I-Shou University Institutional Repository:Item 987654321/18700
64
0
0
全文
(2) 義. 守. 大. 學. 資 訊 管 理 研 究 所 碩士論文 運用資料探勘與模糊邏輯技術建立 糖尿病診斷系統. A Diabetes Diagnosis System Using Data Mining and Fuzzy Logic Techniques. 指導教授:劉振隆博士 研究生:楊巧暄. 中華民國一百零四年六月.
(3) 運用資料探勘與模糊邏輯技術建立 糖尿病診斷系統. A Diabetes Diagnosis System Using Data Mining and Fuzzy Logic Techniques 研 究 生:楊巧暄. Student:Ciao-Syuan Yang. 指導教授:劉振隆 博士. Advisor:Dr. Jenn-Long Liu. 義守大學 資訊管理研究所 碩士論文. A Thesis Submitted to Institute of Information ManAgement I-Shou University in Partial Fulfillment of the Requirements for the Master Degree in Information ManAgement June, 2015 Kaohsiung, Taiwan, Republic of China. 中 華 民 國 一百零四年 六 月 II.
(4) 運用資料探勘與模糊邏輯技術建立 糖尿病診斷系統 研 究 生 : 楊巧暄. 指導教授:劉振隆 博士. 義守大學資訊管理研究所. 摘要 隨著現代人開始注重健康飲食與身體保健,大家常常會去醫院做健康檢查,而健康 報告出來都是一堆密密麻麻的生理數據,一般民眾大部分都是非專業領域,常常會因為 看不懂而困擾著。本研究是以資料探勘技術中的決策樹應用於糖尿病之預測,其病例經 分析後可驗證哪些病例之屬性會引起糖尿疾病。本研究採用 UCI Machine Learning Repository 網站內的 Pima Indians Diabetes Data Set 總共有 768 筆樣本資料,這些資料採 用屬性分析,找出屬性的顯著性,保留顯著性高之屬性,刪除顯著性低之屬性,可使得 預測結果之準確性提高。之後本研究採用模糊理論來建置模糊專家系統,將模糊專家系 統作為罹糖尿病診斷之用,藉由糖尿病的危險因子來建立完整的模糊規則知識庫,讓使 用者輸入對應的生理指數,找出符合的模糊規則,最後預測出得糖尿病的風險評估。本 研究結果可以輔助民眾自行做簡易的糖尿病預測,並亦可提供給醫師做診斷時之分析參 考。. 關鍵字:資料探勘、決策樹、糖尿病、統計分析、模糊理論、專家系統. III.
(5) A Diabetes Diagnosis System Using Data Mining and Fuzzy Logic Techniques Student:Ciao-Syuan Yang. Advisor:Dr. Jenn-Long Liu. Department of Information ManAgement I-Shou University. ABSTRACT. As people began to focus on health, we go to the hospital for a physical examination. But most people do not realize and are confused about the physiological data. This study is based on the decision tree of data mining techniques to predict diabetes. It could verify the property which can cause diabetes disease. This study adopts a total of 768 sample data accessed from Pima Indians Diabetes Data in UCI repository database as the disease database. This study applies attribute analysis to find out the significant attributes. By retaining the attributes with High significance to the disease and deleting those with Low significance to the disease, the accuracy of prediction can be improved. Besides, this study uses fuzzy theory to build up a fuzzy expert system, and then we combine the fuzzy expert and the database of diabetes disease to create fuzzy rules by using the key attributes of diabetes disease. Afterward, a user can enter the physiological indices into the system to create the appropriate fuzzy rules and obtain the risk assessment of diabetes disease. The results of this study not only can assist people to do their own simple diabetes prediction, but also the study can provide a physician for a reference when he/she makes a medical diagnosis to a patient with diabetes disease. Keywords: data mining, decision tree, diabetes, statistical analysis, fuzzy theory, expert system.. IV.
(6) 目錄 摘要 .......................................................................................................................................... III Abstract .................................................................................................................................... IV 目錄 ........................................................................................................................................... V 表目錄 ...................................................................................................................................... VI 圖目錄 ................................................................................................................................... VIII 第一章 緒論 .............................................................................................................................. 1 1-1 研究動機 ......... ……………………………………………………………………………1 1-2 研究目的 ......... ……………………………………………………………………………2 1-3 研究流程 ......... ……………………………………………………………………………3 第二章 文獻探討 ...................................................................................................................... 4 2-1 2-2 2-3 2-4 2-5. 糖尿病…………………………………………………………………………………4 資料探勘概述 ..…………………….…………………………………………………6 模糊理論 …………………………………………….………………….……………11 資料探勘之應用………………………………………………………………………14 糖尿病與資料探勘之相關研究………………………………………………………15. 第三章 研究方法 .................................................................................................................... 16 3-1 3-2 3-3 3-4 3-5. 研究流程………………………………………………………………………………16 研究方法介紹…………………………………………………………………………26 資料屬性………………………………………………………………………………18 屬性之計算方式………………………………………………………………………21 模糊邏輯………………………………………………………………………………21. 第四章 研究結果 .................................................................................................................... 25 4-1 糖尿病屬性分析………………………………………………….…………………...25 4-2 糖尿病疾病資料探勘分析比較………………………………………………………28 4-3 糖尿病資料探勘 J48 決策樹分析…………………………………………………….35 4-4 統計分析結果………………………………………………………………………….36 4-5 模糊專家系統………………………………………………………………………….39 第五章 結論與建議 ................................................................................................................ 50 5-1 結論…………………………………………………………………………………….50 5-2 建議…………………………………………………………………………………….50 參考文獻 .................................................................................................................................. 52 V.
(7) 表. 目. 錄. 表 1-1. 近年來台灣十大死因之死亡人數………………………………………………1. 表 3-1. 資料屬性值域表…………………………………………………………………18. 表 3-2. 類別屬性分析計算公式…………………………………………………………21. 表 3-3. 糖尿病功能檢驗表………………………………………………………………22. 表 3-4. 語意變數及範圍…………………………………………………………………22. 表 4-1. INFORMATION GAIN 重要程度比較…………………………………………25. 表 4-2 GAIN RAIO 重要程度比較…………………………………………………………25 表 4-3 ONER ATTRIBUTE EVALUATOR 屬性重要程度比較……………………………26 表 4-4 SYMMETRICAL UNCERTAINTY 屬性重要程度比較…………………………26 表 4-5 數值屬性懷孕次數分析結果…………………………………………………………27 表 4-6 類別屬性 2 小時內血漿中葡萄糖的含量分析結果…………………………………27 表 4-7 類別屬性舒張壓分析結果……………………………………………………………27 表 4-8 類別屬性三頭肌皮褶厚度分析結果…………………………………………………27 表 4-9 類別屬性 2 小時內血清胰島素分析結果……………………………………………27 表 4-10 類別屬性體重指數分析結果………………………………………………………28 表 4-11 類別屬性糖尿病家族函數分析結果………………………………………………28 表 4-12 類別屬性年齡分析結果……………………………………………………………28 表 4-13 屬性重要程度排名結果……………………………………………………………28 表 4-14 混亂矩陣……………………………………………………………………………29 表 4-15 成本矩陣……………………………………………………………………………29 表 4-16. 768 筆演算法之混亂矩陣(USE. TRAINING. SET)…………………………31. 表 4-17 768 筆演算法之混亂矩陣(10 CROSS VALIDATION)…………………………31 表 4-18 八個變數分析結果(10 CROSS VALIDATION)……….....………………………32 表 4-19 七個變數分析結果(10 CROSS VALIDATION)…………………………………32 VI.
(8) 表 4-20 六個變數分析結果(10 CROSS VALIDATION)…………………………………33 表 4-21 五個變數分析結果(10 CROSS VALIDATION)…………………………………33 表 4-22 四個變數分析結果(10 CROSS VALIDATION)…………………………………34 表 4-23 三個變數分析結果(10 CROSS VALIDATION)…………………………………34 表 4-24 四個變數分析結果(USE TRAINING SET)………………………………………35 表 4-25. PEARSON 卡方檢定整理表…………………………….………………………37. 表 4-26. 獨立樣本 T 檢定整理表…………………………………………………………38. 表 4-27. ANOVA 表格……………………………………………………………………39. VII.
(9) 圖目錄 圖 1-1. 台灣近十年十大死因變化(行政院衛生福利部)………………………………2. 圖 2-1. 資料庫知識發現(KDD)………………………………………………………….7. 圖 2-2. 跨產業標準流程(CRISP-DM)…………………………………………………8. 圖 2-3. BOOLEAN LOGIC 與 FUZZY LOGIC 示意圖…………………………………11. 圖 2-4. 模糊推論系統之架構圖…………………………………………………………13. 圖 2-5. 模糊化示意圖……………………………………………………………………14. 圖 3-1. 研究流程圖………………………………………………………………………16. 圖 3-2. MAMDANI 的 MIN-MIN-MAX 推論……………………………………………24. 圖 4-1. 768 筆 J48 決策樹分析……………………………………………………………36. 圖 4-2. 相關係數整理表…………………………………………………………………36. 圖 4-3 迴歸分析表…………………………………………………………………………37 圖 4-4 JFUZZYLOGIC 之模糊化………………………..…………………………………40 圖 4-5 變數飯後兩小時血糖(GLUCOSE)之歸屬函數圖…………………………………41 圖 4-6 變數舒張壓(DBP)之歸屬函數圖……………………………………………………41 圖 4-7 變數胰島素(INSULIN)之歸屬函數圖………………………………………………41 圖 4-8 變數體重指數(BMI)之歸屬函數圖…………………………………………………42 圖 4-9 變數是否抽菸(SMOKING)之歸屬函數圖…………………………………………42 圖 4-10 變數是否一星期有運動 3 次(EXERCISE)之歸屬函數圖…………………………42 圖 4-11 變數是否常吃垃圾食物(JUNK FOOD)之歸屬函數圖…………………………43 圖 4-12 風險評估等級圖……………………………………………………………………43 圖 4-13 模糊規則……………………………………………………………………………44 圖 4-14 模糊專家系統介面一………………………………………………………………45 圖 4-15 模糊專家系統介面二………………………………………………………………45 圖 4-16 風險評估結果………………………………………………………………………46 VIII.
(10) 圖 4-17 第 255 筆資料測詴………………………………………………………………46 圖 4-18 第 255 筆資料測詴結果…………………………………………………………47 圖 4-19 第 377 筆資料測詴………………………………………………………………47 圖 4-20 第 377 筆資料測詴結果……………………………………………………………48 圖 4-21 第 561 筆資料測詴…………………….……………………………………………48 圖 4-22 第 561 筆資料測詴結果……………………………………………………………49. IX.
