影響預測準確度之因素與判定預測準確度之模型 - 政大學術集成
65
0
0
全文
(2) 致謝 (Acknowledgment). 翻開論文的人,大概都會看到這頁,也是最難寫的一頁~~~ 與 童振源老師、 葉家興老師一同作研究已經來到第 4 個年頭,在這過程當 中我體會「生活節拍」的重要,從童老師那裡學會如何掌握做事的步調,也謝謝 葉老師在數理方面的指導和建議。在 陳樹衡老師的課堂中,我看到經濟學的新 視野、認知,此外,有兩件事要特別在這感謝陳老師:一、博士學位考試前的論. 政 治 大 之外,更要謝謝 林繼文老師、 立 連賢明老師願意在百忙之中,撥空擔任博士口試. 文建言;二、某次,在學校附近餐廳巧遇,您親自幫我一家 4 口結帳買單。除此. ‧. ‧ 國. 直接的建議。. 學. 委員,特別感謝是繼文老師鼓勵、關心,和賢明老師在博士論文討論,提供精闢、. 自從進入政大至今已 8 年多,得到許多系上許多老師的幫忙,因此要格外致. sit. y. Nat. 力感謝幾位老師(依筆劃順序):毛維凌老師、 方中柔老師、 朱美麗老師、 李. al. er. io. 文福老師、 何靜嫺老師、 林祖嘉老師、 林馨怡老師、 周子全博士、 洪福聲. v. n. 老師、 高安邦老師、 徐士勛老師、 陳鎮洲老師、 黃仁德老師、 賴景昌老師、. Ch. engchi. i n U. 蕭明福老師,諸多感謝無法一一以文字表達,但每一老師對我的好,永遠烙印在 學生的心中。 寫到這個段落,心裡不免有些感觸、激動,在這段期間經歷難以渡過關卡, 我學會了解什麼是幸福快樂,也承受至愛至親離世的苦痛。將我帶大的阿嬤、愛 我勝過愛自己的父母,我真的很謝謝您們,感謝您們如此、如此、如此疼愛我, 希望這份光榮,您們在天上也能感受到。 我相信,幾個十年後,我的兩個寶貝兒子會讀到這一段文字,爸爸要告訴你 們:我很開心快樂有你們兩個,謝謝你們的陪伴、參加我這一生的旅程、給我生 命的動能。即使有一天爸爸會老去,你們也不需難過,因為爸爸真的很幸運有你 II.
(3) 們, 「我沒有遺憾、我的幸福已經滿滿」 ;若以後爸爸年老病長,你們要聽爸爸現 在說的話,勇敢向前走,無須擔心我,因為我最大的願望,就是你們兄弟兩人有 個「開心的未來」 。 兒子們,從今天起,我們一起進階至另一人生階段,我們一起遊山玩水、快 樂無限大,啟程出發 Go ~~~. 林鴻文 HungWen Lin. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. III. i n U. v.
(4) 影響預測準確度之因素與判定 預測準確度之模型. 中文摘要 從過去的研究顯示,預測市場(prediction market)已有良好預測準 確率,但該準確率是事後、總體的機率概念,而非更有實際參考 價值:事前、個別合約之鑑別預測。故本文先以建構 4 個選舉預 測市場準確度的鑑別模型,在選前針對每一個選舉合約的交易價 格進行鑑別,模型的鑑別資訊來自於,預測市場在選前一天提供 選舉合約的 40 個原始自變數。我們的研究顯示:Logit 鑑別模型. 立. 政 治 大. ‧ 國. 學. 最能在「選前」精準判斷,並可分辨哪些選舉合約的價格,在未 來將符合「最高價」準則。本文前半部先以:2008 年總統選舉、 2009 年縣市長選舉及 2010 年五都市長選舉,做為樣本外測試的. ‧. 樣本,使用原始自變數的 Logit 模型,其預測力均高於其他 3 個 鑑別模型。Logit 模型樣本外的鑑別正確準確率為 100%,但是, Logit 模型對於鑑別未正確預測組的預測能力仍須改善。最後,本 文再使用全部「非選舉」和選舉類別的合約,成功建構預測市場 的最適價格門檻,作為判定預測事件是否發生的標準,可將事件 發生的機率預測(probabilistic forecasting) ,轉換成事件發生與否 的類別預測(categorical forecasting) ,作為公共政策與企業決策的 重要依據。. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 關鍵字:選舉預測市場、鑑別模型、預測準確率、邊際交易者、最適門檻. IV.
(5) The Discrimination Models of Accuracy for Prediction Markets. Abstract According to literature, election-prediction-markets have excellent accuracy rates of prediction. However, we can only acknowledge the prediction results after the elections and cannot discriminate the accuracy rates of particular election predictions prior to the elections. This paper constructs four models to discriminate the accuracy rate of each election contract prior to the election. According to the information of 40 original variables collected from the election contracts in the prediction markets, the Logit model can precisely discriminate which election contracts to follow the highest price criteria of predictions. This paper uses election contracts of the 2008. 立. 政 治 大. ‧ 國. 學. ‧. presidential election, the 2009 magistrate and mayoral elections, and the 2010 five-metropolis mayoral elections as out-of-sample tests. In terms of prediction accuracy, the Logit model using 40 original variables is the best among the four discrimination models. The accuracy rates of discrimination of the Logit model for correct predictions are all 100%. Nevertheless, the Logit model’s prediction ability for discriminating incorrect prediction groups need to be improved. We also include the non-election contracts into our analysis. This research successfully constructs a methodology to find optimal. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. price thresholds for prediction markets as the basis of categorizing the occurrence of the prediction events. This method enables us to transform the probabilistic forecasting of event occurrence to the categorical forecasting, thereby creating an important reference for public policy and corporate decision-making.. Keywords: Election prediction markets, discrimination model, prediction accuracy, marginal trader, optimal price threshold.. V.
(6) 目錄 第一章 前言................................................................................................................ 1 第二章 研究方法與資料............................................................................................ 3 第一節 Logit 模型與 DA 模型 ........................................................................... 4 第二節 鑑別模型設定與預測說明.................................................................... 5 第三節 合約資料與敘述統計............................................................................ 7 第三章 四個模型之鑑別力測試.............................................................................. 10 第一節 Logit 鑑別模型 .................................................................................... 10 第二節 4 個鑑別模型之鑑別力比較............................................................... 16 第四章 樣本外的預測能力...................................................................................... 17 第一節 2008 年總統大選前夕......................................................................... 18 第二節 2009 年縣市長選舉前夕..................................................................... 23 第三節 2010 年五都市長選舉前夕................................................................. 25. 立. 政 治 大. ‧ 國. 學. 第五章 最適價格門檻.............................................................................................. 27 第一節 緒論...................................................................................................... 27 第二節 資料描述.............................................................................................. 28. ‧. 第三節 認定「最適價格」之程序.................................................................. 32 第四節 實證分析.............................................................................................. 35 第五節 各類預測事件的最適價門檻準則之實證分析.................................... 38 第六節 三種價格門檻準則的樣本外測試與比較.......................................... 42 第六章 結論.............................................................................................................. 47 參考文獻...................................................................................................................... 50 I. 中文部分 ......................................................................................................... 50 II. 外文部分 ........................................................................................................ 50 附錄 1.......................................................................................................................... 55. n. er. io. sit. y. Nat. al. Ch. engchi. VI. i n U. v.
(7) 表目錄 表 1. 四種預測模型分類............................................................................................ 5. 表 2. 鑑別模型對選舉預測事件的分類.................................................................... 6. 表 3. 變數類別與定義 ............................................................................................... 7. 表 4. 所有 40 個原始變數與 650 合約的 Logit 迴歸分組結果 ............................. 10. 表 5. Logit 模型對最高準則鑑別的型一與型二錯誤組別..................................... 11. 表 6. Logit 迴歸模型自變數在各組的平均值比較 ................................................ 14. 表 7. 全部 650 合約的四個鑑別模型鑑別結果 ..................................................... 17. 表 9. 2008 年總統大選之樣本外 78 個合約的 Logit 迴歸分組結果 .................... 20. 學. ‧ 國. 表 8. 政 治 大 2008 年總統大選前之樣本內 333 個合約的 Logit 迴歸分組結果 .............. 20 立. 四個鑑別模型對 2008 年總統大選預測的樣本外測試結果 ..................... 21. 表 11. 選舉預測事件最後一個交易日之加權平均價格(在鑑別模型分析前與選. ‧. 表 10. io. y. sit. Original-Logit 模型鑑別「最高價準則」成立之配適機率與判定組別(選. er. 表 12. Nat. 舉結果揭曉前).................................................................................................. 22. 舉結果揭曉前).................................................................................................. 23. al. n. v i n 選舉預測事件交易價格與 (選舉結果 C hOriginal-Logit 模型鑑別結果之比較 engchi U. 表 13. 揭曉後).............................................................................................................. 23 表 14. 2009 年縣市長選舉前之樣本內 469 個合約的 Logit 迴歸分組結果 ........ 24. 表 15. 2009 年縣市長選舉之樣本外 48 個合約的 Logit 迴歸分組結果 .............. 25. 表 16. 四個鑑別模型對 2009 年縣市長選舉預測的樣本外測試結果 ................. 25. 表 17. 2010 年五都選舉前之樣本內 542 個合約的 Logit 迴歸分組結果 ............ 26. 表 18. 2010 年五都選舉之樣本外 86 個合約的 Logit 迴歸分組結果 .................. 26. 表 19. 四個鑑別模型對 2010 年五都市長選舉預測的樣本外測試結果 ............. 27. 表 20. 未來事件交易所預測事件的全部與分類敘述統計量:2006-2011 .......... 29 VII.
(8) 表 21. 不同價格門檻之全部預測事件的準確率:2006-2011 (單位:%) .......... 36. 表 22. 全部 7881 合約分別在三個門檻準則之觀測個數 ..................................... 37. 表 23. 全部 7881 合約分別在三個門檻準則之期望個數 ..................................... 37. 表 24. 全部預測事件之三種價格門檻準確率的 Z 檢定 ....................................... 38. 表 25. 各類預測事件之三種價格門檻的準確率 ................................................... 39. 表 26. 三種價格門檻的正確預測個數之卡方檢定 ............................................... 40. 表 27. 不同類別預測事件之三種價格門檻準確率的 Z 檢定 ............................... 41. 表 28. 2010-2011 年樣本外測試 ............................................................................. 43. 表 29. 不同類別預測事件之三種價格門檻準確率的卡方檢定:樣本外測試 ... 44. 各類預測事件交易價格之統計數據 ........................................................... 46. 學 ‧. io. sit. y. Nat. n. al. er. 表 31. ‧ 國. 表 30. 政 治 大 不同類別預測事件之三種價格門檻準確率的 Z 檢定:樣本外測試 ....... 45 立. Ch. engchi. VIII. i n U. v.
