國立臺中教育大學教育測驗統計研究所碩士論文
指導教授: 郭伯臣 博士
廖晨惠 博士
中文文本詞彙多樣性自動化
分析系統建置與探討
研究生:葉靜如 撰
中
華
民
國
一
○
三
年
五
月
I
謝辭
蠟燭多頭燒的生涯,終於也快畫下一個句點。此刻心中真是百感交集……。 慶幸一路上獲得了許多的協助與支持,才能順利走到今天! 感謝指導教授郭伯臣教授及廖晨惠教授,由於您們的循循善誘、耐心指導, 令我獲益匪淺;感謝口試委員蔡雅薰教授,於百忙之中仍不吝提出寶貴的意見, 令論文內容更臻完善外也謝謝您給予我相當大的鼓勵。此外更感謝鎧誌學長給 予我在論文上的大力協助;感謝亞韋犧牲寶貴的時間鼎力相助;感謝立祥學長及 建宏對於英文摘要的協助及學妹雅真、琇涵的幫忙。更感謝風雨無阻陪我口考的 燕珠及親愛的妹妹-怡廷。誠摯的感謝這段時間所有給予我支持、幫忙的所有人! 最後將這份喜悅和我的最親愛的家人分享,謝謝總是無怨無悔的為我付出的 爸爸、媽媽。謹此致謝! 葉靜如 一百零三年五月II
摘要
本研究應用 Type-Token Ratio(TTR)及 Measure of Textual Lexical Diversity (MTLD) 建置電腦自動化中文文本指標及線上文本自動化分析系統,以作為日 後師長提供兒童適合閱讀之讀本的參考依據。本研究使用中高年級文本理解測 驗,檢視研究指標與閱讀理解層次能力間的相關,其研究結果如下: 一、根據分析結果得知 TTRA、TTRC 指標整體趨勢並不會隨年級愈高, 詞彙多樣性數值也呈現愈高的一致性,主要原因是因為隨著年級增加,其文本 的詞彙數亦隨之增加,反而造成 TTR 值下降;只有 MTLD 指標不受文本長度 影響,仍舊與年級呈現遞增的現象。 二、採用一般迴歸分析時,整體解釋的變異量為29%,其中只有 MTLD 指 標達顯著水準。利用逐步迴歸分析,MTLD 指標數值解釋量為26.4%。由上述 的分析中可以發現,各個變項以 MTLD 指標對年級的預測度較高。 三、TTRA、TTRC 及 MTLD 指標與文本通過率在直接提取和檢驗評估題 型中,呈現低度負相關;在直接推論題型中,通過率呈現中度負相關,且達顯 著水準;至於詮釋整合的題型,與其他三層次趨勢不同,呈現低度正相關。 四、由本研究結果發現:當閱讀的文本長度越長時、文本中的唯一單字也 隨之增加,導致詞彙多樣性數值越高,這也表示文本內容難度增加,學生對於 文本的理解負荷增加,與文本通過率形成反向趨勢,尤其是在直接提取和直接 推論題型的理解。
關鍵詞:詞彙多樣性;自動化文本分析;Type-Token Ratio(TTR);Measure of Textual Lexical Diversity(MTLD)
III
Abstract
The present study aims at building a set of computerized automatic Chinese text indicators and an online automatic text analysis system on the basis of Type-Token Ratio(TTR) and Measure of Textual Lexical Diversity(MTLD) for teachers to select proper reading materials for children. Reading comprehension tests for middle and senior grades students were administered to invstigate the relationships among proposed indicators and reading comprehension levels. The results are as followed:
1. Trends of TTRA and TTRC indicators would not increase with ascending grades in contrast with vocabulary diversity. The main reason is that the number of text vocabulary would increase with ascending grades resulting in decreasing the TTR value; the MTLD indicator would still increase with ascending grades. 2. When adopting the general regression analysis, the explained variance is 29%.
The MTLD indicator is a significant predictor. When adopting the stepwise regression analysis, the explained variance of the MTLD indicator is 26.4%. The MTLD indicator is a better significant predictor to reading grades than others.
3. TTRA, TTRC, MTLD indicators correlated to the passing rate of text negatively in direct retrieval and examining evaluating question types; the indicators showed significant negative correlation to the passing rate in the direct reasoning qustions; the indicators showed significant positive correlation to the passing rate in the interpretation of integration qustions.
4. Vocabulary would increase with longer reading text. The increasing number of vocabulary diversity means ascending difficulties in reading text. The increasing burden of reading comprehension of students show an opposite trend to that of the passing rate, especially in direct retrieval and direct reasoning questions.
Keywords: Type-Token Ratio, Measure of Textual Lexical Diversity, Chinese lexical diversity analysis system
IV
目 錄
謝辭...Ⅰ 中文摘要...Ⅱ Abstract...Ⅲ 目 錄...Ⅳ 表 目 錄...Ⅴ 圖 目 錄...Ⅶ 第一章 緒論...1 第一節 研究動機...1 第二節 研究目的...3 第三節 名詞解釋...3 第二章 文獻探討...5 第一節 詞彙多樣性...5 第二節 線上文本分析系統Coh-Metrix...15 第三節 閱讀理解的認知歷程與模式...19 第三章 研究方法...27 第一節 研究流程...28 第二節 研究步驟...29 第三節 研究對象與限制...34 第四節 研究工具...35 第五節 資料處理...40 第四章 研究結果與討論...41 第一節 詞彙多樣性趨勢分析...41 第二節 詞彙多樣性指標預測文本適讀年級...56 第三節 文本通過率與研究指標分析...60 第四節 閱讀理解層次與研究指標之分析...61 第五章 結論及建議...69 第一節 結論...69 第二節 建議...70 參考文獻...72 中文摘要...72 英文摘要...74V
表
目 錄
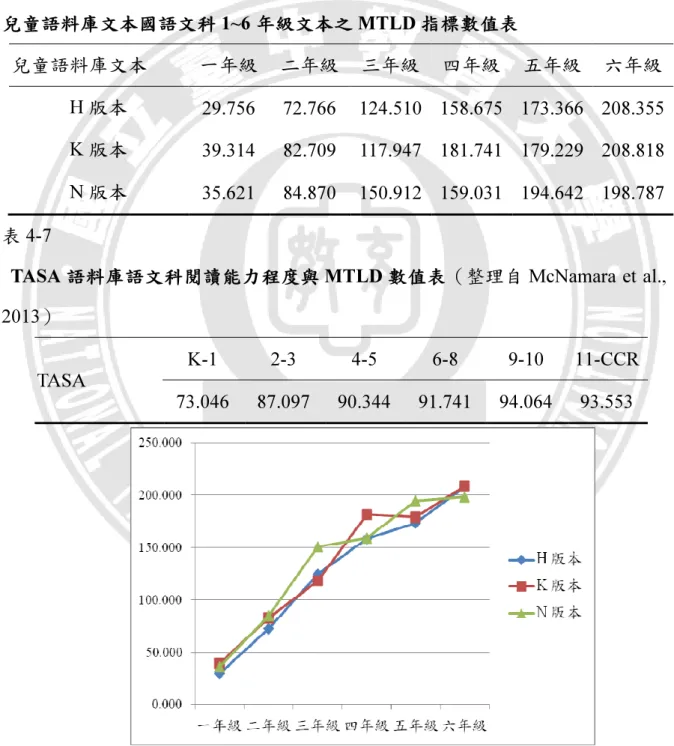
表2-1 TTR指標計算介紹...9 表2-2 詞彙多樣性計算公式...10 表2-3 文字詞彙多樣性演算範例...14 表2-4 Coh-Metrix 3.0 版指標類別與個數. ...18 表2-5 Chall閱讀發展歷程...20 表2-6 閱讀理解歷程階段區分標準對照表...24 表3-1 修改斷詞標記規則...36 表3-2 國際閱讀素養研究(PIRLS)閱讀理解層次.. ...37 表4-1 兒童語料庫文本國語科1~6年級不同版本文本平均長度數值表...41 表4-2 兒童語料庫文本國語科1~6年級文本之TTRA指標數值表...42 表4-3 TASA語料庫語文科閱讀能力程度與TTRA指標數值表...43 表4-4 兒童語料庫文本國語文1~6年級文本之TTRC指標數值表...44 表4-5 TASA語料庫語文科閱讀能力程度與TTRC數值表...44 表4-6 兒童語料庫文本國語文科1~6年級文本之MTLD指標數值表...45 表4-7 TASA語料庫語文科閱讀能力程度與MTLD數值表...45 表4-8 兒童語料庫文本自然科3~6年級不同版本文本平均長度數值表...46 表4-9 兒童語料庫文本自然科3~6年級不同版本TTRA指標數值表...47 表4-10 TASA語料庫自然科閱讀能力程度與TTRA數值表...48 表4-11 兒童語料庫文本自然科3~6年級不同版本TTRC指標數值表...49 表4-12 TASA語料庫自然科閱讀能力程度與TTRC數值表...49 表4-13 兒童語料庫文本自然科1~6年級不同版本MTLD數值表...50 表4-14 TSAS自然科文本利用Coh-Metrix 3.0計算MTLD數值表...50 表4-15 兒童語料庫文本社會科3~6年級不同版本文本平均長度數值表...52 表4-16 兒童語料庫文本社會科3~6年級不同版本TTRA數值表...52 表4-17 TASA語料庫社會科閱讀能力程度與TTRA數值表...53 表4-18 兒童語料庫文本社會科3~6年級不同版本TTRC數值表...54 表4-19 TASA語料庫社會科閱讀能力程度與TTRC數值表...54 表4-20 兒童語料庫文本社會科3~6年級不同版本MTLD數值表...55 表4-21 TASA語料庫社會科閱讀能力程度與MTLD數值表...55 表4-22 個別指標與文本年級相關係數表...57 表4-23 指標變項預測文本年級多元迴歸分析摘要表...58 表4-24 指標變項預測文本年級逐步迴歸分析摘要表...59 表4-25 指標分數與不同年級受試者文本通過率相關係數摘要表...60 表4-26 指標與直接提取層次題型之相關...62 表4-27 指標與直接推論層次題型之相關...63VI 表4-28 指標與詮釋整合層次題型之相關...64 表4-29 指標與檢驗評估層次題型之相關...65 表4-30 閱讀層次4個類型題目與研究建置指標的相關...66 表4-31 PIRLS閱讀理解層次與其他閱讀理解學說區分對照表...67 表4-32 兒童語料庫文本中MTLD指標與LSA指標之相關...68 表4-33 32篇文本中MTLD指標與LSA指標之相關...68 . .
