Department of Psychology, Chinese University of Hong Kong, Shatin, NT, Hong Kong
ing Zhu
Peking University, Beijing, China
ei-tun
National Taiwan University, Taipei, Taiwan
Received October 12, 1990, final revision accepted August 12, 1991
Abstract
Liu, L-m., Zhu, Y., and Wu, I.-t., 1992. The long-term modality effect: In search of differences in processing logographs and alphabetic words. Cognition, 43. 31-66.
The visual superiority effect (a reverse long-term modality effect) has been consis- tently found with Chinese logographs. For its exrPA?ration in terms of script differences. it has been believed that lexical access 1s mo:-e direct or quicker for Chinese logographs than for alphabetic words. It has also been believed that Chinese logographs are more unique in shape or more discriminable than al- phabetic words. Finally, Chinese logographs have been considered to facilitate recall through their graphic features that classify Chinese words into categories. The results of Experiments l-5 show that these three assumptions can be ruled out. The results of Experiments 6-10, on the other hand, support the long-term priming interpretation of the visual super-ii: c: 2.1, c:“rje:.+~: which explains (a) why the visual superiority effect can be consistently (ibtainr:d for recall of Chinese words by Corresponderc ;,I; I.-M. Liu, Departa.._ ‘drt of Psychology, Chinese University of Hong Kong,
Shatin, NT, Hong Kong.
*This study was supported by a grant from the Centrt for Hong Kong Studies, Chinese University of Hong Kong, and a grant from Hong Kong UPGC. We thank two anonymous reviewers for many helpful comments on early drafts. Requests for reprints should be sent to In-mao Liu, Department of Psychology, Chinese University of Hong Kong, Shatin, NT, Hong Kong.
32 h-m70 Lilt et al.
Chinese subjects, (b) why the effect cannot be consistently obtained for recall of
English words by stern subjects, (c) why the effect can be also obtained for recall of English words by Chinese subjects, (d) why ct can be easily obtained for recall of a set of words, but not for recall of a rent set of words by Chinese subjects, and (e) why the eHect can easily obtained fro
subjects speaking a dialect that is different from andarin.
The modality effect refers to the typical finding in i recall that the last few items in the list are better re auditory rath than visual (
Crowder & orton, 1969;
long-term modality effect will be used in this paper to refer to the visual superiority over the other modality obtained for pre-recency it
respect, the long-term modality effect found with recency items by Gardiner and Gregg (1979) and Glenberg (1984) using a special paradigm will not be consid- ered. There are three accounts of the long-term modality e t as follows: (a) the temporal distinctiveness, (b) the differential script, and (c) long-term priming (differential frequency).
Temporal distinctiveness interpretation
As Penney (1989b) remarked, up to the late 197Qs, there was no evidence for consistent modality effects in either long-term memory tasks or in the non-recency
of the serial position curve in short-term memory tasks. For example, no ality effects were found for non-recency items in the study by Engle and bley (1976). It is only more recently that Conway and Gathercole (1987; Gathercole & Conway, 1988) have reported the auditory superiority effect in a long-term recognition memory task. In their studies, auditory memory advantage was present throughout list positions. They invoked the concept of temporal distinctiveness proposed by Gardiner (1983) and elaborated by Glenberg (1984; Glenberg & Swanson, 1986) for explaining their results as follows. The temporal distinctiveness account assumes that the memory trace preserves temporal infor- mation about the time of presentation more accurately for auditory than for visual presentation. They reasoned that the recognition test cues the subject to particu- lar parts of the list, and that the finer grained representation of acoustic information ensures better recognition than the wider grained representation of visual information.
Long-term modality effect 33
elayed recognition tests visual presentation of items produced better per- ante than did auditory. The finding of a visual superiority in delayed free 1 and recognition provides strong evidence against the temporal distinctive-
cross-language view of the long-term modality effect was first proposed by cGinnies (1965). In his study of persuasion through printed versus spoken communication, he found that Japanese subjects were more apt to be persuaded inted than by spoken messages, contrary to findings frequently obtained with
rn subjects (Hovland, 1954; Klapper, 1961). Since Japanese script includes Chinese characters, McGinnies reasoned that the visual superiority effect in persuasion may be due to script differences. Subsequently, Turnage and McGin- nies (1973) had their American and Chinese subjects study a list of 15 words in a serial-learning paradigm. The input modality of the stimulus presentation was manipulated. Their major finding was that Chinese subjects learned the list of two-character words faster when it was presented visually, whereas American subjects learned the list of words faster when it was presented auditorily. Their explanation of this difference was that the Chinese script system contains more characters with similar sounds but different meanings than is the case for English. A problem with Turnage and McGinnies’ interpretation is that their conclusion was not based on the results obtained by manipulating sound similarity.
Fang (1982) presented a list of nine items (either Chinese characters or two-character words) visually or auditorily at a speed of 1.5 s per item to a group of 19 Chinese subj :cts. Their recall results showed that more primacy items were recalled in the visual than in the auditory presentation mode. Fang’s interpreta- tion of her findings was the same as that of Turnage and McGinnies (1973); that is, the Chinese script system contains more characters with similar sounds, although in her experiments she avoided using different characters with similar sounds and similar meanings.
Although experimental detaris were not reported, Tzeng and Wang (1983) obtained a similar finding. In their study their subjects recalled lists of nine Chinese characters according to their position in the series. They also found that their Chinese subjects recalled the beginning items in the series consistently better when the lists were presented visually than auditorily. No such memorial superiority of visually presented items was obtained from their English subjects. Recently, Hue, Fang, and Hsu (1990) replicated Tzeng and Wang’s findings that the visual superiority effect is quite robust when to-be-recalled items are Chinese logographs.
Assuming that the script difference is responsible for the long-term modality effect, there are several views that attempt to account for the visual presentation
superiority obtained with Chinese logographs: direct-image hypothesis, dis- criminability hypothesis, and graphic-feature hypothesis. L?t us consider each hypothesis in turn.
Direct-image hypothesis
This is a widespread view that Chinese logo hs map more directly onto meaning than alphabetic words (e.g., Aaronson
Wang (1973) reads as follows: “To a Chinese the horse with no mediation through the sound ma. The
almost sense an abstract figure galloping across the page.” This passage has been frequently cited to support theories (e.g., Biederman & Tsao, 1979) without receiving rigorous experimental tests.