(9) 圖目錄 圖 1. 所有選舉預測合約的分布情況 ..................................................................... 17. 圖 2. Logit 樣本外測試流程圖 ................................................................................ 19. 圖 3. 未來事件交易所預測事件分布圖:按照價格 ............................................. 30. 圖 4. 預測事件分布示意圖:按照價格與實際結果 ............................................. 31. 圖 5. 未來事件交易所之預測事件分布圖:按照價格與實際結果 ..................... 32. 圖 6. 研究流程圖 ..................................................................................................... 34. 圖 7. 整體預測事件之不同價格門檻的準確率 ..................................................... 35. 學 ‧. ‧ 國 io. sit. y. Nat. n. al. er. 圖 8. 政 治 大 20 次 K-fold 交叉驗證結果 ............................................................................ 36 立. Ch. engchi. IX. i n U. v.
(10) 影響預測準確度之因素與判定 預測準確度之模型1. 第一章. 前言. 預測市場(prediction markets)是透過電子期貨交易,彙整市場參與者資訊 之新興機制,其交易價格為預測事件是否實現的關鍵指標。全球第一個以期貨市. 政 治 大. 場交易模式為藍本的預測市場,為美國愛荷華大學於 1988 年成立的「愛荷華電. 立. 子市場 (Iowa electronic markets, IEM)」。預測市場的特徵在於「提供適當獎懲機. ‧ 國. 學. 制」與「連續修正」。交易者根據公開資訊或私有資訊對未來事件的預測下單, 未來事件的真實結果會決定交易者的報酬,而未來事件的均衡合約價格,可視為. ‧. 整體市場對該事件發生與否的落點預測(Agrawal et al., 2010)。. y. Nat. sit. 說明預測市場的準確性高於其他預測方法之文獻相當豐富,例如:Berg et al.. n. al. er. io. (2008) 比對該市場與蓋洛普、哈里斯、紐約時報等大型媒體共 964 場民調,在. i n U. v. 1988~2004 年間預測美國總統大選的表現,結果顯示預測市場的準確率比傳統民. Ch. engchi. 調的次數高出 74%。其他文獻至少包括:Ortner (1998)、Pennock et al. (2001)、 Wolfers and Leigh (2002)、Brüggelambert (2004)、Servan-Schreiber et al. (2004)、 Wolfers and Zitzewitz (2004)、Gürkaynak and Wolfers (2005) 及 Leigh and Wolfers (2006)。 「預測市場」可否在某預測事件發生之前,提供一個交易價格作判斷該事件 是否成立的預測指標,然而,該價格是否具備一定的參考價值,或者發生價格失. 1. 本篇博士論文的部分內容,引用兩篇已刊登文章重新改編而成,標題分別為: “Multivariate Methods in Assessing the Accuracy of Prediction Markets Ex ante Based on the Highest-Price Criterion” 及〈以預測市場匯聚資訊支援決策之方法:從機率預測到類別判定〉 ,童振源老師與葉家興老師 為此兩篇文章的共同作者。 1.
(11) 真?這應該是一般人希望知道的,而不是事後才知道該事件,在預測市場的結果 是否可以正確預測。因此,本文試以建立一個鑑別模型,在「事前」鑑定單一合 約的價格,是否有偏離失真的風險。 目前的文獻並沒有適當的模型在事件發生前,提供我們判定某預測事件是否 正確預測的方法,僅提供預測市場的總體準確度作為評估的標準。例如:Berg et al. (1997) 以 IEM 在 1996 年及 2000 年的兩次美國總統選舉市場為樣本外 (out-of-sample)測試,發現利用迴歸模型的樣本外預測結果並不好。Berg et al. (2003) 以 1992、1996 及 2000 年美國總統選為例,分析三種模型對於預測誤差. 政 治 大 含波動率(implied volatility)估計預測標準誤 (forecast standard deviation)。他們認 立 的判斷,包括市場微結構因素(交易人數、數量與共識)、長期價格走勢、與隱. 理指標,但是也認為需要更多的資料來驗證。. 學. ‧ 國. 為,贏者全拿合約的預測市場價格可以作為交易者對得票率預測的信心程度的合. ‧. 期貨交易過程的變數相當多,包括交易的時間、交易者的數量與共識、預測. y. Nat. 事件的困難度等變數,都可能影響預測事件的預測準確度。因為每一個事件具備. er. io. sit. 不同時空背景條件或交易資訊品質,我們無法透過過去預測市場的「整體準確度」, 在事前推定未來特定一事件的最終實現結果。舉例來說,非選舉類別的預測事件,. al. n. v i n 沒有候選人可以比較相對價格高低的必要性,單純一事件的交易價格,到底要多 Ch engchi U 高才能斷定該事件未來會發生,「事前」沒有一套客觀判定標準,故本文後半部 的研究,將著重「最適門檻」的建立及探討。. 目前文獻是以最後交易價格超過一定的價格門檻作為判定預測事件的結果, 亦即將「機率預測」(probability forecasting)轉換成「類別預測」(categorical forecasting)。(童振源等,2009;童振源等,2011a;童振源等,2011b)此研究 是以選舉事件為分析對象,第一種價格門檻為價格 50 為門檻。然而,這項門檻 不太適合超過二位以上的候選人,特別是競爭激烈的選區,因為兩個候選人的政 治期貨價格可能都沒有超過 50。第二種價格門檻為 100 除以「有效候選人數. 2.
(12) (Number of effective candidates)」 。2不過,我們希望「事前」判斷事件結果,但是 「有效候選人數」僅能選舉結束後才能取得,因此這項門檻不適合作為本研究的 價格門檻。 進一步而言,事件發生的結果只有發生與未發生,我們如何在事前解讀預測 事件的價格?如何評估預測準確度?將是我們的主要研究課題,本文的前半部分 內容,將以未來事件交易所(http://xfuture.org)(童振源等,2009)之選舉期貨 預測事件作為樣本,評估「最高價準則」在選舉預測市場的預測效果,並且在選 舉前建構 4 個鑑別模型,鑑定選舉事件的預測結果是否準確。本文章節編排:第. 政 治 大 析 4 個鑑別模型的預測力,第五章為最適門檻的建構與確認,最後第六章為本文 立. 二章說明研究方法與資料,第三章分析 4 個鑑別模型的鑑別力,第四章建立並分. 學. 第二章. 研究方法與資料. Nat. sit. y. ‧. ‧ 國. 結論。. n. al. er. io. 本文迴歸依變數所對應的「類別預測」,是使用 Logit 模型和鑑別分析模型. i n U. v. (discriminant analysis, DA),作為事前類別預測的判定機制,且對自變數處理有 2. Ch. engchi. 種方式:原始變數與主成份變數,而主成份變數是經由主成份分析(principal component analysis,PCA)而獲得,我們運用主成份分析的優點,將「全面且大 量」可用的變數全部納入模型體系,同時可避免共線性的問題,使研究者收集到 的資料訊息極 大化,完整的資訊可能讓預測工作更加準確。 PCA 可在所有形形色色及高度相關性的眾多變數中,歸納出這些變數的重 要特徵,這些資料的主要特徵即稱為「主成份變數」,而主成份的使用個數會少 於原始變數個數,且主成份之間不會有相關性。PCA 理論是一個線性代數學上 的應用,它將眾多變數的維度,濃縮成較少數的主成份來描述整個資料型態、性 2. 有效候選人的定義為:NEC = 1/ ∑𝑛𝑖=1 𝑝𝑖 , 𝑛 為該選區候選人總數,𝑝𝑖 為第 i 個候選人得票率。 3.
(13) 質,每一主成份皆為所有原始變數標準化後的線性組合,一個主成份被視為一個 新的自變數。 文獻上以主成份分析為應用方法論的文章族繁不及備載,例如:Perignon et al. (2007)使用 PCA 的方法尋找影響美國、日本及德國公債報酬的共同因子或趨勢。 Chantziara and Skiadopoulos(2008)則發現原油、天然氣等能源的期貨金融商 品,可使用主成份分析來預測期貨價格的變動,但樣本外預測的準確率不高。 Kessler and Scherer(2011)則分別運用 PCA 與狀態空間模型(state space model, SSM)研究影響避險基金流動性的共同因素,實證結果指出:流動性較高的避 險基金,具有較低的報酬率。. 立. 政 治 大. ‧ 國. 學. 第一節 Logit 模型與 DA 模型. ‧. 本文的前四章分析最高價準則成立與否(亦即,某選舉預測事件的價格為該. y. Nat. 選區的最高價,而且該選舉預測事件在選舉後確實發生;某選舉預測事件的價格. er. io. sit. 並非該選區的最高價,而且該選舉預測事件在選舉後確實沒有發生),以虛擬變 數(dummy variable)之 0 或 1 表示。Carvalho et al.(1998)、Hwang et al. (1997)和. al. n. v i n West (1985)曾利用 Logit 迴歸作為預測的方法。本文先採用 Logit 迴歸模型,鑑 Ch engchi U 別每一合約是否滿足最高價準則。其標準格式為:. 𝑒 𝑎+𝑏1 𝑥1 +𝑏2 𝑥2 +⋯+𝑏𝑛 𝑥𝑛. E(𝑦) = 1+𝑒 𝑎+𝑏1𝑥1+𝑏2 𝑥2+⋯+𝑏𝑛 𝑥𝑛. (1). 而迴歸機率配適值可透過 Logit 轉換過程(勝算比再取自然對數)得到,. 𝑦̂. ln (. 1−𝑦̂. ̂2 𝑥2 + ⋯ + 𝑏̂𝑛 𝑥𝑛 ) = 𝑎̂ + 𝑏̂1 𝑥1 + 𝑏. 4. (2).
