行政院國家科學委員會專題研究計畫 成果報告
情境感知遊戲互動之合作式語言學習模式發展與學習成效
評估研究(第 3 年)
研究成果報告(完整版)
計 畫 類 別 : 個別型 計 畫 編 號 : NSC 97-2511-S-004-002-MY3 執 行 期 間 : 99 年 08 月 01 日至 100 年 07 月 31 日 執 行 單 位 : 國立政治大學圖書資訊與檔案學研究所 計 畫 主 持 人 : 陳志銘 共 同 主 持 人 : 陳浩然 計畫參與人員: 碩士班研究生-兼任助理人員:林育如 碩士班研究生-兼任助理人員:黃柏翰 碩士班研究生-兼任助理人員:莊敬璞 碩士班研究生-兼任助理人員:黃勝輝 碩士班研究生-兼任助理人員:郭建成 碩士班研究生-兼任助理人員:王裕智 處 理 方 式 : 本計畫涉及專利或其他智慧財產權,1 年後可公開查詢中 華 民 國 100 年 10 月 17 日
行政院國家科學委員會專題研究計畫成果報告
情境感知遊戲互動之合作式語言學習模式發展與學習成效評
估研究
計畫主持人:陳志銘 教授 計畫共同主持人:陳浩然 教授 計畫執行單位:國立政治大學圖書資訊與檔案學研究所 計畫編號:97-2511-S-004-002-MY3 計畫執行期間:97 年 8 月 1 日~100 年 7 月 31 日摘要
為了提升國家競爭力,英語學習在非英語系國家普遍受到重視,因此發展有利於提升英 語學習成效的電腦輔助學習模式顯得日益重要。因為字彙為組成英語句子的最根本要素,因 此字彙學習對於提升英語學習成效就顯得相當關鍵且重要,因此過去已有不少致力於提升英 語字彙學習成效的研究被提出。情境學習理論強調情境為語言學習歷程需要考量的要素,語 言學習與情境學習結合可以有效提升語言學習成效。換句話說,有意義的語言學習必須與社 會、文化及生活情境相互結合。近年來隨著情境感知技術的快速發展,發展能夠支援學習者 進行不受時空限制的情境感知行動語言學習系統,成為一種提升英語學習成效的可能創新學 習模式。因此,本研究在校園環境中提出一個個人化情境感知無所不在英語字彙學習系統, 能夠根據學習者位置、學習時間、個人字彙能力及空閒時間,適性化的提供適合於個別學習 者單字學習數量、單字程度及學習情境的英語字彙進行學習。實驗顯示本研究所提出之無線 網路定位方法可以達到 92%的正確率,已經足以支援情境感知英語字彙學習。再則,本研究 所提出之個人化情境感知無所不在英語字彙學習系統已經實作於個人數位助理PDA 上,可以 在校園環境提供情境感知英語字彙學習服務。實驗結果顯示,具有情境感知支援之個人化英 語字彙學習系統的英語字彙學習成效優於不具情境感知支援之個人化英語字彙學習系統。 關鍵字:情境感知無所不在學習、無線網路定位、個人化學習、英語學習Abstract
Since learning English is extremely popular in non-native English speaking countries, developing modern assisted-learning schemes that facilitate effective English learning is critical issue in English-language education. Vocabulary learning is vital within English learning because vocabulary comprises the basic building blocks of English sentences. Therefore, numerous studies have attempted to increase the efficiency and performance of learning English vocabulary. “The situational learning approach” proposed that “context” is an important consideration in the language learning process and can enhance learner learning interest and efficiency. Restated, meaningful vocabulary learning occurs only when the learning process is integrated with social, cultural and life contexts. With the rapid development of context-awareness techniques, the development of context-aware mobile learning systems, which can support learners in learning without constraints of time or place via mobile devices and associate learning activities with real learning environment, enables the conduct of a novel context-aware ubiquitous learning mode to enhance English vocabulary learning. Accordingly, this study proposes a personalized context-aware ubiquitous English vocabulary learning system based on learner location as detected by wireless positioning
techniques, learning time, individual English vocabulary abilities, and leisure time, enabling learners to adapt their learning content to effectively support English vocabulary learning in a school environment. Experimental results indicated that the accuracy of the employed wireless positioning scheme is over 92%, which is sufficient to help learners detect their location. Additionally, the personalized context-aware ubiquitous English vocabulary learning system has been successfully implemented on PDA devices in a school environment to support effective situational English vocabulary learning. Experimental analysis of learner learning performance indicates that the learning performance of learners who used personalized English vocabulary learning systems with context awareness was superior to learners who used personalized English vocabulary learning systems without context awareness.
Keywords: Context-aware ubiquitous learning, wireless positioning technique, personalized learning, English vocabulary learning
1. Introduction
The rapid development of wireless network technologies has enabled people to conveniently access the Internet from more diverse locations. WLAN offers an excellent solution for schools and companies wishing to establish Internet infrastructure. Additionally, the pervasiveness of handheld mobile devices, such as Tablet PC, PDA, and cell phone, has transformed learning modes from E-learning (electronic learning) to M-learning (mobile learning). Particularly, compared with traditional classroom learning, M-learning overcomes limitations of learning time and space. Recently, the concept of “context-aware ubiquitous learning” has been further proposed to emphasize the characteristics of learning the “right content” at the “right time” and “right place”, and also to facilitate a seamless ubiquitous learning environment that supports learning without constraints of time or place (Ogata & Yano, 2004). The so-called “context-aware ubiquitous learning” (Rogers et al., 2005; Tummala & Jones, 2005; Wang, 2004; Wilkerson et al., 2005) thus requires the detection of learner context information and provides learning with different learning content via mobile devices in response to different learning contexts. Dey (2000) proposed four main types of contextual information, including identify, time, activity, and location, for building context-aware applications. To determine learner location, GPS (Global Positioning System) detects user location where the GPS receiver simultaneously senses a minimum of three satellites in outdoor environments by the triangulation method (Ahmed, 2006). Compared with GPS, WLAN can provide precise location information in both indoor and outdoor environments and has been widely set up in most public or school environments (Kupper, 2005). WLAN positioning is a more suitable method of enabling the development of “context-aware ubiquitous learning” that can provide learning content associated with learning contexts and assists learners in context-based learning in a campus environment.
Nevertheless, the rapid growth of the Internet has shortened the distance between people from different countries, making the world into a global village. English language abilities have become very important, and are now a basic skill for modern humans. Therefore, developing an effective learning tool for effective English learning has become an important issue in English-language education (Collins, 2005; Shih, 2005). EFL (English as a foreign language) learning requires the support of various learning tools to offer additional opportunities to learn English. Recently, various innovative learning methods have been proposed to support language learning activities, for example mobile English vocabulary learning by PDA (Chen & Chung, 2007), and some studies have proposed using cell phones to assist language learning (Kiernan & Aizawa, 2004; Collins, 2005).
Among all English-language skills, the English vocabulary competence is crucially important and is the foundation of language learning (Beck, McKeown, and Kucan, 2002; Bormuth, 1966; Davis, 1944, 1968). Huckin et al. (1993) indicated that reading ability and vocabulary knowledge
are two key components of second language performance and moreover are mutually dependent, especially in academic settings. Additionally, Stahl & Fairbanks indicated that knowledge of word meanings is strongly related to reading comprehension skills (Stahl & Fairbanks, 1986). Moreover, Wilkins (1972) argued that “without grammar very little can be conveyed, and without vocabulary nothing can be conveyed.” Recently, numerous studies have investigated English learning, and have particularly emphasized the importance of vocabulary learning (Lewis, 1993; McCarthy, 1984; Meara, 1980; DeCarrico, 2001). Excellent vocabulary abilities are beneficial in inferring meaning from English sentences (Harmon, 1998; Rupley, Logan & Nichols, 1999). The English language education field thus should pay more attention to developing innovative English vocabulary learning tools.