If Chinese logographs directly give rise to images or are more like pictures, then the visual presentation superiority of Chinese logographs follows, because the superiority of pictures to words in free recall and recognition is a well- documented result (see a review in Crowder, 1976). A developmental study (Hochberg & Brooks, 1962) also showed that pictures are not linguistic devices but rather accurate depictions of reality, and can be recognized without mediation as well as the objects themselves are recognized.
Thecretically, if Chinese logographs directly give rise to images, they will be coded both verbally and imaginally according to Paivio’s dual coding theory (1971, 1986). For those who propose the direct- e hypothesis, an assumption has to be made. That is, they have to assume alphabetic words are coded verbally and, to a lesser extent, imagi ly. Thus, an added image trace is assumed to result in better memory for inese logographs than for alphabetic words, if they are presented visually.
Why does an added image trace result in better memory? The dual coding eory assumes that the image system is specialized for processing spatial and synchronous information whereas the verbal system is specialized for sequential processing. That dually coded items are remembered better than unitarily coded items follows simply from the additivity of independent verbal and image components of a memory trace (e.g., Paivio, 1986). Experiments 1 and 2 were designed to test the direct-image hypothesis.
In the following, instead of using the term “verbal” a more unambiynous term “phonological” will be used, because Paivio considered “visual words” as verbal. Therefore, any memory traces with visuo-spatial features will be considered as being visually coded and any memory traces with sound features as phonologically coded. With this terminology, the direct-image hypothesis explains the visual presentation superiority of logographs by assuming that, in addition to phonologi- cal traces, logographs leave traces of object images directly, whereas alphabetic words do not, or only indirectly (referentially, according to Paivio, 1971), leave
Long-term modality effect 35
traces of object images. Of course, an added image trace is the source of the visual superiority effect.
Discriminability hypothesis
According to the discriminability hypothesis, as in the direct-image hypothesis the visual presentation superiority of logographs is explained by their visual traces. However, these visual traces represent character shapes. Logographs do not necessarily give rise directly to object images. Since logographs and alphabetic words leave both phonological and visual traces in this case, the visual superiority effect of logographs is now explained by logographs being more unique and distinctive than alphabetic words, when they are presented visually. This interpre- tation is also prevalent (e.g., Tzeng & Hung, 1988). In the input stage, if Chinese characters leave unique traces via their unique shapes, then they would be much easier to retrieve at the time of testing. Experiment 3 was designed to test the widely held hypothesis that Chinese characters are visually mcie unique or discriminable than English words.
Graphic-feature hypothesis
The third hypothesis also attributes the visual presentation superiority of logo- graphs to coded visual traces. This interpretation asserts that the obtained long-term modality effect for Chinese characters is primarily due to meaning components being frequently associated with graphical features in Chinese charac- ters. That most Chinese characters contain an explicit meaning-conveying compo- nent called a radical is well known. Contrary to a widely held hypothesis that inter-character distinctiveness is responsible for the visual presentation advantage of Chinese characters, the third hypothesis asserts that inter-character visual relatedness is mainly responsible for it.
Most Chinese words consist of two characters. There are many two-character words with the same second characters to indicate that a set of words belongs to the same category, such as orchid-flower, peach-flower, etc. At the level of characters, the graphic-feature hypothesis asserts that the visual presentation superiority of logographs is explained by an abundance of Chinese words with the same character endings. Experiments 4 and 5 were designed to test the graphic- feature hypothesis by directly manipulating graphic features.
Long-term priming interpretation
A difficulty with the differential script interpretation is that the visual superiority effect can be sometimes obtained with alphabetic words (Penney, 1989b). A plausible interpretation cannot be, therefore, dependent only on modality-depen-
36 In-ma0 Lilr et al.
dent features (Nairne, 1988), nor on the visual or auditory streams ( I989a) alone. It must depend on an operation that can reverse the
effectiveness of visual versus auditory experiences. In ot words, a viable interpretation must be capable of explaining the presence of visual superiority effect in a specifiable condition and its absence in anot
There is considerable evidence that the prior present facilitates its subsequent processing even when the two several hours or days (Scarborough, Cortese, & Scarb Dunn (1985) refer to this facilitatory effect as long- distinguish it from other priming effects that appear to tics and to be confined to much smaller lags. Jacoby a
repetition of a word during study enhances recognition memory an ing the modality of presentation between study a
memory performance. The finding of long-term pri due to rhe lowered threshold of recognition units in 1969) or as due to the recapitulation of previously (Kolers, 1979).
According to this long-term priming interpretatio ether visually presented items are more recallable than auditorily presented materials depends on the differential availabilities of visual versus auditory traces. If some Korean words are more frequently written in Chinese logographs than in ngul, then the visual traces for these Chinese logographs become more av ble than those for Hungul, as was obtained by Park and Arbuckle (I977 f a set of words is encountered more frequently in readings than in speech, n their visual traces will become more available than their auditory traces, giving rise to a memorial superiority of visually presented items over auditorily presented items, as was
innies (1973) from their Chinese subjects but not The long-term priming interpretation assumes that there are two types of frequency: (a) frequency of a verbal item as it appears in print and (b) frequency of a verbal item as it appears in speech. Visual frequency is responsible for the availability of visual traces and auditory frequency for the availability of auditory traces. Whenever there is a large discrepancy between visual and auditory frequencies in favour of the former, the visual presentation superiority will be obtained. It is perhaps because of this reason that availability was found to be an important predictor of recall but that the classically important variable of word frequency was not (Rubin & Friendly, 1986).
The long-term priming interpretation or differential-frequency account has the following implications. First, if a list of English words is presented visually or auditorily to Chinese subjects for free recall, the visual superiority effect will obtain because English is after all a foreign language for Chinese subjects and English words have been experienced more frequently in print than in speech. This implication was tested in Experiments 6 and 7.
Long-term modality effect 37
As for a second implication of the differential-frequency account, it may be noted that some set of Chinese words is experienced more frequently in print than speech while another set of Chinese words is experiencea more frequently in speec than in print. The differential-frequency account, then, predicts that at least a larger visual superiority effect may be obtained from the former set of words than from the latter. Experimenis 8 and 9 were designed for testing this re many different varieties of Chinese kr,own as “dialects” (see, for Thompson, 1981), even though they may be different from one another to the point of being mutually unintelligible. Thus, it is often pointed out, for example, that Cantonese and Mandarin (national language spoken frequently at formal occasions and in schools) differ from each other roughly as the
omance “languages” Portuguese and Romanian do. Now, it is possible to find a group of subjects who speak the same dialect (Mandarin) at home and in school. It is also possible to find another group of subjects who speak Mandarin in school and use their own dialect at home. For the former group, although the auditory frequency will accumulate across school and home situations, it will not for the latter group,, The differential-frequency account predicts that a larger visual superiority effect will be obtained for the latter group than for the former. This prediction vvas tested in Experiment 10.
