國 立 交 通 大 學
資 訊 科 學 與 工 程 研 究 所
博 士 論 文
無線感測網路之安全資料聚集
與資料搜尋方法設計
The Design of Secure Data Aggregation and
Data Searching for Wireless Sensor Networks
研究生:黃士一
指導教授:謝續平 博士
中華民國九十九年一月
The Design of Secure Data Aggregation and
Data Searching for Wireless Sensor Networks
Student: Shih-I Huang
Advisor: Shiuhpyng Shieh
A Dissertation Submitted to
Institute of Computer Science and Engineering
College of Computer Science
National Chiao-Tung University
In Partial Fulfillment of the Requirements
of the Degree of
Doctor of Philosophy
in
Computer Science and Engineering
Jan, 2010
無線感測網路之安全資料聚集與資料搜尋方法設計
研究生:黃士一
指導教授:謝續平
國立交通大學資訊科學與工程研究所
摘要
無線感測網路中感測器(Sensor Node)之間的通訊方式則是採用無線通訊方式,每個感 測器持續的傳送感測器的讀值(Reading),並將讀值傳到無線資料收集器上再加以處理,因 此在同一時間內會有大量的資料在無線感測網路中傳送,造成網路雍塞及感測器耗損大量 的電力,並進而減損整個網路的使用時效(Lifetime)。為了克服這個問題,有許多研究便以 「資料聚集」(Data Aggregation)的方式來減少資料的傳遞量,但由於Sensor是隨意地散佈 於環境四周,因此資料在聚集或傳送時極易遭到監聽,入侵或修改,因此如何在Sensor彼 此之間建立起認證的管道,以確保資料是正確的傳遞到接收端便是一個重要的議題。 本篇論文所探討的主題為無線感測網路裡資料聚集的安全機制。第一章中我們會深入 的介紹目前常見的資料聚集方法,並針對不同的資料聚集方法在安全上的漏洞加以整理分 析,並針對目前的防護方式加以整理與討論。第二章著重於無線網路的資料聚集方法,在 第二章我們提出了一個安全的資料聚集方法,資料可以在不被第三者知悉且資料是加密的 情形下,將重複的資料剔除。本論文所提出之方法可適用於低成本且低算能力的無線感測 器上,並只需要O(n)的金鑰空間,可實作在無線感測器上,進而強化無線感測器的安全 能力。 第三章中我們提出了在可感知RFID之無線感測網路中認證及輕量(lightweight)的資料且不須解密的情形下,可以搜尋密文中是否有特殊的字串的搜尋方法。本章所提出的可感 知RFID之無線感測網路結合了RFID與無線感測網路,可解決無線感測網路中的距離限制 問題。本章所提出的認證方法可以適用於無線感測網路並減少重新認證的次數。本章所提 出的資料搜尋方法可以在資料不須解密的情形下搜尋特定字串,藉此,可以避免資料在無 線網路中傳送遭到竊取或破壞。 而受制於無線感測器的硬體限制,可以儲存金鑰的空間極少,因此第四章中我們提出 了一個金鑰建佈(Key Distribution)的方法,我們利用了Hash Chain建立Pair-wise金鑰,使得 每個Node所需要的金鑰儲存空間更少,但仍保存相同的Network Connectivity,及藉此建立 起點與點的金鑰,達到點與點的安全性。 藉由本論文提出的方法,可以建立起無線感測網路的安全防禦機制。首先,藉由我們 所 提 出 的 金 鑰 建 佈 方 法 , 可 以 建 立 起 點 與 點 的 安 全 溝 通 管 道(Secure Communication Channel)且只需要較少的儲存空間。而第三章提出的資料搜尋方法,提供了一個在加密資 料的搜尋機制,除了確保資料安全外,更加上搜尋的功能。而第二章提出的資料聚集方 法,除了維持資料的安全性及完整性(Integrity)外,讓感測器可以濾掉由不同的感測器且每 個感測器有不同的加密金鑰的情形下,濾掉重複的資料,除了可以避免資料遭到破壞或竄 改外,更可以延長無線感測網路的整體平均壽命。本論文除了考慮安全性外,更考慮了省 電性,且相關設計都以可以在無線感測上實現為優先,可以做為無線感測網路的安全基礎 建設(Security Infrastructure)。
The Design of Secure Data Aggregation and Data
Searching for Wireless Sensor Networks
Student: Shih-I Huang Advisor: Shiuhpyng Shieh
Institute of Computer Science and Engineering
National Chiao Tung University
ABSTRACT
Wireless Sensor Networks (WSNs) are formed by a set of small devices, called nodes, with limited computing power, storage space, and wireless communication capabilities. Most of these sensor nodes are deployed within a specific area to collect data or monitor a physical phenomenon. Data collected by each sensor node needs to be delivered and integrated to derive the whole picture of sensing phenomenon. To deliver data without being compromised, WSN services rely on secure communication and efficient key distribution. This paper focuses mainly on establishing security protection in WSNs.
The first part of the paper proposes a secure encrypted-data aggregation scheme for wireless sensor networks. Our design for data aggregation eliminates redundant sensor readings without using encryption and maintains data secrecy and privacy during transmission. Conventional aggregation functions operate when readings are received in plaintext. If readings are encrypted, aggregation requires decryption creating extra overhead and key management issues. In contrast to conventional schemes, our proposed scheme provides security and privacy, and duplicate instances of original readings will be aggregated into a single packet. Our scheme is resilient to known-plaintext attacks, chosen-plaintext attacks, ciphertext-only attacks and man-in-the-middle attacks. Our experiments show that our proposed aggregation method significantly reduces
The second part of the paper investigates authentication and secure data retrieval issues in RFID-aware wireless sensor networks. To cope with the problems, we proposes a network architecture (ARIES) consisting of RFIDs and wireless sensor nodes, a mutual authentication protocol (AMULET), and a secret search protocol (SSP). ARIES utilizes RFID-aware sensor nodes to alleviate the distance limitation problem commonly seen in RFID systems. AMULET performs mutual authentication and reduces the cost of re-authentication. SSP solves the privacy problem by offering a lightweight secret search mechanism over encrypted data, thereby preventing data disclosure during communication and query processes. The proposed scheme only uses symmetric cryptosystems, and does not need to decrypt encrypted data files while searching for specific data. In this way, fewer decryption and encryption operations are needed, and the performance of secret search and data retrieval is greatly improved.
In last part, we proposed two key distribution schemes for WSNs, which require less memory than existing schemes for the storage of keys. The Adaptive Random Pre-distributed scheme (ARP) is able to authenticate group membership and minimize the storage requirement for the resource limited sensor nodes. The Uniquely Assigned One-way Hash Function scheme (UAO) extends ARP to mutually authenticate the identity of individual sensors, and can resist against the compromise of sensor nodes. The two proposed schemes are very effective for the storage of keys in a wireless sensor network with a large number of sensors.
