國 立 交 通 大 學
電機與控制工程研究所
碩 士 論 文
結合適應性波束形成與後濾波進行語音強化
Combining adaptive beamforming and
post-filtering for speech enhancement
研 究 生: 李 明 唐
指導教授: 胡 竹 生 博士
結合適應性波束形成與後濾波進行語音強化
研究生:李 明 唐 指導教授:胡 竹 生 博士 國立交通大學電機與控制工程研究所碩士班摘 要
本論文提出一套結合適應性空間濾波與後濾波的方法進行語音強化。利 用麥克風陣列訊號的空間資訊,以空間濾波方式對聲源方向純化語音,論文 中採用成效較佳的 Dahl’s 濾波器。為了進一步純化語音,我們使用單聲道 語音強化的方法進行後濾波。後濾波主要包含雜訊估測與增益函數兩部份, 雜訊估測將分別使用長時間語音活動偵測與最小控制遞迴平均法,搭配以頻 譜刪減法與對數頻譜幅值計算出之增益函數,並實際比較在高速公路雜訊與 音樂雜訊下的純化效果。Combining adaptive beamforming and
post-filtering for speech enhancement
Student: Ming-Tang Lee Advisor: Prof. Jwu-Sheng Hu
Institute of Electrical and Control Engineering
ABSTRACT
An approach combined adaptive spatial filtering and post-filtering for speech enhancement is proposed in this thesis. Using the spatial information of microphone array signals, we purify the speech in the sound source direction by applying spatial filtering. For the spatial filter, we choose Dahl’s beamformer due to it’s relatively better performance. To further purify the speech, we use sigle-channel speech enhancement methods for post-filtering. Post-filtering mainly contains noise estimation and gain function parts. We will use long-term voice activity detection (LTVAD) and minima controlled recursive averaging (MCRA) for noise estimation respectively, cooperating with gain functions computed by spectral subtraction (SS) and log-spectral amplitude (LSA) algorithms. And we will compare the purification results under musical noise and noise from freeway.
誌 謝
對於本論文的完成,首先感謝胡竹生老師為我指引方向,碰到困難時也 是老師為我指點迷津,讓我的研究得以順利完成。此外,老師也教導我作為 一個研究生的態度與觀念,讓我學習如何去認識、研究並解決一個問題,也 讓我了解必須對自己的研究負責。在此,向老師致上最誠摯的謝意。 另外,也感謝實驗室中陪伴我的學長姐、同學與學弟們。感謝興哥一直 以來的照顧;感謝 papa 讓我看到什麼叫做認真的男人;感謝啟揚讓我知道 什麼叫做酷;感謝永融給我的關懷與幫助;感謝畢業的劉大幫助我完成進實 驗室第一件任務;感謝宗敏學長與你的相遇,讓我更確定地進入了 Xlab; 感謝育德學長提供我這麼好的打工機會;另外還有親切的楷祥、唱歌很 high 的鴻齡、有想法的新好男人 alphar、很會辦聯誼的晉源、有著甜美笑容的鏗 元、食量頗大的俊宇、實驗室最強的阿吉、很愛唱歌的 gum、唱歌都會跟去 的瓊文、人脈廣大的 Dodo、很會把妹的 Lundy、打球很準的肉鬆、自由搏 擊冠軍的 Judo,有你們的陪伴,讓我的實驗室生活更精采豐富。 另外,感謝我的爸爸、媽媽多年來的支持,感謝那些陪我打球的大學同 學們,還有所有我愛和愛我的人,謝謝你們。目 錄
摘 要 ...I ABSTRACT... II 誌 謝...III 目 錄 ...IV 表 列 ... V 圖 列 ...VI 第一章 緒論 ... 1 1.1 研究動機 ...1 1.2 研究目標 ...1 1.3 文獻回顧 ...2 1.4 論文架構 ...3 第二章 適應性陣列訊號處理 ... 4 2.1 陣列訊號處理 ...4 2.2 適應性訊號處理 ...8 2.3 適應性陣列訊號處理 ...11 第三章 後濾波(POST-FILTERING) ... 14 3.1 噪音估測 ...15 3.1.1 長時間語音活動偵測(LTVAD)...15 3.1.2 最小控制遞迴平均法(MCRA)...18 3.2 增益函數 ...23 3.2.1 頻譜刪減法(SS) ...23 3.2.2 對數頻譜幅值(LSA) ...26 第四章 實驗結果與分析 ... 32 4.1 適應性空間濾波器測試結果 ...33 4.2 結合空間濾波與POST-FILTERING測試結果...36 第五章 結論 ... 47 5.1 研究成果 ...47 5.2 未來展望 ...47 REFERENCE... 48表 列
表 4-1:高速公路雜訊,訊噪比(SNR)比較表---41
圖 列
圖 2-1:陣列模型---4 圖 2-2:均勻線性陣列之空間響應---7 圖 2-3:Grating Lobe 示意圖---7 圖 2-4:適應性濾波器處理架構圖---8 圖 2-5:Dahl’s Algorithm 訊號擷取架構圖---12 圖 2-6:Dahl’s Algorithm 架構圖---13 圖 3-1:LTVAD 演算法流程圖---17 圖 3-2:上半部:LTSD 與γ關係圖,下半部:VAD 模擬結果---18 圖 3-3:語音頻譜圖---19圖 3-4:第 200 個 frequency bin 的 S 與Smin,fft size = 512---22