If Chinese characters are also visual!! encoded to stand for images, how are these images measured? Following Frege ( 1960), the meaning of a word is identified by its sense or connotation and reference or denotation. The denotational meaning of an expression is the thing that it stands for. The connotational meaning of an expression is the content of the expression, and specifies whether the expression has that object as its reference.
The question “what does horse mean?” asks the connotational meaning of a horse. A partial answer would be that a horse is an animal. The connotational meaning of a word is therefore different from associations. For example, black may be an associate to white, but black is not a connotational meaning of white. The strategy of Experiment 1 is then as follows. First, connotational meanings of a set of Chinese characters and their English translations were obtained from a group of subjects. For each Chinese character or its English translation, the response most frequently given by the subjects JS representing its connotational meaning was then selected as the dominant meaning component. Second, each dominant meaning component was presented as a prime in a reaction time task in which another group of subjects was timed for judging whether a Chinese character or English word presented after the prime contains the prime as its
38 In-mto Liic et al.
dominant meaning. If Chinese characters are coded both verbally and ima then the subject should contact images directly for immediate r
English words are coded predominantly verbally, the subject has two routes to find a match or mismatch between the prime and te reaching the dominant meaning component through as
nerating an image indirectly (referentially) fro
Id be much slower for English words than a direct route for C according to the direct-image hypothesis.
In line with the prediction from the direct-image hypothesis, number of studies conducted for comparing semantic classificatio and words latzky. 1977; Guenther, Kl
Pellcgrino, , & Siegel, 1977; Potter &
lker, 1978). This task requires a subject to indicate contains a target feature or in other words, is a given target category. It was generally found that pictures are classi words.
There are two types of Chinese characters: phonograms, which co phonetic component as a clue to the sound of characters, and pictogr are pictographic in origin. The direct-image hypothesis may apply ts more than phonograms. According!y, the direct-image hypothesis wou
that semantic processing should be fastest for Chinese pictograrns, next for Chinese phonograms, and slowest for English words. The reason for using Chinese characters instead of two-character words is simply because characters
Ire units of the Chinese script system. It would be impossible to choose a sufficient number -character words, each consisting of two pictograms or two onograms. ver, many Chinese characters, being morphemes them- selves. can be used as words. Most Chinese characters selected in t
also function as words.
lan of Experiment 1 was then as follows. -4 set of Chinese pictograms and ms was chosen. These pictograms and phonograms were translated mto words. A dominant meaning component of each item was determined by g with a group of sc5jecis. For example, water is considered as a dominant meaning component of river. Then, another group of subjects was tested for
g a semantic decision of whether a Chinese character or English word contained a given dominant meaning component. The preparatory study con- ducted to determine a dominant meaning component for each Chinese character and English word will be described only briefly.
In the preparatory study, 32 characters were chosen from Tung Lai (1978). Iialf the characters were pictograms and half were phonograms. Their English translations are listed in Table 1. Two comparable high school classes were chosen, each having 40 second year students. Hong Kong students Studied English from Primary school. Therefore, their English is on the average much better than
Long-term modality effect 39
le 1. English transiations and their dominant meaning components
Pictogram Phonogram
Dominant Dominant
meaning meaning
Translation component Translation component
BLOOD CAR CLOTHES cow EAR EAST FIELD FIRE FRUIT HAIR MEAT RAIN SHEEP STEP TREE WHITE RED DRIVE KEEP WARM ANIMAL LISTEN DIRECTION PLANT HEAT FOOD BLACK ANIMAL WATER WHITE FOOT LEAVES CLEAN ATTACK BOARD COLD EMPTY FINISH FLOWER NEAR OIL PULL RJVER SHOP SIMILAR SISTER TASTE THING WORD WAR WOOD WEAR CLOTHES NOTHING END BEAUTIFUL SHORT DISTANCE LIQUID FORCE WATER GOODS SAME GIRL SWEET SHAPE WRITE Mean Strokes 5.875 7.625 Mean Frequency 520 614
Nore: Mean strokes and mean frequency refer to Chinese pictograms and phonograms.
that of students from the other Asian countries where English is usually taught from high school. A set of booklets containing the 32 characters in various randomized orders was used for one class of students, and another set of booklets containing the 32 English translations used for another class of students. For each item printed on a separate page of a booklet, the students were allowed 10 s to write down at most three meanings that came to their mind instantaneously. In Table I is shown the dominant meaning component for each English translatiijn.
Experiment 1 attempted to measure how long it takes for the subject to ic;rify whether an item (Chinese or English) contains a dominant meaning component (Chinese or English).
Method
Subjects and materials
The subjects were 20 freshmen enrolled in an introductory psychology course the Chinese University of Hong Kong. They participated in the experiment fulfil a course requirement.
at to
Itr-ttmo Liic et 01.
The stimulus materials were 32 Chinese characters and their E tions. The dominant meaning component for each item was obt preparatory study as was described. The 32 English translations a nant meaning components are presented in Table 1. The classifcati based on the Chinese characters. Thus, the mean num
phonograms was significantly higher than that for the 16
p < .Ol. The mean word frequencies were, however, not significantly differ from each other, ! < 1.
Procedure
The subject was timed for pressing either of two keys to indicate whet item contained a dominant meaning component presented as
the target. A target was either a Chinese character or its Targets were further subdivided into pictograms and p translations. The present design was then a 2 jlangua
of targets) x 2 (pictogram or phonogra within-subjects factorial.