VII
圖
目 錄
圖2-1 Coh-Metrix 3.0 線上版系統介面...18 圖3-1 研究流程圖...28 圖3-2 指標建置流程圖...29 圖3-3 中文文本自動化分析系統首頁登入畫面...32 圖3-4 中文文本詞彙多樣性指標使用介面...33 圖3-5 中文文本詞彙多樣性指標分析結果畫面...34 圖4-1 兒童語料庫文本國語科1~6年級不同版本文本平均長度數值趨勢...42 圖4-2 兒童語料庫文本國語科1~6年級不同版本TTRA指標趨勢...43 圖4-3 TASA語料庫語文科文本閱讀能力程度與TTRA指標趨勢...43 圖4-4 兒童語料庫文本國語科1~6年級不同版本TTRC指標趨勢...44 圖4-5 TASA語料庫語文科文本閱讀能力程度與TTRC指標趨勢...44 圖4-6 兒童語料庫文本國語科1~6年級不同版本MTLD指標趨勢...45 圖4-7 TASA語料庫語文科文本閱讀能力程度與MTLD指標趨勢...46 圖4-8 兒童語料庫文本自然科3~6年級不同版本文本平均長度數值趨勢圖...47 圖4-9 兒童語料庫文本自然科3~6年級不同版本TTRA指標趨勢...48 圖4-10 TASA語料庫自然科文本閱讀能力程度與TTRA指標趨勢...48 圖4-11 兒童語料庫文本自然科3~6年級不同版本TTRC指標趨勢...49 圖4-12 TASA語料庫自然科文本閱讀能力程度與TTRC指標趨勢...50 圖4-13 兒童語料庫文本自然科3~6年級不同版本MTLD指標趨勢...51 圖4-14 TASA語料庫自然科文本閱讀能力程度與MTLD指標趨勢...51 圖4-15 兒童語料庫文本社會科3~6年級不同版本文本平均長度數值趨勢圖...52 圖4-16 兒童語料庫文本社會科3~6年級不同版本TTRA指標趨勢...53 圖4-17 TASA語料庫社會科文本閱讀能力程度與TTRA指標趨勢...53 圖4-18 兒童語料庫文本社會科3~6年級不同版本TTRC指標趨勢...54 圖4-19 TASA語料庫社會科文本閱讀能力程度與TTRC指標趨勢勢...55 圖4-20 兒童語料庫文本社會科3~6年級不同版本MTLD指標趨勢...56 圖4-21 TASA語料庫社會科文本閱讀能力程度與MTLD指標趨勢...561
第一章
緒論
本研究應用 Type-Token Ratio(TTR)及 Measure of Textual Lexical Diversity (MTLD)發展詞彙多樣性自動化文本分析指標,並建置一套適合中文使用的 線上中文兒童詞彙多樣性文本分析系統,以作為教師及家長提供兒童適合閱讀 之讀本的參考依據。本章分為三節,第一節說明研究動機;第二節說明研究目 的;第三節為名詞解釋。
第一節 研究動機
閱讀的目的為何?為什麼世界各國如此重視閱讀教育?史考斯基認為「閱 讀能帶來希望,開啟生命之窗」;列夫‧托爾斯泰認為「理想的書籍,是智慧的 鑰匙」;卡萊爾認為「書最大的影響力,就是可以刺激讀者自我思考」;莎士比 亞認為「生活裡沒有書籍,就好像沒有陽光;智慧裡沒有書籍,就好像鳥兒沒 有翅膀」;高爾基認為「我覺得,當書本給我講到聞所未聞,見所未見的人物、 感情、思想和態度時,似乎是每一本書都在我面前打開了一扇窗戶,讓我看到 一個不可思議的新世界」。笛卡兒認為「讀一本好書,就是和許多高尚的人談 話」。語文教學以「閱讀」為核心,個體在閱讀的初期主要是以培養閱讀能力為 主,後期則在培養學生對多元文化的尊重及對不同族群、文化的關懷。此外更 希望能藉由廣泛閱讀,養成主動探索、研究的能力。至於閱讀對於兒童而言更 為重要,因為閱讀不僅是汲取知識的主要手段,更是幫助他們開啟通往世界的 窗口,且能培養學生有效應用國語文,從事思考、理解、推理、協調、討論、 欣賞、創作,以融入生活經驗,擴展多元視野,面對國際思潮(教育部,2008)。 因此如何更有效率、更精確的為孩子選擇適當的文本,儼然成為師長們關心的 話題。 自從聯合國教科文組織在 1995 年訂定 4 月 23 日為「世界閱讀日」以來, 世界各國越來越重視閱讀教育的推行,因為一個國家的競爭力可由人民的知識2
程度來代表。為了提升人民的閱讀能力,各國紛紛提出各種閱讀措施,例如: 連 續 兩 屆在「 國 際 學 生 評 量 計 劃 ( Programme for International Student Assessment,簡稱 PISA)」稱霸的芬蘭之「無一人落後」(天下雜誌,2011);英 國於 1998 年啟動的「全國閱讀年」;美國柯林頓總統的「美國閱讀挑戰」;布希 總統「閱讀優先方案」等,都是提倡閱讀的相關措施。尤其「不讓孩子落後法 案」更將「閱讀優先計畫」作為政策主軸;而日本文部省則將 2000 年定為「兒 童閱讀年」,由此可看出世界各國對於閱讀的重視。而我國近幾年也開始積極推 動許多閱讀教育政策,如自 93 年起針對弱勢地區國小推動「焦點三百―國小兒 童閱讀計畫」;95 年起針對偏遠地區國中小閱讀推廣計畫;97 年開始啟動為期 4 年的「悅讀 101 ― 教育部國民中小學閱讀提升計畫」;98-101 年閱讀植根與 空間改善:98-101 年圖書館創新服務發展計畫(教育部電子報,2010)。2011 年公布的國際閱讀素養評比(Progress in International Reading Literacy Study,簡 稱 PIRLS)排名從 22 名進步到第 9 名,成績較 5 年前進步,顯示國內這幾年的 閱讀推廣具有明顯成效。 有鑑於對閱讀教育的重視,本研究發現目前國內已有許多學者針對「閱讀 理解策略」、「閱讀教學方式」及「特殊教育閱讀理解教學」進行研究探討;反 觀對於如何選擇適合不同年齡或不同語文程度之兒童閱讀文本的研究卻少之又 少,此外對於中文詞彙多樣性的相關研究更是欠缺。 「工欲善其事,必先利其器」,因此本研究團隊參考美國 Coh-metrix 線上 文本分析系統分析兒童語料庫文本文本,希望能藉由此次研究建立一套線上自 動化中文文本分析系統,分析文本的詞彙多樣性、詞彙訊息、詞類及文本連貫 性等指標,來分析文本之間的凝聚力。讓家長或老師日後在為孩子選擇適合的 閱讀文本時更為省時、方便,能更快速找出適合不同年齡層孩子的閱讀文本; 更希望能藉由中文自動化文本指標的建置,讓國內的閱讀教育研究更為完整!