(11) 第一章. 緒論. 1-1 研究動機 近年來由於台灣生活品質提高、生活作息與飲食的改變,而高澱粉、高精緻食物以 及國人鮮少運動、日夜顛倒,再加上現代人工作忙碌且普遍都有熬夜的傾向,導致國人 的糖尿病一直是全國十大死因排行之一。目前最新公布的國人十大死因是民國102年之 台灣十大死因之死亡人數資料,如表1-1。 比照過去幾年,民國 90 年時位居第五名,民國 95 年後位居於第四名,如圖 1-1。 雖然從資料中顯示糖尿病在全國十大死因排名幾乎位居第五名,但是在死亡人數方面從 一開始的四千多人上升到九千人,90 年之後就一直維持在九千人左右,居高不下。. 表 1-1 近年來台灣十大死因之死亡人數 疾病名稱 民國. 死亡人數 80年. 85年. 90年. 95年. 102年. 惡性腫瘤. 19,630. 27,961. 32,993. 37,998. 44791. 心臟疾病. 12,026. 11,273. 11,003. 12,283. 17694. 腦血管疾病. 14,137. 13,944. 13,141. 12,596. 11313. 2,644. 3,200. 3,746. 5,396. 9042. 4,210(5). 7,525(5). 9,113(5). 9,690(4). 9438(4). 13,636. 12,422. 9,513. 8,011. 6619. 慢性下呼吸道疾病. 2,176. 2,036. 1,589. 1,231. 5959. 高血壓性疾病. 2,492. 2,656. 1,766. 1,816. 5033. 慢性肝病及肝硬化. 3,601. 4,610. 5,239. 5,049. 4843. 2,527. 3,547. 4,056. 4,712. 4489. 肺炎 糖尿病 事故傷害. 腎炎、腎徵症候群 與腎性病變. 資料來源:行政院衛生福利部,(2014).
(12) 圖 1-1 台灣近十年十大死因變化(行政院衛生福利部). 1-2 研究目的 由於在國人十大死因中,糖尿病已經是排行第四順位,因糖尿病到目前為止並沒有 找到完全根治之方法,且在糖尿病(李秀琴 2003)初期並沒有特別顯著之特徵可供察覺自 身是否已罹患糖尿病,而往往容易被忽略,一旦罹患後就必頇終生以藥物治療與控制, 且糖尿病也與其他慢性疾病有顯著的關係,目前相關衛生單位也開始重視糖尿病的衛教 與預防。而現今資料探勘技術在醫學診斷方面已日益成熟,故本研究希望能利用人工智 慧相關技術,輔助醫療單位判別病患是否有得糖尿病的可能性或者胰臟功能是否有異常 跡象,進而達到預防糖尿病的發生或儘早檢驗出來提早做治療追蹤。 本研究是以糖尿病的資料庫數據運用資料探勘的分類決策樹來做預測,利用屬性分 析來篩選關鍵屬性,移除不顯著的屬性,找出糖尿病的關鍵屬性,預期準確率將可以提 升,再加上本研究透過文獻找出的三項生活危險因子,其用這些變數來建立模糊專家系 統,提供給民眾方便檢測是否有肝病的傾向之簡單分析工具,進而讓民眾了解自己身體 健康狀況,藉此達到提早發現提早做治療的效果。. 2.
(13) 1-3 研究流程 本論文進行流程如圖 1-2 所示。第一章為緒論,說明本研究的動機與目的,並針對 糖尿病在台灣十大死因作簡述。第二章為文獻探討,主要說明糖尿病的基本認知與資料 探勘的概述,再探討糖尿病與資料探勘為主的相關研究。第三章研究方法為本研究架構, 探討糖尿病利用資料探勘方法做分類分析,並依屬性重要程度排行,一一刪除不顯著屬 性,再用決策樹進行案例研究,整理歸納出關鍵屬性,並且提升預測準確率。第四章為 本研究的研究結果,探討糖尿病數據資料採用資料探勘做分類分析,分類方法是以 Weka 資料探勘軟體的 NB Tree、J48、貝氏網路(Bayes Net)、純樸貝氏法(Naive Bayes)、Multilayer Perceptron 共五種分類演算法,接著配合著依屬性重要程度一一做案例研究,並篩選出 關鍵屬性,以提升預測準確度。最後依照相關文獻研究結果做為影響糖尿病的生活因子: 抽菸、飲食及運動,運用模糊邏輯建置模糊專家系統,來方便一般民眾做簡易預測糖尿 病之輔助工具。第五章為本研究結論與建議,說明後續探討的研究方向。. 第一章:緒論. 第二章:文獻探討. 第三章:研究方法. 第四章:研究結果. 第五章:結論與建議. 3.
(14) 第二章. 文獻探討. 本章節將介紹糖尿病的相關病症成因和預防,以及資料探勘與的概念,再來探討資 料探勘為主的相關應用研究。. 2-1 糖尿病 糖尿病(英語:Diabetes Mellitus )是一種代謝性疾病,它的特徵是血糖長時間高 於標準值。高血糖會造成三多一少的症狀:吃多、喝多、尿多、以及體重下降。除此之 外,糖尿病症狀還會使患者有以下幾條症狀。 1.. 容易疲勞:糖尿病患者身體容易疲勞、長青春痘、做事無法像往日精神旺盛。 這種倦怠感有時是全身,有時僅下半身。例如稍微爬樓梯時,就覺得兩腿酸痛, 疲累不堪,或飯後感到倦怠等。. 2.. 視力減退:有些人常因視力模糊、眼睛容易疲勞,經眼科醫師檢後,才發現罹 患了糖尿病。糖尿病性網膜症於中高齡的患者較多;而白內障年輕人較易患, 所以應該特別小心。. 3.. 末稍神經症狀:糖尿病人易有頑固性的手脚痲痺與陣痛感。因糖尿病而引起的 神經炎脚痛症者較多,有時候會激烈的疼痛。也有人夜間小腿會抽筋。. 4.. 皮膚搔癢:糖尿病人皮膚的抵抗力也同時減弱,受傷時易引起感染、長癤瘡、 炎症容易擴張。尤其是女性患者有時會有陰部發癢的情形。. 5.. 傷口不易癒合. 6.. 女性月經異常:女性的糖尿病患者,有時月經不規則,或月經禁閉。這是因為 缺乏胰島素的荷爾蒙所致,是性荷爾蒙失去平衡而引起的。. 7.. 男性陽萎症狀:勃起神經與排尿時都是由骶髓中的神經中樞所控制。糖尿病人 因人體的糖或維他命代謝異常,會有引發陽萎現象。因此,沒有正確的醫學常 識而任意購服強壯劑、民間藥物,對治療陽萎都無效用。. 4.
(15) 如果未經治療,糖尿病可能引發許多併發症。急性併發症包括糖尿病酮酸血症與 高滲透壓高血糖非酮酸性昏迷,嚴重的長程併發症則包括心血管疾病、中風、慢性腎臟 病、糖尿病足、以及視網膜病變等。 糖尿病的成因:糖尿病乃因胰島(藍蓋罕士島,Islands Of Langerhans ) 中的 β 細胞 分泌的胰島素荷爾蒙先天性不足或相對性不足;或是肥胖,使糖質 ( 碳水化合物 ) 代 謝異常及其他原因所引起的慢性病。其中,胰島素由胰臟的β細胞產生。首先由肝臟吸 收後,將葡萄糖合成為肝醣,當胰島素不再產生或無效用時,肝醣的製造會減少,且葡 萄糖在周邊組織的利用就會減少,結果由各種來源進入循環之葡萄糖的移除會減緩,而 形成高血壓糖;此過多的血糖無法完全由腎小管再吸收,於是尿液中糖分上升,稱為糖 尿。換言之,就是胰島素經肝臟再至全身,讓需要胰島素的肌肉細胞和脂肪細胞等使用, 因有胰島素這種荷爾蒙,我們人體的熱量源葡萄糖才能進入上述的細胞內,胰島素從形 成、分泌到讓需要的末稍細胞使用,若某一環節發生問題,便產生所謂的糖尿病。 由此可知,胰島素的主要功能就是把葡萄糖和脂肪轉化成能源,或貯存在體內。 也就是當我們吃下東西後,由於消化的作用,血液裡的血糖會漸漸升高。靠著胰臟分泌 的胰島素,將葡萄糖合成肝醣儲存,使血液中的血糖下降;並使血液中的葡萄糖,轉變 成可供利用的能源。因此要是沒有胰島素或胰島素分泌不正常,人體無法把食物轉變成 身體可利用的能源或營養,那人體的正常功能也就無法維持。 臨床上糖尿病則被分為三類: 1. 第一型糖尿病是由於身體無法生產足夠的胰島素,過去也被叫做胰島素依賴型糖尿 病(Insulin Dependent Diabetes Mellitus, IDDM)或是青少年糖尿病。在台灣,根據 中華民國糖尿病衛教學會在 2002 及 2004 年的調查,第 1 型糖尿病約佔所有糖尿病 的 2~4%。通常從童年或青少年時期即已開始,但也可能在任何年紀發病。這種糖尿 病通常發生於纖瘦或正常體重的人身上。當身體本身的防禦(免疫)系統破壞到胰 臟的 beta 細胞時,就形成了第 1 型糖尿病。雖然沒有人知道確實的發生原因,但科 學家們相信,家族病史和環境刺激因子(例如像 B 型柯沙奇病毒(Coxsackie B Virus) 這類病毒)可能在「自體免疫」中扮演了某種角色。 5.