All stimuli were presented by an I1B PC. Chinese characters were generated by a chip manufactured by Kuo Chiao. Reaction times were measured in units of milliseconds. Sixteen practice trials preceded 64 experimental trials. Type of target (Chinese or English) was mixed. For half the subjects, Chinese primer; preceded English primes. The order WYS reversed for the remaining subjects. For each type of prime, a dominant meaning component preceded a target on half the trials (“true” trials). On the remaining trials (“false” trials), meaning components and targets re randomI; re-paired wi a restriction that were not apparently related. alf thz targets were used positive trials, an remaining half used on negative trials.
esults md discussion
The mean reaction time for identifying the presence of a dominant meaning component in a Chinese character or English word is listed in Table 2 for each type of prime and each type of target. An analysis of variance showed that reaction times were faster for English primes than the Chfncse y nrimes (810 vs. 830 ms), F(I, 19) = 4.43, p < .05. Reaction times were not faster to pictograms than to phonograms (814 vs. 825 ms), F < 1. Chinese characters were also not responded tc; faster than English words (817 vs. 822 ms), F < 1. All two-way and three-way interactions were not significant. An analysis of variance performed on the error data showed that more errors were obtained for Chinese primes than for English primes (12.3% vs. 9.5%), F(1,19) = 5.15, p < .05. All other effects were not significant. The data obtained on the negative trials were not specifically
Long-term moddity effect 4 1
le 2. Semantic decision time in milliseconds to a Chinese character or English word Target Prime Chinese English Chinese Pictogram Phonogram 812 (11.6) 838 (10.6) 797 (7.2) 820 (13.1) English (translation) Pictogram Phonogram 826 (11.6) 842 (15.3) 820 (8.4) 801 (9.4) Note- The percentage of errors is indicated within parentheses.
analysed, because the same tendency was obtained. The only difference was that the absolute reaction times on the positive trials were faster than the+: on the negative trials.
The Chinese and English meaning components used as priming stimuli were not identical. Reaction times were faster for English primes perhaps because a fewer number of meaning components were obtained for English words than for Chinese characters from the first group of Chinese subjects in the preparatory study and because the obtained meaning components were more clustered for English words than for Chinese characters. These observations are consistent with the finding that when words are used more frequently they tend to acquire more meanings (Johnson-Laird, 1983; Miller, 1951). For the Chinese subjects, a Chinese word tends to arouse more meanings than its English translation because the former has been used more frequently.
The mean number of strokes was higher for phonograms than for pictograms. I-Iowever, this difference would have only made the subjects recognize pictograms faster than phonograms (Yeh & Liu, 1972). In spite of this difference that favoured pictograms over phonograms on semantic decision time, pictograms were not responded to faster than phonograms. As a whole, the results of Experiment 1 did not support the direct-image hypothesis.
ent 2
Although reaction time measures of Experiment 1 were found to be sensitive enough to detect a minor difference between Chinese and English primes, a rejection of the direct-image hypothesis cannot be made on the basis of no
difference in the semantic decision times. oreover, semantic decision ma be faster for pictures than for words in som cases (e.g., Paivio & te Link te Linde, 1983). Therefore, in Experiment 2 subjects were not only time judging whether Chinese pictograms or phonograms contained some me components but were also timed for judging whether pictures drawn pictograms and phonograms contained the same meaning c
situation, the direct-image hypothesis would predict for pictograms should be as fast as for pictures and t pictograms than for phonograms.
ethod
Subjects and materials
The subjects were 21 fres enrolled in an introductory the Chinese University of Kong. They had not served participated in the experiment for fulfilling a course r
Twelve pictograms and 12 phonograms of Ex represented by pictures were used.
2.5 cm wide by 1.2 cm high on an I C monitor. The size of a picture was slightly larger and spanned a space of about 3-5 cm wide by 2 cm
Design and procedure
The design was a 2 x 2 x 2 within-subjects factorial. T e first factor refers to type of target, a character or picture; the second to source f target, either based on a pictogram or phonogram; and the third to type of response, a match or mismate between a target and a prime. Following 12 practice trials, each subject received 48 experimental, trials. The set of primes and targets used on the practice trials was entirely different from those used on the experimental trials. On each trial, a dominant meaning component was presented as a prime for 2 s. Then, either a target character or picture followed. The subject verified whether the target contained, or was consistent with, the dominant meaning component. Each target was presented only twice: once on a positive trial and once on a negative trial. Positive and negative trials were counterbalanced between subjects, and the order of trials was randomized for each subject. The other procedural details were the same as in Experiment 1.
Results and discussion
The mean reaction times measured from the target onset are listed in Table 3. An analysis of variance showed that reaction rimes were faster to pictures than to
Loqprenn modality effect 43
e 3. Semantic decision time in rni!liseconds to a character or picture
e OF Character __- Picture response True Pictogram Phonogram 757 762 (10.3) (4.7) Pictogram 736 (15.9) Phonogram 714 (7.9) False 854 901 800 826 (7.1) (12.7) (6.3) (7.9)
Note: The percentage of errors is indicated uithin parentheses.
aracters (769 vs. 819 ms), F( 1,20) = 7.22. p < .025. Reaction times were not faster to pictograms than to phonograms (787 vs. 801 ms), F < 1. Positive ses were faster than negative responses (742 vs. 845 ms), F( 1,20) = 13.77, 01. All two-way and three-way interactions were not significant.
A separate analysis of variance performed on the error data showed that each main effect was not significant, F < 1. The source of target by type of response interaction was significant, F( 1,20) = 20.24, p c .OOl. This interaction was ob- tained apparently because pictures for representing some pictograms were poorly drawn owing to a limitation in computer graphics. Similarly, the type of target by type of response interaction was significant, F( 1,20) = 4.X!, p < .05, also indicat- ing that some pictures for representing characters were poorly drawn.
The obtained results present strong evidence that the direct-image hypothesis should be rejected. Chinese pictograms do not give rise to images directly as pictures. In other words, even Chinese pictograms can be coded only indirectly to give rise to images.
If Chinese characters have more unique shapes than English words, then it follows that Chinese characters are more discriminable from one anothlzr than English words. One of the simplest ways to find aut whether such differential discriminability exists between the two languages is to make use of triadic judgments. On each trial a triangular array of three words is presented. The subject’s task is to indicate, by pressing a right or a left key, which of the bottom words, the left one or the right one, is identicsl to the top word. In this kind of triadic judgment, it is a well-known fact that the more similar are two comparison stimuli the slower is the reaction time. If Chinese characters are visually more unique than English words, the subject’s triadic judgments would be faster when any two Chinese characters are used for comparison than when any two English words are used.
An important varidble that affects stimulus discriminability is stimulus com- plexity. Stimulus complexity for English words can be identified as number of letters in a word. Number of letters in an English word is corn arable to number of strokes in a Chinese character, so far as visual stimul
concerned. In Experiment 3, the variable of st:mulus co manipulated to see whether it has comparable effects on the
Method
Subjects and stittx.dus item
The subjects were 26 freshmen enrolled in an introductory psychology course at the Chinese University. Their English might be as nearly good as t
They participated in the experiment to fulfil a course requirement.