3
第二節 研究目的
根據上述動機,本研究目的如下: I. 建立詞彙多樣性自動化文本分析指標。 II. 發展線上詞彙多樣性文本分析系統。 III. 探討詞彙多樣性與年級之關聯性。第三節 名詞解釋
壹、詞彙多樣性
詞彙多樣性(lexical diversity)是指一篇文本中使用的詞是否豐富多樣、較 少重複。數值高表示用詞範圍廣,具有較高的多樣性。當文本中含有較多不同 的單詞時,新單詞需要被整合到文本的上下文中,所以詞彙多樣性與凝聚力是 息息相關的(Graesser, McNamara, & Kulikowich, 2011)。貳、Coh-Metrix
Coh-Metrix 是一套由美國曼菲斯大學所開發的線上電腦分析工具,藉由提 供多層次的文本分析指標,包含詞彙特性、句子特性、語法、模式分類、語法 解析器、淺層語意口譯及文本中意思的關連性(Graesser et al., 2011),區分學生 定時寫作質量變量之信度和效度的計算工具。叁、閱讀理解
「閱讀理解能力」是複雜的認知處理歷程,指讀者藉由個人既有的認知基 模與作者所提供的訊息產生互動,從中獲得資訊並建構文本內容的意義。成功 的理解是指讀者與文本間互動良好,當讀者閱讀可讀性高的文本時,會產生較 好的理解及較佳的學後保留效果(Klare, 1963, 2000)。肆、詞性分類
4 指一種具體概念的詞彙,能單獨充當句法成分的詞;虛詞是指沒有明確語意的 詞彙,不能單獨充當句子成分,主要用來表達各種語法意義或語氣(現代漢語 語法,2003)。實詞分為:名詞、動詞、形容詞、副詞、數詞、量詞、代詞; 虛詞分為:介詞、連詞、助詞、歎詞、語氣詞、象聲詞。本研究採用(胡裕樹, 1994)定義為分類標準。
伍、Type-Token Ratio(TTR)
Type-Token Ratio(TTR)源自於自然語言文本的語言學測驗之一。其歷史 可以追溯到 70 幾年前(Johnson, 1944)。TTR 即指文本中所有不同的單詞在連 續呈現的單詞總數中所占的百分比,也就是單一文本中使用之不同單詞數量和 總字數數量的比值(Laufer & Nation, 1995)。”token”指一段文本中的任何單詞, 不論是否重複出現,都算作一個單獨的標記;而”type”則是指重複出現的標記。陸、 Measure of Textual Lexical Diversity(MTLD)
Measure of Textual Lexical Diversity(MTLD)是一項計算詞彙多樣性指標 的電腦文本分析工具,它是由 McCarthy 於 2005 年所發展出來的。他認為文本 是有結構的,因此強調應保留文本結構語文章順序來維持文本的原貌,故將「文 本」的概念引入其所提出的 MTLD 指標中。
5
第二章
文獻探討
本研究依據 Coh-Metrix 線上文本分析系統發展詞彙多樣性指標,並檢視 指標與閱讀理解間的關聯性。文本共分三節,第一節介紹詞彙多樣性及詞彙多 樣性之計算工具:Type-Token Ratio(TTR)和 Measure of Textual Lexical Diversity (MTLD);第二節介紹線上文本分析系統 Coh-Metrix;第三節介紹閱讀理解。
第一節 詞彙多樣性
壹、 詞彙多樣性的定義
詞彙學習不但是語言習得的重要組成因素,更是語言發展的反應。當詞彙 越豐富,語言能力相對也就越發展,而個人的表達能力也與其所習得的詞彙數 量有關。詞彙多樣性與詞彙語言樣本的質量有關,因此詞彙多樣性一直被認為 是預測學習者啟蒙語言的能力和描述說話者或寫作者在文本中詞彙部署範圍和 種類的重要性指標(Zareva, Schwanenflugel & Nikolova, 2005)。詞彙多樣性意 味著一篇文本範圍內詞彙的變化和詞彙的複雜組合,也就是指在語言樣本中所 沒有重複出現的詞彙比重,藉由學習詞彙再利用也是我們測量文本詞彙多樣性 的方法之一(Laufer, 2003)。詞彙多樣性能夠影響口語文本的難易程度,當寫作 者或說話者語言程度越高,使用的低頻詞則越多(Mellor, 2010)。當一篇文本 具有高度詞彙多樣性時,表示說話者或寫作者必須使用更多不同的詞彙來組成 此文本,也就是說已經被使用的字在文本中便較少重複。Yu(2010)也發現詞 彙多樣性與寫作及口語質量的測量有密切關係。不同的主題與主題類型的寫作 提示,如果是學生非常熟悉的主題,即使是控制了學生的寫作能力、綜合語言 運用能力,對於詞彙多樣性仍具有顯著的效果。其中文本內容中使用實詞比例 高的文本比包含虛詞(介詞、感嘆詞、代詞、連詞和計算字數)比例高的文本 更能提供詳細信息,因此通常詞彙多樣性高的文本相較於低多樣性的文本被認 為更具有說服力(Johansson, 2008)。Booth(2010)發現詞彙多樣性和文本的整6 體質量等級之間的曲線關係,也就是說,以書寫質量而言,最高的詞彙多樣性 表現出最低的相關性。因為較長的文本是由更多個單詞組合而成的,因此同一 個字的重複機會就更大。詞彙豐富性是學習者語言發展的重要指標,是指寫作 者在寫作時詞彙的多樣性選擇,其功能能更清楚的呈現出學習者在語言產出的 成熟性,當數值越大時,便具有更多的語言技能(鮑貴,2011;陸芸,2012)。 詞彙多樣性幾乎適用於所有的文本類型,因此詞彙多樣性已被廣泛的應用在各 式各樣的研究中,例如:文體學、神經病理學、語言習得、數據探討和鑑識領 域等研究;此外詞彙多樣性指標已被發現可以用來測量各種變量,反應出如: 書寫質量、詞彙知識、詞彙能力、說話者的語言技能和能力、老年癡呆症的發 病率、聽力變化,甚至說話者的社會經濟地位等研究(Malvern, Richards, Chipere, & Duran, 2004)。
MTLD 指標的計算方法是先依據一個標準將文本劃分為數段,但卻沒有辦 法找出一個可以適用於所有文本的標準長度。在 The Project Gutenburg Text Archives(www .archive.org/details/gutenberg)測試中,當文本中的 TTR 值隨著 文本長度下降時,最後都會經過一個共同的點,此時 TTR 值的軌跡往往在大約 0.72 時達到一個穩定點,因此選定 TTR 值為 0.72 時當做分段標準。因此,MTLD 值就是達到一個穩定點的文本中所需單詞的平均數目。文本開頭時的 TTR 值變 動較大,數值過高會影響結果的準確性;數值如果過低,每個因數就會損耗許 多 tokens,造成剩餘部分太長,影響測量的準確性;而因子數目太少也無法正 確的反應結果。為了使每個 types 都有機會被劃分到兩個因數裡,還需要進行逆 向重複計算。至於逆向分析,不但不會改變文本內的真實性文字或打破文本的 序列,又可以提高 MTLD 指標的可靠性。因此他認為 MTLD 指標是目前信度 最高、最穩定的測量詞彙多樣性的方法。有關 MTLD 指標的計算方式說明如下: 表 2-8 中第二行的“is”其 TTR 值是 0.71,則“is”就是我們所得的第一 個因子,接下來由下一個字“a”開始從頭計算 TTR 值。我們發現第二行中的
7 “lake”的 TTR 值是 0.67,小於 0.72,但因為本段文字總 tokes 數只有 3 個字, 少於 10 個字,所以不能當成第二個因子。接著由下一個字“is”從頭計算,我 們找到第四行的“a”之 TTR 值是 0.7,所以“a”就是我們的第二個因子。在 這篇文本中總共有 2 個因子;其 RS 是文本中最後一個字的 TTR 值,也就是 0.92 有關詞彙豐富性測驗的分類,許多學者有不同的看法,其中大約可分為下 述四項:「詞彙豐富性」、「詞彙密度」、「詞彙變化」和「詞彙的獨特性」。「詞彙 豐富性」測驗包含了五個面向:(一)「詞彙多樣性」:指使用多少個不同的詞彙, 也就是單個單詞文字的比例,即 types 和 tokens 之間的比例。(二)「詞彙複雜 性」:指使用了多少高階的字,也就是文本中高階文字的比例。(三)「詞彙密度」: 指在整個文本中名詞、動詞、形容詞和副詞詞彙字在文本中的比例。(四)「詞 彙變化」:指相同詞彙的多樣性,但只注重詞彙字。(五)「詞彙的個性」:指一 組中只有一個人使用這個字的比例。Daller, Van Hout, & Treffers-Daller(2003) 提出測量詞彙豐富性普遍關心的是一篇文本(口頭或書面)中使用了多少個不 同的單詞。至於 Laufer et al.(1995)介紹的詞彙豐富性測量方法,則是包括「詞 彙獨特性」、「詞彙密度」、「詞彙複雜度」和「詞彙變化度」。「詞彙獨特性」是 指學習者所使用的詞彙範圍,包括常用詞彙和非常用詞彙;「詞彙密度」是指實 詞在全部詞彙中所占的比例;「詞彙複雜性」是指非常用詞彙在全部詞彙中所占 的比例;「詞彙變化度」指文本中不同單詞數和詞的總數之比;而 Enger(1995) 則採取另一種衡量詞彙豐富性的方法,內容包含了「詞彙變化度」、「詞彙無誤 變化度」、「詞彙錯誤度」以及「詞彙密度」等四個向度。Read (2002)談到詞 彙豐富性中包含四 個概念:「詞彙多 樣 性(lexical variation )或稱(lexical diversity)」、「詞彙複雜性(lexical sophistcation)」、「詞彙密度(lexical density)」 和「錯誤數量(number of errors)」。「詞彙的密度」最初是由 Ure(1971)創造, 是指詞彙字在文本中占所有字的比值(其中 tokens 是指實詞而不包含虛詞),是 書面文本和口語之間鑑別的維度,而口語文本相較於書面文本其詞彙密度較
8