Keywords: Data Aggregation, Data Searching, Wireless Sensor Networks, Authentication,
Acknowledge
經過七年的磨練,終於完成了博士學位。回想起七年前,還只是個初出社會二年的毛 頭小子,捨棄一份不錯的薪水及工作,然後回到學校再就學。不同於一般求學的學生,在 求學中間背負很多艱辛且不為人知的壓力,也曾受到某些人的曲解,雖然過程不能盡如人 意,但也都一點一點的承受住,熬了過來。 這本論文的產生,首先要感謝我的指導教授謝續平老師。這七年中間,他給我不止課 業上的指導,亦讓我在他身上學到許多做人做事的道理,讓我在面對困難及挑戰時,更有 能力去應對。第二要感謝柏克萊大學的Prof. Doug Tygar 及卡內基美隆大學的 Prof. Adrian Perrig,當我在柏克萊大學及卡內基美隆大學做研究時,他們不遺餘力的教導及頻繁的 meeting,讓我能快速的產出期刊論文及國際會議論文。而工研院的長官們,包括余孝先 副所長、劉智友組長、張隆昌副組長等;及同事們,包括力群、博元等,在我於工研院服 務的日子裡,給我莫大的支持及幫忙,讓我能同時兼顧學業、研究及工作,並且能因此到 此二頂尖學府進修,讓我藉此培養更廣的國際觀。第四要感謝富源學長及嘉寧學長在研究 上的大力協助,藉由跟他們的討論,讓我得知如何做更好的研究及了解自己研究的問題 點。 此外,也要感謝我的口試委員:曾文貴教授、楊武教授、吳宗成教授、雷欽隆教 授、孫宏民教授,及詹進科教授,在百忙中撥空,提供許多寶貴的意見與指正,使本論文 能略臻於完備。 最後,我要以這份博士學位的榮耀獻與我最親愛的父母與家人,在這些日子裡,你 們容忍我的不理性及任性,在我出國工作時,幫我照顧家庭,讓我能兼顧工作及求學,沒 有您們的支持,將不會有這本論文。謹與我最親愛的父母與家人分享。 黃士一 2010 年 1 月 20 日于台中Table of Content
Chapter 1 Introduction ... 1
1.1 Security Requirement ... 3
1.2 Contribution
... 4
1.3 Synopsis
... 4
Chapter 2 Related Work ... 6
Chapter 3 Secure Data-Aggregation for Wireless Sensor Networks ... 12
3.1 Problem Statement and Proposed Data Aggregation... 16
3.2 Proposed Data Aggregation Method ... 16
3.3 Architecture
... 16
3.4 System Setup
... 19
3.5 Proposed Scheme
... 20
3.5 Threat Models
... 25
3.7 Security Analysis and Performance Evaluation ... 26
3.8 Summary
... 36
Chapter 4 Authentication and Secret Search Mechanisms for RFID-Aware
Wireless Sensor Networks ... 38
4.1 ARIES
... 41
4.2 AMULET
... 45
4.3 SSP
... 49
4.4 Security Analysis
... 52
4.5 Summary
... 58
Chapter 5 Adaptive Random Key Distribution Schemes for Wireless Sensor
Networks ... 61
5.1 Adaptive Random Pre-distribution Scheme ... 63
5.2 Evaluation
... 67
Chapter 6 Conclusion and Future Work ... 75
Reference ... 78
Curriculum Viate... 87
List of Figures
Figure 1 Wireless Sensor Network Architecture ... 2
Figure 2 Self-organized WSN architecture and its data aggregation flow
... 13
Figure 3 Conventional data aggregation process ... 14
Figure 4 Encrypted-data aggregation ... 16
Figure 5 A clustered sensor network topology ... 18
Figure 6 Data Aggregation Phase ... 23
Figure 7 Data aggregation verification steps for n=5. ... 25
Figure 8 The growth rate of key size (
2) and the growth rate (
) of PCs
... 32
Figure 9 The number of comparisons for verifying n encrypted-data. 34
Figure 10 ARIES architecture... 44
Figure 11 AMULET architecture. ... 48
Figure 12 Commands verification without re-authentication process. 49
Figure 13 SSP operations for attribute K. ... 50
Figure 14 SSP operations. ... 51
Figure 15 Type-1 man-in-the-middle attack ... 54
Figure 16 Type-2 man-in-the-middle attack. ... 55
Figure 17 Type-3 man-in-the-middle attack. ... 55
Figure 18 Unordered key pool and the Two-Dimension key pool with
t= 10, s = 10. ... 64
Figure 20 Comparison of different configured Two-Dimension Key
Pool Selecting Schemes and basic scheme (key pool size is
100,000) ... 70
Figure 21 Comparison of Random-pairwise keys scheme and UAO
scheme in memory requirement and maximum supported
network size. ... 73
List of Tables
Table 1 Encryption plicies, attacks and vulnerabilities in data
aggregation schemes. ... 15
Table 2 Pre-installed elements in three roles ... 20
Table 3 Estimated time (years) to brute force our proposed scheme with
different key lengths... 32
Table 4 Performance evaluations compared with other schemes... 34
Table 5 Efficiency comparisons for the best, average, and the worst
case ... 36
Table 6 Distributed tiny database. ... 45
Chapter 1
Introduction
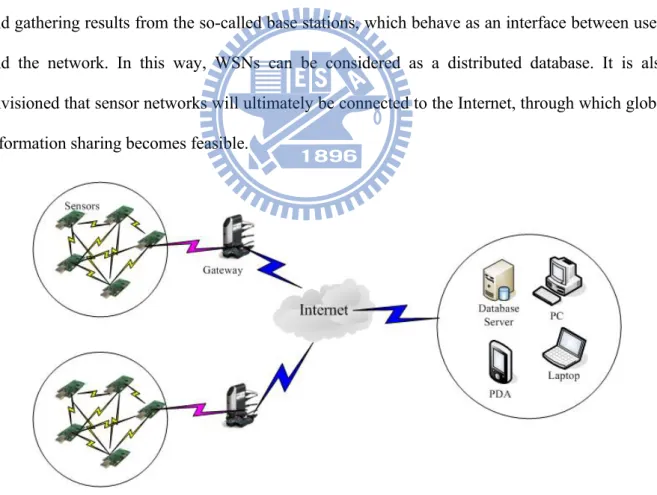
With the popularity of laptops, cell phones, PDAs, GPS devices, RFID, and intelligent electronics in the post-PC era, computing devices have become cheaper, more mobile, more distributed, and more pervasive in daily life. It is now possible to construct, from commercial on-the-shelf components, a wallet size embedded system with the equivalent capability of a 90's PC. Such embedded systems can be supported with scaled down Windows or Linux operating systems. From this perspective, the emergence of wireless sensor networks (WSNs) is essentially the latest trend of Moore's Law toward the miniaturization and ubiquity of computing devices.
Typically, a wireless sensor node (or simply sensor node) consists of sensing, computing, communication, actuation, and power components. These components are integrated on a single or multiple boards, and packaged in a few cubic inches. With state-of-the-art, low-power circuit and networking technologies, a sensor node powered by 2 AA batteries can last for up to three years with a 1% low duty cycle working mode. A WSN usually consists of tens to thousands of such nodes that communicate through wireless channels for information sharing and cooperative processing. WSNs can be deployed on a global scale for environmental monitoring and habitat study, over a battlefield for military surveillance and reconnaissance, in emergent environments for search and rescue, in factories for condition based maintenance, in buildings for infrastructure health monitoring, in homes to realize smart homes, or even in bodies for patient monitoring.
network infrastructure, often with multi-hop connections between sensor nodes. The onboard sensors then start collecting acoustic, seismic, infrared or magnetic information about the environment, using either continuous or event driven working modes. Location and positioning information can also be obtained through the global positioning system (GPS) or local positioning algorithms. This information can be gathered from across the network and appropriately processed to construct a global view of the monitoring phenomena or objects. The basic philosophy behind WSNs is that, while the capability of each individual sensor node is limited, the aggregate power of the entire network is sufficient for the required mission.
In a typical scenario, users can retrieve information of interest from a WSN by injecting queries and gathering results from the so-called base stations, which behave as an interface between users and the network. In this way, WSNs can be considered as a distributed database. It is also envisioned that sensor networks will ultimately be connected to the Internet, through which global information sharing becomes feasible.