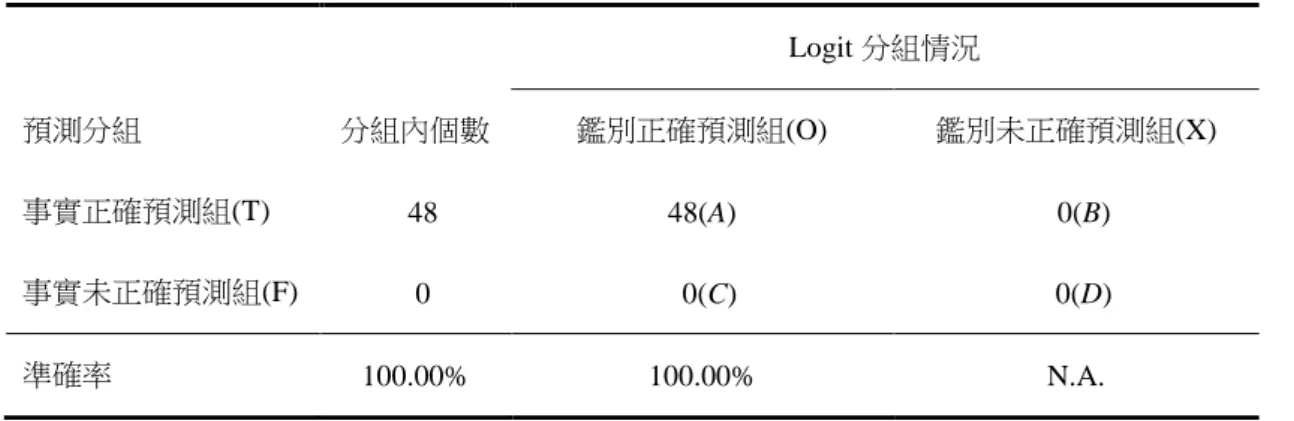
(14) ̂2 , ⋯ , 𝑏̂𝑛 ,再運用文獻常使用的樣本平 本文使用 STATA 計量軟體得到 𝑏̂1 , 𝑏 均數(sample mean),作為我們 Logit 鑑別分組門檻。以本文的最高價準則為例, 在選舉前夕收集一組合約變數(𝑥1 , 𝑥2 , ⋯ , 𝑥𝑛 ),輸入上一方程式等號右邊可算 出一個配適值,此一數值若比樣本平均數大時,則我們判定該合約的加權平均價 「符合」最高價準則,另一種情況,該合約的配適值小於樣本平均數時,則本文 模型判定此合約價格可能「不符合」最高價準則。 另外一種方法是多變量的模型,利用 DA 分組樣本功能以鑑別選舉預測事件 的結果。例如,Blin and Whinston(1975)應用 DA 在多數決的投票研究。Mitchneck. 政 治 大 (2002)使用 DA 討論小型開放國家貿易保護措施的影響。與 Logit 模型相似, 立 (1995)運用 DA 的區分樣本的特質,應用在地理經濟的議題,以及 Mitra et al.. 僅需要依變數與自變數,所以其變數設定上完全與 Logit 相同。在自變數與依變. ‧ 國. 學. 數各有兩種選擇下,我們將測試 4 個模型的鑑別力與預測力,分類如下:. ‧. Nat. 原始自變數 Original-Logit 模型. al. n. DA 鑑別分析. Original-DA 模型. Ch. engchi. 主成份變數. sit. io. Logit 迴歸. y. 四種預測模型分類. PCA-Logit 模型. er. 表 1. i n U. v. PCA-DA 模型. 第二節 鑑別模型設定與預測說明 預測市埸的最主要功能在於選前預測選舉結果。然而,在未來事件交易所發 行眾多的選舉期貨合約當中,並非每一合約都可以收集足夠的選情訊息或者有效 資訊。例如出現「立委補選」交易清淡的合約,其最後交易價格可能不具參考價 值。 因此,本文擬利用四種鑑別模型,在「選舉之前」將所有選舉預測事件合約 區分成兩組:O 組與 X 組合約,O 組的合約價格被模型判定「最高價準則成立」, 5.
(15) 亦即最高價合約的候選人會當選,非最高價合約的候選人不會當選。另外,選前 鑑別模型判定為 X 組合約,則該合約的交易價格被判定「違反最高價準則」 ,亦 即最高價合約的候選人不會當選,非最高價合約的候選人會當選。 在「選舉過後」,我們可觀察每一合約選前的「最後一個交易日價格」,3並 對照事後選舉結果,獲知該合約是否符合最高準則,若最高價準則成立,則定義 為「T 合約」。反之,某一交易價格違反最高價準則,則定義為「F 合約」。底下 依據上述定義,將選舉預測事件分類如下:. 表 2. 鑑別模型對選舉預測事件的分類. 政 治 大. Logit 模型分組情況. 立. 鑑別正確預測組(O). 事實正確預測組. (T). (A). 事實未正確預測組. (F). (C). 鑑別未正確預測組(X). 學. 分組內個數. (B) (D). ‧. ‧ 國. 預測分組. 說明:A 組:選前落在「鑑別正確預測組(O)」且選後為「事實正確預測組(T)」;. y. Nat. io. sit. B 組:選前落在「鑑別未正確預測組(X)」且選後為「事實正確預測組(T)」;. n. al. er. C 組:選前落在「鑑別正確預測組(O) 」且選後為「事實未正確預測組(F)」;. Ch. i n U. v. D 組:選前落在「鑑別未正確預測組(X) 」且選後為「事實未正確預測組(F)」。. engchi. 據此,我們可以根據所有選舉預測合約的鑑別結果分佈,分別得到 「鑑別 正確準確率:A/(A+C )」與「鑑別未正確準確率:D/(B+D)」 。 「鑑別正確準確率」 在預測上的解釋為:「選前」被模型判定合約價格「將會符合」最高價準則的所 有合約中, 「選後」確實與最高價準則一致的合約比例;而「鑑別未正確準確率」 的意義為:選舉前夕被認定「不會符合」最高價準則的所有合約中,選後結果確 實違反最高價準則之合約比例。. 3. 不使用最後一個月或其它計算期價格,其原因為選前一個月前的事實,可能與選舉當天結果不 一致,我們目標為預測最後投票結果,因此選定投票前一日的交易價格。 6.
(16) 第三節 合約資料與敘述統計 根據 Forsythe et al. (1992) 、Forsythe et al. (1999) 及 Oliven and Rietz (2004), 邊際交易者為影響預測市場準確度之重要因素,但邊際交易者的操作定義仍未有 共識,而且不容易取得相關資料。本文根據 Luckner et al. (2006) 之作法,以過 去交易績效較佳的交易者占全部交易者的比重定義邊際交易者。本文將選舉期貨 的各項交易記錄,整理出六大類變數:邊際交易者、市場共識程度、市場交易特 徵、議題預測困難度、分身變數及選舉特徵變數,總共 40 個的原始變數如下:. 表 3 變數類別與定義. 變數名稱. 變數描述. GP_share_lyc_R. 前一年度總績效排名前 R 名當中,參與該合約的人數,佔該. ‧. ‧ 國. 合約清算日前一天總參與人數的比例, R=100, 200, 300。. y. Nat. 前一年度總績效排名前 S %當中,參與該合約的人數,佔該. io. sit. GP_share_lyc_S%. 合約清算日前一天總參與人數的比例, S=1, 5, 10。. n. al. er. 邊際交易者. 立. 學. 變數類別. 政 治 大. Ch. i n U. v. 在最近 365 天清算合約的總績效排名前 T 名當中,參與該合. GP_share_365d_T. e n約g的 人c 數h,i 佔 該 合 約 清 算 日 前 一 天 總 參 與 人 數 的 比 例 , T=100, 200, 300。. GP_share_365d_U%. 在最近 365 天清算合約的總績效排名前 U %當中,參與該合 約的人數,佔該合約清算日前一天總參與人數的比例, U=1, 5, 10。. GP_share_30d_V. 在最近 30 天清算合約的總績效排名前 V 名當中,參與該合 約的人數,佔該合約清算日前一天總參與人數的比例 , V=100, 200, 300。. 7.
(17) GP_share_30d_W%. 在最近 30 天清算合約的總績效排名前 W %當中,參與該合 約的人數,佔該合約清算日前一天總參與人數的比例, W=1, 5, 10。. 市場共識程度. Limit_ratio_volume. 限價成交口數佔全部成交口數之比例。. WBAS2_all. 該合約所有未成交委託單的加權買賣叫價差距,其數學定義. 政 治 大 為:. 立. =. ∑ 賣單口數+ ∑ 買單口數. ‧ 國. 學 委買單口數相對於委賣單口數的比例。. Buy_sell. ‧ y. Nat. sit. 參與該合約交易的交易量。. Trades. io. al. 參與該合約交易者的人數。. n. Traders. er. 市場交易特徵. ∑ 賣單叫價×賣單口數 − ∑ 買單叫價×買單口數. Days. Ch. Volume. i n U. v. 從該合約開始進行交易到合約清算前一天的交易天數。. engchi. 參與該合約的交易合約口數。. Two_way. 雙向交易者佔全部交易者的比例。. IP_share. 臺灣交易者相對於全部交易者的比例,臺灣交者是指使用交 易的網路 IP 註冊地點在臺灣。. 預測議題困難程度. Traded_order_ratio. 全部成交的委託單數量,除以全部的委託單數量。. Highest-price. 該合約組內,所有加權平均價中最高者。. 8.
(18) 分身變數. NC. 合約組的合約數量。. Price_gap. 該合約組內,第一高價與第二高價的差距。. Avatar_ratio_3. 以 3 人同密碼即視為分身的假設,分身交易者人數佔該合約 全部交易者的比率。 以 3 人同密碼即視為分身的假設,結清日前 X 天參與該合約. Avatar_Xd_ratio_3. 的所有交易者當中,其分身交易者人數佔該合約全部交易者 的比率, X= 15, 30, 365。 Avatar_volume_ratio. 以 3 人同密碼即視為分身的假設,分身所完成「交易口數」. _3. 佔該合約全部成交口數的比率。. 立. 政 治 大. Avatar_volume_Yd. ‧ 國. 學. 交筆數當中,分身所完成「交易口數」佔該合約全部成交口. _ratio_3. ‧. 數的比率, Y=15, 30, 365。. w. io. sit. 該合約的最後一天成交日的加權平均價格。. al. n. 資料來原:未來事件交易所(2011),網址:http://xfuture.org。. Ch. engchi. er. P. y. Nat. 選舉特徵變數. 以 3 人同密碼即視為分身的假設,結清日前 Y 天該合約的成. i n U. v. 本章原始資料包含 689 個「是/否」型期貨合約,4研究對象為選舉類合約, 每一合約對應一位候選人的交易價格、成交量等期貨交易資料。選舉類別包括: 2008 年立委選舉、2008 年總統大選、2009 年縣市長選舉、立委補選和 2010 年 五都選舉期貨合約交易資料。資料整理上,本文扣除「委買單口數或委賣單口數 為零」與「單一合約」,最後得到 650 筆樣本資料。5 本文在第 3 章測試四個鑑別模型的鑑別力,使用全部 650 筆樣本資料,將 T 組與 F 組合約的結果視為 Logit 模型或 DA 模型的依變數(虛擬變數 1 或 0)。第 4 4 5. 另有 166 個落點型選舉預測事件(例如,得票率預測)合約不在分析之中。 本文討論最高價預測準則,故任一選區須有兩個合約以上,該最高交易價格才滿足原始定義。 9.