圖 3-5:MCRA 演算法流程圖---23 圖 3-6:MMSE 估測器---26 圖 3-7:LSA 演算法流程圖---31 圖 4-1:數位麥克風陣列裝置(上下各有 3 顆數位麥克風)---32 圖 4-2:實驗環境示意圖---33 圖 4-3:空間濾波器處理前,高速公路雜訊---34 圖 4-4:空間濾波器處理後,高速公路雜訊---34 圖 4-5:空間濾波器處理前,音樂雜訊---35 圖 4-6:空間濾波器處理後,音樂雜訊---35 圖 4-7:高速公路雜訊空間濾波後再經過後處理,LTAD+SS---37 圖 4-8:頻譜分布圖。高速公路雜訊,LTVAD+SS---37 圖 4-9:高速公路雜訊空間濾波後再經過後處理,LTAD+LSA---38 圖 4-10:頻譜分布圖。高速公路雜訊,LTVAD+LSA---38 圖 4-11:高速公路雜訊空間濾波後再經過後處理,MCRA+SS---39 圖 4-12:頻譜分布圖。高速公路雜訊,MCRA+SS---39 圖 4-13:高速公路雜訊空間濾波後再經過後處理,MCRA+LSA---40 圖 4-14:頻譜分布圖。高速公路雜訊,MCRA+LSA---40 圖 4-15:音樂雜訊空間濾波後再經過後處理,LTVAD+SS---42 圖 4-16:頻譜分布圖。音樂雜訊,LTVAD+SS---42 圖 4-17:音樂雜訊空間濾波後再經過後處理,LTVAD+LSA---43 圖 4-18:頻譜分布圖。音樂雜訊,LTVAD+LSA---43 圖 4-19:音樂雜訊空間濾波後再經過後處理,MCRA+SS---44 圖 4-20:頻譜分布圖。音樂雜訊,MCRA+SS---44 圖 4-21:音樂雜訊空間濾波後再經過後處理,MCRA+LSA---45 圖 4-22:頻譜分布圖。音樂雜訊,MCRA+LSA---45
第一章 緒論
1.1 研究動機
環境中聲音的雜訊與干擾源總是無所不在,舉凡冷氣機、電腦風扇、 喇叭、空間反射訊號等,不論是在語音辨識或是通訊方面,都有很大的影 響。因此,若能設計出一套方法,有效降低雜訊與干擾源影響以達到語音 純化效果,將會有很大的應用面。 我們利用麥克風陣列的優勢,透過空間濾波器,可針對聲源方向作純化,並 對其他方向干擾源做壓抑。其中,適應性空間濾波器的效果尤其顯著。但由於聲 源方向仍夾雜部份干擾源,因此我們需要利用單聲道語音強化的方法做進一步純 化。 單聲道語音強化方法對非穩態的噪音壓抑效果較差,這是由於雜訊估測誤差 的影響。藉由空間濾波器的幫助,在非聲源方向的干擾源被壓抑後,使得單聲道 語音強化效果可以更進一步提升。1.2 研究目標
本論文目標將分為: 1. 選定及探討適應性空間濾波器之演算法。 2. 探討與比較不同雜訊估測方式與增益函數的結果。 3. 結合空間濾波器與單聲道語音強化方法(後濾波)。1.3 文獻回顧
麥克風陣列可達到空間濾波的功能,一般而言稱之為 Beamformer[1], Beamformer 用於麥克風陣列早用於第二次世界大戰[2],接著慢慢衍生出 諸 如 Fourier Beamformer[3] 、 MVDR(Minimum Variance Distortionless Response Beamformer)[4][5] 、 Robust MVDR[6] 、 MCMV(Multiply Constrained Minimum Variance Beamformer)[7]、MMSE(Minimum Mean
Square Error Beamformer) [8]、MSNR(Maximum SNR)[6]、ML(Maximum
Likelihood Beamformer)[6]等。在各種 Beamformer 中最簡單實現的技術為 Fourier Beamformer,它具有較高的 SNR,但是它需要較大的麥克風陣列才 可以達到較好的效果,這是因為越多的麥克風可以形成較尖銳的 beam pattern,進而減少其他非聲源角度之干擾源影響。這樣的缺點會造成為了 增加效果而必須一直擴大麥克風陣列的體積,因而提出了一種可以自動消 除干擾源的 beamformer—MVDR,它除了可以將所量測出之聲源角度作完 整聲音之接收,並且還可讓非聲源角度之聲音接收達到最低。此法跟 Fourier Beamformer 有相同之 SNR,然而卻增加了抑制干擾源的效果。然 而,如果接收到的訊號是 coherence 或者是作聲源判斷時產生錯誤(pointing error),MVDR 這方法所形成的效果將大打折扣,甚至會使得原本要接收 之聲源變成完全沒有接收。接下來所提出之 Robust MVDR 便是加入 pseudo noise 以減少 pointing error 的影響。另外還有 MCMV 的方法,這個方法需 先計算出想要接收的角度以及干擾源的角度,Beamformer 的技術針對此聲 源收音並且濾除其他方向之雜訊,則此系統將會變得更為實用,而這方面 的系統複雜程度以及運算量相當的龐大,如何去利用 Beamformer 和 DOA 定義出想接收度,或者是不想接收的角度,然後產生一個 beam 於想要接 收之角度,並且產生 null 於不想接收之角度,此法便可將不想接收的聲源 消除,只是此法還需計算其他之角度,如此增加之計算量將是整體系統的
負擔。
在單聲道語音強化方法中包含雜訊估測與增益函數兩部份。雜訊估測 一般常見到的是用 VAD 的方法,而我們所選用的 VAD 是利用長時間語音 資訊來判斷[10]。除了 VAD 的方法外,另外有利用估測區域最小值的統計 特性來判斷是否有語音成分的方法,如 MCRA(Minima Controlled Recursive Averaging )[11]、MS(Minimum Statistcs)[12]。增益函數最常使用的方法為 SS(Spectral Subtraction)[13],另外,LSA (Log-Spectral Amplitude )[14]有很 顯著的雜訊壓抑效果。
1.4 論文架構
本論文將分別介紹空間濾波器與單聲道語音強化方法,並透過實驗比 較,主要內容如下: 第二章:適應性陣列訊號處理。 第三章:後濾波。 第四章:實驗結果與分析 第五章:結論第二章 適應性陣列訊號處理
2.1 陣列訊號處理
數個感應器排成特定的形狀,接收來自空間中所傳遞的訊號,並經過 訊號處理,此技術稱為陣列訊號處理。在陣列訊號處理領域中,依照其目 的不同,大致可以將其研究領域分為兩大類,第一種類的研究著重於估測 訊 號 的 數 量 或 在 空 間 中 的 方 位 , 此 類研 究 一 般 來 說 稱 為 到 達 角 估 測 (Direction of arrival estimation)。而另一種類的研究則是利用訊號的空間 關係,希望能夠對不同方向的訊號作出不同的增益,以達到空間濾波的效 果,藉以分離空間中不同方向聲源的訊號, 這一類的研究一般稱之為波束 形成(Beamforming),也就是一種空間濾波器(Spatial Filter)。在陣列訊號處理理論中,基於兩個假設