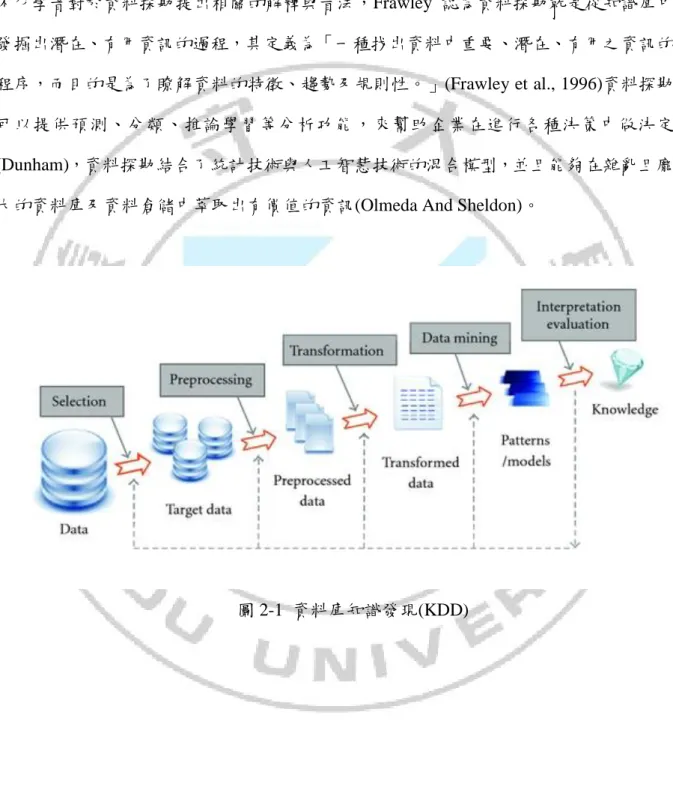
(16) 2. 第二型糖尿病始於胰島素抵抗(細胞對於胰島素的反應不正常),隨著病情進展胰 島素的分泌亦可能漸漸變得不足。這個類型過去被稱為非胰島素依賴型糖尿病 (NonIInsulin Dependent Diabetes Mellitus, NIDDM)或成人型糖尿病,病因是體重過 重或缺乏運動。早期第二類糖尿病患者可能可以通過改善生活方式(如健康飲食、 適量運動、安全減肥、戒菸及避免二手菸暴露等)來控制、甚至治癒糖尿病。大多 數患者可通過口服降糖藥物來幫助控制體內血糖。一些第 2 類糖尿病患者需要胰島 素注射。 3. 妊娠糖尿病是一種發生在懷孕期間的糖尿病,通常在嬰兒出生後就會消失。台灣妊 娠糖尿病發生率為 5.7%,通常在孕期第 24 至 28 週時可以檢測出來。妊娠糖尿病應 在懷孕期間就應嚴密的控制血糖,以預防媽媽和寶寶發生問題。. 糖尿病的預防與治療方式包括維持均衡飲食、規律運動、戒菸、維持理想體重。對 於糖尿病患者來說,血壓控制與足部護理也相當重要。第一型糖尿病必頇注射胰島素控 制血糖;而第二型糖尿病則可以使用口服藥控制,若有需要也可以搭配胰島素注射。糖 尿病用的部分口服藥與胰島素都可能造成低血糖。對同時患有肥胖症的第二型糖尿病患 者而言,減肥手術是有效的治療。而對於妊娠糖尿病的患者來說,血糖通常會在生產後 恢復正常。. 2-2 資料探勘概述 資料探勘(Data Mining)除了廣泛地被運用在各專業領域上,近年來,相關的探勘技 術更是普遍被應用在醫療研究領域。在醫療研究領域上大部分都應用在輔助醫生判斷與 預測疾病方面。 資料探勘(Data Mining)又稱之為資料採礦。在廣義定義中可以解釋為資料庫之知識 發現(Knowledge Discovery In Databases,KDD),如圖 2-1 所示,知識發現的步驟為:資 料選取、資料前置處理、資料倉儲建立、資料探勘、評估與結果展示。也就是說,從一. 6.
(17) 個大型資料庫裡透過特定的方法挖掘出有價值的知識,去除一些不合適的資料,將資料 轉換找出具有意義的資料模式。而現今,是個資料爆炸的時代,要如何在巨量的資料中 快速且有效率地找出有價值的資訊,是目前各個行業領域所必需要的技術。近幾年,有 不少學者對於資料探勘提出相關的解釋與看法,Frawley 認為資料探勘就是從知識庫中 發掘出潛在、有用資訊的過程,其定義為「一種找出資料中重要、潛在、有用之資訊的 程序,而目的是為了瞭解資料的特徵、趨勢及規則性。」(Frawley et al., 1996)資料探勘 可以提供預測、分類、推論學習等分析功能,來幫助企業在進行各種決策中做決定 (Dunham),資料探勘結合了統計技術與人工智慧技術的混合模型,並且能夠在雜亂且龐 大的資料庫及資料倉儲中萃取出有價值的資訊(Olmeda And Sheldon)。. 圖 2-1 資料庫知識發現(KDD). 7.
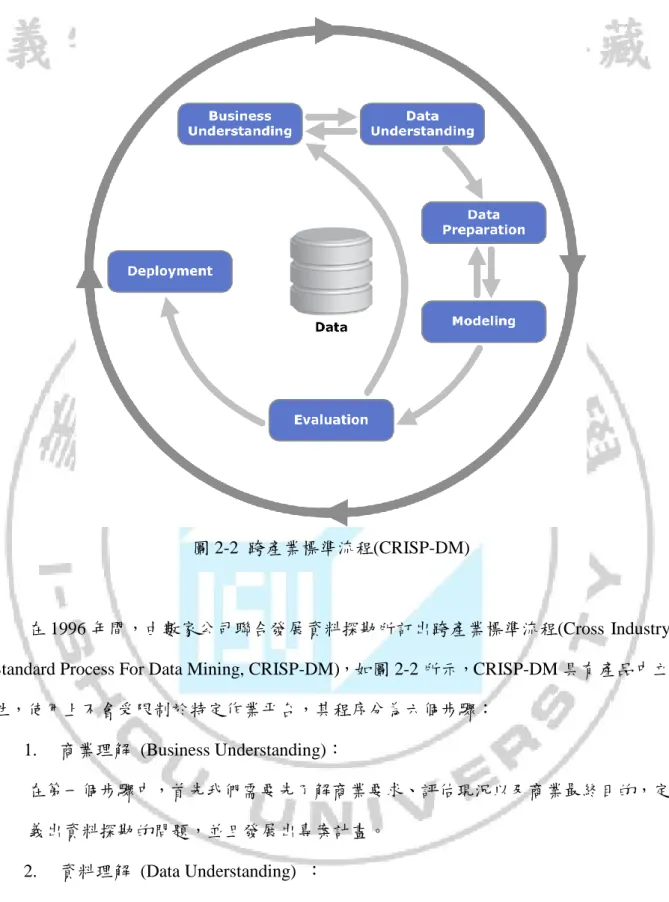
(18) 圖 2-2 跨產業標準流程(CRISP-DM). 在 1996 年間,由數家公司聯合發展資料探勘所訂出跨產業標準流程(Cross Industry Standard Process For Data Mining, CRISP-DM),如圖 2-2 所示,CRISP-DM 具有產品中立 性,使用上不會受限制於特定作業平台,其程序分為六個步驟: 1.. 商業理解 (Business Understanding):. 在第一個步驟中,首先我們需要先了解商業要求、評估現況以及商業最終目的,定 義出資料探勘的問題,並且發展出專案計畫。 2.. 資料理解 (Data Understanding) :. 主要收集完整的資料,並且對資料做初步分析、資料描述以及資料品質的確認。 3.. 資料預備 (Data Preparation) :. 8.
(19) 資料準備是在確認資料的可用性,接著經過選取、整理與處理成所需的資料型態。 主要是資料轉換的工作,必頇把不同數值尺度間的資料轉換以及將類別資料轉換成 數值形式資料,以方便進行資料分析。 4.. 建模 (Modeling) :. 在資料建模階段,頇將資料分割成訓練資料集與測詴資料集,來測詴與建立模型架 構,被用來建構模型的訓練集會占用大多數的資料(80%),而剩下的部分(20%)則被 當作測詴資料集。依照不同的專案會採取不同的方法,資料探勘的以下數種方法: 關聯法則(Association)、分類分析(Classification)、群集分析(Clustering)、預測分析 (Prediction Analysis)、次序分析(Sequential Pattern Analysis)與時間次序分析(Similar Time Sequences)。 5.. 評估 (Evaluation) :. 此階段主要分析結果,證實所設計出來的模型是否有符合專案之目的,確認探勘出 來的知識是否對企業有價值。 6.. 部署 (Deployment) :. 探勘出來的結果頇能與專案目標相結合出新知識,然後將新知識應用在所面臨商業 競爭上,探勘所得到的知識要隨時觀察,以防止時間與環境的改變,而成為不符合 目標所需的舊知識。. 資料探勘發展到現在,已經有許多技術被提出來解決問題,每種技術都有不同的特 性,所以常會依照不同的需求來選用不同的探勘技術,資料探勘技術根據不同的分析方 式與功能可分為:分類分析(Classification Analysis)、關聯規則分析(Association Rule Analysis)、群集分析(Clustering Analysis)、推估(Estimation)、預測(Prediction)、描述及視 覺化(Description And Visualization) (Berry, And Linoff, 1997)。 1.. 分類分析(Classification Analysis): 分類分析是一種監督式學習(Supervised Learning),先給予每一類別的屬性與特徵加 以定義,透過所準備的訓練資料,依據屬性建立一個分類模式,用來將尚未分類的 9.
(20) 原始資料或新進的資料,依照前述的屬性與類別之關係加以分類。換句話說,分類 就是將每一類別的特徵定義好,再透過訓練資料建立分類模式,將尚未分類的資料 進行分類。主要的分類技術有:貝氏分類法(Bayesian Classifiers)、類神經網路(Neural Network)、決策樹(Decision Tree)、模糊理論(Fuzzy Theory)等。 2.. 關聯規則分析(Association Rule Analysis) : 關聯法則是在資料庫中發掘屬性彼此之間的關聯性,這些關聯通常以規則來表示, 與其他的探勘技術不同的是,關聯法則可以不只有一個輸出屬性,且每一個規則的 輸出屬性都可做為另一條規則的輸入屬性,這樣在有限的屬性內,將可發展出數以 百計的關聯法則,並利用這些法則去建立模型,再將此模型拿去分析資料與預測。 最典型的實例應用就是購物籃分析(Market Basket Analysis)。. 3.. 群集分析(Clustering Analysis) : 群集分析也被稱作為分群分析是一種非監督式的學習模式(Unsupervised Learning), 主要是將所有的屬性分成若干群體,同性質屬性會聚集在同一群,達到其群內為同 性質較高,而群與群之間的差異性較大,和分類不同的是,群集過程中不需要事先 定義,也不需要訓練資料,使用者從資料庫中找出群組的屬性規則,就能找出未知 的目標值。常見的群集分析有:階層式群集演算法(Hierarchical Methods)、分割式 群集演算法(Partitioning Methods)、分格式群集演算法(Grid Based Methods)、密度測 量式群集演算法(Density Based Methods)以及混合式群集演算法(Hybrid Methods)。. 4.. 推估(Estimation) : 推估通常是運用在連續性數值之相關屬性資料。根據既有的連續性數值,藉由輸入 資料,來推估出未知的連續性數值走向與趨勢。通常應用在金融商品價格的趨勢變 化以及進銷貨庫存量的變化預測。. 5.. 預測(Prediction) : 預測是根據屬性的過去觀察值來預測該屬性未來的趨勢,作法是利用一種或多種獨 立變數,用來找出某個因變數或標準的值,所有用來進行分類與推估的技術都可以. 10.
