行政院國家科學委員會專題研究計畫 成果報告
數位典藏國家型科技計畫-聯合目錄系統建置計畫
計畫類別: 個別型計畫 計畫編號: NSC92-2422-H-004-012- 執行期間: 92 年 01 月 01 日至 92 年 12 月 31 日 執行單位: 國立政治大學圖書資訊與檔案學研究所 計畫主持人: 楊美華 計畫參與人員: 王梅玲 報告類型: 完整報告 處理方式: 本計畫可公開查詢中 華 民 國 93 年 2 月 13 日
國家數位典藏聯合目錄系統建置計畫
摘要
數位典藏國家型計畫是政府提倡知識經濟之後,開始重視國內數位內容建置的重大施 政。目前數位典藏國家型計畫參與的單位有中央研究院、國立臺灣大學、國家圖書館、國 立故宮博物院、國立自然科學博物館、國立歷史博物館、國史館、國史館臺灣文獻館、文 化建設委員會等單位及數十個學術團體。 欲分享各單位所建置的數位資源,聯合目錄的建置是當務之急;如何透過 metadata 將全文、影像、聲音、視訊等數位物件展現出來,亦同等重要。OAI 詮釋資料擷取協定(Open Archives Initiative Protocol for Metadata Harvesting),於 2001 年 1 月,由開放性資料庫發展 協會(Open Archives Initiative,OAI)發展,提供一個簡單的自動、批次、分散擷取不同 機構資料庫之詮釋資料、及建立集中式聯合目錄的解決方案。 本研究主要目的在: 1. 研討數位圖書館聯合目錄相關理論、技術之研究趨勢,互通性理論、架構與系統 個案之研討。 2. 分析國內數位典藏單位互通性架構與系統需求,探討其系統建置之可行性及效益 評估。 3. 建構符合 OAI 規範之數位典藏聯合目錄系統,本計畫預定建構符合 OAI 規範及 國內環境所需之Service provider 及 Data Provider,並以此為基礎,使之成為數位 典藏計畫聯合目錄之建置機制。透過metadata 之檢索,除能提昇中文資料的國際 能見度外,更能增加我國與國際交流合作之機會。 4. 探討數位檔案命名原則,及分析管理 metadata 與數位資源連結之機制。 本研究報告分:緒論、文獻探討、聯合目錄系統需求分析與規劃、共通欄位與DC XML DTD 格式研究、聯合目錄系統設計與資料測試、聯合目錄工作小組網站建置及結論等七大 部份。最後建議在聯合目錄系統之規劃及管理方面,應該有一個統籌負責的單位,全盤規 劃,積極推動,不應只停留在研究測試階段。在資料之交換方面應加強中央研究院後設資 料工作小組、系統開發資訊人員、主題計畫、與聯合目錄小組四方面作業之共識,尤其是 有關後設資料欄位意涵之規劃,並應考量後續加入計畫之擴充性及整合性。 【關鍵字】:國家數位典藏聯合目錄、OAI、數位檔案命名原則、詮釋資料The Design and Implementation of Union Catalog of
National Digital Archives Program
Abstract
The “National digital Archives Program” (NDAP) was launched on January 1st, 2002. This program, sponsored by the National Science Council (NSC) of the R.O.C. is to promote and coordinate content digitalization and preservation at leading museums, archives, universities, research institutes, and other content holders in Taiwan. There were nine participating institutions, including the Academia Historica, the Academia Sinica, the Council for Cultural Affairs, the National Museum of Natural Science, the National Palace Museum, National Taiwan University and the Taiwan Historica.
In order to share the digital resources built by the NDAP, the construction of a union catalog is urgently needed. For the designing of the union catalog of digital libraries, the efficient mechanism of harvesting metadata, and the digital objects naming principle and the persistent connection method between metadata and the digital objects need to be considered. In this research, the functions and the system architecture of the OAI-based union catalog will be surveyed and defined. The reason why the OAI (Open Archives Initiative) protocol was chosen as the mechanism to create the Union Catalog of National Digital Archives Program will be explained. Finally the implementation of the union catalog with those standards will be demonstrated.
【Keywords】:National Digital Archives Program、Open Archives Initiative (OAI)、Metadata、 Union Catalog
目次
第一章、緒論...1 第一節、問題陳述... 1 第二節、研究目的... 2 第三節、研究方法與步驟... 4 第四節、預期工作成果與效益... 7 第二章、文獻探討...9 第一節、數位圖書館、博物館的合作... 9 第二節、聯合目錄的建置模式... 13 第三節、OAI 協定與技術... 16 第四節、數位圖書館聯合目錄系統... 24 第三章、聯合目錄系統需求分析與規劃 ...53 第一節、國家數位典藏計畫概說... 53 第二節、數位典藏聯合目錄系統規劃... 59 第四章、共通欄位與 DC XML DTD 格式研究 ...78 第一節、數位典藏計畫後設資料共通欄位分析... 78 第二節、DC XML DTD 格式與資料匯入 ... 107 第五章、聯合目錄系統設計與資料測試 ... 111 第一節、聯合目錄系統原型設計... 111 第二節、聯合目錄系統原型資料測試... 123 第六章、聯合目錄工作小組網站建置 ...174 第一節、網站簡介與架構... 174 第二節、軟硬體設備與網站功能... 180 第三節、網站內容... 181第七章、結論與建議 ...189
第一節、結論... 189
第二節、問題探討... 190
第三節、建議... 193
圖表目次
圖1-1 數位典藏國家型科技計畫圖示... 2 圖1-2 確立數位典藏聯合目錄系統之分工與協調... 5 圖2-1 OAI 系統簡易架構圖... 18 圖2-2 COLORADO 網站... 25 圖2-3 CDP 建檔工作站 ... 26 圖2-4 主題名詞查詢... 27 圖2-5 名稱查詢樣本... 27 圖2-6 CDP 檢索模式畫面 ... 28 圖2-7 CDP Advanced 檢索畫面... 28圖2-8 Moffat Tunnel Search... 29
圖2-9 Moffat Display Record... 29
圖2-10 Moffat Tunnel Website Link ... 30
圖2-11 PANDORA 網站... 31 圖2-12 PANDORA 計畫關係示意圖... 33 圖2-13 PANDORA 簡易查詢... 35 圖2-14 PANDORA 進階查詢... 36 圖2-15 PANDORA 檢索結果... 36 圖2-16 PANDORA 檢索結果... 37 圖2-17 American Memory 網站 ... 39 圖2-18 AMICO 網站... 46 圖3-1 數位典藏的應用前景... 54 圖3-2 內容發展分項計畫架構圖... 55 圖3-3 整體系統架構... 60
圖5-1 OAI 基本架構... 112 圖5-2 OAI-based 聯合目錄系統架構 ... 112 圖5-3 主要功能架構圖... 113 圖5-4 數位典藏聯合目錄系統... 114 圖5-5 數位典藏聯合目錄服務系統檢索示意圖... 114 圖5-6 數位典藏資料匯入聯合目錄系統示意圖... 115 圖5-7 數位典藏聯合目錄資料匯入典藏資料提供者類別圖... 116 圖5-8 數位典藏聯合目錄資料匯入典藏資料提供者順序圖... 116 圖5-9 OAICAT 讀取後設資料之類別架構圖 ... 117 圖5-10 數位典藏聯合目錄系統主畫面... 118 圖5-11 數位典藏聯合目錄系統「考古」類瀏覽畫面... 119 圖5-12 數位典藏聯合目錄系統「書畫」類瀏覽畫面... 119 圖5-13 數位典藏聯合目錄系統「檔案」類瀏覽畫面... 120 圖5-14 數位典藏聯合目錄系統「植物」類瀏覽畫面... 120 圖5-15 數位典藏聯合目錄典藏品詳細內容瀏覽畫面... 121 圖5-16 數位典藏聯合目錄連結至漢簡機構資料庫瀏覽畫面... 121 圖5-17 數位典藏聯合目錄全文檢索畫面... 122 圖5-18 數位典藏聯合目錄Dublin Core 檢索畫面 ... 122 圖6-1 國家數位典藏聯合目錄工作小組網站架構圖... 174 表1-1 現有Dublin Core 標準比對數位典藏計畫一覽表 ... 3 表2-1 OAI-PMH 指令說明... 20 表2-2 各類型開放式典藏資料互通協定之比較... 24 表2-3 CDP 檢索欄位必備及選擇要件之比較 ... 26 表2-4 Pandora 數位文獻典藏量統計表... 31