“The situational learning approach” (Hornby, 1950) proposed that “context” is an important factor in language learning, capable of enhancing learning interest and efficiency. Meaningful knowledge is constructed only when learning process integrates with cultural and life contexts. Assimilating knowledge in a real world environment shortens learning time and enhances learning efficiency. Moreover, learners who actively interact with the real word can apply this authentic and social knowledge to the everyday environment that surrounds them. Pestalozzi, an 18th Century philosopher, advocated the principle of Anschauung - direct concrete observation (Silber, K., 1965). Pestaloozi emphasized sensory experiences and encouraged the entry of natural science and geography. He frequently took children to explore the surrounding countryside, and especially to observe the local natural environment and topography. The children would examine the minerals, plants, and animals they encountered in the real environment, and then developed ideas based on their sensory impressions. Thus, exploring the real world and sourrding contexts benefits language learning. Miller and Gildea (1987) also indicated that learning vocabulary is an everyday practice, and using a sample of learners with an average age of 17 years old, they demonstrated that learners learn vocabulary at a rate of about 13 words per day. If vocabulary learning is meaningful to learners, they will naturally understanding the meaning and usage of the words learned. Generally, learning English vocabulary from abstract definitions in the dictionary is slow and less successful. More importantly, dictionary based learning leads to problems when using language in real world situations (Brow, Collins & Dugid, 1989).
Based on the situational learning approach and contextual information in the context-aware computational method proposed by Dey (2000), a “personalized context-aware ubiquitous English vocabulary learning system” based on considering four types of context-aware information, including learner location, current learning time, learner vocabulary ability and leisure time available to the learner is proposed to improve the English vocabulary learning of individual learners in this study. The proposed system uses existing WLAN infrastructure to gather AP signal strength information and detect location based on the employed back-propagation neural networks. Additionally, Item Response Theory (Baker and Frank, 1992; Hambleton et al., 1985; Hambleton et
al., 1991; Hulin et al., 1983) and the fuzzy inference mechanism (Lin & George Lee, 1996) were
respectively employed to evaluate leaner vocabulary ability and the amount of learning vocabularies based on immediate test responses and leisure time of individual learners during learning processes. Experimental results demonstrate that utilizing context-awareness techniques associated with learning environment and content to memorize English vocabulary via mobile devices can reliably enhance English vocabulary ability. The effectiveness of this technique stems from the fact that context-aware ubiquitous learning facilitates learning activities by providing the “right content” at the “right time” and “right place”, and is a convenient method for seamless ubiquitous English learning without constraints of time or place by mobile devices.
2. System Design
vocabulary recommendation mechanism. The functionalities of the proposed system, experimental environment, employed back-propagation neural networks, location estimation scheme are explained in Section 2.1, and the proposed positioning approach is detailed in Section 2.2. Finally, the recommendation mechanism for determining suitable vocabularies for individual learner based on context-aware is described in Section 2.3.
2.1 System Architecture
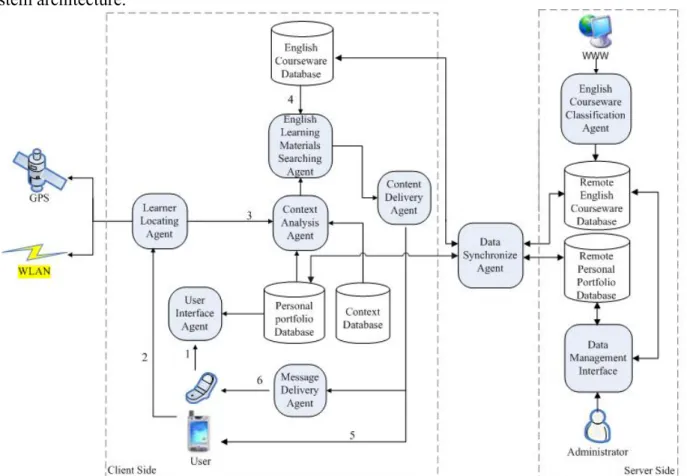
In this study, the ”personalized context-aware ubiquitous English vocabulary learning system” is proposed, and it depends on learner location, learning time, leisure time and personal learning characteristics in terms of vocabulary ability to provide adaptive English vocabulary learning. The proposed system aims to enhance learner impressions and interest in relation to learning English vocabulary, and also to boost the performance of English vocabulary learning based on the situational learning approach supported by WLAN positioning techniques. Figure 1 illustrates the system architecture.
Figure 1. The system architecture of personalized context-aware ubiquitous English vocabulary learning system
2.1.1 System components
The proposed learning system is composed of the client side, data synchronized agent, and server side. The left part of Fig. 1 presents the system architecture of the client side. The client side, which comprises six intelligent agents and three databases, attempts to recommend new words to individual learners based on the proposed context-aware scheme for personalized English vocabulary learning. The right part of Fig. 1 shows the server side system architecture. The server side, which contains two databases, one data management interface, and one English courseware classification agent, is responsible for collecting English vocabulary from web sites that contain required English course materials and providing a friendly user interface for managing
vocabulary by an administrator (i.e. an instructor). To support off-line learning, the data synchronized agent is responsible for maintaining data consistency between the client and server databases following the wireless network connecting. The functionality of each intelligent agent within the system is detailed below:
(1) The Client Side
(a) The learner locating agent
The agent attempts to detect the learner’s location and can assist to choose different vocabularies depending on individual learner location. This study employed the WLAN positioning techniques in a schoolyard environment to sense learner location.
(b) The user interface agent
Learner can log into the learning process and decide to learn or review English vocabulary through the user interface agent. The user interface agent can also display individual learner learning states to improve understanding of individual vocabulary ability. This agent is also responsible for interacting with the user account database to confirm learner identity.
(c) The context analysis agent
Based on learner’s location, this agent cooperates with both the personal portfolio and context databases to determine the learning parameters associated with the context.
(d) English learning materials searching agent
Suitable English learning materials that are related to the context of the sensing learner are discovered from the English courseware database based on the analytical results obtained by the context analysis agent.
(e) The content delivery agent
This agent organizes the English materials discovered by the English learning material searching agent into the right style of learning content that fits the learner’s mobile device, then transmits these learning materials to the learner who is learning English vocabulary via PDA or cell phone.
(f) The message delivery agent
Except learning by personal digital assistant (PDA), if a learner learns English vocabulary through cell phone, the system will send learning content that match the learner ability and context in the form of short message to the learner; otherwise, the learning content will be sent to the PDA.
(g) The English courseware database
The English courseware database comprises English materials to support English vocabulary learning.
(h) The personal portfolio database
The personal portfolio database contains personal information, including learning statuses, and the English vocabulary abilities of individual learners.
(i) The context database
The context database contains the corresponding contextual information for each piece of English vocabulary as well as the location of the campus where the learning takes place, and this information is used to support the analysis of the context analysis agent.
(2) The Server Side
(a) The English courseware classification agent
Through information retrieval techniques, this agent automatically retrieves courseware from the web site with needed English course materials. Then it stores and classifies the course materials according to courseware difficulties and context attributes by human assistance.
(b) The data management interface
An administrator can add, modify or delete learning content, and assess the leaning states of individual learners through the data management interface.
(c) The remote English courseware database
The English courseware database comprises English vocabulary materials from the vocabulary collection of the Taiwan GEPT (General English Proficiency Test). These English vocabulary materials consist of three different GEPT grading levels: elementary, intermediate, and high-intermediate. The gathered GEPT vocabulary were used for English vocabulary learning by tenth grade high school students in this study.