(19) 節建構樣本外預測模型(out-of-sampling test model)。在操作過程中,某些樣本 內合約較少而易發生「共線性問題」,使用 STATA 軟體估計 Logit 時,軟體功能 會自動去除發生問題的原始變數。6第 3 章與第 4 章最大不同處,第 4 章的預測 模型具備預測的性質,透過樣本內資料的訓練(training),即可在選舉前夕產生兩 組樣本外的鑑別預測結果(O 組與 X 組合),鑑別選舉事件在最後一日的交易價格, 是否滿足最高價準則。7. 第三章. 4 個模型之鑑別力測試. 政 治 大 我們利用所有可用的合約資料,包括 650 個選舉合約結果及選舉前夕的 40 立. 第一節 Logit 鑑別模型. ‧ 國. 學. 個自變數,使用 STATA 估計 Logit 的迴歸係數,再將原來 40 個自變數代入迴歸 係數,得到 650 個依變數的配適值,此配適值與「最高價準則成立的樣本比例」. ‧. 對照後,即可將 650 合約區分成表 4 當中的 A 組合約、B 組合約、C 組合約與 D. sit er. io. 別未正確準確率」。. y. Nat. 組合約,並計算 Logit 模型(原始變數)鑑別力測試「鑑別正確準確率」及「鑑. n. al. 表 4. i n C 所有 40 個原始變數與 650 合約的 h Logit e n迴歸分組結果 gchi U. v. Logit 分組情況. 預測分組. 分組內個數. 鑑別正確預測組(O). 鑑別未正確預測組(X). 事實正確預測組(T). 615. 601(A). 14(B). 事實未正確預測組(F). 35. 10(C). 25(D). 94.62%. 98.36%. 64.10%. 鑑別準確率. 6. 選舉類別變數便被去除。 葉家興、童振源、林鴻文、周子全(2011)曾以 PCA-Logit 模型,討論哪些變數對預測市場準確 度的影響較大,其結果為:「邊際交易者、市場共識程度、市場交易特徵」主成份所估計的係數 皆為顯著,因此我們可以說這些主成份,對「最高價預測準則」的準確度有明顯影響。 10. 7.
(20) 從表 4 可看出,選舉預測合約符合最高價準則的合約達至 615 個,整體比例 達 94.62%。這表示在選前觀察一個合約價格是否為最高,可作為該候選人是否 當選的重要指標,但預測市場機制仍有 5.38%會預測錯誤,而且無法判定是哪些 合約會預測錯誤。 Logit 模型的鑑別正確準確率高達 98.36%,表示我們篩選出 611 個合約中, 僅有 1.64%判定錯誤,低於預測市場本身的 5.38%,而且是針對每個合約可以進 行鑑別。不過,Logit 模型的鑑別未正確準確率只有 64.10%。鑑別未正確預測(X) 組共有 39 個合約,其中有 25 個合約確實是「違反最高價準則」,但是出現 14. 政 治 大 為了進一步分析模型錯判的合約,表 5 列出統計上的型 1 錯誤與型 2 錯誤的 立. 個合約鑑別錯誤的情況。. 合約:(B)組合約為最高價準則成立(T) ,但被 Logit 模型判斷為(X) ;(C)組合. ‧ 國. 學. 約為最高價準則不成立(F),但被 Logit 模型判斷為(O)。這 24 個選舉合約絕. sit. y. Nat. Logit 模型對最高準則鑑別的型一與型二錯誤組別. io. n. al. er. 表 5. ‧. 大部分都是涉及立法委員選舉,只有五個選舉合約是涉及 2008 年總統大選。. (B)組合約:型一錯誤(N=14). Ch. 最高價準則成立(T),但被模型判定為(X). i n U. v. (C)組合約:型二錯誤(N=10). engchi. 最高價準則不成立(F),但被模型判定為(O). 呂學樟(中國國民黨)會當選新竹市立法. 吳成典(中國國民黨)會當選金門縣立法. 委員. 委員. 葉宜津(民主進步黨)會當選臺南縣第一 陳福海(無)會當選金門縣立法委員 選區立法委員 林建榮(中國國民黨)會當選宜蘭縣立法. 邱鏡淳(中國國民黨)會當選新竹縣立法. 委員. 委員. 蔡正元(中國國民黨)會當選臺北市第四. 林淑芬(民主進步黨)會當選臺北縣第二 11.
(21) 選區立法委員. 選區立法委員. 張碩文(中國國民黨)會當選雲林縣第二. 江玲君(中國國民黨)會當選高雄縣第四. 選區立法委員. 選區立法委員. 莊碩漢(民主進步黨)會當選臺北縣第七. 陳亭妃(民主進步黨)會當選臺南市第一. 選區立法委員. 選區立法委員. 周守訓(中國國民黨)會當選臺北市第二. 王昱婷(中國國民黨)會當選臺南市第一. 選區立法委員. 選區立法委員. 李鴻鈞(中國國民黨)會當選臺北縣第四. 蘇震清(民主進步黨)會當選屏東縣第一. 選區立法委員. 政 治 大. 選區立法委員. 立. 吳秉叡(民主進步黨)會當選臺北縣第四. 雲林縣最高票_謝長廷. ‧ 國. 學. 選區立法委員. 嘉義市最高票_馬英九. 雲林縣最高票_馬英九. ‧. 高雄市最高票_馬英九. sit. y. Nat. io. n. al. er. 高雄市最高票_其他候選人. 「第七屆北市立委補選」投票率_50.0%+. 桃園縣補選立委_黃仁杼. Ch. engchi. i n U. v. 進一步比較迴歸自變數在各組的平均值(見表 6) ,(B)、(C)兩組的「限價單 的成交比例 (limit_ratio_volume)」和「邊際交易者 (GP share)」相關變數皆明顯 小於整體平均,表示在市場獲利績效較好的參與者(亦即邊際交易者)未能加入 (B)與(C)組合約的交易,導致預測效率不佳,為(B)與(C)組合約預測失準的共同 因素,這個結果與預測市場文獻一致。 「市場共識程度」的變數(WBAS2_all), 在(B)與(C)組數據皆呈現出共識程度不足的狀態,表示其最後的價格可能不是一 12.
(22) 個長期均衡價格。8 在(B)組內合約當中,其事實上是符合最高價準則,但卻被 Logit 模型誤判將 違反最高價準則,因此我們稱該組合約滿足統計學中的「型一錯誤 (type I error)」 定義。9由表 6 發現(B)組 14 個合約中的「第一高價 (maxp)」變數,其平均值 64.35 明顯小於全部合約的平均 85.11;「第一高價與第二高價之價差 (DIFF)」變數, 其平均值 32.63 亦明顯低於全部合約的平均值 67.73。綜合以上兩變數的觀察, 最高價未達一定門檻,以及差價差距尚未完全拉開,使得(B)組合約被 Logit 模型 誤判為「最高價準則不成立」。10. 政 治 大 Logit 模型誤判「將會符合」最高價準則,因此 Logit 模型在選前亦可能發生「型 立 在(C)組合約當中,選後得知實際是「不符合」最高價準則,但在選前卻被. 二錯誤 (type II error)」。觀察表 6 發現,第一,在(C)組的平均交易人數約為 41. ‧ 國. 學. 人,而全部 650 個合約的平均交易人數落在 128 人左右;第二,(C)組的平均成. ‧. 交筆數約為 90 筆,而全部 650 個合約的平均成交筆數落在 560 筆上下;第三,. y. Nat. (C)組的平均成交期貨口數約為 6,028 口,而全部 650 合約的平均成交期貨口數約. er. al. n. 8. io. 判主因。. sit. 為 166,863 口。從以上三項數據發現,「交易量不足」為模型產生型二錯誤之誤. Ch. engchi. i n U. v. 另一個市場共識變數:buy_sell, 「高雄市長_黃俊英」與「國民黨副總統候選人_王金平」 ,其. buy_sell 的數據皆超過 41,428,使得整體平均來到 247 之譜,但我們觀察其他約 630 合約,buy_sell 大致上落於 10 以下,而(B)與(C)組無法根據此一變數,對照整體平均來決定共識程度。 本文設定檢定的虛無假設(null hypothesis)為「最高價準則成立」 ,原因為本文資料合約中,已有. 9. 九成比例符合最高價準則。 10. 「第一高價」與「第一高價與第二高價之價差」變數,在 Logit 迴歸係數未能顯著,因此本文 模型作鑑別樣本時,無法充分運用此兩變數來篩選合約,Logit 迴歸係數可參閱附錄 1。 13.
(23) 表 6. Logit 迴歸模型自變數在各組的平均值比較 (A)組. (B) 組. (C) 組. (D) 組 整體平均. 合約平均. 合約平均. 合約平均. 合約平均. GP_share_lyc_100. 0.0015. 0.0010. 0.0000. 0.0017. 0.0015. GP_share_lyc_200. 0.0026. 0.0014. 0.0000. 0.0024. 0.0025. GP_share_lyc_300. 0.0033. 0.0017. 0.0000. 0.0031. 0.0032. GP_share_lyc_1. 0.0034. 0.0018. 0.0000. 0.0033. 0.0033. 0.0202. 0.0210. 0.0194. 0.0262. 0.0204. 0.0798. 0.0519. 0.0547. 0.0586. 0.0780. GP_share_365d_100. 0.0007. 0.0001. 0.0000. 0.0014. 0.0007. GP_share_365d_200. 0.0011. 0.0002. 0.0000. 0.0015. 0.0011. 0.0047. 0.0003. 0.0000. 0.0018. 0.0044. Ch. 0.0003. 0.0000. 0.0017. 0.0044. n. al. 0.0046. engchi. y. sit. ‧ 國 io. GP_share_365d_1. ‧. Nat. GP_share_365d_300. 學. GP_share_lyc_10. er. 立. GP_share_lyc_5. 政 治 大. i n U. v. GP_share_365d_5. 0.0195. 0.0046. 0.0017. 0.0249. 0.0191. GP_share_365d_10. 0.0527. 0.0211. 0.0239. 0.0402. 0.0511. GP_share_30d_100. 0.0314. 0.0200. 0.0246. 0.0179. 0.0306. GP_share_30d_200. 0.0408. 0.0232. 0.0253. 0.0254. 0.0396. GP_share_30d_300. 0.1054. 0.0272. 0.0573. 0.0274. 0.1000. GP_share_30d_1. 0.0013. 0.0000. 0.0000. 0.0002. 0.0012. 14.
(24) GP_share_30d_5. 0.0080. 0.0036. 0.0031. 0.0065. 0.0077. GP_share_30d_10. 0.0373. 0.0231. 0.0246. 0.0227. 0.0363. limit_ratio_volume. 0.8471. 0.7528. 0.7521. 0.7873. 0.8413. 39.0452. 49.4913. 53.8414. 33.2525. 39.2750. Buy_sell. 110.5650. 1.4991. 1.4547. 3774.0080. 247.4390. trades. 544.4010. 549.8571. 90.3000. 1116.8400. 559.5492. traders. 117.8120. WBAS2_all. 政 治 大. 41.1000. 389.6000. 128.4323. 113.9800. 45.1429. 46.6000. 43.6400. 108.7554. 160596.60. 132702.357. 6027.900. 400959.280. 166862.544. 57. 1. 0. 0. 6. 0.2090. 0.2459. 0.1869. 0.2609. 0.2115. 0.2671. 0.1271. 0.1958. 0.1588. 0.2588. Ch. 0.5464. 0.4954. i n U. 0.5401. 0.5058. 86.5916. 64.3483. 82.0369. 62.2507. 85.1062. 6.1514. 4.4286. 4.1000. 4.4400. 6.0169. 70.3613. 32.6341. 61.9569. 26.6193. 67.7370. avatar_ratio_3. 0.4552. 0.3180. 0.3308. 0.3757. 0.4473. avatar_15d_ratio_3. 0.3177. 0.3716. 0.3211. 0.4537. 0.3242. avatar_30d_ratio_3. 0.3294. 0.3613. 0.3255. 0.4266. 0.3337. al. n traded_order_ratio. maxp. NC. DIFF. 0.5036. engchi. 15. y. sit. io. IP_share. Nat. two_way. ‧. ‧ 國. volume. er. 立. days. 學. 180.3571. v.
