blog portal was constructed to exploit the incentives of bridging Web 2.0 ↔ Web 3.0 where users could enjoy semantic social web query services on this portal. This portal structure is a layer schema shown as Fig. 1. In the bottom layer, crawler collects semi-structured HTML blog pages, structured RSS or FOAF context information, and free tags. Both RSS 1.0 and FOAF ontology schema are based on RDF(S) so their semantics are explicitly specified. Then, we extract and store the crawler’s collected information in our local repository. In the ontology and tags annotation layer, we mash up the blog ontology and the topic ontology with collected free tags from social web annotation by folksonomy. The blog information diffusion patterns will be analyzed by using SNA software Pajek to derive important SNA measures, such as indegree, outdegree, closeness, betweenness, and k-cores, etc[20]. Finally, we provide semantic social web query services for users to satisfy his best interested.
4.1 Data Collection
WRETCH is the biggest BSP platform in Taiwan with more than 2 million
registered bloggers so huge amount of living and recreation information were available for our experiment on the research issues of bridging of Web 2.0
↔ Web 3.0. After filtering out insignificant noise data, the number of useful
bloggers information samples in our analysis is around 108,518 bloggers. The period of time for our data collection was one month spanned from Sep. 09 2006 to Oct. 09 2006.
Fig. 1. A layer conceptual schema for construction a semantic social web blog portal
4.2 Data Analysis
In our mashup model, the free tags collected from users are usually 2-word or 3-word Chinese words (or characters) to annotate their daily real life’s living activities. The scan and parsing processes of Chinese characters are different from the English free tags. There are no spaces between Chinese characters so we use regular expression to extract the meaningful high frequency 2-word or 3-word tags as our folksonomy final consensus social web annotations. With no surprise, the distribution for the top 300 tags is shown as power law that is similar to lots of other studies [12].
Initially the tags addressed by blogger in the WRETCH only imply that the taxonomy of blog articles can be classified as one of 16 broad channel cat-egories, such as living, cuisine, music, drama, travel, etc. When we carefully examined the tags, we surprisingly found that those of significant 54,824 blog-gers (approximate to 50% of 108518 blogblog-gers) with their addressed 1046 tags were converging to some of high frequent 521 2-word and 197 3-word tags. And these tags were evenly distributed to our 16 broad channel categories. This demonstrates that the social consensus opinions are possibly formulated in terms of folksonomy tagging. We are expecting a more powerful folksonomy annotation scheme can be realized in a near future as long as we have more versatile ontology+tag structure.
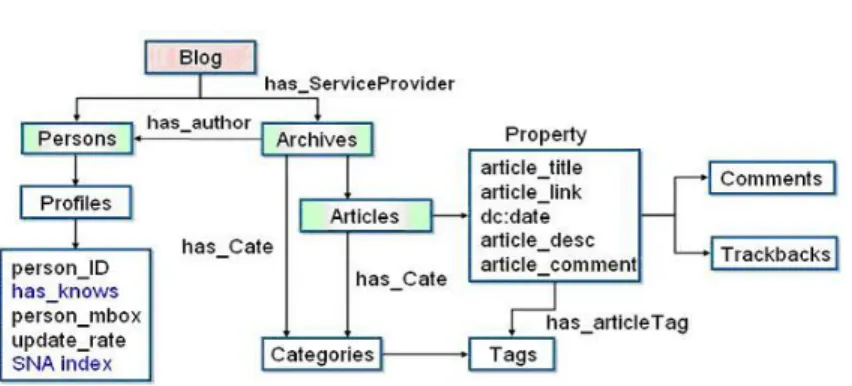
4.3 Blog Ontology
The blog ontology describes the profile of a blogger with his blog articles (see Fig. 2). The profile of a blogger is very similar to FOAF that defines a blogger’s personal ID, friend relationship, and mbox, etc. The attributes of each blog article include article title, date, feedback comment, and trackback, etc. In addition, the SNA index measure is defined as one of a blogger’s pro-file attributes. Therefore, SNA analysis capabilities were embedded into blog ontology to serve our SNA+ontology+tag semantic social web query services.