(d) The remote personal portfolio database
Personal information, including individual learner learning status and English abilities, is stored in the personal portfolio database and the administrator can monitor learner learning activities and provide assistance as appropriate. The remote personal portfolio database maintains data consistency with the databases on the client side using the synchronized agent.
(3) The data synchronized agent
To support off-line learning, the data synchronized agent oversees the task of maintaining data consistency between the client and server databases following the wireless network recovers on-line connection. In this study, the merger replication technique provided in Microsoft SQL server was employed to perform this task.
2.1.2 System operation procedure
Based on the system architecture, the details of the client side system operating procedure are described and summarized below:
Step 1 A learner logs in to the proposed English vocabulary learning system through the
user interface. As the learner logs in to the system, the user interface agent checks the individual learner account stored in the user account database and also checks the leisure time available for English vocabulary learning. Meanwhile, the setting information is stored in the personal portfolio database.
Step 2 Following the learner logs in the system, the learner locating agent automatically
senses the learner location by the proposed neural-network-based WLAN positioning techniques.
Step 3 and 4 Based on the location of the sensing learner, the context analysis agent retrieves the
context information from the personal portfolio and context databases. Consequently, the English learning material searching agent discovers the proper English vocabulary materials that fit learner context according to the analytical results of the context analysis agent.
Step 5 The content delivery agent organizes the English learning materials discovered by
the English learning material searching agent as the appropriate form of content and transmits them to the learner device.
Step 6 The message delivery agent transmits the learning contents in the form of a web
page to the learner’s PDA or in the form of short message to the learner’s cell phone. The user then returns to Step 2 to perform the next learning cycle or logs out, terminating the learning process.
2.2 WLAN Positioning Methodology
Detecting the location context is an important function in this study. After analyzing the advantages and disadvantages of several positioning techniques and considering the limitations of real world environments, this study employed the neural-network-based WLAN positioning technique to develop a positioning service based on the wireless network existing in a schoolyard because WLAN has been widely installed in most schoolyards to provide wireless Internet services. Compared with the RFID, infrared and ultrasound positioning techniques (Kupper, 2005), WLAN has the lowest positioning infrastructure costs. Furthermore, this study employed
back-prorogation neural networks, a machine learning technique, to induce the mapping relationships of the collected signal strength information with learner location. Subsequently, the trained back-prorogation neural networks were used to predict learner positions in accordance with the positioning inducing knowledge. The following subsections first introduce the employed back-propagation neural networks and their applications. Finally, the procedures used to detect learner location are detailed.
2.2.1 The employed back-propagation neural networks
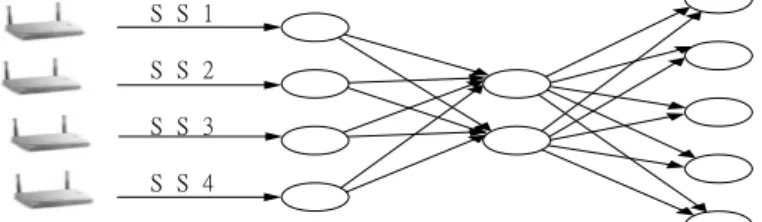
The back-propagation neural network is an artificial neuron computing system (Lin & George Lee, 1996). Much like the human brain, a neural network is composed of interconnected nodes and directed links with corresponding weight information. Among the proposed neural network learning models, back-propagation neural network is the most widely used in practice and it is well known for its high accuracy, good generalization ability and rapid recall process. This study used the back-propagation neural network model to classify signal strength features into corresponding locations. A back-propagation neural network is a supervised model and includes both learning and recall phases. In the learning phase, the model learns how to map the input data to the corresponding output data, and also determines the weights of the network connections. The induced weights are then used to compute the output newly arrived data for prediction purposes. A typical back-propagation neural network architecture consists of input, hidden and output layers. Each layer receives the output of the precedent layer as an input. Figure 2 illustrates the architecture of the neural network with a single hidden layer used in this study. The signal strength of each AP serves as the input feature of each neural node in the input layer, and the outputs represent the corresponding locations.
S S 1 S S 2 S S 3 S S 4
Figure 2. The learning architecture of the employed BP neural network with single hidden layer for WLAN positioning
2.2.2 Location detection
This study utilizes indoor WLAN to estimate learner location. By measuring the signal strengths emitted by each AP, the location is used to infer learner context. The location detection involves two stages, as described below:
The first stage (off-line phase)
To establish the radio map database, plenty of signal strength samples were gathered to construct a neural network classifier model for inferring signal strengths into corresponding geographic locations. Each record represents the signal strength values emitted from n APs and their corresponding locations, and can be stored using the following format: {SS1, SS2, SS3, SS4, … ,
SSn, Location}. During the data collection, some locations may have weak or even no signals
because of long distances between the mobile side and the APs, or blocks of walls. Since the signal strength ranged from –30 dBm to –100 dBm, the signal strength value was assigned to –100 dBm for the location where no signal strength was detected.
The second stage (on-line phase)
The back-propagation neural network model established during the first stage is implemented and installed on the learner mobile side (PDA). When a learner initiates the positioning service,
the trained neural network model implemented in the learner locating agent immediately identifies the location of the learner according to the signal features detected by the learner’s mobile device.
2.3 Recommending Context-Aware English Vocabulary and Testing Sheet
The system learning process comprises learning new English vocabulary and testing learners on their recently learned vocabulary. First, the context analysis agent is in charge of recommending context-based English vocabulary to individual learners based on four considered context information including learner vocabulary ability, learning location, current learning time, and free time available to the learner. A test sheet related to the learned vocabulary is then generated to assess learning performance and re-evaluate the English vocabulary ability of the learner. Figure 3 presents a detailed flowchart on the process of recommending context-aware English vocabulary. First, the proposed English vocabulary recommendation mechanism selects English vocabulary associated with learner location from the English courseware database for further consideration of whether this vocabulary is suited to learner English vocabulary ability and matches their free time availability characteristics. Next, the information function values of the selected vocabularies in the previous step estimated based on individual learner vocabulary ability were applied to identify appropriate English vocabularies for individual learner learning. Meanwhile, these selected vocabularies were also assessed in terms of their time characteristic scores based on learner learning time. A linear combination approach with an adjustable weight was applied to integrate the information function value with the time characteristics score to derive a final score for determining appropriate vocabularies for individual learner learning. In this study, all selected vocabularies associated with learner location were ranked according to final scores. Finally, the proposed system recommends vocabulary based on the ranking order of final scores. Moreover, the recommended amount of learning vocabularies is inferred based on individual leaner ability and leisure time. That is, if the estimated amount of learning vocabulary is K, then the vocabularies with top K high final scores are recommended to individual learners for vocabulary learning. The following subsections explain this vocabulary recommendation strategy in detail.
Figure 3. The proposed context-aware English vocabulary recommendation mechanism
2.3.1 Selecting location-based English vocabulary
Location information is the main factor in context-aware or context-based systems. According to the situational learning approach, this study first focused on recommending English vocabulary related to current learner location to individual learners. For instance, some words, such as exam, student, and assess, are appropriate to be learned if the learner performs the learning process in a classroom, while other words, such as baseball, jump, and athletic, were appropriate for learners in a sports ground environment. Therefore, the first step in vocabulary recommendation is to select English vocabulary based on learner location. Next, the selected English vocabularies associated with current learner location are ranked to determine appropriate vocabularies for individual learners based on a weighted linear combination of the information function values and time characteristics scores. The following subsection demonstrates how to decide appropriate vocabulary for individual learners based on their existing English vocabulary ability using the information function in Item Response Theory (IRT).