(21) 透過已知的變數數值之資料來進行預測。可應用在顧客過去的刷卡消費量來預測未 來的刷卡消費量等。 6.. 描述及視覺化(Description And Visualization): 當資料探勘結果呈現複雜狀況時,會採用這種方式來讓決策者能更快速的了解有用 的資訊,大部分的資料探勘工具都具有描述性與視覺化的功能。. 2-3 模糊理論 在現實生活中,有許多問題是存在著各種模糊現象,無法明確描述某個概念,例如: 天氣的冷熱、聲音的大小、身體的胖瘦等。在我們的生活中存在許多模糊和非定量化的 特性,有時硬要將這些問題使用傳統數學方式,以二分法強行分類,反而可能會產生錯 誤的結果。 模糊理論(Fuzzy Theory)的概念最早是由美國加州大學 Zadeh 教授於 1965 年提出模 糊集合(Fuzzy Set),對於模糊集合理論的解釋,定義為「某一集合元素屬於某個集合的 程度,可用 0 與 1 之間的某個數值來表示的方法」(Zadeh,1965)。1973 年 Zadeh 提出 模糊邏輯(Fuzzy Logic)應用於控制領域(Zadeh, 1975),此理論打破了傳統的二元邏輯觀 念,模糊邏輯理論強調許多事實的結果無法符合傳統的二元邏輯,不在「是」與「否」 兩者選擇其一,而是介於「是」與「否」之間,如圖 2-3 所示。因此在模糊集合內的隸 屬函數可以有無限多種可能,在不同的環境下,模糊系統可以調整隸屬函數的特性,達 到傳統集合所不能做到的適應性。目前模糊理論在應用上非常廣泛,如醫療、控制工程、 空調系統、自動化控制、專家系統、軟體工程、排程、預測、自然語言處理等應用。. 圖 2-3. Boolean Logic 與 Fuzzy Logic 示意圖. 11.
(22) 模糊集合: 模糊集合用來表示邊界不明確的模糊概念集合,當一個元素歸屬於某集合的程度越大時, 則歸屬程度越接近於 1,否則越接近 0,換句話說,在 0 與 1 之間的數值,都可以被當 作元素歸屬於某一個模糊集合的程度,不像傳統集合中,元素的歸屬程度只有 0 或 1。 介紹模糊集合常用的兩種集合: ~ ~ ~ ( A、B、C 為模糊集合, A~、 B~、C~ 分別表示為歸數函數). ~ ~ ~ 聯集:模糊集合 A 與 B 的聯集為 C ,其中取兩者之間較大者為 MAX. c~ A~ B~ max A~ x , B~ x . (2.1). ~ ~ ~ 交集:模糊集合 A 與 B 的交集為 C ,其中取兩者之間較小者為 MIN. c~ A~ B~ max A~ x , B~ x . (2.2). 語意變數與歸屬函數: 語意變數(Linguistic Variables)是用模糊集合來表達其值的變數,可以將敘述性的文 字或詞語表示成值,利用這種特性來解決不確定的情況以及非量化系統的問題(Zadeh, 1975)。一般語意變數採用的詞語都會以自然語言為主,如專家對風險的評估:{非常高、 稍高、高、中、稍低、低、非常低},利用語意變數轉換為模糊邏輯評估數值,來達到 量化之目的。 歸屬函數(Membership Function)是傳統函數的延伸,也就是將傳統集合的 0 與 1 之 間的二元邏輯,延伸為 0 至 1 之間的任何值都可以選擇,而得到的函數稱之為歸屬函數。 對於連續變數而言,歸屬度是由歸屬函數用來表示某一元素是屬於某一個概念程度,將 此數值稱為元素在集合的歸屬程度(Degree Of Membership)。 模糊規則: 模糊規則(Fuzzy Rule)是一種建立知識的方法,每一條規則包含了前提與結論,當前 提成立時,可以得到相對應的結論,由於人類的經驗及語言常常充滿著不確定性,所以. 12.
(23) 利用模糊理論能夠處理好語意變數的特質,故以模糊規則的方式將人類的經驗或感知更 清楚地表達出來。 模糊規則是採用「若…(前提),則…(結論)」(If-Then)法則,根據結論的型態不同, 大致可以分為兩種常用的型態: 輸出為常數: ~ ~ IF ( x1 IS A1 ) AND ( x2 IS A2 ) , THEN y IS c. 輸出為函數: ~ ~ IF ( x1 IS A1 ) AND ( x2 IS A2 ) , THEN y IS f x1 , x2 . 模糊推論系統: 模糊推論系統(Fuzzy Inference Systems)包含了四個主要部分,如圖 2-4 所示。. 圖2-4 模糊推論系統之架構圖. 1.. 模糊化介面 主要接收資料輸入值,並且將值進行量化,也就是將值轉換成可被模糊集合表現的 語意變數,如圖2-5,將輸入值對應到歸屬函數,得到對應過後的歸屬值。. 13.
(24) 圖2-5 模糊化示意圖. 2.. 模糊知識庫 主要是由資料庫(Data Base)與規則庫(Rule Base)組成資料庫提供語意變數所需的定 義,如變數範圍、語言項集合和歸屬函數的設定等,利用定義出來的語言控制規則 來描述控制目標和專家領域經驗的控制策略。. 3.. 模糊推論機構 此部分為模糊推論的核心,具有模擬人類做決策判斷的能力,根據知識庫所給予的 規則經過推論導出新的結論,視為是從模糊規則中獲得結論的推論程序。一般常用 的模糊推論模式有:Mamdani模式、Sugeno模式與Tsukamoto模式等。本研究採用 Mamdani模式。. 4.. 解模糊化介面 此部分與模糊化過程恰好相反,主要是將經過推論所得到的模糊化結果,必頇要轉 化成明確數值或對等的明確值域才能輸出,產生實際明確的控制動作。一般使用的 解模糊化方法有:重心法(Center Of Gravity)、最大值平均值法(Mean Of Maximum)、 總合中心法(Center Of Sums)、高度法(High)…等。. 2-4 資料探勘之應用 曾瑞智(2013)將資料探勘應用於行銷方面上,用來發掘潛在顧客獲取更大的利益。 研究出利用資料探勘技術來提出整合性之目標客戶選擇的模型,整合支援向量機 (Support Vector Machines, SVM)、K-Means 演算法(K-Means Clustering)與類神經網路 (Neural Network, NN)來建構出兩階段分析模型,期望能提升準確率且能夠同時降低型 I. 14.
(25) 誤差與型 II 誤差的效果,經過實例分析後準確率確實有提升,且型 I 與型 II 誤差也都下 降。. 2-5 糖尿病與資料探勘之相關研究 李語嫣(2010)利用資料探勘技術從分析健檢者歷次健康檢查時的生活習慣資料以及 健康檢查紀錄,以獲得各個檢測項目對於糖尿病之健康風險樣式。使用分類技術將此些 有利於預測疾病風險的樣式,建立一套有效的疾病預測模型,並且能將健康風險樣式提 供給醫護人員作為診斷的參考。 吳瑞堯、周駿賢(2008)以國家衛生研究院的全民健康保險研究資料庫包含了大量的 病患門診就醫資料,這些資料中可能隱藏許多未知而有用的知識,因此以該資料庫為基 礎,經資料淨化與篩選後,進行統計分析,找出上述六大死因慢性疾病在不同生活圈、 年齡層及性別上之盛行率,並利用資料探勘技術找出不同生活圈、性別、年齡之慢性疾 病間的關聯性。 張俊郎、張鈺芳(2005) 利用資料探勘的分群技術,針對某地區醫院之門診的健 檢資料,篩選出糖尿病之高危險性族群,並規劃篩檢和預防之道,進而達到早期診斷出 糖尿病,並輔以適當的處置。 其研究的結果可作為指引糖尿病衛教防治小組團隊工作 重點,做為訂定臨床症狀的完整處理原則(步驟、流程、評估工具)的重要依據,以及 作為擬定新陳代謝科及糖尿病衛教防治小組團隊醫護人員教育訓練計畫的參考。. 15.
(26) 第三章. 研究方法. 本研究使用 Weka 這套資料探勘軟體來作為探勘的工具。Weka 是由紐西蘭 Waikato 大學運用 Java 研發出多功能資料探勘的軟體,主要用於資料與數據的探勘分析。 本研究的研究方法採用六種不同的分類演算法,分別為 NB Tree、J48(C 4.5) 、貝氏網 路(Bayes Net)、純樸貝氏法(Naïve Bayes) 與多層感知機(Multi-Layer Perceptron, MLP)共 五種分類演算法,分析出原始資料的準確率,再透過屬性分析刪除不顯著變數,探討其 準確性的變化。. 3-1 研究流程 本研究流程如圖 3-1,首先為蒐集資料,第二步為資料屬性分析,資料屬性分析為 數值分析與類別分析兩種分析,第三步為分類分析,分類分析為 NB Tree、J48(C 4.5)、 C5 、 貝 氏 網 路 (Bayes Net) 、 純 樸 貝 氏 法 (Naïve Bayes) 與 多 層 感 知 機 (Multi-Layer Perceptron, MLP)共五種分類演算法。. 蒐集 資料. 資料屬 性分析. 分類. 模糊邏. 結論. 圖 3-1 研究流程圖. 3-2 研究方法介紹 以下介紹本研究利用 Weka 軟體做資料探勘方法介紹: (1). NB Tree 簡單的貝氏樹適用於類別預測,決策樹葉節點為簡單貝氏分類器,利用交叉驗證判 別節點要分裂成內部節點。 16.