低。「詞彙多樣性」和「詞彙變化」的意思是相同的,都是指避免詞彙重複的範 圍。一篇文本中用了多少種不同的詞彙,可以使用傳統的 types-tokens ratio(TTR) 來測量,也就是詞彙詞與所有詞彙之比(即 types 和 tokens 之間的比例)。Read 認為文本長度對於資料計算上是沒有什麼影響,所產生的數值結果是穩定的。 「詞彙複雜性」是指高階文字在文中的比例有多少是適合、切合主題,這包括 了具有技術性、專業性或領域性的詞彙。「詞彙密度」則是最常用於描述實詞數 與總字數的比重,也就是在整個文本中實詞和虛詞的比例。「錯誤數量」就是錯 誤次數,這些錯誤包括了用錯詞表意及詞型不符合文法結構。文本中如果包含 更多樣性的字,在閱讀理解上更難以處理,因為它們需要在相同的時間內對更 大數目的唯一字的進行解碼(Rupp, Garcia&Jamieson, 2001)。由上述得知詞彙 豐富性的計算方式眾多,但本研究參考 Coh-Metrix 指標僅針對詞彙多樣性 (lexical diversity)進行探討。
貳、 詞彙多樣性公式
一、 Type-Token Ratio(TTR)的定義
過去幾十年來在兒童語言文學中,Type-Token Ratio 指標長期以來一直是相 當普及的測量詞彙多樣性的傳統方法。TTR 指標是一項對話式的詞彙衡量指標, 並且被定義為特定語言文本中不同單詞的總數(types)和文本中所有字(tokens)的總數之比(Templin, 1957)。如果 types 的數量和 tokens 總數量相等時,表示 一篇文本中所使用的詞彙都是不同的,在這種情況下,文本可能有非常低的凝 聚力或是表示文本長度非常短。當比率越接近 0 時,文本中重複出現的詞彙較 多,表示詞彙的多樣性較低;而值越接近 1 時,文本中重複出現的詞彙較少, 代表擁有更豐富的多樣性。Johnson(1944)指出 TTR 指標源自於自然語言學 語言文本測驗,其歷史可以追溯至 20 世紀 40 年代,目的在為寫作者和說話者 發展一項定量的指標。Song Wen-juan & Zheng Hong-bo(2011)指出詞彙多樣
9 性是計算文本詞彙多樣化的方式之一,目的在衡量文本中 types 和 tokens 的關 係。早期詞彙多樣性的計算方式主要以 TTR 指標為主,TTR 指標是一項書面文 字詞彙變化或個人話語品質的測驗。TTR 指標早已經被證明是一項有用的文本 詞彙多樣性測量指標;如果文本中 types 數相較於 tokens 數之數量更多,則表 示此文本擁有多樣化的詞彙量,也就是說有較豐富的詞彙多樣性。「tokens」是 指一篇特定文本中的所有單詞,大多用於量化文本的長度;而「types」則是指 在一篇特定文本中唯一的單詞,因此,這些以各種形式進行重複的單詞只能被 計數一次。當文本變長(字數增加),文本中的總字數(tokens)也隨之增加。 不過,儘管 tokens 的數量是線性增加的(一個新詞等於一個新的 token);不同 單詞(types)數量增加的速度卻逐漸減慢。在 TTR 指標中,types 被嚴格地定 義是字符串的正投影,當文本中出現單複數形式的名詞、不同時態的動詞時, 只要它們拼寫的方式不同,就被計算為一個單獨的 type。TTR 指標即指文本中 所有不同的單詞在連續呈現的單詞總數中所占的百分比,也就是指在規定的文 本內使用不同 types 數(文本中不重複的單詞數)與 tokens 數(文本中所有單 詞,包括重複使用過的)的比值(Laufer et al., 1995)。當 types:tokens 的比值 是 1 時,表示每個字在文本中只出現一次,因為有較多的生字需要被編碼外, 還必須和上下文相結合,故在理解上應該是比較困難;至於 types:tokens 比值 較小,表示文本中有較多重複的文字,可以使文字處理更加容易和快速,其中 TTR 指標只計算實詞,而不算虛詞(Graesser, McNamara, Louwerse, & Cai, 2004)。 詞彙多樣性最簡單的計算方法就是將 types 數除以 tokens 數,其公式如(1): Tokens Types TTR = (1) Coh-Metrix 提供幾個不同的詞彙多樣性指標。其中測量詞彙多樣性的指標 就是利用TTR 指標。其 TTR 指標的計算方法介紹如後表 2-1 所示。例如,在本
10
句子中“ the, big, boy, hit, the, small, boy ”所用的 types 是” the, big, boy, hit, small” 5 個;tokens 是文本中使用的所有詞彙項目” the, big, boy, hit, the, small, boy”共 7 個字。在這個例子中,TTR 值是 0.71,至於 TTR 值的範圍是從 0 到 1。 表 2-1
TTR 指標計算介紹
corpus the big boy hit the small boy
type 1 2 3 4 4 5 5
tokens 1 2 3 4 5 6 7
TTR 1 1 1 1 0.8 0.83 0.71
資料來源:整理自McCarthy, Lehenbauer, Hal, Duran, Fujiwara, & McNamara(2007)
二、 TTR的發展
TTR 指標的確存在著當文本字數相差懸殊時,隨文本長短變化所得出的資 料也會變化的問題,因此當文本長短差異過大時得出的資料結果是不科學的。 詞彙多樣性主要在計算文本中使用了多少不同的單詞,這可以透過簡單地計算 types 數來確定;但是在這種情況下,types 的數量取決於文本的長度,較長的 文本,擁有較多的 types,因此導致在不同長度的文本之下難以使用 TTR 指標 比較。這項測量方法雖然簡單,其信度一直受到質疑,其中最主要的問題是 TTR 值受到文本長度的影響非常敏感,當文本長度變長之後,tokens 的數量均勻增 加,但 types 的數量相對持續減少。也就是說在分母的 tokens 比在分子的 types 以更快的速率增加,造成 TTR 值不可避免地下降,尤其是越長的文本這樣的問 題越嚴重(Andrew Mellor, 2011, 2012; McCarthy & Jarvis, 2010)。由上述內容得 知,一篇較長的文本相較於較短的文本通常具有更低的 TTR 值,這使得在使用 TTR 指標計算詞彙多樣性時更為複雜,尤其是在年齡組別之間。當 tokens 數量 隨著說話者或寫作者的年齡大幅增加時,其 TTR 值卻反而下降。由此我們得到 的結論是,TTR 指標只能用來比較長度相等的文本。11
為了糾正文本長度的這個問題,陸續出現了許多詞彙多樣性的計算公式: 如開根號 TTR 指標(Guiraud, 1960)、校正的 TTR 指標(Carroll, 1964)、LogTTR 指標(Herdan, 1960)、D 指標(Malvern et al., 2004)、Advanced TTR 指標(Daller et al., 2003)、Guiraud Advanced 指標(Daller et al., 2003)與文本詞彙多樣性指 標(McCarthy et al., 2010)等。關於所有詞彙多樣性改良公式整理如下: 表 2-2
詞彙多樣性計算公式
指標名稱 公式 TTR
(Malvern et al., 2004) Tokens Types TTR = Yule’s K (Yule,1944) 2 N / N r V 2 r 4 10 K ∑ − = Guiraud Index (Guiraud, 1960) Tokens Types dexR sin ' Guiraud = Herdan's C
(Herdan, 1960)
log
Tokens
Types
log
sidnexC
'
Herdan
=
Carroll's Corrected TTR ( Carroll, 1964) 2Tokens Types indexC s ' Carroll = Advanced TTR(Daller et al., 2003) Tokens
pes AdvancedTy dvancedTTR A = D estimate (Malvern & Richards, 2000) − + = 1 D N 2 1 N D TTR 2 1 (續下頁)
12 指標名稱 公式 hapax legomenon(100) (在文學作品或某作家作品中)只 出現過一次的詞(或短語) 2 a
(Maas, 1972) log tokens
types log tokens log
a2 = 2 −
Dugast's Uber Index (Dugast, 1978)
(
)
(
logTokens logTypes)
Tokens log UberindexU 2 − = Hockey (Hockey, 1988) 牛津一致性程式 Miller (Miller, 1993) 語言轉錄系統分析 Whinney (Whinney, 1995) 電腦語言分析程序 MTLD (McCarthy, 2005) 2 MTLD MTLD MTLD 1+ 2 =
整理自:Mellor, 2010& Xiaofei Lu, 2012
三、Measure of Textual Lexical Diversity (MTLD)的定義
Measure of Textual Lexical Diversity 指標(MTLD)是 McCarthy(2005)為 了計算詞彙多樣性,所發展的一項電腦文本分析工具,其計算方法是保持標準 詞彙變化中文字字符串的平均長度。McCarthy & Jarvis(2010)為了驗證 MTLD 指標與其他詞彙多樣性指標之間的差異,利用「收斂效度」、「發散有效性」、「內 部效度」和「增量有效性」四個向度來衡量評估,測驗結果發現 MTLD 指標在 這四種有效性的測量中表現相當良好。事實上是 McCarthy 等人所驗證的詞彙 多樣性測量工具中,唯一沒有因文本長度而改變函數的指標。MTLD 指標之所 以 被 選 定 為 除 了 type-token ratio 以 外 的 詞 彙 多 樣 性 的 測 驗 工 具 , 是 因 為