2.3.2 Evaluating English vocabulary ability and recommending English
vocabulary based on information function
Item Response Theory (Baker and Frank, 1992; Hambleton et al., 1985; Hambleton et al., 1991; Hulin et al., 1983) is a widely used theory in education measurement, typically applied in the field of Computerized Adaptive Testing (CAT) (Horward, 1990; Hsu and Sadock, 1985) to select the most suitable items for examinees based on individual abilities. The CAT efficiently reduces test time and number of testing items, and can precisely estimate examinee abilities. The concept of CAT is applied to replace conventional measurement instruments (which are typically fixed-length, fixed-content and paper-pencil tests) in several real-world applications such as the Test of English
as a Foreign Language (TOEFL) (http://www.toefl.org), Graduate Record Examinations (GRE) (http://www.gre.org), and Graduate Management Admission Test (GMAT) (http://www.gmat.org). In this study, IRT was applied to assess learner vocabulary ability for the proposed novel personalized context-aware ubiquitous English vocabulary learning system for personalized learning services.
To estimate a learner’s English vocabulary ability, the item characteristic function with a single difficulty parameter proposed in IRT (Baker and Frank, 1992; Hambleton and Swaminathan, 1985; Hulin et al., 1983) is used to model each vocabulary word. The formula for the item characteristic function with a single difficulty parameter is
n j e e P j j b D b D j 1,2,..., 1 ) ( ( ) ) ( (1) where Pj() denotes the probability that learners can memorize and recognize the
th
j
vocabulary at a level below their ability level , bj is the difficulty of the th
j vocabulary, n is
the number of vocabularies and D is a constant 1.702.
In Eq. (1), the probability Pj() is equal to 0.5 when a learner’s vocabulary ability equals the difficulty parameter for the th
j vocabulary word. Clearly, a learner must have a higher
vocabulary ability to achieve a probability of 0.5 for memorizing the th
j vocabulary word when
the difficulty of the th
j vocabulary word is increased.
In IRT, two methods are widely used when assessing a learner’s ability—maximum likelihood estimation (MLE) and Bayesian estimation schemes (Baker and Frank, 1992; Hambleton and Swaminathan, 1985; Hulin et al., 1983). Although the MLE procedure is simple and easily implemented, it produces divergent estimations for a learner’s vocabulary ability when a learner has completely correct or incorrect test responses for all learned vocabulary words (Baker and Frank, 1992). The MLE method frequently overestimates learner vocabulary ability when test responses are completely correct. Conversely, MLE typically underestimates learner vocabulary ability when test responses are completely incorrect. Compared with the MLE procedure, the Bayesian estimation method is more complex and less efficient, and can solve the divergent estimation problem in the MLE procedure. Hence, the Bayesian estimation procedure always converges for all possible learner responses (Baker and Frank, 1992). Consequently, the Bayesian estimation procedure is applied to estimate learner vocabulary learning ability in this study. Bock and Mislevy (Baker and Frank, 1992) derived the quadrature form to estimate learner ability as
q k k k n q k k k n k A u u u L A u u u L ) ( ) | ,..., , ( ) ( ) | ,..., ( ˆ 2 1 2 , 1 (2) where ˆ denotes the learner’s vocabulary ability of estimation, L(u1,u2,,un|k) is the value oflikelihood function at a level below their ability level k and learner’s responses are u1,u2,...,un, k
is the th
k split value of ability in the standard normal distribution, and A(k) represents the
quadrature weight at a level below their ability level k.
In Eq. (2), the likelihood function L(u1,u2,,un|k) can be further described as
n j u k j u k j k n P jQ j u u u L 1 1 2 1, , , | ) ( ) ( ) ( (3) where ( ( ) ) 1 ) ( j k j k b D b D k j e e P memorize the th
j vocabulary at a level below their ability level k, Qj(k) represents the
probability that learners cannot memorize the th
j vocabulary at a level below their ability level k,
and u is the correct or incorrect testing response obtained from the vocabulary testing result to j
the th
j vocabulary, i.e. if the answer is correct then uj 1; otherwise, uj 0.
In the proposed system, learner vocabulary abilities are limited between –3 and +3. That is, learners with 3 have the poorest ability, those with 0 have moderate abilities, and those with 3 have the best abilities. This system estimates learner vocabulary ability based on learner test responses. If a learner memorizes the recommended vocabulary words and provides correct test responses, then a learner’s vocabulary ability will be promoted based on the estimated formula for learner ability in Eq. (2); otherwise, learner vocabulary ability will be descended.
Two approaches in IRT are commonly used to evaluate appropriate vocabulary words to individual learners—the information function strategy and Bayesian strategy (Baker and Frank, 1992; Hambleton and Swaminathan, 1985; Hulin et al., 1983). The information function strategy assumes that each vocabulary word with its corresponding difficulty parameter exhibits different information to a learner’s learning. Vocabulary with a high information value is more suitable to be recommended to learners. Since the Bayesian strategy is more complex than the information function approach, the information function method is applied to estimate appropriate vocabularies for individual learners. The information function is defined as
1.7( )
1.7( )
2 2 1 ) 7 . 1 ( ) ( j j b b j e e I (4) where Ij() is the information value of theth
j vocabulary at a level below their ability level ,
j
b is the difficulty parameter of the th
j vocabulary.
2.3.3 Evaluating the score of time characteristic of vocabulary
After calculating the corresponding information function value of each vocabulary, the time characteristics of all selected location-based English vocabularies are also considered for use in calculating the time characteristic scores to further integrate with the information function values of vocabularies. The determination of time characteristic scores for vocabulary is designed to identify the English vocabulary associated with learning time when learners conduct learning activities. For example, certain vocabulary items, such as sleep, star, and dark, are suitable for learn at night since they are associated with nighttime. Furthermore, other words, such as cold and snow, should be presented to learners during winter since they are generally associated with this season. Thus, the context analysis agent can monitor learning time and evaluate vocabulary items within the system to seek matches with the current learning time, season or festival. When people discuss the beginning or end of specific times or reasons, different time or seasons have different time measures involving hour, week or month. For example, when discussing the afternoon, it can be said to refer to the period from1:00 pm to 5:30 pm, in which case the relevant unit of time measurement is hours. Moreover, when talking about spring, people may think of the time measure as month and define spring as running from February to April.
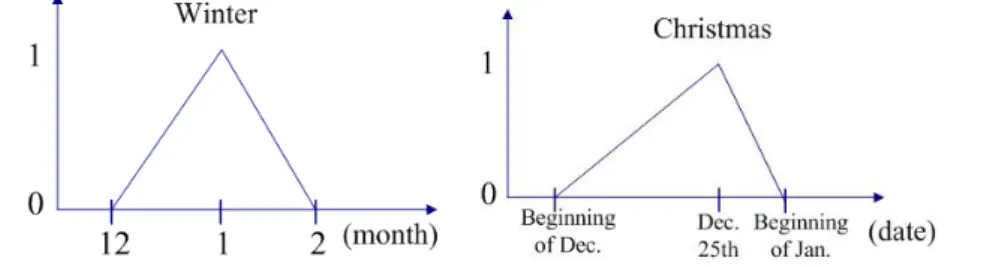
Furthermore, different festivals have different beginning and end ranges. For example, the Chinese New Year is a major celebration for Chinese people, with the celebratory atmosphere lasting two weeks or more. A comparable western festival is Christmas, which sees associated symbols such as Christmas trees, cards, wreaths and so on appear a month or more in advance of December 25th. Compared to Chinese New Year and Christmas, a celebration such as teacher’s day is rather small scale and involves a much shorter time period.
Thus, based on above properties, fuzzy theory (Lin & George Lee, 1996) is suitable for describing the characteristics of different times. Therefore, the score of time characteristic is
computed based on fuzzy inference in this study. Additionally, the vocabularies stored in the English courseware database were manually classified into different situational categories based on various time characteristics in advance. The fuzzy membership functions for each time characteristic are heuristically determined in this study. Figures 4(a) and (b) illustrate two examples of fuzzy membership functions used for the time characteristics of winter and Christmas.