Fig. 2. The blog ontology describes the profile of a blogger with his blog articles
The blog ontology is declared as OWL ontology language, where property can be classified as two types: object property and datatype property. For example, the domain and range of the has author object property are de-clared respectively as Archives class and P ersons class, where Archives is the superclass of both Articles and Categories classes. Based on this object property, we describe the abstract relationships between a blogger and his blog articles. The datatype property allows us to define a concrete XML-Schema attributes, such as SNA index, for P rof iles subclass for further arithmetic operations.
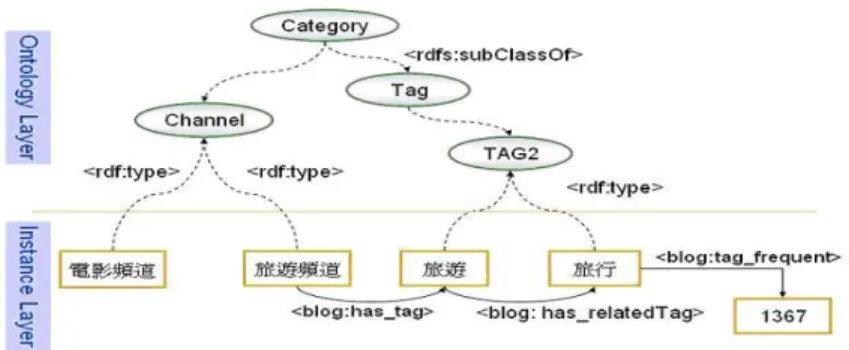
4.4 Topic Ontology
The blog articles in the WRETCH were classified into one of the 16 broad topic channels based on their attachment tags. The design processes of broad classification of blog article channel will be shown as three steps (see Fig. 3): First, we subjectively declare 16 broad topic channel as instances under their superclass Channel. The 16 broad topic channels are life, cuisine, music, etc, where Channel and T ag are subclasses of Category superclass in the topic ontology. Second, a set of possible tags we consider for each channel are those with higher frequent 2-word or 3-word tags presented by users. Third, if a new blog article has attachment tags that match at least one of higher frequent tags in the set declared for one of a broad topic channels, then this new blog article will be automatically classified to that channel.
4.5 Social Web Annotation
The goal of Web 1.0 annotation is to create a well-defined and computer un-derstandable structure knowledge base e.g., ontologies, whose content mirrors that of the WWW. The biggest challenge for bridging of Web 1.0 ↔ Web 3.0 is the terms mining from the Web can not be automatically and exactly fitted into the ontology that defines the vocabularies for the target knowledge base
Fig. 3. Topic ontology - Channel and Tag are subclasses of Category so we can automatically mash up ontology data and search model with the folksonomy tagging system services
[7]. Therefore, most of the semi-automatic annotation systems usually apply machine learning techniques to recognize new class instances and relation in-stances mining from the Web. In the folksonomy annotation for bridging of Web 2.0 ↔ Web 3.0, the granularity of class instances and relation instances are restricted to the resource targets that can be clearly tagged by folksonomy. The folksonomy of social web annotations are explicitly collected from tags or implicitly initiated by users from their activity events. These explicit tags and implicit events are precise terms that describe the instances and relations corresponding to our ontology schema.
The objective and granularity of tags for describing instances and rela-tions that corresponding to the target resources can be further refined if we have more elaborate social web annotation system in the future. As seman-tic wikipedia in [23], we might allow users to enable semanseman-tic tags similar to
typed links and attributes two kinds of property for describing corresponding
abstract relationship and concrete attributes within/between entity. Then var-ious levels of reasoning for discovery of semantic relationship among taggers, tags, and resources can be achieved.
Our semantic social web annotation system takes three inputs either col-lected by web crawler or computed by local software agent. The first is HTML blog pages with hyperlinks , comments, and trackbacks context. The second is RSS context with permalink, publication data, author, and description at-tributes. The third is tags, channel, and SNA indices computed via agents. They are all stored in a local database and to be mashed up for afterward semantic social web query services (see Fig. 4).