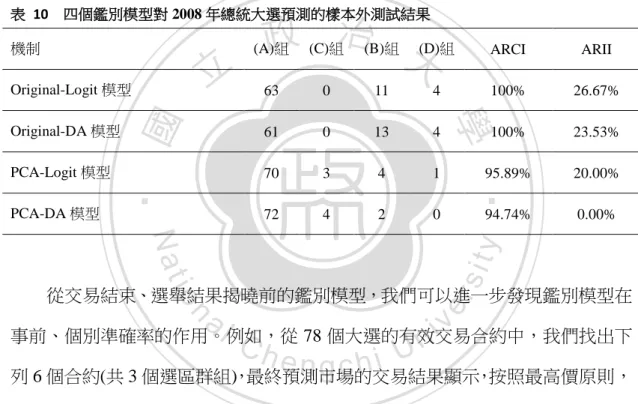
(25) avatar_365d_ratio_3. 0.3717. 0.3589. 0.3264. 0.4224. 0.3727. avatar_volume_ratio_3. 0.6565. 0.6248. 0.5547. 0.6625. 0.6545. avatar_volume_15d_ratio_3. 0.5569. 0.6545. 0.6028. 0.7166. 0.5658. avatar_volume_30d_ratio_3. 0.5827. 0.6491. 0.5722. 0.7077. 0.5888. avatar_volume_365d_ratio_3. 0.6558. 0.6248. 0.5547. 0.6625. 0.6539. 23.1357. 54.4174. 41.0247. 53.5319. 25.2538. Pw. 立. 政 治 大. 綜觀上述數據,邊際交易者少、市場共識程度不足可能造成選舉預測失準。. ‧ 國. 學. 此外,當每一選區的最高價大於整體平均值,且最高價與第二高價有足夠差距, 則最高價準則較容易成立 (例如(A)組內合約),即 Logit 模型愈不易產生型一錯. ‧. 誤。再者,若沒有充足的成交量與選情資訊時,Logit 模型可能發生型二錯誤。. er. io. sit. y. Nat 第二節 4 個鑑別模型之鑑別力比較 a. n. iv l C n hengchi U 其他三個模型依照類似的過程進行預測鑑別分析。為了精簡篇幅,本文省略. 其他三個模型贅述,我們直接比較四種模型的鑑別準確率。上面的模型 Original-Logit 模型為原始變數的 Logit 鑑別模型,PCA-Logit 模型為主成分變數 的 Logit 模型、Original-DA 模型為原始變數的 DA 模型,與 PCA-DA 模型為主 成分變數的 DA 模型。ARCI 為鑑別正確準確率,ARII 為鑑別未正確準確率。 Original-Logit 模型的 ARCI 為 98.36%、ARII 為 64.10%,PCA-Logit 模型的 ARCI 為 96.75%、ARII 為 44.12%,Original-DA 模型的 ARCI 為 96.21%、ARII 為 64.71%,PCA-DA 模型的 ARCI 為 94.88%、ARII 為 33.33%。總體而言, Original-Logit 模型的 ARCI 為最高,ARII 則與略低於 Original-DA 模型。以下將 16.
(26) 進一步進行樣本外預測,以比較四個模型的預測能力。(見表 7). 表 7 全部 650 合約的 4 個鑑別模型鑑別結果 鑑別模型. (A)組. (C)組. (B)組. (D)組. ARCI. ARII. Original-Logit 模型. 601. 10. 14. 25. 98.36%. 64.10%. PCA-Logit 模型. 596. 20. 19. 15. 96.75%. 44.12%. Original-DA 模型. 609. 24. 6. 11. 96.21%. 64.71%. PCA-DA 模型. 611. 33. 4. 2. 94.88%. 33.33%. 政 治 大. 立 第四章. 樣本外的預測能力. ‧ 國. 學. 本章針對 2008 年總統選舉、2009 年縣市長選舉及 2010 年五都選舉進行樣. ‧. 本外測試,在這些選舉前的政治期貨為樣本內的模型訓練樣本。2008 年立委選. Nat. sit. y. 舉之前僅有 45 個合約,而立委選舉合約數量高達 288 個,故我們未將該選舉列. 合約數量. n. al. er. io. 入樣本外測試對象。圖 1 為所有選舉預測合約的分布情況。. 300 250 200 150 100 50 0. Ch. engchi. 200 8年 立 委 選 舉 前. 200 8年 立 委 選 舉. 200 8年 總 統 大 選. 最高價準則不成立. 2. 22. 最高價準則成立. 43. 266. i n U. v. 201 0年 五 都 選 舉. 201 0年 五 都 選 舉 後. 4. 200 200 200 8年 9年 9年 總 縣 縣 統 市 市 選 長 長 舉 選 選 後 舉 舉 ,… 後… 3 0 4. 0. 0. 74. 55. 86. 22. 48. 21. 圖 1 所有選舉預測合約的分布情況 17.
(27) 第一節 2008 年總統大選前夕 首先,本文先以 2008 總統大選為例,說明 Original-Logit 模型的樣本外測試 過程。依時間順序從第 1 個合約至第 T1 個合約為樣本內資料,其每一合約包含 40 個自變數與 1 個依變數(最高價準成立與否的 0 或 1 虛擬變數),總共 T1 組資 料輸入 STATA 軟體,即可得到一組 Logit 迴歸係數。下一步驟我們定義樣本外 資料範圍:第 T1 + 1筆合約至第 T2 筆合約,總共有( T2 − T1 )組的自變數與依變 數,再將此數據代入 Logit 迴歸係數,即可得到( T2 − T1 )個 Logit 配適值。最後,. 政 治 大 正確組。選舉結束後,我們便可以得到樣本外預測的鑑別準確率。分析流程如圖 立 把配適值結果比較樣本平均數後,即可將樣本外合約區分成鑑別正確組和鑑別未. 2 所示:. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 18. i n U. v.
(28) (𝑦1 , 𝑦 2 , ⋯ , 𝑦 𝑇1 ). (𝑥11 , 𝑥21 , ⋯ , 𝑥𝑛1 ) (𝑥12 , 𝑥22 , ⋯ , 𝑥𝑛2 ). 若合約價格符合最高 價準,則𝑦 i = 1,其它. ⋮ 𝑇. 情況𝑦 i = 0. (𝑥1𝑇 , 𝑥2𝑇 , ⋯ , 𝑥𝑛1 ). STATA 統計軟體. 𝑇 +1. 𝑇 𝑇 , 𝑥22 , ⋯ , 𝑥𝑛2 ). 立. 𝑇1. y̅ = ∑ 𝑦 𝑖. 政 治 大. 𝑖=1. 學. ‧ 國. 𝑇 (𝑥12. 樣本平均數. Nat. y. ‧. Logit 迴歸係數 ̂ ̂ (𝑎̂, 𝑏̂ 1 , 𝑏2 , ⋯ , 𝑏𝑛 ). T1 +1 , 𝑦 T1 +2 , ⋯ , 𝑦̂ 𝑇2 ) ̂ (𝑦̂. io. sit. 𝑇 +1. O 組:ŷ𝑖 ≥ y̅ X 組:ŷ𝑖 < y̅. n. al. er. 𝑇 +1. (𝑥11 , 𝑥21 , ⋯ , 𝑥𝑛1 ) 𝑇 +2 𝑇 +2 𝑇 +2 (𝑥11 , 𝑥21 , ⋯ , 𝑥𝑛1 ) ⋮. C h 𝑖 = 𝑇 + 1, ⋯ , 𝑇 engchi 1. 2. i n U. v. 選舉前夕 選舉結束. A 組合約,B 組合約, C 組合約,D 組合約. (𝑦 𝑇1 +1 , 𝑦 𝑇1 +2 , ⋯ , 𝑦 𝑇2 ). 圖 2. Logit 樣本外測試流程圖. 19.
(29) 根據最高價準則,預測市場準確預測樣本內的選舉合約比例為 92.79%,最 高價準則不成立的樣本機率為 7.21% (100-92.79%)。Logit 模型對樣本內合約的鑑 別正確準確率達 97.74%,比最高價準則的預測準確率高,鑑別未正確準確率為 73.91%。(見表 8). 表 8 2008 年總統大選前之樣本內 333 個合約的 Logit 迴歸分組結果 Logit 分組情況 預測分組. 分組內個數. 鑑別正確預測組(O). 鑑別未正確預測組(X). 事實正確預測組(T). 309. 303(A). 6(B). 事實未正確預測組(F). 24. 7(C). 17(D). 97.74%. 73.91%. 政 治 大. 立. 準確率. 92.79%. ‧ 國. 學 ‧. 根據樣本內合約訓練的 Logit 模型進行樣本外測試。表 9 為樣本外測試結果, Logit 模型對樣本外樣本的鑑別正確準確率有改善且高達 100%。不過,Logit 模. y. Nat. n. al. er. io. sit. 型的鑑別未正確準確率卻只有 26.67%,預測能力大幅下降。. i n U. 表 9 2008 年總統大選之樣本外 78 個合約的 Logit 迴歸分組結果. 預測分組. Ch. engchi. v. Logit 分組情況. 分組內個數. 鑑別正確預測組(O). 鑑別未正確預測組(X). 事實正確預測組(T). 74. 63(A). 11(B). 事實未正確預測組(F). 4. 0(C). 4(D). 94.87%. 100.00%. 26.67%. 準確率. 2008 年總統選舉預測的合約共有 78 個。若未使用本文的鑑別模型,僅使用 最高價準則,將有 94.87%正確預測選舉結果。但是,即使在選前知道選舉預測 合約的價格,亦無法區分哪些合約會符合最高價準則,哪些合約會發生預測錯誤。 20.