(27) (2). J48 J48 演算法算是 ID3 的一種改良版,也稱為 C4.5 版,主要是以熵啟發式方法(Entropy Heuristic)來選擇哪個屬性適合成為下一個節點,而產生規則的有用性是用信任度和 支持度來衡量。J48 修改了 ID3 裡的資訊獲利(Information Gain),對測詴屬性內的 資料做正規化,稱之為獲利比例(Gain Ratio),在正規化的動作中可以減少資訊獲利 的偏見(Bias)。J48 是非常有效的資料探勘方法,非常穩定,不會全然地受到雜訊和 錯失資料的影響。此外,可以處理大資料集,也可處理類別或數字型態的資料,對 於所得到的結論有很好的解釋能力,如規則可用自然語言表示,所以很容易和人員 溝通。 (3). Naive Bayes 純樸貝氏(Naive Bayes)是建立在「貝氏定理」(Bayes Theory)的基礎上,其與條件機 率符合統計獨立假設的分類技術。純樸貝氏的優點是簡單的方式來計算未知樣本分 類機率,而缺點是預測準確度和資料中的條件機率是否有符合統計獨立假設還是有 很大的關係。 (4). Bayes Net 貝氏網路是使用聯合條件機率分配,允許變數的子集合有條件獨立,並且建立一個 因果關係的圖形模型,來使學習可以在其模型上操作,其預測結果傳回一個類別機 率分配,而不是單一的類別標籤。 (5). Multilayer Perceptron 多層感知器(Multilayer Perceptron, 縮寫 MLP) 是一種前向結構的人工神經網絡,映 射一組輸入向量到一組輸出向量。MLP 可以被看作是一個有向圖,由多個的節點 層所組成,每一層都全連接到下一層。除了輸入節點,每個節點都是一個帶有非線 性激活函數的神經元(或稱處理單元)。一種被稱為反向傳播算法的監督學習方法 常被用來訓練 MLP。MLP 是感知器的推廣,克服了感知器不能對線性不可分數據 進行識別的弱點。. 17.
(28) 3-3 資料屬性 本研究的資料來源是以UCI Machine Learning Repository網站內的Pima Indians Diabetes Data Set,該數據是以美國皮馬族印度安人(Pima Indians)21歲以上的女性為母體 的檢測資料。其原始資料共有9個條件屬性,包含1個為類別屬性與9個為數值屬性,以 及1個目標屬性,如表3-1所示,判別是否罹患糖尿病。. 表3-1資料屬性值域表 資料名稱. 資料屬性值域. 懷孕次數(Number Of Times Pregnant). 連續型. 2 小時內血漿中葡萄糖的含量(Plasma Glucose Concentration A 2 Hours In An Oral Glucose Tolerance Test) 舒張壓(Diastolic Blood Pressure). 連續型. 三頭肌皮褶厚度(Triceps Skin Fold. 連續型. Thickness) 2 小時內血清胰島素(2-Hour SerumIInsuli. 連續型. n) 體重指數(Body Mass Index). 連續型. 糖尿病家族函數(Diabetes Pedigree. 連續型. Function) 年齡(Age). 連續型. 連續型. 類變量(Class Variable). 有病,沒有病. 病患屬性介紹如下: 1.. 懷孕次數(Number Of Times Pregnant): 此屬性為病患懷孕的次數。. 2.. 2 小時內血漿中葡萄糖的含量(Plasma Glucose Concentration A 2 Hours In An Oral Glucose Tolerance Test): 世界衛生組織診斷糖尿病的標準為空腹血漿葡萄糖濃度≧140Mg/Dl 或葡萄糖 耐量詴驗,二小時血漿葡萄糖濃度≧200Mg/Dl,但是兩者並不相襯。幾乎所有 18.
(29) 空腹血漿葡萄糖濃度≧140Mg/Dl 者,當作葡萄糖耐量詴驗時,二小時血漿葡 萄糖濃度均大於 200Mg/Dl;但是二小時血漿葡萄糖濃度≧200Mg/Dl 之未曾治 療糖尿病患者,其空腹血漿葡萄糖濃度約有四分之一是在 140Mg/Dl 以下。由 於二小時血漿葡萄糖濃度 200Mg/Dl 為雙峰型(Bimodal)血糖分佈的良好分界點, 血糖值超過此點是細血管病變大幅上昇,且許多臨床或流行病學研究均以此為 診斷標準,因此保留葡萄糖耐量詴驗,二小時血漿葡萄糖濃度≧200Mg/Dl 為 糖尿病診斷標準。至於空腹血漿葡萄糖濃度的診斷標準,專家委員會則根據細 血管病變,大血管病變和世界衛生組織口服葡萄糖耐量詴驗二小時血漿葡萄糖 濃度 200Mg/Dl 的對照,定出空腹血漿葡萄糖濃度≧126Mg/Dl 為診斷標準。 3.. 舒張壓(Diastolic Blood Pressure): 舒張壓又叫心舒壓,是在心臟舒張期間,血管反彈回縮所產生的壓力。. 4.. 三頭肌皮褶厚度(Triceps Skin Fold Thickness): 皮褶厚度是推斷全身脂肪含量、判斷皮下脂肪發育情況的一項重要指標。隨著 人年齡的變化,體脂也出現規律性的變化。不同的人群,由於其遺傳素質、生活 環境、飲食習慣等不同,體脂分佈及其占體重百分比均可能呈現各自的特點。皮 褶厚度可用 X 光、超聲波、皮褶卡鉗等方法測量。用卡鉗測量皮褶厚度最為簡 單而經濟,測得結果和 X 光片測量值的相關度可達 0.85~0.90,對人體亦無放 射性傷害。但是此方法需要操作者熟悉儀器的調詴和檢測方式,技術的差異不 可避免的產生誤差,其主要偏差的來源是檢測者用手捏皮褶時施加的壓力的穩 定性,卡鉗頭的夾皮時間的長短,被測者的皮褶厚度的厚薄等。測量皮褶厚度 的常用部位有上臂肱三頭肌部(代表四肢)和肩胛下角部(代表軀體),這些 部位組織均衡、鬆弛,皮下脂肪和肌肉能充分分開,測點明確,測量方便,測 值重複率高。另外還可以測量肱二頭肌部、髂上、腹壁側等。皮褶厚度和體脂 含量間有相關關係,可通過皮褶厚度的測量值估計人體體脂含量的百分比,從 而判定肥胖程度。. 19.
(30) 5.. 2 小時內血清胰島素(2-Hour SerumIInsulin): 血清胰島素是一種蛋白質類激素,由胰島 b 細胞分泌的一種唯一能使血糖降低 的激素,也是唯一同時促進糖原、脂肪、蛋白質合成的激素。它最重要的生理 功能是調控血糖濃度,無論是餐後還是飢餓狀態都能使血糖穩定在一定水平, 用以維持人體正常生理功能所需。因此血清胰島素測定有助於了解血糖昇高與 降低的原因,還可用於糖尿病 I 型與 II 型的鑒別診斷等。空腹正常值為: 5-15Mu/L. 6.. 體重指數(Body Mass Index): BMI 值原來的設計是一個用於公眾健康研究的統計工具。當我們需要知道肥胖 是否為某一疾病的致病原因時,我們可以把病人的身高及體重換算成 BMI 值, 再找出其數值及病發率是否有線性關連。不過,隨著科技進步,現時 BMI 值 只是一個參考值。要真正量度病人是否肥胖,體脂肪率比 BMI 更準確、而腰 圍身高比又比體脂肪率好、但是最好的看法是看內臟脂肪(若內臟脂肪正常, 就算腰圍很大及體脂肪率很高,健康風險不高,日本相撲力士很多都是這種胖 法)。因此,BMI 的角色也慢慢改變,從醫學上的用途,變為一般大眾的纖體 指標。. 7.. 糖尿病家族函數(Diabetes Pedigree Function): 此屬性為病患本身家族成員有得過糖尿病的病史。. 8.. 年齡(Age): 此屬性為病患的年齡資料。. 9.. 類變量(Class Variable): 病患是否患有糖尿病的資料,為類別型之數據資料,以有糖尿病、無糖尿病來 區分。. 20.
(31) 3-4 屬性之計算方式 本研究採用數學統計方式來衡量各項資料屬性的重要程度,先將資料屬性分為類別 與數值兩種型態,再進行計算,其計算公式介紹如下。 類別屬性之計算方式 本研究將有糖尿病與無糖尿病之兩類別群組的資料分佈,對資料中的類別屬性進行 分析,如表 3-2。頻率表示出現的次數;支持度表示頻率在有糖尿病或無糖尿病的類別 群組中的出現機率;信賴度則表示用來判斷該屬性質是偏向該類別屬性中的哪一項屬性; 屬性值重要程度表示該屬性值在該類別內所佔有的重要程度。 表 3-2 類別屬性分析計算公式 名詞 頻率. 計算公式 出現的次數. 支持度. 頻率/有病或無病的類別群組總次數. 信賴度. 無病或有病的個別支持度/(無病支持度+有病支持度). 屬性值重要程度. ABS(無病信賴度-有病信賴度)*((無病頻率+有病頻率)/總人數). 數值屬性之計算方式 本研究將有糖尿病與無糖尿病之兩數值群組的資料分佈,對資料中的數值屬性進行 分析,無肝病和有肝病兩數值群組統計其平均值(Mean)與標準差(Standard Deviation)。 屬性重要程度表示判斷屬性是否有顯著依據,其計算公式為: ABS(無病平均值-有病平均值)/((無病標準差+有病標準差)/2). 3-5 模糊邏輯 採用 UCI Machine Learning Repository 網站內的 Pima Indians Diabetes Data Set,以 美國皮馬族印度安人(Pima Indians)21 歲以上的女性為母體的檢測資料而來的糖尿病資 料庫,經過屬性重要程度篩選,刪除顯著較低的屬性變數,加上糖尿病相關危險因子來 判定罹患肝臟疾病。. 21.
(32) 輸入與輸出之變數的歸屬度建立 本研究利用模糊邏輯推論,來建立糖尿病之輔助評估系統,並以經驗度來表示糖尿 病資料庫所建立之規則,本研究使用的模糊集合之值域參考臺大醫院健康教育資訊網內 在民國 103 年 9 月健康教育中心整理的檢驗參考值,如表 3-3。參考檢驗正常範圍後所 自訂之模糊變數與模糊集,如表 3-4。. 表 3-3 糖尿病功能檢驗表 檢驗項目. 參考值. 飯前血糖 (Glucose [A.C.]). 70-100 Mg/Dl. 飯後兩小時血糖(Glucose [2Hrs P.C.]). < 140 Mg/Dl. 糖化血紅素(HbA1C). 3.8-6.0 %. 葡萄糖耐量詴驗( Glucose. Tolerance [2Hrs]). 胰島素(IInsulin). < 200 Mg/Dl 5-20μIU/mL. 胰島素連結胜肽( C-Peptide [Baseline]). 0.9-7.1 Ng/ML. 資料來源:臺大醫院健康教育資訊網 表 3-4 語意變數及範圍 語意變數 飯後兩小時血糖 (Glucose [2Hrs P.C.]) 舒張壓(Diastolic Blood Pressure). 胰島素(IInsulin). 體重指數(Body Mass Index). 是否抽菸 是否一星期有運動 3 次. 語言值. 模糊範圍. 低. ≦90. 中 高. 80~140 ≧130. 低. ≦53. 中 高. 45~75 ≧68. 低. ≦10. 中 高. 8~15 ≧18. 低. ≦19. 中 高. 18~24 ≧27. 是. 1. 否. 0. 是. 1. 否. 0. 22.