4.6 Semantic Social Web Blog Portal Testbed
An online semantic social web blog portal testbed (see Fig. 5) was constructed based on previous layer conceptual schema (see Fig. 1) to experiment our
Fig. 4. Semantic social web annotation from three inputs of data sources for mashup purpose to enable semantic social web services
mashup model. The crawler collects all of the necessary context information from the WRETCH BSP. The context information shown in Figure 4 were processed to create relevant class and relation instances defined in the blog ontology and the topic ontology (see section 4.3 and section 4.4). This se-mantic social web annotations for folksonomy were automatically generated except in the bootstrapping stage where we have to analyze the blog site de-pendent context to specify our initial lightweight ontology schema. A variety of important SNA measures, such as indegree, closeness, betweenness, and k-core, were computed via Pajek SNA software. 4 to provide semantic social
web query services shown in section 3.3.
Fig. 5. The semantic social web blog portal to experiment our Web 2.0 ↔ Web 3.0 bridging model
5 Conclusions
The goal of this research is to exploit the incentives of bridging Web 2.0 ↔ Web 3.0 via building a semantic social web blog portal. On the Web 2.0, we usually use tagging system to label all kinds of Internet resources. Web 2.0 is a folksonomy social web, where we effectively search what we are desirous of information through tags. The tagging system enables the wisdom of crowds and surprisingly social consensus can be derived from these voluminous and unregular tags. Contrarily, Web 3.0 (semantic web) is aiming at using ontol-ogy for effectively information search under taxonomy classification. We have justified that the concepts of folksonomy and taxonomy can be mashed up to-gether to achieve semantic social web query services via bridging of Web 2.0 ↔ Web 3.0. That allows us to leverage search capabilities from both bottom-up folksonomy indexing and top-down taxonomy ontology two techniques.
Conceptually, tags in the tagging system are equivalent to terms mining from the WWW in the conventional annotation system. The terms mining from the Web are usually defined as instances that are related to a particu-lar class or property in ontology. But tags from the folksonomy are usually instances related to a particular class. Therefore, all of the relation instances have to be created dynamically following the ontology schema. The relation instances that describe the relationships between bloggers, tags, and blogs, are generated from blogger’s daily activity events based on our blog ontology. Although users can effectively search information by folksonomy tagging sys-tem in Web 2.0, we still have the capacity to improve search capability via social network analysis (SNA). A real SNA-based semantic social web query services could possibly encourage users to find out what they are really inter-ested in because well-organized topic-specific ranking contents are ready for user to enjoy.
Acknowledgements
This research was partially supported by Taiwan National Science Council (NSC), Under Grant No. NSC 95-2221-E-004-001-MY3.
References
1. Ali-Hasan, N. and Adamic, L. A., Expressing Social Relationships on the Blog through Links and Comments. http://www-personal.umich.edu/~ladamic. 2. Berners-Lee, Tim, et al. (2001). The Semantic Web. Scientific American, May. 3. Bojars, U. , Breslin, J. G., and Moller, K. (2006). Using Semantics to Enhance
the Blogging Experience. Proceedings of 3rd European Semantic Web Confer-ence (ESWC 2006), 679-696.
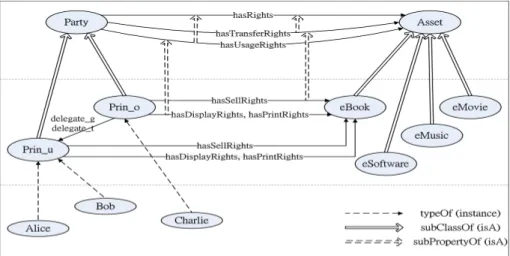
![Fig. 1. A rights delegation ontology for an ODRL foundation model based on [10]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8303620.174227/36.918.210.716.616.956/fig-rights-delegation-ontology-odrl-foundation-model-based.webp)