1. 窄頻訊號(Narrow band signal) 2. 遠場平面波(Far field plane wave)
假設一陣列感應器排置如圖 2-1 所示,s(t)為原始訊號,n(t)為雜訊 source 圖 2-1:陣列模型 d d d θ r unit vecto : rv rv r xv ⋅2 v 2 xv 1 xv xvM
則 M 個感應器輸出可寫成下列向量形式
)
(
)
(
)
(
)
(
)
(
)
(
)
(
)
(
)
(
)
(
)
(
)
(
)
(
1 1 1 1 1t
n
t
s
r
a
t
n
t
n
t
s
e
e
t
n
t
n
e
t
s
e
t
s
t
x
t
x
t
x
M r x jk r x jk M c r x jw c r x jw M M c c M c c+
=
⎥
⎥
⎥
⎦
⎤
⎢
⎢
⎢
⎣
⎡
+
⎥
⎥
⎥
⎦
⎤
⎢
⎢
⎢
⎣
⎡
=
⎥
⎥
⎥
⎦
⎤
⎢
⎢
⎢
⎣
⎡
+
⎥
⎥
⎥
⎥
⎥
⎦
⎤
⎢
⎢
⎢
⎢
⎢
⎣
⎡
=
⎥
⎥
⎥
⎦
⎤
⎢
⎢
⎢
⎣
⎡
=
⋅ ⋅ ⋅ ⋅r
M
M
M
M
M
r r r r r r r r (2-1) c c c c w k λ π 2 = = kc稱為 wavenumber 而λ 為波長,c 為波速,c 稱為 array manifold vector 包含了訊號傳遞到感應器之間時間關係。 ) (r a r 不同的陣列型態會造成不同的空間響應,並會決定陣列的空間解析 度,舉例來說,一維的陣列只能解析一維的空間維度,而二維的陣列就可 解析二維的空間維度,論文中所實現的陣列型態屬於一維陣列的一部分, 因此本章節將介紹屬一維陣列的均勻線性陣列。均勻線性陣列(Uniform Linear Array),是指一組陣列感應器以線性方
式排列,並且感應器之間的距離相等,圖 2-1 其實就是表示一個均勻線性 陣列。 若以第一個感應器當作參考點,每個感應器對於訊號源相對角度皆 為θ,則第 M 個感應器收到的時間為訊號到達第一個感應器後延遲
(
)
c d M −1 ⋅ ⋅sinθ,因此均勻線性陣列的 Array manifold vector 可寫成如(2-2)
式,均勻線性陣列的優點是容易實現且公式容易推導,運算量較其它多維 陣列型態低,但缺點為只能對一維空間作解析。
( )
( )⎥
⎥
⎥
⎥
⎦
⎤
⎢
⎢
⎢
⎢
⎣
⎡
=
− θ θθ
sin 1 sin1
d M jk d jk c ce
e
a
M
(2-2) 空間濾波器(Spatial Filter)指的就是將感應器輸出乘上各自加權值的 線性組合,因此均勻線性陣列的總輸出可寫成如下形式:( )
∑
( ) = −⋅
=
M i d i jk i ce
W
p
1 sin 1 θθ
(2-3) 此種線性組合的空間濾波器可稱為波束形成(beamforming),若將(2-3) 式中的加權值都設為 1,則p( )
θ 可化簡成如下所示:( )
( )1
1
sin sin 1 sin 1−
−
=
=
∑
= − θ θ θθ
M jkjkMdd i d i jk c c ce
e
e
p
( )⎟
⎠
⎞
⎜
⎝
⎛
⎟
⎠
⎞
⎜
⎝
⎛
=
−θ
θ
θsin
2
sin
sin
2
sin
sin 2 1d
k
Md
k
e
c c d M k j c (2-4) 若將p( )
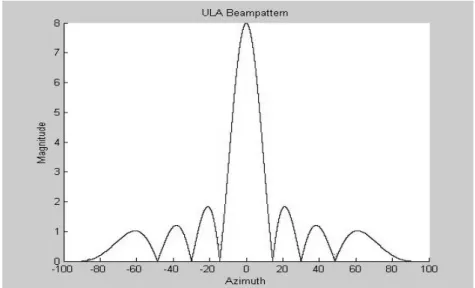
θ 取 Magnitude 可得其 beampattern,如圖 2-2 所示。 從圖 2-2 可看出,不同角度入射的訊號會有不同的增益,而角度和增益的 關係是由陣列的加權值所決定,因此波束形成(beamforming)就可達到空 間濾波的效果,而在波束形成理論中,就是用適當的方法去計算出加權 值,將訊號作空間濾波,就可得到想要的訊號。圖 2-2:均勻線性陣列之空間響應(M=8,frequency=100Hz,d=10) 將(2-4)式取絕對值可得
( )
⎟
⎠
⎞
⎜
⎝
⎛
⎟
⎠
⎞
⎜
⎝
⎛
=
θ
θ
θ
sin
2
sin
sin
2
sin
d
k
Md
k
p
c c (2-5) 由(2-5)式可看出 p( )
θ 對 sinθ是一週期為 d c λ 的週期性的函式,關係 圖如圖 2-3 所示。 圖 2-3:Grating Lobe 示意圖在均勻線性陣列中,預期訊號的角度在 間,而在這角度之間我們 希望 Mainlobe 只會出現一次,如果 Mainlobe 出現兩次以上,則會照成不
預期的訊號被接收近來。從圖 2-4 得知,Grating Lobe 發生在 sinθ= o 90 ± d c λ 的 時候,因此若讓 d c λ > 1,則可避免在 間出現兩個以上的 Mainlobe。 而通常我們都會選取 o 90 ± = d 2 c λ ,以避免 Grating Lobe 的問題。此現象類似於
Nyquist Sampling Theorem,取樣頻率必須是訊號頻率的兩倍以上。
2.2 適應性訊號處理
一般而言,濾波器的係數設計出來後都是固定的,並不會自動的變 動。而適應性濾波器指的是能根據輸入信號,用訊號處理的技巧來適應性 地調整濾波器係數,讓濾波效果更能適應現在環境,以完成某些特定的需 要。 Adaptive Algorithm FilterInput signal Output signal − + error desired signal 圖 2-4:適應性濾波器處理架構圖 適應性濾波器處理架構圖如圖 2-4 所示,當訊號輸入適應性濾波器處 理之後,輸出訊號與希望達成的訊號不同,產生誤差訊號,將誤差訊號代 入適應性演算法,即可調整適應性濾波器的係數,如此經由誤差訊號及適 應性演算法不斷的調整適應性濾波器的係數,係數會不斷的變動,最後達
到某個穩定的值,此時系統輸出訊號與希望達成的訊號就會非常接近。 關於適應性演算法部份,我們採用計算量較小的最小平均平方法 (Least-Mean-Square, LMS)。 LMS 演算法指的是,找出一組權重 W 使得誤差平方項最小[8]。假設 希望達成的訊號為 zero-mean,其變異量為 2,而輸入訊號 x 為一組 d σ M×1 向量,並定義其共異量矩陣和互共異量矩陣
{ }