(33) 是否常吃垃圾食物. 風險值. 是. 1. 否. 0. 非常低. <20%. 低. 15~30%. 稍低. 25~40%. 中. 35~50%. 稍高. 45~60%. 高. 55~70%. 非常高. >65%. 建立模糊規則 模糊規則庫的建立是由語意變數所形成的 IF-THEN 規則來建立系統輸入與輸出的 關係。 語意式模糊規則:. R i : IF X1 is A i1 AND AND X k is A ik THEN Y is Bi , i 1, 2, ..., n. (2.3). 影響糖尿病的危險關鍵因子,包含懷孕次數(Number Of Times Pregnant)、2 小時內 血漿中葡萄糖的含量(Plasma Glucose Concentration A 2 Hours In An Oral Glucose Tolerance Test)、舒張壓(Diastolic Blood Pressure)、三頭肌皮褶厚度(Triceps Skin Fold Thickness)、2 小時內血清胰島素(2-Hour SerumIInsulin)、體重指數(Body Mass Index)、 糖尿病家族函數(Diabetes Pedigree Function)、年齡(Age)、類變量(Class Variable)等九項 危險關鍵因子,經由文獻及自訂出來的模糊集,建立出系統所需要的模糊規則。 模糊推論與解模糊化 本研究的模糊推論模式採用 Mamdani 的 Min-Min-Max 推論方式,如圖 3-2 所示, 產生相對應的圖形方式,再以重心法之計算方法,針對所產生的圖形進行解模糊動作, 而解模糊後,系統會輸出一個明確數值,該數值即為罹患肝病風險評估的百分比機率。 Mamdani 的 Min-Min-Max 推論:. R1 : IF X1 is A11 AND X 2 is A 21 THEN Y is B1 R 2 : IF X1 is A12 AND X 2 is A 22 THEN Y is B2 23. (2.4).
(34) Wi min{max[min( A1i , X1 )], max[min( A 2i , X 2 )]} X1. (2.5). X2. Bi min( Wi , Bi ( y)). (2.6) (2.7). r. B max Bi *. i 1. 推論結果為陰影的部分,重心法再求出重心即為輸出的明確值:. ( y) * ydy ( y)dy Bi. u* . (2.8). Bi. x1 is A11. x 2 is A21. X1. x1 is A12. y is B1. Y. X2. x 2 is A22. B*. y is B2 Y. X1. Y. X2. 圖 3-2 Mamdani 的 Min-Min-Max 推論. 24.
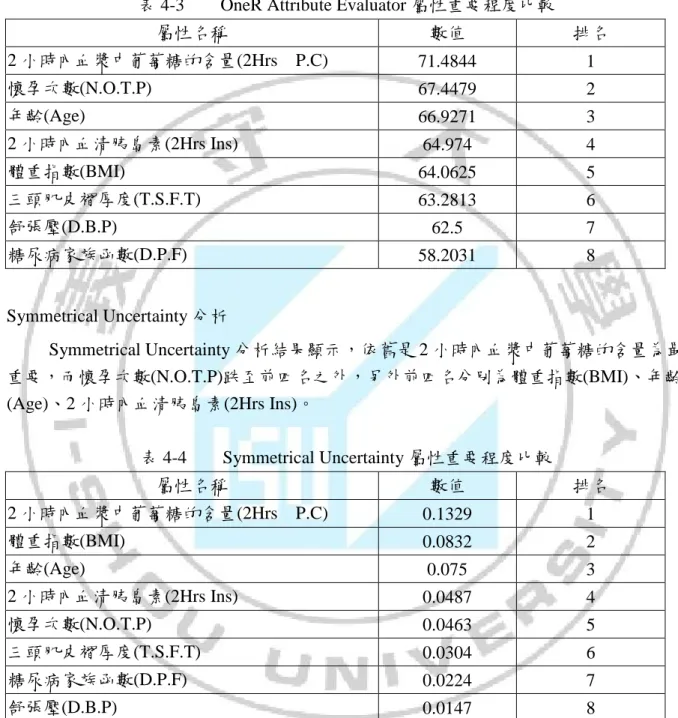
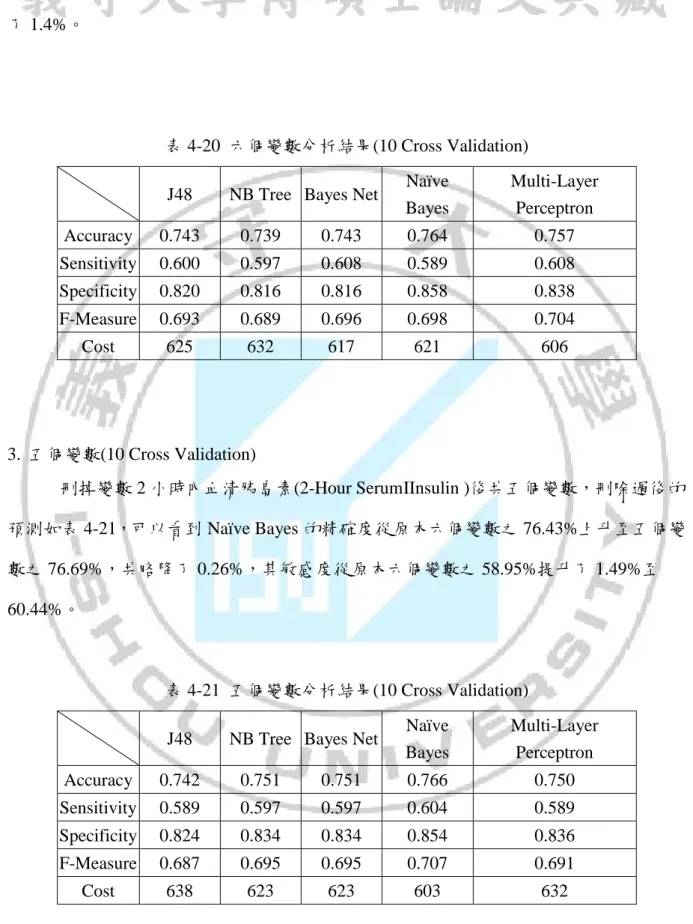
(35) 第四章. 研究結果. 4-1 糖尿病屬性分析 Information Gain 分析 以 Weka 裡面的 Information Gain 分析結果顯示,2 小時內血漿中葡萄糖的含量最 為重要,而前四名分別為體重指數、年齡、2 小時內血清胰島素。 表 4-1. Information Gain 重要程度比較. 屬性名稱. 數值. 排名. 0.1901. 1. 體重指數(BMI). 0.0749. 2. 年齡(Age). 0.0725. 3. 2 小時內血清胰島素(2Hrs Ins). 0.0595. 4. 三頭肌皮褶厚度(T.S.F.T). 0.0443. 5. 懷孕次數(N.O.T.P). 0.0392. 6. 糖尿病家族函數(D.P.F). 0.0208. 7. 舒張壓(D.B.P). 0.014. 8. 2 小時內血漿中葡萄糖的含量(2Hrs. P.C). Gain Ratio 分析 以 Weka 裡面的 Gain Ratio 分析結果顯示,依舊是 2 小時內血漿中葡萄糖的含量最 為重要,而另外前四名分別為體重指數、年齡、懷孕次數(N.O.T.P)。 表 4-2. Gain Ratio 重要程度比較. 屬性名稱. 數值. 排名. 0.0986. 1. 體重指數(BMI). 0.0863. 2. 年齡(Age). 0.0726. 3. 懷孕次數(N.O.T.P). 0.0515. 4. 2 小時內血清胰島素(2Hrs Ins). 0.0394. 5. 糖尿病家族函數(D.P.F). 0.0226. 6. 三頭肌皮褶厚度(T.S.F.T). 0.0224. 7. 舒張壓(D.B.P). 0.0144. 8. 2 小時內血漿中葡萄糖的含量(2Hrs. P.C). 25.
(36) OneR Attribute Evaluator 分析 OneR Attribute Evaluator 分析結果顯示,依舊是 2 小時內血漿中葡萄糖的含量最為 重要,而懷孕次數(N.O.T.P)從第四名攀升到第二名。 表 4-3. OneR Attribute Evaluator 屬性重要程度比較. 屬性名稱. 數值. 排名. 71.4844. 1. 懷孕次數(N.O.T.P). 67.4479. 2. 年齡(Age). 66.9271. 3. 2 小時內血清胰島素(2Hrs Ins). 64.974. 4. 體重指數(BMI). 64.0625. 5. 三頭肌皮褶厚度(T.S.F.T). 63.2813. 6. 62.5. 7. 58.2031. 8. 2 小時內血漿中葡萄糖的含量(2Hrs. P.C). 舒張壓(D.B.P) 糖尿病家族函數(D.P.F) Symmetrical Uncertainty 分析. Symmetrical Uncertainty 分析結果顯示,依舊是 2 小時內血漿中葡萄糖的含量為最 重要,而懷孕次數(N.O.T.P)跌至前四名之外,另外前四名分別為體重指數(BMI)、年齡 (Age)、2 小時內血清胰島素(2Hrs Ins)。 表 4-4. Symmetrical Uncertainty 屬性重要程度比較. 屬性名稱. 數值. 排名. 0.1329. 1. 體重指數(BMI). 0.0832. 2. 年齡(Age). 0.075. 3. 2 小時內血清胰島素(2Hrs Ins). 0.0487. 4. 懷孕次數(N.O.T.P). 0.0463. 5. 三頭肌皮褶厚度(T.S.F.T). 0.0304. 6. 糖尿病家族函數(D.P.F). 0.0224. 7. 舒張壓(D.B.P). 0.0147. 8. 2 小時內血漿中葡萄糖的含量(2Hrs. P.C). 根據前面 Information Gain、Gain Ratio、OneR Attribute Evaluator、Symmetrical Uncertainty 分析結果顯示,2 小時內血漿中葡萄糖的含量(2Hrs P.C)都位居第一,顯然 2 小時內血漿中葡萄糖的含量(2Hrs P.C)為糖尿病的重要參考數值。而體重指數(BMI)、 年齡(Age)、2 小時內血清胰島素(2Hrs Ins)、懷孕次數(N.O.T.P)在此四個分析結果裡面分 別都位於前 2~5 名之間,其對於糖尿病也為重要參考數值。. 26.