(30) 本文引入 Logit 鑑別方法,在「選舉前」可篩選出 63 個合約,該模型對選舉預 測合約的鑑別結果有 100%的預測準確率。 以下進一步比較四個模型對 2008 年總統選舉預測的樣本外預測能力。 Original-Logit 模型樣本外的 ARCI 為 100%,ARII 為 26.67%;Original-DA 模型 的 ARCI 為 100%,ARII 為 23.53%;PCA-Logit 模型的 ARCI 為 95.89%,ARII 為 20.0%;PCA-DA 模型的 ARCI 為 94.74%,ARII 為 0%。整體而言,Original-Logit 模型在 2008 年總統大選預測樣本外的預測能力都是最高。(見表 10). 表 10 四個鑑別模型對 2008 年總統大選預測的樣本外測試結果 機制. 立. PCA-Logit 模型. (B)組. (D)組. ARCI. ARII. 63. 0. 11. 4. 100%. 26.67%. 61. 0. 13. 4. 100%. 23.53%. 70. 3. 4. 1. 95.89%. 20.00%. 72. 4. 2. 0. ‧. PCA-DA 模型. (C)組. 學. Original-DA 模型. ‧ 國. Original-Logit 模型. 政 治 大. (A)組. 0.00%. Nat. io. sit. y. 94.74%. n. al. er. 從交易結束、選舉結果揭曉前的鑑別模型,我們可以進一步發現鑑別模型在. Ch. i n U. v. 事前、個別準確率的作用。例如,從 78 個大選的有效交易合約中,我們找出下. engchi. 列 6 個合約(共 3 個選區群組),最終預測市場的交易結果顯示,按照最高價原則, 馬英九會當選總統(85.57 > 16.10),台南市最高票為謝長廷(58.83 > 42.92), 而雲林縣最高票為馬英九(61.80 > 44.48)。. 21.
(31) 表 11 選舉預測事件最後一個交易日之加權平均價格(在鑑別 模型分析前與選舉結果揭曉前) 合約名稱. 加權平均價. 謝長廷會當選總統. 16.10. 馬英九會當選總統. 85.57. 臺南市最高票_馬英九. 42.92. 臺南市最高票_謝長廷. 58.83. 雲林縣最高票_馬英九. 61.80. 雲林縣最高票_謝長廷. 44.48. 立. 政 治 大. 預測市場依最高價準則在選舉結果揭曉前做出以上判斷,從 2008 大選前的. ‧ 國. 學. 交易數據,我們可以得知預測市場的這些判斷有 92.79%的準確率。然而,哪些 合約更可能預測準確,哪些合約可能預測失準?除了最後一天交易的加權價格可. ‧. 以視為事件發生(候選人當選)的機率外,我們無法針對個別合約作進一步判斷. sit. y. Nat. 其準確率。. n. al. er. io. 然而,鑑別模型的分析卻透露了更多關於個別合約預測準確率的訊息。以. i n U. v. Original-Logit 模型為例,我們看到模型所透露的配適機率(最高價準則成立的機. Ch. engchi. 率)各有不同。以前面 6 個合約而言,鑑別模型告訴我們「馬英九會當選總統」、 「謝長廷會當選總統」的配適機率都高達 100%。換言之,研究者對預測市場的 最高價準則在這兩個合約成立的信心極高,幾乎篤定最高價準則成立。然而,在 「臺南市最高票_馬英九」 、 「臺南市最高票_謝長廷」 、 「雲林縣最高票_馬英九」、 「雲林縣最高票_謝長廷」4 個合約中,最高價準則成立的配適機率卻分別只有 0.4%、27.2%、41.38%、67.51%,都遠低於 2008 年總統選舉前選舉預測事件樣 本內,最高價準則成立的平均樣本比率(92.79%) 。換言之,Original-Logit 鑑別 模型認定最高價準則在此 4 個合約成立不成立(X 組),可以事前認定此 4 合約 的最終結果與「未來事件交易所」的預測未必一致。(見表 12) 22.
(32) 表 12. Original-Logit 模型鑑別「最高價準則」成立之配適機率與判定組別(選舉結果揭曉前) 加權平. Original-Logit 模型鑑別「最. Original-Logit 模型. 均價. 高價準則」成立之配適機率. 鑑別組別. 馬英九會當選總統. 85.57. 1.0000. O組. 謝長廷會當選總統. 16.10. 1.0000. O組. 臺南市最高票_馬英九. 42.92. 0.0040. X組. 臺南市最高票_謝長廷. 58.83. 0.2720. X組. 雲林縣最高票_馬英九. 61.80. 0.4138. X組. 雲林縣最高票_謝長廷. 44.48. 0.6751. X組. 合約名稱. 政 治 大 選總統」,但預測市場預測「臺南市最高票」和「雲林縣最高票」卻失準(見下 立. 果不其然,在最終選舉結果揭曉後,我們發現,預測市場成功預測「馬英九會當. ‧ 國. 前,鑑別模型就已經事前判斷得知。(見表 13). 學. 表之合約清算價格),而彼等相關合約的預測準確率偏低,早在選舉結果未揭曉. ‧. 臺南市最高票_馬英九. y. al. n. 謝長廷會當選總統. 「最高價準則」. 鑑別組別. 成立與否. sit. io 馬英九會當選總統. Original-Logit 模型 加權平均價. er. 合約名稱. Nat. 表 13 選舉預測事件交易價格與 Original-Logit 模型鑑別結果之比較(選舉結果揭曉後). 85.57. C 16.10 hengchi. O組 iv n U O組. 成立 成立. 42.92. X組. 未成立. 臺南市最高票_謝長廷. 58.83. X組. 未成立. 雲林縣最高票_馬英九. 61.80. X組. 未成立. 雲林縣最高票_謝長廷. 44.48. X組. 未成立. 說明:謝長廷在全國、台南市與雲林縣的得票數為:5444949、216815 與 199558,馬英九的得票 數分別為:7659014、223034 與 187705。. 第二節 2009 年縣市長選舉前夕 對於一般的民眾來說,相對會較關注「有興趣」或「所在縣市」等特定的選 23.
(33) 舉合約,而非市場所有合約。以表 14 的 2009 年縣市長選舉為例,預測市場的歷 史準確度為 93.39%,但民眾無法確認自己關注的合約是否落在 6.61% 預測失準 的合約當中。本文方法將 2009 年縣市長選舉前的 469 個樣本內合約,利用 Logit 分組規則,將這些合約重新分兩組,鑑別正確預測組的準確率為 98.15%,比最 高價準則準確率 93.39%要高,鑑別未正確預測組的準確率為 62.16%。. 表 14. 2009 年縣市長選舉前之樣本內 469 個合約的 Logit 迴歸分組結果 Logit 分組情況. 預測分組. 分組內個數. 立. 政 治 大. 鑑別未正確預測組(X). 424(A). 14(B) 23(D). 438. 事實未正確預測組(F). 31. 8(C). 93.39%. 98.15 %. 準確率. 62.16%. ‧. ‧ 國. 事實正確預測組(T). 學. 鑑別正確預測組(O). Nat. sit. y. 觀察表 15 數據,在 2009 年的縣市長選舉 48 個合約當中,Original-Logit 模. n. al. er. io. 型之樣本外鑑別正確準確率為 100%。對照表 14 可知,即使過去樣本內的鑑別正. i n U. v. 確準確率已高達 98.15%,但樣本外鑑別正確準確率仍小幅上揚至 100%。在 2009. Ch. engchi. 年縣市長選舉的鑑別未正確準確率方面,樣本內的準確率只有 62.16%,但在樣 本外測試並無「鑑別未正確預測組(X)」的合約,亦即沒有誤判不符合最高價原 則的樣本,因此無法計算樣本外的鑑別未正確準確率。. 24.
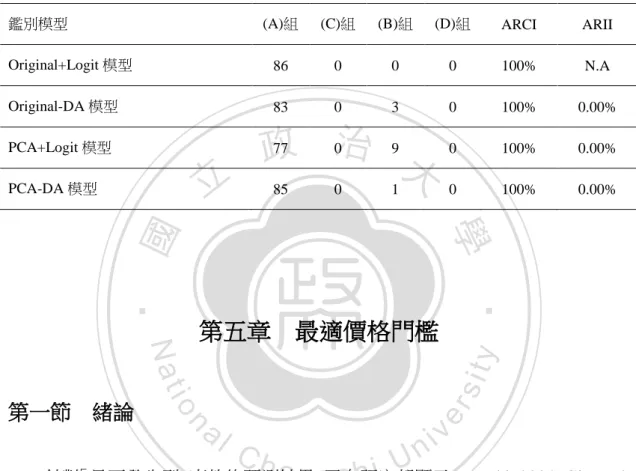
(34) 表 15. 2009 年縣市長選舉之樣本外 48 個合約的 Logit 迴歸分組結果 Logit 分組情況. 預測分組. 分組內個數. 鑑別正確預測組(O). 鑑別未正確預測組(X). 事實正確預測組(T). 48. 48(A). 0(B). 事實未正確預測組(F). 0. 0(C). 0(D). 100.00%. 100.00%. N.A.. 準確率. 以下進一步比較四個模型對 2009 年縣市長選舉預測的樣本外預測能力。. 政 治 大. Original-Logit 模型樣本外的 ARCI 為 100%,沒有出現任何誤判不符合最高價原. 立. 則的合約,所以無法取得 ARII;Original-DA 模型的 ARCI 為 100%,ARII 為 0. ‧ 國. 學. %;PCA-Logit 模型的 ARCI 為 100%,ARII 為 0%;PCA-DA 模型的 ARCI 為 100%,ARII 為 0%。整體而言,Original-Logit 模型在 2009 年縣市長選舉樣本. ‧. 外的預測能力都是最高。(見表 16). n. al. er. io. 鑑別模型. sit. y. Nat 表 16 四個鑑別模型對 2009 年縣市長選舉預測的樣本外測試結果. Ch. (A)組. v i(D)組 n U. (C)組. (B)組. 0. 0. engchi. ARCI. ARII. 0. 100%. N.A. Original+Logit 模型. 48. Original-DA 模型. 47. 0. 1. 0. 100%. 0.00%. PCA+Logit 模型. 47. 0. 1. 0. 100%. 0.00%. PCA-DA 模型. 45. 0. 3. 0. 100%. 0.00%. 第三節 2010 年五都市長選舉前夕 針對 2010 年五都市長選舉的預測,Original-Logit 模型在「鑑別正確準確率」 與「鑑別未正確準確率」的結果,與 2009 年縣市長選舉的情況相似。2010 年五 25.