Security Requirement
Due to resource limitations of WSN, the security requirements of WSN are different from others. Below we list security requirements which must be fulfilled in wireless sensor network architecture.
1) Secrecy: Storing data in an encrypted form helps retain its confidentiality. Because sensors are vulnerable, computation-limited, and low cost devices, allowing sensors to decrypt data to perform a search results in unnecessary risk of disclosure. Thus, sensors must execute a secret search directly on ciphertext, rather than plaintext. Furthermore, data transmitted over a wireless interface is susceptible to exposure. Therefore, sensors must only transmit encrypted data. In summary, the data must remain in an encrypted form and should not be decrypted unless necessary to minimize the possibility of disclosure.
2) Authentication: Since the network obtains data from a large number of sensors or tags, attackers can easily acquire readers with the same specifications to extract data stored in the tags. Therefore, both the reader and the tag need to verify the authenticity of its communication counterpart before executing read or write operations.
3) Integrity: Assuring data integrity prevents attackers from using unauthorized readers to modify or inject data into databases. Readers or tags must verify data integrity upon receipt of data.
4) Performance: Requiring a sensor node to decrypt data before searches causes significant and unnecessary delay. Also, the limited computation capabilities of sensor nodes and tags hinder them from performing complex operations, such as encryption and exponential calculations. Therefore, all operations must be redesigned to fit their computation
Contribution
The contribution of this dissertation is threefold. First, we build a key distribution algorithm, associating random key distribution and hash chain, achieving end-to-end security requirement but saving more storage space. Second, we design an authentication and secret search mechanisms for WSN. Our authentication algorithm achieves mutual authentication among sensor nodes but reducing re-authentication effort. Our proposed secret searching algorithm provides searching method over encrypted data without knowing encryption / decryption key. This could keep both secrecy and privacy for data. Third, we proposed a data aggregation algorithm over encrypted data. Aggregators do not need to have encryption keys and could still perform data aggregation to eliminate redundant data without decrypting them.
Our proposed algorithms aim not only to provide secrecy, privacy, authentication, and data integrity for data, but also aim to be workable in resource limited sensor nodes. Only feasible security algorithms and affordable computation assumption can practically provide robust security to wireless sensor network.
Synopsis
In Chapter 2, we list related work for key distribution, authentication, secret searching, and data aggregation. We showed that the infeasibilities of current algorithms in these four categories.
In Chapter 3, we proposes a new method for determining and eliminating duplicate data while protecting privacy (using encryption) without excessive key-management or power management issues. Our scheme has the following contributions. First, we provide a lightweight data aggregation mechanism which protects data when data are processed in aggregators. Aggregators can help to eliminate redundant data without decrypting data. Thus, aggregators do not need to
spend extra power in data decryption, and more network lifetime can be guaranteed. Second, our proposed scheme is resilient to known-plaintext attacks, chosen-plaintext attacks, ciphertext-only attacks, and man-in-the-middle attacks.
In Chapter 4, we propose an architecture consisting of passive RFIDs and RFID-aware sensor networks (ARIES). This architecture extends RFID’s capabilities through a wireless sensor network by utilizing sensor nodes to locate targets at a distance. Second, we design a private mutual authentication protocol (AMULET) which is feasible for RFIDs and sensor nodes, and reduces the cost of re-authentication. Third, we present a secret search protocol (SSP) that enables readers to perform searches over encrypted data, allowing data to remain encrypted during transmission or at vulnerable locations. By only using one-way hash functions, pseudo random number generation functions, and XOR operations, SSP accommodates the resource limitations of both tags and sensors. In addition, SSP can solve the problem that same plaintexts at different places will be encrypted into the same ciphertexts.
In Chapter 5, we propose two key distribution schemes: Adaptive Random Pre-distributed scheme (ARP) and Uniquely Assigned One-way Hash Function scheme (UAO). Both schemes pre-distribute keys in each node before its deployment. According to random graph theory, a sensor network can be connected as long as enough keys are selected. Therefore, each node can communicate with each other without key exchange, which can save computational overhead for communications. More than that, both schemes minimize the storage requirement for key management. Though UAO scheme needs more storage space than ARP does, it provides mutual authentication. And, Chapter 6 gives an conclusion.
Chapter 2
Related Work
Much research has been done on key distribution in WSN over the past few years. Carman et al [18] analyzed various conventional approaches for key generation and key distribution in WSN on different hardware platforms with respect to computation overhead and energy consumption. The results showed that conventional key generation and distribution protocols are not suitable for WSN. To cope with the problem, a key management protocol [19] is proposed for sensor networks, which is based on group key agreement protocols and identity-based cryptography. This protocol used Diffie-Hellman key exchange scheme to perform group key agreement. However, the high storage and high computation requirements make it unrealistic to be implemented.
Perrig et al. [20] proposed a security protocol for sensor networks named SPINS. SPINS uses base station as a trusted third party to set up session keys between sensor nodes. Liu and Ning [21] extended Perrig’s scheme and proposed an efficient broadcast authentication method for sensor networks. Their scheme uses multi-level key chains to distribute the key chain commitments for the broadcast authentication. Undercoffer et al [22] proposed a resource-driven security protocol, which consider the trade-off between security levels and computational resources. However, in a randomly dispersed wireless sensor network, the base station is not always available for all nodes. Without the base station, SPINS may cause a sensor network disconnected. Therefore, these schemes are not well suitable for sensor networks due to the need of the base station.
Eschenauer and Gligor [23] proposed a key management scheme based on Random Graph Theory. The Random Graph Theory is defined as follows. A random graph G(n, p) is a graph with n nodes, and the probability that a link exists between any two nodes in the graph is p. When p is zero, the graph G has no edges, whereas when p is one, the graph G is fully connected. This approach significant reduce key space requirement. Inspired by this paper, our algorithm could save more key space in compared with Eschenauer’s algorithm.
For authentication and secret searching, some papers propose the use of public key infrastructure (PKI) to authenticate two parties through a trusted-third-party [43]. This solution is inadequate for RFID applications since the PKI requires the reader or tag to save private keys and verify the identity of others with the help of the trusted-third-party. Tags have little storage, and they can only transmit data to devices in close proximity. In other words, the trusted-third-party must be located near the tags, which is a difficult requirement to achieve and one that presents other security risks. Moreover, the tag cannot afford additional computational power required to verify others. Therefore, a PKI scheme is not feasible for RFID applications.
A randomized lock protocol [26] was proposed for private authentication in a highly constrained computation and storage environment. However, this scheme is neither private nor secure against passive eavesdroppers. As an improvement, a PRF-based private authentication protocol [5] was proposed. Unfortunately, both protocols [26][5] require re-authentication of a tag even if another authorized reader previously authenticates the tag. These extra steps are computationally wasteful and unnecessary.
Privacy is a major concern encountered in RFID applications [39]. A RFID tag may store sensitive data associated with a target, which must remain private. Since readers, tags, and sensor nodes send messages through a wireless medium, attackers can easily eavesdrop to their
An intuitive way of protecting private data is encryption [30]. However, tags and sensor nodes have severely limited storage and computation capability; consequently, conventional cryptographic algorithms are not well-suited for these devices. As a result, we must redesign security mechanisms to support RFID tags and sensor nodes.
A new problem arise from encrypting data: RFID readers cannot easily perform queries on data in encypted form [21][5]. Researchers have investigated secret search over encrypted data in an untrusted file server or external memory environment [55][26][23][5][27]. A recent method [3] is proposed for secret searching on untrusted servers. Unfortunately, their scheme requires complex encryption operations unavailable to both tags and sensor nodes. Another problem of the scheme is that same plaintexts at different places will be encrypted into the same ciphertexts in their proposed scheme III. Hence, malicious attackers could inject meaningful plaintexts into the database and use the corresponding ciphertexts to find their interests without decrypting entire or part of the database.