It was reasoned that Chinese characters with numbers of strokes from 5 to 6 are comparable to Engiish words with three letters in terms of stimulus complexi- ty (A category). Similarly, numbers of strokes from 7 to 8 are comparable to four letters (B category), and numbers of strokes from 9 to 10 comparable to five letters (C category).
The above reasoning is based on the following observations. When counting the number of “strokes” for each English letter written in the lower case as a Chinese character is counted, it is readily seen that “a” has two strokes, “b” has two strokes, “c” has one stroke, etc. The average number of strokes for an English letter is therefore between 1.5 and 2.0.
One hundred characters/words each of A, I3 and C categories were randomly selected from high-frequency characters (words) (above 50 per million) in Cheng (1982) and Thorndike and Lorge (1944).
es&p
A 3 x 2 within-subjects factorial design was used. The first factor refers to discriminability between two comparison characters/words used for triadic judg- ments. There were three degrees of discriminability: 0, 1,; 2, to indicate the distance between two comparison characters (words) belonging to two categories. If two characters (words) were from the same category, the distance was 0. If two characters (words) were from two adjacent categories, the distance was 1. Finally, if two characters (words) were from categories A and C, then the distance was 2. The second factor refers to language: Chinese or English.
Procedure
Half the subjects were tested with Chinese characlers first and then tested with English words next. The order was reversed for the remaining subjects. For each
tong-term modality effect 45
guage, following 12 practice trials each subject received 72 experimental trials: 24 trials each under each discriminability condition. Depending on which dis- criminability condition a trial was assigned, two characters/words were randomly chosen from categories A, B and C without replacement. On half the trials the right key was correct, and on the other half the left key was correct. The order of trials was block randomized.
Results and discussion
The mean reaction time obtained under each discriminability condition for each language is presented in Table 4. An analysis of variance showed that type of language was not significant (635 for Chinese vs. 632 ms for English), F c 1. Discriminability was a significant source of variance (652, 638 and 611 ms), F(2, 50) = 17.75, p < .OOl. The discriminability by type of language interaction was not significant. It can also be clearly seen from Table 4 that the obtained error rates under various conditions were very low. An analysis of variance performed on the error data showed that no variable was a significant source of variance.
It is a surprise to find that Chinese characters were discriminated from each other no better than English words by the Chinese subjects. The concept of familiarity cannot be invoked to explain the present finding, because it only favours discriminability of a more familiar language (e.g., Ambler & Proctor,
1976; Egeth & Blecker, 1971). This means that Chinese characters should be more discriminable to the Chinese subjects than English words. Furthermore, in view of a small difference in stimulus complexity producing a significant effect in the present experiment, the discriminability hypothesis should be rejected to the effect that Chinese characters are no more discriminable among themselves than English words.
It is possible to check the correctness of the way in equating the compicxity of the Chinese and English stimuli in the light of the obtained results. If more strokes or fewer strokes of a Chinese character have to be equated with an English letter,
Table 4. Discriminability in milliseconds as a function of language and
distance Language Distance 0 1 2 Chinese characters 617 (l-1) English words 656 633 (2.7) (1.6)
Note: The percentage of errors is indicated within parentheses.
605 (1.6)
Itl-ma0 Lilt et al.
then an interaction between category distance and language will be obtained. Since the interaction was not significant, the rationale of equating 1.5-2.
with one English letter may be still justifiable. Even though the interaction had been significant, the present design would have allowed a legitimate corn
between the two languages by inspecting the difference obtained for the case of 0 distance (first column of Table 4).
If it is not true that Chinese characters have more unique shapes than English words, and if it is also not true that Chinese characters are coded directly to give rise to images, then how do we explain the visual presentation advantage found with Chinese characters (Fang, 1982; Turnage & McGinnies, 1973)? A plausible hypothesis is that the obtained visual advantage is primarily due to meaning components being frequently associated with graphical features in Chinese charac- ters. Most Chinese characters contain an explicit meaning-conveying component called a radical. Contrary to a widely held hypothesis that inter-character distinctiveness is responsible for the visual Lsvantage of Chinese characters, the graphic-feature hypothesis claims that it is because many Chinese characters often share the same graphic features.
According to the graphic-feature hypothesis, logographs and alphabetic words will leave visuai as well as phonological traces. It is with the visual traces left by Chinese characters that the latter can be more effectively used for retrieving the encoded characters. Although the visual traces left by alphabetic words are as distinctively different from each other as those left by Chinese characters, the former are not very helpful because spelling is only highly correlated with sound. In other words, the visual traces lzft by alphabetic words do not provide anything more than phonological information.
The plan of Experiment 4 was then as follows. In the radical-blocked condition, a group of subjects studied lists of words with the same radicals presented in blocks in the visual and auditory modes. In the radical-mixed condition, another group of subjects studied lists of words with the same radicals randomly mixed with others in the visual and auditory modes. In the control condition, a further group of subjects studied lists of words with distinct radicals (every radical appeared only once in some words) in the visual and auditory modes.
Method
Subjects and list items
Long-term modality effect 47
ational Taiwan University. They participated in Experiment 4 for fulfilling a course requirement.
It was impossible to find a sufficient number of two-character words with both characters of each word containing the same radicals. Therefore, the only requirement was the first characters of a set of two-character words being composed of the same radical. Four lists of seven sets of two-character words each were selected from a dictionary as follows. Each set consisted of four words with the same radical. All the sets in the four lists had distinct radicals. This means that all selected words were composed of the first characters with 28 different radicals. The four lists (A, B, C and D) were approximately equated for their mean frequency counts (Liu, Chuang, & Wang, 1975). A word was randomly selected from each set of four words with the same radical to obtain four control lists (Cl, C2, C3 and C4), each of which consisted of 28 ivords with distinct radicals.
A 2 X 3 mixed design was used. Modality (visual or auditory) was a within- subjects variable, while list composition (radical-blocked, radical-mixed or radical- distinct) was a between-subjects variable.
The subjects were assigned to three groups in order of signatures, and tested in a small group of five subjects at a time. Presentation of words was controlled by an IBM-compatible PC. In the auditory mode, digitized sounds were used. For the subjects assigned to the radical-blocked group, they studied two radical- blocked lists, one in the visual and another in the auditory mode. In the radical-blocked lists, each list contained seven sets of words. In each set, there were four words which all had the same radical. The words were presented in seven blocks, grouped according to their radicals. The subjects who were assigned to the radical-mixed group also studied two out of the four lists, A, B, C and D: one list in the visual and another in the auditory mode. In the radical-mixed lists, the words were the same as those in the radical-blocked lists, but the 28 words in each list were mixed up and presented in some random order. Finally, the subjects who were assigned to the radical-distinct group studied two out of the four control lists: one in the visual and another in the auditory mode. The control lists (radical-distinct lists) each contained 28 words, and each word had a distinct radical.