Following the score of time characteristic of the th
j English vocabulary denoted as TC j
and the information function value denoted as I are decided, the final score j S of the j th
j
English vocabulary can be measured using the following weighted linear combination function:
j n
j
j
w
I
w
TC
S
( )(
)
(
1
)
(5) where w is an adjustable weighting factor reflecting the relative importance of learner ability and the time characteristic, TC is the time characteristics score of the j thj English vocabulary, ) ( ) (n j
I represents the normalized information value of the jth vocabulary at a level below their
ability level , and the range of Ij(n)() is between 0 to 1.
After calculating the corresponding final score of vocabulary, vocabularies with higher final scores are delivered first to individual learners. The following section discusses the quantity of vocabulary that should be delivered to individual learners based on learner leisure time.
Figure 4. The defined fuzzy membership functions for winter and Christmas
2.3.4 Estimating the amount of learning words
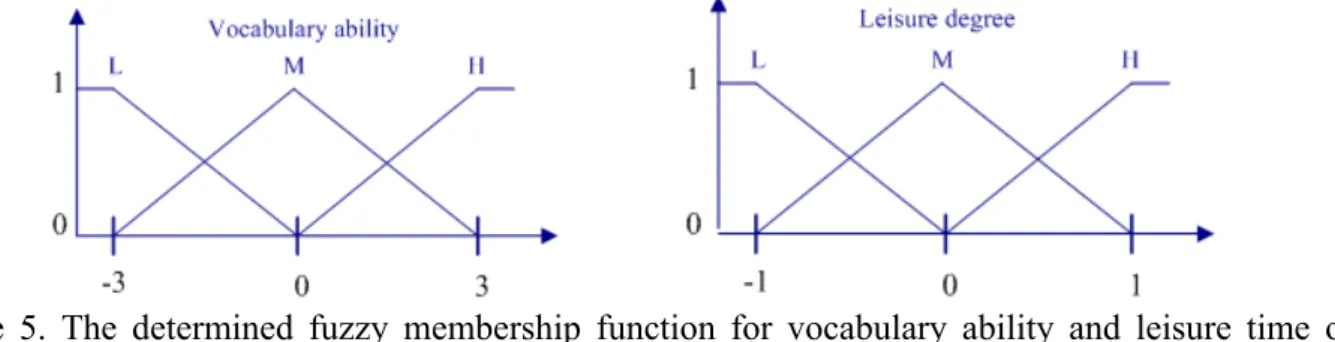
Learners wishing to learn new vocabulary may differ in the free time they have available to do so. Learners may sometimes have very short periods of leisure time, such as when they are waiting for a few minutes for a friend to arrive. At other times learners may have much more time, such as after class. Hence, the quantity of recommended vocabulary to be learned should adapt to differences in the leisure time available to individual learners, to enable them to maximize their limited available time for learning. The context analysis agent decides the amount of learning vocabularies based on learner ability and available free time using pre-designed fuzzy rules. Before performing learning, the learner is asked to select a value between -1 and 1 to indicate the amount of free time they have available. Figure 5 shows the fuzzy membership functions determined for learner vocabulary ability and available leisure time. Table 1 lists nine fuzzy rules used to infer appropriate learning vocabulary based on learner ability and leisure time
Table 1. The designed fuzzy rules for inferring the number of learning vocabularies
Fuzzy rules
No. If Then
1 Leisure.High ∩ Ability.High → Number.Mid 2 Leisure.High ∩ Ability.Mid → Number.High 3 Leisure.High ∩ Ability.Low → Number.High 4 Leisure.Mid ∩ Ability.High → Number.Mid 5 Leisure.Mid ∩ Ability.Low → Number.Mid 6 Leisure.Mid ∩ Ability.Low → Number.Mid 7 Leisure.Low ∩ Ability.High → Number.Low 8 Leisure.Low ∩ Ability.Mid → Number.Low 9 Leisure.Low ∩ Ability.Low → Number.Mid
Taking rules 1 and 2 as an example, if a learner has achieved a relatively high English vocabulary ability as a result of learning, the learning system will recommend more difficult English vocabularies. In contrast, learners with lower English vocabulary abilities will be given easier vocabulary to learn. Under the same leisure time, learners with high English vocabulary ability require more time to memorize more difficult vocabularies than do learners with moderate English vocabulary ability. Thus, in rules 1 and 2, learners with higher English vocabulary ability will be recommended less vocabulary than those with moderate English vocabulary ability to encourage them to completely memorize the recommended vocabulary during their leisure time.
Moreover, Figure 6 shows the defined fuzzy membership function for estimating the number of learning vocabularies. Besides, a defuzzification process was employed to infer learning vocabulary number based on the designed fuzzy rule base via fuzzy inference. In the fuzzy set theory, the center of gravity (COG) (Lin & George Lee, 1996), which is the most widely used defuzzification scheme, calculates the crisp values of learning vocabulary number from the most typical values and respective degrees of membership function. If the estimated number of learning vocabularies is K, the system will deliver the top K English vocabularies to the learner according to the ranking order of the final scores.
Figure 5. The determined fuzzy membership function for vocabulary ability and leisure time of learner
Figure 6. The defined fuzzy membership function for inferring the number of learning vocabularies
3.
Experiments
Section 3.1 first describes the positioning experiment to verify whether the accuracy rate of WLAN positioning scheme satisfies the requirement supporting context-aware learning in the experimental campus environment. Section 3.2 demonstrates the implemented personalized context-aware ubiquitous English vocabulary learning system proposed in this study. Finally, section 3.3 evaluates the learning effectiveness of the proposed personalized context-aware ubiquitous English vocabulary learning system. In this work, a nonequivalent pre-test-post-test group based on the quasi-experimental design was designed to conduct learning activity and 36 tenth grade students in the Affiliated High School of National Chengchi University (http://www.ahs.nccu.edu.tw/) were invited to participate in this experiment during two weeks.
3.1 WLAN Positioning Experiment
To collect signal strength features for training the employed back-propagation neural network is the most important work affecting positioning learner location in the proposed English vocabulary system. Herein, the accuracy and the practicality of this approach were evaluated by the experiment in order to confirm whether this approach satisfies the actual requirement of the proposed system. The following subsections detail the experimental procedure and results.
3.1.1 Experimental environment
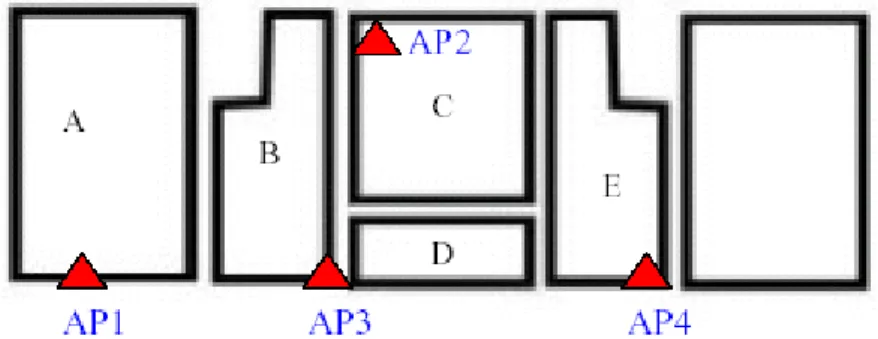
The experimental environment of wireless positioning was established on the fifth floor of the Wu-Shou Building in the National Hualien University of Education. The layout of this floor is shown as Fig. 7. It has dimensions of 80.5m by 11.3m and includes office, meeting room, and hallways. Four IEEE 802.11b WLAN access points were installed on this floor and users use PDA with the Pocket PC 2003 operating system as mobile device. This floor is divided into five areas based on the room spatial distribution: (A) office, (B) U-shaped hallway I, (C) meeting room, (D) U-shaped hallway Ⅱ, and (E) U-shaped hallway Ⅲ.
signify the wireless Aps)
3.1.2 Filtering noisy training data
In this study, the fifth floor of Wu-Shou Building is divided into five areas and 200 records of signal strengths are sampled from each area. Hence, there are totally 1000 records of signal features collected and applied as training data for training the applied back-propagation neural networks. However, for some reasons such as multi-path, and refraction, the signal therefore generates irregular fluctuation and becomes as noisy data. Therefore, it is essential to apply noisy data filtering mechanism to eliminate noisy training data. Once the better training data is generated after filtering out noisy data, the learning effect of neural network can be obviously promoted.