(35) 都市長選舉前之樣本內合約共計 542 個合約,最高價準則之準確度為 93.54%, Logit 模型之鑑別正確準確率為 98.01%,鑑別未正確準確率為 64.10%。 (見表 17). 表 17. 2010 年五都選舉前之樣本內 542 個合約的 Logit 迴歸分組結果 Logit 分組情況. 預測分組. 分組內個數. 鑑別正確預測組(O). 鑑別未正確預測組(X). 事實正確預測組(T). 507. 493(A). 14(B). 事實未正確預測組(F). 35. 10(C). 25(D). 準確率. 政 治 大. 93.54 %. 98.01 %. 立. 64.10 %. ‧ 國. 學. 2010 年五都市長選舉的樣本外樣本有 86 個,事後皆為在事實正確預測組(T)。 即使是此一極端的測試樣本,本模型仍然可以準確判定此 86 個合約將會符合最. ‧. 高價準則,鑑別正確準確率為 100%,沒有任何一個合約被鑑別為未正確預測組。. n. al. er. io. sit. y. Nat. (見表 18). 表 18. i n U. v. 2010 年五都選舉之樣本外 86 個合約的 Logit 迴歸分組結果. 預測分組. Ch. engchi. Logit 分組情況. 分組內個數. 鑑別正確預測組(O). 鑑別未正確預測組(X). 事實正確預測組(T). 86. 86(A). 0(B). 事實未正確預測組(F). 0. 0(C). 0(D). 100.00%. 100.00%. N.A.. 準確率. 以下進一步比較四個模型對 2010 年縣市長選舉預測的樣本外預測能力。 Original-Logit 模型樣本外的 ARCI 為 100%,沒有出現任何誤判不符合最高價原 則的合約,所以無法取得 ARII;Original-DA 模型的 ARCI 為 100%,ARII 為 0 26.
(36) %;PCA-Logit 模型的 ARCI 為 100%,ARII 為 0%;PCA-DA 模型的 ARCI 為 100%,ARII 為 0%。整體而言,Original-Logit 模型在 2010 年五都市長選舉樣 本外的預測能力都是最高。(見表 19). 表 19 四個鑑別模型對 2010 年五都市長選舉預測的樣本外測試結果 鑑別模型. (A)組. (C)組. (B)組. (D)組. ARCI. ARII. Original+Logit 模型. 86. 0. 0. 0. 100%. N.A. Original-DA 模型. 83. 0. 3. 0. 100%. 0.00%. 政 治 大. PCA+Logit 模型. 立. PCA-DA 模型. 0. 9. 0. 100%. 0.00%. 85. 0. 1. 0. 100%. 0.00%. 最適價格門檻. n. al. er. io. sit. y. 第五章. ‧. ‧ 國. 學. Nat 第一節 緒論. 77. Ch. engchi. i n U. v. 針對「是否發生型」事件的預測結果,已有研究都顯示(Manski, 2004; Gjerstad, 2005; Wolfers and Zitzewitz, 2006; Christiansen, 2007; Ottaviani and Sorensen, 2007),預測市場的價格可以視為預測事件發生的機率。近期研究也顯示(童振源 等,2011a,2011b)),預測市場的預測事件價格可以作為候選人當選之機率。然 而,「事前」關切重點在於對該事件的預測結果,是否具有可靠性或正確性,而 不是只觀察,該預測事件結果發生的價格機率高或低,因為很多決策或避險是建 立在該事件是否發生的基礎上。 因此,本章將利用未來事件交易所的交易資料,建構預測市場的最適價格門 檻,作為判定預測事件是否發生的依據,將事件發生的機率預測(probabilistic forecasting)轉換成事件發生與否的類別預測(categorical forecasting)。因應政 27.
(37) 府與企業等預測單位之需要,本章透過計算所有價格的準確率尋找最適價格門檻, 將預測市場客觀產生的最終交易價格(反映事件發生機率),轉換成事件發生與 否的判定基準及公共政策與企業決策的重要依據。 童振源等(2011a)及童振源等(2011b)針對 2006-2009 年的台灣選舉預測 事件研究,以預測事件的最後一天加權平均價格超過某特定價格門檻,則預測市 場預測該事件會發生;如果預測事件的最後一天加權平均價格低於某特定價格門 檻,則預測市場預測該事件不會發生。他們以價格 100 除以有效候選人數作為價 格門檻。在選舉研究當中,「有效候選人數」是衡量選舉競爭激烈程度;「有效 候選人數」愈大,則選舉競爭愈激烈,則每位候選人當選機率愈低 (Cox, 1997)。 因此,預測事件的最後一天加權平均價格超過此價格門檻,則表示該預測事件應. 政 治 大. 該會發生。他們也以價格 50(事件發生機率為 50%)及最高價(在同一個選區. 立. 的候選人當中,最高價的預測事件發生機率最高)作為選舉預測事件的價格門檻,. 學. ‧ 國. 進行穩健性測試。. 除了傳統上的價格 50 門檻及最高價門檻之外,本章將建構最適價格門檻作. ‧. 為判定預測事件是否發生的準則。此外,童振源等(2011a)與童振源等(2011b). Nat. sit. y. 均分析價格 100 除以有效候選人數的價格門檻,但是本章並不只針對選舉,所以. n. al. er. io. 希望建構最適價門檻,以便一體適用到其他類型預測事件。. Ch. engchi. i n U. v. 第二節 資料描述 本章的資料來源為未來事件交易所在 2006 月 7 月至 2011 年 8 月所有「是否 發生型」預測事件,11但不包括個別預測事件,一個預測事件組至少有兩個預測 事件,才能進行最高價門檻的準確率計算與比較。減去交易量為零的預測事件, 全部的預測事件數量共計 7,881 個,政治類有 867 個、選舉類(一定是政治類) 有 650 個、經濟類有 2,761 個、社會類有 259 個、兩岸類有 411 個、國際類有 1,216. 11. 未來事件交易所網址為 http://xfuture.org,為 2006 年 7 月由國立政治大學預測市場研究中心所 創立,目前由未來事件交易股份有限公司經營。 28.
(38) 個、運動類有 2,437 個、娛樂類有 1,730 個,所有預測事件的統計量見表 20:12. 表 20 未來事件交易所預測事件的全部與分類敘述統計量:2006-2011 合約類別. 事件數量. 平均成交筆數. 平均交易人數. 平均交易天數. 平均成交口數. 全部. 7881. 108.04. 33.44. 46.41. 27994.19. 政治. 867. 457.17. 110.96. 115.26. 130414.77. 選舉. 650. 559.55. 128.43. 108.76. 166862.54. 經濟. 2761. 政 治 大 22.4. 39.52. 9176.59. 社會. 259. 70.24. 31.15. 學. 8783.93. 兩岸. 411. 101.21. 39.16. 117.73. 國際. 1216. 53.3. 20.33. 36.69. 運動. 2437. 106.6. 32.21. n. 1730. Ch. 27.19. y. 9237.47. sit. 15383.45. er. io. al. 72.98. ‧. ‧ 國. 54.89. Nat. 娛樂. 立. n U e n g15.83 chi. 46.22. 31297.64. 25.23. 3569.27. iv. 圖 3 按照價格的所有預測事件的次數分布,絕大部分的預測事件分布在價格 低與價格高的兩個區域。當然,價格高的預測事件之發生機率高,價格低的預測 事件之發生機率低;這兩個區域的預測事件應該是呈現預測市場的強烈共識。不 過,即便發生機率高或低,都不代表該預測事件必然會發生或不發生;預測事件 的價格確實隱含諸多資訊,但是我們無法從預測事件的價格直接判斷該事件被預 測會發生或不會發生。. 12. 將來亦可在選舉類別合約,額外區分出「艱難選區」作測試,以便確認本文模型的鑑別能力。 29.
(39) 次數 4000. 3000. 500. 400. 300. 200. 100. 1. 11. 21. 31. 41. 51. 61. 學. 0. ‧ 國. 立. 政 治 大 71. 81. 91. 價格. ‧. 圖 3 未來事件交易所預測事件分布圖:按照價格. io. sit. y. Nat. n. al. er. 本章希望找到一個最適當的價格門檻,判定預測事件是否會發生。如果某預. i n U. v. 測事件價格在此價格門檻以上,便判定該預測事件為「預測會發生」;某預測事. Ch. engchi. 件價格在此價格門檻以下,便判定該預測事件為「預測不會發生」。然而,預測 與事實結果很難完美,所以可能某預測事件價格在此價格門檻以上而判定該預測 事件為「預測會發生」,但事後事實卻「沒有發生」;或者,某預測事件價格在 此價格門檻以下而判定該預測事件為「預測不會發生」,但事後事實卻「真的發 生」。 圖 4 為預測事件的價格與實際結果的分布示意圖。假設價格門檻為 「Threshold」,所有預測事件在此價格門檻以上(預測該事件會發生),而且事 實結果為發生的預測事件分布在 Q1(預測正確組),事實結果為沒有發生的預 測事件分布在 Q4(預測錯誤組)。相對的,所有預測事件在此價格門檻以下(預 測該事件不會發生),但事實結果為發生的預測事件分布在 Q2(預測錯誤組), 30.
(40) 事實結果為沒有發生的預測事件分布在 Q3(預測正確組)。「預測正確組」由 Q1 與 Q3 組成,「預測錯誤組」由 Q2 與 Q4 組成。若將價格門檻設得太高,將 縮小 Q1、擴大 Q2;若將價格門檻降得過低,將縮小 Q3、擴大 Q4。因此,這個 價格門檻要使 Q1+Q3 極大化,使 Q2+Q4 極小化,才能作為日後準確判定某預 測事件是否會發生的準則。. 次數. Ps=100. Q1. Q2. 政 治 大 Threshold. Q3. 立. Q4. 學 ‧. ‧ 國. Ps=0. 價格. 圖 4 預測事件分布示意圖:按照價格與實際結果. n. al. Ch. e n g c𝑄1+𝑄3 hi. 價格門檻準則的準確率=. ∑ 𝑄𝑖. er. io. sit. y. Nat 各個價格門檻準則的準確率計算方式如下:. i n U. v. (3). 方程式(3)當中的 Q1 為該合約價格高於門檻,且事後確實發生的合約數量; 而 Q3 為合約價格小於門檻,且事後事件未成立的合約數量;方程式(3)的分母, 即為圖 2:Q1、Q2、Q3 與 Q4 所有合約的總數。圖 5 為按照預測事件價格與實 際結果區分之未來事件交易所的全部預測事件分布圖。很明顯的,絕大部分價格 低的預測事件都是沒有發生,絕大部分價格高的預測事件都是發生。然而,從圖 3 來看,幾乎無法找到一個價格門檻,使得預測事件價格在價格門檻以上的預測 事件都是發生,同時使預測事件價格在價格門檻以下的預測事件都沒有發生。. 31.
(41) 次數. 200. 價 格. 0. 200. 事件實際發生. 400. 事件未成立. 600. 立. ‧ 國. 學. 3899. 政 治 大. ‧. 圖 5 未來事件交易所之預測事件分布圖:按照價格與實際結果. er. io. sit. y. Nat 第三節 認定「最適價格」之程序說明 a. n. iv l C n hengchi U 本章將從價格 1 至 99 逐一計算個別價格門檻的準確率,將準確率最高的價. 格門檻當做「最適門檻」。此外,本章還計算 50 為價格門檻的準確率及最高價 門檻的準確率。最適價格門檻與價格 50 門檻準則都是固定價格門檻,但是最高 價門檻準則為「浮動」價格門檻,視預測事件的群組之最高價而定,最高價可能 是 95,也可能是 35。例如,在台北市長選舉時有五位候選人,最後只會有一個 候選人當選,因此這五位候選人的事件期貨價格最高者應該被認定為最可能當選 之候選人。不過,不同的選舉態勢會有不同的事件期貨價格分布。例如,如果一 位候選人獨霸,則該候選人的事件期貨價格可能高達 95,其他候選人的事件期 貨價格可能都是個位數;如果三強鼎立,則三位候選人的事件期貨價格可能都趨 近 30,另外兩位候選人的事件期貨價格可能是個位數。 32.