d
=
0
E
,σ
d2=
E
{ }
d
2{ }
x
x
E
R
x=
∗ ,R
dx=
E
{ }
dx
∗ 因此目標函數如 2-6 式所示( )
{
}
2(
)(
)
*min
E
d
xw
E
d
xw
d
xw
w
J
w−
=
−
−
≡
(2-6) (2-6)式的意義就是找出一組 W 使誤差平方項最小,而 W 的找法則需用 Steepest-Descend Method,如(2-7)式,0
,
1+
≥
=
w
−p
i
w
i iμ
(2-7) 其中(2-7)式意義為從wi−1出發,並前進μp的距離,μ為一個比重稱為 stepsize。而 p 的選取必須從(2-6)式開始推導,將(2-6)式展開可得( )
w
R
w
w
R
w
R
w
J
=
σ
d2−
dx∗−
∗ dx+
∗ x (2-8) 為了找一組 W 使J( )
w 最小,對(2-8)式取∇w得( )
=
∗−
∗∇
wJ
w
w
R
xR
dx (2-9) 因此,為了讓 w 往J( )
w 最低處的方向與強度前進,我們取( )
[
1]
−1 ∗ −=
−
∇
−
=
wJ
w
iR
dxR
xw
ip
(2-10) 故(2-7)式可寫為[
1]
0
1+
−
≥
=
w
−R
R
w
−i
w
i iμ
dx x i (2-11) 在實做上,Rdx和Rx可用離散形式近似於瞬間值:( ) ( )
i
x
i
d
R
dx=
∗R
x=
x
∗( ) ( )
i
x
i
(2-12) 所以(2-11)式可寫為:( )
i
=
w
( )
i
−
1
+
x
∗( ) ( ) ( ) ( )
i
[
d
i
−
x
i
w
i
−
1
]
i
≥
0
w
μ
(2-13) 因此,LMS Algorithm 可整理如下: Filter out :y
( ) ( ) ( )
i
=
x
i
w
i
(2-14) Error function:e
( ) ( ) ( )
i
=
d
i
−
y
i
(2-15) Update weight:w
( )
i
=
w
( )
i
−
1
+
μ
x
∗( ) ( )
i
e
i
i
≥
0
(2-16) 在 LMS 演算法中,為了確保其收斂,μ的範圍必須為 max 2 0 λ μ < < ,λmax 為 的最大特徵值,若所需濾波器階數愈高,則解 的特徵值就愈複雜, 以實作方面來講,如此大的運算量會造成龐大的負擔,因此為了簡化其運 算量,衍生出另一種演算法,Normalize LMS Algorithm: xR
Rx Filter out :y
( ) ( ) ( )
i
=
x
i
w
i
(2-17) Error function:e
( ) ( ) ( )
i
=
d
i
−
y
i
(2-18) Update weight:( )
=
( )
−
1
+
+
( ) ( )
∗( ) ( )
i
≥
0
i
x
i
x
i
w
i
x
i
w
i
w
γ
α
(2-19)與 LMS 演算法比較,Normalize LMS 演算法只有在更新權重的部分不一 樣,原有的μ被
( ) ( )
i x i x∗ + γ α 所取代,其中,0<α<2,γ為一個微小的數, 目的只是確保分母項不為零,如此即可確保 Normalize LMS 演算法收斂, 而且如此的運算即不用解 的特徵值,讓運算量降低許多,但在硬體實現 上,除法仍會消耗較大的硬體資源。 x R2.3 適應性陣列訊號處理
一般在作陣列訊號處理時,會假設兩條件: 1. 窄頻訊號(Narrowband signal) 2. 遠場平面波(Far field plane wave)當此兩條件成立時,系統數學式子會簡化許多,空間濾波器的設計也 較為簡單,但若感應器陣列所收到的訊號並非遠場平面波,則空間濾波器 的設計會變的非常複雜,因此為了簡化空間濾波器的設計方法,則將陣列 訊號處理結合了適應性訊號處理的觀念。因為適應性訊號處理只須知道希 望達到訊號在空間上的特徵,則可利用演算法去自動調整適應性濾波器; 若將此觀念用於陣列訊號處理,則只須先用感應器陣列得知希望達到訊號 的空間特徵,在利用適應性訊號處理演算法來設計「適應性空間濾波器的 係數」,於是將適應性觀念用於空間濾波器中。如此,就算感應陣列所收 到的訊號並非遠場平面波,但只要知道訊號在空間的特徵,那麼即可利用 適應性空間濾波器來專門接收某方向的訊號,並且不斷地作適應性調適, 使誤差訊號愈來愈小。 本章節將介紹用於麥克風陣列的適應性空間濾波器設計方法,稱作 Dahl,s Algorithm。依據適應性訊號處理的觀念,必須先得到希望達到訊號
的特性,而Dahl, s Algorithm的訊號擷取架構圖如圖 2-5 所示。 Source (Target) Noise (Jammer) mics 1 2 M Multi-channel Recording Device Memory (Target Data) Memory (Jammer Data) 圖 2-5:Dahl’s Algorithm 訊號擷取架構圖 Dahl,s Algorithm的訊號擷取架構圖分兩部分來操作,首先利用M個麥 克風,在安靜的環境下錄製希望達到的訊號,也就是特定方向的語音訊 號,再將此訊號儲存至記憶體。第二步驟就是錄製固定干擾源,也就是希 望空間濾波器濾掉的訊號,並將此固定干擾源儲存至記憶體。舉例來說, 若環境中有人的講話聲和喇叭所撥放的音樂聲,則Dahl, s Algorithm的操作 方式為先用麥克風陣列在安靜環境下錄製幾秒鐘人講話的聲音,秒數可自 己設定,接下來也在安靜環境下錄製幾秒鐘喇叭所撥放的音樂聲,這樣則 完成Dahl, s Algorithm的預錄部分。 而Dahl,s Algorithm架構圖如圖 2-6 示,此架構用虛線分為兩部分,上 半部分為將麥克風陣列收到的訊號乘上空間濾波器的係數作為輸出 ,而下半部分則為空間濾波器係數的更新。更新空間濾波器係數方式為, 將麥克風陣列即時錄製到的訊號與希望達到的訊號和固定干擾源作相 加,相加的結果當作 LMS Algorithm 的輸入,再利用 LMS Algorithm 去調 變空間濾波器係數,係數會不斷變動,最後收斂到某一範圍,如此適應性 空間濾波器的輸出訊號會和希望達到的訊號誤差最小,也就是說空間濾波 器在希望達到訊號的方向增益最高,而固定干擾源的方向增益會被壓低,