The noisy data filtering mechanism proposed in this study is based on the concepts of mean and bias in the statistics analysis. The steps of filtering out training data are elaborated as follows:
Step 1. Computing the mean {M1, M2, M3, M4} of all signal feature vectors {SS1, SS2, SS3, SS4} in
each area.
Step 2. Computing the bias of each data record against the mean according to the following formula
and denoted as {K1, K2, K3, K4}: i i i i M M SS K (6) Step 3. Normalizing the bias {K1, K2, K3, K4} of each data record into {F1, F2, F3, F4} based on the
following formula: 1 1 2 i i K F (7)
To obtain qualified training data, the threshold of F is set to 0.85 in this study. The record i
that all values in vector {F1, F2, F3, F4} are greater than or equal to 0.85 will then be preserved as
training data, the others are filtered out.
3.1.3 Accuracy rate analysis of detecting learner location
To enhance learning performance for precisely detecting learner location, this study heuristically determines the number of hidden-layer neural nodes of the employed back-propagation neural networks. Furthermore, merely sensing signal strength features once from each AP may simply reflect noise and result in incorrect location decision. To reduce interference from signal fluctuation and improve the accuracy of position prediction, the signal strength features are measured more than once and supplied prior to the positioning estimation in this study. In the estimations, the area label with the largest number of appearances serves as the final positioning result. For example, a learner is located in area A, and the sampling parameter is set to 5. If the location decisions determined by the employed neural-network-based positioning scheme are 4 for area A and 1 for area B, respectively, then the final positioning result is judged to be area A. In contrast, if the location decisions determined by the employed neural-network-based positioning scheme are 2 for area A and 3 for area B, the final positioning result is judged to be area B.
To determine the appropriate number of sampling parameters for positioning estimation, ten measurement points are randomly selected from each area and three iterations are measured on each measurement point. The sampling parameter for the measurement ranges from 3 times to 10 times. The accuracy rate of location estimation in each area can be computed by the following formula:
% 100 ) ( 1 1 ,
n m s v LAR m i n j k n m (8)where LARm,n denotes the location accuracy rate with iteration of m measurements and the n
measurement points randomly selected in some area, the notation i denotes the ith iteration
measurement in some area, j denotes the jth measurement point randomly selected in some area,
and the notation v(sk) denotes the voting result in one measurement point of some area assumed
that the sampling parameter is set to k.
Moreover, v(sk) is further computed as follows:
others 0, label location real with the same the is sample the of label location voting the if , 1 ) (sk kth v (9)
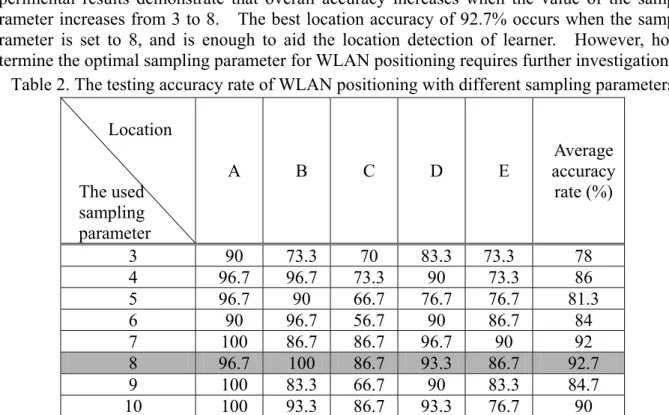
Table 2 illustrates the tested positioning accuracy using different sampling parameters. The experimental results demonstrate that overall accuracy increases when the value of the sampling parameter increases from 3 to 8. The best location accuracy of 92.7% occurs when the sampling parameter is set to 8, and is enough to aid the location detection of learner. However, how to determine the optimal sampling parameter for WLAN positioning requires further investigation.
Table 2. The testing accuracy rate of WLAN positioning with different sampling parameters Location The used sampling parameter A B C D E accuracy Average rate (%) 3 90 73.3 70 83.3 73.3 78 4 96.7 96.7 73.3 90 73.3 86 5 96.7 90 66.7 76.7 76.7 81.3 6 90 96.7 56.7 90 86.7 84 7 100 86.7 86.7 96.7 90 92 8 96.7 100 86.7 93.3 86.7 92.7 9 100 83.3 66.7 90 83.3 84.7 10 100 93.3 86.7 93.3 76.7 90
3.2 The Implemented System on PDA Supported by a Courseware Management
Server
This section details the personalized context-aware ubiquitous learning system implemented by the platform of Microsoft Visual Studio .Net 2003. Currently, the client mobile learning system is implemented on the PDA with the operating system of Windows mobile 2003 and the database of Microsoft SQL Server CE edition 2.0. Moreover, the remote courseware management server is implemented on the Microsoft Windows 2000 Server with Microsoft SQL Server 2000 database.
First, Fig. 8(a) shows the menu of vocabulary learning after a learner logs in the system by a legal account. If the learner would like to perform the context-aware learning mode, then he/she can click the button of “learning by context” and the learning locating agent will begin to sense the learner location. Figure 8(b) reveals the result of location detection and the system will remind learner to adjust the current leisure degree for inferring appropriate number of vocabularies for
learning. Figure 8(c) shows the additional functionality for correcting location information. That is, learners can correct location by the interactive interface with prior building location information.
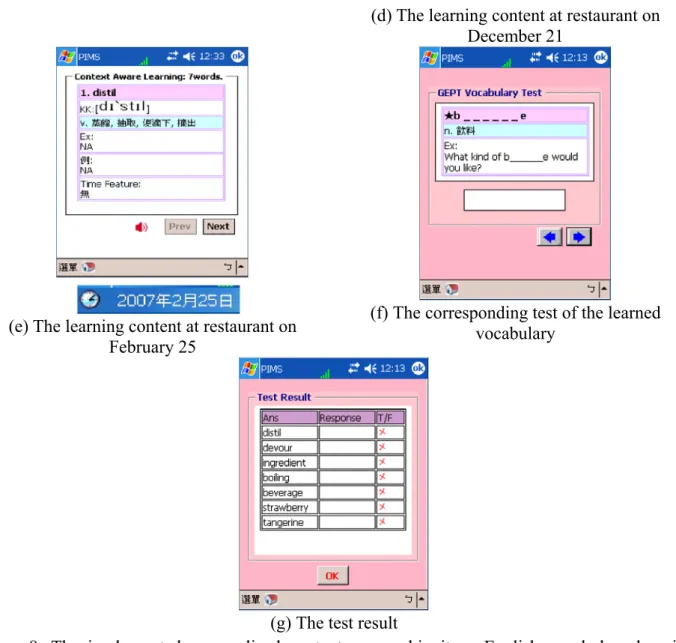
After the learner selects to continues the learning process, the context analysis agent and English learning material searching agent will find out suitable vocabularies to the learner according to the learner’s ability, leisure degree, current location and current learning time. Figures 8(d) and 8(e) show the recommended English vocabulary and the number of learning vocabularies decided by the context analysis agent. Meanwhile, learners can click on the trumpet-shaped button to listen the pronunciation of the selected vocabulary for training listening ability. Suppose that different learners locate at the same place “restaurant”, Figs. 8(d) and 8(e) display the system can recommend appropriate vocabulary to individual learners according to different learning time. In Fig. 8(d), the vocabularies with the characteristic of Christmas have higher priorities to be recommended to the learner because the learning time is close to Dec. 25th. However, Fig. 8(e) shows when the learning time is on Feb. 25th, the vocabularies characterized by Christmas are no longer ranked as the first priority vocabulary owing to approaching to the end of Christmas. After studying these recommended English vocabularies, the learner has to perform the corresponding vocabulary test to re-examine the individual vocabulary ability and the user interface agent will reveal the test results to the learner. Figures 8(f) and 8(g) show the contents of the test question and the test result.