13 McCarthy 曾透露,MTLD 指標是許多知名詞彙多樣性測驗中,唯一沒有受到文 本長度影響的衡量標準。因為先前所有的詞彙多樣性測量公式中(無論是 TTR 或是改良的 TTR 等),均沒有考慮到文本的結構,因此無法正確算出詞彙多樣 性的數值,且所有的詞彙多樣性計算公式均被證實還是會受到文本長度影響而 出現當文本長度越長,其詞彙多樣性越低的趨勢(Koizumi, 2012)。因此, McCarthy 想出了一個可以保留文本結構和文字順序的分析測量工具,便能解決 文本長度的問題。McCarthy 的研究中提出,每一篇文本均存在著結構性,所以 應該維持它的原貌。因此在他所提出的 MTLD 指標中,引入了「文本」的概念 (張豔 & 陳紀梁,2012)。在 Coh-Metrix 中也將 MTLD 指標納入為詞彙多樣 性分析指標,作為量化在特定的文本範圍內詞彙部署之詞彙多樣性測驗。 Step1. 從文本的第一個詞彙開始一直到文本的最後一個詞彙結束,計算每一個 詞彙的 TTR 值,當文本中的 TTR 值隨著文本長度下降時,最後都會經過一個 共同的點,此時 TTR 值的軌跡往往在大約 0.72 時達到一個穩定點,因此選定 TTR 值為 0.72 時當成界限,分割成一段文本,在此我們得到第一個因子(factor) ; 然後從下一個字開始重新計算詞彙的 TTR 值,如此依次把文本劃分為若干因子。 FS -1 RS -1 IFS = (2) IFS:指被加入到因子數的不完全因子得分。 RS:指剩餘的分數:文本分析結束點的 TTR 值。 FS:指因子得分,在這項分析中被設定為 0.72。 Step2. 用文本的總 tokens 數除以因數個數和不完全因子得分總合,得出第一個 MTLD1值。 IFS tokens MTLD 1 + = 因子個數 (3)
14 Step3. 整個文本從篇尾重新以逆向的順序重複一遍上述計算方式,得出第二個 MTLD2值。 Step4. 取兩個 MTLD 的平均值,其公式如(4) : 2 2 MTLD 1 MTLD MTLD= + (4) 進行順向及逆向的兩次計算,足以產生 MTLD 值的一致性和準確性。在兩 次處理步驟之下,就足以抵消這種偶發的差異問題,因為在逆向序列計算出的 餘數因素與前者所得是不一樣的,在順向計算和第二次逆向計算的平均剩餘部 份足夠使結果平穩。其中需特別留意的是,如果在一個分段中詞彙數少於 10 個 字時,因為它們可能僅僅代表一個簡單的語法或修辭,因此是不能被計算為一 個因子的,所以必須從下一個字開始從新計算。最後文字詞彙多樣性得分為正 向 MTLD 得分和逆向 MTLD 得分的平均值;MTLD 得分越高,表示文本中具 有更豐富的詞彙多樣性。也就是說,使用許多不同單詞(很少有重複)的文本 比起重複性高的文本得到較高的 MTLD 值,並且高詞彙多樣性的文本比較低詞 彙多樣性(那些使用通篇相同的話)的文本往往更具凝聚力(McNamara et al., 2010)。我們會使用 MTLD 指標,因為它是最適合評估詞彙多樣性的工具,即 使當文本在長度方面的差異有顯著不同,MTLD 值是不改變的(Jarvi, 2013)。 表 2-3 文字詞彙多樣性演算範例
第一行 this mountain is very big and the scene is very Type 1 2 3 4 5 6 7 8 8 8 Token 1 2 3 4 5 6 7 8 9 10 TTR 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 .89 .8
15
第二行 good and there is a Lake lake is very beautifu Type 9 9 10 10 1 2 2 1 2 3 Token 11 12 13 14 1 2 3 1 2 3 TTR .82 .75 .77 .71 1.0 1.0 .67 1.0 1.0 1.0 第三行 and beside there is a Tree and over there I Type 4 5 6 6 7 8 8 9 9 10 Token 4 5 6 7 8 9 10 11 12 13 TTR 1.0 1.0 1.0 .86 .88 .89 .8 .82 .75 .77 第四行 see the big mountain there is a very beautiful and Type 11 12 13 14 14 14 14 1 2 3 Token 14 15 16 17 18 19 20 1 2 3 TTR .79 .8 .81 .82 .78 .74 .7 1.0 1.0 1.0 第五行 this Taro’s room before is Taro’s name on textbook but Type 4 5 6 7 8 8 9 10 11 12 Token 4 5 6 7 8 9 10 11 12 13 TTR 1.0 1.0 1.0 1.0 1.0 .89 .9 .91 .92 .92 資料來源:引自 Rie Koizumi(2012)
第二節 線上文本分析系統(Coh-Metrix)
壹、 Coh-Metrix的定義
Coh-Metrix 是一套自動線上電腦分析工具,提供各種語言學相關指標如: 詞彙、語法、模式分類、語法解析器、淺層語意口譯等指標,分析、理解文本 凝聚力(cohesion)和文本心理表徵的連貫性(coherence,指凝聚在讀者心中的 影響) (Crossley, Allen & McNamara, 2011)。當凝聚力強大時,能迅速連結句 子、段落及文本間的語意,使文本不再只是零散的片段;而句子間有較佳的連 貫性,則文本語意前後一致,文本自然容易理解。Myers, McCarthy, Duran and McNamara(2011)認為 Coh-Metrix 是分析高品質文本和低品質文本之間差異16 的工具,它提供超過 200 種指標分析文本的凝聚力(連接詞數、人稱代名詞數)、 難度、詞彙(詞頻、詞數)、句法結構(名詞片語數、結構相似度)、潛在語意 類(相鄰兩句的語意相似度)和總體文本層面(其內容分為:詞、詞的信息、 句子、段落層次、字頻、可讀性、多義性和上位詞價值觀、連接詞語法複雜性、 核心凝聚力、因果的凝聚力、單詞和短語的密度、邏輯運算符的密度、潛在語 意分析(LSA)、Type-Token Ratio 等)。 Coh-Metrix 借由自然語言處理技術(計算語言學、語料庫語言學、資訊檢 索等)提供超過 600 個概念性知識如:凝聚力、詞彙使用特點、語法的複雜性、 句法複雜程度、可讀性和詞彙難度指數、文本的銜接與連貫等方面進行自動線 上分析。藉由 Coh-Metrix 多層次的文本分析指標測量各級語言的凝聚力和文本 難度的輸出結果,使人們有可能以計算研究文本語言理解的各種測驗取代語言 的表面構成要素,進而探討更深、更整體的屬性語言,並且提供教師和研究人 員更詳細的統計訊息。這些訊息不但可以辨別學生定時寫作質量,讓學生從中 找到他們寫作的優、缺點外,進而修改自己的寫作策略和風格(Graesser et al., 2004)。Coh-Metrix 是一項測量語言特性中單字、句子和會話之表面結構和深層 結構的工具,其中五個分析向度指標分別為:「共同的參照凝聚力」、「因果凝聚 力」、「語法凝聚力」、「潛在語義分析」和「詞彙多樣性」。內容包括字長的分數、 詞彙多樣性的價值觀、詞頻計數、一詞多義、文字意義、詞的具體性和單詞的 熟悉。Coh-Metrix 可以自動計算出文本的一致性,並確定文字元素和成分被連 接到特定類型的凝聚力。McNamara and Graesser(2010)採用 Coh-Metrix 來檢 測語言學功能上的差異,不但發現語法的複雜性外,更可以預測寫作能力。 Coh-Metrix 的指標甚至強大到足以檢測字彙和語段間細微的差別,而且很多研 究使用 Coh-Metrix 來區別不同類型的文本。例如,Graesse et al(2004)用 Coh-Metrix 發現英語口語和書面的顯著差異。
17
貳、 Coh-Metrix的發展