表2-5 各資料類型之可檢索欄位彙整表... 37
表2-6 PANDORA 提供的分類瀏覽項次... 38
表2-7 Digital Object Metadata ... 41
表2-8 Data Element Metadata for Digital Object... 41
表2-9 國會圖書館數位典藏發展詮釋資料之核心要件... 42
表6-1 機構分類一覽表... 175
表6-2 十二主題分類一覽表... 177
第一章、緒論
第一節、問題陳述
我國於民國91 年開始推動「數位典藏國家型科技計畫」,計畫辦公室下設五個分項計 畫:內容發展、技術研發、應用服務、訓練推廣及辦公室維運分項計畫,負責計畫辦公室 相關業務的推動(其詳如圖1-1)。該計畫旨在將文化建設委員會、自然科學博物館、故宮 博物院、國史館、國家圖書館、國立臺灣大學、國史館台灣文獻館、國立歷史博物館及中 央研究院等九個機構珍貴的重要文物典藏加以數位化,建立國家數位典藏,以保存文化資 產、建構公共資訊系統,促使精緻文化普及、資訊科技與人文融合,並推動產業與經濟發 展。(註1) 依據各機構計畫數位產出內容,設有 12 個主題小組,包括:動物、植物、地質、人 類學、檔案、地圖與遙測影像、金石拓片、善本古籍、考古、器物、書畫與新聞等。本「國 家數位典藏聯合目錄建置計畫」係屬內容發展分項計劃,計畫時間為91 年至 94 年規劃與 執行。 網際網路的普及,使得我們可以便利的查尋遠端資源,全球蔚為風潮的數位化計畫, 更使我們得以從網路上取得更多有價值的數位內容。然而,一個個異質且分散的資訊系 統,對使用者而言,有其優缺點,如果沒有很好的機制,將分散各地的異質系統加以整合, 則使用者將需要個別去連結並使用其不同的檢索功能;除非有一個好的聯合目錄,否則可 能各機構辛苦建立的資訊系統,將不易被人得知。再好的數位典藏資訊,缺乏聯合目錄收 錄,也難被檢索與利用。 聯合目錄除了提供整合檢索的便利外,對數位典藏國家型計畫而言,它更是展現計畫 成效的最佳工具,由聯合目錄,可以得知數位化之現況,而各種主題、類型、地區、時期 及單位的資料可以被排比、查檢,無論對學習者、研究者、加值者而言,都是便利的工具, 更使得數位內容的價值有加乘的效果。OAI(Open Archives Initiative,簡稱OAI)是由Paul Ginsparg, Rick Luce, Herbert Van de Sompel等人,在 1999 年 10 月於Santa Fe的Universal Preprint Service會議中所促成的。有鑒 於各資料庫系統,彼此互不隸屬,相關資料分散而難以統整,使得資料的流通有所限制, 該會議之與會代表認為有必要對於學術性電子期刊之預刊本及相關數位典藏,發展出一套 可以互通(interoperability)的標準架構,因此成立開放典藏計畫(註2)。並於 2001 年 1 月, 發表了名為Open Archives Initiative Protocol for Metadata Harvesting(簡稱為OAI- PMH)的 網路通訊協定,提供在異質性資料庫間互通搜尋一個可行的解決方案。
計畫辦公室 內容發展分項計畫 技術研發分項計畫 應用服務分項計畫 訓 練 推廣分項計畫 辦公室維運分項計畫 機構計畫 中央研究院 文化建設委員會 國立自然科學博物館 國立故宮博物院 國立臺灣大學 國立歷史博物館 國史館 國史館臺灣文獻館 國家圖書館 協調、支援與訓練機制 ◎ 內容發展:12個主題小組 (動物、植物、地圖與遙測 影像、書畫、器物、金石拓 片、善本古籍、考古、人類 學、地質、檔案、新聞) ◎ 技術規範:6個工作群 (數位典藏管理系統參考 平台、命名系統與分散式檢 索、數位物件與檔案格式、 多媒體與數位化參考程 序、數位典藏服務系統、多 語言處理) 公開徵選計畫 內容發展、技術研 發、應用加值三類 公開徵選計畫 圖1-1 數位典藏國家型科技計畫圖示
第二節、研究目的
聯合目錄系統將匯集國家型科技計畫各機構數位典藏成果,提供使用者在此一資訊系 統下進行查檢,並找到與取用數位典藏資訊。開放典藏計畫(Open Archives Initiative,簡稱 OAI)是介面建置的一種技術,其功能 是負責擷取後設資料(metadata)記錄,由於其目標是為了發展及提高互通性的操作標準, 以便內容資料有效的分享與交換,故近年來大量應用在數位圖書館資料交流的應用,廣受
歡迎。在歐美等地,已有許多機構與研究單位著手進行OAI 等互通性架構之研究與實際系
1. 透過文獻閱讀、與個案研討的方式,研究數位圖書館聯合目錄相關理論、技術 之研究趨勢,互通性理論、架構與系統個案之研討。
2. 國內數位典藏單位互通性架構與系統需求分析與其系統建置之可行性及效益評 估。
3. 建構符合 OAI 規範之數位典藏聯合目錄系統,本計畫預定建構符合 OAI 規範及 國內環境所需之Service provider 及 Data Provider,並以此為基礎,使之成為數 位典藏計畫聯合目錄之建置機制。透過metadata 之檢索,除能提昇中文資料的 國際能見度外,更能增加我國與國際交流合作之機會。
4. 探討數位檔案命名原則,及分析管理 metadata 與數位資源連結之機制。
『國家數位典藏聯合目錄建置計畫』預計2 至 3 年完成,本(92)年度以完成聯合目
錄系統原型(prototype)為目標,初期以中央研究院與故宮博物院二機構已有 Dublin Core 標準比對的數位典藏計畫為主要規劃與測試對象。(其詳如表1-1) 表1-1 現有 Dublin Core 標準比對數位典藏計畫一覽表 單位 主題 主題計畫名稱 DC mapping 中研院 金石拓片 拓片與古書數位典藏計畫(漢簡) V 金石拓片 拓片與古書數位典藏計畫(佛教造像) V 金石拓片 拓片與古書數位典藏計畫(青銅器) V 考古 考古發掘標本、照片、記錄與檔案數位典計畫 -- 人類學 台灣原住民數位典藏計畫 -- 人類學 台灣南島語數位典藏計畫 V 檔案 近代外交經濟重要檔案數位典藏計畫 V 檔案 內閣大庫檔案著錄格式、權威檔建立 V 善本古籍 善本圖籍數位典藏計畫 V 動物 台灣動物相典藏之研究:魚類 V 動物 台灣動物相典藏之研究:貝類 -- 植物 台灣本土植物數位典藏計畫 V 故宮 器物 故宮器物數位典藏子計畫 V 書畫 故宮書畫數位典藏子計畫 V
技術方面由中研院何建明副所長工作團隊,依本工作小組與後設小組提出的聯合目錄 資訊系統需求設計,以OAI 方式建置。本工作小組將提分類架構與編碼需求書,後設小組 將提出Dublin Core 標準比對的核心欄位的 XML DTD 格式需求書。本小組、後設小組、與 技術小組合作設計聯合目錄系統原型。 本(92)年度聯合目錄小組工作目標如下: 1. 訂定聯合目錄分類架構:由本小組協同主題小組共同訂定聯合目錄的分類架構。 2. 由後設工作小組確認中央研究院與故宮博物院二機構已有 Dublin Core 標準比對的 數位典藏計畫,並將訂定比對Dublin Core 的 XML DTD,與主題小組溝通確認後, 將比對Dublin Core 的 XML DTD 需求送技術研發組設計檢索功能。 3. 訂定聯合目錄系統分類架構需求書:本小組訂定聯合目錄系統需求書,交由技術 研發組開發系統。 4. 協助系統測試:由中研院與故宮博物院與主題小組提供資料測試,由聯合目錄小 組、主題小組、技術研發組、後設小組共同測試系統,並對未來全體資料輸入工 作程序與問題提出建議。
第三節、研究方法與步驟
一、研究方法
本計畫採用之方法包括: 1. 文獻分析法:蒐集國內外有關 OAI、數位圖書館聯合目錄等相關技術、計畫與系 統之文獻加以研讀分析。 2. 研討、座談與訪談:藉由研討與座談了解學者專家及典藏單位之問題與想法。 3. 系統設計:分析系統需求以提供技術小組針對國内數位典藏環境進行系統設計。二、進行步驟
1. 成立數位典藏聯合目錄工作團隊進行系統分析,由聯合目錄小組、後設小組、內 容主題小組、技術分項小組、相關學者專家等組成。 2. 後設資料小組研究中研院與故宮博物院已有 Dublin Core 標準比對的數位典藏計 畫,並將訂定比對Dublin Core 的 XML DTD 格式,與主題小組溝通確認後,將比 對Dublin Core 的 XML DTD 需求送技術研發組設計檢索功能。3. 本小組研究與訂定聯合目錄分類架構與編碼,參考主題小組的 metadata 與 Dublin Core 標準比對的欄位。
4. 本小組、後設資料小組與主題小組溝通確認 Dublin Core 對照欄位,以及分類架構 與編碼。
5. 視建置聯合目錄之需要,邀請相關典藏單位與學者專家召開會議,探討數位典藏 環境中之OAI service provider、service provider 的角色及系統架構、功能與需求。 6. 後設資料小組將 Dublin Core 標準對照的 XML DTD 需求書,聯合目錄小組將分類
架構與編碼需求書交由技術小組建置OAI 協定的聯合目錄系統原型。
7. 各典藏單位系統與 OAI data provider 的整合。
8. 設計完 OAI 原型系統後,進行系統測試,整合 OAI data provider 端之系統及各單 位之資訊系統,並做必要之修改。 9. 聯合目錄系統網頁設計與維護。 10. 撰寫本年度研究成果報告。
三、執行團隊
1. 執行團隊成員:聯合目錄小組、內容發展分項計畫及各主題小組、技術研發分項 計畫、後設資料工作組,分工如下圖。 數位典藏 聯合目錄系統 聯合目錄小組 後設資料小組 內容分項小組 技術服務分項小組 圖1-2 確立數位典藏聯合目錄系統之分工與協調2. 本聯合目錄小組團隊: 主持人:楊美華 教授 共同主持人:王梅玲副教授 協同主持人:林呈潢館長 研究人員:曾秋香組長、王麗蕉小姐、黃邦欣小姐、郭麗芳小姐 專任助理:黃慧娟、陳澤榮 3. 內容發展分項計畫黃銘崇共同主持人負責聯合目錄協調業務,協助聯合目錄小組 與各主題小組溝通。