Additionally, the learning statuses of each learner will be sent to the courseware management server and stored in the personal portfolio database. The courseware management server provides a friendly user interface for teachers to inspect the learners’ learning portfolios in order to further understand the learning performance of individual learners. Figure 9 shows the server side interface provided for teachers or administrators.
(a) The menu of context-aware ubiquitous
learning (b) The result of learner location estimation
(d) The learning content at restaurant on December 21
(e) The learning content at restaurant on February 25
(f) The corresponding test of the learned vocabulary
(g) The test result
Figure 8. The implemented personalized context-aware ubiquitous English vocabulary learning system
Figure 9. The courseware management server for managing English vocabulary and learner learning portfolios
3.3 Experimental Design and Analysis
3.3.1 Experimental design
To evaluate the learning performance of the proposed personalized context-aware English vocabulary learning system, 36 tenth grade students studying in the Affiliated High School of National Chengchi University were invited to participate in this experiment. The students were randomly assigned to either the experimental or control groups. Each group contained 18 students with the average age being around 16 years old. Each group contained 9 males and 9 females. A nonequivalent pre-test-post-test group based on a quasi-experimental design was employed to analyze the learning performance of the proposed system. Table 3 lists the experimental design of both the experimental and control groups.
Table 3. The experimental design for assessing learning performance
Group
PDA Operation
Training
Pre-test Learning process
(2 weeks) Post-test
Number of
learners Female Male
Experimental group Vocabulary learning with context aware service 18 9 9
Control group without context aware Vocabulary learning
service 18 9 9
Before performing the experiment, all participants received a 100 minute training course in operating PDA and using the proposed English vocabulary learning system with or without context-aware service. Figure 10 shows the learning situation of students who participated in the training course. In this experiment, the experimental group learned the recommended vocabulary with the support of the proposed context-aware service, while the control group learned the same vocabulary without such support. The vocabulary learning activity of two groups lasted two
weeks. Both the learning modes performed the pretest and posttest for comparing the difference in learning performance before and after learning using PDA. To provide a context-aware service for English vocabulary learning in the experimental schoolyard, 12 campus locations in the Affiliated High School of National Chengchi University were chosen to provide a location-based context-aware service. Table 4 lists the selected locations for the context-aware service. The students of the experimental group were free to go to these places at anytime and the proposed system could recommend suitable English vocabulary related to learning environment to individual learners for English vocabulary learning. Figures 11(a) and 11(b) illustrate the learning scenario of the experimental group students that learned English vocabulary via the proposed personalized vocabulary learning system with context-aware service in the library and garden, respectively.
Figure 10. PDA operation training
Figure 11(a). Vocabulary learning in the
library using proposed system Figure 11(b). Vocabulary learning in the garden using proposed system Figure 11. Vocabulary learning in various places using the proposed system
Table 4. The selected locations for English vocabulary learning in the schoolyard of the Affiliated High School of National Chengchi University
Military classroom Clinic center Garden
Computer classroom Restaurant Gym
Meeting room Art classroom Library
English classroom Music classroom Chemistry laboratory To assess learning performance, two parallel versions of the testing sheet were constructed by
an experienced English teacher at the Affiliated High School of National Chengchi University for both the pre-test and post-test, and were used respectively to measure student English vocabulary abilities before and after performing the learning process. Each testing sheet contained 20 multiple-choice items and 20 cloze questions selected equally from among three vocabulary levels of GEPT in Taiwan. Another 40 tenth grade students, excluding students in the experimental and control groups, were invited to participate in the tests before the experiment was conducted, and the test results were submitted for item analysis to measure whether the difficulties of both the pre-test and post-test sheets are identical. The analytical results show that the Kuder-Richardson reliability coefficients for both the pre-test and post-test sheets are 0.66 and 0.80, respectively, meaning both testing sheets have consistent reliability. Moreover, the Pearson Product-Moment correlation coefficient of both the test sheets is 0.70, and thus both testing sheets are confirmed to have identical levels of difficulty.
3.3.2 Experimental analysis
3.3.2.1 Learning performance analysis
Figure 12 displays the comparison result of the learning performance for both the pre-test and post-test. Table 5 shows the summarization of learning performance for both the participating groups. Figure 12 reveals the score differences of pre-test and post-test in the control group are closer than those in the experimental group. In addition, the percentages of learners with progress score in both the experimental and control groups are 94% and 67%, respectively. The results show that the scores of both the groups have progress, but the score progress of the experimental group is obviously superior to the control group.
In order to investigate whether there are significant differences in score progress between both the experimental and control groups, SPSS statistical software was used to analyze the result of pre-test and post-test. The SPSS analysis results of pre-test are presented in Tables 6(a) and 6(b). In this work, the Independent-samples T Test was employed to analyze the collected data of two participating groups. Before performing the PDA learning process for English vocabulary learning, the mean score of the experimental group on the pre-test is 10.39 and the standard deviation is 3.032. The mean score of the control group on the pre-test is 12.61 and the standard deviation is 5.315. The result of Independent Sample T Test (sig of t = 0.135 > 0.05) indicates that these two groups are not significantly different on the pre-test; therefore, the English vocabulary abilities of two groups can be viewed as identical before conducting the designed learning process.
Table 5. Summarization of learning performance for both participating groups Group
Comparison Item Experimental group Control group
Number of learners 18 18
Number of learners with
progress score 17(94%) 12(67%)
Number of learners with
retrogression score 0(0%) 5(27%)
Number of learners with
Table 6. The Independent Samples T Test of pre-test between two groups (a) Group statistics
18 10.39 3.032 .715 18 12.61 5.315 1.253 class experimental group control group pretest
N Mean Std. Deviation Std. Error Mean
(b) Independent Sample T Test
27.004 .135 -2.222 1.442 -5.182 .737 pretest
df Sig. (2-tailed) Mean Difference DifferenceStd. Error Lower Upper 95% Confidence Interval
of the Difference t-test for Equality of Means
Experimental group 0 5 10 15 20 25 30 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 Learners Grade pre-test post-test
(a) The students’ learning performance in the experimental group
Control group 0 5 10 15 20 25 30 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 Learners grade pre-test post-test
(b) The students’ learning performance in the control group Figure 12. The learning performance of two participating groups
Next, Tables 7(a) and 7(b) illustrate the Independent Samples T Test of post-test between two participating groups. The mean scores of the experimental and control groups on the post-test are 15.61 and 14.56, respectively. The T test result (t=0.684, sig of t=0.489 > 0.05) shows that two groups are not significantly different on the post-test. Thus, this study further compared the pre-test and post-test within each group using the Paired-Samples T Test.