The subjects received a short practice list to familiarize themselves with the procedure before studying two assigned lists. The order of receiving visual and auditory lists as well as the choice of two lists for study was counterbalanced between subjects for each group. Immediately after presentation of a list, the subjects engaged in the distractor activity of solving two-digit number addition problems for 20 s before writing down as many words as they could still remember within a 5min period.
Table 5. ean numbers of words cmrec+- recalled as a function of
presentation mode and list composition
Input mode Radical-blocked List composition RadicaLmixed Radical-distinctive Visual 14.1 11.9 10.7 Auditory 11.2 10.0 7.6
Results and discussion
The mean number of words correctly recalled under each input con
group is presented in Table 5. It is clear from the table that recall was higher in the visual than in the auditory mode when words with the same radicals were presented in the blocked or mixed condition. re importantly, recall was also higher in the visual than in the auditory mode n a list consisted of words with distinct radicals. An analysis of variance showed that input mode was a E
source of variance (visual 12.2 vs. auditory 9.6), F( 1,147) = 81.44, p <
composition was also significant (12.7, 11.0 and 9.2), F(2,147) = 18.56, p < ,001. The Scheffe’s S test showed that recall was higher when words with the same radicals were presented in the same lists than when words with distinct radicals were incYuded in the lists (11.9 vs. 9.2), p < .Ol. The interaction between input mode and list composition was not significant, F(2,147) = 1.46, p > .20.
The finding that a list of words with the same radicals was recalled better than a list of words with distinct radicals is easily accounted for in terms of category clustering. A set of words with the same radical often implies that the words are from the same category. However, the finding that recall was higher in the visual than in the auditory mode when radicals were distinct as when radicals were blocked or mixed indicates that the graphic-feature hypothesis cannot explain the results. This is because the graphic-feature hypothesis would predict that the visual presentation advantage should be larger when the words in a list have the same radicals because the shared graphic-features can serve as retrieval cues.
According to the second version of the graphic-feature hypothesis, the visual presentation superiority of Chinese logographs is due mainly to graphic features at the character level.
Long-term modality effect 49
ethod
Subjects and list item-
The subjects were 240 students enrolled at Peking University. They participated in the experiment voluntarily.
Four lists of two-character words were selected from the Liu, Chuang, and Wang (1975) word book as follows. Each list consisted of eight sets of four words each. For one list (Cl), four words in each set had an identical first character. For another list (C2), four words in each set had an identical second character. For still another list (Sl), four words in each set had an identical first syllable but different characters. For the final list (S2), four words in each set had an identical second syllable but different characters. There is a sufficiently large number of words for each list in Chinese. Four control lists (Cn) were obtained by randomly choosing one word from each set in each of the CI, C2, Sl and S2 lists. Each control list, therefore, consisted of 32 two-character words with no two characters nor two sounds in common.
Design and procedwe
The design was a 2 x 5 x 2 factorial. The first factor reft-.rs to modality, and the second to type of list, that is, Cl, C2, Sl, S2 or Cn. These two were between- subjects factors. The last factor was within-subjects, and refers to trial (trial 1 or 2). Excluding the Cn list, the design can be considered as a 2 x 2 x 2 x 2 factorial.
The subjects were randomly assigned to ten groups of 24 subjects each according to the order of appearance in the laboratory, and tested in a subgroup of six subjects at a time. The ten groups will be referred to as Groups Cl-A, Cl-V, C2-A, C2-V, SI-A, Sl-V, S2-A, S2-V, Cn-A and Cn-V. The group notations stand for type of list and input mode (auditory or visual).
In the visuai mode, a list of 32 items was presented at a speed of 2.5 s per word through a computer terminal. A practice list consisting of four words preceded a test list to familiarize the subjects with the procedure. After going through a test list for one trial, eight addition problems were presented at a speed of 3 s per problem before a recall test. The subjects wrote down an answer to each two-digit addition problem within 3 s, and then as many items as they could remember on the same sheet of paper within a 5-min period. The subjects received a second trial in the same way. The order of items within a list was always randomized. In the auditory mode, the same procedure was used except that the list items were presented by a speaker.
Results and discussion
Table 6. ean number of words correctly recalled as n flmction of type of list,
mput mode, and trial Type of list Cl P’) Lr Sl s2 CIl Input mode Visual Auditory
Trial 1 Trial 2 Trial 1 Trial 2
17.50 26.04 17.58 24.92
23.13 29.17 21.21 27.54
13.92 22.29 10.88 18.63
13.46 23.42 13.17
13.83 22.25 12.38 20.17
presented in Table 6. An analysis of variance recalled in the visual than in the auditory i F( 1,230)
= 13.16,
p < .OOl. Type of list was aF&230) = 44.40,
p < ,001. The modahty by ty significant, F < 1, indicating that the modality respect to type of list. Trial was significant (15.71 vs.p < .OOl and interacted with modality (F( 1,230)
(F(4,230)
= 3.86,
~~01).
modality effect became larg
type of list interaction indicates that the diffe the second than on the first trial.
first trial. The trial by
When the data obtained fro were excluded from consi tion, an analysis of variance remaining data from al experimental lists showed that visual presentation super-i y was again obtained (21.12 vs. 19.35), F(l, 184) = 11.72, p < .OOl, that the acter-same condition produced higher recaii than the sound-same Lvndilion (23.39 vs. 17X&$ F(l, 184) = 148.94, p < .OOl, and that recall was higher for the identical character or so in the second position than in the first position (21.49 vs. l&97), F(1, 184) = 23.75, p < .OOl. The interaction between type of identical unit and its position was significant,
F(
1,184) = 5.65, p < .025, indicating that recall was higher for the second characters being identical than for the first characters being identical, but that such tendency was not obtained in the case of sounds being identical.The present results may be explained mainly in terms of the effect of category clustering on recall, because the case of the second characters being identical
generally
produces better categories than the case of the first characters being identical. It is known that the first characters of two-character words usually function as adjectives, as in orchid-flower, and the second characters as nouns.Although
not significant, the observation that recall of the Sl lists tended to be inferior to recall of the control lists only in the auditory condition supportsTurnage and
McGinnies’ (1973) conjecture that the auditory inferiority forlogographs KG
produced by the script system containing more characters w&hLong-term modality effect 51
nds but different meanings. Their view is, however, inconsistent with that the modality effect was also obtained for the control lists in which racters shared the same sound.
ts I-5 tested the hypotheses that some unique characteristics of responsible for their visual input superiority in recall. A hypotheses would be to have Chinese subjects study visual input superiority disappears in this case, tt is le to search further for some characteristics of Chinese logographs le for the modality effect. If the visual superiority effect is still obtained, tor other than scriptal factors may be responsible for the effect.
ethod
Subjects and list materials
Fifty students enrolled in an introductory psychology course at the Chinese Cniversity of Hong Kong participated in the experiment for fulfilling a course requirement.