Other researches tried to solve this searching problem by inserting specific encrypted keywords into the ciphertexts [43][89][8][68][22]. These encrypted keywords can be viewed as indices and could therefore be used in search operations [13][95]. However, these keywords are fixed and must be defined beforehand. Therefore, this inconveniency makes them difficult to use. Another solution is to support searching over encrypted data by using multi-party computation and oblivious functions [82][83][34]. However, this solution requires high computation overhead and therefore is not applicable in a tag or sensor system.
For data aggregation, previous work in data aggregation assumes that every mote is honest and only transmits their correct readings. Intanagonwiwat, Govindan, Estrin, and Heidemann [51] proposed a data-centric diffusion method to aggregate data. Their method enables diffusion to
network. Though their method can achieve significant energy savings, security is not put into consideration in their design.
Hu and Evans [48] further examined the problem that a single compromised sensor mote can render the networks useless, or worse, mislead the operator into trusting a false reading. They proposed an aggregation protocol that is resilient to both intruder devices and single device key compromises, but their scheme suffers a problem that the aggregated data will be expanded every time when it was aggregated and forwarded by any intermediate sensor mote.
Przydatek, Song and Perrig [72] proposed a secure information aggregation protocol to answer queries over the data acquired by the sensors. In particular, their proposed protocols are designed especially for secure computation of the median and the average of the measurements, for the estimation of the network size and for finding the minimum and maximum sensor reading. Even though their scheme provided data authentication to provide secrecy, the data is still delivered in plaintext format which provides no privacy during transmission.
Wagner [88] presented a paper studying related attacks on data aggregation in sensor networks. He thoroughly examined current aggregation functions and proved that these aggregation functions are vulnerable and insecure under several attacks. He also proposed a theoretical framework for evaluating data aggregation resiliently in sensor networks and in its security against these attacks. Still privacy is not guaranteed in his scheme.
Acharya and Girao [1] proposed an end-to-end encryption algorithm supporting operations over ciphertexts for wireless sensor networks. Their scheme uses a special class of encryption functions,
Privacy Homomorphisms (PH) [9][12][25][28][94], that allow end-to-end encryption and provide
homomorphic encryption and decryption if the following property is satisfied: for plaintext operands x and y and key k, xyDk(Ek(x)Ek(y)). However, privacy homomorphisms have
exponential bound in computation. It is too computationally expensive to implement in wireless sensor networks. Moreover, it has been proved that privacy homomorphism is insecure even against ciphertext only attacks which are commonly encountered in wireless sensor networks.
Cam et al. [15] proposed a secure energy-efficient data aggregation (ESPDA) to prevent redundant data transmission in data aggregation. Unlike conventional techniques, their scheme prevents the redundant transmission from sensor motes to the aggregator. Before transmitting sensed data, each sensor transmits a secure pattern to the aggregator. The secure pattern is generated by associating original data with a random number. Instead of transmitting “real” data, the sensor mote transmits the secure patter to the head before transmitting it. The head then uses these secure patterns to check which sensors have same readings. Then, the cluster-head notifies certain sensor motes to transmit their data. Only sensors with different data are allowed to transmit their data to the cluster-head. However, since each sensor at least needs to transmit a packet containing a pattern once, power cannot be significantly saved. In addition, each sensor mote uses a fixed encryption key to encrypt data; data privacy cannot be maintained in their scheme.
Perrig and Tygar [70] proposed several secure broadcast schemes suitable for wireless sensor networks. The computation overhead for their schemes is affordable for tiny sensor motes. They proposed a hashed key-chain scheme to sequentially generate encryption/decryption keys for sensor motes without notifying others. Przydatek, Song and Perrig [72] further extended these schemes and proposed a secure data aggregation scheme for sensor network. Their scheme provided an efficient random sampling mechanisms and interactive proofs to enable the querier to
verify that the answer given by the aggregator is a good approximation of the true value, even when the aggregator and some sensor motes were compromised.
Chapter 3
Secure Data-Aggregation for Wireless Sensor
Networks
Wireless Sensor Networks (WSN) have emerged as an important new area in wireless technology. A wireless sensor network [3] is a distributed system interacting with physical environment. It consists of motes equipped with task-specific sensors to measure the surrounding environment, e.g. temperature, movement, etc. It provides solutions to many challenging problems such as wildlife, battlefield, wildfire, or building safety monitoring. A key component in a WSN is the sensor mote, which contains a) a simple microprocessor, b) application-specific sensors, and c) a wireless transceiver. Each sensor mote is typically powered by batteries, making energy consumption an issue.
A major application for a wireless mote is to measure environmental values using embedded sensors, and transmit sensed data to a remote repository or a remote server. Because of limited transmission capabilities, this often requires multi-hop forwarding of messages, and is power consuming.
One specific power-saving mechanism used in wireless sensor networks is data aggregation [1][4][6][14][15][19][20]. Our paper proposes a novel method for eliminating duplicate encrypted data during aggregation without decryption. Data aggregation [24][37][40][41][48] [88][90][91] has been put forward as an essential paradigm in sensor networks. The aggregator uses specific
functions, such as addition, subtraction or exclusive-or, to aggregate incoming readings, and only aggregated result are forwarded [51][52][54][57][74][76][77]. Therefore, communication overhead can be reduced by decreasing the number of transmitted packets [58][59][63][64][65] [66][72]. Without encryption, adversaries can monitor and inject false data into the network. Encryption can solve this problem, but how can we aggregate over encrypted data [18]?
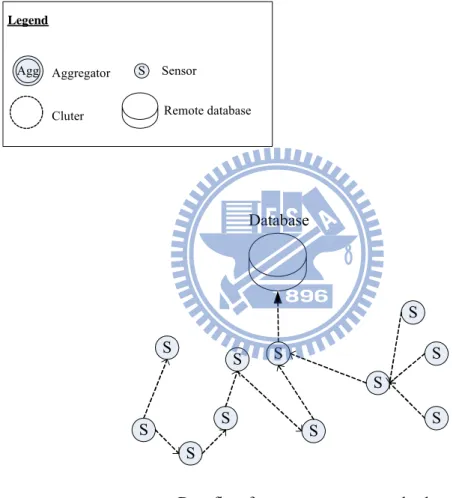
Agg Aggregator S Sensor
Cluter Remote database
Legend S S S S S Database S S S S S S
Data flow from sensor to remote database Data flow from sensor to another sensor
S
Agg
S S S
S S S
R
1R
2R
3R
4R
5R
6R
7V=f(
R
1,R
2, … ,R
7)
Figure 3 Conventional data aggregation process We assume adversaries owned the following attacking capabilities.
Adversaries can deploy sensors near existing sensors to determine their likely value. Adversaries can use common key encryption systems (which always encrypt common
sensor data in the same way) to see when two readings are identical. By using nearby sensors under the adversaries’ control, adversaries can conduct a known-plaintext attack. Adversaries can tamper with sensors to force them to predetermined values (such as
heating a temperature sensor) and thus conduct a chosen-plaintext attack.