四、工作時程
第 1 月 第 2 月 第 3 月 第 4 月 第 5 月 第 6 月 第 7 月 第 8 月 第 9 月 第 10 月 第 11 月 第 12 月 研讀相關文獻,蒐集數位典藏metadata 資料 購買電腦、建立數位典藏計畫的伺服器 成立數位典藏聯合目錄工作團隊 聯合目錄系統網頁設計與維護 研究與訂定聯合目錄分類架構與編碼 與MAAT 進行檔案、人類學、動物、植物後設資 料核心欄位分析,Dublin Core 對照研究 後設資料與內容小組確認XML DTD 與檔案、人類學、動物、植物單位確認聯合目錄 分類架構 提出聯合目錄系統分類架構需求書 技術小組建置聯合目錄系統原型 各典藏單位系統與OAI 資料提供者的整合 請參與測試之典藏單位,整合OAI 資料提供者端 之系統及各單位之資訊系統,並做必要之修改 撰寫計畫報告 進度累計% 5 10 15 20 25 30 50 60 70 80 90 100 月 次 工 作 項 目第四節、預期工作成果與效益
本計畫預計獲得下列研究成果與效益: 1. 數位典藏建立互通性架構與系統之探討分析; 2. 數位典藏聯合目錄系統設計與開發; 3. 數位典藏國家型計畫聯合目錄系統架設與測試; 4. 提出未來聯合目錄系統資料輸入程序與建議。
註釋
1 謝清俊,數位典藏國家型科技計畫簡介(2003)(台北:數位典藏國家型科技計畫,2003 年),頁4。
2 Herbert Van de Sompel and Carl Lagoze, “The Santa Fe Convention of the Open Archives Initiative.” D-Lib Magazine 6 (Feb. 2000). WWW=
Hhttp://www.dlib.org/dlib/february00/vandesompel-oai/02vandesompel-oai.htmlH, 2004-01-01
第二章、文獻探討
第一節、數位圖書館、博物館的合作
(註1)一、數位圖書館的合作
1997 年美國國會圖書館和 Ameritech 建立合作的機制,將不同圖書館的特殊館藏相結合, 並投入「美國記憶」研究計畫(American Memory Project,網址:http://memory.loc.gov),從1997
年至1999 年,這個計畫參單與成員大多是圖書館,但仍有少數的博物館加入這項計畫。隨著
計畫和指南的建立,這些合作計畫的館藏可以透過國會圖書館的網站連結,進行檢索運用。 有超過七百萬件的數位物件從原來僅屬於各圖書館或其他合作單位的館藏,進而能讓全世界 來利用。
美國科學基金會的數位圖書館先導計畫(National Science Foundation’s Digital Library Initiative,網址:http://dli2.nsf.gov)提供數百萬美元進行數位圖書館研究計畫,NSF所進行的 計畫在探就文字與媒體的數位化及展示,而早期計畫中研究的是數位圖書館的互通性及資訊 在網路環境中的檢索情形。1990 年代晚期,NSF引進「數學、工程、科技教育數位圖書館先 導 計 畫 」( National Science Mathematics, Engineering and Technology Education <SMETE>Digital Library,或稱NSDL,網址:http://www.smete.org/nsdl/projects/index.html)的構
想。NSDL建置在一個分散式的網路環境,支援各教育層級有關高品質館藏的利用,以追求卓
越。
有些NSDL的數位圖書館計劃有特定主題,如:The National Biology Digital Library (http://www.inquiry.uiuc.edu/partners/nbdl/nbdl.php3、http://cecssrvl.rnet.missiouri.edu/NSDL Project/index.html)或Digital Library for Earth System Education(DLESE,網址:http://www.dlese. org/)。其他NSF的數位圖書館計畫牽涉到與各個圖書館、或圖書資訊學系所計畫合作,如 Indiana University project for digital music(網址:http://www.dml.indiana.edu/index.html)。
數 位 圖 書 館 聯 盟 ( Digital Library Federation , 簡 稱 DLF , 網 址 : http://www.diglib.org/dlfhomepage.htm)亦自 1996 年開始推動各項合作研究計畫,如:密西根 (Michigan)美國康乃爾(Cornell)大學合作進行的”Making of American”計劃(網址: http://moa.umdl.umich.edu/)主要將1850-1870 年代的資料公開化。這個計畫說明一個成功的模 式,可以利用掃描的方式將文件透過識別的方式呈現,並且可以進行全文檢索原文的資訊。 目前The Making of American的網站可以提供 10,912 冊和 3,166,450 網頁資料的利用。而Duke University Perkins 圖書館、Columbia University 善本和原稿圖書館(Rare Book and Manuscript Library、柏克萊大學(University of California) 的Bancroft圖書館共同合作創造”Digital Scriptorium”(網址:http://sunsite.berkeley.edu/Scriptorium/)。
書館」(California Digital Library,簡稱CDL,網址:http://www.cdlib.org/)、肯德基虛擬圖書 館(Kentucky Virtual Library,網址:http://www.kyvl.org/)以及維及尼亞州的學術圖書館聯盟 ( The Virginia Academic Library Consortia , 簡 稱 VIVA , 網 址 : http://www.viva.lib.va.us/viva/collect/image.html)。這些數位圖書館計劃,包括線上資料庫取 用、圖書館線上目錄、檢索網路資源的路徑以及數位化內容。大部分計畫設計是為了讓大眾 與K-12 社群增加取用這些資源。其中CDL是 10 所加州大學分校的圖書館在 1997 年所設立 的,主要是提供各分校的資源給其他的分校使用。另外;「加州線上檔案」(Online Archive of California,簡稱OAC,網址:http://www.oac.cdlib.org)主要是從加州的 9 所大學的館藏建立 一個資料庫。在1998 年時,CDL開始了第一個計畫Japanese American Relation Digital Archive (簡稱JARDA)。JARDA提供一個優質典藏,館員和系統館員共同努力,不僅是發展數位館 藏,而且能提供遠端使用者找出資料。
二、數位博物館的合作
博物館過去沒有像圖書館社群一樣的合作傳統。過去的10 年中,博物館才開始建立合作
的關係。1997 年有超過 20 個主要的藝術博物館共同建立「博物館影像聯盟」AMICO(The Art Museum Image Consortium)計劃(網址:http://www.amico.org/),其主要的工作是將作品數位
化以便於教育的使用。AMICO計畫網站所呈現的館藏量計有:超過 11,000 件以上的繪畫;超 過4,000 件以上的雕刻品;超過 9,000 幅以上的圖畫;超過 11,000 件以上的印刷品;超過 23,000 以上的張照片;超過1,000 件以上的紡織品;超過 1,000 件以上的服飾珠寶;超過 4,500 件以 上的裝置藝術作品;超過500 本書和手稿。「博物館資訊互通聯盟」(Consortia for the Computer Interchange of Museum Information,簡稱CIMI,網址:http://www.cimi.org/)是一個國際性的
博物館組織,在1990 年建立,目的創造出一個合作的環境,並對於博物館運作標準和科技相 關研究進行探究。在科技的活動範圍中發展、提倡博物館標準。 博物館有鑒於圖書館已經大量的參與圖書館間的合作,分享彼此的館藏,因此博物館也 開始了資源的分享。例如,展覽品的外借、提供研究以及和歐美國家館藏目錄資料的提供。 然而,在網際網路的時代,環境已經改變了,從世界上的任何一個地方,每一天每一個小時, 網際網路都能建立我們文化遺產,從網際網路中獲得資訊,同時更創造了一個增加競爭力的 環境。下列是博物館間合作計劃:
1. ArtConnectEd(網址:http://www.artsmia.org/aboutace.html):由Walker Art Museum和 Minneapolis Institute of Arts分享線上資源和高科技網站展示。該網站重點放在教師課程
計畫和課程指南、線上藝術作品和線上活動。並運用數位導覽和3D展示進行分享。
2. Odyssey Online(網址:http://carlos.emory.edu/ODYSSEY/):一個三方合作共同支持一 個博物館教育展覽的發展。這個展示是關於非洲的多元化與豐富性,讓兒童與教師同 樣著迷,參與的單位有Michael C. Carlos Museum at Emory University、Memorial Art Gallery at the University of Rochester和Dallas Museum of Art。
:是西方文化遺產中心和黃石遺產共同經營發展一個數位化旅程。這個網站包含黃石 流域的文字、圖表、聲音、課程指南和建議課程。
三、數位圖書館與博物館的合作