達到濾除干擾源的效果。 適應性空間濾 波器係數調整 空間濾波器輸出 圖 2-6:Dahl’s Algorithm 架構圖 在Dahl, s Algorithm中,適應性空間濾波器調適和空間濾波器輸出這兩 部分不可同時進行,這部份由Speech Detector判斷進行適應性空間濾波器 調適或是空間濾波器輸出。當判斷為語音時則進行空間濾波器輸出進行空 間濾波器輸出時;反之若判斷為非語音則進行適應性空間濾波器調適。而 當干擾源方向改變或有新的干擾源發生,則必須重新啟動適應性空間濾波 器係數調整的功能並關閉空間濾波器輸出,調整出適合新干擾源方向的空 間濾波器係數。
第三章 後濾波(Post-filtering)
後濾波(Post-filtering)指的就是在空間濾波後做的濾波動作,更進一步 純化語音。而後濾波本身是單聲道語音強化的方法,主要分成兩部份: 1. 噪音估測(Noise estimation) 2. 增益函數(Gain function) 透過噪音估測後,再利用估測時的參數產生增益函數用來濾波。在噪 音估測方面,最常見的就是用語音活動偵測(Voice activity detection, VAD) 的方法,可根據語音資訊如語音能量或過零率等來判斷該音框是否包含語音,而在此將介紹的語音活動偵測演算法是使用長時間語音資訊(long-term
speech information)來判別是否有真人語音[10]。除了語音活動偵測之外, 尚有一些方法利用統計的概念去估測語音是否存在,如最小控制遞迴平均 法(minima controlled recursive averaging, MCRA)[11]、最小統計法(minimum statistics)[12]。在此也將會特別介紹最小控制遞迴平均法(MCRA)。
至於增益函數部份,一般常用的有 Wiener filter,頻譜刪減法(spectral subtraction, SS)或是最大概似法(Maximum likelihood)等。由於 Wiener filter 對於噪音估測的結果非常敏感,較不穩健,而最大概似法的結果較差,在 此針對較穩健且效果不錯的頻譜刪減法(SS)做介紹。另外,一種基於最小 平均平方誤差(minimum mean-square error, MMSE)在對數頻譜(log-spectra) 下的方法將被介紹,也就是所謂的對數頻譜幅值(log-spectral amplitude)。 對數頻譜幅值非常適合使用在聲音的處理上,像是語音辨識中的
MFCC(Mel frequency cepstral coefficients)也是在對數頻譜幅值下做運算, 而在此我們拿來作語音純化。
3.1 噪音估測
3.1.1 長時間語音活動偵測(LTVAD)
近年來語音活動偵測(voice activity detection, VAD)的技術已廣泛應用 在通訊上,最常見的判定真人語音資訊為語音能量和過零率,雜訊及氣音 的過零率都很高,語音能量都較低。例如,由歐洲電信標準協會(ETSI) 所制定用於 GSM(Global System for Mobile Communications)系統中的 AMR(Adaptive Multi Rate)VAD 判定方法就採用了能量、週期、頻譜失 真等三種參數來判定[15][16]。另外由國際電信聯盟(ITU)所制定的 G.729-VAD 採用了全頻帶能量差、低頻帶能量差、頻譜失真和過零率四種 參數來判定[17][18]。論文中使用的 VAD 演算法是使用長時間語音的資訊 而非傳統瞬間音框(instantaneous frame)資訊,以下將針對長時間語音資 訊做下列定義:
z Long-Term Spectral Envelope (LTSE)
若x
( )
n 為一段包含有雜訊的語音訊號,而X( )
k,l 代表著 中第 l 個音 框第 k 個頻率的值,則 N 階的 LTSE 定義為:( )
n x( )
(
)
j N N jj
l
k
X
l
k
,
=
max{
,
+
}
==+−LTSE
N (3-1) 其 代表的意義為,從第 l-N 個音框到第 l+N 個音框,這 2N+1 個音框分別對其取頻譜絕對值(Amplitude Spectrum)後,在第 k 個頻率下,(
k,l LTSEN)
這 2N+1 個頻域絕對值音框內的最大值,這樣的好處是不容易忽略某些字 頭的子音或是摩擦音。z Long-Term Spectral Divergence (LTSD)
( )
( )
( )
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
=
∑
− = 1 0 2 2 10 N,
1
log
10
LTSD
NFFT kN
k
l
k
LTSE
NFFT
l
(3-2)其中 NFFT 代表了作 FFT(Fast Fourier Transform)的點數,而 代表了
雜訊的頻譜絕對值平均,定義如(3-3)式:
( )
k N( )
∑
=(
− =+
+
=
j K K j KX
k
l
j
K
k
N
,
1
2
1
)
)
(3-3) 從(3-3)式可看出, 代表在第 k 個頻率下,第 l 個音框及前後 K 個音 框的頻譜絕對值平均, 和先前定義一樣,代表現階段語音的頻譜絕 對值。因此 LTSD 的意義為:現階段長時間語音的頻譜能量佔了雜訊頻譜 能量的比例,換句話說判定是否為真人語音是用了現階語音能量的大小來 判定,而此能量大小包含了長時間語音資訊,並非只有單一音框資訊。當 LTSD 大於某個臨界值則判定為真人語音,反之則非真人語音,而此臨界 值γ定義如下:( )
k NK(
k l X ,(
)
⎪
⎪
⎩
⎪⎪
⎨
⎧
≥
<
<
≤
−
−
−
+
=
1 1 0 0 1 0 0 1 0 1 0 0E
E
E
E
E
E
E
E
E
E
E
γ
γ
γ
γ
γ
γ
(3-4) 其中 和 代表了在最乾淨和最吵雜的情況下,雜訊的能量,而 E 是指現 階段雜訊的能量。 0 E E1 0 γ 和γ 代表在最乾淨和最吵雜的情況下與 LTSD 比較的 1 臨界值,因此E0,E1,γ 和0 γ 是先設定好的初始值。 1 圖 3-1 為 LTVAD 演算法流程圖,其中 Hang-over 機制是為了延長字母 尾音的機制,而雜訊頻譜更新方式是使用一般遞迴(recursive)方式更新:( )
k
l
N
(
k
l
) (
) ( )
N
k
N
,
=
α
,
−
1
+
1
−
α
(3-5) 表示在第 k 個頻率下,以α為權重,根據上一個音框的雜訊頻譜,更新第 l 個音框的雜訊頻譜。 圖 3-1:LTVAD 演算法流程圖 圖 3-2 是 VAD 的模擬結果,此圖尚未加入 hang-over 機制,所以可看 出第 5 個發聲的尾音被判定成非語音,加上 hang-over 機制即可解決此問題。另外,由圖中上半部的 LTSD 與γ的關係可知,當 LTSD 大於γ時,即 判定為語音,然而γ變動的劇烈程度取決於初始值的選取,也決定了在不同噪音 環境下演算法的穩健性。 0 100 200 300 400 500 600 0 20 40 60 80 frame LT S D 0 5 10 15 x 104 -2 -1 0 1 2x 10 4 samples S p pec h 圖 3-2:上半部:LTSD 與γ關係圖,下半部:VAD 模擬結果