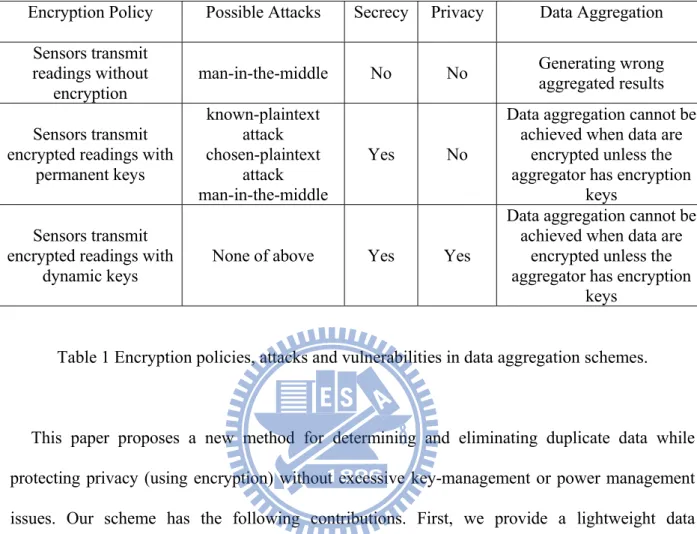
Adversaries can inject false readings or resend logged readings from legitimate sensor motes to manipulate the data aggregation process, conducting a man-in-the-middle attack. Table 1 presents encryption policies, possible attacks, and vulnerabilities in data aggregation schemes.
Encryption Policy Possible Attacks Secrecy Privacy Data Aggregation Sensors transmit
readings without encryption
man-in-the-middle No No Generating wrong aggregated results Sensors transmit
encrypted readings with permanent keys known-plaintext attack chosen-plaintext attack man-in-the-middle Yes No
Data aggregation cannot be achieved when data are
encrypted unless the aggregator has encryption
keys Sensors transmit
encrypted readings with dynamic keys
None of above Yes Yes
Data aggregation cannot be achieved when data are
encrypted unless the aggregator has encryption
keys Table 1 Encryption policies, attacks and vulnerabilities in data aggregation schemes.
This paper proposes a new method for determining and eliminating duplicate data while protecting privacy (using encryption) without excessive key-management or power management issues. Our scheme has the following contributions. First, we provide a lightweight data aggregation mechanism which protects data when data are processed in aggregators. Aggregators can help to eliminate redundant data without decrypting data. Thus, aggregators do not need to spend extra power in data decryption, and more network lifetime can be guaranteed. Second, our proposed scheme is resilient to known-plaintext attacks, chosen-plaintext attacks, ciphertext-only attacks, and man-in-the-middle attacks. The rest of the paper is organized as follows: Section II provides background on related work. In Section III, we describe our system architecture and proposed aggregation protocol.Security analysis and performance evaluation are given in Section V, and Section IV offers conclusions and future directions.
Problem Statement and Proposed Data Aggregation
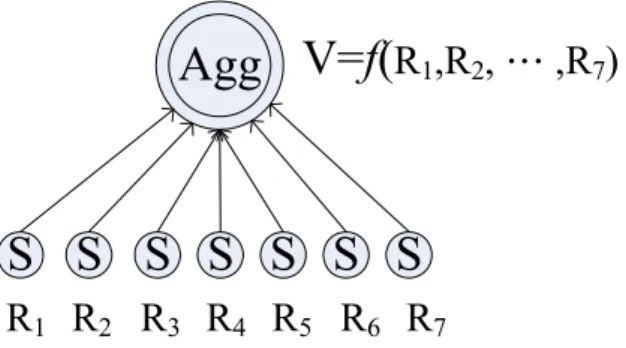
Data aggregation uses primitive functions, such as mean, average, addition, subtraction, and exclusive or to eliminate identical readings, and only unique results are be forwarded, reducing the cost of data transmission.
Figure 4 depicts an overview of data aggregation flow.
S
Agg
S
S
S
S
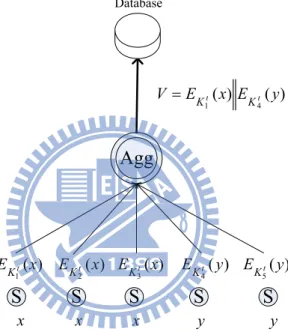
) ( 1 x EKt x x x y ) ( 2 x EKt y ) ( 3 x EKt ( ) 4 y EKt ( ) 5 y EKt ) ( ) ( 4 1 x E y E V Kt Kt DatabaseFigure 4 Encrypted-data aggregation
Proposed Data Aggregation Method
Architecture
There are two commonly used network topologies in sensor networks. One is the
self-organized sensor network. A self-self-organized network is a multi-hop, temporary autonomous
system composed of sensor motes with wireless transmission capability. It is easy to form such networks but every mote in such networks consumes significant amounts of power in data
transmission as each node must spend power to transmit / forward data to other sensor nodes because of the dynamic network topology. The other network topology is the clustered sensor
network. In this architecture, the entire network is partitioned into non-overlapping clusters. Each
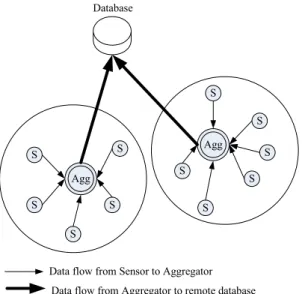
cluster has an aggregator (or cluster head) to receive readings from other sensor motes and to forward these readings to the remote server. To extend operation lifetime, we choose the clustered topology as our network architecture [66]. In a clustered sensor network, each mote temporarily belongs to a cluster, and sensors in this cluster will receive and forward data for sensors in the same cluster. Since a mote only transmits data for several motes instead of all motes, it can obviously reduce its power consumption for data transmission.
In a clustered WSN, we assume the network is divided into clusters. Each cluster owns an aggregator having a more powerful wireless transceiver that can transmit data directly to the backend server. In our framework, we also assume each sensor transmits data only to the aggregator; hence, each sensor mote can reduce overhead in forwarding data packets. We also assume sensor motes have no mobility, i.e. they are fixed in a position and will not be moved forever. The question of how to best deploy sensor motes and how to cluster these sensor motes is interesting to consider but it is beyond the scope of this paper.
S Agg S S S S Database S S S S S S Agg
Data flow from Sensor to Aggregator Data flow from Aggregator to remote database
Figure 5 A clustered sensor network topology
Using a clustered network to reduce power consumption, we propose a data aggregation method which maintains both secrecy and privacy. In terms of secrecy, each sensor mote encrypts its reading and transmits the encrypted data to the aggregator. Adversaries will not be able to recognize what reading it is during data transmission. In terms of privacy, our design aims to eliminate redundant reading for data aggregation but this reading remains secret to the aggregator, i.e., the aggregator cannot know anything about these readings. Besides, our design can also prevent known-plaintext attacks, chosen-plaintext attacks and ciphertext-only attacks.
Here we list special notations we use in this paper:
Notations:
i
S : Sensor mote i
1. Given x,yRn, g(x y)g(x)g(y)Rn
2. Given g(x), one cannot retrieve x in polynomial time 3. Given x x Rn
2
1, , the condition g(x1)g(x2) is possible.
EK i
K : An encryption key randomly generated by sensor mote i
VK i
K : A verification key used to verify data from sensor mote i
System Setup
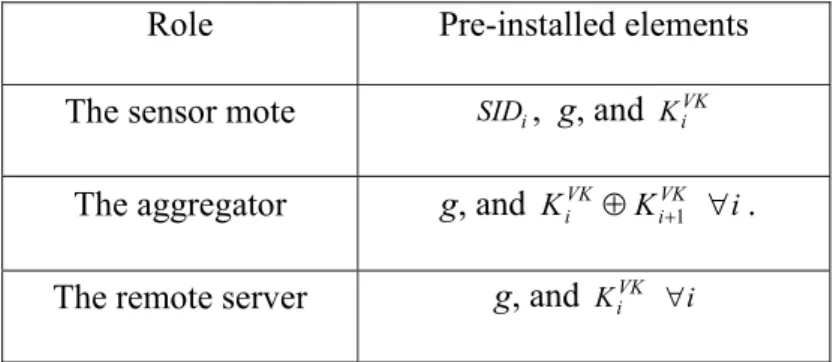
Before deploying a wireless sensor network, we have to set up three roles: the sensor mote, the aggregator, and the remote database.