(一) Colorado 數位計劃Colorado數位計劃(Colorado Digitization Project,簡稱CDP)是博物館與圖書館服務 研究機構(Institute of Museum and Library Services,簡稱IMLS,網址:http://www.imls.gov/) 所支援的計劃中最複雜的一個,合作的內涵包括計劃的發展、管理和建立等層面。CDP 有五個地區性的掃描中心,圖書館或地區性的系統主機也有各自的掃描中心。CDP在數 位化的架構陳述一個合作的模式,使能夠在小型和大型的文化遺產機構都可以獲得相同 的資源去進行數位化,而不用額外投入在訓練、軟體、掃描硬體以及資料庫、或者使用 者面上。在CDP的範圍之內,有一些圖書館、博物館進行合作,證明了就算是小型機構 也可以成功的一同工作,而這些大型、小型機構共有四種類型包括圖書館、博物館、檔 案館和歷史協會。 1998 年,CDP開始時有 15 個Colorado計畫在進行中,有 8 個計畫是建置在圖書館基 礎下,其他則是博物館或歷史協會。在這裡有大量的資訊取用,包含利用Web進入當地 發展的資料庫,收集MARC紀錄,連結到html目標,以MARC為基準的圖書館和沒有運 用Metadata的數位物件展覽。系統必須去接受資料是透過線上的輸入或批次,而且符合 Z39.50 , 整 合 圖 書 館 目 錄 進 入 Colorado Virtual Library 。 OCLC SiteSearch ( 網 址 : http://www.oclc.org/oclc/menu/site.htm)軟體是可以選擇的,在同時開始線上系統支援 Dublin Core,提供批次和線上的輸入,並符合Z39.50 標準,必須建立顧客資料輸入系統。 CDP夥伴,Colorado Alliance of Research Libraries,建立了資料輸入系統和發展轉換紀錄 為Dublin Core的形式。現在Colorado Digitization Project可以下載紀錄以MARC為基礎的 圖書館系統,取用各類型資料,以及博物館系統。
除了CDP,IMLS 還有其他的博物館/圖書館的數位計畫,包括:
1. “Connecticut History Online”(網址:http://www.lib.uconn.edu/cho/):是由Connecticut Historical Society、Mystic Seaport Museum和Thomas J. Dodd Research Center。這 三個組織建立一個以網站為基礎的Connecticut社區影像紀錄的數位館藏。 2. “Images of the Indian People of the Northern Great Plains” ( 網 址 :
http://www.lib.montana.edu~elainep/imlsabst.html):這個計畫是Rockies博物館與蒙大 拿州州立大學圖書館一同建置的資料庫,主要是與印地安人的文化有關。
3. “Digital Cultural Heritage Community"(網址:http://images.library.uiuc.edu/projects/ DCHC/index.htm):伊利諾州大學與三個當地的博物館和三個小學共同建置一個 模組,並進行測試數位歷史影像電子資料庫。
館系統的26 個圖書館包括:Knox College、Illinois College 、Bradley University 等,主要是在做伊利諾州1818-1918 年間的歷史檔案,將這些檔案數位化,成為 數位圖書館。 (二) 其他大型博物館與圖書館合作 美國有數個州已經開始合作數位化的工作,有所有類型的文化遺產,包括 North Carolina、Missouri、New Mexico、Minnesota 州,是最大且最早開始進行當地文化遺產 的計畫。而最主要的一個計畫是「研究圖書館協會」(Research Libraries Group,RLG) 的「文化資料聯盟」(Culture Material Alliance,CMA)計劃。其主要的工作在進行蒐集大 範圍的文化資料,將全球人類的檔案文件分享,並提供學習與檢索之用。而這些資料來
自於圖書館的特殊館藏、檔案館、歷史協會和其他RLG 成員組織。參與者將貢獻資料給
RLG 系統。這個範圍廣大的系統包含當地發展的 Metadata 系統、MARC、Visual Resources Association Core,EAD 這些紀錄將被 RLG 利用 XML 工具做轉換,成為 RLG 資料模組 使用。
四、國際圖書館或博物館的數位化與合作
英國也重視數位發展,立法機構要求增加政府單位的資訊取用、管理、數位化格式資訊 等。早期最先開始發展的”Arts and Humanities Data Service,AHDS”,是一個國際性的數位管 理中心,是”Joint Information System Committee”,(簡稱JISC,網址:http://ahds.ac.uk/)的計 畫之一。AHDS回應與滿足和數位內容有關的問題,收集、描述、保存電子資源,起因於人 文諸學科的學術研究以及為了讓學者可以容易透過線上目錄查找到資料。
JISC 亦支援另一個計畫,「分散式全國電子資源」(Distributed National Electronic Resource,簡稱 DNER),在確保網路環境資訊的品質。這些資源包含有學術期刊、論文、參 考書、手稿、地圖、音樂樂譜、影像、和其他數位化的資源。
英國的「大學研究圖書館聯盟」(The Consortium of University Research Libraries,簡稱 CURL,網址:http://www.curl.ac.uk)有一個Digital Archive(CEDARS)Project,其目標是針 對策略、方法論及實用的議題等,並提供圖書館在實行數位化保存時的實踐指南。其領導機 構包括有Oxford University、Cambridge University和University of Leeds以及其他CURL和非 CURL組織。英國數位圖書館另設立的UKOLN(UK Office for Library Networking),是一個國 際性的數位管理中心。它對圖書館和文化遺產機構提供服務。UKOLN對於文化遺產社群建立 了大範圍的服務,包括科技標準和線上檢索。
博物館和圖書館合作的模式有些計劃必需包含二種不同類型的文化組織,有些計劃則 否。Brooklyn Expedition 是由 Brooklyn Children’s Museum、Brooklyn Library、Brooklyn Museum
合組的計劃,該計劃網站形塑成Brooklyn 地區教育服務和發展模式,每一個參與計劃的單位
合作時也常出現組織文化障礙,博物館與社會文化機構都希望能與圖書館及檔案合作。 因為圖書館有與不同類型單位合作的豐富經驗,重視開放性資訊取用限制,資訊的取用是沒 有特權的,並有館藏政策的制定。而博物館的館藏大多是唯一性的,並有相當的價值,因此 文物的安全與保存則是博物館專注的議題。 Metadata標準的一致性關係著文化遺產館藏的取用,但這有著潛在的衝突。圖書館社群 有一個固定目錄標準傳統,並能描述資料和轉換以及檢索資料。檔案館社群的標準是與保存、 保護資源有關,近來支持一個標準,也就是Encoded Archival Description(簡稱EAD,網址: http://www.loc.gov/ead/)。標準在博物館社群內是不同的,例如藝術博物館標準,與一個歷史 博物館或者動物博物館而言,在描述的使用上是接近但不同的。每一個單位都有自己的標準 和自動化系統,因此決定採用哪一個標準支援合作的機制和相互工作,使不同的系統間能正 常的運作是高難度的挑戰。 從1990 年中期起,數位圖書館社群有了新的發展,少數複雜的標準可以描述數位資源, 包 含 數 位 物 件 , 而 當 中 最 為 人 所 知 的 即 是 Dublin Core ( 簡 稱 DC , 網 址 : http://dublincore.org/index.shtml)。Dublin Core的發展者包含從圖書館社群、電腦科學家、出 版業者、和學者。因為有著廣大社群的共同發展,且有許多組織認可,其已經正式通過,包 含CIMI,對於博物館社群發展了特別的Dublin Core。許多州包括North Carolina、Minnesota 和Colorado都發展的屬於自己的Dublin Core。不像MARC或者Dublin Core的項目描述或館藏, Encoded Archival Description(EAD)反應歷史關係館藏內部的展現。Text Encoding Initiative (簡稱TEI,網址:http://www.tei-c.org/)是一個SGML文件類型定義,利用數碼化的文件內 容和創造來傳達描述的資源。組織描述政府數位文件使用「政府資訊定位標準(Government Information Locator Standard,簡稱GILS)」。當不同類型的機構合作數位化,它可以快速且控 制大量的字彙,並提供不同資訊的呈現。 許多人希望藉著WWW解決這個領域複雜的Metadata標準問題。不同的網站檢索引擎工作 不同,而且結果也是多變的。因為網路的便利性許多搜索引擎提供各種不同的檢索。網際網 路社群的遠見是建立分散式網路系統。只有少數的商業系統支援Dublin Core或EAD甚至有一 些有Z39.50 的機能,來處理這些新的閘道。目前為了讓Metadata可以利用,有些透過Z39.50 來支援。Z39.50 是一個國際閘道支援相互網站間的檢索。有一些問題與使用不同系統有關連, 就是運用一個標準到達另一個系統去。美國國會圖書館就發展了許多這樣的管道,資訊透過 這 些 管 道 可 以 在 圖 書 館 網 站 中 被 利 用 。( 網 址 :http://www.loc.gov/marc/marc2dc.html 或 http://lcweb.loc.gov/ead/lag/agappb.html)
第二節、聯合目錄的建置模式