傳統自然語言的研究方法通常不超出字層級功能(如語法階級和頻率), 但這種研究是有問題的,因為高階文本中母語類文本可能存在凝聚力和修辭風 格的差異。國外通常使用 Flesch-Kincaid Grade Level(Klare, 1974-5),Degrees of Reading Power (DRP; Koslin, Zeno, & Koslin, 1987)和 Lexile scores(Stenner, 2006)來判斷文本的適讀性,但僅用單一維度來定義文本是相當困難的。基於 上述理由,曼菲斯大學開始於 2002 年到 2011 之間不斷發展、測試、改良一套 電腦化線上分析工具-Coh-Metrix。Coh-Metrix 的研究計劃起始於 2002 年,此 專案的初步撥款在 2002 年由教育研究與改進辦公室(Office of Educational Research and Improvement)所授予,此研究團隊是由不同背景的研究人員以跨 學科集合為基礎所組成的,藉此想要了解是否真的可以藉由凝聚力來觀察文 本,又或者它只能針對讀者進行測量(McNamara, Graesser, McCarthy, & Cai, 2013)。Coh-Metrix 的第一個版本僅供內部使用,並不對外開放(Graesser et al., 2004);第二個版本,Coh-Metrix 2.0,則透過網路供大眾使用,其內容包括 54 個 文本特徵的指標。它已經嵌入了大量多層次的語言指標,例如:凝聚力、詞彙 的多樣性和複雜性的句法等(Wang Hongwei, 2013)。目前 Coh-Metrix 已發展 到 3.0 版 , 可 以 用 來 分 析 詞 彙 ( lexicons )、 詞 性 的 分 類 ( part-of-speech classifiers)、語法上剖析器(syntactic parsers)、語義分析器(semantic analyzers) 和潛在語義分析(Latent Semantic Analysis)及被廣泛使用於計算語言學的其他 一些組件。其指標內容涵蓋 11 個類別、106 個指標。Coh-Metrix 可提供「詞 彙(words)」、「句型(syntax)」、「文本基礎(the explicittextbase)」、「情境模式 (the situation model)」及「話語風格和修辭結構(the discoursegenre and rhetorical structure)」等五個面向的分析(McNamara et al., 2013)。
18 圖 2-1 Coh-Metrix 3.0 線上版系統介面 註:資料來源: http://cohmetrix.memphis.edu/cohmetrixpr/index.html 表 2-4 Coh-Metrix 3.0 版指標類別與個數 種類 指標項目 指標個數 1 描述性(Descriptive) 11個 2 文本適讀性分數(Text Easeability 16個 3 參照擬聚力(Referential Cohesion) 10個 4 潛在語意分析(LSA) 8個 5 詞彙多樣性( Lexical Diversity) 4個 6 關聯詞(Connectives) 9個 7 情境模型(Situation Model) 8個 8 語法複雜度( Syntactic Complexity) 7個 9 句型密度(Syntatic Pattern Density) 8個 10 詞彙訊息(Word Information) 22個 11 可讀性指標(Readability) 3個
總計11 個類別,106 個指標
19
如今 Coh-Metrix 已被用於各種不同的領域發展。例如,許多研究採用 Coh-Metrix 探索第二語言習得研究話語的文本差異和母語研究、凝聚力分析 (Crossley, Greenfield, & McNamara, 2008)詞彙和文本體裁等(Louwerse, McCarthy, McNamara, & Graesser, 2004)。
第三節 閱讀理解的認知歷程與模式
壹、 閱讀理解的定義
「閱讀理解」,是讀者依先備知識解釋和建構自己所閱讀的內容;指讀者 在進行閱讀活動時能運用已有的文字再認技巧,區辨符號、轉譯成有意義的形 式,最後產生了理解(Johnson & Pearson, 1978),也可以說是讀者和作者之間 的對話。當讀者閱讀可讀性高的文本時,能產生較好的理解與較佳的學後保留 效果,也就是指成功的理解(Klare, 1963, 2000)。閱讀是依據現有的知識,使 用足夠可用的線索去讀懂文本,從本身具有的概念來建構文本意義的過程。在 閱讀的過程中,不同的讀者會對相同作品建構出不同的意義,換言之,同樣一 篇文本,在不同的讀者手中,就會有不同的詮釋與感受。錡寶香(2000)指出 閱讀是一種複雜、動態的心智活動,包含相互關聯、交互運作的認知歷程(知 覺、語言、認知及動作協調),其兩大核心能力為「識字(word recognition)」 和「語言理解(comprehension)」。Gough 與 Tunmer(1986)提出「閱讀的 簡單觀點模式」,內容包含「識字」和「聽覺理解」兩部分,就「識字」而言, 識字技能必須熟練才有助於閱讀理解;「識字技能熟練」是指能正確、快速, 不出聲地把字、詞默讀出來,且能同時知道單字、詞彙的語義。至於「聽覺理 解」則是將詞彙、句子、對話言談等語言訊息,加以解讀的歷程。
貳、 閱讀理解的發展
Chall(1996)認為閱讀發展從零歲開始,個體的閱讀行為會產生質與量的 變化,她根據各階段的特殊性將閱讀發展分為六個階段:20 表 2-5 Chall閱讀發展歷程 階段 階段名稱 年齡 特徵 學習閱讀期 (learningto read) 階段零 前閱讀階 段 (零到六 歲) 能說出單音節的字,具閱讀 書籍的知識。 階段一 初始閱讀 階段 六~七歲 (一、二年 級) 學習聲音與符號相互符 應,能覺察文字與讀音之間 的對應關係。 尚未完成認字自動化。 階段二 流暢閱讀 階段 七~八歲 (二、三年 級) 能將音韻特性表現閱讀 中,能流暢地閱讀。藉由大 量閱讀來建立閱讀流暢性。 階段三 閱讀新知 階段 九~十四歲 (四到八年 級) 由樂趣閱讀轉為學習閱 讀,閱讀理解與聽的理解發 展良好。 由閱讀中學習 期(reading to learn) 階段四 多元觀點 階段 十四~十八 歲(八到十 二年級) 學生接觸更多元想法,形成 性批判反應。 階段五 建構和重 建階段 十八歲以上 (十二年級 以上) 對於所讀文本,可分析、綜 合及批判,形成自己的觀點 與能力。 資料來源:整理自丁竹君(2011)
参、 閱讀理解的歷程
Kintsch(1988)視閱讀理解為一個複雜的認知歷程,讀者在閱讀時會形成 「微觀結構(microstructure)」、「鉅觀結構(macrostructure)」及「情境模 式(situation model)」等三種層次的理解表徵。(林怡君、張麗麗和陸怡琮, 2013)21 一、「微觀結構」: 是指讀者對文本的初步理解,屬於淺層的知識處理。 二、「鉅觀結構」: 指讀者整合文本內所有的微觀結構,對文本產生整體性理解,屬於較深層 的知識處理歷程。 三、「情境模式」: 則是指讀者除了能理解文本字面的意思外,還能以先備知識為基礎,進行 適當的推論,統整出新的意義。 Gagne(1985)認為閱讀理解歷程可以區分四個子群(subgroups),此四 個子群分別為(一)解碼(decoding)(二)文義理解(literal comprehension) (三)推論理解(inferential comprehension)(四)理解監控(comprehension monitoring)。 一、解碼(decoding): 解碼是指辨識文字符號使其產生意義,解碼認字是閱讀的基礎。辨識文字 符號的方式可分為「配對(matching)」和「譯碼(recoding)」兩項歷程。 (一)「配對」 是指讀者一看到單字即可由長期記憶中檢索出對應的意義,不需要唸出聲 音或猜測,便能見字而直接觸接字義的歷程。 (二)「譯碼」 與「發出聲音」有關,指看到文字時需要運用音素(phonemes)、音節 (syllables)、詞素(morphemes)這類的陳述性知識,指見字後先轉譯為一串 聲碼,再從長期記憶中檢索出對應的字義,也就是見字而間接觸接字義的歷程。 二、文義理解(literal comprehension): 「文義理解」即從字句中瞭解文字意義之階段。此一階段又可以分為「字 義觸接(lexical access)」和「語法剖析(parsing)」兩個過程。
22 (一)「字義觸接」: 又可稱為字義取得,是讀者經由解碼階段辨認出該字的字音、字形後,結 合長期記憶將文本上下文的文字意義予以正確的解釋。 (二)「語法剖析」: 係指分析句子的文法結構,將字依其適當的意義排列,運用語言的句法 (syntactic)及語言學(linguetic)規則,連結字義以了解全句的意義,指讀者 將多個個別的字詞組合成較大的意義單位。 三、推論理解(inferential comprehension): 「推論理解」即讀者對閱讀文本進行加深、加廣的解析階段。此階段包括 「統整(integration)」、「摘要(summarization)」以及「精緻化(elaboration)」 三個部份。 (一)「統整」: 係指讀者利用先備知識連貫文本中所傳達的各種概念,覺察句子間所隱含 的關係,整合文章中兩個以上的概念或命題,使之成為較一致性的心理表徵 (mental representation)。 (二)「摘要」: 指閱讀一段文本之後,讀者能歸納文本大意,將文章的意義濃縮、精簡在 記憶裡對文本的主要概念產生「鉅觀結構」。 (三)「精緻化」: 連結讀者的先備知識與新的訊息使之產生新的體驗,建構文本的意義因而 產生新的體驗。 四、理解監控(comprehension monitoring): 指閱讀者在閱讀初始設定目標後,選擇合適的閱讀理解策略監控歷程,最 後 再 檢 核 目 標 是 否 已 達 成 , 屬 於 閱 讀 理 解 最 高 階 段 , 也 就 是 後 設 認 知 (meta-cognition)歷程。其歷程包括「目標設定(goal setting)」、「選擇策略
23
(strategy selection)」、「目標檢核(goal checking)」、及「修正(remediation)」 等四個歷程。
美國「國家教育發展評量」(National Assessment of Educational Progress, 簡稱 NAEP)界定閱讀為一動態認知歷程,包含「理解書寫文本」、「發展和 解釋意義」及「依照文本類型、目的和情境適當地使用意義」,並以「尋找和 回憶(locate/recall)」、「整合和解釋(integrate/interpret)」及「批判和評鑑 (critique/evaluate) 」三個認知指標層次為測驗編製架構。