Table 7. The Independent Samples T Test of post-test between two groups (a) Group statistics
18 15.61 4.258 1.004 18 14.56 4.973 1.172 class experimental group control group posttest
N Mean Std. Deviation Std. Error Mean
(b) Independent Sample Test
.489 .489 .684 34 .499 1.056 1.543 -2.081 4.192 posttest
F Sig. Levene's Test for Equality of Variances
t df (2-tailed)Sig. DifferenceMean DifferenceStd. Error Lower Upper 95% Confidence Interval
of the Difference t-test for Equality of Means
Tables 8(a) and 8(b) shows the result of Paired Samples T Test of the experimental group. In the experimental group, the difference of the mean scores between pre-test and post-test is –5.222 and the Paired-Samples T Test result reaches the significant level. In other words, after performing the proposed learning process, the promotion of learning performance in the experimental group is significant and the mean testing score increases 5.222 points. Tables 9(a) and 9(b) show the result of Paired Samples T Test of the control group. Similarly, the promotion of learners’ learning performances is also significant and the mean testing score increases 1.94 points in the control group. Hence, these two groups made significantly progress whether using the personalized English vocabulary learning system with or without context-aware service for English vocabulary learning. However, the promotion of the testing score in the experimental group (5.222) is higher than that in the control group (1.944). Thus, this study logically inferred that the learning performance of learners who used personalized English vocabulary learning system with context-aware service is superior to the learners who used personalized English vocabulary learning system without context-aware service.
Table 8. The Paired Samples T Test of the experimental group (a) Paired samples statistics
10.39 18 3.032 .715 15.61 18 4.258 1.004 pretest posttest experimental group
Mean N Std. Deviation Std. Error Mean
(b) Paired Sample T Test
-5.222 3.246 .765 -6.836 -3.608 -6.8 17 .000 pretest - posttest
experimental group
Mean DeviationStd. Std. ErrorMean Lower Upper 95% Confidence Interval
of the Difference Paired Differences
Table 9. The Paired Samples T Test of the control group (a) Paired samples statistics
12.61 18 5.315 1.253 14.56 18 4.973 1.172 pretest posttest control group
Mean N Std. Deviation Std. Error Mean
(b) Paired Sample T Test
-1.944 3.589 .846 -3.729 -.160 -2.299 17 .034 pretest - posttest control group Mean Std. Deviation Std. Error
Mean Lower Upper 95% Confidence Interval
of the Difference Paired Differences
t df Sig. (2-tailed)
In order to further explain inter-group variation associated with pre-test (covariance) and adjust the treatment (group) effect, an analysis of covariance (ANCOVA) was used to analyze the collected pre-test and post-test data. The first step is to analyze the homogeneity of regression coefficients. Table 10 shows the analysis result (F=0.438, sig of F=0.513). The F test result does not reach the significant level, thus it means the regression slope of two groups is equivalent. This result confirms the assumption of homogeneity of coefficients, so this study further preceded the analysis of covariance.
Table 10. The analyze result of the homogeneity of regression coefficients
Dependent Variable: posttest
4.882 1 4.882 .438 .513
Source group* pretest
Type III Sum
of Squares df Mean Square F Sig.
Table 11 shows the ANOCA result (F=5.785, sig of F=0.022) after adjusting the dependent effect (group) with respect to the covariance (pre-test), and it reaches the significant level. This result indicates that the post-test of two groups has significantly different. Next, Table 12 displays the estimated score of post-test after removing the effect of covariance and this study found that the post-test score of the experimental group is higher than that of the control group. Thus, this study concluded that the learners who used the proposed vocabulary learning system with context-aware service had better learning performance than the learners who used the vocabulary learning system without context-aware service.
Table 11. The ANOCA result of two groups
Dependent Variable: posttest
63.336 1 63.336 5.785 .022
Source group
Type III Sum
Table 12. The estimated score of two groups after adjusting the dependent effect with respect to the covariance
Dependent Variable: posttest
13.711a .793 12.097 15.326 16.455a .793 14.841 18.069 class control group experimental group
Mean Std. Error Lower Bound Upper Bound 95% Confidence Interval
Covariates appearing in the model are evaluated at the following values: pretest = 11.50.
a.
3.3.2.2 Questionnaire analysis
To assess learner satisfaction degree for the proposed personalized context-aware English vocabulary learning system, a questionnaire involving 23 questions dealing with four areas was designed to measure whether the proposed English vocabulary learning system satisfies the requirements of most learners. The four question types contain personal information relating to learner learning by PDA, the convenience of system operation, the investigation of learner learning attitude towards using the proposed learning system, and the self assessment of learners’ English vocabulary ability before and after using the proposed English vocabulary learning system. Table 13 summarizes the descriptions of question types. Eighteen learners in the experimental group were invited to complete this questionnaire after attending the two week learning activity.
Table 13. The descriptions of question types
Question Type The number
of questions Description
Personal Information
about Using PDA 3
To get the personal information about learners who attend the learning activity using the proposed system
System Operation 9 Questions related to the user interface and the content of learning materials Learning Attitude 10 To investigate whether the system can enhance learners’ learning motivation or interests and
promote their learning achievements or not
Self Assessment 1
To ask learners for self-assessing their English vocabulary abilities before and after using the proposed learning system
Table 14 lists the results of satisfaction evaluation. To simplify the analytical results, the responses “strongly agree” and “agree” are merged into the single response of “approved”, and the responses of “strongly disagree” and “disagree” are merged into the single response of “disapprove” The evaluation results indicate that the satisfaction degree of “approved” achieves 54.9% in terms of system operation and 56.1% with regard to learning attitude, as listed in Tables 14(b) and (c).
Table 14. The satisfaction evaluation results of questionnaire (a) The investigation results of the personal information
The Number of Learners Question Type Question
Yes No
Do you or your family have PDA or mobile phone with PDA? 3 15
Do you use PDA first time? 13 5
Personal
Information about
Using PDA Have you ever used PDA for learning? 3 15
(b) The investigation results of the system operation
Satisfaction Degree (%) Question Type Question strongly
disagreed disagreed
no
opinion Agreed
strongly agreed
I think that the proposed context-aware ubiquitous English vocabulary learning system
provides a friendly user interface. 0 0 27.8 44.4 27.8
I am very clear about the learning procedure of the proposed context-aware ubiquitous English
vocabulary learning system. 0 0 11.1 72.2 16.7
I agree that applying location-based context-aware technique in the leaning is novel
and it can assist my learning. 0 5.6 50 22.2 22.2
I agree that the English vocabulary materials
presented on the PDA are very clear. 0 17 38.9 44.4 0
I agree that the vocabularies recommended by the system are highly relevant with my learning
location and learning time. 0 5.6 61.1 27.8 5.56
I think the proposed context-aware ubiquitous English vocabulary learning system is a useful learning tool to assist English vocabulary learning.
0 5.6 38.9 33.3 22.2
I agree that learning English vocabulary by PDA is very convenient; because I can perform
English learning at any time and place. 17 5.6 27.7 27.8 22.2
The proposed context-aware ubiquitous English vocabulary learning system can effectively
assist my learning. 5.6 5.6 44.4 38.9 5.56
If there are similar English curriculums in the future, I am pleasure to use the proposed system
to learn English once again. 5.6 11 22.2 38.9 22.2
System Operation
Average 9.4 35.7 54.9
(c) The investigation results of the learning attitude
Satisfaction Degree (%) Question Type Question strongly
disagreed disagreed
no
opinion Agreed
strongly agreed
The design learning materials on the proposed context-aware ubiquitous English vocabulary learning system can promote my learning interests.
0 11 44.4 33.3 11.1
Learning Attitude
I often increase my learning time because learning by the proposed context-aware ubiquitous English vocabulary learning system promotes my learning interest.