(註2) 聯合目錄的建置模式主要有兩種,一種為實體聯合目錄,又稱為集中式聯合目錄;另一 種為虛擬聯合目錄,又稱為分散式聯合目錄。所謂實體聯合目錄是指在聯合目錄伺服器上已 建好索引檔,使用者查尋時乃查尋此索引檔,系統告知使用者找到多少符合查尋條件的資料,再由此索引檔連到實際的網站,如蒐尋引擎,或呼叫出書目記錄,如圖書館界的書目中心。 虛擬聯合目錄則指未在伺服器建立實際的索引檔,只是透過檢索介面將使用者的查尋問句送 到各資料庫,並將查尋結果匯整後顯示在螢幕上。例如以Z39.50 協定所建立的查尋介面,就 是這種做法。這兩種聯合目錄各有優缺點,以下即分別說明其類型與特色。
一、集中式的聯合目錄
(註3) (一) 集中式聯合目錄之類型 集中式的聯合目錄可分為:由人工建立詮釋資料之集中式聯合目錄,及由系統自動 蒐尋抓取資料並做全文索引的集中式索引伺服器。前者又可分為:商業性的聯合目錄、 非商業性的聯合目錄、共用式的聯合目錄,後者則以蒐尋引擎為代表。 (二) 集中式聯合目錄之特性 集中式的聯合目錄,具有下列特性。 1. 查尋與索引的一致性 (1) 這類聯合目錄的資料,雖由不同的單位上載而來,但由於已透過標準軟體處 理,集中儲存在聯合目錄中,所以實際在查尋時只針對一個資料庫查尋,因 此查尋功能及索引方式都是一致的。 (2) 不過由於各館的編目原則並不完全一致,因此送到聯合目錄的資料也無法完 全一致,所以各聯合目錄系統都會處理資料品質控制問題。 (3) 這類聯合目錄的查尋與檢索技術乃以資訊檢索技術為基礎,也可以根據資料 的屬性或統計屬性來排序檢索結果。 2. 記錄的整合 (1) 各聯合目錄系統對資料的整合處理,詳盡情況不盡相同,如OCLC有很多計 畫在做記錄的整合,不過他們的整合,主要在刪除重複,並保留一筆正確的 記錄,而不紀錄各館編目的差異。 (2) 要花很多時間在整合上,對於每一筆新輸入的資料都一欄一欄的與既存的記 錄做比較,當發現有不一致的情形時,系統會一欄欄的紀錄及保存不一致之 處,以致載入速度很慢。 (3) 對集中式的聯合目錄而言,高品質的整合目標是可以達到的。 3. 系統效能及管理 (1) 集中式聯合目錄在管理大量資料的技術已相當成熟,但與一般終端使用者之 間的互動,經驗尚淺。(2) 集中式的聯合目錄有很好的系統效益評估工具,如對於系統反應時間及系統 的使用情況的掌握相當完整。 (3) 若要加入一個新的合作單位,所需成本不高。
二、分散式的聯合目錄
(註4) (一) 分散式聯合目錄之類型 分散式的聯合目錄主要可分為以標準協定來建立主從架構的分散式查尋系統,最有 名的就是 Z39.50 系統,及非依標準設計的分散式查尋系統。其中 Z39.50 是廣被圖書館 界及電子圖書館界/博物館界接受的標準。非依據標準而設計的分散式查尋系統,其查 尋介面需要能轉換查尋問句到各個不同的系統,當異質系統不多時、或只檢索同一種資 訊組織模式時還可以應付,但若要跨不同資訊組織模式、不同國界做檢索,困難度較大。 (二) 分散式聯合目錄的特性 分散式聯合目錄最大的優點,是不需花任何的軟硬體成本及人力資源,去建立及維 護實體的聯合目錄。不過就查尋與索引的一致性、記錄的整合、系統的管理與效能而言, 都較集中式的聯合目錄差。茲說明如下: 1. 就查尋與索引的一致性而言 理論上,就功能而言,分散式應可做到和集中式一樣的效果,事實上有兩個問 題: (1) 所有的系統,必需支援最小共通的查尋功能,如果其中一館無法支援切截 (truncate),或索引欄位不同,就會產生不一致的查尋結果。介面設計的 愈複雜,各館也更需正確的支援這些功能,才能執行複雜的查尋動作。 (2) 不同的系統必需用共通的語意設計Z390.50的查尋屬性,以及以一致的方法 處理這些屬性。由於Z39.50並非資料庫的索引標準,因此屬性集也不是依資 料庫的架構來定義。例如很多系統會接受並回覆Z39.50問句的作者與題名查 尋,但在資料庫中,這些系統並不見得用相同的欄位做作者與題名索引,如 有的系統,題名索引包括正題名、副題名、並列題名、其他題名。有的則不 齊全。 2. 從資料整合的角度而言(1) 有些Z39.50 client只用來以相同的介面檢索遠端的系統,而未做多資料庫同 時查尋(broadcasting,或稱廣域查尋),因此沒有整合的問題。即使做整合, 也是根據單一鍵如ISBN等來刪除重複,但大部份的系統都無此功能。 (2) 如果要做到整合,必需將檢索出來的記錄反複查尋各參與的系統;但要做任 何的整合必需由客戶端將送回的資料加以整合(merging),或在伺服端將 資料以相同的方式排序,並不是一件簡單的事。
(3) 從系統效能與管理的角度而言(Performance and Management)分散式系統 的效能往往視client/server之間的網路速度而定。此外,也常受速度慢的伺 服器的影響,因為它必須等所有的伺服器都回覆後,才能顯示查尋結果。所 以有的系統會考慮設定等待時間,因此是否要設定等待時間,以及等待時間 要設多久,是這類系統必需考慮的問題。 (4) 分散式查尋會增加各系統的查尋負擔,因為每一個查詢都會送到各local system處理。 (5) 查尋反應時間比聯合目錄慢很多。 (6) 各系統專屬的查尋系統功能,往往比虛擬聯合目錄還多,但是如果各系統的 資訊組織模式一致,則共通介面所能提供的功能也會和專屬的查尋功能越接 近。 (7) 小系統參與虛擬聯合目錄做分散式查尋,會使得查尋速度更慢。虛擬聯合目 錄的可靠性也是一個問題,因為隨時會有某一台主機當機,或停止提供服務 的情況發生。
第三節、OAI 協定與技術
一、OAI 的定義
數位典藏的最大特色就是擁有豐富的數位資源,而這些數位資源的管理者與擁有者分散 於各個典藏單位,進而造成使用者不易掌握數位物件,因此為了提高使用者的便利及增進數 位物件使用率,各種整合技術逐漸興起。「開放典藏計劃」(Open Archives Initiative,簡稱OAI)近來受到重視,其定義係介面建 置的一種技術,其功能是在負責擷取(harvesting)後設資料(metadata)記錄,凡是任何一 種電子典藏(electronic archive)或數位圖書館(digital library)利用OAI技術建置介面者,皆 可稱為「開放典藏資料提供者」(Open Archives data provider)。(註5)其目標是為了發展及提 高互通性的操作標準,以方便內容資料有效的分享與交換。
構使數位化文件能更容易、更廣泛的傳播。且採用後設資料擷取的方式,能涵蓋各種多媒體 格式、資料型態與內容等,擴展了數位化資料可存取種類的範圍。(2)實作容易:OAI 後設資 料擷取協定在設計時即以「簡單」為原則。利於在極短的時間內架設起OAI 伺服器。(3)具開 放性:任何人都能使用OAI 定義的架構,來建構資料提供或服務提供的伺服器。(4)採用 HTTP 及 XML 之開放性標準:OAI 後設資料擷取協定目前是利用 HTTP 通訊協定作為其基本的通 訊協定,使得OAI 在先天上就已解決了跨平台及相容性等問題,也節省了另行新架構的困難。 同樣的,XML 也漸漸成為全球共同的標準資料格式。由於 HTTP 及 XML 均為開放性的標準, 採用HTTP 及 XML 的組合不僅考慮了相容性的問題,也確保了 OAI 的開放性原則。
二、OAI發展歷史
(註6)OAI 最初是由 Paul Ginsparg、Rick Luce、Herbert Van de Somel 等人,在 1999 年 10 月於 Santa Fe 發起的 University Preprint Service 會議中所促成。OAI 原本是為了增進多樣性電子印 刷出版資料的互通,藉以促進學術交流為目的,同時亦保證資料在未來也可以互通的需求。
雖然OAI 最初是針對學術性電子期刊預印本的互通性而產生,但這與目前數位圖書館等數位
典藏單位所遭遇的問題極為類似,因此OAI 技術自然而然擴展到數位圖書館領域,亦逐漸受
到重視。
2001 年 1 月,OAI 發表 Open Archives Initiative Protocol for Metadata Harvesting,簡稱 OAI-PMH 是為後設資料擷取協定,。OAI-PMH 初期的發展仍為實驗階段,2001 年至 2002 年間分別提出了 OAI-PMH 1.0 版及修訂 1.1 版,目前已發展至 OAI-PMH 2.0 版,並期望向 W3C 申請成為全球的開放型標準。
三、OAI-PMH
OAI-PMH是由「數位圖書館聯盟」(The Digital Library Federation)與「網路資訊聯盟」 (The Coalition for Networked Information)提供支援,該OAI通訊協定的研究工作獲得美國科 學基金會(National Science Foundation Grant No. IIS-9817416 與Defense Advanced Projects Agency Grant No. N66001-98-1-8908)資助。OAI-PMH提供異質性資料庫之間整合搜尋的解決 方案,利用網際網路與後設資料技術,透過資料擷取共通協定,可不受平台、語言、開發程 式等限制,達到互通的目的。(註7)
(一) 相關名詞定義(註8)
1. 資料提供者(Data Provider):
提供其文件內容,並以OAI 作為發佈 metadata 的協定。主要工作在維護一個或 一個以上支援OAI 協定來將其內容以 metadata 發佈的儲存器,如:Web 伺服器。 2. 服務提供者(Service Provider):
的服務。 3. 資料儲存器(Repository): 透過HTTP,接受 OAI 協定所提出存取資料需求的伺服器。 4. 資料集(Set): 非必備功能,為了方便取得所需資料的目的,儲存器內可將不同類別的資料區 分成不同的群組,並以階層式架構表示,以節點(node)作為各分類的區分, 因此每一個節點即稱之為資料集。 5. 資料錄(Record): 一個資料錄是後端伺服器依據OAI 協定,從儲存器內將資料以 XML 編碼傳回 前端的metadata。 (二) OAI-PMH 系統架構