(42) 在計算完各項價格門檻的準確率,與進行 K-fold 交叉驗證之後,本章以卡 方檢定判定三個準確度的差異性是否存在。其次,本章再以 Z 檢定,測試任意 二價格門檻的準確率在統計上的顯著差異,比較最適價格門檻、價格 50 門檻及 最高價門檻的準確率。以下便先分析全部預測事件的最適價格門檻與比較三種價 格門檻準則的準確度,其整個研究流程圖如下:. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 33. i n U. v.
(43) 間距為 0.1 的情況下,分別從價格 1 至 99 視為門檻,依序計算每個門檻 的準確率,當中產生最高準確率之門檻,即被認定「最適門檻 X」 。. 比較「門檻 50 準則」、 「最高價格門檻」與「最適門檻 X」的準確率. 政 治 大 三個準確率的卡方檢定. 顯著差異. 立. ‧ 國. 學 無法拒絕三者準確率. ‧. 相等的虛無假設. er. io. 個別 Z 檢定:. sit. y. Nat. 「門檻 50 準則」V.S「最適門檻 X」 a l「最高價格門檻」V.S「最適門檻 v i X」 n Ch engchi U. n 顯著差異. 無顯著差異. 無顯著差異. 無法拒絕兩者準確率 相等的虛無假設. 最適門檻 X 準確率明顯高於「門檻 50 準則」與「最高價格門檻」 , 或最適門檻 X 準確率明顯高於「門檻 50 準則」 , 或最適門檻 X 準確率明顯高於「最高價格門檻」,. 圖 6 研究流程圖 34.
(44) 第四節 實證分析 從價格門檻 1 到價格門檻 99,圖 7 為全部預測事件之不同價格門檻的準確 率。很明顯的,價格 50 作為價格門檻的準確率並非最高,也就是 50 非最適價格 門檻。根據價格 50 以後的價格門檻計算,全部預測事件的準確率有顯著提高, 準確率的最高點出現在價格 60。本節測試所有價格的準確率,理論上可找到一 個最高準確率的門檻,此價格即為「最適門檻」。 1 0.9 0.8. 立. 0.7. 政 治 大. 0.4 0.3. io. 0. 101. al. n. 1. sit. 0.1. y. Nat. 0.2. 201. 301. Ch. 401. 501. 價格門檻. 601. engchi U. er. 0.5. ‧. ‧ 國. 學. 準確率. 0.6. v ni 701. 801. 901. 圖 7 整體預測事件之不同價格門檻的準確率. 此外,為確認這些最適門檻的穩定性,本節進行 K=10 的 K-fold 交叉驗證, 將原先樣本隨機區分成 10 等份,每次使用其中九等份作為訓練樣本,計算出各 自的最適門檻價格,總共十個門檻值的平均價格為:60.1625,訓練樣本的平均 準確率為:90.89%,樣本外十分之一等份的測試準確率為 90.88%。為更精確估 計,本節再額外執行 20 次 K=10 的 K-fold,其結果如下圖 8,此交叉驗證結果與 圖 7 的最適價趨於一致,顯示此最適價格門檻具有穩定性。 35.
(45) 95 90 85 K-fold最適門檻 測試準確率. 80 75 70 65 60 55 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20. 圖 8. 20 次 K-fold 交叉驗證結果. 學 ‧. ‧ 國. 立. 政 治 大. 除了價格 50 的價格門檻與最適價格門檻 60 之外,本節再以最高價門檻計算. y. Nat. sit. 全部 7881 個預測事件的準確率,結果在表 2。以價格 50 為價格門檻的全部預測. al. er. io. 事件準確率為 89.47%,以最高價為價格門檻的全部預測事件準確率為 88.45%,. v. n. 以最適價為價格門檻的準確率為 90.79%。最適價似乎是全部預測事件的最好價. Ch. engchi. 格門檻,準確率至少可以提昇 1-2 個百分點。. i n U. 表 21 不同價格門檻之全部預測事件的準確率:2006-2011 (單位:%) 樣本數. 價格 50. 最高價. 最適價(60). 7881. 89.47. 88.45. 90.79. 根據表 21 可知門檻的準確率排名,最適價預測準則最好,價格 50 為次佳與 最高價準則最差,但這三者準確率的差距,是否在統計上顯著差異,則我們可用 36.
(46) 卡方檢定來檢驗。底下表 22 為各準則下的實際預測結果:. 表 22 全部 7881 合約分別在三個門檻準則之觀測個數 價格 50. 最高價. 最適價(60). 總合. 實際正確預測. 7051. 6971. 7155. 21177. 實際錯誤預測. 830. 910. 726. 2466. 總合. 7881. 7881. 23643. 政 治 大 7881. 立. ‧ 國. 學. 觀察上方表 22,最適價門檻準則的正確預測個數最多,最高價門檻準則的 正確預測個數最少,為凸顯實際預測結果的差距,正確預測個數可和樣本期望個. ‧. 數作比較,而樣本期望值可利用表 22 計算得到:觀測值的兩個邊際比例相乘,. n. al. er. io. sit. y. Nat. 之後再乘以全部樣本的總合,其結果如表 23:. Ch. 表 23 全部 7881 合約分別在三個門檻準則之期望個數 價格 50. engchi. i n U. v. 最高價. 最適價(60). 期望正確預測. 7059. 7059. 7059. 期望錯誤預測. 822. 822. 822. 利用上述兩個表格數據和卡方檢定值公式,可算出卡方檢定值為 23.22,此 數值大於自由度為 2 且顯著水準為 5%的卡方臨界值 5.99,故在統計上,三個預 測準則準確率(正確預測合約數量)存在顯著差異。計算過程如方程式(4): 37.
(47) 𝜒 2 = ∑3𝑖=1 ∑2𝑗=1 = +. (𝑓𝑖𝑗 −𝑒𝑖𝑗 ). 2. 𝑒𝑖𝑗. ,其中𝑓𝑖𝑗 為觀測個數和𝑒𝑖𝑗 為理論期望值. (7051−7059)2 7059 (7155−7059)2 7059. + +. (830−822)2 822 (726−822)2 822. +. (6971−7059)2 7059. +. (4). (910−822)2 822. 2 (2) = 23.22 > 𝜒0.05 = 5.99. 本章總共使用 7,881 個樣本合約,因此我們以大樣本的兩個母體比例 z 統計 量,其檢定的樣本分配為:. 𝑝̂𝑖 − 𝑝̂ =. (𝑝𝑖 − 𝑝𝑗 ,. 𝑖 (1− 𝑖 ). 𝑛𝑖. +. 𝑗 (1− 𝑗 ). 𝑛𝑗. ). (5). 政 治 大 與卡方檢定使用相同表 22 的資料, ̂ 、 ̂ 即為任兩個準則的準確率,引入 立 ‧. ‧ 國. 學. 方程式(5)得到 z 值(見表 24)。. 表 24 全部預測事件之三種價格門檻準確率的 Z 檢定. -2.0434**. 2.7788***. n. al. y. ≥. sit. ≥. ≥ 4.8196***. er. io. Z值. Nat. 虛無假設. i n U. v. 說明:1. 為價格門檻 50 準則的準確率, 為最高價門檻準則的準確率, 為最適價門檻準 則的準確率;2. ***表示 1%的顯著水準,**表示 5%的顯著水準,以及*表示 10%的顯準水準。. Ch. engchi. 儘管最適價在全部預測事件作為價格門檻的準確率顯著比其他兩項價格門 檻準則的準確率要高,但是每類預測事件的特性及交易狀況都不一樣,因此接下 來將針對各類預測事件的最適價門檻準則進行實證分析。. 第五節 各類預測事件的最適價門檻準則之實證分析 表 25 呈現各類預測事件的最適價門檻,以及分別使用三種價格門檻準則的 準確率。大致上,各類預測事件的最適價門檻都在價格 60 附近,但是社會類為 38.
(48) 價格 50,娛樂類為價格 78。其次,除了政治類(包括選舉類)與社會類以最高 價門檻準則判定預測事件的準確率最高之外,13其他類別的預測事件都呈現最適 價門檻準則是三種價格門檻準則中的準確率最高。第三,雖然政治類與社會類的 最高價準則判定預測事件的準確率高於其他兩項價格門檻準則,但是雙方的差距 都相當小,不到一個百分點。. 表 25 各類預測事件之三種價格門檻的準確率 最適價. 最適價門檻. 95.27**. 94.93. 62. 91.13. 87.87. 91.49**. 60. 259. 94.21. 94.98**. 94.21. 411. 91.24. 89.29. 94.16**. 國際類. Nat. 合約類別. 樣本數. 門檻 50. 政治類*. 867. 94.69. 82.24. 82.89. 運動類*. 2437. 選舉類*. 娛樂類*. 立. 50. 60. n. al. 85.94**. 60. er. io. 1216. sit. y. ‧. 兩岸類*. 政 治 大. 學. 社會類. 2761. ‧ 國. 經濟類*. 最高價. Ch. i n U. v 89.62**. 87.44. 87.94. 650. 94.15. 94.62**. 94.46. 62. 1730. 87.17. 86.76. 89.42**. 78. engchi. 60. 說明:打*號的各類預測事件存在多個相同準確率之最適價門檻,為精簡篇幅目的,本章僅列出 一個,最接近全部預測事件之最適價格門檻 60 的價格數值。打**號的數值為三項價格門檻準確 率較高者。. 13. 政治類別的合約當中,存在 74.97%的選舉類別合約(650/867)。 39.
數據
Outline
相關文件
Cowell, The Jātaka, or Stories of the Buddha's Former Births, Book XXII, pp.
A factorization method for reconstructing an impenetrable obstacle in a homogeneous medium (Helmholtz equation) using the spectral data of the far-field operator was developed
A factorization method for reconstructing an impenetrable obstacle in a homogeneous medium (Helmholtz equation) using the spectral data of the far- eld operator was developed
According to the information of the 10 exhibitions provided by the organisers in the second quarter, their receipts totalled MOP 74.47 million, which were generated primarily
Now, nearly all of the current flows through wire S since it has a much lower resistance than the light bulb. The light bulb does not glow because the current flowing through it
volume suppressed mass: (TeV) 2 /M P ∼ 10 −4 eV → mm range can be experimentally tested for any number of extra dimensions - Light U(1) gauge bosons: no derivative couplings. =>
O.K., let’s study chiral phase transition. Quark
• Formation of massive primordial stars as origin of objects in the early universe. • Supernova explosions might be visible to the most