Four lists of nine English words each were randomly selected from Kucera and Francis (1947) with the restrictions that their frequency count was above 100 and that they were of two syllables. These restrictions were imposed for the sake of minimizing ambiguity when words were presented auditorily.
Procedure
The subjects were tested in small groups of four to six subjects. Following a short practice list, half the subjects studied two lists presented visually and then two lists presented auditorily. The order was reversed for the remaining half of the subjects. A list of nine words was presented through an overhead projector visually or spoken by the experimenter at a speed of 1.5 s per word. Following presentation of a list the subjects wrote down all words they could recall in a free-recall format.
Results and discussion
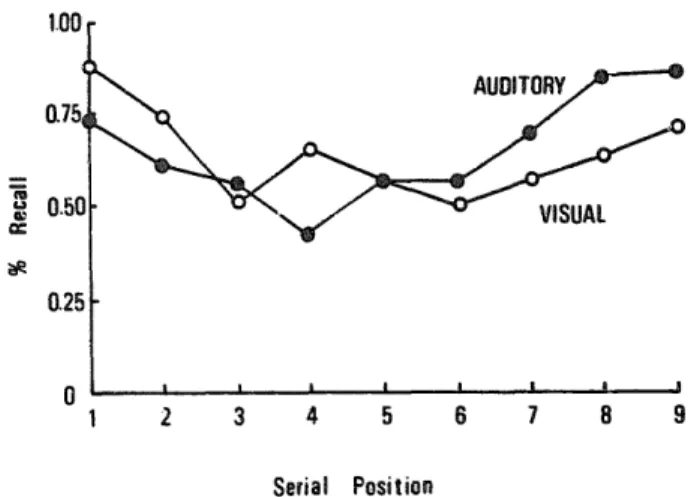
The serial position functions obtained in the visual and auditory input modes are shown in Figure 1. It is clear from the figure that visual presentation was superior
52 h-ma0 Liu et al.
“1 2 3 4 5 6 7 6 9
Serial Position
Figure 1. Recatt as a functiotn of inpub mode and serid position.
to auditory presentation for primacy items but inferior for receney items. An analysis of variance showed that modality was not significant, F < 1, but interacted with serial position, F(8, 392) =‘5.9$, p < .OOl. Serial position was significant,
F(8,392) = 11.49, p < .OOl. Planned comparisons using a t statistic showed that the visual presentation superiority was obtained for the first two primacy items (t(392) = 2.33, p < .05 and t(392) = 2.02, p < .Q5, respectively), but the auditory presentation superiority was obtained for the last two recency items (t(392) = 3.41, p < .Ol and t(392) = 2.48, p < .02, respectively). This pattern of results, which is similar to that obtained by Fang (1982) using Chinese logographs, has been frequently obtained in our laboratory, w en Chinese two-character words were used.
The finding from Western subjects that modality differences at the beginning serial positions are small or non-existent is well documented (e.g., Murdock & Walker, 1969, for free recall; Conrad & Hull? 1968, for serial recall). It is only recently that both auditory and visual superiority effects were obtained from pre-recency items when lists of English words weru studied by English-speaking subjects. It may be concluded, however, that the visual superiority effect is rather rareJy obtained for English words from English-speakitig subjects. In contrast to these findings, the present result of superior visual presentation for the primacy items obtained with English words from Chinese subjects is surprising, if the effect turns out to be robust. This result, however, supports the differential- frequency interpretation of the visual superiority effect, because Chinese students have experienced English more in print than in speech.
Since most Hong Kong college students had studied English as a subject in a primary school for six years and been trained in an English medium secondary school for seven years, an alternative explanation of the present findings in terms of representation of linguistic information in fluent bilinguals has to be consid-
Long-term modality effect 53
ered. According to the single-code (concept mediation) models (e.g., Potter, So, Von Eckart, & Feldman, 1984), bilinguals represent words in a supralinguistic code that is independent of the language in which the words occurred. The visual superiority effect obtained with English words by Chinese subjects is then explained by the single-code models, because English words and Chinese words have common conceptual representations. There are two problems for this type of
lanation. First, the modality effect in this experiment was obtained within one language (English) and a review by Kirsner and Dunn (1985) showed that the amount of repetition priming is virtually nil across a change in language. Second, although the single-code models may be able to account for the mod,llity effect of one language through that of another language, it will be difficult to explain why the modality effect arises in the latter.
eriment 7
As is well known, evidence from a single experiment is hardly convincing. It is desirable to test Chinese subjects with a long-term recall procedure by presenting long lists of English words. The present experiment also attempted to replicate the results obtained with Chinese words in Experiment 5 by using English words. Because of the morphological differences, it would be hardly possible to manipu- late the first and second morphemes of two-morpheme English words as in Experiment 5. It is not difficult, however, to find a sufficient number of English words with their first syllables being identical and a sufficient number of English words with their final syllables being identical. The purpose of Experiment 7 was, then, to find out how input mode affects long-term recall of English words with their first or final sounds being identical.
Method
Subjects and list materials
Thirty-four students enrolled at the Chinese University of Hong Kong served in the experiment voluntarily.
Two types of list, Sl and S2, were constructed as follows. There were four Sl lists, each consisting of four sets of four two-syllable English words each, starting with the same consonant-vowel pronunciation, for example, mearzing, meantime,
meeting and meanwhile. There were also four S2 lists, each consisting of four sets of four two-syllable English words each, ending with the same vowel or vowel- consonant pronunciation, for example, publish, furnish, vanish and cherish. Since it was difficult to find a sufficient number of two-syllable words satisfying the
condition of ending with the same vowel or vowel-consonant ~ro~u~ciatio~, several three-syllable words were included in the S2 lists, such as ~Q~~~~~~,
mimmum, pendulum and platimtm. A pilot study showed t ems could recognize the words selected for the Sl and S2 lists.