OAI-PMH 系統主要是架構在 Internet 上的應用協定,透過「資料提供者」(Data Provider)與「服務提供者」(Service Provider)機制來抓取 metadata 資料,Service Provider 會定期向各典藏單位的資料庫系統(Data Provider)擷取後設資料,利用命令集方式傳輸 給後端的伺服器程式,並遵循OAI 協定 XML Schema 所規範的 XML 格式傳送資料。
Data Providers 主要的工作在維護倉儲(Repositories),並支援 OAI 協定來揭示倉儲 的內容。Service provider 是向 Data Providers 發出 OAI protocol 請求(Requests)並將得 到的後設資料建構具有附加價值的服務。
OAI Protocol request OAI Protocol Response
Users
Service Provider
Data Provider
Repository
(三) 選擇性擷取功能(註9)
OAI-PMH 提供了選擇性擷取功能,可讓擷取程式將資料庫中的部分子集合擷取出 來,可以過濾不需要的資料集合,擷取方式是利用時間戳記與集合兩個參數進行,兩個 參數可以獨立或者合併使用。OAI-PMH 規範每筆記錄必須要包含時間戳記,藉以表示物 件的更新狀況,例如:新增、刪除、修改的時間。擷取時間戳記時,必須符合UTCdatetime 時間格式(coordinated universal time),如此才能與全球世界各地不同時區同步。資料集 (Set)的功能在於將資料庫中的物件,分類成一個一個子集合,並可以有選擇性的指定 範圍。
(四) 後設資料
1. Dublin Core
OAI 協定的技術體系中,指定了 Dublin Core(簡稱 DC)作爲 Data Providers 支 援提供的後設資料格式。同時支援多種後設資料格式的查詢。Metadata 資料規定必 須支援 DC,是否支援其他後設資料格式由倉儲自行决定,或可以利用 metadata 的 前置詞-prefix 進行標識。關於一般內容的部分後設資料,例如:使用權限等,並不 在協定中做規定與規範。 2. 後設資料傳遞方式 OAI協定的請求使用HTTP中的GET或POST方法。請求傳遞至少一個的參數, 形式如:key=vlaue,多個參數時使用`&’隔開。每個OAI請求都必須包括一個名字 爲verb=‘OAI方法名'的參數。為了確保高度的互通性,OAI協定要求所有的倉儲都 必需支援保留在後設資料的前置詞`oai_dc’,DC後設資料格式的schema可在 http://www.openarchives.org/OAI/dc.xsd找到。 3. 後設資料的 Prefix 和 Schema 當向倉儲發送請求時,使用後設資料的前置詞來標識每一種後設資料的格式, 後設資料字首的命名由無空格的字母數位所組成。後設資料 schema 是一個 XML schema 文件,可以用來對記錄中的後設資料的合法性進行驗證。 利用 ListMetadataFormats 命令請求可以列出一個倉儲支援的所有後設資料格 式。針對請求的回應所包括的各種格式的後設資料前置詞和 schema 的 URL,而這 種XML namespace 的 URI 是可選部分。 在ListRecords和GetRecord請求中,後設資料的前置詞也可以作為參數,指定返 回記錄中包含元資料的格式。返回記錄中的後設資料遵循XML namespace的規範, 因 此 後 設 資 料 部 分 必 須 包 含 一 個 屬 性 `xmlns’ ,取值是這種後設資料 格 式 的 namespace的URL。(註10)
(五) OAI 後設資料擷取協定(Open Archives Metadata Harvesting Protocol)指令 說明 此協定的制訂目的是提供與應用程式獨立的交互運作架構。各種從事於文件內容出 版發行至網路上的社群,能夠藉此互相溝通。其主要目標為:(1)簡化文件內容有效的傳 播。(2)提升電子化文件的存取。(3)擴展存取數位化資料種類的範圍。 OAI 提供六項檢索指令: GetRecord Identify ListIdentifier ListMetadataFormats ListRecords ListSets 每當進行請求時都是按照下列格式,(1)每個小節的標題就是必備的verb參數。(2)請 求中其他的參數,共有三種類型:必備的、可選的、獨占的(除了VERB參數,如果有 這個參數,就一定是唯一的參數)。(3)回應的格式定義是一個XML schema。(4)請求的例 外條件,狀態碼在OAI協定的環境中具有特殊意義,各項指令參數說明如表 2-1。(註11) 表2-1 OAI-PMH 指令說明 請求命令 說明 Verb 參數(必備) 其他參數 例外 GetRecord 取得一個單獨的 記錄/後設資料。 GetRecord identifier:必備參數,是記錄的 唯一識別。metadataPrefix:必 備。 識別字不存在時,回應 內容將沒有record container 部分。 後設資料格式不支援 時,該記錄不能以指定 的後設資料格式回 應,此時回應內容將包 括一個header 但是沒 有metadata container。 Identify 取得關於倉儲的 資訊,包括管理、 標識、組織單位的 專門資訊。 Identify 無 無 ListIdentifiers 要求取得可以由 倉儲中查到記錄 的識別字。 ListIdentifiers until:選擇性參數,日期類 型,指定返回時間戳比until 後的時間老的記錄的識別 字。 from:選擇性參數,日期類 型,指定回應時間戳比until 後的時間新的記錄的識別 字。 set:選擇性參數,setSpec 類型,指定回應特定集中的 當沒有符合條件的記錄 時。
請求命令 說明 Verb 參數(必備) 其他參數 例外 記錄的識別字。 ResumptionToken:獨占參 數,顯示不完整結果列表, 所得到的值是前一個 ListIdentifiers 請求回應的 部分結果中所包含的 resumptionToken。 ListMetadata Formats 查詢倉儲或一筆特定記錄所支援 的後設資料格式。 ListMetadataFormats identifier:選擇性參數,指 定一個記錄的識別字,要求 回應此筆記錄所支援的後 設資料格式。假若沒有這個 參數,回應的將是倉儲支援 的全部後設資料格式,但並 不表示全部的記錄都支援 這些格式。 當識別字指示的記錄不存 在時。 ListRecords 從倉儲中取得記 錄。 ListRecords until:選擇性參數,日期類 型,指定回應時間戳比until 後的時間舊的記錄。 from:選擇性參數,日期類 型,指定回應時間戳比until 後的時間新的記錄。 set:選擇性參數,setSpec 類型,指定回應特定集中的 記錄。 ResumptionToken:獨占參 數,指示不完整記錄列表, 取值是前一個ListRecords 請求回應的部分記錄列表 中所包含的 resumptionToken MetadataPrefix:必備參數, 回應記錄中後設資料必須 是前置詞所指定的格式。 當沒有符合的記錄 時。 當符合的記錄不支援 指定的後設資料格式 時。 ListSets 取得倉儲中的資 料集結構(set hierarchy)。 ListSets ResumptionToken:獨占參 數,指示不完整記錄列表, 取值是前一個ListSets 請求 回應的部分集合資訊列表 中所包含的 ResumptionToken。 當倉儲中沒有資料集結構 (set hierarchy)時。
四、OAI 的應用與優缺點
聯合目錄可讓使用者跨資料庫檢索與瀏覽,透過聯合目錄網路介面,可將使用者查詢需 求透過相關技術,擷取到不同單位典藏機構數位物件,有鑑於此,發展出OAI-PMH協定,建 立資料服務提供者來分享所有可辨識的後設資料,並規範資料提供者所應支援的後設資料格 式,開發轉換程式,讓所有後設資料格式能夠對應至規範的,目前被廣為使用的後設資料格 式為Dublin Core,程式開發核心以Java語言為主,系統使用介面則以web-based網介面為主。(註12)
OCLC OAICat是Java Servlet網路應用程式,其支援OAI-PMH v2.0 的網路應用協定架構, 這個架構可以透過JAVA介面程式來處理異質的資料。OAICat也是一個建置工具,並完全支援 OAI-PMH v2.0 協定與物件導向基本功能。OAICat分為兩種檢索模式:(1)oaicat_jar:在伺服 端建置支援OAI-PMH v2.0 的伺服端應用程式。(2)oaicat_war:在OAI-PMH v2.0 應用協定架構 下,利用Java Servlet 2.3 版本引擎檢索。OAICat提供欲使用OAI技術整合一套介面,只要傳送 相關參數至網路應用程式執行,便可快速建置支援OAI整合性系統。(註13) OAI 之理論架構與規範自 2000 年制訂以來,即受到數位圖書館界的重視與討論。OAI 互通性架構之規範有許多優點,分述如下: 1. 提供學術溝通及交流一個新的模式 OAI 架構使數位化文件能更容易、更廣泛的傳播。且採用詮釋資料擷取(metadata harvesting)的方式,能涵蓋各種多媒體格式、資料型態與內容等,擴展了數位化資 料可存取種類的範圍。 2. 實作容易 OAI 詮釋資料擷取協定在設計時即以「簡單」為原則。 3. 具開放性(open) 任何人都能使用OAI 定義的架構,來建構資料提供或服務提供的伺服器。 4. 採用HTTP及XML之開放性標準 OAI詮釋資料擷取協定目前是利用HTTP通訊協定作為其基本的通訊協定。其優點在 於現今所有的網頁伺服器及瀏覽程式等,幾乎毫無例外的支援HTTP。這使得OAI在 先天上就已解決了跨平台及相容性等問題,也節省了另行新架構的困難。同樣的, XML也漸漸成為全球共同的標準資料格式。由於HTTP及XML均為開放性的標準,採 用HTTP及XML的組合不僅考慮了相容性的問題,也確保了OAI的開放性原則。 (註 14) 除此之外,OAI-PMH 在應用上也有一些容易使人誤解的迷思如下: 1. OAI-PMH 發 佈 和 獲 取 的 物 件 , 並 不 包 含 如 文 件 、 影 像 、 聲 音 等 全 文 資 料 (Full-content)。OAI-PMH 只是一個用來交換 metadata 的協定,其餘文件格式、內 容均需透過其他程式應用技術輔助,並不在此協定範圍內。不過 OAI 承諾此協定將 會提供全文資料的交換能力,至少在最新發表的2.0 版本,仍未有此方面的協定規範。 2. OAI-PMH 不是提供兩個檔案系統之間資料交換的協定,而是明確的將兩者之間切割 成資料提供者(發佈metadata 的實體)和服務提供者(獲取元資料並提供前端使用者 加值服務的實體)。當前後端明確地分為資料提供者與服務提供者這兩個實體,並不 是每一個加入OAI-MPH 服務的單位必須只能擇一為之,例如 Cite Base 便是一個既為 資料提供者,也是服務提供者。