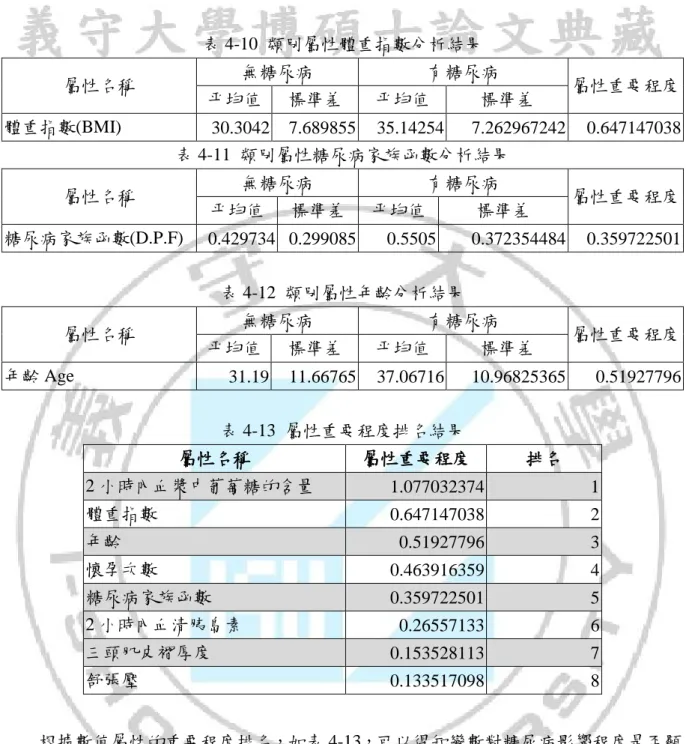
(37) 統計分析 本研究以數值屬性分析來衡量屬性之重要程度,目的主要是把不顯著的屬性刪減, 找出最顯著的關鍵屬性,其屬性分析結果如下。 在數值分析上是分無肝病和有肝病兩組別進行分析,其屬性重要程度為判斷是否顯 著的依據,其公式為:ABS(無病平均值-有病平均值)/((無病標準差+有病標準差)/2),如 以下列表 4-5 至 4-12。. 表 4-5 數值屬性懷孕次數分析結果 無糖尿病. 屬性名稱. 平均值. 懷孕次數(N.O.T.P). 3.298. 有糖尿病. 標準差. 平均值. 3.017185. 4.865672. 標準差 3.741239044. 屬性重要程度 0.463916359. 表 4-6 類別屬性 2 小時內血漿中葡萄糖的含量分析結果 無糖尿病. 屬性名稱. 平均值. 2 小時內血漿中葡萄糖 的含量(2Hrs P.C). 109.98. 有糖尿病. 標準差 26.1412. 平均值 141.2575. 標準差 31.93962206. 屬性重要程度 1.077032374. 表 4-7 類別屬性舒張壓分析結果 屬性名稱 舒張壓(D.B.P). 無糖尿病 平均值 68.184. 有糖尿病. 標準差. 平均值. 18.06308. 70.82463. 標準差 21.49181165. 屬性重要程度 0.133517098. 表 4-8 類別屬性三頭肌皮褶厚度分析結果 屬性名稱 三頭肌皮褶厚度 (T.S.F.T). 無糖尿病 平均值 19.664. 有糖尿病. 標準差. 平均值. 標準差. 14.88995. 22.16418. 17.6797114. 屬性重要程度 0.153528113. 表 4-9 類別屬性 2 小時內血清胰島素分析結果 屬性名稱 2 小時內血清胰島素 (2Hrs Ins). 無糖尿病 平均值 68.792. 有糖尿病. 標準差. 平均值. 98.86529. 100.3358. 27. 標準差 138.6891247. 屬性重要程度 0.26557133.
(38) 表 4-10 類別屬性體重指數分析結果 無糖尿病. 屬性名稱 體重指數(BMI). 平均值. 有糖尿病. 標準差. 平均值. 標準差. 30.3042 7.689855 35.14254 7.262967242 表 4-11 類別屬性糖尿病家族函數分析結果 無糖尿病. 屬性名稱. 平均值. 糖尿病家族函數(D.P.F). 有糖尿病. 標準差. 0.429734 0.299085. 平均值. 標準差. 0.5505. 0.372354484. 屬性重要程度 0.647147038. 屬性重要程度 0.359722501. 表 4-12 類別屬性年齡分析結果 屬性名稱. 無糖尿病 平均值. 年齡 Age. 31.19. 有糖尿病. 標準差. 平均值. 11.66765. 37.06716. 標準差 10.96825365. 屬性重要程度 0.51927796. 表 4-13 屬性重要程度排名結果 屬性名稱. 屬性重要程度. 排名. 2 小時內血漿中葡萄糖的含量. 1.077032374. 1. 體重指數. 0.647147038. 2. 0.51927796. 3. 懷孕次數. 0.463916359. 4. 糖尿病家族函數. 0.359722501. 5. 0.26557133. 6. 三頭肌皮褶厚度. 0.153528113. 7. 舒張壓. 0.133517098. 8. 年齡. 2 小時內血清胰島素. 根據數值屬性的重要程度排名,如表 4-13,可以得知變數對糖尿病影響程度是否顯 著。本研究參考重要程度排名來做案例研究,從最不顯著的變數開始刪除,並觀察準確 率是否有提升或下降,將在下一章節中做詳細介紹。. 4-2 糖尿疾病資料探勘分類分析比較 本研究採用混亂矩陣(Confusion Matrix)做效能分析,如表 4-14。tn 為(True Negative) 表示實際上無病且預測上也無病;fn 為(False Negative)表示實際上有病但預測出來為無. 28.
(39) 病;fp 為(False Positive)表示實際上無病但預測出來為有病;tp 為(True Positive)表示實 際上有病且預測上也有病,而混亂矩陣的主要目的是為了計算出預測準確性。. 表 4-14 混亂矩陣 Predicted Negative Predicted Positive Actual Negative. tn. Fp. Actual Positive. fn. Tp. 李御璽(2007)等人提出成本矩陣,代表著當預測結果發生錯誤時所必頇要承擔的成 本,如表 4-15,如果實際上是無病,但預測的結果是有病,此時的成本為 1;如果實際 是有病,但預測的結果是無病,此時的成本增加為 5 倍。因此,如果成本顯示越高則代 表著預測的效率也表現得越差。. 表 4-15 成本矩陣 Predicted Negative Predicted Positive Actual Negative. 0. 1. Actual Positive. 5. 0. 本研究採用精確度(Accuracy)、敏感度(Sensitivity)、特異度(Specificity)、F 度量 (F-Measure)以及成本(Cost)等五項分析來對 NB Tree、J48(See 4.5)、貝氏網路(Bayes Net)、 純樸貝氏法(Naïve Bayes)與多層感知機(Multi-Layer Perceptron, MLP)等五種方法進行預 測準確性的評估。 精確度(Accuracy)為預測上無病且實際上無病與預測上有病且實際上有病的總和除 以整體數據;敏感度(Sensitivity)為預測上有病且實際上有病除以 Actual Positive 實際上 有病之數據,又稱為真陽性率(true positive rate,TPR);特異度(Specificity)為預測上無病 且實際上無病除以 Actual Negative 實際上無病之數據,又稱為真陰性率(True Negative Rate,TNR),;F 度量(F-Measure)為主要衡量 Sensitivity 和 Specificity,兩者皆高表示 29.
(40) 其預測上無病且實際上無病和預測上有病且實際上有病之準確度是高的;成本(Cost)則 為所需要的成本,實際上有病但預測上卻為無病的消耗成本是實際上無病但預測上為有 病的五倍。 計算方式如下: (1). (2). (3). (4). Accuracy:. Accuracy . (tn tp) (tn+fn+fp+tp). (4-1). Sensitivity . tp (fn+tp). (4-2). Specificity . tn (tn+fp). (4-3). Sensitivity( P):. Specificity( R):. F-Measure:. F Measure . (5). 2 P R (P R). (4-4). Cost:. Cost fp fn 5. (4-5). 表 4-16、表 4-17 為 768 筆訓練樣本資料做 5 種演算法之混亂矩陣。表 4-13 為 768 筆資料之項目比較,將分類分析以 NB Tree、J48(C4.5)、貝氏網路(Bayes Net)、純樸貝 氏法(Naïve Bayes)與多層感知機(Multi-Layer Perceptron, MLP)等分類分析方法做比較, 並且考量 Accuracy、Sensitivity、Specificity、F-Measure 及 Cost 等上述方法之項目比較。. 30.