3.1.2 最小控制遞迴平均法(MCRA)
最小控制遞迴平均法其實是一種實驗性的方法,從頻譜來看,聲音有 一塊塊明顯的聲紋,如圖 3-3。若能在一段範圍中,找出該範圍的最小能 量,藉由與範圍中最小能量比較,再加上一些統計或是遞迴的方法更新, 就可以保留聲紋部份並對雜訊做估測。 最小控制遞迴平均法主要先平緩輸入的能量頻譜,估測一段音框中能 量的最小值,接著算出語音可能存在的機率,最後更新雜訊頻譜。以下將 一一介紹。圖 3-3:語音頻譜圖 為了估測雜訊頻譜,我們將音框判定為有語音與沒有語音的情況,即 和 ,並以常見的遞迴平均法更新估測的雜訊頻譜,如(3-6)式 1 H ′ H ′0
( ) (
)
( ) (
) ( )
( ) (
k
l
k
l
)
( )
k
l
H
l
k
X
l
k
l
k
l
k
H
d d d d d d,
ˆ
1
,
ˆ
:
,
,
1
,
ˆ
1
,
ˆ
:
,
1 2 0λ
λ
α
λ
α
λ
=
+
′
−
+
=
+
′
(3-6) 其中λˆd(
k,l)
為第 k 個頻率,第 l 個音框下的雜訊頻譜。X( )
k,l 代表著 中 第 l 個音框第 k 個頻率的值。( )
n x d α ( 0 <α < 1 )為平滑參數。 d 定義語音存在的條件機率為p′( )
k,l =P(
H1′( ) ( )
k,l |X k,l)
,則(3-6)可改寫 為(
)
( ) ( )
( ) (
) ( )
[
]
(
( )
)
( ) ( )
[
( )
]
( )
2 2,
,
~
1
,
ˆ
,
~
,
1
,
1
,
ˆ
,
,
ˆ
1
,
ˆ
l
k
X
l
k
l
k
l
k
l
k
p
l
k
X
l
k
l
k
p
l
k
l
k
d d d d d d d dα
λ
α
α
λ
α
λ
λ
−
+
=
′
−
−
+
+
′
=
+
(3-7) 其中( )
k
l
d(
d) (
p
k
l
d,
1
,
)
~
=
α
+
−
α
′
α
(3-8)(
k l d ,)
~ α 是一個隨 變動的平滑參數,因此我們只要對 作估 測,即可估測雜訊頻譜。(
k l p′ ,)
)
)
(
k l p′ , 基於對輸入訊號從時域及頻域統計其區域性特性,可以估測語音存在 的條件機率 。首先,為了使估測的雜訊較穩健,我們先對輸入的能 量頻譜在時域與頻域下做平滑(smoothing)動作。在頻域下,用一個視窗函 數 b 決定平滑的範圍,長度為 2w+1,(
k l p′ ,( )
( ) (
)
2 fk
,
l
b
i
X
k
i
,
l
S
w w i−
=
∑
− = (3-9) 其中 X 為輸入訊號做 STFT(short-time Fourier transform)後的訊號。接著,用遞迴平均的方法對時域做平滑動作,
( )
k
l
S
(
k
l
) (
) ( )
S
k
l
S
,
=
α
s,
−
1
+
1
−
α
s f,
(3-10) 其中α ( 0 <s α < 1 )是參數。 s 完成平滑動作後,我們要尋找區域性的最小值。一般來說,搜尋區域 性最小值的視窗(window)長度適當的範圍通常為 1s ~ 1.5s 間,搜尋時必須 包含到非語音的音框才能有準確的估測。然而,使用搜尋比較的方式非常 耗運算量,因此在此使用較簡化的搜尋方式[19]。首先,設定區域能量最 小值Smin( ) ( )
k,0 =S k,0 與暫存變數Stemp( )
k,0 =S( )
k,0 ,接著,在每次的音框下 與現在的輸入能量作比較,( )
,
min
{
min(
,
1
) ( )
,
,
mink
l
S
k
l
S
k
l
S
=
−
}
(3-11)( )
k
,
l
min
{
S
(
k
,
l
1
) ( )
,
S
k
,
l
}
S
temp=
temp−
(3-12) 當音框數到達我們設定的視窗長度 L 時,我們將區域能量最小值與暫 存變數重新做初始化,( )
,
min
{
(
,
1
) ( )
,
,
}
mink
l
S
k
l
S
k
l
S
=
temp−
(3-13)( ) (
k
l
S
k
l
S
temp,
=
,
)
(3-14) 接著,重複做(3-11)與(3-12)式直到下一次音框數到達視窗長度。此法 找出的區域最小值並非如一般移動性視窗搜尋最小值,而是依視窗長度 L 將輸入訊號切割成一段一段的區域性最小值。暫存變數 是確保在視窗 間切換時仍能有一個較合理的區域性最小值。 temp S 有了區域性最小值與平滑後的輸入能量,我們可以計算比值以判別語 音是否存在,( ) ( )
k
l
S
k
l
S
(
k
l
S
r,
=
,
min,
)
(3-15) 根據Bayes minimum-cost decision rule,我們可以得到(
)
(
)
01( )
( )
1 0 10 0 1 ' 0 ' 1|
|
H
P
c
H
P
c
H
S
p
H
S
p
H H r r < > (3-16) 其中 與 為語音不存在和語音存在的事前機率, 表示在 下 判斷成 的代價(cost), 表示在 下判斷成 的代價。由於(
H0 P)
)
)
(
H1 P c10 H0 1 H c01 H1 H0(
S |H1) (
p S |H0 p r r 為單調函數(monotonic function),故(3-16)式可表示成( )
δ
' 0 ' 1,
H H rk
l
S
<> (3-17) 其中δ為參數,不同種類的雜訊對此參數影響不大。 利用此比值決定此音框是否有語音,( )
( )
⎩
⎨
⎧
>
=
otherwise
0
,
1
,
l
S
k
l
δ
k
I
r (3-18) 其中I(
k,l)
代表指標函數。I(
k,l)
=1 代表判斷為H1',表示語音存在的狀況;(
k l I ,)
)
=1 代表判斷為 ',表示語音不存在的狀況。 0 H 透過I(
k,l ,我們可以用以下遞迴平均的方式估測語音存在的條件機率( )
k
l
p
(
k
l
)
(
)
I
( )
k
l
p
ˆ
',
=
α
pˆ
',
−
1
+
1
−
α
p,