夠提供DC作為資料交換的基本格式。但為了考量一些特定領域的應用需求與其metadata格 式,OAI組織並不限制只能使用DC,而且還鼓勵發展特殊的格式以便能提供特殊領域的使用 需求。不僅如此,OAI也在多次會議中宣告支援所有的metadata。(註15)
五、OAI 與其他系統的比較
(一) OAI-PMH與Z39.50 的比較(註16) Z39.50 已經是圖書館系統實現自動化系統間聯盟式的書目資料檢索的開放式檢索協 定,其主要是由「原始系統」(或稱Z39.50 Client)依靠線上即時連結一個以上的「目標 系統」(或稱Z39.50 Server),使用複雜的通訊協定集(protocol set)執行所需的查詢行 為,在逐一取得由目標系統獲得的查詢結果、排序、去除重複,將處理結果呈現出來。 而近年來數位產業與metadata 廣泛的應用,OAI-PMH 也廣泛地應用在許多數位典藏資料 分享、獲取或是聯合目錄。本質上,OAI-PMH 與 Z39.50 均能達成聯盟檢索的需求,也 就是使用者能夠透過單一的介面從多個不同DL 取得所需的資訊。透過一次查詢的動作, 便可從許多不同來源獲得結果,讓使用者不需逐一查詢各個DL。 由於下列三項原因,應用Z39.50 協定的分散式檢索系統之間必須考量回應時間、結 果大小、網路頻寬的條件,使Z39.5 被批評非常難建立一個高品質的聯盟檢索服務(註17): 1. 不同的自動化系統對 Z39.50 查詢請求的語意常會有不同的解釋,而導致不正確的 執行結果。 2. 連結多個目標系統時,由於取得的資訊必須線上即時在原始資料內組合整理,導 致嚴重影響系統的效率。 3. 使用者在獲得結果之前,必須等待資料在系統之間傳輸與處理的時間。 因此,就OAI-PMH 與 Z39.50 兩者作一比較,OAI-PMH 以 XML 做為資料處理的依 據,著重在容易建置,並期望解決所有 metadata 的分享問題。服務提供者可以使用 OAI-PMH 事先取得所有後端資料提供者所有的資料,加值或建立索引之後,間接提供前 端使用使用者所需的資訊,達成聯盟檢索的需求。在這種模式之下,OAI-PMH 服務提供 者是建立在資料中介者(Broker)的角色。而 Z39.50 以 MARC 和 Dublin Core 為資料處 理的依據,著重在點對點(peer to peer)的協定服務模式,透過線上即時查詢目標系統 的資訊,然後處理所有遠端回應的資料集之後,再呈現給前端使用者。強調的是即時性 的聯盟檢索服務,中間不存在任何中介者的角色,前端也不強調資料加值的處理與分析。 由前述討論可知,OAI-PMH 與 Z39.50 兩者協定不僅應用目的不相同,使用的方法 也不相同,雖然兩者都可達聯盟檢索服務的需求,但彼此之間都可達成聯盟檢索服務的 需求,但彼此之間卻無法取代彼此。不過一個改良的方式是將 Z39.50 視為一個橋街器 (bridge)或閘道(gateway),除了處理Z39.50 的命令之外,也能處理 OAI-PMH 的命令, 而其中需要增加的處理能力是能支援metadata 綱要,即可結合彼此的優點。(二) 各類型開放式典藏資料互通協定之比較(註18) 余顯強曾為文比較各類型開放式典藏資料互通協定,其詳如下表: 表2-2 各類型開放式典藏資料互通協定之比較 NCSTRL NCSRL+ OAI-PMH Meta Web Search engine
SDLIP GINF Search Light Z39.50
互通型態 聯盟式 獲取式 聚合式 聚合式 聚合式 聚合式 聯盟式 提供多個 DL 之間 同步互通 可 依服務提供 者功能而定 可 不可 不可 可 可 提供同步 檢索 不可 依服務提供 者功能而定 不可 可 不可 不可 可 資料提供 模式 主動式 被動 被動 被動 被動 被動 被動 包含檢索 協定 無 無 有 有 有 有 有 傳輸協定 HTTP HTTP HTTP TCP、 HTTP、 CORBA 物件 TCP、 HTTP HTTP 不限定 Metadata 格式 任何 metadata 均可 XML 格式 的metadata 無 任何 metadata 均可 RDF 無 MARC、 DC 建置成本 資料提供 者:高 資料提供 者:低 資料提供 者:無 資料提供 者:無 資料提 供者:高 資料提 供者:無 資料提供 者:高 服務提供 者 低 中等,視服 務內容而定 高 高 高 高 高 出處:余顯強,「淺談數位圖書館典藏資料互通之存取協定」,書藝39(2003 年 5 月),頁21。
第四節、數位圖書館聯合目錄系統
以下介紹四數位圖書館計畫的聯合目錄系統,包括Colorado Digitization Project’s Heritage database、PANDORA 數位典藏計畫;Library of Congress American Memory 計畫;AMICO 計 畫,分從計畫簡介、Metadata 標準、系統檢索與瀏覽架構探討。
一、Colorado Digitization Project’s Heritage Database
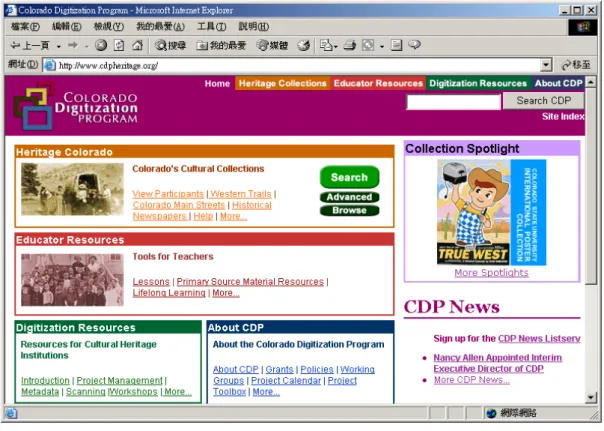
(一) 計畫簡介科 羅 拉 多 州 數 位 化 計 畫 (Colorado Digitization Project , 簡 稱 CDP , 網 址 : http://coloradodigital.coalliance.org)始於 1998 年,是一項由Colorado州的檔案館、歷史學 會、圖書館與博物館合作的數位典藏先導計畫。該計畫建構了一個由metadata紀錄組成的 聯合目錄,發展metadata記錄並編製標題詞(subject term),採用名稱表單(name list)。 CDP計畫也研究藉由WebDewey採用Dewey Decimal Classification分類號,並聯結主題名 詞與高度專門性主題名詞,在聯合目錄提供主題瀏覽功能,可看見這些主題名詞。
圖2-2 COLORAD
(二) metadata 標
1. CDP 聯合目錄採用 Dublin Core/XML metadata 標準。 O 網站
準
2. 採用一系列必備要件,包括:Title、Creator、Subject、Description、Identifier、 Date and Format 等,其詳如表 2-3。
表2-3 CDP 檢索欄位必備及選擇要件之比較
Title Con Creator Subject Description Identifier Date: Digital Format: Creation Format: Use tributor Publisher Relation Type Source Date: Original Language Coverage Rights Managemen
3. 採用標題詞(Subject Term),利用美國國會圖書館標題表(Library of Congress Subject Headings,簡稱 LCSH),這個詞表包括科羅拉多州的地理詞彙和美國國 會的標題詞,不管是簡寫或全稱,使用者可以直接以精確字查詢,或以瀏覽的方 式獲知。
4. 採用姓名稱表單(Name List),包括個人與團體公司。CDP 開始自詞彙表單中, 發展索引典及完整權威控制的概念。後者乃是由州際的名詞權威機構(Name Authority Cooperative,簡稱 NACO)透過合作編目計畫(Program for Cooperative Cataloging)來產生名詞標目及主題標目。
圖2-4 主題名詞查詢
-(三) 系統查詢
提供兩種檢索模式
1. 簡易檢索 Search 模式畫面:提供 title、author、subject headings、keywords 查詢。 圖2 5 名稱查詢樣本
圖2-6 CDP 檢索模式畫面 2. 進階檢索 Advanced S
提供title、author、subject words、De ey number、date、language、project 查詢, 並可用布林邏輯查詢。
earch 模式
w
3. CDP 計畫是用聯合目錄網站與數位影像聯結
圖2-8 Moffat Tunnel Search
(四) 本 分 類 代 碼 :(1) 數 位 典 藏 分 類 ; (2) 館 藏 與 數 位 典 藏 單 位 - participan ion;(4)焦點-Spotlights;(5)地理。 主題瀏覽 ence、 Sports、T
二、PAN O
(一) 計畫 P 全稱為 Preservin a , 網 址 為 http://pan圖2-10 Moffat Tunnel Website Link
瀏覽架構
計 畫 包 括 分 類 與
ts;(3)主題分類-Dewey Decimal Classificat
,包括Agriculture、Arts、Colorado and Western History、People、Social Sci echnology and Engineering 等大類。
D RA 數位典藏計畫
簡介