PISA (Programme for International Student Assessment)提出的閱讀理解層 次有:「擷取與檢索」、「統整與解釋」和「省思與評鑑」三項(OECD, 2010)。
PIRLS(Progress in International Reading Literacy Study)界定的閱讀理解層 次則包含「直接理解歷程」和「解釋理解歷程」兩項:
一、直接理解歷程包含:
(一)直接提取(focus on and retrieve explicitly stated information): 指可直接在文本中找到問題的答案。
(二)直接推論(makestraightforward inferences):
文本中沒有明確描述之關係,讀者需自行連結段落間的訊息。 二、解釋理解歷程則包含:
(一)詮釋、整合觀點與訊息(interpret and integrate ideas and information): 讀者需運用先備知識,加以統整文本各段落間的訊息,以達到完整的理解。 (二)檢驗、評估內容、語言和文本的元素(examine and evaluate content, language, and textualelements):
讀者除需批判文章的訊息外,還須思索作者的意圖。由理解文本意義轉為 批評文本。(柯華葳、詹益綾、張建妤、游婷雅,2008;黃珮選,2012)
24 表 2-6 閱讀理解歷程階段區分標準對照表 學 說 閱 讀 理 解 歷 程 / 層 次 Kintsch 微觀結構 鉅觀結構 情境模式 情境模式 NAEP 尋找和回憶 整合和解釋 批判和評鑑 Gagné 文義理解 文義理解 推論理解 理解監控 PISA 擷取與檢索 統整與解釋 省思與評鑑 PIRLS 直接推論 直接提取 詮釋整合 檢驗評估 整理自:黃琬婉(2010)
肆、 閱讀理解的模式
閱讀的模式大致上可歸為四種類型:「由下而上模式」、「由上而下模式」、 「互動模式」及「循環模式」(連啟舜,2002)。一、由下而上的模式(Bottom-Up Models of Readind):
Gough 首先在 1972 年提出了「由下而上」模式。指出閱讀是從最基礎的 「視覺處理」、「字詞彙辨識」等較小的成分開始,一直擴展到最高級的「記 憶」和「理解」等較大部分才結束(McCormick, 1995)。此過程認為訊息處理 的方式有層級存在,由視覺刺激、影像表徵、字母辨識到單字辨識,著重從「刺 激」到轉換視覺影像成為有意義的語言訊息,忽略讀者先備知識與高層次閱讀 理解的處理歷程,又稱為「文章本位模式」。這個「由下而上」的歷程,較適 合描述初學者的閱讀理解歷程。
25 Goodman(1986)提出當我們在閱讀一篇文本時,讀者會根據自己對閱讀 主題原有的認知結構進行假設、理解文意並預測結果,因此讀者需有充分的先 備知識來理解或同化文本中的新訊息,才可以幫助讀者由後續的閱讀過程中推 論出文本的意義,又稱為「讀者本位模式」。此模式並不重視識字的能力,而 是強調讀者將新訊息與過去的經驗、知識相比較,加以預測文意,主動將閱讀 材料賦與意義的歷程。
三、互動模式(Interactive Models of Readind):
閱讀不僅是被動的理解文本涵義更是將個人經驗主動加入其中,使閱讀產 生獨特的意義,讀者在閱讀時,讀者會視文本的難度,決定其對高低層次處理 的依賴。如果文本陌生且困難,則使用較多低層次的線索;反之,則較偏重高 層次線索的預測,因此閱讀的歷程是會因人而異的。在閱讀的歷程中,較低層 次的處理(字詞辨識)和較高層次的處理(預測文意)是同時發生且相互協助, 閱讀者在這個過程當中同時扮演主動與被動的角色,所以交互模式是包含「由 下而上對視覺刺激的知覺模式」和「由上而下加上結構的認知歷程」。 四、「建構統整模式」(Construction-Integration Model): Kintsch ( 1998 ) 以 認 知 的 觀 點 , 提 出 來 的 「 建 構 統 整 」 模 式 (Construction-Integration Model,簡稱 CI Model)。此模式假定讀者以「命題 (proposition)」方式來分析文本;認為理解文本的過程是一種心理表徵不斷地 被「建構」與「統整」的循環歷程,這兩個階段是不斷循環、交錯進行,閱讀 者會依照文本和自己的先備知識形成新的命題,接著統整新訊息並理解文本涵 義。 (一)建構階段:文本是一項輸入式的刺激,此時讀者對於文本的語意、語法 等概念,能被適時激發,但尚無法區分被激發的訊息的意義。 (二)統整階段:經過建構歷程的不斷的進行,較符合上下文意的概念會被激 發出來,最後達到最穩定的心理表徵。
26 建構統整模式可分為「文本模式(textbase model)」和「情境模式(situation model)」兩部份; (一) 文本模式: 假設讀者以「命題(proposition)」作為閱讀時分析文本的基本單位,並 利用「推論 (inference)」來聯結命題和命題之間的關連,「文本模式」認為 讀者會受到文本層次的命題表徵影響只是單純的閱讀文本內容而非運用先備知 識來 統 整 文 本 。 文 本 中 的 「 微 觀 結 構 ( microstructure ) 」 和 「 鉅 觀 結 構 (macrostructure)」會影響讀者對於文本的理解程度。「微觀結構」是指具體 的知識(特定的字、詞彙等)與事件(細節)的描述,通常是特定的、較具體 的知識或事件,是讀者對文本的初步理解,屬於淺層的知識處理。「鉅觀結構」 指較為抽象的知識(文本的主旨、摘要)與事件的描述,指讀者整合文本內所 有的微觀結構,對文本產生整體性理解,只稱得上是書面意義上的理解,較少 涉及文章言外之意的理解,屬於較深層的知識處理歷程(Kintsch,1998;引自 連啟舜,2002)。 (二) 情境模式: 假設讀者在閱讀時不但受到文本影響,而且會將與文本內容有關的先備知 識類化到文本結構之中,接著統整兩者後轉換為新的階層結構。也就是讀者在 閱讀完文本之後,經由適當的推論歷程,能從文本中將自己的先備知識、舊經 驗等所建構出來的心智表徵,此時表示讀者已對文章的意義有真正的理解。 (Kintsch,1998;引自連啟舜,2002) 。
27
第三章
研究方法
本研究參考 Coh-Metrix3.0 中 TTRA、TTRC 和 MTLD 指標,檢視各指標 與「中、高年級文本閱讀理解測驗」之關係,並分析兒童語料庫文本詞彙多樣 性與年級之趨勢,建置中文文本自動化分析系統。文本共分五節,第一節介紹 研究流程,第二節介紹研究步驟,第三節介紹研究對象與限制,第四節為研究 工具介紹,第五節介紹資料處理。第一節 研究流程
本研究所建置之詞彙多樣性指標中所提及的「兒童語料庫文本」係利用坊間 N、H、K三版本之國小教科書中國語、社會、自然生活與科技、藝術與人文及健 康與體育等五大領域之教科書及經授權的國語日報等共874 篇文本來計算指標 分數,並採用民國78年國立編譯館所出版之國語科四、六年級文本,內容包括記 敘文21 篇、非記敘文11 篇,共計32 篇,依PIRLS閱讀四項理解層次編製「中、 高年級文本閱讀理解測驗」為施測題本。針對台中市、彰化縣和南投縣,四、六 年級共24 班,施測學生647 名,探討詞彙多樣性指標與學生通過率的相關、詞 彙多樣性指標與閱讀理解層次題型的相關。本章共分為五節,依序為研究流程、 研究步驟、發展文本自動化分析指標、中文文本自動化分析系統、研究對象與研 究限制、研究工具及資料分析處理,分述如下圖3-1 所示:28 圖3-1 研究流程圖 兒童語料庫文本蒐集 利用中研院斷詞 第二次斷詞 研究目的 文獻探討 建置詞彙多樣性指標 定義指標計分公式 撰寫計算指標分數程式 定義詞彙多樣性 設計線上使用者介面 施測 分析施測結果 研究結果與建議 國立編譯館文本蒐集 計算詞彙多樣性指標 自編閱讀理解測驗文本 題目修正 預試
29
第二節 研究步驟
本小節分為三部分,第一部分說明研究指標的建置流程,第二部分說明中文 文本分析指標的意義及計算方式,第三部分介紹中文文本自動化分析系統。壹、 詞彙多樣性指標建置
圖3-2 指標建置流程圖貳、中文文本分析指標的意義及計算方式
一、兒童語料庫文本斷詞 本研究之兒童語料庫文本為廖晨惠(2011)之國科會「以LSA為基礎之電腦 化閱讀認知測驗及AutoTutor建置」計畫(編號:NSC 100-2420-H-142-001-MY3) 中所建置完成之語料庫。其來源為經授權的N、H、K三版本之國小教科書中國語、 定義詞彙多樣性 建置詞彙多樣性指標 撰寫計算指標分數程式 設計線上使用者介面 分析施測結果 定義指標計分公式30 社會、自然生活與科技、藝術與人文及健康與體育等五大領域之教科書及國語日 報等 共 874 篇 文 本 , 共 計 兩 萬 多 個 詞 彙 。 運 用 中 央 研 究 院 斷 詞 系 統 (http://ckipsvr.iis.sinica.edu.tw/),完成「兒童語料庫文本」第一階段斷詞。 二、指標建置及計分方式: 本研究參考Coh-Metrix之指標分析兒童語料庫文本,針對所欲探討的詞彙多 樣性部分,建置「Type-token ratio , All word」、「Type-token ratio , content word」 及「Measure of Textual Lexical Diversity」三個分析指標,研究指標敘述如下: (一)指標建置:
1、Type-token ratio , All word(所有詞TTR),其後以TTRA代替。 2、Type-token ratio , content word(實詞TTR),其後以TTRC代替。
3、Measure of Textual Lexical Diversity(MTLD),(文本詞彙多樣性測驗)。 (二)計分方式: 1、TTRA指標公式如下: tokens types TTRA = (5) Token:文 本中所有的 詞彙,不論是否 重 複出現,都算作 一 個單獨的 “token”。 Type: 文本中不同詞彙,重複出現的詞彙都可歸為一個“type”。 2、TTRC指標公式如下: TTRC指標計算方式與TTRA指標相同,唯在types中只選取「實詞」計算, 本研究所說的實詞是指:名詞(表示人﹑地﹑事﹑物等名稱的詞,分專 有名詞﹑普通名詞;或分具體名詞﹑抽象名詞)、動詞(表示人、物的 行為、動作或事件的發生之詞)、形容詞(形容事物的形態、性質的詞, 常附加於名詞之上)、副詞(區別或限制事物的動作、形態、性質的詞, 常附加於動詞、形容詞或其他副詞之上)、代詞(替名詞、動詞、形容
31 詞以及數詞、量詞、副詞等。可分為:「人稱代詞」「指示代詞」「疑問 代詞」「其他代詞」)、數詞(表示數目的詞)、量詞(表示事物或動作的 單位詞,分為「物量詞」、「動量詞」)(教育部重編國語辭典修訂本, http://dict.revised.moe.edu.tw/index.html)。 tokens types TTRC = (6) 3、MTLD公式如下:
FS
-1
RS
-1
IFS =
(7) IFS:是被加入到因子數的不完全因子得分。 RS:是剩餘的分數,指一篇文本中結束點之 TTR 值。 FS:是因子得分上, TTR 值被設定為 0.72。 Step2. 用文本的總 types 數除以因數的數目,得出第一個 MTLD1值。 Step3. 從篇尾向前逆向重複一遍上述計算方式,得出第二個 MTLD2值。 Step4. 取兩個 MTLD 的平均值,其公式下: 2 2 MTLD 1 MTLD MTLD = + (8)叁、中文文本自動化分析系統
一、設計線上使用者介面 本研究利用建置詞彙多樣性自動化分析指標,發展線上文本分析系統,圖3-3 到圖3-5為中文文本自動化分析系統介面。 圖3-3是系統登入介面,簡述中文及英文版線上文本分析系統內容。使用者 需輸入申請之帳號、密碼,便能開始進行文本分析。32
圖3-3 中文文本自動化分析系統登入畫面
登入系統後,點選「詞彙多樣性」按鈕,待出現圖3-4 頁面,依頁面step1 要 求輸入文本標題、資料來源、文本內容,並在step2 處勾選欲分析之詞彙多樣性 指標,最後點選「分析文本」按鈕,即可開始進行文本分析。
33
圖3-4 中文文本詞彙多樣性指標使用介面
圖3-5 為詞彙多樣性分析結果,呈現文本分析後之所有相關內容,如文本斷 詞結果、指標分析結果,其中,TTRC指標數值為0.731 ,TTRA指標數值為0.714 , MTLD指標數值為63 。
34 圖3-5 中文文本詞彙多樣性指標分析結果畫面
第三節 研究對象與限制
壹、研究對象
一、預試對象:施測對象為彰化縣某國小四年級學生78 人、六年級學生88 人, 全體學生總共166 人。 二、正式施測對象:施測對象為台中市、彰化縣和南投縣4 所國小,四、六年級 共24 班,因本研究採用便利抽樣和立意抽樣,以研究者方便施測之四、六 年級學生為受試對象有效樣本共647 人,其中四年級受試人數為307 人,六 年級受試人數共340 人。35 三、受試學生排除智能障礙及情緒障礙之特殊生。
貳、研究限制
一、研究對象方面:本研究採用便利抽樣和立意抽樣,以研究者方便施測之四、 六年級學生為受試對象,由於受試對象均集中於中部地區學校,而且並非採 隨機抽樣取樣,因此本研究結果並不適合套用於其他地區的學童身上。 二、研究推論方面:本研究採用「中高年級文本理解測驗」雖有不錯的信、效度, 但因文本樣本只有三十二篇,對於研究結果不宜作過度的推論。第四節 研究工具
根據研究目的的需要,研究工具如下:壹、兒童語料庫文本
本研究指標建置之兒童語料庫文本文本來源為廖晨惠(2011)之國科會「閱 讀研究議題八:以LSA 為基礎之電腦化閱讀認知測驗及AutoTutor 建置」計畫(編 號:NSC100-2420-H-142-001-MY3)所建置,共收錄經授權之國小坊間N、H、K 三版本之國小教科書中國語、社會、自然生活與科技、藝術與人文及健康與體育 等五大領域之教科書及國語日報等共874 篇文本,共計兩萬多個詞彙。貳、斷詞系統
本研 究使 用中 央 研 究院 數位 典藏 國 家 型科 技計 畫建 置 之 中文 斷詞 系統 (http://ckipsvr.iis.sinica.edu.tw/),完成「兒童語料庫文本文本」第一次斷詞。此 系統提供了自動抽取新詞建立領域用詞或線上即時分詞功能。是一個有新詞辨識 能力並附加詞類標記的選擇性功能之中文斷詞系統。此一系統包含約拾萬詞的詞 彙庫及附加詞類、詞頻、詞類頻率、雙連詞類頻率等資料。分詞依據為此一詞彙 庫及定量詞、重疊詞等構詞規律及線上辨識的新詞,並解決分詞歧義問題。 使用中研院系統進行第一次斷詞後,發現部分詞類標記與現代漢語不甚相36 符,例如以「手的外形」一句為例,中研院斷詞的結果為「手-的-外形(名詞 -介詞-形容詞)」,但實際應分為「手的-外形(形容詞-名詞)」,故就中研院 的斷詞規則篩選出需再做第二階段斷詞的句型,修改部分斷詞規則,並以此為依 據進行二次斷詞。表3-1為節錄本研究部份修改中研院精簡詞性後斷詞標記規則列 表。 表 3-1 修改斷詞標記規則 編號 中文斷詞系 統詞性標記 修改後詞性 標記 中研院斷詞系 統完成斷詞 修改斷詞規則後斷詞 1 (N) (ADJ) (ASP) (N) (Vi) (ASP) 小熊(N)醒 (ADJ) 了 小熊(N)醒(Vi) 了 (ASP) 2 (N) (T) (N) (ADJ) (N) 手(N)的(T) 外形(N) 手的(ADJ)外形(N) 3 (Vi) (Vi) (Vt) (Vi) (ADV) 動動腦(Vi)仔 細(Vi)觀察 動動腦(Vi)仔細 (ADV)觀察(Vt) 4 (Vi) (T) (N) (ADJ) (N) 快樂(Vi)的(T) 成長(N) 快樂的(ADJ)成長 (N) 5 (Vt) (T) (N) (ADJ) (N) 溫暖(Vt)的(T) 地方(N) 溫暖的(ADJ)地方 (N) 6 (Vt) (T) (Vt) (ADV) (Vt) 意想不到(Vt) 的(T)發現(Vt) 意想不到的(ADV) 發現(Vt) 7 (ADV) (Vi) (T) (ADV) (ADJ) (N) 很(ADV)好 (Vi) 的(T) 很(ADV)好的 (ADJ)傳達者(N) 8 (P)(N) (ADJ) (P)(N) (Vi) 當(P)春天(N) 到來(ADJ) 當(P)春天(N) 到來(Vi)
37
参、電腦軟體
一、MATLAB 軟體:依據Coh-Metrix詞彙多樣性指標公式並利用MATLAB 軟體 撰寫程式予以計分。 二、SPSS 軟體:使用皮爾森積差相關、單因子變異分析、迴歸分析等方式分析 指標與文本測驗之關係。肆、中高年級文本理解測驗
一、 測驗編製依據 本測驗題本,採用國立臺中教育大學測驗統計與適性學習研究中心所編製之 詳細內容參閱「中高年級文本理解測驗技術報告」(郭伯臣等,2013)及碩士論 文「兒童文本詞類指標分析系統建置與應用」(陳建宏,2013)之八篇文本,另 外加上後續發展所建置的二十四篇文本,共計三十二篇文本。根據指標結果,按 年級(四、六年級)、文體(記敘文、非記敘文)篩選測驗文本,依據PIRLS四項 閱讀理解層次編製中高年級文本理解測驗題本。在PIRLS的研究中將閱讀歷程分 為「直接理解歷程」和「解釋理解歷程」兩部份;其中「直接理解歷程」分為「直 接提取」以及「直接推論」;至於「解釋理解歷程」則分別為「詮釋、整合觀點 和訊息」以及「檢驗、評估內容、語言和文章的元素」(柯華葳、詹益綾、張建 妤、 游婷雅,2008)。 表 3-2 國際閱讀素養研究(PIRLS)閱讀理解層次 閱讀理解層次 子層次 直接提取 (1)找出與閱讀目標有關訊息 (2)找出特定觀點 (3)搜尋字詞或句子的定義 (4)指出故事的場景 (5)當文本明顯陳述出來時,找出主題句或主旨 (續下頁)38 閱讀理解層次 子層次 直接推論 (1)推論出某事件所導致的另一事件 (2)在一串的論點後,歸納出重點 (3)找出代名詞和主詞的關係 (4)歸納文本的主旨 (5)描述人物間的關係 詮釋整合 (1)清楚分辨出文本整體訊息或主旨 (2)考慮文中人物可選擇的其他行動 (3)比較及對照文本訊息 (4)推測故事中的情緒或氣氛 (5)詮釋文中訊息在真實世界的適用性 檢驗評估 (1)評估文本所描述事件實際發生的可能性 (2)揣測作者如何想出讓人出乎意料的結局 (3)評斷文本中訊息的完整性 (4)找出作者的觀點 資料來源:引自柯華葳等人 (2008) 一、 文本選擇: 本研究之「中高年級文本理解測驗」文本來源,選自民國七十八年國立編譯 館出版之四年級和六年級的國語科教科書,刪除劇本、新詩、故事類等類型,共 擷取三十二篇文本,其中記敘文二十一篇與非記敘文十一篇。 二、 試題編製: 測驗內容命題依據係參考「促進國際閱讀素養研究(PIRLS)」中的「直接提 取」、「直接推論」、「詮釋整合」和「檢驗評估」四個層次。施測題本內容共計192 題試題,預試後刪除3 題鑑別度不良試題,正式施測題本內包含三十二篇測驗文 本及189 題試題,其中直接提取46 題、直接推論47 題、詮釋整合48 題及檢驗 評估48 題,共計189 題單一選擇題。