Since there were altogether 16 sets of four i~it~al-sound-same four Sl lists, it was possible to construct four Sl control lists by word each from each of the 16 sets. Similarly, four S2 co constructed from the four S2 lists.
Design and procedure
A 2 x 2 x 2 factorial design was used. The first factor w variable (control vs. experimental lists); the second, a wt (visual vs. auditory input); and t e third, also a wit
list, i.e., S1 vs. S2 lists).
The subjects were assigned to t to the order of appearance in the
4-5 subjects. The subjects in t e experimental group studied the four Sl lists and four S2 lists, whille those in th control group studied the four Sl control lists and four S2 control lists. If the lists of each type were presente visually through an overhead projector the remaining half spoken by the ex rimenter. Each list was presented at a speed of 2 s per word. The order, and lists selecte
and auditory presentations were systematically counterbalanced b groups. Following each list presentation, the subjects solved ei addition pr sb!ems for 24 s (3 s per problem) before writing down could remember within a 4min period.
Results and discussion
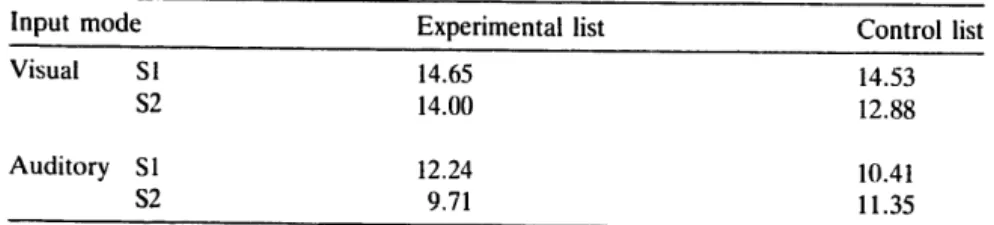
he mean number of English words correctly recalled is presented as a function of list type under each input condition in Table 7. An analysis of variance showed that input mode was significant (visual 14.02 vs. auditory 10.93) F( 1,32) = 17.33, p < .OOl , and did not interact with group, F < 1. More items were recalled from
Table 7. Mean number of English words correctly recalled
Input mode Experimental list Control list
Visual Sl 14.65 14.53
s2 14.00 12.88
Auditory S 1 12.24 10.41
Long-term modality effect 55 s than from the S2 lists (12.96 vs. 11.99) F( 1,32) = 6.47, p < .05, latter contained longer words and thus were harder to recall. sound-clustered lists did not differ from recall of items in the sound-distinctive lists, F < I, apparently because the clustered sounds did not carry any similar meaning.
resent experiment essentially replicates the major finding of Experiment ual presentation superiority was obtained in long-term recall. The finding same initial or final sounds did not produce higher recall also replicates ervation of Experiment 5 and is in line with the view that long-term recall
ing for semantic rather than phonological retrieval cues.
e visual presentatio superiority cannot be explained in terms of any
cteristic sf a script, hat is the underlying mechanism responsible for it? A possible mechanism would be frequency operated through the long-term priming (Jacoby &L Dallas, 1981; Mirsner & Dunn, 1985; Scarborough et al., 1977). According to this frequency interpretation, the visual presentation superiority is obtained because the frequency of experiencing some items in the visual input mode is higher than that of experiencing the same items in the auditory input mode.
The differential-frequency interpretation can account for the visual presenta- tion superiority of Chinese logographs (Turnage & McGinnies, 1973) by noting that there is a discrepancy in kinds of speech many Chinese people use in school and at home. The type of speech (Mandarin) used at formal occasions is different from a dialect used at home for many Chinese people. Moreover, although there is evidence for speech recoding of Chinese logographs in reading (e.g., Tzeng, ung, & Wang, 1977), it may be less prevalent in Chinese readers than in English readers because the former are often not confident about how to pronounce low-frequency characters correctly. For instance, Zhou (1978) estimated that the relationship between graphic cues and sounds in actual characters is very low (30%).
The finding of superior long-term recall of visually presented over auditorily presented English words obtained in Experiments 6 and 7 with Chinese subjects can be easily accounted for by the frequency interpretation as follows. For most Chinese people, English is after all a foreign language. They access English more frequently in print than from speech. They also learn to retrieve English words more from English readings than from English speech. A natural consequence is that the visual presentation superiority will be obtained for Chinese subjects.
The idea that visual frequency is different from auditory frequency may be basic to the effect of associative frequency or availability on recall. The concept of
availability is defined as the relative ease with which an isolated word comes to mind. It is operationalized in terms of associative frequency, which is measured by the number of times a word is given as an associate to a sample of stimulus words. Although the variable of availability is long known to affect recall (Asch & Ebenholtz, 1962; Dale, 1967; Deese, 1965; Leicht, 1968, Tversky & Kahneman,
1973) it is only through a series of studies by Rubin (1980, 1983) and Rubin and Friendly (1986) that availability is found to be one of the best predictors of which words are best recalled.
It is not difficult to see that availability directly reflects auditory frequency, because availability is defined in terms of how many times a word is produced by a group of persons to a set of stimulus words. However, the latter is simply a measure of auditory frequency, if the set of stimulus words is sufficiently large. It is then clear why visual frequency defined by how many times a word appears in print is so ineffective in predicting recallability (Rubhn & Friendly, 1986). The fact is that whenever there is a discrepancy in word frequency and auditory frequency, the former becomes less important because words in print are after all produced in a less straightforward way than speech.
The Chinese people in Hong Kong speak one of the seven major dialect groups in Chinese (Cantonese), which differs from the standard Chinese (Mandarin). There are some Cantonese words that appear neither in dictionaries of standard Chinese nor in formal readings. They are written and pronounced uniquely, and appear only in local newspapers and magazines. We will refer to them as dialectic forms. Therefore, there are two types of Chinese words: (a) one type of word that can be written in two different forms, that is, dialectic and standard forms, and (b) another type of word that can be written only in a standard form, that is, the written form is the same whether one writes in standard Chinese or in a dialect. The majority of the Chinese words belong to the latter type. With respect to those words in double form, they are used in a dialectic form more frequently in everyday speech than in print.
Let us consider those words that can be written in the two different forms. Since a word can be written in the two different forms, relative to the other type of word, the long-term priming effect will accumulate for the latter but not for the former. Consequently, the visual superiority effect should be observed from those words that can be written only in a single form, but not from those words that have two different forms. ,Experiment 8 was designed to test this prediction.
Method
Subjects and list items