ANDORA網站是澳洲國家圖書館的網路文件資源保存與取用的網站, g and Accessing Networked Documentary Resources of Australi dora.nla.gov.au/index.html。 自1 儲存、辨 識及保護 成果公布在「潘朵拉(PANDORA)」 拉」集合了多家圖書館與文化機構的資源,並統合至一個「熊貓系統 )」(註20)共同檢索。此外,澳洲國家圖書館持續將焦點放在數位典藏的活 動上,希望進一步了解保存技術演進與其他相關議題。故計畫性地收錄並保存澳洲本土 及世界各國相關的網路資源。目前持續於「帕迪網(PADI)」(註21)進行這項計畫。 996 年以來,澳洲國家圖書館致力於數位化資源的選擇、轉換、編目、 ,並提供線上出版品的檢索。這部分的工作 (註19)上。「潘朵 (PANDAS
為了長期保存數位 套「數位典藏管理系統 (DCM)」(註22)。本系統的原始目的,在長期保存手稿、地圖、圖像等數位典藏品, 示等可能衍生的法律問題。目前系統包括下列的模組:「熊貓系 統」(PANDAS 慧型圖書館管理系統(ILMS)(註23)、圖像經理(Pictorial manager)、 圖像表列( )、手稿查檢工具(Manuscript finding aids)、數位化系統與專 案( )、1845-1950 年間澳洲期刊(Australian Periodicals 1845-1850)、澳洲國家圖書館目錄(NLA Catalogue)(註24)、權限管理系統(Rights Managem 多媒體出版(Multimedia Publications)。
化的物件,澳洲國家圖書館已建置一
並解決圖檔在網路上顯 )、智 Pictorial lists
Digitisation Systems and Projects
ent Systems)、 圖2-11 Pandora網站 Pandora從 1996 年發展至目前包括五千餘種數位典藏資料,截至 2004 年 1 月 26 日, 其館 統計如下 位文獻典藏 藏量 (註25): 表2-4 Pandora 數 量統計表 本月 上個月 本月成長 總典藏種類 5,279 5,160 119 總典藏實例 10,289 9,975 314 總檔案量 18,116,771 17,761,783 354,988 總GB(gigabytes)量 566.559 554.24 12
計 供獲取、典藏、與提供長期
取用。 起internet 出現大澳洲資訊,為了保存澳洲的歷史文化與
提升未 的 些線上出版品永久取用。澳洲國家圖書館開始發展
PAND 來
使用。
館藏收集原則以凡是Internet 公開提供者為對象,而澳洲國家圖書館(National Library
of Au 包括下列類型
資料:
• 雜 其他期刊(Journals, newspapers, newsletters and other e
Substantial reports, papers and speeches) • 年 • 地 • 重 • 公 ac a ents and ex e
• 公 formation for public access)
• 先前以印刷形式出版的任何文件(Any document that would formerly have be b
• 任 N 的文件(Any document eligible for an ISSN, IS
Web sites or parts of web sites, which provide substantial or unique information about a topic, organisation, person of
• 沒有包含在此的其他領域,而圖書館認為具有長期研究價值者(Other
time to time would have long term research value)
PANDOR 畫目標為國家保存而選擇澳洲良好線上出版品,並提 計畫背景係由於1996 年 來 創造力,有必要提供這 ORA 計畫,這是在出版社同意下,提供線上出版品典藏,並永久保存以提供未 stralia)選擇無印刷品的線上出版物,無論是免費或取用收費。主要 誌、報紙、新聞稿及 s rials) • 研討會論文(Conference proceedings) • 重要的報告、文件及講演( 度報告(Annual reports) 圖(Maps)
要文學作品(Substantial literary works)
共說明文件,例如:作為公共評論的環境影響聲明及揭露草案(Public count bility documents, such as environmental impact statem
posur drafts for public comment) 眾取用的資訊資料庫(Databases of in en pu lished in print) 何有ISSN、ISBN 或 ISM BN or ISMN) • 提供某一主題、組織、國內重要人士、計畫或事件之重要或獨特資訊的 網站或其中部份網頁(
national significance, project or event)
categories not included here, which the Library may consider from
圖2-12 PANDORA 計畫關係示意圖 (二) metadata 標準 A、描述 metadata 描述Metadata 資料包括如下: • 題名(Title) • 後題名(Later Title) • 前題名(Previous Title) • 作者(Creator) • 捐贈者(Contributor) • 語言(Language) • 描述(Description)
• 圖書業識別號,如:ISBN、ISSN、DOI(Book Industry Identifier, e.g., ISBN, ISSN,
• 圖書館業識別號,如:ABN RID(Library Industry Identifier, e.g., ABN RID) • • Pandora PURL • • • • 存在日(Life Date) • 頻率(Frequency) • 主題關鍵字(Subject K • 資源種類(Resource Type B、數位典藏 metadata(preservation metadata)
PANDORA 研訂數位典藏 metadata, 包括三層 Collection Object File DOI) 出版者的全球資源定位器(Publisher's PURL/URL) 商標(Label) 索書號(Call Number) 出版日(Date Of Publication) eyword) )
包括25 要件如下:
1. 永久識別碼 – 種類及識別碼(Persistent Identifier - type and identifier) 2. 產生日(Date of Creation)
3. 結構種類(Structural Type)
4. 複雜物件的技術基礎架構(Technical Infrastructure of Complex Object)
5. 檔案描述 – 5.1 影像、5.2 聲音、5.3 影音、5.4 文本、5.5 資料庫(File Description – 5.1 Image, 5.2 Audio, 5.3 Video, 5.4 Text, 5.5 Database)
6. 已知系統需求(Known System Requirements) 7. 安裝要求(Installation Requirements)
8. 儲存資訊(Storage Information) 9. 取用管控員(Access Inhibitors)
10. 搜尋輔助及取用輔助器(Finding and Searching Aids, and Access Facilitators) 11. 維護行動許可(Preservation Action Permission)
12. 認證(Validation) 13. 關聯(Relationships) 14. 突然的變化(Quirks)
15. 檔案決策(作品)(Archiving Decision(work)) 16. 決策理由(作品)(D
17. 檔案決策(作品)之責任制度(Institution Responsible for Archiving Decision (work))
18. 檔案決策(表現形式)(Archiving Decision(manifestation))
19. 決策理由(表現形式) n))
20. 檔案決策(表現形式)之責任制度(Institution Responsible for Archiving Decision (manifestation))
(Intention Type)
22. 維護責任制度 Institution with preservation responsibility) 23. 過程(Pro
23.1
23.2 負責過程之機構名稱(Name of the Agency Responsible for the Process) 過程中所使用的關鍵硬體(Critical Hardware Used in the Process)
23.4 過程中 軟體 re U )
23.5 過程如 ow Pr ied O
23.6 執行過程的指導方針(Gu ecified to Process) 23.7 日期及 and tim 23.8 結果( 23.9 過程原 ess R 變化( 23.11 其他(Other) 記錄產生者(Record Creator) Other C 理metadata(Administrative metadata) DORA 提供館藏管理者儲存有關典藏的管理 metadata, 括: ecision Reason(work)) (Decision Reason(manifestatio 21. 目的類別 ( cess) 過程描述(Description of Process) 23.3
所使用的關鍵 (Critical Softwa sed in the Process 何被執行(H ocess was Carr ut)
idelines Sp Implement 時間(Date Result) e) 理闡述(Proc ationale) 23.10 Changes) 24. 25. 其他( ) 、行政管 PAN 包