(3-19) 其中αp ( 0 <αp< 1) 為平滑參數。 將此估測到的語音存在條件機率代回(3-7),即可求得雜訊頻譜。 100 200 300 400 500 600 0 2 4 6 8 10 12 14 16x 10 5 frame( )
2 k X-Short-term Spectral Averaging -Smoothing
Local Minimum Tracking
S Compute Ratio min S Speech Presence Probability Estimation r S Smoothing Parameter Computation p′ Noise Spectrum Estimate d α~ d λˆ 圖 3-5:MCRA 演算法流程圖
3.2 增益函數
3.2.1 頻譜刪減法(SS)
頻譜刪減法是一種在頻域中很常見的訊號處理方式[13],一般假設輸 入訊號的能量頻譜密度(power spectral density, PSD)是由原始訊號的 PSD 與雜訊的 PSD 相加。換句話說,即是假設原始訊號與雜訊為不相關。所以, 若能將雜訊的 PSD 成分刪除,即可還原原始訊號的 PSD。( ) ( )
k
S
k
D
( )
k
X
=
+
(3-20) 其中X( )
k 為輸入訊號做 DFT 後在頻率 k 下的值,S( )
k 與D( )
k 則分別代表 原始訊號與雜訊做 DFT 後在頻率 k 下的值。而且( )
( )
j ( )ke
k
X
k
X
=
θ (3-21) 由於假設原始訊號與雜訊不相關,故輸入訊號的 PSD 也可表示成( )
k
S
( )
k
S
( )
k
S
XX=
SS+
DD (3-22) 其中SXX( )
k 、SSS( )
k 、 分別代表輸入訊號、原始訊號與雜訊的 PSD。 可由 3.1 章節中的方法估測。因此我們可以根據輸入訊號與雜訊的 PSD 對原始訊號的 PSD 做估測,( )
k SDD( )
k SDD( )
( )
( )
( )
( )
⎩
⎨
⎧
−
−
>
=
otherwise
0
0
if
ˆ
k
S
k
S
k
S
k
S
k
S
SS XX DD XX DD (3-23) 對(3-23)式開根號並乘上輸入訊號的相位後做 IDFT,即可得到估測的 原始訊號,( )
{
ˆ
( )
( )}
ˆ
n
F
1S
SSk
e
j ks
=
− θ (3-24) 由(3-21)式可將(3-24)式改成,( )
ˆ
( ) ( )
( )
{
( ) ( )
}
ˆ
1F
1G
k
X
k
k
X
k
X
k
S
F
n
s
− SS=
−⎪⎭
⎪
⎬
⎫
⎪⎩
⎪
⎨
⎧
=
(3-25)( )
ˆ
( )
( )
k
X
k
S
k
G
=
SS (3-26) 由 Parseval’s theorem 可知,( )
n
X
( )
k
dk
S
( )
k
dk
x
∫
∫
XX∑
− − ∞ ∞ −=
=
π π π ππ
π
2
1
2
1
2 2 (3-27) 因此可將(3-26)式改寫成( )
( )
( )
( )
( )
⎪⎩
⎪
⎨
⎧
>
−
−
=
otherwise
0
0
if
1
S
k
S
k
k
S
k
S
k
G
XX DD XX DD (3-28)其中 就是頻譜刪減法中最基本的增益函數格式。這種格式也稱為能量 頻譜刪減法(power spectral subtraction)。
( )
k G 利用類似概念,我們也可以對原始訊號 PSD 的指數次方做估測,( )
k
S
( )
k
S
( )
k
S
XXγ=
SSγ+
DDγ (3-29)( )
[
( )
( )
]
( )
( )
⎩
⎨
⎧
−
−
>
=
otherwise
0
0
if
ˆ
k
C
S
k
S
k
S
k
S
k
S
SS XX DD XX DD γ γ γ γ γ (3-30) 其中 C 為標準化係數(normalize factor),當γ小於 1 時,頻譜受到刪減的影 響隨著γ越小而增加,因此需要 C 去做補償,詳細說明在[13]。 經由推導,我們可以得到增益函數( )
( )
( )
( )
( )
⎪
⎪
⎩
⎪⎪
⎨
⎧
>
−
⎥
⎥
⎦
⎤
⎢
⎢
⎣
⎡
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
−
=
otherwise
0
0
if
1
2 1k
S
k
S
k
S
k
S
C
k
G
XX DD XX DD γ γ γ γ (3-31) 在頻譜刪減法中,幾乎都會產生一種稱為音樂性雜訊(musical noise)。 這是由於雜訊頻譜估測的誤差,使得頻譜相减時產生了新的不必要的雜 訊。 為了減少音樂性雜訊的產生,我們會犧牲一點訊噪比(SNR)來抑制。 像是對雜訊的 PSD 前加入係數,來控制刪減的比例;或是使用 spectral floor 的概念,使得雜訊刪減的效果較緩和,如(3-32)、(3-33)式( )
k
S
( )
k
S
( )
k
S
XXγ=
SSγ+
α
DDγ (3-32)( )
[
( )
( )
( )
]
( )
( )
(
⎩
⎨
⎧
−
−
>
=
otherwise
if
ˆ
k
S
k
S
k
S
k
S
k
S
k
S
C
k
S
DD DD NN XX DD XX SSβ
β
α
γ γ γ γ γ)
(3-33)其中α( 0 <α< 1 )用來控制刪減的比例,βSDD
( )
k ( 0 <β<< 1 )則是 spectral floor 的概念。在第五章的實驗分析中,我們採用的是(3-28)式的能量頻譜刪減法。
3.2.2 對數頻譜幅值(LSA)
對數頻譜幅值估測法是由 Ephraim 與 Malah 所提出[14],主要概念是 用最小平均平方誤差(Minima Mean-Square Error, MMSE)估測法所導出。首 先,我們先來看一個 MMSE 的估測器 G + − S e Sˆ X D 圖 3-6:MMSE 估測器 圖 3-6 中,S 為原始訊號,D 為雜訊,X 為輸入訊號, 為估測結果,e 為 估測誤差。為了估測 使得平均平方誤差 Sˆ Sˆ E
{ }
e2 有最小值,其中{ }
( ) ( )
( ) ( )
⎭⎬
⎫
⎩⎨
⎧
⎥⎦
⎤
⎢⎣
⎡
−
−
=
⎥⎦
⎤
⎢⎣
⎡
−
−
=
E
S
S
S
S
E
E
S
S
S
S
X
e
E
2ˆ
Tˆ
Xˆ
Tˆ
|
(3-34) 所以等同於使( ) ( )
有最小值, ⎭⎬ ⎫ ⎩⎨ ⎧ ⎥⎦ ⎤ ⎢⎣ ⎡Sˆ-S Sˆ-S |X E EX T( ) ( )
(
)
(
)
(
)
[
S
E
S
X
]
[
S
E
(
S
X
)
]