1. The sensor mote: Each sensor mote i is assigned an one-way function g, and a verification key
VK i
K .
2. The aggregator: The aggregator is given the one-way function g, and all VK i VK
i K
K 1 i .
Hereafter, these keys are referred as aggregation verification keys.
3. The remote database: The remote database needs to decrypt aggregated data, and thus we need to store the one-way hash function f, the one-way function g, and all verification key
VK i
K for all i.
Necessary keys, identities, and functions are pre-distributed in the sensor mote, the aggregator, and the remote database before they are physically deployed and used. Table 2 lists all pre-installed elements in individual roles.
Role Pre-installed elements The sensor mote SIDi, g, and KiVK
The aggregator g, and VK i VK
i K
K 1 i.
The remote server g, and VK i
K i
Table 2 Pre-installed elements in three roles
Key pre-distribution is a scheme where keys are distributed among all sensor motes prior to deployment. Our proposed key pre-distribution scheme does not rely on prior deployment knowledge. Sensor motes are installed with random keys for encryption. These encryption keys have no mandatory relations between each other, and this makes system setup more flexible. Random keys can be generated by using random source of data, such as values based on CPU clock, radioactive decay, or atmospheric noise. The question of how to generating random numbers is interesting to consider but is beyond the scope of this paper.
Proposed Scheme
There are two phases in our proposed scheme: data encryption phase and data aggregation
phase. The encryption phase provides a lightweight encryption algorithm that supports data
aggregation property, and provides secrecy and privacy for data transmission. The data aggregation phase provides a method to eliminate redundant readings from sensor motes without decrypting them. Since the aggregator cannot decrypt incoming packets, the aggregator cannot know anything about the plaintext, and therefore more power can be saved.
Our encryption design aims to provide lightweight encryption overhead and secrecy while providing data aggregation property.
When a sensor mote i has a reading mi and wishes to transmit this reading to the aggregator,
it first randomly generates a new key EK i
K , which will be used as the next-round encryption key. By using g, EK
i
K , and VK i
K , the corresponding ciphertext Ei(mi) is defined in Eq(1).
VK i EK i EK i EK i i i i m m g K K K K E ( ) ( ) , Eq(1) Where ( ) ( ) ( VK) i EK i i Length K Length K m
Length and indicates data concatenation.
Our proposed scheme is very close to the one-time pad method [75] as each mote changes to a different key for encrypting data but provides more capabilities. It is obvious that the length of data is required to be at least as long as the length of encryption key in our proposed scheme. When the length of data is shorter than the length of the key, extra padding must be appended to the data so that the appended data can be encrypted. As the message mi is xored with
EK i EK
i K
K
g( ) , it does not matter if we pad random values or fixed values (e.g., all 0’s or 1’s). It does not reduce any security strength in our scheme.
Next, we will introduce how to find out redundant readings among these ciphertexts without decrypting them in our data aggregation phase.
Data Aggregation Phase
Our data aggregation method provides a pair-wise method to identify if two readings are identical. Although the goal of our data aggregation scheme is to find redundant readings among
comparisons we can eliminate all redundant readings among them. If n same readings are encrypted and transmitted to the aggregator, the aggregator needs to check n-1 times to verify these inputs and save n-1 packet transmission. It needs computation overhead for data aggregation but saves more energy from fewer data transmissions.
In the following section, first we will introduce our approach to find redundant readings in two packets; then, we will introduce how to extend our approach to find redundant readings among n packets.
Assume sensor mote i and j sends two encrypted readings to the aggregator, and these encrypted readings can be expressed by the following equations:
VK i EK i EK i EK i i i i m m g K K K K E ( ) ( ) , Eq(2) VK j EK j EK j EK j j j j m m g K K K K E ( ) ( ) . Eq(3)
First, the aggregator XOR the first parts of these two ciphertexts, and it can be expressed by the following equation:
EK j EK j j EK i EK i i g K K m g K K m ( ) ( ) Eq(4)
Next, since the aggregator is pre-installed with K KVK i
i VK i 1 ,KiVK KVKj can be obtained by ) ( ) ( )
(KiVK KiVK1 KiVK1 KiVK2 KVKj1KVKj , the aggregator can XOR the last two parts of
Eq(2) and Eq(3) to obtain:
EK j EK i VK j VK i VK j EK j VK i EK i K K K K K K K K Eq(5)
It can be found that the aggregator can use Ei(mi) and Ej(mj) to retrieve KiEKKEKj , but
cannot retrieve EK i
K or EK
j
K separately; therefore, the aggregator cannot decrypt Ei(mi) and
) ( j
j m
Next, we define a check value V, and V is calculated by XOR Eq(4), Eq(5) and ( EK) j EK i K K g .
The check value is used to distinguish if two encrypted readings are the redundant in their plaintext format. As a result, the check value V can be expressed by the following equation:
) ( ) ( ) ( ) , ( EK j EK i EK j EK i EK j EK j j EK i EK i i j i K K g K K K K g m K K g m V Eq(6) By using the properties of function g, Eq (6) can be further reduced to:
j i EK j EK i EK j EK i EK j EK j j EK i EK i i j i m m K K g K K K K g m K K g m V ) ( ) ( ) ( ) , ( Eq(7)
It is easier observed that if mi is equal mj, V(i,j)mimj0, and vice versa. We can formally
describe V( ji, ) by the following equations:
otherwise V m m then V if n j i j i n j i , 0 , 0 ) , ( ) , ( Eq(8) Figure 6 depicts the data aggregation phase
VK j VK i K K EK i VK i EK i EK i i i i m m K g K K K E( ) ( ) EKj VK j EK j EK j j j j m m K g K K K E ( ) ( ) EK j VK j EK i VK i VK j VK i EK j EK i K K K K K K K K j i EK j EK i EK j EK i EK j EK j j EK i EK i i j i m m K K g K K K g K m K g K m V ( ) ( ) ( ) ) , (
If these two readings are the same, the aggregator just needs to send either Ei(mi) or Ej(mj) to
the remote server. If these two readings are different, the aggregator then sends Ei(mi)||Ej(mj) to
the remote server. Since remote server is pre-installed with the verification key VK i
K , the remote server therefore can use VK
i K to obtain EK i K by: VK i VK i EK i EK i K K K
K ( ) . Then, the original data
i
m can be recovered by: EK i EK i EK i EK i i i m g K K g K K
m ( ( ) ) ( ) . In above case, the aggregator only needs to examine two incoming ciphertexts, but in general cases, the aggregator usually receives more than two incoming ciphertexts. When the aggregator receive n (n>2) incoming ciphertexts (E1,E2,,En), our proposed scheme can be easily extended. First, we group these
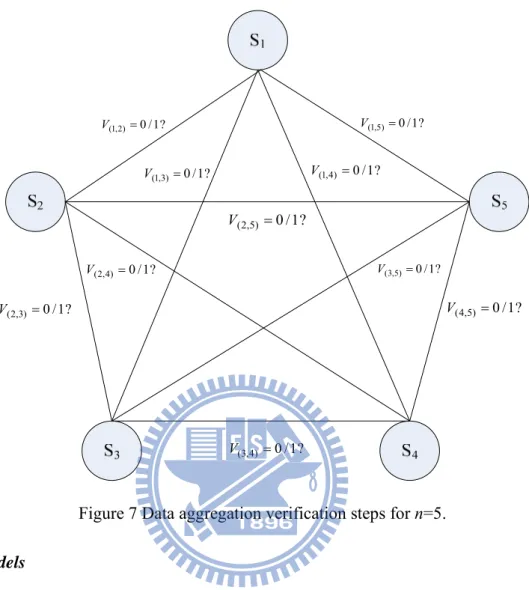
ciphertexts into pairs, i.e. (Ei,Ej)i. Then, we can repeat above steps to generate their check value V. Next, we can use V to check if Ei has the same reading with Ej . Finally, if
) , 1 ( ) 3 , 2 ( ) 2 , 1 ( V Vn n
V , then we can conclude that E1,E2,,En has the same reading. Figure 7
depicts necessary comparisons for data aggregation when n5. It can be observed that these comparisons can be viewed as all edges in a complete graph, and we will discuss this property in next section.