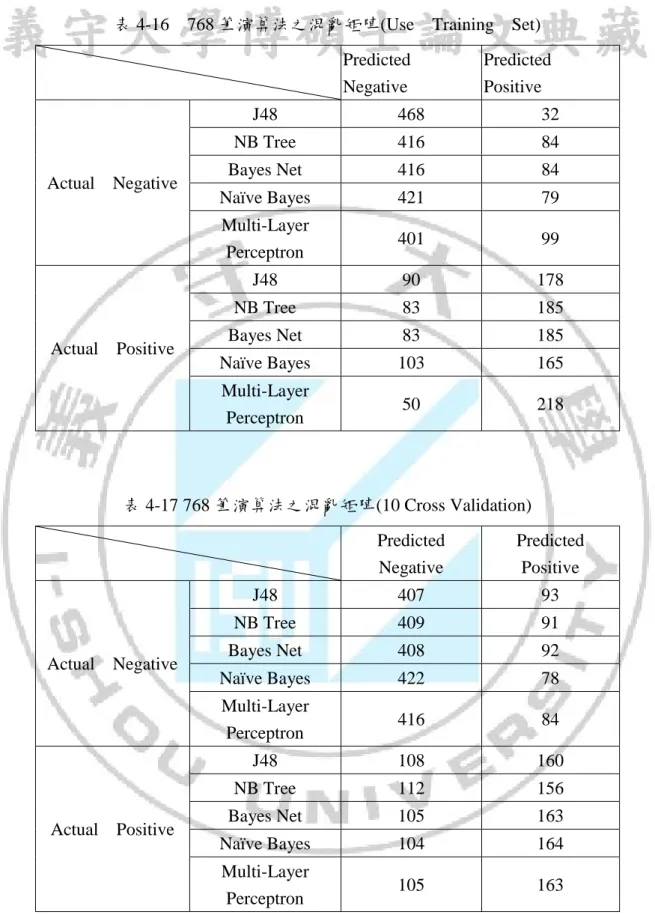
(41) 表 4-16. 768 筆演算法之混亂矩陣(Use Training Set) Predicted Negative. Actual Negative. Actual Positive. Predicted Positive. J48. 468. 32. NB Tree. 416. 84. Bayes Net. 416. 84. Naïve Bayes. 421. 79. Multi-Layer Perceptron. 401. 99. J48. 90. 178. NB Tree. 83. 185. Bayes Net. 83. 185. Naïve Bayes. 103. 165. Multi-Layer Perceptron. 50. 218. 表 4-17 768 筆演算法之混亂矩陣(10 Cross Validation). Actual Negative. Actual Positive. Predicted. Predicted. Negative. Positive. J48. 407. 93. NB Tree. 409. 91. Bayes Net. 408. 92. Naïve Bayes. 422. 78. Multi-Layer Perceptron. 416. 84. J48. 108. 160. NB Tree. 112. 156. Bayes Net. 105. 163. Naïve Bayes. 104. 164. Multi-Layer Perceptron. 105. 163. 表 4-18 為八個變數採用十折交叉驗證(10 Cross Validation),在 Naïve Bayes 得到的 精確度高達 76.3%,其成本為 598 是這五種演算法內最低的,故我們接著都以 Naïve Bayes 31.
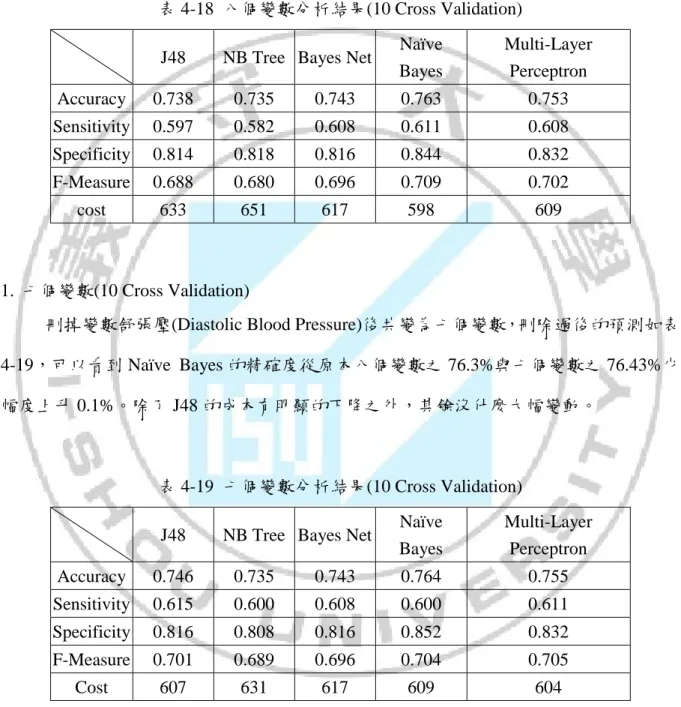
(42) 演算法為這次判別糖尿病準確度為主。表 4-19 至表 4-25 採用十折交叉驗證(10 Cross Validation),分別為七個變數至五個變數的準確度分析。以下一一比較各變數對於糖尿 病預測的準確度,篩選出符合預期效果的屬性組合。. 表 4-18 八個變數分析結果(10 Cross Validation) J48. NB Tree Bayes Net. Naïve Bayes. Multi-Layer Perceptron. Accuracy. 0.738. 0.735. 0.743. 0.763. 0.753. Sensitivity. 0.597. 0.582. 0.608. 0.611. 0.608. Specificity. 0.814. 0.818. 0.816. 0.844. 0.832. F-Measure. 0.688. 0.680. 0.696. 0.709. 0.702. cost. 633. 651. 617. 598. 609. 1. 七個變數(10 Cross Validation) 刪掉變數舒張壓(Diastolic Blood Pressure)後共變為七個變數,刪除過後的預測如表 4-19,可以看到 Naïve Bayes 的精確度從原本八個變數之 76.3%與七個變數之 76.43%少 幅度上升 0.1%。除了 J48 的成本有明顯的下降之外,其餘沒什麼大幅變動。. 表 4-19 七個變數分析結果(10 Cross Validation) J48. NB Tree Bayes Net. Naïve Bayes. Multi-Layer Perceptron. Accuracy. 0.746. 0.735. 0.743. 0.764. 0.755. Sensitivity. 0.615. 0.600. 0.608. 0.600. 0.611. Specificity. 0.816. 0.808. 0.816. 0.852. 0.832. F-Measure. 0.701. 0.689. 0.696. 0.704. 0.705. Cost. 607. 631. 617. 609. 604. 2. 六個變數(10 Cross Validation) 刪除變數三頭肌皮褶厚度(Triceps Skin Fold Thickness)後共六個變數,刪除過後的 預測如表 4-20,可以看到 Naïve Bayes 的精確度從原本七個變數之 76.43%與六個變數之 32.
(43) 76.43%相等維持不變。與八個變數作比較,如表 4-18,成本上升了 23,特異度也上升 了 1.4%。. 表 4-20 六個變數分析結果(10 Cross Validation) J48. NB Tree Bayes Net. Naïve Bayes. Multi-Layer Perceptron. Accuracy. 0.743. 0.739. 0.743. 0.764. 0.757. Sensitivity. 0.600. 0.597. 0.608. 0.589. 0.608. Specificity. 0.820. 0.816. 0.816. 0.858. 0.838. F-Measure. 0.693. 0.689. 0.696. 0.698. 0.704. Cost. 625. 632. 617. 621. 606. 3. 五個變數(10 Cross Validation) 刪掉變數 2 小時內血清胰島素(2-Hour SerumIInsulin )後共五個變數,刪除過後的 預測如表 4-21,可以看到 Naïve Bayes 的精確度從原本六個變數之 76.43%上升至五個變 數之 76.69%,共略降了 0.26%,其敏感度從原本六個變數之 58.95%提升了 1.49%至 60.44%。. 表 4-21 五個變數分析結果(10 Cross Validation) J48. NB Tree Bayes Net. Naïve Bayes. Multi-Layer Perceptron. Accuracy. 0.742. 0.751. 0.751. 0.766. 0.750. Sensitivity. 0.589. 0.597. 0.597. 0.604. 0.589. Specificity. 0.824. 0.834. 0.834. 0.854. 0.836. F-Measure. 0.687. 0.695. 0.695. 0.707. 0.691. Cost. 638. 623. 623. 603. 632. 4. 四個變數(10 Cross Validation). 33.
(44) 刪除變數糖尿病家族函數(Diabetes Pedigree Function Numeric)後共四個變數,刪 除過後的預測如表 4-22,可以看到 Naïve Bayes 的精確度從原本五個變數之 76.69%與四 個變數之 76.69%相等維持不變。其餘變數也無明顯變化。. 表 4-22 四個變數分析結果(10 Cross Validation) J48. NB Tree Bayes Net. Naïve Bayes. Multi-Layer Perceptron. Accuracy. 0.742. 0.751. 0.751. 0.766. 0.750. Sensitivity. 0.589. 0.597. 0.597. 0.604. 0.589. Specificity. 0.824. 0.402. 0.834. 0.854. 0.836. F-Measure. 0.687. 0.481. 0.695. 0.707. 0.691. Cost. 638. 623. 623. 603. 632. 5. 三個變數(10 Cross Validation) 刪除變數懷孕次數(Number Of Times Pregnant)後共三個變數,刪除過後的預測如 表 4-23,可以看到 Naïve Bayes 的精確度從原本四個變數之 76.69%下降至三個變數之 76.43%,共略降了 0.26%,其特異度明顯的下降了 4.47%。由於準確性有下降,因此保 留懷孕次數(Number Of Times Pregnant)變數。. 表 4-23 三個變數分析結果(10 Cross Validation) J48. NB Tree Bayes Net. Naïve Bayes. Multi-Layer Perceptron. Accuracy. 0.746. 0.736. 0.742. 0.764. 0.764. Sensitivity. 0.574. 0.645. 0.570. 0.559. 0.619. Specificity. 0.838. 0.786. 0.834. 0.874. 0.842. F-Measure. 0.681. 0.708. 0.677. 0.682. 0.713. Cost. 651. 582. 658. 653. 589. 表 4-24 為四個變數採用全樣本訓練資料集(Use Training Set)與表 4-18 做相對應的比 較,可以發現在全樣本測詴時準確度、敏感度、特異度與 F 度量都略為下降,而成本則 略微上升。. 34.
數據


+7

Outline
相關文件
在選擇合 適的策略 解決 數學問題 時,能與 別人溝通 、磋商及 作出 協調(例 如在解決 幾何問題 時在演繹 法或 分析法之 間進行選 擇,以及 與小組成 員商 討統計研
3 David Hume, Enquiries Concerning Human Understanding and Concerning the Principles of Morals.. 5 David Hume, Dialogues Concerning Natural
討論結束,整理腦圖。首先嘗試將資料歸類,然 後可以開始收窄範圍,定出文章中心,再按照重
在選擇合 適的策略 解決 數學問題 時,能與 別人溝通 、磋商及 作出 協調(例 如在解決 幾何問題 時在演繹 法或 分析法之 間進行選 擇,以及 與小組成 員商 討統計研
先從上頁「資料一線通 : 2019 冠狀病毒病的數據」網址下 載最新「本港疑似 / 確診 2019 冠狀病毒的個案詳情」的 數據。在這活動同學們將使用試算表分析數據並完成下表.
由於資料探勘 Apriori 演算法具有探勘資訊關聯性之特性,因此文具申請資 訊分析系統將所有文具申請之歷史資訊載入系統,利用
I-STD 是在資料以漸進式增加的前提下進行資料探勘,在醫院的門診診斷紀 錄中,雖然每個月門診數量不盡相同但基本上仍有一固定總門診數量範疇,因此 由圖
由於本計畫之主要目的在於依據 ITeS 傳遞模式建構 IPTV 之服務品質評估量表,並藉由決