E
(
S
S
X
)
[
E
(
S
X
)
]
E
(
S
X
)
X
S
S
E
X
S
E
S
S
S
X
S
S
S
S
E
E
T T T T T T X|
|
|
|
ˆ
|
ˆ
|
|
ˆ
2
ˆ
ˆ
|
ˆ
ˆ
−
+
−
−
=
+
−
=
⎭⎬
⎫
⎩⎨
⎧
⎥⎦
⎤
⎢⎣
⎡
−
−
(3-35) 由(3-35)式可得到最佳估測解(
S
X
E
S
ˆ
opt=
|
)
(3-36) 而在對數頻譜幅值下估測 MMSE,平均平方誤差為{ }
(
) (
)
S
A
A
A
A
A
E
e
E
T=
⎥⎦
⎤
⎢⎣
⎡
−
−
=
where
log
ˆ
log
log
ˆ
log
2 (3-37) 以相同方式推導可得到最佳估測解(
[
E
A
X
A
ˆ
opt=
exp
log
|
)
]
(3-38)在此提出兩個前提,H0
( )
k,l 與H1( )
k,l 分別代表在第 k 個頻率下,第 l 個音框不含語音與包含語音的情況,( ) ( )
( )
( ) ( ) ( )
k
l
X
k
l
S
k
l
D
(
k
l
H
l
k
D
l
k
X
l
k
H
,
,
,
:
,
,
,
:
,
1 0+
=
=
)
(3-39) 假設訊號與雜訊的 STFT 的係數皆為複數的高斯變數[20],則輸入訊號 的條件機率密度函數可表示成( )
( )
(
)
( )
( )
( )
( )
( )
(
)
(
( )
( )
)
( )
( )
( )
⎪⎭
⎪
⎬
⎫
⎪⎩
⎪
⎨
⎧
+
−
+
=
⎪⎭
⎪
⎬
⎫
⎪⎩
⎪
⎨
⎧
−
=
l
k
l
k
l
k
X
l
k
l
k
l
k
H
l
k
X
p
l
k
l
k
X
l
k
l
k
H
l
k
X
p
d s d s d d,
,
,
exp
,
,
1
,
|
,
,
,
exp
,
1
,
|
,
2 1 2 0λ
λ
λ
λ
π
λ
πλ
(3-40) 由 Bayes rule 可知,( ) ( )
(
)
( )
( )
(
)
(
( )
)
( )
( )
(
X
k
l
H
k
l
)
p
(
H
( )
k
l
)
p
(
X
( )
k
l
H
( )
k
l
) (
p
H
( )
k
l
)
p
l
k
H
p
l
k
H
l
k
X
p
l
k
X
l
k
H
p
,
,
|
,
,
,
|
,
,
,
|
,
,
|
,
0 0 1 1 1 1 1+
=
(3-41)在此定義
( )
(
( )
) ( )
( )
( ) ( )
( )
( )
( ) ( ) ( )
( )
l
k
l
k
l
k
l
k
v
l
k
l
k
X
l
k
l
k
l
k
l
k
l
k
H
P
l
k
q
d d s,
1
,
,
,
,
,
,
,
,
,
,
,
,
,
2 0ξ
ξ
γ
λ
γ
λ
λ
ξ
+
=
=
=
=
(3-42) 則將(3-40)、(3-42)式代入(3-41)式可得( ) ( )
(
1)
( )
( )
(
1
( )
,
)
exp
(
(
,
)
1,
1
,
1
,
|
,
−⎭
⎬
⎫
⎩
⎨
⎧
+
×
−
−
+
=
k
l
v
k
l
l
k
q
l
k
q
l
k
X
l
k
H
p
ξ
)
(3-43) 定義語音存在的條件機率p( )
k,l ≡ p(
H1( ) ( )
k,l |X k,l)
,基於(3-39)式的假 設,我們可將(3-38)式的 LSA 最佳估測解改成( )
{
[
( ) ( ) ( )
]
( )
( ) ( ) ( )
[
]
(
( )
)
( ) ( ) ( )
[
]
{
}
(
)
( )( ) ( ) ( )
[
]
{
}
(
)
( p( )kl ) l k pl
k
H
l
k
X
l
k
A
E
l
k
H
l
k
X
l
k
A
E
l
k
p
l
k
H
l
k
X
l
k
A
E
l
k
p
l
k
H
l
k
X
l
k
A
E
l
k
A
, 1 0 , 1 0 1,
,
,
|
,
log
exp
,
,
,
|
,
log
exp
,
1
,
,
,
|
,
log
,
,
,
,
|
,
log
exp
,
ˆ
−×
=
−
+
=
}
(3-44) 因此,我們必須得知exp{
E[
logA( ) ( ) ( )
k,l |X k,l ,H1 k,l]
}
、 與( ) ( ) ( )
[
{
log , | , , , exp E A k l X k l H0 k l]
}
p ,( )
k l 即可求得 LSA 最佳估測解。 z 求語音不存在時exp{
E[
logA( ) ( ) ( )
k,l |X k,l ,H0 k,l]
}
當語音不存在時,根據聲音特徵的客觀標準,增益應該要大於一個門 檻Gmin[13][21]。( ) ( ) ( )
[
]
{
E
log
A
k
,
l
|
X
k
,
l
,
H
k
,
l
}
G
X
( )
k
,
l
exp
0=
min (3-45) 這種概念與頻譜刪減中(3-32)式所提出的 spectral floor 概念大致相同。z 求語音存在時exp
{
E[
logA( ) ( ) ( )
k,l |X k,l ,H1 k,l]
}
根據 Ephraim 與 Malah 的推導[14],最後可得到( ) ( ) ( )
[
]
{
E
log
A
k
,
l
|
X
k
,
l
,
H
k
,
l
}
G
HX
( )
k
,
l
exp
1 1=
(3-46) 其中( )
( )
( )
( )⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
+
=
∫
∞ − ,2
1
exp
,
1
,
,
1 v kl t Hdt
t
e
l
k
l
k
l
k
G
ξ
ξ
(3-47) z 求語音存在條件機率函數 p ,( )
k l 從(3-42)、(3-43)式可得知,只要能求出事前訊噪比(a priori SNR),(
k,l)
ξ
,與事後訊噪比(a posteriori SNR),γ
( )
k,l ,還有語音不存在的事前 機率,p(
H0( )
k,l)
,即可求得p ,( )
k l 。 1. 事後訊噪比γ
(
k,l)
估測 根據(3-42)式的定義,我們可以利用第 3.1 章節中估測的訊號頻譜(
k l d ,)
λ
與輸入訊號振幅的平方X
( )
k
,l
2直接計算。 2. 事前訊噪比ξ
(
k,l)
估測根據 Ephraim 與 Malah 提出的估測方法,Israel Cohen[22]將語音存在 的不確定性加入考慮改良成