Preliminaries: When the aggregator receives n encrypted readings, the minimum number of
comparisons is n-1 under the condition that all these readings (when unencrypted) are the same. The maximum number of comparisons is
2 ) 1 (n
n when all these readings (when unencrypted)
? 1 / 0 ) 2 , 1 ( V ? 1 / 0 ) 3 , 2 ( V ? 1 / 0 ) 4 , 3 ( V ? 1 / 0 ) 5 , 4 ( V ? 1 / 0 ) 5 , 1 ( V ? 1 / 0 ) 4 , 2 ( V V(3,5)0/1? ? 1 / 0 ) 5 , 2 ( V ? 1 / 0 ) 3 , 1 ( V V(1,4) 0/1?
Figure 7 Data aggregation verification steps for n=5.
Threat Models
The goals of the adversaries are to read, insert, and even modify sensor readings. We consider several possible threats, classified according to the capabilities of the adversaries.
Known-plaintext Attacks.
To implement known-plaintext attacks, no capabilities are need except the ability to deploy malicious sensors close to legitimate sensors. In this scenario, an adversary can
Collect all readings from all sensors, calculated aggregated values, know their routing paths, and inject wrong readings or aggregated values to the network.
In practice, known-plaintext attacks can be easily achieved by deploying same sensor very close to legitimate sensors. The goal of these attacks is merely to read readings and to record corresponding responses of a sensor mote.
Chosen-plaintext Attacks.
Adjust the sensors by changing physical conditions, such as temperature or moisture.
Log all plaintext-ciphertext mappings without knowing what the encryption keys are.
In practice, adversaries can take some physical methods to adjust the sensing environment in order to make sensor motes generate false readings the adversaries desired. For example, adversaries can use heaters to raise the temperature to a certain degree, and temperature sensors will send the false temperature readings making the aggregators generate incorrect results.
Man-in-the-middle Attacks.
Read, insert, or modify messages between sensor motes.
Inject false readings or resend logged readings on behalf of legitimate sensor motes to
malfunction data aggregation.
Significantly, we assume that an adversary cannot retrieve encryption keys from a sensor mote by physically compromising it. Otherwise, there will be no security at all.
Security Analysis and Performance Evaluation
In this section, we evaluate our proposed scheme according to two aspects: theoretical and practical. In theoretical aspect, we use random oracle model to justify our protocol is secure in terms of provable security. We firstly built an ideal random oracle model and show that our proposed encryption algorithm is an implementation of the ideal random oracle. Then, we use the
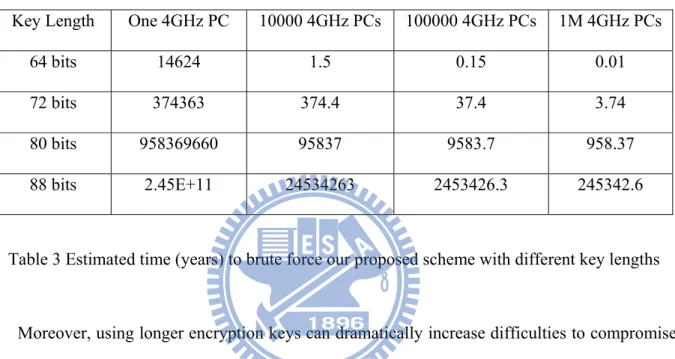
random oracle model to justify that it can resist know-ciphertext attacks. In practical aspect, we estimate necessary time for compromising our proposed scheme using different key lengths. The result shows that using encryption keys longer than 80 bits would be considerable secure enough even if the adversary uses 1,000,000 4GHz PCs running simultaneously to compromise our scheme. Then, we show that our proposed scheme can resist known-plaintext attacks, chose-plaintext attacks, and know-ciphertext attacks.
Before we proceed to theoretical proof, we first describe the security requirement specifying the adversary’s abilities and when the latter is considered successful. The abilities and disabilities of the adversary include:
The adversary has an arbitrary polynomial-time computation power The adversary can eavesdrop on messages in the air
The adversary can know the original readings of any sensor The adversary cannot access the encryption keys
An attack is considered to be successful if the adversary can compromise the encryption keys. In terms of system security, we adopt the idea in [16]. A system is considered secure if any adversary with the given abilities has only a negligible probability of success.
A random oracle is a theoretical black box that replies to queries with random response chosen uniformly in its output domain. A methodology for designing a cryptographic protocol can be divided into two steps. In first step, one designs an ideal system in which all participants as well as adversaries have oracle access to a truly random function, and proves the security of the ideal system. In second step, we replace the random oracle by a “good cryptographic hashing function”. We can therefore obtain an implementation of the ideal system in a real-word where random oracles do not exist. This methodology is referred to as the random oracle methodology.
1 ,
0 : the space of finite binary strings
0,1: the space of infinite binary strings
1
, 0 1 , 0 : G : a random generator f : a trapdoor permutation with inverse f1 k: the security parameter
kH: 0,1 0,1 : a random has function
x r
G( ) : the bitwise XOR of x with the first x bits of the output of G(r)
Preliminaries
Definition. A function (k) is negligible if for every c there exists a kc satisfying (k)kc for
every kkc.
Definition. If AP is a probabilistic algorithm, then for any inputs m1,m2, , AP(m1,m2,) is the
probability space which to the sting assigns the probability that AP outputs . For
probabilistic spaces S,T, , Pr[xS;yT;:p(x,y,)] denotes the probability that the
predicate p(x,y,) is true after the execution of the algorithms xS, yT, etc.
Definition. A random oracle R is a map from
0,1 to
0,1 chosen by selecting each bit of )(x
R uniformly for every x.
Without lost of generosity, our proposed scheme can be formulated as the following oracle:
) ( ) ( ) (m m G r f r EG r …Eq(9) Known-Plaintext Security
For known-plaintext attacks, the adversary knows some m , andPr[The attacker successfully guesses ( )]G r can be described as: 1
0 2 1 )] ( [ 1 1 r r r G r
P , when r1 is large enough.
We suggest that r1 88 is adequate and mathematical induction will be given later.
Chosen-Plaintext Security
We adapt the notion of CP-adversary (chosen-plaintext adversary) in [11] to the random oracle model. A CP-adversary A is a pair of non-uniform polynomial algorithms(F,A1), each
with access to an oracle. For an encryption algorithm to be secure, it requires that
) 1 ( 1 0 1 1 0 5 . 0 ] ) , , , ( : ) ( ; 1 , 0 ); ( ) , ( ); 1 ( ) , ( ; 2 [ ] Fails Plaintext -Chosen [ w R b R R k r k b m m E A m E b E F m m D E R P P . Eq(10)Proof: The proof is by contradiction. Let A(F,A1) be an adversary that defeats our protocol.
Often, the adversary gains advantage (k) for some inverse polynomial . We construct an algorithm M(f,d,y) that, when (f,f1,d)(1k); rd(1k);y f(r), manages to compute
) (
1 y
f . It simulates the oracle G and samples (m0,m1)FG(E). If G is asked an r such that
y r
f( ) , then M outputs r and halts; otherwise, the F(E) terminates and M chooses y ||s
for s{0,1}|m0|. Then M simulates ( , , , ) 1 0 1 E m m
AG , watching the oracle queries that
1
A makes to see if there is any oracle query r for which f(r)y. Let Ak be the event that A1 does not ask for
the image of G at r. It satisfies that
] [ ] | succeeds A [ ] [ ] | succeeds A [ ) ( 2 / 1 k Pr AK Pr Ak Pr Ak Pr Ak . Thus, eq. (10) is satisfied.
The chosen-ciphertext attack is defined as: the adversary can adaptively choose ciphertexts and access to the decryption algorithm to get the corresponding plaintexts. Though it is usually occurred in asymmetric cryptographic systems, it can also be happened in our scheme as the adversary can know both ciphertexts and plaintexts (by using same sensors) in the same time. We adapt the definition of [11] and [73] to the random oracle [16] setting. An RS-adversary (“Rackoff-Simon adversary”) A is a pair of non-uniform algorithmsA(F,A1), each with access
to an oracle R and a black box implementation of DR. The algorithm F is used to generate two
messages m0 and m1 such that if A1 is given the encryption , A1 won’t be able to guess well
whether comes m0 or m1. Formally, an encryption scheme is secure against RS-attack if the
following equation is satisfied:
) 1 ( 1 0 , 1 , 1 0 5 . 0 ] ) , , , ( : ) ( ; 1 , 0 ); ( ) , ( ); 1 ( ) , ( ; 2 [ ] Fails Ciphertext -Chosen [ w D R b R D R k r k b m m E A m E b E F m m D E R P P R R Eq(11)Proof: To see our scheme is secure against chosen ciphertext attacks, we prove the above
equation is satisfied. Let Ak denotes the event that abF(E), for some a and b. Let A(F,A1)
be an RS-adversary that succeeds with probability ( ) 2 1
k
for some non-negligible function (k).
The adversary A can make some oracle call of G(r1) or H(G(r1)). Let Lk denotes the event that
1
A asked DG,H some queries where am f1(r1)H(f1(r1)), but A1 never asked its H-oracle
for H(f1(r1)). Let n(k) denotes the total number of oracle queries made. It is easy to see that
k k n k L
Pr[ ] ( )2 and Pr[A succeedsLK AK]0.5 according to [11].
Thus ( ) 2 1 succeeds] Attack Cipher -Choosen [ succeeds] A [ P k Pr r is bounded above by
2 1 ] [ 2 ) ( ] [ ] | succeeds A [ ] [ ] | succeeds A [ ] [ ] succeeds A [ k r k k k r k k r k k r k k r k r K r A P k n A L P A L P A L P A L P L P L P .
Therefore, our proposed scheme satisfies eq. (11), and is chosen-ciphertext-attack resistant. In practice aspect, we evaluate the difficulties to brute force our proposed scheme. To brute force our proposed scheme, first the adversary need to spend time generating all possible keys and test the result with every possible key. We assume that the adversary can generate an encryption key and test the result in one duty cycle, our proposed scheme uses -bit keys to encrypt data, and the adversary uses a G-Hz PC to brute force our propose scheme. To completely test all possibilities by exhaustive search, the adversary would need to spend
365 86400 000 , 000 , 10 ) ( 2 cycles
years to compromise our scheme.
Assume the adversary uses a 4G-Hz PC to brute force our scheme which uses a 64-bit encryption key, the adversary needs to generate all 264 keys and uses these keys to test the result.
If we assume that the adversary can test our encryption scheme within one duty cycle, the total computation time to test all 264 keys is:
624 , 14 365 / 86400 / 4 / 264 G years.
However, the adversary can use more PCs simultaneously to compromise our algorithm. If the adversary uses 1,000,000 PCs running simultaneously to compromise our scheme, the total computation time to test all conditions is
01 . 0 1 / 365 / 86400 / 4 / 264 G M year.
In this case, it takes about 3~4 days to compromise our scheme which is unacceptably insecure. Table 3 lists estimated time to brute force our proposed scheme with different key lengths. To maintain acceptable security while using minimal key length, we suggest use 80-bit keys to encrypt data as the adversaries need about 958 years to compromise our scheme even if they use 1,000,000 PCs to attack our scheme in parallel.
Key Length One 4GHz PC 10000 4GHz PCs 100000 4GHz PCs 1M 4GHz PCs 64 bits 14624 1.5 0.15 0.01 72 bits 374363 374.4 37.4 3.74 80 bits 958369660 95837 9583.7 958.37 88 bits 2.45E+11 24534263 2453426.3 245342.6 Table 3 Estimated time (years) to brute force our proposed scheme with different key lengths
Moreover, using longer encryption keys can dramatically increase difficulties to compromise our scheme as it exponentially expend the key space which makes adversaries spend more time to brute force the proposed scheme. Figure 8 illustrate the growth rate of key size (2) and the
growth rate () of PCs. 0 40 80 120 160 200 240 1 2 3 4 5 6 7 8 9 10 Key size Number of PCs
Assume the adversary know sensor reading m and corresponding ciphertext VK i EK i EK i EK i i i i m m g K K K K
E ( ) ( ) , the adversary can therefore know g(KiEK)KiEK and VK i EK i X K . Without knowing VK i
K in advance, the adversary cannot compromise KiEK .
Furthermore, since the encryption keys will be arbitrarily changed, our scheme can hence resist known-plaintext attacks. Even adversary can generate designate data m to confuse sensor motes, still the adversary cannot learn anything about the encryption keys. Therefore, our scheme can resist know-ciphertext attacks and chosen-ciphertext attacks.
One workload we have to pay is the number of comparisons it takes to verify encrypted-data from n motes. Our proposed scheme can reduce the number of comparisons as it has transitive property. The transitive property is described as: Given Eh(mh), Ei(mi) , andEj(mj), if V(h,i) 0
and V(i,j) 0, then V(h,j) 0. This is pretty simple to prove. If V(h,i) 0 and V(i,j) 0, then mh mi
and mimj It can therefore be easily seen that mhmi mj.
With this transitive property, if all readings are the same, the minimum number comparisons for verifying data from n sensor motes is n1. And, according to figure 7, the maximum number
comparisons for verifying data from n sensor motes is equal to the number of edges in a n-complete graph which is
2 ) 1 (n
n . It is shown in Figure 9 that our computation bound is limited
0 5 10 15 20 25 30 35 40 45 50 1 2 3 4 5 6 7 8 9 10 n(n-1)/2 n-1
Figure 9 The number of comparisons for verifying n encrypted-data.
In comparison with other schemes, our encryption algorithm uses XOR and a hash function. Our encryption algorithm is more lightweight. Our proposed encryption algorithm changes its encryption key whenever there’s a reading that needs to be transmitted. This makes our scheme more feasible for wireless sensor networks. Table 4 lists the differences between our scheme and other schemes.
Our proposed scheme Flooding-base Scheme Privacy homomorphism-based
scheme
Encryption Lightweight Heavyweight Heavyweight Encryption Key Easy to change, and
always changes
Only one encryption key, and is hard to
change
Only one encryption key, and is hard to
change Decryption (in aggregator) NO YES YES Aggregated Result
Only one data Many redundant data Only one data Table 4 Performance evaluations compared with other schemes